

| Input Audio | +Recognition Result | +
|---|---|
|
+
+ + |
+ I knocked at the door on the ancient side of the building. | +
|
+
+ + |
+ 我认为跑步最重要的就是给我带来了身体健康。 | +
@@ -30,7 +30,7 @@ ## 简介与特性 - PaddleHub旨在为开发者提供丰富的、高质量的、直接可用的预训练模型 -- **【模型种类丰富】**: 涵盖CV、NLP、Audio、Video、工业应用主流五大品类的 350+ 预训练模型,全部开源下载,离线可运行 +- **【模型种类丰富】**: 涵盖CV、NLP、Audio、Video、工业应用主流五大品类的 **360+** 预训练模型,全部开源下载,离线可运行 - **【超低使用门槛】**:无需深度学习背景、无需数据与训练过程,可快速使用AI模型 - **【一键模型快速预测】**:通过一行命令行或者极简的Python API实现模型调用,可快速体验模型效果 - **【一键模型转服务化】**:一行命令,搭建深度学习模型API服务化部署能力 @@ -38,6 +38,7 @@ - **【跨平台兼容性】**:可运行于Linux、Windows、MacOS等多种操作系统 ## 近期更新 +- **2021.12.22**,发布v2.2.0版本。【1】新增100+高质量模型,涵盖对话、语音处理、语义分割、文字识别、文本处理、图像生成等多个领域,预训练模型总量达到[**【360+】**](https://www.paddlepaddle.org.cn/hublist);【2】新增模型[检索列表](./modules/README_ch.md),包含模型名称、网络、数据集和使用场景等信息,快速定位用户所需的模型;【3】模型文档排版优化,呈现数据集、指标、模型大小等更多实用信息。 - **2021.05.12**,新增轻量级中文对话模型[plato-mini](https://www.paddlepaddle.org.cn/hubdetail?name=plato-mini&en_category=TextGeneration),可以配合使用wechaty实现微信闲聊机器人,[参考demo](https://github.com/KPatr1ck/paddlehub-wechaty-demo) - **2021.04.27**,发布v2.1.0版本。【1】新增基于VOC数据集的高精度语义分割模型2个,语音分类模型3个。【2】新增图像语义分割、文本语义匹配、语音分类等相关任务的Fine-Tune能力以及相关任务数据集;完善部署能力:【3】新增ONNX和PaddleInference等模型格式的导出功能。【4】新增[BentoML](https://github.com/bentoml/BentoML) 云原生服务化部署能力,可以支持统一的多框架模型管理和模型部署的工作流,[详细教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v2.1/demo/serving/bentoml/cloud-native-model-serving-with-bentoml.ipynb). 更多内容可以参考BentoML 最新 v0.12.1 [Releasenote](https://github.com/bentoml/BentoML/releases/tag/v0.12.1).(感谢@[parano](https://github.com/parano) @[cqvu](https://github.com/cqvu) @[deehrlic](https://github.com/deehrlic))的贡献与支持。【5】预训练模型总量达到[**【300】**](https://www.paddlepaddle.org.cn/hublist)个。 - **2021.02.18**,发布v2.0.0版本,【1】模型开发调试更简单,finetune接口更加灵活易用。视觉类任务迁移学习能力全面升级,支持[图像分类](./demo/image_classification/README.md)、[图像着色](./demo/colorization/README.md)、[风格迁移](./demo/style_transfer/README.md)等多种任务;BERT、ERNIE、RoBERTa等Transformer类模型升级至动态图,支持[文本分类](./demo/text_classification/README.md)、[序列标注](./demo/sequence_labeling/README.md)的Fine-Tune能力;【2】优化服务化部署Serving能力,支持多卡预测、自动负载均衡,性能大幅度提升;【3】新增自动数据增强能力[Auto Augment](./demo/autoaug/README.md),能高效地搜索适合数据集的数据增强策略组合。【4】新增[词向量模型](./modules/text/embedding)61个,其中包含中文模型51个,英文模型10个;新增[图像分割](./modules/thirdparty/image/semantic_segmentation)模型4个、[深度模型](./modules/thirdparty/image/depth_estimation)2个、[图像生成](./modules/thirdparty/image/Image_gan/style_transfer)模型7个、[文本生成](./modules/thirdparty/text/text_generation)模型3个。【5】预训练模型总量达到[**【274】**](https://www.paddlepaddle.org.cn/hublist) 个。 @@ -47,9 +48,9 @@ -## **精品模型效果展示[【更多】](./docs/docs_ch/visualization.md)** +## **精品模型效果展示[【更多】](./docs/docs_ch/visualization.md)[【模型库】](./modules/README_ch.md)** -### **图像类(161个)** +### **[图像类(212个)](./modules/README_ch.md#图像)** - 包括图像分类、人脸检测、口罩检测、车辆检测、人脸/人体/手部关键点检测、人像分割、80+语言文本识别、图像超分/上色/动漫化等
@@ -58,7 +59,7 @@
- 感谢CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) 提供相关预训练模型,训练能力开放,欢迎体验。
-### **文本类(129个)**
+### **[文本类(130个)](./modules/README_ch.md#文本)**
- 包括中文分词、词性标注与命名实体识别、句法分析、AI写诗/对联/情话/藏头诗、中文的评论情感分析、中文色情文本审核等
@@ -67,9 +68,37 @@
- 感谢CopyRight@[ERNIE](https://github.com/PaddlePaddle/ERNIE)、[LAC](https://github.com/baidu/LAC)、[DDParser](https://github.com/baidu/DDParser)提供相关预训练模型,训练能力开放,欢迎体验。
-### **语音类(3个)**
+### **[语音类(15个)](./modules/README_ch.md#语音)**
+- ASR语音识别算法,多种算法可选
+- 语音识别效果如下:
+| Input Audio | +Recognition Result | +
|---|---|
|
+
+ + |
+ I knocked at the door on the ancient side of the building. | +
|
+
+ + |
+ 我认为跑步最重要的就是给我带来了身体健康。 | +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
-
+
+
+
+
+
+
+
+
+
-
+
-
+
+
+
+ 
 +
+
+ 
 +
+
+ 
 +
+
+ 
 +
+
+
+
+
+
+
+
+  +
+
+ 
+ 图1. AttGAN的效果图(图片属性分别为:original image, Bald, Bangs, Black_Hair, Blond_Hair, Brown_Hair, Bushy_Eyebrows, Eyeglasses, Gender, Mouth_Slightly_Open, Mustache, No_Beard, Pale_Skin, Aged)
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出图像
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输入视频
+
+  +
+
+ 输出视频
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出图像
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出图像(修改age)
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出视频
+
+
+ 
+ 图1. StarGAN的效果图 (属性分别为:origial image, Black_Hair, Blond_Hair, Brown_Hair, Male, Aged)
+
+ 
+ STGAN的效果图(图片属性分别为:original image, Bald, Bangs, Black_Hair, Blond_Hair, Brown_Hair, Bushy_Eyebrows, Eyeglasses, Gender, Mouth_Slightly_Open, Mustache, No_Beard, Pale_Skin, Aged)
+
+  +
+
+ 
 +
+
+  +
+
+ 
+ 输入图像
+
+ 
+ 输出图像
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出图像
+
+
+ 
 +
+
-
MobileNet 系列的网络结构
-
-
MobileNet 系列的网络结构
-
+
+
-
ResNet 系列的网络结构
-
-
ResNet 系列的网络结构
-
+
+
-
ResNet 系列的网络结构
-
+ 
+
+ 

+
-
-
+
+
+ 
+
+ 
 +
+
-
-
+  +
+
+  +
+
+  +
+
-
-
+  +
+

-
+
+
+
+
+
+
+
+
+
+
+
+
+ 
+
+ 
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ 
+
+ +
+
+ 
+
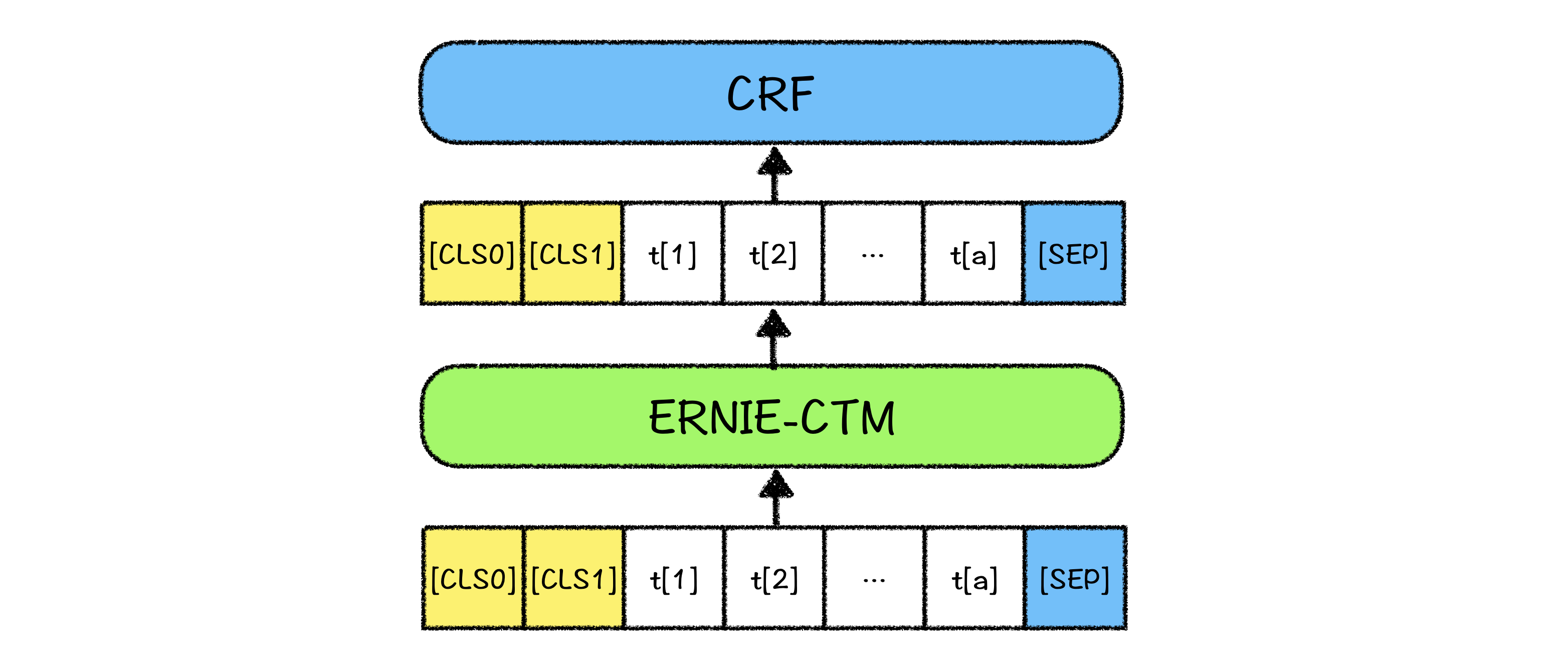
+ 
+
 -
-## 输出结果
-~~~
-[{'category_id': 5, 'category': 'ch5', 'score': 0.47390476}]
-[{'category_id': 2, 'category': 'ch2', 'score': 0.99997914}]
-[{'category_id': 1, 'category': 'ch1', 'score': 0.99996376}]
-~~~
-
-# 贡献者
-郑博培、彭兆帅
-
-# 依赖
-paddlepaddle >= 2.0.0
-
-## 输出结果
-~~~
-[{'category_id': 5, 'category': 'ch5', 'score': 0.47390476}]
-[{'category_id': 2, 'category': 'ch2', 'score': 0.99997914}]
-[{'category_id': 1, 'category': 'ch1', 'score': 0.99996376}]
-~~~
-
-# 贡献者
-郑博培、彭兆帅
-
-# 依赖
-paddlepaddle >= 2.0.0 -
-## 输出结果
-~~~
-[{'category_id': 0, 'category': '水蛇', 'score': 0.9999205}]
-~~~
-
-# 贡献者
-郑博培、彭兆帅
-
-# 依赖
-paddlepaddle >= 2.0.0
-
-## 输出结果
-~~~
-[{'category_id': 0, 'category': '水蛇', 'score': 0.9999205}]
-~~~
-
-# 贡献者
-郑博培、彭兆帅
-
-# 依赖
-paddlepaddle >= 2.0.0 -
-### 输出结果
-```python
-[{'category_id': 0, 'category': 'apple_pie', 'score': 0.9985085}]
-```
-
-## 贡献者
-彭兆帅、郑博培
-
-## 依赖
-paddlepaddle >= 2.0.0
-
-paddlehub >= 2.0.0
-
-paddlex >= 1.3.7
diff --git a/modules/thirdparty/image/classification/marine_biometrics/README.md b/modules/thirdparty/image/classification/marine_biometrics/README.md
deleted file mode 100644
index 6ba7acd92dc5f94c28a65695a7fcd0f93050190e..0000000000000000000000000000000000000000
--- a/modules/thirdparty/image/classification/marine_biometrics/README.md
+++ /dev/null
@@ -1,69 +0,0 @@
-marine_biometrics
-
-类别 图像 - 图像分类
-
-网络 ResNet50_vd_ssld
-
-数据集 Fish4Knowledge
-
-# 模型概述
-海洋生物识别(marine_biometrics),该模型可准确识别鱼的种类。该PaddleHub Module支持API预测及命令行预测。
-
-# 选择模型版本进行安装
-$ hub install marine_biometrics==1.0.0
-
-# 在线体验
-[AI Studio快速体验](https://aistudio.baidu.com/aistudio/projectdetail/1667809)
-
-# 命令行预测示例
-$ hub run marine_biometrics --image 1.png --use_gpu True
-
-# Module API说明
-## def predict(data)
-海洋生物识别预测接口,输入一张图像,输出该图像上鱼的类别
-### 参数
-- data:dict类型,key为image,str类型,value为待检测的图片路径,list类型。
-
-### 返回
-- result:list类型,每个元素为对应输入图片的预测结果。预测结果为dict类型,key为该图片分类结果label,value为该label对应的概率
-
-# 代码示例
-
-## API调用
-
-~~~
-import cv2
-import paddlehub as hub
-
-module = hub.Module(name="MarineBiometrics")
-
-images = [cv2.imread('PATH/TO/IMAGE')]
-
-# execute predict and print the result
-results = module.predict(images=images)
-for result in results:
- print(result)
-~~~
-
-## 命令行调用
-~~~
-$ hub run marine_biometrics --image 1.png --use_gpu True
-~~~
-
-# 效果展示
-
-## 原图
-
-
-### 输出结果
-```python
-[{'category_id': 0, 'category': 'apple_pie', 'score': 0.9985085}]
-```
-
-## 贡献者
-彭兆帅、郑博培
-
-## 依赖
-paddlepaddle >= 2.0.0
-
-paddlehub >= 2.0.0
-
-paddlex >= 1.3.7
diff --git a/modules/thirdparty/image/classification/marine_biometrics/README.md b/modules/thirdparty/image/classification/marine_biometrics/README.md
deleted file mode 100644
index 6ba7acd92dc5f94c28a65695a7fcd0f93050190e..0000000000000000000000000000000000000000
--- a/modules/thirdparty/image/classification/marine_biometrics/README.md
+++ /dev/null
@@ -1,69 +0,0 @@
-marine_biometrics
-
-类别 图像 - 图像分类
-
-网络 ResNet50_vd_ssld
-
-数据集 Fish4Knowledge
-
-# 模型概述
-海洋生物识别(marine_biometrics),该模型可准确识别鱼的种类。该PaddleHub Module支持API预测及命令行预测。
-
-# 选择模型版本进行安装
-$ hub install marine_biometrics==1.0.0
-
-# 在线体验
-[AI Studio快速体验](https://aistudio.baidu.com/aistudio/projectdetail/1667809)
-
-# 命令行预测示例
-$ hub run marine_biometrics --image 1.png --use_gpu True
-
-# Module API说明
-## def predict(data)
-海洋生物识别预测接口,输入一张图像,输出该图像上鱼的类别
-### 参数
-- data:dict类型,key为image,str类型,value为待检测的图片路径,list类型。
-
-### 返回
-- result:list类型,每个元素为对应输入图片的预测结果。预测结果为dict类型,key为该图片分类结果label,value为该label对应的概率
-
-# 代码示例
-
-## API调用
-
-~~~
-import cv2
-import paddlehub as hub
-
-module = hub.Module(name="MarineBiometrics")
-
-images = [cv2.imread('PATH/TO/IMAGE')]
-
-# execute predict and print the result
-results = module.predict(images=images)
-for result in results:
- print(result)
-~~~
-
-## 命令行调用
-~~~
-$ hub run marine_biometrics --image 1.png --use_gpu True
-~~~
-
-# 效果展示
-
-## 原图
- -
-## 输出结果
-~~~
-[{'category_id': 16, 'category': 'Plectroglyphidodon_dickii', 'score': 0.9932127}]
-~~~
-
-# 贡献者
-郑博培、彭兆帅
-
-# 依赖
-paddlepaddle >= 2.0.0
-
-paddlehub >= 2.0.0
diff --git a/modules/thirdparty/image/keypoint_detection/hand_pose_localization/README.md b/modules/thirdparty/image/keypoint_detection/hand_pose_localization/README.md
deleted file mode 100644
index 4e247d9ae24f9f52f3f9f0a87b1d04fe12390b44..0000000000000000000000000000000000000000
--- a/modules/thirdparty/image/keypoint_detection/hand_pose_localization/README.md
+++ /dev/null
@@ -1,112 +0,0 @@
-## 模型概述
-openpose 手部关键点检测模型
-
-模型详情请参考[openpose开源项目](https://github.com/CMU-Perceptual-Computing-Lab/openpose)
-
-## 模型安装
-
-```shell
-$hub install hand_pose_localization
-```
-
-## API 说明
-
-```python
-def keypoint_detection(
- self,
- images=None,
- paths=None,
- batch_size=1,
- output_dir='output',
- visualization=False
-)
-```
-
-预测API,识别出人体手部关键点。
-
-
-
-**参数**
-
-* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\], 默认设为 None;
-* paths (list\[str\]): 图片的路径, 默认设为 None;
-* batch\_size (int): batch 的大小,默认设为 1;
-* visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
-* output\_dir (str): 图片的保存路径,默认设为 output。
-
-**返回**
-
-* res (list[list[list[int]]]): 每张图片识别到的21个手部关键点组成的列表,每个关键点的格式为[x, y],若有关键点未识别到则为None
-
-
-## 预测代码示例
-
-```python
-import cv2
-import paddlehub as hub
-
-# use_gpu:是否使用GPU进行预测
-model = hub.Module(name='hand_pose_localization', use_gpu=False)
-
-# 调用关键点检测API
-result = model.keypoint_detection(images=[cv2.imread('/PATH/TO/IMAGE')])
-
-# or
-# result = model.keypoint_detection(paths=['/PATH/TO/IMAGE'])
-
-# 打印预测结果
-print(result)
-```
-
-## 服务部署
-
-PaddleHub Serving可以部署一个在线人体手部关键点检测服务。
-
-## 第一步:启动PaddleHub Serving
-
-运行启动命令:
-```shell
-$ hub serving start -m hand_pose_localization
-```
-
-这样就完成了一个人体手部关键点检测的在线服务API的部署,默认端口号为8866。
-
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-
-## 第二步:发送预测请求
-
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
-```python
-import requests
-import json
-import cv2
-import base64
-
-# 图片Base64编码函数
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-
-# 发送HTTP请求
-data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/hand_pose_localization"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-
-# 打印预测结果
-print(r.json()["results"])
-```
-
-
-## 模型相关信息
-
-### 模型代码
-
-https://github.com/CMU-Perceptual-Computing-Lab/openpose
-
-### 依赖
-
-paddlepaddle >= 1.8.0
-
-paddlehub >= 1.8.0
diff --git a/modules/thirdparty/image/semantic_segmentation/U2Net/README.md b/modules/thirdparty/image/semantic_segmentation/U2Net/README.md
deleted file mode 100644
index 0bd5cd94cfec98440c20d652ca4afe186d7ee72f..0000000000000000000000000000000000000000
--- a/modules/thirdparty/image/semantic_segmentation/U2Net/README.md
+++ /dev/null
@@ -1,56 +0,0 @@
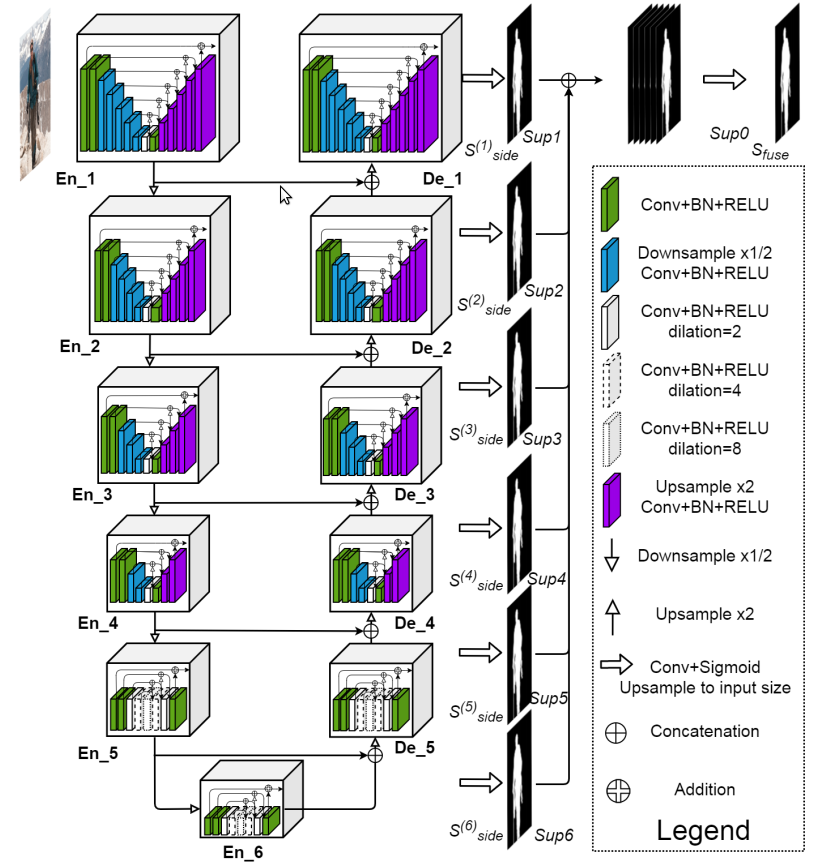
-## 概述
-* 的网络结构如下图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net
-* 每个 stage 由新提出的 RSU模块(residual U-block) 组成. 例如,En_1 即为基于 RSU 构建的
-
-
-
-## 效果展示
-
-
-
-
-## API
-```python
-def Segmentation(
- images=None,
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=False):
-```
-图像前景背景分割 API
-
-**参数**
-* images (list[np.ndarray]) : 输入图像数据列表(BGR)
-* paths (list[str]) : 输入图像路径列表
-* batch_size (int) : 数据批大小
-* input_size (int) : 输入图像大小
-* output_dir (str) : 可视化图像输出目录
-* visualization (bool) : 是否可视化
-
-**返回**
-* results (list[np.ndarray]): 输出图像数据列表
-
-**代码示例**
-```python
-import cv2
-import paddlehub as hub
-
-model = hub.Module(name='U2Net')
-
-result = model.Segmentation(
- images=[cv2.imread('/PATH/TO/IMAGE')],
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=True)
-```
-
-## 查看代码
-https://github.com/NathanUA/U-2-Net
-
-## 依赖
-paddlepaddle >= 2.0.0rc0
-paddlehub >= 2.0.0b1
diff --git a/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md b/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md
deleted file mode 100644
index c0a9be7047ed9397870b4ffde8412c5bc06acdbd..0000000000000000000000000000000000000000
--- a/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md
+++ /dev/null
@@ -1,57 +0,0 @@
-## 概述
-* 的网络结构如下图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net
-* 每个 stage 由新提出的 RSU模块(residual U-block) 组成. 例如,En_1 即为基于 RSU 构建的
-* 是一个小型化的
-
-
-
-## 效果展示
-
-
-
-
-## API
-```python
-def Segmentation(
- images=None,
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=False):
-```
-图像前景背景分割 API
-
-**参数**
-* images (list[np.ndarray]) : 输入图像数据列表(BGR)
-* paths (list[str]) : 输入图像路径列表
-* batch_size (int) : 数据批大小
-* input_size (int) : 输入图像大小
-* output_dir (str) : 可视化图像输出目录
-* visualization (bool) : 是否可视化
-
-**返回**
-* results (list[np.ndarray]): 输出图像数据列表
-
-**代码示例**
-```python
-import cv2
-import paddlehub as hub
-
-model = hub.Module(name='U2Netp')
-
-result = model.Segmentation(
- images=[cv2.imread('/PATH/TO/IMAGE')],
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=True)
-```
-
-## 查看代码
-https://github.com/NathanUA/U-2-Net
-
-## 依赖
-paddlepaddle >= 2.0.0rc0
-paddlehub >= 2.0.0b1
diff --git a/modules/thirdparty/text/text_generation/reading_pictures_writing_poems/README.md b/modules/thirdparty/text/text_generation/reading_pictures_writing_poems/README.md
deleted file mode 100644
index ecc9ad2cb91ba323ed613072d3a0758733022332..0000000000000000000000000000000000000000
--- a/modules/thirdparty/text/text_generation/reading_pictures_writing_poems/README.md
+++ /dev/null
@@ -1,42 +0,0 @@
-reading_pictures_writing_poems
-类别 文本 - 文本生成
-
-# 模型概述
-看图写诗(reading_pictures_writing_poems),该模型可自动根据图像生成古诗词。该PaddleHub Module支持预测。
-
-# 选择模型版本进行安装
-$ hub install reading_pictures_writing_poems==1.0.0
-
-# 命令行预测示例
-$ hub run reading_pictures_writing_poems --input_image "scenery.jpg"
-
-
-
-
-## 输出结果
-~~~
-[{'category_id': 16, 'category': 'Plectroglyphidodon_dickii', 'score': 0.9932127}]
-~~~
-
-# 贡献者
-郑博培、彭兆帅
-
-# 依赖
-paddlepaddle >= 2.0.0
-
-paddlehub >= 2.0.0
diff --git a/modules/thirdparty/image/keypoint_detection/hand_pose_localization/README.md b/modules/thirdparty/image/keypoint_detection/hand_pose_localization/README.md
deleted file mode 100644
index 4e247d9ae24f9f52f3f9f0a87b1d04fe12390b44..0000000000000000000000000000000000000000
--- a/modules/thirdparty/image/keypoint_detection/hand_pose_localization/README.md
+++ /dev/null
@@ -1,112 +0,0 @@
-## 模型概述
-openpose 手部关键点检测模型
-
-模型详情请参考[openpose开源项目](https://github.com/CMU-Perceptual-Computing-Lab/openpose)
-
-## 模型安装
-
-```shell
-$hub install hand_pose_localization
-```
-
-## API 说明
-
-```python
-def keypoint_detection(
- self,
- images=None,
- paths=None,
- batch_size=1,
- output_dir='output',
- visualization=False
-)
-```
-
-预测API,识别出人体手部关键点。
-
-
-
-**参数**
-
-* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\], 默认设为 None;
-* paths (list\[str\]): 图片的路径, 默认设为 None;
-* batch\_size (int): batch 的大小,默认设为 1;
-* visualization (bool): 是否将识别结果保存为图片文件,默认设为 False;
-* output\_dir (str): 图片的保存路径,默认设为 output。
-
-**返回**
-
-* res (list[list[list[int]]]): 每张图片识别到的21个手部关键点组成的列表,每个关键点的格式为[x, y],若有关键点未识别到则为None
-
-
-## 预测代码示例
-
-```python
-import cv2
-import paddlehub as hub
-
-# use_gpu:是否使用GPU进行预测
-model = hub.Module(name='hand_pose_localization', use_gpu=False)
-
-# 调用关键点检测API
-result = model.keypoint_detection(images=[cv2.imread('/PATH/TO/IMAGE')])
-
-# or
-# result = model.keypoint_detection(paths=['/PATH/TO/IMAGE'])
-
-# 打印预测结果
-print(result)
-```
-
-## 服务部署
-
-PaddleHub Serving可以部署一个在线人体手部关键点检测服务。
-
-## 第一步:启动PaddleHub Serving
-
-运行启动命令:
-```shell
-$ hub serving start -m hand_pose_localization
-```
-
-这样就完成了一个人体手部关键点检测的在线服务API的部署,默认端口号为8866。
-
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-
-## 第二步:发送预测请求
-
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
-```python
-import requests
-import json
-import cv2
-import base64
-
-# 图片Base64编码函数
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-
-# 发送HTTP请求
-data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/hand_pose_localization"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-
-# 打印预测结果
-print(r.json()["results"])
-```
-
-
-## 模型相关信息
-
-### 模型代码
-
-https://github.com/CMU-Perceptual-Computing-Lab/openpose
-
-### 依赖
-
-paddlepaddle >= 1.8.0
-
-paddlehub >= 1.8.0
diff --git a/modules/thirdparty/image/semantic_segmentation/U2Net/README.md b/modules/thirdparty/image/semantic_segmentation/U2Net/README.md
deleted file mode 100644
index 0bd5cd94cfec98440c20d652ca4afe186d7ee72f..0000000000000000000000000000000000000000
--- a/modules/thirdparty/image/semantic_segmentation/U2Net/README.md
+++ /dev/null
@@ -1,56 +0,0 @@
-## 概述
-* 的网络结构如下图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net
-* 每个 stage 由新提出的 RSU模块(residual U-block) 组成. 例如,En_1 即为基于 RSU 构建的
-
-
-
-## 效果展示
-
-
-
-
-## API
-```python
-def Segmentation(
- images=None,
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=False):
-```
-图像前景背景分割 API
-
-**参数**
-* images (list[np.ndarray]) : 输入图像数据列表(BGR)
-* paths (list[str]) : 输入图像路径列表
-* batch_size (int) : 数据批大小
-* input_size (int) : 输入图像大小
-* output_dir (str) : 可视化图像输出目录
-* visualization (bool) : 是否可视化
-
-**返回**
-* results (list[np.ndarray]): 输出图像数据列表
-
-**代码示例**
-```python
-import cv2
-import paddlehub as hub
-
-model = hub.Module(name='U2Net')
-
-result = model.Segmentation(
- images=[cv2.imread('/PATH/TO/IMAGE')],
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=True)
-```
-
-## 查看代码
-https://github.com/NathanUA/U-2-Net
-
-## 依赖
-paddlepaddle >= 2.0.0rc0
-paddlehub >= 2.0.0b1
diff --git a/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md b/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md
deleted file mode 100644
index c0a9be7047ed9397870b4ffde8412c5bc06acdbd..0000000000000000000000000000000000000000
--- a/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md
+++ /dev/null
@@ -1,57 +0,0 @@
-## 概述
-* 的网络结构如下图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net
-* 每个 stage 由新提出的 RSU模块(residual U-block) 组成. 例如,En_1 即为基于 RSU 构建的
-* 是一个小型化的
-
-
-
-## 效果展示
-
-
-
-
-## API
-```python
-def Segmentation(
- images=None,
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=False):
-```
-图像前景背景分割 API
-
-**参数**
-* images (list[np.ndarray]) : 输入图像数据列表(BGR)
-* paths (list[str]) : 输入图像路径列表
-* batch_size (int) : 数据批大小
-* input_size (int) : 输入图像大小
-* output_dir (str) : 可视化图像输出目录
-* visualization (bool) : 是否可视化
-
-**返回**
-* results (list[np.ndarray]): 输出图像数据列表
-
-**代码示例**
-```python
-import cv2
-import paddlehub as hub
-
-model = hub.Module(name='U2Netp')
-
-result = model.Segmentation(
- images=[cv2.imread('/PATH/TO/IMAGE')],
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=True)
-```
-
-## 查看代码
-https://github.com/NathanUA/U-2-Net
-
-## 依赖
-paddlepaddle >= 2.0.0rc0
-paddlehub >= 2.0.0b1
diff --git a/modules/thirdparty/text/text_generation/reading_pictures_writing_poems/README.md b/modules/thirdparty/text/text_generation/reading_pictures_writing_poems/README.md
deleted file mode 100644
index ecc9ad2cb91ba323ed613072d3a0758733022332..0000000000000000000000000000000000000000
--- a/modules/thirdparty/text/text_generation/reading_pictures_writing_poems/README.md
+++ /dev/null
@@ -1,42 +0,0 @@
-reading_pictures_writing_poems
-类别 文本 - 文本生成
-
-# 模型概述
-看图写诗(reading_pictures_writing_poems),该模型可自动根据图像生成古诗词。该PaddleHub Module支持预测。
-
-# 选择模型版本进行安装
-$ hub install reading_pictures_writing_poems==1.0.0
-
-# 命令行预测示例
-$ hub run reading_pictures_writing_poems --input_image "scenery.jpg"
-
-
-