Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleOCR
提交
092287ef
P
PaddleOCR
项目概览
PaddlePaddle
/
PaddleOCR
大约 2 年 前同步成功
通知
1557
Star
32965
Fork
6643
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
108
列表
看板
标记
里程碑
合并请求
7
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleOCR
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
108
Issue
108
列表
看板
标记
里程碑
合并请求
7
合并请求
7
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
092287ef
编写于
4月 13, 2022
作者:
M
MissPenguin
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update doc
上级
3cb72788
变更
10
显示空白变更内容
内联
并排
Showing
10 changed file
with
181 addition
and
59 deletion
+181
-59
README_ch.md
README_ch.md
+8
-18
doc/doc_ch/algorithm.md
doc/doc_ch/algorithm.md
+12
-2
doc/doc_ch/algorithm_deploy.md
doc/doc_ch/algorithm_deploy.md
+0
-0
doc/doc_ch/algorithm_det_db.md
doc/doc_ch/algorithm_det_db.md
+119
-0
doc/doc_ch/algorithm_e2e_pgnet.md
doc/doc_ch/algorithm_e2e_pgnet.md
+1
-1
doc/doc_ch/algorithm_overview.md
doc/doc_ch/algorithm_overview.md
+18
-32
doc/doc_ch/algorithm_overview_structure.md
doc/doc_ch/algorithm_overview_structure.md
+0
-6
doc/doc_ch/clone.md
doc/doc_ch/clone.md
+23
-0
doc/features.png
doc/features.png
+0
-0
doc/overview.png
doc/overview.png
+0
-0
未找到文件。
README_ch.md
浏览文件 @
092287ef
...
@@ -41,6 +41,10 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
...
@@ -41,6 +41,10 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-
移动端:
[
安装包DEMO下载地址
](
https://ai.baidu.com/easyedge/app/openSource?from=paddlelite
)(
基于EasyEdge和Paddle-Lite,
支持iOS和Android系统)
-
移动端:
[
安装包DEMO下载地址
](
https://ai.baidu.com/easyedge/app/openSource?from=paddlelite
)(
基于EasyEdge和Paddle-Lite,
支持iOS和Android系统)
## 《动手学OCR》电子书
-
[
《动手学OCR》电子书📚
](
./doc/doc_ch/ocr_book.md
)
<a
name=
"贡献代码"
></a>
<a
name=
"贡献代码"
></a>
## 社区、社区贡献与社区常规赛
## 社区、社区贡献与社区常规赛
...
@@ -97,10 +101,9 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
...
@@ -97,10 +101,9 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-
[
基于Python预测引擎推理
](
./doc/doc_ch/inference_ppstructure.md
)
-
[
基于Python预测引擎推理
](
./doc/doc_ch/inference_ppstructure.md
)
-
[
服务化部署
](
./deploy/pdserving/README_CN.md
)
-
[
服务化部署
](
./deploy/pdserving/README_CN.md
)
-
[
前沿算法与模型🚀
](
./doc/doc_ch/algorithm.md
)
-
[
前沿算法与模型🚀
](
./doc/doc_ch/algorithm.md
)
-
[
OCR算法与模型
](
./doc/doc_ch/algorithm_overview.md
)
-
[
文本检测算法
](
./doc/doc_ch/algorithm_overview.md#11-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E7%AE%97%E6%B3%95
)
-
[
文档分析算法与模型
](
./doc/doc_ch/algorithm_overview_structure.md
)
-
[
文本识别算法
](
./doc/doc_ch/algorithm_overview.md#12-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95
)
-
[
基于Python预测引擎推理
](
./doc/doc_ch/algorithm_inference.md
)
-
[
端到端算法
](
./doc/doc_ch/algorithm_overview.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95
)
-
[
更多推理部署
](
./doc/doc_ch/algorithm_deploy.md
)
-
[
使用PaddleOCR架构添加新算法
](
./doc/doc_ch/add_new_algorithm.md
)
-
[
使用PaddleOCR架构添加新算法
](
./doc/doc_ch/add_new_algorithm.md
)
-
数据标注与合成
-
数据标注与合成
-
[
半自动标注工具PPOCRLabel
](
./PPOCRLabel/README_ch.md
)
-
[
半自动标注工具PPOCRLabel
](
./PPOCRLabel/README_ch.md
)
...
@@ -114,27 +117,14 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
...
@@ -114,27 +117,14 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
-
[
版面分析数据集
](
./doc/doc_ch/layout_datasets.md
)
-
[
版面分析数据集
](
./doc/doc_ch/layout_datasets.md
)
-
[
表格识别数据集
](
./doc/doc_ch/table_datasets.md
)
-
[
表格识别数据集
](
./doc/doc_ch/table_datasets.md
)
-
[
DocVQA数据集
](
./doc/doc_ch/docvqa_datasets.md
)
-
[
DocVQA数据集
](
./doc/doc_ch/docvqa_datasets.md
)
-
[
代码组织结构
](
./doc/doc_ch/tree.md
)
-
[
效果展示
](
#效果展示
)
-
[
效果展示
](
#效果展示
)
-
[
《动手学OCR》电子书📚
](
./doc/doc_ch/ocr_book.md
)
-
FAQ
-
FAQ
-
[
通用问题
](
./doc/doc_ch/FAQ.md
)
-
[
通用问题
](
./doc/doc_ch/FAQ.md
)
-
[
PaddleOCR实战问题
](
./doc/doc_ch/FAQ.md
)
-
[
PaddleOCR实战问题
](
./doc/doc_ch/FAQ.md
)
-
[
参考文献
](
./doc/doc_ch/reference.md
)
-
[
参考文献
](
./doc/doc_ch/reference.md
)
-
[
许可证书
](
#许可证书
)
-
[
许可证书
](
#许可证书
)
-
[
代码组织结构
](
./doc/doc_ch/tree.md
)
<a
name=
"PP-OCRv2"
></a>
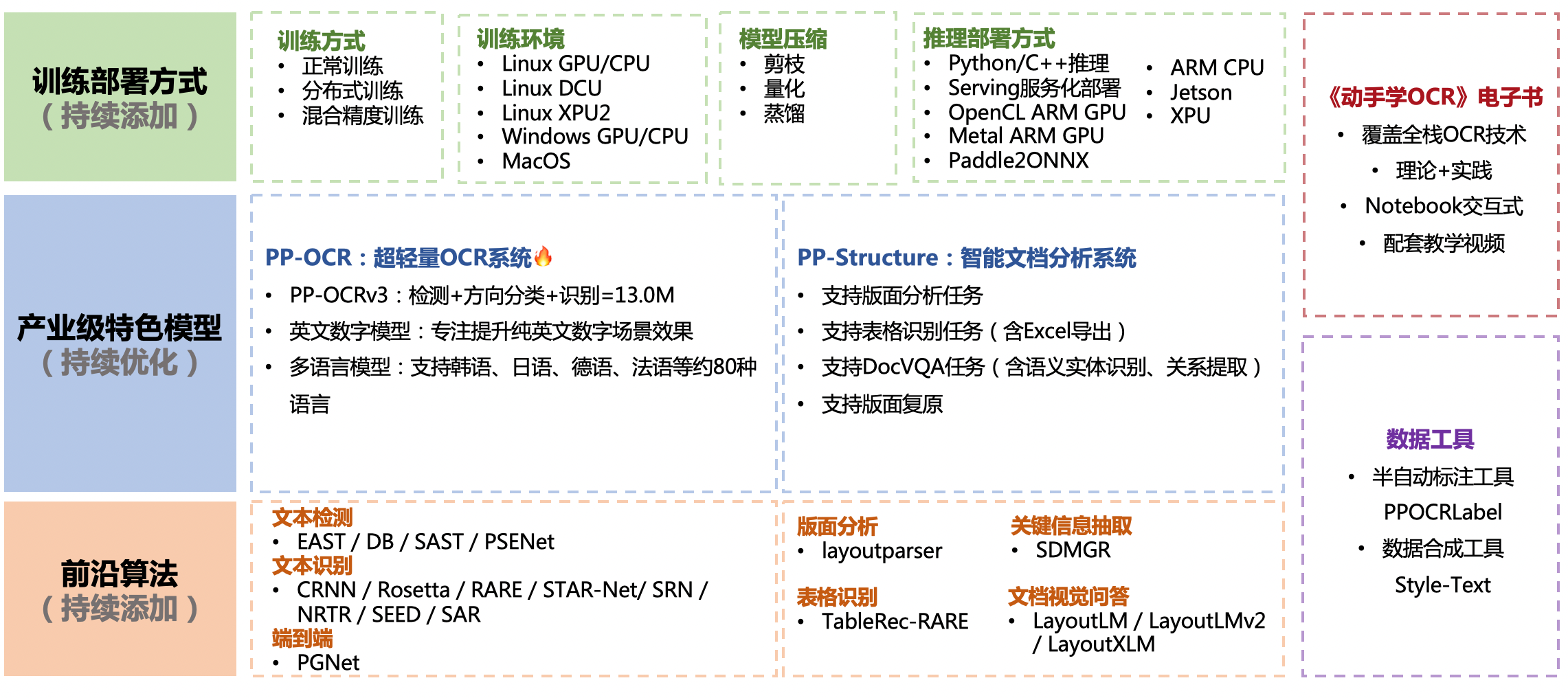
## PP-OCRv2 Pipeline
<div
align=
"center"
>
<img
src=
"./doc/ppocrv2_framework.jpg"
width=
"800"
>
</div>
[1] PP-OCR是一个实用的超轻量OCR系统。主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。更多细节请参考PP-OCR技术方案 https://arxiv.org/abs/2009.09941
[
2] PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和[Enhanced CTC loss
](
./doc/doc_ch/enhanced_ctc_loss.md
)
损失函数改进(如上图红框所示),进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCRv2
[
技术报告
](
https://arxiv.org/abs/2109.03144
)
。
<a
name=
"效果展示"
></a>
<a
name=
"效果展示"
></a>
...
...
doc/doc_ch/algorithm.md
浏览文件 @
092287ef
汇集前沿算法、论文复现结果、打通python预测
# 前沿算法与模型
欢迎贡献更多算法,合入有奖!
PaddleOCR将
**持续新增**
支持OCR领域前沿算法与模型,已支持的模型与使用教程可点击下方列表查看:
\ No newline at end of file
-
[
文本检测算法
](
./algorithm_overview.md#11-%E6%96%87%E6%9C%AC%E6%A3%80%E6%B5%8B%E7%AE%97%E6%B3%95
)
-
[
文本识别算法
](
./algorithm_overview.md#12-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95
)
-
[
端到端算法
](
./algorithm_overview.md#2-%E6%96%87%E6%9C%AC%E8%AF%86%E5%88%AB%E7%AE%97%E6%B3%95
)
**欢迎广大开发者合作共建,贡献更多算法,合入有奖🎁!具体可查看[社区常规赛](https://github.com/PaddlePaddle/PaddleOCR/issues/4982)。**
新增算法可参考如下教程:
-
[
使用PaddleOCR架构添加新算法
](
./add_new_algorithm.md
)
\ No newline at end of file
doc/doc_ch/algorithm_deploy.md
已删除
100644 → 0
浏览文件 @
3cb72788
doc/doc_ch/algorithm_det_db.md
0 → 100644
浏览文件 @
092287ef
# DB
-
[
1. 算法简介
](
#1
)
-
[
2. 环境配置
](
#2
)
-
[
3. 快速使用
](
#3
)
-
[
4. 模型训练、评估、预测
](
#4
)
-
[
5. 推理部署
](
#5
)
-
[
6. FAQ
](
#6
)
<a
name=
"1"
></a>
## 1. 算法简介
论文信息:
> [Real-time Scene Text Detection with Differentiable Binarization](https://arxiv.org/abs/1911.08947)
> Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang
> AAAI, 2020
在ICDAR2015文本检测公开数据集上,算法复现效果如下:
|模型|骨干网络|precision|recall|Hmean|下载链接|
| --- | --- | --- | --- | --- | --- |
|DB|ResNet50_vd|86.41%|78.72%|82.38%|
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar
)
|
|DB|MobileNetV3|77.29%|73.08%|75.12%|
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_mv3_db_v2.0_train.tar
)
|
<a
name=
"2"
></a>
## 2. 环境配置
请先参考
[
《运行环境准备》
](
./environment.md
)
配置PaddleOCR运行环境,参考
[
《项目克隆》
](
./clone.md
)
克隆项目
<a
name=
"3"
></a>
## 3. 快速使用
参考本节,可以直接下载训好的模型,进行基于训练引擎的模型预测。
### 训练模型下载
根据第1节给出的模型列表,选择下载训练模型:
```
bash
mkdir
trained_models
&&
cd
trained_models
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_mv3_db_v2.0_train.tar
&&
tar
xf det_mv3_db_v2.0_train.tar
cd
..
```
*
windows 环境下如果没有安装wget,下载模型时可将链接复制到浏览器中下载,并解压放置在相应目录下
解压完毕后应有如下文件结构:
```
├── det_mv3_db_v2.0_train
│ ├── best_accuracy.states
│ ├── best_accuracy.pdparams
│ ├── best_accuracy.pdopt
│ └── train.log
```
### 单张图像或者图像集合预测
```
bash
# 预测image_dir指定的单张图像
python3 tools/infer/predict_e2e.py
--e2e_algorithm
=
"PGNet"
--image_dir
=
"./doc/imgs_en/img623.jpg"
--e2e_model_dir
=
"./inference/e2e_server_pgnetA_infer/"
--e2e_pgnet_valid_set
=
"totaltext"
# 预测image_dir指定的图像集合
python3 tools/infer/predict_e2e.py
--e2e_algorithm
=
"PGNet"
--image_dir
=
"./doc/imgs_en/"
--e2e_model_dir
=
"./inference/e2e_server_pgnetA_infer/"
--e2e_pgnet_valid_set
=
"totaltext"
# 如果想使用CPU进行预测,需设置use_gpu参数为False
python3 tools/infer/predict_e2e.py
--e2e_algorithm
=
"PGNet"
--image_dir
=
"./doc/imgs_en/img623.jpg"
--e2e_model_dir
=
"./inference/e2e_server_pgnetA_infer/"
--e2e_pgnet_valid_set
=
"totaltext"
--use_gpu
=
False
```
### 可视化结果
可视化文本检测结果默认保存到./inference_results文件夹里面,结果文件的名称前缀为'e2e_res'。结果示例如下:

<a
name=
"4"
></a>
## 4. 模型训练、评估、预测
### 4.1 训练
### 4.2 评估
### 4.3 预测
<a
name=
"5"
></a>
## 5. 推理部署
### 5.1 Python推理
首先将DB文本检测训练过程中保存的模型,转换成inference model。以基于Resnet50_vd骨干网络,在ICDAR2015英文数据集训练的模型为例(
[
模型下载地址
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_db_v2.0_train.tar
)
),可以使用如下命令进行转换:
```
python3 tools/export_model.py -c configs/det/det_r50_vd_db.yml -o Global.pretrained_model=./det_r50_vd_db_v2.0_train/best_accuracy Global.save_inference_dir=./inference/det_db
```
DB文本检测模型推理,可以执行如下命令:
```
python3 tools/infer/predict_det.py --image_dir="./doc/imgs_en/img_10.jpg" --det_model_dir="./inference/det_db/"
```
可视化文本检测结果默认保存到
`./inference_results`
文件夹里面,结果文件的名称前缀为'det_res'。结果示例如下:

**注意**
:由于ICDAR2015数据集只有1000张训练图像,且主要针对英文场景,所以上述模型对中文文本图像检测效果会比较差。
### 5.2 C++推理
敬请期待
### 5.3 Serving服务化部署
敬请期待
### 5.4 Paddle2ONNX推理
敬请期待
<a
name=
"6"
></a>
## 6. FAQ
## 引用
```
bibtex
@inproceedings
{
liao2020real
,
title
=
{Real-time scene text detection with differentiable binarization}
,
author
=
{Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang}
,
booktitle
=
{Proceedings of the AAAI Conference on Artificial Intelligence}
,
volume
=
{34}
,
number
=
{07}
,
pages
=
{11474--11481}
,
year
=
{2020}
}
```
\ No newline at end of file
doc/doc_ch/pgnet.md
→
doc/doc_ch/
algorithm_e2e_
pgnet.md
浏览文件 @
092287ef
...
@@ -43,7 +43,7 @@ PGNet算法细节详见[论文](https://www.aaai.org/AAAI21Papers/AAAI-2885.Wang
...
@@ -43,7 +43,7 @@ PGNet算法细节详见[论文](https://www.aaai.org/AAAI21Papers/AAAI-2885.Wang
<a
name=
"环境配置"
></a>
<a
name=
"环境配置"
></a>
## 二、环境配置
## 二、环境配置
请先参考
[
《运行环境准备》
](
./environment.md
)
配置PaddleOCR运行环境,参考
[
《
PaddleOCR全景图与项目克隆》
](
./paddleOCR_overview
.md
)
克隆项目
请先参考
[
《运行环境准备》
](
./environment.md
)
配置PaddleOCR运行环境,参考
[
《
项目克隆》
](
./clone
.md
)
克隆项目
<a
name=
"快速使用"
></a>
<a
name=
"快速使用"
></a>
## 三、快速使用
## 三、快速使用
...
...
doc/doc_ch/algorithm_overview.md
浏览文件 @
092287ef
...
@@ -16,14 +16,15 @@
...
@@ -16,14 +16,15 @@
### 1.1 文本检测算法
### 1.1 文本检测算法
PaddleOCR开源的文本检测算法列表
:
已支持的文本检测算法列表(戳链接获取使用教程)
:
-
[
x]
DB([paper
](
https://arxiv.org/abs/1911.08947
)
) [2](ppocr推荐)
-
[
x]
[DB
](
./algorithm_det_db.md
)
-
[
x]
EAST([paper
](
https://arxiv.org/abs/1704.03155
)
)[1]
-
[
x]
[EAST
](
./algorithm_det_east.md
)
-
[
x]
SAST([paper
](
https://arxiv.org/abs/1908.05498
)
)[4]
-
[
x]
[SAST
](
./algorithm_det_sast.md
)
-
[
x]
PSENet([paper
](
https://arxiv.org/abs/1903.12473v2
)
)
-
[
x]
[PSENet
](
./algorithm_det_psenet.md
)
-
[
x]
FCENet([paper
](
https://arxiv.org/abs/2104.10442
)
)
-
[
x]
[FCENet
](
./algorithm_det_fcenet.md
)
在ICDAR2015文本检测公开数据集上,算法效果如下:
在ICDAR2015文本检测公开数据集上,算法效果如下:
|模型|骨干网络|precision|recall|Hmean|下载链接|
|模型|骨干网络|precision|recall|Hmean|下载链接|
| --- | --- | --- | --- | --- | --- |
| --- | --- | --- | --- | --- | --- |
|EAST|ResNet50_vd|88.71%|81.36%|84.88%|
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_east_v2.0_train.tar
)
|
|EAST|ResNet50_vd|88.71%|81.36%|84.88%|
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/en/det_r50_vd_east_v2.0_train.tar
)
|
...
@@ -51,25 +52,19 @@ PaddleOCR开源的文本检测算法列表:
...
@@ -51,25 +52,19 @@ PaddleOCR开源的文本检测算法列表:
*
[
Google Drive下载地址
](
https://drive.google.com/drive/folders/1ll2-XEVyCQLpJjawLDiRlvo_i4BqHCJe?usp=sharing
)
*
[
Google Drive下载地址
](
https://drive.google.com/drive/folders/1ll2-XEVyCQLpJjawLDiRlvo_i4BqHCJe?usp=sharing
)
**模型训练与推理**
-
以上文本检测算法的训练请参考文档教程中
[
模型训练/评估中的文本检测部分
](
./detection.md
)
。
-
上述模型中除PP-OCR系列模型以外,其余模型仅支持基于Python引擎的推理,具体内容可参考
[
基于Python预测引擎推理
](
./algorithm_inference.md
)
<a
name=
"12"
></a>
<a
name=
"12"
></a>
### 1.2 文本识别算法
### 1.2 文本识别算法
PaddleOCR开源的文本识别算法列表
:
已支持的文本识别算法列表(戳链接获取使用教程)
:
-
[
x]
CRNN([paper
](
https://arxiv.org/abs/1507.05717
)
)[7](ppocr推荐)
-
[
x]
[CRNN
](
./algorithm_rec_crnn.md
)
-
[
x]
Rosetta([paper
](
https://arxiv.org/abs/1910.05085
)
)[10]
-
[
x]
[Rosetta
](
./algorithm_rec_rosetta.md
)
-
[
x]
STAR-Net([paper
](
http://www.bmva.org/bmvc/2016/papers/paper043/index.html
)
)[11]
-
[
x]
[STAR-Net
](
./algorithm_rec_starnet.md
)
-
[
x]
RARE([paper
](
https://arxiv.org/abs/1603.03915v1
)
)[12]
-
[
x]
[RARE
](
./algorithm_rec_rare.md
)
-
[
x]
SRN([paper
](
https://arxiv.org/abs/2003.12294
)
)[5]
-
[
x]
[SRN
](
./algorithm_rec_srn.md
)
-
[
x]
NRTR([paper
](
https://arxiv.org/abs/1806.00926v2
)
)[13]
-
[
x]
[NRTR
](
./algorithm_rec_nrtr.md
)
-
[
x]
SAR([paper
](
https://arxiv.org/abs/1811.00751v2
)
)
-
[
x]
[SAR
](
./algorithm_rec_sar.md
)
-
[
x]
SEED([paper
](
https://arxiv.org/pdf/2005.10977.pdf
)
)
-
[
x]
[SEED
](
./algorithm_rec_seed.md
)
参考
[
DTRB
](
https://arxiv.org/abs/1904.01906
)[
3
]
文字识别训练和评估流程,使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法效果如下:
参考
[
DTRB
](
https://arxiv.org/abs/1904.01906
)[
3
]
文字识别训练和评估流程,使用MJSynth和SynthText两个文字识别数据集训练,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE数据集上进行评估,算法效果如下:
...
@@ -89,20 +84,11 @@ PaddleOCR开源的文本识别算法列表:
...
@@ -89,20 +84,11 @@ PaddleOCR开源的文本识别算法列表:
|SEED|Aster_Resnet| 85.35% | rec_resnet_stn_bilstm_att |
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_resnet_stn_bilstm_att.tar
)
|
|SEED|Aster_Resnet| 85.35% | rec_resnet_stn_bilstm_att |
[
训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.1/rec/rec_resnet_stn_bilstm_att.tar
)
|
**模型训练与推理**
-
以上文本识别算法的训练请参考文档教程中
[
模型训练/评估中的文本识别部分
](
./recognition.md
)
。
-
上述模型中除PP-OCR系列模型以外,其余模型仅支持基于Python引擎的推理,具体内容可参考
[
基于Python预测引擎推理
](
./algorithm_inference.md
)
<a
name=
"2"
></a>
<a
name=
"2"
></a>
## 2. 端到端算法
## 2. 端到端算法
PaddleOCR开源的端到端OCR算法列表:
已支持的端到端OCR算法列表(戳链接获取使用教程):
-
[
x] PGNet([paper
](
https://www.aaai.org/AAAI21Papers/AAAI-2885.WangP.pdf
)
)
-
[
x] [PGNet
](
./algorithm_e2e_pgnet.md
)
> [PGNet更多信息与教程](./pgnet.md)
doc/doc_ch/algorithm_overview_structure.md
已删除
100644 → 0
浏览文件 @
3cb72788
# 文档分析算法
-
[
1. 版面分析算法
](
)
-
[
2. 表格识别算法
](
)
-
[
3. 关键信息提取算法
](
)
-
[
4. DocVQA算法
](
)
\ No newline at end of file
doc/doc_ch/
paddleOCR_overview
.md
→
doc/doc_ch/
clone
.md
浏览文件 @
092287ef
#
PaddleOCR全景图与
项目克隆
# 项目克隆
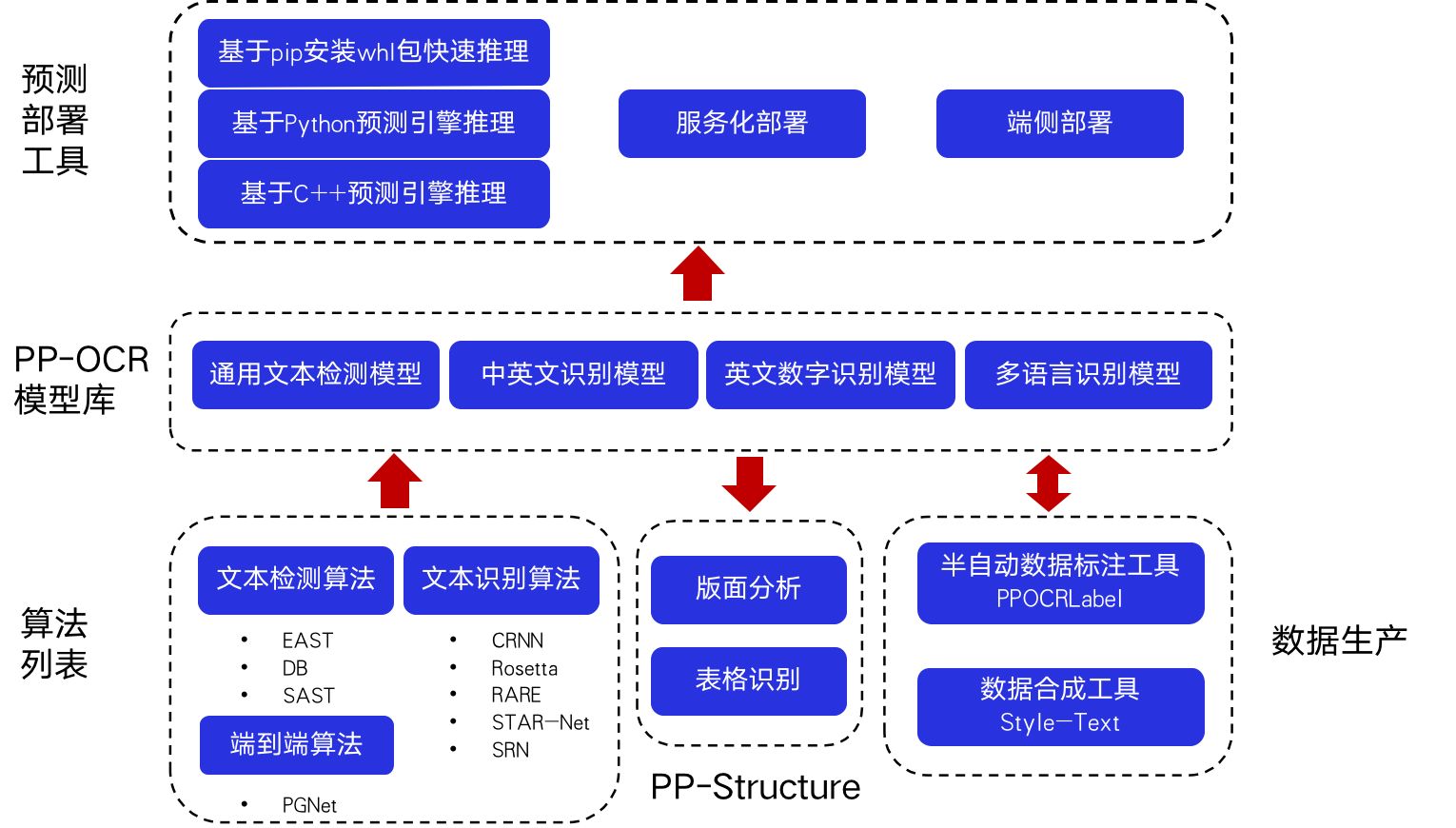
## 1. PaddleOCR全景图
## 1. 克隆PaddleOCR repo代码
PaddleOCR包含丰富的文本检测、文本识别以及端到端算法。结合实际测试与产业经验,PaddleOCR选择DB和CRNN作为基础的检测和识别模型,经过一系列优化策略提出面向产业应用的PP-OCR模型。PP-OCR模型针对通用场景,根据不同语种形成了PP-OCR模型库。基于PP-OCR的能力,PaddleOCR针对文档场景任务发布PP-Structure工具库,包含版面分析和表格识别两大任务。为了打通产业落地的全流程,PaddleOCR提供了规模化的数据生产工具和多种预测部署工具,助力开发者快速落地。
<div
align=
"center"
>
<img
src=
"../overview.png"
>
</div>
## 2. 项目克隆
### **2.1 克隆PaddleOCR repo代码**
```
```
【推荐】git clone https://github.com/PaddlePaddle/PaddleOCR
【推荐】git clone https://github.com/PaddlePaddle/PaddleOCR
...
@@ -24,7 +14,7 @@ git clone https://gitee.com/paddlepaddle/PaddleOCR
...
@@ -24,7 +14,7 @@ git clone https://gitee.com/paddlepaddle/PaddleOCR
注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
注:码云托管代码可能无法实时同步本github项目更新,存在3~5天延时,请优先使用推荐方式。
##
# **2.2 安装第三方库**
##
2. 安装第三方库
```
```
cd PaddleOCR
cd PaddleOCR
...
...
doc/features.png
查看替换文件 @
3cb72788
浏览文件 @
092287ef
1.0 MB
|
W:
|
H:
999.2 KB
|
W:
|
H:
2-up
Swipe
Onion skin
doc/overview.png
已删除
100644 → 0
浏览文件 @
3cb72788
142.8 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}

{kind=link}