diff --git a/PPOCRLabel/PPOCRLabel.py b/PPOCRLabel/PPOCRLabel.py
index b9f35aa352d5be3a77de693a6f3c1acf7469ac41..f09a998a9dcbddb3d1239ec61c7a194751362618 100644
--- a/PPOCRLabel/PPOCRLabel.py
+++ b/PPOCRLabel/PPOCRLabel.py
@@ -1733,7 +1733,7 @@ class MainWindow(QMainWindow):
width, height = self.image.width(), self.image.height()
for shape in self.canvas.lockedShapes:
box = [[int(p[0] * width), int(p[1] * height)] for p in shape['ratio']]
- assert len(box) == 4
+ # assert len(box) == 4
result = [(shape['transcription'], 1)]
result.insert(0, box)
self.result_dic_locked.append(result)
diff --git a/README.md b/README.md
index df53191a12b2a64290db25ba4c6c600f2e489628..259ccb5aa02352ca2a2b81bf81d858cec2b47081 100644
--- a/README.md
+++ b/README.md
@@ -68,6 +68,8 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
| Model introduction | Model name | Recommended scene | Detection model | Direction classifier | Recognition model |
| ------------------------------------------------------------ | ---------------------------- | ----------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| Chinese and English ultra-lightweight PP-OCRv3 model(16.2M) | ch_PP-OCRv3_xx | Mobile & Server | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
+| English ultra-lightweight PP-OCRv3 model(13.4M) | en_PP-OCRv3_xx | Mobile & Server | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [inference model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
| Chinese and English ultra-lightweight PP-OCRv2 model(11.6M) | ch_PP-OCRv2_xx |Mobile & Server|[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar)| [inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar)|
| Chinese and English ultra-lightweight PP-OCR model (9.4M) | ch_ppocr_mobile_v2.0_xx | Mobile & server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar)|[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_train.tar) |
| Chinese and English general PP-OCR model (143.4M) | ch_ppocr_server_v2.0_xx | Server |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) |[inference model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_train.tar) |
diff --git a/README_ch.md b/README_ch.md
index e2e6835c884da16928e7d36419c6daa6895dd9e1..c040853074b3b6f99895ee984ed9828140fa5713 100755
--- a/README_ch.md
+++ b/README_ch.md
@@ -71,6 +71,8 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar) |
+| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar) |
| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
diff --git "a/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md" "b/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
index a831813c1504a0d00db23f0218154cbf36741118..2143a6da86abb5eb83788944cd0381b91dad86c1 100644
--- "a/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
+++ "b/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
@@ -16,7 +16,7 @@
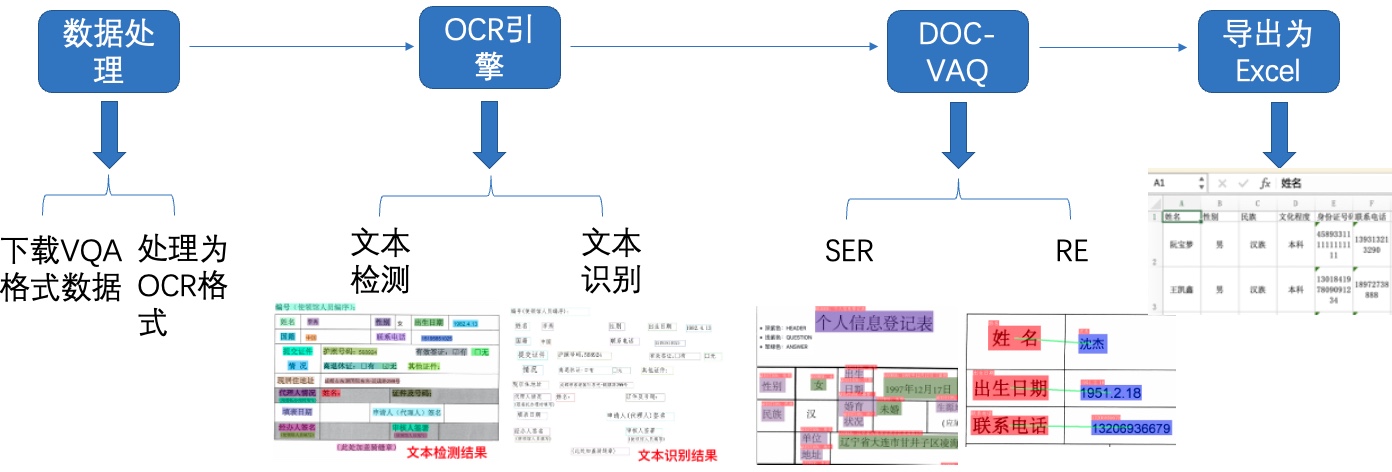 图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: 多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml b/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
similarity index 100%
rename from configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml
rename to configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml b/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
similarity index 100%
rename from configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
rename to configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
diff --git a/configs/rec/PP-OCRv3/multi_language/.gitkeep b/configs/rec/PP-OCRv3/multi_language/.gitkeep
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/deploy/slim/quantization/export_model.py b/deploy/slim/quantization/export_model.py
index 90f79dab34a5f20d4556ae4b10ad1d4e1f8b7f0d..fd1c3e5e109667fa74f5ade18b78f634e4d325db 100755
--- a/deploy/slim/quantization/export_model.py
+++ b/deploy/slim/quantization/export_model.py
@@ -17,9 +17,9 @@ import sys
__dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
-sys.path.append(os.path.abspath(os.path.join(__dir__, '..', '..', '..')))
-sys.path.append(
- os.path.abspath(os.path.join(__dir__, '..', '..', '..', 'tools')))
+sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..', '..', '..')))
+sys.path.insert(
+ 0, os.path.abspath(os.path.join(__dir__, '..', '..', '..', 'tools')))
import argparse
@@ -129,7 +129,6 @@ def main():
quanter.quantize(model)
load_model(config, model)
- model.eval()
# build metric
eval_class = build_metric(config['Metric'])
@@ -142,6 +141,7 @@ def main():
# start eval
metric = program.eval(model, valid_dataloader, post_process_class,
eval_class, model_type, use_srn)
+ model.eval()
logger.info('metric eval ***************')
for k, v in metric.items():
@@ -156,7 +156,6 @@ def main():
if arch_config["algorithm"] in ["Distillation", ]: # distillation model
archs = list(arch_config["Models"].values())
for idx, name in enumerate(model.model_name_list):
- model.model_list[idx].eval()
sub_model_save_path = os.path.join(save_path, name, "inference")
export_single_model(model.model_list[idx], archs[idx],
sub_model_save_path, logger, quanter)
diff --git a/doc/datasets/funsd_demo/gt_train_00040534.jpg b/doc/datasets/funsd_demo/gt_train_00040534.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9f7cf4d4977689b73e2ca91cbe9c877bb8f0c7ff
Binary files /dev/null and b/doc/datasets/funsd_demo/gt_train_00040534.jpg differ
diff --git a/doc/datasets/funsd_demo/gt_train_00070353.jpg b/doc/datasets/funsd_demo/gt_train_00070353.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..36d3345e5ec4c262764e63a972aaa82e98877681
Binary files /dev/null and b/doc/datasets/funsd_demo/gt_train_00070353.jpg differ
diff --git a/doc/datasets/xfund_demo/gt_zh_train_0.jpg b/doc/datasets/xfund_demo/gt_zh_train_0.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6fdaf12fa1d79e6ea9029d665ab7488223459436
Binary files /dev/null and b/doc/datasets/xfund_demo/gt_zh_train_0.jpg differ
diff --git a/doc/datasets/xfund_demo/gt_zh_train_1.jpg b/doc/datasets/xfund_demo/gt_zh_train_1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6a1e53a3ba09b6f84809cfd10a15c42f42b9a163
Binary files /dev/null and b/doc/datasets/xfund_demo/gt_zh_train_1.jpg differ
diff --git a/doc/doc_ch/algorithm_det_sast.md b/doc/doc_ch/algorithm_det_sast.md
new file mode 100644
index 0000000000000000000000000000000000000000..038d73fc15f3203bbcc17997c1a8e1c208f80ba8
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_sast.md
@@ -0,0 +1,115 @@
+# SAST
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning](https://arxiv.org/abs/1908.05498)
+> Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming
+> ACM MM, 2019
+
+在ICDAR2015文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_icdar15.yml](../../configs/det/det_r50_vd_sast_icdar15.yml)|91.39%|83.77%|87.42%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)|
+
+
+在Total-text文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_totaltext.yml](../../configs/det/det_r50_vd_sast_totaltext.yml)|89.63%|78.44%|83.66%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本检测训练教程](./detection.md)。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+#### (1). 四边形文本检测模型(ICDAR2015)
+首先将SAST文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)),可以使用如下命令进行转换:
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_icdar15.yml -o Global.pretrained_model=./det_r50_vd_sast_icdar15_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_ic15
+
+```
+**SAST文本检测模型推理,需要设置参数`--det_algorithm="SAST"`**,可以执行如下命令:
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_sast_ic15/"
+```
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+#### (2). 弯曲文本检测模型(Total-Text)
+首先将SAST文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在Total-Text英文数据集训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_totaltext.yml -o Global.pretrained_model=./det_r50_vd_sast_totaltext_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_tt
+
+```
+
+SAST文本检测模型推理,需要设置参数`--det_algorithm="SAST"`,同时,还需要增加参数`--det_sast_polygon=True`,可以执行如下命令:
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_sast_tt/" --det_sast_polygon=True
+```
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:本代码库中,SAST后处理Locality-Aware NMS有python和c++两种版本,c++版速度明显快于python版。由于c++版本nms编译版本问题,只有python3.5环境下会调用c++版nms,其他情况将调用python版nms。
+
+
+### 4.2 C++推理
+
+暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@inproceedings{wang2019single,
+ title={A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning},
+ author={Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia},
+ pages={1277--1285},
+ year={2019}
+}
+```
diff --git a/doc/doc_ch/algorithm_rec_sar.md b/doc/doc_ch/algorithm_rec_sar.md
new file mode 100644
index 0000000000000000000000000000000000000000..b8304313994754480a89d708e39149d67f828c0d
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_sar.md
@@ -0,0 +1,114 @@
+# SAR
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition](https://arxiv.org/abs/1811.00751)
+> Hui Li, Peng Wang, Chunhua Shen, Guyu Zhang
+> AAAI, 2019
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- |
+|SAR|ResNet31|[rec_r31_sar.yml](../../configs/rec/rec_r31_sar.yml)|87.20%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar)|
+
+注:除了使用MJSynth和SynthText两个文字识别数据集外,还加入了[SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg)数据(提取码:627x),和部分真实数据,具体数据细节可以参考论文。
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r31_sar.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r31_sar.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SAR文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model=./rec_r31_sar_train/best_accuracy Global.save_inference_dir=./inference/rec_sar
+```
+
+SAR文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_sar/" --rec_image_shape="3, 48, 48, 160" --rec_char_type="ch" --rec_algorithm="SAR" --rec_char_dict_path="ppocr/utils/dict90.txt" --max_text_length=30 --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SAR,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Li2019ShowAA,
+ title={Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition},
+ author={Hui Li and Peng Wang and Chunhua Shen and Guyu Zhang},
+ journal={ArXiv},
+ year={2019},
+ volume={abs/1811.00751}
+}
+```
diff --git a/doc/doc_ch/algorithm_rec_srn.md b/doc/doc_ch/algorithm_rec_srn.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca7961359eb902fafee959b26d02f324aece233a
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_srn.md
@@ -0,0 +1,113 @@
+# SRN
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Towards Accurate Scene Text Recognition with Semantic Reasoning Networks](https://arxiv.org/abs/2003.12294#)
+> Deli Yu, Xuan Li, Chengquan Zhang, Junyu Han, Jingtuo Liu, Errui Ding
+> CVPR,2020
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- |
+|SRN|Resnet50_vd_fpn|[rec_r50_fpn_srn.yml](../../configs/rec/rec_r50_fpn_srn.yml)|86.31%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SRN文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model=./rec_r50_vd_srn_train/best_accuracy Global.save_inference_dir=./inference/rec_srn
+```
+
+SRN文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_srn/" --rec_image_shape="1,64,256" --rec_char_type="ch" --rec_algorithm="SRN" --rec_char_dict_path=./ppocr/utils/ic15_dict.txt --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SRN,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Yu2020TowardsAS,
+ title={Towards Accurate Scene Text Recognition With Semantic Reasoning Networks},
+ author={Deli Yu and Xuan Li and Chengquan Zhang and Junyu Han and Jingtuo Liu and Errui Ding},
+ journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year={2020},
+ pages={12110-12119}
+}
+```
diff --git a/doc/doc_ch/dataset/docvqa_datasets.md b/doc/doc_ch/dataset/docvqa_datasets.md
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..3ec1865ee42be99ec19343428cd9ad6439686f15 100644
--- a/doc/doc_ch/dataset/docvqa_datasets.md
+++ b/doc/doc_ch/dataset/docvqa_datasets.md
@@ -0,0 +1,27 @@
+## DocVQA数据集
+这里整理了常见的DocVQA数据集,持续更新中,欢迎各位小伙伴贡献数据集~
+- [FUNSD数据集](#funsd)
+- [XFUND数据集](#xfund)
+
+
+#### 1、FUNSD数据集
+- **数据来源**:https://guillaumejaume.github.io/FUNSD/
+- **数据简介**:FUNSD数据集是一个用于表单理解的数据集,它包含199张真实的、完全标注的扫描版图片,类型包括市场报告、广告以及学术报告等,并分为149张训练集以及50张测试集。FUNSD数据集适用于多种类型的DocVQA任务,如字段级实体分类、字段级实体连接等。部分图像以及标注框可视化如下所示:
+
图1 多模态表单识别流程图
-注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: 多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: [多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml b/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
similarity index 100%
rename from configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml
rename to configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml b/configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
similarity index 100%
rename from configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
rename to configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
diff --git a/configs/rec/PP-OCRv3/multi_language/.gitkeep b/configs/rec/PP-OCRv3/multi_language/.gitkeep
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/deploy/slim/quantization/export_model.py b/deploy/slim/quantization/export_model.py
index 90f79dab34a5f20d4556ae4b10ad1d4e1f8b7f0d..fd1c3e5e109667fa74f5ade18b78f634e4d325db 100755
--- a/deploy/slim/quantization/export_model.py
+++ b/deploy/slim/quantization/export_model.py
@@ -17,9 +17,9 @@ import sys
__dir__ = os.path.dirname(os.path.abspath(__file__))
sys.path.append(__dir__)
-sys.path.append(os.path.abspath(os.path.join(__dir__, '..', '..', '..')))
-sys.path.append(
- os.path.abspath(os.path.join(__dir__, '..', '..', '..', 'tools')))
+sys.path.insert(0, os.path.abspath(os.path.join(__dir__, '..', '..', '..')))
+sys.path.insert(
+ 0, os.path.abspath(os.path.join(__dir__, '..', '..', '..', 'tools')))
import argparse
@@ -129,7 +129,6 @@ def main():
quanter.quantize(model)
load_model(config, model)
- model.eval()
# build metric
eval_class = build_metric(config['Metric'])
@@ -142,6 +141,7 @@ def main():
# start eval
metric = program.eval(model, valid_dataloader, post_process_class,
eval_class, model_type, use_srn)
+ model.eval()
logger.info('metric eval ***************')
for k, v in metric.items():
@@ -156,7 +156,6 @@ def main():
if arch_config["algorithm"] in ["Distillation", ]: # distillation model
archs = list(arch_config["Models"].values())
for idx, name in enumerate(model.model_name_list):
- model.model_list[idx].eval()
sub_model_save_path = os.path.join(save_path, name, "inference")
export_single_model(model.model_list[idx], archs[idx],
sub_model_save_path, logger, quanter)
diff --git a/doc/datasets/funsd_demo/gt_train_00040534.jpg b/doc/datasets/funsd_demo/gt_train_00040534.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..9f7cf4d4977689b73e2ca91cbe9c877bb8f0c7ff
Binary files /dev/null and b/doc/datasets/funsd_demo/gt_train_00040534.jpg differ
diff --git a/doc/datasets/funsd_demo/gt_train_00070353.jpg b/doc/datasets/funsd_demo/gt_train_00070353.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..36d3345e5ec4c262764e63a972aaa82e98877681
Binary files /dev/null and b/doc/datasets/funsd_demo/gt_train_00070353.jpg differ
diff --git a/doc/datasets/xfund_demo/gt_zh_train_0.jpg b/doc/datasets/xfund_demo/gt_zh_train_0.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6fdaf12fa1d79e6ea9029d665ab7488223459436
Binary files /dev/null and b/doc/datasets/xfund_demo/gt_zh_train_0.jpg differ
diff --git a/doc/datasets/xfund_demo/gt_zh_train_1.jpg b/doc/datasets/xfund_demo/gt_zh_train_1.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..6a1e53a3ba09b6f84809cfd10a15c42f42b9a163
Binary files /dev/null and b/doc/datasets/xfund_demo/gt_zh_train_1.jpg differ
diff --git a/doc/doc_ch/algorithm_det_sast.md b/doc/doc_ch/algorithm_det_sast.md
new file mode 100644
index 0000000000000000000000000000000000000000..038d73fc15f3203bbcc17997c1a8e1c208f80ba8
--- /dev/null
+++ b/doc/doc_ch/algorithm_det_sast.md
@@ -0,0 +1,115 @@
+# SAST
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning](https://arxiv.org/abs/1908.05498)
+> Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming
+> ACM MM, 2019
+
+在ICDAR2015文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_icdar15.yml](../../configs/det/det_r50_vd_sast_icdar15.yml)|91.39%|83.77%|87.42%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)|
+
+
+在Total-text文本检测公开数据集上,算法复现效果如下:
+
+|模型|骨干网络|配置文件|precision|recall|Hmean|下载链接|
+| --- | --- | --- | --- | --- | --- | --- |
+|SAST|ResNet50_vd|[configs/det/det_r50_vd_sast_totaltext.yml](../../configs/det/det_r50_vd_sast_totaltext.yml)|89.63%|78.44%|83.66%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本检测训练教程](./detection.md)。PaddleOCR对代码进行了模块化,训练不同的检测模型只需要**更换配置文件**即可。
+
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+#### (1). 四边形文本检测模型(ICDAR2015)
+首先将SAST文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_icdar15_v2.0_train.tar)),可以使用如下命令进行转换:
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_icdar15.yml -o Global.pretrained_model=./det_r50_vd_sast_icdar15_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_ic15
+
+```
+**SAST文本检测模型推理,需要设置参数`--det_algorithm="SAST"`**,可以执行如下命令:
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_sast_ic15/"
+```
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+#### (2). 弯曲文本检测模型(Total-Text)
+首先将SAST文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在Total-Text英文数据集训练的模型为例([模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_sast_totaltext_v2.0_train.tar)),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/det/det_r50_vd_sast_totaltext.yml -o Global.pretrained_model=./det_r50_vd_sast_totaltext_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_sast_tt
+
+```
+
+SAST文本检测模型推理,需要设置参数`--det_algorithm="SAST"`,同时,还需要增加参数`--det_sast_polygon=True`,可以执行如下命令:
+```
+python3 tools/infer/predict_det.py --det_algorithm="SAST" --image_dir="./doc/imgs_en/img623.jpg" --det_model_dir="./inference/det_sast_tt/" --det_sast_polygon=True
+```
+可视化文本检测结果默认保存到`./inference_results`文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:
+
+
+
+**注意**:本代码库中,SAST后处理Locality-Aware NMS有python和c++两种版本,c++版速度明显快于python版。由于c++版本nms编译版本问题,只有python3.5环境下会调用c++版nms,其他情况将调用python版nms。
+
+
+### 4.2 C++推理
+
+暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂未支持
+
+
+### 4.4 更多推理部署
+
+暂未支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@inproceedings{wang2019single,
+ title={A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning},
+ author={Wang, Pengfei and Zhang, Chengquan and Qi, Fei and Huang, Zuming and En, Mengyi and Han, Junyu and Liu, Jingtuo and Ding, Errui and Shi, Guangming},
+ booktitle={Proceedings of the 27th ACM International Conference on Multimedia},
+ pages={1277--1285},
+ year={2019}
+}
+```
diff --git a/doc/doc_ch/algorithm_rec_sar.md b/doc/doc_ch/algorithm_rec_sar.md
new file mode 100644
index 0000000000000000000000000000000000000000..b8304313994754480a89d708e39149d67f828c0d
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_sar.md
@@ -0,0 +1,114 @@
+# SAR
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition](https://arxiv.org/abs/1811.00751)
+> Hui Li, Peng Wang, Chunhua Shen, Guyu Zhang
+> AAAI, 2019
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- |
+|SAR|ResNet31|[rec_r31_sar.yml](../../configs/rec/rec_r31_sar.yml)|87.20%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar)|
+
+注:除了使用MJSynth和SynthText两个文字识别数据集外,还加入了[SynthAdd](https://pan.baidu.com/share/init?surl=uV0LtoNmcxbO-0YA7Ch4dg)数据(提取码:627x),和部分真实数据,具体数据细节可以参考论文。
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r31_sar.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r31_sar.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SAR文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_r31_sar_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r31_sar.yml -o Global.pretrained_model=./rec_r31_sar_train/best_accuracy Global.save_inference_dir=./inference/rec_sar
+```
+
+SAR文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_sar/" --rec_image_shape="3, 48, 48, 160" --rec_char_type="ch" --rec_algorithm="SAR" --rec_char_dict_path="ppocr/utils/dict90.txt" --max_text_length=30 --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SAR,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Li2019ShowAA,
+ title={Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition},
+ author={Hui Li and Peng Wang and Chunhua Shen and Guyu Zhang},
+ journal={ArXiv},
+ year={2019},
+ volume={abs/1811.00751}
+}
+```
diff --git a/doc/doc_ch/algorithm_rec_srn.md b/doc/doc_ch/algorithm_rec_srn.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca7961359eb902fafee959b26d02f324aece233a
--- /dev/null
+++ b/doc/doc_ch/algorithm_rec_srn.md
@@ -0,0 +1,113 @@
+# SRN
+
+- [1. 算法简介](#1)
+- [2. 环境配置](#2)
+- [3. 模型训练、评估、预测](#3)
+ - [3.1 训练](#3-1)
+ - [3.2 评估](#3-2)
+ - [3.3 预测](#3-3)
+- [4. 推理部署](#4)
+ - [4.1 Python推理](#4-1)
+ - [4.2 C++推理](#4-2)
+ - [4.3 Serving服务化部署](#4-3)
+ - [4.4 更多推理部署](#4-4)
+- [5. FAQ](#5)
+
+
+## 1. 算法简介
+
+论文信息:
+> [Towards Accurate Scene Text Recognition with Semantic Reasoning Networks](https://arxiv.org/abs/2003.12294#)
+> Deli Yu, Xuan Li, Chengquan Zhang, Junyu Han, Jingtuo Liu, Errui Ding
+> CVPR,2020
+
+使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法复现效果如下:
+
+|模型|骨干网络|配置文件|Acc|下载链接|
+| --- | --- | --- | --- | --- |
+|SRN|Resnet50_vd_fpn|[rec_r50_fpn_srn.yml](../../configs/rec/rec_r50_fpn_srn.yml)|86.31%|[训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar)|
+
+
+
+## 2. 环境配置
+请先参考[《运行环境准备》](./environment.md)配置PaddleOCR运行环境,参考[《项目克隆》](./clone.md)克隆项目代码。
+
+
+
+## 3. 模型训练、评估、预测
+
+请参考[文本识别教程](./recognition.md)。PaddleOCR对代码进行了模块化,训练不同的识别模型只需要**更换配置文件**即可。
+
+训练
+
+具体地,在完成数据准备后,便可以启动训练,训练命令如下:
+
+```
+#单卡训练(训练周期长,不建议)
+python3 tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+
+#多卡训练,通过--gpus参数指定卡号
+python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_r50_fpn_srn.yml
+```
+
+评估
+
+```
+# GPU 评估, Global.pretrained_model 为待测权重
+python3 -m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy
+```
+
+预测:
+
+```
+# 预测使用的配置文件必须与训练一致
+python3 tools/infer_rec.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model={path/to/weights}/best_accuracy Global.infer_img=doc/imgs_words/en/word_1.png
+```
+
+
+## 4. 推理部署
+
+
+### 4.1 Python推理
+首先将SRN文本识别训练过程中保存的模型,转换成inference model。( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/rec_r50_vd_srn_train.tar) ),可以使用如下命令进行转换:
+
+```
+python3 tools/export_model.py -c configs/rec/rec_r50_fpn_srn.yml -o Global.pretrained_model=./rec_r50_vd_srn_train/best_accuracy Global.save_inference_dir=./inference/rec_srn
+```
+
+SRN文本识别模型推理,可以执行如下命令:
+
+```
+python3 tools/infer/predict_rec.py --image_dir="./doc/imgs_words/en/word_1.png" --rec_model_dir="./inference/rec_srn/" --rec_image_shape="1,64,256" --rec_char_type="ch" --rec_algorithm="SRN" --rec_char_dict_path=./ppocr/utils/ic15_dict.txt --use_space_char=False
+```
+
+
+### 4.2 C++推理
+
+由于C++预处理后处理还未支持SRN,所以暂未支持
+
+
+### 4.3 Serving服务化部署
+
+暂不支持
+
+
+### 4.4 更多推理部署
+
+暂不支持
+
+
+## 5. FAQ
+
+
+## 引用
+
+```bibtex
+@article{Yu2020TowardsAS,
+ title={Towards Accurate Scene Text Recognition With Semantic Reasoning Networks},
+ author={Deli Yu and Xuan Li and Chengquan Zhang and Junyu Han and Jingtuo Liu and Errui Ding},
+ journal={2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
+ year={2020},
+ pages={12110-12119}
+}
+```
diff --git a/doc/doc_ch/dataset/docvqa_datasets.md b/doc/doc_ch/dataset/docvqa_datasets.md
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..3ec1865ee42be99ec19343428cd9ad6439686f15 100644
--- a/doc/doc_ch/dataset/docvqa_datasets.md
+++ b/doc/doc_ch/dataset/docvqa_datasets.md
@@ -0,0 +1,27 @@
+## DocVQA数据集
+这里整理了常见的DocVQA数据集,持续更新中,欢迎各位小伙伴贡献数据集~
+- [FUNSD数据集](#funsd)
+- [XFUND数据集](#xfund)
+
+
+#### 1、FUNSD数据集
+- **数据来源**:https://guillaumejaume.github.io/FUNSD/
+- **数据简介**:FUNSD数据集是一个用于表单理解的数据集,它包含199张真实的、完全标注的扫描版图片,类型包括市场报告、广告以及学术报告等,并分为149张训练集以及50张测试集。FUNSD数据集适用于多种类型的DocVQA任务,如字段级实体分类、字段级实体连接等。部分图像以及标注框可视化如下所示:
+
+

+

+
+

+

+
+
+
+
+
+
+