Merge pull request #1641 from Wgm-Inspur/PaddleHub-TextClasify-RNNPic-WGM
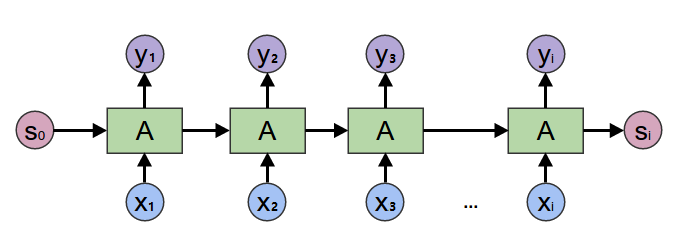
Image mistaken of RNN sample in demo\text_classification\README.md
Showing
docs/imgs/RNN_Sample.png
0 → 100644
{kind=link}
13.9 KB
Image mistaken of RNN sample in demo\text_classification\README.md
13.9 KB