English | [简体中文](README_ch.md)
 ------------------------------------------------------------------------------------------
[](LICENSE)
[](https://github.com/PaddlePaddle/PaddleHub/releases)


## Introduction
- PaddleHub aims to provide developers with rich, high-quality, and directly usable pre-trained models.
- **【No need for deep learning background, no data and training process】**,you can use AI models quickly and enjoy the dividends of the artificial intelligence era.
- Covers the four major categories of CV, NLP, Audio, and Video, and supports **one-click prediction**, **one-click service deployment** and **migration learning**
- All models are open source download, **offline can run**.
**Recent updates**
- 2020.11.20: Release 2.0-beta version, fully migrate the dynamic graph programming mode, and upgrade the service deployment Serving capability; add 1 hand key point detection model, 12 image animation models, 3 image editing models, 3 speech synthesis models, syntax Analyzing one, the total number of pre-trained models reaches **【182】**.
- 2020.10.09: Added 4 new OCR multi-language series models, 4 image editing models, and the total number of pre-trained models reached **【162】**.
- 2020.09.27: 6 new text generation models and 1 image segmentation model were added, and the total number of pre-trained models reached **【154】**.
- 2020.08.13: Released v1.8.1, added a segmentation model, and supports EMNLP2019-Sentence-BERT as a text matching task network. The total number of pre-training models reaches **【147】**.
- 2020.07.29: Release v1.8.0, new AI couplets and AI writing poems, jieba word cutting, text data LDA, semantic similarity calculation, new target detection, short video classification model, ultra-lightweight Chinese and English OCR, new pedestrian detection, vehicle Industrial-grade models such as detection and animal recognition support VisualDL visualization training, and the total number of pre-training models reaches **【135】**.
## Features
- **【Abundant Pre-trained Models】**: 180+ pre-trained models covering the four major categories of CV, NLP, Audio, and Video, all open source downloads, and can be run offline.
- **【Quick Model Prediction】**: Model calls can be realized through a one-line command line or a minimalist Python API to quickly experience the model effect.
- **【Model As Service】**: A one-line command to build deep learning model API service deployment capabilities.
- **【Ten Lines of Code for Transfer Learning】**: Ten lines of code complete the transfer-learning task of image classification and text classification.
- **【PIP installation 】**: Support PIP quick installation and use.
- **【Cross-platform Compatibility】**: Can run on Linux, Windows, MacOS and other operating systems.
## Visualization
### Text recognition
- Contains ultra-lightweight Chinese and English OCR models, high-precision Chinese and English, multilingual German, French, Japanese, Korean OCR recognition.
------------------------------------------------------------------------------------------
[](LICENSE)
[](https://github.com/PaddlePaddle/PaddleHub/releases)


## Introduction
- PaddleHub aims to provide developers with rich, high-quality, and directly usable pre-trained models.
- **【No need for deep learning background, no data and training process】**,you can use AI models quickly and enjoy the dividends of the artificial intelligence era.
- Covers the four major categories of CV, NLP, Audio, and Video, and supports **one-click prediction**, **one-click service deployment** and **migration learning**
- All models are open source download, **offline can run**.
**Recent updates**
- 2020.11.20: Release 2.0-beta version, fully migrate the dynamic graph programming mode, and upgrade the service deployment Serving capability; add 1 hand key point detection model, 12 image animation models, 3 image editing models, 3 speech synthesis models, syntax Analyzing one, the total number of pre-trained models reaches **【182】**.
- 2020.10.09: Added 4 new OCR multi-language series models, 4 image editing models, and the total number of pre-trained models reached **【162】**.
- 2020.09.27: 6 new text generation models and 1 image segmentation model were added, and the total number of pre-trained models reached **【154】**.
- 2020.08.13: Released v1.8.1, added a segmentation model, and supports EMNLP2019-Sentence-BERT as a text matching task network. The total number of pre-training models reaches **【147】**.
- 2020.07.29: Release v1.8.0, new AI couplets and AI writing poems, jieba word cutting, text data LDA, semantic similarity calculation, new target detection, short video classification model, ultra-lightweight Chinese and English OCR, new pedestrian detection, vehicle Industrial-grade models such as detection and animal recognition support VisualDL visualization training, and the total number of pre-training models reaches **【135】**.
## Features
- **【Abundant Pre-trained Models】**: 180+ pre-trained models covering the four major categories of CV, NLP, Audio, and Video, all open source downloads, and can be run offline.
- **【Quick Model Prediction】**: Model calls can be realized through a one-line command line or a minimalist Python API to quickly experience the model effect.
- **【Model As Service】**: A one-line command to build deep learning model API service deployment capabilities.
- **【Ten Lines of Code for Transfer Learning】**: Ten lines of code complete the transfer-learning task of image classification and text classification.
- **【PIP installation 】**: Support PIP quick installation and use.
- **【Cross-platform Compatibility】**: Can run on Linux, Windows, MacOS and other operating systems.
## Visualization
### Text recognition
- Contains ultra-lightweight Chinese and English OCR models, high-precision Chinese and English, multilingual German, French, Japanese, Korean OCR recognition.

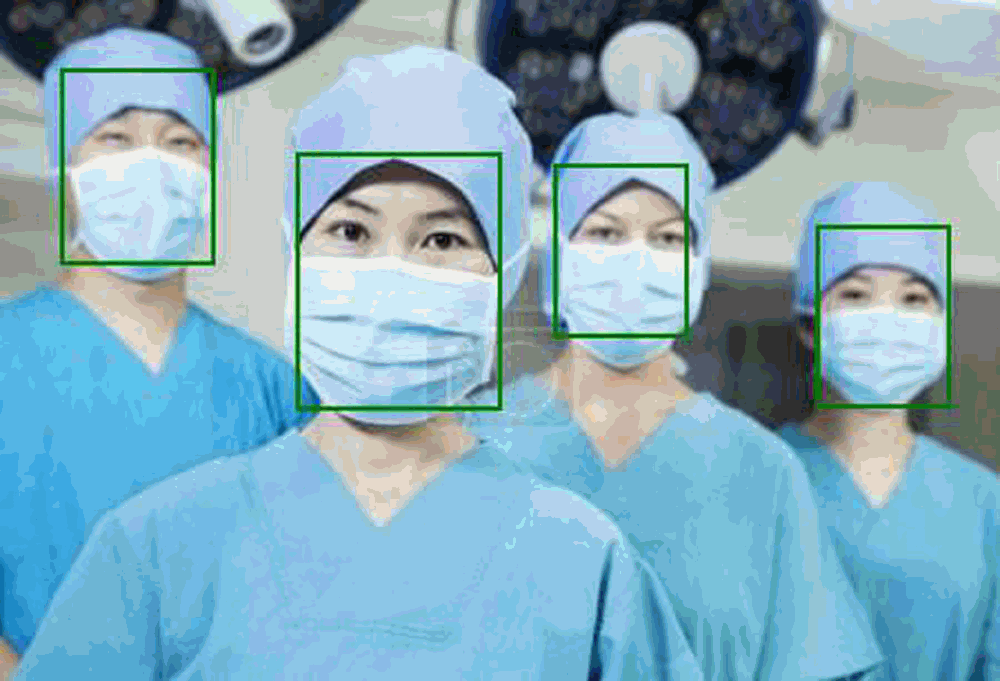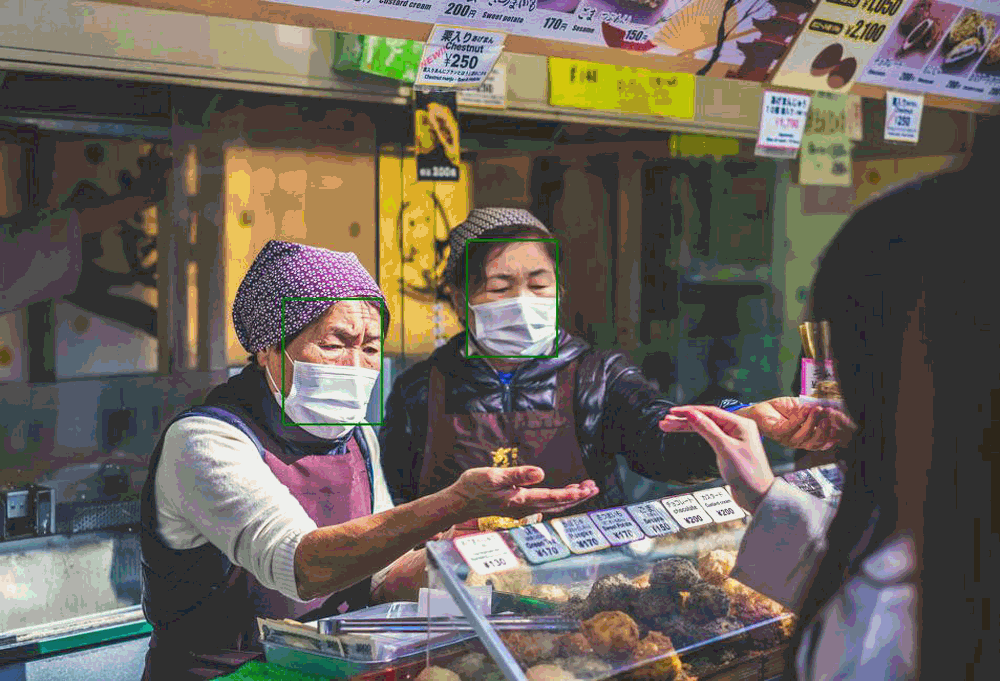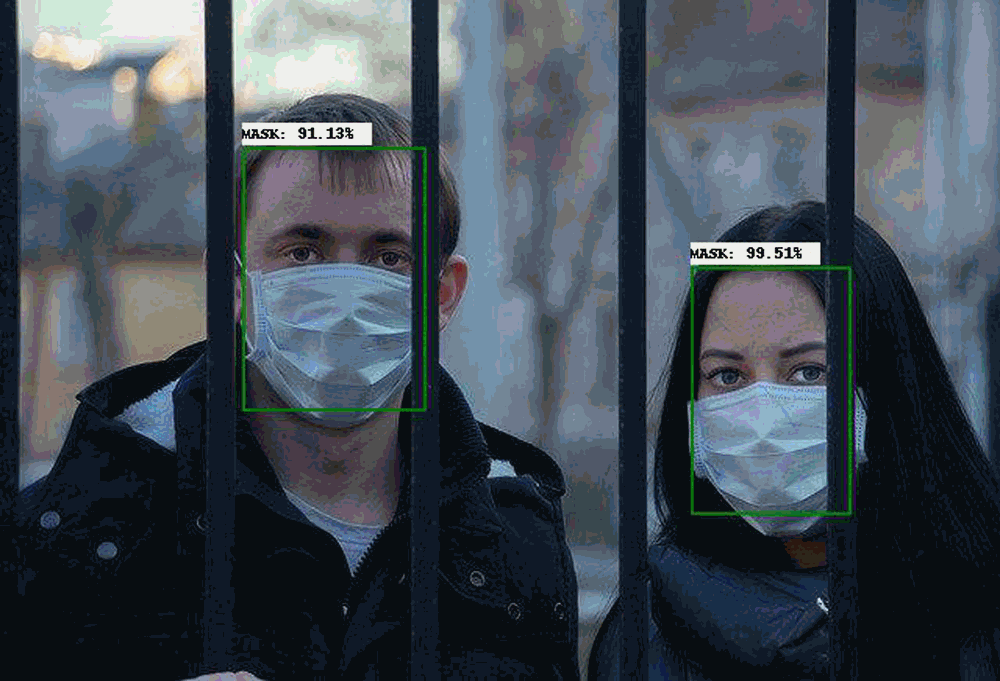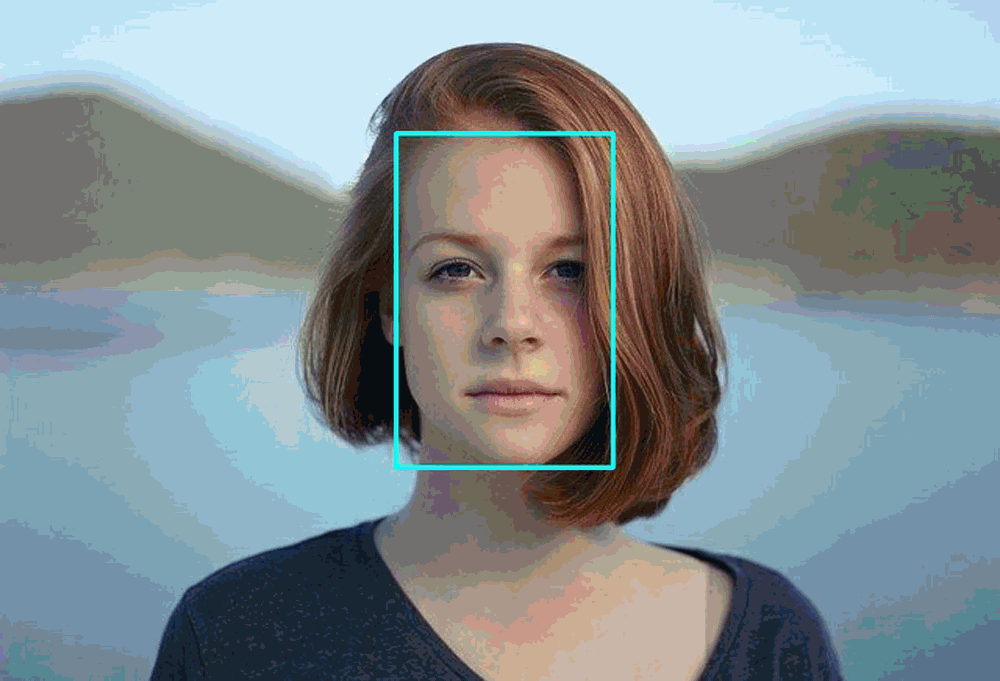
### Face Detection
- Including face detection, mask face detection, multiple algorithms are optional.
### Image editing
- 4 times super resolution effect, multiple super resolution models are optional.
- Colorization models can be used to repair old grayscale photos.
| SuperResolution |
Restoration |

|

|
### Object Detection
- Including pedestrian detection, vehicle detection, and more industrial-grade ultra-large-scale pretrained models are optional.
### Key Point Detection
- Supports body, face and hands key point detection in single or multiple person.
### Image Segmentation
- Contains excellent portrait cutout model, ACE2P human body analysis world champion model
### Image Animation
- Contains image style transfer models with Hayao Miyazaki and Makoto Shinkai styles, etc.
### Image Classification
- Including animal classification, dish classification, wild animal product classification, multiple algorithms are available.
### Lexical Analysis
- Including AI poem writing, AI couplets, AI love words, AI hidden poems, multiple algorithms are available.
### Syntax Analysis
- Leading Chinese syntactic analysis model.
### Sentiment Analysis
- Support Chinese comment sentiment analysis.
### Text Review
- Contains the review of Chinese pornographic text, and multiple algorithms are available.
### Speech Synthesis
- TTS speech synthesis algorithm, multiple algorithms are available
- Input: `Life was like a box of chocolates, you never know what you're gonna get.`
- The synthesis effect is as follows:
| deepvoice3 |
fastspeech |
transformer |

|
|
|
### Video Classification
- Contains short video classification, supports 3000+ tag types, can output TOP-K tags, and multiple algorithms are optional.
- `Example: Input a short video of swimming, the algorithm can output the result of "swimming"`
## ===Key Points===
-All the above pre-trained models are all open source, and the number of models is continuously updated. Welcome Star to pay attention.
## Welcome to join PaddleHub technical group
- If you have any questions during the use of the model, you can join the official WeChat group to get more efficient questions and answers, and fully communicate with developers from all walks of life. We look forward to your joining.
If you fail to scan the code, please add WeChat 15711058002 and note "Hub", the operating class will invite you to join the group.
## Documentation Tutorial
- [PIP Installation](./docs/docs_en/installation_en.md)
- Quick Start
- [Command Line](./docs/docs_en/quick_experience/cmd_quick_run_en.md)
- [Python API](./docs/docs_en/quick_experience/python_use_hub_en.md)
- [More_Demos](./docs/docs_en/quick_experience/more_demos_en.md)
- Rich Pre-trained Models 182
- [Boutique Featured Models](./docs/docs_en/figures_en.md)
- Computer Vision 126
- [Image Classification 64 ](./modules/image/classification/README_en.md)
- [Object Detection 13 ](./modules/image/object_detection/README_en.md)
- [Face Detection 7 ](./modules/image/face_detection/README_en.md)
- [Key Point Detection 3 ](./modules/image/keypoint_detection/README_en.md)
- [Image Segmentation 7 ](./modules/image/semantic_segmentation/README_en.md)
- [Text Recognition 8 ](./modules/image/text_recognition/README_en.md)
- [Image Generation 17 ](./modules/image/Image_gan/README_en.md)
- [Image Editing 7 ](./modules/image/Image_editing/README_en.md)
- Natural Language Processing 48
- [Lexical Analysis 2 ](./modules/text/lexical_analysis/README_en.md)
- [Syntax Analysis 1 ](./modules/text/syntactic_analysis/README_en.md)
- [Sentiment Analysis 7 ](./modules/text/sentiment_analysis/README_en.md)
- [Text Review 3 ](./modules/text/text_review/README_en.md)
- [Text Generation 9 ](./modules/text/text_generation/README_en.md)
- [Semantic Models 26 ](./modules/text/language_model/README_en.md)
- Audio 3
- [Speech Synthesis 3 ](./modules/audio/README_en.md)
- Video 5
- [Video Classification 5 ](./modules/video/README_en.md)
- Deploy
- [Local Inference Deployment](./docs/docs_en/quick_experience/python_use_hub_en.md)
- [One Line of Code Service deployment](./docs/docs_en/tutorial/serving_en.md)
- [Mobile Lite Deployment (link to Lite tutorial)](https://paddle-lite.readthedocs.io/zh/latest/quick_start/tutorial.html)
- Advanced documentation
- [Command_Line](./docs/docs_en/tutorial/cmdintro_en.md)
- [How to Load Data](./docs/docs_en/tutorial/how_to_load_data_en.md)
- Community
- [Join the technical group](#Welcome_joinus)
- [Contribute pre-trained models](./docs/docs_en/contribution/contri_pretrained_model_en.md)
- [Contribute code](./docs/docs_en/contribution/contri_pr_en.md)
- [License](#License)
- [Contribution](#Contribution)
## License
The release of this project is certified by the Apache 2.0 license.
## Contribution
We welcome you to contribute code to PaddleHub, and thank you for your feedback.
* Many thanks to [Austendeng](https://github.com/Austendeng) for fixing the SequenceLabelReader
* Many thanks to [cclauss](https://github.com/cclauss) optimizing travis-ci check
* Many thanks to [奇想天外](http://www.cheerthink.com/),Contributed a demo of mask detection
* Many thanks to [mhlwsk](https://github.com/mhlwsk),Contributed the repair sequence annotation prediction demo
* Many thanks to [zbp-xxxp](https://github.com/zbp-xxxp),Contributed modules for viewing pictures and writing poems
* Many thanks to [zbp-xxxp](https://github.com/zbp-xxxp) and [七年期限](https://github.com/1084667371),Jointly contributed to the Mid-Autumn Festival Special Edition Module
* Many thanks to [livingbody](https://github.com/livingbody),Contributed models for style transfer based on PaddleHub's capabilities and Mid-Autumn Festival WeChat Mini Program











