diff --git a/modules/audio/tts/deepvoice3_ljspeech/README.md b/modules/audio/tts/deepvoice3_ljspeech/README.md
index a1a659d250f9d920e3d104092d033ea3921ab854..ea5d2636f092d36694015727833c0442a2cb247a 100644
--- a/modules/audio/tts/deepvoice3_ljspeech/README.md
+++ b/modules/audio/tts/deepvoice3_ljspeech/README.md
@@ -1,120 +1,147 @@
-## 概述
+# deepvoice3_ljspeech
+
+|模型名称|deepvoice3_ljspeech|
+| :--- | :---: |
+|类别|语音-语音合成|
+|网络|DeepVoice3|
+|数据集|LJSpeech-1.1|
+|是否支持Fine-tuning|否|
+|模型大小|58MB|
+|最新更新日期|2020-10-27|
+|数据指标|-|
+
+## 一、模型基本信息
+
+### 模型介绍
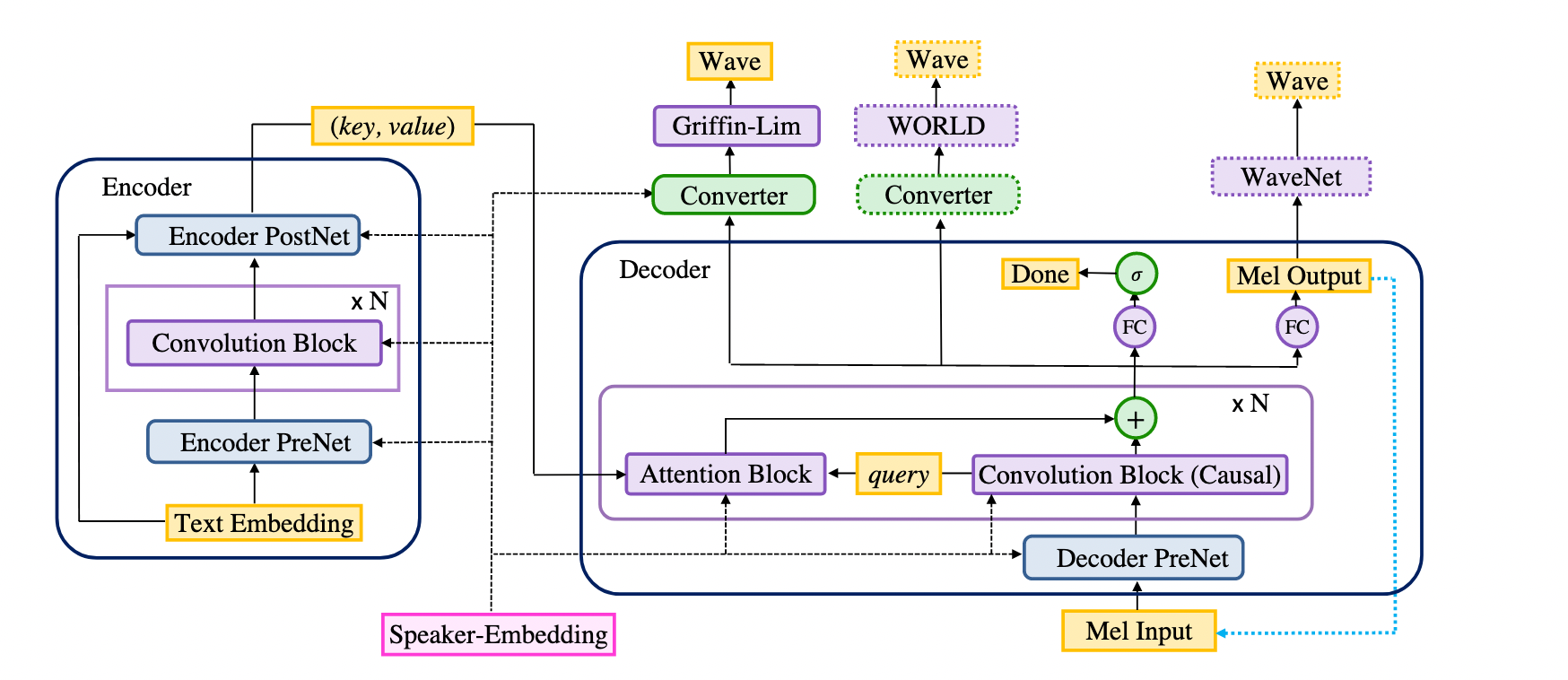
Deep Voice 3是百度研究院2017年发布的端到端的TTS模型(论文录用于ICLR 2018)。它是一个基于卷积神经网络和注意力机制的seq2seq模型,由于不包含循环神经网络,它可以并行训练,远快于基于循环神经网络的模型。Deep Voice 3可以学习到多个说话人的特征,也支持搭配多种声码器使用。deepvoice3_ljspeech是基于ljspeech英文语音数据集预训练得到的英文TTS模型,仅支持预测。
-
+
更多详情参考论文[Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning](https://arxiv.org/abs/1710.07654)
-## 命令行预测
-```shell
-$ hub run deepvoice3_ljspeech --input_text='Simple as this proposition is, it is necessary to be stated' --use_gpu True --vocoder griffin-lim
-```
+## 二、安装
-## API
+- ### 1、系统依赖
-```python
-def synthesize(texts, use_gpu=False, vocoder="griffin-lim"):
-```
+ 对于Ubuntu用户,请执行:
+ ```
+ sudo apt-get install libsndfile1
+ ```
+ 对于Centos用户,请执行:
+ ```
+ sudo yum install libsndfile
+ ```
-预测API,由输入文本合成对应音频波形。
+- ### 2、环境依赖
-**参数**
+ - 2.0.0 > paddlepaddle >= 1.8.2
-* texts (list\[str\]): 待预测文本;
-* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA\_VISIBLE\_DEVICES环境变量**;
-* vocoder: 指定声码器,可选 "griffin-lim"或"waveflow"
+ - 2.0.0 > paddlehub >= 1.7.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**返回**
+- ### 3、安装
-* wavs (list): 语音合成结果列表,列表中每一个元素为对应输入文本的音频波形,可使用`soundfile.write`进一步处理或保存。
-* sample\_rate (int): 合成音频的采样率。
+ - ```shell
+ $ hub install deepvoice3_ljspeech
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-**代码示例**
-```python
-import paddlehub as hub
-import soundfile as sf
+## 三、模型API预测
-# Load deepvoice3_ljspeech module.
-module = hub.Module(name="deepvoice3_ljspeech")
+- ### 1、命令行预测
-# Predict sentiment label
-test_texts = ['Simple as this proposition is, it is necessary to be stated',
- 'Parakeet stands for Paddle PARAllel text-to-speech toolkit']
-wavs, sample_rate = module.synthesize(texts=test_texts)
-for index, wav in enumerate(wavs):
- sf.write(f"{index}.wav", wav, sample_rate)
-```
+ - ```shell
+ $ hub run deepvoice3_ljspeech --input_text='Simple as this proposition is, it is necessary to be stated' --use_gpu True --vocoder griffin-lim
+ ```
+ - 通过命令行方式实现语音合成模型的调用,更多请见[PaddleHub命令行指令](https://github.com/shinichiye/PaddleHub/blob/release/v2.1/docs/docs_ch/tutorial/cmd_usage.rst)
-## 服务部署
+- ### 2、预测代码示例
-PaddleHub Serving 可以部署在线服务。
+ - ```python
+ import paddlehub as hub
+ import soundfile as sf
-### 第一步:启动PaddleHub Serving
+ # Load deepvoice3_ljspeech module.
+ module = hub.Module(name="deepvoice3_ljspeech")
-运行启动命令:
-```shell
-$ hub serving start -m deepvoice3_ljspeech
-```
+ # Predict sentiment label
+ test_texts = ['Simple as this proposition is, it is necessary to be stated',
+ 'Parakeet stands for Paddle PARAllel text-to-speech toolkit']
+ wavs, sample_rate = module.synthesize(texts=test_texts)
+ for index, wav in enumerate(wavs):
+ sf.write(f"{index}.wav", wav, sample_rate)
+ ```
-这样就完成了一个服务化API的部署,默认端口号为8866。
+- ### 3、API
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+ - ```python
+ def synthesize(texts, use_gpu=False, vocoder="griffin-lim"):
+ ```
-### 第二步:发送预测请求
+ - 预测API,由输入文本合成对应音频波形。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **参数**
+ - texts (list\[str\]): 待预测文本;
+ - use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA\_VISIBLE\_DEVICES环境变量**;
+ - vocoder: 指定声码器,可选 "griffin-lim"或"waveflow"
-```python
-import requests
-import json
+ - **返回**
+ - wavs (list): 语音合成结果列表,列表中每一个元素为对应输入文本的音频波形,可使用`soundfile.write`进一步处理或保存。
+ - sample\_rate (int): 合成音频的采样率。
-import soundfile as sf
-# 发送HTTP请求
+## 四、服务部署
-data = {'texts':['Simple as this proposition is, it is necessary to be stated',
- 'Parakeet stands for Paddle PARAllel text-to-speech toolkit'],
- 'use_gpu':False}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/deepvoice3_ljspeech"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
+- PaddleHub Serving可以部署一个在线语音合成服务,可以将此接口用于在线web应用。
-# 保存结果
-result = r.json()["results"]
-wavs = result["wavs"]
-sample_rate = result["sample_rate"]
-for index, wav in enumerate(wavs):
- sf.write(f"{index}.wav", wav, sample_rate)
-```
+- ### 第一步:启动PaddleHub Serving
-## 查看代码
+ - 运行启动命令
+ - ```shell
+ $ hub serving start -m deepvoice3_ljspeech
+ ```
+ - 这样就完成了服务化API的部署,默认端口号为8866。
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-https://github.com/PaddlePaddle/Parakeet
+- ### 第二步:发送预测请求
-### 依赖
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-paddlepaddle >= 1.8.2
+ - ```python
+ import requests
+ import json
-paddlehub >= 1.7.0
+ import soundfile as sf
-**NOTE:** 除了python依赖外还必须安装libsndfile库
+ # 发送HTTP请求
-对于Ubuntu用户,请执行:
-```
-sudo apt-get install libsndfile1
-```
-对于Centos用户,请执行:
-```
-sudo yum install libsndfile
-```
+ data = {'texts':['Simple as this proposition is, it is necessary to be stated',
+ 'Parakeet stands for Paddle PARAllel text-to-speech toolkit'],
+ 'use_gpu':False}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/deepvoice3_ljspeech"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
-## 更新历史
+ # 保存结果
+ result = r.json()["results"]
+ wavs = result["wavs"]
+ sample_rate = result["sample_rate"]
+ for index, wav in enumerate(wavs):
+ sf.write(f"{index}.wav", wav, sample_rate)
+ ```
+
+
+## 五、更新历史
* 1.0.0
初始发布
+
+ ```shell
+ $ hub install deepvoice3_ljspeech
+ ```
diff --git a/modules/audio/tts/fastspeech_ljspeech/README.md b/modules/audio/tts/fastspeech_ljspeech/README.md
index a2be971d3c301bb8c591d381ce43ab27e5beb65a..93dbe77c2b81059b0e52bb2935307c08c0372b2f 100644
--- a/modules/audio/tts/fastspeech_ljspeech/README.md
+++ b/modules/audio/tts/fastspeech_ljspeech/README.md
@@ -1,121 +1,148 @@
-## 概述
+# fastspeech_ljspeech
+
+|模型名称|fastspeech_ljspeech|
+| :--- | :---: |
+|类别|语音-语音合成|
+|网络|FastSpeech|
+|数据集|LJSpeech-1.1|
+|是否支持Fine-tuning|否|
+|模型大小|320MB|
+|最新更新日期|2020-10-27|
+|数据指标|-|
+
+## 一、模型基本信息
+
+### 模型介绍
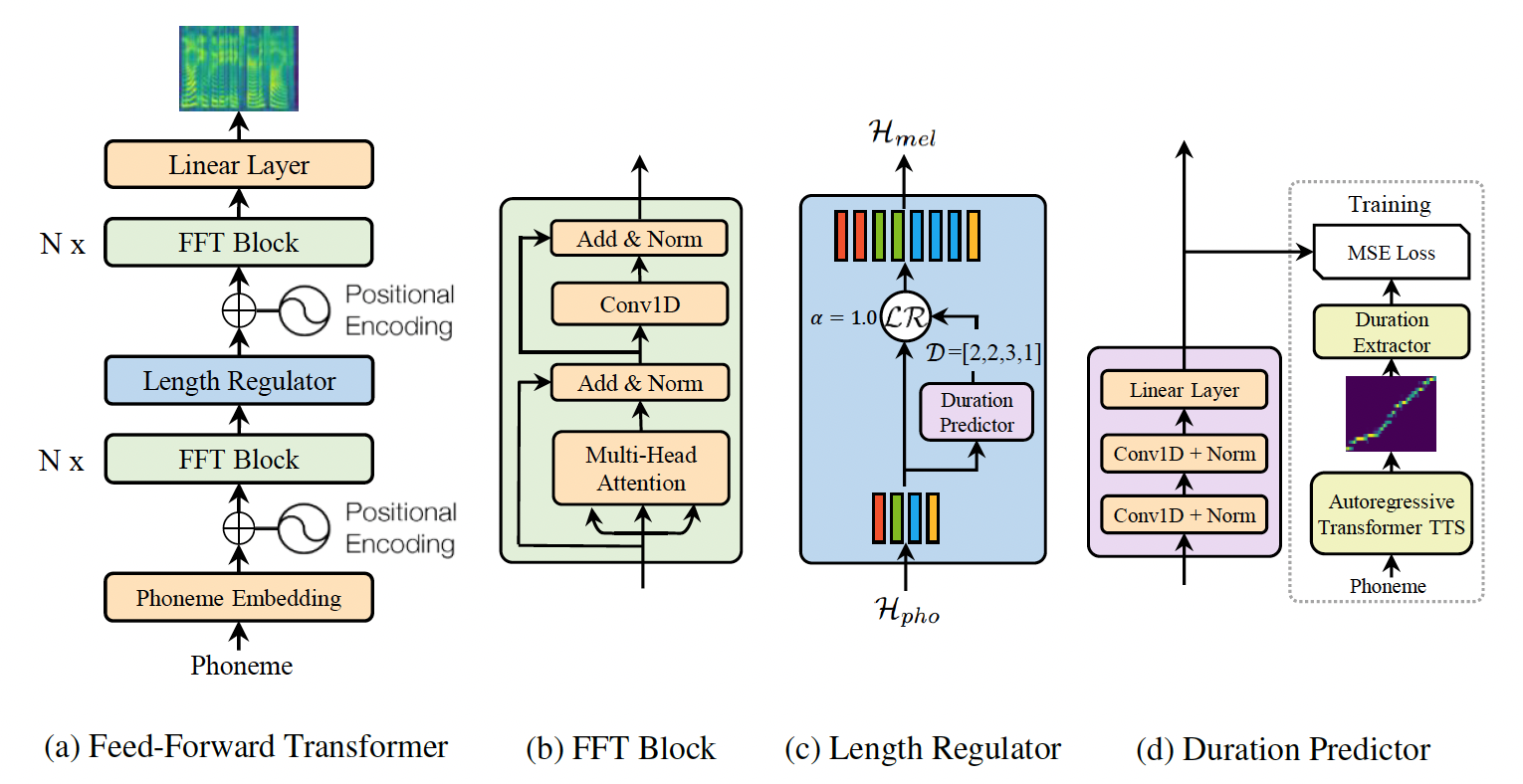
FastSpeech是基于Transformer的前馈神经网络,作者从encoder-decoder结构的teacher model中提取attention对角线来做发音持续时间预测,即使用长度调节器对文本序列进行扩展来匹配目标梅尔频谱的长度,以便并行生成梅尔频谱。该模型基本上消除了复杂情况下的跳词和重复的问题,并且可以平滑地调整语音速度,更重要的是,该模型大幅度提升了梅尔频谱的生成速度。fastspeech_ljspeech是基于ljspeech英文语音数据集预训练得到的英文TTS模型,仅支持预测。
-
+
更多详情参考论文[FastSpeech: Fast, Robust and Controllable Text to Speech](https://arxiv.org/abs/1905.09263)
-## 命令行预测
-```shell
-$ hub run fastspeech_ljspeech --input_text='Simple as this proposition is, it is necessary to be stated' --use_gpu True --vocoder griffin-lim
-```
+## 二、安装
-## API
+- ### 1、系统依赖
-```python
-def synthesize(texts, use_gpu=False, speed=1.0, vocoder="griffin-lim"):
-```
+ 对于Ubuntu用户,请执行:
+ ```
+ sudo apt-get install libsndfile1
+ ```
+ 对于Centos用户,请执行:
+ ```
+ sudo yum install libsndfile
+ ```
-预测API,由输入文本合成对应音频波形。
+- ### 2、环境依赖
-**参数**
+ - 2.0.0 > paddlepaddle >= 1.8.2
-* texts (list\[str\]): 待预测文本;
-* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA\_VISIBLE\_DEVICES环境变量**;
-* speed(float): 音频速度,1.0表示以原速输出。
-* vocoder: 指定声码器,可选 "griffin-lim"或"waveflow"
+ - 2.0.0 > paddlehub >= 1.7.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**返回**
+- ### 3、安装
-* wavs (list): 语音合成结果列表,列表中每一个元素为对应输入文本的音频波形,可使用`soundfile.write`进一步处理或保存。
-* sample\_rate (int): 合成音频的采样率。
+ - ```shell
+ $ hub install fastspeech_ljspeech
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-**代码示例**
-```python
-import paddlehub as hub
-import soundfile as sf
+## 三、模型API预测
-# Load fastspeech_ljspeech module.
-module = hub.Module(name="fastspeech_ljspeech")
+- ### 1、命令行预测
-# Predict sentiment label
-test_texts = ['Simple as this proposition is, it is necessary to be stated',
- 'Parakeet stands for Paddle PARAllel text-to-speech toolkit']
-wavs, sample_rate = module.synthesize(texts=test_texts)
-for index, wav in enumerate(wavs):
- sf.write(f"{index}.wav", wav, sample_rate)
-```
+ - ```shell
+ $ hub run fastspeech_ljspeech --input_text='Simple as this proposition is, it is necessary to be stated' --use_gpu True --vocoder griffin-lim
+ ```
+ - 通过命令行方式实现语音合成模型的调用,更多请见[PaddleHub命令行指令](https://github.com/shinichiye/PaddleHub/blob/release/v2.1/docs/docs_ch/tutorial/cmd_usage.rst)
-## 服务部署
+- ### 2、预测代码示例
-PaddleHub Serving 可以部署在线服务。
+ - ```python
+ import paddlehub as hub
+ import soundfile as sf
-### 第一步:启动PaddleHub Serving
+ # Load fastspeech_ljspeech module.
+ module = hub.Module(name="fastspeech_ljspeech")
-运行启动命令:
-```shell
-$ hub serving start -m fastspeech_ljspeech
-```
+ # Predict sentiment label
+ test_texts = ['Simple as this proposition is, it is necessary to be stated',
+ 'Parakeet stands for Paddle PARAllel text-to-speech toolkit']
+ wavs, sample_rate = module.synthesize(texts=test_texts)
+ for index, wav in enumerate(wavs):
+ sf.write(f"{index}.wav", wav, sample_rate)
+ ```
-这样就完成了一个服务化API的部署,默认端口号为8866。
+- ### 3、API
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+ - ```python
+ def synthesize(texts, use_gpu=False, speed=1.0, vocoder="griffin-lim"):
+ ```
-### 第二步:发送预测请求
+ - 预测API,由输入文本合成对应音频波形。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **参数**
+ - texts (list\[str\]): 待预测文本;
+ - use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA\_VISIBLE\_DEVICES环境变量**;
+ - speed(float): 音频速度,1.0表示以原速输出。
+ - vocoder: 指定声码器,可选 "griffin-lim"或"waveflow"
-```python
-import requests
-import json
+ - **返回**
+ - wavs (list): 语音合成结果列表,列表中每一个元素为对应输入文本的音频波形,可使用`soundfile.write`进一步处理或保存。
+ - sample\_rate (int): 合成音频的采样率。
-import soundfile as sf
-# 发送HTTP请求
+## 四、服务部署
-data = {'texts':['Simple as this proposition is, it is necessary to be stated',
- 'Parakeet stands for Paddle PARAllel text-to-speech toolkit'],
- 'use_gpu':False}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/fastspeech_ljspeech"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
+- PaddleHub Serving可以部署一个在线语音合成服务,可以将此接口用于在线web应用。
-# 保存结果
-result = r.json()["results"]
-wavs = result["wavs"]
-sample_rate = result["sample_rate"]
-for index, wav in enumerate(wavs):
- sf.write(f"{index}.wav", wav, sample_rate)
-```
+- ### 第一步:启动PaddleHub Serving
-## 查看代码
+ - 运行启动命令
+ - ```shell
+ $ hub serving start -m fastspeech_ljspeech
+ ```
+ - 这样就完成了服务化API的部署,默认端口号为8866。
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-https://github.com/PaddlePaddle/Parakeet
+- ### 第二步:发送预测请求
-### 依赖
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-paddlepaddle >= 1.8.2
+ - ```python
+ import requests
+ import json
-paddlehub >= 1.7.0
+ import soundfile as sf
-**NOTE:** 除了python依赖外还必须安装libsndfile库
+ # 发送HTTP请求
-对于Ubuntu用户,请执行:
-```
-sudo apt-get install libsndfile1
-```
-对于Centos用户,请执行:
-```
-sudo yum install libsndfile
-```
+ data = {'texts':['Simple as this proposition is, it is necessary to be stated',
+ 'Parakeet stands for Paddle PARAllel text-to-speech toolkit'],
+ 'use_gpu':False}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/fastspeech_ljspeech"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
-## 更新历史
+ # 保存结果
+ result = r.json()["results"]
+ wavs = result["wavs"]
+ sample_rate = result["sample_rate"]
+ for index, wav in enumerate(wavs):
+ sf.write(f"{index}.wav", wav, sample_rate)
+ ```
+
+
+## 五、更新历史
* 1.0.0
初始发布
+
+ ```shell
+ $ hub install fastspeech_ljspeech
+ ```
diff --git a/modules/audio/tts/transformer_tts_ljspeech/README.md b/modules/audio/tts/transformer_tts_ljspeech/README.md
index 2be5603ed13006f6ab2d6f5ab2d21c6381b943a7..58d1bf569fe7e637a50bfe766bb95059f0486c3e 100644
--- a/modules/audio/tts/transformer_tts_ljspeech/README.md
+++ b/modules/audio/tts/transformer_tts_ljspeech/README.md
@@ -1,119 +1,147 @@
-## 概述
+# transformer_tts_ljspeech
+
+|模型名称|transformer_tts_ljspeech|
+| :--- | :---: |
+|类别|语音-语音合成|
+|网络|Transformer|
+|数据集|LJSpeech-1.1|
+|是否支持Fine-tuning|否|
+|模型大小|54MB|
+|最新更新日期|2020-10-27|
+|数据指标|-|
+
+## 一、模型基本信息
+
+### 模型介绍
TansformerTTS 是使用了 Transformer 结构的端到端语音合成模型,对 Transformer 和 Tacotron2 进行了融合,取得了令人满意的效果。因为删除了 RNN 的循环连接,可并行的提供 decoder 的输入,进行并行训练,大大提升了模型的训练速度。transformer_tts_ljspeech是基于ljspeech英文语音数据集预训练得到的英文TTS模型,仅支持预测。
-
+
更多详情参考论文[Neural Speech Synthesis with Transformer Network](https://arxiv.org/abs/1809.08895)
-## 命令行预测
-```shell
-$ hub run transformer_tts_ljspeech --input_text="Life was like a box of chocolates, you never know what you're gonna get." --use_gpu True --vocoder griffin-lim
-```
+## 二、安装
+
+- ### 1、系统依赖
-## API
+ 对于Ubuntu用户,请执行:
+ ```
+ sudo apt-get install libsndfile1
+ ```
+ 对于Centos用户,请执行:
+ ```
+ sudo yum install libsndfile
+ ```
-```python
-def synthesize(texts, use_gpu=False, vocoder="griffin-lim"):
-```
+- ### 2、环境依赖
-预测API,由输入文本合成对应音频波形。
+ - 2.0.0 > paddlepaddle >= 1.8.2
-**参数**
+ - 2.0.0 > paddlehub >= 1.7.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-* texts (list\[str\]): 待预测文本;
-* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA\_VISIBLE\_DEVICES环境变量**;
-* vocoder: 指定声码器,可选 "griffin-lim"或"waveflow"
+- ### 3、安装
-**返回**
+ - ```shell
+ $ hub install transformer_tts_ljspeech
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-* wavs (list): 语音合成结果列表,列表中每一个元素为对应输入文本的音频波形,可使用`soundfile.write`进一步处理或保存。
-* sample\_rate (int): 合成音频的采样率。
-**代码示例**
+## 三、模型API预测
-```python
-import paddlehub as hub
-import soundfile as sf
+- ### 1、命令行预测
-# Load transformer_tts_ljspeech module.
-module = hub.Module(name="transformer_tts_ljspeech")
+ - ```shell
+ $ hub run transformer_tts_ljspeech --input_text="Life was like a box of chocolates, you never know what you're gonna get." --use_gpu True --vocoder griffin-lim
+ ```
+ - 通过命令行方式实现语音合成模型的调用,更多请见[PaddleHub命令行指令](https://github.com/shinichiye/PaddleHub/blob/release/v2.1/docs/docs_ch/tutorial/cmd_usage.rst)
-# Predict sentiment label
-test_texts = ["Life was like a box of chocolates, you never know what you're gonna get."]
-wavs, sample_rate = module.synthesize(texts=test_texts, use_gpu=True, vocoder="waveflow")
-for index, wav in enumerate(wavs):
- sf.write(f"{index}.wav", wav, sample_rate)
-```
+- ### 2、预测代码示例
-## 服务部署
+ - ```python
+ import paddlehub as hub
+ import soundfile as sf
-PaddleHub Serving 可以部署在线服务。
+ # Load transformer_tts_ljspeech module.
+ module = hub.Module(name="transformer_tts_ljspeech")
-### 第一步:启动PaddleHub Serving
+ # Predict sentiment label
+ test_texts = ["Life was like a box of chocolates, you never know what you're gonna get."]
+ wavs, sample_rate = module.synthesize(texts=test_texts, use_gpu=True, vocoder="waveflow")
+ for index, wav in enumerate(wavs):
+ sf.write(f"{index}.wav", wav, sample_rate)
+ ```
-运行启动命令:
-```shell
-$ hub serving start -m transformer_tts_ljspeech
-```
+- ### 3、API
-这样就完成了一个服务化API的部署,默认端口号为8866。
+ - ```python
+ def synthesize(texts, use_gpu=False, vocoder="griffin-lim"):
+ ```
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+ - 预测API,由输入文本合成对应音频波形。
-### 第二步:发送预测请求
+ - **参数**
+ - texts (list\[str\]): 待预测文本;
+ - use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA\_VISIBLE\_DEVICES环境变量**;
+ - vocoder: 指定声码器,可选 "griffin-lim"或"waveflow"
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **返回**
+ - wavs (list): 语音合成结果列表,列表中每一个元素为对应输入文本的音频波形,可使用`soundfile.write`进一步处理或保存。
+ - sample\_rate (int): 合成音频的采样率。
-```python
-import requests
-import json
-import soundfile as sf
+## 四、服务部署
-# 发送HTTP请求
+- PaddleHub Serving可以部署一个在线语音合成服务,可以将此接口用于在线web应用。
-data = {'texts':['Simple as this proposition is, it is necessary to be stated',
- 'Parakeet stands for Paddle PARAllel text-to-speech toolkit'],
- 'use_gpu':False}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/transformer_tts_ljspeech"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
+- ### 第一步:启动PaddleHub Serving
-# 保存结果
-result = r.json()["results"]
-wavs = result["wavs"]
-sample_rate = result["sample_rate"]
-for index, wav in enumerate(wavs):
- sf.write(f"{index}.wav", wav, sample_rate)
-```
+ - 运行启动命令
-## 查看代码
+ - ```shell
+ $ hub serving start -m transformer_tts_ljspeech
+ ```
+ - 这样就完成了服务化API的部署,默认端口号为8866。
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-https://github.com/PaddlePaddle/Parakeet
+- ### 第二步:发送预测请求
-### 依赖
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-paddlepaddle >= 1.8.2
+ - ```python
+ import requests
+ import json
-paddlehub >= 1.7.0
+ import soundfile as sf
-**NOTE:** 除了python依赖外还必须安装libsndfile库
+ # 发送HTTP请求
-对于Ubuntu用户,请执行:
-```
-sudo apt-get install libsndfile1
-```
-对于Centos用户,请执行:
-```
-sudo yum install libsndfile
-```
+ data = {'texts':['Simple as this proposition is, it is necessary to be stated',
+ 'Parakeet stands for Paddle PARAllel text-to-speech toolkit'],
+ 'use_gpu':False}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/transformer_tts_ljspeech"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
-## 更新历史
+ # 保存结果
+ result = r.json()["results"]
+ wavs = result["wavs"]
+ sample_rate = result["sample_rate"]
+ for index, wav in enumerate(wavs):
+ sf.write(f"{index}.wav", wav, sample_rate)
+ ```
+
+
+## 五、更新历史
* 1.0.0
初始发布
+
+ ```shell
+ $ hub install transformer_tts_ljspeech
+ ```
diff --git a/modules/audio/voice_cloning/lstm_tacotron2/README.md b/modules/audio/voice_cloning/lstm_tacotron2/README.md
index 58d6e846a25ddded31a10d6632aaaf6d7563f723..dedd5017324c10bc7a1f466d4a7367d80237ae53 100644
--- a/modules/audio/voice_cloning/lstm_tacotron2/README.md
+++ b/modules/audio/voice_cloning/lstm_tacotron2/README.md
@@ -1,8 +1,18 @@
-```shell
-$ hub install lstm_tacotron2==1.0.0
-```
+# lstm_tacotron2
+
+|模型名称|lstm_tacotron2|
+| :--- | :---: |
+|类别|语音-语音合成|
+|网络|LSTM、Tacotron2、WaveFlow|
+|数据集|AISHELL-3|
+|是否支持Fine-tuning|否|
+|模型大小|327MB|
+|最新更新日期|2021-06-15|
+|数据指标|-|
+
+## 一、模型基本信息
-## 概述
+### 模型介绍
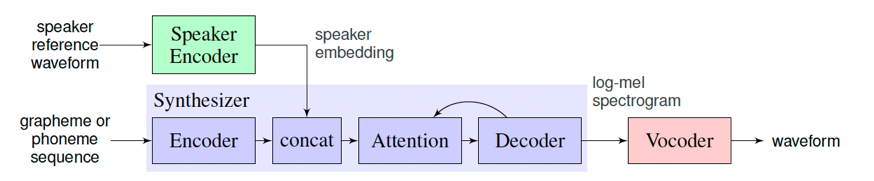
声音克隆是指使用特定的音色,结合文字的读音合成音频,使得合成后的音频具有目标说话人的特征,从而达到克隆的目的。
@@ -10,93 +20,107 @@ $ hub install lstm_tacotron2==1.0.0
在预测时,选取一段新的目标音色作为Speaker Encoder的输入,并提取其说话人特征,最终实现输入为一段文本和一段目标音色,模型生成目标音色说出此段文本的语音片段。
-
+
+
+
`lstm_tacotron2`是一个支持中文的语音克隆模型,分别使用了LSTMSpeakerEncoder、Tacotron2和WaveFlow模型分别用于语音特征提取、目标音频特征合成和语音波形转换。
-关于模型的详请可参考[Parakeet](https://github.com/PaddlePaddle/Parakeet/tree/release/v0.3/parakeet/models)。
+更多详情请参考:
+- [Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis](https://arxiv.org/pdf/1806.04558.pdf)
+- [Parakeet](https://github.com/PaddlePaddle/Parakeet/tree/release/v0.3/parakeet/models)
-## API
+## 二、安装
-```python
-def __init__(speaker_audio: str = None,
- output_dir: str = './')
-```
-初始化module,可配置模型的目标音色的音频文件和输出的路径。
+- ### 1、环境依赖
-**参数**
-- `speaker_audio`(str): 目标说话人语音音频文件(*.wav)的路径,默认为None(使用默认的女声作为目标音色)。
-- `output_dir`(str): 合成音频的输出文件,默认为当前目录。
+ - paddlepaddle >= 2.0.0
+ - paddlehub >= 2.1.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-```python
-def get_speaker_embedding()
-```
-获取模型的目标说话人特征。
+- ### 2、安装
-**返回**
-* `results`(numpy.ndarray): 长度为256的numpy数组,代表目标说话人的特征。
+ - ```shell
+ $ hub install lstm_tacotron2
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-```python
-def set_speaker_embedding(speaker_audio: str)
-```
-设置模型的目标说话人特征。
-**参数**
-- `speaker_audio`(str): 必填,目标说话人语音音频文件(*.wav)的路径。
+## 三、模型API预测
-```python
-def generate(data: List[str], batch_size: int = 1, use_gpu: bool = False):
-```
-根据输入文字,合成目标说话人的语音音频文件。
+- ### 1、预测代码示例
-**参数**
-- `data`(List[str]): 必填,目标音频的内容文本列表,目前只支持中文,不支持添加标点符号。
-- `batch_size`(int): 可选,模型合成语音时的batch_size,默认为1。
-- `use_gpu`(bool): 是否使用gpu执行计算,默认为False。
+ - ```python
+ import paddlehub as hub
+ model = hub.Module(name='lstm_tacotron2', output_dir='/data', speaker_audio='/data/man.wav') # 指定目标音色音频文件
+ texts = [
+ '语音的表现形式在未来将变得越来越重要$',
+ '今天的天气怎么样$', ]
+ wavs = model.generate(texts, use_gpu=True)
-**代码示例**
+ for text, wav in zip(texts, wavs):
+ print('='*30)
+ print(f'Text: {text}')
+ print(f'Wav: {wav}')
+ ```
+ ```
+ ==============================
+ Text: 语音的表现形式在未来将变得越来越重要$
+ Wav: /data/1.wav
+ ==============================
+ Text: 今天的天气怎么样$
+ Wav: /data/2.wav
+ ```
-```python
-import paddlehub as hub
+- ### 2、API
-model = hub.Module(name='lstm_tacotron2', output_dir='./', speaker_audio='/data/man.wav') # 指定目标音色音频文件
-texts = [
- '语音的表现形式在未来将变得越来越重要$',
- '今天的天气怎么样$', ]
-wavs = model.generate(texts, use_gpu=True)
+ - ```python
+ def __init__(speaker_audio: str = None,
+ output_dir: str = './')
+ ```
+ - 初始化module,可配置模型的目标音色的音频文件和输出的路径。
-for text, wav in zip(texts, wavs):
- print('='*30)
- print(f'Text: {text}')
- print(f'Wav: {wav}')
-```
+ - **参数**
+ - `speaker_audio`(str): 目标说话人语音音频文件(*.wav)的路径,默认为None(使用默认的女声作为目标音色)。
+ - `output_dir`(str): 合成音频的输出文件,默认为当前目录。
-输出
-```
-==============================
-Text: 语音的表现形式在未来将变得越来越重要$
-Wav: /data/1.wav
-==============================
-Text: 今天的天气怎么样$
-Wav: /data/2.wav
-```
+ - ```python
+ def get_speaker_embedding()
+ ```
+ - 获取模型的目标说话人特征。
+
+ - **返回**
+ - `results`(numpy.ndarray): 长度为256的numpy数组,代表目标说话人的特征。
-## 查看代码
+ - ```python
+ def set_speaker_embedding(speaker_audio: str)
+ ```
+ - 设置模型的目标说话人特征。
-https://github.com/PaddlePaddle/Parakeet
+ - **参数**
+ - `speaker_audio`(str): 必填,目标说话人语音音频文件(*.wav)的路径。
-## 依赖
+ - ```python
+ def generate(data: List[str], batch_size: int = 1, use_gpu: bool = False):
+ ```
+ - 根据输入文字,合成目标说话人的语音音频文件。
-paddlepaddle >= 2.0.0
+ - **参数**
+ - `data`(List[str]): 必填,目标音频的内容文本列表,目前只支持中文,不支持添加标点符号。
+ - `batch_size`(int): 可选,模型合成语音时的batch_size,默认为1。
+ - `use_gpu`(bool): 是否使用gpu执行计算,默认为False。
-paddlehub >= 2.1.0
-## 更新历史
+## 四、更新历史
* 1.0.0
初始发布
+
+```shell
+$ hub install lstm_tacotron2==1.0.0
+```
diff --git a/modules/text/punctuation_restoration/auto_punc/README.md b/modules/text/punctuation_restoration/auto_punc/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..37e90bfc59f8409639667f1ff94c8ae89fccf31b
--- /dev/null
+++ b/modules/text/punctuation_restoration/auto_punc/README.md
@@ -0,0 +1,141 @@
+# auto_punc
+
+|模型名称|auto_punc|
+| :--- | :---: |
+|类别|文本-标点恢复|
+|网络|Ernie-1.0|
+|数据集|WuDaoCorpora 2.0|
+|是否支持Fine-tuning|否|
+|模型大小|568MB|
+|最新更新日期|2021-11-16|
+|数据指标|-|
+
+## 一、模型基本信息
+
+### 模型介绍
+
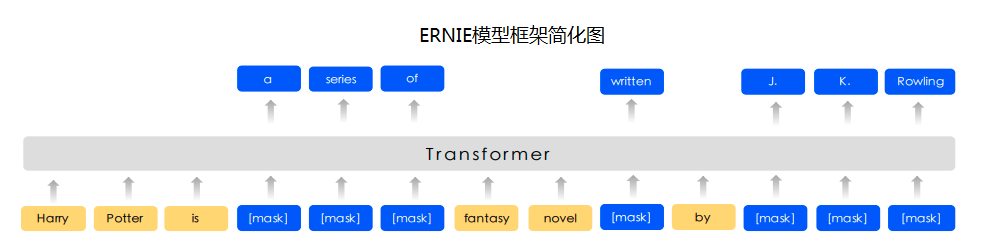
+Ernie是百度提出的基于知识增强的持续学习语义理解模型,该模型将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。
+
+auto_punc采用了Ernie1.0预训练模型,在大规模的"悟道"中文文本数据集[WuDaoCorpora 2.0](https://resource.wudaoai.cn/home)上进行了标点恢复任务的训练,模型可直接用于预测,对输入的对中文文本自动添加7种标点符号:逗号(,)、句号(。)、感叹号(!)、问号(?)、顿号(、)、冒号(:)和分号(;)。
+
+
+
+
+
+
+
+
+
+
+更多详情请参考
+- [ERNIE: Enhanced Representation through Knowledge Integration](https://arxiv.org/abs/1904.09223)
+
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.1.0
+
+ - paddlehub >= 2.1.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install auto_punc
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、预测代码示例
+
+ ```python
+ import paddlehub as hub
+
+ model = hub.Module(
+ name='auto_punc',
+ version='1.0.0')
+
+ texts = [
+ '今天的天气真好啊你下午有空吗我想约你一起去逛街',
+ '我最喜欢的诗句是先天下之忧而忧后天下之乐而乐',
+ ]
+ punc_texts = model.add_puncs(texts)
+ print(punc_texts)
+ # ['我最喜欢的诗句是:先天下之忧而忧,后天下之乐而乐。', '今天的天气真好啊!你下午有空吗?我想约你一起去逛街。']
+ ```
+
+- ### 2、API
+ - ```python
+ def add_puncs(
+ texts: Union[str, List[str]],
+ max_length=256,
+ device='cpu'
+ )
+ ```
+ - 对输入的中文文本自动添加标点符号。
+
+ - **参数**
+
+ - `texts`:输入的中文文本,可为str或List[str]类型,预测时,中英文和数字以外的字符将会被删除。
+ - `max_length`:模型预测时输入的最大长度,超过时文本会被截断,默认为256。
+ - `device`:预测时使用的设备,默认为�`cpu`,如需使用gpu预测,请设置为`gpu`。
+
+ - **返回**
+
+ - `punc_texts`:List[str]类型,返回添加标点后的文本列表。
+
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线的文本标点添加的服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - ```shell
+ $ hub serving start -m auto_punc
+ ```
+
+ - 这样就完成了一个文本标点添加服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ # 输入的中文文本,中英文和数字之外的字符在模型预测前会被删除
+ texts = [
+ '今天的天气真好啊你下午有空吗我想约你一起去逛街',
+ '我最喜欢的诗句是先天下之忧而忧后天下之乐而乐',
+ ]
+
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"texts"
+ data = {"texts": texts}
+
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://127.0.0.1:8866/predict/auto_punc"
+
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install auto_punc
+ ```
diff --git a/modules/text/punctuation_restoration/auto_punc/__init__.py b/modules/text/punctuation_restoration/auto_punc/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/modules/text/punctuation_restoration/auto_punc/module.py b/modules/text/punctuation_restoration/auto_punc/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a6389ab7c25c616eb1ae80fb5eae6ab8c584b1b
--- /dev/null
+++ b/modules/text/punctuation_restoration/auto_punc/module.py
@@ -0,0 +1,127 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import re
+from typing import List, Union
+
+import numpy as np
+import paddle
+from paddlehub.env import MODULE_HOME
+from paddlehub.module.module import moduleinfo, serving
+from paddlehub.utils.log import logger
+from paddlenlp.transformers import ErnieTokenizer, ErnieForTokenClassification
+from paddlenlp.data import Pad
+
+
+@moduleinfo(
+ name="auto_punc",
+ version="1.0.0",
+ summary="",
+ author="PaddlePaddle",
+ author_email="",
+ type="text/punctuation_restoration")
+class Ernie(paddle.nn.Layer):
+ def __init__(self):
+ super(Ernie, self).__init__()
+ res_dir = os.path.join(MODULE_HOME, 'auto_punc')
+ punc_vocab_file = os.path.join(res_dir, 'assets', 'punc_vocab.txt')
+ ckpt_dir = os.path.join(res_dir, 'assets', 'ckpt')
+
+ self.punc_vocab = self._load_dict(punc_vocab_file)
+ self.punc_list = list(self.punc_vocab.keys())
+ self.model = ErnieForTokenClassification.from_pretrained(ckpt_dir)
+ self.model.eval()
+ self.tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0')
+
+ @staticmethod
+ def _load_dict(dict_path):
+ vocab = {}
+ i = 0
+ with open(dict_path, 'r', encoding='utf-8') as fin:
+ for line in fin:
+ key = line.strip('\n')
+ vocab[key] = i
+ i += 1
+ return vocab
+
+ @staticmethod
+ def _clean_text(text, punc_list):
+ text = text.lower()
+ text = re.sub('[^A-Za-z0-9\u4e00-\u9fa5]', '', text)
+ text = re.sub(f'[{"".join([p for p in punc_list][1:])}]', '', text)
+ return text
+
+ def forward(self, text: str):
+ wav = None
+ input_ids = self.frontend.get_input_ids(text, merge_sentences=True)
+ phone_ids = input_ids["phone_ids"]
+ for part_phone_ids in phone_ids:
+ with paddle.no_grad():
+ mel = self.fastspeech2_inference(part_phone_ids)
+ temp_wav = self.pwg_inference(mel)
+ if wav is None:
+ wav = temp_wav
+ else:
+ wav = paddle.concat([wav, temp_wav])
+ return wav
+
+ @serving
+ def add_puncs(self, texts: Union[str, List[str]], max_length=256, device='cpu'):
+ assert isinstance(texts, str) or (isinstance(texts, list) and isinstance(texts[0], str)), \
+ 'Input data should be str or List[str], but got {}'.format(type(texts))
+
+ if isinstance(texts, str):
+ texts = [texts]
+
+ input_ids = []
+ seg_ids = []
+ seq_len = []
+ for i in range(len(texts)):
+ clean_text = self._clean_text(texts[i], self.punc_list)
+ assert len(clean_text) > 0, f'Invalid input string: {texts[i]}'
+
+ tokenized_input = self.tokenizer(
+ list(clean_text), return_length=True, is_split_into_words=True, max_seq_len=max_length)
+
+ input_ids.append(tokenized_input['input_ids'])
+ seg_ids.append(tokenized_input['token_type_ids'])
+ seq_len.append(tokenized_input['seq_len'])
+
+ paddle.set_device(device)
+ with paddle.no_grad():
+ pad_func_for_input_ids = Pad(axis=0, pad_val=self.tokenizer.pad_token_id, dtype='int64')
+ pad_func_for_seg_ids = Pad(axis=0, pad_val=self.tokenizer.pad_token_type_id, dtype='int64')
+ input_ids = paddle.to_tensor(pad_func_for_input_ids(input_ids))
+ seg_ids = paddle.to_tensor(pad_func_for_seg_ids(seg_ids))
+ logits = self.model(input_ids, seg_ids)
+ preds = paddle.argmax(logits, axis=-1)
+
+ tokens = []
+ labels = []
+ for i in range(len(input_ids)):
+ tokens.append(self.tokenizer.convert_ids_to_tokens(input_ids[i, 1:seq_len[i] - 1].tolist()))
+ labels.append(preds[i, 1:seq_len[i] - 1].tolist()) # Remove predictions of special tokens.
+
+ punc_texts = []
+ for token, label in zip(tokens, labels):
+ assert len(token) == len(label)
+ text = ''
+ for t, l in zip(token, label):
+ text += t
+ if l != 0: # Non punc.
+ text += self.punc_list[l]
+ punc_texts.append(text)
+
+ return punc_texts