Merge remote-tracking branch 'origin/dygraph' into dygraph
Showing
文件已移动
文件已移动
文件已移动
文件已移动
configs/rec/rec_r31_sar.yml
0 → 100644
{kind=link}
因为 它太大了无法显示 image diff 。你可以改为 查看blob。
{kind=link}
此差异已折叠。
{kind=link}
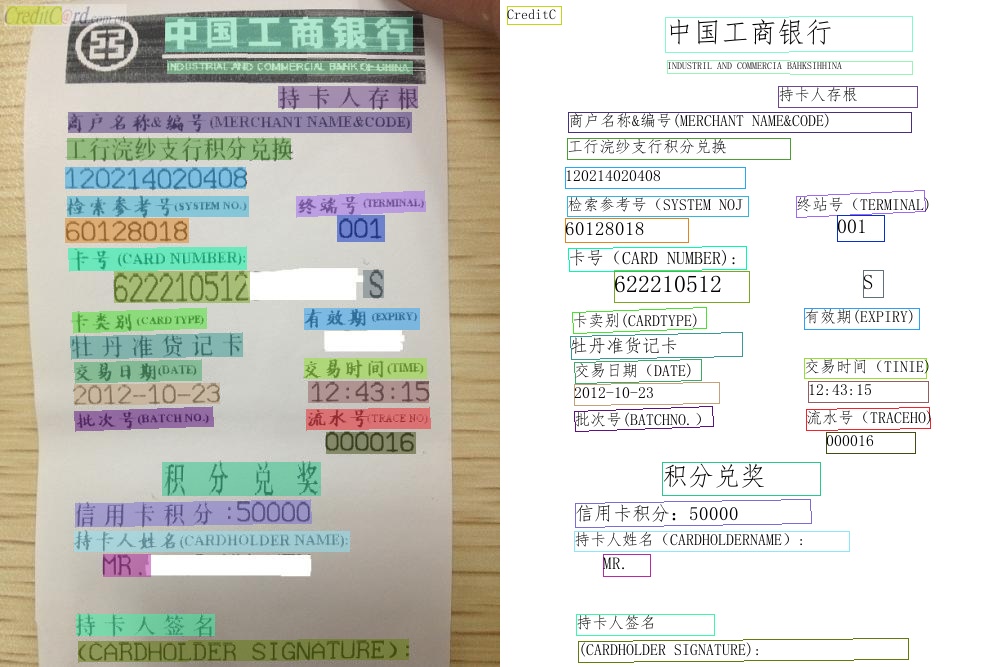
192.4 KB
{kind=link}
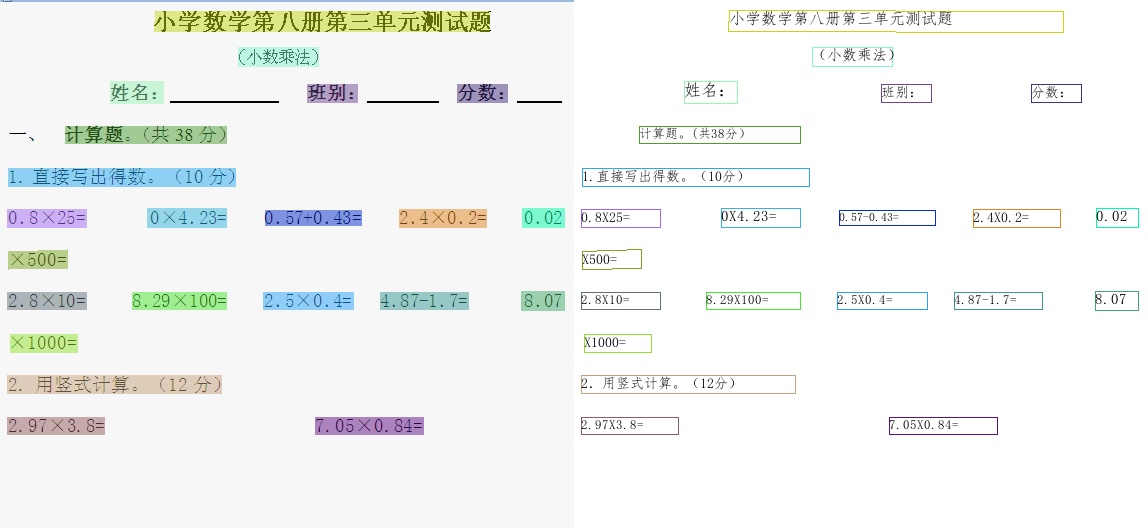
93.6 KB
{kind=link}

246.4 KB
ppocr/losses/rec_sar_loss.py
0 → 100644
tests/configs/det_mv3_db.yml
0 → 100644
tests/configs/det_r50_vd_db.yml
0 → 100644
tests/ocr_ppocr_mobile_params.txt
0 → 100644