# u2_conformer_librispeech
|模型名称|u2_conformer_librispeech|
| :--- | :---: |
|类别|语音-语音识别|
|网络|Conformer|
|数据集|LibriSpeech|
|是否支持Fine-tuning|否|
|模型大小|191MB|
|最新更新日期|2021-11-01|
|数据指标|英文WER 0.034|
## 一、模型基本信息
### 模型介绍
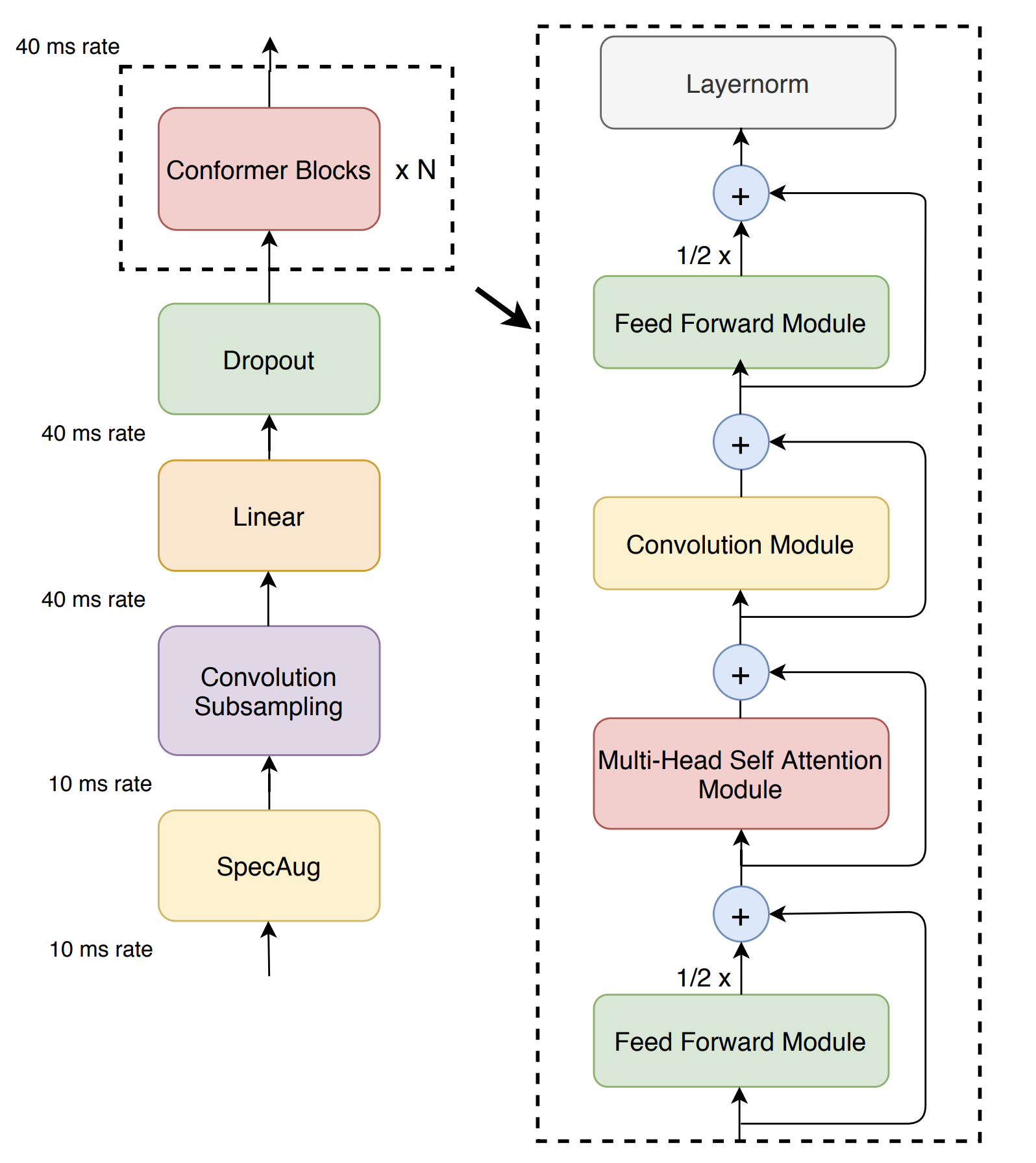
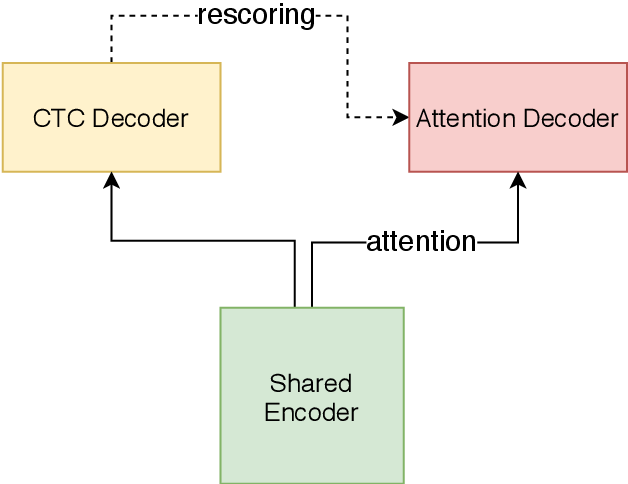
U2 Conformer模型是一种适用于英文和中文的end-to-end语音识别模型。u2_conformer_libirspeech采用了conformer的encoder和transformer的decoder的模型结构,并且使用了ctc-prefix beam search的方式进行一遍打分,再利用attention decoder进行二次打分的方式进行解码来得到最终结果。
u2_conformer_libirspeech在英文开源语音数据集[LibriSpeech ASR corpus](http://www.openslr.org/12/)进行了预训练,该模型在其测试集上的WER指标是0.034655。
更多详情请参考:
- [Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition](https://arxiv.org/abs/2012.05481)
- [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
## 二、安装
- ### 1、系统依赖
- libsndfile
- Linux
```shell
$ sudo apt-get install libsndfile
or
$ sudo yum install libsndfile
```
- MacOs
```
$ brew install libsndfile
```
- ### 2、环境依赖
- paddlepaddle >= 2.1.0
- paddlehub >= 2.1.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
- ### 3、安装
- ```shell
$ hub install u2_conformer_librispeech
```
- 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
| [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
## 三、模型API预测
- ### 1、预测代码示例
- ```python
import paddlehub as hub
# 采样率为16k,格式为wav的英文语音音频
wav_file = '/PATH/TO/AUDIO'
model = hub.Module(
name='u2_conformer_librispeech',
version='1.0.0')
text = model.speech_recognize(wav_file)
print(text)
```
- ### 2、API
- ```python
def check_audio(audio_file)
```
- 检查输入音频格式和采样率是否满足为16000
- **参数**
- `audio_file`:本地音频文件(*.wav)的路径,如`/path/to/input.wav`
- ```python
def speech_recognize(
audio_file,
device='cpu',
)
```
- 将输入的音频识别成文字
- **参数**
- `audio_file`:本地音频文件(*.wav)的路径,如`/path/to/input.wav`
- `device`:预测时使用的设备,默认为�`cpu`,如需使用gpu预测,请设置为`gpu`。
- **返回**
- `text`:str类型,返回输入音频的识别文字结果。
## 四、服务部署
- PaddleHub Serving可以部署一个在线的语音识别服务。
- ### 第一步:启动PaddleHub Serving
- ```shell
$ hub serving start -m u2_conformer_librispeech
```
- 这样就完成了一个语音识别服务化API的部署,默认端口号为8866。
- **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
- ### 第二步:发送预测请求
- 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
- ```python
import requests
import json
# 需要识别的音频的存放路径,确保部署服务的机器可访问
file = '/path/to/input.wav'
# 以key的方式指定text传入预测方法的时的参数,此例中为"audio_file"
data = {"audio_file": file}
# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
url = "http://127.0.0.1:8866/predict/u2_conformer_librispeech"
# 指定post请求的headers为application/json方式
headers = {"Content-Type": "application/json"}
r = requests.post(url=url, headers=headers, data=json.dumps(data))
print(r.json())
```
## 五、更新历史
* 1.0.0
初始发布
```shell
$ hub install u2_conformer_librispeech
```