# Bert as Service
## 1. 简介
### 1.1 什么是embedding
Embedding是指将一个维数为所有词数量的高维空间转换到维数较低的连续向量空间的过程,每个单词或词组被设置为实数域的向量。通过embedding能够在降低输入维度的同时保留其含义,常用于NLP任务的上游任务中。
### 1.2 什么是Bert as Service
Bert as Service是基于Paddle Serving框架的快速部署模型远程计算服务方案,可将embedding过程通过调用API接口的方式实现,减少了对机器资源的依赖。使用PaddleHub可在服务器上一键部署`Bert as Service`服务,在另外的普通机器上通过客户端接口即可轻松的获取文本对应的embedding数据。
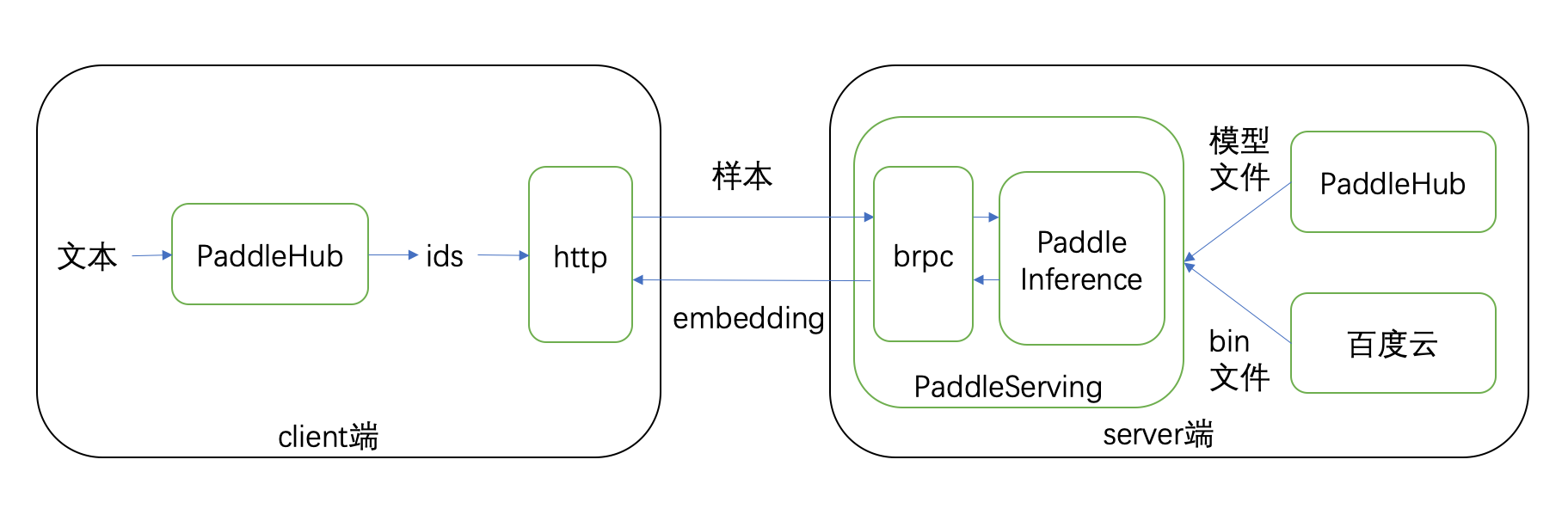
整体流程图如下:
### 1.3 为什么使用Bert as Service
* 算力有限的集群环境中,可利用一台或几台高性能机器部署`Bert as Service`服务端,为全部机器提供在线embedding功能。
* 实际的生产服务器不适宜承担大批量embedding工作,通过API接口可减少资源占用。
* 专注下游深度学习任务,可利用PaddleHub的`Bert as Service`大幅减少embedding代码。
`Bert as Service`具有几个突出的优点:
* 代码精短,易于使用。简单的pip安装方式,服务端仅需一行命令即可启动,客户端仅需一行代码即可获取embedding结果。
* 更高性能,更高效率。通过Paddle AnalysisPredictor API对模型的计算图进行优化,提升了计算速度并减小了显存占用,性能数据可参照[`Bert as Service`性能数据](https://github.com/ShenYuhan/PaddleHub/tree/bert_service/demo/serving/bert_as_service#7-%E6%80%A7%E8%83%BD)。
* 随"机"应变,灵活扩展。可根据机器资源选择不同数量的服务端,并根据实际需求快速、灵活地进行增减,同时支持各张显卡执行不同的模型计算任务。
* 删繁就简,专注任务。`Bert as Service`基于PaddlePaddle和PaddleHub开发,将模型的下载和安装等管理工作交由PaddleHub,开发者可以专注于主要任务,且可无缝对接PaddleHub继续进行文本分类、序列标注等下游任务。
## 2. 环境准备
### 2.1 环境要求
下表是使用`Bert as Service`的环境要求,带有*号标志项为非必需依赖,可根据实际使用需求选择安装。
|项目|版本|说明|
|:-:|:-:|:-:|
|操作系统|Linux|目前仅支持Linux操作系统|
|PaddleHub|>=1.3.0|无|
|PaddlePaddle|>=1.6.0|若使用GPU计算,则对应使用PaddlePaddle-gpu版本|
|GCC|>=4.8|无|
|CUDA*|>=8|若使用GPU,需使用CUDA8以上版本|
|paddle-gpu-serving*|>=0.6.4|在`Bert as Service`服务端需依赖此包|
|ujson*|>=1.35|在Bert as Service客户端需依赖此包|
### 2.2 安装步骤
a) 安装PaddlePaddle,利用pip下载CPU版本命令如下。GPU版本、Docker方式安装等其他更具体的安装过程见[开始使用PaddlePaddle](https://paddlepaddle.org.cn/install/quick)
```shell
$ # 安装paddlepaddle的CPU版本
$ pip install paddlepaddle
```
b) 安装PaddleHub
```shell
$ pip install paddlehub
```
c) server端,需另外安装`paddle-gpu-serving`,以获取快速部署服务的能力
```shell
$ pip install paddle-gpu-serving
```
d) client端,需另外安装ujson
```shell
$ pip install ujson
```
## 3. 支持模型
目前`Bert as Service`支持的语义模型如下表,可根据需要选择模型进行部署embedding服务,未来还将支持更多模型。
|模型|网络|数据集|
|:-|:-:|:-|
|[ERNIE](https://paddlepaddle.org.cn/hubdetail?name=ERNIE&en_category=SemanticModel)|ERNIE|百科类、资讯类、论坛对话类数据等中文语料|
|[roberta_wwm_ext_chinese_L-12_H-768_A-12](https://paddlepaddle.org.cn/hubdetail?name=roberta_wwm_ext_chinese_L-12_H-768_A-12&en_category=SemanticModel)|BERT|中文维基百科、百科、新闻、问答等|
|[roberta_wwm_ext_chinese_L-24_H-1024_A-16](https://paddlepaddle.org.cn/hubdetail?name=roberta_wwm_ext_chinese_L-24_H-1024_A-16&en_category=SemanticModel)|BERT|中文维基百科、百科、新闻、问答等|
|[bert_wwm_ext_chinese_L-12_H-768_A-12](https://paddlepaddle.org.cn/hubdetail?name=bert_wwm_ext_chinese_L-12_H-768_A-12&en_category=SemanticModel)|BERT|中文维基百科、百科、新闻、问答等|
|[bert_uncased_L-12_H-768_A-12](https://paddlepaddle.org.cn/hubdetail?name=bert_uncased_L-12_H-768_A-12&en_category=SemanticModel)|BERT|英文维基百科|
|[bert_uncased_L-24_H-1024_A-16](https://paddlepaddle.org.cn/hubdetail?name=bert_uncased_L-24_H-1024_A-16&en_category=SemanticModel)|BERT|英文维基百科|
|[bert_cased_L-12_H-768_A-12](https://paddlepaddle.org.cn/hubdetail?name=bert_cased_L-12_H-768_A-12&en_category=SemanticModel)|BERT|英文维基百科|
|[bert_cased_L-24_H-1024_A-16](https://paddlepaddle.org.cn/hubdetail?name=bert_cased_L-24_H-1024_A-16&en_category=SemanticModel)|BERT|英文维基百科|
|[bert_multi_cased_L-12_H-768_A-12](https://paddlepaddle.org.cn/hubdetail?name=bert_multi_cased_L-12_H-768_A-12&en_category=SemanticModel)|BERT|英文维基百科|
|[bert_chinese_L-12_H-768_A-12](https://paddlepaddle.org.cn/hubdetail?name=bert_chinese_L-12_H-768_A-12&en_category=SemanticModel)|BERT|中文维基百科|
## 4. 服务端(server)
### 4.1 简介
server端接收client端发送的数据,执行模型计算过程并将计算结果返回给client端。
server端启动时会按照指定的模型名称从PaddleHub获取对应的模型文件进行加载,无需提前下载模型或指定模型路径,对模型的管理工作由PaddleHub负责。在加载模型后在指定的端口启动`BRPC`服务,保持端口监听,当接收到数据后便执行模型计算,并将计算结果通过`BRPC`返回并发送至client端。
### 4.2 启动
使用PaddleHub的命令行工具可一键启动`Bert as Service`,命令如下:
```shell
$ hub serving start bert_serving -m bert_chinese_L-12_H-768_A-12 -p 8866 --use_gpu --gpu 0
```
启动成功则显示
```shell
Server[baidu::paddle_serving::predictor::bert_service::BertServiceImpl] is serving on port=8866.
```
整个启动过程如下图:
其中各参数说明如下表:
|参数|说明|是否必填|
|:--:|:--:|:----:|
|hub serving start bert_serving|启动`Bert as Service`服务端。|必填项|
|--module/-m|指定启动的模型,如果指定的模型不存在,则自动通过PaddleHub下载指定模型。|必填项|
|--port/-p|指定启动的端口,每个端口对应一个模型,可基于不同端口进行多次启动,以实现多个模型的服务部署。|必填项|
|--use_gpu|若指定此项则使用GPU进行工作,反之仅使用CPU。注意需安装GPU版本的PaddlePaddle。|非必填项,默认为不指定|
|--gpu|指定使用的GPU卡号,如未指定use_gpu则填写此项无效,每个服务对应一张卡,部署多个服务时需指定不同卡|非必填项,默认为0号显卡|
### 4.3 关闭
通过在启动服务端的命令行页面使用Ctrl+C终止`Bert as Service`运行,关闭成功则显示:
```shell
Paddle Inference Server exit successfully!
```
## 5.客户端(client)
### 5.1 简介
client端接收文本数据,并获取server端返回的模型计算的embedding结果。
client端利用PaddleHub的语义理解任务将原始文本按照不同模型的数据预处理方案将文本ID化,并生成对应的sentence type、position、input masks数据,将这些信息封装成json数据,通过http协议按照指定的IP端口信息发送至server端,等待并获取模型生成结果。
### 5.2 启动
连接服务端方法原型为:
```python
def connect(input_text,
model_name,
max_seq_len=128,
emb_size=768,
show_ids=False,
do_lower_case=True,
server="127.0.0.1:8866",
retry=3)
```
其中各参数说明如下表:
|参数|说明|类型|样例|
|:--:|:--:|:--:|:--:|
|input_text|输入文本,要获取embedding的原始文本|二维list类型,内部元素为string类型的文本|[['样例1'],['样例2']]|
|model_name|指定使用的模型名称|string|"ernie"|
|max_seq_len|计算时的样例长度,样例长度不足时采用补零策略,超出此参数则超出部分会被截断|int|128|
|emb_size|返回的embedding数据长度,需要与模型计算的embedding长度相等|int|768|
|show_ids|是否展现数据预处理后的样例信息,指定为True则显示样例信息,反之则不显示|bool|False|
|do_lower_case|是否将英文字母转换成小写,指定为True则将所有英文字母转换为小写,反之则保持原状|bool|True|
|server|要访问的server地址,包括ip地址及端口号|string|"127.0.0.1:8866"|
|retry|连接失败后的最大重试次数|int|3|
## 6. Demo
在这里,我们将展示一个实际场景中可能使用的demo,我们利用PaddleHub在一台GPU机器上部署`bert_wwm_ext_chinese_L-12_H-768_A-12`模型服务,并在另一台CPU机器上尝试访问,获取一首七言绝句的embedding。
### 6.1 安装环境依赖
首先需要安装环境依赖,根据第2节内容分别在两台机器上安装相应依赖。
### 6.2 启动`Bert as Serving`服务端
确保环境依赖安装正确后,在要部署服务的GPU机器上使用PaddleHub命令行工具启动`Bert as Service`服务端,命令如下:
```shell
$ hub serving start bert_serving -m bert_chinese_L-12_H-768_A-12 --use_gpu --gpu 0 --port 8866
```
启动成功后打印
```shell
Server[baidu::paddle_serving::predictor::bert_service::BertServiceImpl] is serving on port=8866.
```
这样就启动了`bert_chinese_L-12_H-768_A-12`的在线服务,监听8866端口,并在0号GPU上进行任务。
### 6.3 使用`Bert as Serving`客户端进行远程调用
部署好服务端后,就可以用普通机器作为客户端测试在线embedding功能。
首先导入客户端依赖。
```python
from paddlehub.serving.bert_serving import bert_service
```
接着输入文本信息。
```python
input_text = [["西风吹老洞庭波"], ["一夜湘君白发多"], ["醉后不知天在水"], ["满船清梦压星河"], ]
```
然后利用客户端接口发送文本到服务端,以获取embedding结果(server为虚拟地址,需根据自己实际ip设置)。
```python
result = bert_service.connect(
input_text=input_text,
model_name="bert_chinese_L-12_H-768_A-12",
server="127.0.0.1:8866")
```
最后即可得到embedding结果(此处只展示部分结果)。
```python
[[0.9993321895599361, 0.9994612336158751, 0.9999646544456481, 0.732795298099517, -0.34387934207916204, ... ]]
```
客户端代码demo文件见[示例](./bert_as_service_client.py)。
运行命令如下:
```shell
$ python bert_as_service.py
```
运行过程如下图:
### 6.4 关闭Bert as Serving服务端
如要停止`Bert as Serving`服务端程序,可在其启动命令行页面使用Ctrl+C方式关闭,关闭成功会打印如下日志:
```shell
Paddle Inference Server exit successfully!
```
这样,我们就利用一台GPU机器就完成了Bert as Service的部署,并利用另一台普通机器进行了测试,可见通过`Bert as Service`能够方便地进行在线embedding服务的快速部署。
## 7. 性能
测试环境:
PaddlePaddle:
PaddleHub:
paddle-gpu-serving: 0.7.X
GPU: k40
module: bert_chinese_L-12_H-768_A-12
max_seq_len: 128
batch: 1000
测试结果如下表(单位:秒):
|batch size|总时间|预处理时间|json序列化|连接http|发送request|client端等待|server端op耗时|读取http信息|json反序列化|qps|
|:-|:-|:-|:-|:-|:-|:-|:-|:-|:-|:-|
|1| 35.763| 2.281| 0.055| 0.022| 0.531| 29.614| 28.411| 0.078| 0.108| 27.96186|
|2| 58.793| 4.167| 0.101| 0.024| 0.533| 50.828| 48.793| 0.096| 0.201| 34.0176552|
|4| 83.653| 7.92| 0.18| 0.026| 0.528| 71.83| 69.605| 0.112| 0.416| 47.8165756|
|8| 153.168| 15.741| 0.337| 0.03| 0.558| 132.468| 129.014| 0.162| 0.819| 52.2302309|
|16| 293.131| 31.14| 0.662| 0.034| 0.612| 255.693| 249.737| 0.252| 1.598| 54.5831045|
|32| 595.6| 62.734| 1.315| 0.043| 0.712| 523.998| 513.075| 0.432| 3.196| 53.7273338|
|64| 1170.068| 125.199| 2.68| 0.056| 0.78| 1030.275| 1009.219| 0.95| 6.992| 54.6976757|
|128| 2326.037| 253.642| 5.263| 0.069| 1.028| 2042.25| 2002.016| 3.024| 14.112| 55.0292192|
|256|5147.78| 508.69| 10.619| 0.08| 1.181| 4586.019| 4505.11| 8.142| 29.378| 49.7301749|
## 8. FAQ
> Q : 如何在一台服务器部署多个模型?
> A : 可通过多次启动`Bert as Service`,分配不同端口实现。如果使用GPU,需要指定不同的显卡。如同时部署`ernie`和`bert_chinese_L-12_H-768_A-12`,分别执行命令如下:
> ```shell
> $ hub serving start bert_serving -m ernie -p 8866
> $ hub serving start bert_serving -m bert_serving -m bert_chinese_L-12_H-768_A-12 -p 8867
> ```
> Q : 启动时显示"Check out http://yq01-gpu-255-129-12-00.epc.baidu.com:8887 in web
browser.",这个页面有什么作用。
> A : 这是`BRPC`的内置服务,主要用于查看请求数、资源占用等信息,可对server端性能有大致了解,具体信息可查看[BRPC内置服务](https://github.com/apache/incubator-brpc/blob/master/docs/cn/builtin_service.md)。
> Q : 为什么输入文本的格式为[["文本1"], ["文本2"], ],而不是["文本1", "文本2", ]?
> A : 因为Bert模型可以对一轮对话生成向量表示,例如[["问题1","回答1"],["问题2","回答2"]],为了防止使用时混乱,每个样本使用一个list表示,一个样本list内部可以是1条string或2条string,如下面的文本:
> ```python
> input_text = [
> ["你今天吃饭了吗","我已经吃过饭了"],
> ["今天天气怎么样","今天天气不错"],
> ]
> ```