![]() ------------------------------------------------------------------------------------------
[](LICENSE)
[](https://github.com/PaddlePaddle/PaddleHub/releases)


## AI创造营·PaddleHub创意赛(火热招募)🔥🔥
诚邀各位开发者参加 **AI创造营·PaddleHub创意赛** 第一期。基于PaddleHub实现AI创意项目,只要你的脑洞够强,飞桨小哥哥亲手pick你出道!更有丰厚奖品带回家(1万元RMB、Switch游戏机&健身环、机械键盘、小度耳机、小度熊)。扫描下方图片中二维码参与报名,也可以点击[前往报名](https://aistudio.baidu.com/aistudio/competition/detail/72)立即报名。比赛时间2021年3月1号-2021年3月31号,快来参加吧~
------------------------------------------------------------------------------------------
[](LICENSE)
[](https://github.com/PaddlePaddle/PaddleHub/releases)


## AI创造营·PaddleHub创意赛(火热招募)🔥🔥
诚邀各位开发者参加 **AI创造营·PaddleHub创意赛** 第一期。基于PaddleHub实现AI创意项目,只要你的脑洞够强,飞桨小哥哥亲手pick你出道!更有丰厚奖品带回家(1万元RMB、Switch游戏机&健身环、机械键盘、小度耳机、小度熊)。扫描下方图片中二维码参与报名,也可以点击[前往报名](https://aistudio.baidu.com/aistudio/competition/detail/72)立即报名。比赛时间2021年3月1号-2021年3月31号,快来参加吧~
 ## 简介
- PaddleHub旨在为开发者提供丰富的、高质量的、直接可用的预训练模型。
- **【无需深度学习背景、无需数据与训练过程】**,可快速使用AI模型,享受人工智能时代红利。
- 涵盖CV、NLP、Audio、Video主流四大品类,支持**一键预测**、**一键服务化部署**和**快速迁移学习**
- 全部模型开源下载,**离线可运行**。
## 近期更新
- **2021.02.18**,发布v2.0.0版本,模型开发调试更简单,finetune接口更加灵活易用。视觉类任务迁移学习能力全面升级,支持[图像分类](./demo/image_classification/README.md)、[图像着色](./demo/colorization/README.md)、[风格迁移](./demo/style_transfer/README.md)等多种任务;BERT、ERNIE、RoBERTa等Transformer类模型升级至动态图,支持[文本分类](./demo/text_classification/README.md)、[序列标注](./demo/sequence_labeling/README.md)的Fine-Tune能力;优化服务化部署Serving能力,支持多卡预测、自动负载均衡,性能大幅度提升;新增自动数据增强能力[Auto Augment](./demo/autoaug/README.md),能高效地搜索适合数据集的数据增强策略组合。新增[词向量模型](./modules/text/embedding)61个,其中包含中文模型51个,英文模型10个;新增[图像分割](./modules/thirdparty/image/semantic_segmentation)模型4个、[深度模型](./modules/thirdparty/image/depth_estimation)2个、[图像生成](./modules/thirdparty/image/Image_gan/style_transfer)模型7个、[文本生成](./modules/thirdparty/text/text_generation)模型3个。预训练模型总量达到[**【274】**](https://www.paddlepaddle.org.cn/hublist) 个。
- **2020.11.20**,发布2.0-beta版本,全面迁移动态图编程模式,服务化部署Serving能力升级;新增手部关键点检测1个、图像动漫化类12个、图片编辑类3个,语音合成类3个,句法分析1个,预训练模型总量到达 **【182】** 个。
- **2020.10.09**,新增OCR多语言系列模型4个,图像编辑模型4个,预训练模型总量到达 **【162】** 个。
- **2020.09.27**,新增文本生成模型6个,图像分割模型1个,预训练模型总量到达 **【154】** 个。
- **2020.08.13**,发布v1.8.1,新增人像分割模型Humanseg,支持EMNLP2019-Sentence-BERT作为文本匹配任务网络,预训练模型总量到达 **【147】** 个。
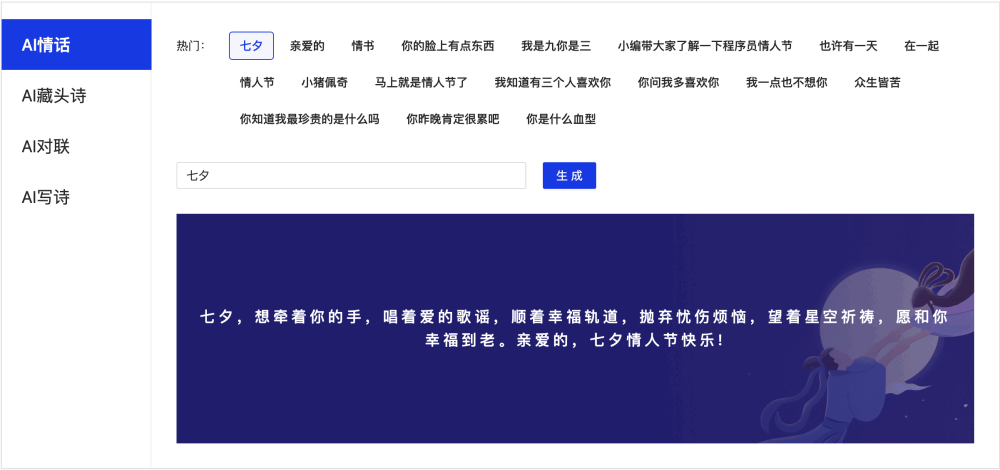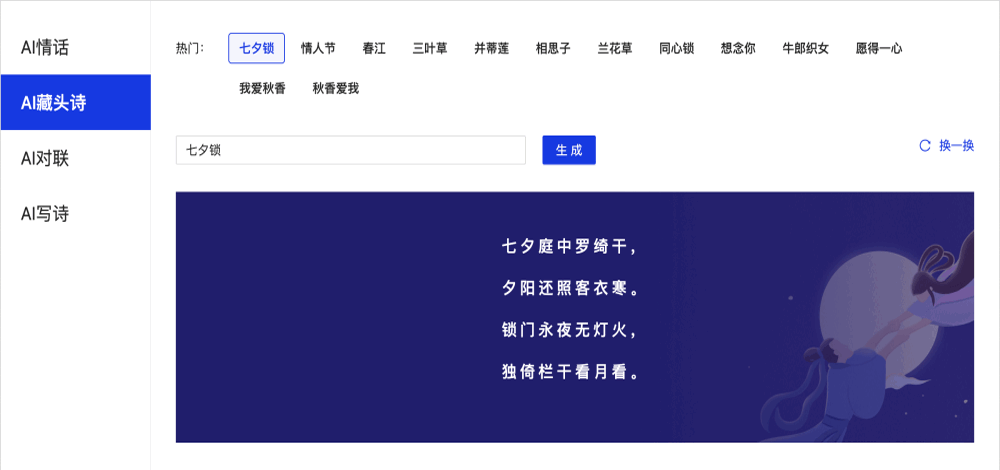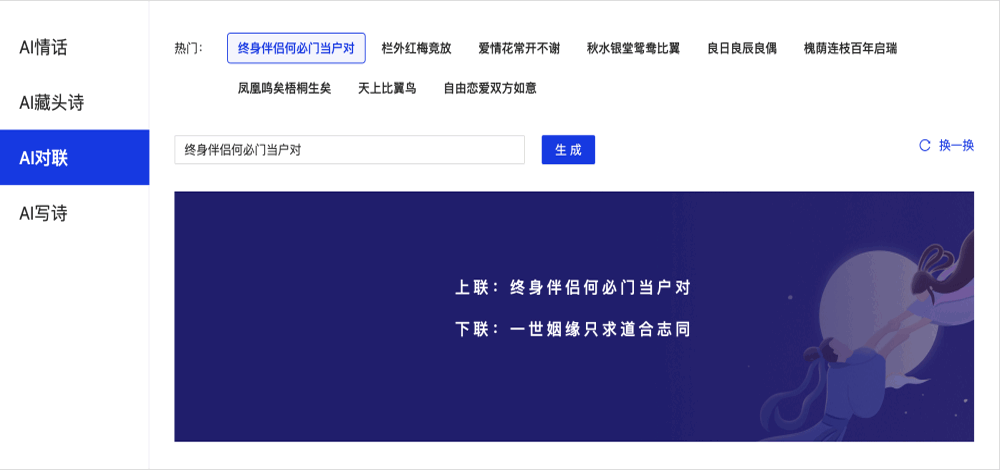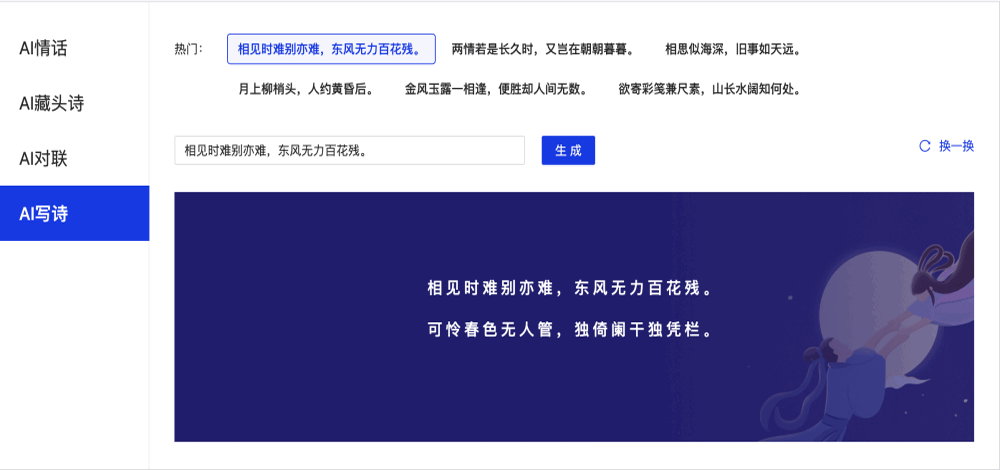
- **2020.07.29**,发布v1.8.0,新增AI对联和AI写诗、jieba切词,文本数据LDA、语义相似度计算,新增目标检测,短视频分类模型,超轻量中英文OCR,新增行人检测、车辆检测、动物识别等工业级模型,支持VisualDL可视化训练,预训练模型总量到达 **【135】** 个。
- [More](./docs/docs_ch/release.md)
## [特性](./docs/docs_ch/figures.md)
- **【丰富的预训练模型】**:涵盖CV、NLP、Audio、Video主流四大品类的 180+ 预训练模型,全部开源下载,离线可运行。
- **【一键模型快速预测】**:通过一行命令行或者极简的Python API实现模型调用,可快速体验模型效果。
- **【一键模型转服务化】**:一行命令,搭建深度学习模型API服务化部署能力。
- **【十行代码迁移学习】**:十行代码完成图片分类、文本分类的迁移学习任务
- **【跨平台兼容性】**:可运行于Linux、Windows、MacOS等多种操作系统
## 精品模型效果展示
### 文本识别
- 包含超轻量中英文OCR模型,高精度中英文、多语种德语、法语、日语、韩语OCR识别。
- 感谢CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)提供预训练模型,训练能力开放,欢迎体验。
## 简介
- PaddleHub旨在为开发者提供丰富的、高质量的、直接可用的预训练模型。
- **【无需深度学习背景、无需数据与训练过程】**,可快速使用AI模型,享受人工智能时代红利。
- 涵盖CV、NLP、Audio、Video主流四大品类,支持**一键预测**、**一键服务化部署**和**快速迁移学习**
- 全部模型开源下载,**离线可运行**。
## 近期更新
- **2021.02.18**,发布v2.0.0版本,模型开发调试更简单,finetune接口更加灵活易用。视觉类任务迁移学习能力全面升级,支持[图像分类](./demo/image_classification/README.md)、[图像着色](./demo/colorization/README.md)、[风格迁移](./demo/style_transfer/README.md)等多种任务;BERT、ERNIE、RoBERTa等Transformer类模型升级至动态图,支持[文本分类](./demo/text_classification/README.md)、[序列标注](./demo/sequence_labeling/README.md)的Fine-Tune能力;优化服务化部署Serving能力,支持多卡预测、自动负载均衡,性能大幅度提升;新增自动数据增强能力[Auto Augment](./demo/autoaug/README.md),能高效地搜索适合数据集的数据增强策略组合。新增[词向量模型](./modules/text/embedding)61个,其中包含中文模型51个,英文模型10个;新增[图像分割](./modules/thirdparty/image/semantic_segmentation)模型4个、[深度模型](./modules/thirdparty/image/depth_estimation)2个、[图像生成](./modules/thirdparty/image/Image_gan/style_transfer)模型7个、[文本生成](./modules/thirdparty/text/text_generation)模型3个。预训练模型总量达到[**【274】**](https://www.paddlepaddle.org.cn/hublist) 个。
- **2020.11.20**,发布2.0-beta版本,全面迁移动态图编程模式,服务化部署Serving能力升级;新增手部关键点检测1个、图像动漫化类12个、图片编辑类3个,语音合成类3个,句法分析1个,预训练模型总量到达 **【182】** 个。
- **2020.10.09**,新增OCR多语言系列模型4个,图像编辑模型4个,预训练模型总量到达 **【162】** 个。
- **2020.09.27**,新增文本生成模型6个,图像分割模型1个,预训练模型总量到达 **【154】** 个。
- **2020.08.13**,发布v1.8.1,新增人像分割模型Humanseg,支持EMNLP2019-Sentence-BERT作为文本匹配任务网络,预训练模型总量到达 **【147】** 个。
- **2020.07.29**,发布v1.8.0,新增AI对联和AI写诗、jieba切词,文本数据LDA、语义相似度计算,新增目标检测,短视频分类模型,超轻量中英文OCR,新增行人检测、车辆检测、动物识别等工业级模型,支持VisualDL可视化训练,预训练模型总量到达 **【135】** 个。
- [More](./docs/docs_ch/release.md)
## [特性](./docs/docs_ch/figures.md)
- **【丰富的预训练模型】**:涵盖CV、NLP、Audio、Video主流四大品类的 180+ 预训练模型,全部开源下载,离线可运行。
- **【一键模型快速预测】**:通过一行命令行或者极简的Python API实现模型调用,可快速体验模型效果。
- **【一键模型转服务化】**:一行命令,搭建深度学习模型API服务化部署能力。
- **【十行代码迁移学习】**:十行代码完成图片分类、文本分类的迁移学习任务
- **【跨平台兼容性】**:可运行于Linux、Windows、MacOS等多种操作系统
## 精品模型效果展示
### 文本识别
- 包含超轻量中英文OCR模型,高精度中英文、多语种德语、法语、日语、韩语OCR识别。
- 感谢CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)提供预训练模型,训练能力开放,欢迎体验。


| 图像超分辨率 | 黑白图片上色 |
|---|---|
 |
 |







| deepvoice3 | fastspeech | transformer |
|---|---|---|
|
|
|
|


