From d32cc73327205688cf9bd7a1cc169a90e09df82a Mon Sep 17 00:00:00 2001
From: linjieccc <40840292+linjieccc@users.noreply.github.com>
Date: Thu, 16 Sep 2021 16:50:59 +0800
Subject: [PATCH] Update nlp pretrained model docs (#1594)
---
.../bert-base-chinese/README.md | 223 +++++++++--------
modules/text/language_model/ernie/README.md | 229 +++++++++--------
.../text/language_model/ernie_tiny/README.md | 231 ++++++++++--------
.../ernie_v2_eng_base/README.md | 228 +++++++++--------
.../ernie_v2_eng_large/README.md | 228 +++++++++--------
.../language_model/roberta-wwm-ext/README.md | 215 ++++++++--------
6 files changed, 738 insertions(+), 616 deletions(-)
diff --git a/modules/text/language_model/bert-base-chinese/README.md b/modules/text/language_model/bert-base-chinese/README.md
index c7299f81..83a2180c 100644
--- a/modules/text/language_model/bert-base-chinese/README.md
+++ b/modules/text/language_model/bert-base-chinese/README.md
@@ -1,78 +1,43 @@
-```shell
-$ hub install bert-base-chinese==2.0.2
-```
+# bert-base-chinese
+|模型名称|bert-base-chinese|
+| :--- | :---: |
+|类别|文本-语义模型|
+|网络|bert-base-chinese|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|是|
+|模型大小|681MB|
+|最新更新日期|2021-02-26|
+|数据指标|-|
+
+## 一、模型基本信息
+
+- ### 模型介绍
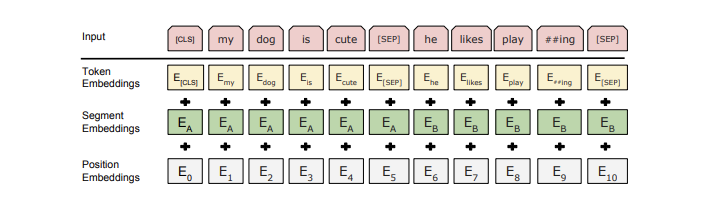
-
+
更多详情请参考[BERT论文](https://arxiv.org/abs/1810.04805)
-## API
-
-```python
-def __init__(
- task=None,
- load_checkpoint=None,
- label_map=None,
- num_classes=2,
- suffix=False,
- **kwargs,
-)
-```
-
-创建Module对象(动态图组网版本)。
-
-**参数**
-
-* `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
-* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
-* `label_map`:预测时的类别映射表。
-* `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
-* `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
-* `**kwargs`:用户额外指定的关键字字典类型的参数。
-```python
-def predict(
- data,
- max_seq_len=128,
- batch_size=1,
- use_gpu=False
-)
-```
-
-**参数**
-
-* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
-* `max_seq_len`:模型处理文本的最大长度
-* `batch_size`:模型批处理大小
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-
-**返回**
-
-* `results`:list类型,不同任务类型的返回结果如下
- * 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
- * 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-
-```python
-def get_embedding(
- data,
- use_gpu=False
-)
-```
+## 二、安装
-用于获取输入文本的句子粒度特征与字粒度特征
+- ### 1、环境依赖
-**参数**
+ - paddlepaddle >= 2.0.0
-* `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**返回**
+- ### 2、安装
-* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+ - ```shell
+ $ hub install bert-base-chinese
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+## 三、模型API预测
-**代码示例**
+- ### 1、预测代码示例
```python
import paddlehub as hub
@@ -96,71 +61,126 @@ for idx, text in enumerate(data):
```
详情可参考PaddleHub示例:
-- [文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classification)
-- [序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/sequence_labeling)
+- [文本分类](../../../../demo/text_classification)
+- [序列标注](../../../../demo/sequence_labeling)
-## 服务部署
+- ### 2、API
-PaddleHub Serving可以部署一个在线获取预训练词向量。
+ - ```python
+ def __init__(
+ task=None,
+ load_checkpoint=None,
+ label_map=None,
+ num_classes=2,
+ suffix=False,
+ **kwargs,
+ )
+ ```
-### Step1: 启动PaddleHub Serving
+ - 创建Module对象(动态图组网版本)
-运行启动命令:
+ - **参数**
-```shell
-$ hub serving start -m bert-base-chinese
-```
+ - `task`: 任务名称,可为`seq-cls`(文本分类任务)或`token-cls`(序列标注任务)。
+ - `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
+ - `label_map`:预测时的类别映射表。
+ - `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
+ - `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
+ - `**kwargs`:用户额外指定的关键字字典类型的参数。
-这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+ - ```python
+ def predict(
+ data,
+ max_seq_len=128,
+ batch_size=1,
+ use_gpu=False
+ )
+ ```
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - **参数**
-### Step2: 发送预测请求
+ - `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
+ - `max_seq_len`:模型处理文本的最大长度
+ - `batch_size`:模型批处理大小
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **返回**
-```python
-import requests
-import json
-
-# 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
-text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
-# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
-# 对应本地部署,则为module.get_embedding(data=text)
-data = {"data": text}
-# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
-url = "http://10.12.121.132:8866/predict/bert-base-chinese"
-# 指定post请求的headers为application/json方式
-headers = {"Content-Type": "application/json"}
-
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-print(r.json())
-```
+ - `results`:list类型,不同任务类型的返回结果如下
+ - 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
+ - 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
+
+ - ```python
+ def get_embedding(
+ data,
+ use_gpu=False
+ )
+ ```
+
+ - 用于获取输入文本的句子粒度特征与字粒度特征
+
+ - **参数**
+
+ - `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+
+ - **返回**
-## 查看代码
+ - `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
-https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/pretrain_langauge_models/BERT
+## 四、服务部署
+- PaddleHub Serving可以部署一个在线获取预训练词向量。
-## 依赖
+- ### 第一步:启动PaddleHub Serving
-paddlepaddle >= 2.0.0
+ - ```shell
+ $ hub serving start -m bert-base-chinese
+ ```
-paddlehub >= 2.0.0
+ - 这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
-## 更新历史
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ # 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
+ text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"data"
+ # 对应本地部署,则为module.get_embedding(data=text)
+ data = {"data": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://10.12.121.132:8866/predict/bert-base-chinese"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+## 五、更新历史
* 1.0.0
初始发布
+* 1.0.1
+
+ 修复python 2的兼容问题
+
* 1.1.0
支持get_embedding与get_params_layer
* 2.0.0
- 全面升级动态图,接口有所变化。
+ 全面升级动态图版本,接口有所变化
* 2.0.1
@@ -168,4 +188,7 @@ paddlehub >= 2.0.0
* 2.0.2
- 增加文本匹配任务`text-matching`
+ 增加文本匹配任务`text-matching`
+ ```shell
+ $ hub install bert-base-chinese==2.0.2
+ ```
diff --git a/modules/text/language_model/ernie/README.md b/modules/text/language_model/ernie/README.md
index 26e12954..09ab85fc 100644
--- a/modules/text/language_model/ernie/README.md
+++ b/modules/text/language_model/ernie/README.md
@@ -1,88 +1,52 @@
-```shell
-$ hub install ernie==2.0.2
-```
-## 在线体验
-AI Studio 快速体验
-
-
-
-
-
-
+# ernie
+|模型名称|ernie|
+| :--- | :---: |
+|类别|文本-语义模型|
+|网络|ernie-1.0|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|是|
+|模型大小|384MB|
+|最新更新日期|2021-02-26|
+|数据指标|-|
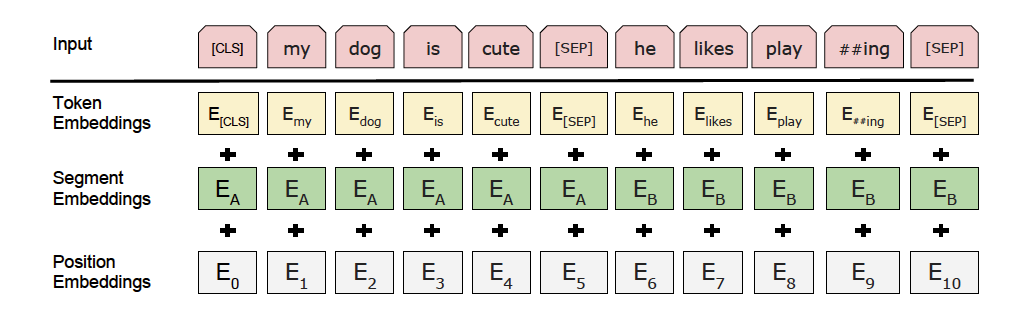
-
-
-
+## 一、模型基本信息
+- ### 模型介绍
-更多详情请参考[ERNIE论文](https://arxiv.org/abs/1904.09223)
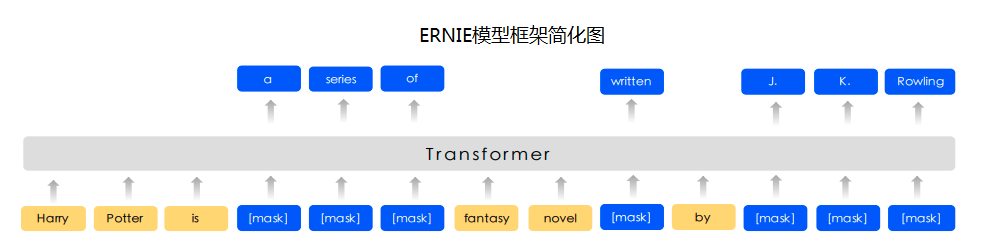
+Ernie是百度提出的基于知识增强的持续学习语义理解模型,该模型将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。
-## API
-```python
-def __init__(
- task=None,
- load_checkpoint=None,
- label_map=None,
- num_classes=2,
- suffix=False,
- **kwargs,
-)
-```
+ - AI Studio 快速体验
-创建Module对象(动态图组网版本)。
+
+
+
-**参数**
+
+
+
-* `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
-* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
-* `label_map`:预测时的类别映射表。
-* `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
-* `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
-* `**kwargs`:用户额外指定的关键字字典类型的参数。
+ - 更多详情请参考[ERNIE论文](https://arxiv.org/abs/1904.09223)
-```python
-def predict(
- data,
- max_seq_len=128,
- batch_size=1,
- use_gpu=False
-)
-```
-
-**参数**
-
-* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
-* `max_seq_len`:模型处理文本的最大长度
-* `batch_size`:模型批处理大小
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-
-**返回**
-
-* `results`:list类型,不同任务类型的返回结果如下
- * 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
- * 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-
-```python
-def get_embedding(
- data,
- use_gpu=False
-)
-```
+## 二、安装
-用于获取输入文本的句子粒度特征与字粒度特征
+- ### 1、环境依赖
-**参数**
+ - paddlepaddle >= 2.0.0
-* `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**返回**
+- ### 2、安装
-* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+ - ```shell
+ $ hub install ernie
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+## 三、模型API预测
-**代码示例**
+- ### 1、预测代码示例
```python
import paddlehub as hub
@@ -106,58 +70,110 @@ for idx, text in enumerate(data):
```
详情可参考PaddleHub示例:
-- [文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classification)
-- [序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/sequence_labeling)
+- [文本分类](../../../../demo/text_classification)
+- [序列标注](../../../../demo/sequence_labeling)
-## 服务部署
+- ### 2、API
-PaddleHub Serving可以部署一个在线获取预训练词向量。
+ - ```python
+ def __init__(
+ task=None,
+ load_checkpoint=None,
+ label_map=None,
+ num_classes=2,
+ suffix=False,
+ **kwargs,
+ )
+ ```
-### Step1: 启动PaddleHub Serving
+ - 创建Module对象(动态图组网版本)
-运行启动命令:
+ - **参数**
-```shell
-$ hub serving start -m ernie
-```
+ - `task`: 任务名称,可为`seq-cls`(文本分类任务)或`token-cls`(序列标注任务)。
+ - `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
+ - `label_map`:预测时的类别映射表。
+ - `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
+ - `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
+ - `**kwargs`:用户额外指定的关键字字典类型的参数。
-这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+ - ```python
+ def predict(
+ data,
+ max_seq_len=128,
+ batch_size=1,
+ use_gpu=False
+ )
+ ```
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - **参数**
-### Step2: 发送预测请求
+ - `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
+ - `max_seq_len`:模型处理文本的最大长度
+ - `batch_size`:模型批处理大小
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **返回**
-```python
-import requests
-import json
-
-# 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
-text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
-# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
-# 对应本地部署,则为module.get_embedding(data=text)
-data = {"data": text}
-# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
-url = "http://10.12.121.132:8866/predict/ernie"
-# 指定post请求的headers为application/json方式
-headers = {"Content-Type": "application/json"}
-
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-print(r.json())
-```
+ - `results`:list类型,不同任务类型的返回结果如下
+ - 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
+ - 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
+
+ - ```python
+ def get_embedding(
+ data,
+ use_gpu=False
+ )
+ ```
+
+ - 用于获取输入文本的句子粒度特征与字粒度特征
+
+ - **参数**
+
+ - `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+
+ - **返回**
+
+ - `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线获取预训练词向量。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - ```shell
+ $ hub serving start -m ernie
+ ```
+
+ - 这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-## 查看代码
+- ### 第二步:发送预测请求
-https://github.com/PaddlePaddle/ERNIE
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-## 依赖
+ - ```python
+ import requests
+ import json
-paddlepaddle >= 2.0.0
+ # 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
+ text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"data"
+ # 对应本地部署,则为module.get_embedding(data=text)
+ data = {"data": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://10.12.121.132:8866/predict/ernie"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
-paddlehub >= 2.0.0
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
-## 更新历史
+## 五、更新历史
* 1.0.0
@@ -190,3 +206,6 @@ paddlehub >= 2.0.0
* 2.0.2
增加文本匹配任务`text-matching`
+ ```shell
+ $ hub install ernie==2.0.2
+ ```
diff --git a/modules/text/language_model/ernie_tiny/README.md b/modules/text/language_model/ernie_tiny/README.md
index 3f2d9f57..d3814a72 100644
--- a/modules/text/language_model/ernie_tiny/README.md
+++ b/modules/text/language_model/ernie_tiny/README.md
@@ -1,88 +1,53 @@
-```shell
-$ hub install ernie_tiny==2.0.2
-```
-## 在线体验
-AI Studio 快速体验
-
+# ernie_tiny
+|模型名称|ernie_tiny|
+| :--- | :---: |
+|类别|文本-语义模型|
+|网络|ernie_tiny|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|是|
+|模型大小|346MB|
+|最新更新日期|2021-02-26|
+|数据指标|-|
-
-
-
+## 一、模型基本信息
+- ### 模型介绍
-
-
-
+Ernie是百度提出的基于知识增强的持续学习语义理解模型,该模型将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。
-更多详情请参考[ERNIE论文](https://arxiv.org/abs/1904.09223)
+ - AI Studio 快速体验
-## API
+
+
+
-```python
-def __init__(
- task=None,
- load_checkpoint=None,
- label_map=None,
- num_classes=2,
- suffix=False,
- **kwargs,
-)
-```
+
+
+
-创建Module对象(动态图组网版本)。
+ - 更多详情请参考[ERNIE论文](https://arxiv.org/abs/1904.09223)
-**参数**
+## 二、安装
-* `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
-* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
-* `label_map`:预测时的类别映射表。
-* `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
-* `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
-* `**kwargs`:用户额外指定的关键字字典类型的参数。
+- ### 1、环境依赖
-```python
-def predict(
- data,
- max_seq_len=128,
- batch_size=1,
- use_gpu=False
-)
-```
+ - paddlepaddle >= 2.0.0
-**参数**
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
-* `max_seq_len`:模型处理文本的最大长度
-* `batch_size`:模型批处理大小
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+- ### 2、安装
-**返回**
+ - ```shell
+ $ hub install ernie_tiny
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-* `results`:list类型,不同任务类型的返回结果如下
- * 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
- * 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-```python
-def get_embedding(
- data,
- use_gpu=False
-)
-```
+## 三、模型API预测
-用于获取输入文本的句子粒度特征与字粒度特征
-
-**参数**
-
-* `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-
-**返回**
-
-* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
-
-
-**代码示例**
+- ### 1、预测代码示例
```python
import paddlehub as hub
@@ -97,7 +62,7 @@ label_map = {0: 'negative', 1: 'positive'}
model = hub.Module(
name='ernie_tiny',
version='2.0.2',
- task='sequence_classification',
+ task='seq-cls',
load_checkpoint='/path/to/parameters',
label_map=label_map)
results = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=False)
@@ -106,58 +71,111 @@ for idx, text in enumerate(data):
```
详情可参考PaddleHub示例:
-- [文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classification)
-- [序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/sequence_labeling)
+- [文本分类](../../../../demo/text_classification)
+- [序列标注](../../../../demo/sequence_labeling)
-## 服务部署
-PaddleHub Serving可以部署一个在线获取预训练词向量。
+- ### 2、API
-### Step1: 启动PaddleHub Serving
+ - ```python
+ def __init__(
+ task=None,
+ load_checkpoint=None,
+ label_map=None,
+ num_classes=2,
+ suffix=False,
+ **kwargs,
+ )
+ ```
-运行启动命令:
+ - 创建Module对象(动态图组网版本)
-```shell
-$ hub serving start -m ernie_tiny
-```
+ - **参数**
-这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+ - `task`: 任务名称,可为`seq-cls`(文本分类任务)或`token-cls`(序列标注任务)。
+ - `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
+ - `label_map`:预测时的类别映射表。
+ - `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
+ - `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
+ - `**kwargs`:用户额外指定的关键字字典类型的参数。
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - ```python
+ def predict(
+ data,
+ max_seq_len=128,
+ batch_size=1,
+ use_gpu=False
+ )
+ ```
-### Step2: 发送预测请求
+ - **参数**
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
+ - `max_seq_len`:模型处理文本的最大长度
+ - `batch_size`:模型批处理大小
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-```python
-import requests
-import json
-
-# 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
-text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
-# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
-# 对应本地部署,则为module.get_embedding(data=text)
-data = {"data": text}
-# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
-url = "http://10.12.121.132:8866/predict/ernie_tiny"
-# 指定post请求的headers为application/json方式
-headers = {"Content-Type": "application/json"}
-
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-print(r.json())
-```
+ - **返回**
+
+ - `results`:list类型,不同任务类型的返回结果如下
+ - 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
+ - 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
+
+ - ```python
+ def get_embedding(
+ data,
+ use_gpu=False
+ )
+ ```
+
+ - 用于获取输入文本的句子粒度特征与字粒度特征
+
+ - **参数**
+
+ - `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+
+ - **返回**
+
+ - `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线获取预训练词向量。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - ```shell
+ $ hub serving start -m ernie_tiny
+ ```
+
+ - 这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-## 查看代码
+- ### 第二步:发送预测请求
-https://github.com/PaddlePaddle/ERNIE
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-## 依赖
+ - ```python
+ import requests
+ import json
-paddlepaddle >= 2.0.0
+ # 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
+ text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"data"
+ # 对应本地部署,则为module.get_embedding(data=text)
+ data = {"data": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://10.12.121.132:8866/predict/ernie_tiny"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
-paddlehub >= 2.0.0
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
-## 更新历史
+## 五、更新历史
* 1.0.0
@@ -182,3 +200,6 @@ paddlehub >= 2.0.0
* 2.0.2
增加文本匹配任务`text-matching`
+ ```shell
+ $ hub install ernie_tiny==2.0.2
+ ```
diff --git a/modules/text/language_model/ernie_v2_eng_base/README.md b/modules/text/language_model/ernie_v2_eng_base/README.md
index 24d0103a..d69e1540 100644
--- a/modules/text/language_model/ernie_v2_eng_base/README.md
+++ b/modules/text/language_model/ernie_v2_eng_base/README.md
@@ -1,84 +1,49 @@
+# ernie_v2_eng_base
+|模型名称|ernie_v2_eng_base|
+| :--- | :---: |
+|类别|文本-语义模型|
+|网络|ernie_v2_eng_base|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|是|
+|模型大小|1.3G|
+|最新更新日期|2021-03-16|
+|数据指标|-|
-```shell
-$ hub install ernie_v2_eng_base==2.0.2
-```
-
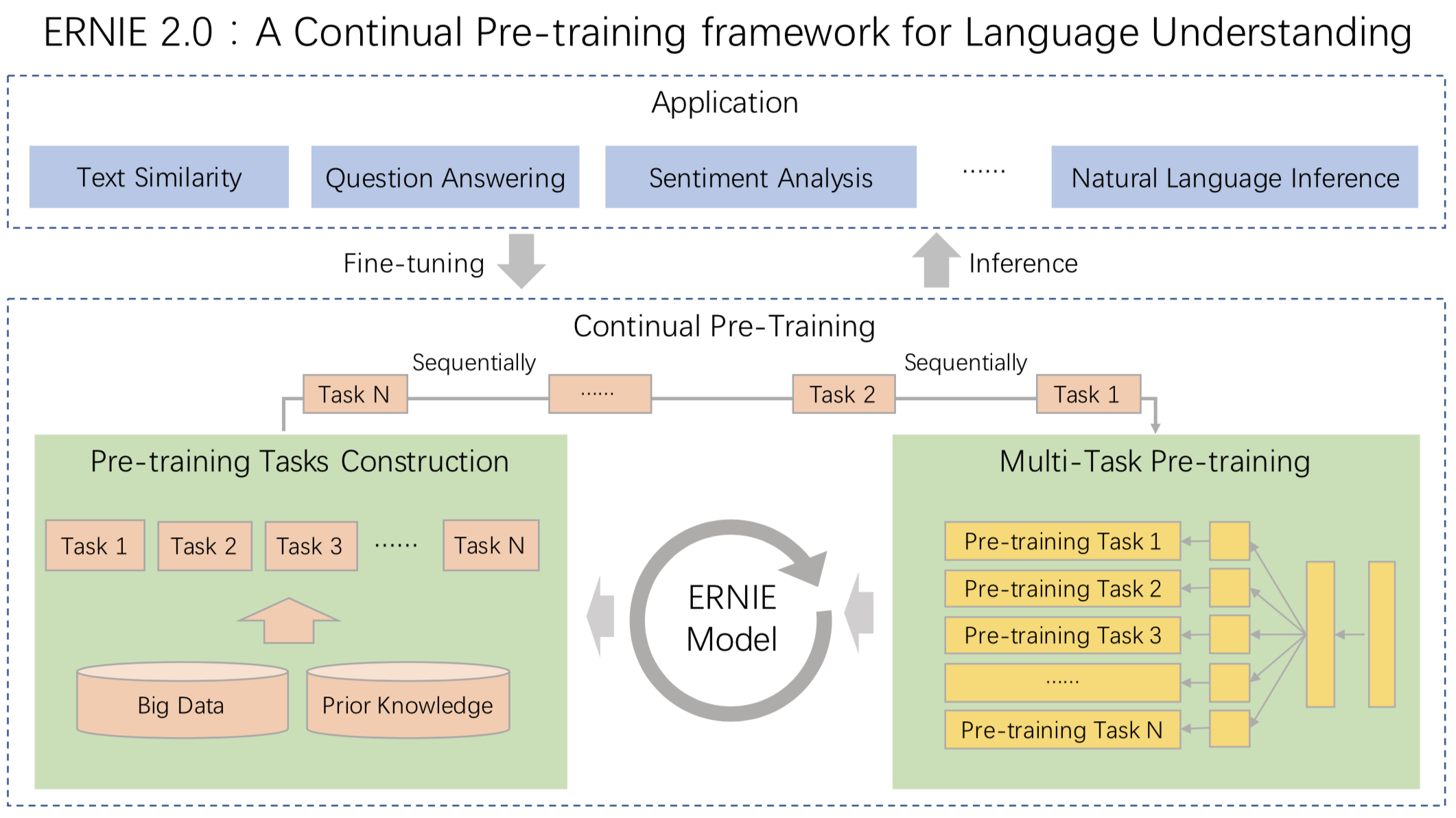
-
-
-
-
-
-
-
-
-更多详情请参考[ERNIE论文](https://arxiv.org/abs/1907.12412)
+## 一、模型基本信息
-## API
+- ### 模型介绍
-```python
-def __init__(
- task=None,
- load_checkpoint=None,
- label_map=None,
- num_classes=2,
- suffix=False,
- **kwargs,
-)
-```
+Ernie是百度提出的基于知识增强的持续学习语义理解模型,该模型将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。
-创建Module对象(动态图组网版本)。
+ -
+
+
-**参数**
+
+
+
-* `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
-* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
-* `label_map`:预测时的类别映射表。
-* `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
-* `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
-* `**kwargs`:用户额外指定的关键字字典类型的参数。
+ - 更多详情请参考[ERNIE论文](https://arxiv.org/abs/1907.12412)
-```python
-def predict(
- data,
- max_seq_len=128,
- batch_size=1,
- use_gpu=False
-)
-```
-
-**参数**
-
-* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
-* `max_seq_len`:模型处理文本的最大长度
-* `batch_size`:模型批处理大小
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-
-**返回**
-
-* `results`:list类型,不同任务类型的返回结果如下
- * 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
- * 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-
-```python
-def get_embedding(
- data,
- use_gpu=False
-)
-```
+## 二、安装
-用于获取输入文本的句子粒度特征与字粒度特征
+- ### 1、环境依赖
-**参数**
+ - paddlepaddle >= 2.0.0
-* `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**返回**
+- ### 2、安装
-* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+ - ```shell
+ $ hub install ernie_tiny
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+## 三、模型API预测
-**代码示例**
+- ### 1、预测代码示例
```python
import paddlehub as hub
@@ -102,58 +67,110 @@ for idx, text in enumerate(data):
```
详情可参考PaddleHub示例:
-- [文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classification)
-- [序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/sequence_labeling)
+- [文本分类](../../../../demo/text_classification)
+- [序列标注](../../../../demo/sequence_labeling)
-## 服务部署
+- ### 2、API
-PaddleHub Serving可以部署一个在线获取预训练词向量。
+ - ```python
+ def __init__(
+ task=None,
+ load_checkpoint=None,
+ label_map=None,
+ num_classes=2,
+ suffix=False,
+ **kwargs,
+ )
+ ```
-### Step1: 启动PaddleHub Serving
+ - 创建Module对象(动态图组网版本)
-运行启动命令:
+ - **参数**
-```shell
-$ hub serving start -m ernie_v2_eng_base
-```
+ - `task`: 任务名称,可为`seq-cls`(文本分类任务)或`token-cls`(序列标注任务)。
+ - `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
+ - `label_map`:预测时的类别映射表。
+ - `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
+ - `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
+ - `**kwargs`:用户额外指定的关键字字典类型的参数。
-这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+ - ```python
+ def predict(
+ data,
+ max_seq_len=128,
+ batch_size=1,
+ use_gpu=False
+ )
+ ```
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - **参数**
-### Step2: 发送预测请求
+ - `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
+ - `max_seq_len`:模型处理文本的最大长度
+ - `batch_size`:模型批处理大小
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **返回**
-```python
-import requests
-import json
-
-# 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
-text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
-# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
-# 对应本地部署,则为module.get_embedding(data=text)
-data = {"data": text}
-# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
-url = "http://10.12.121.132:8866/predict/ernie_v2_eng_base"
-# 指定post请求的headers为application/json方式
-headers = {"Content-Type": "application/json"}
-
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-print(r.json())
-```
+ - `results`:list类型,不同任务类型的返回结果如下
+ - 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
+ - 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
+
+ - ```python
+ def get_embedding(
+ data,
+ use_gpu=False
+ )
+ ```
+
+ - 用于获取输入文本的句子粒度特征与字粒度特征
+
+ - **参数**
+
+ - `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+
+ - **返回**
+
+ - `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线获取预训练词向量。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - ```shell
+ $ hub serving start -m ernie_v2_eng_base
+ ```
+
+ - 这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-## 查看代码
+- ### 第二步:发送预测请求
-https://github.com/PaddlePaddle/ERNIE
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-## 依赖
+ - ```python
+ import requests
+ import json
-paddlepaddle >= 2.0.0
+ # 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
+ text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"data"
+ # 对应本地部署,则为module.get_embedding(data=text)
+ data = {"data": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://10.12.121.132:8866/predict/ernie_v2_eng_base"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
-paddlehub >= 2.0.0
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
-## 更新历史
+## 五、更新历史
* 1.0.0
@@ -177,4 +194,7 @@ paddlehub >= 2.0.0
* 2.0.2
- 增加文本匹配任务`text-matching`
+ 增加文本匹配任务`text-matching`
+ ```shell
+ $ hub install ernie_v2_eng_base==2.0.2
+ ```
diff --git a/modules/text/language_model/ernie_v2_eng_large/README.md b/modules/text/language_model/ernie_v2_eng_large/README.md
index 5552b6ea..84c912a9 100644
--- a/modules/text/language_model/ernie_v2_eng_large/README.md
+++ b/modules/text/language_model/ernie_v2_eng_large/README.md
@@ -1,84 +1,49 @@
+# ernie_v2_eng_large
+|模型名称|ernie_v2_eng_large|
+| :--- | :---: |
+|类别|文本-语义模型|
+|网络|ernie_v2_eng_large|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|是|
+|模型大小|1.3G|
+|最新更新日期|2021-03-16|
+|数据指标|-|
-```shell
-$ hub install ernie_v2_eng_large==2.0.2
-```
-
-
-
-
-
-
-
-
-
-更多详情请参考[ERNIE论文](https://arxiv.org/abs/1907.12412)
+## 一、模型基本信息
-## API
+- ### 模型介绍
-```python
-def __init__(
- task=None,
- load_checkpoint=None,
- label_map=None,
- num_classes=2,
- suffix=False,
- **kwargs,
-)
-```
+Ernie是百度提出的基于知识增强的持续学习语义理解模型,该模型将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。
-创建Module对象(动态图组网版本)。
+ -
+
+
-**参数**
+
+
+
-* `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
-* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
-* `label_map`:预测时的类别映射表。
-* `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
-* `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
-* `**kwargs`:用户额外指定的关键字字典类型的参数。
+ - 更多详情请参考[ERNIE论文](https://arxiv.org/abs/1907.12412)
-```python
-def predict(
- data,
- max_seq_len=128,
- batch_size=1,
- use_gpu=False
-)
-```
-
-**参数**
-
-* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
-* `max_seq_len`:模型处理文本的最大长度
-* `batch_size`:模型批处理大小
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-
-**返回**
-
-* `results`:list类型,不同任务类型的返回结果如下
- * 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
- * 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
-
-```python
-def get_embedding(
- data,
- use_gpu=False
-)
-```
+## 二、安装
-用于获取输入文本的句子粒度特征与字粒度特征
+- ### 1、环境依赖
-**参数**
+ - paddlepaddle >= 2.0.0
-* `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**返回**
+- ### 2、安装
-* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+ - ```shell
+ $ hub install ernie_tiny
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+## 三、模型API预测
-**代码示例**
+- ### 1、预测代码示例
```python
import paddlehub as hub
@@ -102,58 +67,110 @@ for idx, text in enumerate(data):
```
详情可参考PaddleHub示例:
-- [文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classification)
-- [序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/sequence_labeling)
+- [文本分类](../../../../demo/text_classification)
+- [序列标注](../../../../demo/sequence_labeling)
-## 服务部署
+- ### 2、API
-PaddleHub Serving可以部署一个在线获取预训练词向量。
+ - ```python
+ def __init__(
+ task=None,
+ load_checkpoint=None,
+ label_map=None,
+ num_classes=2,
+ suffix=False,
+ **kwargs,
+ )
+ ```
-### Step1: 启动PaddleHub Serving
+ - 创建Module对象(动态图组网版本)
-运行启动命令:
+ - **参数**
-```shell
-$ hub serving start -m ernie_v2_eng_large
-```
+ - `task`: 任务名称,可为`seq-cls`(文本分类任务)或`token-cls`(序列标注任务)。
+ - `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
+ - `label_map`:预测时的类别映射表。
+ - `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
+ - `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
+ - `**kwargs`:用户额外指定的关键字字典类型的参数。
-这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+ - ```python
+ def predict(
+ data,
+ max_seq_len=128,
+ batch_size=1,
+ use_gpu=False
+ )
+ ```
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - **参数**
-### Step2: 发送预测请求
+ - `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
+ - `max_seq_len`:模型处理文本的最大长度
+ - `batch_size`:模型批处理大小
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **返回**
-```python
-import requests
-import json
-
-# 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
-text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
-# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
-# 对应本地部署,则为module.get_embedding(data=text)
-data = {"data": text}
-# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
-url = "http://10.12.121.132:8866/predict/ernie_v2_eng_large"
-# 指定post请求的headers为application/json方式
-headers = {"Content-Type": "application/json"}
-
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-print(r.json())
-```
+ - `results`:list类型,不同任务类型的返回结果如下
+ - 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
+ - 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
+
+ - ```python
+ def get_embedding(
+ data,
+ use_gpu=False
+ )
+ ```
+
+ - 用于获取输入文本的句子粒度特征与字粒度特征
+
+ - **参数**
+
+ - `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+
+ - **返回**
+
+ - `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线获取预训练词向量。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - ```shell
+ $ hub serving start -m ernie_v2_eng_large
+ ```
+
+ - 这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-## 查看代码
+- ### 第二步:发送预测请求
-https://github.com/PaddlePaddle/ERNIE
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-## 依赖
+ - ```python
+ import requests
+ import json
-paddlepaddle >= 2.0.0
+ # 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
+ text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"data"
+ # 对应本地部署,则为module.get_embedding(data=text)
+ data = {"data": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://10.12.121.132:8866/predict/ernie_v2_eng_large"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
-paddlehub >= 2.0.0
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
-## 更新历史
+## 五、更新历史
* 1.0.0
@@ -177,4 +194,7 @@ paddlehub >= 2.0.0
* 2.0.2
- 增加文本匹配任务`text-matching`
+ 增加文本匹配任务`text-matching`
+ ```shell
+ $ hub install ernie_v2_eng_large==2.0.2
+ ```
diff --git a/modules/text/language_model/roberta-wwm-ext/README.md b/modules/text/language_model/roberta-wwm-ext/README.md
index af4e87ee..2f7c5c5f 100644
--- a/modules/text/language_model/roberta-wwm-ext/README.md
+++ b/modules/text/language_model/roberta-wwm-ext/README.md
@@ -1,78 +1,43 @@
-```shell
-$ hub install roberta-wwm-ext==2.0.2
-```
+# roberta-wwm-ext
+|模型名称|roberta-wwm-ext|
+| :--- | :---: |
+|类别|文本-语义模型|
+|网络|roberta-wwm-ext|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|是|
+|模型大小|391MB|
+|最新更新日期|2021-03-16|
+|数据指标|-|
+
+## 一、模型基本信息
+
+- ### 模型介绍
+
更多详情请参考[RoBERTa论文](https://arxiv.org/abs/1907.11692)、[Chinese-BERT-wwm技术报告](https://arxiv.org/abs/1906.08101)
-## API
-
-```python
-def __init__(
- task=None,
- load_checkpoint=None,
- label_map=None,
- num_classes=2,
- suffix=False,
- **kwargs,
-)
-```
-
-创建Module对象(动态图组网版本)。
-
-**参数**
-
-* `task`: 任务名称,可为`seq-cls`(文本分类任务,原来的`sequence_classification`在未来会被弃用)或`token-cls`(序列标注任务)。
-* `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
-* `label_map`:预测时的类别映射表。
-* `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
-* `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
-* `**kwargs`:用户额外指定的关键字字典类型的参数。
-
-```python
-def predict(
- data,
- max_seq_len=128,
- batch_size=1,
- use_gpu=False
-)
-```
-
-**参数**
-
-* `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
-* `max_seq_len`:模型处理文本的最大长度
-* `batch_size`:模型批处理大小
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-
-**返回**
-
-* `results`:list类型,不同任务类型的返回结果如下
- * 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
- * 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
+## 二、安装
-```python
-def get_embedding(
- data,
- use_gpu=False
-)
-```
-
-用于获取输入文本的句子粒度特征与字粒度特征
+- ### 1、环境依赖
-**参数**
+ - paddlepaddle >= 2.0.0
-* `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
-* `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+ - paddlehub >= 2.0.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**返回**
+- ### 2、安装
-* `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+ - ```shell
+ $ hub install roberta-wwm-ext
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+## 三、模型API预测
-**代码示例**
+- ### 1、预测代码示例
```python
import paddlehub as hub
@@ -96,59 +61,110 @@ for idx, text in enumerate(data):
```
详情可参考PaddleHub示例:
-- [文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/text_classification)
-- [序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v2.0.0-beta/demo/sequence_labeling)
+- [文本分类](../../../../demo/text_classification)
+- [序列标注](../../../../demo/sequence_labeling)
-## 服务部署
+- ### 2、API
-PaddleHub Serving可以部署一个在线获取预训练词向量。
+ - ```python
+ def __init__(
+ task=None,
+ load_checkpoint=None,
+ label_map=None,
+ num_classes=2,
+ suffix=False,
+ **kwargs,
+ )
+ ```
-### Step1: 启动PaddleHub Serving
+ - 创建Module对象(动态图组网版本)
-运行启动命令:
+ - **参数**
-```shell
-$ hub serving start -m roberta-wwm-ext
-```
+ - `task`: 任务名称,可为`seq-cls`(文本分类任务)或`token-cls`(序列标注任务)。
+ - `load_checkpoint`:使用PaddleHub Fine-tune api训练保存的模型参数文件路径。
+ - `label_map`:预测时的类别映射表。
+ - `num_classes`:分类任务的类别数,如果指定了`label_map`,此参数可不传,默认2分类。
+ - `suffix`: 序列标注任务的标签格式,如果设定为`True`,标签以'-B', '-I', '-E' 或者 '-S'为结尾,此参数默认为`False`。
+ - `**kwargs`:用户额外指定的关键字字典类型的参数。
-这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
+ - ```python
+ def predict(
+ data,
+ max_seq_len=128,
+ batch_size=1,
+ use_gpu=False
+ )
+ ```
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - **参数**
-### Step2: 发送预测请求
+ - `data`: 待预测数据,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。每个样例文本数量(1个或者2个)需和训练时保持一致。
+ - `max_seq_len`:模型处理文本的最大长度
+ - `batch_size`:模型批处理大小
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **返回**
-```python
-import requests
-import json
-
-# 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
-text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
-# 以key的方式指定text传入预测方法的时的参数,此例中为"data"
-# 对应本地部署,则为module.get_embedding(data=text)
-data = {"data": text}
-# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
-url = "http://10.12.121.132:8866/predict/roberta-wwm-ext"
-# 指定post请求的headers为application/json方式
-headers = {"Content-Type": "application/json"}
-
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-print(r.json())
-```
+ - `results`:list类型,不同任务类型的返回结果如下
+ - 文本分类:列表里包含每个句子的预测标签,格式为\[label\_1, label\_2, …,\]
+ - 序列标注:列表里包含每个句子每个token的预测标签,格式为\[\[token\_1, token\_2, …,\], \[token\_1, token\_2, …,\], …,\]
+
+ - ```python
+ def get_embedding(
+ data,
+ use_gpu=False
+ )
+ ```
+
+ - 用于获取输入文本的句子粒度特征与字粒度特征
+
+ - **参数**
+
+ - `data`:输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+ - `use_gpu`:是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。
+
+ - **返回**
+
+ - `results`:list类型,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线获取预训练词向量。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - ```shell
+ $ hub serving start -m roberta-wwm-ext
+ ```
+
+ - 这样就完成了一个获取预训练词向量服务化API的部署,默认端口号为8866。
-## 查看代码
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-https://github.com/PaddlePaddle/models/tree/develop/PaddleNLP/paddlenlp/transformers/roberta
+- ### 第二步:发送预测请求
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-## 依赖
+ - ```python
+ import requests
+ import json
-paddlepaddle >= 2.0.0
+ # 指定用于获取embedding的文本[[text_1], [text_2], ... ]}
+ text = [["今天是个好日子"], ["天气预报说今天要下雨"]]
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"data"
+ # 对应本地部署,则为module.get_embedding(data=text)
+ data = {"data": text}
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://10.12.121.132:8866/predict/roberta-wwm-ext"
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
-paddlehub >= 2.0.0
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
-## 更新历史
+## 五、更新历史
* 1.0.0
@@ -165,3 +181,6 @@ paddlehub >= 2.0.0
* 2.0.2
增加文本匹配任务`text-matching`
+ ```shell
+ $ hub install roberta-wwm-ext==2.0.2
+ ```
--
GitLab