From 98d598b7fe14ddca68f8107a66a1f8a3e4ce2bd8 Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Fri, 23 Sep 2022 17:42:16 +0800
Subject: [PATCH] Add LSeg Module (#2038)
* add LSeg
* add LSeg README
* add requirements.txt
* update README
* update module
* update
* update
* update
* update
* pre-commit
* update
* save jpg -> save png
* bgr -> bgra
* fix typo
* pre-commit
---
.../semantic_segmentation/lseg/README.md | 178 ++++++++++
.../lseg/models/__init__.py | 3 +
.../semantic_segmentation/lseg/models/clip.py | 45 +++
.../semantic_segmentation/lseg/models/lseg.py | 19 ++
.../lseg/models/scratch.py | 318 ++++++++++++++++++
.../semantic_segmentation/lseg/models/vit.py | 228 +++++++++++++
.../semantic_segmentation/lseg/module.py | 194 +++++++++++
.../lseg/requirements.txt | 4 +
.../image/semantic_segmentation/lseg/test.py | 67 ++++
9 files changed, 1056 insertions(+)
create mode 100644 modules/image/semantic_segmentation/lseg/README.md
create mode 100644 modules/image/semantic_segmentation/lseg/models/__init__.py
create mode 100644 modules/image/semantic_segmentation/lseg/models/clip.py
create mode 100644 modules/image/semantic_segmentation/lseg/models/lseg.py
create mode 100644 modules/image/semantic_segmentation/lseg/models/scratch.py
create mode 100644 modules/image/semantic_segmentation/lseg/models/vit.py
create mode 100644 modules/image/semantic_segmentation/lseg/module.py
create mode 100644 modules/image/semantic_segmentation/lseg/requirements.txt
create mode 100644 modules/image/semantic_segmentation/lseg/test.py
diff --git a/modules/image/semantic_segmentation/lseg/README.md b/modules/image/semantic_segmentation/lseg/README.md
new file mode 100644
index 00000000..63a92931
--- /dev/null
+++ b/modules/image/semantic_segmentation/lseg/README.md
@@ -0,0 +1,178 @@
+# lseg
+
+|模型名称|lseg|
+| :--- | :---: |
+|类别|图像-图像分割|
+|网络|LSeg|
+|数据集|-|
+|是否支持Fine-tuning|否|
+|模型大小|1.63GB|
+|指标|-|
+|最新更新日期|2022-09-22|
+
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+
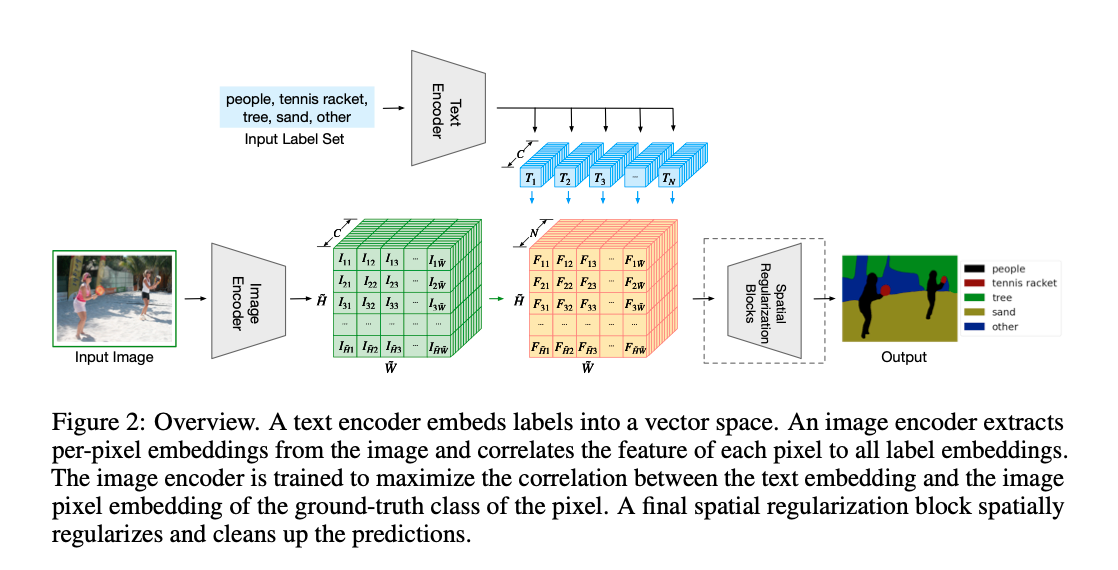
+ - 网络结构:
+
+ 
+
+
+ - 样例结果示例:
+
+ 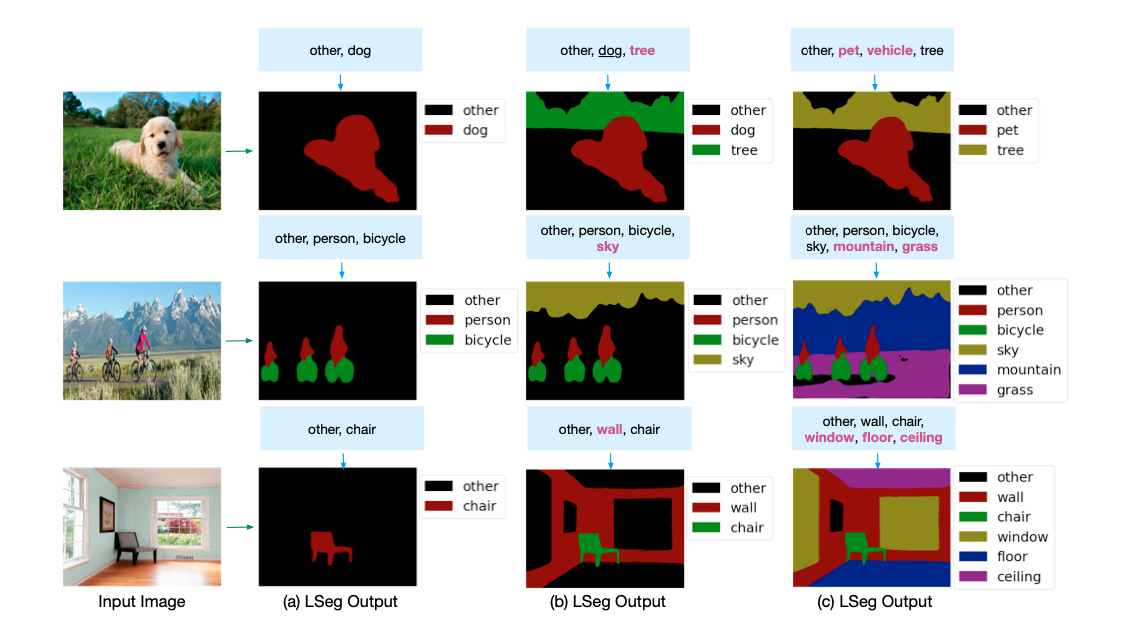 +
+
+
+- ### 模型介绍
+
+ - 文本驱动的图像语义分割模型(Language-driven Semantic Segmentation),即通过文本控制模型的分割类别实现指定类别的图像语义分割算法。
+
+
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2.安装
+
+ - ```shell
+ $ hub install lseg
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## 三、模型API预测
+ - ### 1、命令行预测
+
+ ```shell
+ $ hub run lseg \
+ --input_path "/PATH/TO/IMAGE" \
+ --labels "Category 1" "Category 2" "Category n" \
+ --output_dir "lseg_output"
+ ```
+
+ - ### 2、预测代码示例
+
+ ```python
+ import paddlehub as hub
+ import cv2
+
+ module = hub.Module(name="lseg")
+ result = module.segment(
+ image=cv2.imread('/PATH/TO/IMAGE'),
+ labels=["Category 1", "Category 2", "Category n"],
+ visualization=True,
+ output_dir='lseg_output'
+ )
+ ```
+
+ - ### 3、API
+
+ ```python
+ def segment(
+ image: Union[str, numpy.ndarray],
+ labels: Union[str, List[str]],
+ visualization: bool = False,
+ output_dir: str = 'lseg_output'
+ ) -> Dict[str, Union[numpy.ndarray, Dict[str, numpy.ndarray]]]
+ ```
+
+ - 语义分割 API
+
+ - **参数**
+
+ * image (Union\[str, numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * labels (Union\[str, List\[str\]\]): 类别文本标签;
+ * visualization (bool): 是否将识别结果保存为图片文件;
+ * output\_dir (str): 保存处理结果的文件目录。
+
+ - **返回**
+
+ * res (Dict\[str, Union\[numpy.ndarray, Dict\[str, numpy.ndarray\]\]\]): 识别结果的字典,字典中包含如下元素:
+ * gray (numpy.ndarray): 灰度分割结果 (GRAY);
+ * color (numpy.ndarray): 伪彩色图分割结果 (BGR);
+ * mix (numpy.ndarray): 叠加原图和伪彩色图的分割结果 (BGR);
+ * classes (Dict\[str, numpy.ndarray\]): 各个类别标签的分割抠图结果 (BGRA)。
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个语义驱动的语义分割的在线服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ ```shell
+ $ hub serving start -m lseg
+ ```
+
+ - 这样就完成了一个语义驱动的语义分割服务化API的部署,默认端口号为8866。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ ```python
+ import requests
+ import json
+ import base64
+
+ import cv2
+ import numpy as np
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tobytes()).decode('utf8')
+
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.frombuffer(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/IMAGE')
+ data = {
+ 'image': cv2_to_base64(org_im),
+ 'labels': ["Category 1", "Category 2", "Category n"]
+ }
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/lseg"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 结果转换
+ results = r.json()['results']
+ results = {
+ 'gray': base64_to_cv2(results['gray']),
+ 'color': base64_to_cv2(results['color']),
+ 'mix': base64_to_cv2(results['mix']),
+ 'classes': {
+ k: base64_to_cv2(v) for k, v in results['classes'].items()
+ }
+ }
+
+ # 保存输出
+ cv2.imwrite('mix.jpg', results['mix'])
+ ```
+
+## 五、参考资料
+
+* 论文:[Language-driven Semantic Segmentation](https://arxiv.org/abs/2201.03546)
+
+* 官方实现:[isl-org/lang-seg](https://github.com/isl-org/lang-seg)
+
+## 六、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install lseg==1.0.0
+ ```
diff --git a/modules/image/semantic_segmentation/lseg/models/__init__.py b/modules/image/semantic_segmentation/lseg/models/__init__.py
new file mode 100644
index 00000000..7718276c
--- /dev/null
+++ b/modules/image/semantic_segmentation/lseg/models/__init__.py
@@ -0,0 +1,3 @@
+from .lseg import LSeg
+
+__all__ = ['LSeg']
diff --git a/modules/image/semantic_segmentation/lseg/models/clip.py b/modules/image/semantic_segmentation/lseg/models/clip.py
new file mode 100644
index 00000000..791f3c4b
--- /dev/null
+++ b/modules/image/semantic_segmentation/lseg/models/clip.py
@@ -0,0 +1,45 @@
+import paddle
+import paddle.nn as nn
+from paddlenlp.transformers.clip.modeling import TextTransformer
+
+
+class CLIPText(nn.Layer):
+
+ def __init__(self,
+ max_text_length: int = 77,
+ vocab_size: int = 49408,
+ text_embed_dim: int = 512,
+ text_heads: int = 8,
+ text_layers: int = 12,
+ text_hidden_act: str = "quick_gelu",
+ projection_dim: int = 512):
+ super().__init__()
+
+ self.text_model = TextTransformer(context_length=max_text_length,
+ transformer_width=text_embed_dim,
+ transformer_heads=text_heads,
+ transformer_layers=text_layers,
+ vocab_size=vocab_size,
+ activation=text_hidden_act,
+ normalize_before=True)
+
+ self.text_projection = paddle.create_parameter((text_embed_dim, projection_dim), paddle.get_default_dtype())
+
+ def get_text_features(
+ self,
+ input_ids,
+ attention_mask=None,
+ position_ids=None,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=False,
+ ):
+ text_outputs = self.text_model(input_ids=input_ids,
+ position_ids=position_ids,
+ attention_mask=attention_mask,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict)
+ pooled_output = text_outputs[1]
+ text_features = paddle.matmul(pooled_output, self.text_projection)
+ return text_features
diff --git a/modules/image/semantic_segmentation/lseg/models/lseg.py b/modules/image/semantic_segmentation/lseg/models/lseg.py
new file mode 100644
index 00000000..f2ace02b
--- /dev/null
+++ b/modules/image/semantic_segmentation/lseg/models/lseg.py
@@ -0,0 +1,19 @@
+import paddle.nn as nn
+
+from .clip import CLIPText
+from .scratch import Scratch
+from .vit import ViT
+
+
+class LSeg(nn.Layer):
+
+ def __init__(self):
+ super().__init__()
+ self.clip = CLIPText()
+ self.vit = ViT()
+ self.scratch = Scratch()
+
+ def forward(self, images, texts):
+ layer_1, layer_2, layer_3, layer_4 = self.vit.forward(images)
+ text_features = self.clip.get_text_features(texts)
+ return self.scratch.forward(layer_1, layer_2, layer_3, layer_4, text_features)
diff --git a/modules/image/semantic_segmentation/lseg/models/scratch.py b/modules/image/semantic_segmentation/lseg/models/scratch.py
new file mode 100644
index 00000000..3e407461
--- /dev/null
+++ b/modules/image/semantic_segmentation/lseg/models/scratch.py
@@ -0,0 +1,318 @@
+import numpy as np
+import paddle
+import paddle.nn as nn
+
+
+class Interpolate(nn.Layer):
+ """Interpolation module."""
+
+ def __init__(self, scale_factor, mode, align_corners=False):
+ """Init.
+
+ Args:
+ scale_factor (float): scaling
+ mode (str): interpolation mode
+ """
+ super(Interpolate, self).__init__()
+
+ self.interp = nn.functional.interpolate
+ self.scale_factor = scale_factor
+ self.mode = mode
+ self.align_corners = align_corners
+
+ def forward(self, x):
+ """Forward pass.
+
+ Args:
+ x (tensor): input
+
+ Returns:
+ tensor: interpolated data
+ """
+
+ x = self.interp(
+ x,
+ scale_factor=self.scale_factor,
+ mode=self.mode,
+ align_corners=self.align_corners,
+ )
+
+ return x
+
+
+class ResidualConvUnit(nn.Layer):
+ """Residual convolution module."""
+
+ def __init__(self, features):
+ """Init.
+
+ Args:
+ features (int): number of features
+ """
+ super().__init__()
+
+ self.conv1 = nn.Conv2D(features, features, kernel_size=3, stride=1, padding=1)
+
+ self.conv2 = nn.Conv2D(features, features, kernel_size=3, stride=1, padding=1)
+
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ """Forward pass.
+
+ Args:
+ x (tensor): input
+
+ Returns:
+ tensor: output
+ """
+ out = self.relu(x)
+ out = self.conv1(out)
+ out = self.relu(out)
+ out = self.conv2(out)
+
+ return out + x
+
+
+class FeatureFusionBlock(nn.Layer):
+ """Feature fusion block."""
+
+ def __init__(self, features):
+ """Init.
+
+ Args:
+ features (int): number of features
+ """
+ super(FeatureFusionBlock, self).__init__()
+
+ self.resConfUnit1 = ResidualConvUnit(features)
+ self.resConfUnit2 = ResidualConvUnit(features)
+
+ def forward(self, *xs):
+ """Forward pass.
+
+ Returns:
+ tensor: output
+ """
+ output = xs[0]
+
+ if len(xs) == 2:
+ output += self.resConfUnit1(xs[1])
+
+ output = self.resConfUnit2(output)
+
+ output = nn.functional.interpolate(output, scale_factor=2, mode="bilinear", align_corners=True)
+
+ return output
+
+
+class ResidualConvUnit_custom(nn.Layer):
+ """Residual convolution module."""
+
+ def __init__(self, features, activation, bn):
+ """Init.
+
+ Args:
+ features (int): number of features
+ """
+ super().__init__()
+
+ self.bn = bn
+
+ self.groups = 1
+
+ self.conv1 = nn.Conv2D(
+ features,
+ features,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias_attr=not self.bn,
+ groups=self.groups,
+ )
+
+ self.conv2 = nn.Conv2D(
+ features,
+ features,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias_attr=not self.bn,
+ groups=self.groups,
+ )
+
+ if self.bn == True:
+ self.bn1 = nn.BatchNorm2D(features)
+ self.bn2 = nn.BatchNorm2D(features)
+
+ self.activation = activation
+
+ def forward(self, x):
+ """Forward pass.
+
+ Args:
+ x (tensor): input
+
+ Returns:
+ tensor: output
+ """
+
+ out = self.activation(x)
+ out = self.conv1(out)
+ if self.bn == True:
+ out = self.bn1(out)
+
+ out = self.activation(out)
+ out = self.conv2(out)
+ if self.bn == True:
+ out = self.bn2(out)
+
+ if self.groups > 1:
+ out = self.conv_merge(out)
+
+ return out + x
+
+
+class FeatureFusionBlock_custom(nn.Layer):
+ """Feature fusion block."""
+
+ def __init__(
+ self,
+ features,
+ activation=nn.ReLU(),
+ deconv=False,
+ bn=False,
+ expand=False,
+ align_corners=True,
+ ):
+ """Init.
+
+ Args:
+ features (int): number of features
+ """
+ super(FeatureFusionBlock_custom, self).__init__()
+
+ self.deconv = deconv
+ self.align_corners = align_corners
+
+ self.groups = 1
+
+ self.expand = expand
+ out_features = features
+ if self.expand == True:
+ out_features = features // 2
+
+ self.out_conv = nn.Conv2D(
+ features,
+ out_features,
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ bias_attr=True,
+ groups=1,
+ )
+
+ self.resConfUnit1 = ResidualConvUnit_custom(features, activation, bn)
+ self.resConfUnit2 = ResidualConvUnit_custom(features, activation, bn)
+
+ def forward(self, *xs):
+ """Forward pass.
+
+ Returns:
+ tensor: output
+ """
+ output = xs[0]
+
+ if len(xs) == 2:
+ res = self.resConfUnit1(xs[1])
+ output += res
+
+ output = self.resConfUnit2(output)
+
+ output = nn.functional.interpolate(output, scale_factor=2, mode="bilinear", align_corners=self.align_corners)
+
+ output = self.out_conv(output)
+
+ return output
+
+
+class Scratch(nn.Layer):
+
+ def __init__(self, in_channels=[256, 512, 1024, 1024], out_channels=256):
+ super().__init__()
+ self.out_c = 512
+ self.logit_scale = paddle.to_tensor(np.exp(np.log([1 / 0.07])))
+ self.layer1_rn = nn.Conv2D(
+ in_channels[0],
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias_attr=False,
+ groups=1,
+ )
+ self.layer2_rn = nn.Conv2D(
+ in_channels[1],
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias_attr=False,
+ groups=1,
+ )
+ self.layer3_rn = nn.Conv2D(
+ in_channels[2],
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias_attr=False,
+ groups=1,
+ )
+ self.layer4_rn = nn.Conv2D(
+ in_channels[3],
+ out_channels,
+ kernel_size=3,
+ stride=1,
+ padding=1,
+ bias_attr=False,
+ groups=1,
+ )
+
+ self.refinenet1 = FeatureFusionBlock_custom(out_channels, bn=True)
+ self.refinenet2 = FeatureFusionBlock_custom(out_channels, bn=True)
+ self.refinenet3 = FeatureFusionBlock_custom(out_channels, bn=True)
+ self.refinenet4 = FeatureFusionBlock_custom(out_channels, bn=True)
+
+ self.head1 = nn.Conv2D(out_channels, self.out_c, kernel_size=1)
+
+ self.output_conv = nn.Sequential(Interpolate(scale_factor=2, mode="bilinear", align_corners=True))
+
+ def forward(self, layer_1, layer_2, layer_3, layer_4, text_features):
+
+ layer_1_rn = self.layer1_rn(layer_1)
+ layer_2_rn = self.layer2_rn(layer_2)
+ layer_3_rn = self.layer3_rn(layer_3)
+ layer_4_rn = self.layer4_rn(layer_4)
+
+ path_4 = self.refinenet4(layer_4_rn)
+ path_3 = self.refinenet3(path_4, layer_3_rn)
+ path_2 = self.refinenet2(path_3, layer_2_rn)
+ path_1 = self.refinenet1(path_2, layer_1_rn)
+
+ image_features = self.head1(path_1)
+
+ imshape = image_features.shape
+ image_features = image_features.transpose((0, 2, 3, 1)).reshape((-1, self.out_c))
+
+ # normalized features
+ image_features = image_features / image_features.norm(axis=-1, keepdim=True)
+ text_features = text_features / text_features.norm(axis=-1, keepdim=True)
+
+ logits_per_image = self.logit_scale * image_features @ text_features.t()
+
+ out = logits_per_image.reshape((imshape[0], imshape[2], imshape[3], -1)).transpose((0, 3, 1, 2))
+
+ out = self.output_conv(out)
+
+ return out
diff --git a/modules/image/semantic_segmentation/lseg/models/vit.py b/modules/image/semantic_segmentation/lseg/models/vit.py
new file mode 100644
index 00000000..75c5d019
--- /dev/null
+++ b/modules/image/semantic_segmentation/lseg/models/vit.py
@@ -0,0 +1,228 @@
+import math
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+from paddleclas.ppcls.arch.backbone.model_zoo.vision_transformer import VisionTransformer
+
+
+class Slice(nn.Layer):
+
+ def __init__(self, start_index=1):
+ super(Slice, self).__init__()
+ self.start_index = start_index
+
+ def forward(self, x):
+ return x[:, self.start_index:]
+
+
+class AddReadout(nn.Layer):
+
+ def __init__(self, start_index=1):
+ super(AddReadout, self).__init__()
+ self.start_index = start_index
+
+ def forward(self, x):
+ if self.start_index == 2:
+ readout = (x[:, 0] + x[:, 1]) / 2
+ else:
+ readout = x[:, 0]
+ return x[:, self.start_index:] + readout.unsqueeze(1)
+
+
+class Transpose(nn.Layer):
+
+ def __init__(self, dim0, dim1):
+ super(Transpose, self).__init__()
+ self.dim0 = dim0
+ self.dim1 = dim1
+
+ def forward(self, x):
+ prems = list(range(x.dim()))
+ prems[self.dim0], prems[self.dim1] = prems[self.dim1], prems[self.dim0]
+ x = x.transpose(prems)
+ return x
+
+
+class Unflatten(nn.Layer):
+
+ def __init__(self, start_axis, shape):
+ super(Unflatten, self).__init__()
+ self.start_axis = start_axis
+ self.shape = shape
+
+ def forward(self, x):
+ return paddle.reshape(x, x.shape[:self.start_axis] + [self.shape])
+
+
+class ProjectReadout(nn.Layer):
+
+ def __init__(self, in_features, start_index=1):
+ super(ProjectReadout, self).__init__()
+ self.start_index = start_index
+
+ self.project = nn.Sequential(nn.Linear(2 * in_features, in_features), nn.GELU())
+
+ def forward(self, x):
+ readout = x[:, 0].unsqueeze(1).expand_as(x[:, self.start_index:])
+ features = paddle.concat((x[:, self.start_index:], readout), -1)
+
+ return self.project(features)
+
+
+class ViT(VisionTransformer):
+
+ def __init__(self,
+ img_size=384,
+ patch_size=16,
+ in_chans=3,
+ class_num=1000,
+ embed_dim=1024,
+ depth=24,
+ num_heads=16,
+ mlp_ratio=4,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0,
+ attn_drop_rate=0,
+ drop_path_rate=0,
+ norm_layer='nn.LayerNorm',
+ epsilon=1e-6,
+ **kwargs):
+ super().__init__(img_size, patch_size, in_chans, class_num, embed_dim, depth, num_heads, mlp_ratio, qkv_bias,
+ qk_scale, drop_rate, attn_drop_rate, drop_path_rate, norm_layer, epsilon, **kwargs)
+ self.patch_size = patch_size
+ self.start_index = 1
+ features = [256, 512, 1024, 1024]
+ readout_oper = [ProjectReadout(embed_dim, self.start_index) for out_feat in features]
+ self.act_postprocess1 = nn.Sequential(
+ readout_oper[0],
+ Transpose(1, 2),
+ Unflatten(2, [img_size // 16, img_size // 16]),
+ nn.Conv2D(
+ in_channels=embed_dim,
+ out_channels=features[0],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ nn.Conv2DTranspose(
+ in_channels=features[0],
+ out_channels=features[0],
+ kernel_size=4,
+ stride=4,
+ padding=0,
+ dilation=1,
+ groups=1,
+ ),
+ )
+
+ self.act_postprocess2 = nn.Sequential(
+ readout_oper[1],
+ Transpose(1, 2),
+ Unflatten(2, [img_size // 16, img_size // 16]),
+ nn.Conv2D(
+ in_channels=embed_dim,
+ out_channels=features[1],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ nn.Conv2DTranspose(
+ in_channels=features[1],
+ out_channels=features[1],
+ kernel_size=2,
+ stride=2,
+ padding=0,
+ dilation=1,
+ groups=1,
+ ),
+ )
+
+ self.act_postprocess3 = nn.Sequential(
+ readout_oper[2],
+ Transpose(1, 2),
+ Unflatten(2, [img_size // 16, img_size // 16]),
+ nn.Conv2D(
+ in_channels=embed_dim,
+ out_channels=features[2],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ )
+
+ self.act_postprocess4 = nn.Sequential(
+ readout_oper[3],
+ Transpose(1, 2),
+ Unflatten(2, [img_size // 16, img_size // 16]),
+ nn.Conv2D(
+ in_channels=embed_dim,
+ out_channels=features[3],
+ kernel_size=1,
+ stride=1,
+ padding=0,
+ ),
+ nn.Conv2D(
+ in_channels=features[3],
+ out_channels=features[3],
+ kernel_size=3,
+ stride=2,
+ padding=1,
+ ),
+ )
+
+ self.norm = nn.Identity()
+ self.head = nn.Identity()
+
+ def _resize_pos_embed(self, posemb, gs_h, gs_w):
+ posemb_tok, posemb_grid = (
+ posemb[:, :self.start_index],
+ posemb[0, self.start_index:],
+ )
+
+ gs_old = int(math.sqrt(len(posemb_grid)))
+
+ posemb_grid = posemb_grid.reshape((1, gs_old, gs_old, -1)).transpose((0, 3, 1, 2))
+ posemb_grid = F.interpolate(posemb_grid, size=(gs_h, gs_w), mode="bilinear")
+ posemb_grid = posemb_grid.transpose((0, 2, 3, 1)).reshape((1, gs_h * gs_w, -1))
+
+ posemb = paddle.concat([posemb_tok, posemb_grid], axis=1)
+
+ return posemb
+
+ def forward(self, x):
+ b, c, h, w = x.shape
+
+ pos_embed = self._resize_pos_embed(self.pos_embed, h // self.patch_size, w // self.patch_size)
+ x = self.patch_embed.proj(x).flatten(2).transpose((0, 2, 1))
+
+ cls_tokens = self.cls_token.expand((b, -1, -1))
+ x = paddle.concat((cls_tokens, x), axis=1)
+
+ x = x + pos_embed
+ x = self.pos_drop(x)
+
+ outputs = []
+ for index, blk in enumerate(self.blocks):
+ x = blk(x)
+ if index in [5, 11, 17, 23]:
+ outputs.append(x)
+
+ layer_1 = self.act_postprocess1[0:2](outputs[0])
+ layer_2 = self.act_postprocess2[0:2](outputs[1])
+ layer_3 = self.act_postprocess3[0:2](outputs[2])
+ layer_4 = self.act_postprocess4[0:2](outputs[3])
+
+ shape = (-1, 1024, h // self.patch_size, w // self.patch_size)
+ layer_1 = layer_1.reshape(shape)
+ layer_2 = layer_2.reshape(shape)
+ layer_3 = layer_3.reshape(shape)
+ layer_4 = layer_4.reshape(shape)
+
+ layer_1 = self.act_postprocess1[3:len(self.act_postprocess1)](layer_1)
+ layer_2 = self.act_postprocess2[3:len(self.act_postprocess2)](layer_2)
+ layer_3 = self.act_postprocess3[3:len(self.act_postprocess3)](layer_3)
+ layer_4 = self.act_postprocess4[3:len(self.act_postprocess4)](layer_4)
+
+ return layer_1, layer_2, layer_3, layer_4
diff --git a/modules/image/semantic_segmentation/lseg/module.py b/modules/image/semantic_segmentation/lseg/module.py
new file mode 100644
index 00000000..55ba891e
--- /dev/null
+++ b/modules/image/semantic_segmentation/lseg/module.py
@@ -0,0 +1,194 @@
+import argparse
+import base64
+import os
+import time
+from typing import Dict
+from typing import List
+from typing import Union
+
+import cv2
+import numpy as np
+import paddle
+import paddle.vision.transforms as transforms
+from paddlenlp.transformers.clip.tokenizer import CLIPTokenizer
+
+import paddlehub as hub
+from . import models
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tobytes()).decode('utf8')
+
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.frombuffer(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+
+@moduleinfo(
+ name='lseg',
+ version='1.0.0',
+ type="CV/semantic_segmentation",
+ author="",
+ author_email="",
+ summary="Language-driven Semantic Segmentation.",
+)
+class LSeg(models.LSeg):
+
+ def __init__(self):
+ super(LSeg, self).__init__()
+ self.default_pretrained_model_path = os.path.join(self.directory, 'ckpts', 'LSeg.pdparams')
+ state_dict = paddle.load(self.default_pretrained_model_path)
+ self.set_state_dict(state_dict)
+ self.eval()
+ self.transforms = transforms.Compose([
+ transforms.ToTensor(),
+ transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]),
+ ])
+ self.tokenizer = CLIPTokenizer.from_pretrained('openai/clip-vit-base-patch32')
+
+ self.language_recognition = hub.Module(name='baidu_language_recognition')
+ self.translate = hub.Module(name='baidu_translate')
+
+ @staticmethod
+ def get_colormap(n):
+ assert n <= 256, "num_class should be less than 256."
+
+ pallete = [0] * (256 * 3)
+
+ for j in range(0, n):
+ lab = j
+ pallete[j * 3 + 0] = 0
+ pallete[j * 3 + 1] = 0
+ pallete[j * 3 + 2] = 0
+ i = 0
+ while (lab > 0):
+ pallete[j * 3 + 0] |= (((lab >> 0) & 1) << (7 - i))
+ pallete[j * 3 + 1] |= (((lab >> 1) & 1) << (7 - i))
+ pallete[j * 3 + 2] |= (((lab >> 2) & 1) << (7 - i))
+ i = i + 1
+ lab >>= 3
+
+ return np.asarray(pallete, dtype=np.uint8).reshape(256, 1, 3)
+
+ def segment(self,
+ image: Union[str, np.ndarray],
+ labels: Union[str, List[str]],
+ visualization: bool = False,
+ output_dir: str = 'lseg_output') -> Dict[str, Union[np.ndarray, Dict[str, np.ndarray]]]:
+ if isinstance(image, str):
+ image = cv2.imread(image)
+ elif isinstance(image, np.ndarray):
+ image = image
+ else:
+ raise Exception("image should be a str / np.ndarray")
+
+ if isinstance(labels, str):
+ labels = [labels, 'other']
+ print('"other" category label is automatically added because the length of labels is equal to 1')
+ print('new labels: ', labels)
+ elif isinstance(labels, list):
+ if len(labels) == 1:
+ labels.append('other')
+ print('"other" category label is automatically added because the length of labels is equal to 1')
+ print('new labels: ', labels)
+ elif len(labels) == 0:
+ raise Exception("labels should not be empty.")
+ else:
+ raise Exception("labels should be a str or list.")
+
+ class_num = len(labels)
+
+ labels_ = list(set(labels))
+ labels_.sort(key=labels.index)
+ labels = labels_
+
+ input_labels = []
+ for label in labels:
+ from_lang = self.language_recognition.recognize(query=label)
+ if from_lang != 'en':
+ label = self.translate.translate(query=label, from_lang=from_lang, to_lang='en')
+ input_labels.append(label)
+
+ labels_dict = {k: v for k, v in zip(input_labels, labels)}
+
+ input_labels_ = list(set(input_labels))
+ input_labels_.sort(key=input_labels.index)
+ input_labels = input_labels_
+
+ labels = []
+ for input_label in input_labels:
+ labels.append(labels_dict[input_label])
+
+ if len(labels) < class_num:
+ print('remove the same labels...')
+ print('new labels: ', labels)
+
+ h, w = image.shape[:2]
+ image = image[:-(h % 32) if h % 32 else None, :-(w % 32) if w % 32 else None]
+ images = self.transforms(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)).unsqueeze(0)
+ texts = self.tokenizer(input_labels, padding=True, return_tensors="pd")['input_ids']
+
+ with paddle.no_grad():
+ results = self.forward(images, texts)
+ results = paddle.argmax(results, 1).cast(paddle.uint8)
+ gray_seg = results.numpy()[0]
+
+ colormap = self.get_colormap(len(labels))
+ color_seg = cv2.applyColorMap(gray_seg, colormap)
+ mix_seg = cv2.addWeighted(image, 0.5, color_seg, 0.5, 0.0)
+
+ classes_seg = {}
+ for i, label in enumerate(labels):
+ mask = ((gray_seg == i).astype('uint8') * 255)[..., None]
+ classes_seg[label] = np.concatenate([image, mask], 2)
+
+ if visualization:
+ save_dir = os.path.join(output_dir, str(int(time.time())))
+ if not os.path.isdir(save_dir):
+ os.makedirs(save_dir)
+ for label, dst in classes_seg.items():
+ cv2.imwrite(os.path.join(save_dir, '%s.png' % label), dst)
+
+ return {'gray': gray_seg, 'color': color_seg, 'mix': mix_seg, 'classes': classes_seg}
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.parser.add_argument('--input_path', type=str, help="path to image.")
+ self.parser.add_argument('--labels', type=str, nargs='+', help="segmentation labels.")
+ self.parser.add_argument('--output_dir',
+ type=str,
+ default='lseg_output',
+ help="The directory to save output images.")
+ args = self.parser.parse_args(argvs)
+ self.segment(image=args.input_path, labels=args.labels, visualization=True, output_dir=args.output_dir)
+ return 'segmentation results are saved in %s' % args.output_dir
+
+ @serving
+ def serving_method(self, image, **kwargs):
+ """
+ Run as a service.
+ """
+ image = base64_to_cv2(image)
+ results = self.segment(image=image, **kwargs)
+
+ return {
+ 'gray': cv2_to_base64(results['gray']),
+ 'color': cv2_to_base64(results['color']),
+ 'mix': cv2_to_base64(results['mix']),
+ 'classes': {k: cv2_to_base64(v)
+ for k, v in results['classes'].items()}
+ }
diff --git a/modules/image/semantic_segmentation/lseg/requirements.txt b/modules/image/semantic_segmentation/lseg/requirements.txt
new file mode 100644
index 00000000..1bd663bd
--- /dev/null
+++ b/modules/image/semantic_segmentation/lseg/requirements.txt
@@ -0,0 +1,4 @@
+paddleclas>=2.4.0
+paddlenlp>=2.4.0
+ftfy
+regex
diff --git a/modules/image/semantic_segmentation/lseg/test.py b/modules/image/semantic_segmentation/lseg/test.py
new file mode 100644
index 00000000..d6860e60
--- /dev/null
+++ b/modules/image/semantic_segmentation/lseg/test.py
@@ -0,0 +1,67 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import numpy as np
+import requests
+
+import paddlehub as hub
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/mJaD10XeD7w/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8M3x8Y2F0fGVufDB8fHx8MTY2MzczNDc3Mw&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ cls.module = hub.Module(name="lseg")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('lseg_output')
+
+ def test_segment1(self):
+ results = self.module.segment(image='tests/test.jpg', labels=['other', 'cat'], visualization=False)
+
+ self.assertIsInstance(results['mix'], np.ndarray)
+ self.assertIsInstance(results['color'], np.ndarray)
+ self.assertIsInstance(results['gray'], np.ndarray)
+ self.assertIsInstance(results['classes']['other'], np.ndarray)
+ self.assertIsInstance(results['classes']['cat'], np.ndarray)
+
+ def test_segment2(self):
+ results = self.module.segment(image=cv2.imread('tests/test.jpg'), labels=['other', 'cat'], visualization=True)
+
+ self.assertIsInstance(results['mix'], np.ndarray)
+ self.assertIsInstance(results['color'], np.ndarray)
+ self.assertIsInstance(results['gray'], np.ndarray)
+ self.assertIsInstance(results['classes']['other'], np.ndarray)
+ self.assertIsInstance(results['classes']['cat'], np.ndarray)
+
+ def test_segment3(self):
+ results = self.module.segment(image=cv2.imread('tests/test.jpg'), labels=['其他', '猫'], visualization=False)
+
+ self.assertIsInstance(results['mix'], np.ndarray)
+ self.assertIsInstance(results['color'], np.ndarray)
+ self.assertIsInstance(results['gray'], np.ndarray)
+ self.assertIsInstance(results['classes']['其他'], np.ndarray)
+ self.assertIsInstance(results['classes']['猫'], np.ndarray)
+
+ def test_segment4(self):
+ self.assertRaises(Exception, self.module.segment, image=['tests/test.jpg'], labels=['other', 'cat'])
+
+ def test_segment5(self):
+ self.assertRaises(AttributeError, self.module.segment, image='no.jpg', labels=['other', 'cat'])
+
+
+if __name__ == "__main__":
+ unittest.main()
--
GitLab