# ace2p
|模型名称|ace2p|
| :--- | :---: |
|类别|图像-图像分割|
|网络|ACE2P|
|数据集|LIP|
|是否支持Fine-tuning|否|
|模型大小|259MB|
|指标|-|
|最新更新日期|2021-02-26|
## 一、模型基本信息
- ### 应用效果展示
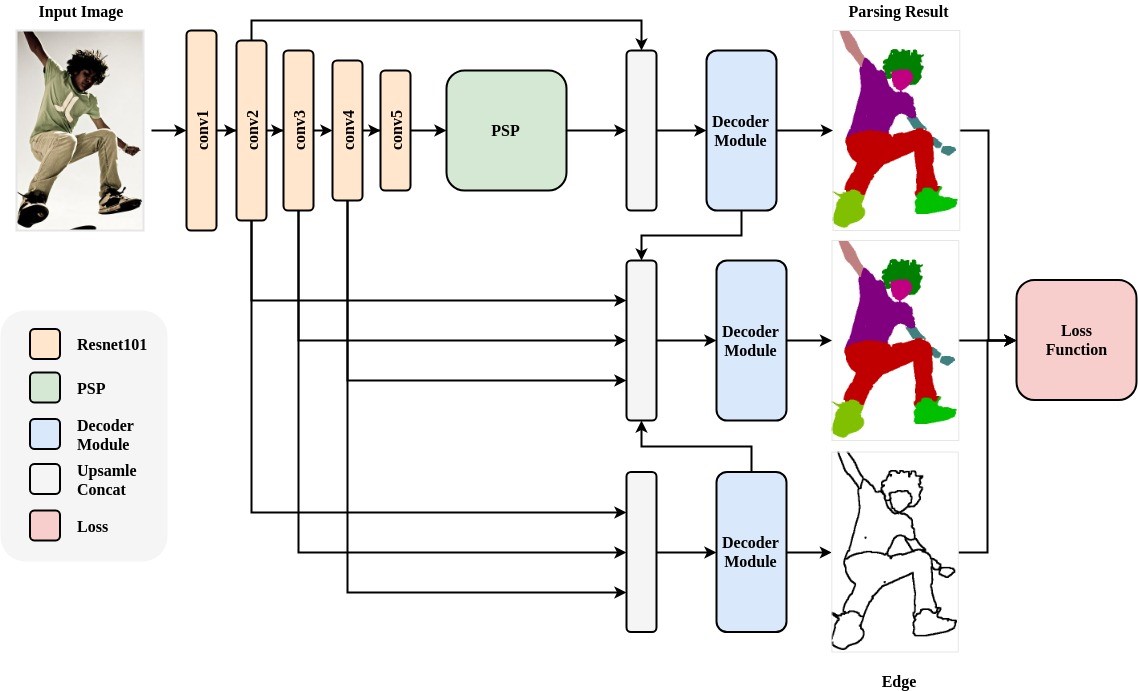
- 网络结构:
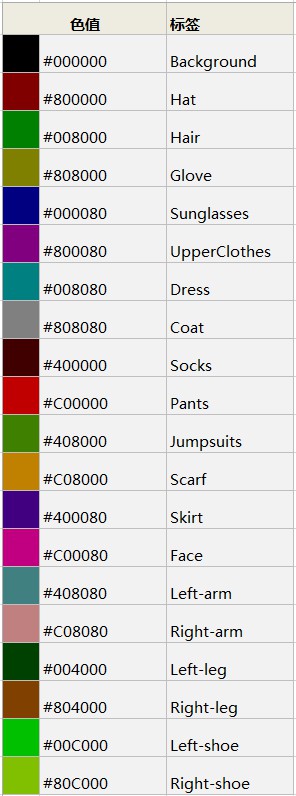
- 调色板
- 样例结果示例:


- ### 模型介绍
- 人体解析(Human Parsing)是细粒度的语义分割任务,其旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。ACE2P通过融合底层特征,全局上下文信息和边缘细节,端到端地训练学习人体解析任务。该结构针对Intersection over Union指标进行针对性的优化学习,提升准确率。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届LIP挑战赛中赢得了全部三个人体解析任务的第一名。该PaddleHub Module采用ResNet101作为骨干网络,接受输入图片大小为473x473x3。
## 二、安装
- ### 1、环境依赖
- paddlepaddle >= 2.0.0
- paddlehub >= 2.0.0
- ### 2.安装
- ```shell
$ hub install ace2p
```
- 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
| [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
## 三、模型API预测
- ### 1、命令行预测
```shell
$ hub run ace2p --input_path "/PATH/TO/IMAGE"
```
- ### 2、预测代码示例
```python
import paddlehub as hub
import cv2
human_parser = hub.Module(name="ace2p")
result = human_parser.segmentation(images=[cv2.imread('/PATH/TO/IMAGE')])
```
- ### 3、API
```python
def segmentation(images=None,
paths=None,
batch_size=1,
use_gpu=False,
output_dir='ace2p_output',
visualization=False):
```
- 预测API,用于图像分割得到人体解析。
- **参数**
* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
* paths (list\[str\]): 图片的路径;
* batch\_size (int): batch 的大小;
* use\_gpu (bool): 是否使用 GPU;
* output\_dir (str): 保存处理结果的文件目录;
* visualization (bool): 是否将识别结果保存为图片文件。
- **返回**
* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有'path', 'data',相应的取值为:
* path (str): 原输入图片的路径;
* data (numpy.ndarray): 图像分割得到的结果,shape 为`H * W`,元素的取值为0-19,表示每个像素的分类结果,映射顺序与下面的调色板相同。
```python
def save_inference_model(dirname,
model_filename=None,
params_filename=None,
combined=True)
```
- 将模型保存到指定路径。
- **参数**
* dirname: 存在模型的目录名称
* model\_filename: 模型文件名称,默认为\_\_model\_\_
* params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
* combined: 是否将参数保存到统一的一个文件中。
## 四、服务部署
- PaddleHub Serving可以部署一个人体解析的在线服务。
- ### 第一步:启动PaddleHub Serving
- 运行启动命令:
```shell
$ hub serving start -m ace2p
```
- 这样就完成了一个人体解析服务化API的部署,默认端口号为8866。
- **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
- ### 第二步:发送预测请求
- 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
import requests
import json
import cv2
import base64
import numpy as np
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
def base64_to_cv2(b64str):
data = base64.b64decode(b64str.encode('utf8'))
data = np.fromstring(data, np.uint8)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
return data
# 发送HTTP请求
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/ace2p"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(base64_to_cv2(r.json()["results"][0]['data']))
```
## 五、更新历史
* 1.0.0
初始发布
* 1.1.0
适配paddlehub2.0版本