fix conflict
Showing
.github/ISSUE_TEMPLATE/custom.md
0 → 100644
因为 它太大了无法显示 source diff 。你可以改为 查看blob。
PPOCRLabel/requirements.txt
0 → 100644
文件已移动
文件已移动
deploy/paddle2onnx/readme.md
0 → 100644
doc/banner.png
0 → 100644
{kind=link}

138.3 KB
doc/doc_ch/enhanced_ctc_loss.md
0 → 100644
doc/doc_ch/equation_a_ctc.png
0 → 100644
{kind=link}
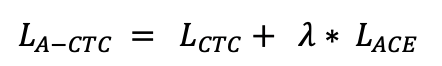
10.2 KB
doc/doc_ch/equation_c_ctc.png
0 → 100644
{kind=link}
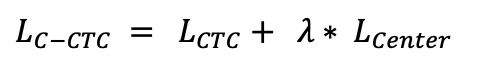
10.6 KB
doc/doc_ch/equation_ctcloss.png
0 → 100644
{kind=link}
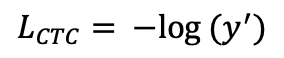
9.3 KB
doc/doc_ch/equation_focal_ctc.png
0 → 100644
{kind=link}
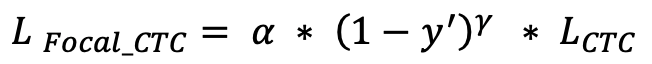
14.5 KB
doc/doc_ch/focal_loss_formula.png
0 → 100644
{kind=link}
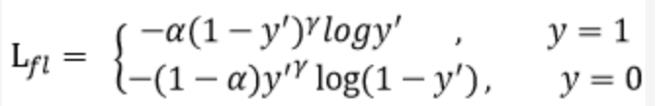
23.3 KB
doc/doc_ch/focal_loss_image.png
0 → 100644
{kind=link}
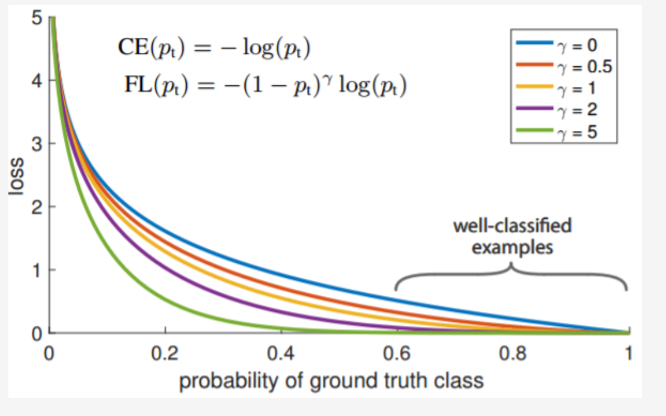
124.7 KB
doc/doc_ch/models.md
0 → 100644
doc/doc_ch/rec_algo_compare.png
0 → 100644
{kind=link}
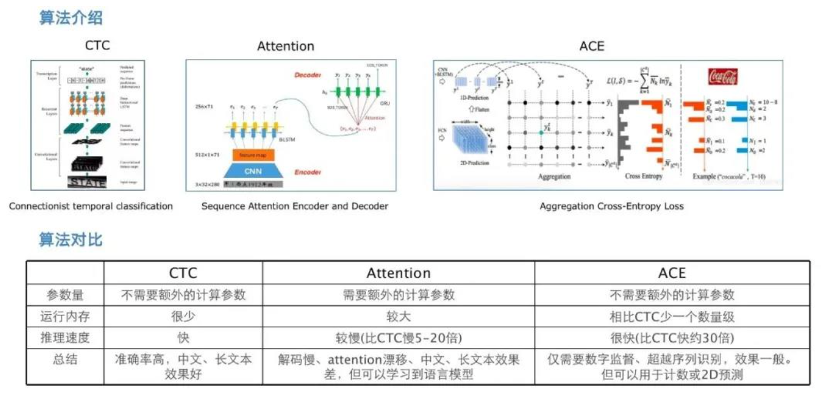
223.6 KB
doc/doc_ch/thirdparty.md
0 → 100644
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/pr.png
0 → 100644
{kind=link}

538.1 KB
ppocr/utils/EN_symbol_dict.txt
0 → 100644
ppocr/utils/dict90.txt
0 → 100644
test_tipc/common_func.sh
0 → 100644
文件已移动
文件已移动
文件已移动
{kind=link}

49.4 KB
{kind=link}
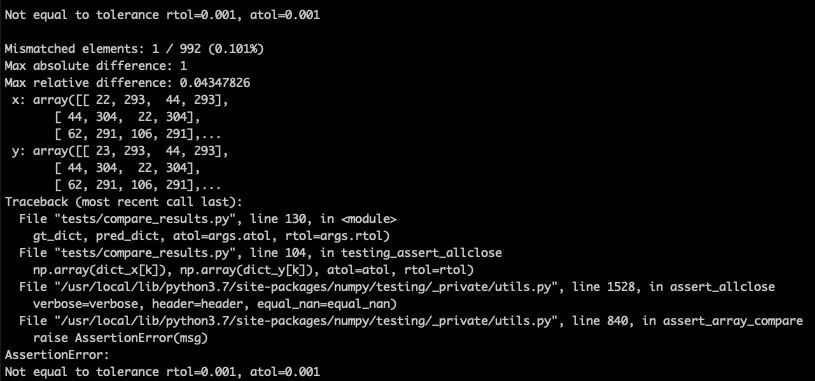
63.3 KB
test_tipc/docs/compare_right.png
0 → 100644
{kind=link}

33.0 KB
test_tipc/docs/compare_wrong.png
0 → 100644
{kind=link}
64.2 KB
test_tipc/docs/guide.png
0 → 100644
{kind=link}
138.3 KB
test_tipc/docs/install.md
0 → 100644
test_tipc/docs/lite_auto_log.png
0 → 100644
{kind=link}
209.8 KB
test_tipc/docs/lite_log.png
0 → 100644
{kind=link}

168.7 KB
test_tipc/docs/ssh_termux_ls.png
0 → 100644
{kind=link}

31.6 KB
test_tipc/docs/termux.jpg
0 → 100644
{kind=link}
74.1 KB
test_tipc/docs/test.png
0 → 100644
{kind=link}
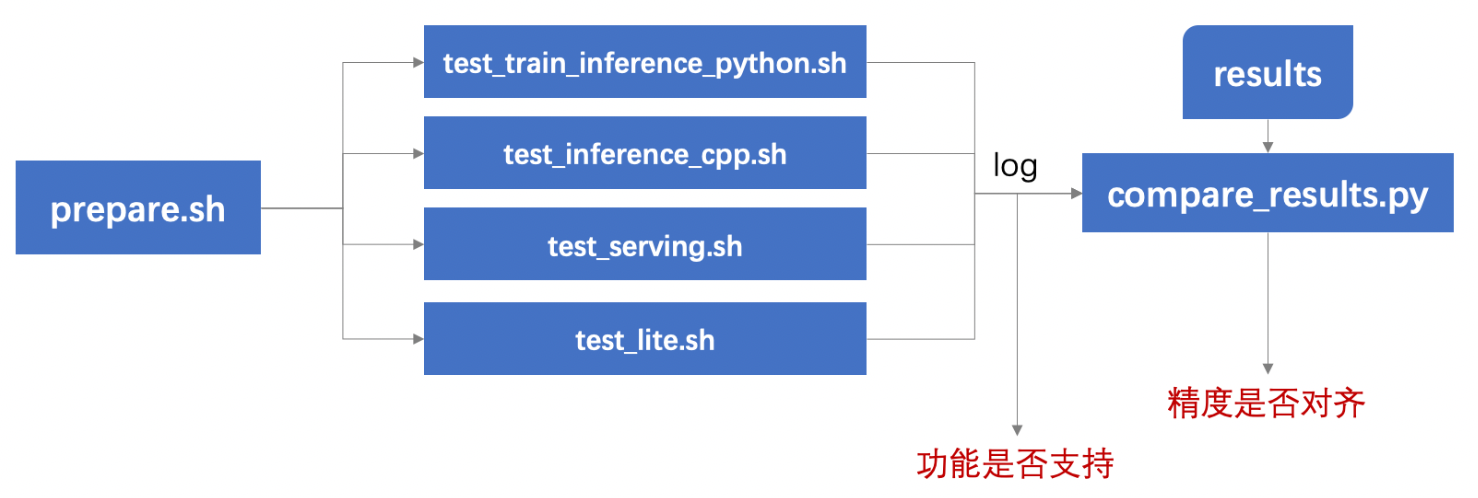
223.8 KB
test_tipc/docs/test_serving.md
0 → 100644
test_tipc/prepare_lite_cpp.sh
0 → 100644
test_tipc/readme.md
0 → 100644
文件已移动
文件已移动
文件已移动
文件已移动
test_tipc/test_inference_cpp.sh
0 → 100644
test_tipc/test_lite_arm_cpp.sh
0 → 100644
test_tipc/test_paddle2onnx.sh
0 → 100644
test_tipc/test_serving.sh
0 → 100644
tests/readme.md
已删除
100644 → 0
tools/__init__.py
0 → 100644
tools/export_center.py
0 → 100644
tools/infer/utility.py
100755 → 100644