# PaddleHub 超参优化(Auto Fine-tune)
## 一、简介
目前深度学习模型参数可分类两类:*模型参数 (Model Parameters)* 与 *超参数 (Hyper Parameters)*,前者是模型通过大量的样本数据进行训练学习得到的参数数据;后者则需要通过人工经验或者不断尝试找到最佳设置(如学习率、dropout_rate、batch_size等),以提高模型训练的效果。如果想得到一个效果好的深度学习神经网络模型,超参的设置非常关键。因为模型参数空间大,目前超参调整都是通过手动,依赖人工经验或者不断尝试,且不同模型、样本数据和场景下不尽相同,所以需要大量尝试,时间成本和资源成本非常浪费。PaddleHub Auto Fine-tune可以实现自动调整超参数。
PaddleHub Auto Fine-tune提供两种超参优化策略:
* **HAZero**: 核心思想是通过对正态分布中协方差矩阵的调整来处理变量之间的依赖关系和scaling。算法基本可以分成以下三步:
1. 采样产生新解
2. 计算目标函数值
3. 更新正态分布参数。
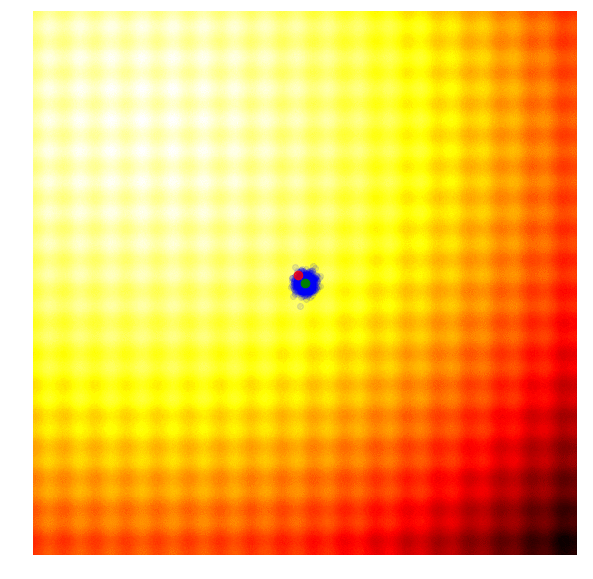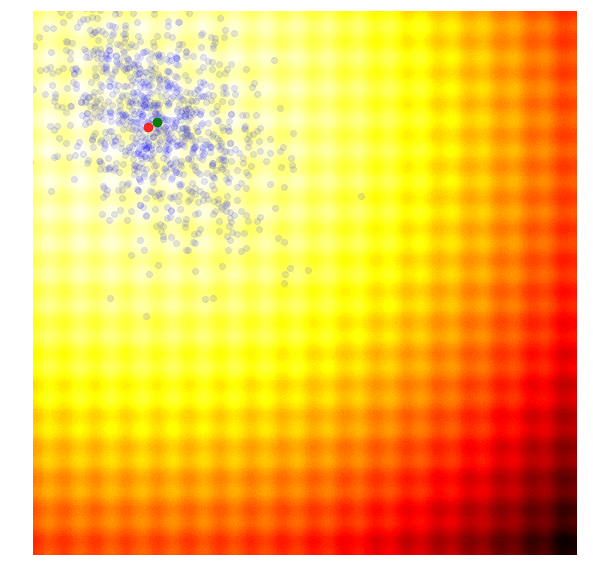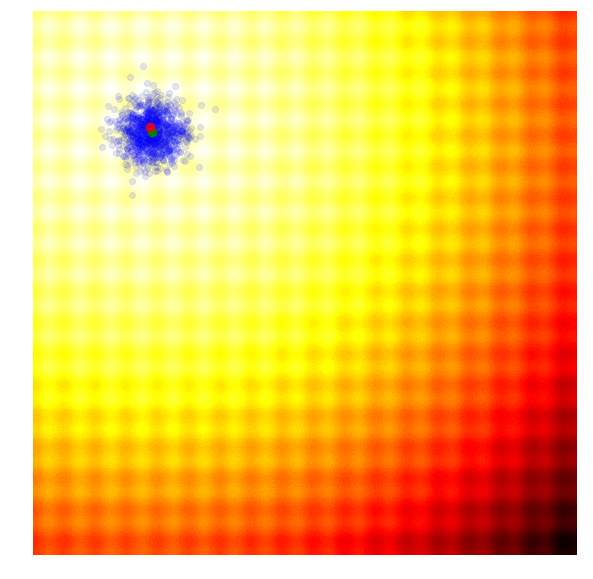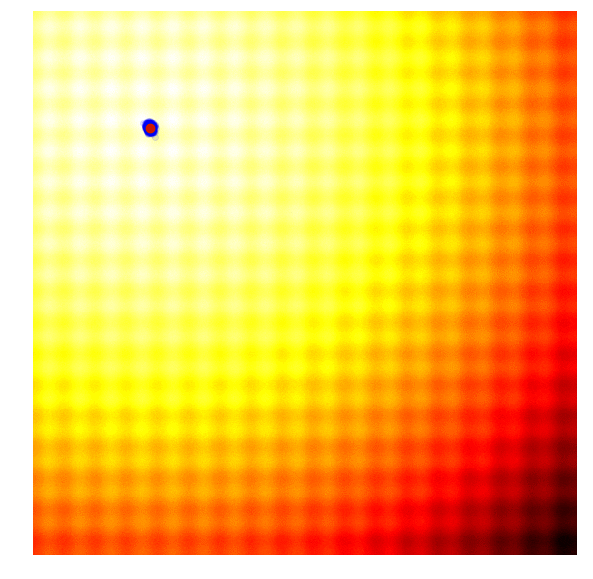
调整参数的基本思路为,调整参数使得产生更优解的概率逐渐增大。优化过程如下图:
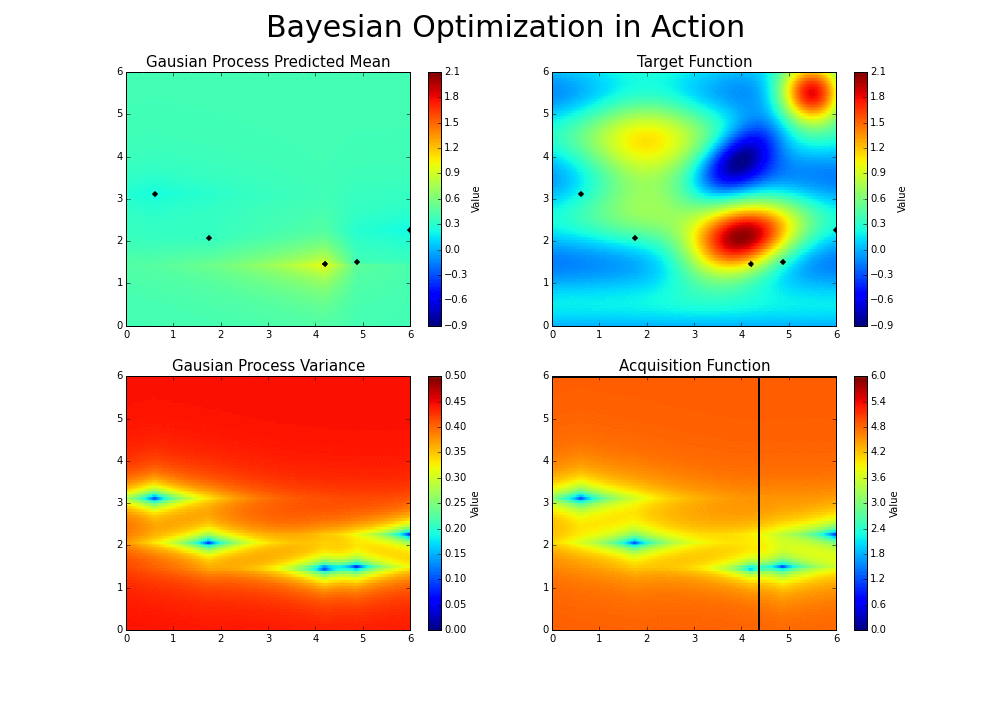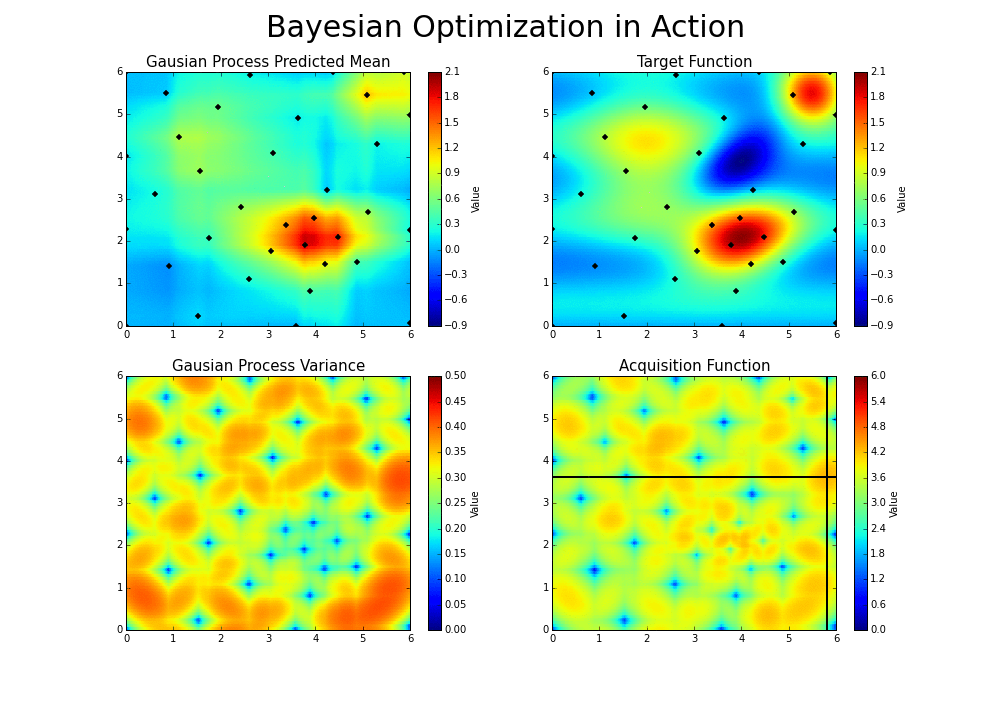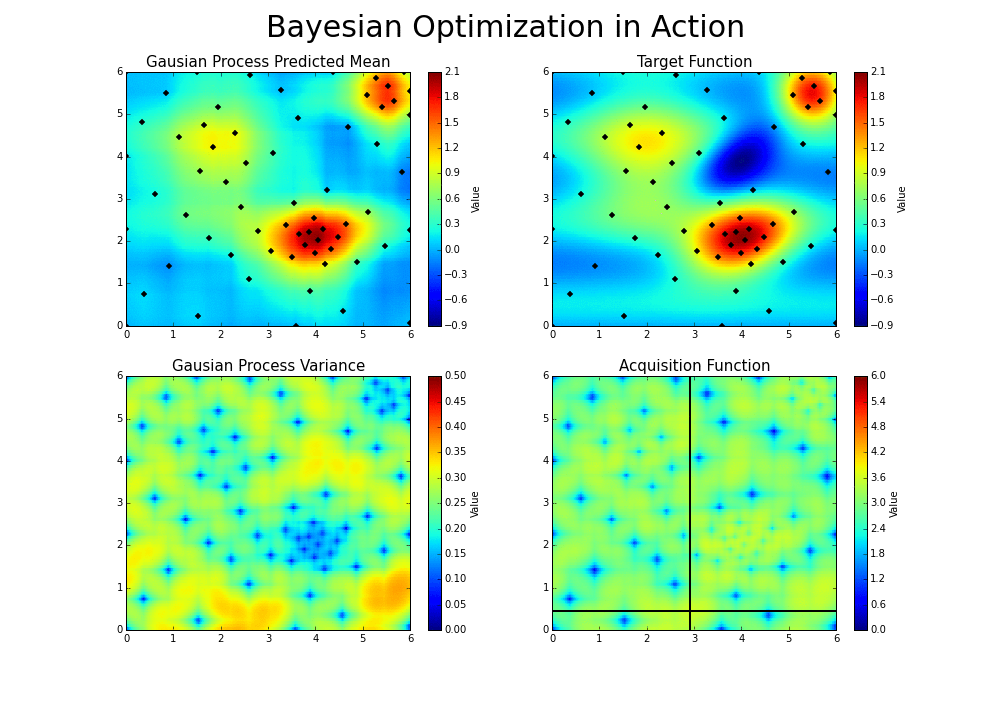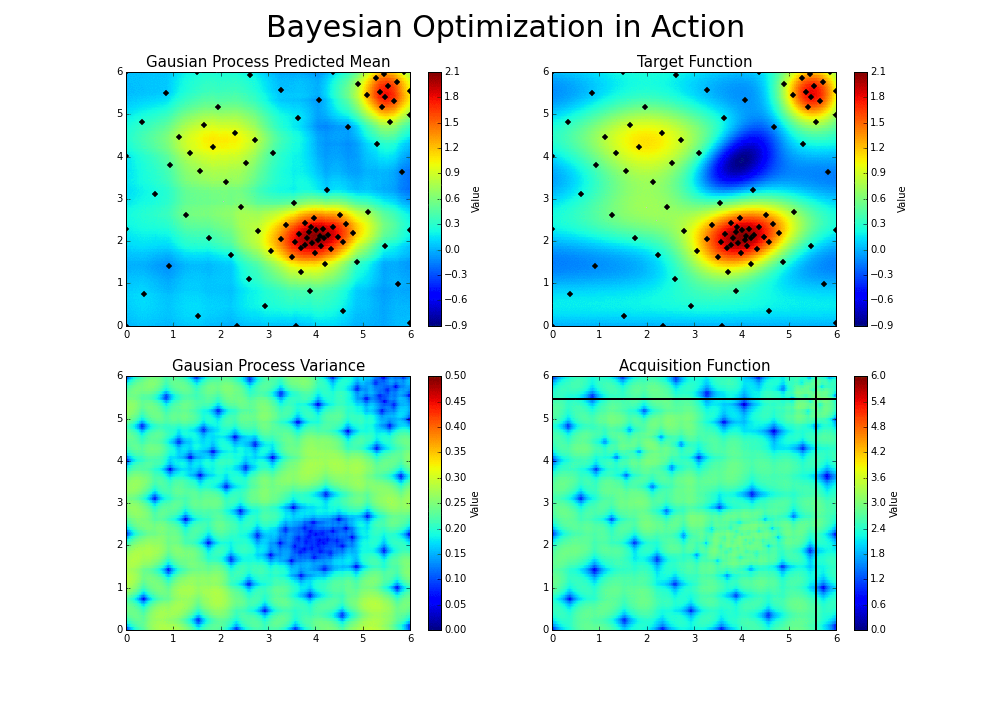
*图片来源于https://www.kaggle.com/clair14/tutorial-bayesian-optimization*
* PSHE2: 采用哈密尔顿动力系统搜索参数空间中“势能”最低的点。而最优超参数组合就是势能低点。现在想求得最优解就是要找到更新超参数组合,即如何更新超参数,才能让算法更快更好的收敛到最优解。PSHE2算法根据超参数本身历史的最优,在一定随机扰动的情况下决定下一步的更新方向。
PaddleHub Auto Fine-tune为了评估搜索的超参对于任务的效果,提供两种超参评估策略:
* **Full-Trail**: 给定一组超参,利用这组超参从头开始Fine-tune一个新模型,之后在验证集评估这个模型
* **Model-Based**: 给定一组超参,若这组超参是第一轮尝试的超参组合,则从头开始Fine-tune一个新模型;否则基于前几轮已保存的较好模型,在当前的超参数组合下继续Fine-tune并评估。
## 二、准备工作
使用PaddleHub Auto Fine-tune需要准备两个指定格式的文件:待优化的超参数信息yaml文件hparam.yaml和需要Fine-tune的python脚本train.py
### 1. hparam.yaml
hparam给出待搜索的超参名字、类型(int或者float,离散型和连续型的两种超参)、搜索范围等信息,通过这些信息构建了一个超参空间,PaddleHub将在这个空间内进行超参数的搜索,将搜索到的超参传入train.py获得评估效果,根据评估效果自动调整超参搜索方向,直到满足搜索次数。
**Note**:
* yaml文件的最外层级的key必须是param_list
```
param_list:
- name : hparam1
init_value : 0.001
type : float
lower_than : 0.05
greater_than : 0.00005
...
```
* 超参名字可以任意指定,PaddleHub会将搜索到的值以指定名称传递给train.py使用
* 优化超参策略选择HAZero时,需要提供两个以上的待优化超参。
### 2. train.py
train.py用于接受PaddleHub搜索到的超参进行一次优化过程,将优化后的效果返回
**NOTE**:
* train.py的选项参数须包含待优化超参数,待搜索超参数选项名字和yaml文件中的超参数名字保持一致。
* train.py须包含选项参数saved_params_dir,优化后的参数将会保存到该路径下。
* 超参评估策略选择ModelBased时,train.py须包含选项参数model_path,自动从model_path指定的路径恢复模型
* train.py须输出模型的评价效果(建议使用验证集或者测试集上的评价效果),输出以“AutoFinetuneEval"开始,与评价效果之间以“\t”分开,如
```python
print("AutoFinetuneEval"+"\t" + str(eval_acc))
```
* 输出的评价效果取值范围应为`(-∞, 1]`,取值越高,表示效果越好。
### 示例
[PaddleHub Auto Fine-tune超参优化--NLP情感分类任务](./autofinetune-nlp.md)
[PaddleHub Auto Fine-tune超参优化--CV图像分类任务](./autofinetune-cv.md)
## 三、启动方式
**确认安装PaddleHub版本在1.2.0以上, 同时PaddleHub Auto Fine-tune功能要求至少有一张GPU显卡可用。**
通过以下命令方式:
```shell
$ OUTPUT=result/
$ hub autofinetune train.py --param_file=hparam.yaml --cuda=['1','2'] --popsize=5 --round=10
--output_dir=${OUTPUT} --evaluate_choice=fulltrail --tuning_strategy=pshe2
```
其中,选项
> `--param_file`: 必填,待优化的超参数信息yaml文件,即上述[hparam.yaml](#hparam.yaml)。
> `--cuda`: 必填,设置运行程序的可用GPU卡号,list类型,中间以逗号隔开,不能有空格,默认为[‘0’]
> `--popsize`: 可选,设置程序运行每轮产生的超参组合数,默认为5
> `--round`: 可选,设置程序运行的轮数,默认为10
> `--output_dir`: 可选,设置程序运行输出结果存放目录,不指定该选项参数时,在当前运行路径下生成存放程序运行输出信息的文件夹
> `--evaluate_choice`: 可选,设置自动优化超参的评价效果方式,可选fulltrail和modelbased, 默认为modelbased
> `--tuning_strategy`: 可选,设置自动优化超参策略,可选hazero和pshe2,默认为pshe2
**NOTE**:
* 进行超参搜索时,一共会进行n轮(--round指定),每轮产生m组超参(--popsize指定)进行搜索。上一轮的优化结果决定下一轮超参数调整方向
* 当指定GPU数量不足以同时跑一轮时,Auto Fine-tune功能自动实现排队为了提高GPU利用率,建议卡数为刚好可以被popsize整除。如popsize=6,cuda=['0','1','2','3'],则每搜索一轮,Auto Fine-tune自动起四个进程训练,所以第5/6组超参组合需要排队一次,在搜索第5/6两组超参时,会存在两张卡出现空闲等待的情况,如果设置为3张可用的卡,则可以避免这种情况的出现。
## 四、目录结构
进行自动超参搜索时,PaddleHub会生成以下目录
```
./output_dir/
├── log_file.txt
├── visualization
├── round0
├── round1
├── ...
└── roundn
├── log-0.info
├── log-1.info
├── ...
├── log-m.info
├── model-0
├── model-1
├── ...
└── model-m
```
其中output_dir为启动autofinetune命令时指定的根目录,目录下:
* log_file.txt记录每一轮搜索所有的超参以及整个过程中所搜索到的最优超参
* visualization记录可视化过程的日志文件
* round0 ~ roundn记录每一轮的数据,在每个round目录下,还存在以下文件:
* log-0.info ~ log-m.info记录每个搜索方向的日志
* model-0 ~ model-m记录对应搜索的参数
## 五、可视化
Auto Fine-tune API在优化超参过程中会自动对关键训练指标进行打点,启动程序后执行下面命令
```shell
$ tensorboard --logdir ${OUTPUT}/visualization --host ${HOST_IP} --port ${PORT_NUM}
```
其中${OUTPUT}为AutoDL根目录,${HOST_IP}为本机IP地址,${PORT_NUM}为可用端口号,如本机IP地址为192.168.0.1,端口号8040,
用浏览器打开192.168.0.1:8040,即可看到搜索过程中各超参以及指标的变化情况
## 六、其他
1. 如在使用Auto Fine-tune功能时,输出信息中包含如下字样:
**WARNING:Program which was ran with hyperparameters as ... was crashed!**
首先根据终端上的输出信息,确定这个输出信息是在第几个round(如round 3),之后查看${OUTPUT}/round3/下的日志文件信息log.info, 查看具体出错原因。
2. PaddleHub Auto Fine-tune 命令行支持从启动命令hub autofinetune传入train.py中不需要搜索的选项参数,如
[PaddleHub Auto Fine-tune超参优化--NLP情感分类任务](./autofinetune-nlp.md)示例中的max_seq_len选项,可以参照以下方式传入。
```shell
$ OUTPUT=result/
$ hub autofinetune train.py --param_file=hparam.yaml --cuda=['1','2'] --popsize=5 --round=10
--output_dir=${OUTPUT} --evaluate_choice=fulltrail --tuning_strategy=pshe2 max_seq_len 128
```
3. PaddleHub Auto Fine-tune功能使用过程中建议使用的GPU卡仅供PaddleHub使用,无其他任务使用。