
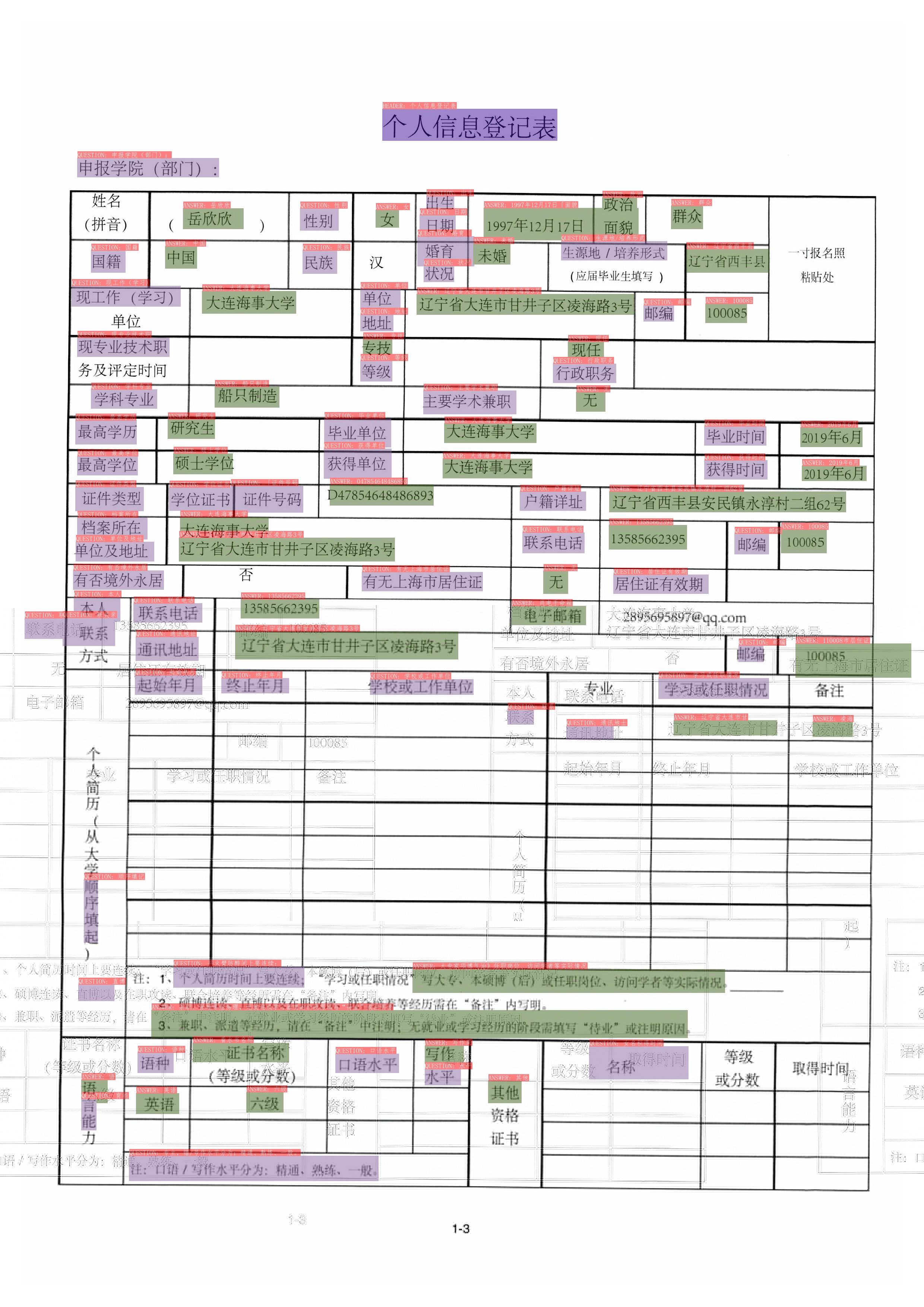
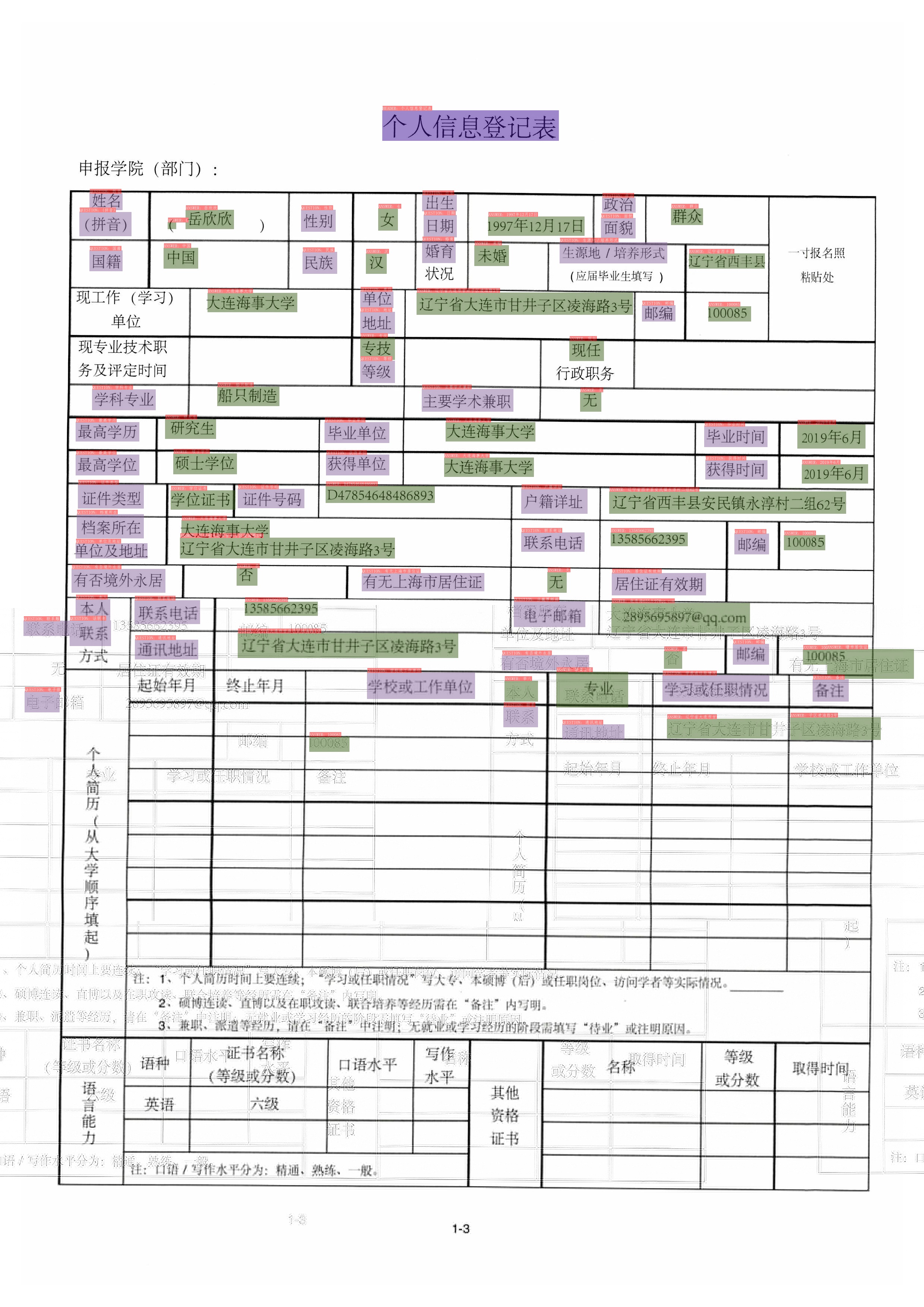
kie doc (#7154)
* kie doc * fix xlm model export * fix doc * add wildreceipt dataset * fix doc * fix doc
Showing
{kind=link}

181.1 KB
{kind=link}

174.6 KB
doc/doc_ch/algorithm_kie_sdmgr.md
0 → 100644
doc/doc_ch/kie.md
0 → 100644
此差异已折叠。
{kind=link}
ppstructure/docs/kie.md
已删除
100644 → 0
{kind=link}

1.6 MB
{kind=link}

1.6 MB
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}

1.5 MB