@@ -80,7 +80,7 @@ In PaddleStructure, the image will be analyzed by layoutparser first. In the lay
...
@@ -80,7 +80,7 @@ In PaddleStructure, the image will be analyzed by layoutparser first. In the lay
### 2.1 LayoutParser
### 2.1 LayoutParser
Layout analysis divides the document data into regions, including the use of Python scripts for layout analysis tools, extraction of special category detection boxes, performance indicators, and custom training layout analysis models. For details, please refer to [document](layout/README.md).
Layout analysis divides the document data into regions, including the use of Python scripts for layout analysis tools, extraction of special category detection boxes, performance indicators, and custom training layout analysis models. For details, please refer to [document](layout/README_en.md).
The following figure shows the result, with different colored detection boxes representing different categories and displaying specific categories in the upper left corner of the box with `show_element_type`
| config_path | model config path | None | Specify config_ path will automatically download the model (only for the first time,the model will exist and will not be downloaded again) |
| model_path | model path | None | local model path, config_ path and model_ path must be set to one, cannot be none at the same time |
| label_map | category mapping table | None | Setting config_ path, it can be none, and the label is automatically obtained according to the dataset name_ map |
| enforce_cpu | whether to use CPU | False | False to use GPU, and True to force the use of CPU |
| enforce_mkldnn | whether mkldnn acceleration is enabled in CPU prediction | True | \ |
| thread_num | the number of CPU threads | 10 | \ |
The following model configurations and label maps are currently supported, which you can use by modifying '--config_path' and '--label_map' to detect different types of content:
* TableBank word and TableBank latex are trained on datasets of word documents and latex documents respectively;
* Download TableBank dataset contains both word and latex。
<aname="PostProcess"></a>
## 3. PostProcess
Layout parser contains multiple categories, if you only want to get the detection box for a specific category (such as the "Text" category), you can use the following code:
**CPU:** Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz,24core
**GPU:** a single NVIDIA Tesla P40
<aname="Training"></a>
## 5. Training
The above model is based on PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection) ,if you want to train your own layout parser model,please refer to:[train_layoutparser_model](train_layoutparser_model_en.md)
For more installation tutorials, please refer to: [Install doc](https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.1/docs/tutorials/INSTALL_cn.md)
<aname="Data preparation"></a>
## 2. Data preparation
Download the [PubLayNet](https://github.com/ibm-aur-nlp/PubLayNet) dataset
| `train/` | Images in the training subset | 335,703 |
| `val/` | Images in the validation subset | 11,245 |
| `test/` | Images in the testing subset | 11,405 |
| `train.json` | Annotations for training images | 1 |
| `val.json` | Annotations for validation images | 1 |
| `LICENSE.txt` | Plaintext version of the CDLA-Permissive license | 1 |
| `README.txt` | Text file with the file names and description | 1 |
For other datasets,please refer to [the PrepareDataSet]((https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.1/docs/tutorials/PrepareDataSet.md) )
<aname="Configuration"></a>
## 3. Configuration
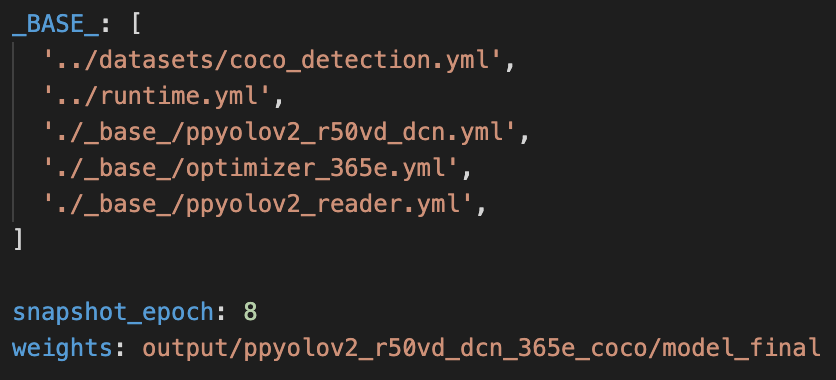
We use the `configs/ppyolo/ppyolov2_r50vd_dcn_365e_coco.yml` configuration for training,the configuration file is as follows
The `ppyolov2_r50vd_dcn_365e_coco.yml` configuration depends on other configuration files, in this case:
- coco_detection.yml:mainly explains the path of training data and verification data
- runtime.yml:mainly describes the common parameters, such as whether to use the GPU and how many epoch to save model etc.
- optimizer_365e.yml:mainly explains the learning rate and optimizer configuration
- ppyolov2_r50vd_dcn.yml:mainly describes the model and the network
- ppyolov2_reader.yml:mainly describes the configuration of data readers, such as batch size and number of concurrent loading child processes, and also includes post preprocessing, such as resize and data augmention etc.
Modify the preceding files, such as the dataset path and batch size etc.
<aname="Training"></a>
## 4. Training
PaddleDetection provides single-card/multi-card training mode to meet various training needs of users:
* GPU single card training
```bash
export CUDA_VISIBLE_DEVICES=0 #Don't need to run this command on Windows and Mac
`--draw_threshold` is an optional parameter. According to the calculation of [NMS](https://ieeexplore.ieee.org/document/1699659), different threshold will produce different results, ` keep_top_k ` represent the maximum amount of output target, the default value is 10. You can set different value according to your own actual situation。
<aname="Deployment"></a>
## 6. Deployment
Use your trained model in Layout Parser
<aname="Export model"></a>
### 6.1 Export model
n the process of model training, the model file saved contains the process of forward prediction and back propagation. In the actual industrial deployment, there is no need for back propagation. Therefore, the model should be translated into the model format required by the deployment. The `tools/export_model.py` script is provided in PaddleDetection to export the model.
The exported model name defaults to `model.*`, Layout Parser's code model is `inference.*`, So change [PaddleDetection/ppdet/engine/trainer. Py ](https://github.com/PaddlePaddle/PaddleDetection/blob/b87a1ea86fa18ce69e44a17ad1b49c1326f19ff9/ppdet/engine/trainer.py# L512) (click on the link to see the detailed line of code), change 'model' to 'inference'.
The prediction model is exported to `inference/ppyolov2_r50vd_dcn_365e_coco` ,including:`infer_cfg.yml`(prediction not required), `inference.pdiparams`, `inference.pdiparams.info`,`inference.pdmodel`
More model export tutorials, please refer to:[EXPORT_MODEL](https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.1/deploy/EXPORT_MODEL.md)
<aname="Inference"></a>
### 6.2 Inference
`model_path` represent the trained model path, and layoutparser is used to predict:
More PaddleDetection training tutorials,please reference:[PaddleDetection Training](https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.1/docs/tutorials/GETTING_STARTED_cn.md)
{kind=link}