```shell
$ hub install ernie==2.0.0
```
## 在线体验
AI Studio 快速体验
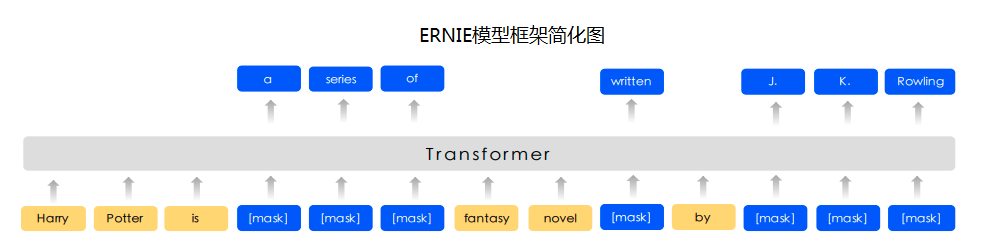
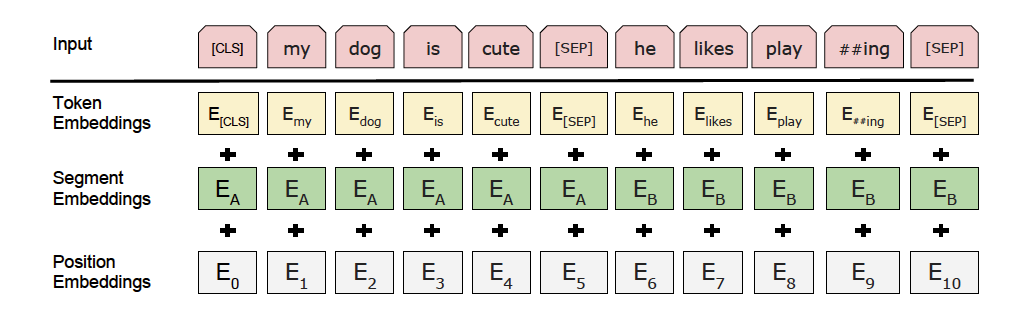
更多详情请参考[ERNIE论文](https://arxiv.org/abs/1904.09223)
## API
```python
def __init__(
task=None,
load_checkpoint=None,
label_map=None)
```
创建Module对象(动态图组网版本)。
**参数**
* `task`: 任务名称,可为`sequence_classification`。
* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
* `label_map`:预测时的类别映射表。
```python
def predict(
data,
max_seq_len=128,
batch_size=1,
use_gpu=False)
```
**参数**
* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,
每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
* `max_seq_len`:模型处理文本的最大长度
* `batch_size`:模型批处理大小
* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
**返回**
```python
def get_embedding(
texts,
use_gpu=False
)
```
用于获取输入文本的句子粒度特征与字粒度特征
**参数**
* `texts`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
**返回**
* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
**代码示例**
```python
import paddlehub as hub
data = [
'这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般',
'怀着十分激动的心情放映,可是看着看着发现,在放映完毕后,出现一集米老鼠的动画片',
'作为老的四星酒店,房间依然很整洁,相当不错。机场接机服务很好,可以在车上办理入住手续,节省时间。',
]
label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='ernie',
version='2.0.0',
task='sequence_classification',
load_checkpoint='/path/to/parameters',
label_map=label_map)
results = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=False)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text, results[idx]))
```
参考PaddleHub 文本分类示例。https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classifcation
## 服务部署
PaddleHub Serving可以部署一个在线获取预训练词向量。
### Step1: 启动PaddleHub Serving
运行启动命令:
```shell
$ hub serving start -m ernie
```
这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
### Step2: 发送预测请求
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
import requests
import json
# 指定用于预测的文本并生成字典{"text": [text_1, text_2, ... ]}
text = [["今天是个好日子", "天气预报说今天要下雨"], ["这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般"]]
# 以key的方式指定text传入预测方法的时的参数,此例中为"texts"
# 对应本地部署,则为module.get_embedding(texts=text)
data = {"texts": text}
# 发送post请求,content-type类型应指定json方式
url = "http://10.12.121.132:8866/predict/ernie"
# 指定post请求的headers为application/json方式
headers = {"Content-Type": "application/json"}
r = requests.post(url=url, headers=headers, data=json.dumps(data))
print(r.json())
```
## 查看代码
https://github.com/PaddlePaddle/ERNIE
## 依赖
paddlepaddle >= 2.0.0
paddlehub >= 2.0.0
## 更新历史
* 1.0.0
初始发布
* 1.0.1
修复该PaddleHub Module在paddlepaddle1.4.0版本、CPU环境下运行错误的问题
* 1.0.2
修复该PaddleHub Module在paddlepaddle1.5.0版本下兼容问题
* 1.1.0
ERNIE预训练时max_seq_len设置为512
* 1.2.0
支持get_embedding与get_params_layer
* 2.0.0
全面升级动态图版本,接口有所变化