diff --git a/demo/image_classification/README.md b/demo/image_classification/README.md
index 489df7782630304f61208185a2b775a7bd83d26e..1ccb9ba5845ff0760961476d8950a9e1a3a0ce33 100644
--- a/demo/image_classification/README.md
+++ b/demo/image_classification/README.md
@@ -8,6 +8,18 @@
$ hub run resnet50_vd_imagenet_ssld --input_path "/PATH/TO/IMAGE" --top_k 5
```
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='resnet50_vd_imagenet_ssld',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
## 如何开始Fine-tune
在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.py`即可开始使用resnet50_vd_imagenet_ssld对[Flowers](../../docs/reference/datasets.md#class-hubdatasetsflowers)等数据集进行Fine-tune。
diff --git a/demo/style_transfer/README.md b/demo/style_transfer/README.md
index d05184898623ecd4aa5f949bcd945c7b62e5ba3c..bf3caa6c26a754452da5a3a66d8ec9d890956a1b 100644
--- a/demo/style_transfer/README.md
+++ b/demo/style_transfer/README.md
@@ -8,6 +8,17 @@
$ hub run msgnet --input_path "/PATH/TO/ORIGIN/IMAGE" --style_path "/PATH/TO/STYLE/IMAGE"
```
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+ model = hub.Module(name='msgnet')
+ result = model.predict(origin=["venice-boat.jpg"], style="candy.jpg", visualization=True, save_path ='style_tranfer')
+```
+
## 如何开始Fine-tune
在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.py`即可开始使用msgnet模型对[MiniCOCO](../../docs/reference/datasets.md#class-hubdatasetsMiniCOCO)等数据集进行Fine-tune。
@@ -164,4 +175,4 @@ https://github.com/zhanghang1989/PyTorch-Multi-Style-Transfer
paddlepaddle >= 2.0.0rc
-paddlehub >= 2.0.0
+paddlehub >= 2.0.0
\ No newline at end of file
diff --git a/modules/image/Image_editing/colorization/deoldify/README.md b/modules/image/Image_editing/colorization/deoldify/README.md
index 21bfe6dabe92a0fd9c054a3cb447c1d166cca1e6..a181b89bdcc802fa5c6129d5d466472e80bfb258 100644
--- a/modules/image/Image_editing/colorization/deoldify/README.md
+++ b/modules/image/Image_editing/colorization/deoldify/README.md
@@ -1,121 +1,172 @@
+# deoldify
-## 模型概述
-deoldify是用于图像和视频的着色渲染模型,该模型能够实现给黑白照片和视频恢复原彩。
+|模型名称|deoldify|
+| :--- | :---: |
+|类别|图像-图像编辑|
+|网络|NoGAN|
+|数据集|ILSVRC 2012|
+|是否支持Fine-tuning|否|
+|模型大小|834MB|
+|指标|-|
+|最新更新日期|2021-04-13|
-## API 说明
-```python
-def predict(self, input):
-```
+## 一、模型基本信息
-着色变换API,得到着色后的图片或者视频。
+- ### 应用效果展示
+
+ - 样例结果示例(左为原图,右为效果图):
+
+ 
 +
+
+- ### 模型介绍
-**参数**
+ - deoldify是用于图像和视频的着色渲染模型,该模型能够实现给黑白照片和视频恢复原彩。
-* input(str): 图片或者视频的路径;
+ - 更多详情请参考:[deoldify](https://github.com/jantic/DeOldify)
-**返回**
+## 二、安装
-若输入是图片,返回值为:
-* pred_img(np.ndarray): BGR图片数据;
-* out_path(str): 保存图片路径。
+- ### 1、环境依赖
-若输入是视频,返回值为:
-* frame_pattern_combined(str): 视频着色后单帧数据保存路径;
-* vid_out_path(str): 视频保存路径。
+ - paddlepaddle >= 2.0.0
-```python
-def run_image(self, img):
-```
-图像着色API, 得到着色后的图片。
+ - paddlehub >= 2.0.0
-**参数**
+ - NOTE: 使用该模型需要自行安装ffmpeg,若您使用conda环境,推荐使用如下语句进行安装。
-* img (str|np.ndarray): 图片路径或则BGR格式图片。
+ ```shell
+ $ conda install x264=='1!152.20180717' ffmpeg=4.0.2 -c conda-forge
+ ```
-**返回**
-* pred_img(np.ndarray): BGR图片数据;
+- ### 2、安装
+ - ```shell
+ $ hub install deoldify
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-```python
-def run_video(self, video):
-```
-视频着色API, 得到着色后的视频。
-**参数**
-* video (str): 待处理视频路径。
-**返回**
+## 三、模型API预测
+ - ### 1、代码示例
-* frame_pattern_combined(str): 视频着色后单帧数据保存路径;
-* vid_out_path(str): 视频保存路径。
+ ```python
+ import paddlehub as hub
-## 预测代码示例
+ model = hub.Module(name='deoldify')
+ model.predict('/PATH/TO/IMAGE/OR/VIDEO')
+ ```
-```python
-import paddlehub as hub
+ - ### 2、API
-model = hub.Module(name='deoldify')
-model.predict('/PATH/TO/IMAGE/OR/VIDEO')
-```
+ - ```python
+ def predict(self, input):
+ ```
-## 服务部署
+ - 着色变换API,得到着色后的图片或者视频。
-PaddleHub Serving可以部署一个在线照片着色服务。
+ - **参数**
-## 第一步:启动PaddleHub Serving
+ - input(str): 图片或者视频的路径;
-运行启动命令:
-```shell
-$ hub serving start -m deoldify
-```
+ - **返回**
-这样就完成了一个图像着色的在线服务API的部署,默认端口号为8866。
+ - 若输入是图片,返回值为:
+ - pred_img(np.ndarray): BGR图片数据;
+ - out_path(str): 保存图片路径。
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+ - 若输入是视频,返回值为:
+ - frame_pattern_combined(str): 视频着色后单帧数据保存路径;
+ - vid_out_path(str): 视频保存路径。
-## 第二步:发送预测请求
+ - ```python
+ def run_image(self, img):
+ ```
+ - 图像着色API, 得到着色后的图片。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **参数**
-```python
-import requests
-import json
-import base64
+ - img (str|np.ndarray): 图片路径或则BGR格式图片。
-import cv2
-import numpy as np
+ - **返回**
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-def base64_to_cv2(b64str):
- data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
- data = cv2.imdecode(data, cv2.IMREAD_COLOR)
- return data
+ - pred_img(np.ndarray): BGR图片数据;
-# 发送HTTP请求
-org_im = cv2.imread('/PATH/TO/ORIGIN/IMAGE')
-data = {'images':cv2_to_base64(org_im)}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/deoldify"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-img = base64_to_cv2(r.json()["results"])
-cv2.imwrite('/PATH/TO/SAVE/IMAGE', img)
-```
+ - ```python
+ def run_video(self, video):
+ ```
+ - 视频着色API, 得到着色后的视频。
-## 模型相关信息
+ - **参数**
-### 模型代码
+ - video (str): 待处理视频路径。
-https://github.com/jantic/DeOldify
+ - **返回**
-### 依赖
+ - frame_pattern_combined(str): 视频着色后单帧数据保存路径;
+ - vid_out_path(str): 视频保存路径。
-paddlepaddle >= 2.0.0rc
+## 四、服务部署
-paddlehub >= 1.8.3
+- PaddleHub Serving可以部署一个在线照片着色服务
+
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m deoldify
+ ```
+
+ - 这样就完成了一个图像着色的在线服务API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ ```python
+ import requests
+ import json
+ import base64
+
+ import cv2
+ import numpy as np
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/ORIGIN/IMAGE')
+ data = {'images':cv2_to_base64(org_im)}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/deoldify"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ img = base64_to_cv2(r.json()["results"])
+ cv2.imwrite('/PATH/TO/SAVE/IMAGE', img)
+ ```
+
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+* 1.0.1
+
+ 适配paddlehub2.0版本
diff --git a/modules/image/Image_editing/colorization/photo_restoration/README.md b/modules/image/Image_editing/colorization/photo_restoration/README.md
index 653b313cf51b7c8b023bda0ec61238d591cdc85e..e3a2d5fd3459e07a4045ccfb3f20b5774826e773 100644
--- a/modules/image/Image_editing/colorization/photo_restoration/README.md
+++ b/modules/image/Image_editing/colorization/photo_restoration/README.md
@@ -1,98 +1,148 @@
-## 模型概述
+# photo_restoration
-photo_restoration 是针对老照片修复的模型。它主要由两个部分组成:着色和超分。着色模型基于deoldify
-,超分模型基于realsr. 用户可以根据自己的需求选择对图像进行着色或超分操作。因此在使用该模型时,请预先安装deoldify和realsr两个模型。
+|模型名称|photo_restoration|
+| :--- | :---: |
+|类别|图像-图像编辑|
+|网络|基于deoldify和realsr模型|
+|是否支持Fine-tuning|否|
+|模型大小|64MB+834MB|
+|指标|-|
+|最新更新日期|2021-08-19|
-## API
-```python
-def run_image(self,
- input,
- model_select= ['Colorization', 'SuperResolution'],
- save_path = 'photo_restoration'):
-```
+## 一、模型基本信息
-预测API,用于图片修复。
+- ### 应用效果展示
+ - 样例结果示例(左为原图,右为效果图):
+
+ 
 +
+
-**参数**
-* input (numpy.ndarray|str): 图片数据,numpy.ndarray 或者 str形式。ndarray.shape 为 \[H, W, C\],BGR格式; str为图片的路径。
-* model_select (list\[str\]): 选择对图片对操作,\['Colorization'\]对图像只进行着色操作, \['SuperResolution'\]对图像只进行超分操作;
-默认值为\['Colorization', 'SuperResolution'\]。
+- ### 模型介绍
-* save_path (str): 保存图片的路径, 默认为'photo_restoration'。
+ - photo_restoration 是针对老照片修复的模型。它主要由两个部分组成:着色和超分。着色模型基于deoldify
+ ,超分模型基于realsr. 用户可以根据自己的需求选择对图像进行着色或超分操作。因此在使用该模型时,请预先安装deoldify和realsr两个模型。
-**返回**
+## 二、安装
-* output (numpy.ndarray): 照片修复结果,ndarray.shape 为 \[H, W, C\],BGR格式。
+- ### 1、环境依赖
+ - paddlepaddle >= 2.0.0
+ - paddlehub >= 2.0.0
-## 代码示例
+ - NOTE: 使用该模型需要自行安装ffmpeg,若您使用conda环境,推荐使用如下语句进行安装。
-图片修复代码示例:
+ ```shell
+ $ conda install x264=='1!152.20180717' ffmpeg=4.0.2 -c conda-forge
+ ```
+
+- ### 2、安装
+ - ```shell
+ $ hub install photo_restoration
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-```python
-import cv2
-import paddlehub as hub
-model = hub.Module(name='photo_restoration', visualization=True)
-im = cv2.imread('/PATH/TO/IMAGE')
-res = model.run_image(im)
-```
+## 三、模型API预测
+ - ### 1、代码示例
-## 服务部署
+ ```python
+ import cv2
+ import paddlehub as hub
-PaddleHub Serving可以部署一个照片修复的在线服务。
+ model = hub.Module(name='photo_restoration', visualization=True)
+ im = cv2.imread('/PATH/TO/IMAGE')
+ res = model.run_image(im)
-## 第一步:启动PaddleHub Serving
+ ```
+- ### 2、API
-运行启动命令:
-```shell
-$ hub serving start -m photo_restoration
-```
+ ```python
+ def run_image(self,
+ input,
+ model_select= ['Colorization', 'SuperResolution'],
+ save_path = 'photo_restoration'):
+ ```
-这样就完成了一个照片修复的服务化API的部署,默认端口号为8866。
+ - 预测API,用于图片修复。
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+ - **参数**
-## 第二步:发送预测请求
+ - input (numpy.ndarray|str): 图片数据,numpy.ndarray 或者 str形式。ndarray.shape 为 \[H, W, C\],BGR格式; str为图片的路径。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - model_select (list\[str\]): 选择对图片对操作,\['Colorization'\]对图像只进行着色操作, \['SuperResolution'\]对图像只进行超分操作;
+ 默认值为\['Colorization', 'SuperResolution'\]。
-```python
-import requests
-import json
-import base64
+ - save_path (str): 保存图片的路径, 默认为'photo_restoration'。
-import cv2
-import numpy as np
+ - **返回**
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-def base64_to_cv2(b64str):
- data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
- data = cv2.imdecode(data, cv2.IMREAD_COLOR)
- return data
+ - output (numpy.ndarray): 照片修复结果,ndarray.shape 为 \[H, W, C\],BGR格式。
-# 发送HTTP请求
-org_im = cv2.imread('PATH/TO/IMAGE')
-data = {'images':cv2_to_base64(org_im), 'model_select': ['Colorization', 'SuperResolution']}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/photo_restoration"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-img = base64_to_cv2(r.json()["results"])
-cv2.imwrite('PATH/TO/SAVE/IMAGE', img)
-```
-### 依赖
-paddlepaddle >= 2.0.0rc
+## 四、服务部署
-paddlehub >= 1.8.2
+- PaddleHub Serving可以部署一个照片修复的在线服务。
+
+- ## 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m photo_restoration
+ ```
+
+ - 这样就完成了一个照片修复的服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ ```python
+ import requests
+ import json
+ import base64
+
+ import cv2
+ import numpy as np
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('PATH/TO/IMAGE')
+ data = {'images':cv2_to_base64(org_im), 'model_select': ['Colorization', 'SuperResolution']}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/photo_restoration"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ img = base64_to_cv2(r.json()["results"])
+ cv2.imwrite('PATH/TO/SAVE/IMAGE', img)
+ ```
+
+## 五、更新历史
+
+
+* 1.0.0
+
+ 初始发布
+
+* 1.0.1
+
+ 适配paddlehub2.0版本
diff --git a/modules/image/Image_editing/super_resolution/falsr_c/README.md b/modules/image/Image_editing/super_resolution/falsr_c/README.md
index c61b2ed416991f4bf70e12070b2499bef1af2bba..3227847494d5b34867aa7ee36e91ff789ad80574 100644
--- a/modules/image/Image_editing/super_resolution/falsr_c/README.md
+++ b/modules/image/Image_editing/super_resolution/falsr_c/README.md
@@ -1,127 +1,168 @@
-## 模型概述
+# falsr_c
-falsr_c是基于Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search设计的轻量化超分辨模型。该模型使用多目标方法处理超分问题,同时使用基于混合控制器的弹性搜索策略来提升模型性能。该模型提供的超分倍数为2倍。
-## 命令行预测
+|模型名称|falsr_c|
+| :--- | :---: |
+|类别|图像-图像编辑|
+|网络|falsr_c|
+|数据集|DIV2k|
+|是否支持Fine-tuning|否|
+|模型大小|4.4MB|
+|PSNR|37.66|
+|最新更新日期|2021-02-26|
-```
-$ hub run falsr_c --input_path "/PATH/TO/IMAGE"
-```
+## 一、模型基本信息
-## API
+- ### 应用效果展示
+
+ - 样例结果示例(左为原图,右为效果图):
+
+ 
 +
+
-```python
-def reconstruct(self,
- images=None,
- paths=None,
- use_gpu=False,
- visualization=False,
- output_dir="falsr_c_output")
-```
-预测API,用于图像超分辨率。
+- ### 模型介绍
-**参数**
+ - falsr_c是基于Fast, Accurate and Lightweight Super-Resolution with Neural Architecture Search设计的轻量化超分辨模型。该模型使用多目标方法处理超分问题,同时使用基于混合控制器的弹性搜索策略来提升模型性能。该模型提供的超分倍数为2倍。
-* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
-* paths (list\[str\]): 图片的路径;
-* use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
-* visualization (bool): 是否将识别结果保存为图片文件;
-* output\_dir (str): 图片的保存路径。
+ - 更多详情请参考:[falsr_c](https://github.com/xiaomi-automl/FALSR)
-**返回**
+## 二、安装
-* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
- * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
- * data (numpy.ndarray): 超分辨后图像。
+- ### 1、环境依赖
-```python
-def save_inference_model(self,
- dirname='falsr_c_save_model',
- model_filename=None,
- params_filename=None,
- combined=False)
-```
+ - paddlepaddle >= 2.0.0
-将模型保存到指定路径。
+ - paddlehub >= 2.0.0
-**参数**
-* dirname: 存在模型的目录名称
-* model\_filename: 模型文件名称,默认为\_\_model\_\_
-* params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
-* combined: 是否将参数保存到统一的一个文件中
+- ### 2、安装
+ - ```shell
+ $ hub install falsr_c
+ ```
-## 代码示例
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-```python
-import cv2
-import paddlehub as hub
+## 三、模型API预测
+- ### 1、命令行预测
-sr_model = hub.Module(name='falsr_c')
-im = cv2.imread('/PATH/TO/IMAGE').astype('float32')
-#visualization=True可以用于查看超分图片效果,可设置为False提升运行速度。
-res = sr_model.reconstruct(images=[im], visualization=True)
-print(res[0]['data'])
-sr_model.save_inference_model()
-```
+ - ```
+ $ hub run falsr_c --input_path "/PATH/TO/IMAGE"
+ ```
+- ### 代码示例
-## 服务部署
+ ```python
+ import cv2
+ import paddlehub as hub
-PaddleHub Serving可以部署一个图像超分的在线服务。
+ sr_model = hub.Module(name='falsr_c')
+ im = cv2.imread('/PATH/TO/IMAGE').astype('float32')
+ #visualization=True可以用于查看超分图片效果,可设置为False提升运行速度。
+ res = sr_model.reconstruct(images=[im], visualization=True)
+ print(res[0]['data'])
+ sr_model.save_inference_model()
+ ```
-## 第一步:启动PaddleHub Serving
+- ### 2、API
-运行启动命令:
+ - ```python
+ def reconstruct(self,
+ images=None,
+ paths=None,
+ use_gpu=False,
+ visualization=False,
+ output_dir="falsr_c_output")
+ ```
-```shell
-$ hub serving start -m falsr_c
-```
+ - 预测API,用于图像超分辨率。
-这样就完成了一个超分任务的服务化API的部署,默认端口号为8866。
+ - **参数**
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ * images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * paths (list\[str\]): 图片的路径;
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
+ * visualization (bool): 是否将识别结果保存为图片文件;
+ * output\_dir (str): 图片的保存路径。
-## 第二步:发送预测请求
+ - **返回**
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ * res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
+ * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
+ * data (numpy.ndarray): 超分辨后图像。
-```python
-import requests
-import json
-import base64
+ - ```python
+ def save_inference_model(self,
+ dirname='falsr_c_save_model',
+ model_filename=None,
+ params_filename=None,
+ combined=False)
+ ```
-import cv2
-import numpy as np
+ - 将模型保存到指定路径。
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-def base64_to_cv2(b64str):
- data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
- data = cv2.imdecode(data, cv2.IMREAD_COLOR)
- return data
+ - **参数**
-# 发送HTTP请求
-org_im = cv2.imread('/PATH/TO/IMAGE')
-data = {'images':[cv2_to_base64(org_im)]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/falsr_c"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-sr = base64_to_cv2(r.json()["results"][0]['data'])
-cv2.imwrite('falsr_c_X2.png', sr)
-print("save image as falsr_c_X2.png")
-```
+ * dirname: 存在模型的目录名称
+ * model\_filename: 模型文件名称,默认为\_\_model\_\_
+ * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
+ * combined: 是否将参数保存到统一的一个文件中
-### 查看代码
-https://github.com/xiaomi-automl/FALSR
+## 四、服务部署
-### 依赖
+- PaddleHub Serving可以部署一个图像超分的在线服务。
-paddlepaddle >= 1.8.0
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m falsr_c
+ ```
+
+ - 这样就完成了一个超分任务的服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+ - ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ ```python
+ import requests
+ import json
+ import base64
+
+ import cv2
+ import numpy as np
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/IMAGE')
+ data = {'images':[cv2_to_base64(org_im)]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/falsr_c"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ sr = base64_to_cv2(r.json()["results"][0]['data'])
+ cv2.imwrite('falsr_c_X2.png', sr)
+ print("save image as falsr_c_X2.png")
+ ```
+
+
+## 五、更新历史
+
+
+* 1.0.0
+
+ 初始发布
-paddlehub >= 1.7.1
diff --git a/modules/image/Image_editing/super_resolution/realsr/README.md b/modules/image/Image_editing/super_resolution/realsr/README.md
index 0ca1f8795bced6f8880678b2739b69b450656570..02e66678c5926f6f9e54344d6f74a1bf91304b39 100644
--- a/modules/image/Image_editing/super_resolution/realsr/README.md
+++ b/modules/image/Image_editing/super_resolution/realsr/README.md
@@ -1,121 +1,176 @@
+# realsr
-## 模型概述
-realsr是用于图像和视频超分模型,该模型基于Toward Real-World Single Image Super-Resolution: A New Benchmark and A New Mode,它能够将输入的图片和视频超分四倍。
+|模型名称|reasr|
+| :--- | :---: |
+|类别|图像-图像编辑|
+|网络|LP-KPN|
+|数据集|RealSR dataset|
+|是否支持Fine-tuning|否|
+|模型大小|64MB|
+|PSNR|29.05|
+|最新更新日期|2021-02-26|
-## API 说明
-```python
-def predict(self, input):
-```
-超分API,得到超分后的图片或者视频。
+## 一、模型基本信息
+- ### 应用效果展示
-**参数**
+ - 样例结果示例(左为原图,右为效果图):
+
+  +
+
-* input (str): 图片或者视频的路径;
+- ### 模型介绍
-**返回**
+ - realsr是用于图像和视频超分模型,该模型基于Toward Real-World Single Image Super-Resolution: A New Benchmark and A New Mode,它能够将输入的图片和视频超分四倍。
+
+ - 更多详情请参考:[realsr](https://github.com/csjcai/RealSR)
+
-若输入是图片,返回值为:
-* pred_img(np.ndarray): BGR图片数据;
-* out_path(str): 保存图片路径。
+## 二、安装
-若输入是视频,返回值为:
-* frame_pattern_combined(str): 视频超分后单帧数据保存路径;
-* vid_out_path(str): 视频保存路径。
+- ### 1、环境依赖
-```python
-def run_image(self, img):
-```
-图像超分API, 得到超分后的图片。
+ - paddlepaddle >= 2.0.0
-**参数**
+ - paddlehub >= 2.0.0
-* img (str|np.ndarray): 图片路径或则BGR格式图片。
+ - NOTE: 使用该模型需要自行安装ffmpeg,若您使用conda环境,推荐使用如下语句进行安装。
-**返回**
+ ```shell
+ $ conda install x264=='1!152.20180717' ffmpeg=4.0.2 -c conda-forge
+ ```
-* pred_img(np.ndarray): BGR图片数据;
-```python
-def run_video(self, video):
-```
-视频超分API, 得到超分后的视频。
+- ### 2、安装
-**参数**
+ - ```shell
+ $ hub install realsr
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-* video(str): 待处理视频路径。
+
-**返回**
-* frame_pattern_combined(str): 视频超分后单帧数据保存路径;
-* vid_out_path(str): 视频保存路径。
+## 三、模型API预测
-## 预测代码示例
+ - ### 1、代码示例
-```python
-import paddlehub as hub
+ ```python
+ import paddlehub as hub
-model = hub.Module(name='realsr')
-model.predict('/PATH/TO/IMAGE/OR/VIDEO')
-```
+ model = hub.Module(name='realsr')
+ model.predict('/PATH/TO/IMAGE/OR/VIDEO')
+ ```
+ - ### 2、API
-## 服务部署
+ - ```python
+ def predict(self, input):
+ ```
-PaddleHub Serving可以部署一个在线照片超分服务。
+ - 超分API,得到超分后的图片或者视频。
-## 第一步:启动PaddleHub Serving
-运行启动命令:
-```shell
-$ hub serving start -m realsr
-```
+ - **参数**
-这样就完成了一个图像超分的在线服务API的部署,默认端口号为8866。
+ - input (str): 图片或者视频的路径;
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+ - **返回**
-## 第二步:发送预测请求
+ - 若输入是图片,返回值为:
+ - pred_img(np.ndarray): BGR图片数据;
+ - out_path(str): 保存图片路径。
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - 若输入是视频,返回值为:
+ - frame_pattern_combined(str): 视频超分后单帧数据保存路径;
+ - vid_out_path(str): 视频保存路径。
-```python
-import requests
-import json
-import base64
+ - ```python
+ def run_image(self, img):
+ ```
+ - 图像超分API, 得到超分后的图片。
-import cv2
-import numpy as np
+ - **参数**
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-def base64_to_cv2(b64str):
- data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
- data = cv2.imdecode(data, cv2.IMREAD_COLOR)
- return data
+ - img (str|np.ndarray): 图片路径或则BGR格式图片。
-# 发送HTTP请求
-org_im = cv2.imread('/PATH/TO/IMAGE')
-data = {'images':cv2_to_base64(org_im)}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/realsr"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-img = base64_to_cv2(r.json()["results"])
-cv2.imwrite('/PATH/TO/SAVE/IMAGE', img)
+ - **返回**
-```
+ - pred_img(np.ndarray): BGR图片数据;
-## 模型相关信息
+ - ```python
+ def run_video(self, video):
+ ```
+ - 视频超分API, 得到超分后的视频。
-### 模型代码
+ - **参数**
-https://github.com/csjcai/RealSR
+ - video(str): 待处理视频路径。
-### 依赖
+ - **返回**
-paddlepaddle >= 2.0.0rc
+ - frame_pattern_combined(str): 视频超分后单帧数据保存路径;
+ - vid_out_path(str): 视频保存路径。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线照片超分服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m realsr
+ ```
+
+ - 这样就完成了一个图像超分的在线服务API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ ```python
+ import requests
+ import json
+ import base64
+
+ import cv2
+ import numpy as np
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/IMAGE')
+ data = {'images':cv2_to_base64(org_im)}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/realsr"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ img = base64_to_cv2(r.json()["results"])
+ cv2.imwrite('/PATH/TO/SAVE/IMAGE', img)
+
+ ```
+
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+* 1.0.1
+
+ 适配paddlehub2.0版本
-paddlehub >= 1.8.3
diff --git a/modules/image/Image_gan/style_transfer/msgnet/README.md b/modules/image/Image_gan/style_transfer/msgnet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b2ead3a2a4c3e185ef2edf31c8b0e8ceac817451
--- /dev/null
+++ b/modules/image/Image_gan/style_transfer/msgnet/README.md
@@ -0,0 +1,187 @@
+# msgnet
+
+|模型名称|msgnet|
+| :--- | :---: |
+|类别|图像-图像编辑|
+|网络|msgnet|
+|数据集|COCO2014|
+|是否支持Fine-tuning|是|
+|模型大小|68MB|
+|指标|-|
+|最新更新日期|2021-07-29|
+
+
+## 一、模型基本信息
+
+ - 样例结果示例:
+
+ 
 +
+
+
+- ### 模型介绍
+
+ - 本示例将展示如何使用PaddleHub对预训练模型进行finetune并完成预测任务。
+ - 更多详情请参考:[msgnet](https://github.com/zhanghang1989/PyTorch-Multi-Style-Transfer)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、安装
+ - ```shell
+ $ hub install msgnet
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1.命令行预测
+
+```
+$ hub run msgnet --input_path "/PATH/TO/ORIGIN/IMAGE" --style_path "/PATH/TO/STYLE/IMAGE"
+```
+
+- ### 2.预测代码示例
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+ model = hub.Module(name='msgnet')
+ result = model.predict(origin=["venice-boat.jpg"], style="candy.jpg", visualization=True, save_path ='style_tranfer')
+```
+
+
+
+- ### 3.如何开始Fine-tune
+
+ - 在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.py`即可开始使用msgnet模型对[MiniCOCO](../../docs/reference/datasets.md#class-hubdatasetsMiniCOCO)等数据集进行Fine-tune。
+
+ - 代码步骤
+
+ - Step1: 定义数据预处理方式
+ - ```python
+ import paddlehub.vision.transforms as T
+
+ transform = T.Compose([T.Resize((256, 256), interpolation='LINEAR')])
+ ```
+
+ - `transforms` 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+ - Step2: 下载数据集并使用
+ - ```python
+ from paddlehub.datasets.minicoco import MiniCOCO
+
+ styledata = MiniCOCO(transform=transform, mode='train')
+
+ ```
+ - `transforms`: 数据预处理方式。
+ - `mode`: 选择数据模式,可选项有 `train`, `test`, 默认为`train`。
+
+ - 数据集的准备代码可以参考 [minicoco.py](../../paddlehub/datasets/flowers.py)。`hub.datasets.MiniCOCO()`会自动从网络下载数据集并解压到用户目录下`$HOME/.paddlehub/dataset`目录。
+
+ - Step3: 加载预训练模型
+
+ - ```python
+ model = hub.Module(name='msgnet', load_checkpoint=None)
+ ```
+ - `name`: 选择预训练模型的名字。
+ - `load_checkpoint`: 是否加载自己训练的模型,若为None,则加载提供的模型默认参数。
+
+ - Step4: 选择优化策略和运行配置
+
+ - ```python
+ optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())
+ trainer = Trainer(model, optimizer, checkpoint_dir='test_style_ckpt')
+ trainer.train(styledata, epochs=101, batch_size=4, eval_dataset=styledata, log_interval=10, save_interval=10)
+ ```
+
+
+
+
+ - 模型预测
+
+ - 当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。我们使用该模型来进行预测。predict.py脚本如下:
+
+ ```python
+ import paddle
+ import paddlehub as hub
+
+ if __name__ == '__main__':
+ model = hub.Module(name='msgnet', load_checkpoint="/PATH/TO/CHECKPOINT")
+ result = model.predict(origin=["venice-boat.jpg"], style="candy.jpg", visualization=True, save_path ='style_tranfer')
+ ```
+
+ - 参数配置正确后,请执行脚本`python predict.py`, 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+ - **Args**
+ * `origin`:原始图像路径或BGR格式图片;
+ * `style`: 风格图像路径;
+ * `visualization`: 是否可视化,默认为True;
+ * `save_path`: 保存结果的路径,默认保存路径为'style_tranfer'。
+
+ **NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线风格迁移服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m msgnet
+ ```
+
+ - 这样就完成了一个风格迁移服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+ import numpy as np
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/ORIGIN/IMAGE')
+ style_im = cv2.imread('/PATH/TO/STYLE/IMAGE')
+ data = {'images':[[cv2_to_base64(org_im)], cv2_to_base64(style_im)]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/msgnet"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ data = base64_to_cv2(r.json()["results"]['data'][0])
+ cv2.imwrite('style.png', data)
+ ```
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
diff --git a/modules/image/classification/resnet50_vd_animals/README.md b/modules/image/classification/resnet50_vd_animals/README.md
index 8b56c5f61fffa193817415d21105624601840e9f..a42168e27330a2e66d93a463ca8ce87553c2a2c8 100644
--- a/modules/image/classification/resnet50_vd_animals/README.md
+++ b/modules/image/classification/resnet50_vd_animals/README.md
@@ -1,159 +1,169 @@
-```shell
-$ hub install resnet50_vd_animals==1.0.0
-```
+# resnet50_vd_animals
-
-
ResNet 系列的网络结构
-
+|模型名称|resnet50_vd_animals|
+| :--- | :---: |
+|类别|图像-图像分类|
+|网络|ResNet50_vd|
+|数据集|百度自建动物数据集|
+|是否支持Fine-tuning|否|
+|模型大小|154MB|
+|指标|-|
+|最新更新日期|2021-02-26|
-模型的详情可参考[论文](https://arxiv.org/pdf/1812.01187.pdf)
-## 命令行预测
+## 一、模型基本信息
-```
-hub run resnet50_vd_animals --input_path "/PATH/TO/IMAGE"
-```
-## API
+- ### 模型介绍
-```python
-def get_expected_image_width()
-```
+ - ResNet-vd 其实就是 ResNet-D,是ResNet 原始结构的变种,可用于图像分类和特征提取。该 PaddleHub Module 采用百度自建动物数据集训练得到,支持7978种动物的分类识别。
-返回预处理的图片宽度,也就是224。
+ - 模型的详情可参考[论文](https://arxiv.org/pdf/1812.01187.pdf)
-```python
-def get_expected_image_height()
-```
+## 二、安装
-返回预处理的图片高度,也就是224。
+- ### 1、环境依赖
-```python
-def get_pretrained_images_mean()
-```
+ - paddlepaddle >= 2.0.0
-返回预处理的图片均值,也就是 \[0.485, 0.456, 0.406\]。
+ - paddlehub >= 2.0.0
-```python
-def get_pretrained_images_std()
-```
+- ### 2、安装
-返回预处理的图片标准差,也就是 \[0.229, 0.224, 0.225\]。
+ - ```shell
+ $ hub install resnet50_vd_animals==1.0.0
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+## 三、模型API预测
+
+- ### 1、命令行预测
-```python
-def context(trainable=True, pretrained=True)
-```
+ - ```
+ hub run resnet50_vd_animals --input_path "/PATH/TO/IMAGE"
+ ```
-**参数**
+- ### 2、代码示例
-* trainable (bool): 计算图的参数是否为可训练的;
-* pretrained (bool): 是否加载默认的预训练模型。
+ - ```python
+ import paddlehub as hub
+ import cv2
-**返回**
+ classifier = hub.Module(name="resnet50_vd_animals")
-* inputs (dict): 计算图的输入,key 为 'image', value 为图片的张量;
-* outputs (dict): 计算图的输出,key 为 'classification' 和 'feature_map',其相应的值为:
- * classification (paddle.fluid.framework.Variable): 分类结果,也就是全连接层的输出;
- * feature\_map (paddle.fluid.framework.Variable): 特征匹配,全连接层前面的那个张量。
-* context\_prog(fluid.Program): 计算图,用于迁移学习。
+ result = classifier.classification(images=[cv2.imread('/PATH/TO/IMAGE')])
+ # or
+ # result = classifier.classification(paths=['/PATH/TO/IMAGE'])
+ ```
+- ### 3、API
-```python
-def classification(images=None,
- paths=None,
- batch_size=1,
- use_gpu=False,
- top_k=1):
-```
+ - ```python
+ def get_expected_image_width()
+ ```
-**参数**
+ - 返回预处理的图片宽度,也就是224。
-* images (list\[numpy.ndarray\]): 图片数据,每一个图片数据的shape 均为 \[H, W, C\],颜色空间为 BGR;
-* paths (list\[str\]): 图片的路径;
-* batch\_size (int): batch 的大小;
-* use\_gpu (bool): 是否使用 GPU 来预测;
-* top\_k (int): 返回预测结果的前 k 个。
+ - ```python
+ def get_expected_image_height()
+ ```
-**返回**
+ - 返回预处理的图片高度,也就是224。
-res (list\[dict\]): 分类结果,列表的每一个元素均为字典,其中 key 为识别动物的类别,value为置信度。
+ - ```python
+ def get_pretrained_images_mean()
+ ```
-```python
-def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
-```
+ - 返回预处理的图片均值,也就是 \[0.485, 0.456, 0.406\]。
-将模型保存到指定路径。
+ - ```python
+ def get_pretrained_images_std()
+ ```
-**参数**
+ - 返回预处理的图片标准差,也就是 \[0.229, 0.224, 0.225\]。
-* dirname: 存在模型的目录名称
-* model_filename: 模型文件名称,默认为\_\_model\_\_
-* params_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
-* combined: 是否将参数保存到统一的一个文件中
-## 代码示例
+ - ```python
+ def classification(images=None,
+ paths=None,
+ batch_size=1,
+ use_gpu=False,
+ top_k=1):
+ ```
-```python
-import paddlehub as hub
-import cv2
+ - **参数**
-classifier = hub.Module(name="resnet50_vd_animals")
+ * images (list\[numpy.ndarray\]): 图片数据,每一个图片数据的shape 均为 \[H, W, C\],颜色空间为 BGR;
+ * paths (list\[str\]): 图片的路径;
+ * batch\_size (int): batch 的大小;
+ * use\_gpu (bool): 是否使用 GPU 来预测;
+ * top\_k (int): 返回预测结果的前 k 个。
-result = classifier.classification(images=[cv2.imread('/PATH/TO/IMAGE')])
-# or
-# result = classifier.classification(paths=['/PATH/TO/IMAGE'])
-```
+ - **返回**
-## 服务部署
+ - res (list\[dict\]): 分类结果,列表的每一个元素均为字典,其中 key 为识别动物的类别,value为置信度。
-PaddleHub Serving可以部署一个在线动物识别服务。
+ - ```python
+ def save_inference_model(dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True)
+ ```
-## 第一步:启动PaddleHub Serving
+ - 将模型保存到指定路径。
-运行启动命令:
-```shell
-$ hub serving start -m resnet50_vd_animals
-```
+ - **参数**
-这样就完成了一个在线动物识别服务化API的部署,默认端口号为8866。
+ * dirname: 存在模型的目录名称
+ * model_filename: 模型文件名称,默认为\_\_model\_\_
+ * params_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
+ * combined: 是否将参数保存到统一的一个文件中
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-## 第二步:发送预测请求
+## 四、服务部署
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+- PaddleHub Serving可以部署一个在线动物识别服务。
-```python
-import requests
-import json
-import cv2
-import base64
+- ### 第一步:启动PaddleHub Serving
+ - 运行启动命令:
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
+ - ```shell
+ $ hub serving start -m resnet50_vd_animals
+ ```
+ - 这样就完成了一个在线动物识别服务化API的部署,默认端口号为8866。
-# 发送HTTP请求
-data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/resnet50_vd_animals"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-# 打印预测结果
-print(r.json()["results"])
-```
+- ### 第二步:发送预测请求
-### 查看代码
+- 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-[PaddlePaddle/models 图像分类](https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/image_classification)
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
-### 依赖
-paddlepaddle >= 1.6.2
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
-paddlehub >= 1.6.0
+
+ # 发送HTTP请求
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/resnet50_vd_animals"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 打印预测结果
+ print(r.json()["results"])
+ ```
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
diff --git a/modules/image/classification/resnet50_vd_imagenet_ssld/README.md b/modules/image/classification/resnet50_vd_imagenet_ssld/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..229e5d0c8400152d73f354f13dab546a3f8b749c
--- /dev/null
+++ b/modules/image/classification/resnet50_vd_imagenet_ssld/README.md
@@ -0,0 +1,200 @@
+# resnet50_vd_imagenet_ssld
+
+|模型名称|resnet50_vd_imagenet_ssld|
+| :--- | :---: |
+|类别|图像-图像分类|
+|网络|ResNet_vd|
+|数据集|ImageNet-2012|
+|是否支持Fine-tuning|是|
+|模型大小|148MB|
+|指标|-|
+|最新更新日期|2021-02-26|
+
+
+## 一、模型基本信息
+
+- ### 模型介绍
+
+ - ResNet-vd 其实就是 ResNet-D,是ResNet 原始结构的变种,可用于图像分类和特征提取。
+
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、安装
+ - ```shell
+ $ hub install resnet50_vd_imagenet_ssld
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## 三、模型API预测
+
+- ### 1.命令行预测
+
+ ```shell
+ $ hub run resnet50_vd_imagenet_ssld --input_path "/PATH/TO/IMAGE" --top_k 5
+ ```
+- ### 2.预测代码示例
+
+ ```python
+ import paddle
+ import paddlehub as hub
+
+ if __name__ == '__main__':
+
+ model = hub.Module(name='resnet50_vd_imagenet_ssld')
+ result = model.predict(['flower.jpg'])
+ ```
+- ### 3.如何开始Fine-tune
+
+ - 在完成安装PaddlePaddle与PaddleHub后,通过执行`python train.py`即可开始使用resnet50_vd_imagenet_ssld对[Flowers](../../docs/reference/datasets.md#class-hubdatasetsflowers)等数据集进行Fine-tune。
+
+ - 代码步骤
+
+ - Step1: 定义数据预处理方式
+ - ```python
+ import paddlehub.vision.transforms as T
+
+ transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+ ```
+
+ - `transforms` 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+ - Step2: 下载数据集并使用
+ - ```python
+ from paddlehub.datasets import Flowers
+
+ flowers = Flowers(transforms)
+
+ flowers_validate = Flowers(transforms, mode='val')
+ ```
+
+ * `transforms`: 数据预处理方式。
+ * `mode`: 选择数据模式,可选项有 `train`, `test`, `val`, 默认为`train`。
+
+ * 数据集的准备代码可以参考 [flowers.py](../../paddlehub/datasets/flowers.py)。`hub.datasets.Flowers()` 会自动从网络下载数据集并解压到用户目录下`$HOME/.paddlehub/dataset`目录。
+
+
+ - Step3: 加载预训练模型
+
+ - ```python
+ model = hub.Module(name="resnet50_vd_imagenet_ssld", label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"])
+ ```
+ * `name`: 选择预训练模型的名字。
+ * `label_list`: 设置输出分类类别,默认为Imagenet2012类别。
+
+ - Step4: 选择优化策略和运行配置
+
+ ```python
+ optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+ trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+ trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+ ```
+
+
+ - 运行配置
+
+ - `Trainer` 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+ * `model`: 被优化模型;
+ * `optimizer`: 优化器选择;
+ * `use_vdl`: 是否使用vdl可视化训练过程;
+ * `checkpoint_dir`: 保存模型参数的地址;
+ * `compare_metrics`: 保存最优模型的衡量指标;
+
+ - `trainer.train` 主要控制具体的训练过程,包含以下可控制的参数:
+
+ * `train_dataset`: 训练时所用的数据集;
+ * `epochs`: 训练轮数;
+ * `batch_size`: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+ * `num_workers`: works的数量,默认为0;
+ * `eval_dataset`: 验证集;
+ * `log_interval`: 打印日志的间隔, 单位为执行批训练的次数。
+ * `save_interval`: 保存模型的间隔频次,单位为执行训练的轮数。
+
+ - 模型预测
+
+ - 当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在`${CHECKPOINT_DIR}/best_model`目录下,其中`${CHECKPOINT_DIR}`目录为Fine-tune时所选择的保存checkpoint的目录。 我们使用该模型来进行预测。predict.py脚本如下:
+
+ - ```python
+ import paddle
+ import paddlehub as hub
+
+ if __name__ == '__main__':
+
+ model = hub.Module(name='resnet50_vd_imagenet_ssld', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+ ```
+
+
+ - **NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线分类任务服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m resnet50_vd_imagenet_ssld
+ ```
+
+ - 这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+ import numpy as np
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/IMAGE')
+
+ data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/resnet50_vd_imagenet_ssld"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ data =r.json()["results"]['data']
+ ```
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+* 1.1.0
+
+ 升级为动态图版本
+
diff --git a/modules/image/semantic_segmentation/ExtremeC3_Portrait_Segmentation/README.md b/modules/image/semantic_segmentation/ExtremeC3_Portrait_Segmentation/README.md
index 4e91fcfe5278a73b6b93938f649f1b88154b5f6c..17d2979a19b9df5963b341e42347921e40c94c40 100644
--- a/modules/image/semantic_segmentation/ExtremeC3_Portrait_Segmentation/README.md
+++ b/modules/image/semantic_segmentation/ExtremeC3_Portrait_Segmentation/README.md
@@ -1,56 +1,89 @@
-## 概述
-* 基于 ExtremeC3 模型实现的轻量化人像分割模型
-* 模型具体规格如下:
- |model|ExtremeC3|
- |----|----|
- |Param|0.038 M|
- |Flop|0.128 G|
-
-* 模型参数转换至 [ext_portrait_segmentation](https://github.com/clovaai/ext_portrait_segmentation) 项目
-* 感谢 [ext_portrait_segmentation](https://github.com/clovaai/ext_portrait_segmentation) 项目提供的开源代码和模型
-
-## 效果展示
-
-
-## API
-```python
-def Segmentation(
- images=None,
- paths=None,
- batch_size=1,
- output_dir='output',
- visualization=False):
-```
-人像分割 API
-
-**参数**
-* images (list[np.ndarray]) : 输入图像数据列表(BGR)
-* paths (list[str]) : 输入图像路径列表
-* batch_size (int) : 数据批大小
-* output_dir (str) : 可视化图像输出目录
-* visualization (bool) : 是否可视化
-
-**返回**
-* results (list[dict{"mask":np.ndarray,"result":np.ndarray}]): 输出图像数据列表
-
-**代码示例**
-```python
-import cv2
-import paddlehub as hub
-
-model = hub.Module(name='ExtremeC3_Portrait_Segmentation')
-
-result = model.Segmentation(
- images=[cv2.imread('/PATH/TO/IMAGE')],
- paths=None,
- batch_size=1,
- output_dir='output',
- visualization=False)
-```
-
-## 查看代码
-https://github.com/clovaai/ext_portrait_segmentation
-
-## 依赖
-paddlepaddle >= 2.0.0rc0
-paddlehub >= 2.0.0b1
+# ExtremeC3_Portrait_Segmentation
+
+|模型名称|ExtremeC3_Portrait_Segmentation|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|ExtremeC3|
+|数据集|EG1800, Baidu fashion dataset|
+|是否支持Fine-tuning|否|
+|模型大小|0.038MB|
+|指标|-|
+|最新更新日期|2021-02-26|
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+
+ - 样例结果示例:
+
+ 
+
+
+
+- ### 模型介绍
+ * 基于 ExtremeC3 模型实现的轻量化人像分割模型
+
+ * 更多详情请参考: [ExtremeC3_Portrait_Segmentation](https://github.com/clovaai/ext_portrait_segmentation) 项目
+
+## 二、安装
+
+- ### 1、环境依赖
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install ExtremeC3_Portrait_Segmentation
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、代码示例
+
+ ```python
+ import cv2
+ import paddlehub as hub
+
+ model = hub.Module(name='ExtremeC3_Portrait_Segmentation')
+
+ result = model.Segmentation(
+ images=[cv2.imread('/PATH/TO/IMAGE')],
+ paths=None,
+ batch_size=1,
+ output_dir='output',
+ visualization=False)
+ ```
+
+ - ### 2、API
+
+ ```python
+ def Segmentation(
+ images=None,
+ paths=None,
+ batch_size=1,
+ output_dir='output',
+ visualization=False):
+ ```
+ - 人像分割 API
+
+ - **参数**
+ * images (list[np.ndarray]) : 输入图像数据列表(BGR)
+ * paths (list[str]) : 输入图像路径列表
+ * batch_size (int) : 数据批大小
+ * output_dir (str) : 可视化图像输出目录
+ * visualization (bool) : 是否可视化
+
+ - **返回**
+ * results (list[dict{"mask":np.ndarray,"result":np.ndarray}]): 输出图像数据列表
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
diff --git a/modules/image/semantic_segmentation/ace2p/README.md b/modules/image/semantic_segmentation/ace2p/README.md
index c122ae728e00f4eb27535ce99fff5d9dc677e626..710c2424a45298d86b1486afbf751eb874ae4764 100644
--- a/modules/image/semantic_segmentation/ace2p/README.md
+++ b/modules/image/semantic_segmentation/ace2p/README.md
@@ -1,131 +1,178 @@
-```shell
-$ hub install ace2p==1.1.0
-```
+# ace2p
-
-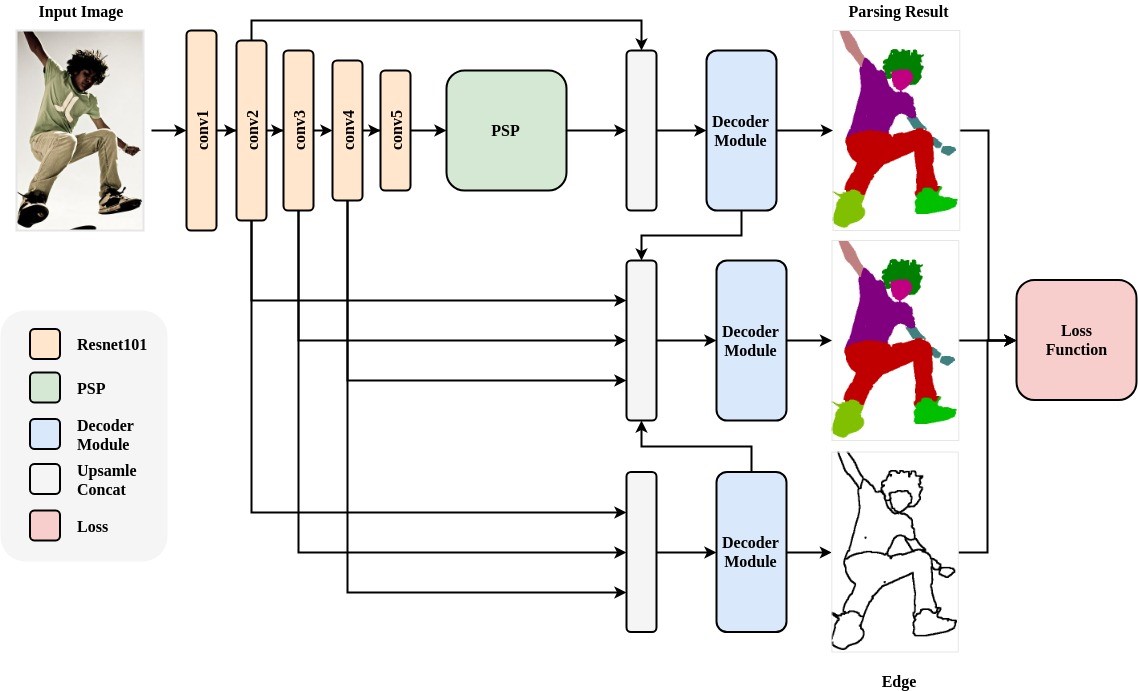
-
+|模型名称|ace2p|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|ACE2P|
+|数据集|LIP|
+|是否支持Fine-tuning|否|
+|模型大小|259MB|
+|指标|-|
+|最新更新日期|2021-02-26|
-## 命令行预测
-```
-hub run ace2p --input_path "/PATH/TO/IMAGE"
-```
+## 一、模型基本信息
-## API
+- ### 应用效果展示
-```python
-def segmentation(images=None,
- paths=None,
- batch_size=1,
- use_gpu=False,
- output_dir='ace2p_output',
- visualization=False):
-```
+ - 网络结构:
+
+
+
-预测API,用于图像分割得到人体解析。
+ - 调色板
-**参数**
+
+ 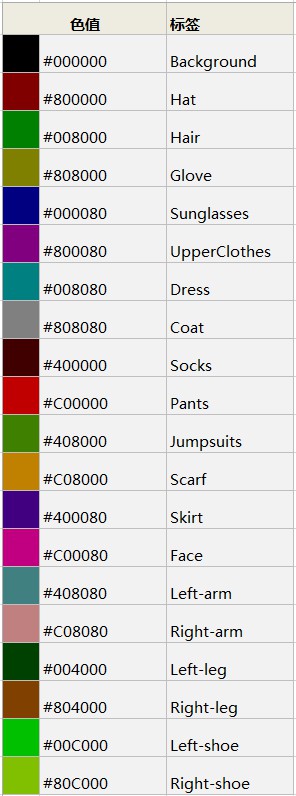
+
-* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
-* paths (list\[str\]): 图片的路径;
-* batch\_size (int): batch 的大小;
-* use\_gpu (bool): 是否使用 GPU;
-* output\_dir (str): 保存处理结果的文件目录;
-* visualization (bool): 是否将识别结果保存为图片文件。
+ - 样例结果示例:
+
+ 
 +
+
-**返回**
+- ### 模型介绍
-* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有'path', 'data',相应的取值为:
- * path (str): 原输入图片的路径;
- * data (numpy.ndarray): 图像分割得到的结果,shape 为`H * W`,元素的取值为0-19,表示每个像素的分类结果,映射顺序与下面的调色板相同。
+ - 人体解析(Human Parsing)是细粒度的语义分割任务,其旨在识别像素级别的人类图像的组成部分(例如,身体部位和服装)。ACE2P通过融合底层特征,全局上下文信息和边缘细节,端到端地训练学习人体解析任务。该结构针对Intersection over Union指标进行针对性的优化学习,提升准确率。以ACE2P单人人体解析网络为基础的解决方案在CVPR2019第三届LIP挑战赛中赢得了全部三个人体解析任务的第一名。该PaddleHub Module采用ResNet101作为骨干网络,接受输入图片大小为473x473x3。
-```python
-def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
-```
-将模型保存到指定路径。
-**参数**
+## 二、安装
-* dirname: 存在模型的目录名称
-* model\_filename: 模型文件名称,默认为\_\_model\_\_
-* params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
-* combined: 是否将参数保存到统一的一个文件中。
+- ### 1、环境依赖
-## 代码示例
+ - paddlepaddle >= 2.0.0
-```python
-import paddlehub as hub
-import cv2
+ - paddlehub >= 2.0.0
-human_parser = hub.Module(name="ace2p")
-result = human_parser.segmentation(images=[cv2.imread('/PATH/TO/IMAGE')])
-# or
-# result = human_parser.segmentation((paths=['/PATH/TO/IMAGE'])
-```
+- ### 2.安装
-## 服务部署
+ - ```shell
+ $ hub install ace2p
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-PaddleHub Serving可以部署一个人体解析的在线服务。
+## 三、模型API预测
+ - ### 1、命令行预测
-### 第一步:启动PaddleHub Serving
+ ```shell
+ $ hub install ace2p==1.1.0
+ ```
-运行启动命令:
-```shell
-$ hub serving start -m ace2p
-```
+ - ### 2、代码示例
-这样就完成了一个人体解析服务化API的部署,默认端口号为8866。
+ ```python
+ import paddlehub as hub
+ import cv2
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+ human_parser = hub.Module(name="ace2p")
+ result = human_parser.segmentation(images=[cv2.imread('/PATH/TO/IMAGE')])
+ ```
+
+ - ### 3、API
-### 第二步:发送预测请求
+ ```python
+ def segmentation(images=None,
+ paths=None,
+ batch_size=1,
+ use_gpu=False,
+ output_dir='ace2p_output',
+ visualization=False):
+ ```
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - 预测API,用于图像分割得到人体解析。
-```python
-import requests
-import json
-import cv2
-import base64
+ - **参数**
-import numpy as np
+ * images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * paths (list\[str\]): 图片的路径;
+ * batch\_size (int): batch 的大小;
+ * use\_gpu (bool): 是否使用 GPU;
+ * output\_dir (str): 保存处理结果的文件目录;
+ * visualization (bool): 是否将识别结果保存为图片文件。
+ - **返回**
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
+ * res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有'path', 'data',相应的取值为:
+ * path (str): 原输入图片的路径;
+ * data (numpy.ndarray): 图像分割得到的结果,shape 为`H * W`,元素的取值为0-19,表示每个像素的分类结果,映射顺序与下面的调色板相同。
+ ```python
+ def save_inference_model(dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True)
+ ```
-def base64_to_cv2(b64str):
- data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
- data = cv2.imdecode(data, cv2.IMREAD_COLOR)
- return data
+ - 将模型保存到指定路径。
+ - **参数**
-# 发送HTTP请求
-data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/ace2p"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ * dirname: 存在模型的目录名称
+ * model\_filename: 模型文件名称,默认为\_\_model\_\_
+ * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
+ * combined: 是否将参数保存到统一的一个文件中。
-# 打印预测结果
-print(base64_to_cv2(r.json()["results"][0]['data']))
-```
-## 调色板
+## 四、服务部署
-
-
-
+- PaddleHub Serving可以部署一个人体解析的在线服务。
-## 依赖
+- ### 第一步:启动PaddleHub Serving
-paddlepaddle >= 1.6.2
+ - 运行启动命令:
+
+ ```shell
+ $ hub serving start -m ace2p
+ ```
-paddlehub >= 1.6.0
+ - 这样就完成了一个人体解析服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+ import numpy as np
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+
+ # 发送HTTP请求
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/ace2p"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 打印预测结果
+ print(base64_to_cv2(r.json()["results"][0]['data']))
+ ```
+
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+* 1.1.0
+
+ 适配paddlehub2.0版本
diff --git a/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/README.md b/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/README.md
index 922273c363b8a76c0cfaa577584a5d55b4eb7465..f84c3578a7f72c94d925df157fa027ed551ed12d 100644
--- a/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/README.md
+++ b/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/README.md
@@ -1,125 +1,179 @@
-## 命令行预测
-
-```
-hub run deeplabv3p_xception65_humanseg --input_path "/PATH/TO/IMAGE"
-```
-
+# deeplabv3p_xception65_humanseg
+
+|模型名称|deeplabv3p_xception65_humanseg|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|deeplabv3p|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|否|
+|模型大小|162MB|
+|指标|-|
+|最新更新日期|2021-02-26|
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+
+ - 样例结果示例:
+
+  +
+
+
+- ### 模型介绍
+
+ - DeepLabv3+使用百度自建数据集进行训练,可用于人像分割,支持任意大小的图片输入。
-## API
+- 更多详情请参考:[deeplabv3p](https://github.com/PaddlePaddle/PaddleSeg)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install deeplabv3p_xception65_humanseg
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## 三、模型API预测
+
+- ### 1.命令行预测
+
+ ```shell
+ hub run deeplabv3p_xception65_humanseg --input_path "/PATH/TO/IMAGE"
+ ```
+
+
+
+- ### 2.预测代码示例
+
+ ```python
+ import paddlehub as hub
+ import cv2
+
+ human_seg = hub.Module(name="deeplabv3p_xception65_humanseg")
+ result = human_seg.segmentation(images=[cv2.imread('/PATH/TO/IMAGE')])
+
+ ```
+
+- ### 3.API
-```python
-def segmentation(images=None,
- paths=None,
- batch_size=1,
- use_gpu=False,
- visualization=False,
- output_dir='humanseg_output')
-```
+ ```python
+ def segmentation(images=None,
+ paths=None,
+ batch_size=1,
+ use_gpu=False,
+ visualization=False,
+ output_dir='humanseg_output')
+ ```
-预测API,用于人像分割。
+ - 预测API,用于人像分割。
-**参数**
+ - **参数**
-* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
-* paths (list\[str\]): 图片的路径;
-* batch\_size (int): batch 的大小;
-* use\_gpu (bool): 是否使用 GPU;
-* visualization (bool): 是否将识别结果保存为图片文件;
-* output\_dir (str): 图片的保存路径。
+ * images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * paths (list\[str\]): 图片的路径;
+ * batch\_size (int): batch 的大小;
+ * use\_gpu (bool): 是否使用 GPU;
+ * visualization (bool): 是否将识别结果保存为图片文件;
+ * output\_dir (str): 图片的保存路径。
-**返回**
+ - **返回**
-* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
- * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
- * data (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-255 (0为全透明,255为不透明),也即取值越大的像素点越可能为人体,取值越小的像素点越可能为背景。
+ * res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
+ * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
+ * data (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-255 (0为全透明,255为不透明),也即取值越大的像素点越可能为人体,取值越小的像素点越可能为背景。
-```python
-def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True)
-```
+ ```python
+ def save_inference_model(dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True)
+ ```
-将模型保存到指定路径。
+ - 将模型保存到指定路径。
-**参数**
+ - **参数**
-* dirname: 存在模型的目录名称
-* model\_filename: 模型文件名称,默认为\_\_model\_\_
-* params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
-* combined: 是否将参数保存到统一的一个文件中
+ * dirname: 存在模型的目录名称
+ * model\_filename: 模型文件名称,默认为\_\_model\_\_
+ * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
+ * combined: 是否将参数保存到统一的一个文件中
-## 代码示例
-```python
-import paddlehub as hub
-import cv2
+## 四、服务部署
-human_seg = hub.Module(name="deeplabv3p_xception65_humanseg")
-result = human_seg.segmentation(images=[cv2.imread('/PATH/TO/IMAGE')])
-# or
-# result = human_seg.segmentation(paths=['/PATH/TO/IMAGE'])
-```
+- PaddleHub Serving可以部署一个人像分割的在线服务。
-## 服务部署
+- ### 第一步:启动PaddleHub Serving
-PaddleHub Serving可以部署一个人像分割的在线服务。
+ - 运行启动命令:
-## 第一步:启动PaddleHub Serving
+ ```shell
+ $ hub serving start -m deeplabv3p_xception65_humanseg
+ ```
-运行启动命令:
-```shell
-$ hub serving start -m deeplabv3p_xception65_humanseg
-```
+ - 这样就完成了一个人像分割的服务化API的部署,默认端口号为8866。
-这样就完成了一个人像分割的服务化API的部署,默认端口号为8866。
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+- ### 第二步:发送预测请求
-## 第二步:发送预测请求
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ import numpy as np
-```python
-import requests
-import json
-import cv2
-import base64
-import numpy as np
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+ # 发送HTTP请求
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/deeplabv3p_xception65_humanseg"
+ r = requests.post(url=url, headers=headers, # 保存图片
+ mask =cv2.cvtColor(base64_to_cv2(r.json()["results"][0]['data']), cv2.COLOR_BGR2GRAY)
+ rgba = np.concatenate((org_im, np.expand_dims(mask, axis=2)), axis=2)
+ cv2.imwrite("segment_human_server.png", rgba)
+ ```
-def base64_to_cv2(b64str):
- data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
- data = cv2.imdecode(data, cv2.IMREAD_COLOR)
- return data
+## 五、更新历史
+* 1.0.0
-# 发送HTTP请求
-data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/deeplabv3p_xception65_humanseg"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ 初始发布
-# 打印预测结果
-print(base64_to_cv2(r.json()["results"][0]['data']))
-```
+* 1.1.0
-### 查看代码
+ 提升预测性能
-[PaddleSeg 特色垂类模型 - 人像分割](https://github.com/PaddlePaddle/PaddleSeg/tree/release/v0.4.0/contrib)
+* 1.1.1
-### 依赖
+ 修复预测后处理图像数据超过[0,255]范围
-paddlepaddle >= 1.6.2
+* 1.1.2
-paddlehub >= 1.6.0
+ 修复cudnn为8.0.4显存泄露问题
diff --git a/modules/image/semantic_segmentation/humanseg_lite/README.md b/modules/image/semantic_segmentation/humanseg_lite/README.md
index 1ddb1e182c9315f950a9c3f13bc77fd4945c90d0..effab0ff515694b2e376711a097c76ab564fdcbe 100644
--- a/modules/image/semantic_segmentation/humanseg_lite/README.md
+++ b/modules/image/semantic_segmentation/humanseg_lite/README.md
@@ -1,205 +1,250 @@
-## 模型概述
+# humanseg_lite
+
+|模型名称|humanseg_lite|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|shufflenet|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|否|
+|模型大小|541k|
+|指标|-|
+|最新更新日期|2021-02-26|
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+
+ - 样例结果示例:
+
+  +
+
+- ### 模型介绍
+
+ - HumanSeg_lite是在ShuffleNetV2网络结构的基础上进行优化,进一步减小了网络规模,网络大小只有541K,量化后只有187K, 适用于手机自拍人像分割,且能在移动端进行实时分割。
+
+ - 更多详情请参考:[humanseg_lite](https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.2/contrib/HumanSeg)
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install humanseg_lite
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ ```
+ hub run humanseg_lite --input_path "/PATH/TO/IMAGE"
+ ```
+- ### 2、代码示例
+
+ - 图片分割及视频分割代码示例:
-HumanSeg_lite是基于ShuffleNetV2网络结构的基础上进行优化的人像分割模型,进一步减小了网络规模,网络大小只有541K,量化后只有187K,适用于手机自拍人像分割等实时分割场景。
+ ```python
+ import cv2
+ import paddlehub as hub
+ human_seg = hub.Module(name='humanseg_lite')
+ im = cv2.imread('/PATH/TO/IMAGE')
+ #visualization=True可以用于查看人像分割图片效果,可设置为False提升运行速度。
+ res = human_seg.segment(images=[im],visualization=True)
+ print(res[0]['data'])
+ human_seg.video_segment('/PATH/TO/VIDEO')
+ human_seg.save_inference_model('/PATH/TO/SAVE/MODEL')
-## 命令行预测
+ ```
+ - 视频流预测代码示例:
-```
-hub run humanseg_lite --input_path "/PATH/TO/IMAGE"
+ ```python
+ import cv2
+ import numpy as np
+ import paddlehub as hub
-```
+ human_seg = hub.Module('humanseg_lite')
+ cap_video = cv2.VideoCapture('\PATH\TO\VIDEO')
+ fps = cap_video.get(cv2.CAP_PROP_FPS)
+ save_path = 'humanseg_lite_video.avi'
+ width = int(cap_video.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height = int(cap_video.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ cap_out = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps, (width, height))
+ prev_gray = None
+ prev_cfd = None
+ while cap_video.isOpened():
+ ret, frame_org = cap_video.read()
+ if ret:
+ [img_matting, prev_gray, prev_cfd] = human_seg.video_stream_segment(frame_org=frame_org, frame_id=cap_video.get(1), prev_gray=prev_gray, prev_cfd=prev_cfd)
+ img_matting = np.repeat(img_matting[:, :, np.newaxis], 3, axis=2)
+ bg_im = np.ones_like(img_matting) * 255
+ comb = (img_matting * frame_org + (1 - img_matting) * bg_im).astype(np.uint8)
+ cap_out.write(comb)
+ else:
+ break
+ cap_video.release()
+ cap_out.release()
-## API
+ ```
-```python
-def segment(images=None,
- paths=None,
- batch_size=1,
- use_gpu=False,
- visualization=False,
- output_dir='humanseg_lite_output')
-```
+- ### 3、API
-预测API,用于人像分割。
+ ```python
+ def segment(images=None,
+ paths=None,
+ batch_size=1,
+ use_gpu=False,
+ visualization=False,
+ output_dir='humanseg_lite_output')
+ ```
-**参数**
+ - 预测API,用于人像分割。
-* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
-* paths (list\[str\]): 图片的路径;
-* batch\_size (int): batch 的大小;
-* use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
-* visualization (bool): 是否将识别结果保存为图片文件;
-* output\_dir (str): 图片的保存路径。
+ - **参数**
-**返回**
+ * images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * paths (list\[str\]): 图片的路径;
+ * batch\_size (int): batch 的大小;
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
+ * visualization (bool): 是否将识别结果保存为图片文件;
+ * output\_dir (str): 图片的保存路径。
-* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
- * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
- * data (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-255 (0为全透明,255为不透明),也即取值越大的像素点越可能为人体,取值越小的像素点越可能为背景。
+ - **返回**
-```python
-def video_stream_segment(self,
- frame_org,
- frame_id,
- prev_gray,
- prev_cfd,
- use_gpu=False):
-```
+ * res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
+ * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
+ * data (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-255 (0为全透明,255为不透明),也即取值越大的像素点越可能为人体,取值越小的像素点越可能为背景。
-预测API,用于逐帧对视频人像分割。
-**参数**
+ ```python
+ def video_stream_segment(self,
+ frame_org,
+ frame_id,
+ prev_gray,
+ prev_cfd,
+ use_gpu=False):
+ ```
-* frame_org (numpy.ndarray): 单帧图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
-* frame_id (int): 当前帧的编号;
-* prev_gray (numpy.ndarray): 前一帧输入网络图像的灰度图;
-* prev_cfd (numpy.ndarray): 前一帧光流追踪图和预测结果融合图
-* use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
+ - 预测API,用于逐帧对视频人像分割。
+ - **参数**
-**返回**
+ * frame_org (numpy.ndarray): 单帧图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * frame_id (int): 当前帧的编号;
+ * prev_gray (numpy.ndarray): 前一帧输入网络图像的灰度图;
+ * prev_cfd (numpy.ndarray): 前一帧光流追踪图和预测结果融合图
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
-* img_matting (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-1 (0为全透明,1为不透明)。
-* cur_gray (numpy.ndarray): 当前帧输入网络图像的灰度图;
-* optflow_map (numpy.ndarray): 当前帧光流追踪图和预测结果融合图
+ - **返回**
-```python
-def video_segment(self,
- video_path=None,
- use_gpu=False,
- save_dir='humanseg_lite_video_result'):
-```
+ * img_matting (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-1 (0为全透明,1为不透明)。
+ * cur_gray (numpy.ndarray): 当前帧输入网络图像的灰度图;
+ * optflow_map (numpy.ndarray): 当前帧光流追踪图和预测结果融合图
-预测API,用于视频人像分割。
-**参数**
+ ```python
+ def video_segment(self,
+ video_path=None,
+ use_gpu=False,
+ save_dir='humanseg_lite_video_result'):
+ ```
-* video\_path (str): 待分割视频路径。若为None,则从本地摄像头获取视频,并弹出窗口显示在线分割结果。
-* use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
-* save\_dir (str): 视频保存路径,仅在video\_path不为None时启用,保存离线视频处理结果。
+ - 预测API,用于视频人像分割。
+ - **参数**
-```python
-def save_inference_model(dirname='humanseg_lite_model',
- model_filename=None,
- params_filename=None,
- combined=True)
-```
+ * video\_path (str): 待分割视频路径。若为None,则从本地摄像头获取视频,并弹出窗口显示在线分割结果。
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
+ * save\_dir (str): 视频保存路径,仅在video\_path不为None时启用,保存离线视频处理结果。
-将模型保存到指定路径。
-**参数**
+ ```python
+ def save_inference_model(dirname='humanseg_lite_model',
+ model_filename=None,
+ params_filename=None,
+ combined=True)
+ ```
-* dirname: 存在模型的目录名称
-* model\_filename: 模型文件名称,默认为\_\_model\_\_
-* params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
-* combined: 是否将参数保存到统一的一个文件中
+ - 将模型保存到指定路径。
-## 代码示例
+ - **参数**
+ * dirname: 存在模型的目录名称
+ * model\_filename: 模型文件名称,默认为\_\_model\_\_
+ * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
+ * combined: 是否将参数保存到统一的一个文件中
-图片分割及视频分割代码示例:
-```python
-import cv2
-import paddlehub as hub
+## 四、服务部署
-human_seg = hub.Module(name='humanseg_lite')
-im = cv2.imread('/PATH/TO/IMAGE')
-#visualization=True可以用于查看超分图片效果,可设置为False提升运行速度。
-res = human_seg.segment(images=[im],visualization=True)
-print(res[0]['data'])
-human_seg.video_segment('/PATH/TO/VIDEO')
-human_seg.save_inference_model('/PATH/TO/SAVE/MODEL')
+- PaddleHub Serving可以部署一个人像分割的在线服务。
-```
-视频流预测代码示例:
-```python
-import cv2
-import numpy as np
-import paddlehub as hub
+- ### 第一步:启动PaddleHub Serving
-human_seg = hub.Module('humanseg_lite')
-cap_video = cv2.VideoCapture('\PATH\TO\VIDEO')
-fps = cap_video.get(cv2.CAP_PROP_FPS)
-save_path = 'humanseg_lite_video.avi'
-width = int(cap_video.get(cv2.CAP_PROP_FRAME_WIDTH))
-height = int(cap_video.get(cv2.CAP_PROP_FRAME_HEIGHT))
-cap_out = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps, (width, height))
-prev_gray = None
-prev_cfd = None
-while cap_video.isOpened():
- ret, frame_org = cap_video.read()
- if ret:
- [img_matting, prev_gray, prev_cfd] = human_seg.video_stream_segment(frame_org=frame_org, frame_id=cap_video.get(1), prev_gray=prev_gray, prev_cfd=prev_cfd)
- img_matting = np.repeat(img_matting[:, :, np.newaxis], 3, axis=2)
- bg_im = np.ones_like(img_matting) * 255
- comb = (img_matting * frame_org + (1 - img_matting) * bg_im).astype(np.uint8)
- cap_out.write(comb)
- else:
- break
+ - 运行启动命令:
-cap_video.release()
-cap_out.release()
+ ```shell
+ $ hub serving start -m humanseg_lite
+ ```
-```
-## 服务部署
+ - 这样就完成了一个人像分割的服务化API的部署,默认端口号为8866。
-PaddleHub Serving可以部署一个人像分割的在线服务。
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-## 第一步:启动PaddleHub Serving
+- ### 第二步:发送预测请求
-运行启动命令:
-```shell
-$ hub serving start -m humanseg_lite
-```
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-这样就完成了一个人像分割的服务化API的部署,默认端口号为8866。
+ ```python
+ import requests
+ import json
+ import base64
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+ import cv2
+ import numpy as np
-## 第二步:发送预测请求
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/IMAGE')
+ data = {'images':[cv2_to_base64(org_im)]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/humanseg_lite"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
-```python
-import requests
-import json
-import base64
-
-import cv2
-import numpy as np
+ # 保存图片
+ mask =cv2.cvtColor(base64_to_cv2(r.json()["results"][0]['data']), cv2.COLOR_BGR2GRAY)
+ rgba = np.concatenate((org_im, np.expand_dims(mask, axis=2)), axis=2)
+ cv2.imwrite("segment_human_lite.png", rgba)
+ ```
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-def base64_to_cv2(b64str):
- data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
- data = cv2.imdecode(data, cv2.IMREAD_COLOR)
- return data
-
-# 发送HTTP请求
-org_im = cv2.imread('PATH/TO/IMAGE')
-data = {'images':[cv2_to_base64(org_im)]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/humanseg_lite"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-
-# 保存图片
-mask =cv2.cvtColor(base64_to_cv2(r.json()["results"][0]['data']), cv2.COLOR_BGR2GRAY)
-rgba = np.concatenate((org_im, np.expand_dims(mask, axis=2)), axis=2)
-cv2.imwrite("segment_human_lite.png", rgba)
-```
-### 查看代码
-
-https://github.com/PaddlePaddle/PaddleSeg/tree/develop/contrib/HumanSeg
-
-
-
-### 依赖
-
-paddlepaddle >= 1.8.0
-
-paddlehub >= 1.7.1
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+* 1.1.0
+
+ 新增视频人像分割接口
+
+ 新增视频流人像分割接口
+* 1.1.1
+
+ 修复cudnn为8.0.4显存泄露问题
diff --git a/modules/image/semantic_segmentation/humanseg_mobile/README.md b/modules/image/semantic_segmentation/humanseg_mobile/README.md
index ae767d34b528884afa904260d3417b8b598c75db..2e65c49b47a6c8751c4581bef5a7258e872cd078 100644
--- a/modules/image/semantic_segmentation/humanseg_mobile/README.md
+++ b/modules/image/semantic_segmentation/humanseg_mobile/README.md
@@ -1,208 +1,254 @@
-## 模型概述
+# humanseg_mobile
+
+|模型名称|humanseg_mobile|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|hrnet|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|否|
+|模型大小|5.8MB|
+|指标|-|
+|最新更新日期|2021-02-26|
+
-HumanSeg-mobile是基于HRNet(Deep High-Resolution Representation Learning for Visual Recognition)的人像分割网络。HRNet在特征提取过程中保持了高分辨率的信息,保持了物体的细节信息,并可通过控制每个分支的通道数调整模型的大小。HumanSeg-mobile采用了HRNet_w18_small_v1的网络结构,模型大小只有5.8M, 适用于移动端或服务端CPU的前置摄像头场景。
-## 命令行预测
+## 一、模型基本信息
-```
-hub run humanseg_mobile --input_path "/PATH/TO/IMAGE"
+- ### 应用效果展示
-```
+
+ - 样例结果示例:
+
+  +
+
+
+- ### 模型介绍
-## API
+ - HumanSeg-mobile采用了HRNet_w18_small_v1的网络结构,模型大小只有5.8M, 适用于移动端或服务端CPU的前置摄像头场景。
-```python
-def segment(images=None,
- paths=None,
- batch_size=1,
- use_gpu=False,
- visualization=False,
- output_dir='humanseg_mobile_output')
-```
+ - 更多详情请参考:[humanseg_mobile](https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.2/contrib/HumanSeg)
-预测API,用于人像分割。
+## 二、安装
-**参数**
+- ### 1、环境依赖
-* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
-* paths (list\[str\]): 图片的路径;
-* batch\_size (int): batch 的大小;
-* use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
-* visualization (bool): 是否将识别结果保存为图片文件;
-* output\_dir (str): 图片的保存路径。
+ - paddlepaddle >= 2.0.0
-**返回**
+ - paddlehub >= 2.0.0
-* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
- * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
- * data (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-255 (0为全透明,255为不透明),也即取值越大的像素点越可能为人体,取值越小的像素点越可能为背景。
+- ### 2、安装
+
+ - ```shell
+ $ hub install humanseg_mobile
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+## 三、模型API预测
-```python
-def video_stream_segment(self,
- frame_org,
- frame_id,
- prev_gray,
- prev_cfd,
- use_gpu=False):
-```
+- ### 1、命令行预测
-预测API,用于逐帧对视频人像分割。
+ ```
+ hub run humanseg_mobile --input_path "/PATH/TO/IMAGE"
+ ```
+- ### 2、代码示例
-**参数**
+ - 图片分割及视频分割代码示例:
-* frame_org (numpy.ndarray): 单帧图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
-* frame_id (int): 当前帧的编号;
-* prev_gray (numpy.ndarray): 前一帧输入网络图像的灰度图;
-* prev_cfd (numpy.ndarray): 前一帧光流追踪图和预测结果融合图
-* use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
+ ```python
+ import cv2
+ import paddlehub as hub
+ human_seg = hub.Module(name='humanseg_mobile')
+ im = cv2.imread('/PATH/TO/IMAGE')
+ #visualization=True可以用于查看人像分割图片效果,可设置为False提升运行速度。
+ res = human_seg.segment(images=[im],visualization=True)
+ print(res[0]['data'])
+ human_seg.video_segment('/PATH/TO/VIDEO')
+ human_seg.save_inference_model('/PATH/TO/SAVE/MODEL')
-**返回**
+ ```
+ - 视频流预测代码示例:
-* img_matting (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-1 (0为全透明,1为不透明)。
-* cur_gray (numpy.ndarray): 当前帧输入网络图像的灰度图;
-* optflow_map (numpy.ndarray): 当前帧光流追踪图和预测结果融合图
+ ```python
+ import cv2
+ import numpy as np
+ import paddlehub as hub
+ human_seg = hub.Module('humanseg_mobile')
+ cap_video = cv2.VideoCapture('\PATH\TO\VIDEO')
+ fps = cap_video.get(cv2.CAP_PROP_FPS)
+ save_path = 'humanseg_mobile_video.avi'
+ width = int(cap_video.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height = int(cap_video.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ cap_out = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps, (width, height))
+ prev_gray = None
+ prev_cfd = None
+ while cap_video.isOpened():
+ ret, frame_org = cap_video.read()
+ if ret:
+ [img_matting, prev_gray, prev_cfd] = human_seg.video_stream_segment(frame_org=frame_org, frame_id=cap_video.get(1), prev_gray=prev_gray, prev_cfd=prev_cfd)
+ img_matting = np.repeat(img_matting[:, :, np.newaxis], 3, axis=2)
+ bg_im = np.ones_like(img_matting) * 255
+ comb = (img_matting * frame_org + (1 - img_matting) * bg_im).astype(np.uint8)
+ cap_out.write(comb)
+ else:
+ break
-```python
-def video_segment(self,
- video_path=None,
- use_gpu=False,
- save_dir='humanseg_mobile_video_result'):
-```
+ cap_video.release()
+ cap_out.release()
-预测API,用于视频人像分割。
+ ```
-**参数**
+- ### 3、API
-* video\_path (str): 待分割视频路径。若为None,则从本地摄像头获取视频,并弹出窗口显示在线分割结果。
-* use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
-* save\_dir (str): 视频保存路径,仅在video\_path不为None时启用,保存离线视频处理结果。
+ ```python
+ def segment(images=None,
+ paths=None,
+ batch_size=1,
+ use_gpu=False,
+ visualization=False,
+ output_dir='humanseg_mobile_output')
+ ```
+ - 预测API,用于人像分割。
-```python
-def save_inference_model(dirname='humanseg_mobile_model',
- model_filename=None,
- params_filename=None,
- combined=True)
-```
+ - **参数**
-将模型保存到指定路径。
+ * images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * paths (list\[str\]): 图片的路径;
+ * batch\_size (int): batch 的大小;
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
+ * visualization (bool): 是否将识别结果保存为图片文件;
+ * output\_dir (str): 图片的保存路径。
-**参数**
+ - **返回**
-* dirname: 存在模型的目录名称
-* model\_filename: 模型文件名称,默认为\_\_model\_\_
-* params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
-* combined: 是否将参数保存到统一的一个文件中
+ * res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
+ * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
+ * data (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-255 (0为全透明,255为不透明),也即取值越大的像素点越可能为人体,取值越小的像素点越可能为背景。
-## 代码示例
-图片分割及视频分割代码示例:
+ ```python
+ def video_stream_segment(self,
+ frame_org,
+ frame_id,
+ prev_gray,
+ prev_cfd,
+ use_gpu=False):
+ ```
-```python
-import cv2
-import paddlehub as hub
+ - 预测API,用于逐帧对视频人像分割。
-human_seg = hub.Module(name='humanseg_mobile')
-im = cv2.imread('/PATH/TO/IMAGE')
-#visualization=True可以用于查看超分图片效果,可设置为False提升运行速度。
-res = human_seg.segment(images=[im],visualization=True)
-print(res[0]['data'])
-human_seg.video_segment('/PATH/TO/VIDEO')
-human_seg.save_inference_model('/PATH/TO/SAVE/MODEL')
+ - **参数**
-```
-视频流预测代码示例:
+ * frame_org (numpy.ndarray): 单帧图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * frame_id (int): 当前帧的编号;
+ * prev_gray (numpy.ndarray): 前一帧输入网络图像的灰度图;
+ * prev_cfd (numpy.ndarray): 前一帧光流追踪图和预测结果融合图
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
-```python
-import cv2
-import numpy as np
-import paddlehub as hub
-human_seg = hub.Module('humanseg_mobile')
-cap_video = cv2.VideoCapture('\PATH\TO\VIDEO')
-fps = cap_video.get(cv2.CAP_PROP_FPS)
-save_path = 'humanseg_mobile_video.avi'
-width = int(cap_video.get(cv2.CAP_PROP_FRAME_WIDTH))
-height = int(cap_video.get(cv2.CAP_PROP_FRAME_HEIGHT))
-cap_out = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps, (width, height))
-prev_gray = None
-prev_cfd = None
-while cap_video.isOpened():
- ret, frame_org = cap_video.read()
- if ret:
- [img_matting, prev_gray, prev_cfd] = human_seg.video_stream_segment(frame_org=frame_org, frame_id=cap_video.get(1), prev_gray=prev_gray, prev_cfd=prev_cfd)
- img_matting = np.repeat(img_matting[:, :, np.newaxis], 3, axis=2)
- bg_im = np.ones_like(img_matting) * 255
- comb = (img_matting * frame_org + (1 - img_matting) * bg_im).astype(np.uint8)
- cap_out.write(comb)
- else:
- break
+ - **返回**
-cap_video.release()
-cap_out.release()
+ * img_matting (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-1 (0为全透明,1为不透明)。
+ * cur_gray (numpy.ndarray): 当前帧输入网络图像的灰度图;
+ * optflow_map (numpy.ndarray): 当前帧光流追踪图和预测结果融合图
-```
-## 服务部署
+ ```python
+ def video_segment(self,
+ video_path=None,
+ use_gpu=False,
+ save_dir='humanseg_mobile_video_result'):
+ ```
-PaddleHub Serving可以部署一个人像分割的在线服务。
+ - 预测API,用于视频人像分割。
-## 第一步:启动PaddleHub Serving
+ - **参数**
-运行启动命令:
+ * video\_path (str): 待分割视频路径。若为None,则从本地摄像头获取视频,并弹出窗口显示在线分割结果。
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
+ * save\_dir (str): 视频保存路径,仅在video\_path不为None时启用,保存离线视频处理结果。
-```shell
-$ hub serving start -m humanseg_mobile
-```
-这样就完成了一个人像分割的服务化API的部署,默认端口号为8866。
+ ```python
+ def save_inference_model(dirname='humanseg_mobile_model',
+ model_filename=None,
+ params_filename=None,
+ combined=True)
+ ```
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - 将模型保存到指定路径。
-## 第二步:发送预测请求
+ - **参数**
+ * dirname: 存在模型的目录名称
+ * model\_filename: 模型文件名称,默认为\_\_model\_\_
+ * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
+ * combined: 是否将参数保存到统一的一个文件中
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+## 四、服务部署
-```python
-import requests
-import json
-import base64
+- PaddleHub Serving可以部署一个人像分割的在线服务。
-import cv2
-import numpy as np
+- ### 第一步:启动PaddleHub Serving
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-def base64_to_cv2(b64str):
- data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
- data = cv2.imdecode(data, cv2.IMREAD_COLOR)
- return data
+ - 运行启动命令:
-# 发送HTTP请求
-org_im = cv2.imread('/PATH/TO/IMAGE')
-data = {'images':[cv2_to_base64(org_im)]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/humanseg_mobile"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ ```shell
+ $ hub serving start -m humanseg_mobile
+ ```
-# 保存图片
-mask =cv2.cvtColor(base64_to_cv2(r.json()["results"][0]['data']), cv2.COLOR_BGR2GRAY)
-rgba = np.concatenate((org_im, np.expand_dims(mask, axis=2)), axis=2)
-cv2.imwrite("segment_human_mobile.png", rgba)
-```
+ - 这样就完成了一个人像分割的服务化API的部署,默认端口号为8866。
-### 查看代码
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-
+- ### 第二步:发送预测请求
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-### 依赖
+ ```python
+ import requests
+ import json
+ import base64
-paddlepaddle >= 1.8.0
+ import cv2
+ import numpy as np
-paddlehub >= 1.7.1
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/IMAGE')
+ data = {'images':[cv2_to_base64(org_im)]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/humanseg_mobile"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 保存图片
+ mask =cv2.cvtColor(base64_to_cv2(r.json()["results"][0]['data']), cv2.COLOR_BGR2GRAY)
+ rgba = np.concatenate((org_im, np.expand_dims(mask, axis=2)), axis=2)
+ cv2.imwrite("segment_human_mobile.png", rgba)
+ ```
+
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+* 1.1.0
+
+ 新增视频人像分割接口
+
+ 新增视频流人像分割接口
+* 1.1.1
+
+ 修复cudnn为8.0.4显存泄露问题
diff --git a/modules/image/semantic_segmentation/humanseg_server/README.md b/modules/image/semantic_segmentation/humanseg_server/README.md
index bf1b0a4c014a8be1e6e2e64572e7edbca65c1dd6..8845cb82cd109e6ddfb7b92f01f607333dada588 100644
--- a/modules/image/semantic_segmentation/humanseg_server/README.md
+++ b/modules/image/semantic_segmentation/humanseg_server/README.md
@@ -1,210 +1,253 @@
-## 模型概述
+# humanseg_server
+
+|模型名称|humanseg_server|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|hrnet|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|否|
+|模型大小|159MB|
+|指标|-|
+|最新更新日期|2021-02-26|
-高精度模型,适用于服务端GPU且背景复杂的人像场景, 模型结构为Deeplabv3+/Xcetion65, 模型大小为158M,网络结构如图:
-
-
-
-## 命令行预测
-```
-hub run humanseg_server --input_path "/PATH/TO/IMAGE"
-```
+## 一、模型基本信息
+- ### 应用效果展示
+
+ - 样例结果示例:
+
+  +
+
+- ### 模型介绍
-## API
+ - HumanSeg-server使用百度自建数据集进行训练,可用于人像分割,支持任意大小的图片输入。
-```python
-def segment(self,
- images=None,
- paths=None,
- batch_size=1,
- use_gpu=False,
- visualization=False,
- output_dir='humanseg_server_output'):
-```
+ - 更多详情请参考:[humanseg_server](https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.2/contrib/HumanSeg)
-预测API,用于人像分割。
+## 二、安装
-**参数**
+- ### 1、环境依赖
-* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
-* paths (list\[str\]): 图片的路径;
-* batch\_size (int): batch 的大小;
-* use\_gpu (bool): 是否使用 GPU;
-* visualization (bool): 是否将识别结果保存为图片文件;
-* output\_dir (str): 图片的保存路径。
+ - paddlepaddle >=2.0.0
-**返回**
-
-* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
- * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
- * data (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-255 (0为全透明,255为不透明),也即取值越大的像素点越可能为人体,取值越小的像素点越可能为背景。
-
-```python
-def video_stream_segment(self,
- frame_org,
- frame_id,
- prev_gray,
- prev_cfd,
- use_gpu=False):
-```
+ - paddlehub >= 2.0.0
-预测API,用于逐帧对视频人像分割。
+- ### 2、安装
-**参数**
+ - ```shell
+ $ hub install humanseg_server
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-* frame_org (numpy.ndarray): 单帧图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
-* frame_id (int): 当前帧的编号;
-* prev_gray (numpy.ndarray): 前一帧输入网络图像的灰度图;
-* prev_cfd (numpy.ndarray): 前一帧光流追踪图和预测结果融合图;
-* use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+## 三、模型API预测
+- ### 1、命令行预测
-**返回**
+ ```
+ hub run humanseg_server --input_path "/PATH/TO/IMAGE"
+ ```
+- ### 2、代码示例
-* img_matting (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-1 (0为全透明,1为不透明);
-* cur_gray (numpy.ndarray): 当前帧输入分割网络图像的灰度图;
-* optflow_map (numpy.ndarray): 当前帧光流追踪图和预测结果融合图。
+ - 图片分割及视频分割代码示例:
+ ```python
+ import cv2
+ import paddlehub as hub
-```python
-def video_segment(self,
- video_path=None,
- use_gpu=False,
- save_dir='humanseg_server_video'):
-```
+ human_seg = hub.Module(name='humanseg_server')
+ im = cv2.imread('/PATH/TO/IMAGE')
+ #visualization=True可以用于查看人像分割图片效果,可设置为False提升运行速度。
+ res = human_seg.segment(images=[im],visualization=True)
+ print(res[0]['data'])
+ human_seg.video_segment('/PATH/TO/VIDEO')
+ human_seg.save_inference_model('/PATH/TO/SAVE/MODEL')
-预测API,用于视频人像分割。
+ ```
+ - 视频流预测代码示例:
-**参数**
+ ```python
+ import cv2
+ import numpy as np
+ import paddlehub as hub
-* video\_path (str): 待分割视频路径。若为None,则从本地摄像头获取视频,并弹出窗口显示在线分割结果;
-* use\_gpu (bool): 是否使用GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
-* save\_dir (str): 视频保存路径,仅在video\_path不为None时启用,保存离线视频处理结果。
+ human_seg = hub.Module('humanseg_server')
+ cap_video = cv2.VideoCapture('\PATH\TO\VIDEO')
+ fps = cap_video.get(cv2.CAP_PROP_FPS)
+ save_path = 'humanseg_server_video.avi'
+ width = int(cap_video.get(cv2.CAP_PROP_FRAME_WIDTH))
+ height = int(cap_video.get(cv2.CAP_PROP_FRAME_HEIGHT))
+ cap_out = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps, (width, height))
+ prev_gray = None
+ prev_cfd = None
+ while cap_video.isOpened():
+ ret, frame_org = cap_video.read()
+ if ret:
+ [img_matting, prev_gray, prev_cfd] = human_seg.video_stream_segment(frame_org=frame_org, frame_id=cap_video.get(1), prev_gray=prev_gray, prev_cfd=prev_cfd)
+ img_matting = np.repeat(img_matting[:, :, np.newaxis], 3, axis=2)
+ bg_im = np.ones_like(img_matting) * 255
+ comb = (img_matting * frame_org + (1 - img_matting) * bg_im).astype(np.uint8)
+ cap_out.write(comb)
+ else:
+ break
+ cap_video.release()
+ cap_out.release()
-```python
-def save_inference_model(dirname,
- model_filename=None,
- params_filename=None,
- combined=True):
-```
+ ```
-将模型保存到指定路径。
+- ### 3、API
-**参数**
+ ```python
+ def segment(images=None,
+ paths=None,
+ batch_size=1,
+ use_gpu=False,
+ visualization=False,
+ output_dir='humanseg_server_output')
+ ```
-* dirname: 存在模型的目录名称
-* model\_filename: 模型文件名称,默认为\_\_model\_\_
-* params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
-* combined: 是否将参数保存到统一的一个文件中
+ - 预测API,用于人像分割。
-## 代码示例
+ - **参数**
-图片分割及视频分割代码示例:
-```python
-import cv2
-import paddlehub as hub
+ * images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * paths (list\[str\]): 图片的路径;
+ * batch\_size (int): batch 的大小;
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
+ * visualization (bool): 是否将识别结果保存为图片文件;
+ * output\_dir (str): 图片的保存路径。
-human_seg = hub.Module(name='humanseg_server')
-im = cv2.imread('/PATH/TO/IMAGE')
-#visualization=True可以用于查看超分图片效果,可设置为False提升运行速度。
-res = human_seg.segment(images=[im],visualization=True)
-print(res[0]['data'])
-human_seg.video_segment('/PATH/TO/VIDEO')
-human_seg.save_inference_model('/PATH/TO/SAVE/MODEL')
+ - **返回**
-```
-视频流预测代码示例:
-```python
-import cv2
-import numpy as np
-import paddlehub as hub
+ * res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,关键字有 'save\_path', 'data',对应的取值为:
+ * save\_path (str, optional): 可视化图片的保存路径(仅当visualization=True时存在);
+ * data (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-255 (0为全透明,255为不透明),也即取值越大的像素点越可能为人体,取值越小的像素点越可能为背景。
-human_seg = hub.Module('humanseg_server')
-cap_video = cv2.VideoCapture('\PATH\TO\VIDEO')
-fps = cap_video.get(cv2.CAP_PROP_FPS)
-save_path = 'humanseg_server_video.avi'
-width = int(cap_video.get(cv2.CAP_PROP_FRAME_WIDTH))
-height = int(cap_video.get(cv2.CAP_PROP_FRAME_HEIGHT))
-cap_out = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'), fps, (width, height))
-prev_gray = None
-prev_cfd = None
-while cap_video.isOpened():
- ret, frame_org = cap_video.read()
- if ret:
- [img_matting, prev_gray, prev_cfd] = human_seg.video_stream_segment(frame_org=frame_org, frame_id=cap_video.get(1), prev_gray=prev_gray, prev_cfd=prev_cfd)
- img_matting = np.repeat(img_matting[:, :, np.newaxis], 3, axis=2)
- bg_im = np.ones_like(img_matting) * 255
- comb = (img_matting * frame_org + (1 - img_matting) * bg_im).astype(np.uint8)
- cap_out.write(comb)
- else:
- break
-cap_video.release()
-cap_out.release()
+ ```python
+ def video_stream_segment(self,
+ frame_org,
+ frame_id,
+ prev_gray,
+ prev_cfd,
+ use_gpu=False):
+ ```
-```
+ - 预测API,用于逐帧对视频人像分割。
-## 服务部署
+ - **参数**
-PaddleHub Serving可以部署一个人像分割的在线服务。
+ * frame_org (numpy.ndarray): 单帧图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * frame_id (int): 当前帧的编号;
+ * prev_gray (numpy.ndarray): 前一帧输入网络图像的灰度图;
+ * prev_cfd (numpy.ndarray): 前一帧光流追踪图和预测结果融合图
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
-## 第一步:启动PaddleHub Serving
-运行启动命令:
-```shell
-$ hub serving start -m humanseg_server
-```
+ - **返回**
-这样就完成了一个人像分割的服务化API的部署,默认端口号为8866。
+ * img_matting (numpy.ndarray): 人像分割结果,仅包含Alpha通道,取值为0-1 (0为全透明,1为不透明)。
+ * cur_gray (numpy.ndarray): 当前帧输入网络图像的灰度图;
+ * optflow_map (numpy.ndarray): 当前帧光流追踪图和预测结果融合图
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
-## 第二步:发送预测请求
+ ```python
+ def video_segment(self,
+ video_path=None,
+ use_gpu=False,
+ save_dir='humanseg_server_video_result'):
+ ```
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - 预测API,用于视频人像分割。
-```python
-import requests
-import json
-import base64
+ - **参数**
-import cv2
-import numpy as np
+ * video\_path (str): 待分割视频路径。若为None,则从本地摄像头获取视频,并弹出窗口显示在线分割结果。
+ * use\_gpu (bool): 是否使用 GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置;
+ * save\_dir (str): 视频保存路径,仅在video\_path不为None时启用,保存离线视频处理结果。
-def cv2_to_base64(image):
- data = cv2.imencode('.jpg', image)[1]
- return base64.b64encode(data.tostring()).decode('utf8')
-def base64_to_cv2(b64str):
- data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
- data = cv2.imdecode(data, cv2.IMREAD_COLOR)
- return data
-# 发送HTTP请求
-org_im = cv2.imread('PATH/TO/IMAGE')
-data = {'images':[cv2_to_base64(org_im)]}
-headers = {"Content-type": "application/json"}
-url = "http://127.0.0.1:8866/predict/humanseg_server"
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
-
-# 保存图片
-mask =cv2.cvtColor(base64_to_cv2(r.json()["results"][0]['data']), cv2.COLOR_BGR2GRAY)
-rgba = np.concatenate((org_im, np.expand_dims(mask, axis=2)), axis=2)
-cv2.imwrite("segment_human_server.png", rgba)
-```
+ ```python
+ def save_inference_model(dirname='humanseg_server_model',
+ model_filename=None,
+ params_filename=None,
+ combined=True)
+ ```
+ - 将模型保存到指定路径。
-### 查看代码
+ - **参数**
+ * dirname: 存在模型的目录名称
+ * model\_filename: 模型文件名称,默认为\_\_model\_\_
+ * params\_filename: 参数文件名称,默认为\_\_params\_\_(仅当`combined`为True时生效)
+ * combined: 是否将参数保存到统一的一个文件中
-https://github.com/PaddlePaddle/PaddleSeg/tree/develop/contrib/HumanSeg
+## 四、服务部署
+- PaddleHub Serving可以部署一个人像分割的在线服务。
-### 依赖
-
-paddlepaddle >= 1.8.0
+- ### 第一步:启动PaddleHub Serving
-paddlehub >= 1.7.1
+ - 运行启动命令:
+
+ ```shell
+ $ hub serving start -m humanseg_server
+ ```
+
+ - 这样就完成了一个人像分割的服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ ```python
+ import requests
+ import json
+ import base64
+
+ import cv2
+ import numpy as np
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/IMAGE')
+ data = {'images':[cv2_to_base64(org_im)]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/humanseg_server"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 保存图片
+ mask =cv2.cvtColor(base64_to_cv2(r.json()["results"][0]['data']), cv2.COLOR_BGR2GRAY)
+ rgba = np.concatenate((org_im, np.expand_dims(mask, axis=2)), axis=2)
+ cv2.imwrite("segment_human_server.png", rgba)
+ ```
+
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+* 1.1.0
+
+ 新增视频人像分割接口
+
+ 新增视频流人像分割接口
+* 1.1.1
+
+ 修复cudnn为8.0.4显存泄露问题
diff --git a/modules/thirdparty/image/semantic_segmentation/U2Net/README.md b/modules/thirdparty/image/semantic_segmentation/U2Net/README.md
index 0bd5cd94cfec98440c20d652ca4afe186d7ee72f..f67fb90c165c19daf2399b47e0f242efd2e558cf 100644
--- a/modules/thirdparty/image/semantic_segmentation/U2Net/README.md
+++ b/modules/thirdparty/image/semantic_segmentation/U2Net/README.md
@@ -1,56 +1,90 @@
-## 概述
-* 的网络结构如下图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net
-* 每个 stage 由新提出的 RSU模块(residual U-block) 组成. 例如,En_1 即为基于 RSU 构建的
+# U2Net
-
+|模型名称|U2Net|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|U^2Net|
+|数据集|-|
+|是否支持Fine-tuning|否|
+|模型大小|254MB|
+|指标|-|
+|最新更新日期|2021-02-26|
-## 效果展示
-
-
-
-## API
-```python
-def Segmentation(
- images=None,
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+
+ - 效果展示
+
+
+ 
 +
+
+
+- ### 模型介绍
+ * 的网络结构如下图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net,每个 stage 由新提出的 RSU模块(residual U-block) 组成. 例如,En_1 即为基于 RSU 构建的
+ * - 更多详情请参考:[U2Net](https://github.com/xuebinqin/U-2-Net)
+
+ 
+
+## 二、安装
+
+- ### 1、环境依赖
+ - paddlepaddle >= 2.0.0
+ - paddlehub >= 2.0.0
+
+- ### 2、安装
+ - ```shell
+ $ hub install U2Net
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## 三、模型API预测
+- ### 1、代码示例
+
+ ```python
+ import cv2
+ import paddlehub as hub
+
+ model = hub.Module(name='U2Net')
+
+ result = model.Segmentation(
+ images=[cv2.imread('/PATH/TO/IMAGE')],
paths=None,
batch_size=1,
input_size=320,
output_dir='output',
- visualization=False):
-```
-图像前景背景分割 API
-
-**参数**
-* images (list[np.ndarray]) : 输入图像数据列表(BGR)
-* paths (list[str]) : 输入图像路径列表
-* batch_size (int) : 数据批大小
-* input_size (int) : 输入图像大小
-* output_dir (str) : 可视化图像输出目录
-* visualization (bool) : 是否可视化
-
-**返回**
-* results (list[np.ndarray]): 输出图像数据列表
-
-**代码示例**
-```python
-import cv2
-import paddlehub as hub
-
-model = hub.Module(name='U2Net')
-
-result = model.Segmentation(
- images=[cv2.imread('/PATH/TO/IMAGE')],
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=True)
-```
-
-## 查看代码
-https://github.com/NathanUA/U-2-Net
-
-## 依赖
-paddlepaddle >= 2.0.0rc0
-paddlehub >= 2.0.0b1
+ visualization=True)
+ ```
+ - ### 2、API
+
+ ```python
+ def Segmentation(
+ images=None,
+ paths=None,
+ batch_size=1,
+ input_size=320,
+ output_dir='output',
+ visualization=False):
+ ```
+ - 图像前景背景分割 API
+
+ - **参数**
+ * images (list[np.ndarray]) : 输入图像数据列表(BGR)
+ * paths (list[str]) : 输入图像路径列表
+ * batch_size (int) : 数据批大小
+ * input_size (int) : 输入图像大小
+ * output_dir (str) : 可视化图像输出目录
+ * visualization (bool) : 是否可视化
+
+ - **返回**
+ * results (list[np.ndarray]): 输出图像数据列表
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
diff --git a/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md b/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md
index c0a9be7047ed9397870b4ffde8412c5bc06acdbd..8de2490455f4ceac16b5940d698022077f6f4c3f 100644
--- a/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md
+++ b/modules/thirdparty/image/semantic_segmentation/U2Netp/README.md
@@ -1,57 +1,101 @@
-## 概述
-* 的网络结构如下图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net
-* 每个 stage 由新提出的 RSU模块(residual U-block) 组成. 例如,En_1 即为基于 RSU 构建的
-* 是一个小型化的
-
-
-
-## 效果展示
-
-
-
-
-## API
-```python
-def Segmentation(
- images=None,
+# U2Netp
+
+|模型名称|U2Netp|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|U^2Net|
+|数据集|-|
+|是否支持Fine-tuning|否|
+|模型大小|6.7MB|
+|指标|-|
+|最新更新日期|2021-02-26|
+
+
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+
+ - 样例结果示例:
+
+
+
+
+
+- ### 模型介绍
+
+ * U2Netp的网络结构如下图,其类似于编码-解码(Encoder-Decoder)结构的 U-Net, 每个 stage 由新提出的 RSU模块(residual U-block) 组成. 例如,En_1 即为基于 RSU 构建的, 它是一个小型化的模型
+
+ 
+
+ * - 更多详情请参考:[U2Net](https://github.com/xuebinqin/U-2-Net)
+
+
+## 二、安装
+
+- ### 1、环境依赖
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、安装
+ - ```shell
+ $ hub install U2Netp
+ ```
+
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## 三、模型API预测
+- ### 1、代码示例
+
+ ```python
+ import cv2
+ import paddlehub as hub
+
+ model = hub.Module(name='U2Netp')
+
+ result = model.Segmentation(
+ images=[cv2.imread('/PATH/TO/IMAGE')],
paths=None,
batch_size=1,
input_size=320,
output_dir='output',
- visualization=False):
-```
-图像前景背景分割 API
-
-**参数**
-* images (list[np.ndarray]) : 输入图像数据列表(BGR)
-* paths (list[str]) : 输入图像路径列表
-* batch_size (int) : 数据批大小
-* input_size (int) : 输入图像大小
-* output_dir (str) : 可视化图像输出目录
-* visualization (bool) : 是否可视化
-
-**返回**
-* results (list[np.ndarray]): 输出图像数据列表
-
-**代码示例**
-```python
-import cv2
-import paddlehub as hub
-
-model = hub.Module(name='U2Netp')
-
-result = model.Segmentation(
- images=[cv2.imread('/PATH/TO/IMAGE')],
- paths=None,
- batch_size=1,
- input_size=320,
- output_dir='output',
- visualization=True)
-```
-
-## 查看代码
-https://github.com/NathanUA/U-2-Net
-
-## 依赖
-paddlepaddle >= 2.0.0rc0
-paddlehub >= 2.0.0b1
+ visualization=True)
+ ```
+ - ### 2、API
+
+ ```python
+ def Segmentation(
+ images=None,
+ paths=None,
+ batch_size=1,
+ input_size=320,
+ output_dir='output',
+ visualization=False):
+ ```
+ - 图像前景背景分割 API
+
+ - **参数**
+ * images (list[np.ndarray]) : 输入图像数据列表(BGR)
+ * paths (list[str]) : 输入图像路径列表
+ * batch_size (int) : 数据批大小
+ * input_size (int) : 输入图像大小
+ * output_dir (str) : 可视化图像输出目录
+ * visualization (bool) : 是否可视化
+
+ - **返回**
+ * results (list[np.ndarray]): 输出图像数据列表
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+
+
+
+
+
+
diff --git a/modules/thirdparty/video/Video_editing/SkyAR/README.md b/modules/thirdparty/video/Video_editing/SkyAR/README.md
index 197fa16e2af158dfcc61d7db4a30da1b75e8f192..47419f5478ff99f85251e7015c72776fab054390 100644
--- a/modules/thirdparty/video/Video_editing/SkyAR/README.md
+++ b/modules/thirdparty/video/Video_editing/SkyAR/README.md
@@ -1,109 +1,128 @@
-## 模型概述
-* SkyAR 是一种用于视频中天空置换与协调的视觉方法,该方法能够在风格可控的视频中自动生成逼真的天空背景。
-* 该算法是一种完全基于视觉的解决方案,它的好处就是可以处理非静态图像,同时不受拍摄设备的限制,也不需要用户交互,可以处理在线或离线视频。
-* 算法主要由三个核心组成:
- * 天空抠图网络(Sky Matting Network):就是一种 Matting 图像分隔,用于检测视频帧中天空区域的视频,可以精确地获得天空蒙版。
- * 运动估计(Motion Estimation):恢复天空运动的运动估计器,使生成的天空与摄像机的运动同步。
- * 图像融合(Image Blending):将用户指定的天空模板混合到视频帧中。除此之外,还用于重置和着色,使混合结果在其颜色和动态范围内更具视觉逼真感。
-* 整体框架图如下:
+# SkyAR
- 
-* 参考论文:Zhengxia Zou. [Castle in the Sky: Dynamic Sky Replacement and Harmonization in Videos](https://arxiv.org/abs/2010.11800). CoRR, abs/2010.118003, 2020.
-* 官方开源项目: [jiupinjia/SkyAR](https://github.com/jiupinjia/SkyAR)
-## 模型安装
-```shell
-$hub install SkyAR
-```
+|模型名称|SkyAR|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|UNet|
+|数据集|UNet|
+|是否支持Fine-tuning|否|
+|模型大小|206MB|
+|指标|-|
+|最新更新日期|2021-02-26|
-## 效果展示
-* 原始视频:
+## 一、模型基本信息
- 
+- ### 应用效果展示
+
+ - 样例结果示例:
+ * 原始视频:
-* 木星:
+ 
- 
-* 雨天:
+ * 木星:
- 
-* 银河:
+ 
+ * 雨天:
- 
-* 第九区飞船:
+ 
+ * 银河:
- 
-* 原始视频:
+ 
+ * 第九区飞船:
- 
-* 漂浮城堡:
+ 
+ * 原始视频:
- 
-* 电闪雷鸣:
+ 
+ * 漂浮城堡:
- 
-* 超级月亮:
+ 
+ * 电闪雷鸣:
- 
+ 
+ * 超级月亮:
-## API 说明
+ 
-```python
-def MagicSky(
- video_path, save_path, config='jupiter',
- is_rainy=False, preview_frames_num=0, is_video_sky=False, is_show=False,
- skybox_img=None, skybox_video=None, rain_cap_path=None,
- halo_effect=True, auto_light_matching=False,
- relighting_factor=0.8, recoloring_factor=0.5, skybox_center_crop=0.5
- )
-```
+- ### 模型介绍
+
+ - SkyAR是一种用于视频中天空置换与协调的视觉方法,主要由三个核心组成:天空抠图网络、运动估计和图像融合。
+
+ - 更多详情请参考:[SkyAR](https://github.com/jiupinjia/SkyAR)
-深度估计API
+ - 参考论文:Zhengxia Zou. [Castle in the Sky: Dynamic Sky Replacement and Harmonization in Videos](https://arxiv.org/abs/2010.11800). CoRR, abs/2010.118003, 2020.
-**参数**
+## 二、安装
-* video_path(str):输入视频路径
-* save_path(str):视频保存路径
-* config(str): 预设 SkyBox 配置,所有预设配置如下,如果使用自定义 SkyBox,请设置为 None:
-```
-[
- 'cloudy', 'district9ship', 'floatingcastle', 'galaxy', 'jupiter',
- 'rainy', 'sunny', 'sunset', 'supermoon', 'thunderstorm'
-]
-```
-* skybox_img(str):自定义的 SkyBox 图像路径
-* skybox_video(str):自定义的 SkyBox 视频路径
-* is_video_sky(bool):自定义 SkyBox 是否为视频
-* rain_cap_path(str):自定义下雨效果视频路径
-* is_rainy(bool): 天空是否下雨
-* halo_effect(bool):是否开启 halo effect
-* auto_light_matching(bool):是否开启自动亮度匹配
-* relighting_factor(float): Relighting factor
-* recoloring_factor(float): Recoloring factor
-* skybox_center_crop(float):SkyBox center crop factor
-* preview_frames_num(int):设置预览帧数量,即只处理开头这几帧,设为 0,则为全部处理
-* is_show(bool):是否图形化预览
+- ### 1、环境依赖
-## 预测代码示例
+ - paddlepaddle >= 2.0.0
-```python
-import paddlehub as hub
+ - paddlehub >= 2.0.0
-model = hub.Module(name='SkyAR')
+- ### 2、安装
-model.MagicSky(
- video_path=[path to input video path],
- save_path=[path to save video path]
-)
-```
+ ```shell
+ $hub install SkyAR
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-## 模型相关信息
-### 模型代码
+## 三、模型API预测
-https://github.com/jm12138/SkyAR_Paddle_GUI
+- ### 1、代码示例
-### 依赖
+ ```python
+ import paddlehub as hub
-paddlepaddle >= 2.0.0rc0
+ model = hub.Module(name='SkyAR')
+
+ model.MagicSky(
+ video_path=[path to input video path],
+ save_path=[path to save video path]
+ )
+ ```
+- ### 2、API
+
+ ```python
+ def MagicSky(
+ video_path, save_path, config='jupiter',
+ is_rainy=False, preview_frames_num=0, is_video_sky=False, is_show=False,
+ skybox_img=None, skybox_video=None, rain_cap_path=None,
+ halo_effect=True, auto_light_matching=False,
+ relighting_factor=0.8, recoloring_factor=0.5, skybox_center_crop=0.5
+ )
+ ```
+
+ - **参数**
+
+ * video_path(str):输入视频路径
+ * save_path(str):视频保存路径
+ * config(str): 预设 SkyBox 配置,所有预设配置如下,如果使用自定义 SkyBox,请设置为 None:
+ ```
+ [
+ 'cloudy', 'district9ship', 'floatingcastle', 'galaxy', 'jupiter',
+ 'rainy', 'sunny', 'sunset', 'supermoon', 'thunderstorm'
+ ]
+ ```
+ * skybox_img(str):自定义的 SkyBox 图像路径
+ * skybox_video(str):自定义的 SkyBox 视频路径
+ * is_video_sky(bool):自定义 SkyBox 是否为视频
+ * rain_cap_path(str):自定义下雨效果视频路径
+ * is_rainy(bool): 天空是否下雨
+ * halo_effect(bool):是否开启 halo effect
+ * auto_light_matching(bool):是否开启自动亮度匹配
+ * relighting_factor(float): Relighting factor
+ * recoloring_factor(float): Recoloring factor
+ * skybox_center_crop(float):SkyBox center crop factor
+ * preview_frames_num(int):设置预览帧数量,即只处理开头这几帧,设为 0,则为全部处理
+ * is_show(bool):是否图形化预览
+
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布
-paddlehub >= 2.0.0rc0