Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleOCR
提交
7261f4ae
P
PaddleOCR
项目概览
PaddlePaddle
/
PaddleOCR
大约 2 年 前同步成功
通知
1557
Star
32965
Fork
6643
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
108
列表
看板
标记
里程碑
合并请求
7
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleOCR
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
108
Issue
108
列表
看板
标记
里程碑
合并请求
7
合并请求
7
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
7261f4ae
编写于
8月 23, 2022
作者:
qq_25193841
浏览文件
操作
浏览文件
下载
差异文件
Merge remote-tracking branch 'origin/dygraph' into dy1
上级
7fd35af4
fe89056c
变更
10
显示空白变更内容
内联
并排
Showing
10 changed file
with
157 addition
and
233 deletion
+157
-233
README_ch.md
README_ch.md
+28
-29
doc/doc_ch/algorithm.md
doc/doc_ch/algorithm.md
+0
-14
doc/doc_ch/algorithm_overview.md
doc/doc_ch/algorithm_overview.md
+7
-2
ppstructure/README_ch.md
ppstructure/README_ch.md
+70
-101
ppstructure/docs/inference.md
ppstructure/docs/inference.md
+3
-3
ppstructure/docs/installation.md
ppstructure/docs/installation.md
+0
-21
ppstructure/docs/installation_en.md
ppstructure/docs/installation_en.md
+0
-24
ppstructure/docs/ppstructurev2_pipeline.png
ppstructure/docs/ppstructurev2_pipeline.png
+0
-0
ppstructure/docs/quickstart.md
ppstructure/docs/quickstart.md
+49
-28
ppstructure/layout/README_ch.md
ppstructure/layout/README_ch.md
+0
-11
未找到文件。
README_ch.md
浏览文件 @
7261f4ae
...
...
@@ -27,15 +27,8 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
## 近期更新
-
**🔥2022.5.11~13 每晚8:30【超强OCR技术详解与产业应用实战】三日直播课**
-
11日:开源最强OCR系统PP-OCRv3揭秘
-
12日:云边端全覆盖的PP-OCRv3训练部署实战
-
13日:OCR产业应用全流程拆解与实战
赶紧扫码报名吧!
<div
align=
"center"
>
<img
src=
"https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/dygraph/doc/joinus.PNG"
width =
"150"
height =
"150"
/>
</div>
-
**🔥2022.7 发布[OCR场景应用集合](./applications)**
-
发布OCR场景应用集合,包含数码管、液晶屏、车牌、高精度SVTR模型等
**7个垂类模型**
,覆盖通用,制造、金融、交通行业的主要OCR垂类应用。
-
**🔥2022.5.9 发布PaddleOCR [release/2.5](https://github.com/PaddlePaddle/PaddleOCR/tree/release/2.5)**
-
发布
[
PP-OCRv3
](
./doc/doc_ch/ppocr_introduction.md#pp-ocrv3
)
,速度可比情况下,中文场景效果相比于PP-OCRv2再提升5%,英文场景提升11%,80语种多语言模型平均识别准确率提升5%以上;
...
...
@@ -71,24 +64,22 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
## 《动手学OCR》电子书
-
[
《动手学OCR》电子书📚
](
./doc/doc_ch/ocr_book.md
)
## 场景应用
-
PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR垂类应用,在PP-OCR、PP-Structure的通用能力基础之上,以notebook的形式展示利用场景数据微调、模型优化方法、数据增广等内容,为开发者快速落地OCR应用提供示范与启发。详情可查看
[
README
](
./applications
)
。
<a
name=
"开源社区"
></a>
## 开源社区
-
**项目合作📑:**
如果您是企业开发者且有明确的OCR垂类应用需求,填写
[
问卷
](
https://paddle.wjx.cn/vj/QwF7GKw.aspx
)
后可免费与官方团队展开不同层次的合作。
-
**加入社区👬:**
微信扫描二维码并填写问卷之后,加入交流群领取福利
-
**获取
5月11-13日每晚20:30《OCR超强技术详解与产业应用实战》的直播课
链接**
-
**获取
PaddleOCR最新发版解说《OCR超强技术详解与产业应用实战》系列直播课回放
链接**
-
**10G重磅OCR学习大礼包:**
《动手学OCR》电子书,配套讲解视频和notebook项目;66篇OCR相关顶会前沿论文打包放送,包括CVPR、AAAI、IJCAI、ICCV等;PaddleOCR历次发版直播课视频;OCR社区优秀开发者项目分享视频。
-
**社区贡献**
🏅️:
[
社区贡献
](
./doc/doc_ch/thirdparty.md
)
文档中包含了社区用户
**使用PaddleOCR开发的各种工具、应用**
以及
**为PaddleOCR贡献的功能、优化的文档与代码**
等,是官方为社区开发者打造的荣誉墙,也是帮助优质项目宣传的广播站。
-
**社区项目**
🏅️:
[
社区项目
](
./doc/doc_ch/thirdparty.md
)
文档中包含了社区用户
**使用PaddleOCR开发的各种工具、应用**
以及
**为PaddleOCR贡献的功能、优化的文档与代码**
等,是官方为社区开发者打造的荣誉墙,也是帮助优质项目宣传的广播站。
-
**社区常规赛**
🎁:社区常规赛是面向OCR开发者的积分赛事,覆盖文档、代码、模型和应用四大类型,以季度为单位评选并发放奖励,赛题详情与报名方法可参考
[
链接
](
https://github.com/PaddlePaddle/PaddleOCR/issues/4982
)
。
<div
align=
"center"
>
<img
src=
"https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/dygraph/doc/joinus.PNG"
width =
"
200"
height =
"20
0"
/>
<img
src=
"https://raw.githubusercontent.com/PaddlePaddle/PaddleOCR/dygraph/doc/joinus.PNG"
width =
"
150"
height =
"15
0"
/>
</div>
<a
name=
"模型下载"
></a>
## PP-OCR系列模型列表(更新中)
...
...
@@ -96,14 +87,21 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 |
[
推理模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
)
|
| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 |
[
推理模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_det_distill_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar
)
|
| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 |
[
推理模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar
)
|
| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 |
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar
)
|
| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 |
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar
)
|
更多模型下载(包括多语言),可以参考
[
PP-OCR 系列模型下载
](
./doc/doc_ch/models_list.md
)
,文档分析相关模型参考
[
PP-Structure 系列模型下载
](
./ppstructure/docs/models_list.md
)
-
超轻量OCR系列更多模型下载(包括多语言),可以参考
[
PP-OCR系列模型下载
](
./doc/doc_ch/models_list.md
)
,文档分析相关模型参考
[
PP-Structure系列模型下载
](
./ppstructure/docs/models_list.md
)
### PaddleOCR场景应用模型
| 行业 | 类别 | 亮点 | 文档说明 | 模型下载 |
| ---- | ------------ | ---------------------------------- | ------------------------------------------------------------ | --------------------------------------------- |
| 制造 | 数码管识别 | 数码管数据合成、漏识别调优 |
[
光功率计数码管字符识别
](
./applications/光功率计数码管字符识别/光功率计数码管字符识别.md
)
|
[
下载链接
](
./applications/README.md#模型下载
)
|
| 金融 | 通用表单识别 | 多模态通用表单结构化提取 |
[
多模态表单识别
](
./applications/多模态表单识别.md
)
|
[
下载链接
](
./applications/README.md#模型下载
)
|
| 交通 | 车牌识别 | 多角度图像处理、轻量模型、端侧部署 |
[
轻量级车牌识别
](
./applications/轻量级车牌识别.md
)
|
[
下载链接
](
./applications/README.md#模型下载
)
|
-
更多制造、金融、交通行业的主要OCR垂类应用模型(如电表、液晶屏、高精度SVTR模型等),可参考
[
场景应用模型下载
](
./applications
)
<a
name=
"文档教程"
></a>
## 文档教程
-
[
运行环境准备
](
./doc/doc_ch/environment.md
)
...
...
@@ -120,7 +118,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-
[
知识蒸馏
](
./doc/doc_ch/knowledge_distillation.md
)
-
[
推理部署
](
./deploy/README_ch.md
)
-
[
基于Python预测引擎推理
](
./doc/doc_ch/inference_ppocr.md
)
-
[
基于C++预测引擎推理
](
./deploy/cpp_infer/readme.md
)
-
[
基于C++预测引擎推理
](
./deploy/cpp_infer/readme
_ch
.md
)
-
[
服务化部署
](
./deploy/pdserving/README_CN.md
)
-
[
端侧部署
](
./deploy/lite/readme.md
)
-
[
Paddle2ONNX模型转化与预测
](
./deploy/paddle2onnx/readme.md
)
...
...
@@ -132,16 +130,17 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-
[
模型训练
](
./doc/doc_ch/training.md
)
-
[
版面分析
](
./ppstructure/layout/README_ch.md
)
-
[
表格识别
](
./ppstructure/table/README_ch.md
)
-
[
关键信息提取
](
./ppstructure/docs/kie.md
)
-
[
DocVQA
](
./ppstructure/vqa/README_ch.md
)
-
[
关键信息提取
](
./ppstructure/kie/README_ch.md
)
-
[
推理部署
](
./deploy/README_ch.md
)
-
[
基于Python预测引擎推理
](
./ppstructure/docs/inference.md
)
-
[
基于C++预测引擎推理
](
)
-
[
基于C++预测引擎推理
](
./deploy/cpp_infer/readme_ch.md
)
-
[
服务化部署
](
./deploy/pdserving/README_CN.md
)
-
[
前沿算法与模型🚀
](
./doc/doc_ch/algorithm.md
)
-
[
文本检测算法
](
./doc/doc_ch/algorithm_overview.md#11-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E7%AE%97%E6%B3%95
)
-
[
文本识别算法
](
./doc/doc_ch/algorithm_overview.md#12-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95
)
-
[
端到端算法
](
./doc/doc_ch/algorithm_overview.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95
)
-
[
前沿算法与模型🚀
](
./doc/doc_ch/algorithm_overview.md
)
-
[
文本检测算法
](
./doc/doc_ch/algorithm_overview.md
)
-
[
文本识别算法
](
./doc/doc_ch/algorithm_overview.md
)
-
[
端到端OCR算法
](
./doc/doc_ch/algorithm_overview.md
)
-
[
表格识别算法
](
./doc/doc_ch/algorithm_overview.md
)
-
[
关键信息抽取算法
](
./doc/doc_ch/algorithm_overview.md
)
-
[
使用PaddleOCR架构添加新算法
](
./doc/doc_ch/add_new_algorithm.md
)
-
[
场景应用
](
./applications
)
-
数据标注与合成
...
...
@@ -155,7 +154,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-
[
垂类多语言OCR数据集
](
doc/doc_ch/dataset/vertical_and_multilingual_datasets.md
)
-
[
版面分析数据集
](
doc/doc_ch/dataset/layout_datasets.md
)
-
[
表格识别数据集
](
doc/doc_ch/dataset/table_datasets.md
)
-
[
DocVQA数据集
](
doc/doc_ch/dataset/docvqa
_datasets.md
)
-
[
关键信息提取数据集
](
doc/doc_ch/dataset/kie
_datasets.md
)
-
[
代码组织结构
](
./doc/doc_ch/tree.md
)
-
[
效果展示
](
#效果展示
)
-
[
《动手学OCR》电子书📚
](
./doc/doc_ch/ocr_book.md
)
...
...
doc/doc_ch/algorithm.md
已删除
100644 → 0
浏览文件 @
7fd35af4
# 前沿算法与模型
PaddleOCR将
**持续新增**
支持OCR领域前沿算法与模型,已支持的模型与使用教程可点击下方列表查看:
-
[
文本检测算法
](
./algorithm_overview.md#11-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E7%AE%97%E6%B3%95
)
-
[
文本识别算法
](
./algorithm_overview.md#12-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95
)
-
[
端到端算法
](
./algorithm_overview.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95
)
-
[
表格识别
](
./algorithm_overview.md#3-%E8%A1%A8%E6%A0%BC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95
)
**欢迎广大开发者合作共建,贡献更多算法,合入有奖🎁!具体可查看[社区常规赛](https://github.com/PaddlePaddle/PaddleOCR/issues/4982)。**
新增算法可参考如下教程:
-
[
使用PaddleOCR架构添加新算法
](
./add_new_algorithm.md
)
doc/doc_ch/algorithm_overview.md
浏览文件 @
7261f4ae
#
算法汇总
#
前沿算法与模型
-
[
1. 两阶段OCR算法
](
#1
)
-
[
1.1 文本检测算法
](
#11
)
...
...
@@ -7,8 +7,13 @@
-
[
3. 表格识别算法
](
#3
)
-
[
4. 关键信息抽取算法
](
#4
)
本文给出了PaddleOCR已支持的OCR算法列表,以及每个算法在
**英文公开数据集**
上的模型和指标,主要用于算法简介和算法性能对比,更多包括中文在内的其他数据集上的模型请参考
[
PP-OCRv3 系列模型下载
](
./models_list.md
)
。
>>
PaddleOCR将
**持续新增**
支持OCR领域前沿算法与模型,
**欢迎广大开发者合作共建,贡献更多算法,合入有奖🎁!具体可查看[社区常规赛](https://github.com/PaddlePaddle/PaddleOCR/issues/4982)。**
>>
新增算法可参考教程:
[
使用PaddleOCR架构添加新算法
](
./add_new_algorithm.md
)
本文给出了PaddleOCR已支持的OCR算法列表,以及每个算法在
**英文公开数据集**
上的模型和指标,主要用于算法简介和算法性能对比,更多包括中文在内的其他数据集上的模型请参考
[
PP-OCR v2.0 系列模型下载
](
./models_list.md
)
。
<a
name=
"1"
></a>
...
...
ppstructure/README_ch.md
浏览文件 @
7261f4ae
...
...
@@ -3,135 +3,104 @@
# PP-Structure 文档分析
-
[
1. 简介
](
#1
)
-
[
2. 近期更新
](
#2
)
-
[
3. 特性
](
#3
)
-
[
4. 效果展示
](
#4
)
-
[
4.1 版面分析和表格识别
](
#41
)
-
[
4.2 关键信息抽取
](
#42
)
-
[
5. 快速体验
](
#5
)
-
[
6. PP-Structure 介绍
](
#6
)
-
[
6.1 版面分析+表格识别
](
#61
)
-
[
6.1.1 版面分析
](
#611
)
-
[
6.1.2 表格识别
](
#612
)
-
[
6.2 关键信息抽取
](
#62
)
-
[
7. 模型库
](
#7
)
-
[
7.1 版面分析模型
](
#71
)
-
[
7.2 OCR和表格识别模型
](
#72
)
-
[
7.3 关键信息抽取模型
](
#73
)
-
[
2. 特性
](
#2
)
-
[
3. 效果展示
](
#3
)
-
[
3.1 版面分析和表格识别
](
#31
)
-
[
3.2 版面恢复
](
#32
)
-
[
3.3 关键信息抽取
](
#33
)
-
[
4. 快速体验
](
#4
)
-
[
5. 模型库
](
#5
)
<a
name=
"1"
></a>
## 1. 简介
PP-Structure是一个可用于复杂文档结构分析和处理的OCR工具包,旨在帮助开发者更好的完成文档理解相关任务。
<a
name=
"2"
></a>
## 2. 近期更新
*
2022.02.12 KIE增加LayoutLMv2模型。
*
2021.12.07 新增
[
关键信息抽取任务SER和RE
](
kie/README.md
)
。
<a
name=
"3"
></a>
## 3. 特性
PP-Structure的主要特性如下:
-
支持对图片形式的文档进行版面分析,可以划分
**文字、标题、表格、图片以及列表**
5类区域(与Layout-Parser联合使用)
-
支持文字、标题、图片以及列表区域提取为文字字段(与PP-OCR联合使用)
-
支持表格区域进行结构化分析,最终结果输出Excel文件
-
支持python whl包和命令行两种方式,简单易用
-
支持版面分析和表格结构化两类任务自定义训练
-
支持基于多模态的关键信息抽取(Key Information Extraction,KIE)任务-语义实体识别(Semantic Entity Recognition,SER)和关系抽取(Relation Extraction,RE)
<a
name=
"4"
></a>
## 4. 效果展示
<a
name=
"41"
></a>
### 4.1 版面分析和表格识别
<img
src=
"./docs/table/ppstructure.GIF"
width=
"100%"
/>
图中展示了版面分析+表格识别的整体流程,图片先有版面分析划分为图像、文本、标题和表格四种区域,然后对图像、文本和标题三种区域进行OCR的检测识别,对表格进行表格识别,其中图像还会被存储下来以便使用。
<a
name=
"42"
></a>
### 4.2 关键信息抽取
*
SER

| !
[](
./docs/kie/result_ser/zh_val_42_ser.jpg
)
---|---
PP-Structure是PaddleOCR团队自研的智能文档分析系统,旨在帮助开发者更好的完成版面分析、表格识别等文档理解相关任务。
图中不同颜色的框表示不同的类别,对于XFUN数据集,有
`QUESTION`
,
`ANSWER`
,
`HEADER`
3种类别
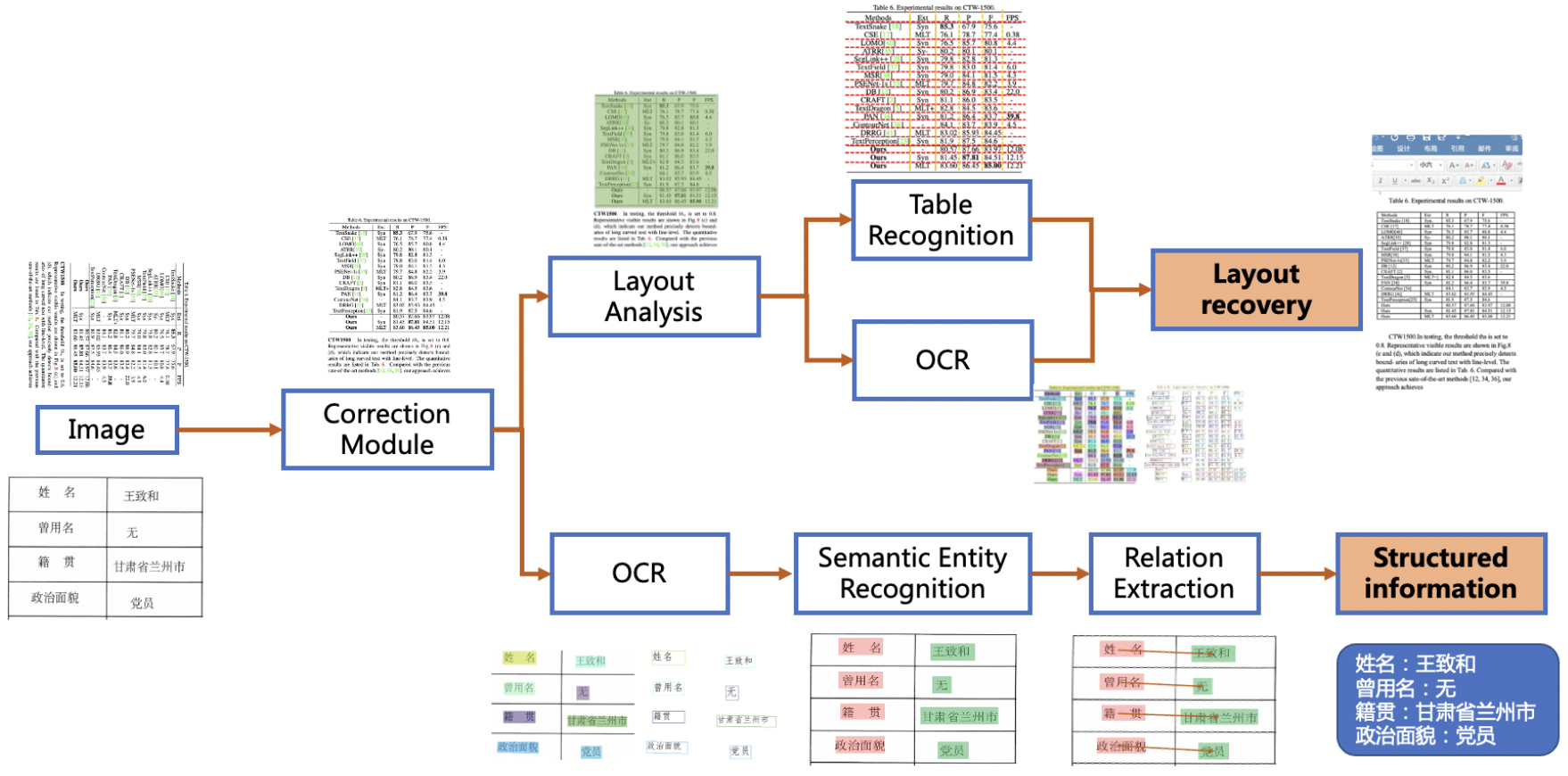
PP-Structurev2系统流程图如下所示,文档图像首先经过图像矫正模块,判断整图方向并完成转正,随后可以完成版面信息分析与关键信息抽取2类任务。
-
版面分析任务中,图像首先经过版面分析模型,将图像划分为文本、表格、图像等不同区域,随后对这些区域分别进行识别,如,将表格区域送入表格识别模块进行结构化识别,将文本区域送入OCR引擎进行文字识别,最后使用版面恢复模块将其恢复为与原始图像布局一致的word或者pdf格式的文件;
-
关键信息抽取任务中,首先使用OCR引擎提取文本内容,然后由语义实体识别模块获取图像中的语义实体,最后经关系抽取模块获取语义实体之间的对应关系,从而提取需要的关键信息。
<img
src=
"./docs/ppstructurev2_pipeline.png"
width=
"100%"
/>
*
深紫色:HEADER
*
浅紫色:QUESTION
*
军绿色:ANSWER
更多技术细节:👉
[
PP-Structurev2技术报告
](
)
在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
PP-Structurev2支持各个模块独立使用或灵活搭配,如,可以单独使用版面分析,或单独使用表格识别,点击下面相应链接获取各个独立模块的使用教程:
*
RE

| !
[](
./docs/kie/result_re/zh_val_40_re.jpg
)
---|---
图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
-
[
版面分析
](
layout/README_ch.md
)
-
[
表格识别
](
table/README_ch.md
)
-
[
关键信息抽取
](
kie/README_ch.md
)
-
[
版面复原
](
recovery/README_ch.md
)
<a
name=
"
5
"
></a>
##
5. 快速体验
<a
name=
"
2
"
></a>
##
2. 特性
请参考
[
快速使用
](
./docs/quickstart.md
)
教程。
PP-Structurev2的主要特性如下:
-
支持对图片/pdf形式的文档进行版面分析,可以划分
**文字、标题、表格、图片、公式等**
区域;
-
支持通用的中英文
**表格检测**
任务;
-
支持表格区域进行结构化识别,最终结果输出
**Excel文件**
;
-
支持基于多模态的关键信息抽取(Key Information Extraction,KIE)任务-
**语义实体识别**
(Semantic Entity Recognition,SER)和
**关系抽取**
(Relation Extraction,RE);
-
支持
**版面复原**
,即恢复为与原始图像布局一致的word或者pdf格式的文件;
-
支持自定义训练及python whl包调用等多种推理部署方式,简单易用;
-
与半自动数据标注工具PPOCRLabel打通,支持版面分析、表格识别、SER三种任务的标注。
<a
name=
"6"
></a>
## 6. PP-Structure 介绍
<a
name=
"3"
></a>
## 3. 效果展示
PP-Structurev2支持各个模块独立使用或灵活搭配,如,可以单独使用版面分析,或单独使用表格识别,这里仅展示几种代表性使用方式的可视化效果。
<a
name=
"61"
></a>
### 6.1 版面分析+表格识别
<a
name=
"31"
></a>
### 3.1 版面分析和表格识别
下图展示了版面分析+表格识别的整体流程,图片先有版面分析划分为图像、文本、标题和表格四种区域,然后对图像、文本和标题三种区域进行OCR的检测识别,对表格进行表格识别,其中图像还会被存储下来以便使用。
<img
src=
"./docs/table/ppstructure.GIF"
width=
"100%"
/>

<a
name=
"32"
></a>
### 3.2 版面恢复
下图展示了基于上一节版面分析和表格识别的结果进行版面恢复的效果。
<img
src=
"./docs/recovery/recovery.jpg"
width=
"100%"
/>
在PP-Structure中,图片会先经由Layout-Parser进行版面分析,在版面分析中,会对图片里的区域进行分类,包括
**文字、标题、图片、列表和表格**
5类。对于前4类区域,直接使用PP-OCR完成对应区域文字检测与识别。对于表格类区域,经过表格结构化处理后,表格图片转换为相同表格样式的Excel文件。
<a
name=
"
611
"
></a>
###
# 6.1.1 版面分析
<a
name=
"
33
"
></a>
###
3.3 关键信息抽取
版面分析对文档数据进行区域分类,其中包括版面分析工具的Python脚本使用、提取指定类别检测框、性能指标以及自定义训练版面分析模型,详细内容可以参考
[
文档
](
layout/README_ch.md
)
。
*
SER
<a
name=
"612"
></a>
#### 6.1.2 表格识别
图中不同颜色的框表示不同的类别。
表格识别将表格图片转换为excel文档,其中包含对于表格文本的检测和识别以及对于表格结构和单元格坐标的预测,详细说明参考
[
文档
](
table/README_ch.md
)
。
<div
align=
"center"
>
<img
src=
"https://user-images.githubusercontent.com/14270174/185539141-68e71c75-5cf7-4529-b2ca-219d29fa5f68.jpg"
width=
"600"
>
</div>
<a
name=
"62"
></a>
### 6.2 关键信息抽取
<div
align=
"center"
>
<img
src=
"https://user-images.githubusercontent.com/14270174/185310636-6ce02f7c-790d-479f-b163-ea97a5a04808.jpg"
width=
"600"
>
</div>
关键信息抽取包括语义实体识别 (Semantic Entity Recognition, SER) 和关系抽取 (Relation Extraction, RE) 任务。基于 SER 任务,可以完成对图像中的文本识别与分类;基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair),详细说明参考
[
文档
](
kie/README.md
)
。
<div
align=
"center"
>
<img
src=
"https://user-images.githubusercontent.com/14270174/185539517-ccf2372a-f026-4a7c-ad28-c741c770f60a.png"
width=
"600"
>
</div>
<a
name=
"7"
></a>
## 7. 模型库
*
RE
PP-Structure系列模型列表(更新中)
图中红色框表示
`问题`
,蓝色框表示
`答案`
,
`问题`
和
`答案`
之间使用绿色线连接。
<a
name=
"71"
></a>
### 7.1 版面分析模型
<div
align=
"center"
>
<img
src=
"https://user-images.githubusercontent.com/14270174/185393805-c67ff571-cf7e-4217-a4b0-8b396c4f22bb.jpg"
width=
"600"
>
</div>
|模型名称|模型简介|下载地址| label_map|
| --- | --- | --- | --- |
| ppyolov2_r50vd_dcn_365e_publaynet | PubLayNet 数据集训练的版面分析模型,可以划分
**文字、标题、表格、图片以及列表**
5类区域 |
[
PubLayNet
](
https://paddle-model-ecology.bj.bcebos.com/model/layout-parser/ppyolov2_r50vd_dcn_365e_publaynet.tar
)
| {0: "Text", 1: "Title", 2: "List", 3:"Table", 4:"Figure"}|
<div
align=
"center"
>
<img
src=
"https://user-images.githubusercontent.com/14270174/185540080-0431e006-9235-4b6d-b63d-0b3c6e1de48f.jpg"
width=
"600"
>
</div>
<a
name=
"
72
"
></a>
##
# 7.2 OCR和表格识别模型
<a
name=
"
4
"
></a>
##
4. 快速体验
|模型名称|模型简介|模型大小|下载地址|
| --- | --- | --- | --- |
|ch_PP-OCRv3_det| 【最新】超轻量模型,支持中英文、多语种文本检测 | 3.8M |
[
推理模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
)
|
|ch_PP-OCRv3_rec|【最新】超轻量模型,支持中英文、数字识别|12.4M |
[
推理模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
)
|
|ch_ppstructure_mobile_v2.0_SLANet|基于SLANet的中文表格识别模型|9.3M|
[
推理模型
](
https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/ch_ppstructure_mobile_v2.0_SLANet_infer.tar
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/ppstructure/models/slanet/ch_ppstructure_mobile_v2.0_SLANet_train.tar
)
|
请参考
[
快速使用
](
./docs/quickstart.md
)
教程。
<a
name=
"5"
></a>
## 5. 模型库
<a
name=
"73"
></a>
### 7.3 KIE 模型
部分任务需要同时用到结构化分析模型和OCR模型,如表格识别需要使用表格识别模型进行结构化解析,同时也要用到OCR模型对表格内的文字进行识别,请根据具体需求选择合适的模型。
|模型名称|模型简介|模型大小|下载地址|
| --- | --- | --- | --- |
|ser_LayoutXLM_xfun_zhd|基于LayoutXLM在xfun中文数据集上训练的SER模型|1.4G|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar
)
|
|re_LayoutXLM_xfun_zh|基于LayoutXLM在xfun中文数据集上训练的RE模型|1.4G|
[
推理模型 coming soon
](
)
/
[
训练模型
](
https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar
)
|
结构化分析相关模型下载可以参考:
-
[
PP-Structure 模型库
](
./docs/models_list.md
)
OCR相关模型下载可以参考:
-
[
PP-OCR 模型库
](
../doc/doc_ch/models_list.md
)
更多模型下载,可以参考
[
PP-OCR model_list
](
../doc/doc_ch/models_list.md
)
and
[
PP-Structure model_list
](
./docs/models_list.md
)
ppstructure/docs/inference.md
浏览文件 @
7261f4ae
# 基于Python预测引擎推理
-
[
1.
Structure
](
#1
)
-
[
1.
版面信息抽取
](
#1
)
-
[
1.1 版面分析+表格识别
](
#1.1
)
-
[
1.2 版面分析
](
#1.2
)
-
[
1.3 表格识别
](
#1.3
)
-
[
2. 关键信息抽取
](
#2
)
<a
name=
"1"
></a>
## 1.
Structure
## 1.
版面信息抽取
进入
`ppstructure`
目录
```
bash
cd
ppstructure
```
`
```
下载模型
```
bash
mkdir
inference
&&
cd
inference
...
...
ppstructure/docs/installation.md
已删除
100644 → 0
浏览文件 @
7fd35af4
-
[
快速安装
](
#快速安装
)
-
[
1. PaddlePaddle 和 PaddleOCR
](
#1-paddlepaddle-和-paddleocr
)
-
[
2. 安装其他依赖
](
#2-安装其他依赖
)
-
[
2.1 KIE所需依赖
](
#21-kie所需依赖
)
# 快速安装
## 1. PaddlePaddle 和 PaddleOCR
可参考
[
PaddleOCR安装文档
](
../../doc/doc_ch/installation.md
)
## 2. 安装其他依赖
### 2.1 KIE所需依赖
*
paddleocr
```
bash
pip
install
paddleocr
-U
pip
install
-r
./kie/requirements.txt
```
ppstructure/docs/installation_en.md
已删除
100644 → 0
浏览文件 @
7fd35af4
# Quick installation
-
[
1. PaddlePaddle 和 PaddleOCR
](
#1
)
-
[
2. Install other dependencies
](
#2
)
-
[
2.1 KIE
](
#21
)
<a
name=
"1"
></a>
## 1. PaddlePaddle and PaddleOCR
Please refer to
[
PaddleOCR installation documentation
](
../../doc/doc_en/installation_en.md
)
<a
name=
"2"
></a>
## 2. Install other dependencies
<a
name=
"21"
></a>
### 2.1 KIE
*
paddleocr
```
bash
pip
install
paddleocr
-U
pip
install
-r
./kie/requirements.txt
```
ppstructure/docs/ppstructurev2_pipeline.png
0 → 100644
浏览文件 @
7261f4ae
1021.2 KB
ppstructure/docs/quickstart.md
浏览文件 @
7261f4ae
# PP-Structure 快速开始
-
[
1.
安装依赖包
](
#1-安装依赖包
)
-
[
1.
准备环境
](
#1-准备环境
)
-
[
2. 便捷使用
](
#2-便捷使用
)
-
[
2.1 命令行使用
](
#21-命令行使用
)
-
[
2.1.1 图像方向分类+版面分析+表格识别
](
#211-图像方向分类版面分析表格识别
)
...
...
@@ -9,33 +9,49 @@
-
[
2.1.4 表格识别
](
#214-表格识别
)
-
[
2.1.5 关键信息抽取
](
#215-关键信息抽取
)
-
[
2.1.6 版面恢复
](
#216-版面恢复
)
-
[
2.2 代码使用
](
#22-代码使用
)
- [2.2.1 图像方向+分类版面分析+表格识别](#221-图像方向分类版面分析表格识别)
-
[
2.2 Python脚本使用
](
#22-Python脚本使用
)
-
[
2.2.1 图像方向分类+版面分析+表格识别
](
#221-图像方向分类版面分析表格识别
)
-
[
2.2.2 版面分析+表格识别
](
#222-版面分析表格识别
)
-
[
2.2.3 版面分析
](
#223-版面分析
)
-
[
2.2.4 表格识别
](
#224-表格识别
)
-
[
2.2.5 关键信息抽取
](
#225-关键信息抽取
)
-
[
2.2.6 版面恢复
](
#226-版面恢复
)
-
[
2.3 返回结果说明
](
#23-返回结果说明
)
-
[
2.3.1 版面分析+表格识别
](
#231-版面分析表格识别
)
-
[
2.3.2 关键信息抽取
](
#232-关键信息抽取
)
-
[
2.4 参数说明
](
#24-参数说明
)
-
[
3. 小结
](
#3-小结
)
<a
name=
"1"
></a>
## 1. 安装依赖包
## 1. 准备环境
### 1.1 安装PaddlePaddle
> 如果您没有基础的Python运行环境,请参考[运行环境准备](../../doc/doc_ch/environment.md)。
-
您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
```
bash
python3
-m
pip
install
paddlepaddle-gpu
-i
https://mirror.baidu.com/pypi/simple
```
-
您的机器是CPU,请运行以下命令安装
```
bash
python3
-m
pip
install
paddlepaddle
-i
https://mirror.baidu.com/pypi/simple
```
更多的版本需求,请参照
[
飞桨官网安装文档
](
https://www.paddlepaddle.org.cn/install/quick
)
中的说明进行操作。
### 1.2 安装PaddleOCR whl包
```
bash
# 安装 paddleocr,推荐使用2.6版本
pip3
install
"paddleocr>=2.6"
# 安装 关键信息抽取 依赖包(如不需要KIE功能,可跳过)
pip
install
-r
kie/requirements.txt
# 安装 图像方向分类依赖包paddleclas(如不需要图像方向分类功能,可跳过)
pip3
install
paddleclas
# 安装 关键信息抽取 依赖包(如不需要KIE功能,可跳过)
pip3
install
-r
kie/requirements.txt
```
<a
name=
"2"
></a>
...
...
@@ -47,43 +63,43 @@ pip3 install paddleclas
<a
name=
"211"
></a>
#### 2.1.1 图像方向分类+版面分析+表格识别
```
bash
paddleocr
--image_dir
=
PaddleOCR/
ppstructure/docs/table/1.png
--type
=
structure
--image_orientation
=
true
paddleocr
--image_dir
=
ppstructure/docs/table/1.png
--type
=
structure
--image_orientation
=
true
```
<a
name=
"212"
></a>
#### 2.1.2 版面分析+表格识别
```
bash
paddleocr
--image_dir
=
PaddleOCR/
ppstructure/docs/table/1.png
--type
=
structure
paddleocr
--image_dir
=
ppstructure/docs/table/1.png
--type
=
structure
```
<a
name=
"213"
></a>
#### 2.1.3 版面分析
```
bash
paddleocr
--image_dir
=
PaddleOCR/
ppstructure/docs/table/1.png
--type
=
structure
--table
=
false
--ocr
=
false
paddleocr
--image_dir
=
ppstructure/docs/table/1.png
--type
=
structure
--table
=
false
--ocr
=
false
```
<a
name=
"214"
></a>
#### 2.1.4 表格识别
```
bash
paddleocr
--image_dir
=
PaddleOCR/
ppstructure/docs/table/table.jpg
--type
=
structure
--layout
=
false
paddleocr
--image_dir
=
ppstructure/docs/table/table.jpg
--type
=
structure
--layout
=
false
```
<a
name=
"215"
></a>
#### 2.1.5 关键信息抽取
请参考:
[
关键信息抽取教程
](
../kie/README_ch.md
)
。
关键信息抽取暂不支持通过whl包调用,详细使用教程
请参考:
[
关键信息抽取教程
](
../kie/README_ch.md
)
。
<a
name=
"216"
></a>
#### 2.1.6 版面恢复
```
bash
paddleocr
--image_dir
=
PaddleOCR/
ppstructure/docs/table/1.png
--type
=
structure
--recovery
=
true
paddleocr
--image_dir
=
ppstructure/docs/table/1.png
--type
=
structure
--recovery
=
true
```
<a
name=
"22"
></a>
### 2.2
代码
使用
### 2.2
Python脚本
使用
<a
name=
"221"
></a>
#### 2.2.1 图像方向分类+版面分析+表格识别
...
...
@@ -96,7 +112,7 @@ from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine
=
PPStructure
(
show_log
=
True
,
image_orientation
=
True
)
save_folder
=
'./output'
img_path
=
'
PaddleOCR/
ppstructure/docs/table/1.png'
img_path
=
'ppstructure/docs/table/1.png'
img
=
cv2
.
imread
(
img_path
)
result
=
table_engine
(
img
)
save_structure_res
(
result
,
save_folder
,
os
.
path
.
basename
(
img_path
).
split
(
'.'
)[
0
])
...
...
@@ -107,7 +123,7 @@ for line in result:
from
PIL
import
Image
font_path
=
'
PaddleOCR/
doc/fonts/simfang.ttf'
# PaddleOCR下提供字体包
font_path
=
'doc/fonts/simfang.ttf'
# PaddleOCR下提供字体包
image
=
Image
.
open
(
img_path
).
convert
(
'RGB'
)
im_show
=
draw_structure_result
(
image
,
result
,
font_path
=
font_path
)
im_show
=
Image
.
fromarray
(
im_show
)
...
...
@@ -125,7 +141,7 @@ from paddleocr import PPStructure,draw_structure_result,save_structure_res
table_engine
=
PPStructure
(
show_log
=
True
)
save_folder
=
'./output'
img_path
=
'
PaddleOCR/
ppstructure/docs/table/1.png'
img_path
=
'ppstructure/docs/table/1.png'
img
=
cv2
.
imread
(
img_path
)
result
=
table_engine
(
img
)
save_structure_res
(
result
,
save_folder
,
os
.
path
.
basename
(
img_path
).
split
(
'.'
)[
0
])
...
...
@@ -136,7 +152,7 @@ for line in result:
from
PIL
import
Image
font_path
=
'
PaddleOCR/
doc/fonts/simfang.ttf'
# PaddleOCR下提供字体包
font_path
=
'doc/fonts/simfang.ttf'
# PaddleOCR下提供字体包
image
=
Image
.
open
(
img_path
).
convert
(
'RGB'
)
im_show
=
draw_structure_result
(
image
,
result
,
font_path
=
font_path
)
im_show
=
Image
.
fromarray
(
im_show
)
...
...
@@ -154,7 +170,7 @@ from paddleocr import PPStructure,save_structure_res
table_engine
=
PPStructure
(
table
=
False
,
ocr
=
False
,
show_log
=
True
)
save_folder
=
'./output'
img_path
=
'
PaddleOCR/
ppstructure/docs/table/1.png'
img_path
=
'ppstructure/docs/table/1.png'
img
=
cv2
.
imread
(
img_path
)
result
=
table_engine
(
img
)
save_structure_res
(
result
,
save_folder
,
os
.
path
.
basename
(
img_path
).
split
(
'.'
)[
0
])
...
...
@@ -176,7 +192,7 @@ from paddleocr import PPStructure,save_structure_res
table_engine
=
PPStructure
(
layout
=
False
,
show_log
=
True
)
save_folder
=
'./output'
img_path
=
'
PaddleOCR/
ppstructure/docs/table/table.jpg'
img_path
=
'ppstructure/docs/table/table.jpg'
img
=
cv2
.
imread
(
img_path
)
result
=
table_engine
(
img
)
save_structure_res
(
result
,
save_folder
,
os
.
path
.
basename
(
img_path
).
split
(
'.'
)[
0
])
...
...
@@ -189,7 +205,7 @@ for line in result:
<a
name=
"225"
></a>
#### 2.2.5 关键信息抽取
请参考:
[
关键信息抽取教程
](
../kie/README_ch.md
)
。
关键信息抽取暂不支持通过whl包调用,详细使用教程
请参考:
[
关键信息抽取教程
](
../kie/README_ch.md
)
。
<a
name=
"226"
></a>
...
...
@@ -204,7 +220,7 @@ from paddelocr.ppstructure.recovery.recovery_to_doc import sorted_layout_boxes,
table_engine
=
PPStructure
(
layout
=
False
,
show_log
=
True
)
save_folder
=
'./output'
img_path
=
'
PaddleOCR/
ppstructure/docs/table/1.png'
img_path
=
'ppstructure/docs/table/1.png'
img
=
cv2
.
imread
(
img_path
)
result
=
table_engine
(
img
)
save_structure_res
(
result
,
save_folder
,
os
.
path
.
basename
(
img_path
).
split
(
'.'
)[
0
])
...
...
@@ -220,7 +236,7 @@ convert_info_docx(img, result, save_folder, os.path.basename(img_path).split('.'
<a
name=
"23"
></a>
### 2.3 返回结果说明
PP-Structure的返回结果为一个dict组成的list,示例如下
PP-Structure的返回结果为一个dict组成的list,示例如下
:
<a
name=
"231"
></a>
#### 2.3.1 版面分析+表格识别
...
...
@@ -233,7 +249,7 @@ PP-Structure的返回结果为一个dict组成的list,示例如下
}
]
```
dict 里各个字段说明如下
dict 里各个字段说明如下
:
| 字段 | 说明|
| --- |---|
...
...
@@ -283,3 +299,8 @@ dict 里各个字段说明如下
| structure_version | 模型版本,可选 PP-structure和PP-structurev2 | PP-structure |
大部分参数和PaddleOCR whl包保持一致,见
[
whl包文档
](
../../doc/doc_ch/whl.md
)
<a
name=
"3"
></a>
## 3. 小结
通过本节内容,相信您已经熟练掌握通过PaddleOCR whl包调用PP-Structure相关功能的使用方法,您可以参考
[
文档教程
](
../../README_ch.md#文档教程
)
,获取包括模型训练、推理部署等更详细的使用教程。
\ No newline at end of file
ppstructure/layout/README.md
→
ppstructure/layout/README
_ch
.md
浏览文件 @
7261f4ae
-
[
1. 简介
](
#1-简介
)
-
[
2. 安装
](
#2-安装
)
-
[
2.1 安装PaddlePaddle
](
#21-安装paddlepaddle
)
-
[
2.2 安装PaddleDetection
](
#22-安装paddledetection
)
-
[
3. 数据准备
](
#3-数据准备
)
-
[
3.1 英文数据集
](
#31-英文数据集
)
-
[
3.2 更多数据集
](
#32-更多数据集
)
-
[
4. 开始训练
](
#4-开始训练
)
-
[
4.1 启动训练
](
#41-启动训练
)
-
[
4.2 FGD蒸馏训练
](
#42-FGD蒸馏训练
)
-
[
5. 模型评估与预测
](
#5-模型评估与预测
)
-
[
5.1 指标评估
](
#51-指标评估
)
-
[
5.2 测试版面分析结果
](
#52-测试版面分析结果
)
-
[
6 模型导出与预测
](
#6-模型导出与预测
)
-
[
6.1 模型导出
](
#61-模型导出
)
-
[
6.2 模型推理
](
#62-模型推理
)
# 版面分析
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}