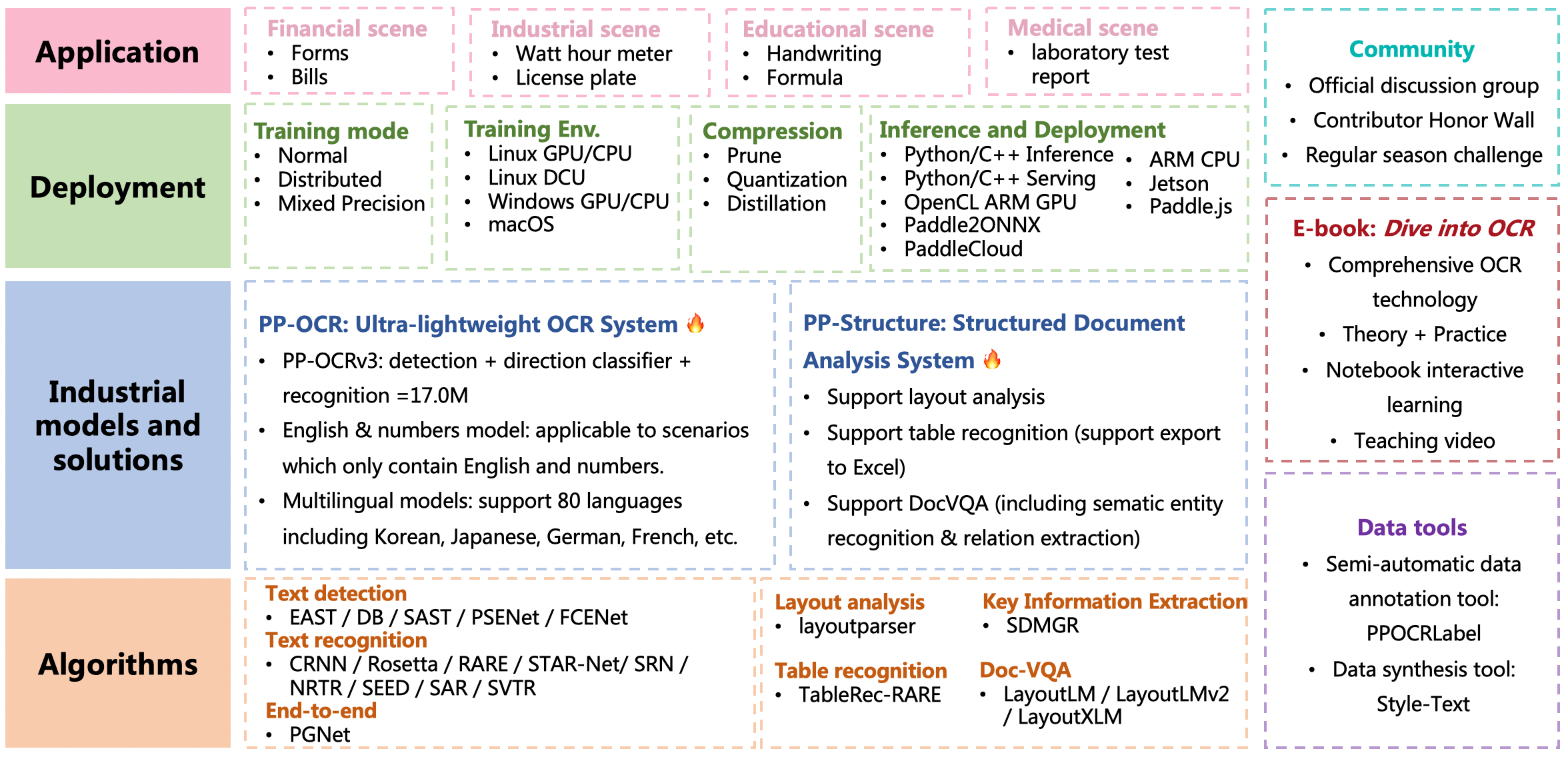
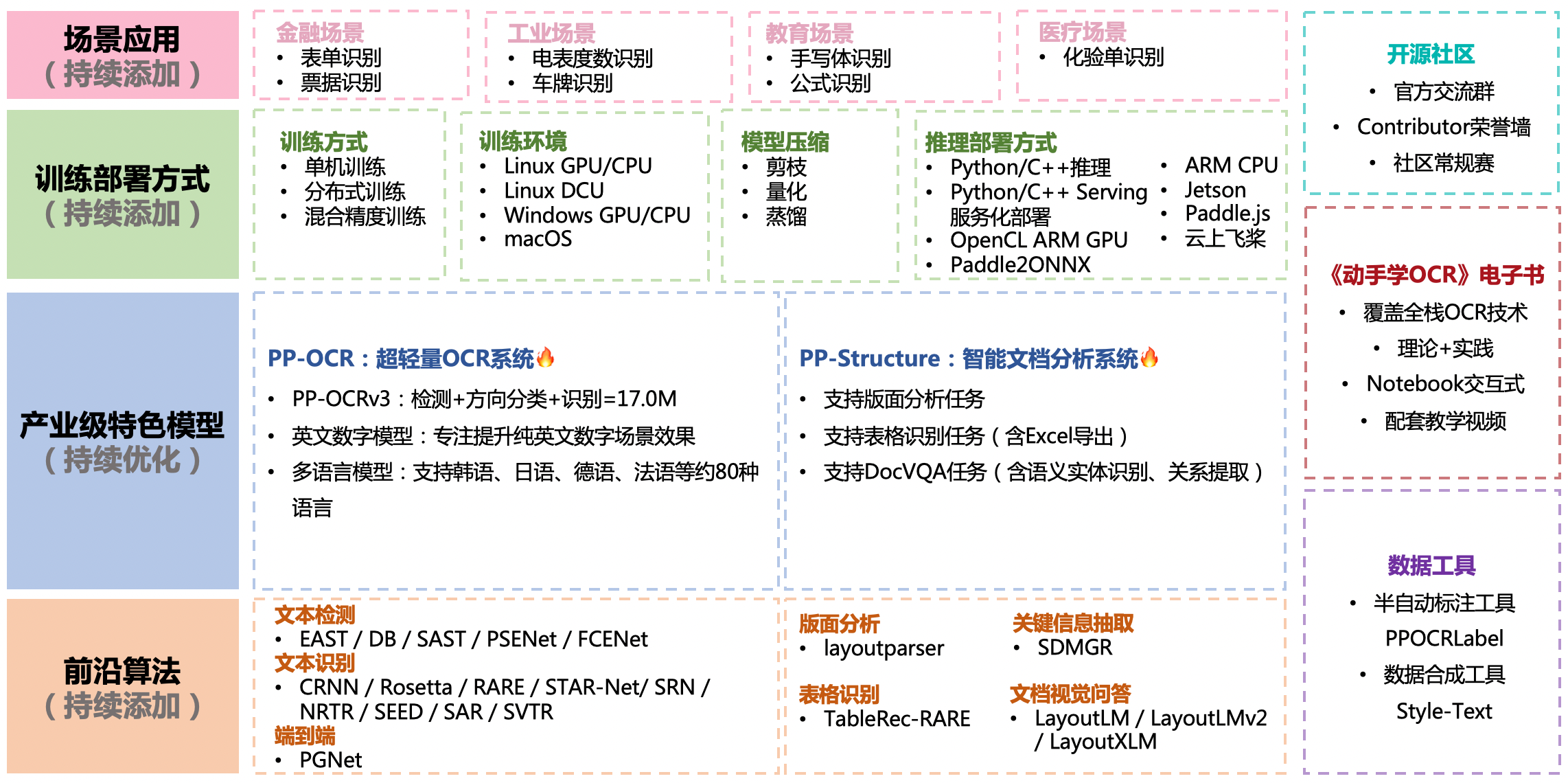
- Release [PP-Structurev2](./ppstructure/),with functions and performance fully upgraded, adapted to Chinese scenes, and new support for [Layout Recovery](./ppstructure/recovery) and [PDF to Word]();
-[Layout Analysis](./ppstructure/layout) optimization: model storage reduced by 95%, while speed increased by 11 times, and the average CPU time-cost is only 41ms;
-[Table Recognition](./ppstructure/table) optimization: 3 optimization strategies are designed, and the model accuracy is improved by 6% under comparable time consumption;
-[Key Information Extraction](./ppstructure/kie) optimization:a visual-independent model structure is designed, the accuracy of semantic entity recognition is increased by 2.8%, and the accuracy of relation extraction is increased by 9.1%.
- Release [PP-OCRv3](./doc/doc_en/ppocr_introduction_en.md#pp-ocrv3): With comparable speed, the effect of Chinese scene is further improved by 5% compared with PP-OCRv2, the effect of English scene is improved by 11%, and the average recognition accuracy of 80 language multilingual models is improved by more than 5%.
- Release [PPOCRLabelv2](./PPOCRLabel): Add the annotation function for table recognition task, key information extraction task and irregular text image.
- Release interactive e-book [*"Dive into OCR"*](./doc/doc_en/ocr_book_en.md), covers the cutting-edge theory and code practice of OCR full stack technology.
- Release [PP-OCRv2](./doc/doc_en/ppocr_introduction_en.md#pp-ocrv2). The inference speed of PP-OCRv2 is 220% higher than that of PP-OCR server in CPU device. The F-score of PP-OCRv2 is 7% higher than that of PP-OCR mobile.
- Release a new structured documents analysis toolkit, i.e., [PP-Structure](./ppstructure/README.md), support layout analysis and table recognition (One-key to export chart images to Excel files).
-[more](./doc/doc_en/update_en.md)
...
...
@@ -45,7 +44,9 @@ PaddleOCR aims to create multilingual, awesome, leading, and practical OCR tools
PaddleOCR support a variety of cutting-edge algorithms related to OCR, and developed industrial featured models/solution [PP-OCR](./doc/doc_en/ppocr_introduction_en.md) and [PP-Structure](./ppstructure/README.md) on this basis, and get through the whole process of data production, model training, compression, inference and deployment.
{kind=link}
{kind=link}