```shell
$ hub install ernie==1.2.0
```
## 在线体验
AI Studio 快速体验
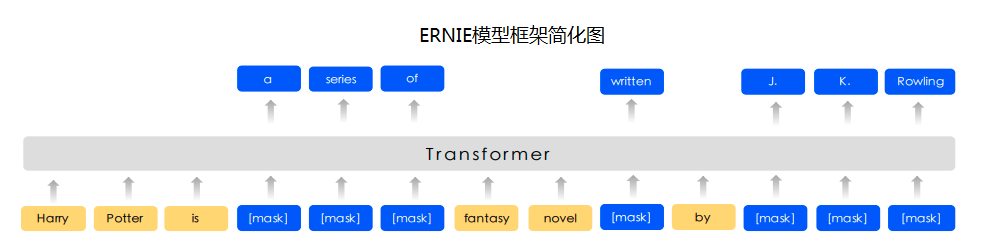
更多详情请参考[ERNIE论文](https://arxiv.org/abs/1904.09223)
## API
```python
def context(
trainable=True,
max_seq_len=128
)
```
用于获取Module的上下文信息,得到输入、输出以及预训练的Paddle Program副本
**参数**
> trainable:设置为True时,Module中的参数在Fine-tune时也会随之训练,否则保持不变。
> max_seq_len:BERT模型的最大序列长度,若序列长度不足,会通过padding方式补到**max_seq_len**, 若序列长度大于该值,则会以截断方式让序列长度为**max_seq_len**,max_seq_len可取值范围为0~512;
**返回**
> inputs:dict类型,有以下字段:
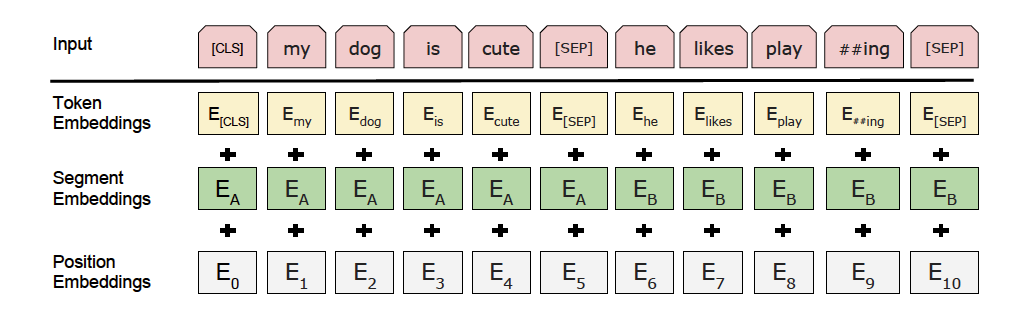
> >**input_ids**存放输入文本tokenize后各token对应BERT词汇表的word ids, shape为\[batch_size, max_seq_len\],int64类型;
> >**position_ids**存放输入文本tokenize后各token所在该文本的位置,shape为\[batch_size, max_seq_len\],int64类型;
> >**segment_ids**存放各token所在文本的标识(token属于文本1或者文本2),shape为\[batch_size, max_seq_len\],int64类型;
> >**input_mask**存放token是否为padding的标识,shape为\[batch_size, max_seq_len\],int64类型;
>
> outputs:dict类型,Module的输出特征,有以下字段:
> >**pooled_output**字段存放句子粒度的特征,可用于文本分类等任务,shape为 \[batch_size, 768\],int64类型;
> >**sequence_output**字段存放字粒度的特征,可用于序列标注等任务,shape为 \[batch_size, seq_len, 768\],int64类型;
>
> program:包含该Module计算图的Program。
```python
def get_embedding(
texts,
use_gpu=False,
batch_size=1
)
```
用于获取输入文本的句子粒度特征与字粒度特征
**参数**
> texts:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
> use_gpu:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
**返回**
> results:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
>
```python
def get_params_layer()
```
用于获取参数层信息,该方法与ULMFiTStrategy联用可以严格按照层数设置分层学习率与逐层解冻。
**参数**
> 无
**返回**
> params_layer:dict类型,key为参数名,值为参数所在层数
**代码示例**
```python
import paddlehub as hub
# Load $ hub install ernie pretrained model
module = hub.Module(name="ernie")
inputs, outputs, program = module.context(trainable=True, max_seq_len=128)
# Must feed all the tensor of ernie's module need
input_ids = inputs["input_ids"]
position_ids = inputs["position_ids"]
segment_ids = inputs["segment_ids"]
input_mask = inputs["input_mask"]
# Use "pooled_output" for sentence-level output.
pooled_output = outputs["pooled_output"]
# Use "sequence_output" for token-level output.
sequence_output = outputs["sequence_output"]
# Use "get_embedding" to get embedding result.
embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text_a","Sample2_text_b"]], use_gpu=True)
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
利用该PaddleHub Module Fine-tune示例,可参考[文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.2/demo/text-classification)、[序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.2/demo/sequence-labeling)。
`Note`:建议该PaddleHub Module在**GPU**环境中运行。如出现显存不足,可以将**batch_size**或**max_seq_len**调小。
## 查看代码
https://github.com/PaddlePaddle/ERNIE
## 依赖
paddlepaddle >= 1.6.2
paddlehub >= 1.6.0
## 更新历史
* 1.0.0
初始发布
* 1.0.1
修复该PaddleHub Module在paddlepaddle1.4.0版本、CPU环境下运行错误的问题
* 1.0.2
修复该PaddleHub Module在paddlepaddle1.5.0版本下兼容问题
* 1.1.0
ERNIE预训练时max_seq_len设置为512
* 1.2.0
支持get_embedding与get_params_layer