diff --git a/README.md b/README.md
index 5f85aaaa1409acc755b4bbb45df7c2ee7bd29429..8e869f6de551dd18ea0e8e4768081b5129ba87ea 100644
--- a/README.md
+++ b/README.md
@@ -1,4 +1,4 @@
-English | [简体中文](README_ch.md)
+English | [简体中文](README_ch.md) | [हिन्दी](./doc/doc_i18n/README_हिन्द.md) | [日本語](./doc/doc_i18n/README_日本語.md) | [한국인](./doc/doc_i18n/README_한국어.md) | [Pу́сский язы́к](./doc/doc_i18n/README_Ру́сский_язы́к.md)
 @@ -25,25 +25,33 @@ PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools
@@ -25,25 +25,33 @@ PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools
 -## Recent updates
+## 📣 Recent updates
+- 💥 **Live Preview: Oct 24 - Oct 26, China Standard Time, 20:30**, Engineers@PaddleOCR will show PP-StructureV2 optimization strategy for 3 days.
+ - Scan the QR code below using WeChat, follow the PaddlePaddle official account and fill out the questionnaire to join the WeChat group, get the live link and 20G OCR learning materials (including PDF2Word application, 10 models in vertical scenarios, etc.)
+
+
-## Recent updates
+## 📣 Recent updates
+- 💥 **Live Preview: Oct 24 - Oct 26, China Standard Time, 20:30**, Engineers@PaddleOCR will show PP-StructureV2 optimization strategy for 3 days.
+ - Scan the QR code below using WeChat, follow the PaddlePaddle official account and fill out the questionnaire to join the WeChat group, get the live link and 20G OCR learning materials (including PDF2Word application, 10 models in vertical scenarios, etc.)
+
+
+

+
-

+
PP-OCRv3 Chinese model
@@ -217,7 +226,7 @@ PaddleOCR support a variety of cutting-edge algorithms related to OCR, and devel
-## Guideline for New Language Requests
+## 🇺🇳 Guideline for New Language Requests
If you want to request a new language support, a PR with 1 following files are needed:
@@ -230,5 +239,5 @@ More details, please refer to [Multilingual OCR Development Plan](https://github
-## License
+## 📄 License
This project is released under Apache 2.0 license
diff --git a/README_ch.md b/README_ch.md
index 8e1cfeacd5795bb100c0e1d33e605178144f6cbe..5fec27bd66d35596126e84f81d6019ce31217f2e 100755
--- a/README_ch.md
+++ b/README_ch.md
@@ -1,4 +1,4 @@
-[English](README.md) | 简体中文
+[English](README.md) | 简体中文 | [हिन्दी](./doc/doc_i18n/README_हिन्द.md) | [日本語](./doc/doc_i18n/README_日本語.md) | [한국인](./doc/doc_i18n/README_한국어.md) | [Pу́сский язы́к](./doc/doc_i18n/README_Ру́сский_язы́к.md)
@@ -25,17 +25,31 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-## 近期更新
+## 📣 近期更新
+
+- **💥 直播预告:10.24-10.26日每晚8点半**,PaddleOCR研发团队详解PP-StructureV2优化策略。微信扫描下方二维码,关注公众号并填写问卷后进入官方交流群,获取直播链接与20G重磅OCR学习大礼包(内含PDF转Word应用程序、10种垂类模型、《动手学OCR》电子书等)
+
+
+
+
@@ -82,7 +97,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-## PP-OCR系列模型列表(更新中)
+## 🛠️ PP-OCR系列模型列表(更新中)
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
| ------------------------------------- | ----------------------- | --------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
@@ -103,7 +118,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-## 文档教程
+## 📖 文档教程
- [运行环境准备](./doc/doc_ch/environment.md)
- [PP-OCR文本检测识别🔥](./doc/doc_ch/ppocr_introduction.md)
@@ -169,7 +184,7 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-## 效果展示 [more](./doc/doc_ch/visualization.md)
+## 👀 效果展示 [more](./doc/doc_ch/visualization.md)
PP-OCRv3 中文模型
diff --git a/applications/README.md b/applications/README.md
index 2637cd6eaf0c3c59d56673c5e2d294ee7fca2b8b..950adf7644ae684abd1f23a4127ad389013ad85b 100644
--- a/applications/README.md
+++ b/applications/README.md
@@ -42,14 +42,14 @@ PaddleOCR场景应用覆盖通用,制造、金融、交通行业的主要OCR
### 金融
-| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
-| -------------- | ----------------------------- | -------------- | ------------------------------------- | ------------------------------------------------------------ |
-| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English |  |
-| 增值税发票 | 关键信息抽取,SER、RE任务训练 | [模型下载](#2) | [中文](./发票关键信息抽取.md)/English |
|
-| 增值税发票 | 关键信息抽取,SER、RE任务训练 | [模型下载](#2) | [中文](./发票关键信息抽取.md)/English |  |
-| 印章检测与识别 | 端到端弯曲文本识别 | | | |
-| 通用卡证识别 | 通用结构化提取 | | | |
-| 身份证识别 | 结构化提取、图像阴影 | | | |
-| 合同比对 | 密集文本检测、NLP串联 | | | |
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ----------------------------- | -------------- | ----------------------------------------- | ------------------------------------------------------------ |
+| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English | |
+| 增值税发票 | 关键信息抽取,SER、RE任务训练 | [模型下载](#2) | [中文](./发票关键信息抽取.md)/English | |
+| 印章检测与识别 | 端到端弯曲文本识别 | [模型下载](#2) | [中文](./印章弯曲文字识别.md)/English |
|
-| 印章检测与识别 | 端到端弯曲文本识别 | | | |
-| 通用卡证识别 | 通用结构化提取 | | | |
-| 身份证识别 | 结构化提取、图像阴影 | | | |
-| 合同比对 | 密集文本检测、NLP串联 | | | |
+| 类别 | 亮点 | 模型下载 | 教程 | 示例图 |
+| -------------- | ----------------------------- | -------------- | ----------------------------------------- | ------------------------------------------------------------ |
+| 表单VQA | 多模态通用表单结构化提取 | [模型下载](#2) | [中文](./多模态表单识别.md)/English | |
+| 增值税发票 | 关键信息抽取,SER、RE任务训练 | [模型下载](#2) | [中文](./发票关键信息抽取.md)/English | |
+| 印章检测与识别 | 端到端弯曲文本识别 | [模型下载](#2) | [中文](./印章弯曲文字识别.md)/English |  |
+| 通用卡证识别 | 通用结构化提取 | [模型下载](#2) | [中文](./快速构建卡证类OCR.md)/English |
|
+| 通用卡证识别 | 通用结构化提取 | [模型下载](#2) | [中文](./快速构建卡证类OCR.md)/English |  |
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP关键信息抽取 | [模型下载](#2) | [中文](./扫描合同关键信息提取.md)/English |
|
+| 身份证识别 | 结构化提取、图像阴影 | | | |
+| 合同比对 | 密集文本检测、NLP关键信息抽取 | [模型下载](#2) | [中文](./扫描合同关键信息提取.md)/English | 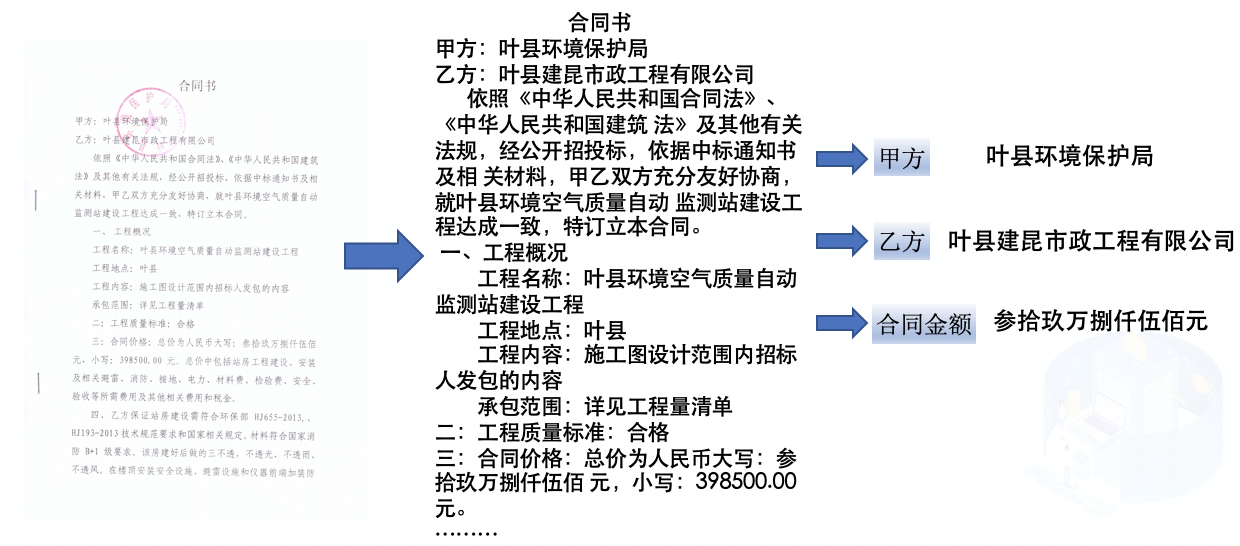 |
diff --git a/applications/README_en.md b/applications/README_en.md
index 95c56a1f740faa95e1fe3adeaeb90bfe902f8ed8..df18465e55253e98a3caf750bee203ff451b6ac9 100644
--- a/applications/README_en.md
+++ b/applications/README_en.md
@@ -42,14 +42,14 @@ PaddleOCR scene application covers general, manufacturing, finance, transportati
### Finance
-| Case | Feature | Model Download | Tutorial | Example |
-| ----------------------------------- | -------------------------------------------------- | -------------------- | ------------------------------------- | ------------------------------------------------------------ |
-| Form visual question and answer | Multimodal general form structured extraction | [Model Download](#2) | [中文](./多模态表单识别.md)/English | |
-| VAT invoice | Key information extraction, SER, RE task fine-tune | [Model Download](#2) | [中文](./发票关键信息抽取.md)/English | |
-| Seal detection and recognition | End-to-end curved text recognition | | | |
-| Universal card recognition | Universal structured extraction | | | |
-| ID card recognition | Structured extraction, image shading | | | |
-| Contract key information extraction | Dense text detection, NLP concatenation | | | |
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------- | -------------------------------------------------- | -------------------- | ----------------------------------------- | ------------------------------------------------------------ |
+| Form visual question and answer | Multimodal general form structured extraction | [Model Download](#2) | [中文](./多模态表单识别.md)/English | |
+| VAT invoice | Key information extraction, SER, RE task fine-tune | [Model Download](#2) | [中文](./发票关键信息抽取.md)/English | |
+| Seal detection and recognition | End-to-end curved text recognition | [Model Download](#2) | [中文](./印章弯曲文字识别.md)/English | |
+| Universal card recognition | Universal structured extraction | [Model Download](#2) | [中文](./快速构建卡证类OCR.md)/English | |
+| ID card recognition | Structured extraction, image shading | | | |
+| Contract key information extraction | Dense text detection, NLP concatenation | [Model Download](#2) | [中文](./扫描合同关键信息提取.md)/English | |
diff --git "a/applications/\345\215\260\347\253\240\345\274\257\346\233\262\346\226\207\345\255\227\350\257\206\345\210\253.md" "b/applications/\345\215\260\347\253\240\345\274\257\346\233\262\346\226\207\345\255\227\350\257\206\345\210\253.md"
index 702561cef62434ea98e78659b2eddb373eedef4a..07a146f489d4a70c82a2f2d44bf1caa1ea6facd1 100644
--- "a/applications/\345\215\260\347\253\240\345\274\257\346\233\262\346\226\207\345\255\227\350\257\206\345\210\253.md"
+++ "b/applications/\345\215\260\347\253\240\345\274\257\346\233\262\346\226\207\345\255\227\350\257\206\345\210\253.md"
@@ -1029,5 +1029,6 @@ Train:
如需获取已训练模型,请扫下图二维码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
-
-
+
|
diff --git a/applications/README_en.md b/applications/README_en.md
index 95c56a1f740faa95e1fe3adeaeb90bfe902f8ed8..df18465e55253e98a3caf750bee203ff451b6ac9 100644
--- a/applications/README_en.md
+++ b/applications/README_en.md
@@ -42,14 +42,14 @@ PaddleOCR scene application covers general, manufacturing, finance, transportati
### Finance
-| Case | Feature | Model Download | Tutorial | Example |
-| ----------------------------------- | -------------------------------------------------- | -------------------- | ------------------------------------- | ------------------------------------------------------------ |
-| Form visual question and answer | Multimodal general form structured extraction | [Model Download](#2) | [中文](./多模态表单识别.md)/English | |
-| VAT invoice | Key information extraction, SER, RE task fine-tune | [Model Download](#2) | [中文](./发票关键信息抽取.md)/English | |
-| Seal detection and recognition | End-to-end curved text recognition | | | |
-| Universal card recognition | Universal structured extraction | | | |
-| ID card recognition | Structured extraction, image shading | | | |
-| Contract key information extraction | Dense text detection, NLP concatenation | | | |
+| Case | Feature | Model Download | Tutorial | Example |
+| ----------------------------------- | -------------------------------------------------- | -------------------- | ----------------------------------------- | ------------------------------------------------------------ |
+| Form visual question and answer | Multimodal general form structured extraction | [Model Download](#2) | [中文](./多模态表单识别.md)/English | |
+| VAT invoice | Key information extraction, SER, RE task fine-tune | [Model Download](#2) | [中文](./发票关键信息抽取.md)/English | |
+| Seal detection and recognition | End-to-end curved text recognition | [Model Download](#2) | [中文](./印章弯曲文字识别.md)/English | |
+| Universal card recognition | Universal structured extraction | [Model Download](#2) | [中文](./快速构建卡证类OCR.md)/English | |
+| ID card recognition | Structured extraction, image shading | | | |
+| Contract key information extraction | Dense text detection, NLP concatenation | [Model Download](#2) | [中文](./扫描合同关键信息提取.md)/English | |
diff --git "a/applications/\345\215\260\347\253\240\345\274\257\346\233\262\346\226\207\345\255\227\350\257\206\345\210\253.md" "b/applications/\345\215\260\347\253\240\345\274\257\346\233\262\346\226\207\345\255\227\350\257\206\345\210\253.md"
index 702561cef62434ea98e78659b2eddb373eedef4a..07a146f489d4a70c82a2f2d44bf1caa1ea6facd1 100644
--- "a/applications/\345\215\260\347\253\240\345\274\257\346\233\262\346\226\207\345\255\227\350\257\206\345\210\253.md"
+++ "b/applications/\345\215\260\347\253\240\345\274\257\346\233\262\346\226\207\345\255\227\350\257\206\345\210\253.md"
@@ -1029,5 +1029,6 @@ Train:
如需获取已训练模型,请扫下图二维码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
-
-
+
+

+
+  +
+
+
+  +
+  +
+  +
+  +
+  +
+  +
+  +
+
+
+
+## Введение
+
+PaddleOCR стремится создавать многоязычные, потрясающие, передовые и практичные инструменты OCR, которые помогают пользователям обучать лучшие модели и применять их на практике
+
+
+

+
+

+
+

+
+

+
+PP-OCRv3 Многоязычная модель
+
+

+

+
+
+
+PP-OCRv3 Aнглийская модель
+
+

+

+
+
+PP-OCRv3 Kитайская модель
+
+
+
+
+PP-Structurev2
+1. анализ макета + распознавание таблиц
+
+

+
+

+
+

+
+

+
+

+
+
+
+

+
+
+
+
+## 📄 Лицензия
+Этот проект выпущен под Apache 2.0 license
diff --git "a/doc/doc_i18n/README_\340\244\271\340\244\277\340\244\250\340\245\215\340\244\246.md" "b/doc/doc_i18n/README_\340\244\271\340\244\277\340\244\250\340\245\215\340\244\246.md"
new file mode 100644
index 0000000000000000000000000000000000000000..ef8a22f28939d2c2a93935d6b85d5418b3d92323
--- /dev/null
+++ "b/doc/doc_i18n/README_\340\244\271\340\244\277\340\244\250\340\245\215\340\244\246.md"
@@ -0,0 +1,228 @@
+[English](../../README.md) | [简体中文](../../README_ch.md) | हिन्दी | [日本語](./README_日本語.md) | [한국인](./README_한국어.md) | [Pу́сский язы́к](./README_Ру́сский_язы́к.md)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## प्रस्तावना
+पैडलओसीआर का उद्देश्य बहुभाषी,शानदार , ओसीआर और व्यावहारिक ओसीआरउपकरण बनाना है जो यूजर्स को बेहतर मॉडलों के लिए प्रशिक्षित करने और उन्हें व्यवहार में लागू करने में मदद करते हैं।
+
+
+
+
+
+
+
+
+

+
+PP-OCRv3 बहुभाषी मॉडल
+
+
+
+
+
+
+PP-OCRv3 अंग्रेजी मॉडल
+
+
+
+
+
+PP-OCRv3 चीनी मॉडल
+
+
+
+
+PP-Structurev2
+1. लेआउट एनालाइस + टेबल रिकोगनाइजेशन
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## 📄 लाइसेंस
+इस प्रोजेक्ट को इन परियोजना के तहत जारी किया गया है Apache 2.0 license
diff --git "a/doc/doc_i18n/README_\346\227\245\346\234\254\350\252\236.md" "b/doc/doc_i18n/README_\346\227\245\346\234\254\350\252\236.md"
new file mode 100644
index 0000000000000000000000000000000000000000..a75003ecfebb3a86a7d0eb4ea4fe47b3c5715a31
--- /dev/null
+++ "b/doc/doc_i18n/README_\346\227\245\346\234\254\350\252\236.md"
@@ -0,0 +1,227 @@
+[English](../../README.md) | [简体中文](../../README_ch.md) | [हिन्दी](./README_हिन्द.md) | 日本語 | [한국인](./README_한국어.md) | [Pу́сский язы́к](./README_Ру́сский_язы́к.md)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## 紹介
+
+PaddleOCR は、さまざまな言語で、優れた最先端かつ実用的な OCR ツールを作成することを目的とし、ユーザーがより優れたモデルをトレーニングし、実践的に対応できるようになるために役立つAIOCRです。
+
+
+
+
+
+
+
+
+

+
+PP-OCRv3 多言語モデル
+
+
+
+
+
+
+PP-OCRv3 英語 モデル
+
+
+
+
+
+PP-OCRv3 中国語 モデル
+
+
+
+
+PP-Structurev2
+1. レイアウト分析+テーブル認識
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## 📄 ライセンス
+このプロジェクトは以下の場所でリリースされています Apache 2.0 license
diff --git "a/doc/doc_i18n/README_\355\225\234\352\265\255\354\226\264.md" "b/doc/doc_i18n/README_\355\225\234\352\265\255\354\226\264.md"
new file mode 100644
index 0000000000000000000000000000000000000000..7ec3072404fa2bdfaf6a4eedc4476ca3841231e8
--- /dev/null
+++ "b/doc/doc_i18n/README_\355\225\234\352\265\255\354\226\264.md"
@@ -0,0 +1,224 @@
+[English](../../README.md) | [简体中文](../../README_ch.md) | [हिन्दी](./README_हिन्द.md) | [日本語](./README_日本語.md) | 한국인 | [Pу́сский язы́к](./README_Ру́сский_язы́к.md)
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## 소개
+
+PaddleOCR은 사용자들이 보다 나은 모델을 훈련하여 실전에 투입하는데 도움을 주는 다중 언어로 된 엄청나게 멋지고 주도적이며 실용적인 OCR 툴을 만드는데 목표를 두고 있습니다.
+
+
+
+
+
+
+
+

+
+PP-OCRv3 다중 언어 모델
+
+
+
+
+
+
+
+PP-OCRv3 영어 모델
+
+
+
+
+
+PP-OCRv3 중국어 모델
+
+
+
+
+
+PP-Structurev2
+1. 레이아웃 분석 + 표 인식
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+## 📄 라이선스
+본 프로젝트는 Apache 2.0 license 하에 출시됨.
diff --git a/ppstructure/docs/quickstart.md b/ppstructure/docs/quickstart.md
index 9909f7950c9810bd99ee0b0504ccdf3d0a9b06ff..287b0d13c7642fea8091dc77c8a0a443381bc910 100644
--- a/ppstructure/docs/quickstart.md
+++ b/ppstructure/docs/quickstart.md
@@ -104,6 +104,19 @@ paddleocr --image_dir=ppstructure/recovery/UnrealText.pdf --type=structure --rec
通过OCR技术:
+版面恢复分为2种方法,详细介绍请参考:[版面恢复教程](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/recovery/README_ch.md):
+
+- PDF解析
+- OCR技术
+
+通过PDF解析(只支持pdf格式的输入):
+
+```bash
+paddleocr --image_dir=ppstructure/recovery/UnrealText.pdf --type=structure --recovery=true --use_pdf2docx_api=true
+```
+
+通过OCR技术:
+
```bash
# 中文测试图
paddleocr --image_dir=ppstructure/docs/table/1.png --type=structure --recovery=true
diff --git a/ppstructure/docs/quickstart_en.md b/ppstructure/docs/quickstart_en.md
index c990088a28a6849d53f05a42fc7e0d14adc1ca51..9229a79de1f14ea738a4ca2b93cf44d48508ff40 100644
--- a/ppstructure/docs/quickstart_en.md
+++ b/ppstructure/docs/quickstart_en.md
@@ -91,9 +91,9 @@ paddleocr --image_dir=ppstructure/docs/table/table.jpg --type=structure --layout
Key information extraction does not currently support use by the whl package. For detailed usage tutorials, please refer to: [inference document](./inference_en.md).
-#### 2.1.6 layout recovery
+#### 2.1.6 layout recovery(PDF to Word)
-Two layout recovery methods are provided, For detailed usage tutorials, please refer to: [Layout Recovery](../recovery/README.md).
+Two layout recovery methods are provided, For detailed usage tutorials, please refer to: [Layout Recovery](https://github.com/PaddlePaddle/PaddleOCR/blob/dygraph/ppstructure/recovery/README.md).
- PDF parse
- OCR
diff --git a/ppstructure/pdf2word/README.md b/ppstructure/pdf2word/README.md
index 45869124ff6bdb8f4301f04d58e6f6a6339e74dc..783555a3017d365bf4d0e969f2b0bdf81d03a779 100644
--- a/ppstructure/pdf2word/README.md
+++ b/ppstructure/pdf2word/README.md
@@ -19,7 +19,7 @@ PDF2Word是PaddleOCR社区开发者 [whjdark](https://github.com/whjdark) 基于
> - 初次安装程序根据不同设备需要等待1-2分钟不等
> - 使用Office与WPS打开的Word结果会出现不同,推荐以Office为准
> - 本程序使用 [QPT](https://github.com/QPT-Family/QPT) 进行应用程序打包,感谢 [GT-ZhangAcer](https://github.com/GT-ZhangAcer) 对打包过程的支持
-> - 应用程序不支持盗版Windows系统,若在安装过程中出现报错或缺少依赖,推荐直接使用 `paddleocr` whl包应用PDF2Word功能,详情可查看[链接](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/ppstructure/docs/quickstart.md)
+> - 应用程序仅支持正版win10,11系统,不支持盗版Windows系统,若在安装过程中出现报错或缺少依赖,推荐直接使用 `paddleocr` whl包应用PDF2Word功能,详情可查看[链接](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/ppstructure/docs/quickstart.md)
### 脚本启动界面
 +
+  +
+  +
+