diff --git "a/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md" "b/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
new file mode 100644
index 0000000000000000000000000000000000000000..a831813c1504a0d00db23f0218154cbf36741118
--- /dev/null
+++ "b/applications/\345\244\232\346\250\241\346\200\201\350\241\250\345\215\225\350\257\206\345\210\253.md"
@@ -0,0 +1,879 @@
+# 1 项目说明
+
+计算机视觉在金融领域的应用覆盖文字识别、图像识别、视频识别等,其中文字识别(OCR)是金融领域中的核心AI能力,其应用覆盖客户服务、风险防控、运营管理等各项业务,针对的对象包括通用卡证票据识别(银行卡、身份证、营业执照等)、通用文本表格识别(印刷体、多语言、手写体等)以及一些金融特色票据凭证。通过因此如果能够在结构化信息提取时同时利用文字、页面布局等信息,便可增强不同版式下的泛化性。
+
+表单识别旨在识别各种具有表格性质的证件、房产证、营业执照、个人信息表、发票等关键键值对(如姓名-张三),其广泛应用于银行、证券、公司财务等领域,具有很高的商业价值。本次范例项目开源了全流程表单识别方案,能够在多个场景快速实现迁移能力。表单识别通常存在以下难点:
+
+- 人工摘录工作效率低;
+- 国内常见表单版式多;
+- 传统技术方案泛化效果不满足。
+
+
+表单识别包含两大阶段:OCR阶段和文档视觉问答阶段。
+
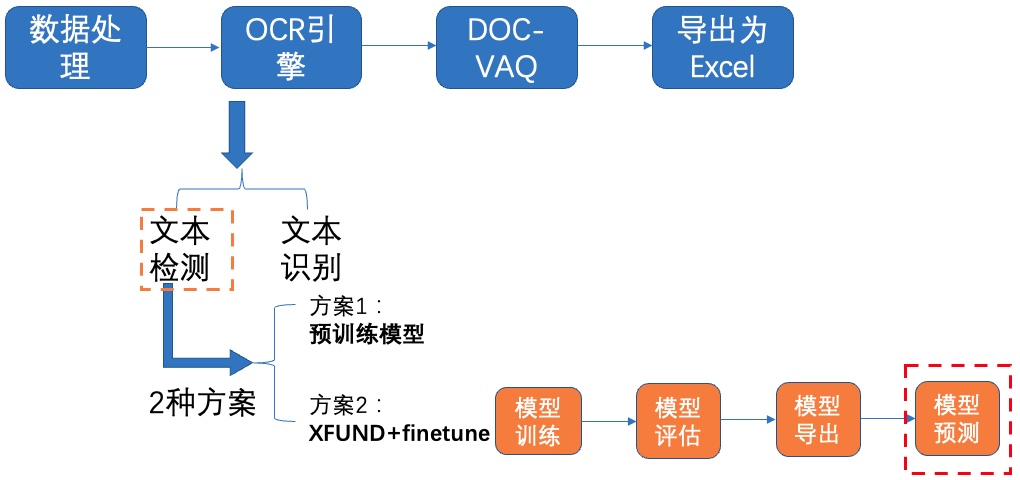
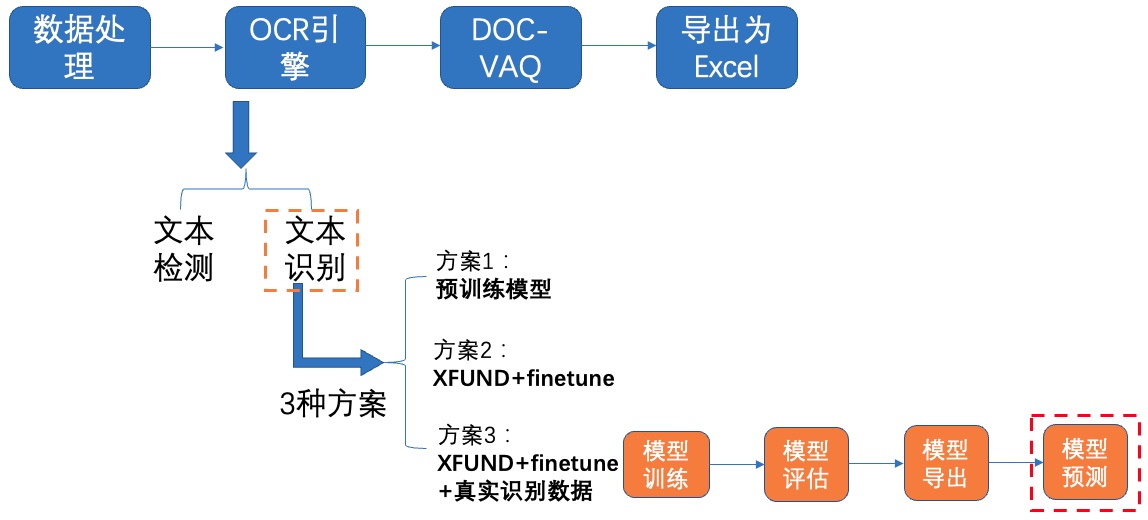
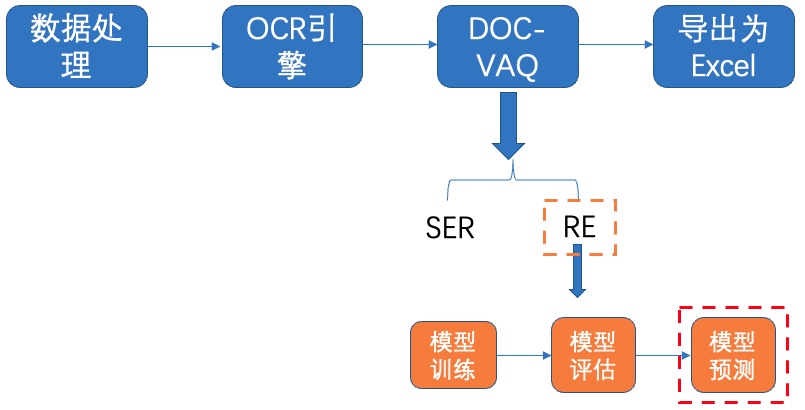
+其中,OCR阶段选取了PaddleOCR的PP-OCRv2模型,主要由文本检测和文本识别两个模块组成。DOC-VQA文档视觉问答阶段基于PaddleNLP自然语言处理算法库实现的LayoutXLM模型,支持基于多模态方法的语义实体识别(Semantic Entity Recognition, SER)以及关系抽取(Relation Extraction, RE)任务。本案例流程如 **图1** 所示:
+
+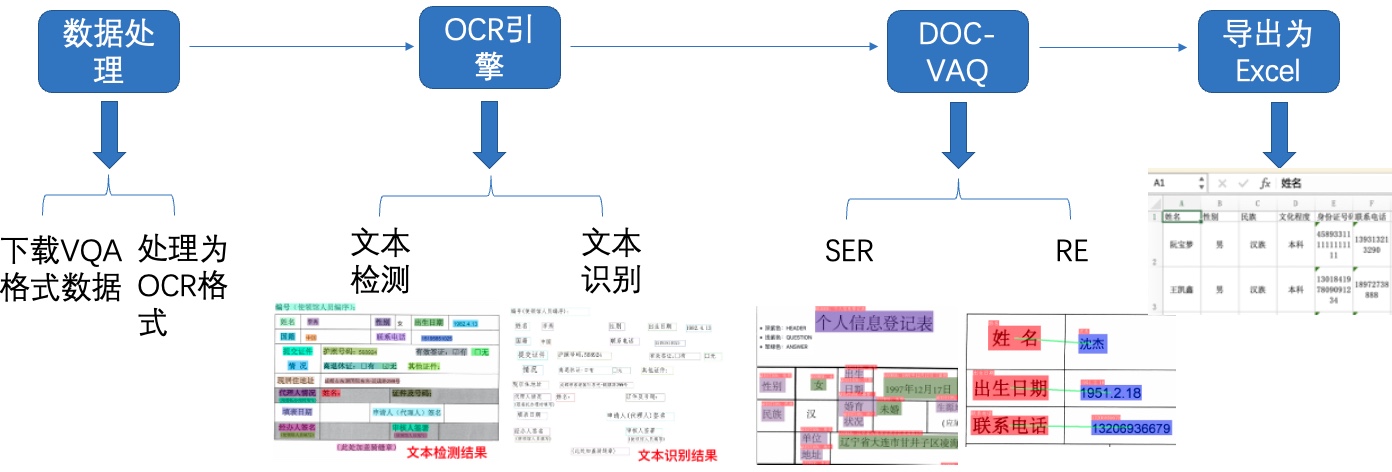 +图1 多模态表单识别流程图
+
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: 多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+
+
+
+# 2 安装说明
+
+
+下载PaddleOCR源码,本项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
+
+
+```python
+! unzip -q PaddleOCR.zip
+```
+
+
+```python
+# 如仍需安装or安装更新,可以执行以下步骤
+! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
+```
+
+
+```python
+# 安装依赖包
+! pip install -U pip
+! pip install -r /home/aistudio/PaddleOCR/requirements.txt
+! pip install paddleocr
+
+! pip install yacs gnureadline paddlenlp==2.2.1
+! pip install xlsxwriter
+```
+
+# 3 数据准备
+
+这里使用[XFUN数据集](https://github.com/doc-analysis/XFUND)做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
+
+分别为:ZH(中文)、JA(日语)、ES(西班牙)、FR(法语)、IT(意大利)、DE(德语)、PT(葡萄牙)
+
+本次实验选取中文数据集作为我们的演示数据集。法语数据集作为实践课程的数据集,数据集样例图如 **图2** 所示。
+
+
+图1 多模态表单识别流程图
+
+注:欢迎再AIStudio领取免费算力体验线上实训,项目链接: 多模态表单识别](https://aistudio.baidu.com/aistudio/projectdetail/3815918)(配备Tesla V100、A100等高级算力资源)
+
+
+
+# 2 安装说明
+
+
+下载PaddleOCR源码,本项目中已经帮大家打包好的PaddleOCR(已经修改好配置文件),无需下载解压即可,只需安装依赖环境~
+
+
+```python
+! unzip -q PaddleOCR.zip
+```
+
+
+```python
+# 如仍需安装or安装更新,可以执行以下步骤
+! git clone https://github.com/PaddlePaddle/PaddleOCR.git -b dygraph
+# ! git clone https://gitee.com/PaddlePaddle/PaddleOCR
+```
+
+
+```python
+# 安装依赖包
+! pip install -U pip
+! pip install -r /home/aistudio/PaddleOCR/requirements.txt
+! pip install paddleocr
+
+! pip install yacs gnureadline paddlenlp==2.2.1
+! pip install xlsxwriter
+```
+
+# 3 数据准备
+
+这里使用[XFUN数据集](https://github.com/doc-analysis/XFUND)做为实验数据集。 XFUN数据集是微软提出的一个用于KIE任务的多语言数据集,共包含七个数据集,每个数据集包含149张训练集和50张验证集
+
+分别为:ZH(中文)、JA(日语)、ES(西班牙)、FR(法语)、IT(意大利)、DE(德语)、PT(葡萄牙)
+
+本次实验选取中文数据集作为我们的演示数据集。法语数据集作为实践课程的数据集,数据集样例图如 **图2** 所示。
+
+ +图2 数据集样例,左中文,右法语
+
+## 3.1 下载处理好的数据集
+
+
+处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar) ,可以运行如下指令完成中文数据集下载和解压。
+
+
+图2 数据集样例,左中文,右法语
+
+## 3.1 下载处理好的数据集
+
+
+处理好的XFUND中文数据集下载地址:[https://paddleocr.bj.bcebos.com/dataset/XFUND.tar](https://paddleocr.bj.bcebos.com/dataset/XFUND.tar) ,可以运行如下指令完成中文数据集下载和解压。
+
+ +图3 下载数据集
+
+
+```python
+! wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+! tar -xf XFUND.tar
+
+# XFUN其他数据集使用下面的代码进行转换
+# 代码链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppstructure/vqa/helper/trans_xfun_data.py
+# %cd PaddleOCR
+# !python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
+# %cd ../
+```
+
+运行上述指令后在 /home/aistudio/PaddleOCR/ppstructure/vqa/XFUND 目录下有2个文件夹,目录结构如下所示:
+
+```bash
+/home/aistudio/PaddleOCR/ppstructure/vqa/XFUND
+ └─ zh_train/ 训练集
+ ├── image/ 图片存放文件夹
+ ├── xfun_normalize_train.json 标注信息
+ └─ zh_val/ 验证集
+ ├── image/ 图片存放文件夹
+ ├── xfun_normalize_val.json 标注信息
+
+```
+
+该数据集的标注格式为
+
+```bash
+{
+ "height": 3508, # 图像高度
+ "width": 2480, # 图像宽度
+ "ocr_info": [
+ {
+ "text": "邮政地址:", # 单个文本内容
+ "label": "question", # 文本所属类别
+ "bbox": [261, 802, 483, 859], # 单个文本框
+ "id": 54, # 文本索引
+ "linking": [[54, 60]], # 当前文本和其他文本的关系 [question, answer]
+ "words": []
+ },
+ {
+ "text": "湖南省怀化市市辖区",
+ "label": "answer",
+ "bbox": [487, 810, 862, 859],
+ "id": 60,
+ "linking": [[54, 60]],
+ "words": []
+ }
+ ]
+}
+```
+
+## 3.2 转换为PaddleOCR检测和识别格式
+
+使用XFUND训练PaddleOCR检测和识别模型,需要将数据集格式改为训练需求的格式。
+
+
+图3 下载数据集
+
+
+```python
+! wget https://paddleocr.bj.bcebos.com/dataset/XFUND.tar
+! tar -xf XFUND.tar
+
+# XFUN其他数据集使用下面的代码进行转换
+# 代码链接:https://github.com/PaddlePaddle/PaddleOCR/blob/release%2F2.4/ppstructure/vqa/helper/trans_xfun_data.py
+# %cd PaddleOCR
+# !python3 ppstructure/vqa/tools/trans_xfun_data.py --ori_gt_path=path/to/json_path --output_path=path/to/save_path
+# %cd ../
+```
+
+运行上述指令后在 /home/aistudio/PaddleOCR/ppstructure/vqa/XFUND 目录下有2个文件夹,目录结构如下所示:
+
+```bash
+/home/aistudio/PaddleOCR/ppstructure/vqa/XFUND
+ └─ zh_train/ 训练集
+ ├── image/ 图片存放文件夹
+ ├── xfun_normalize_train.json 标注信息
+ └─ zh_val/ 验证集
+ ├── image/ 图片存放文件夹
+ ├── xfun_normalize_val.json 标注信息
+
+```
+
+该数据集的标注格式为
+
+```bash
+{
+ "height": 3508, # 图像高度
+ "width": 2480, # 图像宽度
+ "ocr_info": [
+ {
+ "text": "邮政地址:", # 单个文本内容
+ "label": "question", # 文本所属类别
+ "bbox": [261, 802, 483, 859], # 单个文本框
+ "id": 54, # 文本索引
+ "linking": [[54, 60]], # 当前文本和其他文本的关系 [question, answer]
+ "words": []
+ },
+ {
+ "text": "湖南省怀化市市辖区",
+ "label": "answer",
+ "bbox": [487, 810, 862, 859],
+ "id": 60,
+ "linking": [[54, 60]],
+ "words": []
+ }
+ ]
+}
+```
+
+## 3.2 转换为PaddleOCR检测和识别格式
+
+使用XFUND训练PaddleOCR检测和识别模型,需要将数据集格式改为训练需求的格式。
+
+ +图4 转换为OCR格式
+
+- **文本检测** 标注文件格式如下,中间用'\t'分隔:
+
+" 图像文件名 json.dumps编码的图像标注信息"
+ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
+
+json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 `transcription` 表示当前文本框的文字,***当其内容为“###”时,表示该文本框无效,在训练时会跳过。***
+
+- **文本识别** 标注文件的格式如下, txt文件中默认请将图片路径和图片标签用'\t'分割,如用其他方式分割将造成训练报错。
+
+```
+" 图像文件名 图像标注信息 "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+
+
+
+```python
+! unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
+```
+
+已经提供转换脚本,执行如下代码即可转换成功:
+
+
+```python
+%cd /home/aistudio/
+! python trans_xfund_data.py
+```
+
+# 4 OCR
+
+选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md)中的PP-OCRv2模型进行文本检测和识别。PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/enhanced_ctc_loss.md)损失函数改进,进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2[技术报告](https://arxiv.org/abs/2109.03144)。
+
+
+## 4.1 文本检测
+
+我们使用2种方案进行训练、评估:
+- **PP-OCRv2中英文超轻量检测预训练模型**
+- **XFUND数据集+fine-tune**
+
+### **4.1.1 方案1:预训练模型**
+
+**1)下载预训练模型**
+
+
+图4 转换为OCR格式
+
+- **文本检测** 标注文件格式如下,中间用'\t'分隔:
+
+" 图像文件名 json.dumps编码的图像标注信息"
+ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
+
+json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 `points` 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 `transcription` 表示当前文本框的文字,***当其内容为“###”时,表示该文本框无效,在训练时会跳过。***
+
+- **文本识别** 标注文件的格式如下, txt文件中默认请将图片路径和图片标签用'\t'分割,如用其他方式分割将造成训练报错。
+
+```
+" 图像文件名 图像标注信息 "
+
+train_data/rec/train/word_001.jpg 简单可依赖
+train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
+...
+```
+
+
+
+
+```python
+! unzip -q /home/aistudio/data/data140302/XFUND_ori.zip -d /home/aistudio/data/data140302/
+```
+
+已经提供转换脚本,执行如下代码即可转换成功:
+
+
+```python
+%cd /home/aistudio/
+! python trans_xfund_data.py
+```
+
+# 4 OCR
+
+选用飞桨OCR开发套件[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/README_ch.md)中的PP-OCRv2模型进行文本检测和识别。PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/doc/doc_ch/enhanced_ctc_loss.md)损失函数改进,进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2[技术报告](https://arxiv.org/abs/2109.03144)。
+
+
+## 4.1 文本检测
+
+我们使用2种方案进行训练、评估:
+- **PP-OCRv2中英文超轻量检测预训练模型**
+- **XFUND数据集+fine-tune**
+
+### **4.1.1 方案1:预训练模型**
+
+**1)下载预训练模型**
+
+ +图5 文本检测方案1-下载预训练模型
+
+
+PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示:
+
+| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
+| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
+| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
+
+更多模型下载(包括多语言),可以参考[PP-OCR 系列模型下载](./doc/doc_ch/models_list.md)
+
+
+这里我们使用PP-OCRv2中英文超轻量检测模型,下载并解压预训练模型:
+
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/pretrain/
+! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
+! tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
+% cd ..
+```
+
+**2)模型评估**
+
+
+图5 文本检测方案1-下载预训练模型
+
+
+PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示:
+
+| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
+| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
+| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_infer.tar) / [训练模型](https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar) |
+| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar) |
+| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_det_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar) | [推理模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_infer.tar) / [预训练模型](https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_server_v2.0_rec_pre.tar) |
+
+更多模型下载(包括多语言),可以参考[PP-OCR 系列模型下载](./doc/doc_ch/models_list.md)
+
+
+这里我们使用PP-OCRv2中英文超轻量检测模型,下载并解压预训练模型:
+
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/pretrain/
+! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_det_distill_train.tar
+! tar -xf ch_PP-OCRv2_det_distill_train.tar && rm -rf ch_PP-OCRv2_det_distill_train.tar
+% cd ..
+```
+
+**2)模型评估**
+
+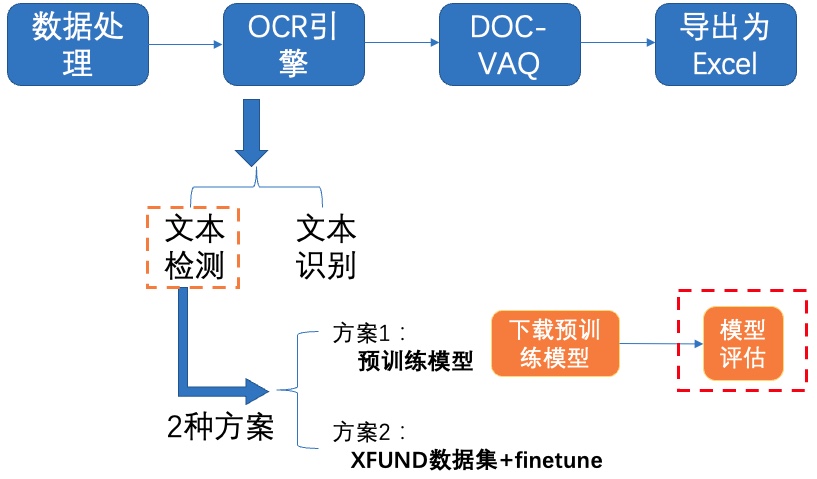 +图6 文本检测方案1-模型评估
+
+接着使用下载的超轻量检测模型在XFUND验证集上进行评估,由于蒸馏需要包含多个网络,甚至多个Student网络,在计算指标的时候只需要计算一个Student网络的指标即可,key字段设置为Student则表示只计算Student网络的精度。
+
+```
+Metric:
+ name: DistillationMetric
+ base_metric_name: DetMetric
+ main_indicator: hmean
+ key: "Student"
+```
+首先修改配置文件`configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
+
+然后在XFUND验证集上进行评估,具体代码如下:
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+! python tools/eval.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml \
+ -o Global.checkpoints="./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy"
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | hmeans |
+| -------- | -------- |
+| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% |
+
+使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
+
+### **4.1.2 方案2:XFUND数据集+fine-tune**
+
+PaddleOCR提供的蒸馏预训练模型包含了多个模型的参数,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("pretrain/ch_PP-OCRv2_det_distill_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+# print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("student_model."):]: all_params[key] for key in all_params if "student_model." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "pretrain/ch_PP-OCRv2_det_distill_train/student.pdparams")
+```
+
+**1)模型训练**
+
+
+图6 文本检测方案1-模型评估
+
+接着使用下载的超轻量检测模型在XFUND验证集上进行评估,由于蒸馏需要包含多个网络,甚至多个Student网络,在计算指标的时候只需要计算一个Student网络的指标即可,key字段设置为Student则表示只计算Student网络的精度。
+
+```
+Metric:
+ name: DistillationMetric
+ base_metric_name: DetMetric
+ main_indicator: hmean
+ key: "Student"
+```
+首先修改配置文件`configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml`中的以下字段:
+```
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
+
+然后在XFUND验证集上进行评估,具体代码如下:
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+! python tools/eval.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_distill.yml \
+ -o Global.checkpoints="./pretrain_models/ch_PP-OCRv2_det_distill_train/best_accuracy"
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | hmeans |
+| -------- | -------- |
+| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% |
+
+使用文本检测预训练模型在XFUND验证集上评估,达到77%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
+
+### **4.1.2 方案2:XFUND数据集+fine-tune**
+
+PaddleOCR提供的蒸馏预训练模型包含了多个模型的参数,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("pretrain/ch_PP-OCRv2_det_distill_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+# print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("student_model."):]: all_params[key] for key in all_params if "student_model." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "pretrain/ch_PP-OCRv2_det_distill_train/student.pdparams")
+```
+
+**1)模型训练**
+
+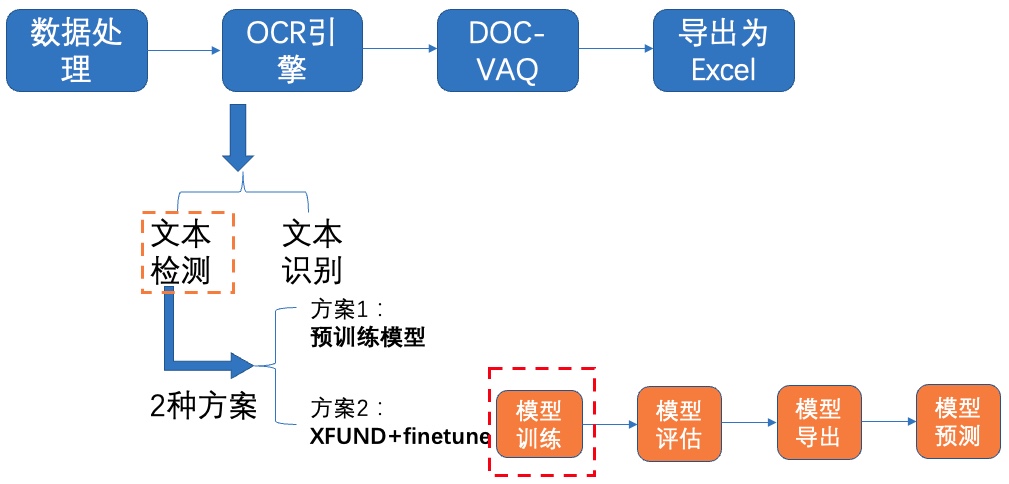 +图7 文本检测方案2-模型训练
+
+
+修改配置文件`configs/det/ch_PP-OCRv2_det_student.yml`中的以下字段:
+```
+Global.pretrained_model:指向预训练模型路径
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+Optimizer.lr.learning_rate:调整学习率,本实验设置为0.005
+Train.dataset.transforms.EastRandomCropData.size:训练尺寸改为[1600, 1600]
+Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
+ limit_side_len: 1600
+ limit_type: 'min'
+
+```
+执行下面命令启动训练:
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
+```
+
+**2)模型评估**
+
+
+图7 文本检测方案2-模型训练
+
+
+修改配置文件`configs/det/ch_PP-OCRv2_det_student.yml`中的以下字段:
+```
+Global.pretrained_model:指向预训练模型路径
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+Optimizer.lr.learning_rate:调整学习率,本实验设置为0.005
+Train.dataset.transforms.EastRandomCropData.size:训练尺寸改为[1600, 1600]
+Eval.dataset.transforms.DetResizeForTest:评估尺寸,添加如下参数
+ limit_side_len: 1600
+ limit_type: 'min'
+
+```
+执行下面命令启动训练:
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml
+```
+
+**2)模型评估**
+
+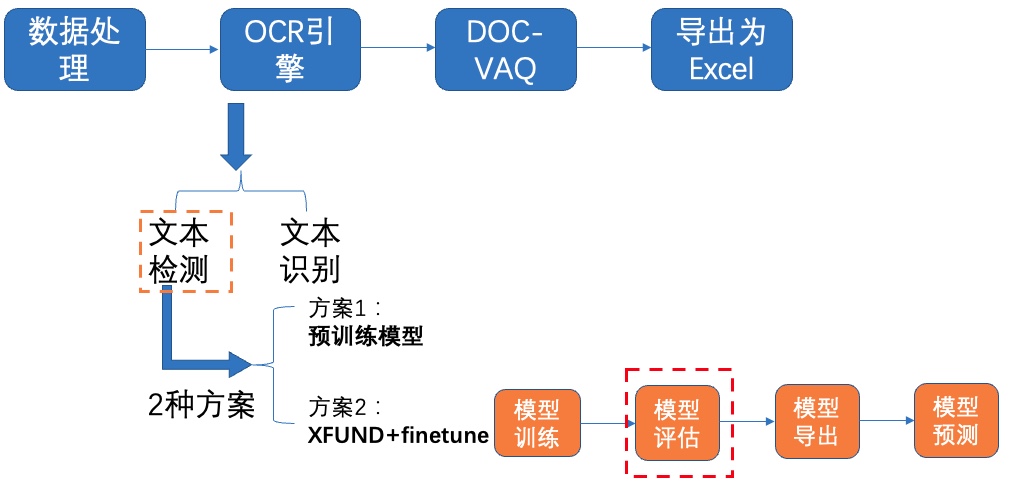 +图8 文本检测方案2-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! python tools/eval.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
+ -o Global.checkpoints="pretrain/ch_db_mv3-student1600-finetune/best_accuracy"
+```
+
+同时我们提供了未finetuen的模型,配置文件参数(`pretrained_model`设置为空,`learning_rate` 设置为0.001)
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! python tools/eval.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
+ -o Global.checkpoints="pretrain/ch_db_mv3-student1600/best_accuracy"
+```
+
+使用训练好的模型进行评估,指标如下所示:
+
+| 方案 | hmeans |
+| -------- | -------- |
+| XFUND数据集 | 79.27% |
+| XFUND数据集+fine-tune | 85.24% |
+
+对比仅使用XFUND数据集训练的模型,使用XFUND数据集+finetune训练,在验证集上评估达到85%左右,说明 finetune会提升垂类场景效果。
+
+**3)导出模型**
+
+
+图8 文本检测方案2-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/ch_db_mv3-student1600-finetune/best_accuracy`
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! python tools/eval.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
+ -o Global.checkpoints="pretrain/ch_db_mv3-student1600-finetune/best_accuracy"
+```
+
+同时我们提供了未finetuen的模型,配置文件参数(`pretrained_model`设置为空,`learning_rate` 设置为0.001)
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! python tools/eval.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
+ -o Global.checkpoints="pretrain/ch_db_mv3-student1600/best_accuracy"
+```
+
+使用训练好的模型进行评估,指标如下所示:
+
+| 方案 | hmeans |
+| -------- | -------- |
+| XFUND数据集 | 79.27% |
+| XFUND数据集+fine-tune | 85.24% |
+
+对比仅使用XFUND数据集训练的模型,使用XFUND数据集+finetune训练,在验证集上评估达到85%左右,说明 finetune会提升垂类场景效果。
+
+**3)导出模型**
+
+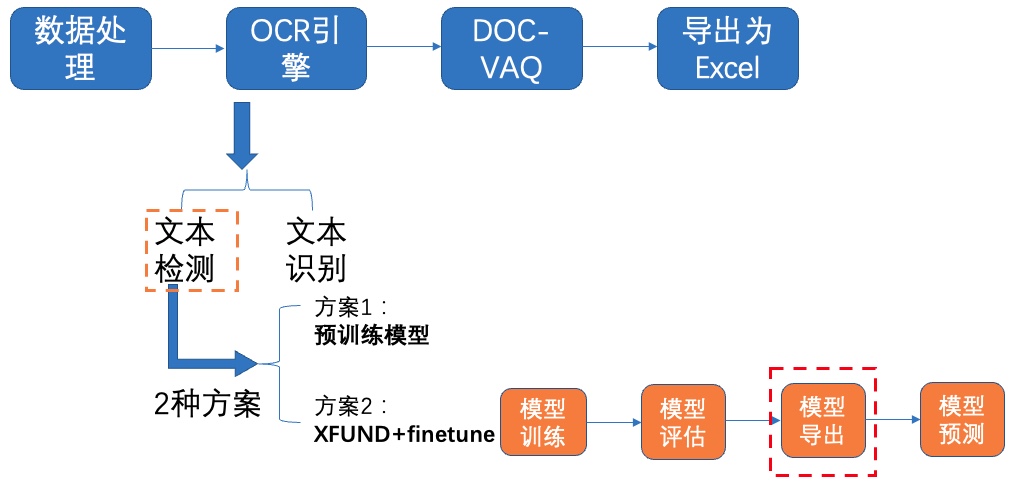 +图9 文本检测方案2-模型导出
+
+在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型。
+
+
+```python
+# 加载配置文件`ch_PP-OCRv2_det_student.yml`,从`pretrain/ch_db_mv3-student1600-finetune`目录下加载`best_accuracy`模型
+# inference模型保存在`./output/det_db_inference`目录下
+%cd /home/aistudio/PaddleOCR/
+! python tools/export_model.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
+ -o Global.pretrained_model="pretrain/ch_db_mv3-student1600-finetune/best_accuracy" \
+ Global.save_inference_dir="./output/det_db_inference/"
+```
+
+转换成功后,在目录下有三个文件:
+```
+/inference/rec_crnn/
+ ├── inference.pdiparams # 识别inference模型的参数文件
+ ├── inference.pdiparams.info # 识别inference模型的参数信息,可忽略
+ └── inference.pdmodel # 识别inference模型的program文件
+```
+
+**4)模型预测**
+
+
+图9 文本检测方案2-模型导出
+
+在模型训练过程中保存的模型文件是包含前向预测和反向传播的过程,在实际的工业部署则不需要反向传播,因此需要将模型进行导成部署需要的模型格式。 执行下面命令,即可导出模型。
+
+
+```python
+# 加载配置文件`ch_PP-OCRv2_det_student.yml`,从`pretrain/ch_db_mv3-student1600-finetune`目录下加载`best_accuracy`模型
+# inference模型保存在`./output/det_db_inference`目录下
+%cd /home/aistudio/PaddleOCR/
+! python tools/export_model.py \
+ -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_student.yml \
+ -o Global.pretrained_model="pretrain/ch_db_mv3-student1600-finetune/best_accuracy" \
+ Global.save_inference_dir="./output/det_db_inference/"
+```
+
+转换成功后,在目录下有三个文件:
+```
+/inference/rec_crnn/
+ ├── inference.pdiparams # 识别inference模型的参数文件
+ ├── inference.pdiparams.info # 识别inference模型的参数信息,可忽略
+ └── inference.pdmodel # 识别inference模型的program文件
+```
+
+**4)模型预测**
+
+ +图10 文本检测方案2-模型预测
+
+加载上面导出的模型,执行如下命令对验证集或测试集图片进行预测:
+
+```
+det_model_dir:预测模型
+image_dir:测试图片路径
+use_gpu:是否使用GPU
+```
+
+检测可视化结果保存在`/home/aistudio/inference_results/`目录下,查看检测效果。
+
+
+```python
+%pwd
+!python tools/infer/predict_det.py \
+ --det_algorithm="DB" \
+ --det_model_dir="./output/det_db_inference/" \
+ --image_dir="./doc/vqa/input/zh_val_21.jpg" \
+ --use_gpu=True
+```
+
+总结,我们分别使用PP-OCRv2中英文超轻量检测预训练模型、XFUND数据集+finetune2种方案进行评估、训练等,指标对比如下:
+
+| 方案 | hmeans | 结果分析 |
+| -------- | -------- | -------- |
+| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% | ppocr提供的预训练模型有一定的泛化能力 |
+| XFUND数据集 | 79.27% | |
+| XFUND数据集+finetune | 85.24% | finetune会提升垂类场景效果 |
+
+
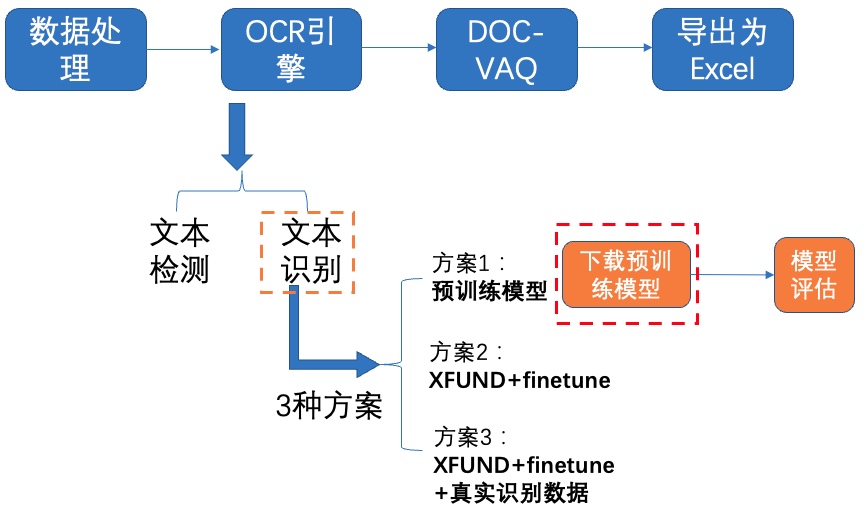
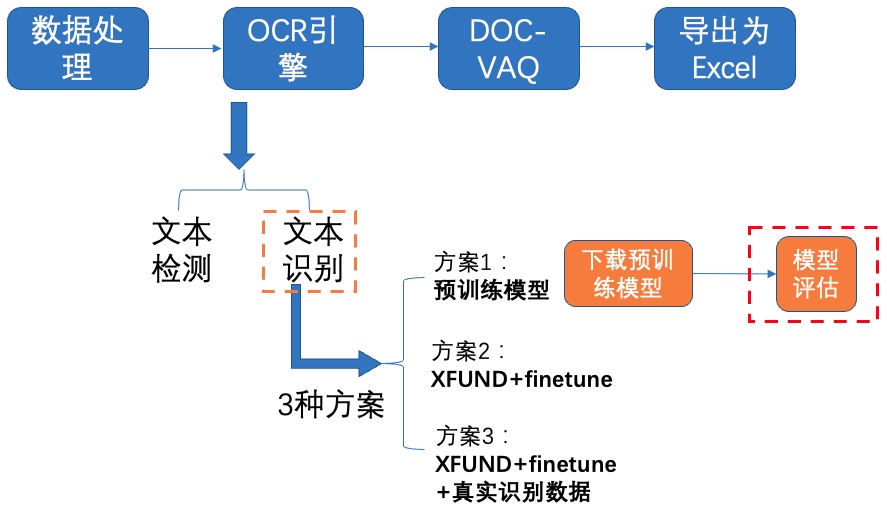
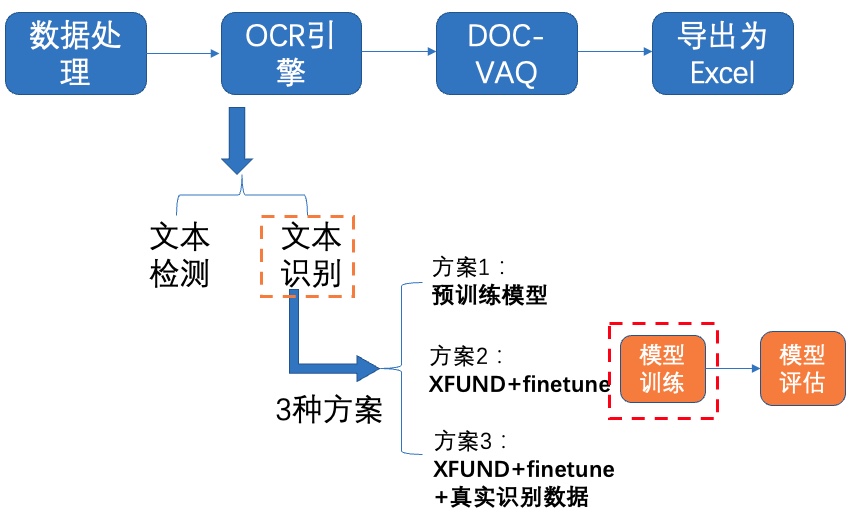
+## 4.2 文本识别
+
+我们分别使用如下3种方案进行训练、评估:
+
+- PP-OCRv2中英文超轻量识别预训练模型
+- XFUND数据集+fine-tune
+- XFUND数据集+fine-tune+真实通用识别数据
+
+
+### **4.2.1 方案1:预训练模型**
+
+**1)下载预训练模型**
+
+
+图10 文本检测方案2-模型预测
+
+加载上面导出的模型,执行如下命令对验证集或测试集图片进行预测:
+
+```
+det_model_dir:预测模型
+image_dir:测试图片路径
+use_gpu:是否使用GPU
+```
+
+检测可视化结果保存在`/home/aistudio/inference_results/`目录下,查看检测效果。
+
+
+```python
+%pwd
+!python tools/infer/predict_det.py \
+ --det_algorithm="DB" \
+ --det_model_dir="./output/det_db_inference/" \
+ --image_dir="./doc/vqa/input/zh_val_21.jpg" \
+ --use_gpu=True
+```
+
+总结,我们分别使用PP-OCRv2中英文超轻量检测预训练模型、XFUND数据集+finetune2种方案进行评估、训练等,指标对比如下:
+
+| 方案 | hmeans | 结果分析 |
+| -------- | -------- | -------- |
+| PP-OCRv2中英文超轻量检测预训练模型 | 77.26% | ppocr提供的预训练模型有一定的泛化能力 |
+| XFUND数据集 | 79.27% | |
+| XFUND数据集+finetune | 85.24% | finetune会提升垂类场景效果 |
+
+
+## 4.2 文本识别
+
+我们分别使用如下3种方案进行训练、评估:
+
+- PP-OCRv2中英文超轻量识别预训练模型
+- XFUND数据集+fine-tune
+- XFUND数据集+fine-tune+真实通用识别数据
+
+
+### **4.2.1 方案1:预训练模型**
+
+**1)下载预训练模型**
+
+ +
+图11 文本识别方案1-下载预训练模型
+
+我们使用PP-OCRv2中英文超轻量文本识别模型,下载并解压预训练模型:
+
+
+```python
+%cd /home/aistudio/PaddleOCR/pretrain/
+! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar
+! tar -xf ch_PP-OCRv2_rec_train.tar && rm -rf ch_PP-OCRv2_rec_train.tar
+% cd ..
+```
+
+**2)模型评估**
+
+
+
+图11 文本识别方案1-下载预训练模型
+
+我们使用PP-OCRv2中英文超轻量文本识别模型,下载并解压预训练模型:
+
+
+```python
+%cd /home/aistudio/PaddleOCR/pretrain/
+! wget https://paddleocr.bj.bcebos.com/PP-OCRv2/chinese/ch_PP-OCRv2_rec_train.tar
+! tar -xf ch_PP-OCRv2_rec_train.tar && rm -rf ch_PP-OCRv2_rec_train.tar
+% cd ..
+```
+
+**2)模型评估**
+
+ +
+图12 文本识别方案1-模型评估
+
+首先修改配置文件`configs/det/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml`中的以下字段:
+
+```
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
+我们使用下载的预训练模型进行评估:
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml \
+ -o Global.checkpoints=./pretrain/ch_PP-OCRv2_rec_train/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% |
+
+使用文本预训练模型在XFUND验证集上评估,acc达到67%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
+
+### **4.2.2 方案2:XFUND数据集+finetune**
+
+同检测模型,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
+
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("pretrain/ch_PP-OCRv2_rec_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("Student."):]: all_params[key] for key in all_params if "Student." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "pretrain/ch_PP-OCRv2_rec_train/student.pdparams")
+```
+
+**1)模型训练**
+
+
+
+图12 文本识别方案1-模型评估
+
+首先修改配置文件`configs/det/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml`中的以下字段:
+
+```
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+
+我们使用下载的预训练模型进行评估:
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec_distillation.yml \
+ -o Global.checkpoints=./pretrain/ch_PP-OCRv2_rec_train/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% |
+
+使用文本预训练模型在XFUND验证集上评估,acc达到67%左右,充分说明ppocr提供的预训练模型有一定的泛化能力。
+
+### **4.2.2 方案2:XFUND数据集+finetune**
+
+同检测模型,我们提取Student模型的参数,在XFUND数据集上进行finetune,可以参考如下代码:
+
+
+```python
+import paddle
+# 加载预训练模型
+all_params = paddle.load("pretrain/ch_PP-OCRv2_rec_train/best_accuracy.pdparams")
+# 查看权重参数的keys
+print(all_params.keys())
+# 学生模型的权重提取
+s_params = {key[len("Student."):]: all_params[key] for key in all_params if "Student." in key}
+# 查看学生模型权重参数的keys
+print(s_params.keys())
+# 保存
+paddle.save(s_params, "pretrain/ch_PP-OCRv2_rec_train/student.pdparams")
+```
+
+**1)模型训练**
+
+ +图13 文本识别方案2-模型训练
+
+修改配置文件`configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml`中的以下字段:
+
+```
+Global.pretrained_model:指向预训练模型路径
+Global.character_dict_path: 字典路径
+Optimizer.lr.values:学习率
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+执行如下命令启动训练:
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
+```
+
+**2)模型评估**
+
+
+图13 文本识别方案2-模型训练
+
+修改配置文件`configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml`中的以下字段:
+
+```
+Global.pretrained_model:指向预训练模型路径
+Global.character_dict_path: 字典路径
+Optimizer.lr.values:学习率
+Train.dataset.data_dir:指向训练集图片存放目录
+Train.dataset.label_file_list:指向训练集标注文件
+Eval.dataset.data_dir:指向验证集图片存放目录
+Eval.dataset.label_file_list:指向验证集标注文件
+```
+执行如下命令启动训练:
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
+```
+
+**2)模型评估**
+
+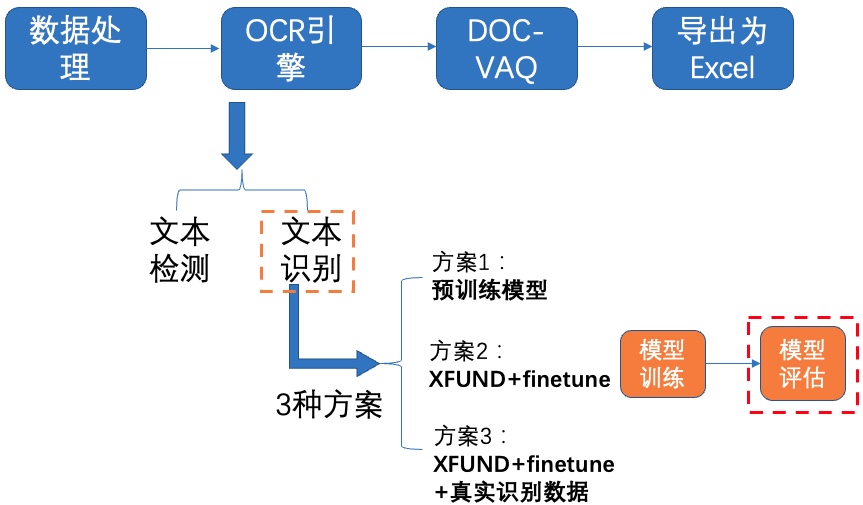 +
+图14 文本识别方案2-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-finetune/best_accuracy`
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-finetune/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| XFUND数据集+finetune | 72.33% |
+
+使用XFUND数据集+finetune训练,在验证集上评估达到72%左右,说明 finetune会提升垂类场景效果。
+
+### **4.2.3 方案3:XFUND数据集+finetune+真实通用识别数据**
+
+接着我们在上述`XFUND数据集+finetune`实验的基础上,添加真实通用识别数据,进一步提升识别效果。首先准备真实通用识别数据,并上传到AIStudio:
+
+**1)模型训练**
+
+
+
+图14 文本识别方案2-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-finetune/best_accuracy`
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-finetune/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| XFUND数据集+finetune | 72.33% |
+
+使用XFUND数据集+finetune训练,在验证集上评估达到72%左右,说明 finetune会提升垂类场景效果。
+
+### **4.2.3 方案3:XFUND数据集+finetune+真实通用识别数据**
+
+接着我们在上述`XFUND数据集+finetune`实验的基础上,添加真实通用识别数据,进一步提升识别效果。首先准备真实通用识别数据,并上传到AIStudio:
+
+**1)模型训练**
+
+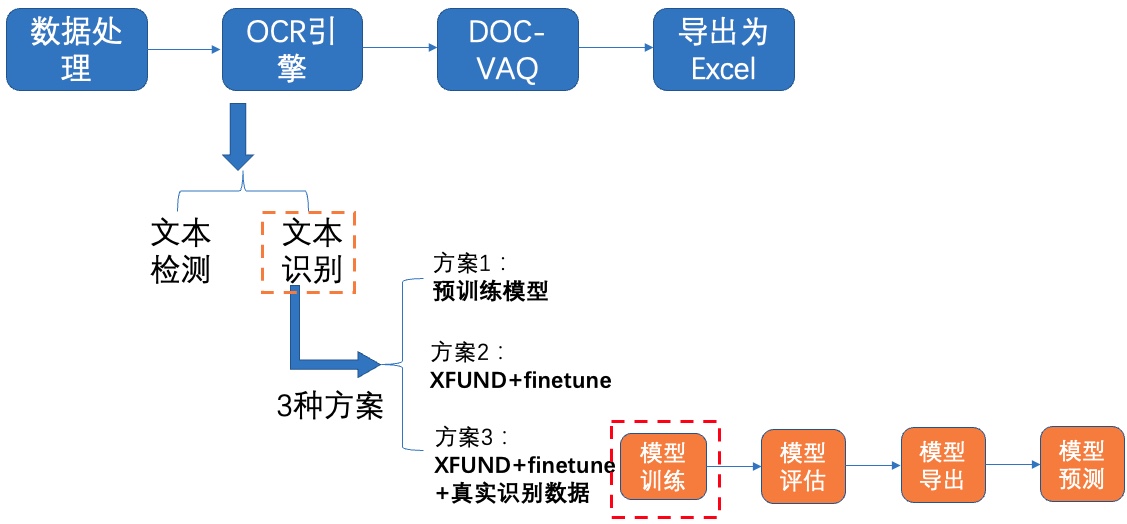 +
+图15 文本识别方案3-模型训练
+
+在上述`XFUND数据集+finetune`实验中修改配置文件`configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml`的基础上,继续修改以下字段:
+
+```
+Train.dataset.label_file_list:指向真实识别训练集图片存放目录
+Train.dataset.ratio_list:动态采样
+```
+执行如下命令启动训练:
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
+```
+
+**2)模型评估**
+
+
+
+图15 文本识别方案3-模型训练
+
+在上述`XFUND数据集+finetune`实验中修改配置文件`configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml`的基础上,继续修改以下字段:
+
+```
+Train.dataset.label_file_list:指向真实识别训练集图片存放目录
+Train.dataset.ratio_list:动态采样
+```
+执行如下命令启动训练:
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! CUDA_VISIBLE_DEVICES=0 python tools/train.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml
+```
+
+**2)模型评估**
+
+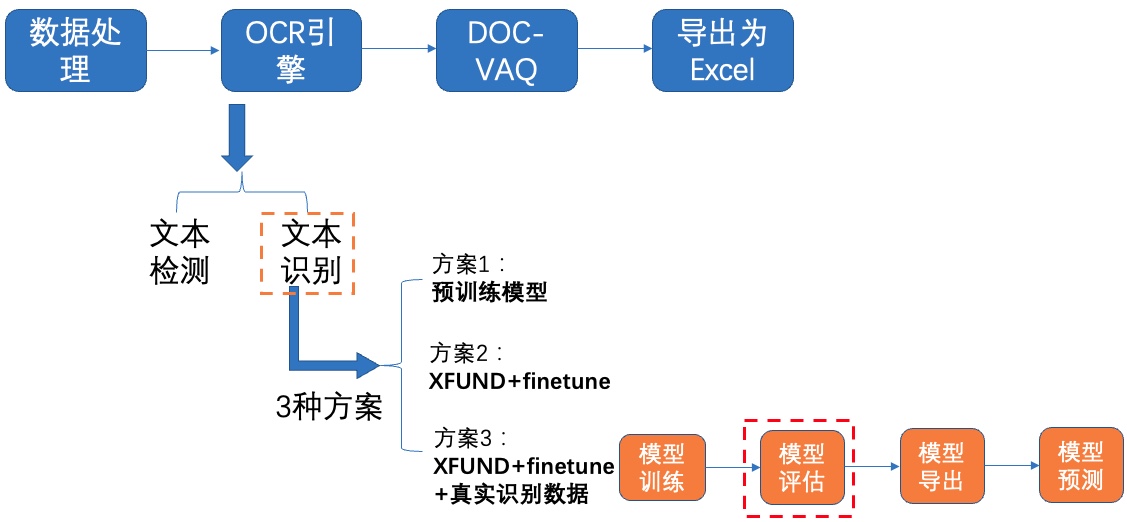 +
+图16 文本识别方案3-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-realdata/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| XFUND数据集+fine-tune+真实通用识别数据 | 85.29% |
+
+使用XFUND数据集+finetune训练,在验证集上评估达到85%左右,说明真实通用识别数据对于性能提升很有帮助。
+
+**3)导出模型**
+
+
+
+图16 文本识别方案3-模型评估
+
+使用训练好的模型进行评估,更新模型路径`Global.checkpoints`,这里为大家提供训练好的模型`./pretrain/rec_mobile_pp-OCRv2-student-readldata/best_accuracy`
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.checkpoints=./pretrain/rec_mobile_pp-OCRv2-student-realdata/best_accuracy
+```
+
+使用预训练模型进行评估,指标如下所示:
+
+| 方案 | acc |
+| -------- | -------- |
+| XFUND数据集+fine-tune+真实通用识别数据 | 85.29% |
+
+使用XFUND数据集+finetune训练,在验证集上评估达到85%左右,说明真实通用识别数据对于性能提升很有帮助。
+
+**3)导出模型**
+
+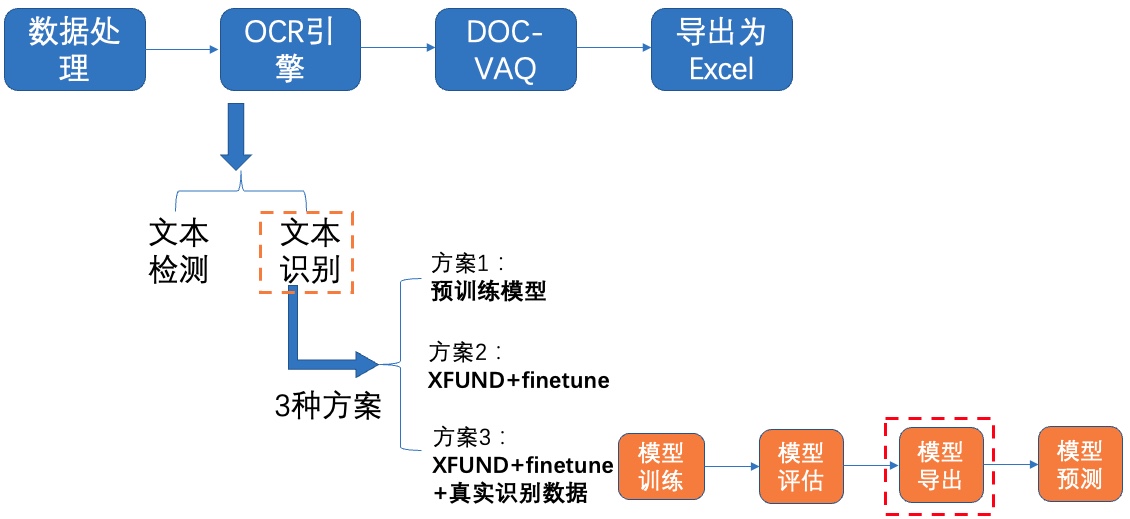 +图17 文本识别方案3-导出模型
+
+导出模型只保留前向预测的过程:
+
+
+```python
+!python tools/export_model.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.pretrained_model=pretrain/rec_mobile_pp-OCRv2-student-realdata/best_accuracy \
+ Global.save_inference_dir=./output/rec_crnn_inference/
+```
+
+**4)模型预测**
+
+
+图17 文本识别方案3-导出模型
+
+导出模型只保留前向预测的过程:
+
+
+```python
+!python tools/export_model.py \
+ -c configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml \
+ -o Global.pretrained_model=pretrain/rec_mobile_pp-OCRv2-student-realdata/best_accuracy \
+ Global.save_inference_dir=./output/rec_crnn_inference/
+```
+
+**4)模型预测**
+
+ +
+图18 文本识别方案3-模型预测
+
+加载上面导出的模型,执行如下命令对验证集或测试集图片进行预测,检测可视化结果保存在`/home/aistudio/inference_results/`目录下,查看检测、识别效果。需要通过`--rec_char_dict_path`指定使用的字典路径
+
+
+```python
+! python tools/infer/predict_system.py \
+ --image_dir="./doc/vqa/input/zh_val_21.jpg" \
+ --det_model_dir="./output/det_db_inference/" \
+ --rec_model_dir="./output/rec_crnn_inference/" \
+ --rec_image_shape="3, 32, 320" \
+ --rec_char_dict_path="/home/aistudio/XFUND/word_dict.txt"
+```
+
+总结,我们分别使用PP-OCRv2中英文超轻量检测预训练模型、XFUND数据集+finetune2种方案进行评估、训练等,指标对比如下:
+
+| 方案 | acc | 结果分析 |
+| -------- | -------- | -------- |
+| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% | ppocr提供的预训练模型有一定的泛化能力 |
+| XFUND数据集+fine-tune |72.33% | finetune会提升垂类场景效果 |
+| XFUND数据集+fine-tune+真实通用识别数据 | 85.29% | 真实通用识别数据对于性能提升很有帮助 |
+
+# 5 文档视觉问答(DOC-VQA)
+
+VQA指视觉问答,主要针对图像内容进行提问和回答,DOC-VQA是VQA任务中的一种,DOC-VQA主要针对文本图像的文字内容提出问题。
+
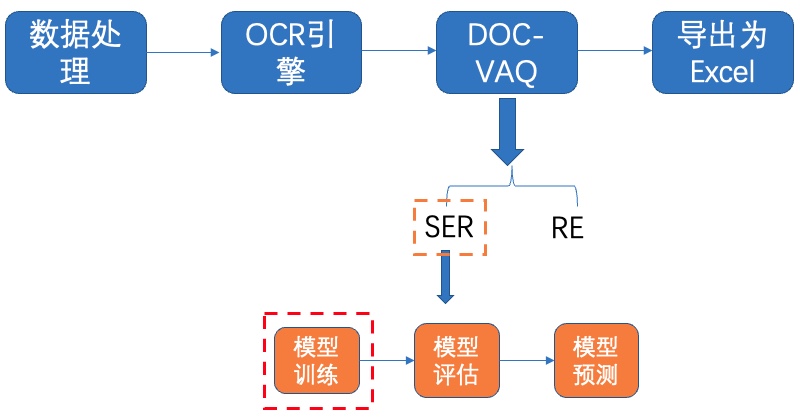
+PaddleOCR中DOC-VQA系列算法基于PaddleNLP自然语言处理算法库实现LayoutXLM论文,支持基于多模态方法的 **语义实体识别 (Semantic Entity Recognition, SER)** 以及 **关系抽取 (Relation Extraction, RE)** 任务。
+
+如果希望直接体验预测过程,可以下载我们提供的预训练模型,跳过训练过程,直接预测即可。
+
+
+```python
+%cd pretrain
+#下载SER模型
+! wget https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar && tar -xvf ser_LayoutXLM_xfun_zh.tar
+#下载RE模型
+! wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar && tar -xvf re_LayoutXLM_xfun_zh.tar
+%cd ../
+```
+
+
+## 5.1 SER
+
+SER: 语义实体识别 (Semantic Entity Recognition), 可以完成对图像中的文本识别与分类。
+
+
+
+图18 文本识别方案3-模型预测
+
+加载上面导出的模型,执行如下命令对验证集或测试集图片进行预测,检测可视化结果保存在`/home/aistudio/inference_results/`目录下,查看检测、识别效果。需要通过`--rec_char_dict_path`指定使用的字典路径
+
+
+```python
+! python tools/infer/predict_system.py \
+ --image_dir="./doc/vqa/input/zh_val_21.jpg" \
+ --det_model_dir="./output/det_db_inference/" \
+ --rec_model_dir="./output/rec_crnn_inference/" \
+ --rec_image_shape="3, 32, 320" \
+ --rec_char_dict_path="/home/aistudio/XFUND/word_dict.txt"
+```
+
+总结,我们分别使用PP-OCRv2中英文超轻量检测预训练模型、XFUND数据集+finetune2种方案进行评估、训练等,指标对比如下:
+
+| 方案 | acc | 结果分析 |
+| -------- | -------- | -------- |
+| PP-OCRv2中英文超轻量识别预训练模型 | 67.48% | ppocr提供的预训练模型有一定的泛化能力 |
+| XFUND数据集+fine-tune |72.33% | finetune会提升垂类场景效果 |
+| XFUND数据集+fine-tune+真实通用识别数据 | 85.29% | 真实通用识别数据对于性能提升很有帮助 |
+
+# 5 文档视觉问答(DOC-VQA)
+
+VQA指视觉问答,主要针对图像内容进行提问和回答,DOC-VQA是VQA任务中的一种,DOC-VQA主要针对文本图像的文字内容提出问题。
+
+PaddleOCR中DOC-VQA系列算法基于PaddleNLP自然语言处理算法库实现LayoutXLM论文,支持基于多模态方法的 **语义实体识别 (Semantic Entity Recognition, SER)** 以及 **关系抽取 (Relation Extraction, RE)** 任务。
+
+如果希望直接体验预测过程,可以下载我们提供的预训练模型,跳过训练过程,直接预测即可。
+
+
+```python
+%cd pretrain
+#下载SER模型
+! wget https://paddleocr.bj.bcebos.com/pplayout/ser_LayoutXLM_xfun_zh.tar && tar -xvf ser_LayoutXLM_xfun_zh.tar
+#下载RE模型
+! wget https://paddleocr.bj.bcebos.com/pplayout/re_LayoutXLM_xfun_zh.tar && tar -xvf re_LayoutXLM_xfun_zh.tar
+%cd ../
+```
+
+
+## 5.1 SER
+
+SER: 语义实体识别 (Semantic Entity Recognition), 可以完成对图像中的文本识别与分类。
+
+ +图19 SER测试效果图
+
+**图19** 中不同颜色的框表示不同的类别,对于XFUND数据集,有QUESTION, ANSWER, HEADER 3种类别
+
+- 深紫色:HEADER
+- 浅紫色:QUESTION
+- 军绿色:ANSWER
+
+在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
+#### 5.1.1 模型训练
+
+
+图19 SER测试效果图
+
+**图19** 中不同颜色的框表示不同的类别,对于XFUND数据集,有QUESTION, ANSWER, HEADER 3种类别
+
+- 深紫色:HEADER
+- 浅紫色:QUESTION
+- 军绿色:ANSWER
+
+在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
+#### 5.1.1 模型训练
+
+ +
+图20 SER-模型训练
+
+启动训练之前,需要修改配置文件 `configs/vqa/ser/layoutxlm.yml` 以下四个字段:
+
+ 1. Train.dataset.data_dir:指向训练集图片存放目录
+ 2. Train.dataset.label_file_list:指向训练集标注文件
+ 3. Eval.dataset.data_dir:指指向验证集图片存放目录
+ 4. Eval.dataset.label_file_list:指向验证集标注文件
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! CUDA_VISIBLE_DEVICES=0 python tools/train.py -c configs/vqa/ser/layoutxlm.yml
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/ser_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型。
+
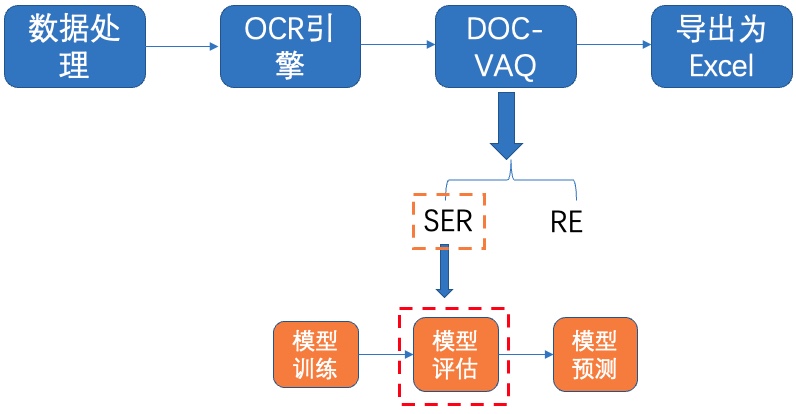
+#### 5.1.2 模型评估
+
+
+
+图20 SER-模型训练
+
+启动训练之前,需要修改配置文件 `configs/vqa/ser/layoutxlm.yml` 以下四个字段:
+
+ 1. Train.dataset.data_dir:指向训练集图片存放目录
+ 2. Train.dataset.label_file_list:指向训练集标注文件
+ 3. Eval.dataset.data_dir:指指向验证集图片存放目录
+ 4. Eval.dataset.label_file_list:指向验证集标注文件
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR/
+! CUDA_VISIBLE_DEVICES=0 python tools/train.py -c configs/vqa/ser/layoutxlm.yml
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/ser_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型。
+
+#### 5.1.2 模型评估
+
+ +
+图21 SER-模型评估
+
+我们使用下载的预训练模型进行评估,如果使用自己训练好的模型进行评估,将待评估的模型所在文件夹路径赋值给 `Architecture.Backbone.checkpoints` 字段即可。
+
+
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/vqa/ser/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
+```
+
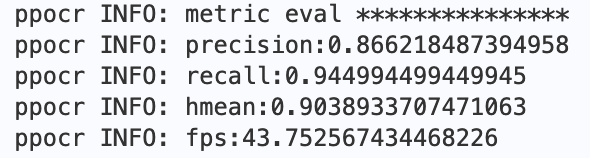
+最终会打印出`precision`, `recall`, `hmean`等指标,预训练模型评估指标如下:
+
+
+
+图21 SER-模型评估
+
+我们使用下载的预训练模型进行评估,如果使用自己训练好的模型进行评估,将待评估的模型所在文件夹路径赋值给 `Architecture.Backbone.checkpoints` 字段即可。
+
+
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python tools/eval.py \
+ -c configs/vqa/ser/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标,预训练模型评估指标如下:
+
+ +图 SER预训练模型评估指标
+
+#### 5.1.3 模型预测
+
+
+图 SER预训练模型评估指标
+
+#### 5.1.3 模型预测
+
+ +
+图22 SER-模型预测
+
+使用如下命令即可完成`OCR引擎 + SER`的串联预测, 以SER预训练模型为例:
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python tools/infer_vqa_token_ser.py \
+ -c configs/vqa/ser/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/ \
+ Global.infer_img=doc/vqa/input/zh_val_42.jpg
+```
+
+最终会在`config.Global.save_res_path`字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为`infer_results.txt`。通过如下命令查看预测图片:
+
+
+```python
+import cv2
+from matplotlib import pyplot as plt
+# 在notebook中使用matplotlib.pyplot绘图时,需要添加该命令进行显示
+%matplotlib inline
+
+img = cv2.imread('output/ser/zh_val_42_ser.jpg')
+plt.figure(figsize=(48,24))
+plt.imshow(img)
+```
+
+## 5.2 RE
+
+基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair)。
+
+
+
+图22 SER-模型预测
+
+使用如下命令即可完成`OCR引擎 + SER`的串联预测, 以SER预训练模型为例:
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python tools/infer_vqa_token_ser.py \
+ -c configs/vqa/ser/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/ \
+ Global.infer_img=doc/vqa/input/zh_val_42.jpg
+```
+
+最终会在`config.Global.save_res_path`字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为`infer_results.txt`。通过如下命令查看预测图片:
+
+
+```python
+import cv2
+from matplotlib import pyplot as plt
+# 在notebook中使用matplotlib.pyplot绘图时,需要添加该命令进行显示
+%matplotlib inline
+
+img = cv2.imread('output/ser/zh_val_42_ser.jpg')
+plt.figure(figsize=(48,24))
+plt.imshow(img)
+```
+
+## 5.2 RE
+
+基于 RE 任务,可以完成对图象中的文本内容的关系提取,如判断问题对(pair)。
+
+ +图23 RE预测效果图
+
+图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
+#### 5.2.1 模型训练
+
+
+图23 RE预测效果图
+
+图中红色框表示问题,蓝色框表示答案,问题和答案之间使用绿色线连接。在OCR检测框的左上方也标出了对应的类别和OCR识别结果。
+
+#### 5.2.1 模型训练
+
+ +
+图24 RE-模型训练
+
+启动训练之前,需要修改配置文件`configs/vqa/re/layoutxlm.yml`中的以下四个字段
+
+ Train.dataset.data_dir:指向训练集图片存放目录
+ Train.dataset.label_file_list:指向训练集标注文件
+ Eval.dataset.data_dir:指指向验证集图片存放目录
+ Eval.dataset.label_file_list:指向验证集标注文件
+
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python3 tools/train.py -c configs/vqa/re/layoutxlm.yml
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/re_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型
+
+#### 5.2.2 模型评估
+
+
+
+图24 RE-模型训练
+
+启动训练之前,需要修改配置文件`configs/vqa/re/layoutxlm.yml`中的以下四个字段
+
+ Train.dataset.data_dir:指向训练集图片存放目录
+ Train.dataset.label_file_list:指向训练集标注文件
+ Eval.dataset.data_dir:指指向验证集图片存放目录
+ Eval.dataset.label_file_list:指向验证集标注文件
+
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python3 tools/train.py -c configs/vqa/re/layoutxlm.yml
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标。 在`./output/re_layoutxlm/`文件夹中会保存训练日志,最优的模型和最新epoch的模型
+
+#### 5.2.2 模型评估
+
+ +图25 RE-模型评估
+
+
+我们使用下载的预训练模型进行评估,如果使用自己训练好的模型进行评估,将待评估的模型所在文件夹路径赋值给 `Architecture.Backbone.checkpoints` 字段即可。
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py \
+ -c configs/vqa/re/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标,预训练模型评估指标如下:
+
+
+图25 RE-模型评估
+
+
+我们使用下载的预训练模型进行评估,如果使用自己训练好的模型进行评估,将待评估的模型所在文件夹路径赋值给 `Architecture.Backbone.checkpoints` 字段即可。
+
+
+```python
+! CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py \
+ -c configs/vqa/re/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/
+```
+
+最终会打印出`precision`, `recall`, `hmean`等指标,预训练模型评估指标如下:
+
+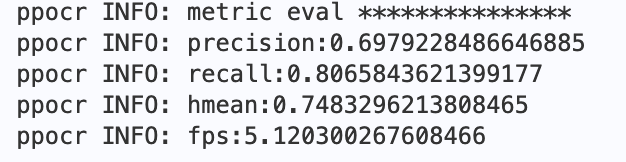 +图 RE预训练模型评估指标
+
+#### 5.2.3 模型预测
+
+
+图 RE预训练模型评估指标
+
+#### 5.2.3 模型预测
+
+ +
+图26 RE-模型预测
+
+ 使用OCR引擎 + SER + RE串联预测
+
+使用如下命令即可完成OCR引擎 + SER + RE的串联预测, 以预训练SER和RE模型为例:
+
+
+
+最终会在config.Global.save_res_path字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为infer_results.txt。
+
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+! CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser_re.py \
+ -c configs/vqa/re/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/ \
+ Global.infer_img=test_imgs/ \
+ -c_ser configs/vqa/ser/layoutxlm.yml \
+ -o_ser Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
+```
+
+最终会在config.Global.save_res_path字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为infer_results.txt, 每一行表示一张图片的结果,每张图片的结果如下所示,前面表示测试图片路径,后面为测试结果:key字段及对应的value字段。
+
+```
+test_imgs/t131.jpg {"政治面税": "群众", "性别": "男", "籍贯": "河北省邯郸市", "婚姻状况": "亏末婚口已婚口已娇", "通讯地址": "邯郸市阳光苑7号楼003", "民族": "汉族", "毕业院校": "河南工业大学", "户口性质": "口农村城镇", "户口地址": "河北省邯郸市", "联系电话": "13288888888", "健康状况": "健康", "姓名": "小六", "好高cm": "180", "出生年月": "1996年8月9日", "文化程度": "本科", "身份证号码": "458933777777777777"}
+````
+
+
+
+```python
+# 展示预测结果
+import cv2
+from matplotlib import pyplot as plt
+%matplotlib inline
+
+img = cv2.imread('./output/re/t131_ser.jpg')
+plt.figure(figsize=(48,24))
+plt.imshow(img)
+```
+
+# 6 导出Excel
+
+
+
+图26 RE-模型预测
+
+ 使用OCR引擎 + SER + RE串联预测
+
+使用如下命令即可完成OCR引擎 + SER + RE的串联预测, 以预训练SER和RE模型为例:
+
+
+
+最终会在config.Global.save_res_path字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为infer_results.txt。
+
+
+
+
+```python
+%cd /home/aistudio/PaddleOCR
+! CUDA_VISIBLE_DEVICES=0 python3 tools/infer_vqa_token_ser_re.py \
+ -c configs/vqa/re/layoutxlm.yml \
+ -o Architecture.Backbone.checkpoints=pretrain/re_LayoutXLM_xfun_zh/ \
+ Global.infer_img=test_imgs/ \
+ -c_ser configs/vqa/ser/layoutxlm.yml \
+ -o_ser Architecture.Backbone.checkpoints=pretrain/ser_LayoutXLM_xfun_zh/
+```
+
+最终会在config.Global.save_res_path字段所配置的目录下保存预测结果可视化图像以及预测结果文本文件,预测结果文本文件名为infer_results.txt, 每一行表示一张图片的结果,每张图片的结果如下所示,前面表示测试图片路径,后面为测试结果:key字段及对应的value字段。
+
+```
+test_imgs/t131.jpg {"政治面税": "群众", "性别": "男", "籍贯": "河北省邯郸市", "婚姻状况": "亏末婚口已婚口已娇", "通讯地址": "邯郸市阳光苑7号楼003", "民族": "汉族", "毕业院校": "河南工业大学", "户口性质": "口农村城镇", "户口地址": "河北省邯郸市", "联系电话": "13288888888", "健康状况": "健康", "姓名": "小六", "好高cm": "180", "出生年月": "1996年8月9日", "文化程度": "本科", "身份证号码": "458933777777777777"}
+````
+
+
+
+```python
+# 展示预测结果
+import cv2
+from matplotlib import pyplot as plt
+%matplotlib inline
+
+img = cv2.imread('./output/re/t131_ser.jpg')
+plt.figure(figsize=(48,24))
+plt.imshow(img)
+```
+
+# 6 导出Excel
+
+ +图27 导出Excel
+
+为了输出信息匹配对,我们修改`tools/infer_vqa_token_ser_re.py`文件中的`line 194-197`。
+```
+ fout.write(img_path + "\t" + json.dumps(
+ {
+ "ser_resule": result,
+ }, ensure_ascii=False) + "\n")
+
+```
+更改为
+```
+result_key = {}
+for ocr_info_head, ocr_info_tail in result:
+ result_key[ocr_info_head['text']] = ocr_info_tail['text']
+
+fout.write(img_path + "\t" + json.dumps(
+ result_key, ensure_ascii=False) + "\n")
+```
+
+同时将输出结果导出到Excel中,效果如 图28 所示:
+
+
+图27 导出Excel
+
+为了输出信息匹配对,我们修改`tools/infer_vqa_token_ser_re.py`文件中的`line 194-197`。
+```
+ fout.write(img_path + "\t" + json.dumps(
+ {
+ "ser_resule": result,
+ }, ensure_ascii=False) + "\n")
+
+```
+更改为
+```
+result_key = {}
+for ocr_info_head, ocr_info_tail in result:
+ result_key[ocr_info_head['text']] = ocr_info_tail['text']
+
+fout.write(img_path + "\t" + json.dumps(
+ result_key, ensure_ascii=False) + "\n")
+```
+
+同时将输出结果导出到Excel中,效果如 图28 所示:
+
+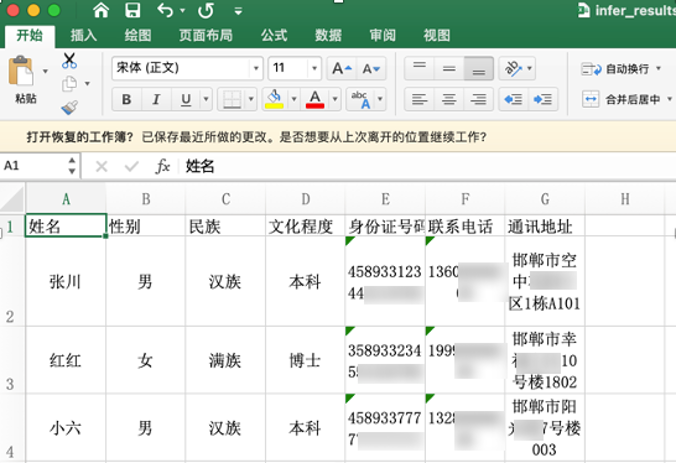 +图28 Excel效果图
+
+
+```python
+import json
+import xlsxwriter as xw
+
+workbook = xw.Workbook('output/re/infer_results.xlsx')
+format1 = workbook.add_format({
+ 'align': 'center',
+ 'valign': 'vcenter',
+ 'text_wrap': True,
+})
+worksheet1 = workbook.add_worksheet('sheet1')
+worksheet1.activate()
+title = ['姓名', '性别', '民族', '文化程度', '身份证号码', '联系电话', '通讯地址']
+worksheet1.write_row('A1', title)
+i = 2
+
+with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
+ lines = fin.readlines()
+ for line in lines:
+ img_path, result = line.strip().split('\t')
+ result_key = json.loads(result)
+ # 写入Excel
+ row_data = [result_key['姓名'], result_key['性别'], result_key['民族'], result_key['文化程度'], result_key['身份证号码'],
+ result_key['联系电话'], result_key['通讯地址']]
+ row = 'A' + str(i)
+ worksheet1.write_row(row, row_data, format1)
+ i+=1
+workbook.close()
+```
+
+# 更多资源
+
+- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
+
+- 更多PaddleOCR使用教程,请参考:[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph)
+
+- 更多PaddleNLP使用教程,请参考:[PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP)
+
+- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
+
+# 参考链接
+
+- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, https://arxiv.org/pdf/2104.08836.pdf
+
+- microsoft/unilm/layoutxlm, https://github.com/microsoft/unilm/tree/master/layoutxlm
+
+- XFUND dataset, https://github.com/doc-analysis/XFUND
+
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml b/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c45a1a3c8b8edc8a542bc740f6abd958b9a1e701
--- /dev/null
+++ b/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml
@@ -0,0 +1,131 @@
+Global:
+ debug: false
+ use_gpu: true
+ epoch_num: 500
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/rec_ppocr_v3
+ save_epoch_step: 3
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: true
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: false
+ infer_img: doc/imgs_words/ch/word_1.jpg
+ character_dict_path: ppocr/utils/ppocr_keys_v1.txt
+ max_text_length: &max_text_length 25
+ infer_mode: false
+ use_space_char: true
+ distributed: true
+ save_res_path: ./output/rec/predicts_ppocrv3.txt
+
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ warmup_epoch: 5
+ regularizer:
+ name: L2
+ factor: 3.0e-05
+
+
+Architecture:
+ model_type: rec
+ algorithm: SVTR
+ Transform:
+ Backbone:
+ name: MobileNetV1Enhance
+ scale: 0.5
+ last_conv_stride: [1, 2]
+ last_pool_type: avg
+ Head:
+ name: MultiHead
+ head_list:
+ - CTCHead:
+ Neck:
+ name: svtr
+ dims: 64
+ depth: 2
+ hidden_dims: 120
+ use_guide: True
+ Head:
+ fc_decay: 0.00001
+ - SARHead:
+ enc_dim: 512
+ max_text_length: *max_text_length
+
+Loss:
+ name: MultiLoss
+ loss_config_list:
+ - CTCLoss:
+ - SARLoss:
+
+PostProcess:
+ name: CTCLabelDecode
+
+Metric:
+ name: RecMetric
+ main_indicator: acc
+ ignore_space: True
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/
+ ext_op_transform_idx: 1
+ label_file_list:
+ - ./train_data/train_list.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - RecConAug:
+ prob: 0.5
+ ext_data_num: 2
+ image_shape: [48, 320, 3]
+ - RecAug:
+ - MultiLabelEncode:
+ - RecResizeImg:
+ image_shape: [3, 48, 320]
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label_ctc
+ - label_sar
+ - length
+ - valid_ratio
+ loader:
+ shuffle: true
+ batch_size_per_card: 128
+ drop_last: true
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data
+ label_file_list:
+ - ./train_data/val_list.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - MultiLabelEncode:
+ - RecResizeImg:
+ image_shape: [3, 48, 320]
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label_ctc
+ - label_sar
+ - length
+ - valid_ratio
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 128
+ num_workers: 4
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml b/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
new file mode 100644
index 0000000000000000000000000000000000000000..80ec7c6308aa006f46331503e00368444c425559
--- /dev/null
+++ b/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
@@ -0,0 +1,205 @@
+Global:
+ debug: false
+ use_gpu: true
+ epoch_num: 800
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/rec_ppocr_v3_distillation
+ save_epoch_step: 3
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: true
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: false
+ infer_img: doc/imgs_words/ch/word_1.jpg
+ character_dict_path: ppocr/utils/ppocr_keys_v1.txt
+ max_text_length: &max_text_length 25
+ infer_mode: false
+ use_space_char: true
+ distributed: true
+ save_res_path: ./output/rec/predicts_ppocrv3_distillation.txt
+
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ name: Piecewise
+ decay_epochs : [700, 800]
+ values : [0.0005, 0.00005]
+ warmup_epoch: 5
+ regularizer:
+ name: L2
+ factor: 3.0e-05
+
+
+Architecture:
+ model_type: &model_type "rec"
+ name: DistillationModel
+ algorithm: Distillation
+ Models:
+ Teacher:
+ pretrained:
+ freeze_params: false
+ return_all_feats: true
+ model_type: *model_type
+ algorithm: SVTR
+ Transform:
+ Backbone:
+ name: MobileNetV1Enhance
+ scale: 0.5
+ last_conv_stride: [1, 2]
+ last_pool_type: avg
+ Head:
+ name: MultiHead
+ head_list:
+ - CTCHead:
+ Neck:
+ name: svtr
+ dims: 64
+ depth: 2
+ hidden_dims: 120
+ use_guide: True
+ Head:
+ fc_decay: 0.00001
+ - SARHead:
+ enc_dim: 512
+ max_text_length: *max_text_length
+ Student:
+ pretrained:
+ freeze_params: false
+ return_all_feats: true
+ model_type: *model_type
+ algorithm: SVTR
+ Transform:
+ Backbone:
+ name: MobileNetV1Enhance
+ scale: 0.5
+ last_conv_stride: [1, 2]
+ last_pool_type: avg
+ Head:
+ name: MultiHead
+ head_list:
+ - CTCHead:
+ Neck:
+ name: svtr
+ dims: 64
+ depth: 2
+ hidden_dims: 120
+ use_guide: True
+ Head:
+ fc_decay: 0.00001
+ - SARHead:
+ enc_dim: 512
+ max_text_length: *max_text_length
+Loss:
+ name: CombinedLoss
+ loss_config_list:
+ - DistillationDMLLoss:
+ weight: 1.0
+ act: "softmax"
+ use_log: true
+ model_name_pairs:
+ - ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+ dis_head: ctc
+ name: dml_ctc
+ - DistillationDMLLoss:
+ weight: 0.5
+ act: "softmax"
+ use_log: true
+ model_name_pairs:
+ - ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+ dis_head: sar
+ name: dml_sar
+ - DistillationDistanceLoss:
+ weight: 1.0
+ mode: "l2"
+ model_name_pairs:
+ - ["Student", "Teacher"]
+ key: backbone_out
+ - DistillationCTCLoss:
+ weight: 1.0
+ model_name_list: ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+ - DistillationSARLoss:
+ weight: 1.0
+ model_name_list: ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+
+PostProcess:
+ name: DistillationCTCLabelDecode
+ model_name: ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+
+Metric:
+ name: DistillationMetric
+ base_metric_name: RecMetric
+ main_indicator: acc
+ key: "Student"
+ ignore_space: True
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/
+ ext_op_transform_idx: 1
+ label_file_list:
+ - ./train_data/train_list.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - RecConAug:
+ prob: 0.5
+ ext_data_num: 2
+ image_shape: [48, 320, 3]
+ - RecAug:
+ - MultiLabelEncode:
+ - RecResizeImg:
+ image_shape: [3, 48, 320]
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label_ctc
+ - label_sar
+ - length
+ - valid_ratio
+ loader:
+ shuffle: true
+ batch_size_per_card: 128
+ drop_last: true
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data
+ label_file_list:
+ - ./train_data/val_list.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - MultiLabelEncode:
+ - RecResizeImg:
+ image_shape: [3, 48, 320]
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label_ctc
+ - label_sar
+ - length
+ - valid_ratio
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 128
+ num_workers: 4
diff --git a/configs/rec/rec_svtrnet.yml b/configs/rec/rec_svtrnet.yml
new file mode 100644
index 0000000000000000000000000000000000000000..233d5e276577cad0144456ef7df1e20de99891f9
--- /dev/null
+++ b/configs/rec/rec_svtrnet.yml
@@ -0,0 +1,117 @@
+Global:
+ use_gpu: True
+ epoch_num: 20
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/rec/svtr/
+ save_epoch_step: 1
+ # evaluation is run every 2000 iterations after the 0th iteration
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: doc/imgs_words_en/word_10.png
+ # for data or label process
+ character_dict_path:
+ character_type: en
+ max_text_length: 25
+ infer_mode: False
+ use_space_char: False
+ save_res_path: ./output/rec/predicts_svtr_tiny.txt
+
+
+Optimizer:
+ name: AdamW
+ beta1: 0.9
+ beta2: 0.99
+ epsilon: 0.00000008
+ weight_decay: 0.05
+ no_weight_decay_name: norm pos_embed
+ one_dim_param_no_weight_decay: true
+ lr:
+ name: Cosine
+ learning_rate: 0.0005
+ warmup_epoch: 2
+
+Architecture:
+ model_type: rec
+ algorithm: SVTR
+ Transform:
+ name: STN_ON
+ tps_inputsize: [32, 64]
+ tps_outputsize: [32, 100]
+ num_control_points: 20
+ tps_margins: [0.05,0.05]
+ stn_activation: none
+ Backbone:
+ name: SVTRNet
+ img_size: [32, 100]
+ out_char_num: 25
+ out_channels: 192
+ patch_merging: 'Conv'
+ embed_dim: [64, 128, 256]
+ depth: [3, 6, 3]
+ num_heads: [2, 4, 8]
+ mixer: ['Local','Local','Local','Local','Local','Local','Global','Global','Global','Global','Global','Global']
+ local_mixer: [[7, 11], [7, 11], [7, 11]]
+ last_stage: True
+ prenorm: false
+ Neck:
+ name: SequenceEncoder
+ encoder_type: reshape
+ Head:
+ name: CTCHead
+
+Loss:
+ name: CTCLoss
+
+PostProcess:
+ name: CTCLabelDecode
+
+Metric:
+ name: RecMetric
+ main_indicator: acc
+
+Train:
+ dataset:
+ name: LMDBDataSet
+ data_dir: ./train_data/data_lmdb_release/training/
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - CTCLabelEncode: # Class handling label
+ - RecResizeImg:
+ character_dict_path:
+ image_shape: [3, 64, 256]
+ padding: False
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: True
+ batch_size_per_card: 512
+ drop_last: True
+ num_workers: 4
+
+Eval:
+ dataset:
+ name: LMDBDataSet
+ data_dir: ./train_data/data_lmdb_release/validation/
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - CTCLabelEncode: # Class handling label
+ - RecResizeImg:
+ character_dict_path:
+ image_shape: [3, 64, 256]
+ padding: False
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 256
+ num_workers: 2
diff --git a/deploy/cpp_infer/readme.md b/deploy/cpp_infer/readme.md
index 66c3a4c0719154152a2029572a8b88af3adcfcf4..c62fe32bc310eb3f91a6c55c3ecf25cfa53c0c61 100644
--- a/deploy/cpp_infer/readme.md
+++ b/deploy/cpp_infer/readme.md
@@ -1,38 +1,34 @@
-- [Server-side C++ Inference](#server-side-c-inference)
- - [1. Prepare the Environment](#1-prepare-the-environment)
- - [Environment](#environment)
- - [1.1 Compile OpenCV](#11-compile-opencv)
- - [1.2 Compile or Download or the Paddle Inference Library](#12-compile-or-download-or-the-paddle-inference-library)
- - [1.2.1 Direct download and installation](#121-direct-download-and-installation)
- - [1.2.2 Compile the inference source code](#122-compile-the-inference-source-code)
- - [2. Compile and Run the Demo](#2-compile-and-run-the-demo)
- - [2.1 Export the inference model](#21-export-the-inference-model)
- - [2.2 Compile PaddleOCR C++ inference demo](#22-compile-paddleocr-c-inference-demo)
- - [Run the demo](#run-the-demo)
- - [1. det+cls+rec:](#1-detclsrec)
- - [2. det+rec:](#2-detrec)
- - [3. det](#3-det)
- - [4. cls+rec:](#4-clsrec)
- - [5. rec](#5-rec)
- - [6. cls](#6-cls)
- - [3. FAQ](#3-faq)
+English | [简体中文](readme_ch.md)
# Server-side C++ Inference
-This chapter introduces the C++ deployment steps of the PaddleOCR model. The corresponding Python predictive deployment method refers to [document](../../doc/doc_ch/inference.md).
-C++ is better than python in terms of performance. Therefore, in CPU and GPU deployment scenarios, C++ deployment is mostly used.
+- [1. Prepare the Environment](#1)
+ - [1.1 Environment](#11)
+ - [1.2 Compile OpenCV](#12)
+ - [1.3 Compile or Download or the Paddle Inference Library](#13)
+- [2. Compile and Run the Demo](#2)
+ - [2.1 Export the inference model](#21)
+ - [2.2 Compile PaddleOCR C++ inference demo](#22)
+ - [2.3 Run the demo](#23)
+- [3. FAQ](#3)
+
+
+This chapter introduces the C++ deployment steps of the PaddleOCR model. C++ is better than Python in terms of performance. Therefore, in CPU and GPU deployment scenarios, C++ deployment is mostly used.
This section will introduce how to configure the C++ environment and deploy PaddleOCR in Linux (CPU\GPU) environment. For Windows deployment please refer to [Windows](./docs/windows_vs2019_build.md) compilation guidelines.
+
## 1. Prepare the Environment
-### Environment
+
+### 1.1 Environment
- Linux, docker is recommended.
- Windows.
-### 1.1 Compile OpenCV
+
+### 1.2 Compile OpenCV
* First of all, you need to download the source code compiled package in the Linux environment from the OpenCV official website. Taking OpenCV 3.4.7 as an example, the download command is as follows.
@@ -92,11 +88,12 @@ opencv3/
|-- share
```
-### 1.2 Compile or Download or the Paddle Inference Library
+
+### 1.3 Compile or Download or the Paddle Inference Library
* There are 2 ways to obtain the Paddle inference library, described in detail below.
-#### 1.2.1 Direct download and installation
+#### 1.3.1 Direct download and installation
[Paddle inference library official website](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#linux). You can review and select the appropriate version of the inference library on the official website.
@@ -109,7 +106,7 @@ tar -xf paddle_inference.tgz
Finally you will see the the folder of `paddle_inference/` in the current path.
-#### 1.2.2 Compile the inference source code
+#### 1.3.2 Compile the inference source code
* If you want to get the latest Paddle inference library features, you can download the latest code from Paddle GitHub repository and compile the inference library from the source code. It is recommended to download the inference library with paddle version greater than or equal to 2.0.1.
* You can refer to [Paddle inference library] (https://www.paddlepaddle.org.cn/documentation/docs/en/advanced_guide/inference_deployment/inference/build_and_install_lib_en.html) to get the Paddle source code from GitHub, and then compile To generate the latest inference library. The method of using git to access the code is as follows.
@@ -155,8 +152,10 @@ build/paddle_inference_install_dir/
`paddle` is the Paddle library required for C++ prediction later, and `version.txt` contains the version information of the current inference library.
+
## 2. Compile and Run the Demo
+
### 2.1 Export the inference model
* You can refer to [Model inference](../../doc/doc_ch/inference.md) and export the inference model. After the model is exported, assuming it is placed in the `inference` directory, the directory structure is as follows.
@@ -175,9 +174,9 @@ inference/
```
+
### 2.2 Compile PaddleOCR C++ inference demo
-
* The compilation commands are as follows. The addresses of Paddle C++ inference library, opencv and other Dependencies need to be replaced with the actual addresses on your own machines.
```shell
@@ -201,7 +200,9 @@ or the generated Paddle inference library path (`build/paddle_inference_install_
* After the compilation is completed, an executable file named `ppocr` will be generated in the `build` folder.
-### Run the demo
+
+### 2.3 Run the demo
+
Execute the built executable file:
```shell
./build/ppocr [--param1] [--param2] [...]
@@ -342,6 +343,7 @@ The detection visualized image saved in ./output//12.jpg
```
+
## 3. FAQ
1. Encountered the error `unable to access 'https://github.com/LDOUBLEV/AutoLog.git/': gnutls_handshake() failed: The TLS connection was non-properly terminated.`, change the github address in `deploy/cpp_infer/external-cmake/auto-log.cmake` to the https://gitee.com/Double_V/AutoLog address.
diff --git a/deploy/cpp_infer/readme_ch.md b/deploy/cpp_infer/readme_ch.md
index 47c7e032ebb350625adae8f500f91c0a7b96dbf4..2a81e15a97cca45d525efe8739255acd12f8117f 100644
--- a/deploy/cpp_infer/readme_ch.md
+++ b/deploy/cpp_infer/readme_ch.md
@@ -1,45 +1,36 @@
-- [服务器端C++预测](#服务器端c预测)
- - [1. 准备环境](#1-准备环境)
- - [1.0 运行准备](#10-运行准备)
- - [1.1 编译opencv库](#11-编译opencv库)
- - [1.2 下载或者编译Paddle预测库](#12-下载或者编译paddle预测库)
- - [1.2.1 直接下载安装](#121-直接下载安装)
- - [1.2.2 预测库源码编译](#122-预测库源码编译)
- - [2 开始运行](#2-开始运行)
- - [2.1 将模型导出为inference model](#21-将模型导出为inference-model)
- - [2.2 编译PaddleOCR C++预测demo](#22-编译paddleocr-c预测demo)
- - [2.3 运行demo](#23-运行demo)
- - [1. 检测+分类+识别:](#1-检测分类识别)
- - [2. 检测+识别:](#2-检测识别)
- - [3. 检测:](#3-检测)
- - [4. 分类+识别:](#4-分类识别)
- - [5. 识别:](#5-识别)
- - [6. 分类:](#6-分类)
- - [3. FAQ](#3-faq)
+[English](readme.md) | 简体中文
# 服务器端C++预测
-本章节介绍PaddleOCR 模型的的C++部署方法,与之对应的python预测部署方式参考[文档](../../doc/doc_ch/inference.md)。
-C++在性能计算上优于python,因此,在大多数CPU、GPU部署场景,多采用C++的部署方式,本节将介绍如何在Linux\Windows (CPU\GPU)环境下配置C++环境并完成
-PaddleOCR模型部署。
+- [1. 准备环境](#1)
+ - [1.1 运行准备](#11)
+ - [1.2 编译opencv库](#12)
+ - [1.3 下载或者编译Paddle预测库](#13)
+- [2 开始运行](#2)
+ - [2.1 准备模型](#21)
+ - [2.2 编译PaddleOCR C++预测demo](#22)
+ - [2.3 运行demo](#23)
+- [3. FAQ](#3)
+
+本章节介绍PaddleOCR 模型的的C++部署方法。C++在性能计算上优于Python,因此,在大多数CPU、GPU部署场景,多采用C++的部署方式,本节将介绍如何在Linux\Windows (CPU\GPU)环境下配置C++环境并完成PaddleOCR模型部署。
## 1. 准备环境
-
+
-### 1.0 运行准备
+### 1.1 运行准备
- Linux环境,推荐使用docker。
- Windows环境。
* 该文档主要介绍基于Linux环境的PaddleOCR C++预测流程,如果需要在Windows下基于预测库进行C++预测,具体编译方法请参考[Windows下编译教程](./docs/windows_vs2019_build.md)
-
+
-### 1.1 编译opencv库
+### 1.2 编译opencv库
* 首先需要从opencv官网上下载在Linux环境下源码编译的包,以opencv3.4.7为例,下载命令如下。
@@ -103,35 +94,38 @@ opencv3/
|-- share
```
-
-
-### 1.2 下载或者编译Paddle预测库
+
-* 有2种方式获取Paddle预测库,下面进行详细介绍。
+### 1.3 下载或者编译Paddle预测库
+可以选择直接下载安装或者从源码编译,下文分别进行具体说明。
-#### 1.2.1 直接下载安装
+
+#### 1.3.1 直接下载安装
-* [Paddle预测库官网](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#linux) 上提供了不同cuda版本的Linux预测库,可以在官网查看并选择合适的预测库版本(*建议选择paddle版本>=2.0.1版本的预测库* )。
+[Paddle预测库官网](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#linux) 上提供了不同cuda版本的Linux预测库,可以在官网查看并选择合适的预测库版本(*建议选择paddle版本>=2.0.1版本的预测库* )。
-* 下载之后使用下面的方法解压。
+下载之后解压:
-```
+```shell
tar -xf paddle_inference.tgz
```
最终会在当前的文件夹中生成`paddle_inference/`的子文件夹。
-#### 1.2.2 预测库源码编译
-* 如果希望获取最新预测库特性,可以从Paddle github上克隆最新代码,源码编译预测库。
-* 可以参考[Paddle预测库安装编译说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0/guides/05_inference_deployment/inference/build_and_install_lib_cn.html#congyuanmabianyi) 的说明,从github上获取Paddle代码,然后进行编译,生成最新的预测库。使用git获取代码方法如下。
+
+#### 1.3.2 预测库源码编译
+
+如果希望获取最新预测库特性,可以从github上克隆最新Paddle代码进行编译,生成最新的预测库。
+
+* 使用git获取代码:
```shell
git clone https://github.com/PaddlePaddle/Paddle.git
git checkout develop
```
-* 进入Paddle目录后,编译方法如下。
+* 进入Paddle目录,进行编译:
```shell
rm -rf build
@@ -151,7 +145,7 @@ make -j
make inference_lib_dist
```
-更多编译参数选项介绍可以参考[文档说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0/guides/05_inference_deployment/inference/build_and_install_lib_cn.html#congyuanmabianyi)。
+更多编译参数选项介绍可以参考[Paddle预测库编译文档](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0/guides/05_inference_deployment/inference/build_and_install_lib_cn.html#congyuanmabianyi)。
* 编译完成之后,可以在`build/paddle_inference_install_dir/`文件下看到生成了以下文件及文件夹。
@@ -168,13 +162,13 @@ build/paddle_inference_install_dir/
-## 2 开始运行
+## 2. 开始运行
-### 2.1 将模型导出为inference model
+### 2.1 准备模型
-* 可以参考[模型预测章节](../../doc/doc_ch/inference.md),导出inference model,用于模型预测。模型导出之后,假设放在`inference`目录下,则目录结构如下。
+直接下载PaddleOCR提供的推理模型,或者参考[模型预测章节](../../doc/doc_ch/inference_ppocr.md),将训练好的模型导出为推理模型。模型导出之后,假设放在`inference`目录下,则目录结构如下。
```
inference/
@@ -193,13 +187,13 @@ inference/
### 2.2 编译PaddleOCR C++预测demo
-* 编译命令如下,其中Paddle C++预测库、opencv等其他依赖库的地址需要换成自己机器上的实际地址。
+编译命令如下,其中Paddle C++预测库、opencv等其他依赖库的地址需要换成自己机器上的实际地址。
```shell
sh tools/build.sh
```
-* 具体的,需要修改`tools/build.sh`中环境路径,相关内容如下:
+具体的,需要修改`tools/build.sh`中环境路径,相关内容如下:
```shell
OPENCV_DIR=your_opencv_dir
@@ -211,12 +205,14 @@ CUDNN_LIB_DIR=/your_cudnn_lib_dir
其中,`OPENCV_DIR`为opencv编译安装的地址;`LIB_DIR`为下载(`paddle_inference`文件夹)或者编译生成的Paddle预测库地址(`build/paddle_inference_install_dir`文件夹);`CUDA_LIB_DIR`为cuda库文件地址,在docker中为`/usr/local/cuda/lib64`;`CUDNN_LIB_DIR`为cudnn库文件地址,在docker中为`/usr/lib/x86_64-linux-gnu/`。**注意:以上路径都写绝对路径,不要写相对路径。**
-* 编译完成之后,会在`build`文件夹下生成一个名为`ppocr`的可执行文件。
+编译完成之后,会在`build`文件夹下生成一个名为`ppocr`的可执行文件。
### 2.3 运行demo
+本demo支持系统串联调用,也支持单个功能的调用,如,只使用检测或识别功能。
+
运行方式:
```shell
./build/ppocr [--param1] [--param2] [...]
@@ -354,6 +350,7 @@ predict img: ../../doc/imgs/12.jpg
The detection visualized image saved in ./output//12.jpg
```
+
## 3. FAQ
1. 遇到报错 `unable to access 'https://github.com/LDOUBLEV/AutoLog.git/': gnutls_handshake() failed: The TLS connection was non-properly terminated.`, 将 `deploy/cpp_infer/external-cmake/auto-log.cmake` 中的github地址改为 https://gitee.com/Double_V/AutoLog 地址即可。
diff --git a/deploy/slim/quantization/quant.py b/deploy/slim/quantization/quant.py
index 1dffaab0eef35ec41c27c9c6e00f25dda048d490..355ba77f83121d07a52b1b8645bc6d4893373c42 100755
--- a/deploy/slim/quantization/quant.py
+++ b/deploy/slim/quantization/quant.py
@@ -137,7 +137,7 @@ def main(config, device, logger, vdl_writer):
config['Optimizer'],
epochs=config['Global']['epoch_num'],
step_each_epoch=len(train_dataloader),
- parameters=model.parameters())
+ model=model)
# resume PACT training process
if config["Global"]["checkpoints"] is not None:
diff --git a/doc/doc_ch/algorithm_det_db.md b/doc/doc_ch/algorithm_det_db.md
index fc887743bcdb4cf6e29ac4d8e643dda9520e4795..7f94ceaee06ac41a42c785f26bffa30005a98355 100644
--- a/doc/doc_ch/algorithm_det_db.md
+++ b/doc/doc_ch/algorithm_det_db.md
@@ -47,13 +47,13 @@
### 4.1 Python推理
首先将DB文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar) ),可以使用如下命令进行转换:
-```
+```shell
python3 tools/export_model.py -c configs/det/det_r50_vd_db.yml -o Global.pretrained_model=./det_r50_vd_db_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_db
```
DB文本检测模型推理,可以执行如下命令:
-```
+```shell
python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_db/"
```
@@ -65,15 +65,20 @@ python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_
### 4.2 C++推理
-敬请期待
+
+准备好推理模型后,参考[cpp infer](../../deploy/cpp_infer/)教程进行操作即可。
### 4.3 Serving服务化部署
-敬请期待
+
+准备好推理模型后,参考[pdserving](../../deploy/pdserving/)教程进行Serving服务化部署,包括Python Serving和C++ Serving两种模式。
### 4.4 更多推理部署
-敬请期待
+
+DB模型还支持以下推理部署方式:
+
+- Paddle2ONNX推理:准备好推理模型后,参考[paddle2onnx](../../deploy/paddle2onnx/)教程操作。
## 5. FAQ
diff --git a/doc/doc_en/algorithm_det_db_en.md b/doc/doc_en/algorithm_det_db_en.md
index 40ba022f84786f3538f348e350a41506962c9c2c..b387a8ec217b351164d7cac878539bab19157a6e 100644
--- a/doc/doc_en/algorithm_det_db_en.md
+++ b/doc/doc_en/algorithm_det_db_en.md
@@ -14,4 +14,86 @@
- [5. FAQ](#5)
-## 1. Introduction
\ No newline at end of file
+## 1. Introduction
+
+Paper:
+> [Real-time Scene Text Detection with Differentiable Binarization](https://arxiv.org/abs/1911.08947)
+> Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang
+> AAAI, 2020
+
+On the ICDAR2015 dataset, the text detection result is as follows:
+
+|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
+| --- | --- | --- | --- | --- | --- | --- |
+|DB|ResNet50_vd|configs/det/det_r50_vd_db.yml|86.41%|78.72%|82.38%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar)|
+|DB|MobileNetV3|configs/det/det_mv3_db.yml|77.29%|73.08%|75.12%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_mv3_db_v2.0_train.tar)|
+
+
+
+## 2. Environment
+Please prepare your environment referring to [prepare the environment](./environment_en.md) and [clone the repo](./clone_en.md).
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+Please refer to [text detection training tutorial](./detection_en.md). PaddleOCR has modularized the code structure, so that you only need to **replace the configuration file** to train different detection models.
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, convert the model saved in the DB text detection training process into an inference model. Taking the model based on the Resnet50_vd backbone network and trained on the ICDAR2015 English dataset as example ([model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar)), you can use the following command to convert:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_db.yml -o Global.pretrained_model=./det_r50_vd_db_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_db
+```
+
+DB text detection model inference, you can execute the following command:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_db/"
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+**Note**: Since the ICDAR2015 dataset has only 1,000 training images, mainly for English scenes, the above model has very poor detection result on Chinese text images.
+
+
+
+### 4.2 C++ Inference
+
+With the inference model prepared, refer to the [cpp infer](../../deploy/cpp_infer/) tutorial for C++ inference.
+
+
+### 4.3 Serving
+
+With the inference model prepared, refer to the [pdserving](../../deploy/pdserving/) tutorial for service deployment by Paddle Serving.
+
+
+### 4.4 More
+
+More deployment schemes supported for DB:
+
+- Paddle2ONNX: with the inference model prepared, please refer to the [paddle2onnx](../../deploy/paddle2onnx/) tutorial.
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@inproceedings{liao2020real,
+ title={Real-time scene text detection with differentiable binarization},
+ author={Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang},
+ booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
+ volume={34},
+ number={07},
+ pages={11474--11481},
+ year={2020}
+}
+```
\ No newline at end of file
diff --git a/doc/joinus.PNG b/doc/joinus.PNG
index 133e42b8de6c4ec2c0ae4f85aab0d4a7fb425526..6eacac65d268a17dd717fff1790d5c0c84acc5ea 100644
Binary files a/doc/joinus.PNG and b/doc/joinus.PNG differ
diff --git a/ppocr/data/imaug/__init__.py b/ppocr/data/imaug/__init__.py
index 164f1d2224d6cdba589d0502fc17438d346788dd..7580e607afb356a1032c4d6b2d2267bff608a80d 100644
--- a/ppocr/data/imaug/__init__.py
+++ b/ppocr/data/imaug/__init__.py
@@ -22,8 +22,8 @@ from .make_shrink_map import MakeShrinkMap
from .random_crop_data import EastRandomCropData, RandomCropImgMask
from .make_pse_gt import MakePseGt
-from .rec_img_aug import RecAug, RecResizeImg, ClsResizeImg, \
- SRNRecResizeImg, NRTRRecResizeImg, SARRecResizeImg, PRENResizeImg
+from .rec_img_aug import RecAug, RecConAug, RecResizeImg, ClsResizeImg, \
+ SRNRecResizeImg, NRTRRecResizeImg, SARRecResizeImg, PRENResizeImg, SVTRRecResizeImg
from .randaugment import RandAugment
from .copy_paste import CopyPaste
from .ColorJitter import ColorJitter
diff --git a/ppocr/data/imaug/label_ops.py b/ppocr/data/imaug/label_ops.py
index 6f86be7da002cc6a9fb649f532a73b109286be6b..c9bc2e7722e8027ce870e4969bfcdab720495c28 100644
--- a/ppocr/data/imaug/label_ops.py
+++ b/ppocr/data/imaug/label_ops.py
@@ -22,6 +22,7 @@ import numpy as np
import string
from shapely.geometry import LineString, Point, Polygon
import json
+import copy
from ppocr.utils.logging import get_logger
@@ -112,14 +113,14 @@ class BaseRecLabelEncode(object):
dict_character = list(self.character_str)
self.lower = True
else:
- self.character_str = ""
+ self.character_str = []
with open(character_dict_path, "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode('utf-8').strip("\n").strip("\r\n")
- self.character_str += line
+ self.character_str.append(line)
if use_space_char:
- self.character_str += " "
+ self.character_str.append(" ")
dict_character = list(self.character_str)
dict_character = self.add_special_char(dict_character)
self.dict = {}
@@ -1007,3 +1008,34 @@ class VQATokenLabelEncode(object):
gt_label.extend([self.label2id_map[("i-" + label).upper()]] *
(len(encode_res["input_ids"]) - 1))
return gt_label
+
+
+class MultiLabelEncode(BaseRecLabelEncode):
+ def __init__(self,
+ max_text_length,
+ character_dict_path=None,
+ use_space_char=False,
+ **kwargs):
+ super(MultiLabelEncode, self).__init__(
+ max_text_length, character_dict_path, use_space_char)
+
+ self.ctc_encode = CTCLabelEncode(max_text_length, character_dict_path,
+ use_space_char, **kwargs)
+ self.sar_encode = SARLabelEncode(max_text_length, character_dict_path,
+ use_space_char, **kwargs)
+
+ def __call__(self, data):
+
+ data_ctc = copy.deepcopy(data)
+ data_sar = copy.deepcopy(data)
+ data_out = dict()
+ data_out['img_path'] = data.get('img_path', None)
+ data_out['image'] = data['image']
+ ctc = self.ctc_encode.__call__(data_ctc)
+ sar = self.sar_encode.__call__(data_sar)
+ if ctc is None or sar is None:
+ return None
+ data_out['label_ctc'] = ctc['label']
+ data_out['label_sar'] = sar['label']
+ data_out['length'] = ctc['length']
+ return data_out
diff --git a/ppocr/data/imaug/rec_img_aug.py b/ppocr/data/imaug/rec_img_aug.py
index 6f59fef63d85090b0e433d79b0c3e3f381ac1b38..2f70b51a3b88422274353046209c6d0d4dc79489 100644
--- a/ppocr/data/imaug/rec_img_aug.py
+++ b/ppocr/data/imaug/rec_img_aug.py
@@ -16,6 +16,7 @@ import math
import cv2
import numpy as np
import random
+import copy
from PIL import Image
from .text_image_aug import tia_perspective, tia_stretch, tia_distort
@@ -32,13 +33,56 @@ class RecAug(object):
return data
+class RecConAug(object):
+ def __init__(self,
+ prob=0.5,
+ image_shape=(32, 320, 3),
+ max_text_length=25,
+ ext_data_num=1,
+ **kwargs):
+ self.ext_data_num = ext_data_num
+ self.prob = prob
+ self.max_text_length = max_text_length
+ self.image_shape = image_shape
+ self.max_wh_ratio = self.image_shape[1] / self.image_shape[0]
+
+ def merge_ext_data(self, data, ext_data):
+ ori_w = round(data['image'].shape[1] / data['image'].shape[0] *
+ self.image_shape[0])
+ ext_w = round(ext_data['image'].shape[1] / ext_data['image'].shape[0] *
+ self.image_shape[0])
+ data['image'] = cv2.resize(data['image'], (ori_w, self.image_shape[0]))
+ ext_data['image'] = cv2.resize(ext_data['image'],
+ (ext_w, self.image_shape[0]))
+ data['image'] = np.concatenate(
+ [data['image'], ext_data['image']], axis=1)
+ data["label"] += ext_data["label"]
+ return data
+
+ def __call__(self, data):
+ rnd_num = random.random()
+ if rnd_num > self.prob:
+ return data
+ for idx, ext_data in enumerate(data["ext_data"]):
+ if len(data["label"]) + len(ext_data[
+ "label"]) > self.max_text_length:
+ break
+ concat_ratio = data['image'].shape[1] / data['image'].shape[
+ 0] + ext_data['image'].shape[1] / ext_data['image'].shape[0]
+ if concat_ratio > self.max_wh_ratio:
+ break
+ data = self.merge_ext_data(data, ext_data)
+ data.pop("ext_data")
+ return data
+
+
class ClsResizeImg(object):
def __init__(self, image_shape, **kwargs):
self.image_shape = image_shape
def __call__(self, data):
img = data['image']
- norm_img = resize_norm_img(img, self.image_shape)
+ norm_img, _ = resize_norm_img(img, self.image_shape)
data['image'] = norm_img
return data
@@ -98,10 +142,13 @@ class RecResizeImg(object):
def __call__(self, data):
img = data['image']
if self.infer_mode and self.character_dict_path is not None:
- norm_img = resize_norm_img_chinese(img, self.image_shape)
+ norm_img, valid_ratio = resize_norm_img_chinese(img,
+ self.image_shape)
else:
- norm_img = resize_norm_img(img, self.image_shape, self.padding)
+ norm_img, valid_ratio = resize_norm_img(img, self.image_shape,
+ self.padding)
data['image'] = norm_img
+ data['valid_ratio'] = valid_ratio
return data
@@ -160,6 +207,25 @@ class PRENResizeImg(object):
return data
+class SVTRRecResizeImg(object):
+ def __init__(self,
+ image_shape,
+ infer_mode=False,
+ character_dict_path='./ppocr/utils/ppocr_keys_v1.txt',
+ padding=True,
+ **kwargs):
+ self.image_shape = image_shape
+ self.infer_mode = infer_mode
+ self.character_dict_path = character_dict_path
+ self.padding = padding
+
+ def __call__(self, data):
+ img = data['image']
+ norm_img = resize_norm_img_svtr(img, self.image_shape, self.padding)
+ data['image'] = norm_img
+ return data
+
+
def resize_norm_img_sar(img, image_shape, width_downsample_ratio=0.25):
imgC, imgH, imgW_min, imgW_max = image_shape
h = img.shape[0]
@@ -220,7 +286,8 @@ def resize_norm_img(img, image_shape, padding=True):
resized_image /= 0.5
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
- return padding_im
+ valid_ratio = min(1.0, float(resized_w / imgW))
+ return padding_im, valid_ratio
def resize_norm_img_chinese(img, image_shape):
@@ -230,7 +297,7 @@ def resize_norm_img_chinese(img, image_shape):
h, w = img.shape[0], img.shape[1]
ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, ratio)
- imgW = int(32 * max_wh_ratio)
+ imgW = int(imgH * max_wh_ratio)
if math.ceil(imgH * ratio) > imgW:
resized_w = imgW
else:
@@ -246,7 +313,8 @@ def resize_norm_img_chinese(img, image_shape):
resized_image /= 0.5
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
- return padding_im
+ valid_ratio = min(1.0, float(resized_w / imgW))
+ return padding_im, valid_ratio
def resize_norm_img_srn(img, image_shape):
@@ -276,6 +344,58 @@ def resize_norm_img_srn(img, image_shape):
return np.reshape(img_black, (c, row, col)).astype(np.float32)
+def resize_norm_img_svtr(img, image_shape, padding=False):
+ imgC, imgH, imgW = image_shape
+ h = img.shape[0]
+ w = img.shape[1]
+ if not padding:
+ if h > 2.0 * w:
+ image = Image.fromarray(img)
+ image1 = image.rotate(90, expand=True)
+ image2 = image.rotate(-90, expand=True)
+ img1 = np.array(image1)
+ img2 = np.array(image2)
+ else:
+ img1 = copy.deepcopy(img)
+ img2 = copy.deepcopy(img)
+
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image1 = cv2.resize(
+ img1, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image2 = cv2.resize(
+ img2, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_w = imgW
+ else:
+ ratio = w / float(h)
+ if math.ceil(imgH * ratio) > imgW:
+ resized_w = imgW
+ else:
+ resized_w = int(math.ceil(imgH * ratio))
+ resized_image = cv2.resize(img, (resized_w, imgH))
+ resized_image = resized_image.astype('float32')
+ resized_image1 = resized_image1.astype('float32')
+ resized_image2 = resized_image2.astype('float32')
+ if image_shape[0] == 1:
+ resized_image = resized_image / 255
+ resized_image = resized_image[np.newaxis, :]
+ else:
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image1 = resized_image1.transpose((2, 0, 1)) / 255
+ resized_image2 = resized_image2.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ resized_image1 -= 0.5
+ resized_image1 /= 0.5
+ resized_image2 -= 0.5
+ resized_image2 /= 0.5
+ padding_im = np.zeros((3, imgC, imgH, imgW), dtype=np.float32)
+ padding_im[0, :, :, 0:resized_w] = resized_image
+ padding_im[1, :, :, 0:resized_w] = resized_image1
+ padding_im[2, :, :, 0:resized_w] = resized_image2
+ return padding_im
+
+
def srn_other_inputs(image_shape, num_heads, max_text_length):
imgC, imgH, imgW = image_shape
diff --git a/ppocr/data/simple_dataset.py b/ppocr/data/simple_dataset.py
index 13f9411e29430843bb808aede15e8305dbc2d028..b5da9b8898423facf888839f941dff01caa03643 100644
--- a/ppocr/data/simple_dataset.py
+++ b/ppocr/data/simple_dataset.py
@@ -49,7 +49,8 @@ class SimpleDataSet(Dataset):
if self.mode == "train" and self.do_shuffle:
self.shuffle_data_random()
self.ops = create_operators(dataset_config['transforms'], global_config)
-
+ self.ext_op_transform_idx = dataset_config.get("ext_op_transform_idx",
+ 2)
self.need_reset = True in [x < 1 for x in ratio_list]
def get_image_info_list(self, file_list, ratio_list):
@@ -87,7 +88,7 @@ class SimpleDataSet(Dataset):
if hasattr(op, 'ext_data_num'):
ext_data_num = getattr(op, 'ext_data_num')
break
- load_data_ops = self.ops[:2]
+ load_data_ops = self.ops[:self.ext_op_transform_idx]
ext_data = []
while len(ext_data) < ext_data_num:
@@ -108,8 +109,11 @@ class SimpleDataSet(Dataset):
data['image'] = img
data = transform(data, load_data_ops)
- if data is None or data['polys'].shape[1] != 4:
+ if data is None:
continue
+ if 'polys' in data.keys():
+ if data['polys'].shape[1] != 4:
+ continue
ext_data.append(data)
return ext_data
diff --git a/ppocr/losses/__init__.py b/ppocr/losses/__init__.py
index 6505fca77ec6ff6b18dc840c6b2e443eecf2af2a..de8419b7c1cf6a30ab7195a1cbcbb10a5e52642d 100755
--- a/ppocr/losses/__init__.py
+++ b/ppocr/losses/__init__.py
@@ -34,6 +34,7 @@ from .rec_nrtr_loss import NRTRLoss
from .rec_sar_loss import SARLoss
from .rec_aster_loss import AsterLoss
from .rec_pren_loss import PRENLoss
+from .rec_multi_loss import MultiLoss
# cls loss
from .cls_loss import ClsLoss
@@ -60,7 +61,7 @@ def build_loss(config):
'DBLoss', 'PSELoss', 'EASTLoss', 'SASTLoss', 'FCELoss', 'CTCLoss',
'ClsLoss', 'AttentionLoss', 'SRNLoss', 'PGLoss', 'CombinedLoss',
'NRTRLoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
- 'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss'
+ 'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss', 'MultiLoss'
]
config = copy.deepcopy(config)
module_name = config.pop('name')
diff --git a/ppocr/losses/basic_loss.py b/ppocr/losses/basic_loss.py
index b19ce57dcaf463d8be30fd1111b521d632308786..2df96ea2642d10a50eb892d738f89318dc5e0f4c 100644
--- a/ppocr/losses/basic_loss.py
+++ b/ppocr/losses/basic_loss.py
@@ -106,8 +106,8 @@ class DMLLoss(nn.Layer):
def forward(self, out1, out2):
if self.act is not None:
- out1 = self.act(out1)
- out2 = self.act(out2)
+ out1 = self.act(out1) + 1e-10
+ out2 = self.act(out2) + 1e-10
if self.use_log:
# for recognition distillation, log is needed for feature map
log_out1 = paddle.log(out1)
diff --git a/ppocr/losses/combined_loss.py b/ppocr/losses/combined_loss.py
index 72f706e37d6eb0c640cc30de80afe00bce82fd13..f4cdee8f90465e863b89d1e32b4a0285adb29eff 100644
--- a/ppocr/losses/combined_loss.py
+++ b/ppocr/losses/combined_loss.py
@@ -18,8 +18,10 @@ import paddle.nn as nn
from .rec_ctc_loss import CTCLoss
from .center_loss import CenterLoss
from .ace_loss import ACELoss
+from .rec_sar_loss import SARLoss
from .distillation_loss import DistillationCTCLoss
+from .distillation_loss import DistillationSARLoss
from .distillation_loss import DistillationDMLLoss
from .distillation_loss import DistillationDistanceLoss, DistillationDBLoss, DistillationDilaDBLoss
diff --git a/ppocr/losses/distillation_loss.py b/ppocr/losses/distillation_loss.py
index 06aa7fa8458a5deece75f1393fe7300e8227d3ca..565b066d1334e6caa1b6b4094706265f363b66ef 100644
--- a/ppocr/losses/distillation_loss.py
+++ b/ppocr/losses/distillation_loss.py
@@ -18,6 +18,7 @@ import numpy as np
import cv2
from .rec_ctc_loss import CTCLoss
+from .rec_sar_loss import SARLoss
from .basic_loss import DMLLoss
from .basic_loss import DistanceLoss
from .det_db_loss import DBLoss
@@ -46,11 +47,15 @@ class DistillationDMLLoss(DMLLoss):
act=None,
use_log=False,
key=None,
+ multi_head=False,
+ dis_head='ctc',
maps_name=None,
name="dml"):
super().__init__(act=act, use_log=use_log)
assert isinstance(model_name_pairs, list)
self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
self.name = name
self.maps_name = self._check_maps_name(maps_name)
@@ -97,7 +102,11 @@ class DistillationDMLLoss(DMLLoss):
out2 = out2[self.key]
if self.maps_name is None:
- loss = super().forward(out1, out2)
+ if self.multi_head:
+ loss = super().forward(out1[self.dis_head],
+ out2[self.dis_head])
+ else:
+ loss = super().forward(out1, out2)
if isinstance(loss, dict):
for key in loss:
loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
@@ -123,11 +132,16 @@ class DistillationDMLLoss(DMLLoss):
class DistillationCTCLoss(CTCLoss):
- def __init__(self, model_name_list=[], key=None, name="loss_ctc"):
+ def __init__(self,
+ model_name_list=[],
+ key=None,
+ multi_head=False,
+ name="loss_ctc"):
super().__init__()
self.model_name_list = model_name_list
self.key = key
self.name = name
+ self.multi_head = multi_head
def forward(self, predicts, batch):
loss_dict = dict()
@@ -135,7 +149,45 @@ class DistillationCTCLoss(CTCLoss):
out = predicts[model_name]
if self.key is not None:
out = out[self.key]
- loss = super().forward(out, batch)
+ if self.multi_head:
+ assert 'ctc' in out, 'multi head has multi out'
+ loss = super().forward(out['ctc'], batch[:2] + batch[3:])
+ else:
+ loss = super().forward(out, batch)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}".format(self.name, model_name,
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, model_name)] = loss
+ return loss_dict
+
+
+class DistillationSARLoss(SARLoss):
+ def __init__(self,
+ model_name_list=[],
+ key=None,
+ multi_head=False,
+ name="loss_sar",
+ **kwargs):
+ ignore_index = kwargs.get('ignore_index', 92)
+ super().__init__(ignore_index=ignore_index)
+ self.model_name_list = model_name_list
+ self.key = key
+ self.name = name
+ self.multi_head = multi_head
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, model_name in enumerate(self.model_name_list):
+ out = predicts[model_name]
+ if self.key is not None:
+ out = out[self.key]
+ if self.multi_head:
+ assert 'sar' in out, 'multi head has multi out'
+ loss = super().forward(out['sar'], batch[:1] + batch[2:])
+ else:
+ loss = super().forward(out, batch)
if isinstance(loss, dict):
for key in loss:
loss_dict["{}_{}_{}".format(self.name, model_name,
diff --git a/ppocr/losses/rec_multi_loss.py b/ppocr/losses/rec_multi_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..09f007afe6303e83b9a6948df553ec0fca8b6b2d
--- /dev/null
+++ b/ppocr/losses/rec_multi_loss.py
@@ -0,0 +1,58 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import paddle
+from paddle import nn
+
+from .rec_ctc_loss import CTCLoss
+from .rec_sar_loss import SARLoss
+
+
+class MultiLoss(nn.Layer):
+ def __init__(self, **kwargs):
+ super().__init__()
+ self.loss_funcs = {}
+ self.loss_list = kwargs.pop('loss_config_list')
+ self.weight_1 = kwargs.get('weight_1', 1.0)
+ self.weight_2 = kwargs.get('weight_2', 1.0)
+ self.gtc_loss = kwargs.get('gtc_loss', 'sar')
+ for loss_info in self.loss_list:
+ for name, param in loss_info.items():
+ if param is not None:
+ kwargs.update(param)
+ loss = eval(name)(**kwargs)
+ self.loss_funcs[name] = loss
+
+ def forward(self, predicts, batch):
+ self.total_loss = {}
+ total_loss = 0.0
+ # batch [image, label_ctc, label_sar, length, valid_ratio]
+ for name, loss_func in self.loss_funcs.items():
+ if name == 'CTCLoss':
+ loss = loss_func(predicts['ctc'],
+ batch[:2] + batch[3:])['loss'] * self.weight_1
+ elif name == 'SARLoss':
+ loss = loss_func(predicts['sar'],
+ batch[:1] + batch[2:])['loss'] * self.weight_2
+ else:
+ raise NotImplementedError(
+ '{} is not supported in MultiLoss yet'.format(name))
+ self.total_loss[name] = loss
+ total_loss += loss
+ self.total_loss['loss'] = total_loss
+ return self.total_loss
diff --git a/ppocr/losses/rec_sar_loss.py b/ppocr/losses/rec_sar_loss.py
index c8bd8bb0ca395fa4658e57b8dcac52a3e94aadce..a4f83f03c08e4c4e6bab308aebc2daa8aa612400 100644
--- a/ppocr/losses/rec_sar_loss.py
+++ b/ppocr/losses/rec_sar_loss.py
@@ -9,8 +9,9 @@ from paddle import nn
class SARLoss(nn.Layer):
def __init__(self, **kwargs):
super(SARLoss, self).__init__()
+ ignore_index = kwargs.get('ignore_index', 92) # 6626
self.loss_func = paddle.nn.loss.CrossEntropyLoss(
- reduction="mean", ignore_index=92)
+ reduction="mean", ignore_index=ignore_index)
def forward(self, predicts, batch):
predict = predicts[:, :
diff --git a/ppocr/metrics/rec_metric.py b/ppocr/metrics/rec_metric.py
index b047bbcb972cadf227daaeb8797c46095ac0af43..515b9372e38a7213cde29fdc9834ed6df45a0a80 100644
--- a/ppocr/metrics/rec_metric.py
+++ b/ppocr/metrics/rec_metric.py
@@ -17,9 +17,14 @@ import string
class RecMetric(object):
- def __init__(self, main_indicator='acc', is_filter=False, **kwargs):
+ def __init__(self,
+ main_indicator='acc',
+ is_filter=False,
+ ignore_space=True,
+ **kwargs):
self.main_indicator = main_indicator
self.is_filter = is_filter
+ self.ignore_space = ignore_space
self.eps = 1e-5
self.reset()
@@ -34,8 +39,9 @@ class RecMetric(object):
all_num = 0
norm_edit_dis = 0.0
for (pred, pred_conf), (target, _) in zip(preds, labels):
- pred = pred.replace(" ", "")
- target = target.replace(" ", "")
+ if self.ignore_space:
+ pred = pred.replace(" ", "")
+ target = target.replace(" ", "")
if self.is_filter:
pred = self._normalize_text(pred)
target = self._normalize_text(target)
diff --git a/ppocr/modeling/architectures/base_model.py b/ppocr/modeling/architectures/base_model.py
index e622db25677069f9a4470db4966b7523def35472..f5b29f94057d5b1f1fbec27686d5f1d679b15479 100644
--- a/ppocr/modeling/architectures/base_model.py
+++ b/ppocr/modeling/architectures/base_model.py
@@ -83,7 +83,11 @@ class BaseModel(nn.Layer):
y["neck_out"] = x
if self.use_head:
x = self.head(x, targets=data)
- if isinstance(x, dict):
+ # for multi head, save ctc neck out for udml
+ if isinstance(x, dict) and 'ctc_neck' in x.keys():
+ y["neck_out"] = x["ctc_neck"]
+ y["head_out"] = x
+ elif isinstance(x, dict):
y.update(x)
else:
y["head_out"] = x
diff --git a/ppocr/modeling/architectures/distillation_model.py b/ppocr/modeling/architectures/distillation_model.py
index 5e867940e796841111fc668a0b3eb12547807d76..cce8fd311d4e847afda0fbb035743f0a10564c7d 100644
--- a/ppocr/modeling/architectures/distillation_model.py
+++ b/ppocr/modeling/architectures/distillation_model.py
@@ -53,8 +53,8 @@ class DistillationModel(nn.Layer):
self.model_list.append(self.add_sublayer(key, model))
self.model_name_list.append(key)
- def forward(self, x):
+ def forward(self, x, data=None):
result_dict = dict()
for idx, model_name in enumerate(self.model_name_list):
- result_dict[model_name] = self.model_list[idx](x)
+ result_dict[model_name] = self.model_list[idx](x, data)
return result_dict
diff --git a/ppocr/modeling/backbones/__init__.py b/ppocr/modeling/backbones/__init__.py
index c89c7c25aeb7c905428a4813d74f0514ed59e8e1..072d6e0f84d4126d256c26aa5baf17c9dc4e63df 100755
--- a/ppocr/modeling/backbones/__init__.py
+++ b/ppocr/modeling/backbones/__init__.py
@@ -31,9 +31,11 @@ def build_backbone(config, model_type):
from .rec_resnet_aster import ResNet_ASTER
from .rec_micronet import MicroNet
from .rec_efficientb3_pren import EfficientNetb3_PREN
+ from .rec_svtrnet import SVTRNet
support_dict = [
'MobileNetV1Enhance', 'MobileNetV3', 'ResNet', 'ResNetFPN', 'MTB',
- "ResNet31", "ResNet_ASTER", 'MicroNet', 'EfficientNetb3_PREN'
+ "ResNet31", "ResNet_ASTER", 'MicroNet', 'EfficientNetb3_PREN',
+ 'SVTRNet'
]
elif model_type == "e2e":
from .e2e_resnet_vd_pg import ResNet
diff --git a/ppocr/modeling/backbones/rec_mv1_enhance.py b/ppocr/modeling/backbones/rec_mv1_enhance.py
index d8a7f4b5646eb70b5202aa3b3ac6494318b424ad..bb6af5e82cf13ac42d9a970787596a65986ade54 100644
--- a/ppocr/modeling/backbones/rec_mv1_enhance.py
+++ b/ppocr/modeling/backbones/rec_mv1_enhance.py
@@ -103,7 +103,12 @@ class DepthwiseSeparable(nn.Layer):
class MobileNetV1Enhance(nn.Layer):
- def __init__(self, in_channels=3, scale=0.5, **kwargs):
+ def __init__(self,
+ in_channels=3,
+ scale=0.5,
+ last_conv_stride=1,
+ last_pool_type='max',
+ **kwargs):
super().__init__()
self.scale = scale
self.block_list = []
@@ -200,7 +205,7 @@ class MobileNetV1Enhance(nn.Layer):
num_filters1=1024,
num_filters2=1024,
num_groups=1024,
- stride=1,
+ stride=last_conv_stride,
dw_size=5,
padding=2,
use_se=True,
@@ -208,8 +213,10 @@ class MobileNetV1Enhance(nn.Layer):
self.block_list.append(conv6)
self.block_list = nn.Sequential(*self.block_list)
-
- self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
+ if last_pool_type == 'avg':
+ self.pool = nn.AvgPool2D(kernel_size=2, stride=2, padding=0)
+ else:
+ self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
self.out_channels = int(1024 * scale)
def forward(self, inputs):
diff --git a/ppocr/modeling/backbones/rec_svtrnet.py b/ppocr/modeling/backbones/rec_svtrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ded74378c60e6f08a4adf68671afaa1168737b6
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_svtrnet.py
@@ -0,0 +1,597 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from collections import Callable
+from paddle import ParamAttr
+from paddle.nn.initializer import KaimingNormal
+import numpy as np
+import paddle
+import paddle.nn as nn
+from paddle.nn.initializer import TruncatedNormal, Constant, Normal
+
+trunc_normal_ = TruncatedNormal(std=.02)
+normal_ = Normal
+zeros_ = Constant(value=0.)
+ones_ = Constant(value=1.)
+
+
+def drop_path(x, drop_prob=0., training=False):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
+ See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
+ """
+ if drop_prob == 0. or not training:
+ return x
+ keep_prob = paddle.to_tensor(1 - drop_prob)
+ shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1)
+ random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
+ random_tensor = paddle.floor(random_tensor) # binarize
+ output = x.divide(keep_prob) * random_tensor
+ return output
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=0,
+ bias_attr=False,
+ groups=1,
+ act=nn.GELU):
+ super().__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ weight_attr=paddle.ParamAttr(
+ initializer=nn.initializer.KaimingUniform()),
+ bias_attr=bias_attr)
+ self.norm = nn.BatchNorm2D(out_channels)
+ self.act = act()
+
+ def forward(self, inputs):
+ out = self.conv(inputs)
+ out = self.norm(out)
+ out = self.act(out)
+ return out
+
+
+class DropPath(nn.Layer):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ """
+
+ def __init__(self, drop_prob=None):
+ super(DropPath, self).__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+class Identity(nn.Layer):
+ def __init__(self):
+ super(Identity, self).__init__()
+
+ def forward(self, input):
+ return input
+
+
+class Mlp(nn.Layer):
+ def __init__(self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_layer=nn.GELU,
+ drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+class ConvMixer(nn.Layer):
+ def __init__(
+ self,
+ dim,
+ num_heads=8,
+ HW=[8, 25],
+ local_k=[3, 3], ):
+ super().__init__()
+ self.HW = HW
+ self.dim = dim
+ self.local_mixer = nn.Conv2D(
+ dim,
+ dim,
+ local_k,
+ 1, [local_k[0] // 2, local_k[1] // 2],
+ groups=num_heads,
+ weight_attr=ParamAttr(initializer=KaimingNormal()))
+
+ def forward(self, x):
+ h = self.HW[0]
+ w = self.HW[1]
+ x = x.transpose([0, 2, 1]).reshape([0, self.dim, h, w])
+ x = self.local_mixer(x)
+ x = x.flatten(2).transpose([0, 2, 1])
+ return x
+
+
+class Attention(nn.Layer):
+ def __init__(self,
+ dim,
+ num_heads=8,
+ mixer='Global',
+ HW=[8, 25],
+ local_k=[7, 11],
+ qkv_bias=False,
+ qk_scale=None,
+ attn_drop=0.,
+ proj_drop=0.):
+ super().__init__()
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.proj_drop = nn.Dropout(proj_drop)
+ self.HW = HW
+ if HW is not None:
+ H = HW[0]
+ W = HW[1]
+ self.N = H * W
+ self.C = dim
+ if mixer == 'Local' and HW is not None:
+
+ hk = local_k[0]
+ wk = local_k[1]
+ mask = np.ones([H * W, H * W])
+ for h in range(H):
+ for w in range(W):
+ for kh in range(-(hk // 2), (hk // 2) + 1):
+ for kw in range(-(wk // 2), (wk // 2) + 1):
+ if H > (h + kh) >= 0 and W > (w + kw) >= 0:
+ mask[h * W + w][(h + kh) * W + (w + kw)] = 0
+ mask_paddle = paddle.to_tensor(mask, dtype='float32')
+ mask_inf = paddle.full([H * W, H * W], '-inf', dtype='float32')
+ mask = paddle.where(mask_paddle < 1, mask_paddle, mask_inf)
+ self.mask = mask.unsqueeze([0, 1])
+ self.mixer = mixer
+
+ def forward(self, x):
+ if self.HW is not None:
+ N = self.N
+ C = self.C
+ else:
+ _, N, C = x.shape
+ qkv = self.qkv(x).reshape((0, N, 3, self.num_heads, C //
+ self.num_heads)).transpose((2, 0, 3, 1, 4))
+ q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
+
+ attn = (q.matmul(k.transpose((0, 1, 3, 2))))
+ if self.mixer == 'Local':
+ attn += self.mask
+ attn = nn.functional.softmax(attn, axis=-1)
+ attn = self.attn_drop(attn)
+
+ x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((0, N, C))
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class Block(nn.Layer):
+ def __init__(self,
+ dim,
+ num_heads,
+ mixer='Global',
+ local_mixer=[7, 11],
+ HW=[8, 25],
+ mlp_ratio=4.,
+ qkv_bias=False,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer='nn.LayerNorm',
+ epsilon=1e-6,
+ prenorm=True):
+ super().__init__()
+ if isinstance(norm_layer, str):
+ self.norm1 = eval(norm_layer)(dim, epsilon=epsilon)
+ elif isinstance(norm_layer, Callable):
+ self.norm1 = norm_layer(dim)
+ else:
+ raise TypeError(
+ "The norm_layer must be str or paddle.nn.layer.Layer class")
+ if mixer == 'Global' or mixer == 'Local':
+ self.mixer = Attention(
+ dim,
+ num_heads=num_heads,
+ mixer=mixer,
+ HW=HW,
+ local_k=local_mixer,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop)
+ elif mixer == 'Conv':
+ self.mixer = ConvMixer(
+ dim, num_heads=num_heads, HW=HW, local_k=local_mixer)
+ else:
+ raise TypeError("The mixer must be one of [Global, Local, Conv]")
+
+ # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
+ if isinstance(norm_layer, str):
+ self.norm2 = eval(norm_layer)(dim, epsilon=epsilon)
+ elif isinstance(norm_layer, Callable):
+ self.norm2 = norm_layer(dim)
+ else:
+ raise TypeError(
+ "The norm_layer must be str or paddle.nn.layer.Layer class")
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp_ratio = mlp_ratio
+ self.mlp = Mlp(in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ act_layer=act_layer,
+ drop=drop)
+ self.prenorm = prenorm
+
+ def forward(self, x):
+ if self.prenorm:
+ x = self.norm1(x + self.drop_path(self.mixer(x)))
+ x = self.norm2(x + self.drop_path(self.mlp(x)))
+ else:
+ x = x + self.drop_path(self.mixer(self.norm1(x)))
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+ return x
+
+
+class PatchEmbed(nn.Layer):
+ """ Image to Patch Embedding
+ """
+
+ def __init__(self,
+ img_size=[32, 100],
+ in_channels=3,
+ embed_dim=768,
+ sub_num=2):
+ super().__init__()
+ num_patches = (img_size[1] // (2 ** sub_num)) * \
+ (img_size[0] // (2 ** sub_num))
+ self.img_size = img_size
+ self.num_patches = num_patches
+ self.embed_dim = embed_dim
+ self.norm = None
+ if sub_num == 2:
+ self.proj = nn.Sequential(
+ ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=embed_dim // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ in_channels=embed_dim // 2,
+ out_channels=embed_dim,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None))
+ if sub_num == 3:
+ self.proj = nn.Sequential(
+ ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=embed_dim // 4,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ in_channels=embed_dim // 4,
+ out_channels=embed_dim // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ embed_dim // 2,
+ embed_dim,
+ in_channels=embed_dim // 2,
+ out_channels=embed_dim,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None))
+
+ def forward(self, x):
+ B, C, H, W = x.shape
+ assert H == self.img_size[0] and W == self.img_size[1], \
+ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
+ x = self.proj(x).flatten(2).transpose((0, 2, 1))
+ return x
+
+
+class SubSample(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ types='Pool',
+ stride=[2, 1],
+ sub_norm='nn.LayerNorm',
+ act=None):
+ super().__init__()
+ self.types = types
+ if types == 'Pool':
+ self.avgpool = nn.AvgPool2D(
+ kernel_size=[3, 5], stride=stride, padding=[1, 2])
+ self.maxpool = nn.MaxPool2D(
+ kernel_size=[3, 5], stride=stride, padding=[1, 2])
+ self.proj = nn.Linear(in_channels, out_channels)
+ else:
+ self.conv = nn.Conv2D(
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ weight_attr=ParamAttr(initializer=KaimingNormal()))
+ self.norm = eval(sub_norm)(out_channels)
+ if act is not None:
+ self.act = act()
+ else:
+ self.act = None
+
+ def forward(self, x):
+
+ if self.types == 'Pool':
+ x1 = self.avgpool(x)
+ x2 = self.maxpool(x)
+ x = (x1 + x2) * 0.5
+ out = self.proj(x.flatten(2).transpose((0, 2, 1)))
+ else:
+ x = self.conv(x)
+ out = x.flatten(2).transpose((0, 2, 1))
+ out = self.norm(out)
+ if self.act is not None:
+ out = self.act(out)
+
+ return out
+
+
+class SVTRNet(nn.Layer):
+ def __init__(
+ self,
+ img_size=[32, 100],
+ in_channels=3,
+ embed_dim=[64, 128, 256],
+ depth=[3, 6, 3],
+ num_heads=[2, 4, 8],
+ mixer=['Local'] * 6 + ['Global'] *
+ 6, # Local atten, Global atten, Conv
+ local_mixer=[[7, 11], [7, 11], [7, 11]],
+ patch_merging='Conv', # Conv, Pool, None
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ last_drop=0.1,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ norm_layer='nn.LayerNorm',
+ sub_norm='nn.LayerNorm',
+ epsilon=1e-6,
+ out_channels=192,
+ out_char_num=25,
+ block_unit='Block',
+ act='nn.GELU',
+ last_stage=True,
+ sub_num=2,
+ prenorm=True,
+ use_lenhead=False,
+ **kwargs):
+ super().__init__()
+ self.img_size = img_size
+ self.embed_dim = embed_dim
+ self.out_channels = out_channels
+ self.prenorm = prenorm
+ patch_merging = None if patch_merging != 'Conv' and patch_merging != 'Pool' else patch_merging
+ self.patch_embed = PatchEmbed(
+ img_size=img_size,
+ in_channels=in_channels,
+ embed_dim=embed_dim[0],
+ sub_num=sub_num)
+ num_patches = self.patch_embed.num_patches
+ self.HW = [img_size[0] // (2**sub_num), img_size[1] // (2**sub_num)]
+ self.pos_embed = self.create_parameter(
+ shape=[1, num_patches, embed_dim[0]], default_initializer=zeros_)
+ self.add_parameter("pos_embed", self.pos_embed)
+ self.pos_drop = nn.Dropout(p=drop_rate)
+ Block_unit = eval(block_unit)
+
+ dpr = np.linspace(0, drop_path_rate, sum(depth))
+ self.blocks1 = nn.LayerList([
+ Block_unit(
+ dim=embed_dim[0],
+ num_heads=num_heads[0],
+ mixer=mixer[0:depth[0]][i],
+ HW=self.HW,
+ local_mixer=local_mixer[0],
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=eval(act),
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[0:depth[0]][i],
+ norm_layer=norm_layer,
+ epsilon=epsilon,
+ prenorm=prenorm) for i in range(depth[0])
+ ])
+ if patch_merging is not None:
+ self.sub_sample1 = SubSample(
+ embed_dim[0],
+ embed_dim[1],
+ sub_norm=sub_norm,
+ stride=[2, 1],
+ types=patch_merging)
+ HW = [self.HW[0] // 2, self.HW[1]]
+ else:
+ HW = self.HW
+ self.patch_merging = patch_merging
+ self.blocks2 = nn.LayerList([
+ Block_unit(
+ dim=embed_dim[1],
+ num_heads=num_heads[1],
+ mixer=mixer[depth[0]:depth[0] + depth[1]][i],
+ HW=HW,
+ local_mixer=local_mixer[1],
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=eval(act),
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[depth[0]:depth[0] + depth[1]][i],
+ norm_layer=norm_layer,
+ epsilon=epsilon,
+ prenorm=prenorm) for i in range(depth[1])
+ ])
+ if patch_merging is not None:
+ self.sub_sample2 = SubSample(
+ embed_dim[1],
+ embed_dim[2],
+ sub_norm=sub_norm,
+ stride=[2, 1],
+ types=patch_merging)
+ HW = [self.HW[0] // 4, self.HW[1]]
+ else:
+ HW = self.HW
+ self.blocks3 = nn.LayerList([
+ Block_unit(
+ dim=embed_dim[2],
+ num_heads=num_heads[2],
+ mixer=mixer[depth[0] + depth[1]:][i],
+ HW=HW,
+ local_mixer=local_mixer[2],
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=eval(act),
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[depth[0] + depth[1]:][i],
+ norm_layer=norm_layer,
+ epsilon=epsilon,
+ prenorm=prenorm) for i in range(depth[2])
+ ])
+ self.last_stage = last_stage
+ if last_stage:
+ self.avg_pool = nn.AdaptiveAvgPool2D([1, out_char_num])
+ self.last_conv = nn.Conv2D(
+ in_channels=embed_dim[2],
+ out_channels=self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias_attr=False)
+ self.hardswish = nn.Hardswish()
+ self.dropout = nn.Dropout(p=last_drop, mode="downscale_in_infer")
+ if not prenorm:
+ self.norm = eval(norm_layer)(embed_dim[-1], epsilon=epsilon)
+ self.use_lenhead = use_lenhead
+ if use_lenhead:
+ self.len_conv = nn.Linear(embed_dim[2], self.out_channels)
+ self.hardswish_len = nn.Hardswish()
+ self.dropout_len = nn.Dropout(
+ p=last_drop, mode="downscale_in_infer")
+
+ trunc_normal_(self.pos_embed)
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ zeros_(m.bias)
+ elif isinstance(m, nn.LayerNorm):
+ zeros_(m.bias)
+ ones_(m.weight)
+
+ def forward_features(self, x):
+ x = self.patch_embed(x)
+ x = x + self.pos_embed
+ x = self.pos_drop(x)
+ for blk in self.blocks1:
+ x = blk(x)
+ if self.patch_merging is not None:
+ x = self.sub_sample1(
+ x.transpose([0, 2, 1]).reshape(
+ [0, self.embed_dim[0], self.HW[0], self.HW[1]]))
+ for blk in self.blocks2:
+ x = blk(x)
+ if self.patch_merging is not None:
+ x = self.sub_sample2(
+ x.transpose([0, 2, 1]).reshape(
+ [0, self.embed_dim[1], self.HW[0] // 2, self.HW[1]]))
+ for blk in self.blocks3:
+ x = blk(x)
+ if not self.prenorm:
+ x = self.norm(x)
+ return x
+
+ def forward(self, x):
+ x = self.forward_features(x)
+ if self.use_lenhead:
+ len_x = self.len_conv(x.mean(1))
+ len_x = self.dropout_len(self.hardswish_len(len_x))
+ if self.last_stage:
+ if self.patch_merging is not None:
+ h = self.HW[0] // 4
+ else:
+ h = self.HW[0]
+ x = self.avg_pool(
+ x.transpose([0, 2, 1]).reshape(
+ [0, self.embed_dim[2], h, self.HW[1]]))
+ x = self.last_conv(x)
+ x = self.hardswish(x)
+ x = self.dropout(x)
+ if self.use_lenhead:
+ return x, len_x
+ return x
diff --git a/ppocr/modeling/heads/__init__.py b/ppocr/modeling/heads/__init__.py
index b13fe2ecfdf877771237ad7a1fb0ef829de94a15..1670ea38e66baa683e6faab0ec4b12bc517f3c41 100755
--- a/ppocr/modeling/heads/__init__.py
+++ b/ppocr/modeling/heads/__init__.py
@@ -32,6 +32,7 @@ def build_head(config):
from .rec_sar_head import SARHead
from .rec_aster_head import AsterHead
from .rec_pren_head import PRENHead
+ from .rec_multi_head import MultiHead
# cls head
from .cls_head import ClsHead
@@ -44,7 +45,8 @@ def build_head(config):
support_dict = [
'DBHead', 'PSEHead', 'FCEHead', 'EASTHead', 'SASTHead', 'CTCHead',
'ClsHead', 'AttentionHead', 'SRNHead', 'PGHead', 'Transformer',
- 'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead'
+ 'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead',
+ 'MultiHead'
]
#table head
diff --git a/ppocr/modeling/heads/rec_multi_head.py b/ppocr/modeling/heads/rec_multi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f10e7bdf90025d3304128e720ce561c8bb269c1
--- /dev/null
+++ b/ppocr/modeling/heads/rec_multi_head.py
@@ -0,0 +1,73 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import math
+import paddle
+from paddle import ParamAttr
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+from ppocr.modeling.necks.rnn import Im2Seq, EncoderWithRNN, EncoderWithFC, SequenceEncoder, EncoderWithSVTR
+from .rec_ctc_head import CTCHead
+from .rec_sar_head import SARHead
+
+
+class MultiHead(nn.Layer):
+ def __init__(self, in_channels, out_channels_list, **kwargs):
+ super().__init__()
+ self.head_list = kwargs.pop('head_list')
+ self.gtc_head = 'sar'
+ assert len(self.head_list) >= 2
+ for idx, head_name in enumerate(self.head_list):
+ name = list(head_name)[0]
+ if name == 'SARHead':
+ # sar head
+ sar_args = self.head_list[idx][name]
+ self.sar_head = eval(name)(in_channels=in_channels, \
+ out_channels=out_channels_list['SARLabelDecode'], **sar_args)
+ elif name == 'CTCHead':
+ # ctc neck
+ self.encoder_reshape = Im2Seq(in_channels)
+ neck_args = self.head_list[idx][name]['Neck']
+ encoder_type = neck_args.pop('name')
+ self.encoder = encoder_type
+ self.ctc_encoder = SequenceEncoder(in_channels=in_channels, \
+ encoder_type=encoder_type, **neck_args)
+ # ctc head
+ head_args = self.head_list[idx][name]['Head']
+ self.ctc_head = eval(name)(in_channels=self.ctc_encoder.out_channels, \
+ out_channels=out_channels_list['CTCLabelDecode'], **head_args)
+ else:
+ raise NotImplementedError(
+ '{} is not supported in MultiHead yet'.format(name))
+
+ def forward(self, x, targets=None):
+ ctc_encoder = self.ctc_encoder(x)
+ ctc_out = self.ctc_head(ctc_encoder, targets)
+ head_out = dict()
+ head_out['ctc'] = ctc_out
+ head_out['ctc_neck'] = ctc_encoder
+ # eval mode
+ if not self.training:
+ return ctc_out
+ if self.gtc_head == 'sar':
+ sar_out = self.sar_head(x, targets[1:])
+ head_out['sar'] = sar_out
+ return head_out
+ else:
+ return head_out
diff --git a/ppocr/modeling/heads/rec_sar_head.py b/ppocr/modeling/heads/rec_sar_head.py
index 3b7674268772d8a332b963fd6b82dfb71ee40212..27693ebc16a2b494d25455892ac4513b4d16803b 100644
--- a/ppocr/modeling/heads/rec_sar_head.py
+++ b/ppocr/modeling/heads/rec_sar_head.py
@@ -349,7 +349,10 @@ class ParallelSARDecoder(BaseDecoder):
class SARHead(nn.Layer):
def __init__(self,
+ in_channels,
out_channels,
+ enc_dim=512,
+ max_text_length=30,
enc_bi_rnn=False,
enc_drop_rnn=0.1,
enc_gru=False,
@@ -358,14 +361,17 @@ class SARHead(nn.Layer):
dec_gru=False,
d_k=512,
pred_dropout=0.1,
- max_text_length=30,
pred_concat=True,
**kwargs):
super(SARHead, self).__init__()
# encoder module
self.encoder = SAREncoder(
- enc_bi_rnn=enc_bi_rnn, enc_drop_rnn=enc_drop_rnn, enc_gru=enc_gru)
+ enc_bi_rnn=enc_bi_rnn,
+ enc_drop_rnn=enc_drop_rnn,
+ enc_gru=enc_gru,
+ d_model=in_channels,
+ d_enc=enc_dim)
# decoder module
self.decoder = ParallelSARDecoder(
@@ -374,6 +380,8 @@ class SARHead(nn.Layer):
dec_bi_rnn=dec_bi_rnn,
dec_drop_rnn=dec_drop_rnn,
dec_gru=dec_gru,
+ d_model=in_channels,
+ d_enc=enc_dim,
d_k=d_k,
pred_dropout=pred_dropout,
max_text_length=max_text_length,
@@ -390,7 +398,7 @@ class SARHead(nn.Layer):
label = paddle.to_tensor(label, dtype='int64')
final_out = self.decoder(
feat, holistic_feat, label, img_metas=targets)
- if not self.training:
+ else:
final_out = self.decoder(
feat,
holistic_feat,
diff --git a/ppocr/modeling/necks/rnn.py b/ppocr/modeling/necks/rnn.py
index 86e649028f8fbb76cb5a1fd85381bd361277c6ee..c8a774b8c543b9ccc14223c52f1b79ce690592f6 100644
--- a/ppocr/modeling/necks/rnn.py
+++ b/ppocr/modeling/necks/rnn.py
@@ -16,9 +16,11 @@ from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
+import paddle
from paddle import nn
from ppocr.modeling.heads.rec_ctc_head import get_para_bias_attr
+from ppocr.modeling.backbones.rec_svtrnet import Block, ConvBNLayer, trunc_normal_, zeros_, ones_
class Im2Seq(nn.Layer):
@@ -64,29 +66,126 @@ class EncoderWithFC(nn.Layer):
return x
+class EncoderWithSVTR(nn.Layer):
+ def __init__(
+ self,
+ in_channels,
+ dims=64, # XS
+ depth=2,
+ hidden_dims=120,
+ use_guide=False,
+ num_heads=8,
+ qkv_bias=True,
+ mlp_ratio=2.0,
+ drop_rate=0.1,
+ attn_drop_rate=0.1,
+ drop_path=0.,
+ qk_scale=None):
+ super(EncoderWithSVTR, self).__init__()
+ self.depth = depth
+ self.use_guide = use_guide
+ self.conv1 = ConvBNLayer(
+ in_channels, in_channels // 8, padding=1, act=nn.Swish)
+ self.conv2 = ConvBNLayer(
+ in_channels // 8, hidden_dims, kernel_size=1, act=nn.Swish)
+
+ self.svtr_block = nn.LayerList([
+ Block(
+ dim=hidden_dims,
+ num_heads=num_heads,
+ mixer='Global',
+ HW=None,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=nn.Swish,
+ attn_drop=attn_drop_rate,
+ drop_path=drop_path,
+ norm_layer='nn.LayerNorm',
+ epsilon=1e-05,
+ prenorm=False) for i in range(depth)
+ ])
+ self.norm = nn.LayerNorm(hidden_dims, epsilon=1e-6)
+ self.conv3 = ConvBNLayer(
+ hidden_dims, in_channels, kernel_size=1, act=nn.Swish)
+ # last conv-nxn, the input is concat of input tensor and conv3 output tensor
+ self.conv4 = ConvBNLayer(
+ 2 * in_channels, in_channels // 8, padding=1, act=nn.Swish)
+
+ self.conv1x1 = ConvBNLayer(
+ in_channels // 8, dims, kernel_size=1, act=nn.Swish)
+ self.out_channels = dims
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ zeros_(m.bias)
+ elif isinstance(m, nn.LayerNorm):
+ zeros_(m.bias)
+ ones_(m.weight)
+
+ def forward(self, x):
+ # for use guide
+ if self.use_guide:
+ z = x.clone()
+ z.stop_gradient = True
+ else:
+ z = x
+ # for short cut
+ h = z
+ # reduce dim
+ z = self.conv1(z)
+ z = self.conv2(z)
+ # SVTR global block
+ B, C, H, W = z.shape
+ z = z.flatten(2).transpose([0, 2, 1])
+ for blk in self.svtr_block:
+ z = blk(z)
+ z = self.norm(z)
+ # last stage
+ z = z.reshape([0, H, W, C]).transpose([0, 3, 1, 2])
+ z = self.conv3(z)
+ z = paddle.concat((h, z), axis=1)
+ z = self.conv1x1(self.conv4(z))
+ return z
+
+
class SequenceEncoder(nn.Layer):
def __init__(self, in_channels, encoder_type, hidden_size=48, **kwargs):
super(SequenceEncoder, self).__init__()
self.encoder_reshape = Im2Seq(in_channels)
self.out_channels = self.encoder_reshape.out_channels
+ self.encoder_type = encoder_type
if encoder_type == 'reshape':
self.only_reshape = True
else:
support_encoder_dict = {
'reshape': Im2Seq,
'fc': EncoderWithFC,
- 'rnn': EncoderWithRNN
+ 'rnn': EncoderWithRNN,
+ 'svtr': EncoderWithSVTR
}
assert encoder_type in support_encoder_dict, '{} must in {}'.format(
encoder_type, support_encoder_dict.keys())
-
- self.encoder = support_encoder_dict[encoder_type](
- self.encoder_reshape.out_channels, hidden_size)
+ if encoder_type == "svtr":
+ self.encoder = support_encoder_dict[encoder_type](
+ self.encoder_reshape.out_channels, **kwargs)
+ else:
+ self.encoder = support_encoder_dict[encoder_type](
+ self.encoder_reshape.out_channels, hidden_size)
self.out_channels = self.encoder.out_channels
self.only_reshape = False
def forward(self, x):
- x = self.encoder_reshape(x)
- if not self.only_reshape:
+ if self.encoder_type != 'svtr':
+ x = self.encoder_reshape(x)
+ if not self.only_reshape:
+ x = self.encoder(x)
+ return x
+ else:
x = self.encoder(x)
- return x
+ x = self.encoder_reshape(x)
+ return x
diff --git a/ppocr/modeling/transforms/stn.py b/ppocr/modeling/transforms/stn.py
index 6f2bdda050f217d8253740001901fbff4065782a..1b15d5b8a7b7a1b1ab686d20acea750437463939 100644
--- a/ppocr/modeling/transforms/stn.py
+++ b/ppocr/modeling/transforms/stn.py
@@ -128,6 +128,8 @@ class STN_ON(nn.Layer):
self.out_channels = in_channels
def forward(self, image):
+ if len(image.shape)==5:
+ image = image.reshape([0, image.shape[-3], image.shape[-2], image.shape[-1]])
stn_input = paddle.nn.functional.interpolate(
image, self.tps_inputsize, mode="bilinear", align_corners=True)
stn_img_feat, ctrl_points = self.stn_head(stn_input)
diff --git a/ppocr/modeling/transforms/tps_spatial_transformer.py b/ppocr/modeling/transforms/tps_spatial_transformer.py
index 043bb56b8a526c12b2e0799bf41e128c6499c1fc..cb1cb10aaa98dffa2f720dc81afdf82d25e071ca 100644
--- a/ppocr/modeling/transforms/tps_spatial_transformer.py
+++ b/ppocr/modeling/transforms/tps_spatial_transformer.py
@@ -138,9 +138,9 @@ class TPSSpatialTransformer(nn.Layer):
assert source_control_points.shape[2] == 2
batch_size = paddle.shape(source_control_points)[0]
- self.padding_matrix = paddle.expand(
+ padding_matrix = paddle.expand(
self.padding_matrix, shape=[batch_size, 3, 2])
- Y = paddle.concat([source_control_points, self.padding_matrix], 1)
+ Y = paddle.concat([source_control_points, padding_matrix], 1)
mapping_matrix = paddle.matmul(self.inverse_kernel, Y)
source_coordinate = paddle.matmul(self.target_coordinate_repr,
mapping_matrix)
diff --git a/ppocr/optimizer/__init__.py b/ppocr/optimizer/__init__.py
index 4110fb47678583cff826a9bc855b3fb378a533f9..a6bd2ebb4a81427245dc10e446cd2da101d53bd4 100644
--- a/ppocr/optimizer/__init__.py
+++ b/ppocr/optimizer/__init__.py
@@ -30,7 +30,7 @@ def build_lr_scheduler(lr_config, epochs, step_each_epoch):
return lr
-def build_optimizer(config, epochs, step_each_epoch, parameters):
+def build_optimizer(config, epochs, step_each_epoch, model):
from . import regularizer, optimizer
config = copy.deepcopy(config)
# step1 build lr
@@ -43,6 +43,8 @@ def build_optimizer(config, epochs, step_each_epoch, parameters):
if not hasattr(regularizer, reg_name):
reg_name += 'Decay'
reg = getattr(regularizer, reg_name)(**reg_config)()
+ elif 'weight_decay' in config:
+ reg = config.pop('weight_decay')
else:
reg = None
@@ -57,4 +59,4 @@ def build_optimizer(config, epochs, step_each_epoch, parameters):
weight_decay=reg,
grad_clip=grad_clip,
**config)
- return optim(parameters), lr
+ return optim(model), lr
diff --git a/ppocr/optimizer/optimizer.py b/ppocr/optimizer/optimizer.py
index b98081227e180edbf023a8b5b7a0b82bb7c631e5..c450a3a3684eb44cdc758a2b27783b5a81945c38 100644
--- a/ppocr/optimizer/optimizer.py
+++ b/ppocr/optimizer/optimizer.py
@@ -42,13 +42,13 @@ class Momentum(object):
self.weight_decay = weight_decay
self.grad_clip = grad_clip
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.Momentum(
learning_rate=self.learning_rate,
momentum=self.momentum,
weight_decay=self.weight_decay,
grad_clip=self.grad_clip,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -75,7 +75,7 @@ class Adam(object):
self.name = name
self.lazy_mode = lazy_mode
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.Adam(
learning_rate=self.learning_rate,
beta1=self.beta1,
@@ -85,7 +85,7 @@ class Adam(object):
grad_clip=self.grad_clip,
name=self.name,
lazy_mode=self.lazy_mode,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -117,7 +117,7 @@ class RMSProp(object):
self.weight_decay = weight_decay
self.grad_clip = grad_clip
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.RMSProp(
learning_rate=self.learning_rate,
momentum=self.momentum,
@@ -125,7 +125,7 @@ class RMSProp(object):
epsilon=self.epsilon,
weight_decay=self.weight_decay,
grad_clip=self.grad_clip,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -148,7 +148,7 @@ class Adadelta(object):
self.grad_clip = grad_clip
self.name = name
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.Adadelta(
learning_rate=self.learning_rate,
epsilon=self.epsilon,
@@ -156,7 +156,7 @@ class Adadelta(object):
weight_decay=self.weight_decay,
grad_clip=self.grad_clip,
name=self.name,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -165,31 +165,55 @@ class AdamW(object):
learning_rate=0.001,
beta1=0.9,
beta2=0.999,
- epsilon=1e-08,
+ epsilon=1e-8,
weight_decay=0.01,
+ multi_precision=False,
grad_clip=None,
+ no_weight_decay_name=None,
+ one_dim_param_no_weight_decay=False,
name=None,
lazy_mode=False,
- **kwargs):
+ **args):
+ super().__init__()
self.learning_rate = learning_rate
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
- self.learning_rate = learning_rate
+ self.grad_clip = grad_clip
self.weight_decay = 0.01 if weight_decay is None else weight_decay
self.grad_clip = grad_clip
self.name = name
self.lazy_mode = lazy_mode
-
- def __call__(self, parameters):
+ self.multi_precision = multi_precision
+ self.no_weight_decay_name_list = no_weight_decay_name.split(
+ ) if no_weight_decay_name else []
+ self.one_dim_param_no_weight_decay = one_dim_param_no_weight_decay
+
+ def __call__(self, model):
+ parameters = model.parameters()
+
+ self.no_weight_decay_param_name_list = [
+ p.name for n, p in model.named_parameters() if any(nd in n for nd in self.no_weight_decay_name_list)
+ ]
+
+ if self.one_dim_param_no_weight_decay:
+ self.no_weight_decay_param_name_list += [
+ p.name for n, p in model.named_parameters() if len(p.shape) == 1
+ ]
+
opt = optim.AdamW(
learning_rate=self.learning_rate,
beta1=self.beta1,
beta2=self.beta2,
epsilon=self.epsilon,
+ parameters=parameters,
weight_decay=self.weight_decay,
+ multi_precision=self.multi_precision,
grad_clip=self.grad_clip,
name=self.name,
lazy_mode=self.lazy_mode,
- parameters=parameters)
+ apply_decay_param_fun=self._apply_decay_param_fun)
return opt
+
+ def _apply_decay_param_fun(self, name):
+ return name not in self.no_weight_decay_param_name_list
\ No newline at end of file
diff --git a/ppocr/postprocess/__init__.py b/ppocr/postprocess/__init__.py
index 14be63ddf93bd3bdab5df9bfa9e949ee4326a5ef..390f6f4560f9814a3af757a4fd16c55fe93d01f9 100644
--- a/ppocr/postprocess/__init__.py
+++ b/ppocr/postprocess/__init__.py
@@ -27,7 +27,7 @@ from .sast_postprocess import SASTPostProcess
from .fce_postprocess import FCEPostProcess
from .rec_postprocess import CTCLabelDecode, AttnLabelDecode, SRNLabelDecode, \
DistillationCTCLabelDecode, TableLabelDecode, NRTRLabelDecode, SARLabelDecode, \
- SEEDLabelDecode, PRENLabelDecode
+ SEEDLabelDecode, PRENLabelDecode, SVTRLabelDecode
from .cls_postprocess import ClsPostProcess
from .pg_postprocess import PGPostProcess
from .vqa_token_ser_layoutlm_postprocess import VQASerTokenLayoutLMPostProcess
@@ -41,7 +41,8 @@ def build_post_process(config, global_config=None):
'PGPostProcess', 'DistillationCTCLabelDecode', 'TableLabelDecode',
'DistillationDBPostProcess', 'NRTRLabelDecode', 'SARLabelDecode',
'SEEDLabelDecode', 'VQASerTokenLayoutLMPostProcess',
- 'VQAReTokenLayoutLMPostProcess', 'PRENLabelDecode'
+ 'VQAReTokenLayoutLMPostProcess', 'PRENLabelDecode',
+ 'DistillationSARLabelDecode', 'SVTRLabelDecode'
]
if config['name'] == 'PSEPostProcess':
diff --git a/ppocr/postprocess/rec_postprocess.py b/ppocr/postprocess/rec_postprocess.py
index 47825dc7d43dc5fb68f7ec9c45c7d4d91c1144a3..50f11f899fb4dd49da75199095772a92cc4a8d7b 100644
--- a/ppocr/postprocess/rec_postprocess.py
+++ b/ppocr/postprocess/rec_postprocess.py
@@ -117,6 +117,7 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
use_space_char=False,
model_name=["student"],
key=None,
+ multi_head=False,
**kwargs):
super(DistillationCTCLabelDecode, self).__init__(character_dict_path,
use_space_char)
@@ -125,6 +126,7 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
self.model_name = model_name
self.key = key
+ self.multi_head = multi_head
def __call__(self, preds, label=None, *args, **kwargs):
output = dict()
@@ -132,6 +134,8 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
pred = preds[name]
if self.key is not None:
pred = pred[self.key]
+ if self.multi_head and isinstance(pred, dict):
+ pred = pred['ctc']
output[name] = super().__call__(pred, label=label, *args, **kwargs)
return output
@@ -656,6 +660,40 @@ class SARLabelDecode(BaseRecLabelDecode):
return [self.padding_idx]
+class DistillationSARLabelDecode(SARLabelDecode):
+ """
+ Convert
+ Convert between text-label and text-index
+ """
+
+ def __init__(self,
+ character_dict_path=None,
+ use_space_char=False,
+ model_name=["student"],
+ key=None,
+ multi_head=False,
+ **kwargs):
+ super(DistillationSARLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+ if not isinstance(model_name, list):
+ model_name = [model_name]
+ self.model_name = model_name
+
+ self.key = key
+ self.multi_head = multi_head
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ output = dict()
+ for name in self.model_name:
+ pred = preds[name]
+ if self.key is not None:
+ pred = pred[self.key]
+ if self.multi_head and isinstance(pred, dict):
+ pred = pred['sar']
+ output[name] = super().__call__(pred, label=label, *args, **kwargs)
+ return output
+
+
class PRENLabelDecode(BaseRecLabelDecode):
""" Convert between text-label and text-index """
@@ -714,3 +752,40 @@ class PRENLabelDecode(BaseRecLabelDecode):
return text
label = self.decode(label)
return text, label
+
+
+class SVTRLabelDecode(BaseRecLabelDecode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, character_dict_path=None, use_space_char=False,
+ **kwargs):
+ super(SVTRLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ if isinstance(preds, tuple):
+ preds = preds[-1]
+ if isinstance(preds, paddle.Tensor):
+ preds = preds.numpy()
+ preds_idx = preds.argmax(axis=-1)
+ preds_prob = preds.max(axis=-1)
+
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True)
+ return_text = []
+ for i in range(0, len(text), 3):
+ text0 = text[i]
+ text1 = text[i + 1]
+ text2 = text[i + 2]
+
+ text_pred = [text0[0], text1[0], text2[0]]
+ text_prob = [text0[1], text1[1], text2[1]]
+ id_max = text_prob.index(max(text_prob))
+ return_text.append((text_pred[id_max], text_prob[id_max]))
+ if label is None:
+ return return_text
+ label = self.decode(label)
+ return return_text, label
+
+ def add_special_char(self, dict_character):
+ dict_character = ['blank'] + dict_character
+ return dict_character
\ No newline at end of file
diff --git a/ppocr/utils/dict/ka_dict.txt b/ppocr/utils/dict/ka_dict.txt
index 33d605c4de106c3c4b2504f5b3c42cdadd076dd8..d506b691bd1a6c55299ad89a72cf3a69a2c879a9 100644
--- a/ppocr/utils/dict/ka_dict.txt
+++ b/ppocr/utils/dict/ka_dict.txt
@@ -21,7 +21,7 @@ l
8
.
j
-p
+p
ಗ
ು
ಣ
diff --git a/ppocr/utils/dict/ta_dict.txt b/ppocr/utils/dict/ta_dict.txt
index d1bae501ad2556bb59b16a6c4b27a27091a6cbcf..19d81892c205627f296adbf8b20ea41aba2de5d0 100644
--- a/ppocr/utils/dict/ta_dict.txt
+++ b/ppocr/utils/dict/ta_dict.txt
@@ -22,7 +22,7 @@ l
8
.
j
-p
+p
ப
ூ
த
diff --git a/test_tipc/configs/ch_PP-OCRv2_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..033d40a80a3569f8bfd408cdb6df37e7ba5ecd0c
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_PPOCRv2_det
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=500
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+quant_export:null
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
diff --git a/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..d922a4a5dad67da81e3c9cf7bed48a0431a88b84
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_PPOCRv2_det_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=500
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
diff --git a/test_tipc/configs/ch_PP-OCRv2_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7c438cb8a3b6907c9ca352e90605d8b4f6fb17fd
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:PPOCRv2_ocr_rec
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
diff --git a/test_tipc/configs/ch_PP-OCRv2_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e22d8a564b008206611469048b424b528dd379bd
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_PPOCRv2_rec_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+fpgm_export: null
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_rec_slim_quant_infer
+infer_export:null
+infer_quant:True
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/det_mv3_db.yml b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/det_mv3_db.yml
deleted file mode 100644
index 5eada6d53dd3364238bdfc6a3c40515ca0726688..0000000000000000000000000000000000000000
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/det_mv3_db.yml
+++ /dev/null
@@ -1,126 +0,0 @@
-Global:
- use_gpu: false
- epoch_num: 5
- log_smooth_window: 20
- print_batch_step: 1
- save_model_dir: ./output/db_mv3/
- save_epoch_step: 1200
- # evaluation is run every 2000 iterations
- eval_batch_step: [0, 400]
- cal_metric_during_train: False
- pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
- checkpoints:
- save_inference_dir:
- use_visualdl: False
- infer_img: doc/imgs_en/img_10.jpg
- save_res_path: ./output/det_db/predicts_db.txt
-
-Architecture:
- model_type: det
- algorithm: DB
- Transform:
- Backbone:
- name: MobileNetV3
- scale: 0.5
- model_name: large
- disable_se: False
- Neck:
- name: DBFPN
- out_channels: 256
- Head:
- name: DBHead
- k: 50
-
-Loss:
- name: DBLoss
- balance_loss: true
- main_loss_type: DiceLoss
- alpha: 5
- beta: 10
- ohem_ratio: 3
-
-Optimizer:
- name: Adam #Momentum
- #momentum: 0.9
- beta1: 0.9
- beta2: 0.999
- lr:
- learning_rate: 0.001
- regularizer:
- name: 'L2'
- factor: 0
-
-PostProcess:
- name: DBPostProcess
- thresh: 0.3
- box_thresh: 0.6
- max_candidates: 1000
- unclip_ratio: 1.5
-
-Metric:
- name: DetMetric
- main_indicator: hmean
-
-Train:
- dataset:
- name: SimpleDataSet
- data_dir: ./train_data/icdar2015/text_localization/
- label_file_list:
- - ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
- ratio_list: [1.0]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - DetLabelEncode: # Class handling label
- - Resize:
- size: [640, 640]
- - MakeBorderMap:
- shrink_ratio: 0.4
- thresh_min: 0.3
- thresh_max: 0.7
- - MakeShrinkMap:
- shrink_ratio: 0.4
- min_text_size: 8
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - ToCHWImage:
- - KeepKeys:
- keep_keys: ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask'] # the order of the dataloader list
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 1
- num_workers: 0
- use_shared_memory: False
-
-Eval:
- dataset:
- name: SimpleDataSet
- data_dir: ./train_data/icdar2015/text_localization/
- label_file_list:
- - ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - DetLabelEncode: # Class handling label
- - DetResizeForTest:
- image_shape: [736, 1280]
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - ToCHWImage:
- - KeepKeys:
- keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 1 # must be 1
- num_workers: 0
- use_shared_memory: False
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
index ff1c7432df75f78fd6c45d995f50a9642d44637c..593e7ec7ed42af9b65c520852ff6372f89890170 100644
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -1,10 +1,10 @@
===========================train_params===========================
-model_name:ocr_det
+model_name:ch_ppocr_mobile_v2.0_det
python:python3.7
gpu_list:0|0,1
Global.use_gpu:True|True
Global.auto_cast:amp
-Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
+Global.epoch_num:lite_train_lite_infer=100|whole_train_whole_infer=300
Global.save_model_dir:./output/
Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
Global.pretrained_model:null
@@ -12,10 +12,10 @@ train_model_name:latest
train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
null:null
##
-trainer:norm_train|pact_train|fpgm_train
-norm_train:tools/train.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
-pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-fpgm_train:deploy/slim/prune/sensitivity_anal.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/det_mv3_db_v2.0_train/best_accuracy
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+pact_train:null
+fpgm_train:null
distill_train:null
null:null
null:null
@@ -26,10 +26,10 @@ null:null
##
===========================infer_params===========================
Global.save_inference_dir:./output/
-Global.pretrained_model:
-norm_export:tools/export_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-fpgm_export:deploy/slim/prune/export_prune_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+quant_export:null
+fpgm_export:null
distill_export:null
export1:null
export2:null
@@ -49,3 +49,5 @@ inference:tools/infer/predict_det.py
null:null
--benchmark:True
null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_mobile_V2.0_det_FPGM/train_infer_python.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_infer_python.txt
similarity index 97%
rename from test_tipc/configs/ch_ppocr_mobile_V2.0_det_FPGM/train_infer_python.txt
rename to test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_infer_python.txt
index 331d6bdb7103294eb1b33b9978e5f99c2212195b..47ccf2e69e75bc8c215be8d1837e5248d1b4b513 100644
--- a/test_tipc/configs/ch_ppocr_mobile_V2.0_det_FPGM/train_infer_python.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_infer_python.txt
@@ -1,5 +1,5 @@
===========================train_params===========================
-model_name:ocr_det
+model_name:ch_ppocr_mobile_v2.0_det_FPGM
python:python3.7
gpu_list:0|0,1
Global.use_gpu:True|True
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5a95f026850b750bfadb85e0955f7426e5e73cb6
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_det_FPGM
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:fpgm_train
+norm_train:null
+pact_train:null
+fpgm_train:deploy/slim/prune/sensitivity_anal.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./pretrain_models/det_mv3_db_v2.0_train/best_accuracy
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:null
+fpgm_export:deploy/slim/prune/export_prune_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+train_model:null
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1f9bec12ada6894fcffbe697ae4da2f0df95cc62
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_det_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=20|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+train_model:./inference/ch_ppocr_mobile_v2.0_det_prune_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..30fb939bff646adf301191f88a9a499acf9c61de
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_rec
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=2|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/rec_icdar15_train.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c configs/rec/rec_icdar15_train.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/rec_icdar15_train.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/ch_ppocr_mobile_v2.0_rec_train/best_accuracy
+infer_export:tools/export_model.py -c configs/rec/rec_icdar15_train.yml -o
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:True|False
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,100]}]
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..fda9cf4ddec6d3ab64045a4a7fdbb62183212021
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_rec_FPGM
+python:python3.7
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/ic15_data/test/word_1.png
+null:null
+##
+trainer:fpgm_train
+norm_train:null
+pact_train:null
+fpgm_train:deploy/slim/prune/sensitivity_anal.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./pretrain_models/ch_ppocr_mobile_v2.0_rec_train/best_accuracy
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:null
+fpgm_export:deploy/slim/prune/export_prune_model.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/rec_chinese_lite_train_v2.0.yml -o
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+train_model:null
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..abed3cfba9b3f8c0ed626dbfcbda8621d8787001
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_rec_PACT
+python:python3.7
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.checkpoints:null
+train_model_name:latest
+train_infer_img_dir:./train_data/ic15_data/test/word_1.png
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/rec_chinese_lite_train_v2.0.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/rec_chinese_lite_train_v2.0.yml -o
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+infer_model:./inference/ch_ppocr_mobile_v2.0_rec_slim_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/ppocr_keys_v1.txt --rec_image_shape="3,32,100"
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
diff --git a/test_tipc/configs/ch_ppocr_server_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_server_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3e3764e8c6f62c72ffb8ceb268c8ceee660d02de
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_server_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_server_v2.0_det
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=2|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_lite_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/ch_ppocr_server_v2.0_det/det_r50_vd_db.yml -o
+quant_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c test_tipc/configs/ch_ppocr_server_v2.0_det/det_r50_vd_db.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/ch_ppocr_server_v2.0_det/det_r50_vd_db.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/ch_ppocr_server_v2.0_det_train/best_accuracy
+infer_export:tools/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml -o
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+--save_log_path:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_server_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_server_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..78c15047fb522127075591cc9687392af77a300a
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_server_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_server_v2.0_rec
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=100
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/ch_ppocr_server_v2.0_rec_train/best_accuracy
+infer_export:tools/export_model.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:True|False
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,100]}]
diff --git a/tools/eval.py b/tools/eval.py
index f6fcf14c873984e15606b9fae1799bae6b021f05..7fd4fa7ada7b1550bcca8766f5acb9b4d4ed2049 100755
--- a/tools/eval.py
+++ b/tools/eval.py
@@ -47,14 +47,40 @@ def main():
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ out_channels_list = {}
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ out_channels_list = {}
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
model = build_model(config['Architecture'])
- extra_input = config['Architecture'][
- 'algorithm'] in ["SRN", "NRTR", "SAR", "SEED"]
+ extra_input_models = ["SRN", "NRTR", "SAR", "SEED", "SVTR"]
+ extra_input = False
+ if config['Architecture']['algorithm'] == 'Distillation':
+ for key in config['Architecture']["Models"]:
+ extra_input = extra_input or config['Architecture']['Models'][key][
+ 'algorithm'] in extra_input_models
+ else:
+ extra_input = config['Architecture']['algorithm'] in extra_input_models
if "model_type" in config['Architecture'].keys():
model_type = config['Architecture']['model_type']
else:
diff --git a/tools/export_model.py b/tools/export_model.py
index bd647fc72cf111b910d215fecbbef354bd5e6c08..003bc61f791b6c41a3b08d58ab87f12109744f9a 100755
--- a/tools/export_model.py
+++ b/tools/export_model.py
@@ -55,6 +55,18 @@ def export_single_model(model, arch_config, save_path, logger):
shape=[None, 3, 48, 160], dtype="float32"),
]
model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] == "SVTR":
+ if arch_config["Head"]["name"] == 'MultiHead':
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 48, -1], dtype="float32"),
+ ]
+ else:
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 64, 256], dtype="float32"),
+ ]
+ model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "PREN":
other_shape = [
paddle.static.InputSpec(
@@ -105,13 +117,36 @@ def main():
if config["Architecture"]["algorithm"] in ["Distillation",
]: # distillation model
for key in config["Architecture"]["Models"]:
- config["Architecture"]["Models"][key]["Head"][
- "out_channels"] = char_num
+ if config["Architecture"]["Models"][key]["Head"][
+ "name"] == 'MultiHead': # multi head
+ out_channels_list = {}
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ loss_list = config['Loss']['loss_config_list']
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config["Architecture"]["Models"][key]["Head"][
+ "out_channels"] = char_num
# just one final tensor needs to to exported for inference
config["Architecture"]["Models"][key][
"return_all_feats"] = False
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # multi head
+ out_channels_list = {}
+ char_num = len(getattr(post_process_class, 'character'))
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config["Architecture"]["Head"]["out_channels"] = char_num
+
model = build_model(config["Architecture"])
load_model(config, model)
model.eval()
diff --git a/tools/infer/predict_rec.py b/tools/infer/predict_rec.py
index c5aacb060060068ec4b0b9432b2fb045aaff0370..2abc0220937175f95ee4c1e4b0b949d24d5fa3e8 100755
--- a/tools/infer/predict_rec.py
+++ b/tools/infer/predict_rec.py
@@ -107,7 +107,7 @@ class TextRecognizer(object):
return norm_img.astype(np.float32) / 128. - 1.
assert imgC == img.shape[2]
- imgW = int((32 * max_wh_ratio))
+ imgW = int((imgH * max_wh_ratio))
if self.use_onnx:
w = self.input_tensor.shape[3:][0]
if w is not None and w > 0:
@@ -131,6 +131,17 @@ class TextRecognizer(object):
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
+
+ def resize_norm_img_svtr(self, img, image_shape):
+
+ imgC, imgH, imgW = image_shape
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image = resized_image.astype('float32')
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ return resized_image
def resize_norm_img_srn(self, img, image_shape):
imgC, imgH, imgW = image_shape
@@ -255,18 +266,16 @@ class TextRecognizer(object):
for beg_img_no in range(0, img_num, batch_num):
end_img_no = min(img_num, beg_img_no + batch_num)
norm_img_batch = []
- max_wh_ratio = 0
+ imgC, imgH, imgW = self.rec_image_shape
+ max_wh_ratio = imgW / imgH
+ # max_wh_ratio = 0
for ino in range(beg_img_no, end_img_no):
h, w = img_list[indices[ino]].shape[0:2]
wh_ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, wh_ratio)
for ino in range(beg_img_no, end_img_no):
- if self.rec_algorithm != "SRN" and self.rec_algorithm != "SAR":
- norm_img = self.resize_norm_img(img_list[indices[ino]],
- max_wh_ratio)
- norm_img = norm_img[np.newaxis, :]
- norm_img_batch.append(norm_img)
- elif self.rec_algorithm == "SAR":
+
+ if self.rec_algorithm == "SAR":
norm_img, _, _, valid_ratio = self.resize_norm_img_sar(
img_list[indices[ino]], self.rec_image_shape)
norm_img = norm_img[np.newaxis, :]
@@ -274,7 +283,7 @@ class TextRecognizer(object):
valid_ratios = []
valid_ratios.append(valid_ratio)
norm_img_batch.append(norm_img)
- else:
+ elif self.rec_algorithm == "SRN":
norm_img = self.process_image_srn(
img_list[indices[ino]], self.rec_image_shape, 8, 25)
encoder_word_pos_list = []
@@ -286,6 +295,16 @@ class TextRecognizer(object):
gsrm_slf_attn_bias1_list.append(norm_img[3])
gsrm_slf_attn_bias2_list.append(norm_img[4])
norm_img_batch.append(norm_img[0])
+ elif self.rec_algorithm == "SVTR":
+ norm_img = self.resize_norm_img_svtr(
+ img_list[indices[ino]], self.rec_image_shape)
+ norm_img = norm_img[np.newaxis, :]
+ norm_img_batch.append(norm_img)
+ else:
+ norm_img = self.resize_norm_img(img_list[indices[ino]],
+ max_wh_ratio)
+ norm_img = norm_img[np.newaxis, :]
+ norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
norm_img_batch = norm_img_batch.copy()
if self.benchmark:
diff --git a/tools/infer/utility.py b/tools/infer/utility.py
index b16aecd496ec291fcbe9c66dccf3ec04bb662034..a93f364b31d6d9cb718337b0731330a172296396 100644
--- a/tools/infer/utility.py
+++ b/tools/infer/utility.py
@@ -271,9 +271,10 @@ def create_predictor(args, mode, logger):
elif mode == "rec":
if args.rec_algorithm != "CRNN":
use_dynamic_shape = False
- min_input_shape = {"x": [1, 3, 32, 10]}
- max_input_shape = {"x": [args.rec_batch_num, 3, 32, 1536]}
- opt_input_shape = {"x": [args.rec_batch_num, 3, 32, 320]}
+ imgH = int(args.rec_image_shape.split(',')[-2])
+ min_input_shape = {"x": [1, 3, imgH, 10]}
+ max_input_shape = {"x": [args.rec_batch_num, 3, imgH, 1536]}
+ opt_input_shape = {"x": [args.rec_batch_num, 3, imgH, 320]}
elif mode == "cls":
min_input_shape = {"x": [1, 3, 48, 10]}
max_input_shape = {"x": [args.rec_batch_num, 3, 48, 1024]}
@@ -300,7 +301,8 @@ def create_predictor(args, mode, logger):
# enable memory optim
config.enable_memory_optim()
config.disable_glog_info()
-
+ config.delete_pass("reshape_transpose_matmul_v2_mkldnn_fuse_pass")
+ config.delete_pass("reshape_transpose_matmul_mkldnn_fuse_pass")
config.delete_pass("conv_transpose_eltwiseadd_bn_fuse_pass")
if mode == 'table':
config.delete_pass("fc_fuse_pass") # not supported for table
diff --git a/tools/infer_rec.py b/tools/infer_rec.py
index 02b3afd8a1b32c3c9c1e4a9a121f08b58c10151d..63d410b627f3868191c9299f9bc99e7fcab69d35 100755
--- a/tools/infer_rec.py
+++ b/tools/infer_rec.py
@@ -51,8 +51,28 @@ def main():
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ out_channels_list = {}
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head loss
+ out_channels_list = {}
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
diff --git a/tools/program.py b/tools/program.py
index 8ec152bb92f0855d44b2597ce2420b16a4fa007e..90fd309ae9e1ae23723d8e67c62a905e79a073d3 100755
--- a/tools/program.py
+++ b/tools/program.py
@@ -201,12 +201,19 @@ def train(config,
model.train()
use_srn = config['Architecture']['algorithm'] == "SRN"
- extra_input = config['Architecture'][
- 'algorithm'] in ["SRN", "NRTR", "SAR", "SEED"]
+ extra_input_models = ["SRN", "NRTR", "SAR", "SEED", "SVTR"]
+ extra_input = False
+ if config['Architecture']['algorithm'] == 'Distillation':
+ for key in config['Architecture']["Models"]:
+ extra_input = extra_input or config['Architecture']['Models'][key][
+ 'algorithm'] in extra_input_models
+ else:
+ extra_input = config['Architecture']['algorithm'] in extra_input_models
try:
model_type = config['Architecture']['model_type']
except:
model_type = None
+
algorithm = config['Architecture']['algorithm']
start_epoch = best_model_dict[
@@ -269,7 +276,12 @@ def train(config,
if model_type in ['table', 'kie']:
eval_class(preds, batch)
else:
- post_result = post_process_class(preds, batch[1])
+ if config['Loss']['name'] in ['MultiLoss', 'MultiLoss_v2'
+ ]: # for multi head loss
+ post_result = post_process_class(
+ preds['ctc'], batch[1]) # for CTC head out
+ else:
+ post_result = post_process_class(preds, batch[1])
eval_class(post_result, batch)
metric = eval_class.get_metric()
train_stats.update(metric)
@@ -541,7 +553,7 @@ def preprocess(is_train=False):
assert alg in [
'EAST', 'DB', 'SAST', 'Rosetta', 'CRNN', 'STARNet', 'RARE', 'SRN',
'CLS', 'PGNet', 'Distillation', 'NRTR', 'TableAttn', 'SAR', 'PSE',
- 'SEED', 'SDMGR', 'LayoutXLM', 'LayoutLM', 'PREN', 'FCE'
+ 'SEED', 'SDMGR', 'LayoutXLM', 'LayoutLM', 'PREN', 'FCE', 'SVTR'
]
device = 'cpu'
diff --git a/tools/train.py b/tools/train.py
index f6cd0e7d12cdc572dd8d2c402e03e160001a9f4a..42aba548d6bf5fc35f033ef2baca0fb54d79e75a 100755
--- a/tools/train.py
+++ b/tools/train.py
@@ -74,11 +74,49 @@ def main(config, device, logger, vdl_writer):
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][-1].keys())[
+ 0] == 'DistillationSARLoss'
+ config['Loss']['loss_config_list'][-1][
+ 'DistillationSARLoss']['ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][1].keys())[
+ 0] == 'SARLoss'
+ if config['Loss']['loss_config_list'][1]['SARLoss'] is None:
+ config['Loss']['loss_config_list'][1]['SARLoss'] = {
+ 'ignore_index': char_num + 1
+ }
+ else:
+ config['Loss']['loss_config_list'][1]['SARLoss'][
+ 'ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
+ if config['PostProcess']['name'] == 'SARLabelDecode': # for SAR model
+ config['Loss']['ignore_index'] = char_num - 1
+
model = build_model(config['Architecture'])
if config['Global']['distributed']:
model = paddle.DataParallel(model)
@@ -91,7 +129,7 @@ def main(config, device, logger, vdl_writer):
config['Optimizer'],
epochs=config['Global']['epoch_num'],
step_each_epoch=len(train_dataloader),
- parameters=model.parameters())
+ model=model)
# build metric
eval_class = build_metric(config['Metric'])
+图28 Excel效果图
+
+
+```python
+import json
+import xlsxwriter as xw
+
+workbook = xw.Workbook('output/re/infer_results.xlsx')
+format1 = workbook.add_format({
+ 'align': 'center',
+ 'valign': 'vcenter',
+ 'text_wrap': True,
+})
+worksheet1 = workbook.add_worksheet('sheet1')
+worksheet1.activate()
+title = ['姓名', '性别', '民族', '文化程度', '身份证号码', '联系电话', '通讯地址']
+worksheet1.write_row('A1', title)
+i = 2
+
+with open('output/re/infer_results.txt', 'r', encoding='utf-8') as fin:
+ lines = fin.readlines()
+ for line in lines:
+ img_path, result = line.strip().split('\t')
+ result_key = json.loads(result)
+ # 写入Excel
+ row_data = [result_key['姓名'], result_key['性别'], result_key['民族'], result_key['文化程度'], result_key['身份证号码'],
+ result_key['联系电话'], result_key['通讯地址']]
+ row = 'A' + str(i)
+ worksheet1.write_row(row, row_data, format1)
+ i+=1
+workbook.close()
+```
+
+# 更多资源
+
+- 更多深度学习知识、产业案例、面试宝典等,请参考:[awesome-DeepLearning](https://github.com/paddlepaddle/awesome-DeepLearning)
+
+- 更多PaddleOCR使用教程,请参考:[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph)
+
+- 更多PaddleNLP使用教程,请参考:[PaddleNLP](https://github.com/PaddlePaddle/PaddleNLP)
+
+- 飞桨框架相关资料,请参考:[飞桨深度学习平台](https://www.paddlepaddle.org.cn/?fr=paddleEdu_aistudio)
+
+# 参考链接
+
+- LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding, https://arxiv.org/pdf/2104.08836.pdf
+
+- microsoft/unilm/layoutxlm, https://github.com/microsoft/unilm/tree/master/layoutxlm
+
+- XFUND dataset, https://github.com/doc-analysis/XFUND
+
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml b/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c45a1a3c8b8edc8a542bc740f6abd958b9a1e701
--- /dev/null
+++ b/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec.yml
@@ -0,0 +1,131 @@
+Global:
+ debug: false
+ use_gpu: true
+ epoch_num: 500
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/rec_ppocr_v3
+ save_epoch_step: 3
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: true
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: false
+ infer_img: doc/imgs_words/ch/word_1.jpg
+ character_dict_path: ppocr/utils/ppocr_keys_v1.txt
+ max_text_length: &max_text_length 25
+ infer_mode: false
+ use_space_char: true
+ distributed: true
+ save_res_path: ./output/rec/predicts_ppocrv3.txt
+
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ name: Cosine
+ learning_rate: 0.001
+ warmup_epoch: 5
+ regularizer:
+ name: L2
+ factor: 3.0e-05
+
+
+Architecture:
+ model_type: rec
+ algorithm: SVTR
+ Transform:
+ Backbone:
+ name: MobileNetV1Enhance
+ scale: 0.5
+ last_conv_stride: [1, 2]
+ last_pool_type: avg
+ Head:
+ name: MultiHead
+ head_list:
+ - CTCHead:
+ Neck:
+ name: svtr
+ dims: 64
+ depth: 2
+ hidden_dims: 120
+ use_guide: True
+ Head:
+ fc_decay: 0.00001
+ - SARHead:
+ enc_dim: 512
+ max_text_length: *max_text_length
+
+Loss:
+ name: MultiLoss
+ loss_config_list:
+ - CTCLoss:
+ - SARLoss:
+
+PostProcess:
+ name: CTCLabelDecode
+
+Metric:
+ name: RecMetric
+ main_indicator: acc
+ ignore_space: True
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/
+ ext_op_transform_idx: 1
+ label_file_list:
+ - ./train_data/train_list.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - RecConAug:
+ prob: 0.5
+ ext_data_num: 2
+ image_shape: [48, 320, 3]
+ - RecAug:
+ - MultiLabelEncode:
+ - RecResizeImg:
+ image_shape: [3, 48, 320]
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label_ctc
+ - label_sar
+ - length
+ - valid_ratio
+ loader:
+ shuffle: true
+ batch_size_per_card: 128
+ drop_last: true
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data
+ label_file_list:
+ - ./train_data/val_list.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - MultiLabelEncode:
+ - RecResizeImg:
+ image_shape: [3, 48, 320]
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label_ctc
+ - label_sar
+ - length
+ - valid_ratio
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 128
+ num_workers: 4
diff --git a/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml b/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
new file mode 100644
index 0000000000000000000000000000000000000000..80ec7c6308aa006f46331503e00368444c425559
--- /dev/null
+++ b/configs/rec/ch_PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml
@@ -0,0 +1,205 @@
+Global:
+ debug: false
+ use_gpu: true
+ epoch_num: 800
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/rec_ppocr_v3_distillation
+ save_epoch_step: 3
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: true
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: false
+ infer_img: doc/imgs_words/ch/word_1.jpg
+ character_dict_path: ppocr/utils/ppocr_keys_v1.txt
+ max_text_length: &max_text_length 25
+ infer_mode: false
+ use_space_char: true
+ distributed: true
+ save_res_path: ./output/rec/predicts_ppocrv3_distillation.txt
+
+
+Optimizer:
+ name: Adam
+ beta1: 0.9
+ beta2: 0.999
+ lr:
+ name: Piecewise
+ decay_epochs : [700, 800]
+ values : [0.0005, 0.00005]
+ warmup_epoch: 5
+ regularizer:
+ name: L2
+ factor: 3.0e-05
+
+
+Architecture:
+ model_type: &model_type "rec"
+ name: DistillationModel
+ algorithm: Distillation
+ Models:
+ Teacher:
+ pretrained:
+ freeze_params: false
+ return_all_feats: true
+ model_type: *model_type
+ algorithm: SVTR
+ Transform:
+ Backbone:
+ name: MobileNetV1Enhance
+ scale: 0.5
+ last_conv_stride: [1, 2]
+ last_pool_type: avg
+ Head:
+ name: MultiHead
+ head_list:
+ - CTCHead:
+ Neck:
+ name: svtr
+ dims: 64
+ depth: 2
+ hidden_dims: 120
+ use_guide: True
+ Head:
+ fc_decay: 0.00001
+ - SARHead:
+ enc_dim: 512
+ max_text_length: *max_text_length
+ Student:
+ pretrained:
+ freeze_params: false
+ return_all_feats: true
+ model_type: *model_type
+ algorithm: SVTR
+ Transform:
+ Backbone:
+ name: MobileNetV1Enhance
+ scale: 0.5
+ last_conv_stride: [1, 2]
+ last_pool_type: avg
+ Head:
+ name: MultiHead
+ head_list:
+ - CTCHead:
+ Neck:
+ name: svtr
+ dims: 64
+ depth: 2
+ hidden_dims: 120
+ use_guide: True
+ Head:
+ fc_decay: 0.00001
+ - SARHead:
+ enc_dim: 512
+ max_text_length: *max_text_length
+Loss:
+ name: CombinedLoss
+ loss_config_list:
+ - DistillationDMLLoss:
+ weight: 1.0
+ act: "softmax"
+ use_log: true
+ model_name_pairs:
+ - ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+ dis_head: ctc
+ name: dml_ctc
+ - DistillationDMLLoss:
+ weight: 0.5
+ act: "softmax"
+ use_log: true
+ model_name_pairs:
+ - ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+ dis_head: sar
+ name: dml_sar
+ - DistillationDistanceLoss:
+ weight: 1.0
+ mode: "l2"
+ model_name_pairs:
+ - ["Student", "Teacher"]
+ key: backbone_out
+ - DistillationCTCLoss:
+ weight: 1.0
+ model_name_list: ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+ - DistillationSARLoss:
+ weight: 1.0
+ model_name_list: ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+
+PostProcess:
+ name: DistillationCTCLabelDecode
+ model_name: ["Student", "Teacher"]
+ key: head_out
+ multi_head: True
+
+Metric:
+ name: DistillationMetric
+ base_metric_name: RecMetric
+ main_indicator: acc
+ key: "Student"
+ ignore_space: True
+
+Train:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data/
+ ext_op_transform_idx: 1
+ label_file_list:
+ - ./train_data/train_list.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - RecConAug:
+ prob: 0.5
+ ext_data_num: 2
+ image_shape: [48, 320, 3]
+ - RecAug:
+ - MultiLabelEncode:
+ - RecResizeImg:
+ image_shape: [3, 48, 320]
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label_ctc
+ - label_sar
+ - length
+ - valid_ratio
+ loader:
+ shuffle: true
+ batch_size_per_card: 128
+ drop_last: true
+ num_workers: 4
+Eval:
+ dataset:
+ name: SimpleDataSet
+ data_dir: ./train_data
+ label_file_list:
+ - ./train_data/val_list.txt
+ transforms:
+ - DecodeImage:
+ img_mode: BGR
+ channel_first: false
+ - MultiLabelEncode:
+ - RecResizeImg:
+ image_shape: [3, 48, 320]
+ - KeepKeys:
+ keep_keys:
+ - image
+ - label_ctc
+ - label_sar
+ - length
+ - valid_ratio
+ loader:
+ shuffle: false
+ drop_last: false
+ batch_size_per_card: 128
+ num_workers: 4
diff --git a/configs/rec/rec_svtrnet.yml b/configs/rec/rec_svtrnet.yml
new file mode 100644
index 0000000000000000000000000000000000000000..233d5e276577cad0144456ef7df1e20de99891f9
--- /dev/null
+++ b/configs/rec/rec_svtrnet.yml
@@ -0,0 +1,117 @@
+Global:
+ use_gpu: True
+ epoch_num: 20
+ log_smooth_window: 20
+ print_batch_step: 10
+ save_model_dir: ./output/rec/svtr/
+ save_epoch_step: 1
+ # evaluation is run every 2000 iterations after the 0th iteration
+ eval_batch_step: [0, 2000]
+ cal_metric_during_train: True
+ pretrained_model:
+ checkpoints:
+ save_inference_dir:
+ use_visualdl: False
+ infer_img: doc/imgs_words_en/word_10.png
+ # for data or label process
+ character_dict_path:
+ character_type: en
+ max_text_length: 25
+ infer_mode: False
+ use_space_char: False
+ save_res_path: ./output/rec/predicts_svtr_tiny.txt
+
+
+Optimizer:
+ name: AdamW
+ beta1: 0.9
+ beta2: 0.99
+ epsilon: 0.00000008
+ weight_decay: 0.05
+ no_weight_decay_name: norm pos_embed
+ one_dim_param_no_weight_decay: true
+ lr:
+ name: Cosine
+ learning_rate: 0.0005
+ warmup_epoch: 2
+
+Architecture:
+ model_type: rec
+ algorithm: SVTR
+ Transform:
+ name: STN_ON
+ tps_inputsize: [32, 64]
+ tps_outputsize: [32, 100]
+ num_control_points: 20
+ tps_margins: [0.05,0.05]
+ stn_activation: none
+ Backbone:
+ name: SVTRNet
+ img_size: [32, 100]
+ out_char_num: 25
+ out_channels: 192
+ patch_merging: 'Conv'
+ embed_dim: [64, 128, 256]
+ depth: [3, 6, 3]
+ num_heads: [2, 4, 8]
+ mixer: ['Local','Local','Local','Local','Local','Local','Global','Global','Global','Global','Global','Global']
+ local_mixer: [[7, 11], [7, 11], [7, 11]]
+ last_stage: True
+ prenorm: false
+ Neck:
+ name: SequenceEncoder
+ encoder_type: reshape
+ Head:
+ name: CTCHead
+
+Loss:
+ name: CTCLoss
+
+PostProcess:
+ name: CTCLabelDecode
+
+Metric:
+ name: RecMetric
+ main_indicator: acc
+
+Train:
+ dataset:
+ name: LMDBDataSet
+ data_dir: ./train_data/data_lmdb_release/training/
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - CTCLabelEncode: # Class handling label
+ - RecResizeImg:
+ character_dict_path:
+ image_shape: [3, 64, 256]
+ padding: False
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: True
+ batch_size_per_card: 512
+ drop_last: True
+ num_workers: 4
+
+Eval:
+ dataset:
+ name: LMDBDataSet
+ data_dir: ./train_data/data_lmdb_release/validation/
+ transforms:
+ - DecodeImage: # load image
+ img_mode: BGR
+ channel_first: False
+ - CTCLabelEncode: # Class handling label
+ - RecResizeImg:
+ character_dict_path:
+ image_shape: [3, 64, 256]
+ padding: False
+ - KeepKeys:
+ keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
+ loader:
+ shuffle: False
+ drop_last: False
+ batch_size_per_card: 256
+ num_workers: 2
diff --git a/deploy/cpp_infer/readme.md b/deploy/cpp_infer/readme.md
index 66c3a4c0719154152a2029572a8b88af3adcfcf4..c62fe32bc310eb3f91a6c55c3ecf25cfa53c0c61 100644
--- a/deploy/cpp_infer/readme.md
+++ b/deploy/cpp_infer/readme.md
@@ -1,38 +1,34 @@
-- [Server-side C++ Inference](#server-side-c-inference)
- - [1. Prepare the Environment](#1-prepare-the-environment)
- - [Environment](#environment)
- - [1.1 Compile OpenCV](#11-compile-opencv)
- - [1.2 Compile or Download or the Paddle Inference Library](#12-compile-or-download-or-the-paddle-inference-library)
- - [1.2.1 Direct download and installation](#121-direct-download-and-installation)
- - [1.2.2 Compile the inference source code](#122-compile-the-inference-source-code)
- - [2. Compile and Run the Demo](#2-compile-and-run-the-demo)
- - [2.1 Export the inference model](#21-export-the-inference-model)
- - [2.2 Compile PaddleOCR C++ inference demo](#22-compile-paddleocr-c-inference-demo)
- - [Run the demo](#run-the-demo)
- - [1. det+cls+rec:](#1-detclsrec)
- - [2. det+rec:](#2-detrec)
- - [3. det](#3-det)
- - [4. cls+rec:](#4-clsrec)
- - [5. rec](#5-rec)
- - [6. cls](#6-cls)
- - [3. FAQ](#3-faq)
+English | [简体中文](readme_ch.md)
# Server-side C++ Inference
-This chapter introduces the C++ deployment steps of the PaddleOCR model. The corresponding Python predictive deployment method refers to [document](../../doc/doc_ch/inference.md).
-C++ is better than python in terms of performance. Therefore, in CPU and GPU deployment scenarios, C++ deployment is mostly used.
+- [1. Prepare the Environment](#1)
+ - [1.1 Environment](#11)
+ - [1.2 Compile OpenCV](#12)
+ - [1.3 Compile or Download or the Paddle Inference Library](#13)
+- [2. Compile and Run the Demo](#2)
+ - [2.1 Export the inference model](#21)
+ - [2.2 Compile PaddleOCR C++ inference demo](#22)
+ - [2.3 Run the demo](#23)
+- [3. FAQ](#3)
+
+
+This chapter introduces the C++ deployment steps of the PaddleOCR model. C++ is better than Python in terms of performance. Therefore, in CPU and GPU deployment scenarios, C++ deployment is mostly used.
This section will introduce how to configure the C++ environment and deploy PaddleOCR in Linux (CPU\GPU) environment. For Windows deployment please refer to [Windows](./docs/windows_vs2019_build.md) compilation guidelines.
+
## 1. Prepare the Environment
-### Environment
+
+### 1.1 Environment
- Linux, docker is recommended.
- Windows.
-### 1.1 Compile OpenCV
+
+### 1.2 Compile OpenCV
* First of all, you need to download the source code compiled package in the Linux environment from the OpenCV official website. Taking OpenCV 3.4.7 as an example, the download command is as follows.
@@ -92,11 +88,12 @@ opencv3/
|-- share
```
-### 1.2 Compile or Download or the Paddle Inference Library
+
+### 1.3 Compile or Download or the Paddle Inference Library
* There are 2 ways to obtain the Paddle inference library, described in detail below.
-#### 1.2.1 Direct download and installation
+#### 1.3.1 Direct download and installation
[Paddle inference library official website](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#linux). You can review and select the appropriate version of the inference library on the official website.
@@ -109,7 +106,7 @@ tar -xf paddle_inference.tgz
Finally you will see the the folder of `paddle_inference/` in the current path.
-#### 1.2.2 Compile the inference source code
+#### 1.3.2 Compile the inference source code
* If you want to get the latest Paddle inference library features, you can download the latest code from Paddle GitHub repository and compile the inference library from the source code. It is recommended to download the inference library with paddle version greater than or equal to 2.0.1.
* You can refer to [Paddle inference library] (https://www.paddlepaddle.org.cn/documentation/docs/en/advanced_guide/inference_deployment/inference/build_and_install_lib_en.html) to get the Paddle source code from GitHub, and then compile To generate the latest inference library. The method of using git to access the code is as follows.
@@ -155,8 +152,10 @@ build/paddle_inference_install_dir/
`paddle` is the Paddle library required for C++ prediction later, and `version.txt` contains the version information of the current inference library.
+
## 2. Compile and Run the Demo
+
### 2.1 Export the inference model
* You can refer to [Model inference](../../doc/doc_ch/inference.md) and export the inference model. After the model is exported, assuming it is placed in the `inference` directory, the directory structure is as follows.
@@ -175,9 +174,9 @@ inference/
```
+
### 2.2 Compile PaddleOCR C++ inference demo
-
* The compilation commands are as follows. The addresses of Paddle C++ inference library, opencv and other Dependencies need to be replaced with the actual addresses on your own machines.
```shell
@@ -201,7 +200,9 @@ or the generated Paddle inference library path (`build/paddle_inference_install_
* After the compilation is completed, an executable file named `ppocr` will be generated in the `build` folder.
-### Run the demo
+
+### 2.3 Run the demo
+
Execute the built executable file:
```shell
./build/ppocr [--param1] [--param2] [...]
@@ -342,6 +343,7 @@ The detection visualized image saved in ./output//12.jpg
```
+
## 3. FAQ
1. Encountered the error `unable to access 'https://github.com/LDOUBLEV/AutoLog.git/': gnutls_handshake() failed: The TLS connection was non-properly terminated.`, change the github address in `deploy/cpp_infer/external-cmake/auto-log.cmake` to the https://gitee.com/Double_V/AutoLog address.
diff --git a/deploy/cpp_infer/readme_ch.md b/deploy/cpp_infer/readme_ch.md
index 47c7e032ebb350625adae8f500f91c0a7b96dbf4..2a81e15a97cca45d525efe8739255acd12f8117f 100644
--- a/deploy/cpp_infer/readme_ch.md
+++ b/deploy/cpp_infer/readme_ch.md
@@ -1,45 +1,36 @@
-- [服务器端C++预测](#服务器端c预测)
- - [1. 准备环境](#1-准备环境)
- - [1.0 运行准备](#10-运行准备)
- - [1.1 编译opencv库](#11-编译opencv库)
- - [1.2 下载或者编译Paddle预测库](#12-下载或者编译paddle预测库)
- - [1.2.1 直接下载安装](#121-直接下载安装)
- - [1.2.2 预测库源码编译](#122-预测库源码编译)
- - [2 开始运行](#2-开始运行)
- - [2.1 将模型导出为inference model](#21-将模型导出为inference-model)
- - [2.2 编译PaddleOCR C++预测demo](#22-编译paddleocr-c预测demo)
- - [2.3 运行demo](#23-运行demo)
- - [1. 检测+分类+识别:](#1-检测分类识别)
- - [2. 检测+识别:](#2-检测识别)
- - [3. 检测:](#3-检测)
- - [4. 分类+识别:](#4-分类识别)
- - [5. 识别:](#5-识别)
- - [6. 分类:](#6-分类)
- - [3. FAQ](#3-faq)
+[English](readme.md) | 简体中文
# 服务器端C++预测
-本章节介绍PaddleOCR 模型的的C++部署方法,与之对应的python预测部署方式参考[文档](../../doc/doc_ch/inference.md)。
-C++在性能计算上优于python,因此,在大多数CPU、GPU部署场景,多采用C++的部署方式,本节将介绍如何在Linux\Windows (CPU\GPU)环境下配置C++环境并完成
-PaddleOCR模型部署。
+- [1. 准备环境](#1)
+ - [1.1 运行准备](#11)
+ - [1.2 编译opencv库](#12)
+ - [1.3 下载或者编译Paddle预测库](#13)
+- [2 开始运行](#2)
+ - [2.1 准备模型](#21)
+ - [2.2 编译PaddleOCR C++预测demo](#22)
+ - [2.3 运行demo](#23)
+- [3. FAQ](#3)
+
+本章节介绍PaddleOCR 模型的的C++部署方法。C++在性能计算上优于Python,因此,在大多数CPU、GPU部署场景,多采用C++的部署方式,本节将介绍如何在Linux\Windows (CPU\GPU)环境下配置C++环境并完成PaddleOCR模型部署。
## 1. 准备环境
-
+
-### 1.0 运行准备
+### 1.1 运行准备
- Linux环境,推荐使用docker。
- Windows环境。
* 该文档主要介绍基于Linux环境的PaddleOCR C++预测流程,如果需要在Windows下基于预测库进行C++预测,具体编译方法请参考[Windows下编译教程](./docs/windows_vs2019_build.md)
-
+
-### 1.1 编译opencv库
+### 1.2 编译opencv库
* 首先需要从opencv官网上下载在Linux环境下源码编译的包,以opencv3.4.7为例,下载命令如下。
@@ -103,35 +94,38 @@ opencv3/
|-- share
```
-
-
-### 1.2 下载或者编译Paddle预测库
+
-* 有2种方式获取Paddle预测库,下面进行详细介绍。
+### 1.3 下载或者编译Paddle预测库
+可以选择直接下载安装或者从源码编译,下文分别进行具体说明。
-#### 1.2.1 直接下载安装
+
+#### 1.3.1 直接下载安装
-* [Paddle预测库官网](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#linux) 上提供了不同cuda版本的Linux预测库,可以在官网查看并选择合适的预测库版本(*建议选择paddle版本>=2.0.1版本的预测库* )。
+[Paddle预测库官网](https://paddleinference.paddlepaddle.org.cn/user_guides/download_lib.html#linux) 上提供了不同cuda版本的Linux预测库,可以在官网查看并选择合适的预测库版本(*建议选择paddle版本>=2.0.1版本的预测库* )。
-* 下载之后使用下面的方法解压。
+下载之后解压:
-```
+```shell
tar -xf paddle_inference.tgz
```
最终会在当前的文件夹中生成`paddle_inference/`的子文件夹。
-#### 1.2.2 预测库源码编译
-* 如果希望获取最新预测库特性,可以从Paddle github上克隆最新代码,源码编译预测库。
-* 可以参考[Paddle预测库安装编译说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0/guides/05_inference_deployment/inference/build_and_install_lib_cn.html#congyuanmabianyi) 的说明,从github上获取Paddle代码,然后进行编译,生成最新的预测库。使用git获取代码方法如下。
+
+#### 1.3.2 预测库源码编译
+
+如果希望获取最新预测库特性,可以从github上克隆最新Paddle代码进行编译,生成最新的预测库。
+
+* 使用git获取代码:
```shell
git clone https://github.com/PaddlePaddle/Paddle.git
git checkout develop
```
-* 进入Paddle目录后,编译方法如下。
+* 进入Paddle目录,进行编译:
```shell
rm -rf build
@@ -151,7 +145,7 @@ make -j
make inference_lib_dist
```
-更多编译参数选项介绍可以参考[文档说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0/guides/05_inference_deployment/inference/build_and_install_lib_cn.html#congyuanmabianyi)。
+更多编译参数选项介绍可以参考[Paddle预测库编译文档](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0/guides/05_inference_deployment/inference/build_and_install_lib_cn.html#congyuanmabianyi)。
* 编译完成之后,可以在`build/paddle_inference_install_dir/`文件下看到生成了以下文件及文件夹。
@@ -168,13 +162,13 @@ build/paddle_inference_install_dir/
-## 2 开始运行
+## 2. 开始运行
-### 2.1 将模型导出为inference model
+### 2.1 准备模型
-* 可以参考[模型预测章节](../../doc/doc_ch/inference.md),导出inference model,用于模型预测。模型导出之后,假设放在`inference`目录下,则目录结构如下。
+直接下载PaddleOCR提供的推理模型,或者参考[模型预测章节](../../doc/doc_ch/inference_ppocr.md),将训练好的模型导出为推理模型。模型导出之后,假设放在`inference`目录下,则目录结构如下。
```
inference/
@@ -193,13 +187,13 @@ inference/
### 2.2 编译PaddleOCR C++预测demo
-* 编译命令如下,其中Paddle C++预测库、opencv等其他依赖库的地址需要换成自己机器上的实际地址。
+编译命令如下,其中Paddle C++预测库、opencv等其他依赖库的地址需要换成自己机器上的实际地址。
```shell
sh tools/build.sh
```
-* 具体的,需要修改`tools/build.sh`中环境路径,相关内容如下:
+具体的,需要修改`tools/build.sh`中环境路径,相关内容如下:
```shell
OPENCV_DIR=your_opencv_dir
@@ -211,12 +205,14 @@ CUDNN_LIB_DIR=/your_cudnn_lib_dir
其中,`OPENCV_DIR`为opencv编译安装的地址;`LIB_DIR`为下载(`paddle_inference`文件夹)或者编译生成的Paddle预测库地址(`build/paddle_inference_install_dir`文件夹);`CUDA_LIB_DIR`为cuda库文件地址,在docker中为`/usr/local/cuda/lib64`;`CUDNN_LIB_DIR`为cudnn库文件地址,在docker中为`/usr/lib/x86_64-linux-gnu/`。**注意:以上路径都写绝对路径,不要写相对路径。**
-* 编译完成之后,会在`build`文件夹下生成一个名为`ppocr`的可执行文件。
+编译完成之后,会在`build`文件夹下生成一个名为`ppocr`的可执行文件。
### 2.3 运行demo
+本demo支持系统串联调用,也支持单个功能的调用,如,只使用检测或识别功能。
+
运行方式:
```shell
./build/ppocr [--param1] [--param2] [...]
@@ -354,6 +350,7 @@ predict img: ../../doc/imgs/12.jpg
The detection visualized image saved in ./output//12.jpg
```
+
## 3. FAQ
1. 遇到报错 `unable to access 'https://github.com/LDOUBLEV/AutoLog.git/': gnutls_handshake() failed: The TLS connection was non-properly terminated.`, 将 `deploy/cpp_infer/external-cmake/auto-log.cmake` 中的github地址改为 https://gitee.com/Double_V/AutoLog 地址即可。
diff --git a/deploy/slim/quantization/quant.py b/deploy/slim/quantization/quant.py
index 1dffaab0eef35ec41c27c9c6e00f25dda048d490..355ba77f83121d07a52b1b8645bc6d4893373c42 100755
--- a/deploy/slim/quantization/quant.py
+++ b/deploy/slim/quantization/quant.py
@@ -137,7 +137,7 @@ def main(config, device, logger, vdl_writer):
config['Optimizer'],
epochs=config['Global']['epoch_num'],
step_each_epoch=len(train_dataloader),
- parameters=model.parameters())
+ model=model)
# resume PACT training process
if config["Global"]["checkpoints"] is not None:
diff --git a/doc/doc_ch/algorithm_det_db.md b/doc/doc_ch/algorithm_det_db.md
index fc887743bcdb4cf6e29ac4d8e643dda9520e4795..7f94ceaee06ac41a42c785f26bffa30005a98355 100644
--- a/doc/doc_ch/algorithm_det_db.md
+++ b/doc/doc_ch/algorithm_det_db.md
@@ -47,13 +47,13 @@
### 4.1 Python推理
首先将DB文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例( [模型下载地址](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar) ),可以使用如下命令进行转换:
-```
+```shell
python3 tools/export_model.py -c configs/det/det_r50_vd_db.yml -o Global.pretrained_model=./det_r50_vd_db_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_db
```
DB文本检测模型推理,可以执行如下命令:
-```
+```shell
python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_db/"
```
@@ -65,15 +65,20 @@ python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_
### 4.2 C++推理
-敬请期待
+
+准备好推理模型后,参考[cpp infer](../../deploy/cpp_infer/)教程进行操作即可。
### 4.3 Serving服务化部署
-敬请期待
+
+准备好推理模型后,参考[pdserving](../../deploy/pdserving/)教程进行Serving服务化部署,包括Python Serving和C++ Serving两种模式。
### 4.4 更多推理部署
-敬请期待
+
+DB模型还支持以下推理部署方式:
+
+- Paddle2ONNX推理:准备好推理模型后,参考[paddle2onnx](../../deploy/paddle2onnx/)教程操作。
## 5. FAQ
diff --git a/doc/doc_en/algorithm_det_db_en.md b/doc/doc_en/algorithm_det_db_en.md
index 40ba022f84786f3538f348e350a41506962c9c2c..b387a8ec217b351164d7cac878539bab19157a6e 100644
--- a/doc/doc_en/algorithm_det_db_en.md
+++ b/doc/doc_en/algorithm_det_db_en.md
@@ -14,4 +14,86 @@
- [5. FAQ](#5)
-## 1. Introduction
\ No newline at end of file
+## 1. Introduction
+
+Paper:
+> [Real-time Scene Text Detection with Differentiable Binarization](https://arxiv.org/abs/1911.08947)
+> Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang
+> AAAI, 2020
+
+On the ICDAR2015 dataset, the text detection result is as follows:
+
+|Model|Backbone|Configuration|Precision|Recall|Hmean|Download|
+| --- | --- | --- | --- | --- | --- | --- |
+|DB|ResNet50_vd|configs/det/det_r50_vd_db.yml|86.41%|78.72%|82.38%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar)|
+|DB|MobileNetV3|configs/det/det_mv3_db.yml|77.29%|73.08%|75.12%|[trained model](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_mv3_db_v2.0_train.tar)|
+
+
+
+## 2. Environment
+Please prepare your environment referring to [prepare the environment](./environment_en.md) and [clone the repo](./clone_en.md).
+
+
+
+## 3. Model Training / Evaluation / Prediction
+
+Please refer to [text detection training tutorial](./detection_en.md). PaddleOCR has modularized the code structure, so that you only need to **replace the configuration file** to train different detection models.
+
+
+## 4. Inference and Deployment
+
+
+### 4.1 Python Inference
+First, convert the model saved in the DB text detection training process into an inference model. Taking the model based on the Resnet50_vd backbone network and trained on the ICDAR2015 English dataset as example ([model download link](https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar)), you can use the following command to convert:
+
+```shell
+python3 tools/export_model.py -c configs/det/det_r50_vd_db.yml -o Global.pretrained_model=./det_r50_vd_db_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_db
+```
+
+DB text detection model inference, you can execute the following command:
+
+```shell
+python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_db/"
+```
+
+The visualized text detection results are saved to the `./inference_results` folder by default, and the name of the result file is prefixed with 'det_res'. Examples of results are as follows:
+
+
+
+**Note**: Since the ICDAR2015 dataset has only 1,000 training images, mainly for English scenes, the above model has very poor detection result on Chinese text images.
+
+
+
+### 4.2 C++ Inference
+
+With the inference model prepared, refer to the [cpp infer](../../deploy/cpp_infer/) tutorial for C++ inference.
+
+
+### 4.3 Serving
+
+With the inference model prepared, refer to the [pdserving](../../deploy/pdserving/) tutorial for service deployment by Paddle Serving.
+
+
+### 4.4 More
+
+More deployment schemes supported for DB:
+
+- Paddle2ONNX: with the inference model prepared, please refer to the [paddle2onnx](../../deploy/paddle2onnx/) tutorial.
+
+
+## 5. FAQ
+
+
+## Citation
+
+```bibtex
+@inproceedings{liao2020real,
+ title={Real-time scene text detection with differentiable binarization},
+ author={Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang},
+ booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
+ volume={34},
+ number={07},
+ pages={11474--11481},
+ year={2020}
+}
+```
\ No newline at end of file
diff --git a/doc/joinus.PNG b/doc/joinus.PNG
index 133e42b8de6c4ec2c0ae4f85aab0d4a7fb425526..6eacac65d268a17dd717fff1790d5c0c84acc5ea 100644
Binary files a/doc/joinus.PNG and b/doc/joinus.PNG differ
diff --git a/ppocr/data/imaug/__init__.py b/ppocr/data/imaug/__init__.py
index 164f1d2224d6cdba589d0502fc17438d346788dd..7580e607afb356a1032c4d6b2d2267bff608a80d 100644
--- a/ppocr/data/imaug/__init__.py
+++ b/ppocr/data/imaug/__init__.py
@@ -22,8 +22,8 @@ from .make_shrink_map import MakeShrinkMap
from .random_crop_data import EastRandomCropData, RandomCropImgMask
from .make_pse_gt import MakePseGt
-from .rec_img_aug import RecAug, RecResizeImg, ClsResizeImg, \
- SRNRecResizeImg, NRTRRecResizeImg, SARRecResizeImg, PRENResizeImg
+from .rec_img_aug import RecAug, RecConAug, RecResizeImg, ClsResizeImg, \
+ SRNRecResizeImg, NRTRRecResizeImg, SARRecResizeImg, PRENResizeImg, SVTRRecResizeImg
from .randaugment import RandAugment
from .copy_paste import CopyPaste
from .ColorJitter import ColorJitter
diff --git a/ppocr/data/imaug/label_ops.py b/ppocr/data/imaug/label_ops.py
index 6f86be7da002cc6a9fb649f532a73b109286be6b..c9bc2e7722e8027ce870e4969bfcdab720495c28 100644
--- a/ppocr/data/imaug/label_ops.py
+++ b/ppocr/data/imaug/label_ops.py
@@ -22,6 +22,7 @@ import numpy as np
import string
from shapely.geometry import LineString, Point, Polygon
import json
+import copy
from ppocr.utils.logging import get_logger
@@ -112,14 +113,14 @@ class BaseRecLabelEncode(object):
dict_character = list(self.character_str)
self.lower = True
else:
- self.character_str = ""
+ self.character_str = []
with open(character_dict_path, "rb") as fin:
lines = fin.readlines()
for line in lines:
line = line.decode('utf-8').strip("\n").strip("\r\n")
- self.character_str += line
+ self.character_str.append(line)
if use_space_char:
- self.character_str += " "
+ self.character_str.append(" ")
dict_character = list(self.character_str)
dict_character = self.add_special_char(dict_character)
self.dict = {}
@@ -1007,3 +1008,34 @@ class VQATokenLabelEncode(object):
gt_label.extend([self.label2id_map[("i-" + label).upper()]] *
(len(encode_res["input_ids"]) - 1))
return gt_label
+
+
+class MultiLabelEncode(BaseRecLabelEncode):
+ def __init__(self,
+ max_text_length,
+ character_dict_path=None,
+ use_space_char=False,
+ **kwargs):
+ super(MultiLabelEncode, self).__init__(
+ max_text_length, character_dict_path, use_space_char)
+
+ self.ctc_encode = CTCLabelEncode(max_text_length, character_dict_path,
+ use_space_char, **kwargs)
+ self.sar_encode = SARLabelEncode(max_text_length, character_dict_path,
+ use_space_char, **kwargs)
+
+ def __call__(self, data):
+
+ data_ctc = copy.deepcopy(data)
+ data_sar = copy.deepcopy(data)
+ data_out = dict()
+ data_out['img_path'] = data.get('img_path', None)
+ data_out['image'] = data['image']
+ ctc = self.ctc_encode.__call__(data_ctc)
+ sar = self.sar_encode.__call__(data_sar)
+ if ctc is None or sar is None:
+ return None
+ data_out['label_ctc'] = ctc['label']
+ data_out['label_sar'] = sar['label']
+ data_out['length'] = ctc['length']
+ return data_out
diff --git a/ppocr/data/imaug/rec_img_aug.py b/ppocr/data/imaug/rec_img_aug.py
index 6f59fef63d85090b0e433d79b0c3e3f381ac1b38..2f70b51a3b88422274353046209c6d0d4dc79489 100644
--- a/ppocr/data/imaug/rec_img_aug.py
+++ b/ppocr/data/imaug/rec_img_aug.py
@@ -16,6 +16,7 @@ import math
import cv2
import numpy as np
import random
+import copy
from PIL import Image
from .text_image_aug import tia_perspective, tia_stretch, tia_distort
@@ -32,13 +33,56 @@ class RecAug(object):
return data
+class RecConAug(object):
+ def __init__(self,
+ prob=0.5,
+ image_shape=(32, 320, 3),
+ max_text_length=25,
+ ext_data_num=1,
+ **kwargs):
+ self.ext_data_num = ext_data_num
+ self.prob = prob
+ self.max_text_length = max_text_length
+ self.image_shape = image_shape
+ self.max_wh_ratio = self.image_shape[1] / self.image_shape[0]
+
+ def merge_ext_data(self, data, ext_data):
+ ori_w = round(data['image'].shape[1] / data['image'].shape[0] *
+ self.image_shape[0])
+ ext_w = round(ext_data['image'].shape[1] / ext_data['image'].shape[0] *
+ self.image_shape[0])
+ data['image'] = cv2.resize(data['image'], (ori_w, self.image_shape[0]))
+ ext_data['image'] = cv2.resize(ext_data['image'],
+ (ext_w, self.image_shape[0]))
+ data['image'] = np.concatenate(
+ [data['image'], ext_data['image']], axis=1)
+ data["label"] += ext_data["label"]
+ return data
+
+ def __call__(self, data):
+ rnd_num = random.random()
+ if rnd_num > self.prob:
+ return data
+ for idx, ext_data in enumerate(data["ext_data"]):
+ if len(data["label"]) + len(ext_data[
+ "label"]) > self.max_text_length:
+ break
+ concat_ratio = data['image'].shape[1] / data['image'].shape[
+ 0] + ext_data['image'].shape[1] / ext_data['image'].shape[0]
+ if concat_ratio > self.max_wh_ratio:
+ break
+ data = self.merge_ext_data(data, ext_data)
+ data.pop("ext_data")
+ return data
+
+
class ClsResizeImg(object):
def __init__(self, image_shape, **kwargs):
self.image_shape = image_shape
def __call__(self, data):
img = data['image']
- norm_img = resize_norm_img(img, self.image_shape)
+ norm_img, _ = resize_norm_img(img, self.image_shape)
data['image'] = norm_img
return data
@@ -98,10 +142,13 @@ class RecResizeImg(object):
def __call__(self, data):
img = data['image']
if self.infer_mode and self.character_dict_path is not None:
- norm_img = resize_norm_img_chinese(img, self.image_shape)
+ norm_img, valid_ratio = resize_norm_img_chinese(img,
+ self.image_shape)
else:
- norm_img = resize_norm_img(img, self.image_shape, self.padding)
+ norm_img, valid_ratio = resize_norm_img(img, self.image_shape,
+ self.padding)
data['image'] = norm_img
+ data['valid_ratio'] = valid_ratio
return data
@@ -160,6 +207,25 @@ class PRENResizeImg(object):
return data
+class SVTRRecResizeImg(object):
+ def __init__(self,
+ image_shape,
+ infer_mode=False,
+ character_dict_path='./ppocr/utils/ppocr_keys_v1.txt',
+ padding=True,
+ **kwargs):
+ self.image_shape = image_shape
+ self.infer_mode = infer_mode
+ self.character_dict_path = character_dict_path
+ self.padding = padding
+
+ def __call__(self, data):
+ img = data['image']
+ norm_img = resize_norm_img_svtr(img, self.image_shape, self.padding)
+ data['image'] = norm_img
+ return data
+
+
def resize_norm_img_sar(img, image_shape, width_downsample_ratio=0.25):
imgC, imgH, imgW_min, imgW_max = image_shape
h = img.shape[0]
@@ -220,7 +286,8 @@ def resize_norm_img(img, image_shape, padding=True):
resized_image /= 0.5
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
- return padding_im
+ valid_ratio = min(1.0, float(resized_w / imgW))
+ return padding_im, valid_ratio
def resize_norm_img_chinese(img, image_shape):
@@ -230,7 +297,7 @@ def resize_norm_img_chinese(img, image_shape):
h, w = img.shape[0], img.shape[1]
ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, ratio)
- imgW = int(32 * max_wh_ratio)
+ imgW = int(imgH * max_wh_ratio)
if math.ceil(imgH * ratio) > imgW:
resized_w = imgW
else:
@@ -246,7 +313,8 @@ def resize_norm_img_chinese(img, image_shape):
resized_image /= 0.5
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
- return padding_im
+ valid_ratio = min(1.0, float(resized_w / imgW))
+ return padding_im, valid_ratio
def resize_norm_img_srn(img, image_shape):
@@ -276,6 +344,58 @@ def resize_norm_img_srn(img, image_shape):
return np.reshape(img_black, (c, row, col)).astype(np.float32)
+def resize_norm_img_svtr(img, image_shape, padding=False):
+ imgC, imgH, imgW = image_shape
+ h = img.shape[0]
+ w = img.shape[1]
+ if not padding:
+ if h > 2.0 * w:
+ image = Image.fromarray(img)
+ image1 = image.rotate(90, expand=True)
+ image2 = image.rotate(-90, expand=True)
+ img1 = np.array(image1)
+ img2 = np.array(image2)
+ else:
+ img1 = copy.deepcopy(img)
+ img2 = copy.deepcopy(img)
+
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image1 = cv2.resize(
+ img1, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image2 = cv2.resize(
+ img2, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_w = imgW
+ else:
+ ratio = w / float(h)
+ if math.ceil(imgH * ratio) > imgW:
+ resized_w = imgW
+ else:
+ resized_w = int(math.ceil(imgH * ratio))
+ resized_image = cv2.resize(img, (resized_w, imgH))
+ resized_image = resized_image.astype('float32')
+ resized_image1 = resized_image1.astype('float32')
+ resized_image2 = resized_image2.astype('float32')
+ if image_shape[0] == 1:
+ resized_image = resized_image / 255
+ resized_image = resized_image[np.newaxis, :]
+ else:
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image1 = resized_image1.transpose((2, 0, 1)) / 255
+ resized_image2 = resized_image2.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ resized_image1 -= 0.5
+ resized_image1 /= 0.5
+ resized_image2 -= 0.5
+ resized_image2 /= 0.5
+ padding_im = np.zeros((3, imgC, imgH, imgW), dtype=np.float32)
+ padding_im[0, :, :, 0:resized_w] = resized_image
+ padding_im[1, :, :, 0:resized_w] = resized_image1
+ padding_im[2, :, :, 0:resized_w] = resized_image2
+ return padding_im
+
+
def srn_other_inputs(image_shape, num_heads, max_text_length):
imgC, imgH, imgW = image_shape
diff --git a/ppocr/data/simple_dataset.py b/ppocr/data/simple_dataset.py
index 13f9411e29430843bb808aede15e8305dbc2d028..b5da9b8898423facf888839f941dff01caa03643 100644
--- a/ppocr/data/simple_dataset.py
+++ b/ppocr/data/simple_dataset.py
@@ -49,7 +49,8 @@ class SimpleDataSet(Dataset):
if self.mode == "train" and self.do_shuffle:
self.shuffle_data_random()
self.ops = create_operators(dataset_config['transforms'], global_config)
-
+ self.ext_op_transform_idx = dataset_config.get("ext_op_transform_idx",
+ 2)
self.need_reset = True in [x < 1 for x in ratio_list]
def get_image_info_list(self, file_list, ratio_list):
@@ -87,7 +88,7 @@ class SimpleDataSet(Dataset):
if hasattr(op, 'ext_data_num'):
ext_data_num = getattr(op, 'ext_data_num')
break
- load_data_ops = self.ops[:2]
+ load_data_ops = self.ops[:self.ext_op_transform_idx]
ext_data = []
while len(ext_data) < ext_data_num:
@@ -108,8 +109,11 @@ class SimpleDataSet(Dataset):
data['image'] = img
data = transform(data, load_data_ops)
- if data is None or data['polys'].shape[1] != 4:
+ if data is None:
continue
+ if 'polys' in data.keys():
+ if data['polys'].shape[1] != 4:
+ continue
ext_data.append(data)
return ext_data
diff --git a/ppocr/losses/__init__.py b/ppocr/losses/__init__.py
index 6505fca77ec6ff6b18dc840c6b2e443eecf2af2a..de8419b7c1cf6a30ab7195a1cbcbb10a5e52642d 100755
--- a/ppocr/losses/__init__.py
+++ b/ppocr/losses/__init__.py
@@ -34,6 +34,7 @@ from .rec_nrtr_loss import NRTRLoss
from .rec_sar_loss import SARLoss
from .rec_aster_loss import AsterLoss
from .rec_pren_loss import PRENLoss
+from .rec_multi_loss import MultiLoss
# cls loss
from .cls_loss import ClsLoss
@@ -60,7 +61,7 @@ def build_loss(config):
'DBLoss', 'PSELoss', 'EASTLoss', 'SASTLoss', 'FCELoss', 'CTCLoss',
'ClsLoss', 'AttentionLoss', 'SRNLoss', 'PGLoss', 'CombinedLoss',
'NRTRLoss', 'TableAttentionLoss', 'SARLoss', 'AsterLoss', 'SDMGRLoss',
- 'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss'
+ 'VQASerTokenLayoutLMLoss', 'LossFromOutput', 'PRENLoss', 'MultiLoss'
]
config = copy.deepcopy(config)
module_name = config.pop('name')
diff --git a/ppocr/losses/basic_loss.py b/ppocr/losses/basic_loss.py
index b19ce57dcaf463d8be30fd1111b521d632308786..2df96ea2642d10a50eb892d738f89318dc5e0f4c 100644
--- a/ppocr/losses/basic_loss.py
+++ b/ppocr/losses/basic_loss.py
@@ -106,8 +106,8 @@ class DMLLoss(nn.Layer):
def forward(self, out1, out2):
if self.act is not None:
- out1 = self.act(out1)
- out2 = self.act(out2)
+ out1 = self.act(out1) + 1e-10
+ out2 = self.act(out2) + 1e-10
if self.use_log:
# for recognition distillation, log is needed for feature map
log_out1 = paddle.log(out1)
diff --git a/ppocr/losses/combined_loss.py b/ppocr/losses/combined_loss.py
index 72f706e37d6eb0c640cc30de80afe00bce82fd13..f4cdee8f90465e863b89d1e32b4a0285adb29eff 100644
--- a/ppocr/losses/combined_loss.py
+++ b/ppocr/losses/combined_loss.py
@@ -18,8 +18,10 @@ import paddle.nn as nn
from .rec_ctc_loss import CTCLoss
from .center_loss import CenterLoss
from .ace_loss import ACELoss
+from .rec_sar_loss import SARLoss
from .distillation_loss import DistillationCTCLoss
+from .distillation_loss import DistillationSARLoss
from .distillation_loss import DistillationDMLLoss
from .distillation_loss import DistillationDistanceLoss, DistillationDBLoss, DistillationDilaDBLoss
diff --git a/ppocr/losses/distillation_loss.py b/ppocr/losses/distillation_loss.py
index 06aa7fa8458a5deece75f1393fe7300e8227d3ca..565b066d1334e6caa1b6b4094706265f363b66ef 100644
--- a/ppocr/losses/distillation_loss.py
+++ b/ppocr/losses/distillation_loss.py
@@ -18,6 +18,7 @@ import numpy as np
import cv2
from .rec_ctc_loss import CTCLoss
+from .rec_sar_loss import SARLoss
from .basic_loss import DMLLoss
from .basic_loss import DistanceLoss
from .det_db_loss import DBLoss
@@ -46,11 +47,15 @@ class DistillationDMLLoss(DMLLoss):
act=None,
use_log=False,
key=None,
+ multi_head=False,
+ dis_head='ctc',
maps_name=None,
name="dml"):
super().__init__(act=act, use_log=use_log)
assert isinstance(model_name_pairs, list)
self.key = key
+ self.multi_head = multi_head
+ self.dis_head = dis_head
self.model_name_pairs = self._check_model_name_pairs(model_name_pairs)
self.name = name
self.maps_name = self._check_maps_name(maps_name)
@@ -97,7 +102,11 @@ class DistillationDMLLoss(DMLLoss):
out2 = out2[self.key]
if self.maps_name is None:
- loss = super().forward(out1, out2)
+ if self.multi_head:
+ loss = super().forward(out1[self.dis_head],
+ out2[self.dis_head])
+ else:
+ loss = super().forward(out1, out2)
if isinstance(loss, dict):
for key in loss:
loss_dict["{}_{}_{}_{}".format(key, pair[0], pair[1],
@@ -123,11 +132,16 @@ class DistillationDMLLoss(DMLLoss):
class DistillationCTCLoss(CTCLoss):
- def __init__(self, model_name_list=[], key=None, name="loss_ctc"):
+ def __init__(self,
+ model_name_list=[],
+ key=None,
+ multi_head=False,
+ name="loss_ctc"):
super().__init__()
self.model_name_list = model_name_list
self.key = key
self.name = name
+ self.multi_head = multi_head
def forward(self, predicts, batch):
loss_dict = dict()
@@ -135,7 +149,45 @@ class DistillationCTCLoss(CTCLoss):
out = predicts[model_name]
if self.key is not None:
out = out[self.key]
- loss = super().forward(out, batch)
+ if self.multi_head:
+ assert 'ctc' in out, 'multi head has multi out'
+ loss = super().forward(out['ctc'], batch[:2] + batch[3:])
+ else:
+ loss = super().forward(out, batch)
+ if isinstance(loss, dict):
+ for key in loss:
+ loss_dict["{}_{}_{}".format(self.name, model_name,
+ idx)] = loss[key]
+ else:
+ loss_dict["{}_{}".format(self.name, model_name)] = loss
+ return loss_dict
+
+
+class DistillationSARLoss(SARLoss):
+ def __init__(self,
+ model_name_list=[],
+ key=None,
+ multi_head=False,
+ name="loss_sar",
+ **kwargs):
+ ignore_index = kwargs.get('ignore_index', 92)
+ super().__init__(ignore_index=ignore_index)
+ self.model_name_list = model_name_list
+ self.key = key
+ self.name = name
+ self.multi_head = multi_head
+
+ def forward(self, predicts, batch):
+ loss_dict = dict()
+ for idx, model_name in enumerate(self.model_name_list):
+ out = predicts[model_name]
+ if self.key is not None:
+ out = out[self.key]
+ if self.multi_head:
+ assert 'sar' in out, 'multi head has multi out'
+ loss = super().forward(out['sar'], batch[:1] + batch[2:])
+ else:
+ loss = super().forward(out, batch)
if isinstance(loss, dict):
for key in loss:
loss_dict["{}_{}_{}".format(self.name, model_name,
diff --git a/ppocr/losses/rec_multi_loss.py b/ppocr/losses/rec_multi_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..09f007afe6303e83b9a6948df553ec0fca8b6b2d
--- /dev/null
+++ b/ppocr/losses/rec_multi_loss.py
@@ -0,0 +1,58 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import paddle
+from paddle import nn
+
+from .rec_ctc_loss import CTCLoss
+from .rec_sar_loss import SARLoss
+
+
+class MultiLoss(nn.Layer):
+ def __init__(self, **kwargs):
+ super().__init__()
+ self.loss_funcs = {}
+ self.loss_list = kwargs.pop('loss_config_list')
+ self.weight_1 = kwargs.get('weight_1', 1.0)
+ self.weight_2 = kwargs.get('weight_2', 1.0)
+ self.gtc_loss = kwargs.get('gtc_loss', 'sar')
+ for loss_info in self.loss_list:
+ for name, param in loss_info.items():
+ if param is not None:
+ kwargs.update(param)
+ loss = eval(name)(**kwargs)
+ self.loss_funcs[name] = loss
+
+ def forward(self, predicts, batch):
+ self.total_loss = {}
+ total_loss = 0.0
+ # batch [image, label_ctc, label_sar, length, valid_ratio]
+ for name, loss_func in self.loss_funcs.items():
+ if name == 'CTCLoss':
+ loss = loss_func(predicts['ctc'],
+ batch[:2] + batch[3:])['loss'] * self.weight_1
+ elif name == 'SARLoss':
+ loss = loss_func(predicts['sar'],
+ batch[:1] + batch[2:])['loss'] * self.weight_2
+ else:
+ raise NotImplementedError(
+ '{} is not supported in MultiLoss yet'.format(name))
+ self.total_loss[name] = loss
+ total_loss += loss
+ self.total_loss['loss'] = total_loss
+ return self.total_loss
diff --git a/ppocr/losses/rec_sar_loss.py b/ppocr/losses/rec_sar_loss.py
index c8bd8bb0ca395fa4658e57b8dcac52a3e94aadce..a4f83f03c08e4c4e6bab308aebc2daa8aa612400 100644
--- a/ppocr/losses/rec_sar_loss.py
+++ b/ppocr/losses/rec_sar_loss.py
@@ -9,8 +9,9 @@ from paddle import nn
class SARLoss(nn.Layer):
def __init__(self, **kwargs):
super(SARLoss, self).__init__()
+ ignore_index = kwargs.get('ignore_index', 92) # 6626
self.loss_func = paddle.nn.loss.CrossEntropyLoss(
- reduction="mean", ignore_index=92)
+ reduction="mean", ignore_index=ignore_index)
def forward(self, predicts, batch):
predict = predicts[:, :
diff --git a/ppocr/metrics/rec_metric.py b/ppocr/metrics/rec_metric.py
index b047bbcb972cadf227daaeb8797c46095ac0af43..515b9372e38a7213cde29fdc9834ed6df45a0a80 100644
--- a/ppocr/metrics/rec_metric.py
+++ b/ppocr/metrics/rec_metric.py
@@ -17,9 +17,14 @@ import string
class RecMetric(object):
- def __init__(self, main_indicator='acc', is_filter=False, **kwargs):
+ def __init__(self,
+ main_indicator='acc',
+ is_filter=False,
+ ignore_space=True,
+ **kwargs):
self.main_indicator = main_indicator
self.is_filter = is_filter
+ self.ignore_space = ignore_space
self.eps = 1e-5
self.reset()
@@ -34,8 +39,9 @@ class RecMetric(object):
all_num = 0
norm_edit_dis = 0.0
for (pred, pred_conf), (target, _) in zip(preds, labels):
- pred = pred.replace(" ", "")
- target = target.replace(" ", "")
+ if self.ignore_space:
+ pred = pred.replace(" ", "")
+ target = target.replace(" ", "")
if self.is_filter:
pred = self._normalize_text(pred)
target = self._normalize_text(target)
diff --git a/ppocr/modeling/architectures/base_model.py b/ppocr/modeling/architectures/base_model.py
index e622db25677069f9a4470db4966b7523def35472..f5b29f94057d5b1f1fbec27686d5f1d679b15479 100644
--- a/ppocr/modeling/architectures/base_model.py
+++ b/ppocr/modeling/architectures/base_model.py
@@ -83,7 +83,11 @@ class BaseModel(nn.Layer):
y["neck_out"] = x
if self.use_head:
x = self.head(x, targets=data)
- if isinstance(x, dict):
+ # for multi head, save ctc neck out for udml
+ if isinstance(x, dict) and 'ctc_neck' in x.keys():
+ y["neck_out"] = x["ctc_neck"]
+ y["head_out"] = x
+ elif isinstance(x, dict):
y.update(x)
else:
y["head_out"] = x
diff --git a/ppocr/modeling/architectures/distillation_model.py b/ppocr/modeling/architectures/distillation_model.py
index 5e867940e796841111fc668a0b3eb12547807d76..cce8fd311d4e847afda0fbb035743f0a10564c7d 100644
--- a/ppocr/modeling/architectures/distillation_model.py
+++ b/ppocr/modeling/architectures/distillation_model.py
@@ -53,8 +53,8 @@ class DistillationModel(nn.Layer):
self.model_list.append(self.add_sublayer(key, model))
self.model_name_list.append(key)
- def forward(self, x):
+ def forward(self, x, data=None):
result_dict = dict()
for idx, model_name in enumerate(self.model_name_list):
- result_dict[model_name] = self.model_list[idx](x)
+ result_dict[model_name] = self.model_list[idx](x, data)
return result_dict
diff --git a/ppocr/modeling/backbones/__init__.py b/ppocr/modeling/backbones/__init__.py
index c89c7c25aeb7c905428a4813d74f0514ed59e8e1..072d6e0f84d4126d256c26aa5baf17c9dc4e63df 100755
--- a/ppocr/modeling/backbones/__init__.py
+++ b/ppocr/modeling/backbones/__init__.py
@@ -31,9 +31,11 @@ def build_backbone(config, model_type):
from .rec_resnet_aster import ResNet_ASTER
from .rec_micronet import MicroNet
from .rec_efficientb3_pren import EfficientNetb3_PREN
+ from .rec_svtrnet import SVTRNet
support_dict = [
'MobileNetV1Enhance', 'MobileNetV3', 'ResNet', 'ResNetFPN', 'MTB',
- "ResNet31", "ResNet_ASTER", 'MicroNet', 'EfficientNetb3_PREN'
+ "ResNet31", "ResNet_ASTER", 'MicroNet', 'EfficientNetb3_PREN',
+ 'SVTRNet'
]
elif model_type == "e2e":
from .e2e_resnet_vd_pg import ResNet
diff --git a/ppocr/modeling/backbones/rec_mv1_enhance.py b/ppocr/modeling/backbones/rec_mv1_enhance.py
index d8a7f4b5646eb70b5202aa3b3ac6494318b424ad..bb6af5e82cf13ac42d9a970787596a65986ade54 100644
--- a/ppocr/modeling/backbones/rec_mv1_enhance.py
+++ b/ppocr/modeling/backbones/rec_mv1_enhance.py
@@ -103,7 +103,12 @@ class DepthwiseSeparable(nn.Layer):
class MobileNetV1Enhance(nn.Layer):
- def __init__(self, in_channels=3, scale=0.5, **kwargs):
+ def __init__(self,
+ in_channels=3,
+ scale=0.5,
+ last_conv_stride=1,
+ last_pool_type='max',
+ **kwargs):
super().__init__()
self.scale = scale
self.block_list = []
@@ -200,7 +205,7 @@ class MobileNetV1Enhance(nn.Layer):
num_filters1=1024,
num_filters2=1024,
num_groups=1024,
- stride=1,
+ stride=last_conv_stride,
dw_size=5,
padding=2,
use_se=True,
@@ -208,8 +213,10 @@ class MobileNetV1Enhance(nn.Layer):
self.block_list.append(conv6)
self.block_list = nn.Sequential(*self.block_list)
-
- self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
+ if last_pool_type == 'avg':
+ self.pool = nn.AvgPool2D(kernel_size=2, stride=2, padding=0)
+ else:
+ self.pool = nn.MaxPool2D(kernel_size=2, stride=2, padding=0)
self.out_channels = int(1024 * scale)
def forward(self, inputs):
diff --git a/ppocr/modeling/backbones/rec_svtrnet.py b/ppocr/modeling/backbones/rec_svtrnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ded74378c60e6f08a4adf68671afaa1168737b6
--- /dev/null
+++ b/ppocr/modeling/backbones/rec_svtrnet.py
@@ -0,0 +1,597 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from collections import Callable
+from paddle import ParamAttr
+from paddle.nn.initializer import KaimingNormal
+import numpy as np
+import paddle
+import paddle.nn as nn
+from paddle.nn.initializer import TruncatedNormal, Constant, Normal
+
+trunc_normal_ = TruncatedNormal(std=.02)
+normal_ = Normal
+zeros_ = Constant(value=0.)
+ones_ = Constant(value=1.)
+
+
+def drop_path(x, drop_prob=0., training=False):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
+ See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ...
+ """
+ if drop_prob == 0. or not training:
+ return x
+ keep_prob = paddle.to_tensor(1 - drop_prob)
+ shape = (paddle.shape(x)[0], ) + (1, ) * (x.ndim - 1)
+ random_tensor = keep_prob + paddle.rand(shape, dtype=x.dtype)
+ random_tensor = paddle.floor(random_tensor) # binarize
+ output = x.divide(keep_prob) * random_tensor
+ return output
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=0,
+ bias_attr=False,
+ groups=1,
+ act=nn.GELU):
+ super().__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ weight_attr=paddle.ParamAttr(
+ initializer=nn.initializer.KaimingUniform()),
+ bias_attr=bias_attr)
+ self.norm = nn.BatchNorm2D(out_channels)
+ self.act = act()
+
+ def forward(self, inputs):
+ out = self.conv(inputs)
+ out = self.norm(out)
+ out = self.act(out)
+ return out
+
+
+class DropPath(nn.Layer):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+ """
+
+ def __init__(self, drop_prob=None):
+ super(DropPath, self).__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+class Identity(nn.Layer):
+ def __init__(self):
+ super(Identity, self).__init__()
+
+ def forward(self, input):
+ return input
+
+
+class Mlp(nn.Layer):
+ def __init__(self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_layer=nn.GELU,
+ drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+class ConvMixer(nn.Layer):
+ def __init__(
+ self,
+ dim,
+ num_heads=8,
+ HW=[8, 25],
+ local_k=[3, 3], ):
+ super().__init__()
+ self.HW = HW
+ self.dim = dim
+ self.local_mixer = nn.Conv2D(
+ dim,
+ dim,
+ local_k,
+ 1, [local_k[0] // 2, local_k[1] // 2],
+ groups=num_heads,
+ weight_attr=ParamAttr(initializer=KaimingNormal()))
+
+ def forward(self, x):
+ h = self.HW[0]
+ w = self.HW[1]
+ x = x.transpose([0, 2, 1]).reshape([0, self.dim, h, w])
+ x = self.local_mixer(x)
+ x = x.flatten(2).transpose([0, 2, 1])
+ return x
+
+
+class Attention(nn.Layer):
+ def __init__(self,
+ dim,
+ num_heads=8,
+ mixer='Global',
+ HW=[8, 25],
+ local_k=[7, 11],
+ qkv_bias=False,
+ qk_scale=None,
+ attn_drop=0.,
+ proj_drop=0.):
+ super().__init__()
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.proj_drop = nn.Dropout(proj_drop)
+ self.HW = HW
+ if HW is not None:
+ H = HW[0]
+ W = HW[1]
+ self.N = H * W
+ self.C = dim
+ if mixer == 'Local' and HW is not None:
+
+ hk = local_k[0]
+ wk = local_k[1]
+ mask = np.ones([H * W, H * W])
+ for h in range(H):
+ for w in range(W):
+ for kh in range(-(hk // 2), (hk // 2) + 1):
+ for kw in range(-(wk // 2), (wk // 2) + 1):
+ if H > (h + kh) >= 0 and W > (w + kw) >= 0:
+ mask[h * W + w][(h + kh) * W + (w + kw)] = 0
+ mask_paddle = paddle.to_tensor(mask, dtype='float32')
+ mask_inf = paddle.full([H * W, H * W], '-inf', dtype='float32')
+ mask = paddle.where(mask_paddle < 1, mask_paddle, mask_inf)
+ self.mask = mask.unsqueeze([0, 1])
+ self.mixer = mixer
+
+ def forward(self, x):
+ if self.HW is not None:
+ N = self.N
+ C = self.C
+ else:
+ _, N, C = x.shape
+ qkv = self.qkv(x).reshape((0, N, 3, self.num_heads, C //
+ self.num_heads)).transpose((2, 0, 3, 1, 4))
+ q, k, v = qkv[0] * self.scale, qkv[1], qkv[2]
+
+ attn = (q.matmul(k.transpose((0, 1, 3, 2))))
+ if self.mixer == 'Local':
+ attn += self.mask
+ attn = nn.functional.softmax(attn, axis=-1)
+ attn = self.attn_drop(attn)
+
+ x = (attn.matmul(v)).transpose((0, 2, 1, 3)).reshape((0, N, C))
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class Block(nn.Layer):
+ def __init__(self,
+ dim,
+ num_heads,
+ mixer='Global',
+ local_mixer=[7, 11],
+ HW=[8, 25],
+ mlp_ratio=4.,
+ qkv_bias=False,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer='nn.LayerNorm',
+ epsilon=1e-6,
+ prenorm=True):
+ super().__init__()
+ if isinstance(norm_layer, str):
+ self.norm1 = eval(norm_layer)(dim, epsilon=epsilon)
+ elif isinstance(norm_layer, Callable):
+ self.norm1 = norm_layer(dim)
+ else:
+ raise TypeError(
+ "The norm_layer must be str or paddle.nn.layer.Layer class")
+ if mixer == 'Global' or mixer == 'Local':
+ self.mixer = Attention(
+ dim,
+ num_heads=num_heads,
+ mixer=mixer,
+ HW=HW,
+ local_k=local_mixer,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop)
+ elif mixer == 'Conv':
+ self.mixer = ConvMixer(
+ dim, num_heads=num_heads, HW=HW, local_k=local_mixer)
+ else:
+ raise TypeError("The mixer must be one of [Global, Local, Conv]")
+
+ # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else Identity()
+ if isinstance(norm_layer, str):
+ self.norm2 = eval(norm_layer)(dim, epsilon=epsilon)
+ elif isinstance(norm_layer, Callable):
+ self.norm2 = norm_layer(dim)
+ else:
+ raise TypeError(
+ "The norm_layer must be str or paddle.nn.layer.Layer class")
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp_ratio = mlp_ratio
+ self.mlp = Mlp(in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ act_layer=act_layer,
+ drop=drop)
+ self.prenorm = prenorm
+
+ def forward(self, x):
+ if self.prenorm:
+ x = self.norm1(x + self.drop_path(self.mixer(x)))
+ x = self.norm2(x + self.drop_path(self.mlp(x)))
+ else:
+ x = x + self.drop_path(self.mixer(self.norm1(x)))
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+ return x
+
+
+class PatchEmbed(nn.Layer):
+ """ Image to Patch Embedding
+ """
+
+ def __init__(self,
+ img_size=[32, 100],
+ in_channels=3,
+ embed_dim=768,
+ sub_num=2):
+ super().__init__()
+ num_patches = (img_size[1] // (2 ** sub_num)) * \
+ (img_size[0] // (2 ** sub_num))
+ self.img_size = img_size
+ self.num_patches = num_patches
+ self.embed_dim = embed_dim
+ self.norm = None
+ if sub_num == 2:
+ self.proj = nn.Sequential(
+ ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=embed_dim // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ in_channels=embed_dim // 2,
+ out_channels=embed_dim,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None))
+ if sub_num == 3:
+ self.proj = nn.Sequential(
+ ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=embed_dim // 4,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ in_channels=embed_dim // 4,
+ out_channels=embed_dim // 2,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None),
+ ConvBNLayer(
+ embed_dim // 2,
+ embed_dim,
+ in_channels=embed_dim // 2,
+ out_channels=embed_dim,
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ act=nn.GELU,
+ bias_attr=None))
+
+ def forward(self, x):
+ B, C, H, W = x.shape
+ assert H == self.img_size[0] and W == self.img_size[1], \
+ f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
+ x = self.proj(x).flatten(2).transpose((0, 2, 1))
+ return x
+
+
+class SubSample(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ types='Pool',
+ stride=[2, 1],
+ sub_norm='nn.LayerNorm',
+ act=None):
+ super().__init__()
+ self.types = types
+ if types == 'Pool':
+ self.avgpool = nn.AvgPool2D(
+ kernel_size=[3, 5], stride=stride, padding=[1, 2])
+ self.maxpool = nn.MaxPool2D(
+ kernel_size=[3, 5], stride=stride, padding=[1, 2])
+ self.proj = nn.Linear(in_channels, out_channels)
+ else:
+ self.conv = nn.Conv2D(
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ weight_attr=ParamAttr(initializer=KaimingNormal()))
+ self.norm = eval(sub_norm)(out_channels)
+ if act is not None:
+ self.act = act()
+ else:
+ self.act = None
+
+ def forward(self, x):
+
+ if self.types == 'Pool':
+ x1 = self.avgpool(x)
+ x2 = self.maxpool(x)
+ x = (x1 + x2) * 0.5
+ out = self.proj(x.flatten(2).transpose((0, 2, 1)))
+ else:
+ x = self.conv(x)
+ out = x.flatten(2).transpose((0, 2, 1))
+ out = self.norm(out)
+ if self.act is not None:
+ out = self.act(out)
+
+ return out
+
+
+class SVTRNet(nn.Layer):
+ def __init__(
+ self,
+ img_size=[32, 100],
+ in_channels=3,
+ embed_dim=[64, 128, 256],
+ depth=[3, 6, 3],
+ num_heads=[2, 4, 8],
+ mixer=['Local'] * 6 + ['Global'] *
+ 6, # Local atten, Global atten, Conv
+ local_mixer=[[7, 11], [7, 11], [7, 11]],
+ patch_merging='Conv', # Conv, Pool, None
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ last_drop=0.1,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ norm_layer='nn.LayerNorm',
+ sub_norm='nn.LayerNorm',
+ epsilon=1e-6,
+ out_channels=192,
+ out_char_num=25,
+ block_unit='Block',
+ act='nn.GELU',
+ last_stage=True,
+ sub_num=2,
+ prenorm=True,
+ use_lenhead=False,
+ **kwargs):
+ super().__init__()
+ self.img_size = img_size
+ self.embed_dim = embed_dim
+ self.out_channels = out_channels
+ self.prenorm = prenorm
+ patch_merging = None if patch_merging != 'Conv' and patch_merging != 'Pool' else patch_merging
+ self.patch_embed = PatchEmbed(
+ img_size=img_size,
+ in_channels=in_channels,
+ embed_dim=embed_dim[0],
+ sub_num=sub_num)
+ num_patches = self.patch_embed.num_patches
+ self.HW = [img_size[0] // (2**sub_num), img_size[1] // (2**sub_num)]
+ self.pos_embed = self.create_parameter(
+ shape=[1, num_patches, embed_dim[0]], default_initializer=zeros_)
+ self.add_parameter("pos_embed", self.pos_embed)
+ self.pos_drop = nn.Dropout(p=drop_rate)
+ Block_unit = eval(block_unit)
+
+ dpr = np.linspace(0, drop_path_rate, sum(depth))
+ self.blocks1 = nn.LayerList([
+ Block_unit(
+ dim=embed_dim[0],
+ num_heads=num_heads[0],
+ mixer=mixer[0:depth[0]][i],
+ HW=self.HW,
+ local_mixer=local_mixer[0],
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=eval(act),
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[0:depth[0]][i],
+ norm_layer=norm_layer,
+ epsilon=epsilon,
+ prenorm=prenorm) for i in range(depth[0])
+ ])
+ if patch_merging is not None:
+ self.sub_sample1 = SubSample(
+ embed_dim[0],
+ embed_dim[1],
+ sub_norm=sub_norm,
+ stride=[2, 1],
+ types=patch_merging)
+ HW = [self.HW[0] // 2, self.HW[1]]
+ else:
+ HW = self.HW
+ self.patch_merging = patch_merging
+ self.blocks2 = nn.LayerList([
+ Block_unit(
+ dim=embed_dim[1],
+ num_heads=num_heads[1],
+ mixer=mixer[depth[0]:depth[0] + depth[1]][i],
+ HW=HW,
+ local_mixer=local_mixer[1],
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=eval(act),
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[depth[0]:depth[0] + depth[1]][i],
+ norm_layer=norm_layer,
+ epsilon=epsilon,
+ prenorm=prenorm) for i in range(depth[1])
+ ])
+ if patch_merging is not None:
+ self.sub_sample2 = SubSample(
+ embed_dim[1],
+ embed_dim[2],
+ sub_norm=sub_norm,
+ stride=[2, 1],
+ types=patch_merging)
+ HW = [self.HW[0] // 4, self.HW[1]]
+ else:
+ HW = self.HW
+ self.blocks3 = nn.LayerList([
+ Block_unit(
+ dim=embed_dim[2],
+ num_heads=num_heads[2],
+ mixer=mixer[depth[0] + depth[1]:][i],
+ HW=HW,
+ local_mixer=local_mixer[2],
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=eval(act),
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[depth[0] + depth[1]:][i],
+ norm_layer=norm_layer,
+ epsilon=epsilon,
+ prenorm=prenorm) for i in range(depth[2])
+ ])
+ self.last_stage = last_stage
+ if last_stage:
+ self.avg_pool = nn.AdaptiveAvgPool2D([1, out_char_num])
+ self.last_conv = nn.Conv2D(
+ in_channels=embed_dim[2],
+ out_channels=self.out_channels,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias_attr=False)
+ self.hardswish = nn.Hardswish()
+ self.dropout = nn.Dropout(p=last_drop, mode="downscale_in_infer")
+ if not prenorm:
+ self.norm = eval(norm_layer)(embed_dim[-1], epsilon=epsilon)
+ self.use_lenhead = use_lenhead
+ if use_lenhead:
+ self.len_conv = nn.Linear(embed_dim[2], self.out_channels)
+ self.hardswish_len = nn.Hardswish()
+ self.dropout_len = nn.Dropout(
+ p=last_drop, mode="downscale_in_infer")
+
+ trunc_normal_(self.pos_embed)
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ zeros_(m.bias)
+ elif isinstance(m, nn.LayerNorm):
+ zeros_(m.bias)
+ ones_(m.weight)
+
+ def forward_features(self, x):
+ x = self.patch_embed(x)
+ x = x + self.pos_embed
+ x = self.pos_drop(x)
+ for blk in self.blocks1:
+ x = blk(x)
+ if self.patch_merging is not None:
+ x = self.sub_sample1(
+ x.transpose([0, 2, 1]).reshape(
+ [0, self.embed_dim[0], self.HW[0], self.HW[1]]))
+ for blk in self.blocks2:
+ x = blk(x)
+ if self.patch_merging is not None:
+ x = self.sub_sample2(
+ x.transpose([0, 2, 1]).reshape(
+ [0, self.embed_dim[1], self.HW[0] // 2, self.HW[1]]))
+ for blk in self.blocks3:
+ x = blk(x)
+ if not self.prenorm:
+ x = self.norm(x)
+ return x
+
+ def forward(self, x):
+ x = self.forward_features(x)
+ if self.use_lenhead:
+ len_x = self.len_conv(x.mean(1))
+ len_x = self.dropout_len(self.hardswish_len(len_x))
+ if self.last_stage:
+ if self.patch_merging is not None:
+ h = self.HW[0] // 4
+ else:
+ h = self.HW[0]
+ x = self.avg_pool(
+ x.transpose([0, 2, 1]).reshape(
+ [0, self.embed_dim[2], h, self.HW[1]]))
+ x = self.last_conv(x)
+ x = self.hardswish(x)
+ x = self.dropout(x)
+ if self.use_lenhead:
+ return x, len_x
+ return x
diff --git a/ppocr/modeling/heads/__init__.py b/ppocr/modeling/heads/__init__.py
index b13fe2ecfdf877771237ad7a1fb0ef829de94a15..1670ea38e66baa683e6faab0ec4b12bc517f3c41 100755
--- a/ppocr/modeling/heads/__init__.py
+++ b/ppocr/modeling/heads/__init__.py
@@ -32,6 +32,7 @@ def build_head(config):
from .rec_sar_head import SARHead
from .rec_aster_head import AsterHead
from .rec_pren_head import PRENHead
+ from .rec_multi_head import MultiHead
# cls head
from .cls_head import ClsHead
@@ -44,7 +45,8 @@ def build_head(config):
support_dict = [
'DBHead', 'PSEHead', 'FCEHead', 'EASTHead', 'SASTHead', 'CTCHead',
'ClsHead', 'AttentionHead', 'SRNHead', 'PGHead', 'Transformer',
- 'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead'
+ 'TableAttentionHead', 'SARHead', 'AsterHead', 'SDMGRHead', 'PRENHead',
+ 'MultiHead'
]
#table head
diff --git a/ppocr/modeling/heads/rec_multi_head.py b/ppocr/modeling/heads/rec_multi_head.py
new file mode 100644
index 0000000000000000000000000000000000000000..2f10e7bdf90025d3304128e720ce561c8bb269c1
--- /dev/null
+++ b/ppocr/modeling/heads/rec_multi_head.py
@@ -0,0 +1,73 @@
+# copyright (c) 2022 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import math
+import paddle
+from paddle import ParamAttr
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+from ppocr.modeling.necks.rnn import Im2Seq, EncoderWithRNN, EncoderWithFC, SequenceEncoder, EncoderWithSVTR
+from .rec_ctc_head import CTCHead
+from .rec_sar_head import SARHead
+
+
+class MultiHead(nn.Layer):
+ def __init__(self, in_channels, out_channels_list, **kwargs):
+ super().__init__()
+ self.head_list = kwargs.pop('head_list')
+ self.gtc_head = 'sar'
+ assert len(self.head_list) >= 2
+ for idx, head_name in enumerate(self.head_list):
+ name = list(head_name)[0]
+ if name == 'SARHead':
+ # sar head
+ sar_args = self.head_list[idx][name]
+ self.sar_head = eval(name)(in_channels=in_channels, \
+ out_channels=out_channels_list['SARLabelDecode'], **sar_args)
+ elif name == 'CTCHead':
+ # ctc neck
+ self.encoder_reshape = Im2Seq(in_channels)
+ neck_args = self.head_list[idx][name]['Neck']
+ encoder_type = neck_args.pop('name')
+ self.encoder = encoder_type
+ self.ctc_encoder = SequenceEncoder(in_channels=in_channels, \
+ encoder_type=encoder_type, **neck_args)
+ # ctc head
+ head_args = self.head_list[idx][name]['Head']
+ self.ctc_head = eval(name)(in_channels=self.ctc_encoder.out_channels, \
+ out_channels=out_channels_list['CTCLabelDecode'], **head_args)
+ else:
+ raise NotImplementedError(
+ '{} is not supported in MultiHead yet'.format(name))
+
+ def forward(self, x, targets=None):
+ ctc_encoder = self.ctc_encoder(x)
+ ctc_out = self.ctc_head(ctc_encoder, targets)
+ head_out = dict()
+ head_out['ctc'] = ctc_out
+ head_out['ctc_neck'] = ctc_encoder
+ # eval mode
+ if not self.training:
+ return ctc_out
+ if self.gtc_head == 'sar':
+ sar_out = self.sar_head(x, targets[1:])
+ head_out['sar'] = sar_out
+ return head_out
+ else:
+ return head_out
diff --git a/ppocr/modeling/heads/rec_sar_head.py b/ppocr/modeling/heads/rec_sar_head.py
index 3b7674268772d8a332b963fd6b82dfb71ee40212..27693ebc16a2b494d25455892ac4513b4d16803b 100644
--- a/ppocr/modeling/heads/rec_sar_head.py
+++ b/ppocr/modeling/heads/rec_sar_head.py
@@ -349,7 +349,10 @@ class ParallelSARDecoder(BaseDecoder):
class SARHead(nn.Layer):
def __init__(self,
+ in_channels,
out_channels,
+ enc_dim=512,
+ max_text_length=30,
enc_bi_rnn=False,
enc_drop_rnn=0.1,
enc_gru=False,
@@ -358,14 +361,17 @@ class SARHead(nn.Layer):
dec_gru=False,
d_k=512,
pred_dropout=0.1,
- max_text_length=30,
pred_concat=True,
**kwargs):
super(SARHead, self).__init__()
# encoder module
self.encoder = SAREncoder(
- enc_bi_rnn=enc_bi_rnn, enc_drop_rnn=enc_drop_rnn, enc_gru=enc_gru)
+ enc_bi_rnn=enc_bi_rnn,
+ enc_drop_rnn=enc_drop_rnn,
+ enc_gru=enc_gru,
+ d_model=in_channels,
+ d_enc=enc_dim)
# decoder module
self.decoder = ParallelSARDecoder(
@@ -374,6 +380,8 @@ class SARHead(nn.Layer):
dec_bi_rnn=dec_bi_rnn,
dec_drop_rnn=dec_drop_rnn,
dec_gru=dec_gru,
+ d_model=in_channels,
+ d_enc=enc_dim,
d_k=d_k,
pred_dropout=pred_dropout,
max_text_length=max_text_length,
@@ -390,7 +398,7 @@ class SARHead(nn.Layer):
label = paddle.to_tensor(label, dtype='int64')
final_out = self.decoder(
feat, holistic_feat, label, img_metas=targets)
- if not self.training:
+ else:
final_out = self.decoder(
feat,
holistic_feat,
diff --git a/ppocr/modeling/necks/rnn.py b/ppocr/modeling/necks/rnn.py
index 86e649028f8fbb76cb5a1fd85381bd361277c6ee..c8a774b8c543b9ccc14223c52f1b79ce690592f6 100644
--- a/ppocr/modeling/necks/rnn.py
+++ b/ppocr/modeling/necks/rnn.py
@@ -16,9 +16,11 @@ from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
+import paddle
from paddle import nn
from ppocr.modeling.heads.rec_ctc_head import get_para_bias_attr
+from ppocr.modeling.backbones.rec_svtrnet import Block, ConvBNLayer, trunc_normal_, zeros_, ones_
class Im2Seq(nn.Layer):
@@ -64,29 +66,126 @@ class EncoderWithFC(nn.Layer):
return x
+class EncoderWithSVTR(nn.Layer):
+ def __init__(
+ self,
+ in_channels,
+ dims=64, # XS
+ depth=2,
+ hidden_dims=120,
+ use_guide=False,
+ num_heads=8,
+ qkv_bias=True,
+ mlp_ratio=2.0,
+ drop_rate=0.1,
+ attn_drop_rate=0.1,
+ drop_path=0.,
+ qk_scale=None):
+ super(EncoderWithSVTR, self).__init__()
+ self.depth = depth
+ self.use_guide = use_guide
+ self.conv1 = ConvBNLayer(
+ in_channels, in_channels // 8, padding=1, act=nn.Swish)
+ self.conv2 = ConvBNLayer(
+ in_channels // 8, hidden_dims, kernel_size=1, act=nn.Swish)
+
+ self.svtr_block = nn.LayerList([
+ Block(
+ dim=hidden_dims,
+ num_heads=num_heads,
+ mixer='Global',
+ HW=None,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ act_layer=nn.Swish,
+ attn_drop=attn_drop_rate,
+ drop_path=drop_path,
+ norm_layer='nn.LayerNorm',
+ epsilon=1e-05,
+ prenorm=False) for i in range(depth)
+ ])
+ self.norm = nn.LayerNorm(hidden_dims, epsilon=1e-6)
+ self.conv3 = ConvBNLayer(
+ hidden_dims, in_channels, kernel_size=1, act=nn.Swish)
+ # last conv-nxn, the input is concat of input tensor and conv3 output tensor
+ self.conv4 = ConvBNLayer(
+ 2 * in_channels, in_channels // 8, padding=1, act=nn.Swish)
+
+ self.conv1x1 = ConvBNLayer(
+ in_channels // 8, dims, kernel_size=1, act=nn.Swish)
+ self.out_channels = dims
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ zeros_(m.bias)
+ elif isinstance(m, nn.LayerNorm):
+ zeros_(m.bias)
+ ones_(m.weight)
+
+ def forward(self, x):
+ # for use guide
+ if self.use_guide:
+ z = x.clone()
+ z.stop_gradient = True
+ else:
+ z = x
+ # for short cut
+ h = z
+ # reduce dim
+ z = self.conv1(z)
+ z = self.conv2(z)
+ # SVTR global block
+ B, C, H, W = z.shape
+ z = z.flatten(2).transpose([0, 2, 1])
+ for blk in self.svtr_block:
+ z = blk(z)
+ z = self.norm(z)
+ # last stage
+ z = z.reshape([0, H, W, C]).transpose([0, 3, 1, 2])
+ z = self.conv3(z)
+ z = paddle.concat((h, z), axis=1)
+ z = self.conv1x1(self.conv4(z))
+ return z
+
+
class SequenceEncoder(nn.Layer):
def __init__(self, in_channels, encoder_type, hidden_size=48, **kwargs):
super(SequenceEncoder, self).__init__()
self.encoder_reshape = Im2Seq(in_channels)
self.out_channels = self.encoder_reshape.out_channels
+ self.encoder_type = encoder_type
if encoder_type == 'reshape':
self.only_reshape = True
else:
support_encoder_dict = {
'reshape': Im2Seq,
'fc': EncoderWithFC,
- 'rnn': EncoderWithRNN
+ 'rnn': EncoderWithRNN,
+ 'svtr': EncoderWithSVTR
}
assert encoder_type in support_encoder_dict, '{} must in {}'.format(
encoder_type, support_encoder_dict.keys())
-
- self.encoder = support_encoder_dict[encoder_type](
- self.encoder_reshape.out_channels, hidden_size)
+ if encoder_type == "svtr":
+ self.encoder = support_encoder_dict[encoder_type](
+ self.encoder_reshape.out_channels, **kwargs)
+ else:
+ self.encoder = support_encoder_dict[encoder_type](
+ self.encoder_reshape.out_channels, hidden_size)
self.out_channels = self.encoder.out_channels
self.only_reshape = False
def forward(self, x):
- x = self.encoder_reshape(x)
- if not self.only_reshape:
+ if self.encoder_type != 'svtr':
+ x = self.encoder_reshape(x)
+ if not self.only_reshape:
+ x = self.encoder(x)
+ return x
+ else:
x = self.encoder(x)
- return x
+ x = self.encoder_reshape(x)
+ return x
diff --git a/ppocr/modeling/transforms/stn.py b/ppocr/modeling/transforms/stn.py
index 6f2bdda050f217d8253740001901fbff4065782a..1b15d5b8a7b7a1b1ab686d20acea750437463939 100644
--- a/ppocr/modeling/transforms/stn.py
+++ b/ppocr/modeling/transforms/stn.py
@@ -128,6 +128,8 @@ class STN_ON(nn.Layer):
self.out_channels = in_channels
def forward(self, image):
+ if len(image.shape)==5:
+ image = image.reshape([0, image.shape[-3], image.shape[-2], image.shape[-1]])
stn_input = paddle.nn.functional.interpolate(
image, self.tps_inputsize, mode="bilinear", align_corners=True)
stn_img_feat, ctrl_points = self.stn_head(stn_input)
diff --git a/ppocr/modeling/transforms/tps_spatial_transformer.py b/ppocr/modeling/transforms/tps_spatial_transformer.py
index 043bb56b8a526c12b2e0799bf41e128c6499c1fc..cb1cb10aaa98dffa2f720dc81afdf82d25e071ca 100644
--- a/ppocr/modeling/transforms/tps_spatial_transformer.py
+++ b/ppocr/modeling/transforms/tps_spatial_transformer.py
@@ -138,9 +138,9 @@ class TPSSpatialTransformer(nn.Layer):
assert source_control_points.shape[2] == 2
batch_size = paddle.shape(source_control_points)[0]
- self.padding_matrix = paddle.expand(
+ padding_matrix = paddle.expand(
self.padding_matrix, shape=[batch_size, 3, 2])
- Y = paddle.concat([source_control_points, self.padding_matrix], 1)
+ Y = paddle.concat([source_control_points, padding_matrix], 1)
mapping_matrix = paddle.matmul(self.inverse_kernel, Y)
source_coordinate = paddle.matmul(self.target_coordinate_repr,
mapping_matrix)
diff --git a/ppocr/optimizer/__init__.py b/ppocr/optimizer/__init__.py
index 4110fb47678583cff826a9bc855b3fb378a533f9..a6bd2ebb4a81427245dc10e446cd2da101d53bd4 100644
--- a/ppocr/optimizer/__init__.py
+++ b/ppocr/optimizer/__init__.py
@@ -30,7 +30,7 @@ def build_lr_scheduler(lr_config, epochs, step_each_epoch):
return lr
-def build_optimizer(config, epochs, step_each_epoch, parameters):
+def build_optimizer(config, epochs, step_each_epoch, model):
from . import regularizer, optimizer
config = copy.deepcopy(config)
# step1 build lr
@@ -43,6 +43,8 @@ def build_optimizer(config, epochs, step_each_epoch, parameters):
if not hasattr(regularizer, reg_name):
reg_name += 'Decay'
reg = getattr(regularizer, reg_name)(**reg_config)()
+ elif 'weight_decay' in config:
+ reg = config.pop('weight_decay')
else:
reg = None
@@ -57,4 +59,4 @@ def build_optimizer(config, epochs, step_each_epoch, parameters):
weight_decay=reg,
grad_clip=grad_clip,
**config)
- return optim(parameters), lr
+ return optim(model), lr
diff --git a/ppocr/optimizer/optimizer.py b/ppocr/optimizer/optimizer.py
index b98081227e180edbf023a8b5b7a0b82bb7c631e5..c450a3a3684eb44cdc758a2b27783b5a81945c38 100644
--- a/ppocr/optimizer/optimizer.py
+++ b/ppocr/optimizer/optimizer.py
@@ -42,13 +42,13 @@ class Momentum(object):
self.weight_decay = weight_decay
self.grad_clip = grad_clip
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.Momentum(
learning_rate=self.learning_rate,
momentum=self.momentum,
weight_decay=self.weight_decay,
grad_clip=self.grad_clip,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -75,7 +75,7 @@ class Adam(object):
self.name = name
self.lazy_mode = lazy_mode
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.Adam(
learning_rate=self.learning_rate,
beta1=self.beta1,
@@ -85,7 +85,7 @@ class Adam(object):
grad_clip=self.grad_clip,
name=self.name,
lazy_mode=self.lazy_mode,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -117,7 +117,7 @@ class RMSProp(object):
self.weight_decay = weight_decay
self.grad_clip = grad_clip
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.RMSProp(
learning_rate=self.learning_rate,
momentum=self.momentum,
@@ -125,7 +125,7 @@ class RMSProp(object):
epsilon=self.epsilon,
weight_decay=self.weight_decay,
grad_clip=self.grad_clip,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -148,7 +148,7 @@ class Adadelta(object):
self.grad_clip = grad_clip
self.name = name
- def __call__(self, parameters):
+ def __call__(self, model):
opt = optim.Adadelta(
learning_rate=self.learning_rate,
epsilon=self.epsilon,
@@ -156,7 +156,7 @@ class Adadelta(object):
weight_decay=self.weight_decay,
grad_clip=self.grad_clip,
name=self.name,
- parameters=parameters)
+ parameters=model.parameters())
return opt
@@ -165,31 +165,55 @@ class AdamW(object):
learning_rate=0.001,
beta1=0.9,
beta2=0.999,
- epsilon=1e-08,
+ epsilon=1e-8,
weight_decay=0.01,
+ multi_precision=False,
grad_clip=None,
+ no_weight_decay_name=None,
+ one_dim_param_no_weight_decay=False,
name=None,
lazy_mode=False,
- **kwargs):
+ **args):
+ super().__init__()
self.learning_rate = learning_rate
self.beta1 = beta1
self.beta2 = beta2
self.epsilon = epsilon
- self.learning_rate = learning_rate
+ self.grad_clip = grad_clip
self.weight_decay = 0.01 if weight_decay is None else weight_decay
self.grad_clip = grad_clip
self.name = name
self.lazy_mode = lazy_mode
-
- def __call__(self, parameters):
+ self.multi_precision = multi_precision
+ self.no_weight_decay_name_list = no_weight_decay_name.split(
+ ) if no_weight_decay_name else []
+ self.one_dim_param_no_weight_decay = one_dim_param_no_weight_decay
+
+ def __call__(self, model):
+ parameters = model.parameters()
+
+ self.no_weight_decay_param_name_list = [
+ p.name for n, p in model.named_parameters() if any(nd in n for nd in self.no_weight_decay_name_list)
+ ]
+
+ if self.one_dim_param_no_weight_decay:
+ self.no_weight_decay_param_name_list += [
+ p.name for n, p in model.named_parameters() if len(p.shape) == 1
+ ]
+
opt = optim.AdamW(
learning_rate=self.learning_rate,
beta1=self.beta1,
beta2=self.beta2,
epsilon=self.epsilon,
+ parameters=parameters,
weight_decay=self.weight_decay,
+ multi_precision=self.multi_precision,
grad_clip=self.grad_clip,
name=self.name,
lazy_mode=self.lazy_mode,
- parameters=parameters)
+ apply_decay_param_fun=self._apply_decay_param_fun)
return opt
+
+ def _apply_decay_param_fun(self, name):
+ return name not in self.no_weight_decay_param_name_list
\ No newline at end of file
diff --git a/ppocr/postprocess/__init__.py b/ppocr/postprocess/__init__.py
index 14be63ddf93bd3bdab5df9bfa9e949ee4326a5ef..390f6f4560f9814a3af757a4fd16c55fe93d01f9 100644
--- a/ppocr/postprocess/__init__.py
+++ b/ppocr/postprocess/__init__.py
@@ -27,7 +27,7 @@ from .sast_postprocess import SASTPostProcess
from .fce_postprocess import FCEPostProcess
from .rec_postprocess import CTCLabelDecode, AttnLabelDecode, SRNLabelDecode, \
DistillationCTCLabelDecode, TableLabelDecode, NRTRLabelDecode, SARLabelDecode, \
- SEEDLabelDecode, PRENLabelDecode
+ SEEDLabelDecode, PRENLabelDecode, SVTRLabelDecode
from .cls_postprocess import ClsPostProcess
from .pg_postprocess import PGPostProcess
from .vqa_token_ser_layoutlm_postprocess import VQASerTokenLayoutLMPostProcess
@@ -41,7 +41,8 @@ def build_post_process(config, global_config=None):
'PGPostProcess', 'DistillationCTCLabelDecode', 'TableLabelDecode',
'DistillationDBPostProcess', 'NRTRLabelDecode', 'SARLabelDecode',
'SEEDLabelDecode', 'VQASerTokenLayoutLMPostProcess',
- 'VQAReTokenLayoutLMPostProcess', 'PRENLabelDecode'
+ 'VQAReTokenLayoutLMPostProcess', 'PRENLabelDecode',
+ 'DistillationSARLabelDecode', 'SVTRLabelDecode'
]
if config['name'] == 'PSEPostProcess':
diff --git a/ppocr/postprocess/rec_postprocess.py b/ppocr/postprocess/rec_postprocess.py
index 47825dc7d43dc5fb68f7ec9c45c7d4d91c1144a3..50f11f899fb4dd49da75199095772a92cc4a8d7b 100644
--- a/ppocr/postprocess/rec_postprocess.py
+++ b/ppocr/postprocess/rec_postprocess.py
@@ -117,6 +117,7 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
use_space_char=False,
model_name=["student"],
key=None,
+ multi_head=False,
**kwargs):
super(DistillationCTCLabelDecode, self).__init__(character_dict_path,
use_space_char)
@@ -125,6 +126,7 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
self.model_name = model_name
self.key = key
+ self.multi_head = multi_head
def __call__(self, preds, label=None, *args, **kwargs):
output = dict()
@@ -132,6 +134,8 @@ class DistillationCTCLabelDecode(CTCLabelDecode):
pred = preds[name]
if self.key is not None:
pred = pred[self.key]
+ if self.multi_head and isinstance(pred, dict):
+ pred = pred['ctc']
output[name] = super().__call__(pred, label=label, *args, **kwargs)
return output
@@ -656,6 +660,40 @@ class SARLabelDecode(BaseRecLabelDecode):
return [self.padding_idx]
+class DistillationSARLabelDecode(SARLabelDecode):
+ """
+ Convert
+ Convert between text-label and text-index
+ """
+
+ def __init__(self,
+ character_dict_path=None,
+ use_space_char=False,
+ model_name=["student"],
+ key=None,
+ multi_head=False,
+ **kwargs):
+ super(DistillationSARLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+ if not isinstance(model_name, list):
+ model_name = [model_name]
+ self.model_name = model_name
+
+ self.key = key
+ self.multi_head = multi_head
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ output = dict()
+ for name in self.model_name:
+ pred = preds[name]
+ if self.key is not None:
+ pred = pred[self.key]
+ if self.multi_head and isinstance(pred, dict):
+ pred = pred['sar']
+ output[name] = super().__call__(pred, label=label, *args, **kwargs)
+ return output
+
+
class PRENLabelDecode(BaseRecLabelDecode):
""" Convert between text-label and text-index """
@@ -714,3 +752,40 @@ class PRENLabelDecode(BaseRecLabelDecode):
return text
label = self.decode(label)
return text, label
+
+
+class SVTRLabelDecode(BaseRecLabelDecode):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, character_dict_path=None, use_space_char=False,
+ **kwargs):
+ super(SVTRLabelDecode, self).__init__(character_dict_path,
+ use_space_char)
+
+ def __call__(self, preds, label=None, *args, **kwargs):
+ if isinstance(preds, tuple):
+ preds = preds[-1]
+ if isinstance(preds, paddle.Tensor):
+ preds = preds.numpy()
+ preds_idx = preds.argmax(axis=-1)
+ preds_prob = preds.max(axis=-1)
+
+ text = self.decode(preds_idx, preds_prob, is_remove_duplicate=True)
+ return_text = []
+ for i in range(0, len(text), 3):
+ text0 = text[i]
+ text1 = text[i + 1]
+ text2 = text[i + 2]
+
+ text_pred = [text0[0], text1[0], text2[0]]
+ text_prob = [text0[1], text1[1], text2[1]]
+ id_max = text_prob.index(max(text_prob))
+ return_text.append((text_pred[id_max], text_prob[id_max]))
+ if label is None:
+ return return_text
+ label = self.decode(label)
+ return return_text, label
+
+ def add_special_char(self, dict_character):
+ dict_character = ['blank'] + dict_character
+ return dict_character
\ No newline at end of file
diff --git a/ppocr/utils/dict/ka_dict.txt b/ppocr/utils/dict/ka_dict.txt
index 33d605c4de106c3c4b2504f5b3c42cdadd076dd8..d506b691bd1a6c55299ad89a72cf3a69a2c879a9 100644
--- a/ppocr/utils/dict/ka_dict.txt
+++ b/ppocr/utils/dict/ka_dict.txt
@@ -21,7 +21,7 @@ l
8
.
j
-p
+p
ಗ
ು
ಣ
diff --git a/ppocr/utils/dict/ta_dict.txt b/ppocr/utils/dict/ta_dict.txt
index d1bae501ad2556bb59b16a6c4b27a27091a6cbcf..19d81892c205627f296adbf8b20ea41aba2de5d0 100644
--- a/ppocr/utils/dict/ta_dict.txt
+++ b/ppocr/utils/dict/ta_dict.txt
@@ -22,7 +22,7 @@ l
8
.
j
-p
+p
ப
ூ
த
diff --git a/test_tipc/configs/ch_PP-OCRv2_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..033d40a80a3569f8bfd408cdb6df37e7ba5ecd0c
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_PPOCRv2_det
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=500
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+quant_export:null
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
diff --git a/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..d922a4a5dad67da81e3c9cf7bed48a0431a88b84
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_PPOCRv2_det_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=500
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c configs/det/ch_PP-OCRv2/ch_PP-OCRv2_det_cml.yml -o
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_det_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
diff --git a/test_tipc/configs/ch_PP-OCRv2_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7c438cb8a3b6907c9ca352e90605d8b4f6fb17fd
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:PPOCRv2_ocr_rec
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+quant_export:
+fpgm_export:
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_rec_infer
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
diff --git a/test_tipc/configs/ch_PP-OCRv2_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_PP-OCRv2_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e22d8a564b008206611469048b424b528dd379bd
--- /dev/null
+++ b/test_tipc/configs/ch_PP-OCRv2_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_PPOCRv2_rec_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=3|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=16|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ch_PP-OCRv2_rec/ch_PP-OCRv2_rec_distillation.yml -o
+fpgm_export: null
+distill_export:null
+export1:null
+export2:null
+inference_dir:Student
+infer_model:./inference/ch_PP-OCRv2_rec_slim_quant_infer
+infer_export:null
+infer_quant:True
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/det_mv3_db.yml b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/det_mv3_db.yml
deleted file mode 100644
index 5eada6d53dd3364238bdfc6a3c40515ca0726688..0000000000000000000000000000000000000000
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/det_mv3_db.yml
+++ /dev/null
@@ -1,126 +0,0 @@
-Global:
- use_gpu: false
- epoch_num: 5
- log_smooth_window: 20
- print_batch_step: 1
- save_model_dir: ./output/db_mv3/
- save_epoch_step: 1200
- # evaluation is run every 2000 iterations
- eval_batch_step: [0, 400]
- cal_metric_during_train: False
- pretrained_model: ./pretrain_models/MobileNetV3_large_x0_5_pretrained
- checkpoints:
- save_inference_dir:
- use_visualdl: False
- infer_img: doc/imgs_en/img_10.jpg
- save_res_path: ./output/det_db/predicts_db.txt
-
-Architecture:
- model_type: det
- algorithm: DB
- Transform:
- Backbone:
- name: MobileNetV3
- scale: 0.5
- model_name: large
- disable_se: False
- Neck:
- name: DBFPN
- out_channels: 256
- Head:
- name: DBHead
- k: 50
-
-Loss:
- name: DBLoss
- balance_loss: true
- main_loss_type: DiceLoss
- alpha: 5
- beta: 10
- ohem_ratio: 3
-
-Optimizer:
- name: Adam #Momentum
- #momentum: 0.9
- beta1: 0.9
- beta2: 0.999
- lr:
- learning_rate: 0.001
- regularizer:
- name: 'L2'
- factor: 0
-
-PostProcess:
- name: DBPostProcess
- thresh: 0.3
- box_thresh: 0.6
- max_candidates: 1000
- unclip_ratio: 1.5
-
-Metric:
- name: DetMetric
- main_indicator: hmean
-
-Train:
- dataset:
- name: SimpleDataSet
- data_dir: ./train_data/icdar2015/text_localization/
- label_file_list:
- - ./train_data/icdar2015/text_localization/train_icdar2015_label.txt
- ratio_list: [1.0]
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - DetLabelEncode: # Class handling label
- - Resize:
- size: [640, 640]
- - MakeBorderMap:
- shrink_ratio: 0.4
- thresh_min: 0.3
- thresh_max: 0.7
- - MakeShrinkMap:
- shrink_ratio: 0.4
- min_text_size: 8
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - ToCHWImage:
- - KeepKeys:
- keep_keys: ['image', 'threshold_map', 'threshold_mask', 'shrink_map', 'shrink_mask'] # the order of the dataloader list
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 1
- num_workers: 0
- use_shared_memory: False
-
-Eval:
- dataset:
- name: SimpleDataSet
- data_dir: ./train_data/icdar2015/text_localization/
- label_file_list:
- - ./train_data/icdar2015/text_localization/test_icdar2015_label.txt
- transforms:
- - DecodeImage: # load image
- img_mode: BGR
- channel_first: False
- - DetLabelEncode: # Class handling label
- - DetResizeForTest:
- image_shape: [736, 1280]
- - NormalizeImage:
- scale: 1./255.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- order: 'hwc'
- - ToCHWImage:
- - KeepKeys:
- keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
- loader:
- shuffle: False
- drop_last: False
- batch_size_per_card: 1 # must be 1
- num_workers: 0
- use_shared_memory: False
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
index ff1c7432df75f78fd6c45d995f50a9642d44637c..593e7ec7ed42af9b65c520852ff6372f89890170 100644
--- a/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -1,10 +1,10 @@
===========================train_params===========================
-model_name:ocr_det
+model_name:ch_ppocr_mobile_v2.0_det
python:python3.7
gpu_list:0|0,1
Global.use_gpu:True|True
Global.auto_cast:amp
-Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
+Global.epoch_num:lite_train_lite_infer=100|whole_train_whole_infer=300
Global.save_model_dir:./output/
Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
Global.pretrained_model:null
@@ -12,10 +12,10 @@ train_model_name:latest
train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
null:null
##
-trainer:norm_train|pact_train|fpgm_train
-norm_train:tools/train.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
-pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-fpgm_train:deploy/slim/prune/sensitivity_anal.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o Global.pretrained_model=./pretrain_models/det_mv3_db_v2.0_train/best_accuracy
+trainer:norm_train
+norm_train:tools/train.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./pretrain_models/MobileNetV3_large_x0_5_pretrained
+pact_train:null
+fpgm_train:null
distill_train:null
null:null
null:null
@@ -26,10 +26,10 @@ null:null
##
===========================infer_params===========================
Global.save_inference_dir:./output/
-Global.pretrained_model:
-norm_export:tools/export_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
-fpgm_export:deploy/slim/prune/export_prune_model.py -c test_tipc/configs/ppocr_det_mobile/det_mv3_db.yml -o
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+quant_export:null
+fpgm_export:null
distill_export:null
export1:null
export2:null
@@ -49,3 +49,5 @@ inference:tools/infer/predict_det.py
null:null
--benchmark:True
null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_mobile_V2.0_det_FPGM/train_infer_python.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_infer_python.txt
similarity index 97%
rename from test_tipc/configs/ch_ppocr_mobile_V2.0_det_FPGM/train_infer_python.txt
rename to test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_infer_python.txt
index 331d6bdb7103294eb1b33b9978e5f99c2212195b..47ccf2e69e75bc8c215be8d1837e5248d1b4b513 100644
--- a/test_tipc/configs/ch_ppocr_mobile_V2.0_det_FPGM/train_infer_python.txt
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_infer_python.txt
@@ -1,5 +1,5 @@
===========================train_params===========================
-model_name:ocr_det
+model_name:ch_ppocr_mobile_v2.0_det_FPGM
python:python3.7
gpu_list:0|0,1
Global.use_gpu:True|True
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..5a95f026850b750bfadb85e0955f7426e5e73cb6
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_det_FPGM
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:fpgm_train
+norm_train:null
+pact_train:null
+fpgm_train:deploy/slim/prune/sensitivity_anal.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o Global.pretrained_model=./pretrain_models/det_mv3_db_v2.0_train/best_accuracy
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:null
+fpgm_export:deploy/slim/prune/export_prune_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+train_model:null
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1f9bec12ada6894fcffbe697ae4da2f0df95cc62
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_det_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_det_PACT
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=20|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_whole_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_mv3_db_v2.0.yml -o
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+train_model:./inference/ch_ppocr_mobile_v2.0_det_prune_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..30fb939bff646adf301191f88a9a499acf9c61de
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_rec
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=2|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c configs/rec/rec_icdar15_train.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c configs/rec/rec_icdar15_train.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c configs/rec/rec_icdar15_train.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/ch_ppocr_mobile_v2.0_rec_train/best_accuracy
+infer_export:tools/export_model.py -c configs/rec/rec_icdar15_train.yml -o
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:True|False
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,100]}]
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..fda9cf4ddec6d3ab64045a4a7fdbb62183212021
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_rec_FPGM
+python:python3.7
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/ic15_data/test/word_1.png
+null:null
+##
+trainer:fpgm_train
+norm_train:null
+pact_train:null
+fpgm_train:deploy/slim/prune/sensitivity_anal.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./pretrain_models/ch_ppocr_mobile_v2.0_rec_train/best_accuracy
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:null
+fpgm_export:deploy/slim/prune/export_prune_model.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_FPGM/rec_chinese_lite_train_v2.0.yml -o
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+train_model:null
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+null:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..abed3cfba9b3f8c0ed626dbfcbda8621d8787001
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_mobile_v2.0_rec_PACT
+python:python3.7
+gpu_list:0
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=1|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.checkpoints:null
+train_model_name:latest
+train_infer_img_dir:./train_data/ic15_data/test/word_1.png
+null:null
+##
+trainer:pact_train
+norm_train:null
+pact_train:deploy/slim/quantization/quant.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/rec_chinese_lite_train_v2.0.yml -o
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:null
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:null
+quant_export:deploy/slim/quantization/export_model.py -c test_tipc/configs/ch_ppocr_mobile_v2.0_rec_PACT/rec_chinese_lite_train_v2.0.yml -o
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+inference_dir:null
+infer_model:./inference/ch_ppocr_mobile_v2.0_rec_slim_infer/
+infer_export:null
+infer_quant:False
+inference:tools/infer/predict_rec.py --rec_char_dict_path=./ppocr/utils/ppocr_keys_v1.txt --rec_image_shape="3,32,100"
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:False|True
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,320]}]
diff --git a/test_tipc/configs/ch_ppocr_server_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_server_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3e3764e8c6f62c72ffb8ceb268c8ceee660d02de
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_server_v2.0_det/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_server_v2.0_det
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=2|whole_train_whole_infer=300
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=2|whole_train_lite_infer=4
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./train_data/icdar2015/text_localization/ch4_test_images/
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/ch_ppocr_server_v2.0_det/det_r50_vd_db.yml -o
+quant_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c test_tipc/configs/ch_ppocr_server_v2.0_det/det_r50_vd_db.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/ch_ppocr_server_v2.0_det/det_r50_vd_db.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/ch_ppocr_server_v2.0_det_train/best_accuracy
+infer_export:tools/export_model.py -c configs/det/ch_ppocr_v2.0/ch_det_res18_db_v2.0.yml -o
+infer_quant:False
+inference:tools/infer/predict_det.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1
+--use_tensorrt:False|True
+--precision:fp32|fp16|int8
+--det_model_dir:
+--image_dir:./inference/ch_det_data_50/all-sum-510/
+--save_log_path:null
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,640,640]}];[{float32,[3,960,960]}]
\ No newline at end of file
diff --git a/test_tipc/configs/ch_ppocr_server_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt b/test_tipc/configs/ch_ppocr_server_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
new file mode 100644
index 0000000000000000000000000000000000000000..78c15047fb522127075591cc9687392af77a300a
--- /dev/null
+++ b/test_tipc/configs/ch_ppocr_server_v2.0_rec/train_linux_gpu_normal_amp_infer_python_linux_gpu_cpu.txt
@@ -0,0 +1,53 @@
+===========================train_params===========================
+model_name:ch_ppocr_server_v2.0_rec
+python:python3.7
+gpu_list:0|0,1
+Global.use_gpu:True|True
+Global.auto_cast:amp
+Global.epoch_num:lite_train_lite_infer=5|whole_train_whole_infer=100
+Global.save_model_dir:./output/
+Train.loader.batch_size_per_card:lite_train_lite_infer=128|whole_train_whole_infer=128
+Global.pretrained_model:null
+train_model_name:latest
+train_infer_img_dir:./inference/rec_inference
+null:null
+##
+trainer:norm_train
+norm_train:tools/train.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+pact_train:null
+fpgm_train:null
+distill_train:null
+null:null
+null:null
+##
+===========================eval_params===========================
+eval:tools/eval.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+null:null
+##
+===========================infer_params===========================
+Global.save_inference_dir:./output/
+Global.checkpoints:
+norm_export:tools/export_model.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+quant_export:null
+fpgm_export:null
+distill_export:null
+export1:null
+export2:null
+##
+train_model:./inference/ch_ppocr_server_v2.0_rec_train/best_accuracy
+infer_export:tools/export_model.py -c test_tipc/configs/ch_ppocr_server_v2.0_rec/rec_icdar15_train.yml -o
+infer_quant:False
+inference:tools/infer/predict_rec.py
+--use_gpu:True|False
+--enable_mkldnn:True|False
+--cpu_threads:1|6
+--rec_batch_num:1|6
+--use_tensorrt:True|False
+--precision:fp32|int8
+--rec_model_dir:
+--image_dir:./inference/rec_inference
+--save_log_path:./test/output/
+--benchmark:True
+null:null
+===========================infer_benchmark_params==========================
+random_infer_input:[{float32,[3,32,100]}]
diff --git a/tools/eval.py b/tools/eval.py
index f6fcf14c873984e15606b9fae1799bae6b021f05..7fd4fa7ada7b1550bcca8766f5acb9b4d4ed2049 100755
--- a/tools/eval.py
+++ b/tools/eval.py
@@ -47,14 +47,40 @@ def main():
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ out_channels_list = {}
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ out_channels_list = {}
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
model = build_model(config['Architecture'])
- extra_input = config['Architecture'][
- 'algorithm'] in ["SRN", "NRTR", "SAR", "SEED"]
+ extra_input_models = ["SRN", "NRTR", "SAR", "SEED", "SVTR"]
+ extra_input = False
+ if config['Architecture']['algorithm'] == 'Distillation':
+ for key in config['Architecture']["Models"]:
+ extra_input = extra_input or config['Architecture']['Models'][key][
+ 'algorithm'] in extra_input_models
+ else:
+ extra_input = config['Architecture']['algorithm'] in extra_input_models
if "model_type" in config['Architecture'].keys():
model_type = config['Architecture']['model_type']
else:
diff --git a/tools/export_model.py b/tools/export_model.py
index bd647fc72cf111b910d215fecbbef354bd5e6c08..003bc61f791b6c41a3b08d58ab87f12109744f9a 100755
--- a/tools/export_model.py
+++ b/tools/export_model.py
@@ -55,6 +55,18 @@ def export_single_model(model, arch_config, save_path, logger):
shape=[None, 3, 48, 160], dtype="float32"),
]
model = to_static(model, input_spec=other_shape)
+ elif arch_config["algorithm"] == "SVTR":
+ if arch_config["Head"]["name"] == 'MultiHead':
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 48, -1], dtype="float32"),
+ ]
+ else:
+ other_shape = [
+ paddle.static.InputSpec(
+ shape=[None, 3, 64, 256], dtype="float32"),
+ ]
+ model = to_static(model, input_spec=other_shape)
elif arch_config["algorithm"] == "PREN":
other_shape = [
paddle.static.InputSpec(
@@ -105,13 +117,36 @@ def main():
if config["Architecture"]["algorithm"] in ["Distillation",
]: # distillation model
for key in config["Architecture"]["Models"]:
- config["Architecture"]["Models"][key]["Head"][
- "out_channels"] = char_num
+ if config["Architecture"]["Models"][key]["Head"][
+ "name"] == 'MultiHead': # multi head
+ out_channels_list = {}
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ loss_list = config['Loss']['loss_config_list']
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config["Architecture"]["Models"][key]["Head"][
+ "out_channels"] = char_num
# just one final tensor needs to to exported for inference
config["Architecture"]["Models"][key][
"return_all_feats"] = False
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # multi head
+ out_channels_list = {}
+ char_num = len(getattr(post_process_class, 'character'))
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config["Architecture"]["Head"]["out_channels"] = char_num
+
model = build_model(config["Architecture"])
load_model(config, model)
model.eval()
diff --git a/tools/infer/predict_rec.py b/tools/infer/predict_rec.py
index c5aacb060060068ec4b0b9432b2fb045aaff0370..2abc0220937175f95ee4c1e4b0b949d24d5fa3e8 100755
--- a/tools/infer/predict_rec.py
+++ b/tools/infer/predict_rec.py
@@ -107,7 +107,7 @@ class TextRecognizer(object):
return norm_img.astype(np.float32) / 128. - 1.
assert imgC == img.shape[2]
- imgW = int((32 * max_wh_ratio))
+ imgW = int((imgH * max_wh_ratio))
if self.use_onnx:
w = self.input_tensor.shape[3:][0]
if w is not None and w > 0:
@@ -131,6 +131,17 @@ class TextRecognizer(object):
padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
padding_im[:, :, 0:resized_w] = resized_image
return padding_im
+
+ def resize_norm_img_svtr(self, img, image_shape):
+
+ imgC, imgH, imgW = image_shape
+ resized_image = cv2.resize(
+ img, (imgW, imgH), interpolation=cv2.INTER_LINEAR)
+ resized_image = resized_image.astype('float32')
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ return resized_image
def resize_norm_img_srn(self, img, image_shape):
imgC, imgH, imgW = image_shape
@@ -255,18 +266,16 @@ class TextRecognizer(object):
for beg_img_no in range(0, img_num, batch_num):
end_img_no = min(img_num, beg_img_no + batch_num)
norm_img_batch = []
- max_wh_ratio = 0
+ imgC, imgH, imgW = self.rec_image_shape
+ max_wh_ratio = imgW / imgH
+ # max_wh_ratio = 0
for ino in range(beg_img_no, end_img_no):
h, w = img_list[indices[ino]].shape[0:2]
wh_ratio = w * 1.0 / h
max_wh_ratio = max(max_wh_ratio, wh_ratio)
for ino in range(beg_img_no, end_img_no):
- if self.rec_algorithm != "SRN" and self.rec_algorithm != "SAR":
- norm_img = self.resize_norm_img(img_list[indices[ino]],
- max_wh_ratio)
- norm_img = norm_img[np.newaxis, :]
- norm_img_batch.append(norm_img)
- elif self.rec_algorithm == "SAR":
+
+ if self.rec_algorithm == "SAR":
norm_img, _, _, valid_ratio = self.resize_norm_img_sar(
img_list[indices[ino]], self.rec_image_shape)
norm_img = norm_img[np.newaxis, :]
@@ -274,7 +283,7 @@ class TextRecognizer(object):
valid_ratios = []
valid_ratios.append(valid_ratio)
norm_img_batch.append(norm_img)
- else:
+ elif self.rec_algorithm == "SRN":
norm_img = self.process_image_srn(
img_list[indices[ino]], self.rec_image_shape, 8, 25)
encoder_word_pos_list = []
@@ -286,6 +295,16 @@ class TextRecognizer(object):
gsrm_slf_attn_bias1_list.append(norm_img[3])
gsrm_slf_attn_bias2_list.append(norm_img[4])
norm_img_batch.append(norm_img[0])
+ elif self.rec_algorithm == "SVTR":
+ norm_img = self.resize_norm_img_svtr(
+ img_list[indices[ino]], self.rec_image_shape)
+ norm_img = norm_img[np.newaxis, :]
+ norm_img_batch.append(norm_img)
+ else:
+ norm_img = self.resize_norm_img(img_list[indices[ino]],
+ max_wh_ratio)
+ norm_img = norm_img[np.newaxis, :]
+ norm_img_batch.append(norm_img)
norm_img_batch = np.concatenate(norm_img_batch)
norm_img_batch = norm_img_batch.copy()
if self.benchmark:
diff --git a/tools/infer/utility.py b/tools/infer/utility.py
index b16aecd496ec291fcbe9c66dccf3ec04bb662034..a93f364b31d6d9cb718337b0731330a172296396 100644
--- a/tools/infer/utility.py
+++ b/tools/infer/utility.py
@@ -271,9 +271,10 @@ def create_predictor(args, mode, logger):
elif mode == "rec":
if args.rec_algorithm != "CRNN":
use_dynamic_shape = False
- min_input_shape = {"x": [1, 3, 32, 10]}
- max_input_shape = {"x": [args.rec_batch_num, 3, 32, 1536]}
- opt_input_shape = {"x": [args.rec_batch_num, 3, 32, 320]}
+ imgH = int(args.rec_image_shape.split(',')[-2])
+ min_input_shape = {"x": [1, 3, imgH, 10]}
+ max_input_shape = {"x": [args.rec_batch_num, 3, imgH, 1536]}
+ opt_input_shape = {"x": [args.rec_batch_num, 3, imgH, 320]}
elif mode == "cls":
min_input_shape = {"x": [1, 3, 48, 10]}
max_input_shape = {"x": [args.rec_batch_num, 3, 48, 1024]}
@@ -300,7 +301,8 @@ def create_predictor(args, mode, logger):
# enable memory optim
config.enable_memory_optim()
config.disable_glog_info()
-
+ config.delete_pass("reshape_transpose_matmul_v2_mkldnn_fuse_pass")
+ config.delete_pass("reshape_transpose_matmul_mkldnn_fuse_pass")
config.delete_pass("conv_transpose_eltwiseadd_bn_fuse_pass")
if mode == 'table':
config.delete_pass("fc_fuse_pass") # not supported for table
diff --git a/tools/infer_rec.py b/tools/infer_rec.py
index 02b3afd8a1b32c3c9c1e4a9a121f08b58c10151d..63d410b627f3868191c9299f9bc99e7fcab69d35 100755
--- a/tools/infer_rec.py
+++ b/tools/infer_rec.py
@@ -51,8 +51,28 @@ def main():
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ out_channels_list = {}
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head loss
+ out_channels_list = {}
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
diff --git a/tools/program.py b/tools/program.py
index 8ec152bb92f0855d44b2597ce2420b16a4fa007e..90fd309ae9e1ae23723d8e67c62a905e79a073d3 100755
--- a/tools/program.py
+++ b/tools/program.py
@@ -201,12 +201,19 @@ def train(config,
model.train()
use_srn = config['Architecture']['algorithm'] == "SRN"
- extra_input = config['Architecture'][
- 'algorithm'] in ["SRN", "NRTR", "SAR", "SEED"]
+ extra_input_models = ["SRN", "NRTR", "SAR", "SEED", "SVTR"]
+ extra_input = False
+ if config['Architecture']['algorithm'] == 'Distillation':
+ for key in config['Architecture']["Models"]:
+ extra_input = extra_input or config['Architecture']['Models'][key][
+ 'algorithm'] in extra_input_models
+ else:
+ extra_input = config['Architecture']['algorithm'] in extra_input_models
try:
model_type = config['Architecture']['model_type']
except:
model_type = None
+
algorithm = config['Architecture']['algorithm']
start_epoch = best_model_dict[
@@ -269,7 +276,12 @@ def train(config,
if model_type in ['table', 'kie']:
eval_class(preds, batch)
else:
- post_result = post_process_class(preds, batch[1])
+ if config['Loss']['name'] in ['MultiLoss', 'MultiLoss_v2'
+ ]: # for multi head loss
+ post_result = post_process_class(
+ preds['ctc'], batch[1]) # for CTC head out
+ else:
+ post_result = post_process_class(preds, batch[1])
eval_class(post_result, batch)
metric = eval_class.get_metric()
train_stats.update(metric)
@@ -541,7 +553,7 @@ def preprocess(is_train=False):
assert alg in [
'EAST', 'DB', 'SAST', 'Rosetta', 'CRNN', 'STARNet', 'RARE', 'SRN',
'CLS', 'PGNet', 'Distillation', 'NRTR', 'TableAttn', 'SAR', 'PSE',
- 'SEED', 'SDMGR', 'LayoutXLM', 'LayoutLM', 'PREN', 'FCE'
+ 'SEED', 'SDMGR', 'LayoutXLM', 'LayoutLM', 'PREN', 'FCE', 'SVTR'
]
device = 'cpu'
diff --git a/tools/train.py b/tools/train.py
index f6cd0e7d12cdc572dd8d2c402e03e160001a9f4a..42aba548d6bf5fc35f033ef2baca0fb54d79e75a 100755
--- a/tools/train.py
+++ b/tools/train.py
@@ -74,11 +74,49 @@ def main(config, device, logger, vdl_writer):
if config['Architecture']["algorithm"] in ["Distillation",
]: # distillation model
for key in config['Architecture']["Models"]:
- config['Architecture']["Models"][key]["Head"][
- 'out_channels'] = char_num
+ if config['Architecture']['Models'][key]['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess'][
+ 'name'] == 'DistillationSARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][-1].keys())[
+ 0] == 'DistillationSARLoss'
+ config['Loss']['loss_config_list'][-1][
+ 'DistillationSARLoss']['ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Models'][key]['Head'][
+ 'out_channels_list'] = out_channels_list
+ else:
+ config['Architecture']["Models"][key]["Head"][
+ 'out_channels'] = char_num
+ elif config['Architecture']['Head'][
+ 'name'] == 'MultiHead': # for multi head
+ if config['PostProcess']['name'] == 'SARLabelDecode':
+ char_num = char_num - 2
+ # update SARLoss params
+ assert list(config['Loss']['loss_config_list'][1].keys())[
+ 0] == 'SARLoss'
+ if config['Loss']['loss_config_list'][1]['SARLoss'] is None:
+ config['Loss']['loss_config_list'][1]['SARLoss'] = {
+ 'ignore_index': char_num + 1
+ }
+ else:
+ config['Loss']['loss_config_list'][1]['SARLoss'][
+ 'ignore_index'] = char_num + 1
+ out_channels_list = {}
+ out_channels_list['CTCLabelDecode'] = char_num
+ out_channels_list['SARLabelDecode'] = char_num + 2
+ config['Architecture']['Head'][
+ 'out_channels_list'] = out_channels_list
else: # base rec model
config['Architecture']["Head"]['out_channels'] = char_num
+ if config['PostProcess']['name'] == 'SARLabelDecode': # for SAR model
+ config['Loss']['ignore_index'] = char_num - 1
+
model = build_model(config['Architecture'])
if config['Global']['distributed']:
model = paddle.DataParallel(model)
@@ -91,7 +129,7 @@ def main(config, device, logger, vdl_writer):
config['Optimizer'],
epochs=config['Global']['epoch_num'],
step_each_epoch=len(train_dataloader),
- parameters=model.parameters())
+ model=model)
# build metric
eval_class = build_metric(config['Metric'])