Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PaddleHub
提交
dbca09ae
P
PaddleHub
项目概览
PaddlePaddle
/
PaddleHub
大约 2 年 前同步成功
通知
285
Star
12117
Fork
2091
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
200
列表
看板
标记
里程碑
合并请求
4
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleHub
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
200
Issue
200
列表
看板
标记
里程碑
合并请求
4
合并请求
4
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
dbca09ae
编写于
5月 15, 2020
作者:
Z
Zeyu Chen
提交者:
GitHub
5月 15, 2020
浏览文件
操作
浏览文件
下载
差异文件
Add VideoTag model
accelerate video_tag
上级
16710e75
200fdc8b
变更
3
显示空白变更内容
内联
并排
Showing
3 changed file
with
38 addition
and
266 deletion
+38
-266
hub_module/modules/video/classification/videotag_tsn_lstm/README.md
.../modules/video/classification/videotag_tsn_lstm/README.md
+8
-10
hub_module/modules/video/classification/videotag_tsn_lstm/module.py
.../modules/video/classification/videotag_tsn_lstm/module.py
+10
-9
hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/kinetics_reader.py
...tion/videotag_tsn_lstm/resource/reader/kinetics_reader.py
+20
-247
未找到文件。
hub_module/modules/video/classification/videotag_tsn_lstm/README.md
浏览文件 @
dbca09ae
```
shell
```
shell
$
hub
install
videotag_tsn_lstm
==
1.0.0
$
hub
install
videotag_tsn_lstm
==
1.0.0
```
```
<p
align=
"center"
>
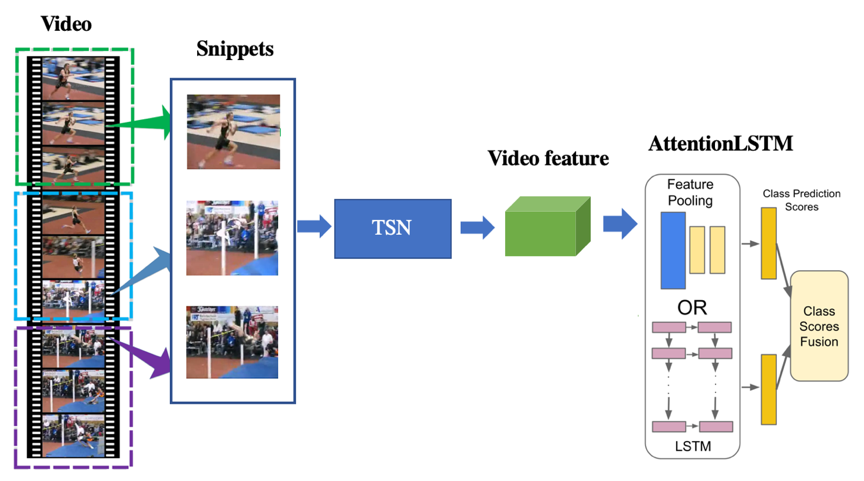
<img
src=
"https://paddlehub.bj.bcebos.com/model/video/video_classifcation/VideoTag_TSN_AttentionLSTM.png"
hspace=
'10'
/>
<br
/>
</p>
具体网络结构可参考论文
[
TSN
](
https://arxiv.org/abs/1608.00859
)
和
[
AttentionLSTM
](
https://arxiv.org/abs/1503.08909
)
。
具体网络结构可参考论文
[
TSN
](
https://arxiv.org/abs/1608.00859
)
和
[
AttentionLSTM
](
https://arxiv.org/abs/1503.08909
)
。
## 命令行预测示例
## 命令行预测示例
...
@@ -16,7 +15,7 @@ hub run videotag_tsn_lstm --input_path 1.mp4 --use_gpu False
...
@@ -16,7 +15,7 @@ hub run videotag_tsn_lstm --input_path 1.mp4 --use_gpu False
## API
## API
```
python
```
python
def
classif
ication
(
paths
,
def
classif
y
(
paths
,
use_gpu
=
False
,
use_gpu
=
False
,
threshold
=
0.5
,
threshold
=
0.5
,
top_k
=
10
)
top_k
=
10
)
...
@@ -46,9 +45,8 @@ import paddlehub as hub
...
@@ -46,9 +45,8 @@ import paddlehub as hub
videotag
=
hub
.
Module
(
name
=
"videotag_tsn_lstm"
)
videotag
=
hub
.
Module
(
name
=
"videotag_tsn_lstm"
)
# execute predict and print the result
# execute predict and print the result
results
=
videotag
.
classification
(
paths
=
[
"1.mp4"
,
"2.mp4"
],
use_gpu
=
True
)
results
=
videotag
.
classify
(
paths
=
[
"1.mp4"
,
"2.mp4"
],
use_gpu
=
True
)
for
result
in
results
:
print
(
results
)
print
(
result
)
```
```
## 依赖
## 依赖
...
...
hub_module/modules/video/classification/videotag_tsn_lstm/module.py
浏览文件 @
dbca09ae
...
@@ -88,12 +88,9 @@ class VideoTag(hub.Module):
...
@@ -88,12 +88,9 @@ class VideoTag(hub.Module):
extractor_model
.
load_test_weights
(
exe
,
args
.
extractor_weights
,
extractor_model
.
load_test_weights
(
exe
,
args
.
extractor_weights
,
extractor_main_prog
)
extractor_main_prog
)
# get reader and metrics
extractor_reader
=
get_reader
(
"TSN"
,
'infer'
,
extractor_infer_config
)
extractor_feeder
=
fluid
.
DataFeeder
(
extractor_feeder
=
fluid
.
DataFeeder
(
place
=
place
,
feed_list
=
extractor_feeds
)
place
=
place
,
feed_list
=
extractor_feeds
)
return
extractor_
reader
,
extractor_
main_prog
,
extractor_fetch_list
,
extractor_feeder
,
extractor_scope
return
extractor_main_prog
,
extractor_fetch_list
,
extractor_feeder
,
extractor_scope
def
_predictor
(
self
,
args
,
exe
,
place
):
def
_predictor
(
self
,
args
,
exe
,
place
):
predictor_scope
=
fluid
.
Scope
()
predictor_scope
=
fluid
.
Scope
()
...
@@ -129,11 +126,10 @@ class VideoTag(hub.Module):
...
@@ -129,11 +126,10 @@ class VideoTag(hub.Module):
@
runnable
@
runnable
def
run_cmd
(
self
,
argsv
):
def
run_cmd
(
self
,
argsv
):
args
=
self
.
parser
.
parse_args
(
argsv
)
args
=
self
.
parser
.
parse_args
(
argsv
)
results
=
self
.
classification
(
results
=
self
.
classify
(
paths
=
[
args
.
input_path
],
use_gpu
=
args
.
use_gpu
)
paths
=
[
args
.
input_path
],
use_gpu
=
args
.
use_gpu
)
return
results
return
results
def
classif
ication
(
self
,
paths
,
use_gpu
=
False
,
threshold
=
0.5
,
top_k
=
10
):
def
classif
y
(
self
,
paths
,
use_gpu
=
False
,
threshold
=
0.5
,
top_k
=
10
):
"""
"""
API of Classification.
API of Classification.
...
@@ -169,15 +165,20 @@ class VideoTag(hub.Module):
...
@@ -169,15 +165,20 @@ class VideoTag(hub.Module):
self
.
place
=
fluid
.
CUDAPlace
(
self
.
place
=
fluid
.
CUDAPlace
(
0
)
if
args
.
use_gpu
else
fluid
.
CPUPlace
()
0
)
if
args
.
use_gpu
else
fluid
.
CPUPlace
()
self
.
exe
=
fluid
.
Executor
(
self
.
place
)
self
.
exe
=
fluid
.
Executor
(
self
.
place
)
self
.
extractor_
reader
,
self
.
extractor_
main_prog
,
self
.
extractor_fetch_list
,
self
.
extractor_feeder
,
self
.
extractor_scope
=
self
.
_extractor
(
self
.
extractor_main_prog
,
self
.
extractor_fetch_list
,
self
.
extractor_feeder
,
self
.
extractor_scope
=
self
.
_extractor
(
args
,
self
.
exe
,
self
.
place
)
args
,
self
.
exe
,
self
.
place
)
self
.
predictor_main_prog
,
self
.
predictor_fetch_list
,
self
.
predictor_feeder
,
self
.
predictor_scope
=
self
.
_predictor
(
self
.
predictor_main_prog
,
self
.
predictor_fetch_list
,
self
.
predictor_feeder
,
self
.
predictor_scope
=
self
.
_predictor
(
args
,
self
.
exe
,
self
.
place
)
args
,
self
.
exe
,
self
.
place
)
self
.
_has_load
=
True
self
.
_has_load
=
True
extractor_config
=
parse_config
(
args
.
extractor_config
)
extractor_infer_config
=
merge_configs
(
extractor_config
,
'infer'
,
vars
(
args
))
extractor_reader
=
get_reader
(
"TSN"
,
'infer'
,
extractor_infer_config
)
feature_list
=
[]
feature_list
=
[]
file_list
=
[]
file_list
=
[]
for
idx
,
data
in
enumerate
(
self
.
extractor_reader
()):
for
idx
,
data
in
enumerate
(
extractor_reader
()):
file_id
=
[
item
[
-
1
]
for
item
in
data
]
file_id
=
[
item
[
-
1
]
for
item
in
data
]
feed_data
=
[
item
[:
-
1
]
for
item
in
data
]
feed_data
=
[
item
[:
-
1
]
for
item
in
data
]
feature_out
=
self
.
exe
.
run
(
feature_out
=
self
.
exe
.
run
(
...
...
hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/kinetics_reader.py
浏览文件 @
dbca09ae
...
@@ -87,38 +87,15 @@ class KineticsReader(DataReader):
...
@@ -87,38 +87,15 @@ class KineticsReader(DataReader):
def
_batch_reader
():
def
_batch_reader
():
batch_out
=
[]
batch_out
=
[]
for
imgs
,
label
in
_reader
():
for
imgs
,
label
in
_reader
():
#for imgs in _reader():
if
imgs
is
None
:
if
imgs
is
None
:
continue
continue
batch_out
.
append
((
imgs
,
label
))
batch_out
.
append
((
imgs
,
label
))
#batch_out.append((imgs,))
if
len
(
batch_out
)
==
self
.
batch_size
:
if
len
(
batch_out
)
==
self
.
batch_size
:
yield
batch_out
yield
batch_out
batch_out
=
[]
batch_out
=
[]
return
_batch_reader
return
_batch_reader
def
_inference_reader_creator
(
self
,
video_path
,
mode
,
seg_num
,
seglen
,
short_size
,
target_size
,
img_mean
,
img_std
):
def
reader
():
try
:
imgs
=
mp4_loader
(
video_path
,
seg_num
,
seglen
,
mode
)
if
len
(
imgs
)
<
1
:
logger
.
error
(
'{} frame length {} less than 1.'
.
format
(
video_path
,
len
(
imgs
)))
yield
None
,
None
except
:
logger
.
error
(
'Error when loading {}'
.
format
(
video_path
))
yield
None
,
None
imgs_ret
=
imgs_transform
(
imgs
,
mode
,
seg_num
,
seglen
,
short_size
,
target_size
,
img_mean
,
img_std
)
label_ret
=
video_path
yield
imgs_ret
,
label_ret
return
reader
def
_reader_creator
(
self
,
def
_reader_creator
(
self
,
pickle_list
,
pickle_list
,
mode
,
mode
,
...
@@ -149,37 +126,7 @@ class KineticsReader(DataReader):
...
@@ -149,37 +126,7 @@ class KineticsReader(DataReader):
return
imgs_transform
(
imgs
,
mode
,
seg_num
,
seglen
,
\
return
imgs_transform
(
imgs
,
mode
,
seg_num
,
seglen
,
\
short_size
,
target_size
,
img_mean
,
img_std
,
name
=
self
.
name
),
mp4_path
short_size
,
target_size
,
img_mean
,
img_std
,
name
=
self
.
name
),
mp4_path
def
decode_pickle
(
sample
,
mode
,
seg_num
,
seglen
,
short_size
,
target_size
,
img_mean
,
img_std
):
pickle_path
=
sample
[
0
]
try
:
if
python_ver
<
(
3
,
0
):
data_loaded
=
pickle
.
load
(
open
(
pickle_path
,
'rb'
))
else
:
data_loaded
=
pickle
.
load
(
open
(
pickle_path
,
'rb'
),
encoding
=
'bytes'
)
vid
,
label
,
frames
=
data_loaded
if
len
(
frames
)
<
1
:
logger
.
error
(
'{} frame length {} less than 1.'
.
format
(
pickle_path
,
len
(
frames
)))
return
None
,
None
except
:
logger
.
info
(
'Error when loading {}'
.
format
(
pickle_path
))
return
None
,
None
if
mode
==
'train'
or
mode
==
'valid'
or
mode
==
'test'
:
ret_label
=
label
elif
mode
==
'infer'
:
ret_label
=
vid
imgs
=
video_loader
(
frames
,
seg_num
,
seglen
,
mode
)
return
imgs_transform
(
imgs
,
mode
,
seg_num
,
seglen
,
\
short_size
,
target_size
,
img_mean
,
img_std
,
name
=
self
.
name
),
ret_label
def
reader
():
def
reader
():
# with open(pickle_list) as flist:
# lines = [line.strip() for line in flist]
lines
=
[
line
.
strip
()
for
line
in
pickle_list
]
lines
=
[
line
.
strip
()
for
line
in
pickle_list
]
if
shuffle
:
if
shuffle
:
random
.
shuffle
(
lines
)
random
.
shuffle
(
lines
)
...
@@ -187,15 +134,8 @@ class KineticsReader(DataReader):
...
@@ -187,15 +134,8 @@ class KineticsReader(DataReader):
pickle_path
=
line
.
strip
()
pickle_path
=
line
.
strip
()
yield
[
pickle_path
]
yield
[
pickle_path
]
if
format
==
'pkl'
:
decode_func
=
decode_pickle
elif
format
==
'mp4'
:
decode_func
=
decode_mp4
else
:
raise
"Not implemented format {}"
.
format
(
format
)
mapper
=
functools
.
partial
(
mapper
=
functools
.
partial
(
decode_
func
,
decode_
mp4
,
mode
=
mode
,
mode
=
mode
,
seg_num
=
seg_num
,
seg_num
=
seg_num
,
seglen
=
seglen
,
seglen
=
seglen
,
...
@@ -218,142 +158,26 @@ def imgs_transform(imgs,
...
@@ -218,142 +158,26 @@ def imgs_transform(imgs,
name
=
''
):
name
=
''
):
imgs
=
group_scale
(
imgs
,
short_size
)
imgs
=
group_scale
(
imgs
,
short_size
)
if
mode
==
'train'
:
np_imgs
=
np
.
array
([
np
.
array
(
img
).
astype
(
'float32'
)
for
img
in
imgs
])
#dhwc
if
name
==
"TSM"
:
np_imgs
=
group_center_crop
(
np_imgs
,
target_size
)
imgs
=
group_multi_scale_crop
(
imgs
,
short_size
)
np_imgs
=
np_imgs
.
transpose
(
0
,
3
,
1
,
2
)
/
255
#dchw
imgs
=
group_random_crop
(
imgs
,
target_size
)
np_imgs
-=
img_mean
imgs
=
group_random_flip
(
imgs
)
np_imgs
/=
img_std
else
:
imgs
=
group_center_crop
(
imgs
,
target_size
)
np_imgs
=
(
np
.
array
(
imgs
[
0
]).
astype
(
'float32'
).
transpose
(
(
2
,
0
,
1
))).
reshape
(
1
,
3
,
target_size
,
target_size
)
/
255
for
i
in
range
(
len
(
imgs
)
-
1
):
img
=
(
np
.
array
(
imgs
[
i
+
1
]).
astype
(
'float32'
).
transpose
(
(
2
,
0
,
1
))).
reshape
(
1
,
3
,
target_size
,
target_size
)
/
255
np_imgs
=
np
.
concatenate
((
np_imgs
,
img
))
imgs
=
np_imgs
imgs
-=
img_mean
imgs
/=
img_std
imgs
=
np
.
reshape
(
imgs
,
(
seg_num
,
seglen
*
3
,
target_size
,
target_size
))
return
imgs
def
group_multi_scale_crop
(
img_group
,
target_size
,
scales
=
None
,
\
max_distort
=
1
,
fix_crop
=
True
,
more_fix_crop
=
True
):
scales
=
scales
if
scales
is
not
None
else
[
1
,
.
875
,
.
75
,
.
66
]
input_size
=
[
target_size
,
target_size
]
im_size
=
img_group
[
0
].
size
# get random crop offset
def
_sample_crop_size
(
im_size
):
image_w
,
image_h
=
im_size
[
0
],
im_size
[
1
]
base_size
=
min
(
image_w
,
image_h
)
crop_sizes
=
[
int
(
base_size
*
x
)
for
x
in
scales
]
crop_h
=
[
input_size
[
1
]
if
abs
(
x
-
input_size
[
1
])
<
3
else
x
for
x
in
crop_sizes
]
crop_w
=
[
input_size
[
0
]
if
abs
(
x
-
input_size
[
0
])
<
3
else
x
for
x
in
crop_sizes
]
pairs
=
[]
for
i
,
h
in
enumerate
(
crop_h
):
for
j
,
w
in
enumerate
(
crop_w
):
if
abs
(
i
-
j
)
<=
max_distort
:
pairs
.
append
((
w
,
h
))
crop_pair
=
random
.
choice
(
pairs
)
if
not
fix_crop
:
w_offset
=
random
.
randint
(
0
,
image_w
-
crop_pair
[
0
])
h_offset
=
random
.
randint
(
0
,
image_h
-
crop_pair
[
1
])
else
:
w_step
=
(
image_w
-
crop_pair
[
0
])
/
4
h_step
=
(
image_h
-
crop_pair
[
1
])
/
4
ret
=
list
()
return
np_imgs
ret
.
append
((
0
,
0
))
# upper left
if
w_step
!=
0
:
ret
.
append
((
4
*
w_step
,
0
))
# upper right
if
h_step
!=
0
:
ret
.
append
((
0
,
4
*
h_step
))
# lower left
if
h_step
!=
0
and
w_step
!=
0
:
ret
.
append
((
4
*
w_step
,
4
*
h_step
))
# lower right
if
h_step
!=
0
or
w_step
!=
0
:
ret
.
append
((
2
*
w_step
,
2
*
h_step
))
# center
if
more_fix_crop
:
ret
.
append
((
0
,
2
*
h_step
))
# center left
ret
.
append
((
4
*
w_step
,
2
*
h_step
))
# center right
ret
.
append
((
2
*
w_step
,
4
*
h_step
))
# lower center
ret
.
append
((
2
*
w_step
,
0
*
h_step
))
# upper center
ret
.
append
((
1
*
w_step
,
1
*
h_step
))
# upper left quarter
def
group_center_crop
(
np_imgs
,
target_size
):
ret
.
append
((
3
*
w_step
,
1
*
h_step
))
# upper right quarter
d
,
h
,
w
,
c
=
np_imgs
.
shape
ret
.
append
((
1
*
w_step
,
3
*
h_step
))
# lower left quarter
ret
.
append
((
3
*
w_step
,
3
*
h_step
))
# lower righ quarter
w_offset
,
h_offset
=
random
.
choice
(
ret
)
return
crop_pair
[
0
],
crop_pair
[
1
],
w_offset
,
h_offset
crop_w
,
crop_h
,
offset_w
,
offset_h
=
_sample_crop_size
(
im_size
)
crop_img_group
=
[
img
.
crop
((
offset_w
,
offset_h
,
offset_w
+
crop_w
,
offset_h
+
crop_h
))
for
img
in
img_group
]
ret_img_group
=
[
img
.
resize
((
input_size
[
0
],
input_size
[
1
]),
Image
.
BILINEAR
)
for
img
in
crop_img_group
]
return
ret_img_group
def
group_random_crop
(
img_group
,
target_size
):
w
,
h
=
img_group
[
0
].
size
th
,
tw
=
target_size
,
target_size
th
,
tw
=
target_size
,
target_size
assert
(
w
>=
target_size
)
and
(
h
>=
target_size
),
\
assert
(
w
>=
target_size
)
and
(
h
>=
target_size
),
\
"image width({}) and height({}) should be larger than crop size"
.
format
(
w
,
h
,
target_size
)
"image width({}) and height({}) should be larger than crop size"
.
format
(
w
,
h
,
target_size
)
out_images
=
[]
h_off
=
int
(
round
((
h
-
th
)
/
2.
))
x1
=
random
.
randint
(
0
,
w
-
tw
)
w_off
=
int
(
round
((
w
-
tw
)
/
2.
))
y1
=
random
.
randint
(
0
,
h
-
th
)
for
img
in
img_group
:
if
w
==
tw
and
h
==
th
:
out_images
.
append
(
img
)
else
:
out_images
.
append
(
img
.
crop
((
x1
,
y1
,
x1
+
tw
,
y1
+
th
)))
return
out_images
def
group_random_flip
(
img_group
):
v
=
random
.
random
()
if
v
<
0.5
:
ret
=
[
img
.
transpose
(
Image
.
FLIP_LEFT_RIGHT
)
for
img
in
img_group
]
return
ret
else
:
return
img_group
def
group_center_crop
(
img_group
,
target_size
):
img_crop
=
[]
for
img
in
img_group
:
w
,
h
=
img
.
size
th
,
tw
=
target_size
,
target_size
assert
(
w
>=
target_size
)
and
(
h
>=
target_size
),
\
"image width({}) and height({}) should be larger than crop size"
.
format
(
w
,
h
,
target_size
)
x1
=
int
(
round
((
w
-
tw
)
/
2.
))
y1
=
int
(
round
((
h
-
th
)
/
2.
))
img_crop
.
append
(
img
.
crop
((
x1
,
y1
,
x1
+
tw
,
y1
+
th
)))
img_crop
=
np_imgs
[:,
h_off
:
h_off
+
target_size
,
w_off
:
w_off
+
target_size
,
:]
return
img_crop
return
img_crop
...
@@ -378,47 +202,6 @@ def group_scale(imgs, target_size):
...
@@ -378,47 +202,6 @@ def group_scale(imgs, target_size):
return
resized_imgs
return
resized_imgs
def
imageloader
(
buf
):
if
isinstance
(
buf
,
str
):
img
=
Image
.
open
(
StringIO
(
buf
))
else
:
img
=
Image
.
open
(
BytesIO
(
buf
))
return
img
.
convert
(
'RGB'
)
def
video_loader
(
frames
,
nsample
,
seglen
,
mode
):
videolen
=
len
(
frames
)
average_dur
=
int
(
videolen
/
nsample
)
imgs
=
[]
for
i
in
range
(
nsample
):
idx
=
0
if
mode
==
'train'
:
if
average_dur
>=
seglen
:
idx
=
random
.
randint
(
0
,
average_dur
-
seglen
)
idx
+=
i
*
average_dur
elif
average_dur
>=
1
:
idx
+=
i
*
average_dur
else
:
idx
=
i
else
:
if
average_dur
>=
seglen
:
idx
=
(
average_dur
-
seglen
)
//
2
idx
+=
i
*
average_dur
elif
average_dur
>=
1
:
idx
+=
i
*
average_dur
else
:
idx
=
i
for
jj
in
range
(
idx
,
idx
+
seglen
):
imgbuf
=
frames
[
int
(
jj
%
videolen
)]
img
=
imageloader
(
imgbuf
)
imgs
.
append
(
img
)
return
imgs
def
mp4_loader
(
filepath
,
nsample
,
seglen
,
mode
):
def
mp4_loader
(
filepath
,
nsample
,
seglen
,
mode
):
cap
=
cv2
.
VideoCapture
(
filepath
)
cap
=
cv2
.
VideoCapture
(
filepath
)
videolen
=
int
(
cap
.
get
(
cv2
.
CAP_PROP_FRAME_COUNT
))
videolen
=
int
(
cap
.
get
(
cv2
.
CAP_PROP_FRAME_COUNT
))
...
@@ -434,15 +217,6 @@ def mp4_loader(filepath, nsample, seglen, mode):
...
@@ -434,15 +217,6 @@ def mp4_loader(filepath, nsample, seglen, mode):
imgs
=
[]
imgs
=
[]
for
i
in
range
(
nsample
):
for
i
in
range
(
nsample
):
idx
=
0
idx
=
0
if
mode
==
'train'
:
if
average_dur
>=
seglen
:
idx
=
random
.
randint
(
0
,
average_dur
-
seglen
)
idx
+=
i
*
average_dur
elif
average_dur
>=
1
:
idx
+=
i
*
average_dur
else
:
idx
=
i
else
:
if
average_dur
>=
seglen
:
if
average_dur
>=
seglen
:
idx
=
(
average_dur
-
1
)
//
2
idx
=
(
average_dur
-
1
)
//
2
idx
+=
i
*
average_dur
idx
+=
i
*
average_dur
...
@@ -455,5 +229,4 @@ def mp4_loader(filepath, nsample, seglen, mode):
...
@@ -455,5 +229,4 @@ def mp4_loader(filepath, nsample, seglen, mode):
imgbuf
=
sampledFrames
[
int
(
jj
%
len
(
sampledFrames
))]
imgbuf
=
sampledFrames
[
int
(
jj
%
len
(
sampledFrames
))]
img
=
Image
.
fromarray
(
imgbuf
,
mode
=
'RGB'
)
img
=
Image
.
fromarray
(
imgbuf
,
mode
=
'RGB'
)
imgs
.
append
(
img
)
imgs
.
append
(
img
)
return
imgs
return
imgs
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录