diff --git a/.travis.yml b/.travis.yml
index b9308b0258039a3d6b6c69183b0e37d3cfec48ff..fdb117ee50798740ff56d566ec8c66420759a8c4 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -21,8 +21,13 @@ env:
- PYTHONPATH=${PWD}
install:
- - pip install --upgrade paddlepaddle
- - pip install -r requirements.txt
+ - if [[ $TRAVIS_OS_NAME == osx ]]; then
+ pip3 install --upgrade paddlepaddle;
+ pip3 install -r requirements.txt;
+ else
+ pip install --upgrade paddlepaddle;
+ pip install -r requirements.txt;
+ fi
notifications:
email:
diff --git a/README.md b/README.md
index a5f6636c3a05912e91cdb21b207288ca7b57a6e6..9a8c178c7d4a6520392b700158e7b11da900741d 100644
--- a/README.md
+++ b/README.md
@@ -50,7 +50,7 @@ PaddleHub以预训练模型应用为核心具备以下特点:
### 安装命令
-PaddlePaddle框架的安装请查阅[飞桨快速安装](https://www.paddlepaddle.org.cn/install/quick)
+在安装PaddleHub之前,请先安装PaddlePaddle深度学习框架,更多安装说明请查阅[飞桨快速安装](https://www.paddlepaddle.org.cn/install/quick)
```shell
pip install paddlehub
@@ -66,6 +66,18 @@ PaddleHub采用模型即软件的设计理念,所有的预训练模型与Pytho
安装PaddleHub后,执行命令[hub run](./docs/tutorial/cmdintro.md),即可快速体验无需代码、一键预测的功能:
+* 使用[文字识别](https://www.paddlepaddle.org.cn/hublist?filter=en_category&value=TextRecognition)轻量级中文OCR模型chinese_ocr_db_crnn_mobile即可一键快速识别图片中的文字。
+```shell
+$ wget https://paddlehub.bj.bcebos.com/model/image/ocr/test_ocr.jpg
+$ hub run chinese_ocr_db_crnn_mobile --input_path test_ocr.jpg --visualization=True
+```
+
+预测结果图片保存在当前运行路径下ocr_result文件夹中,如下图所示。
+
+
+  +
* 使用[目标检测](https://www.paddlepaddle.org.cn/hublist?filter=en_category&value=ObjectDetection)模型pyramidbox_lite_mobile_mask对图片进行口罩检测
```shell
$ wget https://paddlehub.bj.bcebos.com/resources/test_mask_detection.jpg
@@ -192,5 +204,5 @@ $ hub uninstall ernie
## 更新历史
-PaddleHub v1.6 已发布!
+PaddleHub v1.7 已发布!
更多升级详情参考[更新历史](./RELEASE.md)
diff --git a/RELEASE.md b/RELEASE.md
index b2e177dfa2de3d09d5e85be59dcd2d1914c8368c..8c8a7a08e085d756f02f5cf9490128a550f27a51 100644
--- a/RELEASE.md
+++ b/RELEASE.md
@@ -1,3 +1,23 @@
+## `v1.7.0`
+
+* 丰富预训练模型,提升应用性
+ * 新增VENUS系列视觉预训练模型[yolov3_darknet53_venus](https://www.paddlepaddle.org.cn/hubdetail?name=yolov3_darknet53_venus&en_category=ObjectDetection),[faster_rcnn_resnet50_fpn_venus](https://www.paddlepaddle.org.cn/hubdetail?name=faster_rcnn_resnet50_fpn_venus&en_category=ObjectDetection),可大幅度提升图像分类和目标检测任务的Fine-tune效果
+ * 新增工业级短视频分类模型[videotag_tsn_lstm](https://paddlepaddle.org.cn/hubdetail?name=videotag_tsn_lstm&en_category=VideoClassification),支持3000类中文标签识别
+ * 新增轻量级中文OCR模型[chinese_ocr_db_rcnn](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_ocr_db_rcnn&en_category=TextRecognition)、[chinese_text_detection_db](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_text_detection_db&en_category=TextRecognition),支持一键快速OCR识别
+ * 新增行人检测、车辆检测、动物识别、Object等工业级模型
+
+* Fine-tune API升级
+ * 文本分类任务新增6个预置网络,包括CNN, BOW, LSTM, BiLSTM, DPCNN等
+ * 使用VisualDL可视化训练评估性能数据
+
+## `v1.6.2`
+
+* 修复图像分类在windows下运行错误
+
+## `v1.6.1`
+
+* 修复windows下安装PaddleHub缺失config.json文件
+
# `v1.6.0`
* NLP Module全面升级,提升应用性和灵活性
diff --git a/paddlehub/autodl/DELTA/README.md b/autodl/DELTA/README.md
similarity index 84%
rename from paddlehub/autodl/DELTA/README.md
rename to autodl/DELTA/README.md
index 7b235d46f085ba05aa41ab0dabd9317b3efd09da..8620bb0dec9c0fad617abe6537f5ac93c7c503b8 100644
--- a/paddlehub/autodl/DELTA/README.md
+++ b/autodl/DELTA/README.md
@@ -1,10 +1,12 @@
+# DELTA: DEep Learning Transfer using Feature Map with Attention for Convolutional Networks
-# Introduction
-This page implements the [DELTA](https://arxiv.org/abs/1901.09229) algorithm in [PaddlePaddle](https://www.paddlepaddle.org.cn/install/quick).
+## Introduction
+
+This page implements the [DELTA](https://arxiv.org/abs/1901.09229) algorithm in [PaddlePaddle](https://www.paddlepaddle.org.cn).
> Li, Xingjian, et al. "DELTA: Deep learning transfer using feature map with attention for convolutional networks." ICLR 2019.
-# Preparation of Data and Pre-trained Model
+## Preparation of Data and Pre-trained Model
- Download transfer learning target datasets, like [Caltech-256](http://www.vision.caltech.edu/Image_Datasets/Caltech256/), [CUB_200_2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html) or others. Arrange the dataset in this way:
```
@@ -23,7 +25,7 @@ This page implements the [DELTA](https://arxiv.org/abs/1901.09229) algorithm in
- Download [the pretrained models](https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification#resnet-series). We give the results of ResNet-101 below.
-# Running Scripts
+## Running Scripts
Modify `global_data_path` in `datasets/data_path` to the path root where the dataset is.
diff --git a/paddlehub/autodl/DELTA/args.py b/autodl/DELTA/args.py
similarity index 100%
rename from paddlehub/autodl/DELTA/args.py
rename to autodl/DELTA/args.py
diff --git a/paddlehub/autodl/DELTA/datasets/data_path.py b/autodl/DELTA/datasets/data_path.py
similarity index 100%
rename from paddlehub/autodl/DELTA/datasets/data_path.py
rename to autodl/DELTA/datasets/data_path.py
diff --git a/paddlehub/autodl/DELTA/datasets/readers.py b/autodl/DELTA/datasets/readers.py
similarity index 100%
rename from paddlehub/autodl/DELTA/datasets/readers.py
rename to autodl/DELTA/datasets/readers.py
diff --git a/paddlehub/autodl/DELTA/main.py b/autodl/DELTA/main.py
similarity index 100%
rename from paddlehub/autodl/DELTA/main.py
rename to autodl/DELTA/main.py
diff --git a/paddlehub/autodl/DELTA/models/__init__.py b/autodl/DELTA/models/__init__.py
similarity index 100%
rename from paddlehub/autodl/DELTA/models/__init__.py
rename to autodl/DELTA/models/__init__.py
diff --git a/paddlehub/autodl/DELTA/models/resnet.py b/autodl/DELTA/models/resnet.py
similarity index 100%
rename from paddlehub/autodl/DELTA/models/resnet.py
rename to autodl/DELTA/models/resnet.py
diff --git a/paddlehub/autodl/DELTA/models/resnet_vc.py b/autodl/DELTA/models/resnet_vc.py
similarity index 100%
rename from paddlehub/autodl/DELTA/models/resnet_vc.py
rename to autodl/DELTA/models/resnet_vc.py
diff --git a/demo/autofinetune_image_classification/img_cls.py b/demo/autofinetune_image_classification/img_cls.py
index c1194de2f52877b23924a91610e50284c1e3734a..ba61db1a9d584cde8952ac1f839137c2d604625c 100644
--- a/demo/autofinetune_image_classification/img_cls.py
+++ b/demo/autofinetune_image_classification/img_cls.py
@@ -18,7 +18,7 @@ parser.add_argument(
default="mobilenet",
help="Module used as feature extractor.")
-# the name of hyperparameters to be searched should keep with hparam.py
+# the name of hyper-parameters to be searched should keep with hparam.py
parser.add_argument(
"--batch_size",
type=int,
@@ -27,7 +27,7 @@ parser.add_argument(
parser.add_argument(
"--learning_rate", type=float, default=1e-4, help="learning_rate.")
-# saved_params_dir and model_path are needed by auto finetune
+# saved_params_dir and model_path are needed by auto fine-tune
parser.add_argument(
"--saved_params_dir",
type=str,
@@ -76,7 +76,7 @@ def finetune(args):
img = input_dict["image"]
feed_list = [img.name]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.DefaultFinetuneStrategy(learning_rate=args.learning_rate)
config = hub.RunConfig(
use_cuda=True,
@@ -100,7 +100,7 @@ def finetune(args):
task.load_parameters(args.model_path)
logger.info("PaddleHub has loaded model from %s" % args.model_path)
- # Finetune by PaddleHub's API
+ # Fine-tune by PaddleHub's API
task.finetune()
# Evaluate by PaddleHub's API
run_states = task.eval()
@@ -114,7 +114,7 @@ def finetune(args):
shutil.copytree(best_model_dir, args.saved_params_dir)
shutil.rmtree(config.checkpoint_dir)
- # acc on dev will be used by auto finetune
+ # acc on dev will be used by auto fine-tune
hub.report_final_result(eval_avg_score["acc"])
diff --git a/demo/autofinetune_text_classification/text_cls.py b/demo/autofinetune_text_classification/text_cls.py
index a08ef35b9468dc7ca76e8b4b9f570c62cc96c58c..198523430b0a07b1afebbc1ef9078b8c41472965 100644
--- a/demo/autofinetune_text_classification/text_cls.py
+++ b/demo/autofinetune_text_classification/text_cls.py
@@ -13,7 +13,7 @@ from paddlehub.common.logger import logger
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--epochs", type=int, default=3, help="epochs.")
-# the name of hyperparameters to be searched should keep with hparam.py
+# the name of hyper-parameters to be searched should keep with hparam.py
parser.add_argument("--batch_size", type=int, default=32, help="batch_size.")
parser.add_argument(
"--learning_rate", type=float, default=5e-5, help="learning_rate.")
@@ -33,7 +33,7 @@ parser.add_argument(
default=None,
help="Directory to model checkpoint")
-# saved_params_dir and model_path are needed by auto finetune
+# saved_params_dir and model_path are needed by auto fine-tune
parser.add_argument(
"--saved_params_dir",
type=str,
@@ -82,14 +82,14 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_prop,
learning_rate=args.learning_rate,
weight_decay=args.weight_decay,
lr_scheduler="linear_decay")
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
checkpoint_dir=args.checkpoint_dir,
use_cuda=True,
@@ -98,7 +98,7 @@ if __name__ == '__main__':
enable_memory_optim=True,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
@@ -125,5 +125,5 @@ if __name__ == '__main__':
shutil.copytree(best_model_dir, args.saved_params_dir)
shutil.rmtree(config.checkpoint_dir)
- # acc on dev will be used by auto finetune
+ # acc on dev will be used by auto fine-tune
hub.report_final_result(eval_avg_score["acc"])
diff --git a/demo/image_classification/img_classifier.py b/demo/image_classification/img_classifier.py
index 40e170a564ddcc9c54a6d6aff08e898466da5320..f79323be30f79509dcf4a0588383a724e2cbbcc5 100644
--- a/demo/image_classification/img_classifier.py
+++ b/demo/image_classification/img_classifier.py
@@ -14,7 +14,7 @@ parser.add_argument("--use_gpu", type=ast.literal_eval, default=True
parser.add_argument("--checkpoint_dir", type=str, default="paddlehub_finetune_ckpt", help="Path to save log data.")
parser.add_argument("--batch_size", type=int, default=16, help="Total examples' number in batch for training.")
parser.add_argument("--module", type=str, default="resnet50", help="Module used as feature extractor.")
-parser.add_argument("--dataset", type=str, default="flowers", help="Dataset to finetune.")
+parser.add_argument("--dataset", type=str, default="flowers", help="Dataset to fine-tune.")
parser.add_argument("--use_data_parallel", type=ast.literal_eval, default=True, help="Whether use data parallel.")
# yapf: enable.
@@ -60,7 +60,7 @@ def finetune(args):
# Setup feed list for data feeder
feed_list = [input_dict["image"].name]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -69,7 +69,7 @@ def finetune(args):
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a reading comprehension finetune task by PaddleHub's API
+ # Define a image classification task by PaddleHub Fine-tune API
task = hub.ImageClassifierTask(
data_reader=data_reader,
feed_list=feed_list,
@@ -77,7 +77,7 @@ def finetune(args):
num_classes=dataset.num_labels,
config=config)
- # Finetune by PaddleHub's API
+ # Fine-tune by PaddleHub's API
task.finetune_and_eval()
diff --git a/demo/image_classification/predict.py b/demo/image_classification/predict.py
index bc2192686b049f95fbfdd9bef6da92598404848c..ac6bc802e2dc3d2b2c54bfcb59a0e58c3161354f 100644
--- a/demo/image_classification/predict.py
+++ b/demo/image_classification/predict.py
@@ -13,7 +13,7 @@ parser.add_argument("--use_gpu", type=ast.literal_eval, default=True
parser.add_argument("--checkpoint_dir", type=str, default="paddlehub_finetune_ckpt", help="Path to save log data.")
parser.add_argument("--batch_size", type=int, default=16, help="Total examples' number in batch for training.")
parser.add_argument("--module", type=str, default="resnet50", help="Module used as a feature extractor.")
-parser.add_argument("--dataset", type=str, default="flowers", help="Dataset to finetune.")
+parser.add_argument("--dataset", type=str, default="flowers", help="Dataset to fine-tune.")
# yapf: enable.
module_map = {
@@ -58,7 +58,7 @@ def predict(args):
# Setup feed list for data feeder
feed_list = [input_dict["image"].name]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -66,7 +66,7 @@ def predict(args):
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a reading comprehension finetune task by PaddleHub's API
+ # Define a image classification task by PaddleHub Fine-tune API
task = hub.ImageClassifierTask(
data_reader=data_reader,
feed_list=feed_list,
diff --git a/demo/multi_label_classification/multi_label_classifier.py b/demo/multi_label_classification/multi_label_classifier.py
index f958902fe4cade75e5a624e7c84225e4344aae78..76645d2f88fb390e3b36ea3e2c86809d17451284 100644
--- a/demo/multi_label_classification/multi_label_classifier.py
+++ b/demo/multi_label_classification/multi_label_classifier.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -23,7 +23,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -56,13 +56,13 @@ if __name__ == '__main__':
# Use "pooled_output" for classification tasks on an entire sentence.
pooled_output = outputs["pooled_output"]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_cuda=args.use_gpu,
num_epoch=args.num_epoch,
@@ -70,7 +70,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
multi_label_cls_task = hub.MultiLabelClassifierTask(
data_reader=reader,
feature=pooled_output,
@@ -78,6 +78,6 @@ if __name__ == '__main__':
num_classes=dataset.num_labels,
config=config)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
multi_label_cls_task.finetune_and_eval()
diff --git a/demo/multi_label_classification/predict.py b/demo/multi_label_classification/predict.py
index bcc11592232d1f946c945d0d6ca6eff87cde7090..bcd849061e5a663933a83c9a39b2d0d5cf2f8705 100644
--- a/demo/multi_label_classification/predict.py
+++ b/demo/multi_label_classification/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -35,7 +35,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=128, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
# yapf: enable.
@@ -65,7 +65,7 @@ if __name__ == '__main__':
# Use "sequence_output" for token-level output.
pooled_output = outputs["pooled_output"]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -73,7 +73,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
multi_label_cls_task = hub.MultiLabelClassifierTask(
data_reader=reader,
feature=pooled_output,
diff --git a/demo/qa_classification/classifier.py b/demo/qa_classification/classifier.py
index 4c1fad8030e567b7dcb4c1576209d1ac06ee65e6..70f22a70938017ca270f0d3577a1574053c0fa9f 100644
--- a/demo/qa_classification/classifier.py
+++ b/demo/qa_classification/classifier.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -23,7 +23,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.0, help="Warmup proportion params for warmup strategy")
@@ -61,13 +61,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -76,7 +76,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
@@ -84,6 +84,6 @@ if __name__ == '__main__':
num_classes=dataset.num_labels,
config=config)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
cls_task.finetune_and_eval()
diff --git a/demo/qa_classification/predict.py b/demo/qa_classification/predict.py
index fd8ab5a48047eebdc45776e6aeb9be8839a7c3ee..170319d2ee55f0c8060d42fb3f18ec920152ccc7 100644
--- a/demo/qa_classification/predict.py
+++ b/demo/qa_classification/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -33,7 +33,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=128, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
# yapf: enable.
@@ -63,7 +63,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -71,7 +71,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
diff --git a/demo/reading_comprehension/predict.py b/demo/reading_comprehension/predict.py
index a9f8c2f998fb0a29ea76473f412142806ea36b3b..2cc96f62acea550e3ffa9d9e0bb12bfbb9d3ce7b 100644
--- a/demo/reading_comprehension/predict.py
+++ b/demo/reading_comprehension/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -28,7 +28,7 @@ hub.common.logger.logger.setLevel("INFO")
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=1, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint.")
parser.add_argument("--max_seq_len", type=int, default=384, help="Number of words of the longest seqence.")
parser.add_argument("--batch_size", type=int, default=8, help="Total examples' number in batch for training.")
@@ -64,7 +64,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -72,7 +72,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a reading comprehension finetune task by PaddleHub's API
+ # Define a reading comprehension fine-tune task by PaddleHub's API
reading_comprehension_task = hub.ReadingComprehensionTask(
data_reader=reader,
feature=seq_output,
diff --git a/demo/reading_comprehension/reading_comprehension.py b/demo/reading_comprehension/reading_comprehension.py
index 11fe241d8aff97591979e2dcde16f74a7ef67367..d4793823d2147ecb6f8badb776d4cb827b541a8d 100644
--- a/demo/reading_comprehension/reading_comprehension.py
+++ b/demo/reading_comprehension/reading_comprehension.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -25,7 +25,7 @@ hub.common.logger.logger.setLevel("INFO")
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=1, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=3e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.0, help="Warmup proportion params for warmup strategy")
@@ -64,13 +64,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
weight_decay=args.weight_decay,
learning_rate=args.learning_rate,
warmup_proportion=args.warmup_proportion)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
eval_interval=300,
use_data_parallel=args.use_data_parallel,
@@ -80,7 +80,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a reading comprehension finetune task by PaddleHub's API
+ # Define a reading comprehension fine-tune task by PaddleHub's API
reading_comprehension_task = hub.ReadingComprehensionTask(
data_reader=reader,
feature=seq_output,
@@ -89,5 +89,5 @@ if __name__ == '__main__':
sub_task="squad",
)
- # Finetune by PaddleHub's API
+ # Fine-tune by PaddleHub's API
reading_comprehension_task.finetune_and_eval()
diff --git a/demo/regression/predict.py b/demo/regression/predict.py
index 0adfc3886a54f60b7282fbc0584793f7b1c06a5d..b9e73d995f9c63fd847bda46561bd35c66a31f2a 100644
--- a/demo/regression/predict.py
+++ b/demo/regression/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -33,7 +33,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=512, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
# yapf: enable.
@@ -64,7 +64,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -72,7 +72,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a regression finetune task by PaddleHub's API
+ # Define a regression fine-tune task by PaddleHub's API
reg_task = hub.RegressionTask(
data_reader=reader,
feature=pooled_output,
diff --git a/demo/regression/regression.py b/demo/regression/regression.py
index e2c1c0bf5da280b9c7a701a6c393a6ddd8bea145..0979e1c639ca728c46151ad151aaaa9bd389ecc1 100644
--- a/demo/regression/regression.py
+++ b/demo/regression/regression.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -23,7 +23,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -62,13 +62,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
eval_interval=300,
use_data_parallel=args.use_data_parallel,
@@ -78,13 +78,13 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a regression finetune task by PaddleHub's API
+ # Define a regression fine-tune task by PaddleHub's API
reg_task = hub.RegressionTask(
data_reader=reader,
feature=pooled_output,
feed_list=feed_list,
config=config)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
reg_task.finetune_and_eval()
diff --git a/demo/senta/predict.py b/demo/senta/predict.py
index a1d800889fe72876a733629e2f822efd53fecfd4..f287c576d95588aedf4baf5e8563a2d09f6f61b6 100644
--- a/demo/senta/predict.py
+++ b/demo/senta/predict.py
@@ -16,7 +16,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch when the program predicts.")
args = parser.parse_args()
# yapf: enable.
@@ -37,7 +37,7 @@ if __name__ == '__main__':
# Must feed all the tensor of senta's module need
feed_list = [inputs["words"].name]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -45,7 +45,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=sent_feature,
diff --git a/demo/senta/senta_finetune.py b/demo/senta/senta_finetune.py
index 18b0a092dc25a2bbcd3313a9e6a66cd3976d303f..cba8326e5aa04ca71a05862a5de8524350b26ac8 100644
--- a/demo/senta/senta_finetune.py
+++ b/demo/senta/senta_finetune.py
@@ -8,7 +8,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=32, help="Total examples' number in batch for training.")
args = parser.parse_args()
@@ -30,7 +30,7 @@ if __name__ == '__main__':
# Must feed all the tensor of senta's module need
feed_list = [inputs["words"].name]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_cuda=args.use_gpu,
use_pyreader=False,
@@ -40,7 +40,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=sent_feature,
@@ -48,6 +48,6 @@ if __name__ == '__main__':
num_classes=dataset.num_labels,
config=config)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
cls_task.finetune_and_eval()
diff --git a/demo/sequence_labeling/predict.py b/demo/sequence_labeling/predict.py
index fb189b42b83319bcee2823d71ca25bb94e52ec18..54deb81d41f848719b7d1263b56b0cdadefa7de4 100644
--- a/demo/sequence_labeling/predict.py
+++ b/demo/sequence_labeling/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on sequence labeling task """
+"""Fine-tuning on sequence labeling task """
from __future__ import absolute_import
from __future__ import division
@@ -27,14 +27,13 @@ import time
import paddle
import paddle.fluid as fluid
import paddlehub as hub
-from paddlehub.finetune.evaluate import chunk_eval, calculate_f1
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--max_seq_len", type=int, default=512, help="Number of words of the longest seqence.")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
# yapf: enable.
@@ -67,7 +66,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -75,7 +74,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a sequence labeling finetune task by PaddleHub's API
+ # Define a sequence labeling fine-tune task by PaddleHub's API
# if add crf, the network use crf as decoder
seq_label_task = hub.SequenceLabelTask(
data_reader=reader,
@@ -84,7 +83,7 @@ if __name__ == '__main__':
max_seq_len=args.max_seq_len,
num_classes=dataset.num_labels,
config=config,
- add_crf=True)
+ add_crf=False)
# Data to be predicted
# If using python 2, prefix "u" is necessary
diff --git a/demo/sequence_labeling/sequence_label.py b/demo/sequence_labeling/sequence_label.py
index a2b283e857c39ff60912a5df5560ddc08f5f4a1c..958f9839b9fa1ea4655dec20e56165eaf7883da1 100644
--- a/demo/sequence_labeling/sequence_label.py
+++ b/demo/sequence_labeling/sequence_label.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on sequence labeling task."""
+"""Fine-tuning on sequence labeling task."""
import argparse
import ast
@@ -23,7 +23,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -60,13 +60,13 @@ if __name__ == '__main__':
inputs["segment_ids"].name, inputs["input_mask"].name
]
- # Select a finetune strategy
+ # Select a fine-tune strategy
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -75,7 +75,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a sequence labeling finetune task by PaddleHub's API
+ # Define a sequence labeling fine-tune task by PaddleHub's API
# If add crf, the network use crf as decoder
seq_label_task = hub.SequenceLabelTask(
data_reader=reader,
@@ -84,8 +84,8 @@ if __name__ == '__main__':
max_seq_len=args.max_seq_len,
num_classes=dataset.num_labels,
config=config,
- add_crf=True)
+ add_crf=False)
- # Finetune and evaluate model by PaddleHub's API
+ # Fine-tune and evaluate model by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
seq_label_task.finetune_and_eval()
diff --git a/demo/ssd/ssd_demo.py b/demo/ssd/ssd_demo.py
index 3d4b376984f877dbd1fe25585d9b71b826e2ef20..cedeb1cfc5edd9b2d790413024f40d8433b4f413 100644
--- a/demo/ssd/ssd_demo.py
+++ b/demo/ssd/ssd_demo.py
@@ -1,20 +1,14 @@
#coding:utf-8
import os
import paddlehub as hub
+import cv2
if __name__ == "__main__":
ssd = hub.Module(name="ssd_mobilenet_v1_pascal")
test_img_path = os.path.join("test", "test_img_bird.jpg")
- # get the input keys for signature 'object_detection'
- data_format = ssd.processor.data_format(sign_name='object_detection')
- key = list(data_format.keys())[0]
-
- # set input dict
- input_dict = {key: [test_img_path]}
-
# execute predict and print the result
- results = ssd.object_detection(data=input_dict)
+ results = ssd.object_detection(images=[cv2.imread(test_img_path)])
for result in results:
- hub.logger.info(result)
+ print(result)
diff --git a/demo/text_classification/README.md b/demo/text_classification/README.md
index 65c064eb2fcaa075de5e5102ba2dea2c42150ebe..7e3c7c643fdf2adb18576b2a10564eab87e7a8ff 100644
--- a/demo/text_classification/README.md
+++ b/demo/text_classification/README.md
@@ -2,9 +2,31 @@
本示例将展示如何使用PaddleHub Fine-tune API以及Transformer类预训练模型(ERNIE/BERT/RoBERTa)完成分类任务。
+**PaddleHub 1.7.0以上版本支持在Transformer类预训练模型之后拼接预置网络(bow, bilstm, cnn, dpcnn, gru, lstm)完成文本分类任务**
+
+## 目录结构
+```
+text_classification
+├── finetuned_model_to_module # PaddleHub Fine-tune得到模型如何转化为module,从而利用PaddleHub Serving部署
+│ ├── __init__.py
+│ └── module.py
+├── predict_predefine_net.py # 加入预置网络预测脚本
+├── predict.py # 不使用预置网络(使用fc网络)的预测脚本
+├── README.md # 文本分类迁移学习文档说明
+├── run_cls_predefine_net.sh # 加入预置网络的文本分类任务训练启动脚本
+├── run_cls.sh # 不使用预置网络(使用fc网络)的训练启动脚本
+├── run_predict_predefine_net.sh # 使用预置网络(使用fc网络)的预测启动脚本
+├── run_predict.sh # # 不使用预置网络(使用fc网络)的预测启动脚本
+├── text_classifier_dygraph.py # 动态图训练脚本
+├── text_cls_predefine_net.py # 加入预置网络训练脚本
+└── text_cls.py # 不使用预置网络(使用fc网络)的训练脚本
+```
+
## 如何开始Fine-tune
-在完成安装PaddlePaddle与PaddleHub后,通过执行脚本`sh run_classifier.sh`即可开始使用ERNIE对ChnSentiCorp数据集进行Fine-tune。
+以下例子已不使用预置网络完成文本分类任务,说明PaddleHub如何完成迁移学习。使用预置网络完成文本分类任务,步骤类似。
+
+在完成安装PaddlePaddle与PaddleHub后,通过执行脚本`sh run_cls.sh`即可开始使用ERNIE对ChnSentiCorp数据集进行Fine-tune。
其中脚本参数说明如下:
@@ -164,9 +186,27 @@ cls_task = hub.TextClassifierTask(
cls_task.finetune_and_eval()
```
**NOTE:**
-1. `outputs["pooled_output"]`返回了ERNIE/BERT模型对应的[CLS]向量,可以用于句子或句对的特征表达。
-2. `feed_list`中的inputs参数指名了ERNIE/BERT中的输入tensor的顺序,与ClassifyReader返回的结果一致。
+1. `outputs["pooled_output"]`返回了Transformer类预训练模型对应的[CLS]向量,可以用于句子或句对的特征表达。
+2. `feed_list`中的inputs参数指名了Transformer类预训练模型中的输入tensor的顺序,与ClassifyReader返回的结果一致。
3. `hub.TextClassifierTask`通过输入特征,label与迁移的类别数,可以生成适用于文本分类的迁移任务`TextClassifierTask`。
+4. 使用预置网络与否,传入`hub.TextClassifierTask`的特征不相同。`hub.TextClassifierTask`通过参数`feature`和`token_feature`区分。
+ `feature`应是sentence-level特征,shape应为[-1, emb_size];`token_feature`是token-levle特征,shape应为[-1, max_seq_len, emb_size]。
+ 如果使用预置网络,则应取Transformer类预训练模型的sequence_output特征(`outputs["sequence_output"]`)。并且`hub.TextClassifierTask(token_feature=outputs["sequence_output"])`。
+ 如果不使用预置网络,直接通过fc网络进行分类,则应取Transformer类预训练模型的pooled_output特征(`outputs["pooled_output"]`)。并且`hub.TextClassifierTask(feature=outputs["pooled_output"])`。
+5. 使用预置网络,可以通过`hub.TextClassifierTask`参数network进行指定不同的网络结构。如下代码表示选择bilstm网络拼接在Transformer类预训练模型之后。
+ PaddleHub文本分类任务预置网络支持BOW,Bi-LSTM,CNN,DPCNN,GRU,LSTM。指定network应是其中之一。
+ 其中DPCNN网络实现为[ACL2017-Deep Pyramid Convolutional Neural Networks for Text Categorization](https://www.aclweb.org/anthology/P17-1052.pdf)。
+```python
+cls_task = hub.TextClassifierTask(
+ data_reader=reader,
+ token_feature=outputs["sequence_output"],
+ feed_list=feed_list,
+ network='bilstm',
+ num_classes=dataset.num_labels,
+ config=config,
+ metrics_choices=metrics_choices)
+```
+
#### 自定义迁移任务
@@ -190,29 +230,9 @@ python predict.py --checkpoint_dir $CKPT_DIR --max_seq_len 128
```
其中CKPT_DIR为Fine-tune API保存最佳模型的路径, max_seq_len是ERNIE模型的最大序列长度,*请与训练时配置的参数保持一致*
-参数配置正确后,请执行脚本`sh run_predict.sh`,即可看到以下文本分类预测结果, 以及最终准确率。
-如需了解更多预测步骤,请参考`predict.py`。
-
-```
-这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般 predict=0
-交通方便;环境很好;服务态度很好 房间较小 predict=1
-19天硬盘就罢工了~~~算上运来的一周都没用上15天~~~可就是不能换了~~~唉~~~~你说这算什么事呀~~~ predict=0
-```
+参数配置正确后,请执行脚本`sh run_predict.sh`,即可看到文本分类预测结果。
-我们在AI Studio上提供了IPython NoteBook形式的demo,您可以直接在平台上在线体验,链接如下:
-
-|预训练模型|任务类型|数据集|AIStudio链接|备注|
-|-|-|-|-|-|
-|ResNet|图像分类|猫狗数据集DogCat|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/147010)||
-|ERNIE|文本分类|中文情感分类数据集ChnSentiCorp|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/147006)||
-|ERNIE|文本分类|中文新闻分类数据集THUNEWS|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/221999)|本教程讲述了如何将自定义数据集加载,并利用Fine-tune API完成文本分类迁移学习。|
-|ERNIE|序列标注|中文序列标注数据集MSRA_NER|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/147009)||
-|ERNIE|序列标注|中文快递单数据集Express|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/184200)|本教程讲述了如何将自定义数据集加载,并利用Fine-tune API完成序列标注迁移学习。|
-|ERNIE Tiny|文本分类|中文情感分类数据集ChnSentiCorp|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/186443)||
-|Senta|文本分类|中文情感分类数据集ChnSentiCorp|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/216846)|本教程讲述了任何利用Senta和Fine-tune API完成情感分类迁移学习。|
-|Senta|情感分析预测|N/A|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/215814)||
-|LAC|词法分析|N/A|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/215711)||
-|Ultra-Light-Fast-Generic-Face-Detector-1MB|人脸检测|N/A|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/215962)||
+我们在AI Studio上提供了IPython NoteBook形式的demo,点击[PaddleHub教程合集](https://aistudio.baidu.com/aistudio/projectdetail/231146),可使用AI Studio平台提供的GPU算力进行快速尝试。
## 超参优化AutoDL Finetuner
diff --git a/demo/text_classification/predict.py b/demo/text_classification/predict.py
index 81dcd41ecf193a7329a003827351f3b843118de8..3a63e63b1078d537e502aad0613cccd712186b72 100644
--- a/demo/text_classification/predict.py
+++ b/demo/text_classification/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -32,7 +32,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=512, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--use_data_parallel", type=ast.literal_eval, default=False, help="Whether use data parallel.")
args = parser.parse_args()
# yapf: enable.
@@ -70,7 +70,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -78,7 +78,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
diff --git a/demo/text_classification/predict_predefine_net.py b/demo/text_classification/predict_predefine_net.py
index e53cf2b8712f1160abb99e985ca85fb5a4174127..3255270310527b81c3eb272d8331ff7ce3dfd3b3 100644
--- a/demo/text_classification/predict_predefine_net.py
+++ b/demo/text_classification/predict_predefine_net.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -32,7 +32,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=512, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--use_data_parallel", type=ast.literal_eval, default=False, help="Whether use data parallel.")
parser.add_argument("--network", type=str, default='bilstm', help="Pre-defined network which was connected after Transformer model, such as ERNIE, BERT ,RoBERTa and ELECTRA.")
args = parser.parse_args()
@@ -71,7 +71,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -79,7 +79,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
# network choice: bilstm, bow, cnn, dpcnn, gru, lstm (PaddleHub pre-defined network)
# If you wanna add network after ERNIE/BERT/RoBERTa/ELECTRA module,
# you must use the outputs["sequence_output"] as the token_feature of TextClassifierTask,
diff --git a/demo/text_classification/text_cls.py b/demo/text_classification/text_cls.py
index e221cdc7e9fbc0c63162c9a43e9751ddc6ac223a..b68925ba282775b0c57ceb6b249bc53ac258c55e 100644
--- a/demo/text_classification/text_cls.py
+++ b/demo/text_classification/text_cls.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -21,7 +21,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -68,13 +68,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -83,7 +83,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
@@ -92,6 +92,6 @@ if __name__ == '__main__':
config=config,
metrics_choices=metrics_choices)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
cls_task.finetune_and_eval()
diff --git a/demo/text_classification/text_cls_predefine_net.py b/demo/text_classification/text_cls_predefine_net.py
index 23746c03e2563ca2696ff0351cb93d73ae17de1f..4194bb4264bf86631fc9f550cc9b59f421be021d 100644
--- a/demo/text_classification/text_cls_predefine_net.py
+++ b/demo/text_classification/text_cls_predefine_net.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -21,7 +21,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -69,13 +69,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -84,7 +84,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
# network choice: bilstm, bow, cnn, dpcnn, gru, lstm (PaddleHub pre-defined network)
# If you wanna add network after ERNIE/BERT/RoBERTa/ELECTRA module,
# you must use the outputs["sequence_output"] as the token_feature of TextClassifierTask,
@@ -98,6 +98,6 @@ if __name__ == '__main__':
config=config,
metrics_choices=metrics_choices)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
cls_task.finetune_and_eval()
diff --git a/docs/imgs/ocr_res.jpg b/docs/imgs/ocr_res.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..387298de8d3d62ceb8c32c7e091a5e701f92ad43
Binary files /dev/null and b/docs/imgs/ocr_res.jpg differ
diff --git a/docs/reference/task/task.md b/docs/reference/task/task.md
index a1286b25a19fff6d3f881c95ad2ac76690f95cc7..216f035667ba57613399cdd495faca14f0cf3f96 100644
--- a/docs/reference/task/task.md
+++ b/docs/reference/task/task.md
@@ -13,22 +13,22 @@ Task的基本方法和属性参见[BaseTask](base_task.md)。
PaddleHub预置了常见任务的Task,每种Task都有自己特有的应用场景以及提供了对应的度量指标,用于适应用户的不同需求。预置的任务类型如下:
* 图像分类任务
-[ImageClassifierTask]()
+[ImageClassifierTask](image_classify_task.md)
* 文本分类任务
-[TextClassifierTask]()
+[TextClassifierTask](text_classify_task.md)
* 序列标注任务
-[SequenceLabelTask]()
+[SequenceLabelTask](sequence_label_task.md)
* 多标签分类任务
-[MultiLabelClassifierTask]()
+[MultiLabelClassifierTask](multi_lable_classify_task.md)
* 回归任务
-[RegressionTask]()
+[RegressionTask](regression_task.md)
* 阅读理解任务
-[ReadingComprehensionTask]()
+[ReadingComprehensionTask](reading_comprehension_task.md)
## 自定义Task
-如果这些Task不支持您的特定需求,您也可以通过继承BasicTask来实现自己的任务,具体实现细节参见[自定义Task]()
+如果这些Task不支持您的特定需求,您也可以通过继承BasicTask来实现自己的任务,具体实现细节参见[自定义Task](../../tutorial/how_to_define_task.md)以及[修改Task中的模型网络](../../tutorial/define_task_example.md)
## 修改Task内置方法
-如果Task内置方法不满足您的需求,您可以通过Task支持的Hook机制修改方法实现,详细信息参见[修改Task内置方法]()
+如果Task内置方法不满足您的需求,您可以通过Task支持的Hook机制修改方法实现,详细信息参见[修改Task内置方法](../../tutorial/hook.md)
diff --git a/docs/reference/task/text_classify_task.md b/docs/reference/task/text_classify_task.md
index 560977fd5134bbc74ee3d74b9f7288a02e5131a2..9501cfcd60769ee71cc01019d95ccf4a202a9204 100644
--- a/docs/reference/task/text_classify_task.md
+++ b/docs/reference/task/text_classify_task.md
@@ -2,23 +2,28 @@
文本分类任务Task,继承自[BaseTask](base_task.md),该Task基于输入的特征,添加一个Dropout层,以及一个或多个全连接层来创建一个文本分类任务用于finetune,度量指标为准确率,损失函数为交叉熵Loss。
```python
hub.TextClassifierTask(
- feature,
num_classes,
feed_list,
data_reader,
+ feature=None,
+ token_feature=None,
startup_program=None,
config=None,
hidden_units=None,
+ network=None,
metrics_choices="default"):
```
**参数**
-* feature (fluid.Variable): 输入的特征矩阵。
+
* num_classes (int): 分类任务的类别数量
* feed_list (list): 待feed变量的名字列表
-* data_reader: 提供数据的Reader
+* data_reader: 提供数据的Reader,可选为ClassifyReader和LACClassifyReader。
+* feature(fluid.Variable): 输入的sentence-level特征矩阵,shape应为[-1, emb_size]。默认为None。
+* token_feature(fluid.Variable): 输入的token-level特征矩阵,shape应为[-1, seq_len, emb_size]。默认为None。feature和token_feature须指定其中一个。
+* network(str): 文本分类任务PaddleHub预置网络,支持BOW,Bi-LSTM,CNN,DPCNN,GRU,LSTM。如果指定network,则应使用token_feature作为输入特征。其中DPCNN网络实现为[ACL2017-Deep Pyramid Convolutional Neural Networks for Text Categorization](https://www.aclweb.org/anthology/P17-1052.pdf)。
* startup_program (fluid.Program): 存储了模型参数初始化op的Program,如果未提供,则使用fluid.default_startup_program()
-* config ([RunConfig](../config.md)): 运行配置
+* config ([RunConfig](../config.md)): 运行配置,如设置batch_size,epoch,learning_rate等。
* hidden_units (list): TextClassifierTask最终的全连接层输出维度为label_size,是每个label的概率值。在这个全连接层之前可以设置额外的全连接层,并指定它们的输出维度,例如hidden_units=[4,2]表示先经过一层输出维度为4的全连接层,再输入一层输出维度为2的全连接层,最后再输入输出维度为label_size的全连接层。
* metrics_choices("default" or list ⊂ ["acc", "f1", "matthews"]): 任务训练过程中需要计算的评估指标,默认为“default”,此时等效于["acc"]。metrics_choices支持训练过程中同时评估多个指标,其中指定的第一个指标将被作为主指标用于判断当前得分是否为最佳分值,例如["matthews", "acc"],"matthews"将作为主指标,参与最佳模型的判断中;“acc”只计算并输出,不参与最佳模型的判断。
@@ -28,4 +33,4 @@ hub.TextClassifierTask(
**示例**
-[文本分类](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.4/demo/text_classification/text_classifier.py)
+[文本分类](../../../demo/text_classification/text_cls.py)
diff --git a/docs/release.md b/docs/release.md
index 1849191883628e92de3cebf4f3fb51a9830f753f..9a59ba48fd4f44654ba6c6d2166e3c087f31be00 100644
--- a/docs/release.md
+++ b/docs/release.md
@@ -1,5 +1,40 @@
# 更新历史
+## `v1.7.0`
+
+* 丰富预训练模型,提升应用性
+ * 新增VENUS系列视觉预训练模型[yolov3_darknet53_venus](https://www.paddlepaddle.org.cn/hubdetail?name=yolov3_darknet53_venus&en_category=ObjectDetection),[faster_rcnn_resnet50_fpn_venus](https://www.paddlepaddle.org.cn/hubdetail?name=faster_rcnn_resnet50_fpn_venus&en_category=ObjectDetection),可大幅度提升图像分类和目标检测任务的Fine-tune效果
+ * 新增工业级短视频分类模型[videotag_tsn_lstm](https://paddlepaddle.org.cn/hubdetail?name=videotag_tsn_lstm&en_category=VideoClassification),支持3000类中文标签识别
+ * 新增轻量级中文OCR模型[chinese_ocr_db_rcnn](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_ocr_db_rcnn&en_category=TextRecognition)、[chinese_text_detection_db](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_text_detection_db&en_category=TextRecognition),支持一键快速OCR识别
+ * 新增行人检测、车辆检测、动物识别、Object等工业级模型
+
+* Fine-tune API升级
+ * 文本分类任务新增6个预置网络,包括CNN, BOW, LSTM, BiLSTM, DPCNN等
+ * 使用VisualDL可视化训练评估性能数据
+
+## `v1.6.2`
+
+* 修复图像分类在windows下运行错误
+
+## `v1.6.1`
+
+* 修复windows下安装PaddleHub缺失config.json文件
+
+## `v1.6.0`
+
+* NLP Module全面升级,提升应用性和灵活性
+ * lac、senta系列(bow、cnn、bilstm、gru、lstm)、simnet_bow、porn_detection系列(cnn、gru、lstm)升级高性能预测,性能提升高达50%
+ * ERNIE、BERT、RoBERTa等Transformer类语义模型新增获取预训练embedding接口get_embedding,方便接入下游任务,提升应用性
+ * 新增RoBERTa通过模型结构压缩得到的3层Transformer模型[rbt3](https://www.paddlepaddle.org.cn/hubdetail?name=rbt3&en_category=SemanticModel)、[rbtl3](https://www.paddlepaddle.org.cn/hubdetail?name=rbtl3&en_category=SemanticModel)
+
+* Task predict接口增加高性能预测模式accelerate_mode,性能提升高达90%
+
+* PaddleHub Module创建流程开放,支持Fine-tune模型转化,全面提升应用性和灵活性
+ * [预训练模型转化为PaddleHub Module教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/contribution/contri_pretrained_model.md)
+ * [Fine-tune模型转化为PaddleHub Module教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/tutorial/finetuned_model_to_module.md)
+
+* [PaddleHub Serving](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/tutorial/serving.md)优化启动方式,支持更加灵活的参数配置
+
## `v1.5.2`
* 优化pyramidbox_lite_server_mask、pyramidbox_lite_mobile_mask模型的服务化部署性能
diff --git a/docs/tutorial/how_to_load_data.md b/docs/tutorial/how_to_load_data.md
index b56b0e8eb0b624fe458b9ad6ab81868778a98d30..ac3694e005e0730d7abc8ce2d2fe21215ba7ec6a 100644
--- a/docs/tutorial/how_to_load_data.md
+++ b/docs/tutorial/how_to_load_data.md
@@ -95,7 +95,7 @@ label_list.txt的格式如下
```
示例:
-以[DogCat数据集](https://github.com/PaddlePaddle/PaddleHub/wiki/PaddleHub-API:-Dataset#class-hubdatasetdogcatdataset)为示例,train_list.txt/test_list.txt/validate_list.txt内容如下示例
+以[DogCat数据集](../reference/dataset.md#class-hubdatasetdogcatdataset)为示例,train_list.txt/test_list.txt/validate_list.txt内容如下示例
```
cat/3270.jpg 0
cat/646.jpg 0
diff --git a/hub_module/modules/image/classification/efficientnetb0_small_imagenet/module.py b/hub_module/modules/image/classification/efficientnetb0_small_imagenet/module.py
index efd069f36a3cd996dfd98c7116877ac2b60f56a9..393092cb385703f4b2c7fc93c99cb3804baeee2c 100644
--- a/hub_module/modules/image/classification/efficientnetb0_small_imagenet/module.py
+++ b/hub_module/modules/image/classification/efficientnetb0_small_imagenet/module.py
@@ -175,7 +175,7 @@ class EfficientNetB0ImageNet(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/module.py b/hub_module/modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/module.py
index 40a12edfeaecad12264425230d3e8b00ee9c8698..ffd4d06462e5ccb5703b6d0a21a538fdfe3af6f7 100644
--- a/hub_module/modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/module.py
+++ b/hub_module/modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/module.py
@@ -161,7 +161,7 @@ class FixResnext10132x48dwslImagenet(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
if not self.predictor_set:
diff --git a/hub_module/modules/image/classification/mobilenet_v2_animals/module.py b/hub_module/modules/image/classification/mobilenet_v2_animals/module.py
index 87f6f53a7f1a9adaebe951466814cbc1a167ad59..b8afcae07c3fbdc082c821faa288c29bb34b1982 100644
--- a/hub_module/modules/image/classification/mobilenet_v2_animals/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v2_animals/module.py
@@ -161,7 +161,7 @@ class MobileNetV2Animals(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/mobilenet_v2_dishes/module.py b/hub_module/modules/image/classification/mobilenet_v2_dishes/module.py
index 3b9abdd5f7bab314cc7108f6190f00b9a8bdc848..f1be00a305e164b363bb9c8266833f5a986a52a5 100644
--- a/hub_module/modules/image/classification/mobilenet_v2_dishes/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v2_dishes/module.py
@@ -161,7 +161,7 @@ class MobileNetV2Dishes(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/mobilenet_v2_imagenet_ssld/module.py b/hub_module/modules/image/classification/mobilenet_v2_imagenet_ssld/module.py
index 598d7112d8b24b71f2771ce5ed6945a6656a020c..a2bacc749572129cbb5c8e1a4c3257b812df416b 100644
--- a/hub_module/modules/image/classification/mobilenet_v2_imagenet_ssld/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v2_imagenet_ssld/module.py
@@ -184,7 +184,7 @@ class MobileNetV2ImageNetSSLD(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/mobilenet_v3_large_imagenet_ssld/module.py b/hub_module/modules/image/classification/mobilenet_v3_large_imagenet_ssld/module.py
index fcbe73744ce86c98b27ddf9c8c5e5bf442741cbb..07dd93a770a13036f4a1fa74d7cdc11de7a8b2d4 100644
--- a/hub_module/modules/image/classification/mobilenet_v3_large_imagenet_ssld/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v3_large_imagenet_ssld/module.py
@@ -161,7 +161,7 @@ class MobileNetV3Large(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/mobilenet_v3_small_imagenet_ssld/module.py b/hub_module/modules/image/classification/mobilenet_v3_small_imagenet_ssld/module.py
index 4c447dbf3dd64f79061297aca0bad365dbc44c53..5e24ce93d810e40d2f27b658394d3d59586b5754 100644
--- a/hub_module/modules/image/classification/mobilenet_v3_small_imagenet_ssld/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v3_small_imagenet_ssld/module.py
@@ -161,7 +161,7 @@ class MobileNetV3Small(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/resnet18_vd_imagenet/module.py b/hub_module/modules/image/classification/resnet18_vd_imagenet/module.py
index 9870a5db5a5d7f9d150d57a0ac601add77023c38..8171f3f03ab28ec68f5cf4337890899382557e7b 100644
--- a/hub_module/modules/image/classification/resnet18_vd_imagenet/module.py
+++ b/hub_module/modules/image/classification/resnet18_vd_imagenet/module.py
@@ -161,7 +161,7 @@ class ResNet18vdImageNet(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
if not self.predictor_set:
diff --git a/hub_module/modules/image/classification/resnet50_vd_animals/module.py b/hub_module/modules/image/classification/resnet50_vd_animals/module.py
index 5c555ebaca934b6b4f86a3d8a587efce58bcbce3..ed6abe6a873ad1df687792e854a9b5a7c405fe45 100644
--- a/hub_module/modules/image/classification/resnet50_vd_animals/module.py
+++ b/hub_module/modules/image/classification/resnet50_vd_animals/module.py
@@ -161,7 +161,7 @@ class ResNet50vdAnimals(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/resnet50_vd_dishes/module.py b/hub_module/modules/image/classification/resnet50_vd_dishes/module.py
index fb2f3de8f228302af77acf5918d52aaaaba56963..b554a8fc63d98f7e79edc2d634f6dd91a18e915d 100644
--- a/hub_module/modules/image/classification/resnet50_vd_dishes/module.py
+++ b/hub_module/modules/image/classification/resnet50_vd_dishes/module.py
@@ -161,7 +161,7 @@ class ResNet50vdDishes(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/resnet50_vd_imagenet_ssld/module.py b/hub_module/modules/image/classification/resnet50_vd_imagenet_ssld/module.py
index 9464a722d26f28058ef0cafe55f7d7a0a2603ffd..380eb839f7f8df17f6588ad0bbfd04c3c155972f 100644
--- a/hub_module/modules/image/classification/resnet50_vd_imagenet_ssld/module.py
+++ b/hub_module/modules/image/classification/resnet50_vd_imagenet_ssld/module.py
@@ -161,7 +161,7 @@ class ResNet50vdDishes(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/resnet50_vd_wildanimals/module.py b/hub_module/modules/image/classification/resnet50_vd_wildanimals/module.py
index 14fd2f9cf7ac80f686b2fe7f5f1200652b1629f9..3a8d811adac5ebbd6a6f3c729e82accab4272736 100644
--- a/hub_module/modules/image/classification/resnet50_vd_wildanimals/module.py
+++ b/hub_module/modules/image/classification/resnet50_vd_wildanimals/module.py
@@ -161,7 +161,7 @@ class ResNet50vdWildAnimals(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/se_resnet18_vd_imagenet/module.py b/hub_module/modules/image/classification/se_resnet18_vd_imagenet/module.py
index ec219bd8a8aca688ff491b85ad10a5e8f0c65d43..4e6d6db7fd3140ca659e7ffcc29de3fe35af37bd 100644
--- a/hub_module/modules/image/classification/se_resnet18_vd_imagenet/module.py
+++ b/hub_module/modules/image/classification/se_resnet18_vd_imagenet/module.py
@@ -161,7 +161,7 @@ class SEResNet18vdImageNet(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
if not self.predictor_set:
diff --git a/hub_module/modules/image/face_detection/pyramidbox_face_detection/module.py b/hub_module/modules/image/face_detection/pyramidbox_face_detection/module.py
index de0354e2f7e45504ab6c11427f713dfb5394f3f8..c62b8f4374161e330ccf3a3366ae7c7f6aa14b64 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_face_detection/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_face_detection/module.py
@@ -83,7 +83,7 @@ class PyramidBoxFaceDetection(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile/module.py b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile/module.py
index 9e30c5898ea2b94852a547c80333aa5eaf622c92..8d0294a55eb59f83011b90dce8e4b8369dc1e066 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile/module.py
@@ -28,6 +28,7 @@ class PyramidBoxLiteMobile(hub.Module):
self.default_pretrained_model_path = os.path.join(
self.directory, "pyramidbox_lite_mobile_face_detection")
self._set_config()
+ self.processor = self
def _set_config(self):
"""
@@ -81,7 +82,7 @@ class PyramidBoxLiteMobile(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
@@ -130,6 +131,9 @@ class PyramidBoxLiteMobile(hub.Module):
program, feeded_var_names, target_vars = fluid.io.load_inference_model(
dirname=self.default_pretrained_model_path, executor=exe)
+ var = program.global_block().vars['detection_output_0.tmp_1']
+ var.desc.set_dtype(fluid.core.VarDesc.VarType.INT32)
+
fluid.io.save_inference_model(
dirname=dirname,
main_program=program,
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py
index 391aaedfab74ba15124d0dc7b81faa95632ac4f4..e98c9944ff76c8baa97988580fd994c5431048d7 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py
@@ -37,6 +37,7 @@ class PyramidBoxLiteMobileMask(hub.Module):
else:
self.face_detector = face_detector_module
self._set_config()
+ self.processor = self
def _set_config(self):
"""
@@ -107,7 +108,7 @@ class PyramidBoxLiteMobileMask(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py
index 3e3bf1515143cfbcd1dccda71b03cd3b0cf1e77b..61c7be6addd3c1791d1c8e46d0bcd58dcf93e8c9 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py
@@ -94,12 +94,12 @@ def draw_bounding_box_on_image(save_im_path, output_data):
box_fill = (255)
text_fill = (0)
- draw.rectangle(
- xy=(bbox['left'], bbox['top'] - (textsize_height + 5),
- bbox['left'] + textsize_width + 10, bbox['top'] - 3),
- fill=box_fill)
- draw.text(
- xy=(bbox['left'], bbox['top'] - 15), text=text, fill=text_fill)
+ draw.rectangle(
+ xy=(bbox['left'], bbox['top'] - (textsize_height + 5),
+ bbox['left'] + textsize_width + 10, bbox['top'] - 3),
+ fill=box_fill)
+ draw.text(
+ xy=(bbox['left'], bbox['top'] - 15), text=text, fill=text_fill)
image.save(save_im_path)
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_server/module.py b/hub_module/modules/image/face_detection/pyramidbox_lite_server/module.py
index fe9b3b8437720df5bb2bc4731b43dc075f6a04e6..5e7be439d8c6a22a43fa020982e7bc1709639499 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_server/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_server/module.py
@@ -28,6 +28,7 @@ class PyramidBoxLiteServer(hub.Module):
self.default_pretrained_model_path = os.path.join(
self.directory, "pyramidbox_lite_server_face_detection")
self._set_config()
+ self.processor = self
def _set_config(self):
"""
@@ -81,7 +82,7 @@ class PyramidBoxLiteServer(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/module.py b/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/module.py
index 8fd45be7a5e03d9ed8a4434cdcf859ebe847eb01..06cc0f3cee0101b6806f6dfa4545cbe3a8babddc 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/module.py
@@ -37,6 +37,7 @@ class PyramidBoxLiteServerMask(hub.Module):
else:
self.face_detector = face_detector_module
self._set_config()
+ self.processor = self
def _set_config(self):
"""
@@ -106,7 +107,7 @@ class PyramidBoxLiteServerMask(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py b/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py
index 3e3bf1515143cfbcd1dccda71b03cd3b0cf1e77b..61c7be6addd3c1791d1c8e46d0bcd58dcf93e8c9 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py
@@ -94,12 +94,12 @@ def draw_bounding_box_on_image(save_im_path, output_data):
box_fill = (255)
text_fill = (0)
- draw.rectangle(
- xy=(bbox['left'], bbox['top'] - (textsize_height + 5),
- bbox['left'] + textsize_width + 10, bbox['top'] - 3),
- fill=box_fill)
- draw.text(
- xy=(bbox['left'], bbox['top'] - 15), text=text, fill=text_fill)
+ draw.rectangle(
+ xy=(bbox['left'], bbox['top'] - (textsize_height + 5),
+ bbox['left'] + textsize_width + 10, bbox['top'] - 3),
+ fill=box_fill)
+ draw.text(
+ xy=(bbox['left'], bbox['top'] - 15), text=text, fill=text_fill)
image.save(save_im_path)
diff --git a/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py b/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py
index dafd852508a6aea11955d6d9cb8cced18e35aa8d..8237b7f3d743bdb29923c6dab0ff3d6f576127d2 100644
--- a/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py
+++ b/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py
@@ -107,7 +107,7 @@ class FaceDetector320(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py b/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py
index 32075ed6c33ea03b1670dbe8fdd6082046fe64fe..1635237858b6a6c757d52e4df843063c46f7a0f6 100644
--- a/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py
+++ b/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py
@@ -106,7 +106,7 @@ class FaceDetector640(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/keypoint_detection/face_landmark_localization/module.py b/hub_module/modules/image/keypoint_detection/face_landmark_localization/module.py
index 7c8d25d657e470209b20190d0e74ac8d1f792e48..5b21ad7902119b3e0d448f570fa474ebf8a79b1c 100644
--- a/hub_module/modules/image/keypoint_detection/face_landmark_localization/module.py
+++ b/hub_module/modules/image/keypoint_detection/face_landmark_localization/module.py
@@ -133,7 +133,7 @@ class FaceLandmarkLocalization(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# get all data
diff --git a/hub_module/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py b/hub_module/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py
index b65aa88ebdd33e91af3bd731bbede657478a35d5..c61cc84ab900a7c700993ab7ce5fc5fa8320ac44 100644
--- a/hub_module/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py
@@ -323,7 +323,7 @@ class FasterRCNNResNet50(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
if data and 'image' in data:
diff --git a/hub_module/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py b/hub_module/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py
index c64f12978b247ec942f6337d856fb674b0cffda8..f84521ac284742934681fa8ad5e96a11b0990831 100644
--- a/hub_module/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py
@@ -333,7 +333,7 @@ class FasterRCNNResNet50RPN(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
diff --git a/hub_module/modules/image/object_detection/retinanet_resnet50_fpn_coco2017/module.py b/hub_module/modules/image/object_detection/retinanet_resnet50_fpn_coco2017/module.py
index 97d195f28cf4f6c61258ec8c4414eca60e9befaf..ceec9ca585e2a52d592638c0a9ebffc39ccb0cab 100644
--- a/hub_module/modules/image/object_detection/retinanet_resnet50_fpn_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/retinanet_resnet50_fpn_coco2017/module.py
@@ -246,7 +246,7 @@ class RetinaNetResNet50FPN(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_images = list()
diff --git a/hub_module/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py b/hub_module/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py
index 315bb2dd8ef6e75918ccb4e7142a9056a49d8854..8ee1e7edf1ced1b0e1d616e780d91a7f4e53cb20 100644
--- a/hub_module/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py
+++ b/hub_module/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py
@@ -21,7 +21,7 @@ from ssd_mobilenet_v1_pascal.data_feed import reader
@moduleinfo(
name="ssd_mobilenet_v1_pascal",
- version="1.1.0",
+ version="1.1.1",
type="cv/object_detection",
summary="SSD with backbone MobileNet_V1, trained with dataset Pasecal VOC.",
author="paddlepaddle",
@@ -194,7 +194,7 @@ class SSDMobileNetv1(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -275,7 +275,7 @@ class SSDMobileNetv1(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py b/hub_module/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py
index 6027bcd0d22659a47597ef2fe6615e79751adce2..7310bf04d9e208e36e4d72a25ccc93b8a001012f 100644
--- a/hub_module/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py
@@ -21,7 +21,7 @@ from ssd_vgg16_300_coco2017.data_feed import reader
@moduleinfo(
name="ssd_vgg16_300_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="cv/object_detection",
summary="SSD with backbone VGG16, trained with dataset COCO.",
author="paddlepaddle",
@@ -264,7 +264,7 @@ class SSDVGG16(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py b/hub_module/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py
index a0514153734b0857cc5548697ecf716ccb6bea3c..e7246367c5e9e895e8d840f37bb66ce8e0ad2b17 100644
--- a/hub_module/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py
@@ -21,7 +21,7 @@ from ssd_vgg16_512_coco2017.data_feed import reader
@moduleinfo(
name="ssd_vgg16_512_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="cv/object_detection",
summary="SSD with backbone VGG16, trained with dataset COCO.",
author="paddlepaddle",
@@ -200,7 +200,7 @@ class SSDVGG16_512(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -278,7 +278,7 @@ class SSDVGG16_512(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_darknet53_coco2017/module.py b/hub_module/modules/image/object_detection/yolov3_darknet53_coco2017/module.py
index 9ffe7022db9049cd290aa0a8a398257d01b9fb59..1b693fb27c695e14030e81c3f3e623f7d04a0651 100644
--- a/hub_module/modules/image/object_detection/yolov3_darknet53_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_darknet53_coco2017/module.py
@@ -21,7 +21,7 @@ from yolov3_darknet53_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_darknet53_coco2017",
- version="1.1.0",
+ version="1.1.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection, with backbone DarkNet53, trained with dataset coco2017.",
@@ -186,7 +186,7 @@ class YOLOv3DarkNet53Coco2017(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -270,7 +270,7 @@ class YOLOv3DarkNet53Coco2017(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py b/hub_module/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py
index 6f76e25c03540af13c7477d307d81b2bdc568fe4..7630d372801bb633d765ba966bb2eaa458df58e0 100644
--- a/hub_module/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py
@@ -21,7 +21,7 @@ from yolov3_darknet53_pedestrian.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_darknet53_pedestrian",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for pedestrian detection, with backbone DarkNet53.",
@@ -199,7 +199,7 @@ class YOLOv3DarkNet53Pedestrian(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -280,7 +280,7 @@ class YOLOv3DarkNet53Pedestrian(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_darknet53_vehicles/module.py b/hub_module/modules/image/object_detection/yolov3_darknet53_vehicles/module.py
index 685afbff579609f0a855486d87a3ada24315ba1c..801228f6b576b34bfcf8de04d0f56f956d17c709 100644
--- a/hub_module/modules/image/object_detection/yolov3_darknet53_vehicles/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_darknet53_vehicles/module.py
@@ -21,7 +21,7 @@ from yolov3_darknet53_vehicles.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_darknet53_vehicles",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for vehicles detection, with backbone DarkNet53.",
@@ -199,7 +199,7 @@ class YOLOv3DarkNet53Vehicles(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -280,7 +280,7 @@ class YOLOv3DarkNet53Vehicles(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py b/hub_module/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py
index 03bde930aa07a529455f6adae80e70d0cc899b31..659cde37ca481f524ebd33daedc80eb3adc24b3a 100644
--- a/hub_module/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py
@@ -21,7 +21,7 @@ from yolov3_mobilenet_v1_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_mobilenet_v1_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection with backbone MobileNet_V1, trained with dataset COCO2017.",
@@ -189,7 +189,7 @@ class YOLOv3MobileNetV1Coco2017(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -270,7 +270,7 @@ class YOLOv3MobileNetV1Coco2017(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_resnet34_coco2017/module.py b/hub_module/modules/image/object_detection/yolov3_resnet34_coco2017/module.py
index 98712df2b55d6777e2c827a9d6104ed406e671f0..14e31fdd667d3fc9eaa78f185d0c57984fb7ebe0 100644
--- a/hub_module/modules/image/object_detection/yolov3_resnet34_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_resnet34_coco2017/module.py
@@ -21,7 +21,7 @@ from yolov3_resnet34_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_resnet34_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection with backbone ResNet34, trained with dataset coco2017.",
@@ -191,7 +191,7 @@ class YOLOv3ResNet34Coco2017(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -272,7 +272,7 @@ class YOLOv3ResNet34Coco2017(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py b/hub_module/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py
index 4e5a4d053d85b98ada94ea1776f6c3c0376d9dd7..5c25f17cd37df1a7e67dba76ade582ddbc0b89e5 100644
--- a/hub_module/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py
@@ -21,7 +21,7 @@ from yolov3_resnet50_vd_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_resnet50_vd_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection with backbone ResNet50, trained with dataset coco2017.",
@@ -193,7 +193,7 @@ class YOLOv3ResNet50Coco2017(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -274,7 +274,7 @@ class YOLOv3ResNet50Coco2017(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/semantic_segmentation/ace2p/module.py b/hub_module/modules/image/semantic_segmentation/ace2p/module.py
index 149b981e779292f28250f686f0c3bac487ac3903..d8908525ddd5c0c1d98a0f9ce0dddff453a9c128 100644
--- a/hub_module/modules/image/semantic_segmentation/ace2p/module.py
+++ b/hub_module/modules/image/semantic_segmentation/ace2p/module.py
@@ -86,7 +86,7 @@ class ACE2P(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/module.py b/hub_module/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/module.py
index 84c4b7621a5ac22d2765aab20682169fd42170a0..b6f0f22749119fe72f8d046806073aa10b6fa0a2 100644
--- a/hub_module/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/module.py
+++ b/hub_module/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/module.py
@@ -82,7 +82,7 @@ class DeeplabV3pXception65HumanSeg(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/style_transfer/stylepro_artistic/module.py b/hub_module/modules/image/style_transfer/stylepro_artistic/module.py
index 86373516364c6f14e45bc516d88bf417cf7b531d..7fc1461246899d8f21a2d12d8dce6dd4aa65f331 100644
--- a/hub_module/modules/image/style_transfer/stylepro_artistic/module.py
+++ b/hub_module/modules/image/style_transfer/stylepro_artistic/module.py
@@ -104,7 +104,7 @@ class StyleProjection(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
im_output = []
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/README.md b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..08533849bf00a8dbb11db70af7cf051db0ebf6ed
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/README.md
@@ -0,0 +1,134 @@
+## 概述
+
+chinese_ocr_db_crnn_mobile Module用于识别图片当中的汉字。其基于[chinese_text_detection_db_mobile Module](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_text_detection_db_mobile&en_category=TextRecognition)检测得到的文本框,继续识别文本框中的中文文字。识别文字算法采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module是一个超轻量级中文OCR模型,支持直接预测。
+
+
+
+
* 使用[目标检测](https://www.paddlepaddle.org.cn/hublist?filter=en_category&value=ObjectDetection)模型pyramidbox_lite_mobile_mask对图片进行口罩检测
```shell
$ wget https://paddlehub.bj.bcebos.com/resources/test_mask_detection.jpg
@@ -192,5 +204,5 @@ $ hub uninstall ernie
## 更新历史
-PaddleHub v1.6 已发布!
+PaddleHub v1.7 已发布!
更多升级详情参考[更新历史](./RELEASE.md)
diff --git a/RELEASE.md b/RELEASE.md
index b2e177dfa2de3d09d5e85be59dcd2d1914c8368c..8c8a7a08e085d756f02f5cf9490128a550f27a51 100644
--- a/RELEASE.md
+++ b/RELEASE.md
@@ -1,3 +1,23 @@
+## `v1.7.0`
+
+* 丰富预训练模型,提升应用性
+ * 新增VENUS系列视觉预训练模型[yolov3_darknet53_venus](https://www.paddlepaddle.org.cn/hubdetail?name=yolov3_darknet53_venus&en_category=ObjectDetection),[faster_rcnn_resnet50_fpn_venus](https://www.paddlepaddle.org.cn/hubdetail?name=faster_rcnn_resnet50_fpn_venus&en_category=ObjectDetection),可大幅度提升图像分类和目标检测任务的Fine-tune效果
+ * 新增工业级短视频分类模型[videotag_tsn_lstm](https://paddlepaddle.org.cn/hubdetail?name=videotag_tsn_lstm&en_category=VideoClassification),支持3000类中文标签识别
+ * 新增轻量级中文OCR模型[chinese_ocr_db_rcnn](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_ocr_db_rcnn&en_category=TextRecognition)、[chinese_text_detection_db](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_text_detection_db&en_category=TextRecognition),支持一键快速OCR识别
+ * 新增行人检测、车辆检测、动物识别、Object等工业级模型
+
+* Fine-tune API升级
+ * 文本分类任务新增6个预置网络,包括CNN, BOW, LSTM, BiLSTM, DPCNN等
+ * 使用VisualDL可视化训练评估性能数据
+
+## `v1.6.2`
+
+* 修复图像分类在windows下运行错误
+
+## `v1.6.1`
+
+* 修复windows下安装PaddleHub缺失config.json文件
+
# `v1.6.0`
* NLP Module全面升级,提升应用性和灵活性
diff --git a/paddlehub/autodl/DELTA/README.md b/autodl/DELTA/README.md
similarity index 84%
rename from paddlehub/autodl/DELTA/README.md
rename to autodl/DELTA/README.md
index 7b235d46f085ba05aa41ab0dabd9317b3efd09da..8620bb0dec9c0fad617abe6537f5ac93c7c503b8 100644
--- a/paddlehub/autodl/DELTA/README.md
+++ b/autodl/DELTA/README.md
@@ -1,10 +1,12 @@
+# DELTA: DEep Learning Transfer using Feature Map with Attention for Convolutional Networks
-# Introduction
-This page implements the [DELTA](https://arxiv.org/abs/1901.09229) algorithm in [PaddlePaddle](https://www.paddlepaddle.org.cn/install/quick).
+## Introduction
+
+This page implements the [DELTA](https://arxiv.org/abs/1901.09229) algorithm in [PaddlePaddle](https://www.paddlepaddle.org.cn).
> Li, Xingjian, et al. "DELTA: Deep learning transfer using feature map with attention for convolutional networks." ICLR 2019.
-# Preparation of Data and Pre-trained Model
+## Preparation of Data and Pre-trained Model
- Download transfer learning target datasets, like [Caltech-256](http://www.vision.caltech.edu/Image_Datasets/Caltech256/), [CUB_200_2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html) or others. Arrange the dataset in this way:
```
@@ -23,7 +25,7 @@ This page implements the [DELTA](https://arxiv.org/abs/1901.09229) algorithm in
- Download [the pretrained models](https://github.com/PaddlePaddle/models/tree/release/1.7/PaddleCV/image_classification#resnet-series). We give the results of ResNet-101 below.
-# Running Scripts
+## Running Scripts
Modify `global_data_path` in `datasets/data_path` to the path root where the dataset is.
diff --git a/paddlehub/autodl/DELTA/args.py b/autodl/DELTA/args.py
similarity index 100%
rename from paddlehub/autodl/DELTA/args.py
rename to autodl/DELTA/args.py
diff --git a/paddlehub/autodl/DELTA/datasets/data_path.py b/autodl/DELTA/datasets/data_path.py
similarity index 100%
rename from paddlehub/autodl/DELTA/datasets/data_path.py
rename to autodl/DELTA/datasets/data_path.py
diff --git a/paddlehub/autodl/DELTA/datasets/readers.py b/autodl/DELTA/datasets/readers.py
similarity index 100%
rename from paddlehub/autodl/DELTA/datasets/readers.py
rename to autodl/DELTA/datasets/readers.py
diff --git a/paddlehub/autodl/DELTA/main.py b/autodl/DELTA/main.py
similarity index 100%
rename from paddlehub/autodl/DELTA/main.py
rename to autodl/DELTA/main.py
diff --git a/paddlehub/autodl/DELTA/models/__init__.py b/autodl/DELTA/models/__init__.py
similarity index 100%
rename from paddlehub/autodl/DELTA/models/__init__.py
rename to autodl/DELTA/models/__init__.py
diff --git a/paddlehub/autodl/DELTA/models/resnet.py b/autodl/DELTA/models/resnet.py
similarity index 100%
rename from paddlehub/autodl/DELTA/models/resnet.py
rename to autodl/DELTA/models/resnet.py
diff --git a/paddlehub/autodl/DELTA/models/resnet_vc.py b/autodl/DELTA/models/resnet_vc.py
similarity index 100%
rename from paddlehub/autodl/DELTA/models/resnet_vc.py
rename to autodl/DELTA/models/resnet_vc.py
diff --git a/demo/autofinetune_image_classification/img_cls.py b/demo/autofinetune_image_classification/img_cls.py
index c1194de2f52877b23924a91610e50284c1e3734a..ba61db1a9d584cde8952ac1f839137c2d604625c 100644
--- a/demo/autofinetune_image_classification/img_cls.py
+++ b/demo/autofinetune_image_classification/img_cls.py
@@ -18,7 +18,7 @@ parser.add_argument(
default="mobilenet",
help="Module used as feature extractor.")
-# the name of hyperparameters to be searched should keep with hparam.py
+# the name of hyper-parameters to be searched should keep with hparam.py
parser.add_argument(
"--batch_size",
type=int,
@@ -27,7 +27,7 @@ parser.add_argument(
parser.add_argument(
"--learning_rate", type=float, default=1e-4, help="learning_rate.")
-# saved_params_dir and model_path are needed by auto finetune
+# saved_params_dir and model_path are needed by auto fine-tune
parser.add_argument(
"--saved_params_dir",
type=str,
@@ -76,7 +76,7 @@ def finetune(args):
img = input_dict["image"]
feed_list = [img.name]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.DefaultFinetuneStrategy(learning_rate=args.learning_rate)
config = hub.RunConfig(
use_cuda=True,
@@ -100,7 +100,7 @@ def finetune(args):
task.load_parameters(args.model_path)
logger.info("PaddleHub has loaded model from %s" % args.model_path)
- # Finetune by PaddleHub's API
+ # Fine-tune by PaddleHub's API
task.finetune()
# Evaluate by PaddleHub's API
run_states = task.eval()
@@ -114,7 +114,7 @@ def finetune(args):
shutil.copytree(best_model_dir, args.saved_params_dir)
shutil.rmtree(config.checkpoint_dir)
- # acc on dev will be used by auto finetune
+ # acc on dev will be used by auto fine-tune
hub.report_final_result(eval_avg_score["acc"])
diff --git a/demo/autofinetune_text_classification/text_cls.py b/demo/autofinetune_text_classification/text_cls.py
index a08ef35b9468dc7ca76e8b4b9f570c62cc96c58c..198523430b0a07b1afebbc1ef9078b8c41472965 100644
--- a/demo/autofinetune_text_classification/text_cls.py
+++ b/demo/autofinetune_text_classification/text_cls.py
@@ -13,7 +13,7 @@ from paddlehub.common.logger import logger
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--epochs", type=int, default=3, help="epochs.")
-# the name of hyperparameters to be searched should keep with hparam.py
+# the name of hyper-parameters to be searched should keep with hparam.py
parser.add_argument("--batch_size", type=int, default=32, help="batch_size.")
parser.add_argument(
"--learning_rate", type=float, default=5e-5, help="learning_rate.")
@@ -33,7 +33,7 @@ parser.add_argument(
default=None,
help="Directory to model checkpoint")
-# saved_params_dir and model_path are needed by auto finetune
+# saved_params_dir and model_path are needed by auto fine-tune
parser.add_argument(
"--saved_params_dir",
type=str,
@@ -82,14 +82,14 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_prop,
learning_rate=args.learning_rate,
weight_decay=args.weight_decay,
lr_scheduler="linear_decay")
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
checkpoint_dir=args.checkpoint_dir,
use_cuda=True,
@@ -98,7 +98,7 @@ if __name__ == '__main__':
enable_memory_optim=True,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
@@ -125,5 +125,5 @@ if __name__ == '__main__':
shutil.copytree(best_model_dir, args.saved_params_dir)
shutil.rmtree(config.checkpoint_dir)
- # acc on dev will be used by auto finetune
+ # acc on dev will be used by auto fine-tune
hub.report_final_result(eval_avg_score["acc"])
diff --git a/demo/image_classification/img_classifier.py b/demo/image_classification/img_classifier.py
index 40e170a564ddcc9c54a6d6aff08e898466da5320..f79323be30f79509dcf4a0588383a724e2cbbcc5 100644
--- a/demo/image_classification/img_classifier.py
+++ b/demo/image_classification/img_classifier.py
@@ -14,7 +14,7 @@ parser.add_argument("--use_gpu", type=ast.literal_eval, default=True
parser.add_argument("--checkpoint_dir", type=str, default="paddlehub_finetune_ckpt", help="Path to save log data.")
parser.add_argument("--batch_size", type=int, default=16, help="Total examples' number in batch for training.")
parser.add_argument("--module", type=str, default="resnet50", help="Module used as feature extractor.")
-parser.add_argument("--dataset", type=str, default="flowers", help="Dataset to finetune.")
+parser.add_argument("--dataset", type=str, default="flowers", help="Dataset to fine-tune.")
parser.add_argument("--use_data_parallel", type=ast.literal_eval, default=True, help="Whether use data parallel.")
# yapf: enable.
@@ -60,7 +60,7 @@ def finetune(args):
# Setup feed list for data feeder
feed_list = [input_dict["image"].name]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -69,7 +69,7 @@ def finetune(args):
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a reading comprehension finetune task by PaddleHub's API
+ # Define a image classification task by PaddleHub Fine-tune API
task = hub.ImageClassifierTask(
data_reader=data_reader,
feed_list=feed_list,
@@ -77,7 +77,7 @@ def finetune(args):
num_classes=dataset.num_labels,
config=config)
- # Finetune by PaddleHub's API
+ # Fine-tune by PaddleHub's API
task.finetune_and_eval()
diff --git a/demo/image_classification/predict.py b/demo/image_classification/predict.py
index bc2192686b049f95fbfdd9bef6da92598404848c..ac6bc802e2dc3d2b2c54bfcb59a0e58c3161354f 100644
--- a/demo/image_classification/predict.py
+++ b/demo/image_classification/predict.py
@@ -13,7 +13,7 @@ parser.add_argument("--use_gpu", type=ast.literal_eval, default=True
parser.add_argument("--checkpoint_dir", type=str, default="paddlehub_finetune_ckpt", help="Path to save log data.")
parser.add_argument("--batch_size", type=int, default=16, help="Total examples' number in batch for training.")
parser.add_argument("--module", type=str, default="resnet50", help="Module used as a feature extractor.")
-parser.add_argument("--dataset", type=str, default="flowers", help="Dataset to finetune.")
+parser.add_argument("--dataset", type=str, default="flowers", help="Dataset to fine-tune.")
# yapf: enable.
module_map = {
@@ -58,7 +58,7 @@ def predict(args):
# Setup feed list for data feeder
feed_list = [input_dict["image"].name]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -66,7 +66,7 @@ def predict(args):
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a reading comprehension finetune task by PaddleHub's API
+ # Define a image classification task by PaddleHub Fine-tune API
task = hub.ImageClassifierTask(
data_reader=data_reader,
feed_list=feed_list,
diff --git a/demo/multi_label_classification/multi_label_classifier.py b/demo/multi_label_classification/multi_label_classifier.py
index f958902fe4cade75e5a624e7c84225e4344aae78..76645d2f88fb390e3b36ea3e2c86809d17451284 100644
--- a/demo/multi_label_classification/multi_label_classifier.py
+++ b/demo/multi_label_classification/multi_label_classifier.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -23,7 +23,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -56,13 +56,13 @@ if __name__ == '__main__':
# Use "pooled_output" for classification tasks on an entire sentence.
pooled_output = outputs["pooled_output"]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_cuda=args.use_gpu,
num_epoch=args.num_epoch,
@@ -70,7 +70,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
multi_label_cls_task = hub.MultiLabelClassifierTask(
data_reader=reader,
feature=pooled_output,
@@ -78,6 +78,6 @@ if __name__ == '__main__':
num_classes=dataset.num_labels,
config=config)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
multi_label_cls_task.finetune_and_eval()
diff --git a/demo/multi_label_classification/predict.py b/demo/multi_label_classification/predict.py
index bcc11592232d1f946c945d0d6ca6eff87cde7090..bcd849061e5a663933a83c9a39b2d0d5cf2f8705 100644
--- a/demo/multi_label_classification/predict.py
+++ b/demo/multi_label_classification/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -35,7 +35,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=128, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
# yapf: enable.
@@ -65,7 +65,7 @@ if __name__ == '__main__':
# Use "sequence_output" for token-level output.
pooled_output = outputs["pooled_output"]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -73,7 +73,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
multi_label_cls_task = hub.MultiLabelClassifierTask(
data_reader=reader,
feature=pooled_output,
diff --git a/demo/qa_classification/classifier.py b/demo/qa_classification/classifier.py
index 4c1fad8030e567b7dcb4c1576209d1ac06ee65e6..70f22a70938017ca270f0d3577a1574053c0fa9f 100644
--- a/demo/qa_classification/classifier.py
+++ b/demo/qa_classification/classifier.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -23,7 +23,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.0, help="Warmup proportion params for warmup strategy")
@@ -61,13 +61,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -76,7 +76,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
@@ -84,6 +84,6 @@ if __name__ == '__main__':
num_classes=dataset.num_labels,
config=config)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
cls_task.finetune_and_eval()
diff --git a/demo/qa_classification/predict.py b/demo/qa_classification/predict.py
index fd8ab5a48047eebdc45776e6aeb9be8839a7c3ee..170319d2ee55f0c8060d42fb3f18ec920152ccc7 100644
--- a/demo/qa_classification/predict.py
+++ b/demo/qa_classification/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -33,7 +33,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=128, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
# yapf: enable.
@@ -63,7 +63,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -71,7 +71,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
diff --git a/demo/reading_comprehension/predict.py b/demo/reading_comprehension/predict.py
index a9f8c2f998fb0a29ea76473f412142806ea36b3b..2cc96f62acea550e3ffa9d9e0bb12bfbb9d3ce7b 100644
--- a/demo/reading_comprehension/predict.py
+++ b/demo/reading_comprehension/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -28,7 +28,7 @@ hub.common.logger.logger.setLevel("INFO")
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=1, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint.")
parser.add_argument("--max_seq_len", type=int, default=384, help="Number of words of the longest seqence.")
parser.add_argument("--batch_size", type=int, default=8, help="Total examples' number in batch for training.")
@@ -64,7 +64,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -72,7 +72,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a reading comprehension finetune task by PaddleHub's API
+ # Define a reading comprehension fine-tune task by PaddleHub's API
reading_comprehension_task = hub.ReadingComprehensionTask(
data_reader=reader,
feature=seq_output,
diff --git a/demo/reading_comprehension/reading_comprehension.py b/demo/reading_comprehension/reading_comprehension.py
index 11fe241d8aff97591979e2dcde16f74a7ef67367..d4793823d2147ecb6f8badb776d4cb827b541a8d 100644
--- a/demo/reading_comprehension/reading_comprehension.py
+++ b/demo/reading_comprehension/reading_comprehension.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -25,7 +25,7 @@ hub.common.logger.logger.setLevel("INFO")
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=1, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=3e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.0, help="Warmup proportion params for warmup strategy")
@@ -64,13 +64,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
weight_decay=args.weight_decay,
learning_rate=args.learning_rate,
warmup_proportion=args.warmup_proportion)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
eval_interval=300,
use_data_parallel=args.use_data_parallel,
@@ -80,7 +80,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a reading comprehension finetune task by PaddleHub's API
+ # Define a reading comprehension fine-tune task by PaddleHub's API
reading_comprehension_task = hub.ReadingComprehensionTask(
data_reader=reader,
feature=seq_output,
@@ -89,5 +89,5 @@ if __name__ == '__main__':
sub_task="squad",
)
- # Finetune by PaddleHub's API
+ # Fine-tune by PaddleHub's API
reading_comprehension_task.finetune_and_eval()
diff --git a/demo/regression/predict.py b/demo/regression/predict.py
index 0adfc3886a54f60b7282fbc0584793f7b1c06a5d..b9e73d995f9c63fd847bda46561bd35c66a31f2a 100644
--- a/demo/regression/predict.py
+++ b/demo/regression/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -33,7 +33,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=512, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
# yapf: enable.
@@ -64,7 +64,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -72,7 +72,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a regression finetune task by PaddleHub's API
+ # Define a regression fine-tune task by PaddleHub's API
reg_task = hub.RegressionTask(
data_reader=reader,
feature=pooled_output,
diff --git a/demo/regression/regression.py b/demo/regression/regression.py
index e2c1c0bf5da280b9c7a701a6c393a6ddd8bea145..0979e1c639ca728c46151ad151aaaa9bd389ecc1 100644
--- a/demo/regression/regression.py
+++ b/demo/regression/regression.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -23,7 +23,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -62,13 +62,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
eval_interval=300,
use_data_parallel=args.use_data_parallel,
@@ -78,13 +78,13 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a regression finetune task by PaddleHub's API
+ # Define a regression fine-tune task by PaddleHub's API
reg_task = hub.RegressionTask(
data_reader=reader,
feature=pooled_output,
feed_list=feed_list,
config=config)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
reg_task.finetune_and_eval()
diff --git a/demo/senta/predict.py b/demo/senta/predict.py
index a1d800889fe72876a733629e2f822efd53fecfd4..f287c576d95588aedf4baf5e8563a2d09f6f61b6 100644
--- a/demo/senta/predict.py
+++ b/demo/senta/predict.py
@@ -16,7 +16,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch when the program predicts.")
args = parser.parse_args()
# yapf: enable.
@@ -37,7 +37,7 @@ if __name__ == '__main__':
# Must feed all the tensor of senta's module need
feed_list = [inputs["words"].name]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -45,7 +45,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=sent_feature,
diff --git a/demo/senta/senta_finetune.py b/demo/senta/senta_finetune.py
index 18b0a092dc25a2bbcd3313a9e6a66cd3976d303f..cba8326e5aa04ca71a05862a5de8524350b26ac8 100644
--- a/demo/senta/senta_finetune.py
+++ b/demo/senta/senta_finetune.py
@@ -8,7 +8,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=32, help="Total examples' number in batch for training.")
args = parser.parse_args()
@@ -30,7 +30,7 @@ if __name__ == '__main__':
# Must feed all the tensor of senta's module need
feed_list = [inputs["words"].name]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_cuda=args.use_gpu,
use_pyreader=False,
@@ -40,7 +40,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=sent_feature,
@@ -48,6 +48,6 @@ if __name__ == '__main__':
num_classes=dataset.num_labels,
config=config)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
cls_task.finetune_and_eval()
diff --git a/demo/sequence_labeling/predict.py b/demo/sequence_labeling/predict.py
index fb189b42b83319bcee2823d71ca25bb94e52ec18..54deb81d41f848719b7d1263b56b0cdadefa7de4 100644
--- a/demo/sequence_labeling/predict.py
+++ b/demo/sequence_labeling/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on sequence labeling task """
+"""Fine-tuning on sequence labeling task """
from __future__ import absolute_import
from __future__ import division
@@ -27,14 +27,13 @@ import time
import paddle
import paddle.fluid as fluid
import paddlehub as hub
-from paddlehub.finetune.evaluate import chunk_eval, calculate_f1
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--max_seq_len", type=int, default=512, help="Number of words of the longest seqence.")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
args = parser.parse_args()
# yapf: enable.
@@ -67,7 +66,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=False,
use_cuda=args.use_gpu,
@@ -75,7 +74,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.finetune.strategy.DefaultFinetuneStrategy())
- # Define a sequence labeling finetune task by PaddleHub's API
+ # Define a sequence labeling fine-tune task by PaddleHub's API
# if add crf, the network use crf as decoder
seq_label_task = hub.SequenceLabelTask(
data_reader=reader,
@@ -84,7 +83,7 @@ if __name__ == '__main__':
max_seq_len=args.max_seq_len,
num_classes=dataset.num_labels,
config=config,
- add_crf=True)
+ add_crf=False)
# Data to be predicted
# If using python 2, prefix "u" is necessary
diff --git a/demo/sequence_labeling/sequence_label.py b/demo/sequence_labeling/sequence_label.py
index a2b283e857c39ff60912a5df5560ddc08f5f4a1c..958f9839b9fa1ea4655dec20e56165eaf7883da1 100644
--- a/demo/sequence_labeling/sequence_label.py
+++ b/demo/sequence_labeling/sequence_label.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on sequence labeling task."""
+"""Fine-tuning on sequence labeling task."""
import argparse
import ast
@@ -23,7 +23,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -60,13 +60,13 @@ if __name__ == '__main__':
inputs["segment_ids"].name, inputs["input_mask"].name
]
- # Select a finetune strategy
+ # Select a fine-tune strategy
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -75,7 +75,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a sequence labeling finetune task by PaddleHub's API
+ # Define a sequence labeling fine-tune task by PaddleHub's API
# If add crf, the network use crf as decoder
seq_label_task = hub.SequenceLabelTask(
data_reader=reader,
@@ -84,8 +84,8 @@ if __name__ == '__main__':
max_seq_len=args.max_seq_len,
num_classes=dataset.num_labels,
config=config,
- add_crf=True)
+ add_crf=False)
- # Finetune and evaluate model by PaddleHub's API
+ # Fine-tune and evaluate model by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
seq_label_task.finetune_and_eval()
diff --git a/demo/ssd/ssd_demo.py b/demo/ssd/ssd_demo.py
index 3d4b376984f877dbd1fe25585d9b71b826e2ef20..cedeb1cfc5edd9b2d790413024f40d8433b4f413 100644
--- a/demo/ssd/ssd_demo.py
+++ b/demo/ssd/ssd_demo.py
@@ -1,20 +1,14 @@
#coding:utf-8
import os
import paddlehub as hub
+import cv2
if __name__ == "__main__":
ssd = hub.Module(name="ssd_mobilenet_v1_pascal")
test_img_path = os.path.join("test", "test_img_bird.jpg")
- # get the input keys for signature 'object_detection'
- data_format = ssd.processor.data_format(sign_name='object_detection')
- key = list(data_format.keys())[0]
-
- # set input dict
- input_dict = {key: [test_img_path]}
-
# execute predict and print the result
- results = ssd.object_detection(data=input_dict)
+ results = ssd.object_detection(images=[cv2.imread(test_img_path)])
for result in results:
- hub.logger.info(result)
+ print(result)
diff --git a/demo/text_classification/README.md b/demo/text_classification/README.md
index 65c064eb2fcaa075de5e5102ba2dea2c42150ebe..7e3c7c643fdf2adb18576b2a10564eab87e7a8ff 100644
--- a/demo/text_classification/README.md
+++ b/demo/text_classification/README.md
@@ -2,9 +2,31 @@
本示例将展示如何使用PaddleHub Fine-tune API以及Transformer类预训练模型(ERNIE/BERT/RoBERTa)完成分类任务。
+**PaddleHub 1.7.0以上版本支持在Transformer类预训练模型之后拼接预置网络(bow, bilstm, cnn, dpcnn, gru, lstm)完成文本分类任务**
+
+## 目录结构
+```
+text_classification
+├── finetuned_model_to_module # PaddleHub Fine-tune得到模型如何转化为module,从而利用PaddleHub Serving部署
+│ ├── __init__.py
+│ └── module.py
+├── predict_predefine_net.py # 加入预置网络预测脚本
+├── predict.py # 不使用预置网络(使用fc网络)的预测脚本
+├── README.md # 文本分类迁移学习文档说明
+├── run_cls_predefine_net.sh # 加入预置网络的文本分类任务训练启动脚本
+├── run_cls.sh # 不使用预置网络(使用fc网络)的训练启动脚本
+├── run_predict_predefine_net.sh # 使用预置网络(使用fc网络)的预测启动脚本
+├── run_predict.sh # # 不使用预置网络(使用fc网络)的预测启动脚本
+├── text_classifier_dygraph.py # 动态图训练脚本
+├── text_cls_predefine_net.py # 加入预置网络训练脚本
+└── text_cls.py # 不使用预置网络(使用fc网络)的训练脚本
+```
+
## 如何开始Fine-tune
-在完成安装PaddlePaddle与PaddleHub后,通过执行脚本`sh run_classifier.sh`即可开始使用ERNIE对ChnSentiCorp数据集进行Fine-tune。
+以下例子已不使用预置网络完成文本分类任务,说明PaddleHub如何完成迁移学习。使用预置网络完成文本分类任务,步骤类似。
+
+在完成安装PaddlePaddle与PaddleHub后,通过执行脚本`sh run_cls.sh`即可开始使用ERNIE对ChnSentiCorp数据集进行Fine-tune。
其中脚本参数说明如下:
@@ -164,9 +186,27 @@ cls_task = hub.TextClassifierTask(
cls_task.finetune_and_eval()
```
**NOTE:**
-1. `outputs["pooled_output"]`返回了ERNIE/BERT模型对应的[CLS]向量,可以用于句子或句对的特征表达。
-2. `feed_list`中的inputs参数指名了ERNIE/BERT中的输入tensor的顺序,与ClassifyReader返回的结果一致。
+1. `outputs["pooled_output"]`返回了Transformer类预训练模型对应的[CLS]向量,可以用于句子或句对的特征表达。
+2. `feed_list`中的inputs参数指名了Transformer类预训练模型中的输入tensor的顺序,与ClassifyReader返回的结果一致。
3. `hub.TextClassifierTask`通过输入特征,label与迁移的类别数,可以生成适用于文本分类的迁移任务`TextClassifierTask`。
+4. 使用预置网络与否,传入`hub.TextClassifierTask`的特征不相同。`hub.TextClassifierTask`通过参数`feature`和`token_feature`区分。
+ `feature`应是sentence-level特征,shape应为[-1, emb_size];`token_feature`是token-levle特征,shape应为[-1, max_seq_len, emb_size]。
+ 如果使用预置网络,则应取Transformer类预训练模型的sequence_output特征(`outputs["sequence_output"]`)。并且`hub.TextClassifierTask(token_feature=outputs["sequence_output"])`。
+ 如果不使用预置网络,直接通过fc网络进行分类,则应取Transformer类预训练模型的pooled_output特征(`outputs["pooled_output"]`)。并且`hub.TextClassifierTask(feature=outputs["pooled_output"])`。
+5. 使用预置网络,可以通过`hub.TextClassifierTask`参数network进行指定不同的网络结构。如下代码表示选择bilstm网络拼接在Transformer类预训练模型之后。
+ PaddleHub文本分类任务预置网络支持BOW,Bi-LSTM,CNN,DPCNN,GRU,LSTM。指定network应是其中之一。
+ 其中DPCNN网络实现为[ACL2017-Deep Pyramid Convolutional Neural Networks for Text Categorization](https://www.aclweb.org/anthology/P17-1052.pdf)。
+```python
+cls_task = hub.TextClassifierTask(
+ data_reader=reader,
+ token_feature=outputs["sequence_output"],
+ feed_list=feed_list,
+ network='bilstm',
+ num_classes=dataset.num_labels,
+ config=config,
+ metrics_choices=metrics_choices)
+```
+
#### 自定义迁移任务
@@ -190,29 +230,9 @@ python predict.py --checkpoint_dir $CKPT_DIR --max_seq_len 128
```
其中CKPT_DIR为Fine-tune API保存最佳模型的路径, max_seq_len是ERNIE模型的最大序列长度,*请与训练时配置的参数保持一致*
-参数配置正确后,请执行脚本`sh run_predict.sh`,即可看到以下文本分类预测结果, 以及最终准确率。
-如需了解更多预测步骤,请参考`predict.py`。
-
-```
-这个宾馆比较陈旧了,特价的房间也很一般。总体来说一般 predict=0
-交通方便;环境很好;服务态度很好 房间较小 predict=1
-19天硬盘就罢工了~~~算上运来的一周都没用上15天~~~可就是不能换了~~~唉~~~~你说这算什么事呀~~~ predict=0
-```
+参数配置正确后,请执行脚本`sh run_predict.sh`,即可看到文本分类预测结果。
-我们在AI Studio上提供了IPython NoteBook形式的demo,您可以直接在平台上在线体验,链接如下:
-
-|预训练模型|任务类型|数据集|AIStudio链接|备注|
-|-|-|-|-|-|
-|ResNet|图像分类|猫狗数据集DogCat|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/147010)||
-|ERNIE|文本分类|中文情感分类数据集ChnSentiCorp|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/147006)||
-|ERNIE|文本分类|中文新闻分类数据集THUNEWS|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/221999)|本教程讲述了如何将自定义数据集加载,并利用Fine-tune API完成文本分类迁移学习。|
-|ERNIE|序列标注|中文序列标注数据集MSRA_NER|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/147009)||
-|ERNIE|序列标注|中文快递单数据集Express|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/184200)|本教程讲述了如何将自定义数据集加载,并利用Fine-tune API完成序列标注迁移学习。|
-|ERNIE Tiny|文本分类|中文情感分类数据集ChnSentiCorp|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/186443)||
-|Senta|文本分类|中文情感分类数据集ChnSentiCorp|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/216846)|本教程讲述了任何利用Senta和Fine-tune API完成情感分类迁移学习。|
-|Senta|情感分析预测|N/A|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/215814)||
-|LAC|词法分析|N/A|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/215711)||
-|Ultra-Light-Fast-Generic-Face-Detector-1MB|人脸检测|N/A|[点击体验](https://aistudio.baidu.com/aistudio/projectdetail/215962)||
+我们在AI Studio上提供了IPython NoteBook形式的demo,点击[PaddleHub教程合集](https://aistudio.baidu.com/aistudio/projectdetail/231146),可使用AI Studio平台提供的GPU算力进行快速尝试。
## 超参优化AutoDL Finetuner
diff --git a/demo/text_classification/predict.py b/demo/text_classification/predict.py
index 81dcd41ecf193a7329a003827351f3b843118de8..3a63e63b1078d537e502aad0613cccd712186b72 100644
--- a/demo/text_classification/predict.py
+++ b/demo/text_classification/predict.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -32,7 +32,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=512, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--use_data_parallel", type=ast.literal_eval, default=False, help="Whether use data parallel.")
args = parser.parse_args()
# yapf: enable.
@@ -70,7 +70,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -78,7 +78,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
diff --git a/demo/text_classification/predict_predefine_net.py b/demo/text_classification/predict_predefine_net.py
index e53cf2b8712f1160abb99e985ca85fb5a4174127..3255270310527b81c3eb272d8331ff7ce3dfd3b3 100644
--- a/demo/text_classification/predict_predefine_net.py
+++ b/demo/text_classification/predict_predefine_net.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
from __future__ import absolute_import
from __future__ import division
@@ -32,7 +32,7 @@ parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--checkpoint_dir", type=str, default=None, help="Directory to model checkpoint")
parser.add_argument("--batch_size", type=int, default=1, help="Total examples' number in batch for training.")
parser.add_argument("--max_seq_len", type=int, default=512, help="Number of words of the longest seqence.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=False, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--use_data_parallel", type=ast.literal_eval, default=False, help="Whether use data parallel.")
parser.add_argument("--network", type=str, default='bilstm', help="Pre-defined network which was connected after Transformer model, such as ERNIE, BERT ,RoBERTa and ELECTRA.")
args = parser.parse_args()
@@ -71,7 +71,7 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -79,7 +79,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=hub.AdamWeightDecayStrategy())
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
# network choice: bilstm, bow, cnn, dpcnn, gru, lstm (PaddleHub pre-defined network)
# If you wanna add network after ERNIE/BERT/RoBERTa/ELECTRA module,
# you must use the outputs["sequence_output"] as the token_feature of TextClassifierTask,
diff --git a/demo/text_classification/text_cls.py b/demo/text_classification/text_cls.py
index e221cdc7e9fbc0c63162c9a43e9751ddc6ac223a..b68925ba282775b0c57ceb6b249bc53ac258c55e 100644
--- a/demo/text_classification/text_cls.py
+++ b/demo/text_classification/text_cls.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -21,7 +21,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -68,13 +68,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -83,7 +83,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
cls_task = hub.TextClassifierTask(
data_reader=reader,
feature=pooled_output,
@@ -92,6 +92,6 @@ if __name__ == '__main__':
config=config,
metrics_choices=metrics_choices)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
cls_task.finetune_and_eval()
diff --git a/demo/text_classification/text_cls_predefine_net.py b/demo/text_classification/text_cls_predefine_net.py
index 23746c03e2563ca2696ff0351cb93d73ae17de1f..4194bb4264bf86631fc9f550cc9b59f421be021d 100644
--- a/demo/text_classification/text_cls_predefine_net.py
+++ b/demo/text_classification/text_cls_predefine_net.py
@@ -12,7 +12,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-"""Finetuning on classification task """
+"""Fine-tuning on classification task """
import argparse
import ast
@@ -21,7 +21,7 @@ import paddlehub as hub
# yapf: disable
parser = argparse.ArgumentParser(__doc__)
parser.add_argument("--num_epoch", type=int, default=3, help="Number of epoches for fine-tuning.")
-parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for finetuning, input should be True or False")
+parser.add_argument("--use_gpu", type=ast.literal_eval, default=True, help="Whether use GPU for fine-tuning, input should be True or False")
parser.add_argument("--learning_rate", type=float, default=5e-5, help="Learning rate used to train with warmup.")
parser.add_argument("--weight_decay", type=float, default=0.01, help="Weight decay rate for L2 regularizer.")
parser.add_argument("--warmup_proportion", type=float, default=0.1, help="Warmup proportion params for warmup strategy")
@@ -69,13 +69,13 @@ if __name__ == '__main__':
inputs["input_mask"].name,
]
- # Select finetune strategy, setup config and finetune
+ # Select fine-tune strategy, setup config and fine-tune
strategy = hub.AdamWeightDecayStrategy(
warmup_proportion=args.warmup_proportion,
weight_decay=args.weight_decay,
learning_rate=args.learning_rate)
- # Setup runing config for PaddleHub Finetune API
+ # Setup RunConfig for PaddleHub Fine-tune API
config = hub.RunConfig(
use_data_parallel=args.use_data_parallel,
use_cuda=args.use_gpu,
@@ -84,7 +84,7 @@ if __name__ == '__main__':
checkpoint_dir=args.checkpoint_dir,
strategy=strategy)
- # Define a classfication finetune task by PaddleHub's API
+ # Define a classfication fine-tune task by PaddleHub's API
# network choice: bilstm, bow, cnn, dpcnn, gru, lstm (PaddleHub pre-defined network)
# If you wanna add network after ERNIE/BERT/RoBERTa/ELECTRA module,
# you must use the outputs["sequence_output"] as the token_feature of TextClassifierTask,
@@ -98,6 +98,6 @@ if __name__ == '__main__':
config=config,
metrics_choices=metrics_choices)
- # Finetune and evaluate by PaddleHub's API
+ # Fine-tune and evaluate by PaddleHub's API
# will finish training, evaluation, testing, save model automatically
cls_task.finetune_and_eval()
diff --git a/docs/imgs/ocr_res.jpg b/docs/imgs/ocr_res.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..387298de8d3d62ceb8c32c7e091a5e701f92ad43
Binary files /dev/null and b/docs/imgs/ocr_res.jpg differ
diff --git a/docs/reference/task/task.md b/docs/reference/task/task.md
index a1286b25a19fff6d3f881c95ad2ac76690f95cc7..216f035667ba57613399cdd495faca14f0cf3f96 100644
--- a/docs/reference/task/task.md
+++ b/docs/reference/task/task.md
@@ -13,22 +13,22 @@ Task的基本方法和属性参见[BaseTask](base_task.md)。
PaddleHub预置了常见任务的Task,每种Task都有自己特有的应用场景以及提供了对应的度量指标,用于适应用户的不同需求。预置的任务类型如下:
* 图像分类任务
-[ImageClassifierTask]()
+[ImageClassifierTask](image_classify_task.md)
* 文本分类任务
-[TextClassifierTask]()
+[TextClassifierTask](text_classify_task.md)
* 序列标注任务
-[SequenceLabelTask]()
+[SequenceLabelTask](sequence_label_task.md)
* 多标签分类任务
-[MultiLabelClassifierTask]()
+[MultiLabelClassifierTask](multi_lable_classify_task.md)
* 回归任务
-[RegressionTask]()
+[RegressionTask](regression_task.md)
* 阅读理解任务
-[ReadingComprehensionTask]()
+[ReadingComprehensionTask](reading_comprehension_task.md)
## 自定义Task
-如果这些Task不支持您的特定需求,您也可以通过继承BasicTask来实现自己的任务,具体实现细节参见[自定义Task]()
+如果这些Task不支持您的特定需求,您也可以通过继承BasicTask来实现自己的任务,具体实现细节参见[自定义Task](../../tutorial/how_to_define_task.md)以及[修改Task中的模型网络](../../tutorial/define_task_example.md)
## 修改Task内置方法
-如果Task内置方法不满足您的需求,您可以通过Task支持的Hook机制修改方法实现,详细信息参见[修改Task内置方法]()
+如果Task内置方法不满足您的需求,您可以通过Task支持的Hook机制修改方法实现,详细信息参见[修改Task内置方法](../../tutorial/hook.md)
diff --git a/docs/reference/task/text_classify_task.md b/docs/reference/task/text_classify_task.md
index 560977fd5134bbc74ee3d74b9f7288a02e5131a2..9501cfcd60769ee71cc01019d95ccf4a202a9204 100644
--- a/docs/reference/task/text_classify_task.md
+++ b/docs/reference/task/text_classify_task.md
@@ -2,23 +2,28 @@
文本分类任务Task,继承自[BaseTask](base_task.md),该Task基于输入的特征,添加一个Dropout层,以及一个或多个全连接层来创建一个文本分类任务用于finetune,度量指标为准确率,损失函数为交叉熵Loss。
```python
hub.TextClassifierTask(
- feature,
num_classes,
feed_list,
data_reader,
+ feature=None,
+ token_feature=None,
startup_program=None,
config=None,
hidden_units=None,
+ network=None,
metrics_choices="default"):
```
**参数**
-* feature (fluid.Variable): 输入的特征矩阵。
+
* num_classes (int): 分类任务的类别数量
* feed_list (list): 待feed变量的名字列表
-* data_reader: 提供数据的Reader
+* data_reader: 提供数据的Reader,可选为ClassifyReader和LACClassifyReader。
+* feature(fluid.Variable): 输入的sentence-level特征矩阵,shape应为[-1, emb_size]。默认为None。
+* token_feature(fluid.Variable): 输入的token-level特征矩阵,shape应为[-1, seq_len, emb_size]。默认为None。feature和token_feature须指定其中一个。
+* network(str): 文本分类任务PaddleHub预置网络,支持BOW,Bi-LSTM,CNN,DPCNN,GRU,LSTM。如果指定network,则应使用token_feature作为输入特征。其中DPCNN网络实现为[ACL2017-Deep Pyramid Convolutional Neural Networks for Text Categorization](https://www.aclweb.org/anthology/P17-1052.pdf)。
* startup_program (fluid.Program): 存储了模型参数初始化op的Program,如果未提供,则使用fluid.default_startup_program()
-* config ([RunConfig](../config.md)): 运行配置
+* config ([RunConfig](../config.md)): 运行配置,如设置batch_size,epoch,learning_rate等。
* hidden_units (list): TextClassifierTask最终的全连接层输出维度为label_size,是每个label的概率值。在这个全连接层之前可以设置额外的全连接层,并指定它们的输出维度,例如hidden_units=[4,2]表示先经过一层输出维度为4的全连接层,再输入一层输出维度为2的全连接层,最后再输入输出维度为label_size的全连接层。
* metrics_choices("default" or list ⊂ ["acc", "f1", "matthews"]): 任务训练过程中需要计算的评估指标,默认为“default”,此时等效于["acc"]。metrics_choices支持训练过程中同时评估多个指标,其中指定的第一个指标将被作为主指标用于判断当前得分是否为最佳分值,例如["matthews", "acc"],"matthews"将作为主指标,参与最佳模型的判断中;“acc”只计算并输出,不参与最佳模型的判断。
@@ -28,4 +33,4 @@ hub.TextClassifierTask(
**示例**
-[文本分类](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.4/demo/text_classification/text_classifier.py)
+[文本分类](../../../demo/text_classification/text_cls.py)
diff --git a/docs/release.md b/docs/release.md
index 1849191883628e92de3cebf4f3fb51a9830f753f..9a59ba48fd4f44654ba6c6d2166e3c087f31be00 100644
--- a/docs/release.md
+++ b/docs/release.md
@@ -1,5 +1,40 @@
# 更新历史
+## `v1.7.0`
+
+* 丰富预训练模型,提升应用性
+ * 新增VENUS系列视觉预训练模型[yolov3_darknet53_venus](https://www.paddlepaddle.org.cn/hubdetail?name=yolov3_darknet53_venus&en_category=ObjectDetection),[faster_rcnn_resnet50_fpn_venus](https://www.paddlepaddle.org.cn/hubdetail?name=faster_rcnn_resnet50_fpn_venus&en_category=ObjectDetection),可大幅度提升图像分类和目标检测任务的Fine-tune效果
+ * 新增工业级短视频分类模型[videotag_tsn_lstm](https://paddlepaddle.org.cn/hubdetail?name=videotag_tsn_lstm&en_category=VideoClassification),支持3000类中文标签识别
+ * 新增轻量级中文OCR模型[chinese_ocr_db_rcnn](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_ocr_db_rcnn&en_category=TextRecognition)、[chinese_text_detection_db](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_text_detection_db&en_category=TextRecognition),支持一键快速OCR识别
+ * 新增行人检测、车辆检测、动物识别、Object等工业级模型
+
+* Fine-tune API升级
+ * 文本分类任务新增6个预置网络,包括CNN, BOW, LSTM, BiLSTM, DPCNN等
+ * 使用VisualDL可视化训练评估性能数据
+
+## `v1.6.2`
+
+* 修复图像分类在windows下运行错误
+
+## `v1.6.1`
+
+* 修复windows下安装PaddleHub缺失config.json文件
+
+## `v1.6.0`
+
+* NLP Module全面升级,提升应用性和灵活性
+ * lac、senta系列(bow、cnn、bilstm、gru、lstm)、simnet_bow、porn_detection系列(cnn、gru、lstm)升级高性能预测,性能提升高达50%
+ * ERNIE、BERT、RoBERTa等Transformer类语义模型新增获取预训练embedding接口get_embedding,方便接入下游任务,提升应用性
+ * 新增RoBERTa通过模型结构压缩得到的3层Transformer模型[rbt3](https://www.paddlepaddle.org.cn/hubdetail?name=rbt3&en_category=SemanticModel)、[rbtl3](https://www.paddlepaddle.org.cn/hubdetail?name=rbtl3&en_category=SemanticModel)
+
+* Task predict接口增加高性能预测模式accelerate_mode,性能提升高达90%
+
+* PaddleHub Module创建流程开放,支持Fine-tune模型转化,全面提升应用性和灵活性
+ * [预训练模型转化为PaddleHub Module教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/contribution/contri_pretrained_model.md)
+ * [Fine-tune模型转化为PaddleHub Module教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/tutorial/finetuned_model_to_module.md)
+
+* [PaddleHub Serving](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/tutorial/serving.md)优化启动方式,支持更加灵活的参数配置
+
## `v1.5.2`
* 优化pyramidbox_lite_server_mask、pyramidbox_lite_mobile_mask模型的服务化部署性能
diff --git a/docs/tutorial/how_to_load_data.md b/docs/tutorial/how_to_load_data.md
index b56b0e8eb0b624fe458b9ad6ab81868778a98d30..ac3694e005e0730d7abc8ce2d2fe21215ba7ec6a 100644
--- a/docs/tutorial/how_to_load_data.md
+++ b/docs/tutorial/how_to_load_data.md
@@ -95,7 +95,7 @@ label_list.txt的格式如下
```
示例:
-以[DogCat数据集](https://github.com/PaddlePaddle/PaddleHub/wiki/PaddleHub-API:-Dataset#class-hubdatasetdogcatdataset)为示例,train_list.txt/test_list.txt/validate_list.txt内容如下示例
+以[DogCat数据集](../reference/dataset.md#class-hubdatasetdogcatdataset)为示例,train_list.txt/test_list.txt/validate_list.txt内容如下示例
```
cat/3270.jpg 0
cat/646.jpg 0
diff --git a/hub_module/modules/image/classification/efficientnetb0_small_imagenet/module.py b/hub_module/modules/image/classification/efficientnetb0_small_imagenet/module.py
index efd069f36a3cd996dfd98c7116877ac2b60f56a9..393092cb385703f4b2c7fc93c99cb3804baeee2c 100644
--- a/hub_module/modules/image/classification/efficientnetb0_small_imagenet/module.py
+++ b/hub_module/modules/image/classification/efficientnetb0_small_imagenet/module.py
@@ -175,7 +175,7 @@ class EfficientNetB0ImageNet(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/module.py b/hub_module/modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/module.py
index 40a12edfeaecad12264425230d3e8b00ee9c8698..ffd4d06462e5ccb5703b6d0a21a538fdfe3af6f7 100644
--- a/hub_module/modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/module.py
+++ b/hub_module/modules/image/classification/fix_resnext101_32x48d_wsl_imagenet/module.py
@@ -161,7 +161,7 @@ class FixResnext10132x48dwslImagenet(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
if not self.predictor_set:
diff --git a/hub_module/modules/image/classification/mobilenet_v2_animals/module.py b/hub_module/modules/image/classification/mobilenet_v2_animals/module.py
index 87f6f53a7f1a9adaebe951466814cbc1a167ad59..b8afcae07c3fbdc082c821faa288c29bb34b1982 100644
--- a/hub_module/modules/image/classification/mobilenet_v2_animals/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v2_animals/module.py
@@ -161,7 +161,7 @@ class MobileNetV2Animals(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/mobilenet_v2_dishes/module.py b/hub_module/modules/image/classification/mobilenet_v2_dishes/module.py
index 3b9abdd5f7bab314cc7108f6190f00b9a8bdc848..f1be00a305e164b363bb9c8266833f5a986a52a5 100644
--- a/hub_module/modules/image/classification/mobilenet_v2_dishes/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v2_dishes/module.py
@@ -161,7 +161,7 @@ class MobileNetV2Dishes(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/mobilenet_v2_imagenet_ssld/module.py b/hub_module/modules/image/classification/mobilenet_v2_imagenet_ssld/module.py
index 598d7112d8b24b71f2771ce5ed6945a6656a020c..a2bacc749572129cbb5c8e1a4c3257b812df416b 100644
--- a/hub_module/modules/image/classification/mobilenet_v2_imagenet_ssld/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v2_imagenet_ssld/module.py
@@ -184,7 +184,7 @@ class MobileNetV2ImageNetSSLD(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/mobilenet_v3_large_imagenet_ssld/module.py b/hub_module/modules/image/classification/mobilenet_v3_large_imagenet_ssld/module.py
index fcbe73744ce86c98b27ddf9c8c5e5bf442741cbb..07dd93a770a13036f4a1fa74d7cdc11de7a8b2d4 100644
--- a/hub_module/modules/image/classification/mobilenet_v3_large_imagenet_ssld/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v3_large_imagenet_ssld/module.py
@@ -161,7 +161,7 @@ class MobileNetV3Large(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/mobilenet_v3_small_imagenet_ssld/module.py b/hub_module/modules/image/classification/mobilenet_v3_small_imagenet_ssld/module.py
index 4c447dbf3dd64f79061297aca0bad365dbc44c53..5e24ce93d810e40d2f27b658394d3d59586b5754 100644
--- a/hub_module/modules/image/classification/mobilenet_v3_small_imagenet_ssld/module.py
+++ b/hub_module/modules/image/classification/mobilenet_v3_small_imagenet_ssld/module.py
@@ -161,7 +161,7 @@ class MobileNetV3Small(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/resnet18_vd_imagenet/module.py b/hub_module/modules/image/classification/resnet18_vd_imagenet/module.py
index 9870a5db5a5d7f9d150d57a0ac601add77023c38..8171f3f03ab28ec68f5cf4337890899382557e7b 100644
--- a/hub_module/modules/image/classification/resnet18_vd_imagenet/module.py
+++ b/hub_module/modules/image/classification/resnet18_vd_imagenet/module.py
@@ -161,7 +161,7 @@ class ResNet18vdImageNet(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
if not self.predictor_set:
diff --git a/hub_module/modules/image/classification/resnet50_vd_animals/module.py b/hub_module/modules/image/classification/resnet50_vd_animals/module.py
index 5c555ebaca934b6b4f86a3d8a587efce58bcbce3..ed6abe6a873ad1df687792e854a9b5a7c405fe45 100644
--- a/hub_module/modules/image/classification/resnet50_vd_animals/module.py
+++ b/hub_module/modules/image/classification/resnet50_vd_animals/module.py
@@ -161,7 +161,7 @@ class ResNet50vdAnimals(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/resnet50_vd_dishes/module.py b/hub_module/modules/image/classification/resnet50_vd_dishes/module.py
index fb2f3de8f228302af77acf5918d52aaaaba56963..b554a8fc63d98f7e79edc2d634f6dd91a18e915d 100644
--- a/hub_module/modules/image/classification/resnet50_vd_dishes/module.py
+++ b/hub_module/modules/image/classification/resnet50_vd_dishes/module.py
@@ -161,7 +161,7 @@ class ResNet50vdDishes(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/resnet50_vd_imagenet_ssld/module.py b/hub_module/modules/image/classification/resnet50_vd_imagenet_ssld/module.py
index 9464a722d26f28058ef0cafe55f7d7a0a2603ffd..380eb839f7f8df17f6588ad0bbfd04c3c155972f 100644
--- a/hub_module/modules/image/classification/resnet50_vd_imagenet_ssld/module.py
+++ b/hub_module/modules/image/classification/resnet50_vd_imagenet_ssld/module.py
@@ -161,7 +161,7 @@ class ResNet50vdDishes(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/resnet50_vd_wildanimals/module.py b/hub_module/modules/image/classification/resnet50_vd_wildanimals/module.py
index 14fd2f9cf7ac80f686b2fe7f5f1200652b1629f9..3a8d811adac5ebbd6a6f3c729e82accab4272736 100644
--- a/hub_module/modules/image/classification/resnet50_vd_wildanimals/module.py
+++ b/hub_module/modules/image/classification/resnet50_vd_wildanimals/module.py
@@ -161,7 +161,7 @@ class ResNet50vdWildAnimals(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_data = list()
diff --git a/hub_module/modules/image/classification/se_resnet18_vd_imagenet/module.py b/hub_module/modules/image/classification/se_resnet18_vd_imagenet/module.py
index ec219bd8a8aca688ff491b85ad10a5e8f0c65d43..4e6d6db7fd3140ca659e7ffcc29de3fe35af37bd 100644
--- a/hub_module/modules/image/classification/se_resnet18_vd_imagenet/module.py
+++ b/hub_module/modules/image/classification/se_resnet18_vd_imagenet/module.py
@@ -161,7 +161,7 @@ class SEResNet18vdImageNet(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
if not self.predictor_set:
diff --git a/hub_module/modules/image/face_detection/pyramidbox_face_detection/module.py b/hub_module/modules/image/face_detection/pyramidbox_face_detection/module.py
index de0354e2f7e45504ab6c11427f713dfb5394f3f8..c62b8f4374161e330ccf3a3366ae7c7f6aa14b64 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_face_detection/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_face_detection/module.py
@@ -83,7 +83,7 @@ class PyramidBoxFaceDetection(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile/module.py b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile/module.py
index 9e30c5898ea2b94852a547c80333aa5eaf622c92..8d0294a55eb59f83011b90dce8e4b8369dc1e066 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile/module.py
@@ -28,6 +28,7 @@ class PyramidBoxLiteMobile(hub.Module):
self.default_pretrained_model_path = os.path.join(
self.directory, "pyramidbox_lite_mobile_face_detection")
self._set_config()
+ self.processor = self
def _set_config(self):
"""
@@ -81,7 +82,7 @@ class PyramidBoxLiteMobile(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
@@ -130,6 +131,9 @@ class PyramidBoxLiteMobile(hub.Module):
program, feeded_var_names, target_vars = fluid.io.load_inference_model(
dirname=self.default_pretrained_model_path, executor=exe)
+ var = program.global_block().vars['detection_output_0.tmp_1']
+ var.desc.set_dtype(fluid.core.VarDesc.VarType.INT32)
+
fluid.io.save_inference_model(
dirname=dirname,
main_program=program,
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py
index 391aaedfab74ba15124d0dc7b81faa95632ac4f4..e98c9944ff76c8baa97988580fd994c5431048d7 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/module.py
@@ -37,6 +37,7 @@ class PyramidBoxLiteMobileMask(hub.Module):
else:
self.face_detector = face_detector_module
self._set_config()
+ self.processor = self
def _set_config(self):
"""
@@ -107,7 +108,7 @@ class PyramidBoxLiteMobileMask(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py
index 3e3bf1515143cfbcd1dccda71b03cd3b0cf1e77b..61c7be6addd3c1791d1c8e46d0bcd58dcf93e8c9 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_mobile_mask/processor.py
@@ -94,12 +94,12 @@ def draw_bounding_box_on_image(save_im_path, output_data):
box_fill = (255)
text_fill = (0)
- draw.rectangle(
- xy=(bbox['left'], bbox['top'] - (textsize_height + 5),
- bbox['left'] + textsize_width + 10, bbox['top'] - 3),
- fill=box_fill)
- draw.text(
- xy=(bbox['left'], bbox['top'] - 15), text=text, fill=text_fill)
+ draw.rectangle(
+ xy=(bbox['left'], bbox['top'] - (textsize_height + 5),
+ bbox['left'] + textsize_width + 10, bbox['top'] - 3),
+ fill=box_fill)
+ draw.text(
+ xy=(bbox['left'], bbox['top'] - 15), text=text, fill=text_fill)
image.save(save_im_path)
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_server/module.py b/hub_module/modules/image/face_detection/pyramidbox_lite_server/module.py
index fe9b3b8437720df5bb2bc4731b43dc075f6a04e6..5e7be439d8c6a22a43fa020982e7bc1709639499 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_server/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_server/module.py
@@ -28,6 +28,7 @@ class PyramidBoxLiteServer(hub.Module):
self.default_pretrained_model_path = os.path.join(
self.directory, "pyramidbox_lite_server_face_detection")
self._set_config()
+ self.processor = self
def _set_config(self):
"""
@@ -81,7 +82,7 @@ class PyramidBoxLiteServer(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/module.py b/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/module.py
index 8fd45be7a5e03d9ed8a4434cdcf859ebe847eb01..06cc0f3cee0101b6806f6dfa4545cbe3a8babddc 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/module.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/module.py
@@ -37,6 +37,7 @@ class PyramidBoxLiteServerMask(hub.Module):
else:
self.face_detector = face_detector_module
self._set_config()
+ self.processor = self
def _set_config(self):
"""
@@ -106,7 +107,7 @@ class PyramidBoxLiteServerMask(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py b/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py
index 3e3bf1515143cfbcd1dccda71b03cd3b0cf1e77b..61c7be6addd3c1791d1c8e46d0bcd58dcf93e8c9 100644
--- a/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py
+++ b/hub_module/modules/image/face_detection/pyramidbox_lite_server_mask/processor.py
@@ -94,12 +94,12 @@ def draw_bounding_box_on_image(save_im_path, output_data):
box_fill = (255)
text_fill = (0)
- draw.rectangle(
- xy=(bbox['left'], bbox['top'] - (textsize_height + 5),
- bbox['left'] + textsize_width + 10, bbox['top'] - 3),
- fill=box_fill)
- draw.text(
- xy=(bbox['left'], bbox['top'] - 15), text=text, fill=text_fill)
+ draw.rectangle(
+ xy=(bbox['left'], bbox['top'] - (textsize_height + 5),
+ bbox['left'] + textsize_width + 10, bbox['top'] - 3),
+ fill=box_fill)
+ draw.text(
+ xy=(bbox['left'], bbox['top'] - 15), text=text, fill=text_fill)
image.save(save_im_path)
diff --git a/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py b/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py
index dafd852508a6aea11955d6d9cb8cced18e35aa8d..8237b7f3d743bdb29923c6dab0ff3d6f576127d2 100644
--- a/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py
+++ b/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_320/module.py
@@ -107,7 +107,7 @@ class FaceDetector320(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py b/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py
index 32075ed6c33ea03b1670dbe8fdd6082046fe64fe..1635237858b6a6c757d52e4df843063c46f7a0f6 100644
--- a/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py
+++ b/hub_module/modules/image/face_detection/ultra_light_fast_generic_face_detector_1mb_640/module.py
@@ -106,7 +106,7 @@ class FaceDetector640(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/keypoint_detection/face_landmark_localization/module.py b/hub_module/modules/image/keypoint_detection/face_landmark_localization/module.py
index 7c8d25d657e470209b20190d0e74ac8d1f792e48..5b21ad7902119b3e0d448f570fa474ebf8a79b1c 100644
--- a/hub_module/modules/image/keypoint_detection/face_landmark_localization/module.py
+++ b/hub_module/modules/image/keypoint_detection/face_landmark_localization/module.py
@@ -133,7 +133,7 @@ class FaceLandmarkLocalization(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# get all data
diff --git a/hub_module/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py b/hub_module/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py
index b65aa88ebdd33e91af3bd731bbede657478a35d5..c61cc84ab900a7c700993ab7ce5fc5fa8320ac44 100644
--- a/hub_module/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/faster_rcnn_resnet50_coco2017/module.py
@@ -323,7 +323,7 @@ class FasterRCNNResNet50(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
if data and 'image' in data:
diff --git a/hub_module/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py b/hub_module/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py
index c64f12978b247ec942f6337d856fb674b0cffda8..f84521ac284742934681fa8ad5e96a11b0990831 100644
--- a/hub_module/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/faster_rcnn_resnet50_fpn_coco2017/module.py
@@ -333,7 +333,7 @@ class FasterRCNNResNet50RPN(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
diff --git a/hub_module/modules/image/object_detection/retinanet_resnet50_fpn_coco2017/module.py b/hub_module/modules/image/object_detection/retinanet_resnet50_fpn_coco2017/module.py
index 97d195f28cf4f6c61258ec8c4414eca60e9befaf..ceec9ca585e2a52d592638c0a9ebffc39ccb0cab 100644
--- a/hub_module/modules/image/object_detection/retinanet_resnet50_fpn_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/retinanet_resnet50_fpn_coco2017/module.py
@@ -246,7 +246,7 @@ class RetinaNetResNet50FPN(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
all_images = list()
diff --git a/hub_module/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py b/hub_module/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py
index 315bb2dd8ef6e75918ccb4e7142a9056a49d8854..8ee1e7edf1ced1b0e1d616e780d91a7f4e53cb20 100644
--- a/hub_module/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py
+++ b/hub_module/modules/image/object_detection/ssd_mobilenet_v1_pascal/module.py
@@ -21,7 +21,7 @@ from ssd_mobilenet_v1_pascal.data_feed import reader
@moduleinfo(
name="ssd_mobilenet_v1_pascal",
- version="1.1.0",
+ version="1.1.1",
type="cv/object_detection",
summary="SSD with backbone MobileNet_V1, trained with dataset Pasecal VOC.",
author="paddlepaddle",
@@ -194,7 +194,7 @@ class SSDMobileNetv1(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -275,7 +275,7 @@ class SSDMobileNetv1(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py b/hub_module/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py
index 6027bcd0d22659a47597ef2fe6615e79751adce2..7310bf04d9e208e36e4d72a25ccc93b8a001012f 100644
--- a/hub_module/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/ssd_vgg16_300_coco2017/module.py
@@ -21,7 +21,7 @@ from ssd_vgg16_300_coco2017.data_feed import reader
@moduleinfo(
name="ssd_vgg16_300_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="cv/object_detection",
summary="SSD with backbone VGG16, trained with dataset COCO.",
author="paddlepaddle",
@@ -264,7 +264,7 @@ class SSDVGG16(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py b/hub_module/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py
index a0514153734b0857cc5548697ecf716ccb6bea3c..e7246367c5e9e895e8d840f37bb66ce8e0ad2b17 100644
--- a/hub_module/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/ssd_vgg16_512_coco2017/module.py
@@ -21,7 +21,7 @@ from ssd_vgg16_512_coco2017.data_feed import reader
@moduleinfo(
name="ssd_vgg16_512_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="cv/object_detection",
summary="SSD with backbone VGG16, trained with dataset COCO.",
author="paddlepaddle",
@@ -200,7 +200,7 @@ class SSDVGG16_512(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -278,7 +278,7 @@ class SSDVGG16_512(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_darknet53_coco2017/module.py b/hub_module/modules/image/object_detection/yolov3_darknet53_coco2017/module.py
index 9ffe7022db9049cd290aa0a8a398257d01b9fb59..1b693fb27c695e14030e81c3f3e623f7d04a0651 100644
--- a/hub_module/modules/image/object_detection/yolov3_darknet53_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_darknet53_coco2017/module.py
@@ -21,7 +21,7 @@ from yolov3_darknet53_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_darknet53_coco2017",
- version="1.1.0",
+ version="1.1.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection, with backbone DarkNet53, trained with dataset coco2017.",
@@ -186,7 +186,7 @@ class YOLOv3DarkNet53Coco2017(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -270,7 +270,7 @@ class YOLOv3DarkNet53Coco2017(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py b/hub_module/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py
index 6f76e25c03540af13c7477d307d81b2bdc568fe4..7630d372801bb633d765ba966bb2eaa458df58e0 100644
--- a/hub_module/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_darknet53_pedestrian/module.py
@@ -21,7 +21,7 @@ from yolov3_darknet53_pedestrian.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_darknet53_pedestrian",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for pedestrian detection, with backbone DarkNet53.",
@@ -199,7 +199,7 @@ class YOLOv3DarkNet53Pedestrian(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -280,7 +280,7 @@ class YOLOv3DarkNet53Pedestrian(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_darknet53_vehicles/module.py b/hub_module/modules/image/object_detection/yolov3_darknet53_vehicles/module.py
index 685afbff579609f0a855486d87a3ada24315ba1c..801228f6b576b34bfcf8de04d0f56f956d17c709 100644
--- a/hub_module/modules/image/object_detection/yolov3_darknet53_vehicles/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_darknet53_vehicles/module.py
@@ -21,7 +21,7 @@ from yolov3_darknet53_vehicles.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_darknet53_vehicles",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for vehicles detection, with backbone DarkNet53.",
@@ -199,7 +199,7 @@ class YOLOv3DarkNet53Vehicles(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -280,7 +280,7 @@ class YOLOv3DarkNet53Vehicles(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py b/hub_module/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py
index 03bde930aa07a529455f6adae80e70d0cc899b31..659cde37ca481f524ebd33daedc80eb3adc24b3a 100644
--- a/hub_module/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_mobilenet_v1_coco2017/module.py
@@ -21,7 +21,7 @@ from yolov3_mobilenet_v1_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_mobilenet_v1_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection with backbone MobileNet_V1, trained with dataset COCO2017.",
@@ -189,7 +189,7 @@ class YOLOv3MobileNetV1Coco2017(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -270,7 +270,7 @@ class YOLOv3MobileNetV1Coco2017(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_resnet34_coco2017/module.py b/hub_module/modules/image/object_detection/yolov3_resnet34_coco2017/module.py
index 98712df2b55d6777e2c827a9d6104ed406e671f0..14e31fdd667d3fc9eaa78f185d0c57984fb7ebe0 100644
--- a/hub_module/modules/image/object_detection/yolov3_resnet34_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_resnet34_coco2017/module.py
@@ -21,7 +21,7 @@ from yolov3_resnet34_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_resnet34_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection with backbone ResNet34, trained with dataset coco2017.",
@@ -191,7 +191,7 @@ class YOLOv3ResNet34Coco2017(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -272,7 +272,7 @@ class YOLOv3ResNet34Coco2017(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py b/hub_module/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py
index 4e5a4d053d85b98ada94ea1776f6c3c0376d9dd7..5c25f17cd37df1a7e67dba76ade582ddbc0b89e5 100644
--- a/hub_module/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py
+++ b/hub_module/modules/image/object_detection/yolov3_resnet50_vd_coco2017/module.py
@@ -21,7 +21,7 @@ from yolov3_resnet50_vd_coco2017.yolo_head import MultiClassNMS, YOLOv3Head
@moduleinfo(
name="yolov3_resnet50_vd_coco2017",
- version="1.0.0",
+ version="1.0.1",
type="CV/object_detection",
summary=
"Baidu's YOLOv3 model for object detection with backbone ResNet50, trained with dataset coco2017.",
@@ -193,7 +193,7 @@ class YOLOv3ResNet50Coco2017(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
paths = paths if paths else list()
@@ -274,7 +274,7 @@ class YOLOv3ResNet50Coco2017(hub.Module):
self.add_module_config_arg()
self.add_module_input_arg()
args = self.parser.parse_args(argvs)
- results = self.face_detection(
+ results = self.object_detection(
paths=[args.input_path],
batch_size=args.batch_size,
use_gpu=args.use_gpu,
diff --git a/hub_module/modules/image/semantic_segmentation/ace2p/module.py b/hub_module/modules/image/semantic_segmentation/ace2p/module.py
index 149b981e779292f28250f686f0c3bac487ac3903..d8908525ddd5c0c1d98a0f9ce0dddff453a9c128 100644
--- a/hub_module/modules/image/semantic_segmentation/ace2p/module.py
+++ b/hub_module/modules/image/semantic_segmentation/ace2p/module.py
@@ -86,7 +86,7 @@ class ACE2P(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/module.py b/hub_module/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/module.py
index 84c4b7621a5ac22d2765aab20682169fd42170a0..b6f0f22749119fe72f8d046806073aa10b6fa0a2 100644
--- a/hub_module/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/module.py
+++ b/hub_module/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/module.py
@@ -82,7 +82,7 @@ class DeeplabV3pXception65HumanSeg(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
# compatibility with older versions
diff --git a/hub_module/modules/image/style_transfer/stylepro_artistic/module.py b/hub_module/modules/image/style_transfer/stylepro_artistic/module.py
index 86373516364c6f14e45bc516d88bf417cf7b531d..7fc1461246899d8f21a2d12d8dce6dd4aa65f331 100644
--- a/hub_module/modules/image/style_transfer/stylepro_artistic/module.py
+++ b/hub_module/modules/image/style_transfer/stylepro_artistic/module.py
@@ -104,7 +104,7 @@ class StyleProjection(hub.Module):
int(_places[0])
except:
raise RuntimeError(
- "Attempt to use GPU for prediction, but environment variable CUDA_VISIBLE_DEVICES was not set correctly."
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
)
im_output = []
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/README.md b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..08533849bf00a8dbb11db70af7cf051db0ebf6ed
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/README.md
@@ -0,0 +1,134 @@
+## 概述
+
+chinese_ocr_db_crnn_mobile Module用于识别图片当中的汉字。其基于[chinese_text_detection_db_mobile Module](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_text_detection_db_mobile&en_category=TextRecognition)检测得到的文本框,继续识别文本框中的中文文字。识别文字算法采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module是一个超轻量级中文OCR模型,支持直接预测。
+
+
+
+
+
+
+更多详情参考[An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition](https://arxiv.org/pdf/1507.05717.pdf)
+
+## 命令行预测
+
+```shell
+$ hub run chinese_ocr_db_crnn_mobile --input_path "/PATH/TO/IMAGE"
+```
+
+**该Module依赖于第三方库shapely和pyclipper,使用该Module之前,请先安装shapely和pyclipper。**
+
+## API
+
+```python
+def recognize_text(images=[],
+ paths=[],
+ use_gpu=False,
+ output_dir='ocr_result',
+ visualization=False,
+ box_thresh=0.5,
+ text_thresh=0.5)
+```
+
+预测API,检测输入图片中的所有中文文本的位置。
+
+**参数**
+
+* paths (list\[str\]): 图片的路径;
+* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量**
+* box\_thresh (float): 检测文本框置信度的阈值;
+* text\_thresh (float): 识别中文文本置信度的阈值;
+* visualization (bool): 是否将识别结果保存为图片文件;
+* output\_dir (str): 图片的保存路径,默认设为 ocr\_result;
+
+**返回**
+
+* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
+ * data (list\[dict\]): 识别文本结果,列表中每一个元素为 dict,各字段为:
+ * text(str): 识别得到的文本
+ * confidence(float): 识别文本结果置信度
+ * text_box_position(list): 文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标
+ 如果无识别结果则data为\[\]
+ * save_path (str, optional): 识别结果的保存路径,如不保存图片则save_path为''
+
+### 代码示例
+
+```python
+import paddlehub as hub
+import cv2
+
+ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
+result = ocr.recognize_text(images=[cv2.imread('/PATH/TO/IMAGE')])
+
+# or
+# result = ocr.recognize_text(paths=['/PATH/TO/IMAGE'])
+```
+
+* 样例结果示例
+
+
+
+
+
+## 服务部署
+
+PaddleHub Serving 可以部署一个目标检测的在线服务。
+
+### 第一步:启动PaddleHub Serving
+
+运行启动命令:
+```shell
+$ hub serving start -m chinese_ocr_db_crnn_mobile
+```
+
+这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+### 第二步:发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+# 发送HTTP请求
+data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/chinese_ocr_db_crnn_mobile"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+# 打印预测结果
+print(r.json()["results"])
+```
+
+## 查看代码
+
+https://github.com/PaddlePaddle/PaddleOCR
+
+### 依赖
+
+paddlepaddle >= 1.7.2
+
+paddlehub >= 1.6.0
+
+shapely
+
+pyclipper
+
+## 更新历史
+
+* 1.0.0
+
+ 初始发布
+
+* 1.0.1
+
+ 修复使用在线服务调用模型失败问题
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/__init__.py b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/assets/ppocr_keys_v1.txt b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/assets/ppocr_keys_v1.txt
new file mode 100644
index 0000000000000000000000000000000000000000..b75af2130342e619dbb9f3f87dc8b74aa27b4a76
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/assets/ppocr_keys_v1.txt
@@ -0,0 +1,6623 @@
+'
+疗
+绚
+诚
+娇
+溜
+题
+贿
+者
+廖
+更
+纳
+加
+奉
+公
+一
+就
+汴
+计
+与
+路
+房
+原
+妇
+2
+0
+8
+-
+7
+其
+>
+:
+]
+,
+,
+骑
+刈
+全
+消
+昏
+傈
+安
+久
+钟
+嗅
+不
+影
+处
+驽
+蜿
+资
+关
+椤
+地
+瘸
+专
+问
+忖
+票
+嫉
+炎
+韵
+要
+月
+田
+节
+陂
+鄙
+捌
+备
+拳
+伺
+眼
+网
+盎
+大
+傍
+心
+东
+愉
+汇
+蹿
+科
+每
+业
+里
+航
+晏
+字
+平
+录
+先
+1
+3
+彤
+鲶
+产
+稍
+督
+腴
+有
+象
+岳
+注
+绍
+在
+泺
+文
+定
+核
+名
+水
+过
+理
+让
+偷
+率
+等
+这
+发
+”
+为
+含
+肥
+酉
+相
+鄱
+七
+编
+猥
+锛
+日
+镀
+蒂
+掰
+倒
+辆
+栾
+栗
+综
+涩
+州
+雌
+滑
+馀
+了
+机
+块
+司
+宰
+甙
+兴
+矽
+抚
+保
+用
+沧
+秩
+如
+收
+息
+滥
+页
+疑
+埠
+!
+!
+姥
+异
+橹
+钇
+向
+下
+跄
+的
+椴
+沫
+国
+绥
+獠
+报
+开
+民
+蜇
+何
+分
+凇
+长
+讥
+藏
+掏
+施
+羽
+中
+讲
+派
+嘟
+人
+提
+浼
+间
+世
+而
+古
+多
+倪
+唇
+饯
+控
+庚
+首
+赛
+蜓
+味
+断
+制
+觉
+技
+替
+艰
+溢
+潮
+夕
+钺
+外
+摘
+枋
+动
+双
+单
+啮
+户
+枇
+确
+锦
+曜
+杜
+或
+能
+效
+霜
+盒
+然
+侗
+电
+晁
+放
+步
+鹃
+新
+杖
+蜂
+吒
+濂
+瞬
+评
+总
+隍
+对
+独
+合
+也
+是
+府
+青
+天
+诲
+墙
+组
+滴
+级
+邀
+帘
+示
+已
+时
+骸
+仄
+泅
+和
+遨
+店
+雇
+疫
+持
+巍
+踮
+境
+只
+亨
+目
+鉴
+崤
+闲
+体
+泄
+杂
+作
+般
+轰
+化
+解
+迂
+诿
+蛭
+璀
+腾
+告
+版
+服
+省
+师
+小
+规
+程
+线
+海
+办
+引
+二
+桧
+牌
+砺
+洄
+裴
+修
+图
+痫
+胡
+许
+犊
+事
+郛
+基
+柴
+呼
+食
+研
+奶
+律
+蛋
+因
+葆
+察
+戏
+褒
+戒
+再
+李
+骁
+工
+貂
+油
+鹅
+章
+啄
+休
+场
+给
+睡
+纷
+豆
+器
+捎
+说
+敏
+学
+会
+浒
+设
+诊
+格
+廓
+查
+来
+霓
+室
+溆
+¢
+诡
+寥
+焕
+舜
+柒
+狐
+回
+戟
+砾
+厄
+实
+翩
+尿
+五
+入
+径
+惭
+喹
+股
+宇
+篝
+|
+;
+美
+期
+云
+九
+祺
+扮
+靠
+锝
+槌
+系
+企
+酰
+阊
+暂
+蚕
+忻
+豁
+本
+羹
+执
+条
+钦
+H
+獒
+限
+进
+季
+楦
+于
+芘
+玖
+铋
+茯
+未
+答
+粘
+括
+样
+精
+欠
+矢
+甥
+帷
+嵩
+扣
+令
+仔
+风
+皈
+行
+支
+部
+蓉
+刮
+站
+蜡
+救
+钊
+汗
+松
+嫌
+成
+可
+.
+鹤
+院
+从
+交
+政
+怕
+活
+调
+球
+局
+验
+髌
+第
+韫
+谗
+串
+到
+圆
+年
+米
+/
+*
+友
+忿
+检
+区
+看
+自
+敢
+刃
+个
+兹
+弄
+流
+留
+同
+没
+齿
+星
+聆
+轼
+湖
+什
+三
+建
+蛔
+儿
+椋
+汕
+震
+颧
+鲤
+跟
+力
+情
+璺
+铨
+陪
+务
+指
+族
+训
+滦
+鄣
+濮
+扒
+商
+箱
+十
+召
+慷
+辗
+所
+莞
+管
+护
+臭
+横
+硒
+嗓
+接
+侦
+六
+露
+党
+馋
+驾
+剖
+高
+侬
+妪
+幂
+猗
+绺
+骐
+央
+酐
+孝
+筝
+课
+徇
+缰
+门
+男
+西
+项
+句
+谙
+瞒
+秃
+篇
+教
+碲
+罚
+声
+呐
+景
+前
+富
+嘴
+鳌
+稀
+免
+朋
+啬
+睐
+去
+赈
+鱼
+住
+肩
+愕
+速
+旁
+波
+厅
+健
+茼
+厥
+鲟
+谅
+投
+攸
+炔
+数
+方
+击
+呋
+谈
+绩
+别
+愫
+僚
+躬
+鹧
+胪
+炳
+招
+喇
+膨
+泵
+蹦
+毛
+结
+5
+4
+谱
+识
+陕
+粽
+婚
+拟
+构
+且
+搜
+任
+潘
+比
+郢
+妨
+醪
+陀
+桔
+碘
+扎
+选
+哈
+骷
+楷
+亿
+明
+缆
+脯
+监
+睫
+逻
+婵
+共
+赴
+淝
+凡
+惦
+及
+达
+揖
+谩
+澹
+减
+焰
+蛹
+番
+祁
+柏
+员
+禄
+怡
+峤
+龙
+白
+叽
+生
+闯
+起
+细
+装
+谕
+竟
+聚
+钙
+上
+导
+渊
+按
+艾
+辘
+挡
+耒
+盹
+饪
+臀
+记
+邮
+蕙
+受
+各
+医
+搂
+普
+滇
+朗
+茸
+带
+翻
+酚
+(
+光
+堤
+墟
+蔷
+万
+幻
+〓
+瑙
+辈
+昧
+盏
+亘
+蛀
+吉
+铰
+请
+子
+假
+闻
+税
+井
+诩
+哨
+嫂
+好
+面
+琐
+校
+馊
+鬣
+缂
+营
+访
+炖
+占
+农
+缀
+否
+经
+钚
+棵
+趟
+张
+亟
+吏
+茶
+谨
+捻
+论
+迸
+堂
+玉
+信
+吧
+瞠
+乡
+姬
+寺
+咬
+溏
+苄
+皿
+意
+赉
+宝
+尔
+钰
+艺
+特
+唳
+踉
+都
+荣
+倚
+登
+荐
+丧
+奇
+涵
+批
+炭
+近
+符
+傩
+感
+道
+着
+菊
+虹
+仲
+众
+懈
+濯
+颞
+眺
+南
+释
+北
+缝
+标
+既
+茗
+整
+撼
+迤
+贲
+挎
+耱
+拒
+某
+妍
+卫
+哇
+英
+矶
+藩
+治
+他
+元
+领
+膜
+遮
+穗
+蛾
+飞
+荒
+棺
+劫
+么
+市
+火
+温
+拈
+棚
+洼
+转
+果
+奕
+卸
+迪
+伸
+泳
+斗
+邡
+侄
+涨
+屯
+萋
+胭
+氡
+崮
+枞
+惧
+冒
+彩
+斜
+手
+豚
+随
+旭
+淑
+妞
+形
+菌
+吲
+沱
+争
+驯
+歹
+挟
+兆
+柱
+传
+至
+包
+内
+响
+临
+红
+功
+弩
+衡
+寂
+禁
+老
+棍
+耆
+渍
+织
+害
+氵
+渑
+布
+载
+靥
+嗬
+虽
+苹
+咨
+娄
+库
+雉
+榜
+帜
+嘲
+套
+瑚
+亲
+簸
+欧
+边
+6
+腿
+旮
+抛
+吹
+瞳
+得
+镓
+梗
+厨
+继
+漾
+愣
+憨
+士
+策
+窑
+抑
+躯
+襟
+脏
+参
+贸
+言
+干
+绸
+鳄
+穷
+藜
+音
+折
+详
+)
+举
+悍
+甸
+癌
+黎
+谴
+死
+罩
+迁
+寒
+驷
+袖
+媒
+蒋
+掘
+模
+纠
+恣
+观
+祖
+蛆
+碍
+位
+稿
+主
+澧
+跌
+筏
+京
+锏
+帝
+贴
+证
+糠
+才
+黄
+鲸
+略
+炯
+饱
+四
+出
+园
+犀
+牧
+容
+汉
+杆
+浈
+汰
+瑷
+造
+虫
+瘩
+怪
+驴
+济
+应
+花
+沣
+谔
+夙
+旅
+价
+矿
+以
+考
+s
+u
+呦
+晒
+巡
+茅
+准
+肟
+瓴
+詹
+仟
+褂
+译
+桌
+混
+宁
+怦
+郑
+抿
+些
+余
+鄂
+饴
+攒
+珑
+群
+阖
+岔
+琨
+藓
+预
+环
+洮
+岌
+宀
+杲
+瀵
+最
+常
+囡
+周
+踊
+女
+鼓
+袭
+喉
+简
+范
+薯
+遐
+疏
+粱
+黜
+禧
+法
+箔
+斤
+遥
+汝
+奥
+直
+贞
+撑
+置
+绱
+集
+她
+馅
+逗
+钧
+橱
+魉
+[
+恙
+躁
+唤
+9
+旺
+膘
+待
+脾
+惫
+购
+吗
+依
+盲
+度
+瘿
+蠖
+俾
+之
+镗
+拇
+鲵
+厝
+簧
+续
+款
+展
+啃
+表
+剔
+品
+钻
+腭
+损
+清
+锶
+统
+涌
+寸
+滨
+贪
+链
+吠
+冈
+伎
+迥
+咏
+吁
+览
+防
+迅
+失
+汾
+阔
+逵
+绀
+蔑
+列
+川
+凭
+努
+熨
+揪
+利
+俱
+绉
+抢
+鸨
+我
+即
+责
+膦
+易
+毓
+鹊
+刹
+玷
+岿
+空
+嘞
+绊
+排
+术
+估
+锷
+违
+们
+苟
+铜
+播
+肘
+件
+烫
+审
+鲂
+广
+像
+铌
+惰
+铟
+巳
+胍
+鲍
+康
+憧
+色
+恢
+想
+拷
+尤
+疳
+知
+S
+Y
+F
+D
+A
+峄
+裕
+帮
+握
+搔
+氐
+氘
+难
+墒
+沮
+雨
+叁
+缥
+悴
+藐
+湫
+娟
+苑
+稠
+颛
+簇
+后
+阕
+闭
+蕤
+缚
+怎
+佞
+码
+嘤
+蔡
+痊
+舱
+螯
+帕
+赫
+昵
+升
+烬
+岫
+、
+疵
+蜻
+髁
+蕨
+隶
+烛
+械
+丑
+盂
+梁
+强
+鲛
+由
+拘
+揉
+劭
+龟
+撤
+钩
+呕
+孛
+费
+妻
+漂
+求
+阑
+崖
+秤
+甘
+通
+深
+补
+赃
+坎
+床
+啪
+承
+吼
+量
+暇
+钼
+烨
+阂
+擎
+脱
+逮
+称
+P
+神
+属
+矗
+华
+届
+狍
+葑
+汹
+育
+患
+窒
+蛰
+佼
+静
+槎
+运
+鳗
+庆
+逝
+曼
+疱
+克
+代
+官
+此
+麸
+耧
+蚌
+晟
+例
+础
+榛
+副
+测
+唰
+缢
+迹
+灬
+霁
+身
+岁
+赭
+扛
+又
+菡
+乜
+雾
+板
+读
+陷
+徉
+贯
+郁
+虑
+变
+钓
+菜
+圾
+现
+琢
+式
+乐
+维
+渔
+浜
+左
+吾
+脑
+钡
+警
+T
+啵
+拴
+偌
+漱
+湿
+硕
+止
+骼
+魄
+积
+燥
+联
+踢
+玛
+则
+窿
+见
+振
+畿
+送
+班
+钽
+您
+赵
+刨
+印
+讨
+踝
+籍
+谡
+舌
+崧
+汽
+蔽
+沪
+酥
+绒
+怖
+财
+帖
+肱
+私
+莎
+勋
+羔
+霸
+励
+哼
+帐
+将
+帅
+渠
+纪
+婴
+娩
+岭
+厘
+滕
+吻
+伤
+坝
+冠
+戊
+隆
+瘁
+介
+涧
+物
+黍
+并
+姗
+奢
+蹑
+掣
+垸
+锴
+命
+箍
+捉
+病
+辖
+琰
+眭
+迩
+艘
+绌
+繁
+寅
+若
+毋
+思
+诉
+类
+诈
+燮
+轲
+酮
+狂
+重
+反
+职
+筱
+县
+委
+磕
+绣
+奖
+晋
+濉
+志
+徽
+肠
+呈
+獐
+坻
+口
+片
+碰
+几
+村
+柿
+劳
+料
+获
+亩
+惕
+晕
+厌
+号
+罢
+池
+正
+鏖
+煨
+家
+棕
+复
+尝
+懋
+蜥
+锅
+岛
+扰
+队
+坠
+瘾
+钬
+@
+卧
+疣
+镇
+譬
+冰
+彷
+频
+黯
+据
+垄
+采
+八
+缪
+瘫
+型
+熹
+砰
+楠
+襁
+箐
+但
+嘶
+绳
+啤
+拍
+盥
+穆
+傲
+洗
+盯
+塘
+怔
+筛
+丿
+台
+恒
+喂
+葛
+永
+¥
+烟
+酒
+桦
+书
+砂
+蚝
+缉
+态
+瀚
+袄
+圳
+轻
+蛛
+超
+榧
+遛
+姒
+奘
+铮
+右
+荽
+望
+偻
+卡
+丶
+氰
+附
+做
+革
+索
+戚
+坨
+桷
+唁
+垅
+榻
+岐
+偎
+坛
+莨
+山
+殊
+微
+骇
+陈
+爨
+推
+嗝
+驹
+澡
+藁
+呤
+卤
+嘻
+糅
+逛
+侵
+郓
+酌
+德
+摇
+※
+鬃
+被
+慨
+殡
+羸
+昌
+泡
+戛
+鞋
+河
+宪
+沿
+玲
+鲨
+翅
+哽
+源
+铅
+语
+照
+邯
+址
+荃
+佬
+顺
+鸳
+町
+霭
+睾
+瓢
+夸
+椁
+晓
+酿
+痈
+咔
+侏
+券
+噎
+湍
+签
+嚷
+离
+午
+尚
+社
+锤
+背
+孟
+使
+浪
+缦
+潍
+鞅
+军
+姹
+驶
+笑
+鳟
+鲁
+》
+孽
+钜
+绿
+洱
+礴
+焯
+椰
+颖
+囔
+乌
+孔
+巴
+互
+性
+椽
+哞
+聘
+昨
+早
+暮
+胶
+炀
+隧
+低
+彗
+昝
+铁
+呓
+氽
+藉
+喔
+癖
+瑗
+姨
+权
+胱
+韦
+堑
+蜜
+酋
+楝
+砝
+毁
+靓
+歙
+锲
+究
+屋
+喳
+骨
+辨
+碑
+武
+鸠
+宫
+辜
+烊
+适
+坡
+殃
+培
+佩
+供
+走
+蜈
+迟
+翼
+况
+姣
+凛
+浔
+吃
+飘
+债
+犟
+金
+促
+苛
+崇
+坂
+莳
+畔
+绂
+兵
+蠕
+斋
+根
+砍
+亢
+欢
+恬
+崔
+剁
+餐
+榫
+快
+扶
+‖
+濒
+缠
+鳜
+当
+彭
+驭
+浦
+篮
+昀
+锆
+秸
+钳
+弋
+娣
+瞑
+夷
+龛
+苫
+拱
+致
+%
+嵊
+障
+隐
+弑
+初
+娓
+抉
+汩
+累
+蓖
+"
+唬
+助
+苓
+昙
+押
+毙
+破
+城
+郧
+逢
+嚏
+獭
+瞻
+溱
+婿
+赊
+跨
+恼
+璧
+萃
+姻
+貉
+灵
+炉
+密
+氛
+陶
+砸
+谬
+衔
+点
+琛
+沛
+枳
+层
+岱
+诺
+脍
+榈
+埂
+征
+冷
+裁
+打
+蹴
+素
+瘘
+逞
+蛐
+聊
+激
+腱
+萘
+踵
+飒
+蓟
+吆
+取
+咙
+簋
+涓
+矩
+曝
+挺
+揣
+座
+你
+史
+舵
+焱
+尘
+苏
+笈
+脚
+溉
+榨
+诵
+樊
+邓
+焊
+义
+庶
+儋
+蟋
+蒲
+赦
+呷
+杞
+诠
+豪
+还
+试
+颓
+茉
+太
+除
+紫
+逃
+痴
+草
+充
+鳕
+珉
+祗
+墨
+渭
+烩
+蘸
+慕
+璇
+镶
+穴
+嵘
+恶
+骂
+险
+绋
+幕
+碉
+肺
+戳
+刘
+潞
+秣
+纾
+潜
+銮
+洛
+须
+罘
+销
+瘪
+汞
+兮
+屉
+r
+林
+厕
+质
+探
+划
+狸
+殚
+善
+煊
+烹
+〒
+锈
+逯
+宸
+辍
+泱
+柚
+袍
+远
+蹋
+嶙
+绝
+峥
+娥
+缍
+雀
+徵
+认
+镱
+谷
+=
+贩
+勉
+撩
+鄯
+斐
+洋
+非
+祚
+泾
+诒
+饿
+撬
+威
+晷
+搭
+芍
+锥
+笺
+蓦
+候
+琊
+档
+礁
+沼
+卵
+荠
+忑
+朝
+凹
+瑞
+头
+仪
+弧
+孵
+畏
+铆
+突
+衲
+车
+浩
+气
+茂
+悖
+厢
+枕
+酝
+戴
+湾
+邹
+飚
+攘
+锂
+写
+宵
+翁
+岷
+无
+喜
+丈
+挑
+嗟
+绛
+殉
+议
+槽
+具
+醇
+淞
+笃
+郴
+阅
+饼
+底
+壕
+砚
+弈
+询
+缕
+庹
+翟
+零
+筷
+暨
+舟
+闺
+甯
+撞
+麂
+茌
+蔼
+很
+珲
+捕
+棠
+角
+阉
+媛
+娲
+诽
+剿
+尉
+爵
+睬
+韩
+诰
+匣
+危
+糍
+镯
+立
+浏
+阳
+少
+盆
+舔
+擘
+匪
+申
+尬
+铣
+旯
+抖
+赘
+瓯
+居
+ˇ
+哮
+游
+锭
+茏
+歌
+坏
+甚
+秒
+舞
+沙
+仗
+劲
+潺
+阿
+燧
+郭
+嗖
+霏
+忠
+材
+奂
+耐
+跺
+砀
+输
+岖
+媳
+氟
+极
+摆
+灿
+今
+扔
+腻
+枝
+奎
+药
+熄
+吨
+话
+q
+额
+慑
+嘌
+协
+喀
+壳
+埭
+视
+著
+於
+愧
+陲
+翌
+峁
+颅
+佛
+腹
+聋
+侯
+咎
+叟
+秀
+颇
+存
+较
+罪
+哄
+岗
+扫
+栏
+钾
+羌
+己
+璨
+枭
+霉
+煌
+涸
+衿
+键
+镝
+益
+岢
+奏
+连
+夯
+睿
+冥
+均
+糖
+狞
+蹊
+稻
+爸
+刿
+胥
+煜
+丽
+肿
+璃
+掸
+跚
+灾
+垂
+樾
+濑
+乎
+莲
+窄
+犹
+撮
+战
+馄
+软
+络
+显
+鸢
+胸
+宾
+妲
+恕
+埔
+蝌
+份
+遇
+巧
+瞟
+粒
+恰
+剥
+桡
+博
+讯
+凯
+堇
+阶
+滤
+卖
+斌
+骚
+彬
+兑
+磺
+樱
+舷
+两
+娱
+福
+仃
+差
+找
+桁
+÷
+净
+把
+阴
+污
+戬
+雷
+碓
+蕲
+楚
+罡
+焖
+抽
+妫
+咒
+仑
+闱
+尽
+邑
+菁
+爱
+贷
+沥
+鞑
+牡
+嗉
+崴
+骤
+塌
+嗦
+订
+拮
+滓
+捡
+锻
+次
+坪
+杩
+臃
+箬
+融
+珂
+鹗
+宗
+枚
+降
+鸬
+妯
+阄
+堰
+盐
+毅
+必
+杨
+崃
+俺
+甬
+状
+莘
+货
+耸
+菱
+腼
+铸
+唏
+痤
+孚
+澳
+懒
+溅
+翘
+疙
+杷
+淼
+缙
+骰
+喊
+悉
+砻
+坷
+艇
+赁
+界
+谤
+纣
+宴
+晃
+茹
+归
+饭
+梢
+铡
+街
+抄
+肼
+鬟
+苯
+颂
+撷
+戈
+炒
+咆
+茭
+瘙
+负
+仰
+客
+琉
+铢
+封
+卑
+珥
+椿
+镧
+窨
+鬲
+寿
+御
+袤
+铃
+萎
+砖
+餮
+脒
+裳
+肪
+孕
+嫣
+馗
+嵇
+恳
+氯
+江
+石
+褶
+冢
+祸
+阻
+狈
+羞
+银
+靳
+透
+咳
+叼
+敷
+芷
+啥
+它
+瓤
+兰
+痘
+懊
+逑
+肌
+往
+捺
+坊
+甩
+呻
+〃
+沦
+忘
+膻
+祟
+菅
+剧
+崆
+智
+坯
+臧
+霍
+墅
+攻
+眯
+倘
+拢
+骠
+铐
+庭
+岙
+瓠
+′
+缺
+泥
+迢
+捶
+?
+?
+郏
+喙
+掷
+沌
+纯
+秘
+种
+听
+绘
+固
+螨
+团
+香
+盗
+妒
+埚
+蓝
+拖
+旱
+荞
+铀
+血
+遏
+汲
+辰
+叩
+拽
+幅
+硬
+惶
+桀
+漠
+措
+泼
+唑
+齐
+肾
+念
+酱
+虚
+屁
+耶
+旗
+砦
+闵
+婉
+馆
+拭
+绅
+韧
+忏
+窝
+醋
+葺
+顾
+辞
+倜
+堆
+辋
+逆
+玟
+贱
+疾
+董
+惘
+倌
+锕
+淘
+嘀
+莽
+俭
+笏
+绑
+鲷
+杈
+择
+蟀
+粥
+嗯
+驰
+逾
+案
+谪
+褓
+胫
+哩
+昕
+颚
+鲢
+绠
+躺
+鹄
+崂
+儒
+俨
+丝
+尕
+泌
+啊
+萸
+彰
+幺
+吟
+骄
+苣
+弦
+脊
+瑰
+〈
+诛
+镁
+析
+闪
+剪
+侧
+哟
+框
+螃
+守
+嬗
+燕
+狭
+铈
+缮
+概
+迳
+痧
+鲲
+俯
+售
+笼
+痣
+扉
+挖
+满
+咋
+援
+邱
+扇
+歪
+便
+玑
+绦
+峡
+蛇
+叨
+〖
+泽
+胃
+斓
+喋
+怂
+坟
+猪
+该
+蚬
+炕
+弥
+赞
+棣
+晔
+娠
+挲
+狡
+创
+疖
+铕
+镭
+稷
+挫
+弭
+啾
+翔
+粉
+履
+苘
+哦
+楼
+秕
+铂
+土
+锣
+瘟
+挣
+栉
+习
+享
+桢
+袅
+磨
+桂
+谦
+延
+坚
+蔚
+噗
+署
+谟
+猬
+钎
+恐
+嬉
+雒
+倦
+衅
+亏
+璩
+睹
+刻
+殿
+王
+算
+雕
+麻
+丘
+柯
+骆
+丸
+塍
+谚
+添
+鲈
+垓
+桎
+蚯
+芥
+予
+飕
+镦
+谌
+窗
+醚
+菀
+亮
+搪
+莺
+蒿
+羁
+足
+J
+真
+轶
+悬
+衷
+靛
+翊
+掩
+哒
+炅
+掐
+冼
+妮
+l
+谐
+稚
+荆
+擒
+犯
+陵
+虏
+浓
+崽
+刍
+陌
+傻
+孜
+千
+靖
+演
+矜
+钕
+煽
+杰
+酗
+渗
+伞
+栋
+俗
+泫
+戍
+罕
+沾
+疽
+灏
+煦
+芬
+磴
+叱
+阱
+榉
+湃
+蜀
+叉
+醒
+彪
+租
+郡
+篷
+屎
+良
+垢
+隗
+弱
+陨
+峪
+砷
+掴
+颁
+胎
+雯
+绵
+贬
+沐
+撵
+隘
+篙
+暖
+曹
+陡
+栓
+填
+臼
+彦
+瓶
+琪
+潼
+哪
+鸡
+摩
+啦
+俟
+锋
+域
+耻
+蔫
+疯
+纹
+撇
+毒
+绶
+痛
+酯
+忍
+爪
+赳
+歆
+嘹
+辕
+烈
+册
+朴
+钱
+吮
+毯
+癜
+娃
+谀
+邵
+厮
+炽
+璞
+邃
+丐
+追
+词
+瓒
+忆
+轧
+芫
+谯
+喷
+弟
+半
+冕
+裙
+掖
+墉
+绮
+寝
+苔
+势
+顷
+褥
+切
+衮
+君
+佳
+嫒
+蚩
+霞
+佚
+洙
+逊
+镖
+暹
+唛
+&
+殒
+顶
+碗
+獗
+轭
+铺
+蛊
+废
+恹
+汨
+崩
+珍
+那
+杵
+曲
+纺
+夏
+薰
+傀
+闳
+淬
+姘
+舀
+拧
+卷
+楂
+恍
+讪
+厩
+寮
+篪
+赓
+乘
+灭
+盅
+鞣
+沟
+慎
+挂
+饺
+鼾
+杳
+树
+缨
+丛
+絮
+娌
+臻
+嗳
+篡
+侩
+述
+衰
+矛
+圈
+蚜
+匕
+筹
+匿
+濞
+晨
+叶
+骋
+郝
+挚
+蚴
+滞
+增
+侍
+描
+瓣
+吖
+嫦
+蟒
+匾
+圣
+赌
+毡
+癞
+恺
+百
+曳
+需
+篓
+肮
+庖
+帏
+卿
+驿
+遗
+蹬
+鬓
+骡
+歉
+芎
+胳
+屐
+禽
+烦
+晌
+寄
+媾
+狄
+翡
+苒
+船
+廉
+终
+痞
+殇
+々
+畦
+饶
+改
+拆
+悻
+萄
+£
+瓿
+乃
+訾
+桅
+匮
+溧
+拥
+纱
+铍
+骗
+蕃
+龋
+缬
+父
+佐
+疚
+栎
+醍
+掳
+蓄
+x
+惆
+颜
+鲆
+榆
+〔
+猎
+敌
+暴
+谥
+鲫
+贾
+罗
+玻
+缄
+扦
+芪
+癣
+落
+徒
+臾
+恿
+猩
+托
+邴
+肄
+牵
+春
+陛
+耀
+刊
+拓
+蓓
+邳
+堕
+寇
+枉
+淌
+啡
+湄
+兽
+酷
+萼
+碚
+濠
+萤
+夹
+旬
+戮
+梭
+琥
+椭
+昔
+勺
+蜊
+绐
+晚
+孺
+僵
+宣
+摄
+冽
+旨
+萌
+忙
+蚤
+眉
+噼
+蟑
+付
+契
+瓜
+悼
+颡
+壁
+曾
+窕
+颢
+澎
+仿
+俑
+浑
+嵌
+浣
+乍
+碌
+褪
+乱
+蔟
+隙
+玩
+剐
+葫
+箫
+纲
+围
+伐
+决
+伙
+漩
+瑟
+刑
+肓
+镳
+缓
+蹭
+氨
+皓
+典
+畲
+坍
+铑
+檐
+塑
+洞
+倬
+储
+胴
+淳
+戾
+吐
+灼
+惺
+妙
+毕
+珐
+缈
+虱
+盖
+羰
+鸿
+磅
+谓
+髅
+娴
+苴
+唷
+蚣
+霹
+抨
+贤
+唠
+犬
+誓
+逍
+庠
+逼
+麓
+籼
+釉
+呜
+碧
+秧
+氩
+摔
+霄
+穸
+纨
+辟
+妈
+映
+完
+牛
+缴
+嗷
+炊
+恩
+荔
+茆
+掉
+紊
+慌
+莓
+羟
+阙
+萁
+磐
+另
+蕹
+辱
+鳐
+湮
+吡
+吩
+唐
+睦
+垠
+舒
+圜
+冗
+瞿
+溺
+芾
+囱
+匠
+僳
+汐
+菩
+饬
+漓
+黑
+霰
+浸
+濡
+窥
+毂
+蒡
+兢
+驻
+鹉
+芮
+诙
+迫
+雳
+厂
+忐
+臆
+猴
+鸣
+蚪
+栈
+箕
+羡
+渐
+莆
+捍
+眈
+哓
+趴
+蹼
+埕
+嚣
+骛
+宏
+淄
+斑
+噜
+严
+瑛
+垃
+椎
+诱
+压
+庾
+绞
+焘
+廿
+抡
+迄
+棘
+夫
+纬
+锹
+眨
+瞌
+侠
+脐
+竞
+瀑
+孳
+骧
+遁
+姜
+颦
+荪
+滚
+萦
+伪
+逸
+粳
+爬
+锁
+矣
+役
+趣
+洒
+颔
+诏
+逐
+奸
+甭
+惠
+攀
+蹄
+泛
+尼
+拼
+阮
+鹰
+亚
+颈
+惑
+勒
+〉
+际
+肛
+爷
+刚
+钨
+丰
+养
+冶
+鲽
+辉
+蔻
+画
+覆
+皴
+妊
+麦
+返
+醉
+皂
+擀
+〗
+酶
+凑
+粹
+悟
+诀
+硖
+港
+卜
+z
+杀
+涕
+±
+舍
+铠
+抵
+弛
+段
+敝
+镐
+奠
+拂
+轴
+跛
+袱
+e
+t
+沉
+菇
+俎
+薪
+峦
+秭
+蟹
+历
+盟
+菠
+寡
+液
+肢
+喻
+染
+裱
+悱
+抱
+氙
+赤
+捅
+猛
+跑
+氮
+谣
+仁
+尺
+辊
+窍
+烙
+衍
+架
+擦
+倏
+璐
+瑁
+币
+楞
+胖
+夔
+趸
+邛
+惴
+饕
+虔
+蝎
+§
+哉
+贝
+宽
+辫
+炮
+扩
+饲
+籽
+魏
+菟
+锰
+伍
+猝
+末
+琳
+哚
+蛎
+邂
+呀
+姿
+鄞
+却
+歧
+仙
+恸
+椐
+森
+牒
+寤
+袒
+婆
+虢
+雅
+钉
+朵
+贼
+欲
+苞
+寰
+故
+龚
+坭
+嘘
+咫
+礼
+硷
+兀
+睢
+汶
+’
+铲
+烧
+绕
+诃
+浃
+钿
+哺
+柜
+讼
+颊
+璁
+腔
+洽
+咐
+脲
+簌
+筠
+镣
+玮
+鞠
+谁
+兼
+姆
+挥
+梯
+蝴
+谘
+漕
+刷
+躏
+宦
+弼
+b
+垌
+劈
+麟
+莉
+揭
+笙
+渎
+仕
+嗤
+仓
+配
+怏
+抬
+错
+泯
+镊
+孰
+猿
+邪
+仍
+秋
+鼬
+壹
+歇
+吵
+炼
+<
+尧
+射
+柬
+廷
+胧
+霾
+凳
+隋
+肚
+浮
+梦
+祥
+株
+堵
+退
+L
+鹫
+跎
+凶
+毽
+荟
+炫
+栩
+玳
+甜
+沂
+鹿
+顽
+伯
+爹
+赔
+蛴
+徐
+匡
+欣
+狰
+缸
+雹
+蟆
+疤
+默
+沤
+啜
+痂
+衣
+禅
+w
+i
+h
+辽
+葳
+黝
+钗
+停
+沽
+棒
+馨
+颌
+肉
+吴
+硫
+悯
+劾
+娈
+马
+啧
+吊
+悌
+镑
+峭
+帆
+瀣
+涉
+咸
+疸
+滋
+泣
+翦
+拙
+癸
+钥
+蜒
++
+尾
+庄
+凝
+泉
+婢
+渴
+谊
+乞
+陆
+锉
+糊
+鸦
+淮
+I
+B
+N
+晦
+弗
+乔
+庥
+葡
+尻
+席
+橡
+傣
+渣
+拿
+惩
+麋
+斛
+缃
+矮
+蛏
+岘
+鸽
+姐
+膏
+催
+奔
+镒
+喱
+蠡
+摧
+钯
+胤
+柠
+拐
+璋
+鸥
+卢
+荡
+倾
+^
+_
+珀
+逄
+萧
+塾
+掇
+贮
+笆
+聂
+圃
+冲
+嵬
+M
+滔
+笕
+值
+炙
+偶
+蜱
+搐
+梆
+汪
+蔬
+腑
+鸯
+蹇
+敞
+绯
+仨
+祯
+谆
+梧
+糗
+鑫
+啸
+豺
+囹
+猾
+巢
+柄
+瀛
+筑
+踌
+沭
+暗
+苁
+鱿
+蹉
+脂
+蘖
+牢
+热
+木
+吸
+溃
+宠
+序
+泞
+偿
+拜
+檩
+厚
+朐
+毗
+螳
+吞
+媚
+朽
+担
+蝗
+橘
+畴
+祈
+糟
+盱
+隼
+郜
+惜
+珠
+裨
+铵
+焙
+琚
+唯
+咚
+噪
+骊
+丫
+滢
+勤
+棉
+呸
+咣
+淀
+隔
+蕾
+窈
+饨
+挨
+煅
+短
+匙
+粕
+镜
+赣
+撕
+墩
+酬
+馁
+豌
+颐
+抗
+酣
+氓
+佑
+搁
+哭
+递
+耷
+涡
+桃
+贻
+碣
+截
+瘦
+昭
+镌
+蔓
+氚
+甲
+猕
+蕴
+蓬
+散
+拾
+纛
+狼
+猷
+铎
+埋
+旖
+矾
+讳
+囊
+糜
+迈
+粟
+蚂
+紧
+鲳
+瘢
+栽
+稼
+羊
+锄
+斟
+睁
+桥
+瓮
+蹙
+祉
+醺
+鼻
+昱
+剃
+跳
+篱
+跷
+蒜
+翎
+宅
+晖
+嗑
+壑
+峻
+癫
+屏
+狠
+陋
+袜
+途
+憎
+祀
+莹
+滟
+佶
+溥
+臣
+约
+盛
+峰
+磁
+慵
+婪
+拦
+莅
+朕
+鹦
+粲
+裤
+哎
+疡
+嫖
+琵
+窟
+堪
+谛
+嘉
+儡
+鳝
+斩
+郾
+驸
+酊
+妄
+胜
+贺
+徙
+傅
+噌
+钢
+栅
+庇
+恋
+匝
+巯
+邈
+尸
+锚
+粗
+佟
+蛟
+薹
+纵
+蚊
+郅
+绢
+锐
+苗
+俞
+篆
+淆
+膀
+鲜
+煎
+诶
+秽
+寻
+涮
+刺
+怀
+噶
+巨
+褰
+魅
+灶
+灌
+桉
+藕
+谜
+舸
+薄
+搀
+恽
+借
+牯
+痉
+渥
+愿
+亓
+耘
+杠
+柩
+锔
+蚶
+钣
+珈
+喘
+蹒
+幽
+赐
+稗
+晤
+莱
+泔
+扯
+肯
+菪
+裆
+腩
+豉
+疆
+骜
+腐
+倭
+珏
+唔
+粮
+亡
+润
+慰
+伽
+橄
+玄
+誉
+醐
+胆
+龊
+粼
+塬
+陇
+彼
+削
+嗣
+绾
+芽
+妗
+垭
+瘴
+爽
+薏
+寨
+龈
+泠
+弹
+赢
+漪
+猫
+嘧
+涂
+恤
+圭
+茧
+烽
+屑
+痕
+巾
+赖
+荸
+凰
+腮
+畈
+亵
+蹲
+偃
+苇
+澜
+艮
+换
+骺
+烘
+苕
+梓
+颉
+肇
+哗
+悄
+氤
+涠
+葬
+屠
+鹭
+植
+竺
+佯
+诣
+鲇
+瘀
+鲅
+邦
+移
+滁
+冯
+耕
+癔
+戌
+茬
+沁
+巩
+悠
+湘
+洪
+痹
+锟
+循
+谋
+腕
+鳃
+钠
+捞
+焉
+迎
+碱
+伫
+急
+榷
+奈
+邝
+卯
+辄
+皲
+卟
+醛
+畹
+忧
+稳
+雄
+昼
+缩
+阈
+睑
+扌
+耗
+曦
+涅
+捏
+瞧
+邕
+淖
+漉
+铝
+耦
+禹
+湛
+喽
+莼
+琅
+诸
+苎
+纂
+硅
+始
+嗨
+傥
+燃
+臂
+赅
+嘈
+呆
+贵
+屹
+壮
+肋
+亍
+蚀
+卅
+豹
+腆
+邬
+迭
+浊
+}
+童
+螂
+捐
+圩
+勐
+触
+寞
+汊
+壤
+荫
+膺
+渌
+芳
+懿
+遴
+螈
+泰
+蓼
+蛤
+茜
+舅
+枫
+朔
+膝
+眙
+避
+梅
+判
+鹜
+璜
+牍
+缅
+垫
+藻
+黔
+侥
+惚
+懂
+踩
+腰
+腈
+札
+丞
+唾
+慈
+顿
+摹
+荻
+琬
+~
+斧
+沈
+滂
+胁
+胀
+幄
+莜
+Z
+匀
+鄄
+掌
+绰
+茎
+焚
+赋
+萱
+谑
+汁
+铒
+瞎
+夺
+蜗
+野
+娆
+冀
+弯
+篁
+懵
+灞
+隽
+芡
+脘
+俐
+辩
+芯
+掺
+喏
+膈
+蝈
+觐
+悚
+踹
+蔗
+熠
+鼠
+呵
+抓
+橼
+峨
+畜
+缔
+禾
+崭
+弃
+熊
+摒
+凸
+拗
+穹
+蒙
+抒
+祛
+劝
+闫
+扳
+阵
+醌
+踪
+喵
+侣
+搬
+仅
+荧
+赎
+蝾
+琦
+买
+婧
+瞄
+寓
+皎
+冻
+赝
+箩
+莫
+瞰
+郊
+笫
+姝
+筒
+枪
+遣
+煸
+袋
+舆
+痱
+涛
+母
+〇
+启
+践
+耙
+绲
+盘
+遂
+昊
+搞
+槿
+诬
+纰
+泓
+惨
+檬
+亻
+越
+C
+o
+憩
+熵
+祷
+钒
+暧
+塔
+阗
+胰
+咄
+娶
+魔
+琶
+钞
+邻
+扬
+杉
+殴
+咽
+弓
+〆
+髻
+】
+吭
+揽
+霆
+拄
+殖
+脆
+彻
+岩
+芝
+勃
+辣
+剌
+钝
+嘎
+甄
+佘
+皖
+伦
+授
+徕
+憔
+挪
+皇
+庞
+稔
+芜
+踏
+溴
+兖
+卒
+擢
+饥
+鳞
+煲
+‰
+账
+颗
+叻
+斯
+捧
+鳍
+琮
+讹
+蛙
+纽
+谭
+酸
+兔
+莒
+睇
+伟
+觑
+羲
+嗜
+宜
+褐
+旎
+辛
+卦
+诘
+筋
+鎏
+溪
+挛
+熔
+阜
+晰
+鳅
+丢
+奚
+灸
+呱
+献
+陉
+黛
+鸪
+甾
+萨
+疮
+拯
+洲
+疹
+辑
+叙
+恻
+谒
+允
+柔
+烂
+氏
+逅
+漆
+拎
+惋
+扈
+湟
+纭
+啕
+掬
+擞
+哥
+忽
+涤
+鸵
+靡
+郗
+瓷
+扁
+廊
+怨
+雏
+钮
+敦
+E
+懦
+憋
+汀
+拚
+啉
+腌
+岸
+f
+痼
+瞅
+尊
+咀
+眩
+飙
+忌
+仝
+迦
+熬
+毫
+胯
+篑
+茄
+腺
+凄
+舛
+碴
+锵
+诧
+羯
+後
+漏
+汤
+宓
+仞
+蚁
+壶
+谰
+皑
+铄
+棰
+罔
+辅
+晶
+苦
+牟
+闽
+\
+烃
+饮
+聿
+丙
+蛳
+朱
+煤
+涔
+鳖
+犁
+罐
+荼
+砒
+淦
+妤
+黏
+戎
+孑
+婕
+瑾
+戢
+钵
+枣
+捋
+砥
+衩
+狙
+桠
+稣
+阎
+肃
+梏
+诫
+孪
+昶
+婊
+衫
+嗔
+侃
+塞
+蜃
+樵
+峒
+貌
+屿
+欺
+缫
+阐
+栖
+诟
+珞
+荭
+吝
+萍
+嗽
+恂
+啻
+蜴
+磬
+峋
+俸
+豫
+谎
+徊
+镍
+韬
+魇
+晴
+U
+囟
+猜
+蛮
+坐
+囿
+伴
+亭
+肝
+佗
+蝠
+妃
+胞
+滩
+榴
+氖
+垩
+苋
+砣
+扪
+馏
+姓
+轩
+厉
+夥
+侈
+禀
+垒
+岑
+赏
+钛
+辐
+痔
+披
+纸
+碳
+“
+坞
+蠓
+挤
+荥
+沅
+悔
+铧
+帼
+蒌
+蝇
+a
+p
+y
+n
+g
+哀
+浆
+瑶
+凿
+桶
+馈
+皮
+奴
+苜
+佤
+伶
+晗
+铱
+炬
+优
+弊
+氢
+恃
+甫
+攥
+端
+锌
+灰
+稹
+炝
+曙
+邋
+亥
+眶
+碾
+拉
+萝
+绔
+捷
+浍
+腋
+姑
+菖
+凌
+涞
+麽
+锢
+桨
+潢
+绎
+镰
+殆
+锑
+渝
+铬
+困
+绽
+觎
+匈
+糙
+暑
+裹
+鸟
+盔
+肽
+迷
+綦
+『
+亳
+佝
+俘
+钴
+觇
+骥
+仆
+疝
+跪
+婶
+郯
+瀹
+唉
+脖
+踞
+针
+晾
+忒
+扼
+瞩
+叛
+椒
+疟
+嗡
+邗
+肆
+跆
+玫
+忡
+捣
+咧
+唆
+艄
+蘑
+潦
+笛
+阚
+沸
+泻
+掊
+菽
+贫
+斥
+髂
+孢
+镂
+赂
+麝
+鸾
+屡
+衬
+苷
+恪
+叠
+希
+粤
+爻
+喝
+茫
+惬
+郸
+绻
+庸
+撅
+碟
+宄
+妹
+膛
+叮
+饵
+崛
+嗲
+椅
+冤
+搅
+咕
+敛
+尹
+垦
+闷
+蝉
+霎
+勰
+败
+蓑
+泸
+肤
+鹌
+幌
+焦
+浠
+鞍
+刁
+舰
+乙
+竿
+裔
+。
+茵
+函
+伊
+兄
+丨
+娜
+匍
+謇
+莪
+宥
+似
+蝽
+翳
+酪
+翠
+粑
+薇
+祢
+骏
+赠
+叫
+Q
+噤
+噻
+竖
+芗
+莠
+潭
+俊
+羿
+耜
+O
+郫
+趁
+嗪
+囚
+蹶
+芒
+洁
+笋
+鹑
+敲
+硝
+啶
+堡
+渲
+揩
+』
+携
+宿
+遒
+颍
+扭
+棱
+割
+萜
+蔸
+葵
+琴
+捂
+饰
+衙
+耿
+掠
+募
+岂
+窖
+涟
+蔺
+瘤
+柞
+瞪
+怜
+匹
+距
+楔
+炜
+哆
+秦
+缎
+幼
+茁
+绪
+痨
+恨
+楸
+娅
+瓦
+桩
+雪
+嬴
+伏
+榔
+妥
+铿
+拌
+眠
+雍
+缇
+‘
+卓
+搓
+哌
+觞
+噩
+屈
+哧
+髓
+咦
+巅
+娑
+侑
+淫
+膳
+祝
+勾
+姊
+莴
+胄
+疃
+薛
+蜷
+胛
+巷
+芙
+芋
+熙
+闰
+勿
+窃
+狱
+剩
+钏
+幢
+陟
+铛
+慧
+靴
+耍
+k
+浙
+浇
+飨
+惟
+绗
+祜
+澈
+啼
+咪
+磷
+摞
+诅
+郦
+抹
+跃
+壬
+吕
+肖
+琏
+颤
+尴
+剡
+抠
+凋
+赚
+泊
+津
+宕
+殷
+倔
+氲
+漫
+邺
+涎
+怠
+$
+垮
+荬
+遵
+俏
+叹
+噢
+饽
+蜘
+孙
+筵
+疼
+鞭
+羧
+牦
+箭
+潴
+c
+眸
+祭
+髯
+啖
+坳
+愁
+芩
+驮
+倡
+巽
+穰
+沃
+胚
+怒
+凤
+槛
+剂
+趵
+嫁
+v
+邢
+灯
+鄢
+桐
+睽
+檗
+锯
+槟
+婷
+嵋
+圻
+诗
+蕈
+颠
+遭
+痢
+芸
+怯
+馥
+竭
+锗
+徜
+恭
+遍
+籁
+剑
+嘱
+苡
+龄
+僧
+桑
+潸
+弘
+澶
+楹
+悲
+讫
+愤
+腥
+悸
+谍
+椹
+呢
+桓
+葭
+攫
+阀
+翰
+躲
+敖
+柑
+郎
+笨
+橇
+呃
+魁
+燎
+脓
+葩
+磋
+垛
+玺
+狮
+沓
+砜
+蕊
+锺
+罹
+蕉
+翱
+虐
+闾
+巫
+旦
+茱
+嬷
+枯
+鹏
+贡
+芹
+汛
+矫
+绁
+拣
+禺
+佃
+讣
+舫
+惯
+乳
+趋
+疲
+挽
+岚
+虾
+衾
+蠹
+蹂
+飓
+氦
+铖
+孩
+稞
+瑜
+壅
+掀
+勘
+妓
+畅
+髋
+W
+庐
+牲
+蓿
+榕
+练
+垣
+唱
+邸
+菲
+昆
+婺
+穿
+绡
+麒
+蚱
+掂
+愚
+泷
+涪
+漳
+妩
+娉
+榄
+讷
+觅
+旧
+藤
+煮
+呛
+柳
+腓
+叭
+庵
+烷
+阡
+罂
+蜕
+擂
+猖
+咿
+媲
+脉
+【
+沏
+貅
+黠
+熏
+哲
+烁
+坦
+酵
+兜
+×
+潇
+撒
+剽
+珩
+圹
+乾
+摸
+樟
+帽
+嗒
+襄
+魂
+轿
+憬
+锡
+〕
+喃
+皆
+咖
+隅
+脸
+残
+泮
+袂
+鹂
+珊
+囤
+捆
+咤
+误
+徨
+闹
+淙
+芊
+淋
+怆
+囗
+拨
+梳
+渤
+R
+G
+绨
+蚓
+婀
+幡
+狩
+麾
+谢
+唢
+裸
+旌
+伉
+纶
+裂
+驳
+砼
+咛
+澄
+樨
+蹈
+宙
+澍
+倍
+貔
+操
+勇
+蟠
+摈
+砧
+虬
+够
+缁
+悦
+藿
+撸
+艹
+摁
+淹
+豇
+虎
+榭
+ˉ
+吱
+d
+°
+喧
+荀
+踱
+侮
+奋
+偕
+饷
+犍
+惮
+坑
+璎
+徘
+宛
+妆
+袈
+倩
+窦
+昂
+荏
+乖
+K
+怅
+撰
+鳙
+牙
+袁
+酞
+X
+痿
+琼
+闸
+雁
+趾
+荚
+虻
+涝
+《
+杏
+韭
+偈
+烤
+绫
+鞘
+卉
+症
+遢
+蓥
+诋
+杭
+荨
+匆
+竣
+簪
+辙
+敕
+虞
+丹
+缭
+咩
+黟
+m
+淤
+瑕
+咂
+铉
+硼
+茨
+嶂
+痒
+畸
+敬
+涿
+粪
+窘
+熟
+叔
+嫔
+盾
+忱
+裘
+憾
+梵
+赡
+珙
+咯
+娘
+庙
+溯
+胺
+葱
+痪
+摊
+荷
+卞
+乒
+髦
+寐
+铭
+坩
+胗
+枷
+爆
+溟
+嚼
+羚
+砬
+轨
+惊
+挠
+罄
+竽
+菏
+氧
+浅
+楣
+盼
+枢
+炸
+阆
+杯
+谏
+噬
+淇
+渺
+俪
+秆
+墓
+泪
+跻
+砌
+痰
+垡
+渡
+耽
+釜
+讶
+鳎
+煞
+呗
+韶
+舶
+绷
+鹳
+缜
+旷
+铊
+皱
+龌
+檀
+霖
+奄
+槐
+艳
+蝶
+旋
+哝
+赶
+骞
+蚧
+腊
+盈
+丁
+`
+蜚
+矸
+蝙
+睨
+嚓
+僻
+鬼
+醴
+夜
+彝
+磊
+笔
+拔
+栀
+糕
+厦
+邰
+纫
+逭
+纤
+眦
+膊
+馍
+躇
+烯
+蘼
+冬
+诤
+暄
+骶
+哑
+瘠
+」
+臊
+丕
+愈
+咱
+螺
+擅
+跋
+搏
+硪
+谄
+笠
+淡
+嘿
+骅
+谧
+鼎
+皋
+姚
+歼
+蠢
+驼
+耳
+胬
+挝
+涯
+狗
+蒽
+孓
+犷
+凉
+芦
+箴
+铤
+孤
+嘛
+坤
+V
+茴
+朦
+挞
+尖
+橙
+诞
+搴
+碇
+洵
+浚
+帚
+蜍
+漯
+柘
+嚎
+讽
+芭
+荤
+咻
+祠
+秉
+跖
+埃
+吓
+糯
+眷
+馒
+惹
+娼
+鲑
+嫩
+讴
+轮
+瞥
+靶
+褚
+乏
+缤
+宋
+帧
+删
+驱
+碎
+扑
+俩
+俄
+偏
+涣
+竹
+噱
+皙
+佰
+渚
+唧
+斡
+#
+镉
+刀
+崎
+筐
+佣
+夭
+贰
+肴
+峙
+哔
+艿
+匐
+牺
+镛
+缘
+仡
+嫡
+劣
+枸
+堀
+梨
+簿
+鸭
+蒸
+亦
+稽
+浴
+{
+衢
+束
+槲
+j
+阁
+揍
+疥
+棋
+潋
+聪
+窜
+乓
+睛
+插
+冉
+阪
+苍
+搽
+「
+蟾
+螟
+幸
+仇
+樽
+撂
+慢
+跤
+幔
+俚
+淅
+覃
+觊
+溶
+妖
+帛
+侨
+曰
+妾
+泗
+·
+:
+瀘
+風
+Ë
+(
+)
+∶
+紅
+紗
+瑭
+雲
+頭
+鶏
+財
+許
+•
+¥
+樂
+焗
+麗
+—
+;
+滙
+東
+榮
+繪
+興
+…
+門
+業
+π
+楊
+國
+顧
+é
+盤
+寳
+Λ
+龍
+鳳
+島
+誌
+緣
+結
+銭
+萬
+勝
+祎
+璟
+優
+歡
+臨
+時
+購
+=
+★
+藍
+昇
+鐵
+觀
+勅
+農
+聲
+畫
+兿
+術
+發
+劉
+記
+專
+耑
+園
+書
+壴
+種
+Ο
+●
+褀
+號
+銀
+匯
+敟
+锘
+葉
+橪
+廣
+進
+蒄
+鑽
+阝
+祙
+貢
+鍋
+豊
+夬
+喆
+團
+閣
+開
+燁
+賓
+館
+酡
+沔
+順
++
+硚
+劵
+饸
+陽
+車
+湓
+復
+萊
+氣
+軒
+華
+堃
+迮
+纟
+戶
+馬
+學
+裡
+電
+嶽
+獨
+マ
+シ
+サ
+ジ
+燘
+袪
+環
+❤
+臺
+灣
+専
+賣
+孖
+聖
+攝
+線
+▪
+α
+傢
+俬
+夢
+達
+莊
+喬
+貝
+薩
+劍
+羅
+壓
+棛
+饦
+尃
+璈
+囍
+醫
+G
+I
+A
+#
+N
+鷄
+髙
+嬰
+啓
+約
+隹
+潔
+賴
+藝
+~
+寶
+籣
+麺
+
+嶺
+√
+義
+網
+峩
+長
+∧
+魚
+機
+構
+②
+鳯
+偉
+L
+B
+㙟
+畵
+鴿
+'
+詩
+溝
+嚞
+屌
+藔
+佧
+玥
+蘭
+織
+1
+3
+9
+0
+7
+點
+砭
+鴨
+鋪
+銘
+廳
+弍
+‧
+創
+湯
+坶
+℃
+卩
+骝
+&
+烜
+荘
+當
+潤
+扞
+係
+懷
+碶
+钅
+蚨
+讠
+☆
+叢
+爲
+埗
+涫
+塗
+→
+楽
+現
+鯨
+愛
+瑪
+鈺
+忄
+悶
+藥
+飾
+樓
+視
+孬
+ㆍ
+燚
+苪
+師
+①
+丼
+锽
+│
+韓
+標
+è
+兒
+閏
+匋
+張
+漢
+Ü
+髪
+會
+閑
+檔
+習
+裝
+の
+峯
+菘
+輝
+И
+雞
+釣
+億
+浐
+K
+O
+R
+8
+H
+E
+P
+T
+W
+D
+S
+C
+M
+F
+姌
+饹
+»
+晞
+廰
+ä
+嵯
+鷹
+負
+飲
+絲
+冚
+楗
+澤
+綫
+區
+❋
+←
+質
+靑
+揚
+③
+滬
+統
+産
+協
+﹑
+乸
+畐
+經
+運
+際
+洺
+岽
+為
+粵
+諾
+崋
+豐
+碁
+ɔ
+V
+2
+6
+齋
+誠
+訂
+´
+勑
+雙
+陳
+無
+í
+泩
+媄
+夌
+刂
+i
+c
+t
+o
+r
+a
+嘢
+耄
+燴
+暃
+壽
+媽
+靈
+抻
+體
+唻
+É
+冮
+甹
+鎮
+錦
+ʌ
+蜛
+蠄
+尓
+駕
+戀
+飬
+逹
+倫
+貴
+極
+Я
+Й
+寬
+磚
+嶪
+郎
+職
+|
+間
+n
+d
+剎
+伈
+課
+飛
+橋
+瘊
+№
+譜
+骓
+圗
+滘
+縣
+粿
+咅
+養
+濤
+彳
+®
+%
+Ⅱ
+啰
+㴪
+見
+矞
+薬
+糁
+邨
+鲮
+顔
+罱
+З
+選
+話
+贏
+氪
+俵
+競
+瑩
+繡
+枱
+β
+綉
+á
+獅
+爾
+™
+麵
+戋
+淩
+徳
+個
+劇
+場
+務
+簡
+寵
+h
+實
+膠
+轱
+圖
+築
+嘣
+樹
+㸃
+營
+耵
+孫
+饃
+鄺
+飯
+麯
+遠
+輸
+坫
+孃
+乚
+閃
+鏢
+㎡
+題
+廠
+關
+↑
+爺
+將
+軍
+連
+篦
+覌
+參
+箸
+-
+窠
+棽
+寕
+夀
+爰
+歐
+呙
+閥
+頡
+熱
+雎
+垟
+裟
+凬
+勁
+帑
+馕
+夆
+疌
+枼
+馮
+貨
+蒤
+樸
+彧
+旸
+靜
+龢
+暢
+㐱
+鳥
+珺
+鏡
+灡
+爭
+堷
+廚
+Ó
+騰
+診
+┅
+蘇
+褔
+凱
+頂
+豕
+亞
+帥
+嘬
+⊥
+仺
+桖
+複
+饣
+絡
+穂
+顏
+棟
+納
+▏
+濟
+親
+設
+計
+攵
+埌
+烺
+ò
+頤
+燦
+蓮
+撻
+節
+講
+濱
+濃
+娽
+洳
+朿
+燈
+鈴
+護
+膚
+铔
+過
+補
+Z
+U
+5
+4
+坋
+闿
+䖝
+餘
+缐
+铞
+貿
+铪
+桼
+趙
+鍊
+[
+㐂
+垚
+菓
+揸
+捲
+鐘
+滏
+𣇉
+爍
+輪
+燜
+鴻
+鮮
+動
+鹞
+鷗
+丄
+慶
+鉌
+翥
+飮
+腸
+⇋
+漁
+覺
+來
+熘
+昴
+翏
+鲱
+圧
+鄉
+萭
+頔
+爐
+嫚
+г
+貭
+類
+聯
+幛
+輕
+訓
+鑒
+夋
+锨
+芃
+珣
+䝉
+扙
+嵐
+銷
+處
+ㄱ
+語
+誘
+苝
+歸
+儀
+燒
+楿
+內
+粢
+葒
+奧
+麥
+礻
+滿
+蠔
+穵
+瞭
+態
+鱬
+榞
+硂
+鄭
+黃
+煙
+祐
+奓
+逺
+*
+瑄
+獲
+聞
+薦
+讀
+這
+樣
+決
+問
+啟
+們
+執
+説
+轉
+單
+隨
+唘
+帶
+倉
+庫
+還
+贈
+尙
+皺
+■
+餅
+產
+○
+∈
+報
+狀
+楓
+賠
+琯
+嗮
+禮
+`
+傳
+>
+≤
+嗞
+Φ
+≥
+換
+咭
+∣
+↓
+曬
+ε
+応
+寫
+″
+終
+様
+純
+費
+療
+聨
+凍
+壐
+郵
+ü
+黒
+∫
+製
+塊
+調
+軽
+確
+撃
+級
+馴
+Ⅲ
+涇
+繹
+數
+碼
+證
+狒
+処
+劑
+<
+晧
+賀
+衆
+]
+櫥
+兩
+陰
+絶
+對
+鯉
+憶
+◎
+p
+e
+Y
+蕒
+煖
+頓
+測
+試
+鼽
+僑
+碩
+妝
+帯
+≈
+鐡
+舖
+權
+喫
+倆
+ˋ
+該
+悅
+ā
+俫
+.
+f
+s
+b
+m
+k
+g
+u
+j
+貼
+淨
+濕
+針
+適
+備
+l
+/
+給
+謢
+強
+觸
+衛
+與
+⊙
+$
+緯
+變
+⑴
+⑵
+⑶
+㎏
+殺
+∩
+幚
+─
+價
+▲
+離
+ú
+ó
+飄
+烏
+関
+閟
+﹝
+﹞
+邏
+輯
+鍵
+驗
+訣
+導
+歷
+屆
+層
+▼
+儱
+錄
+熳
+ē
+艦
+吋
+錶
+辧
+飼
+顯
+④
+禦
+販
+気
+対
+枰
+閩
+紀
+幹
+瞓
+貊
+淚
+△
+眞
+墊
+Ω
+獻
+褲
+縫
+緑
+亜
+鉅
+餠
+{
+}
+◆
+蘆
+薈
+█
+◇
+溫
+彈
+晳
+粧
+犸
+穩
+訊
+崬
+凖
+熥
+П
+舊
+條
+紋
+圍
+Ⅳ
+筆
+尷
+難
+雜
+錯
+綁
+識
+頰
+鎖
+艶
+□
+殁
+殼
+⑧
+├
+▕
+鵬
+ǐ
+ō
+ǒ
+糝
+綱
+▎
+μ
+盜
+饅
+醬
+籤
+蓋
+釀
+鹽
+據
+à
+ɡ
+辦
+◥
+彐
+┌
+婦
+獸
+鲩
+伱
+ī
+蒟
+蒻
+齊
+袆
+腦
+寧
+凈
+妳
+煥
+詢
+偽
+謹
+啫
+鯽
+騷
+鱸
+損
+傷
+鎻
+髮
+買
+冏
+儥
+両
+﹢
+∞
+載
+喰
+z
+羙
+悵
+燙
+曉
+員
+組
+徹
+艷
+痠
+鋼
+鼙
+縮
+細
+嚒
+爯
+≠
+維
+"
+鱻
+壇
+厍
+帰
+浥
+犇
+薡
+軎
+²
+應
+醜
+刪
+緻
+鶴
+賜
+噁
+軌
+尨
+镔
+鷺
+槗
+彌
+葚
+濛
+請
+溇
+緹
+賢
+訪
+獴
+瑅
+資
+縤
+陣
+蕟
+栢
+韻
+祼
+恁
+伢
+謝
+劃
+涑
+總
+衖
+踺
+砋
+凉
+籃
+駿
+苼
+瘋
+昽
+紡
+驊
+腎
+﹗
+響
+杋
+剛
+嚴
+禪
+歓
+槍
+傘
+檸
+檫
+炣
+勢
+鏜
+鎢
+銑
+尐
+減
+奪
+惡
+θ
+僮
+婭
+臘
+ū
+ì
+殻
+鉄
+∑
+蛲
+焼
+緖
+續
+紹
+懮
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/assets/simfang.ttf b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/assets/simfang.ttf
new file mode 100644
index 0000000000000000000000000000000000000000..2b59eae4195d1cdbea375503c0cc34d5631cb0f9
Binary files /dev/null and b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/assets/simfang.ttf differ
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/character.py b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/character.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e5f10211ba441a7dd9b4948413b79c8721eab07
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/character.py
@@ -0,0 +1,168 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import numpy as np
+import string
+
+
+class CharacterOps(object):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, config):
+ self.character_type = config['character_type']
+ self.loss_type = config['loss_type']
+ if self.character_type == "en":
+ self.character_str = "0123456789abcdefghijklmnopqrstuvwxyz"
+ dict_character = list(self.character_str)
+ elif self.character_type == "ch":
+ character_dict_path = config['character_dict_path']
+ self.character_str = ""
+ with open(character_dict_path, "rb") as fin:
+ lines = fin.readlines()
+ for line in lines:
+ line = line.decode('utf-8').strip("\n")
+ self.character_str += line
+ dict_character = list(self.character_str)
+ elif self.character_type == "en_sensitive":
+ # same with ASTER setting (use 94 char).
+ self.character_str = string.printable[:-6]
+ dict_character = list(self.character_str)
+ else:
+ self.character_str = None
+ assert self.character_str is not None, \
+ "Nonsupport type of the character: {}".format(self.character_str)
+ self.beg_str = "sos"
+ self.end_str = "eos"
+ if self.loss_type == "attention":
+ dict_character = [self.beg_str, self.end_str] + dict_character
+ self.dict = {}
+ for i, char in enumerate(dict_character):
+ self.dict[char] = i
+ self.character = dict_character
+
+ def encode(self, text):
+ """convert text-label into text-index.
+ input:
+ text: text labels of each image. [batch_size]
+
+ output:
+ text: concatenated text index for CTCLoss.
+ [sum(text_lengths)] = [text_index_0 + text_index_1 + ... + text_index_(n - 1)]
+ length: length of each text. [batch_size]
+ """
+ if self.character_type == "en":
+ text = text.lower()
+
+ text_list = []
+ for char in text:
+ if char not in self.dict:
+ continue
+ text_list.append(self.dict[char])
+ text = np.array(text_list)
+ return text
+
+ def decode(self, text_index, is_remove_duplicate=False):
+ """ convert text-index into text-label. """
+ char_list = []
+ char_num = self.get_char_num()
+
+ if self.loss_type == "attention":
+ beg_idx = self.get_beg_end_flag_idx("beg")
+ end_idx = self.get_beg_end_flag_idx("end")
+ ignored_tokens = [beg_idx, end_idx]
+ else:
+ ignored_tokens = [char_num]
+
+ for idx in range(len(text_index)):
+ if text_index[idx] in ignored_tokens:
+ continue
+ if is_remove_duplicate:
+ if idx > 0 and text_index[idx - 1] == text_index[idx]:
+ continue
+ char_list.append(self.character[text_index[idx]])
+ text = ''.join(char_list)
+ return text
+
+ def get_char_num(self):
+ return len(self.character)
+
+ def get_beg_end_flag_idx(self, beg_or_end):
+ if self.loss_type == "attention":
+ if beg_or_end == "beg":
+ idx = np.array(self.dict[self.beg_str])
+ elif beg_or_end == "end":
+ idx = np.array(self.dict[self.end_str])
+ else:
+ assert False, "Unsupport type %s in get_beg_end_flag_idx"\
+ % beg_or_end
+ return idx
+ else:
+ err = "error in get_beg_end_flag_idx when using the loss %s"\
+ % (self.loss_type)
+ assert False, err
+
+
+def cal_predicts_accuracy(char_ops,
+ preds,
+ preds_lod,
+ labels,
+ labels_lod,
+ is_remove_duplicate=False):
+ acc_num = 0
+ img_num = 0
+ for ino in range(len(labels_lod) - 1):
+ beg_no = preds_lod[ino]
+ end_no = preds_lod[ino + 1]
+ preds_text = preds[beg_no:end_no].reshape(-1)
+ preds_text = char_ops.decode(preds_text, is_remove_duplicate)
+
+ beg_no = labels_lod[ino]
+ end_no = labels_lod[ino + 1]
+ labels_text = labels[beg_no:end_no].reshape(-1)
+ labels_text = char_ops.decode(labels_text, is_remove_duplicate)
+ img_num += 1
+
+ if preds_text == labels_text:
+ acc_num += 1
+ acc = acc_num * 1.0 / img_num
+ return acc, acc_num, img_num
+
+
+def convert_rec_attention_infer_res(preds):
+ img_num = preds.shape[0]
+ target_lod = [0]
+ convert_ids = []
+ for ino in range(img_num):
+ end_pos = np.where(preds[ino, :] == 1)[0]
+ if len(end_pos) <= 1:
+ text_list = preds[ino, 1:]
+ else:
+ text_list = preds[ino, 1:end_pos[1]]
+ target_lod.append(target_lod[ino] + len(text_list))
+ convert_ids = convert_ids + list(text_list)
+ convert_ids = np.array(convert_ids)
+ convert_ids = convert_ids.reshape((-1, 1))
+ return convert_ids, target_lod
+
+
+def convert_rec_label_to_lod(ori_labels):
+ img_num = len(ori_labels)
+ target_lod = [0]
+ convert_ids = []
+ for ino in range(img_num):
+ target_lod.append(target_lod[ino] + len(ori_labels[ino]))
+ convert_ids = convert_ids + list(ori_labels[ino])
+ convert_ids = np.array(convert_ids)
+ convert_ids = convert_ids.reshape((-1, 1))
+ return convert_ids, target_lod
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/module.py b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..4289f416789bd113f06ec694932c7a26f29e23c2
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/module.py
@@ -0,0 +1,432 @@
+# -*- coding:utf-8 -*-
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import ast
+import copy
+import math
+import os
+import time
+
+from paddle.fluid.core import AnalysisConfig, create_paddle_predictor, PaddleTensor
+from paddlehub.common.logger import logger
+from paddlehub.module.module import moduleinfo, runnable, serving
+from PIL import Image
+import cv2
+import numpy as np
+import paddle.fluid as fluid
+import paddlehub as hub
+
+from chinese_ocr_db_crnn_mobile.character import CharacterOps
+from chinese_ocr_db_crnn_mobile.utils import base64_to_cv2, draw_ocr, get_image_ext, sorted_boxes
+
+
+@moduleinfo(
+ name="chinese_ocr_db_crnn_mobile",
+ version="1.0.1",
+ summary=
+ "The module can recognize the chinese texts in an image. Firstly, it will detect the text box positions based on the differentiable_binarization_chn module. Then it recognizes the chinese texts. ",
+ author="paddle-dev",
+ author_email="paddle-dev@baidu.com",
+ type="cv/text_recognition")
+class ChineseOCRDBCRNN(hub.Module):
+ def _initialize(self, text_detector_module=None):
+ """
+ initialize with the necessary elements
+ """
+ self.character_dict_path = os.path.join(self.directory, 'assets',
+ 'ppocr_keys_v1.txt')
+ char_ops_params = {
+ 'character_type': 'ch',
+ 'character_dict_path': self.character_dict_path,
+ 'loss_type': 'ctc'
+ }
+ self.char_ops = CharacterOps(char_ops_params)
+ self.rec_image_shape = [3, 32, 320]
+ self._text_detector_module = text_detector_module
+ self.font_file = os.path.join(self.directory, 'assets', 'simfang.ttf')
+ self.pretrained_model_path = os.path.join(self.directory,
+ 'inference_model')
+ self._set_config()
+
+ def _set_config(self):
+ """
+ predictor config setting
+ """
+ model_file_path = os.path.join(self.pretrained_model_path, 'model')
+ params_file_path = os.path.join(self.pretrained_model_path, 'params')
+
+ config = AnalysisConfig(model_file_path, params_file_path)
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ use_gpu = True
+ except:
+ use_gpu = False
+
+ if use_gpu:
+ config.enable_use_gpu(8000, 0)
+ else:
+ config.disable_gpu()
+
+ config.disable_glog_info()
+
+ # use zero copy
+ config.delete_pass("conv_transpose_eltwiseadd_bn_fuse_pass")
+ config.switch_use_feed_fetch_ops(False)
+ self.predictor = create_paddle_predictor(config)
+ input_names = self.predictor.get_input_names()
+ self.input_tensor = self.predictor.get_input_tensor(input_names[0])
+ output_names = self.predictor.get_output_names()
+ self.output_tensors = []
+ for output_name in output_names:
+ output_tensor = self.predictor.get_output_tensor(output_name)
+ self.output_tensors.append(output_tensor)
+
+ @property
+ def text_detector_module(self):
+ """
+ text detect module
+ """
+ if not self._text_detector_module:
+ self._text_detector_module = hub.Module(
+ name='chinese_text_detection_db_mobile')
+ return self._text_detector_module
+
+ def read_images(self, paths=[]):
+ images = []
+ for img_path in paths:
+ assert os.path.isfile(
+ img_path), "The {} isn't a valid file.".format(img_path)
+ img = cv2.imread(img_path)
+ if img is None:
+ logger.info("error in loading image:{}".format(img_path))
+ continue
+ images.append(img)
+ return images
+
+ def get_rotate_crop_image(self, img, points):
+ img_height, img_width = img.shape[0:2]
+ left = int(np.min(points[:, 0]))
+ right = int(np.max(points[:, 0]))
+ top = int(np.min(points[:, 1]))
+ bottom = int(np.max(points[:, 1]))
+ img_crop = img[top:bottom, left:right, :].copy()
+ points[:, 0] = points[:, 0] - left
+ points[:, 1] = points[:, 1] - top
+ img_crop_width = int(np.linalg.norm(points[0] - points[1]))
+ img_crop_height = int(np.linalg.norm(points[0] - points[3]))
+ pts_std = np.float32([[0, 0], [img_crop_width, 0],\
+ [img_crop_width, img_crop_height], [0, img_crop_height]])
+ M = cv2.getPerspectiveTransform(points, pts_std)
+ dst_img = cv2.warpPerspective(
+ img_crop,
+ M, (img_crop_width, img_crop_height),
+ borderMode=cv2.BORDER_REPLICATE)
+ dst_img_height, dst_img_width = dst_img.shape[0:2]
+ if dst_img_height * 1.0 / dst_img_width >= 1.5:
+ dst_img = np.rot90(dst_img)
+ return dst_img
+
+ def resize_norm_img(self, img, max_wh_ratio):
+ imgC, imgH, imgW = self.rec_image_shape
+ imgW = int(32 * max_wh_ratio)
+ h = img.shape[0]
+ w = img.shape[1]
+ ratio = w / float(h)
+ if math.ceil(imgH * ratio) > imgW:
+ resized_w = imgW
+ else:
+ resized_w = int(math.ceil(imgH * ratio))
+ resized_image = cv2.resize(img, (resized_w, imgH))
+ resized_image = resized_image.astype('float32')
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
+ padding_im[:, :, 0:resized_w] = resized_image
+ return padding_im
+
+ def recognize_text(self,
+ images=[],
+ paths=[],
+ use_gpu=False,
+ output_dir='ocr_result',
+ visualization=False,
+ box_thresh=0.5,
+ text_thresh=0.5):
+ """
+ Get the chinese texts in the predicted images.
+ Args:
+ images (list(numpy.ndarray)): images data, shape of each is [H, W, C]. If images not paths
+ paths (list[str]): The paths of images. If paths not images
+ use_gpu (bool): Whether to use gpu.
+ batch_size(int): the program deals once with one
+ output_dir (str): The directory to store output images.
+ visualization (bool): Whether to save image or not.
+ box_thresh(float): the threshold of the detected text box's confidence
+ text_thresh(float): the threshold of the recognize chinese texts' confidence
+ Returns:
+ res (list): The result of chinese texts and save path of images.
+ """
+ if use_gpu:
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES via export CUDA_VISIBLE_DEVICES=cuda_device_id."
+ )
+
+ self.use_gpu = use_gpu
+
+ if images != [] and isinstance(images, list) and paths == []:
+ predicted_data = images
+ elif images == [] and isinstance(paths, list) and paths != []:
+ predicted_data = self.read_images(paths)
+ else:
+ raise TypeError("The input data is inconsistent with expectations.")
+
+ assert predicted_data != [], "There is not any image to be predicted. Please check the input data."
+
+ detection_results = self.text_detector_module.detect_text(
+ images=predicted_data, use_gpu=self.use_gpu, box_thresh=box_thresh)
+ boxes = [
+ np.array(item['data']).astype(np.float32)
+ for item in detection_results
+ ]
+ all_results = []
+ for index, img_boxes in enumerate(boxes):
+ original_image = predicted_data[index].copy()
+ result = {'save_path': ''}
+ if img_boxes is None:
+ result['data'] = []
+ else:
+ img_crop_list = []
+ boxes = sorted_boxes(img_boxes)
+ for num_box in range(len(boxes)):
+ tmp_box = copy.deepcopy(boxes[num_box])
+ img_crop = self.get_rotate_crop_image(
+ original_image, tmp_box)
+ img_crop_list.append(img_crop)
+
+ rec_results = self._recognize_text(img_crop_list)
+ # if the recognized text confidence score is lower than text_thresh, then drop it
+ rec_res_final = []
+ for index, res in enumerate(rec_results):
+ text, score = res
+ if score >= text_thresh:
+ rec_res_final.append({
+ 'text':
+ text,
+ 'confidence':
+ float(score),
+ 'text_box_position':
+ boxes[index].astype(np.int).tolist()
+ })
+ result['data'] = rec_res_final
+
+ if visualization and result['data']:
+ result['save_path'] = self.save_result_image(
+ original_image, boxes, rec_results, output_dir,
+ text_thresh)
+ all_results.append(result)
+
+ return all_results
+
+ @serving
+ def serving_method(self, images, **kwargs):
+ """
+ Run as a service.
+ """
+ images_decode = [base64_to_cv2(image) for image in images]
+ results = self.recognize_text(images_decode, **kwargs)
+ return results
+
+ def save_result_image(self,
+ original_image,
+ detection_boxes,
+ rec_results,
+ output_dir='ocr_result',
+ text_thresh=0.5):
+ image = Image.fromarray(cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB))
+ txts = [item[0] for item in rec_results]
+ scores = [item[1] for item in rec_results]
+ draw_img = draw_ocr(
+ image,
+ detection_boxes,
+ txts,
+ scores,
+ font_file=self.font_file,
+ draw_txt=True,
+ drop_score=text_thresh)
+
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir)
+ ext = get_image_ext(original_image)
+ saved_name = 'ndarray_{}{}'.format(time.time(), ext)
+ save_file_path = os.path.join(output_dir, saved_name)
+ cv2.imwrite(save_file_path, draw_img[:, :, ::-1])
+ return save_file_path
+
+ def _recognize_text(self, image_list):
+ img_num = len(image_list)
+ batch_num = 30
+ rec_res = []
+ predict_time = 0
+ for beg_img_no in range(0, img_num, batch_num):
+ end_img_no = min(img_num, beg_img_no + batch_num)
+ norm_img_batch = []
+ max_wh_ratio = 0
+ for ino in range(beg_img_no, end_img_no):
+ h, w = image_list[ino].shape[0:2]
+ wh_ratio = w / h
+ max_wh_ratio = max(max_wh_ratio, wh_ratio)
+ for ino in range(beg_img_no, end_img_no):
+ norm_img = self.resize_norm_img(image_list[ino], max_wh_ratio)
+ norm_img = norm_img[np.newaxis, :]
+ norm_img_batch.append(norm_img)
+ norm_img_batch = np.concatenate(norm_img_batch)
+ norm_img_batch = norm_img_batch.copy()
+ self.input_tensor.copy_from_cpu(norm_img_batch)
+ self.predictor.zero_copy_run()
+ rec_idx_batch = self.output_tensors[0].copy_to_cpu()
+ rec_idx_lod = self.output_tensors[0].lod()[0]
+ predict_batch = self.output_tensors[1].copy_to_cpu()
+ predict_lod = self.output_tensors[1].lod()[0]
+
+ for rno in range(len(rec_idx_lod) - 1):
+ beg = rec_idx_lod[rno]
+ end = rec_idx_lod[rno + 1]
+ rec_idx_tmp = rec_idx_batch[beg:end, 0]
+ preds_text = self.char_ops.decode(rec_idx_tmp)
+ beg = predict_lod[rno]
+ end = predict_lod[rno + 1]
+ probs = predict_batch[beg:end, :]
+ ind = np.argmax(probs, axis=1)
+ blank = probs.shape[1]
+ valid_ind = np.where(ind != (blank - 1))[0]
+ score = np.mean(probs[valid_ind, ind[valid_ind]])
+ rec_res.append([preds_text, score])
+
+ return rec_res
+
+ def save_inference_model(self,
+ dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True):
+ detector_dir = os.path.join(dirname, 'text_detector')
+ recognizer_dir = os.path.join(dirname, 'text_recognizer')
+ self._save_detector_model(detector_dir, model_filename, params_filename,
+ combined)
+ self._save_recognizer_model(recognizer_dir, model_filename,
+ params_filename, combined)
+ logger.info("The inference model has been saved in the path {}".format(
+ os.path.realpath(dirname)))
+
+ def _save_detector_model(self,
+ dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True):
+ self.text_detector_module.save_inference_model(
+ dirname, model_filename, params_filename, combined)
+
+ def _save_recognizer_model(self,
+ dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True):
+ if combined:
+ model_filename = "__model__" if not model_filename else model_filename
+ params_filename = "__params__" if not params_filename else params_filename
+ place = fluid.CPUPlace()
+ exe = fluid.Executor(place)
+
+ model_file_path = os.path.join(self.pretrained_model_path, 'model')
+ params_file_path = os.path.join(self.pretrained_model_path, 'params')
+ program, feeded_var_names, target_vars = fluid.io.load_inference_model(
+ dirname=self.pretrained_model_path,
+ model_filename=model_file_path,
+ params_filename=params_file_path,
+ executor=exe)
+
+ fluid.io.save_inference_model(
+ dirname=dirname,
+ main_program=program,
+ executor=exe,
+ feeded_var_names=feeded_var_names,
+ target_vars=target_vars,
+ model_filename=model_filename,
+ params_filename=params_filename)
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command
+ """
+ self.parser = argparse.ArgumentParser(
+ description="Run the %s module." % self.name,
+ prog='hub run %s' % self.name,
+ usage='%(prog)s',
+ add_help=True)
+
+ self.arg_input_group = self.parser.add_argument_group(
+ title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options",
+ description=
+ "Run configuration for controlling module behavior, not required.")
+
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+
+ args = self.parser.parse_args(argvs)
+ results = self.recognize_text(
+ paths=[args.input_path],
+ use_gpu=args.use_gpu,
+ output_dir=args.output_dir,
+ visualization=args.visualization)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options
+ """
+ self.arg_config_group.add_argument(
+ '--use_gpu',
+ type=ast.literal_eval,
+ default=False,
+ help="whether use GPU or not")
+ self.arg_config_group.add_argument(
+ '--output_dir',
+ type=str,
+ default='ocr_result',
+ help="The directory to save output images.")
+ self.arg_config_group.add_argument(
+ '--visualization',
+ type=ast.literal_eval,
+ default=False,
+ help="whether to save output as images.")
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options
+ """
+ self.arg_input_group.add_argument(
+ '--input_path', type=str, default=None, help="diretory to image")
+
+
+if __name__ == '__main__':
+ ocr = ChineseOCRDBCRNN()
+ image_path = [
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/11.jpg',
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/12.jpg',
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/test_image.jpg'
+ ]
+ res = ocr.recognize_text(paths=image_path, visualization=True)
+ ocr.save_inference_model('save')
+ print(res)
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/utils.py b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..3af0ae4d7b6a34159dcb9e69b4d0b470a2df3597
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_mobile/utils.py
@@ -0,0 +1,190 @@
+# -*- coding:utf-8 -*-
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import math
+
+from PIL import Image, ImageDraw, ImageFont
+import base64
+import cv2
+import numpy as np
+
+
+def draw_ocr(image,
+ boxes,
+ txts,
+ scores,
+ font_file,
+ draw_txt=True,
+ drop_score=0.5):
+ """
+ Visualize the results of OCR detection and recognition
+ args:
+ image(Image|array): RGB image
+ boxes(list): boxes with shape(N, 4, 2)
+ txts(list): the texts
+ scores(list): txxs corresponding scores
+ draw_txt(bool): whether draw text or not
+ drop_score(float): only scores greater than drop_threshold will be visualized
+ return(array):
+ the visualized img
+ """
+ if scores is None:
+ scores = [1] * len(boxes)
+ for (box, score) in zip(boxes, scores):
+ if score < drop_score or math.isnan(score):
+ continue
+ box = np.reshape(np.array(box), [-1, 1, 2]).astype(np.int64)
+ image = cv2.polylines(np.array(image), [box], True, (255, 0, 0), 2)
+
+ if draw_txt:
+ img = np.array(resize_img(image, input_size=600))
+ txt_img = text_visual(
+ txts,
+ scores,
+ font_file,
+ img_h=img.shape[0],
+ img_w=600,
+ threshold=drop_score)
+ img = np.concatenate([np.array(img), np.array(txt_img)], axis=1)
+ return img
+ return image
+
+
+def text_visual(texts, scores, font_file, img_h=400, img_w=600, threshold=0.):
+ """
+ create new blank img and draw txt on it
+ args:
+ texts(list): the text will be draw
+ scores(list|None): corresponding score of each txt
+ img_h(int): the height of blank img
+ img_w(int): the width of blank img
+ return(array):
+ """
+ if scores is not None:
+ assert len(texts) == len(
+ scores), "The number of txts and corresponding scores must match"
+
+ def create_blank_img():
+ blank_img = np.ones(shape=[img_h, img_w], dtype=np.int8) * 255
+ blank_img[:, img_w - 1:] = 0
+ blank_img = Image.fromarray(blank_img).convert("RGB")
+ draw_txt = ImageDraw.Draw(blank_img)
+ return blank_img, draw_txt
+
+ blank_img, draw_txt = create_blank_img()
+
+ font_size = 20
+ txt_color = (0, 0, 0)
+ font = ImageFont.truetype(font_file, font_size, encoding="utf-8")
+
+ gap = font_size + 5
+ txt_img_list = []
+ count, index = 1, 0
+ for idx, txt in enumerate(texts):
+ index += 1
+ if scores[idx] < threshold or math.isnan(scores[idx]):
+ index -= 1
+ continue
+ first_line = True
+ while str_count(txt) >= img_w // font_size - 4:
+ tmp = txt
+ txt = tmp[:img_w // font_size - 4]
+ if first_line:
+ new_txt = str(index) + ': ' + txt
+ first_line = False
+ else:
+ new_txt = ' ' + txt
+ draw_txt.text((0, gap * count), new_txt, txt_color, font=font)
+ txt = tmp[img_w // font_size - 4:]
+ if count >= img_h // gap - 1:
+ txt_img_list.append(np.array(blank_img))
+ blank_img, draw_txt = create_blank_img()
+ count = 0
+ count += 1
+ if first_line:
+ new_txt = str(index) + ': ' + txt + ' ' + '%.3f' % (scores[idx])
+ else:
+ new_txt = " " + txt + " " + '%.3f' % (scores[idx])
+ draw_txt.text((0, gap * count), new_txt, txt_color, font=font)
+ # whether add new blank img or not
+ if count >= img_h // gap - 1 and idx + 1 < len(texts):
+ txt_img_list.append(np.array(blank_img))
+ blank_img, draw_txt = create_blank_img()
+ count = 0
+ count += 1
+ txt_img_list.append(np.array(blank_img))
+ if len(txt_img_list) == 1:
+ blank_img = np.array(txt_img_list[0])
+ else:
+ blank_img = np.concatenate(txt_img_list, axis=1)
+ return np.array(blank_img)
+
+
+def str_count(s):
+ """
+ Count the number of Chinese characters,
+ a single English character and a single number
+ equal to half the length of Chinese characters.
+ args:
+ s(string): the input of string
+ return(int):
+ the number of Chinese characters
+ """
+ import string
+ count_zh = count_pu = 0
+ s_len = len(s)
+ en_dg_count = 0
+ for c in s:
+ if c in string.ascii_letters or c.isdigit() or c.isspace():
+ en_dg_count += 1
+ elif c.isalpha():
+ count_zh += 1
+ else:
+ count_pu += 1
+ return s_len - math.ceil(en_dg_count / 2)
+
+
+def resize_img(img, input_size=600):
+ img = np.array(img)
+ im_shape = img.shape
+ im_size_min = np.min(im_shape[0:2])
+ im_size_max = np.max(im_shape[0:2])
+ im_scale = float(input_size) / float(im_size_max)
+ im = cv2.resize(img, None, None, fx=im_scale, fy=im_scale)
+ return im
+
+
+def get_image_ext(image):
+ if image.shape[2] == 4:
+ return ".png"
+ return ".jpg"
+
+
+def sorted_boxes(dt_boxes):
+ """
+ Sort text boxes in order from top to bottom, left to right
+ args:
+ dt_boxes(array):detected text boxes with shape [4, 2]
+ return:
+ sorted boxes(array) with shape [4, 2]
+ """
+ num_boxes = dt_boxes.shape[0]
+ sorted_boxes = sorted(dt_boxes, key=lambda x: x[0][1])
+ _boxes = list(sorted_boxes)
+
+ for i in range(num_boxes - 1):
+ if abs(_boxes[i+1][0][1] - _boxes[i][0][1]) < 10 and \
+ (_boxes[i + 1][0][0] < _boxes[i][0][0]):
+ tmp = _boxes[i]
+ _boxes[i] = _boxes[i + 1]
+ _boxes[i + 1] = tmp
+ return _boxes
+
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/README.md b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..472a65325aea64a37c7be991123da0ab38b08615
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/README.md
@@ -0,0 +1,130 @@
+## 概述
+
+chinese_ocr_db_crnn_server Module用于识别图片当中的汉字。其基于[chinese_text_detection_db_server Module](https://www.paddlepaddle.org.cn/hubdetail?name=chinese_text_detection_db_server&en_category=TextRecognition)检测得到的文本框,继续识别文本框中的中文文字。识别文字算法采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module是一个通用的OCR模型,支持直接预测。
+
+
+
+
+
+
+更多详情参考[An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition](https://arxiv.org/pdf/1507.05717.pdf)
+
+## 命令行预测
+
+```shell
+$ hub run chinese_ocr_db_crnn_server --input_path "/PATH/TO/IMAGE"
+```
+
+**该Module依赖于第三方库shapely和pyclipper,使用该Module之前,请先安装shapely和pyclipper。**
+
+## API
+
+```python
+def recognize_text(images=[],
+ paths=[],
+ use_gpu=False,
+ output_dir='ocr_result',
+ visualization=False,
+ box_thresh=0.5,
+ text_thresh=0.5)
+```
+
+预测API,检测输入图片中的所有中文文本的位置。
+
+**参数**
+
+* paths (list\[str\]): 图片的路径;
+* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量**
+* box\_thresh (float): 检测文本框置信度的阈值;
+* text\_thresh (float): 识别中文文本置信度的阈值;
+* visualization (bool): 是否将识别结果保存为图片文件;
+* output\_dir (str): 图片的保存路径,默认设为 ocr\_result;
+
+**返回**
+
+* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
+ * data (list\[dict\]): 识别文本结果,列表中每一个元素为 dict,各字段为:
+ * text(str): 识别得到的文本
+ * confidence(float): 识别文本结果置信度
+ * text_box_position(list): 文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标
+ 如果无识别结果则data为\[\]
+ * save_path (str, optional): 识别结果的保存路径,如不保存图片则save_path为''
+
+### 代码示例
+
+```python
+import paddlehub as hub
+import cv2
+
+ocr = hub.Module(name="chinese_ocr_db_crnn_server")
+result = ocr.recognize_text(images=[cv2.imread('/PATH/TO/IMAGE')])
+
+# or
+# result = ocr.recognize_text(paths=['/PATH/TO/IMAGE'])
+```
+
+* 样例结果示例
+
+
+
+
+
+## 服务部署
+
+PaddleHub Serving 可以部署一个目标检测的在线服务。
+
+### 第一步:启动PaddleHub Serving
+
+运行启动命令:
+```shell
+$ hub serving start -m chinese_ocr_db_crnn_server
+```
+
+这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+### 第二步:发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+# 发送HTTP请求
+data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/chinese_ocr_db_crnn_server"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+# 打印预测结果
+print(r.json()["results"])
+```
+
+## 查看代码
+
+https://github.com/PaddlePaddle/PaddleOCR
+
+### 依赖
+
+paddlepaddle >= 1.7.2
+
+paddlehub >= 1.6.0
+
+shapely
+
+pyclipper
+
+## 更新历史
+
+* 1.0.0
+
+ 初始发布
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/__init__.py b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/character.py b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/character.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e5f10211ba441a7dd9b4948413b79c8721eab07
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/character.py
@@ -0,0 +1,168 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import numpy as np
+import string
+
+
+class CharacterOps(object):
+ """ Convert between text-label and text-index """
+
+ def __init__(self, config):
+ self.character_type = config['character_type']
+ self.loss_type = config['loss_type']
+ if self.character_type == "en":
+ self.character_str = "0123456789abcdefghijklmnopqrstuvwxyz"
+ dict_character = list(self.character_str)
+ elif self.character_type == "ch":
+ character_dict_path = config['character_dict_path']
+ self.character_str = ""
+ with open(character_dict_path, "rb") as fin:
+ lines = fin.readlines()
+ for line in lines:
+ line = line.decode('utf-8').strip("\n")
+ self.character_str += line
+ dict_character = list(self.character_str)
+ elif self.character_type == "en_sensitive":
+ # same with ASTER setting (use 94 char).
+ self.character_str = string.printable[:-6]
+ dict_character = list(self.character_str)
+ else:
+ self.character_str = None
+ assert self.character_str is not None, \
+ "Nonsupport type of the character: {}".format(self.character_str)
+ self.beg_str = "sos"
+ self.end_str = "eos"
+ if self.loss_type == "attention":
+ dict_character = [self.beg_str, self.end_str] + dict_character
+ self.dict = {}
+ for i, char in enumerate(dict_character):
+ self.dict[char] = i
+ self.character = dict_character
+
+ def encode(self, text):
+ """convert text-label into text-index.
+ input:
+ text: text labels of each image. [batch_size]
+
+ output:
+ text: concatenated text index for CTCLoss.
+ [sum(text_lengths)] = [text_index_0 + text_index_1 + ... + text_index_(n - 1)]
+ length: length of each text. [batch_size]
+ """
+ if self.character_type == "en":
+ text = text.lower()
+
+ text_list = []
+ for char in text:
+ if char not in self.dict:
+ continue
+ text_list.append(self.dict[char])
+ text = np.array(text_list)
+ return text
+
+ def decode(self, text_index, is_remove_duplicate=False):
+ """ convert text-index into text-label. """
+ char_list = []
+ char_num = self.get_char_num()
+
+ if self.loss_type == "attention":
+ beg_idx = self.get_beg_end_flag_idx("beg")
+ end_idx = self.get_beg_end_flag_idx("end")
+ ignored_tokens = [beg_idx, end_idx]
+ else:
+ ignored_tokens = [char_num]
+
+ for idx in range(len(text_index)):
+ if text_index[idx] in ignored_tokens:
+ continue
+ if is_remove_duplicate:
+ if idx > 0 and text_index[idx - 1] == text_index[idx]:
+ continue
+ char_list.append(self.character[text_index[idx]])
+ text = ''.join(char_list)
+ return text
+
+ def get_char_num(self):
+ return len(self.character)
+
+ def get_beg_end_flag_idx(self, beg_or_end):
+ if self.loss_type == "attention":
+ if beg_or_end == "beg":
+ idx = np.array(self.dict[self.beg_str])
+ elif beg_or_end == "end":
+ idx = np.array(self.dict[self.end_str])
+ else:
+ assert False, "Unsupport type %s in get_beg_end_flag_idx"\
+ % beg_or_end
+ return idx
+ else:
+ err = "error in get_beg_end_flag_idx when using the loss %s"\
+ % (self.loss_type)
+ assert False, err
+
+
+def cal_predicts_accuracy(char_ops,
+ preds,
+ preds_lod,
+ labels,
+ labels_lod,
+ is_remove_duplicate=False):
+ acc_num = 0
+ img_num = 0
+ for ino in range(len(labels_lod) - 1):
+ beg_no = preds_lod[ino]
+ end_no = preds_lod[ino + 1]
+ preds_text = preds[beg_no:end_no].reshape(-1)
+ preds_text = char_ops.decode(preds_text, is_remove_duplicate)
+
+ beg_no = labels_lod[ino]
+ end_no = labels_lod[ino + 1]
+ labels_text = labels[beg_no:end_no].reshape(-1)
+ labels_text = char_ops.decode(labels_text, is_remove_duplicate)
+ img_num += 1
+
+ if preds_text == labels_text:
+ acc_num += 1
+ acc = acc_num * 1.0 / img_num
+ return acc, acc_num, img_num
+
+
+def convert_rec_attention_infer_res(preds):
+ img_num = preds.shape[0]
+ target_lod = [0]
+ convert_ids = []
+ for ino in range(img_num):
+ end_pos = np.where(preds[ino, :] == 1)[0]
+ if len(end_pos) <= 1:
+ text_list = preds[ino, 1:]
+ else:
+ text_list = preds[ino, 1:end_pos[1]]
+ target_lod.append(target_lod[ino] + len(text_list))
+ convert_ids = convert_ids + list(text_list)
+ convert_ids = np.array(convert_ids)
+ convert_ids = convert_ids.reshape((-1, 1))
+ return convert_ids, target_lod
+
+
+def convert_rec_label_to_lod(ori_labels):
+ img_num = len(ori_labels)
+ target_lod = [0]
+ convert_ids = []
+ for ino in range(img_num):
+ target_lod.append(target_lod[ino] + len(ori_labels[ino]))
+ convert_ids = convert_ids + list(ori_labels[ino])
+ convert_ids = np.array(convert_ids)
+ convert_ids = convert_ids.reshape((-1, 1))
+ return convert_ids, target_lod
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/module.py b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..8090b65fcfb50ff9ede71f575b708421ca012268
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/module.py
@@ -0,0 +1,433 @@
+# -*- coding:utf-8 -*-
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import ast
+import copy
+import math
+import os
+import time
+
+from paddle.fluid.core import AnalysisConfig, create_paddle_predictor, PaddleTensor
+from paddlehub.common.logger import logger
+from paddlehub.module.module import moduleinfo, runnable, serving
+from PIL import Image
+import cv2
+import numpy as np
+import paddle.fluid as fluid
+import paddlehub as hub
+
+from chinese_ocr_db_crnn_server.character import CharacterOps
+from chinese_ocr_db_crnn_server.utils import base64_to_cv2, draw_ocr, get_image_ext, sorted_boxes
+
+
+@moduleinfo(
+ name="chinese_ocr_db_crnn_server",
+ version="1.0.0",
+ summary=
+ "The module can recognize the chinese texts in an image. Firstly, it will detect the text box positions based on the differentiable_binarization_chn module. Then it recognizes the chinese texts. ",
+ author="paddle-dev",
+ author_email="paddle-dev@baidu.com",
+ type="cv/text_recognition")
+class ChineseOCRDBCRNNServer(hub.Module):
+ def _initialize(self, text_detector_module=None):
+ """
+ initialize with the necessary elements
+ """
+ self.character_dict_path = os.path.join(self.directory, 'assets',
+ 'ppocr_keys_v1.txt')
+ char_ops_params = {
+ 'character_type': 'ch',
+ 'character_dict_path': self.character_dict_path,
+ 'loss_type': 'ctc'
+ }
+ self.char_ops = CharacterOps(char_ops_params)
+ self.rec_image_shape = [3, 32, 320]
+ self._text_detector_module = text_detector_module
+ self.font_file = os.path.join(self.directory, 'assets', 'simfang.ttf')
+ self.pretrained_model_path = os.path.join(self.directory, 'assets',
+ 'ch_rec_r34_vd_crnn')
+ self._set_config()
+
+ def _set_config(self):
+ """
+ predictor config setting
+ """
+ model_file_path = os.path.join(self.pretrained_model_path, 'model')
+ params_file_path = os.path.join(self.pretrained_model_path, 'params')
+
+ config = AnalysisConfig(model_file_path, params_file_path)
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ use_gpu = True
+ except:
+ use_gpu = False
+
+ if use_gpu:
+ config.enable_use_gpu(8000, 0)
+ else:
+ config.disable_gpu()
+
+ config.disable_glog_info()
+
+ # use zero copy
+ config.delete_pass("conv_transpose_eltwiseadd_bn_fuse_pass")
+ config.switch_use_feed_fetch_ops(False)
+ self.predictor = create_paddle_predictor(config)
+ input_names = self.predictor.get_input_names()
+ self.input_tensor = self.predictor.get_input_tensor(input_names[0])
+ output_names = self.predictor.get_output_names()
+ self.output_tensors = []
+ for output_name in output_names:
+ output_tensor = self.predictor.get_output_tensor(output_name)
+ self.output_tensors.append(output_tensor)
+
+ @property
+ def text_detector_module(self):
+ """
+ text detect module
+ """
+ if not self._text_detector_module:
+ self._text_detector_module = hub.Module(
+ name='chinese_text_detection_db_server')
+ return self._text_detector_module
+
+ def read_images(self, paths=[]):
+ images = []
+ for img_path in paths:
+ assert os.path.isfile(
+ img_path), "The {} isn't a valid file.".format(img_path)
+ img = cv2.imread(img_path)
+ if img is None:
+ logger.info("error in loading image:{}".format(img_path))
+ continue
+ images.append(img)
+ return images
+
+ def get_rotate_crop_image(self, img, points):
+ img_height, img_width = img.shape[0:2]
+ left = int(np.min(points[:, 0]))
+ right = int(np.max(points[:, 0]))
+ top = int(np.min(points[:, 1]))
+ bottom = int(np.max(points[:, 1]))
+ img_crop = img[top:bottom, left:right, :].copy()
+ points[:, 0] = points[:, 0] - left
+ points[:, 1] = points[:, 1] - top
+ img_crop_width = int(np.linalg.norm(points[0] - points[1]))
+ img_crop_height = int(np.linalg.norm(points[0] - points[3]))
+ pts_std = np.float32([[0, 0], [img_crop_width, 0],\
+ [img_crop_width, img_crop_height], [0, img_crop_height]])
+ M = cv2.getPerspectiveTransform(points, pts_std)
+ dst_img = cv2.warpPerspective(
+ img_crop,
+ M, (img_crop_width, img_crop_height),
+ borderMode=cv2.BORDER_REPLICATE)
+ dst_img_height, dst_img_width = dst_img.shape[0:2]
+ if dst_img_height * 1.0 / dst_img_width >= 1.5:
+ dst_img = np.rot90(dst_img)
+ return dst_img
+
+ def resize_norm_img(self, img, max_wh_ratio):
+ imgC, imgH, imgW = self.rec_image_shape
+ imgW = int(32 * max_wh_ratio)
+ h = img.shape[0]
+ w = img.shape[1]
+ ratio = w / float(h)
+ if math.ceil(imgH * ratio) > imgW:
+ resized_w = imgW
+ else:
+ resized_w = int(math.ceil(imgH * ratio))
+ resized_image = cv2.resize(img, (resized_w, imgH))
+ resized_image = resized_image.astype('float32')
+ resized_image = resized_image.transpose((2, 0, 1)) / 255
+ resized_image -= 0.5
+ resized_image /= 0.5
+ padding_im = np.zeros((imgC, imgH, imgW), dtype=np.float32)
+ padding_im[:, :, 0:resized_w] = resized_image
+ return padding_im
+
+ def recognize_text(self,
+ images=[],
+ paths=[],
+ use_gpu=False,
+ output_dir='ocr_result',
+ visualization=False,
+ box_thresh=0.5,
+ text_thresh=0.5):
+ """
+ Get the chinese texts in the predicted images.
+ Args:
+ images (list(numpy.ndarray)): images data, shape of each is [H, W, C]. If images not paths
+ paths (list[str]): The paths of images. If paths not images
+ use_gpu (bool): Whether to use gpu.
+ batch_size(int): the program deals once with one
+ output_dir (str): The directory to store output images.
+ visualization (bool): Whether to save image or not.
+ box_thresh(float): the threshold of the detected text box's confidence
+ text_thresh(float): the threshold of the recognize chinese texts' confidence
+ Returns:
+ res (list): The result of chinese texts and save path of images.
+ """
+ if use_gpu:
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES via export CUDA_VISIBLE_DEVICES=cuda_device_id."
+ )
+
+ self.use_gpu = use_gpu
+
+ if images != [] and isinstance(images, list) and paths == []:
+ predicted_data = images
+ elif images == [] and isinstance(paths, list) and paths != []:
+ predicted_data = self.read_images(paths)
+ else:
+ raise TypeError("The input data is inconsistent with expectations.")
+
+ assert predicted_data != [], "There is not any image to be predicted. Please check the input data."
+
+ detection_results = self.text_detector_module.detect_text(
+ images=predicted_data, use_gpu=self.use_gpu, box_thresh=box_thresh)
+ boxes = [
+ np.array(item['data']).astype(np.float32)
+ for item in detection_results
+ ]
+ all_results = []
+ for index, img_boxes in enumerate(boxes):
+ original_image = predicted_data[index].copy()
+ result = {'save_path': ''}
+ if img_boxes is None:
+ result['data'] = []
+ else:
+ img_crop_list = []
+ boxes = sorted_boxes(img_boxes)
+ for num_box in range(len(boxes)):
+ tmp_box = copy.deepcopy(boxes[num_box])
+ img_crop = self.get_rotate_crop_image(
+ original_image, tmp_box)
+ img_crop_list.append(img_crop)
+
+ rec_results = self._recognize_text(img_crop_list)
+ # if the recognized text confidence score is lower than text_thresh, then drop it
+ rec_res_final = []
+ for index, res in enumerate(rec_results):
+ text, score = res
+ if score >= text_thresh:
+ rec_res_final.append({
+ 'text':
+ text,
+ 'confidence':
+ float(score),
+ 'text_box_position':
+ boxes[index].astype(np.int).tolist()
+ })
+ result['data'] = rec_res_final
+
+ if visualization and result['data']:
+ result['save_path'] = self.save_result_image(
+ original_image, boxes, rec_results, output_dir,
+ text_thresh)
+ all_results.append(result)
+
+ return all_results
+
+ @serving
+ def serving_method(self, images, **kwargs):
+ """
+ Run as a service.
+ """
+ images_decode = [base64_to_cv2(image) for image in images]
+ results = self.recognize_text(images_decode, **kwargs)
+ return results
+
+ def save_result_image(self,
+ original_image,
+ detection_boxes,
+ rec_results,
+ output_dir='ocr_result',
+ text_thresh=0.5):
+ image = Image.fromarray(cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB))
+ txts = [item[0] for item in rec_results]
+ scores = [item[1] for item in rec_results]
+ draw_img = draw_ocr(
+ image,
+ detection_boxes,
+ txts,
+ scores,
+ font_file=self.font_file,
+ draw_txt=True,
+ drop_score=text_thresh)
+
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir)
+ ext = get_image_ext(original_image)
+ saved_name = 'ndarray_{}{}'.format(time.time(), ext)
+ save_file_path = os.path.join(output_dir, saved_name)
+ cv2.imwrite(save_file_path, draw_img[:, :, ::-1])
+ return save_file_path
+
+ def _recognize_text(self, image_list):
+ img_num = len(image_list)
+ batch_num = 30
+ rec_res = []
+ predict_time = 0
+ for beg_img_no in range(0, img_num, batch_num):
+ end_img_no = min(img_num, beg_img_no + batch_num)
+ norm_img_batch = []
+ max_wh_ratio = 0
+ for ino in range(beg_img_no, end_img_no):
+ h, w = image_list[ino].shape[0:2]
+ wh_ratio = w / h
+ max_wh_ratio = max(max_wh_ratio, wh_ratio)
+ for ino in range(beg_img_no, end_img_no):
+ norm_img = self.resize_norm_img(image_list[ino], max_wh_ratio)
+ norm_img = norm_img[np.newaxis, :]
+ norm_img_batch.append(norm_img)
+ norm_img_batch = np.concatenate(norm_img_batch)
+ norm_img_batch = norm_img_batch.copy()
+ self.input_tensor.copy_from_cpu(norm_img_batch)
+ self.predictor.zero_copy_run()
+ rec_idx_batch = self.output_tensors[0].copy_to_cpu()
+ rec_idx_lod = self.output_tensors[0].lod()[0]
+ predict_batch = self.output_tensors[1].copy_to_cpu()
+ predict_lod = self.output_tensors[1].lod()[0]
+
+ for rno in range(len(rec_idx_lod) - 1):
+ beg = rec_idx_lod[rno]
+ end = rec_idx_lod[rno + 1]
+ rec_idx_tmp = rec_idx_batch[beg:end, 0]
+ preds_text = self.char_ops.decode(rec_idx_tmp)
+ beg = predict_lod[rno]
+ end = predict_lod[rno + 1]
+ probs = predict_batch[beg:end, :]
+ ind = np.argmax(probs, axis=1)
+ blank = probs.shape[1]
+ valid_ind = np.where(ind != (blank - 1))[0]
+ score = np.mean(probs[valid_ind, ind[valid_ind]])
+ rec_res.append([preds_text, score])
+
+ return rec_res
+
+ def save_inference_model(self,
+ dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True):
+ detector_dir = os.path.join(dirname, 'text_detector')
+ recognizer_dir = os.path.join(dirname, 'text_recognizer')
+ self._save_detector_model(detector_dir, model_filename, params_filename,
+ combined)
+ self._save_recognizer_model(recognizer_dir, model_filename,
+ params_filename, combined)
+ logger.info("The inference model has been saved in the path {}".format(
+ os.path.realpath(dirname)))
+
+ def _save_detector_model(self,
+ dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True):
+ self.text_detector_module.save_inference_model(
+ dirname, model_filename, params_filename, combined)
+
+ def _save_recognizer_model(self,
+ dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True):
+ if combined:
+ model_filename = "__model__" if not model_filename else model_filename
+ params_filename = "__params__" if not params_filename else params_filename
+ place = fluid.CPUPlace()
+ exe = fluid.Executor(place)
+
+ model_file_path = os.path.join(self.pretrained_model_path, 'model')
+ params_file_path = os.path.join(self.pretrained_model_path, 'params')
+ program, feeded_var_names, target_vars = fluid.io.load_inference_model(
+ dirname=self.pretrained_model_path,
+ model_filename=model_file_path,
+ params_filename=params_file_path,
+ executor=exe)
+
+ fluid.io.save_inference_model(
+ dirname=dirname,
+ main_program=program,
+ executor=exe,
+ feeded_var_names=feeded_var_names,
+ target_vars=target_vars,
+ model_filename=model_filename,
+ params_filename=params_filename)
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command
+ """
+ self.parser = argparse.ArgumentParser(
+ description="Run the %s module." % self.name,
+ prog='hub run %s' % self.name,
+ usage='%(prog)s',
+ add_help=True)
+
+ self.arg_input_group = self.parser.add_argument_group(
+ title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options",
+ description=
+ "Run configuration for controlling module behavior, not required.")
+
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+
+ args = self.parser.parse_args(argvs)
+ results = self.recognize_text(
+ paths=[args.input_path],
+ use_gpu=args.use_gpu,
+ output_dir=args.output_dir,
+ visualization=args.visualization)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options
+ """
+ self.arg_config_group.add_argument(
+ '--use_gpu',
+ type=ast.literal_eval,
+ default=False,
+ help="whether use GPU or not")
+ self.arg_config_group.add_argument(
+ '--output_dir',
+ type=str,
+ default='ocr_result',
+ help="The directory to save output images.")
+ self.arg_config_group.add_argument(
+ '--visualization',
+ type=ast.literal_eval,
+ default=False,
+ help="whether to save output as images.")
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options
+ """
+ self.arg_input_group.add_argument(
+ '--input_path', type=str, default=None, help="diretory to image")
+
+
+if __name__ == '__main__':
+ ocr = ChineseOCRDBCRNNServer()
+ print(ocr.name)
+ image_path = [
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/11.jpg',
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/12.jpg',
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/test_image.jpg'
+ ]
+ res = ocr.recognize_text(paths=image_path, visualization=True)
+ ocr.save_inference_model('save')
+ print(res)
diff --git a/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/utils.py b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..3af0ae4d7b6a34159dcb9e69b4d0b470a2df3597
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_ocr_db_crnn_server/utils.py
@@ -0,0 +1,190 @@
+# -*- coding:utf-8 -*-
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import math
+
+from PIL import Image, ImageDraw, ImageFont
+import base64
+import cv2
+import numpy as np
+
+
+def draw_ocr(image,
+ boxes,
+ txts,
+ scores,
+ font_file,
+ draw_txt=True,
+ drop_score=0.5):
+ """
+ Visualize the results of OCR detection and recognition
+ args:
+ image(Image|array): RGB image
+ boxes(list): boxes with shape(N, 4, 2)
+ txts(list): the texts
+ scores(list): txxs corresponding scores
+ draw_txt(bool): whether draw text or not
+ drop_score(float): only scores greater than drop_threshold will be visualized
+ return(array):
+ the visualized img
+ """
+ if scores is None:
+ scores = [1] * len(boxes)
+ for (box, score) in zip(boxes, scores):
+ if score < drop_score or math.isnan(score):
+ continue
+ box = np.reshape(np.array(box), [-1, 1, 2]).astype(np.int64)
+ image = cv2.polylines(np.array(image), [box], True, (255, 0, 0), 2)
+
+ if draw_txt:
+ img = np.array(resize_img(image, input_size=600))
+ txt_img = text_visual(
+ txts,
+ scores,
+ font_file,
+ img_h=img.shape[0],
+ img_w=600,
+ threshold=drop_score)
+ img = np.concatenate([np.array(img), np.array(txt_img)], axis=1)
+ return img
+ return image
+
+
+def text_visual(texts, scores, font_file, img_h=400, img_w=600, threshold=0.):
+ """
+ create new blank img and draw txt on it
+ args:
+ texts(list): the text will be draw
+ scores(list|None): corresponding score of each txt
+ img_h(int): the height of blank img
+ img_w(int): the width of blank img
+ return(array):
+ """
+ if scores is not None:
+ assert len(texts) == len(
+ scores), "The number of txts and corresponding scores must match"
+
+ def create_blank_img():
+ blank_img = np.ones(shape=[img_h, img_w], dtype=np.int8) * 255
+ blank_img[:, img_w - 1:] = 0
+ blank_img = Image.fromarray(blank_img).convert("RGB")
+ draw_txt = ImageDraw.Draw(blank_img)
+ return blank_img, draw_txt
+
+ blank_img, draw_txt = create_blank_img()
+
+ font_size = 20
+ txt_color = (0, 0, 0)
+ font = ImageFont.truetype(font_file, font_size, encoding="utf-8")
+
+ gap = font_size + 5
+ txt_img_list = []
+ count, index = 1, 0
+ for idx, txt in enumerate(texts):
+ index += 1
+ if scores[idx] < threshold or math.isnan(scores[idx]):
+ index -= 1
+ continue
+ first_line = True
+ while str_count(txt) >= img_w // font_size - 4:
+ tmp = txt
+ txt = tmp[:img_w // font_size - 4]
+ if first_line:
+ new_txt = str(index) + ': ' + txt
+ first_line = False
+ else:
+ new_txt = ' ' + txt
+ draw_txt.text((0, gap * count), new_txt, txt_color, font=font)
+ txt = tmp[img_w // font_size - 4:]
+ if count >= img_h // gap - 1:
+ txt_img_list.append(np.array(blank_img))
+ blank_img, draw_txt = create_blank_img()
+ count = 0
+ count += 1
+ if first_line:
+ new_txt = str(index) + ': ' + txt + ' ' + '%.3f' % (scores[idx])
+ else:
+ new_txt = " " + txt + " " + '%.3f' % (scores[idx])
+ draw_txt.text((0, gap * count), new_txt, txt_color, font=font)
+ # whether add new blank img or not
+ if count >= img_h // gap - 1 and idx + 1 < len(texts):
+ txt_img_list.append(np.array(blank_img))
+ blank_img, draw_txt = create_blank_img()
+ count = 0
+ count += 1
+ txt_img_list.append(np.array(blank_img))
+ if len(txt_img_list) == 1:
+ blank_img = np.array(txt_img_list[0])
+ else:
+ blank_img = np.concatenate(txt_img_list, axis=1)
+ return np.array(blank_img)
+
+
+def str_count(s):
+ """
+ Count the number of Chinese characters,
+ a single English character and a single number
+ equal to half the length of Chinese characters.
+ args:
+ s(string): the input of string
+ return(int):
+ the number of Chinese characters
+ """
+ import string
+ count_zh = count_pu = 0
+ s_len = len(s)
+ en_dg_count = 0
+ for c in s:
+ if c in string.ascii_letters or c.isdigit() or c.isspace():
+ en_dg_count += 1
+ elif c.isalpha():
+ count_zh += 1
+ else:
+ count_pu += 1
+ return s_len - math.ceil(en_dg_count / 2)
+
+
+def resize_img(img, input_size=600):
+ img = np.array(img)
+ im_shape = img.shape
+ im_size_min = np.min(im_shape[0:2])
+ im_size_max = np.max(im_shape[0:2])
+ im_scale = float(input_size) / float(im_size_max)
+ im = cv2.resize(img, None, None, fx=im_scale, fy=im_scale)
+ return im
+
+
+def get_image_ext(image):
+ if image.shape[2] == 4:
+ return ".png"
+ return ".jpg"
+
+
+def sorted_boxes(dt_boxes):
+ """
+ Sort text boxes in order from top to bottom, left to right
+ args:
+ dt_boxes(array):detected text boxes with shape [4, 2]
+ return:
+ sorted boxes(array) with shape [4, 2]
+ """
+ num_boxes = dt_boxes.shape[0]
+ sorted_boxes = sorted(dt_boxes, key=lambda x: x[0][1])
+ _boxes = list(sorted_boxes)
+
+ for i in range(num_boxes - 1):
+ if abs(_boxes[i+1][0][1] - _boxes[i][0][1]) < 10 and \
+ (_boxes[i + 1][0][0] < _boxes[i][0][0]):
+ tmp = _boxes[i]
+ _boxes[i] = _boxes[i + 1]
+ _boxes[i + 1] = tmp
+ return _boxes
+
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
diff --git a/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/README.md b/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8dd066c5c1733a77e1257a1e8190ffa31209dc35
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/README.md
@@ -0,0 +1,123 @@
+## 概述
+
+Differentiable Binarization(简称DB)是一种基于分割的文本检测算法。在各种文本检测算法中,基于分割的检测算法可以更好地处理弯曲等不规则形状文本,因此往往能取得更好的检测效果。但分割法后处理步骤中将分割结果转化为检测框的流程复杂,耗时严重。DB将二值化阈值加入训练中学习,可以获得更准确的检测边界,从而简化后处理流程。该Module是一个超轻量级文本检测模型,支持直接预测。
+
+
+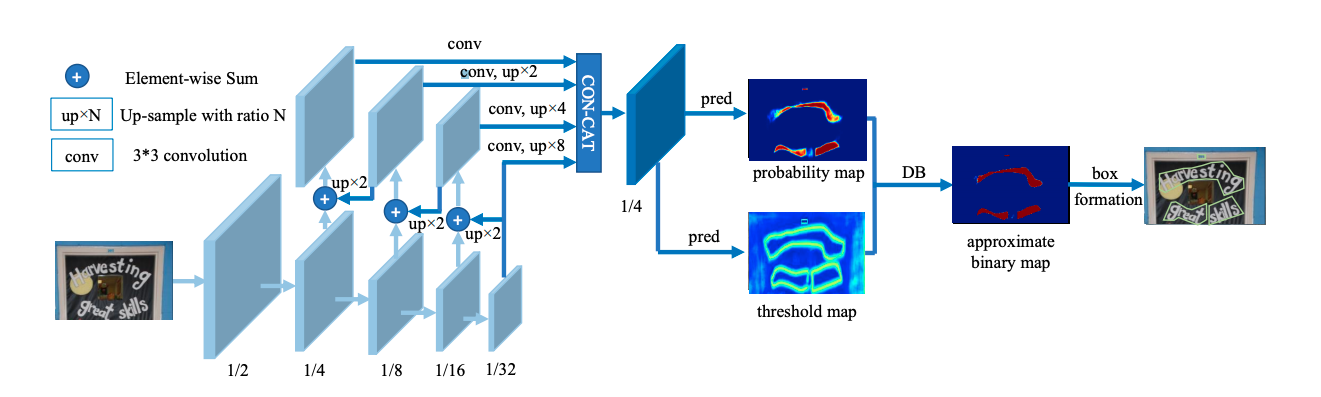
+
+
+更多详情参考[Real-time Scene Text Detection with Differentiable Binarization](https://arxiv.org/pdf/1911.08947.pdf)
+
+
+## 命令行预测
+
+```shell
+$ hub run chinese_text_detection_db_mobile --input_path "/PATH/TO/IMAGE"
+```
+
+**该Module依赖于第三方库shapely和pyclipper,使用该Module之前,请先安装shapely和pyclipper。**
+
+## API
+
+```python
+def detect_text(paths=[],
+ images=[],
+ use_gpu=False,
+ output_dir='detection_result',
+ box_thresh=0.5,
+ visualization=False)
+```
+
+预测API,检测输入图片中的所有中文文本的位置。
+
+**参数**
+
+* paths (list\[str\]): 图片的路径;
+* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量**
+* box\_thresh (float): 检测文本框置信度的阈值;
+* visualization (bool): 是否将识别结果保存为图片文件;
+* output\_dir (str): 图片的保存路径,默认设为 detection\_result;
+
+**返回**
+
+* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
+ * data (list): 检测文本框结果,文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标
+ * save_path (str): 识别结果的保存路径, 如不保存图片则save_path为''
+
+### 代码示例
+
+```python
+import paddlehub as hub
+import cv2
+
+text_detector = hub.Module(name="chinese_text_detection_db_mobile")
+result = text_detector.detect_text(images=[cv2.imread('/PATH/TO/IMAGE')])
+
+# or
+# result =text_detector.detect_text(paths=['/PATH/TO/IMAGE'])
+```
+
+
+## 服务部署
+
+PaddleHub Serving 可以部署一个目标检测的在线服务。
+
+### 第一步:启动PaddleHub Serving
+
+运行启动命令:
+```shell
+$ hub serving start -m chinese_text_detection_db_mobile
+```
+
+这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+### 第二步:发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+# 发送HTTP请求
+data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/chinese_text_detection_db_mobile"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+# 打印预测结果
+print(r.json()["results"])
+```
+
+## 查看代码
+
+https://github.com/PaddlePaddle/PaddleOCR
+
+## 依赖
+
+paddlepaddle >= 1.7.2
+
+paddlehub >= 1.6.0
+
+shapely
+
+pyclipper
+
+## 更新历史
+
+* 1.0.0
+
+ 初始发布
+
+* 1.0.1
+
+ 修复使用在线服务调用模型失败问题
diff --git a/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/__init__.py b/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/module.py b/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..d709311dcac8fa85c9966078d70d670ded9e1ec9
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/module.py
@@ -0,0 +1,334 @@
+# -*- coding:utf-8 -*-
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import ast
+import math
+import os
+import time
+
+from paddle.fluid.core import AnalysisConfig, create_paddle_predictor, PaddleTensor
+from paddlehub.common.logger import logger
+from paddlehub.module.module import moduleinfo, runnable, serving
+from PIL import Image
+import base64
+import cv2
+import numpy as np
+import paddle.fluid as fluid
+import paddlehub as hub
+
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+
+@moduleinfo(
+ name="chinese_text_detection_db_mobile",
+ version="1.0.1",
+ summary=
+ "The module aims to detect chinese text position in the image, which is based on differentiable_binarization algorithm.",
+ author="paddle-dev",
+ author_email="paddle-dev@baidu.com",
+ type="cv/text_recognition")
+class ChineseTextDetectionDB(hub.Module):
+ def _initialize(self):
+ """
+ initialize with the necessary elements
+ """
+ self.pretrained_model_path = os.path.join(self.directory,
+ 'inference_model')
+ self._set_config()
+
+ def check_requirements(self):
+ try:
+ import shapely, pyclipper
+ except:
+ print(
+ 'This module requires the shapely, pyclipper tools. The running enviroment does not meet the requirments. Please install the two packages.'
+ )
+ exit()
+
+ def _set_config(self):
+ """
+ predictor config setting
+ """
+ model_file_path = os.path.join(self.pretrained_model_path, 'model')
+ params_file_path = os.path.join(self.pretrained_model_path, 'params')
+
+ config = AnalysisConfig(model_file_path, params_file_path)
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ use_gpu = True
+ except:
+ use_gpu = False
+
+ if use_gpu:
+ config.enable_use_gpu(8000, 0)
+ else:
+ config.disable_gpu()
+
+ config.disable_glog_info()
+
+ # use zero copy
+ config.delete_pass("conv_transpose_eltwiseadd_bn_fuse_pass")
+ config.switch_use_feed_fetch_ops(False)
+ self.predictor = create_paddle_predictor(config)
+ input_names = self.predictor.get_input_names()
+ self.input_tensor = self.predictor.get_input_tensor(input_names[0])
+ output_names = self.predictor.get_output_names()
+ self.output_tensors = []
+ for output_name in output_names:
+ output_tensor = self.predictor.get_output_tensor(output_name)
+ self.output_tensors.append(output_tensor)
+
+ def read_images(self, paths=[]):
+ images = []
+ for img_path in paths:
+ assert os.path.isfile(
+ img_path), "The {} isn't a valid file.".format(img_path)
+ img = cv2.imread(img_path)
+ if img is None:
+ logger.info("error in loading image:{}".format(img_path))
+ continue
+ images.append(img)
+ return images
+
+ def filter_tag_det_res(self, dt_boxes, image_shape):
+ img_height, img_width = image_shape[0:2]
+ dt_boxes_new = []
+ for box in dt_boxes:
+ box = self.order_points_clockwise(box)
+ left = int(np.min(box[:, 0]))
+ right = int(np.max(box[:, 0]))
+ top = int(np.min(box[:, 1]))
+ bottom = int(np.max(box[:, 1]))
+ bbox_height = bottom - top
+ bbox_width = right - left
+ diffh = math.fabs(box[0, 1] - box[1, 1])
+ diffw = math.fabs(box[0, 0] - box[3, 0])
+ rect_width = int(np.linalg.norm(box[0] - box[1]))
+ rect_height = int(np.linalg.norm(box[0] - box[3]))
+ if rect_width <= 10 or rect_height <= 10:
+ continue
+ dt_boxes_new.append(box)
+ dt_boxes = np.array(dt_boxes_new)
+ return dt_boxes
+
+ def order_points_clockwise(self, pts):
+ """
+ reference from: https://github.com/jrosebr1/imutils/blob/master/imutils/perspective.py
+ # sort the points based on their x-coordinates
+ """
+ xSorted = pts[np.argsort(pts[:, 0]), :]
+
+ # grab the left-most and right-most points from the sorted
+ # x-roodinate points
+ leftMost = xSorted[:2, :]
+ rightMost = xSorted[2:, :]
+
+ # now, sort the left-most coordinates according to their
+ # y-coordinates so we can grab the top-left and bottom-left
+ # points, respectively
+ leftMost = leftMost[np.argsort(leftMost[:, 1]), :]
+ (tl, bl) = leftMost
+
+ rightMost = rightMost[np.argsort(rightMost[:, 1]), :]
+ (tr, br) = rightMost
+
+ rect = np.array([tl, tr, br, bl], dtype="float32")
+ return rect
+
+ def detect_text(self,
+ images=[],
+ paths=[],
+ use_gpu=False,
+ output_dir='detection_result',
+ visualization=False,
+ box_thresh=0.5):
+ """
+ Get the text box in the predicted images.
+ Args:
+ images (list(numpy.ndarray)): images data, shape of each is [H, W, C]. If images not paths
+ paths (list[str]): The paths of images. If paths not images
+ use_gpu (bool): Whether to use gpu. Default false.
+ output_dir (str): The directory to store output images.
+ visualization (bool): Whether to save image or not.
+ box_thresh(float): the threshold of the detected text box's confidence
+ Returns:
+ res (list): The result of text detection box and save path of images.
+ """
+ self.check_requirements()
+
+ from chinese_text_detection_db_mobile.processor import DBPreProcess, DBPostProcess, draw_boxes, get_image_ext
+
+ if use_gpu:
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES via export CUDA_VISIBLE_DEVICES=cuda_device_id."
+ )
+
+ if images != [] and isinstance(images, list) and paths == []:
+ predicted_data = images
+ elif images == [] and isinstance(paths, list) and paths != []:
+ predicted_data = self.read_images(paths)
+ else:
+ raise TypeError("The input data is inconsistent with expectations.")
+
+ assert predicted_data != [], "There is not any image to be predicted. Please check the input data."
+
+ preprocessor = DBPreProcess()
+ postprocessor = DBPostProcess(box_thresh)
+
+ all_imgs = []
+ all_ratios = []
+ all_results = []
+ for original_image in predicted_data:
+ im, ratio_list = preprocessor(original_image)
+ res = {'save_path': ''}
+ if im is None:
+ res['data'] = []
+
+ else:
+ im = im.copy()
+ starttime = time.time()
+ self.input_tensor.copy_from_cpu(im)
+ self.predictor.zero_copy_run()
+ data_out = self.output_tensors[0].copy_to_cpu()
+ dt_boxes_list = postprocessor(data_out, [ratio_list])
+ boxes = self.filter_tag_det_res(dt_boxes_list[0],
+ original_image.shape)
+ res['data'] = boxes.astype(np.int).tolist()
+
+ all_imgs.append(im)
+ all_ratios.append(ratio_list)
+ if visualization:
+ img = Image.fromarray(
+ cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB))
+ draw_img = draw_boxes(img, boxes)
+ draw_img = np.array(draw_img)
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir)
+ ext = get_image_ext(original_image)
+ saved_name = 'ndarray_{}{}'.format(time.time(), ext)
+ cv2.imwrite(
+ os.path.join(output_dir, saved_name),
+ draw_img[:, :, ::-1])
+ res['save_path'] = os.path.join(output_dir, saved_name)
+
+ all_results.append(res)
+
+ return all_results
+
+ def save_inference_model(self,
+ dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True):
+ if combined:
+ model_filename = "__model__" if not model_filename else model_filename
+ params_filename = "__params__" if not params_filename else params_filename
+ place = fluid.CPUPlace()
+ exe = fluid.Executor(place)
+
+ model_file_path = os.path.join(self.pretrained_model_path, 'model')
+ params_file_path = os.path.join(self.pretrained_model_path, 'params')
+ program, feeded_var_names, target_vars = fluid.io.load_inference_model(
+ dirname=self.pretrained_model_path,
+ model_filename=model_file_path,
+ params_filename=params_file_path,
+ executor=exe)
+
+ fluid.io.save_inference_model(
+ dirname=dirname,
+ main_program=program,
+ executor=exe,
+ feeded_var_names=feeded_var_names,
+ target_vars=target_vars,
+ model_filename=model_filename,
+ params_filename=params_filename)
+
+ @serving
+ def serving_method(self, images, **kwargs):
+ """
+ Run as a service.
+ """
+ images_decode = [base64_to_cv2(image) for image in images]
+ results = self.detect_text(images=images_decode, **kwargs)
+ return results
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command
+ """
+ self.parser = argparse.ArgumentParser(
+ description="Run the %s module." % self.name,
+ prog='hub run %s' % self.name,
+ usage='%(prog)s',
+ add_help=True)
+
+ self.arg_input_group = self.parser.add_argument_group(
+ title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options",
+ description=
+ "Run configuration for controlling module behavior, not required.")
+
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+
+ args = self.parser.parse_args(argvs)
+ results = self.detect_text(
+ paths=[args.input_path],
+ use_gpu=args.use_gpu,
+ output_dir=args.output_dir,
+ visualization=args.visualization)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options
+ """
+ self.arg_config_group.add_argument(
+ '--use_gpu',
+ type=ast.literal_eval,
+ default=False,
+ help="whether use GPU or not")
+ self.arg_config_group.add_argument(
+ '--output_dir',
+ type=str,
+ default='detection_result',
+ help="The directory to save output images.")
+ self.arg_config_group.add_argument(
+ '--visualization',
+ type=ast.literal_eval,
+ default=False,
+ help="whether to save output as images.")
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options
+ """
+ self.arg_input_group.add_argument(
+ '--input_path', type=str, default=None, help="diretory to image")
+
+
+if __name__ == '__main__':
+ db = ChineseTextDetectionDB()
+ image_path = [
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/11.jpg',
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/12.jpg',
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/test_image.jpg'
+ ]
+ res = db.detect_text(paths=image_path, visualization=True)
+ db.save_inference_model('save')
+ print(res)
diff --git a/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/processor.py b/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/processor.py
new file mode 100644
index 0000000000000000000000000000000000000000..aec5a11953bc094e21401acb81ca0074e22fd5de
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_text_detection_db_mobile/processor.py
@@ -0,0 +1,237 @@
+# -*- coding:utf-8 -*-
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import sys
+
+from PIL import Image, ImageDraw, ImageFont
+from shapely.geometry import Polygon
+import cv2
+import numpy as np
+import pyclipper
+
+
+class DBPreProcess(object):
+ def __init__(self, max_side_len=960):
+ self.max_side_len = max_side_len
+
+ def resize_image_type(self, im):
+ """
+ resize image to a size multiple of 32 which is required by the network
+ """
+ h, w, _ = im.shape
+
+ resize_w = w
+ resize_h = h
+
+ # limit the max side
+ if max(resize_h, resize_w) > self.max_side_len:
+ if resize_h > resize_w:
+ ratio = float(self.max_side_len) / resize_h
+ else:
+ ratio = float(self.max_side_len) / resize_w
+ else:
+ ratio = 1.
+ resize_h = int(resize_h * ratio)
+ resize_w = int(resize_w * ratio)
+ if resize_h % 32 == 0:
+ resize_h = resize_h
+ elif resize_h // 32 <= 1:
+ resize_h = 32
+ else:
+ resize_h = (resize_h // 32 - 1) * 32
+ if resize_w % 32 == 0:
+ resize_w = resize_w
+ elif resize_w // 32 <= 1:
+ resize_w = 32
+ else:
+ resize_w = (resize_w // 32 - 1) * 32
+ try:
+ if int(resize_w) <= 0 or int(resize_h) <= 0:
+ return None, (None, None)
+ im = cv2.resize(im, (int(resize_w), int(resize_h)))
+ except:
+ print(im.shape, resize_w, resize_h)
+ sys.exit(0)
+ ratio_h = resize_h / float(h)
+ ratio_w = resize_w / float(w)
+ return im, (ratio_h, ratio_w)
+
+ def normalize(self, im):
+ img_mean = [0.485, 0.456, 0.406]
+ img_std = [0.229, 0.224, 0.225]
+ im = im.astype(np.float32, copy=False)
+ im = im / 255
+ im -= img_mean
+ im /= img_std
+ channel_swap = (2, 0, 1)
+ im = im.transpose(channel_swap)
+ return im
+
+ def __call__(self, im):
+ im, (ratio_h, ratio_w) = self.resize_image_type(im)
+ im = self.normalize(im)
+ im = im[np.newaxis, :]
+ return [im, (ratio_h, ratio_w)]
+
+
+class DBPostProcess(object):
+ """
+ The post process for Differentiable Binarization (DB).
+ """
+
+ def __init__(self, thresh=0.3, box_thresh=0.5, max_candidates=1000):
+ self.thresh = thresh
+ self.box_thresh = box_thresh
+ self.max_candidates = max_candidates
+ self.min_size = 3
+
+ def boxes_from_bitmap(self, pred, _bitmap, dest_width, dest_height):
+ '''
+ _bitmap: single map with shape (1, H, W),
+ whose values are binarized as {0, 1}
+ '''
+
+ bitmap = _bitmap
+ height, width = bitmap.shape
+
+ outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST,
+ cv2.CHAIN_APPROX_SIMPLE)
+ if len(outs) == 3:
+ img, contours, _ = outs[0], outs[1], outs[2]
+ elif len(outs) == 2:
+ contours, _ = outs[0], outs[1]
+
+ num_contours = min(len(contours), self.max_candidates)
+ boxes = np.zeros((num_contours, 4, 2), dtype=np.int16)
+ scores = np.zeros((num_contours, ), dtype=np.float32)
+
+ for index in range(num_contours):
+ contour = contours[index]
+ points, sside = self.get_mini_boxes(contour)
+ if sside < self.min_size:
+ continue
+ points = np.array(points)
+ score = self.box_score_fast(pred, points.reshape(-1, 2))
+ if self.box_thresh > score:
+ continue
+
+ box = self.unclip(points).reshape(-1, 1, 2)
+ box, sside = self.get_mini_boxes(box)
+ if sside < self.min_size + 2:
+ continue
+ box = np.array(box)
+ if not isinstance(dest_width, int):
+ dest_width = dest_width.item()
+ dest_height = dest_height.item()
+
+ box[:, 0] = np.clip(
+ np.round(box[:, 0] / width * dest_width), 0, dest_width)
+ box[:, 1] = np.clip(
+ np.round(box[:, 1] / height * dest_height), 0, dest_height)
+ boxes[index, :, :] = box.astype(np.int16)
+ scores[index] = score
+ return boxes, scores
+
+ def unclip(self, box, unclip_ratio=2.0):
+ poly = Polygon(box)
+ distance = poly.area * unclip_ratio / poly.length
+ offset = pyclipper.PyclipperOffset()
+ offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
+ expanded = np.array(offset.Execute(distance))
+ return expanded
+
+ def get_mini_boxes(self, contour):
+ bounding_box = cv2.minAreaRect(contour)
+ points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
+
+ index_1, index_2, index_3, index_4 = 0, 1, 2, 3
+ if points[1][1] > points[0][1]:
+ index_1 = 0
+ index_4 = 1
+ else:
+ index_1 = 1
+ index_4 = 0
+ if points[3][1] > points[2][1]:
+ index_2 = 2
+ index_3 = 3
+ else:
+ index_2 = 3
+ index_3 = 2
+
+ box = [
+ points[index_1], points[index_2], points[index_3], points[index_4]
+ ]
+ return box, min(bounding_box[1])
+
+ def box_score_fast(self, bitmap, _box):
+ h, w = bitmap.shape[:2]
+ box = _box.copy()
+ xmin = np.clip(np.floor(box[:, 0].min()).astype(np.int), 0, w - 1)
+ xmax = np.clip(np.ceil(box[:, 0].max()).astype(np.int), 0, w - 1)
+ ymin = np.clip(np.floor(box[:, 1].min()).astype(np.int), 0, h - 1)
+ ymax = np.clip(np.ceil(box[:, 1].max()).astype(np.int), 0, h - 1)
+
+ mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
+ box[:, 0] = box[:, 0] - xmin
+ box[:, 1] = box[:, 1] - ymin
+ cv2.fillPoly(mask, box.reshape(1, -1, 2).astype(np.int32), 1)
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
+
+ def __call__(self, predictions, ratio_list):
+ pred = predictions[:, 0, :, :]
+ segmentation = pred > self.thresh
+
+ boxes_batch = []
+ for batch_index in range(pred.shape[0]):
+ height, width = pred.shape[-2:]
+ tmp_boxes, tmp_scores = self.boxes_from_bitmap(
+ pred[batch_index], segmentation[batch_index], width, height)
+
+ boxes = []
+ for k in range(len(tmp_boxes)):
+ if tmp_scores[k] > self.box_thresh:
+ boxes.append(tmp_boxes[k])
+ if len(boxes) > 0:
+ boxes = np.array(boxes)
+
+ ratio_h, ratio_w = ratio_list[batch_index]
+ boxes[:, :, 0] = boxes[:, :, 0] / ratio_w
+ boxes[:, :, 1] = boxes[:, :, 1] / ratio_h
+
+ boxes_batch.append(boxes)
+ return boxes_batch
+
+
+def draw_boxes(image, boxes, scores=None, drop_score=0.5):
+ img = image.copy()
+ draw = ImageDraw.Draw(img)
+ if scores is None:
+ scores = [1] * len(boxes)
+ for (box, score) in zip(boxes, scores):
+ if score < drop_score:
+ continue
+ draw.line([(box[0][0], box[0][1]), (box[1][0], box[1][1])], fill='red')
+ draw.line([(box[1][0], box[1][1]), (box[2][0], box[2][1])], fill='red')
+ draw.line([(box[2][0], box[2][1]), (box[3][0], box[3][1])], fill='red')
+ draw.line([(box[3][0], box[3][1]), (box[0][0], box[0][1])], fill='red')
+ draw.line([(box[0][0] - 1, box[0][1] + 1),
+ (box[1][0] - 1, box[1][1] + 1)],
+ fill='red')
+ draw.line([(box[1][0] - 1, box[1][1] + 1),
+ (box[2][0] - 1, box[2][1] + 1)],
+ fill='red')
+ draw.line([(box[2][0] - 1, box[2][1] + 1),
+ (box[3][0] - 1, box[3][1] + 1)],
+ fill='red')
+ draw.line([(box[3][0] - 1, box[3][1] + 1),
+ (box[0][0] - 1, box[0][1] + 1)],
+ fill='red')
+ return img
+
+
+def get_image_ext(image):
+ if image.shape[2] == 4:
+ return ".png"
+ return ".jpg"
diff --git a/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/README.md b/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..37a70e19de5e0fdba4a9a1f1b185748e0ff629a5
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/README.md
@@ -0,0 +1,119 @@
+## 概述
+
+Differentiable Binarization(简称DB)是一种基于分割的文本检测算法。在各种文本检测算法中,基于分割的检测算法可以更好地处理弯曲等不规则形状文本,因此往往能取得更好的检测效果。但分割法后处理步骤中将分割结果转化为检测框的流程复杂,耗时严重。DB将二值化阈值加入训练中学习,可以获得更准确的检测边界,从而简化后处理流程。该Module是一个通用的文本检测模型,支持直接预测。
+
+
+
+
+
+更多详情参考[Real-time Scene Text Detection with Differentiable Binarization](https://arxiv.org/pdf/1911.08947.pdf)
+
+
+## 命令行预测
+
+```shell
+$ hub run chinese_text_detection_db_server --input_path "/PATH/TO/IMAGE"
+```
+
+**该Module依赖于第三方库shapely和pyclipper,使用该Module之前,请先安装shapely和pyclipper。**
+
+## API
+
+```python
+def detect_text(paths=[],
+ images=[],
+ use_gpu=False,
+ output_dir='detection_result',
+ box_thresh=0.5,
+ visualization=False)
+```
+
+预测API,检测输入图片中的所有中文文本的位置。
+
+**参数**
+
+* paths (list\[str\]): 图片的路径;
+* images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量**
+* box\_thresh (float): 检测文本框置信度的阈值;
+* visualization (bool): 是否将识别结果保存为图片文件;
+* output\_dir (str): 图片的保存路径,默认设为 detection\_result;
+
+**返回**
+
+* res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
+ * data (list): 检测文本框结果,文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标
+ * save_path (str): 识别结果的保存路径, 如不保存图片则save_path为''
+
+### 代码示例
+
+```python
+import paddlehub as hub
+import cv2
+
+text_detector = hub.Module(name="chinese_text_detection_db_server")
+result = text_detector.detect_text(images=[cv2.imread('/PATH/TO/IMAGE')])
+
+# or
+# result =text_detector.detect_text(paths=['/PATH/TO/IMAGE'])
+```
+
+
+## 服务部署
+
+PaddleHub Serving 可以部署一个目标检测的在线服务。
+
+### 第一步:启动PaddleHub Serving
+
+运行启动命令:
+```shell
+$ hub serving start -m chinese_text_detection_db_server
+```
+
+这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+### 第二步:发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+# 发送HTTP请求
+data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/chinese_text_detection_db_server"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+# 打印预测结果
+print(r.json()["results"])
+```
+
+## 查看代码
+
+https://github.com/PaddlePaddle/PaddleOCR
+
+## 依赖
+
+paddlepaddle >= 1.7.2
+
+paddlehub >= 1.6.0
+
+shapely
+
+pyclipper
+
+## 更新历史
+
+* 1.0.0
+
+ 初始发布
diff --git a/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/__init__.py b/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/module.py b/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..f75812fb05cd197c4968dd572a41caf727fb05fa
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/module.py
@@ -0,0 +1,333 @@
+# -*- coding:utf-8 -*-
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import ast
+import math
+import os
+import time
+
+from paddle.fluid.core import AnalysisConfig, create_paddle_predictor, PaddleTensor
+from paddlehub.common.logger import logger
+from paddlehub.module.module import moduleinfo, runnable, serving
+from PIL import Image
+import base64
+import cv2
+import numpy as np
+import paddle.fluid as fluid
+import paddlehub as hub
+
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+
+@moduleinfo(
+ name="chinese_text_detection_db_server",
+ version="1.0.0",
+ summary=
+ "The module aims to detect chinese text position in the image, which is based on differentiable_binarization algorithm.",
+ author="paddle-dev",
+ author_email="paddle-dev@baidu.com",
+ type="cv/text_recognition")
+class ChineseTextDetectionDBServer(hub.Module):
+ def _initialize(self):
+ """
+ initialize with the necessary elements
+ """
+ self.pretrained_model_path = os.path.join(self.directory,
+ 'ch_det_r50_vd_db')
+ self._set_config()
+
+ def check_requirements(self):
+ try:
+ import shapely, pyclipper
+ except:
+ print(
+ 'This module requires the shapely, pyclipper tools. The running enviroment does not meet the requirments. Please install the two packages.'
+ )
+ exit()
+
+ def _set_config(self):
+ """
+ predictor config setting
+ """
+ model_file_path = os.path.join(self.pretrained_model_path, 'model')
+ params_file_path = os.path.join(self.pretrained_model_path, 'params')
+
+ config = AnalysisConfig(model_file_path, params_file_path)
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ use_gpu = True
+ except:
+ use_gpu = False
+
+ if use_gpu:
+ config.enable_use_gpu(8000, 0)
+ else:
+ config.disable_gpu()
+
+ config.disable_glog_info()
+
+ # use zero copy
+ config.delete_pass("conv_transpose_eltwiseadd_bn_fuse_pass")
+ config.switch_use_feed_fetch_ops(False)
+ self.predictor = create_paddle_predictor(config)
+ input_names = self.predictor.get_input_names()
+ self.input_tensor = self.predictor.get_input_tensor(input_names[0])
+ output_names = self.predictor.get_output_names()
+ self.output_tensors = []
+ for output_name in output_names:
+ output_tensor = self.predictor.get_output_tensor(output_name)
+ self.output_tensors.append(output_tensor)
+
+ def read_images(self, paths=[]):
+ images = []
+ for img_path in paths:
+ assert os.path.isfile(
+ img_path), "The {} isn't a valid file.".format(img_path)
+ img = cv2.imread(img_path)
+ if img is None:
+ logger.info("error in loading image:{}".format(img_path))
+ continue
+ images.append(img)
+ return images
+
+ def filter_tag_det_res(self, dt_boxes, image_shape):
+ img_height, img_width = image_shape[0:2]
+ dt_boxes_new = []
+ for box in dt_boxes:
+ box = self.order_points_clockwise(box)
+ left = int(np.min(box[:, 0]))
+ right = int(np.max(box[:, 0]))
+ top = int(np.min(box[:, 1]))
+ bottom = int(np.max(box[:, 1]))
+ bbox_height = bottom - top
+ bbox_width = right - left
+ diffh = math.fabs(box[0, 1] - box[1, 1])
+ diffw = math.fabs(box[0, 0] - box[3, 0])
+ rect_width = int(np.linalg.norm(box[0] - box[1]))
+ rect_height = int(np.linalg.norm(box[0] - box[3]))
+ if rect_width <= 10 or rect_height <= 10:
+ continue
+ dt_boxes_new.append(box)
+ dt_boxes = np.array(dt_boxes_new)
+ return dt_boxes
+
+ def order_points_clockwise(self, pts):
+ """
+ reference from: https://github.com/jrosebr1/imutils/blob/master/imutils/perspective.py
+ # sort the points based on their x-coordinates
+ """
+ xSorted = pts[np.argsort(pts[:, 0]), :]
+
+ # grab the left-most and right-most points from the sorted
+ # x-roodinate points
+ leftMost = xSorted[:2, :]
+ rightMost = xSorted[2:, :]
+
+ # now, sort the left-most coordinates according to their
+ # y-coordinates so we can grab the top-left and bottom-left
+ # points, respectively
+ leftMost = leftMost[np.argsort(leftMost[:, 1]), :]
+ (tl, bl) = leftMost
+
+ rightMost = rightMost[np.argsort(rightMost[:, 1]), :]
+ (tr, br) = rightMost
+
+ rect = np.array([tl, tr, br, bl], dtype="float32")
+ return rect
+
+ def detect_text(self,
+ images=[],
+ paths=[],
+ use_gpu=False,
+ output_dir='detection_result',
+ visualization=False,
+ box_thresh=0.5):
+ """
+ Get the text box in the predicted images.
+ Args:
+ images (list(numpy.ndarray)): images data, shape of each is [H, W, C]. If images not paths
+ paths (list[str]): The paths of images. If paths not images
+ use_gpu (bool): Whether to use gpu. Default false.
+ output_dir (str): The directory to store output images.
+ visualization (bool): Whether to save image or not.
+ box_thresh(float): the threshold of the detected text box's confidence
+ Returns:
+ res (list): The result of text detection box and save path of images.
+ """
+ self.check_requirements()
+
+ from chinese_text_detection_db_server.processor import DBPreProcess, DBPostProcess, draw_boxes, get_image_ext
+
+ if use_gpu:
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES via export CUDA_VISIBLE_DEVICES=cuda_device_id."
+ )
+
+ if images != [] and isinstance(images, list) and paths == []:
+ predicted_data = images
+ elif images == [] and isinstance(paths, list) and paths != []:
+ predicted_data = self.read_images(paths)
+ else:
+ raise TypeError("The input data is inconsistent with expectations.")
+
+ assert predicted_data != [], "There is not any image to be predicted. Please check the input data."
+
+ preprocessor = DBPreProcess()
+ postprocessor = DBPostProcess(box_thresh)
+
+ all_imgs = []
+ all_ratios = []
+ all_results = []
+ for original_image in predicted_data:
+ im, ratio_list = preprocessor(original_image)
+ res = {'save_path': ''}
+ if im is None:
+ res['data'] = []
+
+ else:
+ im = im.copy()
+ starttime = time.time()
+ self.input_tensor.copy_from_cpu(im)
+ self.predictor.zero_copy_run()
+ data_out = self.output_tensors[0].copy_to_cpu()
+ dt_boxes_list = postprocessor(data_out, [ratio_list])
+ boxes = self.filter_tag_det_res(dt_boxes_list[0],
+ original_image.shape)
+ res['data'] = boxes.astype(np.int).tolist()
+
+ all_imgs.append(im)
+ all_ratios.append(ratio_list)
+ if visualization:
+ img = Image.fromarray(
+ cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB))
+ draw_img = draw_boxes(img, boxes)
+ draw_img = np.array(draw_img)
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir)
+ ext = get_image_ext(original_image)
+ saved_name = 'ndarray_{}{}'.format(time.time(), ext)
+ cv2.imwrite(
+ os.path.join(output_dir, saved_name),
+ draw_img[:, :, ::-1])
+ res['save_path'] = os.path.join(output_dir, saved_name)
+
+ all_results.append(res)
+
+ return all_results
+
+ def save_inference_model(self,
+ dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True):
+ if combined:
+ model_filename = "__model__" if not model_filename else model_filename
+ params_filename = "__params__" if not params_filename else params_filename
+ place = fluid.CPUPlace()
+ exe = fluid.Executor(place)
+
+ model_file_path = os.path.join(self.pretrained_model_path, 'model')
+ params_file_path = os.path.join(self.pretrained_model_path, 'params')
+ program, feeded_var_names, target_vars = fluid.io.load_inference_model(
+ dirname=self.pretrained_model_path,
+ model_filename=model_file_path,
+ params_filename=params_file_path,
+ executor=exe)
+
+ fluid.io.save_inference_model(
+ dirname=dirname,
+ main_program=program,
+ executor=exe,
+ feeded_var_names=feeded_var_names,
+ target_vars=target_vars,
+ model_filename=model_filename,
+ params_filename=params_filename)
+
+ @serving
+ def serving_method(self, images, **kwargs):
+ """
+ Run as a service.
+ """
+ images_decode = [base64_to_cv2(image) for image in images]
+ results = self.detect_text(images=images_decode, **kwargs)
+ return results
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command
+ """
+ self.parser = argparse.ArgumentParser(
+ description="Run the %s module." % self.name,
+ prog='hub run %s' % self.name,
+ usage='%(prog)s',
+ add_help=True)
+
+ self.arg_input_group = self.parser.add_argument_group(
+ title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options",
+ description=
+ "Run configuration for controlling module behavior, not required.")
+
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+
+ args = self.parser.parse_args(argvs)
+ results = self.detect_text(
+ paths=[args.input_path],
+ use_gpu=args.use_gpu,
+ output_dir=args.output_dir,
+ visualization=args.visualization)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options
+ """
+ self.arg_config_group.add_argument(
+ '--use_gpu',
+ type=ast.literal_eval,
+ default=False,
+ help="whether use GPU or not")
+ self.arg_config_group.add_argument(
+ '--output_dir',
+ type=str,
+ default='detection_result',
+ help="The directory to save output images.")
+ self.arg_config_group.add_argument(
+ '--visualization',
+ type=ast.literal_eval,
+ default=False,
+ help="whether to save output as images.")
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options
+ """
+ self.arg_input_group.add_argument(
+ '--input_path', type=str, default=None, help="diretory to image")
+
+
+if __name__ == '__main__':
+ db = ChineseTextDetectionDBServer()
+ image_path = [
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/11.jpg',
+ '/mnt/zhangxuefei/PaddleOCR/doc/imgs/12.jpg'
+ ]
+ res = db.detect_text(paths=image_path, visualization=True)
+ db.save_inference_model('save')
+ print(res)
diff --git a/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/processor.py b/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/processor.py
new file mode 100644
index 0000000000000000000000000000000000000000..aec5a11953bc094e21401acb81ca0074e22fd5de
--- /dev/null
+++ b/hub_module/modules/image/text_recognition/chinese_text_detection_db_server/processor.py
@@ -0,0 +1,237 @@
+# -*- coding:utf-8 -*-
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import sys
+
+from PIL import Image, ImageDraw, ImageFont
+from shapely.geometry import Polygon
+import cv2
+import numpy as np
+import pyclipper
+
+
+class DBPreProcess(object):
+ def __init__(self, max_side_len=960):
+ self.max_side_len = max_side_len
+
+ def resize_image_type(self, im):
+ """
+ resize image to a size multiple of 32 which is required by the network
+ """
+ h, w, _ = im.shape
+
+ resize_w = w
+ resize_h = h
+
+ # limit the max side
+ if max(resize_h, resize_w) > self.max_side_len:
+ if resize_h > resize_w:
+ ratio = float(self.max_side_len) / resize_h
+ else:
+ ratio = float(self.max_side_len) / resize_w
+ else:
+ ratio = 1.
+ resize_h = int(resize_h * ratio)
+ resize_w = int(resize_w * ratio)
+ if resize_h % 32 == 0:
+ resize_h = resize_h
+ elif resize_h // 32 <= 1:
+ resize_h = 32
+ else:
+ resize_h = (resize_h // 32 - 1) * 32
+ if resize_w % 32 == 0:
+ resize_w = resize_w
+ elif resize_w // 32 <= 1:
+ resize_w = 32
+ else:
+ resize_w = (resize_w // 32 - 1) * 32
+ try:
+ if int(resize_w) <= 0 or int(resize_h) <= 0:
+ return None, (None, None)
+ im = cv2.resize(im, (int(resize_w), int(resize_h)))
+ except:
+ print(im.shape, resize_w, resize_h)
+ sys.exit(0)
+ ratio_h = resize_h / float(h)
+ ratio_w = resize_w / float(w)
+ return im, (ratio_h, ratio_w)
+
+ def normalize(self, im):
+ img_mean = [0.485, 0.456, 0.406]
+ img_std = [0.229, 0.224, 0.225]
+ im = im.astype(np.float32, copy=False)
+ im = im / 255
+ im -= img_mean
+ im /= img_std
+ channel_swap = (2, 0, 1)
+ im = im.transpose(channel_swap)
+ return im
+
+ def __call__(self, im):
+ im, (ratio_h, ratio_w) = self.resize_image_type(im)
+ im = self.normalize(im)
+ im = im[np.newaxis, :]
+ return [im, (ratio_h, ratio_w)]
+
+
+class DBPostProcess(object):
+ """
+ The post process for Differentiable Binarization (DB).
+ """
+
+ def __init__(self, thresh=0.3, box_thresh=0.5, max_candidates=1000):
+ self.thresh = thresh
+ self.box_thresh = box_thresh
+ self.max_candidates = max_candidates
+ self.min_size = 3
+
+ def boxes_from_bitmap(self, pred, _bitmap, dest_width, dest_height):
+ '''
+ _bitmap: single map with shape (1, H, W),
+ whose values are binarized as {0, 1}
+ '''
+
+ bitmap = _bitmap
+ height, width = bitmap.shape
+
+ outs = cv2.findContours((bitmap * 255).astype(np.uint8), cv2.RETR_LIST,
+ cv2.CHAIN_APPROX_SIMPLE)
+ if len(outs) == 3:
+ img, contours, _ = outs[0], outs[1], outs[2]
+ elif len(outs) == 2:
+ contours, _ = outs[0], outs[1]
+
+ num_contours = min(len(contours), self.max_candidates)
+ boxes = np.zeros((num_contours, 4, 2), dtype=np.int16)
+ scores = np.zeros((num_contours, ), dtype=np.float32)
+
+ for index in range(num_contours):
+ contour = contours[index]
+ points, sside = self.get_mini_boxes(contour)
+ if sside < self.min_size:
+ continue
+ points = np.array(points)
+ score = self.box_score_fast(pred, points.reshape(-1, 2))
+ if self.box_thresh > score:
+ continue
+
+ box = self.unclip(points).reshape(-1, 1, 2)
+ box, sside = self.get_mini_boxes(box)
+ if sside < self.min_size + 2:
+ continue
+ box = np.array(box)
+ if not isinstance(dest_width, int):
+ dest_width = dest_width.item()
+ dest_height = dest_height.item()
+
+ box[:, 0] = np.clip(
+ np.round(box[:, 0] / width * dest_width), 0, dest_width)
+ box[:, 1] = np.clip(
+ np.round(box[:, 1] / height * dest_height), 0, dest_height)
+ boxes[index, :, :] = box.astype(np.int16)
+ scores[index] = score
+ return boxes, scores
+
+ def unclip(self, box, unclip_ratio=2.0):
+ poly = Polygon(box)
+ distance = poly.area * unclip_ratio / poly.length
+ offset = pyclipper.PyclipperOffset()
+ offset.AddPath(box, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
+ expanded = np.array(offset.Execute(distance))
+ return expanded
+
+ def get_mini_boxes(self, contour):
+ bounding_box = cv2.minAreaRect(contour)
+ points = sorted(list(cv2.boxPoints(bounding_box)), key=lambda x: x[0])
+
+ index_1, index_2, index_3, index_4 = 0, 1, 2, 3
+ if points[1][1] > points[0][1]:
+ index_1 = 0
+ index_4 = 1
+ else:
+ index_1 = 1
+ index_4 = 0
+ if points[3][1] > points[2][1]:
+ index_2 = 2
+ index_3 = 3
+ else:
+ index_2 = 3
+ index_3 = 2
+
+ box = [
+ points[index_1], points[index_2], points[index_3], points[index_4]
+ ]
+ return box, min(bounding_box[1])
+
+ def box_score_fast(self, bitmap, _box):
+ h, w = bitmap.shape[:2]
+ box = _box.copy()
+ xmin = np.clip(np.floor(box[:, 0].min()).astype(np.int), 0, w - 1)
+ xmax = np.clip(np.ceil(box[:, 0].max()).astype(np.int), 0, w - 1)
+ ymin = np.clip(np.floor(box[:, 1].min()).astype(np.int), 0, h - 1)
+ ymax = np.clip(np.ceil(box[:, 1].max()).astype(np.int), 0, h - 1)
+
+ mask = np.zeros((ymax - ymin + 1, xmax - xmin + 1), dtype=np.uint8)
+ box[:, 0] = box[:, 0] - xmin
+ box[:, 1] = box[:, 1] - ymin
+ cv2.fillPoly(mask, box.reshape(1, -1, 2).astype(np.int32), 1)
+ return cv2.mean(bitmap[ymin:ymax + 1, xmin:xmax + 1], mask)[0]
+
+ def __call__(self, predictions, ratio_list):
+ pred = predictions[:, 0, :, :]
+ segmentation = pred > self.thresh
+
+ boxes_batch = []
+ for batch_index in range(pred.shape[0]):
+ height, width = pred.shape[-2:]
+ tmp_boxes, tmp_scores = self.boxes_from_bitmap(
+ pred[batch_index], segmentation[batch_index], width, height)
+
+ boxes = []
+ for k in range(len(tmp_boxes)):
+ if tmp_scores[k] > self.box_thresh:
+ boxes.append(tmp_boxes[k])
+ if len(boxes) > 0:
+ boxes = np.array(boxes)
+
+ ratio_h, ratio_w = ratio_list[batch_index]
+ boxes[:, :, 0] = boxes[:, :, 0] / ratio_w
+ boxes[:, :, 1] = boxes[:, :, 1] / ratio_h
+
+ boxes_batch.append(boxes)
+ return boxes_batch
+
+
+def draw_boxes(image, boxes, scores=None, drop_score=0.5):
+ img = image.copy()
+ draw = ImageDraw.Draw(img)
+ if scores is None:
+ scores = [1] * len(boxes)
+ for (box, score) in zip(boxes, scores):
+ if score < drop_score:
+ continue
+ draw.line([(box[0][0], box[0][1]), (box[1][0], box[1][1])], fill='red')
+ draw.line([(box[1][0], box[1][1]), (box[2][0], box[2][1])], fill='red')
+ draw.line([(box[2][0], box[2][1]), (box[3][0], box[3][1])], fill='red')
+ draw.line([(box[3][0], box[3][1]), (box[0][0], box[0][1])], fill='red')
+ draw.line([(box[0][0] - 1, box[0][1] + 1),
+ (box[1][0] - 1, box[1][1] + 1)],
+ fill='red')
+ draw.line([(box[1][0] - 1, box[1][1] + 1),
+ (box[2][0] - 1, box[2][1] + 1)],
+ fill='red')
+ draw.line([(box[2][0] - 1, box[2][1] + 1),
+ (box[3][0] - 1, box[3][1] + 1)],
+ fill='red')
+ draw.line([(box[3][0] - 1, box[3][1] + 1),
+ (box[0][0] - 1, box[0][1] + 1)],
+ fill='red')
+ return img
+
+
+def get_image_ext(image):
+ if image.shape[2] == 4:
+ return ".png"
+ return ".jpg"
diff --git a/hub_module/modules/text/semantic_model/bert_cased_L_12_H_768_A_12/README.md b/hub_module/modules/text/semantic_model/bert_cased_L_12_H_768_A_12/README.md
index 8466b8e43cee52670ca79829e260deee8559662e..002f621e8dd650bb0a8b7c80a2209e180dda84af 100644
--- a/hub_module/modules/text/semantic_model/bert_cased_L_12_H_768_A_12/README.md
+++ b/hub_module/modules/text/semantic_model/bert_cased_L_12_H_768_A_12/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
diff --git a/hub_module/modules/text/semantic_model/bert_cased_L_24_H_1024_A_16/README.md b/hub_module/modules/text/semantic_model/bert_cased_L_24_H_1024_A_16/README.md
index 3b09123d10683761f1269a701fb97849c2981b2d..1e3421417439c17df69ab76bfd437c577fd320af 100644
--- a/hub_module/modules/text/semantic_model/bert_cased_L_24_H_1024_A_16/README.md
+++ b/hub_module/modules/text/semantic_model/bert_cased_L_24_H_1024_A_16/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/bert_chinese_L_12_H_768_A_12/README.md b/hub_module/modules/text/semantic_model/bert_chinese_L_12_H_768_A_12/README.md
index 320511c44dc5deda8ee98e4b22ddb4f1b0523ed9..9604701172489ea9853460fde5c08dd9198eb4eb 100644
--- a/hub_module/modules/text/semantic_model/bert_chinese_L_12_H_768_A_12/README.md
+++ b/hub_module/modules/text/semantic_model/bert_chinese_L_12_H_768_A_12/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/bert_multi_cased_L_12_H_768_A_12/README.md b/hub_module/modules/text/semantic_model/bert_multi_cased_L_12_H_768_A_12/README.md
index 9a1914088faa50ab27d5505a1964e94d3fe5b3bd..48621361df149195a52c4d3069626afe000e650e 100644
--- a/hub_module/modules/text/semantic_model/bert_multi_cased_L_12_H_768_A_12/README.md
+++ b/hub_module/modules/text/semantic_model/bert_multi_cased_L_12_H_768_A_12/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/bert_multi_uncased_L_12_H_768_A_12/README.md b/hub_module/modules/text/semantic_model/bert_multi_uncased_L_12_H_768_A_12/README.md
index a19701ed17694188ffc3e739fbeb3c2acb7ca9d0..754f1ee0a26aed6d12e5ffebf968007ce5be273c 100644
--- a/hub_module/modules/text/semantic_model/bert_multi_uncased_L_12_H_768_A_12/README.md
+++ b/hub_module/modules/text/semantic_model/bert_multi_uncased_L_12_H_768_A_12/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/bert_uncased_L_12_H_768_A_12/README.md b/hub_module/modules/text/semantic_model/bert_uncased_L_12_H_768_A_12/README.md
index a62212d4e09aceca78f5471f24a3d27dfbb8c9a5..b157a8bb40b1c4a7a604dd0f052be8dfcdf576dc 100644
--- a/hub_module/modules/text/semantic_model/bert_uncased_L_12_H_768_A_12/README.md
+++ b/hub_module/modules/text/semantic_model/bert_uncased_L_12_H_768_A_12/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/bert_uncased_L_24_H_1024_A_16/README.md b/hub_module/modules/text/semantic_model/bert_uncased_L_24_H_1024_A_16/README.md
index 73893de6d3a7668a14b2b91f47d1eb4f5769e388..bf84872d2fae8b3f06627913d41b57f5627838f3 100644
--- a/hub_module/modules/text/semantic_model/bert_uncased_L_24_H_1024_A_16/README.md
+++ b/hub_module/modules/text/semantic_model/bert_uncased_L_24_H_1024_A_16/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/chinese_bert_wwm/README.md b/hub_module/modules/text/semantic_model/chinese_bert_wwm/README.md
index 34900f514c012dc58f3fcd782b973406a615ff05..96ae17ac8cd73754c04000c8f2f847b2c2556402 100644
--- a/hub_module/modules/text/semantic_model/chinese_bert_wwm/README.md
+++ b/hub_module/modules/text/semantic_model/chinese_bert_wwm/README.md
@@ -114,7 +114,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
@@ -218,7 +218,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/chinese_bert_wwm_ext/README.md b/hub_module/modules/text/semantic_model/chinese_bert_wwm_ext/README.md
index 99c6319f658ba5325f11fe7225e905b2322af102..79d742a5d9cd842cacd26024ca04995c4b81009b 100644
--- a/hub_module/modules/text/semantic_model/chinese_bert_wwm_ext/README.md
+++ b/hub_module/modules/text/semantic_model/chinese_bert_wwm_ext/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/chinese_electra_base/README.md b/hub_module/modules/text/semantic_model/chinese_electra_base/README.md
index 0d4345652c16e101d5e53433b4a38a454a12f038..9fbf6b605e656c101e8e2bd96e4c910f697384f4 100644
--- a/hub_module/modules/text/semantic_model/chinese_electra_base/README.md
+++ b/hub_module/modules/text/semantic_model/chinese_electra_base/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
diff --git a/hub_module/modules/text/semantic_model/chinese_electra_small/README.md b/hub_module/modules/text/semantic_model/chinese_electra_small/README.md
index d704b823716370cb68d87041395b11c2b93d5311..34580f1d635a49df7c4d5e978cfb1ac2e4bd8ebd 100644
--- a/hub_module/modules/text/semantic_model/chinese_electra_small/README.md
+++ b/hub_module/modules/text/semantic_model/chinese_electra_small/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
diff --git a/hub_module/modules/text/semantic_model/chinese_roberta_wwm_ext/README.md b/hub_module/modules/text/semantic_model/chinese_roberta_wwm_ext/README.md
index e0c4027daecf9f7a127059ff99a725f77011f748..fcd9cd5c3030d210573916ce5da112c698e580ad 100644
--- a/hub_module/modules/text/semantic_model/chinese_roberta_wwm_ext/README.md
+++ b/hub_module/modules/text/semantic_model/chinese_roberta_wwm_ext/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/chinese_roberta_wwm_ext_large/README.md b/hub_module/modules/text/semantic_model/chinese_roberta_wwm_ext_large/README.md
index 16fc2068a44c46562d350e2efec1480381b3f19b..517ced4bd655b5e756788d77f42222c8628391f3 100644
--- a/hub_module/modules/text/semantic_model/chinese_roberta_wwm_ext_large/README.md
+++ b/hub_module/modules/text/semantic_model/chinese_roberta_wwm_ext_large/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/ernie/README.md b/hub_module/modules/text/semantic_model/ernie/README.md
index a5c662dc866c040750a337f1dd6381e9e9473f59..ce5e557368a1b192033add891f928189901c0140 100644
--- a/hub_module/modules/text/semantic_model/ernie/README.md
+++ b/hub_module/modules/text/semantic_model/ernie/README.md
@@ -107,7 +107,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
利用该PaddleHub Module Fine-tune示例,可参考[文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.2/demo/text-classification)、[序列标注](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.2/demo/sequence-labeling)。
diff --git a/hub_module/modules/text/semantic_model/ernie_tiny/README.md b/hub_module/modules/text/semantic_model/ernie_tiny/README.md
index b4ecaae282e74338f64c0ab0706fb1697aa5552c..19805393c915cbb1a4123f8741fc4876b7a4a68b 100644
--- a/hub_module/modules/text/semantic_model/ernie_tiny/README.md
+++ b/hub_module/modules/text/semantic_model/ernie_tiny/README.md
@@ -94,7 +94,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
利用该PaddleHub Module Fine-tune示例,可参考[文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.4.0/demo/text-classification)。
diff --git a/hub_module/modules/text/semantic_model/ernie_v2_eng_base/README.md b/hub_module/modules/text/semantic_model/ernie_v2_eng_base/README.md
index f625dfced1059366983b9a94d5e9f14323743795..784b63d1b392c5cae948020b45789d8f03118d6b 100644
--- a/hub_module/modules/text/semantic_model/ernie_v2_eng_base/README.md
+++ b/hub_module/modules/text/semantic_model/ernie_v2_eng_base/README.md
@@ -100,7 +100,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
利用该PaddleHub Module Fine-tune示例,可参考[文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.4.0/demo/text-classification)。
diff --git a/hub_module/modules/text/semantic_model/ernie_v2_eng_large/README.md b/hub_module/modules/text/semantic_model/ernie_v2_eng_large/README.md
index 47386cc2ccfcbec0b5dccd926be74e7c6b2e73db..e10d7d26eb2b32bc09f5efd5e1442d3a7014e058 100644
--- a/hub_module/modules/text/semantic_model/ernie_v2_eng_large/README.md
+++ b/hub_module/modules/text/semantic_model/ernie_v2_eng_large/README.md
@@ -103,7 +103,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
利用该PaddleHub Module Fine-tune示例,可参考[文本分类](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.2/demo/text-classification)。
diff --git a/hub_module/modules/text/semantic_model/rbt3/README.md b/hub_module/modules/text/semantic_model/rbt3/README.md
index 522ac1a309e5e0d8b654b37889694a9cd9003dc2..a9a001d882329fa4d28ac44a0f21627753bb320b 100644
--- a/hub_module/modules/text/semantic_model/rbt3/README.md
+++ b/hub_module/modules/text/semantic_model/rbt3/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/semantic_model/rbtl3/README.md b/hub_module/modules/text/semantic_model/rbtl3/README.md
index a61a7ca948702e0611745d1bc7894809fc06826b..531072714c66b53a9b3b2d854c6a78ab52ed85a4 100644
--- a/hub_module/modules/text/semantic_model/rbtl3/README.md
+++ b/hub_module/modules/text/semantic_model/rbtl3/README.md
@@ -96,7 +96,7 @@ embedding_result = module.get_embedding(texts=[["Sample1_text_a"],["Sample2_text
# Use "get_params_layer" to get params layer and used to ULMFiTStrategy.
params_layer = module.get_params_layer()
-strategy = hub.finetune.strategy.ULMFiTStrategy(params_layer=params_layer)
+strategy = hub.finetune.strategy.ULMFiTStrategy(frz_params_layer=params_layer, dis_params_layer=params_layer)
```
## 查看代码
diff --git a/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/README.md b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..46417e6f3cf314d887a8dc656f66bf0aa918df39
--- /dev/null
+++ b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/README.md
@@ -0,0 +1,152 @@
+## 概述
+
+SKEP(Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis)是百度研究团队在2020年提出的基于情感知识增强的情感预训练算法,此算法采用无监督方法自动挖掘情感知识,然后利用情感知识构建预训练目标,从而让机器学会理解情感语义,在14项中英情感分析典型任务上全面超越SOTA,相关工作已经被ACL 2020录用。SKEP为各类情感分析任务提供统一且强大的情感语义表示。ernie_skep_sentiment_analysis Module可用于句子级情感分析任务预测。其在预训练时使用ERNIE 1.0 large预训练参数作为其网络参数初始化继续预训练。同时,该Module支持完成句子级情感分析任务迁移学习Fine-tune。
+
+
+
+
+
+更多详情参考ACL 2020论文[SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis](https://arxiv.org/abs/2005.05635)
+
+## 命令行预测
+
+```shell
+$ hub run ernie_skep_sentiment_analysis --input_text='虽然小明很努力,但是他还是没有考100分'
+```
+
+## API
+
+```python
+def predict_sentiment(texts=[], use_gpu=False)
+```
+
+预测API,分类输入文本的情感极性。
+
+**参数**
+
+* texts (list\[str\]): 待预测文本;
+* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量**;
+
+**返回**
+
+* res (list\[dict\]): 情感分类结果的列表,列表中每一个元素为 dict,各字段为:
+ * text(str): 输入预测文本
+ * sentiment_label(str): 情感分类结果,或为positive或为negative
+ * positive_probs: 输入预测文本情感极性属于positive的概率
+ * negative_probs: 输入预测文本情感极性属于negative的概率
+
+```python
+def context(trainable=True, max_seq_len=128)
+```
+用于获取Module的上下文信息,得到输入、输出以及预训练的Paddle Program副本
+
+**参数**
+* trainable(bool): 设置为True时,Module中的参数在Fine-tune时也会随之训练,否则保持不变。
+* max_seq_len(int): SKEP模型的最大序列长度,若序列长度不足,会通过padding方式补到**max_seq_len**, 若序列长度大于该值,则会以截断方式让序列长度为**max_seq_len**,max_seq_len可取值范围为0~512;
+
+**返回**
+* inputs: dict类型,各字段为:
+ * input_ids(Variable): Token Embedding,shape为\[batch_size, max_seq_len\],dtype为int64类型;
+ * position_id(Variable): Position Embedding,shape为\[batch_size, max_seq_len\],dtype为int64类型;
+ * segment_ids(Variable): Sentence Embedding,shape为\[batch_size, max_seq_len\],dtype为int64类型;
+ * input_mask(Variable): token是否为padding的标识,shape为\[batch_size, max_seq_len\],dtype为int64类型;
+
+* outputs:dict类型,Module的输出特征,各字段为:
+ * pooled_output(Variable): 句子粒度的特征,可用于文本分类等任务,shape为 \[batch_size, 768\],dtype为int64类型;
+ * sequence_output(Variable): 字粒度的特征,可用于序列标注等任务,shape为 \[batch_size, seq_len, 768\],dtype为int64类型;
+
+* program:包含该Module计算图的Program。
+
+```python
+def get_embedding(texts, use_gpu=False, batch_size=1)
+```
+
+用于获取输入文本的句子粒度特征与字粒度特征
+
+**参数**
+
+* texts(list):输入文本列表,格式为\[\[sample\_a\_text\_a, sample\_a\_text\_b\], \[sample\_b\_text\_a, sample\_b\_text\_b\],…,\],其中每个元素都是一个样例,每个样例可以包含text\_a与text\_b。
+* use_gpu(bool):是否使用gpu,默认为False。对于GPU用户,建议开启use_gpu。**若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量**;
+
+**返回**
+
+* results(list): embedding特征,格式为\[\[sample\_a\_pooled\_feature, sample\_a\_seq\_feature\], \[sample\_b\_pooled\_feature, sample\_b\_seq\_feature\],…,\],其中每个元素都是对应样例的特征输出,每个样例都有句子粒度特征pooled\_feature与字粒度特征seq\_feature。
+
+```python
+def get_params_layer()
+```
+
+用于获取参数层信息,该方法与ULMFiTStrategy联用可以严格按照层数设置分层学习率与逐层解冻。
+
+**参数**
+
+* 无
+
+**返回**
+
+* params_layer(dict): key为参数名,值为参数所在层数
+
+**代码示例**
+
+情感极性预测代码示例:
+
+```python
+import paddlehub as hub
+
+# Load ernie_skep_sentiment_analysis module.
+module = hub.Module(name="ernie_skep_sentiment_analysis")
+
+# Predict sentiment label
+test_texts = ['你不是不聪明,而是不认真', '虽然小明很努力,但是他还是没有考100分']
+results = module.predict_sentiment(test_texts, use_gpu=False)
+```
+
+## 服务部署
+
+PaddleHub Serving 可以部署一个目标检测的在线服务。
+
+### 第一步:启动PaddleHub Serving
+
+运行启动命令:
+```shell
+$ hub serving start -m ernie_skep_sentiment_analysis
+```
+
+这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+### 第二步:发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+
+# 发送HTTP请求
+data = {'texts':['你不是不聪明,而是不认真', '虽然小明很努力,但是他还是没有考100分']}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/ernie_skep_sentiment_analysis"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+# 打印预测结果
+print(r.json()["results"])
+```
+
+## 查看代码
+
+https://github.com/baidu/Senta
+
+### 依赖
+
+paddlepaddle >= 1.8.0
+
+paddlehub >= 1.7.0
+
+
+## 更新历史
+
+* 1.0.0
+
+ 初始发布
diff --git a/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/assets/ernie_1.0_large_ch.config.json b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/assets/ernie_1.0_large_ch.config.json
new file mode 100644
index 0000000000000000000000000000000000000000..75c3303b93a504af856621783d26b8cb44455be3
--- /dev/null
+++ b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/assets/ernie_1.0_large_ch.config.json
@@ -0,0 +1,14 @@
+{
+ "attention_probs_dropout_prob": 0.1,
+ "hidden_act": "relu",
+ "hidden_dropout_prob": 0.1,
+ "hidden_size": 1024,
+ "initializer_range": 0.02,
+ "max_position_embeddings": 512,
+ "num_attention_heads": 16,
+ "num_hidden_layers": 24,
+ "sent_type_vocab_size": 4,
+ "task_type_vocab_size": 16,
+ "vocab_size": 12800,
+ "use_task_id": false
+}
diff --git a/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/assets/ernie_1.0_large_ch.vocab.txt b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/assets/ernie_1.0_large_ch.vocab.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e9604e7a218cd3d814b76b59e153e5b27ac44998
--- /dev/null
+++ b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/assets/ernie_1.0_large_ch.vocab.txt
@@ -0,0 +1,12089 @@
+[PAD] 0
+[CLS] 1
+[SEP] 2
+[MASK] 3
+, 4
+的 5
+、 6
+一 7
+人 8
+有 9
+是 10
+在 11
+中 12
+为 13
+和 14
+了 15
+不 16
+年 17
+学 18
+大 19
+国 20
+生 21
+以 22
+“ 23
+” 24
+作 25
+业 26
+个 27
+上 28
+用 29
+, 30
+地 31
+会 32
+成 33
+发 34
+工 35
+时 36
+于 37
+理 38
+出 39
+行 40
+要 41
+. 42
+等 43
+他 44
+到 45
+之 46
+这 47
+可 48
+后 49
+家 50
+对 51
+能 52
+公 53
+与 54
+》 55
+《 56
+主 57
+方 58
+分 59
+经 60
+来 61
+全 62
+其 63
+部 64
+多 65
+产 66
+自 67
+文 68
+高 69
+动 70
+进 71
+法 72
+化 73
+: 74
+我 75
+面 76
+) 77
+( 78
+实 79
+教 80
+建 81
+体 82
+而 83
+长 84
+子 85
+下 86
+现 87
+开 88
+本 89
+力 90
+定 91
+性 92
+过 93
+设 94
+合 95
+小 96
+同 97
+机 98
+市 99
+品 100
+水 101
+新 102
+内 103
+事 104
+也 105
+种 106
+及 107
+制 108
+入 109
+所 110
+心 111
+务 112
+就 113
+管 114
+们 115
+得 116
+展 117
+重 118
+民 119
+加 120
+区 121
+物 122
+者 123
+通 124
+天 125
+政 126
+三 127
+电 128
+关 129
+度 130
+第 131
+名 132
+术 133
+最 134
+系 135
+月 136
+外 137
+资 138
+日 139
+代 140
+员 141
+如 142
+间 143
+位 144
+并 145
+书 146
+科 147
+村 148
+应 149
+量 150
+道 151
+前 152
+当 153
+无 154
+里 155
+相 156
+平 157
+从 158
+计 159
+提 160
+保 161
+任 162
+程 163
+技 164
+都 165
+研 166
+十 167
+基 168
+特 169
+好 170
+被 171
+或 172
+目 173
+将 174
+使 175
+山 176
+二 177
+说 178
+数 179
+点 180
+明 181
+情 182
+元 183
+着 184
+收 185
+组 186
+然 187
+美 188
+各 189
+由 190
+场 191
+金 192
+形 193
+农 194
+期 195
+因 196
+表 197
+此 198
+色 199
+起 200
+还 201
+立 202
+世 203
+安 204
+活 205
+专 206
+质 207
+1 208
+规 209
+社 210
+万 211
+信 212
+西 213
+统 214
+结 215
+路 216
+利 217
+次 218
+南 219
+式 220
+意 221
+级 222
+常 223
+师 224
+校 225
+你 226
+育 227
+果 228
+究 229
+司 230
+服 231
+门 232
+海 233
+导 234
+流 235
+项 236
+她 237
+总 238
+处 239
+两 240
+传 241
+东 242
+正 243
+省 244
+院 245
+户 246
+手 247
+具 248
+2 249
+原 250
+强 251
+北 252
+向 253
+先 254
+但 255
+米 256
+城 257
+企 258
+件 259
+风 260
+军 261
+身 262
+更 263
+知 264
+已 265
+气 266
+战 267
+至 268
+单 269
+口 270
+集 271
+创 272
+解 273
+四 274
+标 275
+交 276
+比 277
+商 278
+论 279
+界 280
+题 281
+变 282
+花 283
+3 284
+改 285
+类 286
+运 287
+指 288
+型 289
+调 290
+女 291
+神 292
+接 293
+造 294
+受 295
+广 296
+只 297
+委 298
+去 299
+共 300
+治 301
+达 302
+持 303
+条 304
+网 305
+头 306
+构 307
+县 308
+些 309
+该 310
+又 311
+那 312
+想 313
+样 314
+办 315
+济 316
+5 317
+格 318
+责 319
+车 320
+很 321
+施 322
+求 323
+己 324
+光 325
+精 326
+林 327
+完 328
+爱 329
+线 330
+参 331
+少 332
+积 333
+清 334
+看 335
+优 336
+报 337
+王 338
+直 339
+没 340
+每 341
+据 342
+游 343
+效 344
+感 345
+五 346
+影 347
+别 348
+获 349
+领 350
+称 351
+选 352
+供 353
+乐 354
+老 355
+么 356
+台 357
+问 358
+划 359
+带 360
+器 361
+源 362
+织 363
+放 364
+深 365
+备 366
+视 367
+白 368
+功 369
+取 370
+装 371
+营 372
+见 373
+记 374
+环 375
+队 376
+节 377
+准 378
+石 379
+它 380
+回 381
+历 382
+负 383
+真 384
+增 385
+医 386
+联 387
+做 388
+职 389
+容 390
+士 391
+包 392
+义 393
+观 394
+团 395
+病 396
+4 397
+府 398
+息 399
+则 400
+考 401
+料 402
+华 403
+州 404
+语 405
+证 406
+整 407
+让 408
+江 409
+史 410
+空 411
+验 412
+需 413
+支 414
+命 415
+给 416
+离 417
+认 418
+艺 419
+较 420
+土 421
+古 422
+养 423
+才 424
+境 425
+推 426
+把 427
+均 428
+图 429
+际 430
+斯 431
+近 432
+片 433
+局 434
+修 435
+字 436
+德 437
+权 438
+步 439
+始 440
+复 441
+转 442
+协 443
+即 444
+打 445
+画 446
+投 447
+决 448
+何 449
+约 450
+反 451
+quot 452
+费 453
+议 454
+护 455
+极 456
+河 457
+房 458
+查 459
+布 460
+思 461
+干 462
+价 463
+儿 464
+非 465
+马 466
+党 467
+奖 468
+模 469
+故 470
+编 471
+音 472
+范 473
+识 474
+率 475
+存 476
+引 477
+客 478
+属 479
+评 480
+采 481
+尔 482
+配 483
+镇 484
+室 485
+再 486
+案 487
+监 488
+习 489
+注 490
+根 491
+克 492
+演 493
+食 494
+族 495
+示 496
+球 497
+状 498
+青 499
+号 500
+张 501
+百 502
+素 503
+首 504
+易 505
+热 506
+阳 507
+今 508
+园 509
+防 510
+版 511
+太 512
+乡 513
+英 514
+6 515
+材 516
+列 517
+便 518
+写 519
+住 520
+置 521
+层 522
+助 523
+确 524
+试 525
+难 526
+承 527
+象 528
+居 529
+10 530
+黄 531
+快 532
+断 533
+维 534
+却 535
+红 536
+速 537
+连 538
+众 539
+0 540
+细 541
+态 542
+话 543
+周 544
+言 545
+药 546
+培 547
+血 548
+亩 549
+龙 550
+越 551
+值 552
+几 553
+边 554
+读 555
+未 556
+曾 557
+测 558
+算 559
+京 560
+景 561
+余 562
+站 563
+低 564
+温 565
+消 566
+必 567
+切 568
+依 569
+随 570
+且 571
+志 572
+卫 573
+域 574
+照 575
+许 576
+限 577
+著 578
+销 579
+落 580
+足 581
+适 582
+争 583
+策 584
+8 585
+控 586
+武 587
+按 588
+7 589
+初 590
+角 591
+核 592
+死 593
+检 594
+富 595
+满 596
+显 597
+审 598
+除 599
+致 600
+亲 601
+占 602
+失 603
+星 604
+章 605
+善 606
+续 607
+千 608
+叶 609
+火 610
+副 611
+告 612
+段 613
+什 614
+声 615
+终 616
+况 617
+走 618
+木 619
+益 620
+戏 621
+独 622
+纪 623
+植 624
+财 625
+群 626
+六 627
+赛 628
+远 629
+拉 630
+亚 631
+密 632
+排 633
+超 634
+像 635
+课 636
+围 637
+往 638
+响 639
+击 640
+疗 641
+念 642
+八 643
+云 644
+险 645
+律 646
+请 647
+革 648
+诗 649
+批 650
+底 651
+压 652
+双 653
+男 654
+训 655
+例 656
+汉 657
+升 658
+拥 659
+势 660
+酒 661
+眼 662
+官 663
+牌 664
+油 665
+曲 666
+友 667
+望 668
+黑 669
+歌 670
+筑 671
+础 672
+香 673
+仅 674
+担 675
+括 676
+湖 677
+严 678
+秀 679
+剧 680
+九 681
+举 682
+执 683
+充 684
+兴 685
+督 686
+博 687
+草 688
+般 689
+李 690
+健 691
+喜 692
+授 693
+普 694
+预 695
+灵 696
+突 697
+良 698
+款 699
+罗 700
+9 701
+微 702
+七 703
+录 704
+朝 705
+飞 706
+宝 707
+令 708
+轻 709
+劳 710
+距 711
+异 712
+简 713
+兵 714
+树 715
+序 716
+候 717
+含 718
+福 719
+尽 720
+留 721
+20 722
+丰 723
+旅 724
+征 725
+临 726
+破 727
+移 728
+篇 729
+抗 730
+典 731
+端 732
+苏 733
+奇 734
+止 735
+康 736
+店 737
+毛 738
+觉 739
+春 740
+售 741
+络 742
+降 743
+板 744
+坚 745
+母 746
+讲 747
+早 748
+印 749
+略 750
+孩 751
+夫 752
+藏 753
+铁 754
+害 755
+互 756
+帝 757
+田 758
+融 759
+皮 760
+宗 761
+岁 762
+载 763
+析 764
+斗 765
+须 766
+伤 767
+12 768
+介 769
+另 770
+00 771
+半 772
+班 773
+馆 774
+味 775
+楼 776
+卡 777
+射 778
+述 779
+杀 780
+波 781
+绿 782
+免 783
+兰 784
+绝 785
+刻 786
+短 787
+察 788
+输 789
+择 790
+综 791
+杂 792
+份 793
+纳 794
+父 795
+词 796
+银 797
+送 798
+座 799
+左 800
+继 801
+固 802
+宣 803
+厂 804
+肉 805
+换 806
+补 807
+税 808
+派 809
+套 810
+欢 811
+播 812
+吸 813
+圆 814
+攻 815
+阿 816
+购 817
+听 818
+右 819
+减 820
+激 821
+巴 822
+背 823
+够 824
+遇 825
+智 826
+玉 827
+找 828
+宽 829
+陈 830
+练 831
+追 832
+毕 833
+彩 834
+软 835
+帮 836
+股 837
+荣 838
+托 839
+予 840
+佛 841
+堂 842
+障 843
+皇 844
+若 845
+守 846
+似 847
+届 848
+待 849
+货 850
+散 851
+额 852
+30 853
+尚 854
+穿 855
+丽 856
+骨 857
+享 858
+差 859
+针 860
+索 861
+稳 862
+宁 863
+贵 864
+酸 865
+液 866
+唐 867
+操 868
+探 869
+玩 870
+促 871
+笔 872
+库 873
+救 874
+虽 875
+久 876
+闻 877
+顶 878
+床 879
+港 880
+鱼 881
+亿 882
+登 883
+11 884
+永 885
+毒 886
+桥 887
+冷 888
+魔 889
+秘 890
+陆 891
+您 892
+童 893
+归 894
+侧 895
+沙 896
+染 897
+封 898
+紧 899
+松 900
+川 901
+刘 902
+15 903
+雄 904
+希 905
+毫 906
+卷 907
+某 908
+季 909
+菜 910
+庭 911
+附 912
+逐 913
+夜 914
+宫 915
+洲 916
+退 917
+顾 918
+尼 919
+胜 920
+剂 921
+纯 922
+舞 923
+遗 924
+苦 925
+梦 926
+挥 927
+航 928
+愿 929
+街 930
+招 931
+矿 932
+夏 933
+盖 934
+献 935
+怎 936
+茶 937
+申 938
+39 939
+吧 940
+脑 941
+亦 942
+吃 943
+频 944
+宋 945
+央 946
+威 947
+厚 948
+块 949
+冲 950
+叫 951
+熟 952
+礼 953
+厅 954
+否 955
+渐 956
+笑 957
+钱 958
+钟 959
+甚 960
+牛 961
+丝 962
+靠 963
+岛 964
+绍 965
+盘 966
+缘 967
+聚 968
+静 969
+雨 970
+氏 971
+圣 972
+顺 973
+唱 974
+刊 975
+阶 976
+困 977
+急 978
+饰 979
+弹 980
+庄 981
+既 982
+野 983
+阴 984
+混 985
+饮 986
+损 987
+齐 988
+末 989
+错 990
+轮 991
+宜 992
+鲜 993
+兼 994
+敌 995
+粉 996
+祖 997
+延 998
+100 999
+钢 1000
+辑 1001
+欧 1002
+硬 1003
+甲 1004
+诉 1005
+册 1006
+痛 1007
+订 1008
+缺 1009
+晚 1010
+衣 1011
+佳 1012
+脉 1013
+gt 1014
+盛 1015
+乎 1016
+拟 1017
+贸 1018
+扩 1019
+船 1020
+仪 1021
+谁 1022
+警 1023
+50 1024
+停 1025
+席 1026
+竞 1027
+释 1028
+庆 1029
+汽 1030
+仍 1031
+掌 1032
+诸 1033
+仙 1034
+弟 1035
+吉 1036
+洋 1037
+奥 1038
+票 1039
+危 1040
+架 1041
+买 1042
+径 1043
+塔 1044
+休 1045
+付 1046
+恶 1047
+雷 1048
+怀 1049
+秋 1050
+借 1051
+巨 1052
+透 1053
+誉 1054
+厘 1055
+句 1056
+跟 1057
+胞 1058
+婚 1059
+幼 1060
+烈 1061
+峰 1062
+寻 1063
+君 1064
+汇 1065
+趣 1066
+纸 1067
+假 1068
+肥 1069
+患 1070
+杨 1071
+雅 1072
+罪 1073
+谓 1074
+亮 1075
+脱 1076
+寺 1077
+烟 1078
+判 1079
+绩 1080
+乱 1081
+刚 1082
+摄 1083
+洞 1084
+践 1085
+码 1086
+启 1087
+励 1088
+呈 1089
+曰 1090
+呢 1091
+符 1092
+哥 1093
+媒 1094
+疾 1095
+坐 1096
+雪 1097
+孔 1098
+倒 1099
+旧 1100
+菌 1101
+岩 1102
+鼓 1103
+亡 1104
+访 1105
+症 1106
+暗 1107
+湾 1108
+幸 1109
+池 1110
+讨 1111
+努 1112
+露 1113
+吗 1114
+繁 1115
+途 1116
+殖 1117
+败 1118
+蛋 1119
+握 1120
+刺 1121
+耕 1122
+洗 1123
+沉 1124
+概 1125
+哈 1126
+泛 1127
+凡 1128
+残 1129
+隐 1130
+虫 1131
+朋 1132
+虚 1133
+餐 1134
+殊 1135
+慢 1136
+询 1137
+蒙 1138
+孙 1139
+谈 1140
+鲁 1141
+裂 1142
+贴 1143
+污 1144
+漫 1145
+谷 1146
+违 1147
+泉 1148
+拿 1149
+森 1150
+横 1151
+扬 1152
+键 1153
+膜 1154
+迁 1155
+尤 1156
+涉 1157
+净 1158
+诚 1159
+折 1160
+冰 1161
+械 1162
+拍 1163
+梁 1164
+沿 1165
+避 1166
+吴 1167
+惊 1168
+犯 1169
+灭 1170
+湿 1171
+迷 1172
+姓 1173
+阅 1174
+灯 1175
+妇 1176
+触 1177
+冠 1178
+答 1179
+俗 1180
+档 1181
+尊 1182
+谢 1183
+措 1184
+筹 1185
+竟 1186
+韩 1187
+签 1188
+剑 1189
+鉴 1190
+灾 1191
+贯 1192
+迹 1193
+洛 1194
+沟 1195
+束 1196
+翻 1197
+巧 1198
+坏 1199
+弱 1200
+零 1201
+壁 1202
+枝 1203
+映 1204
+恩 1205
+抓 1206
+屋 1207
+呼 1208
+脚 1209
+绘 1210
+40 1211
+淡 1212
+辖 1213
+2010 1214
+伊 1215
+粒 1216
+欲 1217
+震 1218
+伯 1219
+私 1220
+蓝 1221
+甘 1222
+储 1223
+胡 1224
+卖 1225
+梅 1226
+16 1227
+耳 1228
+疑 1229
+润 1230
+伴 1231
+泽 1232
+牧 1233
+烧 1234
+尾 1235
+累 1236
+糖 1237
+怪 1238
+唯 1239
+莫 1240
+粮 1241
+柱 1242
+18 1243
+竹 1244
+灰 1245
+岸 1246
+缩 1247
+井 1248
+伦 1249
+柔 1250
+盟 1251
+珠 1252
+丹 1253
+amp 1254
+皆 1255
+哪 1256
+迎 1257
+颜 1258
+衡 1259
+啊 1260
+塑 1261
+寒 1262
+13 1263
+紫 1264
+镜 1265
+25 1266
+氧 1267
+误 1268
+伍 1269
+彻 1270
+刀 1271
+览 1272
+炎 1273
+津 1274
+耐 1275
+秦 1276
+尖 1277
+潮 1278
+描 1279
+浓 1280
+召 1281
+禁 1282
+阻 1283
+胶 1284
+译 1285
+腹 1286
+泰 1287
+乃 1288
+盐 1289
+潜 1290
+鸡 1291
+诺 1292
+遍 1293
+2000 1294
+纹 1295
+冬 1296
+牙 1297
+麻 1298
+辅 1299
+猪 1300
+弃 1301
+楚 1302
+羊 1303
+晋 1304
+14 1305
+鸟 1306
+赵 1307
+洁 1308
+谋 1309
+隆 1310
+滑 1311
+60 1312
+2008 1313
+籍 1314
+臣 1315
+朱 1316
+泥 1317
+墨 1318
+辆 1319
+墙 1320
+浪 1321
+姐 1322
+赏 1323
+纵 1324
+2006 1325
+拔 1326
+倍 1327
+纷 1328
+摩 1329
+壮 1330
+苗 1331
+偏 1332
+塞 1333
+贡 1334
+仁 1335
+宇 1336
+卵 1337
+瓦 1338
+枪 1339
+覆 1340
+殿 1341
+刑 1342
+贫 1343
+妈 1344
+幅 1345
+幕 1346
+忆 1347
+丁 1348
+估 1349
+废 1350
+萨 1351
+舍 1352
+详 1353
+旗 1354
+岗 1355
+洪 1356
+80 1357
+贝 1358
+2009 1359
+迅 1360
+凭 1361
+勇 1362
+雕 1363
+奏 1364
+旋 1365
+杰 1366
+煤 1367
+阵 1368
+乘 1369
+溪 1370
+奉 1371
+畜 1372
+挑 1373
+昌 1374
+硕 1375
+庙 1376
+惠 1377
+薄 1378
+逃 1379
+爆 1380
+哲 1381
+浙 1382
+珍 1383
+炼 1384
+栏 1385
+暴 1386
+币 1387
+隔 1388
+吨 1389
+倾 1390
+嘉 1391
+址 1392
+陶 1393
+绕 1394
+诊 1395
+遭 1396
+桃 1397
+魂 1398
+兽 1399
+豆 1400
+闲 1401
+箱 1402
+拓 1403
+燃 1404
+裁 1405
+晶 1406
+掉 1407
+脂 1408
+溶 1409
+顿 1410
+肤 1411
+虑 1412
+鬼 1413
+2007 1414
+灌 1415
+徐 1416
+龄 1417
+陵 1418
+恋 1419
+侵 1420
+坡 1421
+寿 1422
+勤 1423
+磨 1424
+妹 1425
+瑞 1426
+缓 1427
+轴 1428
+麦 1429
+羽 1430
+咨 1431
+凝 1432
+默 1433
+驻 1434
+敢 1435
+债 1436
+17 1437
+浮 1438
+幻 1439
+株 1440
+浅 1441
+敬 1442
+敏 1443
+陷 1444
+凤 1445
+坛 1446
+虎 1447
+乌 1448
+铜 1449
+御 1450
+乳 1451
+讯 1452
+循 1453
+圈 1454
+肌 1455
+妙 1456
+奋 1457
+忘 1458
+闭 1459
+墓 1460
+21 1461
+汤 1462
+忠 1463
+2005 1464
+跨 1465
+怕 1466
+振 1467
+宾 1468
+跑 1469
+屏 1470
+坦 1471
+粗 1472
+租 1473
+悲 1474
+伟 1475
+拜 1476
+24 1477
+妻 1478
+赞 1479
+兄 1480
+宿 1481
+碑 1482
+貌 1483
+勒 1484
+罚 1485
+夺 1486
+偶 1487
+截 1488
+纤 1489
+2011 1490
+齿 1491
+郑 1492
+聘 1493
+偿 1494
+扶 1495
+豪 1496
+慧 1497
+跳 1498
+the 1499
+疏 1500
+莱 1501
+腐 1502
+插 1503
+恐 1504
+郎 1505
+辞 1506
+挂 1507
+娘 1508
+肿 1509
+徒 1510
+伏 1511
+磁 1512
+杯 1513
+丛 1514
+旨 1515
+琴 1516
+19 1517
+炮 1518
+醒 1519
+砖 1520
+替 1521
+辛 1522
+暖 1523
+锁 1524
+杜 1525
+肠 1526
+孤 1527
+饭 1528
+脸 1529
+邮 1530
+贷 1531
+lt 1532
+俄 1533
+毁 1534
+荷 1535
+谐 1536
+荒 1537
+肝 1538
+链 1539
+2004 1540
+2012 1541
+尺 1542
+尘 1543
+援 1544
+a 1545
+疫 1546
+崇 1547
+恢 1548
+扎 1549
+伸 1550
+幽 1551
+抵 1552
+胸 1553
+谱 1554
+舒 1555
+迫 1556
+200 1557
+畅 1558
+泡 1559
+岭 1560
+喷 1561
+70 1562
+窗 1563
+捷 1564
+宏 1565
+肯 1566
+90 1567
+狂 1568
+铺 1569
+骑 1570
+抽 1571
+券 1572
+俱 1573
+徽 1574
+胆 1575
+碎 1576
+邀 1577
+褐 1578
+斤 1579
+涂 1580
+赋 1581
+署 1582
+颗 1583
+2003 1584
+渠 1585
+仿 1586
+迪 1587
+炉 1588
+辉 1589
+涵 1590
+耗 1591
+22 1592
+返 1593
+邻 1594
+斑 1595
+董 1596
+魏 1597
+午 1598
+娱 1599
+浴 1600
+尿 1601
+曼 1602
+锅 1603
+柳 1604
+舰 1605
+搭 1606
+旁 1607
+宅 1608
+趋 1609
+of 1610
+凉 1611
+赢 1612
+伙 1613
+爷 1614
+廷 1615
+戴 1616
+壤 1617
+奶 1618
+页 1619
+玄 1620
+驾 1621
+阔 1622
+轨 1623
+朗 1624
+捕 1625
+肾 1626
+稿 1627
+惯 1628
+侯 1629
+乙 1630
+渡 1631
+稍 1632
+恨 1633
+脏 1634
+2002 1635
+姆 1636
+腔 1637
+抱 1638
+杆 1639
+垂 1640
+赴 1641
+赶 1642
+莲 1643
+辽 1644
+荐 1645
+旦 1646
+妖 1647
+2013 1648
+稀 1649
+驱 1650
+沈 1651
+役 1652
+晓 1653
+亭 1654
+仲 1655
+澳 1656
+500 1657
+炸 1658
+绪 1659
+28 1660
+陕 1661
+and 1662
+23 1663
+恒 1664
+堡 1665
+纠 1666
+仇 1667
+懂 1668
+焦 1669
+搜 1670
+s 1671
+忍 1672
+贤 1673
+添 1674
+i 1675
+艾 1676
+赤 1677
+犹 1678
+尝 1679
+锦 1680
+稻 1681
+撰 1682
+填 1683
+衰 1684
+栽 1685
+邪 1686
+粘 1687
+跃 1688
+桌 1689
+胃 1690
+悬 1691
+c 1692
+翼 1693
+彼 1694
+睡 1695
+曹 1696
+刷 1697
+摆 1698
+悉 1699
+锋 1700
+26 1701
+摇 1702
+抢 1703
+乏 1704
+廉 1705
+鼠 1706
+盾 1707
+瓷 1708
+抑 1709
+埃 1710
+邦 1711
+遂 1712
+寸 1713
+渔 1714
+祥 1715
+胎 1716
+牵 1717
+壳 1718
+甜 1719
+卓 1720
+瓜 1721
+袭 1722
+遵 1723
+巡 1724
+逆 1725
+玛 1726
+韵 1727
+2001 1728
+桑 1729
+酷 1730
+赖 1731
+桂 1732
+郡 1733
+肃 1734
+仓 1735
+寄 1736
+塘 1737
+瘤 1738
+300 1739
+碳 1740
+搞 1741
+燕 1742
+蒸 1743
+允 1744
+忽 1745
+斜 1746
+穷 1747
+郁 1748
+囊 1749
+奔 1750
+昆 1751
+盆 1752
+愈 1753
+递 1754
+1000 1755
+黎 1756
+祭 1757
+怒 1758
+辈 1759
+腺 1760
+滚 1761
+暂 1762
+郭 1763
+璃 1764
+踪 1765
+芳 1766
+碍 1767
+肺 1768
+狱 1769
+冒 1770
+阁 1771
+砂 1772
+35 1773
+苍 1774
+揭 1775
+踏 1776
+颇 1777
+柄 1778
+闪 1779
+孝 1780
+葡 1781
+腾 1782
+茎 1783
+鸣 1784
+撤 1785
+仰 1786
+伐 1787
+丘 1788
+於 1789
+泪 1790
+荡 1791
+扰 1792
+纲 1793
+拼 1794
+欣 1795
+纽 1796
+癌 1797
+堆 1798
+27 1799
+菲 1800
+b 1801
+披 1802
+挖 1803
+寓 1804
+履 1805
+捐 1806
+悟 1807
+乾 1808
+嘴 1809
+钻 1810
+拳 1811
+吹 1812
+柏 1813
+遥 1814
+抚 1815
+忧 1816
+赠 1817
+霸 1818
+艰 1819
+淋 1820
+猫 1821
+帅 1822
+奈 1823
+寨 1824
+滴 1825
+鼻 1826
+掘 1827
+狗 1828
+驶 1829
+朴 1830
+拆 1831
+惜 1832
+玻 1833
+扣 1834
+萄 1835
+蔬 1836
+宠 1837
+2014 1838
+缴 1839
+赫 1840
+凯 1841
+滨 1842
+乔 1843
+腰 1844
+葬 1845
+孟 1846
+吾 1847
+枚 1848
+圳 1849
+忙 1850
+扫 1851
+杭 1852
+凌 1853
+1998 1854
+梯 1855
+丈 1856
+隶 1857
+1999 1858
+剪 1859
+盗 1860
+擅 1861
+疆 1862
+弯 1863
+携 1864
+拒 1865
+秒 1866
+颁 1867
+醇 1868
+割 1869
+浆 1870
+姑 1871
+爸 1872
+螺 1873
+穗 1874
+缝 1875
+慈 1876
+喝 1877
+瓶 1878
+漏 1879
+悠 1880
+猎 1881
+番 1882
+孕 1883
+伪 1884
+漂 1885
+腿 1886
+吐 1887
+坝 1888
+滤 1889
+函 1890
+匀 1891
+偷 1892
+浩 1893
+矛 1894
+僧 1895
+辨 1896
+俊 1897
+棉 1898
+铸 1899
+29 1900
+诞 1901
+丧 1902
+夹 1903
+to 1904
+姿 1905
+睛 1906
+淮 1907
+阀 1908
+姜 1909
+45 1910
+尸 1911
+猛 1912
+1997 1913
+芽 1914
+账 1915
+旱 1916
+醉 1917
+弄 1918
+坊 1919
+烤 1920
+萧 1921
+矣 1922
+雾 1923
+倡 1924
+榜 1925
+弗 1926
+氨 1927
+朵 1928
+锡 1929
+袋 1930
+拨 1931
+湘 1932
+岳 1933
+烦 1934
+肩 1935
+熙 1936
+炭 1937
+婆 1938
+棋 1939
+禅 1940
+穴 1941
+宙 1942
+汗 1943
+艳 1944
+儒 1945
+叙 1946
+晨 1947
+颈 1948
+峡 1949
+拖 1950
+烂 1951
+茂 1952
+戒 1953
+飘 1954
+氛 1955
+蒂 1956
+撞 1957
+瓣 1958
+箭 1959
+叛 1960
+1996 1961
+31 1962
+鞋 1963
+劲 1964
+祝 1965
+娜 1966
+饲 1967
+侍 1968
+诱 1969
+叹 1970
+卢 1971
+弥 1972
+32 1973
+鼎 1974
+厦 1975
+屈 1976
+慕 1977
+魅 1978
+m 1979
+厨 1980
+嫁 1981
+绵 1982
+逼 1983
+扮 1984
+叔 1985
+酶 1986
+燥 1987
+狼 1988
+滋 1989
+汁 1990
+辐 1991
+怨 1992
+翅 1993
+佩 1994
+坑 1995
+旬 1996
+沃 1997
+剩 1998
+蛇 1999
+颖 2000
+篮 2001
+锐 2002
+侠 2003
+匹 2004
+唤 2005
+熊 2006
+漠 2007
+迟 2008
+敦 2009
+雌 2010
+谨 2011
+婴 2012
+浸 2013
+磷 2014
+筒 2015
+2015 2016
+滩 2017
+埋 2018
+框 2019
+弘 2020
+吕 2021
+碰 2022
+纺 2023
+硫 2024
+堪 2025
+契 2026
+蜜 2027
+蓄 2028
+1995 2029
+阐 2030
+apos 2031
+傲 2032
+碱 2033
+晰 2034
+狭 2035
+撑 2036
+叉 2037
+卧 2038
+劫 2039
+闹 2040
+赐 2041
+邓 2042
+奴 2043
+溉 2044
+浦 2045
+蹈 2046
+辣 2047
+遣 2048
+耀 2049
+耶 2050
+翠 2051
+t 2052
+叠 2053
+迈 2054
+霍 2055
+碧 2056
+恰 2057
+脊 2058
+昭 2059
+摸 2060
+饱 2061
+赔 2062
+泄 2063
+哭 2064
+讼 2065
+逝 2066
+逻 2067
+廊 2068
+擦 2069
+渗 2070
+彰 2071
+you 2072
+卿 2073
+旺 2074
+宪 2075
+36 2076
+顷 2077
+妆 2078
+陪 2079
+葛 2080
+仔 2081
+淀 2082
+翰 2083
+悦 2084
+穆 2085
+煮 2086
+辩 2087
+弦 2088
+in 2089
+串 2090
+押 2091
+蚀 2092
+逢 2093
+贺 2094
+焊 2095
+煌 2096
+缔 2097
+惑 2098
+鹿 2099
+袁 2100
+糊 2101
+逸 2102
+舟 2103
+勃 2104
+侦 2105
+涯 2106
+蔡 2107
+辟 2108
+涌 2109
+枯 2110
+痕 2111
+疼 2112
+莉 2113
+柴 2114
+1993 2115
+眉 2116
+1992 2117
+罢 2118
+催 2119
+衔 2120
+秉 2121
+妃 2122
+鸿 2123
+傅 2124
+400 2125
+辰 2126
+聪 2127
+咸 2128
+1994 2129
+扇 2130
+盈 2131
+勘 2132
+佐 2133
+泊 2134
+抛 2135
+搬 2136
+牢 2137
+宴 2138
+牲 2139
+贾 2140
+摘 2141
+姻 2142
+慎 2143
+帕 2144
+忌 2145
+卒 2146
+夕 2147
+卜 2148
+惟 2149
+挺 2150
+崖 2151
+炒 2152
+爵 2153
+冻 2154
+椒 2155
+鳞 2156
+祸 2157
+潭 2158
+腊 2159
+蒋 2160
+缠 2161
+寂 2162
+眠 2163
+冯 2164
+芯 2165
+槽 2166
+吊 2167
+33 2168
+150 2169
+聊 2170
+梗 2171
+嫩 2172
+凶 2173
+铭 2174
+爽 2175
+筋 2176
+韦 2177
+脾 2178
+铝 2179
+肢 2180
+栋 2181
+勾 2182
+萌 2183
+渊 2184
+掩 2185
+狮 2186
+撒 2187
+漆 2188
+骗 2189
+禽 2190
+38 2191
+蕴 2192
+坪 2193
+洒 2194
+冶 2195
+兹 2196
+椭 2197
+喻 2198
+泵 2199
+哀 2200
+翔 2201
+1990 2202
+棒 2203
+芝 2204
+x 2205
+扑 2206
+3000 2207
+毅 2208
+衍 2209
+惨 2210
+疯 2211
+欺 2212
+贼 2213
+肖 2214
+轰 2215
+巢 2216
+臂 2217
+轩 2218
+扁 2219
+淘 2220
+犬 2221
+宰 2222
+祠 2223
+挡 2224
+厌 2225
+帐 2226
+蜂 2227
+狐 2228
+垃 2229
+昂 2230
+圾 2231
+秩 2232
+芬 2233
+瞬 2234
+枢 2235
+舌 2236
+唇 2237
+棕 2238
+1984 2239
+霞 2240
+霜 2241
+艇 2242
+侨 2243
+鹤 2244
+硅 2245
+靖 2246
+哦 2247
+削 2248
+泌 2249
+奠 2250
+d 2251
+吏 2252
+夷 2253
+咖 2254
+彭 2255
+窑 2256
+胁 2257
+肪 2258
+120 2259
+贞 2260
+劝 2261
+钙 2262
+柜 2263
+鸭 2264
+75 2265
+庞 2266
+兔 2267
+荆 2268
+丙 2269
+纱 2270
+34 2271
+戈 2272
+藤 2273
+矩 2274
+泳 2275
+惧 2276
+铃 2277
+渴 2278
+胀 2279
+袖 2280
+丸 2281
+狠 2282
+豫 2283
+茫 2284
+1985 2285
+浇 2286
+菩 2287
+氯 2288
+啡 2289
+1988 2290
+葱 2291
+37 2292
+梨 2293
+霉 2294
+脆 2295
+氢 2296
+巷 2297
+丑 2298
+娃 2299
+锻 2300
+愤 2301
+贪 2302
+蝶 2303
+1991 2304
+厉 2305
+闽 2306
+浑 2307
+斩 2308
+栖 2309
+l 2310
+茅 2311
+昏 2312
+龟 2313
+碗 2314
+棚 2315
+滞 2316
+慰 2317
+600 2318
+2016 2319
+斋 2320
+虹 2321
+屯 2322
+萝 2323
+饼 2324
+窄 2325
+潘 2326
+绣 2327
+丢 2328
+芦 2329
+鳍 2330
+42 2331
+裕 2332
+誓 2333
+腻 2334
+48 2335
+95 2336
+锈 2337
+吞 2338
+蜀 2339
+啦 2340
+扭 2341
+5000 2342
+巩 2343
+髓 2344
+1987 2345
+劣 2346
+拌 2347
+谊 2348
+涛 2349
+勋 2350
+郊 2351
+莎 2352
+痴 2353
+窝 2354
+驰 2355
+1986 2356
+跌 2357
+笼 2358
+挤 2359
+溢 2360
+1989 2361
+隙 2362
+55 2363
+鹰 2364
+诏 2365
+帽 2366
+65 2367
+芒 2368
+爬 2369
+凸 2370
+牺 2371
+熔 2372
+吻 2373
+竭 2374
+瘦 2375
+冥 2376
+800 2377
+搏 2378
+屡 2379
+昔 2380
+萼 2381
+愁 2382
+捉 2383
+翁 2384
+怖 2385
+汪 2386
+烯 2387
+疲 2388
+缸 2389
+溃 2390
+85 2391
+泼 2392
+剖 2393
+涨 2394
+橡 2395
+谜 2396
+悔 2397
+嫌 2398
+盒 2399
+苯 2400
+凹 2401
+绳 2402
+畏 2403
+罐 2404
+虾 2405
+柯 2406
+邑 2407
+馨 2408
+兆 2409
+帖 2410
+陌 2411
+禄 2412
+垫 2413
+壶 2414
+逊 2415
+骤 2416
+祀 2417
+晴 2418
+蓬 2419
+e 2420
+苞 2421
+煎 2422
+菊 2423
+堤 2424
+甫 2425
+拱 2426
+氮 2427
+罕 2428
+舶 2429
+伞 2430
+姚 2431
+弓 2432
+嵌 2433
+1983 2434
+1982 2435
+馈 2436
+琼 2437
+噪 2438
+雀 2439
+呵 2440
+汝 2441
+焉 2442
+陀 2443
+胺 2444
+惩 2445
+沼 2446
+枣 2447
+桐 2448
+酱 2449
+遮 2450
+孢 2451
+钝 2452
+呀 2453
+锥 2454
+妥 2455
+酿 2456
+巫 2457
+闯 2458
+沧 2459
+崩 2460
+蕊 2461
+酬 2462
+匠 2463
+躲 2464
+43 2465
+喊 2466
+98 2467
+琳 2468
+46 2469
+绎 2470
+喉 2471
+凰 2472
+抬 2473
+93 2474
+膨 2475
+盲 2476
+剥 2477
+喂 2478
+庸 2479
+奸 2480
+n 2481
+钩 2482
+冈 2483
+募 2484
+苑 2485
+杏 2486
+杉 2487
+辱 2488
+隋 2489
+薪 2490
+绒 2491
+1980 2492
+99 2493
+欠 2494
+尉 2495
+r 2496
+攀 2497
+抹 2498
+巾 2499
+1958 2500
+渣 2501
+苹 2502
+猴 2503
+悄 2504
+屠 2505
+41 2506
+颂 2507
+湛 2508
+魄 2509
+颠 2510
+1949 2511
+呆 2512
+粤 2513
+岂 2514
+娇 2515
+暑 2516
+44 2517
+56 2518
+52 2519
+鹅 2520
+筛 2521
+膏 2522
+樱 2523
+p 2524
+缆 2525
+襄 2526
+瑟 2527
+恭 2528
+泻 2529
+匪 2530
+兮 2531
+恼 2532
+吟 2533
+仕 2534
+蔽 2535
+骄 2536
+蚕 2537
+斥 2538
+椅 2539
+姬 2540
+谦 2541
+for 2542
+椎 2543
+搅 2544
+卸 2545
+沫 2546
+怜 2547
+坎 2548
+瑰 2549
+1978 2550
+钦 2551
+h 2552
+拾 2553
+厕 2554
+後 2555
+逾 2556
+薯 2557
+衬 2558
+钾 2559
+崔 2560
+稽 2561
+蛮 2562
+殷 2563
+晒 2564
+47 2565
+菇 2566
+臭 2567
+弧 2568
+擎 2569
+粹 2570
+纬 2571
+1500 2572
+焰 2573
+玲 2574
+竣 2575
+咒 2576
+歇 2577
+糕 2578
+诵 2579
+茨 2580
+妮 2581
+酯 2582
+麟 2583
+卑 2584
+浏 2585
+咽 2586
+罩 2587
+舱 2588
+酵 2589
+晕 2590
+顽 2591
+赁 2592
+咬 2593
+枫 2594
+冀 2595
+贮 2596
+艘 2597
+亏 2598
+薛 2599
+瀑 2600
+篆 2601
+膀 2602
+沸 2603
+雍 2604
+咳 2605
+尹 2606
+愉 2607
+烹 2608
+坠 2609
+勿 2610
+钠 2611
+64 2612
+坤 2613
+甸 2614
+墅 2615
+闸 2616
+藻 2617
+韧 2618
+鄂 2619
+58 2620
+51 2621
+91 2622
+j 2623
+瑶 2624
+舆 2625
+夸 2626
+54 2627
+蕾 2628
+栗 2629
+咏 2630
+丞 2631
+抄 2632
+鹏 2633
+弊 2634
+檐 2635
+骂 2636
+仆 2637
+峻 2638
+爪 2639
+赚 2640
+帆 2641
+娶 2642
+嘛 2643
+钓 2644
+澄 2645
+猜 2646
+1979 2647
+裔 2648
+抒 2649
+铅 2650
+卉 2651
+彦 2652
+f 2653
+删 2654
+衷 2655
+禹 2656
+寡 2657
+蒲 2658
+砌 2659
+on 2660
+棱 2661
+72 2662
+拘 2663
+堵 2664
+雁 2665
+仄 2666
+荫 2667
+53 2668
+k 2669
+1981 2670
+祈 2671
+49 2672
+奢 2673
+赌 2674
+寇 2675
+3d 2676
+隧 2677
+摊 2678
+雇 2679
+卦 2680
+婉 2681
+敲 2682
+挣 2683
+皱 2684
+虞 2685
+亨 2686
+懈 2687
+挽 2688
+珊 2689
+饶 2690
+滥 2691
+锯 2692
+闷 2693
+it 2694
+酮 2695
+虐 2696
+兑 2697
+僵 2698
+傻 2699
+62 2700
+沦 2701
+巅 2702
+鞭 2703
+梳 2704
+赣 2705
+锌 2706
+庐 2707
+薇 2708
+庵 2709
+57 2710
+96 2711
+慨 2712
+肚 2713
+妄 2714
+g 2715
+仗 2716
+绑 2717
+2017 2718
+枕 2719
+牡 2720
+000 2721
+胖 2722
+沪 2723
+垒 2724
+捞 2725
+捧 2726
+竖 2727
+蜡 2728
+桩 2729
+厢 2730
+孵 2731
+黏 2732
+拯 2733
+63 2734
+谭 2735
+68 2736
+诈 2737
+灿 2738
+釉 2739
+1956 2740
+裹 2741
+钮 2742
+俩 2743
+o 2744
+灶 2745
+彝 2746
+蟹 2747
+涩 2748
+醋 2749
+110 2750
+匙 2751
+歧 2752
+刹 2753
+玫 2754
+棘 2755
+橙 2756
+凑 2757
+桶 2758
+刃 2759
+伽 2760
+4000 2761
+硝 2762
+怡 2763
+籽 2764
+敞 2765
+淳 2766
+矮 2767
+镶 2768
+戚 2769
+幢 2770
+涡 2771
+66 2772
+尧 2773
+膝 2774
+is 2775
+哉 2776
+肆 2777
+畔 2778
+溯 2779
+97 2780
+媚 2781
+烘 2782
+01 2783
+67 2784
+窃 2785
+焚 2786
+澜 2787
+愚 2788
+棵 2789
+乞 2790
+86 2791
+78 2792
+佑 2793
+76 2794
+iphone 2795
+暨 2796
+敷 2797
+饥 2798
+俯 2799
+蔓 2800
+v 2801
+05 2802
+88 2803
+暮 2804
+砍 2805
+邵 2806
+仑 2807
+毗 2808
+剿 2809
+馀 2810
+180 2811
+锤 2812
+刮 2813
+1950 2814
+梭 2815
+摧 2816
+250 2817
+掠 2818
+躯 2819
+诡 2820
+匈 2821
+侣 2822
+胚 2823
+疮 2824
+59 2825
+裙 2826
+windows 2827
+裸 2828
+08 2829
+塌 2830
+吓 2831
+俘 2832
+糙 2833
+藩 2834
+楷 2835
+羞 2836
+with 2837
+鲍 2838
+帘 2839
+裤 2840
+宛 2841
+憾 2842
+桓 2843
+痰 2844
+寞 2845
+骚 2846
+惹 2847
+笋 2848
+萃 2849
+92 2850
+栓 2851
+61 2852
+挫 2853
+矢 2854
+垦 2855
+09 2856
+垄 2857
+绸 2858
+凄 2859
+your 2860
+镀 2861
+熏 2862
+钉 2863
+1945 2864
+led 2865
+粪 2866
+缅 2867
+洽 2868
+鞘 2869
+蔗 2870
+82 2871
+迄 2872
+沐 2873
+凿 2874
+勉 2875
+昨 2876
+喘 2877
+700 2878
+爹 2879
+屑 2880
+耻 2881
+沥 2882
+庶 2883
+涅 2884
+腕 2885
+袍 2886
+懒 2887
+阜 2888
+嗜 2889
+朔 2890
+1200 2891
+蒜 2892
+沛 2893
+坟 2894
+轿 2895
+喀 2896
+笛 2897
+狄 2898
+饿 2899
+蓉 2900
+泣 2901
+窟 2902
+130 2903
+豹 2904
+屿 2905
+73 2906
+崛 2907
+迦 2908
+诠 2909
+贬 2910
+腥 2911
+83 2912
+钥 2913
+嗣 2914
+瑜 2915
+07 2916
+倦 2917
+萎 2918
+拦 2919
+冤 2920
+讽 2921
+潇 2922
+谣 2923
+趁 2924
+1960 2925
+妨 2926
+84 2927
+贩 2928
+74 2929
+萍 2930
+窦 2931
+纂 2932
+缀 2933
+矫 2934
+淑 2935
+墩 2936
+梵 2937
+沾 2938
+淫 2939
+乖 2940
+汰 2941
+莞 2942
+81 2943
+旷 2944
+浊 2945
+挚 2946
+撼 2947
+69 2948
+87 2949
+氟 2950
+焕 2951
+06 2952
+庚 2953
+掀 2954
+诀 2955
+kg 2956
+盼 2957
+71 2958
+疹 2959
+窖 2960
+匆 2961
+厥 2962
+轧 2963
+89 2964
+淹 2965
+94 2966
+160 2967
+亥 2968
+鸦 2969
+棍 2970
+谅 2971
+歼 2972
+汕 2973
+挪 2974
+蚁 2975
+敛 2976
+魁 2977
+畴 2978
+炫 2979
+丫 2980
+奎 2981
+菱 2982
+沂 2983
+撕 2984
+阎 2985
+詹 2986
+03 2987
+蛛 2988
+77 2989
+靡 2990
+瞻 2991
+咱 2992
+愧 2993
+烷 2994
+畸 2995
+灸 2996
+眸 2997
+that 2998
+觅 2999
+芜 3000
+1955 3001
+廓 3002
+斌 3003
+躁 3004
+麓 3005
+摔 3006
+1970 3007
+烛 3008
+睹 3009
+孜 3010
+缚 3011
+堕 3012
+昼 3013
+睿 3014
+琪 3015
+琉 3016
+贱 3017
+6000 3018
+渝 3019
+跋 3020
+1959 3021
+茄 3022
+1957 3023
+舜 3024
+1976 3025
+诛 3026
+1952 3027
+捣 3028
+芙 3029
+04 3030
+1961 3031
+倚 3032
+1938 3033
+酰 3034
+澈 3035
+慌 3036
+帜 3037
+颤 3038
+陇 3039
+1962 3040
+02 3041
+颌 3042
+昧 3043
+佣 3044
+眷 3045
+徙 3046
+禾 3047
+逮 3048
+1948 3049
+79 3050
+莹 3051
+碟 3052
+梢 3053
+朽 3054
+粥 3055
+喇 3056
+1964 3057
+榆 3058
+驳 3059
+楔 3060
+1965 3061
+啸 3062
+肋 3063
+dna 3064
+踢 3065
+1975 3066
+1937 3067
+u 3068
+傍 3069
+桔 3070
+肴 3071
+呕 3072
+旭 3073
+埠 3074
+贿 3075
+曝 3076
+杖 3077
+俭 3078
+栩 3079
+1953 3080
+斧 3081
+镁 3082
+匾 3083
+踩 3084
+橘 3085
+颅 3086
+1963 3087
+囚 3088
+蛙 3089
+1946 3090
+膳 3091
+坞 3092
+琐 3093
+荧 3094
+瘟 3095
+涤 3096
+胰 3097
+衫 3098
+噬 3099
+皖 3100
+邱 3101
+埔 3102
+汀 3103
+羡 3104
+睐 3105
+葵 3106
+耿 3107
+糟 3108
+厄 3109
+秧 3110
+黔 3111
+蹄 3112
+140 3113
+漳 3114
+鞍 3115
+谏 3116
+腋 3117
+簇 3118
+梧 3119
+戎 3120
+1977 3121
+榴 3122
+诣 3123
+宦 3124
+苔 3125
+揽 3126
+簧 3127
+狸 3128
+阙 3129
+扯 3130
+耍 3131
+棠 3132
+脓 3133
+烫 3134
+翘 3135
+芭 3136
+躺 3137
+羁 3138
+藉 3139
+拐 3140
+1966 3141
+陡 3142
+1954 3143
+漓 3144
+棺 3145
+钧 3146
+琅 3147
+扔 3148
+寝 3149
+绚 3150
+熬 3151
+驿 3152
+邹 3153
+杠 3154
+1972 3155
+w 3156
+绥 3157
+窥 3158
+晃 3159
+渭 3160
+1947 3161
+樊 3162
+鑫 3163
+祁 3164
+陋 3165
+哺 3166
+堰 3167
+祛 3168
+y 3169
+梓 3170
+崎 3171
+1968 3172
+孽 3173
+蝴 3174
+蔚 3175
+抖 3176
+苟 3177
+肇 3178
+溜 3179
+绅 3180
+妾 3181
+1940 3182
+跪 3183
+沁 3184
+q 3185
+1973 3186
+莽 3187
+虏 3188
+be 3189
+瞄 3190
+砸 3191
+稚 3192
+僚 3193
+崭 3194
+迭 3195
+皂 3196
+彬 3197
+雏 3198
+ip 3199
+羲 3200
+缕 3201
+绞 3202
+俞 3203
+簿 3204
+耸 3205
+廖 3206
+嘲 3207
+can 3208
+1969 3209
+翌 3210
+榄 3211
+裴 3212
+槐 3213
+1939 3214
+洼 3215
+睁 3216
+1951 3217
+灼 3218
+啤 3219
+臀 3220
+啥 3221
+濒 3222
+醛 3223
+峨 3224
+葫 3225
+悍 3226
+笨 3227
+嘱 3228
+1935 3229
+稠 3230
+360 3231
+韶 3232
+1941 3233
+陛 3234
+峭 3235
+1974 3236
+酚 3237
+翩 3238
+舅 3239
+8000 3240
+寅 3241
+1936 3242
+蕉 3243
+阮 3244
+垣 3245
+戮 3246
+me 3247
+趾 3248
+犀 3249
+巍 3250
+re 3251
+霄 3252
+1942 3253
+1930 3254
+饪 3255
+sci 3256
+秆 3257
+朕 3258
+驼 3259
+肛 3260
+揉 3261
+ipad 3262
+楠 3263
+岚 3264
+疡 3265
+帧 3266
+柑 3267
+iso9001 3268
+赎 3269
+逍 3270
+滇 3271
+璋 3272
+礁 3273
+黛 3274
+钞 3275
+邢 3276
+涧 3277
+劈 3278
+瞳 3279
+砚 3280
+驴 3281
+1944 3282
+锣 3283
+恳 3284
+栅 3285
+吵 3286
+牟 3287
+沌 3288
+瞩 3289
+咪 3290
+毯 3291
+炳 3292
+淤 3293
+盯 3294
+芋 3295
+粟 3296
+350 3297
+栈 3298
+戊 3299
+盏 3300
+峪 3301
+拂 3302
+暇 3303
+酥 3304
+汛 3305
+900 3306
+pc 3307
+嚣 3308
+2500 3309
+轼 3310
+妒 3311
+匿 3312
+1934 3313
+鸽 3314
+蝉 3315
+cd 3316
+痒 3317
+宵 3318
+瘫 3319
+1927 3320
+1943 3321
+璧 3322
+汲 3323
+1971 3324
+冢 3325
+碌 3326
+琢 3327
+磅 3328
+卤 3329
+105 3330
+剔 3331
+谎 3332
+圩 3333
+酌 3334
+捏 3335
+渺 3336
+媳 3337
+1933 3338
+穹 3339
+谥 3340
+骏 3341
+哨 3342
+骆 3343
+乒 3344
+10000 3345
+摹 3346
+兜 3347
+柿 3348
+喧 3349
+呜 3350
+捡 3351
+橄 3352
+逗 3353
+瑚 3354
+呐 3355
+檀 3356
+辜 3357
+妊 3358
+祯 3359
+1931 3360
+苷 3361
+don 3362
+衙 3363
+笃 3364
+芸 3365
+霖 3366
+荔 3367
+闺 3368
+羌 3369
+芹 3370
+dvd 3371
+哼 3372
+糯 3373
+吼 3374
+蕃 3375
+嵩 3376
+矶 3377
+绽 3378
+坯 3379
+娠 3380
+1928 3381
+祷 3382
+锰 3383
+qq 3384
+by 3385
+瘀 3386
+108 3387
+岐 3388
+1932 3389
+茵 3390
+筝 3391
+斐 3392
+肽 3393
+歉 3394
+1929 3395
+嗽 3396
+恤 3397
+汶 3398
+聂 3399
+樟 3400
+擒 3401
+鹃 3402
+拙 3403
+鲤 3404
+絮 3405
+鄙 3406
+彪 3407
+ipod 3408
+z 3409
+嗓 3410
+墟 3411
+骼 3412
+渤 3413
+僻 3414
+豁 3415
+谕 3416
+荟 3417
+姨 3418
+婷 3419
+挠 3420
+哇 3421
+炙 3422
+220 3423
+诅 3424
+娥 3425
+哑 3426
+阱 3427
+嫉 3428
+圭 3429
+乓 3430
+橱 3431
+歪 3432
+禧 3433
+甩 3434
+坷 3435
+晏 3436
+驯 3437
+讳 3438
+泗 3439
+煞 3440
+my 3441
+淄 3442
+倪 3443
+妓 3444
+窍 3445
+竿 3446
+襟 3447
+匡 3448
+钛 3449
+侈 3450
+ll 3451
+侄 3452
+铲 3453
+哮 3454
+厩 3455
+1967 3456
+亢 3457
+101 3458
+辕 3459
+瘾 3460
+辊 3461
+狩 3462
+掷 3463
+潍 3464
+240 3465
+伺 3466
+嘿 3467
+弈 3468
+嘎 3469
+陨 3470
+娅 3471
+1800 3472
+昊 3473
+犁 3474
+屁 3475
+蜘 3476
+170 3477
+寥 3478
+滕 3479
+毙 3480
+as 3481
+涝 3482
+谛 3483
+all 3484
+郝 3485
+痹 3486
+溺 3487
+汾 3488
+脐 3489
+馅 3490
+蠢 3491
+珀 3492
+腌 3493
+扼 3494
+敕 3495
+莓 3496
+峦 3497
+铬 3498
+谍 3499
+炬 3500
+龚 3501
+麒 3502
+睦 3503
+磺 3504
+吁 3505
+掺 3506
+烁 3507
+靶 3508
+or 3509
+圃 3510
+饵 3511
+褶 3512
+娟 3513
+滔 3514
+挨 3515
+android 3516
+褒 3517
+胱 3518
+cpu 3519
+晖 3520
+脖 3521
+垢 3522
+抉 3523
+冉 3524
+茧 3525
+from 3526
+渲 3527
+癫 3528
+125 3529
+de 3530
+悼 3531
+嫂 3532
+瞒 3533
+纶 3534
+肘 3535
+炖 3536
+瀚 3537
+皋 3538
+姊 3539
+颐 3540
+1600 3541
+俏 3542
+颊 3543
+gps 3544
+讶 3545
+札 3546
+奕 3547
+磊 3548
+镖 3549
+遐 3550
+眺 3551
+腑 3552
+boss 3553
+琦 3554
+蚊 3555
+窜 3556
+渍 3557
+嗯 3558
+102 3559
+1926 3560
+touch 3561
+夯 3562
+1300 3563
+笙 3564
+蘑 3565
+翡 3566
+碘 3567
+卯 3568
+啼 3569
+靓 3570
+辍 3571
+莺 3572
+躬 3573
+猿 3574
+杞 3575
+眩 3576
+虔 3577
+凋 3578
+遁 3579
+泾 3580
+岔 3581
+羟 3582
+弛 3583
+娄 3584
+茸 3585
+皓 3586
+峙 3587
+逅 3588
+邂 3589
+苇 3590
+楹 3591
+蹲 3592
+拢 3593
+甄 3594
+鳃 3595
+104 3596
+邯 3597
+捆 3598
+勺 3599
+450 3600
+酉 3601
+荚 3602
+唑 3603
+臻 3604
+辗 3605
+绰 3606
+徊 3607
+榨 3608
+苛 3609
+赦 3610
+盔 3611
+壬 3612
+恍 3613
+缉 3614
+2020 3615
+熨 3616
+7000 3617
+澡 3618
+桨 3619
+匣 3620
+兢 3621
+106 3622
+驭 3623
+x1 3624
+镍 3625
+孰 3626
+绮 3627
+馏 3628
+蝇 3629
+佼 3630
+鲸 3631
+128 3632
+哎 3633
+裳 3634
+蜕 3635
+嚼 3636
+嘻 3637
+web 3638
+庇 3639
+绢 3640
+倩 3641
+钵 3642
+ii 3643
+恪 3644
+帷 3645
+莆 3646
+柠 3647
+藕 3648
+砾 3649
+115 3650
+绊 3651
+喙 3652
+坂 3653
+徘 3654
+荀 3655
+瞧 3656
+蛾 3657
+1925 3658
+晦 3659
+ph 3660
+mm 3661
+铎 3662
+107 3663
+紊 3664
+锚 3665
+酪 3666
+稷 3667
+聋 3668
+闵 3669
+熹 3670
+冕 3671
+诫 3672
+珑 3673
+曦 3674
+篷 3675
+320 3676
+迥 3677
+蘖 3678
+胤 3679
+103 3680
+檬 3681
+瑾 3682
+钳 3683
+遏 3684
+辄 3685
+嬉 3686
+隅 3687
+ps 3688
+秃 3689
+112 3690
+帛 3691
+聆 3692
+芥 3693
+诬 3694
+1100 3695
+挟 3696
+宕 3697
+2018 3698
+鹊 3699
+琶 3700
+膛 3701
+mv 3702
+兀 3703
+gb 3704
+懿 3705
+碾 3706
+叮 3707
+863 3708
+蠕 3709
+譬 3710
+缮 3711
+烽 3712
+妍 3713
+榕 3714
+260 3715
+1920 3716
+邃 3717
+焙 3718
+倘 3719
+210 3720
+戌 3721
+茹 3722
+豚 3723
+晾 3724
+浒 3725
+玺 3726
+醚 3727
+祐 3728
+炽 3729
+this 3730
+缪 3731
+凛 3732
+噩 3733
+溅 3734
+毋 3735
+槛 3736
+ei 3737
+are 3738
+嫡 3739
+蝠 3740
+娴 3741
+稣 3742
+禀 3743
+壑 3744
+殆 3745
+敖 3746
+cm 3747
+ios 3748
+倭 3749
+挛 3750
+侃 3751
+蚌 3752
+咀 3753
+盎 3754
+殉 3755
+岑 3756
+浚 3757
+谬 3758
+狡 3759
+1924 3760
+癸 3761
+280 3762
+逛 3763
+耽 3764
+俺 3765
+璨 3766
+巳 3767
+茜 3768
+郸 3769
+蒴 3770
+琵 3771
+we 3772
+230 3773
+叩 3774
+泸 3775
+塾 3776
+one 3777
+稼 3778
+reg 3779
+侮 3780
+锂 3781
+曙 3782
+3500 3783
+up 3784
+薰 3785
+婿 3786
+惶 3787
+拭 3788
+篱 3789
+恬 3790
+淌 3791
+烙 3792
+袜 3793
+徵 3794
+慷 3795
+夭 3796
+噶 3797
+莘 3798
+135 3799
+鸳 3800
+殡 3801
+蚂 3802
+1900 3803
+憎 3804
+喃 3805
+佚 3806
+龛 3807
+潢 3808
+烃 3809
+at 3810
+岱 3811
+潺 3812
+109 3813
+衢 3814
+璀 3815
+5cm 3816
+1400 3817
+鹭 3818
+揣 3819
+痢 3820
+know 3821
+厮 3822
+氓 3823
+怠 3824
+no 3825
+nbsp 3826
+痘 3827
+硒 3828
+镌 3829
+乍 3830
+咯 3831
+惬 3832
+not 3833
+桦 3834
+骇 3835
+枉 3836
+蜗 3837
+睾 3838
+淇 3839
+耘 3840
+娓 3841
+弼 3842
+鳌 3843
+嗅 3844
+gdp 3845
+狙 3846
+箫 3847
+朦 3848
+椰 3849
+胥 3850
+丐 3851
+陂 3852
+唾 3853
+鳄 3854
+柚 3855
+谒 3856
+journal 3857
+戍 3858
+1912 3859
+刁 3860
+鸾 3861
+缭 3862
+骸 3863
+铣 3864
+酋 3865
+蝎 3866
+掏 3867
+耦 3868
+怯 3869
+娲 3870
+拇 3871
+汹 3872
+胧 3873
+疤 3874
+118 3875
+硼 3876
+恕 3877
+哗 3878
+眶 3879
+痫 3880
+凳 3881
+鲨 3882
+擢 3883
+歹 3884
+樵 3885
+瘠 3886
+app 3887
+茗 3888
+翟 3889
+黯 3890
+蜒 3891
+壹 3892
+殇 3893
+伶 3894
+辙 3895
+an 3896
+瑕 3897
+町 3898
+孚 3899
+痉 3900
+铵 3901
+搁 3902
+漾 3903
+戟 3904
+镰 3905
+鸯 3906
+猩 3907
+190 3908
+蔷 3909
+缤 3910
+叭 3911
+垩 3912
+113 3913
+曳 3914
+usb 3915
+奚 3916
+毓 3917
+ibm 3918
+颓 3919
+汐 3920
+靴 3921
+china 3922
+傣 3923
+尬 3924
+濮 3925
+赂 3926
+媛 3927
+懦 3928
+扦 3929
+111 3930
+韬 3931
+like 3932
+戳 3933
+java 3934
+雯 3935
+114 3936
+蜿 3937
+116 3938
+1923 3939
+笺 3940
+裘 3941
+尴 3942
+侗 3943
+mba 3944
+3g 3945
+钨 3946
+1919 3947
+苓 3948
+1922 3949
+寰 3950
+蛊 3951
+扳 3952
+搓 3953
+涟 3954
+睫 3955
+淬 3956
+5mm 3957
+123 3958
+ve 3959
+121 3960
+赈 3961
+恺 3962
+瞎 3963
+蝙 3964
+1921 3965
+枸 3966
+萱 3967
+颚 3968
+憩 3969
+秽 3970
+秸 3971
+拷 3972
+阑 3973
+貂 3974
+粱 3975
+煲 3976
+隘 3977
+暧 3978
+惕 3979
+沽 3980
+time 3981
+菠 3982
+1911 3983
+趟 3984
+磋 3985
+偕 3986
+涕 3987
+邸 3988
+so 3989
+踞 3990
+惫 3991
+122 3992
+阪 3993
+鞠 3994
+饺 3995
+汞 3996
+颍 3997
+氰 3998
+屹 3999
+蛟 4000
+跻 4001
+哟 4002
+have 4003
+126 4004
+臼 4005
+熄 4006
+绛 4007
+弩 4008
+褪 4009
+117 4010
+渎 4011
+亟 4012
+匮 4013
+撇 4014
+internet 4015
+霆 4016
+攒 4017
+舵 4018
+扛 4019
+彤 4020
+nba 4021
+蛤 4022
+婢 4023
+偃 4024
+胫 4025
+姥 4026
+睑 4027
+love 4028
+iso 4029
+pk 4030
+诙 4031
+what 4032
+诲 4033
+锭 4034
+悚 4035
+扒 4036
+洱 4037
+劾 4038
+惰 4039
+篡 4040
+瓯 4041
+徇 4042
+铀 4043
+骋 4044
+flash 4045
+1918 4046
+out 4047
+筷 4048
+渚 4049
+踵 4050
+俨 4051
+ceo 4052
+榻 4053
+糜 4054
+捻 4055
+釜 4056
+哩 4057
+萤 4058
+270 4059
+蛹 4060
+隽 4061
+垮 4062
+鸠 4063
+鸥 4064
+漕 4065
+瑙 4066
+礴 4067
+憧 4068
+殴 4069
+潼 4070
+悯 4071
+砺 4072
+拽 4073
+钗 4074
+ct 4075
+酣 4076
+镂 4077
+mp3 4078
+膺 4079
+楞 4080
+竺 4081
+迂 4082
+嫣 4083
+忱 4084
+cad 4085
+哄 4086
+疣 4087
+鹦 4088
+1700 4089
+枭 4090
+憬 4091
+疱 4092
+will 4093
+婪 4094
+沮 4095
+1914 4096
+怅 4097
+119 4098
+筱 4099
+扉 4100
+瞰 4101
+linux 4102
+旌 4103
+蔑 4104
+铠 4105
+瀛 4106
+vip 4107
+琥 4108
+750 4109
+127 4110
+懵 4111
+谴 4112
+捍 4113
+蟾 4114
+漩 4115
+1913 4116
+拣 4117
+汴 4118
+university 4119
+刨 4120
+叱 4121
+曜 4122
+妞 4123
+澎 4124
+镑 4125
+翎 4126
+瞪 4127
+sh 4128
+倔 4129
+芍 4130
+璞 4131
+瓮 4132
+驹 4133
+芷 4134
+寐 4135
+擂 4136
+丕 4137
+蟠 4138
+诃 4139
+悸 4140
+亘 4141
+溴 4142
+宸 4143
+廿 4144
+恃 4145
+棣 4146
+1917 4147
+荼 4148
+筠 4149
+羚 4150
+慑 4151
+唉 4152
+纣 4153
+麼 4154
+蹦 4155
+锄 4156
+145 4157
+international 4158
+124 4159
+淆 4160
+甙 4161
+132 4162
+蚜 4163
+椿 4164
+禺 4165
+绯 4166
+冗 4167
+168 4168
+葩 4169
+厝 4170
+媲 4171
+蒿 4172
+痪 4173
+650 4174
+菁 4175
+炊 4176
+wifi 4177
+俑 4178
+new 4179
+讥 4180
+min 4181
+桀 4182
+祺 4183
+129 4184
+吡 4185
+迩 4186
+do 4187
+john 4188
+箔 4189
+皿 4190
+缎 4191
+萦 4192
+剃 4193
+霓 4194
+酝 4195
+mg 4196
+诰 4197
+茉 4198
+just 4199
+get 4200
+飙 4201
+湍 4202
+蜥 4203
+箕 4204
+蘸 4205
+550 4206
+4500 4207
+柬 4208
+韭 4209
+溥 4210
+but 4211
+熠 4212
+鹉 4213
+咐 4214
+剌 4215
+138 4216
+悖 4217
+瞿 4218
+槟 4219
+娩 4220
+闾 4221
+pvc 4222
+遴 4223
+咫 4224
+20000 4225
+孺 4226
+彷 4227
+茬 4228
+211 4229
+蓟 4230
+li 4231
+if 4232
+憨 4233
+袅 4234
+佬 4235
+炯 4236
+erp 4237
+1910 4238
+啶 4239
+昙 4240
+蚩 4241
+136 4242
+痔 4243
+蕨 4244
+瓢 4245
+夔 4246
+毡 4247
+赃 4248
+鳖 4249
+沅 4250
+wang 4251
+go 4252
+饷 4253
+165 4254
+臧 4255
+掖 4256
+褚 4257
+羹 4258
+ic 4259
+勐 4260
+tv 4261
+谚 4262
+畦 4263
+眨 4264
+贻 4265
+攸 4266
+涎 4267
+弑 4268
+咎 4269
+铂 4270
+瑛 4271
+1905 4272
+矗 4273
+虱 4274
+more 4275
+133 4276
+秤 4277
+谟 4278
+漱 4279
+俸 4280
+夙 4281
+1915 4282
+br 4283
+game 4284
+雉 4285
+螨 4286
+恣 4287
+斛 4288
+175 4289
+谙 4290
+隍 4291
+131 4292
+奄 4293
+480 4294
+yy 4295
+1916 4296
+壕 4297
+髻 4298
+155 4299
+鄱 4300
+嘶 4301
+磕 4302
+濡 4303
+赘 4304
+荞 4305
+讹 4306
+猕 4307
+痞 4308
+鬓 4309
+铮 4310
+腱 4311
+幡 4312
+榭 4313
+爻 4314
+5m 4315
+涓 4316
+晤 4317
+咕 4318
+惭 4319
+钼 4320
+匕 4321
+ok 4322
+撮 4323
+庾 4324
+笠 4325
+窘 4326
+癖 4327
+365 4328
+垛 4329
+窒 4330
+畲 4331
+甬 4332
+彗 4333
+缨 4334
+湮 4335
+寮 4336
+et 4337
+衅 4338
+谪 4339
+156 4340
+绫 4341
+9000 4342
+152 4343
+兖 4344
+疽 4345
+磐 4346
+380 4347
+菏 4348
+沱 4349
+骁 4350
+嫔 4351
+盂 4352
+娆 4353
+钊 4354
+蟒 4355
+忏 4356
+谤 4357
+148 4358
+137 4359
+server 4360
+2200 4361
+晟 4362
+ng 4363
+15000 4364
+google 4365
+痈 4366
+耆 4367
+谧 4368
+簪 4369
+134 4370
+ml 4371
+疟 4372
+扈 4373
+脍 4374
+琛 4375
+咋 4376
+胄 4377
+142 4378
+144 4379
+葆 4380
+轶 4381
+桢 4382
+973 4383
+攘 4384
+was 4385
+邕 4386
+拧 4387
+茯 4388
+205 4389
+摒 4390
+1908 4391
+intel 4392
+傀 4393
+祚 4394
+嘟 4395
+帼 4396
+1906 4397
+wto 4398
+筵 4399
+when 4400
+馒 4401
+疚 4402
+璇 4403
+砧 4404
+merge 4405
+槃 4406
+microsoft 4407
+犷 4408
+exe 4409
+腓 4410
+煜 4411
+弋 4412
+疸 4413
+濑 4414
+310 4415
+201 4416
+麝 4417
+嗟 4418
+忻 4419
+愣 4420
+facebook 4421
+斓 4422
+吝 4423
+咧 4424
+矾 4425
+愫 4426
+151 4427
+158 4428
+漪 4429
+珂 4430
+rna 4431
+逞 4432
+146 4433
+206 4434
+糠 4435
+璐 4436
+藓 4437
+昕 4438
+妩 4439
+屌 4440
+疵 4441
+excel 4442
+嘘 4443
+he 4444
+plc 4445
+袂 4446
+2400 4447
+139 4448
+稃 4449
+剁 4450
+侏 4451
+掐 4452
+猾 4453
+匍 4454
+2800 4455
+坳 4456
+黜 4457
+邺 4458
+闫 4459
+猥 4460
+湃 4461
+斟 4462
+癣 4463
+1904 4464
+185 4465
+匐 4466
+粳 4467
+sql 4468
+330 4469
+141 4470
+cp 4471
+1909 4472
+叟 4473
+俾 4474
+儡 4475
+莒 4476
+12000 4477
+骥 4478
+跤 4479
+耙 4480
+矜 4481
+翱 4482
+zhang 4483
+ms 4484
+赡 4485
+1907 4486
+浣 4487
+栾 4488
+拈 4489
+science 4490
+420 4491
+螟 4492
+aaa 4493
+桧 4494
+坍 4495
+睢 4496
+趴 4497
+id 4498
+伎 4499
+2100 4500
+婺 4501
+霹 4502
+痊 4503
+膊 4504
+眯 4505
+豌 4506
+202 4507
+驮 4508
+骈 4509
+850 4510
+iii 4511
+嶂 4512
+淞 4513
+143 4514
+腮 4515
+髅 4516
+炀 4517
+啄 4518
+亳 4519
+麾 4520
+147 4521
+筐 4522
+叨 4523
+徨 4524
+跷 4525
+ac 4526
+楂 4527
+郴 4528
+绶 4529
+hp 4530
+羔 4531
+xp 4532
+ieee 4533
+咤 4534
+now 4535
+there 4536
+靳 4537
+they 4538
+屎 4539
+雳 4540
+瘘 4541
+蹬 4542
+2300 4543
+惮 4544
+acid 4545
+涪 4546
+阖 4547
+煽 4548
+蹊 4549
+225 4550
+栉 4551
+153 4552
+俟 4553
+涸 4554
+辫 4555
+锢 4556
+佟 4557
+176 4558
+皎 4559
+cctv 4560
+啮 4561
+钰 4562
+螂 4563
+dc 4564
+啪 4565
+绷 4566
+204 4567
+闰 4568
+畿 4569
+2d 4570
+覃 4571
+2600 4572
+惘 4573
+贰 4574
+154 4575
+碉 4576
+卞 4577
+酐 4578
+枷 4579
+葺 4580
+芪 4581
+207 4582
+蕙 4583
+192 4584
+咚 4585
+籁 4586
+pro 4587
+钴 4588
+162 4589
+冽 4590
+玮 4591
+骷 4592
+啃 4593
+焖 4594
+猝 4595
+榈 4596
+滁 4597
+拮 4598
+跗 4599
+讷 4600
+蝗 4601
+208 4602
+蠡 4603
+world 4604
+烨 4605
+been 4606
+hd 4607
+gmp 4608
+256 4609
+脯 4610
+歙 4611
+泠 4612
+刍 4613
+掳 4614
+pe 4615
+his 4616
+僳 4617
+340 4618
+1902 4619
+螯 4620
+胳 4621
+髦 4622
+粽 4623
+戾 4624
+祜 4625
+178 4626
+186 4627
+岷 4628
+懋 4629
+馥 4630
+昵 4631
+踊 4632
+湄 4633
+郢 4634
+斡 4635
+迢 4636
+ce 4637
+photoshop 4638
+嗪 4639
+about 4640
+裨 4641
+1903 4642
+羧 4643
+膈 4644
+翊 4645
+lcd 4646
+鲫 4647
+163 4648
+螃 4649
+沓 4650
+疝 4651
+笈 4652
+ktv 4653
+榔 4654
+157 4655
+诘 4656
+autocad 4657
+195 4658
+颉 4659
+蛀 4660
+鸢 4661
+焯 4662
+囧 4663
+make 4664
+梆 4665
+npc 4666
+潞 4667
+戛 4668
+see 4669
+system 4670
+149 4671
+佗 4672
+艮 4673
+chinese 4674
+let 4675
+霾 4676
+鬟 4677
+215 4678
+net 4679
+玖 4680
+1898 4681
+腭 4682
+喔 4683
+172 4684
+罔 4685
+佥 4686
+粑 4687
+visual 4688
+舷 4689
+泯 4690
+m2 4691
+198 4692
+has 4693
+203 4694
+sd 4695
+泓 4696
+炜 4697
+谗 4698
+烬 4699
+跆 4700
+rpg 4701
+傩 4702
+飓 4703
+浔 4704
+钤 4705
+惚 4706
+胭 4707
+踝 4708
+镯 4709
+ep 4710
+221 4711
+臆 4712
+196 4713
+蜚 4714
+揪 4715
+觞 4716
+皈 4717
+dj 4718
+183 4719
+api 4720
+迸 4721
+匝 4722
+筏 4723
+167 4724
+醴 4725
+黍 4726
+洮 4727
+滦 4728
+侬 4729
+甾 4730
+290 4731
+way 4732
+3200 4733
+188 4734
+diy 4735
+2cm 4736
+com 4737
+澧 4738
+阈 4739
+袱 4740
+迤 4741
+衮 4742
+166 4743
+濂 4744
+娑 4745
+砥 4746
+砷 4747
+铨 4748
+缜 4749
+箴 4750
+30000 4751
+逵 4752
+猖 4753
+159 4754
+蛰 4755
+箍 4756
+侥 4757
+2mm 4758
+搂 4759
+纨 4760
+裱 4761
+枋 4762
+嫦 4763
+敝 4764
+挝 4765
+贲 4766
+潦 4767
+235 4768
+撩 4769
+惺 4770
+铰 4771
+f1 4772
+忒 4773
+咆 4774
+哆 4775
+莅 4776
+164 4777
+炕 4778
+抨 4779
+涿 4780
+龈 4781
+猷 4782
+got 4783
+b1 4784
+182 4785
+2m 4786
+212 4787
+遒 4788
+缥 4789
+vs 4790
+捂 4791
+俐 4792
+la 4793
+瘙 4794
+搐 4795
+牍 4796
+isbn 4797
+馍 4798
+our 4799
+痿 4800
+袤 4801
+峥 4802
+184 4803
+栎 4804
+罹 4805
+燎 4806
+喵 4807
+209 4808
+1901 4809
+璜 4810
+飒 4811
+蔼 4812
+珞 4813
+澹 4814
+奘 4815
+岖 4816
+芡 4817
+簸 4818
+杵 4819
+甥 4820
+骊 4821
+216 4822
+悴 4823
+173 4824
+惆 4825
+5mg 4826
+殃 4827
+1895 4828
+呃 4829
+161 4830
+5g 4831
+祗 4832
+3600 4833
+髋 4834
+169 4835
+liu 4836
+who 4837
+幔 4838
+down 4839
+榛 4840
+犊 4841
+霁 4842
+芮 4843
+520 4844
+牒 4845
+佰 4846
+her 4847
+狈 4848
+薨 4849
+co 4850
+吩 4851
+鳝 4852
+嵘 4853
+濠 4854
+呤 4855
+纫 4856
+3mm 4857
+檄 4858
+214 4859
+浜 4860
+370 4861
+189 4862
+缙 4863
+缢 4864
+煦 4865
+蓦 4866
+揖 4867
+拴 4868
+缈 4869
+218 4870
+褥 4871
+铿 4872
+312 4873
+燮 4874
+life 4875
+锵 4876
+174 4877
+荥 4878
+187 4879
+忿 4880
+4s 4881
+僖 4882
+婶 4883
+171 4884
+chen 4885
+芾 4886
+镐 4887
+痣 4888
+research 4889
+眈 4890
+460 4891
+祇 4892
+邈 4893
+翳 4894
+碣 4895
+遨 4896
+鳗 4897
+诂 4898
+never 4899
+岫 4900
+焘 4901
+3cm 4902
+co2 4903
+茱 4904
+tcp 4905
+only 4906
+255 4907
+gsm 4908
+say 4909
+洵 4910
+晁 4911
+right 4912
+噢 4913
+she 4914
+over 4915
+偈 4916
+旖 4917
+david 4918
+181 4919
+232 4920
+蚓 4921
+柘 4922
+珐 4923
+遽 4924
+岌 4925
+桅 4926
+213 4927
+唔 4928
+222 4929
+鄞 4930
+雹 4931
+michael 4932
+驸 4933
+苻 4934
+恻 4935
+鬃 4936
+玑 4937
+磬 4938
+崂 4939
+304 4940
+祉 4941
+荤 4942
+淼 4943
+560 4944
+264 4945
+肱 4946
+呗 4947
+pp 4948
+b2 4949
+骡 4950
+囱 4951
+10cm 4952
+佞 4953
+back 4954
+1890 4955
+226 4956
+耒 4957
+伫 4958
+嚷 4959
+粼 4960
+aa 4961
+歆 4962
+佃 4963
+旎 4964
+惋 4965
+殁 4966
+杳 4967
+their 4968
+阡 4969
+red 4970
+畈 4971
+蔺 4972
+os 4973
+177 4974
+map 4975
+巽 4976
+cbd 4977
+昱 4978
+啰 4979
+吠 4980
+179 4981
+199 4982
+嗔 4983
+涮 4984
+238 4985
+奂 4986
+1896 4987
+撷 4988
+301 4989
+袒 4990
+720 4991
+爰 4992
+捶 4993
+赭 4994
+蜓 4995
+姗 4996
+蔻 4997
+垠 4998
+193 4999
+gis 5000
+噻 5001
+ab 5002
+峒 5003
+皙 5004
+want 5005
+245 5006
+憔 5007
+帚 5008
+office 5009
+xx 5010
+杷 5011
+蟆 5012
+iso14001 5013
+觐 5014
+钒 5015
+岙 5016
+2700 5017
+1899 5018
+栀 5019
+幄 5020
+啧 5021
+癜 5022
+擀 5023
+轲 5024
+铆 5025
+them 5026
+讴 5027
+樽 5028
+霏 5029
+mtv 5030
+肮 5031
+枳 5032
+骞 5033
+诧 5034
+瘢 5035
+虬 5036
+拗 5037
+play 5038
+219 5039
+蕲 5040
+316 5041
+茁 5042
+唆 5043
+technology 5044
+word 5045
+沭 5046
+毂 5047
+蛎 5048
+芊 5049
+銮 5050
+瞥 5051
+呱 5052
+223 5053
+羿 5054
+吒 5055
+傥 5056
+髯 5057
+濯 5058
+蜻 5059
+皴 5060
+802 5061
+430 5062
+邳 5063
+燧 5064
+1860 5065
+獭 5066
+垭 5067
+祟 5068
+217 5069
+虢 5070
+how 5071
+枇 5072
+abs 5073
+鹫 5074
+194 5075
+颞 5076
+1894 5077
+333 5078
+皑 5079
+脲 5080
+197 5081
+舔 5082
+魇 5083
+霭 5084
+org 5085
+坨 5086
+郧 5087
+baby 5088
+椽 5089
+舫 5090
+228 5091
+oh 5092
+305 5093
+荠 5094
+琊 5095
+溟 5096
+1897 5097
+煨 5098
+265 5099
+谯 5100
+粲 5101
+罂 5102
+gonna 5103
+屉 5104
+佯 5105
+郦 5106
+亵 5107
+诽 5108
+芩 5109
+嵇 5110
+蚤 5111
+哒 5112
+315 5113
+啬 5114
+ain 5115
+嚎 5116
+玥 5117
+twitter 5118
+191 5119
+隼 5120
+唢 5121
+铛 5122
+cause 5123
+壅 5124
+藜 5125
+won 5126
+吱 5127
+rom 5128
+楣 5129
+璟 5130
+锆 5131
+憋 5132
+罡 5133
+al 5134
+咙 5135
+1850 5136
+腈 5137
+oslash 5138
+job 5139
+233 5140
+廪 5141
+堑 5142
+into 5143
+诩 5144
+b2c 5145
+溧 5146
+鹑 5147
+讫 5148
+哌 5149
+铢 5150
+蜴 5151
+1ml 5152
+稹 5153
+噜 5154
+镉 5155
+224 5156
+愕 5157
+桁 5158
+晔 5159
+琰 5160
+陲 5161
+疙 5162
+667 5163
+崮 5164
+need 5165
+540 5166
+8mm 5167
+html 5168
+颛 5169
+through 5170
+asp 5171
+桡 5172
+钜 5173
+580 5174
+take 5175
+谑 5176
+仞 5177
+咦 5178
+珪 5179
+揍 5180
+鱿 5181
+阉 5182
+3800 5183
+瘩 5184
+410 5185
+槌 5186
+滓 5187
+茴 5188
+tft 5189
+泮 5190
+涣 5191
+atm 5192
+pci 5193
+柞 5194
+渥 5195
+飨 5196
+孪 5197
+沔 5198
+谲 5199
+桉 5200
+vcd 5201
+慵 5202
+318 5203
+oem 5204
+other 5205
+俚 5206
+paul 5207
+跖 5208
+纭 5209
+恙 5210
+which 5211
+fi 5212
+佘 5213
+236 5214
+荃 5215
+咄 5216
+鞅 5217
+叁 5218
+james 5219
+恽 5220
+m3 5221
+253 5222
+炔 5223
+萘 5224
+钺 5225
+6500 5226
+1880 5227
+ccd 5228
+楫 5229
+塬 5230
+钡 5231
+琮 5232
+苄 5233
+950 5234
+325 5235
+275 5236
+1g 5237
+day 5238
+o2o 5239
+960 5240
+music 5241
+骰 5242
+偎 5243
+粕 5244
+amd 5245
+咔 5246
+鹄 5247
+瓒 5248
+阆 5249
+捅 5250
+嬴 5251
+adobe 5252
+箨 5253
+name 5254
+390 5255
+680 5256
+640 5257
+氦 5258
+倜 5259
+b2b 5260
+觊 5261
+xml 5262
+婕 5263
+229 5264
+jar 5265
+锑 5266
+撬 5267
+chem 5268
+掰 5269
+嗷 5270
+5500 5271
+1cm 5272
+饯 5273
+蓓 5274
+234 5275
+good 5276
+鼬 5277
+spa 5278
+佤 5279
+5a 5280
+ss 5281
+蚯 5282
+挞 5283
+臾 5284
+where 5285
+atp 5286
+227 5287
+嶙 5288
+幂 5289
+饬 5290
+闱 5291
+live 5292
+high 5293
+煅 5294
+嘧 5295
+1mm 5296
+蹭 5297
+sun 5298
+abc 5299
+瞭 5300
+顼 5301
+箐 5302
+here 5303
+徉 5304
+231 5305
+骜 5306
+302 5307
+嗨 5308
+邛 5309
+庑 5310
+柩 5311
+饕 5312
+俎 5313
+4mm 5314
+15g 5315
+嘌 5316
+50000 5317
+颏 5318
+cssci 5319
+椁 5320
+崧 5321
+锉 5322
+籼 5323
+1870 5324
+狞 5325
+弁 5326
+6mm 5327
+羯 5328
+踹 5329
+糅 5330
+248 5331
+1840 5332
+砼 5333
+263 5334
+嫖 5335
+tmp 5336
+252 5337
+mac 5338
+285 5339
+豉 5340
+啉 5341
+榷 5342
+嘈 5343
+en 5344
+俪 5345
+痂 5346
+308 5347
+inf 5348
+630 5349
+儋 5350
+4a 5351
+芎 5352
+ai 5353
+man 5354
+繇 5355
+1889 5356
+bt 5357
+239 5358
+meta 5359
+蹇 5360
+242 5361
+530 5362
+诋 5363
+bbc 5364
+煸 5365
+峋 5366
+淙 5367
+324 5368
+management 5369
+1885 5370
+泱 5371
+徜 5372
+crm 5373
+4cm 5374
+free 5375
+汩 5376
+纥 5377
+246 5378
+蝼 5379
+囿 5380
+uv 5381
+暹 5382
+谆 5383
+蹂 5384
+鞣 5385
+3c 5386
+mr 5387
+螳 5388
+cs 5389
+馗 5390
+幺 5391
+鞑 5392
+贽 5393
+268 5394
+istp 5395
+243 5396
+漯 5397
+237 5398
+牦 5399
+淖 5400
+engineering 5401
+dr 5402
+囤 5403
+than 5404
+gprs 5405
+sp 5406
+440 5407
+晗 5408
+1888 5409
+258 5410
+忡 5411
+懊 5412
+呋 5413
+埂 5414
+pcb 5415
+307 5416
+first 5417
+321 5418
+robert 5419
+鲈 5420
+sup2 5421
+阕 5422
+3m 5423
+幌 5424
+cg 5425
+303 5426
+鳅 5427
+勰 5428
+find 5429
+8cm 5430
+萸 5431
+剽 5432
+蚝 5433
+wi 5434
+绔 5435
+pdf 5436
+1250 5437
+262 5438
+php 5439
+辇 5440
+10mg 5441
+use 5442
+ie 5443
+麋 5444
+1884 5445
+陟 5446
+宥 5447
+oracle 5448
+锺 5449
+喽 5450
+620 5451
+1892 5452
+1893 5453
+淅 5454
+熵 5455
+荨 5456
+247 5457
+忤 5458
+american 5459
+266 5460
+seo 5461
+轭 5462
+嗦 5463
+荪 5464
+also 5465
+骠 5466
+鹘 5467
+p2p 5468
+4g 5469
+聿 5470
+绾 5471
+诶 5472
+985 5473
+怆 5474
+244 5475
+喋 5476
+恸 5477
+湟 5478
+睨 5479
+翦 5480
+fe 5481
+蜈 5482
+1875 5483
+褂 5484
+娼 5485
+1886 5486
+羸 5487
+觎 5488
+470 5489
+瘁 5490
+306 5491
+蚣 5492
+呻 5493
+241 5494
+1882 5495
+昶 5496
+谶 5497
+猬 5498
+荻 5499
+school 5500
+286 5501
+酗 5502
+unit 5503
+肄 5504
+躏 5505
+膑 5506
+288 5507
+2g 5508
+嗡 5509
+273 5510
+iv 5511
+cam 5512
+510 5513
+庠 5514
+崽 5515
+254 5516
+搪 5517
+pcr 5518
+胯 5519
+309 5520
+铉 5521
+峤 5522
+郯 5523
+藐 5524
+舂 5525
+come 5526
+蓼 5527
+some 5528
+薏 5529
+窿 5530
+羣 5531
+氽 5532
+徕 5533
+冼 5534
+rs 5535
+阂 5536
+欤 5537
+殒 5538
+窈 5539
+脘 5540
+780 5541
+篝 5542
+yang 5543
+1861 5544
+3300 5545
+iso9000 5546
+麸 5547
+砭 5548
+max 5549
+砰 5550
+骶 5551
+豺 5552
+lg 5553
+窠 5554
+獒 5555
+think 5556
+腴 5557
+苕 5558
+any 5559
+its 5560
+缇 5561
+骅 5562
+劭 5563
+college 5564
+卅 5565
+ups 5566
+揆 5567
+垅 5568
+na 5569
+6cm 5570
+琏 5571
+镗 5572
+苜 5573
+胛 5574
+1881 5575
+black 5576
+珏 5577
+吮 5578
+抠 5579
+搔 5580
+276 5581
+rock 5582
+251 5583
+槎 5584
+4200 5585
+323 5586
+掣 5587
+pet 5588
+1887 5589
+ap 5590
+琨 5591
+餮 5592
+375 5593
+舛 5594
+give 5595
+si 5596
+痤 5597
+us 5598
+311 5599
+278 5600
+埭 5601
+english 5602
+peter 5603
+1891 5604
+820 5605
+胪 5606
+喹 5607
+妲 5608
+婀 5609
+帙 5610
+10g 5611
+oa 5612
+7500 5613
+箩 5614
+灏 5615
+霎 5616
+logo 5617
+袄 5618
+dsp 5619
+bl 5620
+镭 5621
+蓿 5622
+power 5623
+long 5624
+墉 5625
+too 5626
+嵊 5627
+1862 5628
+girl 5629
+堇 5630
+king 5631
+蟋 5632
+610 5633
+叽 5634
+249 5635
+钎 5636
+30cm 5637
+fm 5638
+録 5639
+group 5640
+1883 5641
+郓 5642
+瘴 5643
+vol 5644
+丶 5645
+呦 5646
+邬 5647
+頫 5648
+272 5649
+馁 5650
+hiv 5651
+鄢 5652
+257 5653
+1876 5654
+ordm 5655
+蛭 5656
+322 5657
+愍 5658
+锲 5659
+槿 5660
+珈 5661
+best 5662
+4800 5663
+mri 5664
+1080 5665
+fda 5666
+10mm 5667
+261 5668
+nt 5669
+660 5670
+super 5671
+1m 5672
+center 5673
+ui 5674
+335 5675
+蜃 5676
+298 5677
+拎 5678
+鎏 5679
+裟 5680
+沏 5681
+np 5682
+螭 5683
+7mm 5684
+觑 5685
+墒 5686
+捺 5687
+轸 5688
+micro 5689
+榫 5690
+based 5691
+319 5692
+怔 5693
+ram 5694
+618 5695
+昀 5696
+even 5697
+泷 5698
+1864 5699
+ca 5700
+凫 5701
+唠 5702
+狰 5703
+鲛 5704
+氐 5705
+呛 5706
+绀 5707
+碛 5708
+茏 5709
+盅 5710
+蟀 5711
+洙 5712
+off 5713
+訇 5714
+蠹 5715
+auml 5716
+dos 5717
+20cm 5718
+267 5719
+棂 5720
+18000 5721
+蚴 5722
+篾 5723
+two 5724
+靛 5725
+暄 5726
+show 5727
+1868 5728
+泞 5729
+cdma 5730
+mark 5731
+vc 5732
+洄 5733
+赓 5734
+麽 5735
+25000 5736
+篓 5737
+孑 5738
+860 5739
+烩 5740
+980 5741
+design 5742
+颢 5743
+钣 5744
+var 5745
+髂 5746
+蹴 5747
+wanna 5748
+筮 5749
+蝌 5750
+醮 5751
+home 5752
+菖 5753
+fun 5754
+cmos 5755
+獗 5756
+friends 5757
+business 5758
+岘 5759
+570 5760
+鼐 5761
+1865 5762
+姣 5763
+national 5764
+1874 5765
+蟑 5766
+袈 5767
+葶 5768
+掬 5769
+most 5770
+vga 5771
+emba 5772
+躇 5773
+30g 5774
+鹌 5775
+city 5776
+踌 5777
+282 5778
+钹 5779
+蚪 5780
+颧 5781
+001 5782
+13000 5783
+鹳 5784
+274 5785
+km 5786
+345 5787
+1050 5788
+stop 5789
+328 5790
+then 5791
+鲲 5792
+驷 5793
+潴 5794
+295 5795
+386 5796
+焱 5797
+稔 5798
+悌 5799
+mpeg 5800
+st 5801
+suv 5802
+vista 5803
+a1 5804
+vi 5805
+283 5806
+help 5807
+basic 5808
+唏 5809
+11000 5810
+苒 5811
+蹙 5812
+house 5813
+heart 5814
+ouml 5815
+281 5816
+氩 5817
+bug 5818
+mobile 5819
+宓 5820
+service 5821
+dll 5822
+綦 5823
+苎 5824
+application 5825
+疃 5826
+methyl 5827
+攫 5828
+rfid 5829
+100g 5830
+287 5831
+掾 5832
+1871 5833
+徭 5834
+490 5835
+舀 5836
+逶 5837
+嗤 5838
+760 5839
+0m 5840
+ge 5841
+1872 5842
+people 5843
+hr 5844
+蜷 5845
+茔 5846
+512 5847
+疳 5848
+迳 5849
+罄 5850
+瓠 5851
+100mg 5852
+讪 5853
+psp 5854
+av 5855
+傈 5856
+ppp 5857
+杲 5858
+灞 5859
+氲 5860
+鬲 5861
+獠 5862
+柒 5863
+骧 5864
+1848 5865
+away 5866
+william 5867
+326 5868
+搀 5869
+珩 5870
+绦 5871
+1879 5872
+嚏 5873
+710 5874
+镛 5875
+喱 5876
+倏 5877
+馋 5878
+茭 5879
+擘 5880
+斫 5881
+284 5882
+1mg 5883
+怂 5884
+hdmi 5885
+唧 5886
+犍 5887
+谩 5888
+赊 5889
+317 5890
+271 5891
+wu 5892
+鬻 5893
+禛 5894
+15cm 5895
+259 5896
+840 5897
+feel 5898
+485 5899
+圻 5900
+10m 5901
+蹶 5902
+5kg 5903
+1877 5904
+1873 5905
+缄 5906
+瘿 5907
+黠 5908
+甑 5909
+矸 5910
+嘀 5911
+il 5912
+蹼 5913
+jack 5914
+lee 5915
+269 5916
+叼 5917
+di 5918
+313 5919
+旻 5920
+auc 5921
+502 5922
+1350 5923
+鹜 5924
+289 5925
+fc 5926
+稗 5927
+336 5928
+999 5929
+association 5930
+many 5931
+293 5932
+雒 5933
+george 5934
+td 5935
+赉 5936
+style 5937
+馔 5938
+颦 5939
+ul 5940
+ld50 5941
+1867 5942
+颔 5943
+掇 5944
+1863 5945
+each 5946
+赅 5947
+桎 5948
+inc 5949
+痧 5950
+dv 5951
+谄 5952
+孛 5953
+笆 5954
+鲶 5955
+铳 5956
+3100 5957
+mc 5958
+tell 5959
+4m 5960
+blue 5961
+327 5962
+299 5963
+bios 5964
+龋 5965
+385 5966
+盱 5967
+笏 5968
+2030 5969
+窕 5970
+苴 5971
+314 5972
+big 5973
+1866 5974
+296 5975
+萋 5976
+355 5977
+辘 5978
+琬 5979
+cu 5980
+梏 5981
+much 5982
+蚧 5983
+3400 5984
+1280 5985
+镳 5986
+24h 5987
+own 5988
+670 5989
+studio 5990
+瞅 5991
+keep 5992
+6g 5993
+ppt 5994
+conference 5995
+around 5996
+information 5997
+睬 5998
+1878 5999
+class 6000
+偌 6001
+鲵 6002
+惦 6003
+1830 6004
+蜍 6005
+mp4 6006
+why 6007
+靼 6008
+1851 6009
+332 6010
+阗 6011
+菟 6012
+黝 6013
+1650 6014
+control 6015
+挈 6016
+嵴 6017
+剡 6018
+358 6019
+楸 6020
+dha 6021
+氤 6022
+m1 6023
+vr 6024
+呎 6025
+珲 6026
+5ml 6027
+馄 6028
+滂 6029
+338 6030
+蹉 6031
+蓑 6032
+锷 6033
+297 6034
+279 6035
+啜 6036
+1644 6037
+sm 6038
+婵 6039
+well 6040
+鬣 6041
+7cm 6042
+钿 6043
+bbs 6044
+晌 6045
+蛆 6046
+隗 6047
+酞 6048
+枞 6049
+352 6050
+work 6051
+always 6052
+9g 6053
+戬 6054
+獾 6055
+镕 6056
+star 6057
+easy 6058
+饨 6059
+娣 6060
+缰 6061
+邾 6062
+334 6063
+8m 6064
+ni 6065
+鹗 6066
+277 6067
+425 6068
+end 6069
+had 6070
+嗒 6071
+苋 6072
+薮 6073
+棹 6074
+type 6075
+richard 6076
+880 6077
+6m 6078
+拄 6079
+air 6080
+埕 6081
+勖 6082
+鹞 6083
+殚 6084
+鲢 6085
+pop 6086
+a4 6087
+1750 6088
+ftp 6089
+16000 6090
+啖 6091
+ad 6092
+沣 6093
+501 6094
+靥 6095
+葭 6096
+诿 6097
+htc 6098
+鸪 6099
+007 6100
+饴 6101
+t1 6102
+疖 6103
+抟 6104
+睽 6105
+770 6106
+access 6107
+tcl 6108
+稞 6109
+吋 6110
+谀 6111
+澍 6112
+杈 6113
+妤 6114
+sata 6115
+part 6116
+峄 6117
+systems 6118
+漉 6119
+40000 6120
+ever 6121
+気 6122
+368 6123
+咲 6124
+qs 6125
+ta 6126
+璘 6127
+ltd 6128
+mol 6129
+media 6130
+萜 6131
+僭 6132
+朐 6133
+742 6134
+1855 6135
+cc 6136
+圜 6137
+癞 6138
+藿 6139
+555 6140
+珉 6141
+isp 6142
+set 6143
+1450 6144
+陉 6145
+him 6146
+僮 6147
+292 6148
+膻 6149
+1853 6150
+薹 6151
+810 6152
+汊 6153
+still 6154
+锗 6155
+昉 6156
+pvp 6157
+猗 6158
+http 6159
+1859 6160
+3700 6161
+strong 6162
+3a 6163
+锶 6164
+real 6165
+跛 6166
+art 6167
+1869 6168
+331 6169
+1368 6170
+嘹 6171
+337 6172
+瓤 6173
+402 6174
+衄 6175
+1856 6176
+1820 6177
+1150 6178
+matlab 6179
+豕 6180
+吆 6181
+腆 6182
+thomas 6183
+a2 6184
+294 6185
+le 6186
+366 6187
+using 6188
+356 6189
+bb 6190
+喆 6191
+smith 6192
+different 6193
+莴 6194
+401 6195
+谌 6196
+ci 6197
+珙 6198
+疥 6199
+kw 6200
+鲑 6201
+405 6202
+玷 6203
+蛔 6204
+砀 6205
+361 6206
+zh 6207
+nasa 6208
+materials 6209
+329 6210
+nature 6211
+1h 6212
+谔 6213
+睥 6214
+ch 6215
+20mg 6216
+2mg 6217
+du 6218
+mail 6219
+data 6220
+every 6221
+蹑 6222
+诒 6223
+逋 6224
+372 6225
+while 6226
+姝 6227
+刈 6228
+婧 6229
+going 6230
+喳 6231
+镞 6232
+铌 6233
+291 6234
+712 6235
+辎 6236
+鹧 6237
+檩 6238
+740 6239
+扪 6240
+10ml 6241
+霰 6242
+ar 6243
+裆 6244
+ol 6245
+嬷 6246
+0mm 6247
+ufo 6248
+charles 6249
+20mm 6250
+tvb 6251
+apple 6252
+刎 6253
+iec 6254
+project 6255
+sbs 6256
+嵋 6257
+342 6258
+690 6259
+悱 6260
+920 6261
+嘤 6262
+jean 6263
+篁 6264
+荸 6265
+瞑 6266
+殓 6267
+搽 6268
+50mg 6269
+343 6270
+橇 6271
+include 6272
+eva 6273
+雎 6274
+弭 6275
+獐 6276
+haccp 6277
+恿 6278
+video 6279
+cf 6280
+vpn 6281
+society 6282
+眦 6283
+730 6284
+铐 6285
+song 6286
+尕 6287
+捎 6288
+诟 6289
+institute 6290
+痨 6291
+cn 6292
+369 6293
+笞 6294
+756 6295
+version 6296
+des 6297
+sns 6298
+趺 6299
+590 6300
+award 6301
+唬 6302
+苣 6303
+css 6304
+lte 6305
+xu 6306
+fbi 6307
+啾 6308
+瘪 6309
+垸 6310
+357 6311
+橹 6312
+after 6313
+濛 6314
+曷 6315
+level 6316
+樾 6317
+very 6318
+汨 6319
+仟 6320
+姒 6321
+1858 6322
+again 6323
+怦 6324
+荏 6325
+tom 6326
+诤 6327
+苡 6328
+吭 6329
+830 6330
+dm 6331
+before 6332
+406 6333
+崆 6334
+氡 6335
+young 6336
+脩 6337
+lan 6338
+胝 6339
+钏 6340
+3ds 6341
+cr 6342
+arm 6343
+pos 6344
+night 6345
+屐 6346
+395 6347
+忐 6348
+彧 6349
+拚 6350
+鏖 6351
+344 6352
+100ml 6353
+525 6354
+孳 6355
+1024 6356
+yu 6357
+忑 6358
+384 6359
+邝 6360
+穰 6361
+403 6362
+摈 6363
+庖 6364
+351 6365
+鸵 6366
+398 6367
+hello 6368
+矽 6369
+354 6370
+鲟 6371
+said 6372
+381 6373
+768 6374
+発 6375
+762 6376
+sap 6377
+1854 6378
+msn 6379
+菅 6380
+book 6381
+353 6382
+true 6383
+339 6384
+javascript 6385
+348 6386
+2900 6387
+圪 6388
+蹋 6389
+衾 6390
+簋 6391
+璎 6392
+367 6393
+噎 6394
+911 6395
+嬗 6396
+346 6397
+肼 6398
+362 6399
+359 6400
+跎 6401
+滟 6402
+little 6403
+4300 6404
+701 6405
+戦 6406
+嵬 6407
+look 6408
+仝 6409
+phys 6410
+club 6411
+惇 6412
+纾 6413
+times 6414
+14000 6415
+炁 6416
+382 6417
+xyz 6418
+number 6419
+ak 6420
+mind 6421
+huang 6422
+闳 6423
+骐 6424
+秣 6425
+眙 6426
+谘 6427
+碓 6428
+iso9002 6429
+疔 6430
+412 6431
+恂 6432
+am 6433
+top 6434
+master 6435
+鳕 6436
+green 6437
+鸱 6438
+int 6439
+爨 6440
+镊 6441
+404 6442
+were 6443
+4600 6444
+em 6445
+better 6446
+钯 6447
+圮 6448
+楽 6449
+堀 6450
+1852 6451
+408 6452
+sat 6453
+1857 6454
+378 6455
+422 6456
+膘 6457
+705 6458
+噗 6459
+347 6460
+start 6461
+486 6462
+锹 6463
+505 6464
+杼 6465
+酊 6466
+same 6467
+376 6468
+white 6469
+挎 6470
+箸 6471
+郗 6472
+垌 6473
+sa 6474
+溏 6475
+martin 6476
+蔫 6477
+偻 6478
+364 6479
+妫 6480
+飚 6481
+625 6482
+601 6483
+辔 6484
+濬 6485
+666 6486
+ds 6487
+瑄 6488
+621 6489
+觚 6490
+5600 6491
+nhk 6492
+415 6493
+express 6494
+铍 6495
+bit 6496
+跚 6497
+9mm 6498
+翕 6499
+煊 6500
+these 6501
+50mm 6502
+gpu 6503
+b6 6504
+hip 6505
+耄 6506
+铋 6507
+篦 6508
+zhou 6509
+阇 6510
+骛 6511
+nvidia 6512
+莪 6513
+吲 6514
+youtube 6515
+唁 6516
+870 6517
+箧 6518
+503 6519
+tm 6520
+8500 6521
+really 6522
+珅 6523
+潋 6524
+迨 6525
+哽 6526
+without 6527
+砦 6528
+model 6529
+缗 6530
+hey 6531
+謇 6532
+呸 6533
+mrna 6534
+垓 6535
+糍 6536
+park 6537
+wap 6538
+璠 6539
+妣 6540
+狎 6541
+攥 6542
+396 6543
+闇 6544
+york 6545
+蛉 6546
+瑁 6547
+joe 6548
+腼 6549
+蹒 6550
+great 6551
+review 6552
+200mg 6553
+chris 6554
+www 6555
+嶷 6556
+online 6557
+莠 6558
+沤 6559
+哚 6560
+475 6561
+遑 6562
+v1 6563
+such 6564
+跺 6565
+膦 6566
+蹿 6567
+unix 6568
+hard 6569
+40cm 6570
+50cm 6571
+nothing 6572
+郫 6573
+zhao 6574
+玳 6575
+ma 6576
+boy 6577
+埚 6578
+url 6579
+432 6580
+network 6581
+aaaa 6582
+衿 6583
+371 6584
+try 6585
+醪 6586
+full 6587
+挹 6588
+raid 6589
+bg 6590
+绡 6591
+汜 6592
+digital 6593
+mb 6594
+c1 6595
+坩 6596
+ccc 6597
+旃 6598
+5200 6599
+607 6600
+itunes 6601
+powerpoint 6602
+鸨 6603
+between 6604
+407 6605
+翈 6606
+1842 6607
+1844 6608
+435 6609
+838 6610
+抡 6611
+chemistry 6612
+team 6613
+party 6614
+die 6615
+晞 6616
+place 6617
+care 6618
+盥 6619
+藁 6620
+蓖 6621
+383 6622
+cv 6623
+臊 6624
+made 6625
+state 6626
+465 6627
+羰 6628
+388 6629
+1620 6630
+sas 6631
+楝 6632
+噱 6633
+ji 6634
+饽 6635
+苌 6636
+soho 6637
+褓 6638
+佶 6639
+mp 6640
+581 6641
+years 6642
+1260 6643
+1680 6644
+hop 6645
+稜 6646
+瞠 6647
+仡 6648
+25mm 6649
+605 6650
+423 6651
+341 6652
+363 6653
+374 6654
+627 6655
+text 6656
+development 6657
+518 6658
+伉 6659
+襁 6660
+ug 6661
+change 6662
+713 6663
+涞 6664
+1849 6665
+蜇 6666
+抿 6667
+瑗 6668
+pda 6669
+418 6670
+un 6671
+line 6672
+958 6673
+孱 6674
+懑 6675
+416 6676
+von 6677
+373 6678
+淦 6679
+赝 6680
+core 6681
+dns 6682
+747 6683
+427 6684
+387 6685
+would 6686
+ipo 6687
+醌 6688
+551 6689
+缫 6690
+蠲 6691
+alt 6692
+嚓 6693
+鲷 6694
+湫 6695
+捋 6696
+1845 6697
+咩 6698
+裏 6699
+avi 6700
+犒 6701
+2050 6702
+墀 6703
+yeah 6704
+god 6705
+445 6706
+lesson 6707
+硐 6708
+蔸 6709
+399 6710
+758 6711
+pu 6712
+computer 6713
+456 6714
+钽 6715
+1847 6716
+麂 6717
+brown 6718
+store 6719
+蒡 6720
+鼹 6721
+绻 6722
+1821 6723
+錾 6724
+仃 6725
+515 6726
+篙 6727
+蕤 6728
+589 6729
+applied 6730
+737 6731
+930 6732
+c3 6733
+1841 6734
+铤 6735
+billboard 6736
+apec 6737
+槁 6738
+牖 6739
+螈 6740
+mary 6741
+俦 6742
+family 6743
+笄 6744
+color 6745
+啻 6746
+対 6747
+jsp 6748
+郤 6749
+next 6750
+iq 6751
+645 6752
+506 6753
+hbv 6754
+闼 6755
+a3 6756
+349 6757
+value 6758
+413 6759
+igg 6760
+411 6761
+426 6762
+醺 6763
+赍 6764
+檗 6765
+usa 6766
+裾 6767
+head 6768
+噫 6769
+掸 6770
+mike 6771
+箓 6772
+usb2 6773
+things 6774
+5800 6775
+5v 6776
+o2 6777
+妪 6778
+乂 6779
+蝈 6780
+砻 6781
+胍 6782
+220v 6783
+392 6784
+cba 6785
+397 6786
+535 6787
+idc 6788
+analysis 6789
+25mg 6790
+蜱 6791
+ti 6792
+2h 6793
+聃 6794
+雠 6795
+碚 6796
+椤 6797
+缯 6798
+昴 6799
+890 6800
+缱 6801
+祎 6802
+der 6803
+缬 6804
+ex 6805
+508 6806
+铙 6807
+cnc 6808
+pentium 6809
+孀 6810
+533 6811
+advanced 6812
+mpa 6813
+yl 6814
+笳 6815
+蘇 6816
+愆 6817
+685 6818
+榉 6819
+old 6820
+氙 6821
+call 6822
+alex 6823
+燹 6824
+撂 6825
+菽 6826
+583 6827
+箬 6828
+蛄 6829
+瘸 6830
+嬛 6831
+495 6832
+橐 6833
+could 6834
+60000 6835
+something 6836
+纡 6837
+刽 6838
+辂 6839
+hong 6840
+377 6841
+law 6842
+蒯 6843
+邨 6844
+1846 6845
+1550 6846
+r2 6847
+1837 6848
+赀 6849
+player 6850
+414 6851
+跸 6852
+phone 6853
+邙 6854
+hold 6855
+rgb 6856
+421 6857
+henry 6858
+2025 6859
+黟 6860
+409 6861
+磴 6862
+1815 6863
+mode 6864
+1843 6865
+闿 6866
+504 6867
+letters 6868
+1780 6869
+428 6870
+垟 6871
+389 6872
+t2 6873
+london 6874
+528 6875
+jpeg 6876
+嵯 6877
+钚 6878
+steve 6879
+跄 6880
+30min 6881
+527 6882
+潸 6883
+h2 6884
+35000 6885
+崴 6886
+eric 6887
+379 6888
+run 6889
+three 6890
+rf 6891
+left 6892
+455 6893
+恁 6894
+open 6895
+楮 6896
+556 6897
+bc 6898
+476 6899
+腧 6900
+458 6901
+plus 6902
+1812 6903
+1839 6904
+胨 6905
+b12 6906
+4d 6907
+芫 6908
+america 6909
+est 6910
+dream 6911
+碴 6912
+隰 6913
+杓 6914
+md 6915
+ya 6916
+global 6917
+436 6918
+15mm 6919
+2ml 6920
+貉 6921
+欹 6922
+sup3 6923
+侑 6924
+ea 6925
+鳜 6926
+910 6927
+ben 6928
+铄 6929
+椴 6930
+昇 6931
+醍 6932
+1020 6933
+798 6934
+midi 6935
+肓 6936
+features 6937
+lc 6938
+brian 6939
+akb48 6940
+缂 6941
+1835 6942
+test 6943
+铡 6944
+light 6945
+978 6946
+s1 6947
+1799 6948
+key 6949
+sim 6950
+1795 6951
+simple 6952
+energy 6953
+蹠 6954
+徂 6955
+west 6956
+725 6957
+body 6958
+豢 6959
+424 6960
+face 6961
+蒽 6962
+lin 6963
+805 6964
+1120 6965
+479 6966
+菡 6967
+bill 6968
+433 6969
+衲 6970
+阚 6971
+believe 6972
+brt 6973
+pa 6974
+last 6975
+芗 6976
+hu 6977
+sam 6978
+wei 6979
+adsl 6980
+602 6981
+mk 6982
+痍 6983
+玠 6984
+1832 6985
+523 6986
+晷 6987
+604 6988
+jj 6989
+468 6990
+淝 6991
+1560 6992
+鄯 6993
+ck 6994
+473 6995
+糗 6996
+耨 6997
+榧 6998
+394 6999
+940 7000
+eq 7001
+498 7002
+used 7003
+sc 7004
+胴 7005
+c2 7006
+蕈 7007
+screen 7008
+镬 7009
+635 7010
+鼾 7011
+431 7012
+education 7013
+wwe 7014
+摭 7015
+鸮 7016
+cl 7017
+5400 7018
+fpga 7019
+恚 7020
+419 7021
+実 7022
+asia 7023
+534 7024
+552 7025
+砝 7026
+100mm 7027
+pid 7028
+741 7029
+珣 7030
+under 7031
+603 7032
+寤 7033
+埙 7034
+mbc 7035
+tc 7036
+xxx 7037
+didn 7038
+478 7039
+mn 7040
+p1 7041
+锏 7042
+simon 7043
+ansi 7044
+438 7045
+hi 7046
+615 7047
+喟 7048
+蘅 7049
+骺 7050
+cell 7051
+捭 7052
+study 7053
+586 7054
+393 7055
+莜 7056
+should 7057
+xi 7058
+缶 7059
+f2 7060
+games 7061
+0g 7062
+1760 7063
+mini 7064
+johnson 7065
+jones 7066
+yes 7067
+锟 7068
+1825 7069
+叵 7070
+cm3 7071
+炷 7072
+1580 7073
+stay 7074
+675 7075
+another 7076
+6800 7077
+鲧 7078
+1736 7079
+ps2 7080
+胼 7081
+517 7082
+査 7083
+岬 7084
+2019 7085
+1640 7086
+rose 7087
+鹂 7088
+牯 7089
+珥 7090
+entertainment 7091
+448 7092
+und 7093
+496 7094
+莼 7095
+software 7096
+970 7097
+邠 7098
+5300 7099
+h1n1 7100
+488 7101
+da 7102
+眇 7103
+卟 7104
+変 7105
+20m 7106
+may 7107
+417 7108
+lady 7109
+galaxy 7110
+4100 7111
+惴 7112
+1789 7113
+846 7114
+801 7115
+渑 7116
+907 7117
+put 7118
+蚱 7119
+gone 7120
+606 7121
+t3 7122
+company 7123
+632 7124
+454 7125
+516 7126
+998 7127
+548 7128
+391 7129
+4700 7130
+瞌 7131
+ide 7132
+瘰 7133
+7200 7134
+佝 7135
+together 7136
+street 7137
+旸 7138
+626 7139
+衽 7140
+郅 7141
+奁 7142
+731 7143
+30mg 7144
+mvp 7145
+1370 7146
+60cm 7147
+12cm 7148
+魑 7149
+1828 7150
+628 7151
+everything 7152
+612 7153
+san 7154
+937 7155
+缛 7156
+2gb 7157
+lu 7158
+angel 7159
+20ml 7160
+576 7161
+颙 7162
+sony 7163
+790 7164
+press 7165
+镫 7166
+hall 7167
+簌 7168
+beautiful 7169
+豇 7170
+711 7171
+453 7172
+pm 7173
+姹 7174
+thing 7175
+442 7176
+邋 7177
+alpha 7178
+leave 7179
+暝 7180
+441 7181
+30mm 7182
+chapter 7183
+507 7184
+100000 7185
+526 7186
+directx 7187
+511 7188
+9cm 7189
+words 7190
+釐 7191
+619 7192
+洹 7193
+444 7194
+frank 7195
+咿 7196
+eyes 7197
+483 7198
+俳 7199
+522 7200
+蜊 7201
+醐 7202
+541 7203
+water 7204
+499 7205
+聩 7206
+non 7207
+bob 7208
+坻 7209
+532 7210
+757 7211
+545 7212
+毽 7213
+oo 7214
+喾 7215
+alone 7216
+scott 7217
+744 7218
+辋 7219
+river 7220
+zhu 7221
+倌 7222
+媪 7223
+蛳 7224
+滹 7225
+哙 7226
+nc 7227
+20g 7228
+阊 7229
+gs 7230
+queen 7231
+趸 7232
+1130 7233
+1645 7234
+祢 7235
+4mg 7236
+1814 7237
+girls 7238
+544 7239
+e1 7240
+籀 7241
+1210 7242
+1573 7243
+徼 7244
+ipv6 7245
+訾 7246
+髁 7247
+1a 7248
+jackson 7249
+砜 7250
+1836 7251
+les 7252
+4gb 7253
+撸 7254
+瓘 7255
+1790 7256
+缁 7257
+镓 7258
+sars 7259
+eps 7260
+519 7261
+sod 7262
+bp 7263
+1810 7264
+year 7265
+縻 7266
+sound 7267
+617 7268
+菀 7269
+1125 7270
+598 7271
+酢 7272
+桠 7273
+466 7274
+emc 7275
+撵 7276
+怏 7277
+429 7278
+1838 7279
+ready 7280
+渌 7281
+546 7282
+taylor 7283
+452 7284
+news 7285
+1180 7286
+568 7287
+2a 7288
+af 7289
+538 7290
+list 7291
+hot 7292
+1380 7293
+etc 7294
+1796 7295
+摞 7296
+mo 7297
+槲 7298
+levels 7299
+ht 7300
+浠 7301
+诜 7302
+魉 7303
+韫 7304
+daniel 7305
+亓 7306
+盤 7307
+pv 7308
+瑭 7309
+魍 7310
+1831 7311
+emi 7312
+襞 7313
+social 7314
+dreamweaver 7315
+爿 7316
+kbs 7317
+565 7318
+613 7319
+990 7320
+浃 7321
+樯 7322
+jb 7323
+讵 7324
+揩 7325
+physics 7326
+耋 7327
+帏 7328
+lng 7329
+崃 7330
+bs 7331
+457 7332
+enough 7333
+shy 7334
+521 7335
+596 7336
+ec 7337
+451 7338
+鸩 7339
+遢 7340
+turn 7341
+臃 7342
+available 7343
+4400 7344
+585 7345
+粿 7346
+1010 7347
+禳 7348
+hand 7349
+439 7350
+536 7351
+桫 7352
+link 7353
+side 7354
+earth 7355
+mx 7356
+髹 7357
+7m 7358
+482 7359
+诳 7360
+472 7361
+1140 7362
+707 7363
+622 7364
+wcdma 7365
+513 7366
+must 7367
+492 7368
+462 7369
+踉 7370
+40mg 7371
+948 7372
+cmax 7373
+郃 7374
+1320 7375
+v2 7376
+542 7377
+email 7378
+493 7379
+嗖 7380
+sup 7381
+讧 7382
+cnn 7383
+446 7384
+碁 7385
+17000 7386
+湎 7387
+30m 7388
+529 7389
+653 7390
+531 7391
+575 7392
+阏 7393
+sr 7394
+united 7395
+pm2 7396
+mt 7397
+媾 7398
+443 7399
+様 7400
+aac 7401
+806 7402
+哔 7403
+舸 7404
+vb 7405
+611 7406
+曩 7407
+821 7408
+gre 7409
+gl 7410
+cisco 7411
+忝 7412
+峁 7413
+掂 7414
+464 7415
+葳 7416
+487 7417
+437 7418
+including 7419
+715 7420
+鄄 7421
+558 7422
+both 7423
+谵 7424
+463 7425
+jim 7426
+608 7427
+m4 7428
+5100 7429
+彊 7430
+锴 7431
+war 7432
+郜 7433
+money 7434
+481 7435
+葖 7436
+1824 7437
+tnt 7438
+蓇 7439
+瓴 7440
+鳟 7441
+橼 7442
+5s 7443
+louis 7444
+434 7445
+鲇 7446
+邗 7447
+el 7448
+犄 7449
+秭 7450
+3900 7451
+records 7452
+view 7453
+chemical 7454
+1001 7455
+1mol 7456
+dance 7457
+668 7458
+dl 7459
+槭 7460
+缵 7461
+que 7462
+624 7463
+rt 7464
+1823 7465
+1805 7466
+005 7467
+1826 7468
+巯 7469
+sgs 7470
+user 7471
+龊 7472
+qc 7473
+狍 7474
+island 7475
+language 7476
+space 7477
+擞 7478
+saint 7479
+2n 7480
+pt 7481
+share 7482
+瞽 7483
+hotel 7484
+christian 7485
+557 7486
+栲 7487
+撅 7488
+2b 7489
+1801 7490
+447 7491
+1822 7492
+瑀 7493
+smt 7494
+hk 7495
+1834 7496
+戢 7497
+825 7498
+50ml 7499
+朓 7500
+逖 7501
+general 7502
+椹 7503
+nm 7504
+洺 7505
+cae 7506
+484 7507
+艏 7508
+wma 7509
+zn 7510
+苁 7511
+single 7512
+599 7513
+c4 7514
+滘 7515
+777 7516
+铧 7517
+侪 7518
+ocirc 7519
+1kg 7520
+684 7521
+豳 7522
+skf 7523
+12mm 7524
+489 7525
+hla 7526
+竦 7527
+貔 7528
+ld 7529
+being 7530
+562 7531
+圄 7532
+van 7533
+gm 7534
+688 7535
+655 7536
+special 7537
+呷 7538
+edition 7539
+1s 7540
+jiang 7541
+131108 7542
+514 7543
+1792 7544
+ncaa 7545
+1833 7546
+旄 7547
+遛 7548
+jr 7549
+program 7550
+656 7551
+467 7552
+ing 7553
+901 7554
+755 7555
+509 7556
+芈 7557
+kong 7558
+rp 7559
+砣 7560
+桷 7561
+audio 7562
+icp 7563
+happy 7564
+龌 7565
+done 7566
+疬 7567
+japan 7568
+ts 7569
+mit 7570
+p2 7571
+524 7572
+looking 7573
+miss 7574
+缟 7575
+582 7576
+洌 7577
+35mm 7578
+494 7579
+grand 7580
+跏 7581
+those 7582
+joseph 7583
+ctrl 7584
+547 7585
+1040 7586
+686 7587
+蝮 7588
+lp 7589
+cod 7590
+菰 7591
+sio2 7592
+txt 7593
+1770 7594
+1060 7595
+帑 7596
+767 7597
+north 7598
+fcc 7599
+怙 7600
+ester 7601
+718 7602
+story 7603
+edi 7604
+634 7605
+1360 7606
+豸 7607
+1660 7608
+lh 7609
+雩 7610
+1230 7611
+magic 7612
+誊 7613
+549 7614
+臬 7615
+4k 7616
+op 7617
+1662 7618
+651 7619
+镣 7620
+箇 7621
+616 7622
+title 7623
+sciences 7624
+25cm 7625
+踱 7626
+s2 7627
+t4 7628
+钍 7629
+648 7630
+100m 7631
+543 7632
+588 7633
+苫 7634
+554 7635
+蝽 7636
+r1 7637
+3mg 7638
+amino 7639
+1776 7640
+浯 7641
+609 7642
+772 7643
+ca2 7644
+vlan 7645
+469 7646
+500mg 7647
+単 7648
+road 7649
+亶 7650
+636 7651
+metal 7652
+device 7653
+40mm 7654
+囹 7655
+穑 7656
+1730 7657
+佻 7658
+1818 7659
+绌 7660
+12g 7661
+537 7662
+诔 7663
+pve 7664
+autodesk 7665
+477 7666
+v8 7667
+ray 7668
+gp 7669
+span 7670
+gc 7671
+size 7672
+716 7673
+鹬 7674
+ssl 7675
+crt 7676
+1670 7677
+925 7678
+髌 7679
+pn 7680
+1127 7681
+702 7682
+658 7683
+services 7684
+support 7685
+1802 7686
+蒌 7687
+coming 7688
+experience 7689
+nbc 7690
+鳏 7691
+631 7692
+638 7693
+ace 7694
+0cm 7695
+ems 7696
+9001 7697
+殄 7698
+yen 7699
+soc 7700
+ethyl 7701
+怛 7702
+tf 7703
+筌 7704
+刳 7705
+studies 7706
+theory 7707
+1030 7708
+578 7709
+radio 7710
+翮 7711
+卍 7712
+畹 7713
+471 7714
+704 7715
+because 7716
+1610 7717
+箜 7718
+save 7719
+燔 7720
+赳 7721
+553 7722
+1809 7723
+篌 7724
+窨 7725
+翥 7726
+785 7727
+炅 7728
+钕 7729
+lett 7730
+803 7731
+1827 7732
+academy 7733
+ed 7734
+629 7735
+sf 7736
+pr 7737
+hill 7738
+explorer 7739
+future 7740
+food 7741
+莳 7742
+662 7743
+567 7744
+dcs 7745
+忖 7746
+戡 7747
+1086 7748
+1190 7749
+1829 7750
+bad 7751
+es 7752
+15m 7753
+order 7754
+spring 7755
+沢 7756
+south 7757
+497 7758
+025 7759
+move 7760
+狒 7761
+1630 7762
+圉 7763
+abb 7764
+449 7765
+learn 7766
+l0 7767
+d2 7768
+5d 7769
+wav 7770
+琯 7771
+邰 7772
+cis 7773
+quality 7774
+odm 7775
+926 7776
+acta 7777
+root 7778
+smart 7779
+1661 7780
+苾 7781
+cm2 7782
+photos 7783
+l2 7784
+via 7785
+sk 7786
+犸 7787
+623 7788
+邡 7789
+feeling 7790
+572 7791
+郏 7792
+襦 7793
+python 7794
+bmw 7795
+888 7796
+guo 7797
+epa 7798
+williams 7799
+沆 7800
+813 7801
+bot 7802
+read 7803
+function 7804
+wilson 7805
+1723 7806
+enterprise 7807
+玟 7808
+50hz 7809
+s26 7810
+fire 7811
+engineer 7812
+tony 7813
+1819 7814
+濉 7815
+rh 7816
+洎 7817
+莨 7818
+氘 7819
+pb 7820
+咛 7821
+1720 7822
+佺 7823
+1460 7824
+815 7825
+cbs 7826
+腩 7827
+beta 7828
+鳔 7829
+1735 7830
+yan 7831
+1gb 7832
+x2 7833
+剜 7834
+秕 7835
+牝 7836
+芨 7837
+din 7838
+関 7839
+del 7840
+sms 7841
+649 7842
+pal 7843
+1369 7844
+far 7845
+maya 7846
+654 7847
+拊 7848
+812 7849
+595 7850
+竑 7851
+50m 7852
+圹 7853
+close 7854
+eos 7855
+颡 7856
+1420 7857
+6300 7858
+1816 7859
+wrong 7860
+break 7861
+573 7862
+765 7863
+file 7864
+friend 7865
+002 7866
+摺 7867
+683 7868
+nx 7869
+沩 7870
+蜉 7871
+please 7872
+1170 7873
+ro 7874
+6400 7875
+筚 7876
+nick 7877
+acm 7878
+愔 7879
+ati 7880
+point 7881
+肟 7882
+766 7883
+俶 7884
+fast 7885
+ata 7886
+d1 7887
+678 7888
+geforce 7889
+1710 7890
+yahoo 7891
+堃 7892
+绉 7893
+mysql 7894
+1793 7895
+奭 7896
+gap 7897
+iso14000 7898
+uk 7899
+astm 7900
+h2o 7901
+n2 7902
+film 7903
+method 7904
+1804 7905
+罅 7906
+so2 7907
+嗳 7908
+665 7909
+adam 7910
+uc 7911
+蜢 7912
+1806 7913
+1775 7914
+photo 7915
+疠 7916
+474 7917
+image 7918
+200mm 7919
+sure 7920
+561 7921
+帔 7922
+髡 7923
+643 7924
+黥 7925
+1813 7926
+proceedings 7927
+褛 7928
+柰 7929
+beyond 7930
+royal 7931
+else 7932
+eda 7933
+808 7934
+ddr 7935
+gif 7936
+鏊 7937
+l1 7938
+痼 7939
+571 7940
+waiting 7941
+堞 7942
+code 7943
+652 7944
+rss 7945
+learning 7946
+嗝 7947
+461 7948
+beijing 7949
+娉 7950
+566 7951
+577 7952
+708 7953
+1520 7954
+689 7955
+kevin 7956
+human 7957
+661 7958
+539 7959
+875 7960
+1811 7961
+ssci 7962
+6600 7963
+戕 7964
+587 7965
+735 7966
+3s 7967
+铱 7968
+耜 7969
+觥 7970
+867 7971
+镒 7972
+584 7973
+呓 7974
+1522 7975
+904 7976
+case 7977
+1101 7978
+491 7979
+1080p 7980
+history 7981
+蒹 7982
+栱 7983
+im 7984
+564 7985
+f4 7986
+卮 7987
+琚 7988
+salt 7989
+jason 7990
+rohs 7991
+12v 7992
+hydroxy 7993
+逦 7994
+modem 7995
+font 7996
+酩 7997
+蓍 7998
+cry 7999
+65536 8000
+health 8001
+虺 8002
+1798 8003
+tonight 8004
+small 8005
+谠 8006
+1570 8007
+1220 8008
+jane 8009
+against 8010
+597 8011
+751 8012
+459 8013
+bd 8014
+鼋 8015
+焗 8016
+udp 8017
+process 8018
+1070 8019
+1807 8020
+children 8021
+8g 8022
+eb 8023
+62mm 8024
+22000 8025
+add 8026
+1440 8027
+褴 8028
+rm 8029
+25g 8030
+ccedil 8031
+706 8032
+714 8033
+5l 8034
+砒 8035
+赧 8036
+蛏 8037
+709 8038
+蚬 8039
+1530 8040
+瘕 8041
+5h 8042
+559 8043
+jay 8044
+iga 8045
+020 8046
+fall 8047
+scsi 8048
+顗 8049
+isdn 8050
+death 8051
+563 8052
+today 8053
+愠 8054
+dvi 8055
+勣 8056
+wait 8057
+1642 8058
+飕 8059
+徳 8060
+滢 8061
+琇 8062
+鳙 8063
+db 8064
+瞟 8065
+尻 8066
+force 8067
+400mg 8068
+澶 8069
+荽 8070
+舐 8071
+arts 8072
+ha 8073
+east 8074
+lost 8075
+effects 8076
+1628 8077
+album 8078
+harry 8079
+633 8080
+dark 8081
+public 8082
+2250 8083
+soul 8084
+826 8085
+659 8086
+exo 8087
+侂 8088
+733 8089
+se 8090
+黼 8091
+icu 8092
+4h 8093
+market 8094
+潟 8095
+7800 8096
+绂 8097
+瘗 8098
+ngc 8099
+1794 8100
+crazy 8101
+蓥 8102
+竽 8103
+濞 8104
+igm 8105
+scdma 8106
+6200 8107
+cb 8108
+835 8109
+699 8110
+骖 8111
+偁 8112
+bmp 8113
+809 8114
+1270 8115
+oled 8116
+応 8117
+1160 8118
+1621 8119
+锜 8120
+g3 8121
+ova 8122
+cheng 8123
+614 8124
+匏 8125
+thinkpad 8126
+赑 8127
+fps 8128
+create 8129
+kim 8130
+讦 8131
+1480 8132
+诨 8133
+1540 8134
+rev 8135
+1v1 8136
+罘 8137
+fans 8138
+巖 8139
+1740 8140
+ag 8141
+嫘 8142
+1649 8143
+ps3 8144
+908 8145
+颀 8146
+g1 8147
+703 8148
+岿 8149
+v3 8150
+虻 8151
+936 8152
+fl 8153
+c2c 8154
+罴 8155
+environmental 8156
+paris 8157
+594 8158
+hear 8159
+囗 8160
+jump 8161
+communications 8162
+溆 8163
+talk 8164
+噤 8165
+824 8166
+骝 8167
+003 8168
+咂 8169
+695 8170
+728 8171
+e2 8172
+nec 8173
+iptv 8174
+1797 8175
+kelly 8176
+500ml 8177
+锛 8178
+721 8179
+rc 8180
+1808 8181
+ldl 8182
+1240 8183
+槊 8184
+radeon 8185
+676 8186
+啕 8187
+tang 8188
+plant 8189
+50g 8190
+驽 8191
+professional 8192
+凇 8193
+698 8194
+s36 8195
+lord 8196
+search 8197
+alan 8198
+籴 8199
+pd 8200
+1403 8201
+硖 8202
+1791 8203
+816 8204
+1636 8205
+3h 8206
+gsp 8207
+811 8208
+sky 8209
+1632 8210
+铯 8211
+christmas 8212
+怿 8213
+笥 8214
+matter 8215
+574 8216
+噙 8217
+倨 8218
+effect 8219
+647 8220
+779 8221
+1803 8222
+657 8223
+sorry 8224
+awards 8225
+igbt 8226
+pwm 8227
+坭 8228
+醅 8229
+sos 8230
+976 8231
+592 8232
+滏 8233
+10min 8234
+682 8235
+cs3 8236
+悻 8237
+did 8238
+mater 8239
+579 8240
+聒 8241
+1724 8242
+feng 8243
+low 8244
+mhz 8245
+836 8246
+722 8247
+枥 8248
+726 8249
+昺 8250
+bank 8251
+memory 8252
+rap 8253
+975 8254
+663 8255
+ips 8256
+酆 8257
+2kg 8258
+787 8259
+簟 8260
+睇 8261
+轫 8262
+溱 8263
+骢 8264
+榘 8265
+642 8266
+珺 8267
+跹 8268
+677 8269
+series 8270
+nlp 8271
+raquo 8272
+蚶 8273
+stone 8274
+1672 8275
+1817 8276
+1646 8277
+827 8278
+驺 8279
+ko 8280
+security 8281
+perfect 8282
+alexander 8283
+746 8284
+tt 8285
+check 8286
+804 8287
+饧 8288
+15mg 8289
+sir 8290
+moon 8291
+doesn 8292
+591 8293
+inside 8294
+tim 8295
+672 8296
+641 8297
+噼 8298
+儆 8299
+1w 8300
+氚 8301
+646 8302
+哧 8303
+1783 8304
+旒 8305
+鸬 8306
+1648 8307
+夥 8308
+ev 8309
+1688 8310
+score 8311
+standard 8312
+玦 8313
+723 8314
+貅 8315
+揄 8316
+戗 8317
+fx 8318
+938 8319
+璩 8320
+fu 8321
+1654 8322
+剐 8323
+010 8324
+cpi 8325
+垴 8326
+蘼 8327
+hz 8328
+1521 8329
+1067 8330
+727 8331
+ah 8332
+lv 8333
+916 8334
+裒 8335
+639 8336
+han 8337
+躅 8338
+1715 8339
+唳 8340
+form 8341
+second 8342
+嗑 8343
+荦 8344
+674 8345
+霈 8346
+jin 8347
+缦 8348
+啭 8349
+pi 8350
+1788 8351
+rx 8352
+隈 8353
+gao 8354
+sdk 8355
+zheng 8356
+悫 8357
+745 8358
+href 8359
+593 8360
+ngo 8361
+multi 8362
+d3 8363
+彀 8364
+637 8365
+1276 8366
+悭 8367
+found 8368
+jis 8369
+5700 8370
+焓 8371
+1234 8372
+80cm 8373
+磔 8374
+aim 8375
+1778 8376
+蓊 8377
+act 8378
+569 8379
+xiao 8380
+郾 8381
+717 8382
+786 8383
+return 8384
+5min 8385
+1582 8386
+etf 8387
+1590 8388
+action 8389
+1625 8390
+sarah 8391
+yourself 8392
+枧 8393
+鹚 8394
+10kg 8395
+80000 8396
+検 8397
+775 8398
+818 8399
+stephen 8400
+gui 8401
+屃 8402
+644 8403
+9500 8404
+v6 8405
+馑 8406
+wlan 8407
+hs 8408
+2048 8409
+area 8410
+1616 8411
+andrew 8412
+8226 8413
+6mg 8414
+1567 8415
+1763 8416
+1470 8417
+嗲 8418
+pps 8419
+铟 8420
+rca 8421
+pierre 8422
+687 8423
+null 8424
+manager 8425
+738 8426
+sdh 8427
+828 8428
+薤 8429
+60g 8430
+300mg 8431
+jun 8432
+1685 8433
+favorite 8434
+making 8435
+playing 8436
+summer 8437
+754 8438
+692 8439
+涔 8440
+樗 8441
+664 8442
+忾 8443
+収 8444
+绺 8445
+945 8446
+h2s 8447
+bis 8448
+self 8449
+300mm 8450
+烊 8451
+opengl 8452
+912 8453
+acute 8454
+螫 8455
+黩 8456
+996 8457
+magazine 8458
+edward 8459
+su 8460
+elisa 8461
+hdl 8462
+cyp3a4 8463
+鞫 8464
+foundation 8465
+alice 8466
+ddr3 8467
+915 8468
+923 8469
+tbs 8470
+andy 8471
+field 8472
+date 8473
+transactions 8474
+limited 8475
+during 8476
+1126 8477
+鲠 8478
+1057 8479
+fan 8480
+嘭 8481
+缣 8482
+845 8483
+681 8484
+rw 8485
+mean 8486
+1566 8487
+become 8488
+economic 8489
+852 8490
+johnny 8491
+蒺 8492
+unique 8493
+黒 8494
+tu 8495
+boys 8496
+1330 8497
+885 8498
+getting 8499
+cj 8500
+1072 8501
+nh 8502
+ne 8503
+band 8504
+cool 8505
+724 8506
+771 8507
+骘 8508
+氖 8509
+content 8510
+842 8511
+镝 8512
+俅 8513
+谮 8514
+te 8515
+9600 8516
+drive 8517
+phenyl 8518
+1275 8519
+屦 8520
+cao 8521
+menu 8522
+823 8523
+摁 8524
+氪 8525
+蘧 8526
+active 8527
+sb 8528
+appl 8529
+988 8530
+1622 8531
+伝 8532
+1725 8533
+zero 8534
+1008 8535
+3kg 8536
+腠 8537
+叡 8538
+hit 8539
+鲂 8540
+mi 8541
+0kg 8542
+748 8543
+lite 8544
+enjoy 8545
+local 8546
+789 8547
+続 8548
+1506 8549
+seen 8550
+s3 8551
+1765 8552
+european 8553
+讣 8554
+gold 8555
+1279 8556
+736 8557
+965 8558
+pl 8559
+button 8560
+耷 8561
+1430 8562
+986 8563
+763 8564
+toefl 8565
+燊 8566
+鸷 8567
+jimmy 8568
+dota 8569
+955 8570
+861 8571
+猊 8572
+732 8573
+xbox 8574
+days 8575
+dan 8576
+673 8577
+833 8578
+囡 8579
+崤 8580
+4c 8581
+economics 8582
+23000 8583
+agent 8584
+html5 8585
+points 8586
+ryan 8587
+shi 8588
+砬 8589
+湜 8590
+reading 8591
+918 8592
+mine 8593
+adc 8594
+917 8595
+1592 8596
+1781 8597
+翚 8598
+峯 8599
+909 8600
+once 8601
+exchange 8602
+choose 8603
+current 8604
+symbian 8605
+ts16949 8606
+dave 8607
+machine 8608
+鲎 8609
+qos 8610
+蕖 8611
+1785 8612
+9m 8613
+cia 8614
+until 8615
+cs4 8616
+759 8617
+f3 8618
+903 8619
+24000 8620
+968 8621
+8mg 8622
+lewis 8623
+鹈 8624
+凼 8625
+snh48 8626
+866 8627
+泫 8628
+荑 8629
+黻 8630
+牂 8631
+1722 8632
+鄣 8633
+篑 8634
+ho 8635
+1110 8636
+1784 8637
+髭 8638
+陬 8639
+寔 8640
+dt 8641
+shanghai 8642
+疴 8643
+邽 8644
+987 8645
+45000 8646
+1042 8647
+喏 8648
+彖 8649
+sl 8650
+saas 8651
+814 8652
+28000 8653
+a5 8654
+彘 8655
+赟 8656
+819 8657
+foxpro 8658
+shit 8659
+822 8660
+盹 8661
+诮 8662
+鸫 8663
+per 8664
+does 8665
+150mm 8666
+products 8667
+camp 8668
+select 8669
+capital 8670
+茕 8671
+corporation 8672
+26000 8673
+铖 8674
+954 8675
+dd 8676
+闩 8677
+string 8678
+page 8679
+ba 8680
+671 8681
+読 8682
+782 8683
+鄜 8684
+漈 8685
+盍 8686
+dlp 8687
+729 8688
+甭 8689
+愎 8690
+outlook 8691
+wii 8692
+ue 8693
+1787 8694
+festival 8695
+communication 8696
+channel 8697
+gary 8698
+1755 8699
+1774 8700
+8600 8701
+copy 8702
+150mg 8703
+魃 8704
+dragon 8705
+1056 8706
+c5 8707
+炆 8708
+track 8709
+hdpe 8710
+liang 8711
+鍊 8712
+1800mhz 8713
+1619 8714
+蛐 8715
+995 8716
+21000 8717
+薜 8718
+win 8719
+1394 8720
+1786 8721
+rain 8722
+楯 8723
+table 8724
+鲀 8725
+逡 8726
+itu 8727
+applications 8728
+mmorpg 8729
+嘞 8730
+s7 8731
+696 8732
+侔 8733
+1069 8734
+觇 8735
+lbs 8736
+0mg 8737
+car 8738
+wave 8739
+糸 8740
+踮 8741
+狷 8742
+1552 8743
+1627 8744
+latest 8745
+step 8746
+886 8747
+761 8748
+菘 8749
+783 8750
+寳 8751
+esp 8752
+扃 8753
+865 8754
+jazz 8755
+k1 8756
+fine 8757
+child 8758
+kind 8759
+anna 8760
+60mg 8761
+997 8762
+maria 8763
+nk 8764
+792 8765
+raw 8766
+late 8767
+soa 8768
+905 8769
+cai 8770
+ttl 8771
+delphi 8772
+prince 8773
+1340 8774
+禊 8775
+synthesis 8776
+喑 8777
+rmb 8778
+miller 8779
+patrick 8780
+933 8781
+running 8782
+50kg 8783
+1398 8784
+ast 8785
+752 8786
+location 8787
+dead 8788
+塍 8789
+chateau 8790
+allows 8791
+forget 8792
+tg 8793
+921 8794
+栝 8795
+5w 8796
+kiss 8797
+1690 8798
+691 8799
+arthur 8800
+瓿 8801
+index 8802
+csa 8803
+rmvb 8804
+msc 8805
+廨 8806
+cas 8807
+known 8808
+h1 8809
+tj 8810
+j2ee 8811
+asian 8812
+841 8813
+1227 8814
+g20 8815
+cross 8816
+cos 8817
+ntilde 8818
+719 8819
+貘 8820
+dnf 8821
+california 8822
+france 8823
+modern 8824
+pacific 8825
+769 8826
+1066 8827
+turbo 8828
+753 8829
+795 8830
+669 8831
+1764 8832
+868 8833
+馕 8834
+僰 8835
+union 8836
+1772 8837
+2150 8838
+1063 8839
+哏 8840
+double 8841
+fight 8842
+858 8843
+math 8844
+bo 8845
+瑷 8846
+men 8847
+sea 8848
+6700 8849
+sem 8850
+697 8851
+疎 8852
+882 8853
+note 8854
+qi 8855
+uml 8856
+902 8857
+1637 8858
+tp 8859
+1290 8860
+1085 8861
+776 8862
+蝣 8863
+怵 8864
+阃 8865
+dps 8866
+1687 8867
+弢 8868
+镲 8869
+hcl 8870
+al2o3 8871
+js 8872
+auto 8873
+螅 8874
+1683 8875
+v5 8876
+culture 8877
+935 8878
+吖 8879
+edge 8880
+碲 8881
+voice 8882
+1007 8883
+bridge 8884
+855 8885
+008 8886
+夼 8887
+茌 8888
+battle 8889
+嗬 8890
+靺 8891
+dp 8892
+ae 8893
+1090 8894
+895 8895
+1012 8896
+1162 8897
+bi 8898
+778 8899
+髀 8900
+1575 8901
+pcm 8902
+15min 8903
+1598 8904
+铊 8905
+secret 8906
+739 8907
+200m 8908
+6h 8909
+matt 8910
+谡 8911
+card 8912
+mic 8913
+癔 8914
+ecu 8915
+16mm 8916
+984 8917
+镠 8918
+5km 8919
+dhcp 8920
+1753 8921
+巻 8922
+秾 8923
+living 8924
+gn 8925
+1643 8926
+framework 8927
+菪 8928
+679 8929
+赜 8930
+1782 8931
+four 8932
+铈 8933
+1777 8934
+british 8935
+shell 8936
+santa 8937
+yuan 8938
+20ma 8939
+fly 8940
+927 8941
+qu 8942
+nds 8943
+qaq 8944
+bar 8945
+髙 8946
+arp 8947
+1667 8948
+1773 8949
+693 8950
+main 8951
+鲳 8952
+1510 8953
+1002 8954
+2022 8955
+cdna 8956
+box 8957
+珰 8958
+100km 8959
+004 8960
+畋 8961
+bring 8962
+泅 8963
+959 8964
+hpv 8965
+makes 8966
+cmv 8967
+鲅 8968
+tmd 8969
+1762 8970
+854 8971
+泚 8972
+ghost 8973
+short 8974
+mcu 8975
+1768 8976
+cat 8977
+963 8978
+1757 8979
+1206 8980
+1207 8981
+puzzle 8982
+793 8983
+central 8984
+859 8985
+飏 8986
+walter 8987
+60hz 8988
+anderson 8989
+1727 8990
+thought 8991
+屍 8992
+仨 8993
+864 8994
+molecular 8995
+856 8996
+dong 8997
+financial 8998
+1728 8999
+surface 9000
+g2 9001
+mf 9002
+葚 9003
+叻 9004
+solidworks 9005
+res 9006
+speed 9007
+1195 9008
+咻 9009
+ascii 9010
+1404 9011
+784 9012
+jeff 9013
+衩 9014
+1371 9015
+land 9016
+biology 9017
+1655 9018
+郄 9019
+otc 9020
+sio 9021
+1310 9022
+1605 9023
+蹩 9024
+mems 9025
+1618 9026
+m16 9027
+complete 9028
+industrial 9029
+acs 9030
+1603 9031
+kids 9032
+tour 9033
+u2 9034
+allen 9035
+1756 9036
+743 9037
+嬖 9038
+踽 9039
+davis 9040
+柽 9041
+鞨 9042
+65279 9043
+7600 9044
+30ml 9045
+957 9046
+0l 9047
+734 9048
+p450 9049
+956 9050
+ir 9051
+麴 9052
+500mm 9053
+casio 9054
+1038 9055
+roger 9056
+library 9057
+015 9058
+1652 9059
+薙 9060
+within 9061
+hands 9062
+874 9063
+ntsc 9064
+钇 9065
+whole 9066
+jq 9067
+氵 9068
+垆 9069
+post 9070
+sweet 9071
+wall 9072
+898 9073
+cs5 9074
+feo 9075
+9800 9076
+cms 9077
+1390 9078
+since 9079
+medical 9080
+犟 9081
+1492 9082
+罍 9083
+stand 9084
+justin 9085
+lake 9086
+i5 9087
+1729 9088
+bell 9089
+ruby 9090
+important 9091
+bout 9092
+images 9093
+lab 9094
+962 9095
+1759 9096
+rj 9097
+cache 9098
+nb 9099
+production 9100
+経 9101
+807 9102
+1771 9103
+doing 9104
+粜 9105
+tnf 9106
+ws 9107
+guide 9108
+bim 9109
+events 9110
+1626 9111
+1016 9112
+焜 9113
+performance 9114
+ra 9115
+zl 9116
+牀 9117
+1568 9118
+1647 9119
+埝 9120
+洧 9121
+1615 9122
+shift 9123
+788 9124
+shen 9125
+1588 9126
+60mm 9127
+覧 9128
+tuv 9129
+1673 9130
+electronic 9131
+mos 9132
+蓣 9133
+8kg 9134
+862 9135
+echo 9136
+1572 9137
+section 9138
+981 9139
+甯 9140
+sg 9141
+1664 9142
+understand 9143
+hsk 9144
+delta 9145
+x86 9146
+eap 9147
+block 9148
+1578 9149
+er 9150
+xl 9151
+蒐 9152
+馐 9153
+nox 9154
+畑 9155
+ib 9156
+trying 9157
+ann 9158
+1635 9159
+apache 9160
+naoh 9161
+12345 9162
+缑 9163
+礽 9164
+1624 9165
+694 9166
+瞋 9167
+1601 9168
+浍 9169
+983 9170
+773 9171
+1000m 9172
+someone 9173
+15kg 9174
+25m 9175
+847 9176
+袢 9177
+桕 9178
+1037 9179
+jerry 9180
+843 9181
+picture 9182
+919 9183
+e3 9184
+printf 9185
+3gs 9186
+marie 9187
+853 9188
+rj45 9189
+侩 9190
+913 9191
+896 9192
+lose 9193
+unicode 9194
+100cm 9195
+1711 9196
+charlie 9197
+詈 9198
+戸 9199
+1689 9200
+room 9201
+烝 9202
+beat 9203
+堌 9204
+伋 9205
+hplc 9206
+9300 9207
+110kv 9208
+nfc 9209
+倬 9210
+764 9211
+iis 9212
+圯 9213
+solo 9214
+碇 9215
+ef 9216
+round 9217
+chang 9218
+1366 9219
+781 9220
+1585 9221
+982 9222
+socket 9223
+df 9224
+892 9225
+1536 9226
+831 9227
+ren 9228
+6kg 9229
+4900 9230
+纰 9231
+object 9232
+forever 9233
+832 9234
+951 9235
+qr 9236
+1023 9237
+8800 9238
+4kg 9239
+磾 9240
+泔 9241
+1131 9242
+纮 9243
+蓁 9244
+971 9245
+building 9246
+1021 9247
+铗 9248
+939 9249
+弇 9250
+挲 9251
+crystal 9252
+艉 9253
+smtp 9254
+鱬 9255
+cims 9256
+fang 9257
+1265 9258
+trans 9259
+pan 9260
+1745 9261
+1604 9262
+泺 9263
+橛 9264
+817 9265
+796 9266
+袴 9267
+cosplay 9268
+1154 9269
+1189 9270
+749 9271
+794 9272
+1068 9273
+881 9274
+hc 9275
+hope 9276
+1410 9277
+couldn 9278
+1638 9279
+992 9280
+along 9281
+age 9282
+250mg 9283
+clear 9284
+aps 9285
+1631 9286
+1011 9287
+provides 9288
+1123 9289
+1701 9290
+36000 9291
+csf 9292
+韪 9293
+n1 9294
+works 9295
+籓 9296
+967 9297
+ptc 9298
+贶 9299
+1111 9300
+1651 9301
+棰 9302
+1726 9303
+sar 9304
+1666 9305
+qvga 9306
+hf 9307
+coreldraw 9308
+possible 9309
+趵 9310
+1629 9311
+943 9312
+marc 9313
+luo 9314
+樨 9315
+848 9316
+county 9317
+944 9318
+tb 9319
+dts 9320
+junior 9321
+vba 9322
+lot 9323
+傕 9324
+玕 9325
+毎 9326
+direct 9327
+839 9328
+繸 9329
+2350 9330
+774 9331
+劵 9332
+fsh 9333
+wmv 9334
+镧 9335
+秫 9336
+1094 9337
+osi 9338
+1602 9339
+邶 9340
+猞 9341
+dior 9342
+1766 9343
+1623 9344
+廛 9345
+栌 9346
+钲 9347
+镦 9348
+1607 9349
+psa 9350
+spss 9351
+xy 9352
+1769 9353
+cells 9354
+1465 9355
+1577 9356
+gon 9357
+send 9358
+vision 9359
+thinking 9360
+imf 9361
+嘏 9362
+carl 9363
+蝰 9364
+32000 9365
+bay 9366
+928 9367
+is09001 9368
+镏 9369
+20kg 9370
+淠 9371
+imax 9372
+novel 9373
+qt 9374
+1684 9375
+荇 9376
+逄 9377
+au 9378
+author 9379
+mod 9380
+80mm 9381
+1748 9382
+849 9383
+1612 9384
+yet 9385
+嘅 9386
+929 9387
+6l 9388
+karl 9389
+6100 9390
+students 9391
+gmat 9392
+myself 9393
+kate 9394
+jpg 9395
+979 9396
+1752 9397
+829 9398
+2450 9399
+914 9400
+876 9401
+祕 9402
+瑠 9403
+48h 9404
+mpv 9405
+1734 9406
+mis 9407
+1565 9408
+walk 9409
+941 9410
+1075 9411
+1235 9412
+natural 9413
+k2 9414
+977 9415
+炝 9416
+杪 9417
+4050 9418
+1669 9419
+p3 9420
+1004 9421
+fn 9422
+埴 9423
+1555 9424
+vmware 9425
+chloride 9426
+942 9427
+steven 9428
+1078 9429
+獬 9430
+966 9431
+1135 9432
+country 9433
+947 9434
+柢 9435
+捱 9436
+跣 9437
+887 9438
+涑 9439
+75mm 9440
+1278 9441
+1583 9442
+western 9443
+watch 9444
+撃 9445
+伢 9446
+堠 9447
+1045 9448
+12m 9449
+museum 9450
+1215 9451
+document 9452
+marketing 9453
+952 9454
+卽 9455
+猁 9456
+usb3 9457
+906 9458
+厣 9459
+physical 9460
+辏 9461
+1668 9462
+旆 9463
+agp 9464
+茆 9465
+1488 9466
+pg 9467
+乜 9468
+deep 9469
+1082 9470
+961 9471
+踯 9472
+1526 9473
+# 9474
+[ 9475
+yam 9476
+lofter 9477
+##s 9478
+##0 9479
+##a 9480
+##2 9481
+##1 9482
+##3 9483
+##e 9484
+##8 9485
+##5 9486
+##6 9487
+##4 9488
+##9 9489
+##7 9490
+##t 9491
+##o 9492
+##d 9493
+##i 9494
+##n 9495
+##m 9496
+##c 9497
+##l 9498
+##y 9499
+##r 9500
+##g 9501
+##p 9502
+##f 9503
+pixnet 9504
+cookies 9505
+tripadvisor 9506
+##er 9507
+##k 9508
+##h 9509
+##b 9510
+##x 9511
+##u 9512
+##w 9513
+##ing 9514
+ctrip 9515
+##on 9516
+##v 9517
+llc 9518
+##an 9519
+##z 9520
+blogthis 9521
+##le 9522
+##in 9523
+##mm 9524
+##00 9525
+ig 9526
+##ng 9527
+##us 9528
+##te 9529
+##ed 9530
+ncc 9531
+blog 9532
+##10 9533
+##al 9534
+##ic 9535
+##ia 9536
+##q 9537
+##ce 9538
+##en 9539
+##is 9540
+##ra 9541
+##es 9542
+##j 9543
+##cm 9544
+tw 9545
+##ne 9546
+##re 9547
+##tion 9548
+pony 9549
+##2017 9550
+##ch 9551
+##or 9552
+##na 9553
+cafe 9554
+pinterest 9555
+pixstyleme3c 9556
+##ta 9557
+##2016 9558
+##ll 9559
+##20 9560
+##ie 9561
+##ma 9562
+##17 9563
+##ion 9564
+##th 9565
+##st 9566
+##se 9567
+##et 9568
+##ck 9569
+##ly 9570
+web885 9571
+##ge 9572
+xd 9573
+##ry 9574
+##11 9575
+0fork 9576
+##12 9577
+##ter 9578
+##ar 9579
+##la 9580
+##os 9581
+##30 9582
+##el 9583
+##50 9584
+##ml 9585
+tue 9586
+posted 9587
+##at 9588
+##man 9589
+##15 9590
+ago 9591
+##it 9592
+##me 9593
+##de 9594
+##nt 9595
+##mb 9596
+##16 9597
+##ve 9598
+##da 9599
+##ps 9600
+##to 9601
+https 9602
+momo 9603
+##son 9604
+##ke 9605
+##80 9606
+ebd 9607
+apk 9608
+##88 9609
+##um 9610
+wiki 9611
+brake 9612
+mon 9613
+po 9614
+june 9615
+##ss 9616
+fb 9617
+##as 9618
+leonardo 9619
+safari 9620
+##60 9621
+wed 9622
+win7 9623
+kiehl 9624
+##co 9625
+##go 9626
+vfm 9627
+kanye 9628
+##90 9629
+##2015 9630
+##id 9631
+##ey 9632
+##sa 9633
+##ro 9634
+##am 9635
+##no 9636
+thu 9637
+fri 9638
+##sh 9639
+##ki 9640
+comments 9641
+##pe 9642
+##ine 9643
+uber 9644
+##mi 9645
+##ton 9646
+wordpress 9647
+##ment 9648
+win10 9649
+##ld 9650
+##li 9651
+gmail 9652
+##rs 9653
+##ri 9654
+##rd 9655
+##21 9656
+##io 9657
+##99 9658
+paypal 9659
+policy 9660
+##40 9661
+##ty 9662
+##18 9663
+##01 9664
+##ba 9665
+taiwan 9666
+##ga 9667
+privacy 9668
+agoda 9669
+##13 9670
+##ny 9671
+##24 9672
+##22 9673
+##by 9674
+##ur 9675
+##hz 9676
+##ang 9677
+cookie 9678
+netscape 9679
+##ka 9680
+##ad 9681
+nike 9682
+survey 9683
+##016 9684
+wikia 9685
+##32 9686
+##017 9687
+cbc 9688
+##tor 9689
+##kg 9690
+##rt 9691
+##14 9692
+campaign 9693
+##ct 9694
+##ts 9695
+##ns 9696
+##ao 9697
+##nd 9698
+##70 9699
+##ya 9700
+##il 9701
+##25 9702
+0020 9703
+897 9704
+##23 9705
+hotels 9706
+##ian 9707
+6606 9708
+##ers 9709
+##26 9710
+##day 9711
+##ay 9712
+##line 9713
+##be 9714
+talk2yam 9715
+yamservice 9716
+coco 9717
+##dy 9718
+##ies 9719
+##ha 9720
+instagram 9721
+##ot 9722
+##va 9723
+##mo 9724
+##land 9725
+ltxsw 9726
+##ation 9727
+##pa 9728
+##ol 9729
+tag 9730
+##ue 9731
+##31 9732
+oppo 9733
+##ca 9734
+##om 9735
+chrome 9736
+##ure 9737
+lol 9738
+##19 9739
+##bo 9740
+##100 9741
+##way 9742
+##ko 9743
+##do 9744
+##un 9745
+##ni 9746
+herme 9747
+##28 9748
+##up 9749
+##06 9750
+##ds 9751
+admin 9752
+##48 9753
+##015 9754
+##35 9755
+##ee 9756
+tpp 9757
+##ive 9758
+##cc 9759
+##ble 9760
+##ity 9761
+##ex 9762
+##ler 9763
+##ap 9764
+##book 9765
+##ice 9766
+##km 9767
+##mg 9768
+##ms 9769
+ebay 9770
+##29 9771
+ubuntu 9772
+##cy 9773
+##view 9774
+##lo 9775
+##oo 9776
+##02 9777
+step1 9778
+july 9779
+##net 9780
+##ls 9781
+##ii 9782
+##05 9783
+##33 9784
+step2 9785
+ios9 9786
+##box 9787
+##ley 9788
+samsung 9789
+pokemon 9790
+##ent 9791
+##les 9792
+s8 9793
+atom 9794
+##said 9795
+##55 9796
+##2014 9797
+##66 9798
+adidas 9799
+amazon 9800
+##ber 9801
+##ner 9802
+visa 9803
+##77 9804
+##der 9805
+connectivity 9806
+##hi 9807
+firefox 9808
+skip 9809
+##27 9810
+##ir 9811
+##61 9812
+##ai 9813
+##ver 9814
+cafe2017 9815
+##ron 9816
+##ster 9817
+##sk 9818
+##ft 9819
+longchamp 9820
+ssd 9821
+##ti 9822
+reply 9823
+##my 9824
+apr 9825
+##ker 9826
+source 9827
+##one 9828
+##2013 9829
+##ow 9830
+goods 9831
+##lin 9832
+##ip 9833
+##ics 9834
+##45 9835
+##03 9836
+##ff 9837
+##47 9838
+ganji 9839
+##nce 9840
+##per 9841
+faq 9842
+comment 9843
+##ock 9844
+##bs 9845
+##ah 9846
+##lv 9847
+##mp 9848
+##000 9849
+melody 9850
+17life 9851
+##au 9852
+##71 9853
+##04 9854
+##95 9855
+##age 9856
+tips 9857
+##68 9858
+##ting 9859
+##ung 9860
+wonderland 9861
+##ction 9862
+mar 9863
+article 9864
+##db 9865
+##07 9866
+##ore 9867
+##op 9868
+##78 9869
+##38 9870
+##ong 9871
+##73 9872
+##08 9873
+##ica 9874
+##36 9875
+##wa 9876
+##64 9877
+homemesh 9878
+##85 9879
+##tv 9880
+##di 9881
+macbook 9882
+##ier 9883
+##si 9884
+##75 9885
+##ok 9886
+goris 9887
+lock 9888
+##ut 9889
+carol 9890
+##vi 9891
+##ac 9892
+anti 9893
+jan 9894
+tags 9895
+##98 9896
+##51 9897
+august 9898
+##86 9899
+##fs 9900
+##sion 9901
+jordan 9902
+##tt 9903
+##lt 9904
+##42 9905
+##bc 9906
+vivi 9907
+##rry 9908
+##ted 9909
+##rn 9910
+usd 9911
+##t00 9912
+##58 9913
+##09 9914
+##34 9915
+goo 9916
+##ui 9917
+##ary 9918
+item 9919
+##pm 9920
+##41 9921
+##za 9922
+##2012 9923
+blogabstract 9924
+##ger 9925
+##62 9926
+##44 9927
+gr2 9928
+asus 9929
+cindy 9930
+##hd 9931
+esc 9932
+##od 9933
+booking 9934
+##53 9935
+fed 9936
+##81 9937
+##ina 9938
+chan 9939
+distribution 9940
+steam 9941
+pk10 9942
+##ix 9943
+##65 9944
+##91 9945
+dec 9946
+##ana 9947
+icecat 9948
+00z 9949
+##46 9950
+##ji 9951
+##ard 9952
+oct 9953
+##ain 9954
+jp 9955
+##ze 9956
+##bi 9957
+cio 9958
+##56 9959
+h5 9960
+##39 9961
+##port 9962
+curve 9963
+##nm 9964
+##dia 9965
+utc 9966
+12345678910 9967
+##52 9968
+chanel 9969
+##and 9970
+##im 9971
+##63 9972
+vera 9973
+vivo 9974
+##ei 9975
+2756 9976
+##69 9977
+msci 9978
+##po 9979
+##89 9980
+##bit 9981
+##out 9982
+##zz 9983
+##97 9984
+##67 9985
+opec 9986
+##96 9987
+##tes 9988
+##ast 9989
+##ling 9990
+##ory 9991
+##ical 9992
+kitty 9993
+##43 9994
+step3 9995
+##cn 9996
+win8 9997
+iphone7 9998
+beauty 9999
+##87 10000
+dollars 10001
+##ys 10002
+##oc 10003
+pay 10004
+##2011 10005
+##lly 10006
+##ks 10007
+download 10008
+sep 10009
+##board 10010
+##37 10011
+##lan 10012
+winrar 10013
+##que 10014
+##ua 10015
+##com 10016
+ettoday 10017
+##54 10018
+##ren 10019
+##via 10020
+##72 10021
+##79 10022
+##tch 10023
+##49 10024
+##ial 10025
+##nn 10026
+step4 10027
+2765 10028
+gov 10029
+##xx 10030
+mandy 10031
+##ser 10032
+copyright 10033
+fashion 10034
+##ist 10035
+##art 10036
+##lm 10037
+##ek 10038
+##ning 10039
+##if 10040
+##ite 10041
+iot 10042
+##84 10043
+##2010 10044
+##ku 10045
+october 10046
+##ux 10047
+trump 10048
+##hs 10049
+##ide 10050
+##ins 10051
+april 10052
+##ight 10053
+##83 10054
+protected 10055
+##fe 10056
+##ho 10057
+ofo 10058
+gomaji 10059
+march 10060
+##lla 10061
+##pp 10062
+##ec 10063
+6s 10064
+720p 10065
+##rm 10066
+##ham 10067
+##92 10068
+fandom 10069
+##ell 10070
+info 10071
+##82 10072
+sina 10073
+4066 10074
+##able 10075
+##ctor 10076
+rights 10077
+jul 10078
+##76 10079
+mall 10080
+##59 10081
+donald 10082
+sodu 10083
+##light 10084
+reserved 10085
+htm 10086
+##han 10087
+##57 10088
+##ise 10089
+##tions 10090
+##shi 10091
+doc 10092
+055 10093
+##ram 10094
+shopping 10095
+aug 10096
+##pi 10097
+##well 10098
+wam 10099
+##hu 10100
+##gb 10101
+##93 10102
+mix 10103
+##ef 10104
+##uan 10105
+bwl 10106
+##plus 10107
+##res 10108
+##ess 10109
+tea 10110
+hktvmall 10111
+##ate 10112
+##ese 10113
+feb 10114
+inn 10115
+nov 10116
+##ci 10117
+pass 10118
+##bet 10119
+##nk 10120
+coffee 10121
+airbnb 10122
+##ute 10123
+woshipm 10124
+skype 10125
+##fc 10126
+##www 10127
+##94 10128
+##ght 10129
+##gs 10130
+##ile 10131
+##wood 10132
+##uo 10133
+icon 10134
+##em 10135
+says 10136
+##king 10137
+##tive 10138
+blogger 10139
+##74 10140
+##ox 10141
+##zy 10142
+##red 10143
+##ium 10144
+##lf 10145
+nokia 10146
+claire 10147
+##ding 10148
+november 10149
+lohas 10150
+##500 10151
+##tic 10152
+##cs 10153
+##che 10154
+##ire 10155
+##gy 10156
+##ult 10157
+january 10158
+ptt 10159
+##fa 10160
+##mer 10161
+pchome 10162
+udn 10163
+##time 10164
+##tte 10165
+garden 10166
+eleven 10167
+309b 10168
+bat 10169
+##123 10170
+##tra 10171
+kindle 10172
+##ern 10173
+xperia 10174
+ces 10175
+travel 10176
+##ous 10177
+##int 10178
+edu 10179
+cho 10180
+##car 10181
+##our 10182
+##ant 10183
+rends 10184
+##jo 10185
+mastercard 10186
+##2000 10187
+kb 10188
+##min 10189
+##ino 10190
+##ris 10191
+##ud 10192
+##set 10193
+##her 10194
+##ou 10195
+taipei 10196
+##fi 10197
+##ill 10198
+aphojoy 10199
+december 10200
+meiki 10201
+##ick 10202
+tweet 10203
+##av 10204
+iphone6 10205
+##dd 10206
+views 10207
+##mark 10208
+##ash 10209
+##ome 10210
+koreanmall 10211
+##ak 10212
+q2 10213
+##200 10214
+mlb 10215
+##lle 10216
+##watch 10217
+##und 10218
+##tal 10219
+##less 10220
+4399 10221
+##rl 10222
+update 10223
+shop 10224
+##mhz 10225
+##house 10226
+##key 10227
+##001 10228
+##hy 10229
+##web 10230
+##2009 10231
+##gg 10232
+##wan 10233
+##val 10234
+2021 10235
+##ons 10236
+doi 10237
+trivago 10238
+overdope 10239
+##ance 10240
+573032185 10241
+wx17house 10242
+##so 10243
+audi 10244
+##he 10245
+##rp 10246
+##ake 10247
+beach 10248
+cfa 10249
+ps4 10250
+##800 10251
+##link 10252
+##hp 10253
+ferragamo 10254
+##eng 10255
+##style 10256
+##gi 10257
+i7 10258
+##ray 10259
+##max 10260
+##pc 10261
+september 10262
+##ace 10263
+vps 10264
+february 10265
+pantos 10266
+wp 10267
+lisa 10268
+jquery 10269
+offer 10270
+##berg 10271
+##news 10272
+fks 10273
+##all 10274
+##rus 10275
+##888 10276
+##works 10277
+blogtitle 10278
+loftpermalink 10279
+ling 10280
+##ja 10281
+outlet 10282
+##ea 10283
+##top 10284
+##ness 10285
+salvatore 10286
+##lu 10287
+swift 10288
+##ul 10289
+week 10290
+##ean 10291
+##300 10292
+##gle 10293
+##back 10294
+powered 10295
+##tan 10296
+##nes 10297
+canon 10298
+##zi 10299
+##las 10300
+##oe 10301
+##sd 10302
+##bot 10303
+##world 10304
+##zo 10305
+top100 10306
+pmi 10307
+##vr 10308
+ball 10309
+vogue 10310
+ofweek 10311
+##list 10312
+##ort 10313
+##lon 10314
+##tc 10315
+##of 10316
+##bus 10317
+##gen 10318
+nas 10319
+##lie 10320
+##ria 10321
+##coin 10322
+##bt 10323
+nata 10324
+vive 10325
+cup 10326
+##ook 10327
+##sy 10328
+msg 10329
+3ce 10330
+##word 10331
+ebooks 10332
+r8 10333
+nice 10334
+months 10335
+rewards 10336
+##ther 10337
+0800 10338
+##xi 10339
+##sc 10340
+gg 10341
+blogfp 10342
+daily 10343
+##bb 10344
+##tar 10345
+##ky 10346
+anthony 10347
+##yo 10348
+##ara 10349
+##aa 10350
+##rc 10351
+##tz 10352
+##ston 10353
+gear 10354
+##eo 10355
+##ade 10356
+##win 10357
+##ura 10358
+##den 10359
+##ita 10360
+##sm 10361
+png 10362
+rakuten 10363
+whatsapp 10364
+##use 10365
+pad 10366
+gucci 10367
+##ode 10368
+##fo 10369
+chicago 10370
+##hone 10371
+io 10372
+sogo 10373
+be2 10374
+##ology 10375
+cloud 10376
+##con 10377
+##ford 10378
+##joy 10379
+##kb 10380
+##rade 10381
+##ach 10382
+docker 10383
+##ful 10384
+##ase 10385
+ford 10386
+##star 10387
+edited 10388
+##are 10389
+##mc 10390
+siri 10391
+##ella 10392
+bloomberg 10393
+##read 10394
+pizza 10395
+##ison 10396
+##vm 10397
+node 10398
+18k 10399
+##play 10400
+##cer 10401
+##yu 10402
+##ings 10403
+asr 10404
+##lia 10405
+step5 10406
+##cd 10407
+pixstyleme 10408
+##600 10409
+##tus 10410
+tokyo 10411
+##rial 10412
+##life 10413
+##ae 10414
+tcs 10415
+##rk 10416
+##wang 10417
+##sp 10418
+##ving 10419
+premium 10420
+netflix 10421
+##lton 10422
+##ple 10423
+##cal 10424
+021 10425
+##sen 10426
+##ville 10427
+nexus 10428
+##ius 10429
+##mah 10430
+tila 10431
+##tin 10432
+resort 10433
+##ws 10434
+p10 10435
+report 10436
+##360 10437
+##ru 10438
+bus 10439
+vans 10440
+##est 10441
+links 10442
+rebecca 10443
+##dm 10444
+azure 10445
+##365 10446
+##mon 10447
+moto 10448
+##eam 10449
+blogspot 10450
+##ments 10451
+##ik 10452
+##kw 10453
+##bin 10454
+##ata 10455
+##vin 10456
+##tu 10457
+##ula 10458
+station 10459
+##ature 10460
+files 10461
+zara 10462
+hdr 10463
+top10 10464
+s6 10465
+marriott 10466
+avira 10467
+tab 10468
+##ran 10469
+##home 10470
+oculus 10471
+##ral 10472
+rosie 10473
+##force 10474
+##ini 10475
+ice 10476
+##bert 10477
+##nder 10478
+##mber 10479
+plurk 10480
+##sis 10481
+00kg 10482
+##ence 10483
+##nc 10484
+##name 10485
+log 10486
+ikea 10487
+malaysia 10488
+##ncy 10489
+##nie 10490
+##ye 10491
+##oid 10492
+##chi 10493
+xuehai 10494
+##1000 10495
+##orm 10496
+##rf 10497
+##ware 10498
+##pro 10499
+##era 10500
+##ub 10501
+##2008 10502
+8891 10503
+scp 10504
+##zen 10505
+qvod 10506
+jcb 10507
+##hr 10508
+weibo 10509
+##row 10510
+##ish 10511
+github 10512
+mate 10513
+##lot 10514
+##ane 10515
+##tina 10516
+ed2k 10517
+##vel 10518
+##900 10519
+final 10520
+ns 10521
+bytes 10522
+##ene 10523
+##cker 10524
+##2007 10525
+##px 10526
+topapp 10527
+helpapp 10528
+14k 10529
+g4g 10530
+ldquo 10531
+##fork 10532
+##gan 10533
+##zon 10534
+##qq 10535
+##google 10536
+##ism 10537
+##zer 10538
+toyota 10539
+category 10540
+##labels 10541
+restaurant 10542
+##md 10543
+posts 10544
+##ico 10545
+angelababy 10546
+123456 10547
+sports 10548
+candy 10549
+##new 10550
+##here 10551
+swissinfo 10552
+dram 10553
+##ual 10554
+##vice 10555
+##wer 10556
+sport 10557
+q1 10558
+ios10 10559
+##mll 10560
+wan 10561
+##uk 10562
+x3 10563
+0t 10564
+##ming 10565
+e5 10566
+##3d 10567
+h7n9 10568
+worldcat 10569
+##vo 10570
+##led 10571
+##580 10572
+##ax 10573
+##ert 10574
+polo 10575
+##lr 10576
+##hing 10577
+##chat 10578
+##ule 10579
+hotmail 10580
+##pad 10581
+bbq 10582
+##ring 10583
+wali 10584
+2k 10585
+costco 10586
+switch 10587
+##city 10588
+philips 10589
+##mann 10590
+panasonic 10591
+##cl 10592
+##vd 10593
+##ping 10594
+##rge 10595
+##lk 10596
+css3 10597
+##ney 10598
+##ular 10599
+##400 10600
+##tter 10601
+lz 10602
+##tm 10603
+##yan 10604
+##let 10605
+coach 10606
+##pt 10607
+a8 10608
+follow 10609
+##berry 10610
+##ew 10611
+##wn 10612
+##og 10613
+##code 10614
+##rid 10615
+villa 10616
+git 10617
+r11 10618
+##cket 10619
+error 10620
+##anonymoussaid 10621
+##ag 10622
+##ame 10623
+##gc 10624
+qa 10625
+##lis 10626
+##gin 10627
+vmalife 10628
+##cher 10629
+wedding 10630
+##tis 10631
+demo 10632
+bye 10633
+##rant 10634
+orz 10635
+acer 10636
+##ats 10637
+##ven 10638
+macd 10639
+yougou 10640
+##dn 10641
+##ano 10642
+##urt 10643
+##rent 10644
+continue 10645
+script 10646
+##wen 10647
+##ect 10648
+paper 10649
+##chel 10650
+##cat 10651
+x5 10652
+fox 10653
+##blog 10654
+loading 10655
+##yn 10656
+##tp 10657
+kuso 10658
+799 10659
+vdc 10660
+forest 10661
+prime 10662
+ultra 10663
+##rmb 10664
+square 10665
+##field 10666
+##reen 10667
+##ors 10668
+##ju 10669
+##air 10670
+##map 10671
+cdn 10672
+##wo 10673
+m8 10674
+##get 10675
+opera 10676
+##base 10677
+##ood 10678
+vsa 10679
+##aw 10680
+##ail 10681
+count 10682
+##een 10683
+##gp 10684
+vsc 10685
+tree 10686
+##eg 10687
+##ose 10688
+##ories 10689
+##shop 10690
+alphago 10691
+v4 10692
+fluke62max 10693
+zip 10694
+##sta 10695
+bas 10696
+##yer 10697
+hadoop 10698
+##ube 10699
+##wi 10700
+0755 10701
+hola 10702
+##low 10703
+centre 10704
+##fer 10705
+##750 10706
+##media 10707
+##san 10708
+##bank 10709
+q3 10710
+##nge 10711
+##mail 10712
+##lp 10713
+client 10714
+event 10715
+vincent 10716
+##nse 10717
+sui 10718
+adchoice 10719
+##stry 10720
+##zone 10721
+ga 10722
+apps 10723
+##ab 10724
+##rner 10725
+kymco 10726
+##care 10727
+##pu 10728
+##yi 10729
+minkoff 10730
+annie 10731
+collection 10732
+kpi 10733
+playstation 10734
+bh 10735
+##bar 10736
+armani 10737
+##xy 10738
+iherb 10739
+##ery 10740
+##share 10741
+##ob 10742
+volvo 10743
+##ball 10744
+##hk 10745
+##cp 10746
+##rie 10747
+##ona 10748
+##sl 10749
+gtx 10750
+rdquo 10751
+jayz 10752
+##lex 10753
+##rum 10754
+namespace 10755
+##ale 10756
+##atic 10757
+##erson 10758
+##ql 10759
+##ves 10760
+##type 10761
+enter 10762
+##168 10763
+##mix 10764
+##bian 10765
+a9 10766
+ky 10767
+##lc 10768
+movie 10769
+##hc 10770
+tower 10771
+##ration 10772
+##mit 10773
+##nch 10774
+ua 10775
+tel 10776
+prefix 10777
+##o2 10778
+##point 10779
+ott 10780
+##http 10781
+##ury 10782
+baidu 10783
+##ink 10784
+member 10785
+##logy 10786
+bigbang 10787
+nownews 10788
+##js 10789
+##shot 10790
+##tb 10791
+eba 10792
+##tics 10793
+##lus 10794
+spark 10795
+##ama 10796
+##ions 10797
+##lls 10798
+##down 10799
+##ress 10800
+burberry 10801
+day2 10802
+##kv 10803
+related 10804
+edit 10805
+##ark 10806
+cx 10807
+32gb 10808
+g9 10809
+##ans 10810
+##tty 10811
+s5 10812
+##bee 10813
+thread 10814
+xr 10815
+buy 10816
+spotify 10817
+##ari 10818
+##verse 10819
+7headlines 10820
+nego 10821
+sunny 10822
+dom 10823
+positioning 10824
+fit 10825
+##tton 10826
+alexa 10827
+##ties 10828
+##llow 10829
+amy 10830
+##du 10831
+##rth 10832
+##lar 10833
+2345 10834
+##des 10835
+sidebar 10836
+site 10837
+##cky 10838
+##kit 10839
+##ime 10840
+##009 10841
+season 10842
+##fun 10843
+gogoro 10844
+a7 10845
+lily 10846
+twd600 10847
+##vis 10848
+##cture 10849
+friday 10850
+yi 10851
+##tta 10852
+##tel 10853
+##lock 10854
+economy 10855
+tinker 10856
+8gb 10857
+##app 10858
+oops 10859
+##right 10860
+edm 10861
+##cent 10862
+supreme 10863
+##its 10864
+##asia 10865
+dropbox 10866
+##tti 10867
+books 10868
+##tle 10869
+##ller 10870
+##ken 10871
+##more 10872
+##boy 10873
+sex 10874
+##dom 10875
+##ider 10876
+##unch 10877
+##put 10878
+##gh 10879
+ka 10880
+amoled 10881
+div 10882
+##tr 10883
+##n1 10884
+port 10885
+howard 10886
+##tags 10887
+ken 10888
+##nus 10889
+adsense 10890
+buff 10891
+thunder 10892
+##town 10893
+##ique 10894
+##body 10895
+pin 10896
+##erry 10897
+tee 10898
+##the 10899
+##013 10900
+udnbkk 10901
+16gb 10902
+##mic 10903
+miui 10904
+##tro 10905
+##alk 10906
+##nity 10907
+s4 10908
+##oa 10909
+docomo 10910
+##tf 10911
+##ack 10912
+fc2 10913
+##ded 10914
+##sco 10915
+##014 10916
+##rite 10917
+linkedin 10918
+##ada 10919
+##now 10920
+##ndy 10921
+ucbug 10922
+sputniknews 10923
+legalminer 10924
+##ika 10925
+##xp 10926
+##bu 10927
+q10 10928
+##rman 10929
+cheese 10930
+ming 10931
+maker 10932
+##gm 10933
+nikon 10934
+##fig 10935
+ppi 10936
+jchere 10937
+ted 10938
+fgo 10939
+tech 10940
+##tto 10941
+##gl 10942
+##len 10943
+hair 10944
+img 10945
+##pper 10946
+##a1 10947
+acca 10948
+##ition 10949
+##ference 10950
+suite 10951
+##ig 10952
+##mond 10953
+##cation 10954
+##pr 10955
+101vip 10956
+##999 10957
+64gb 10958
+airport 10959
+##over 10960
+##ith 10961
+##su 10962
+town 10963
+piece 10964
+##llo 10965
+no1 10966
+##qi 10967
+focus 10968
+reader 10969
+##admin 10970
+##ora 10971
+false 10972
+##log 10973
+##ces 10974
+##ume 10975
+motel 10976
+##oper 10977
+flickr 10978
+netcomponents 10979
+##af 10980
+pose 10981
+##ound 10982
+##cg 10983
+##site 10984
+##iko 10985
+con 10986
+##ath 10987
+##hip 10988
+##rey 10989
+cream 10990
+##cks 10991
+012 10992
+##dp 10993
+facebooktwitterpinterestgoogle 10994
+sso 10995
+shtml 10996
+swiss 10997
+##mw 10998
+lumia 10999
+xdd 11000
+tiffany 11001
+insee 11002
+russell 11003
+dell 11004
+##ations 11005
+camera 11006
+##vs 11007
+##flow 11008
+##late 11009
+classic 11010
+##nter 11011
+##ever 11012
+##lab 11013
+##nger 11014
+qe 11015
+##cing 11016
+editor 11017
+##nap 11018
+sunday 11019
+##ens 11020
+##700 11021
+##bra 11022
+acg 11023
+sofascore 11024
+mkv 11025
+##ign 11026
+jonathan 11027
+build 11028
+labels 11029
+##oto 11030
+tesla 11031
+moba 11032
+gohappy 11033
+ajax 11034
+##test 11035
+##urs 11036
+wps 11037
+fedora 11038
+##ich 11039
+mozilla 11040
+##480 11041
+##dr 11042
+urn 11043
+##lina 11044
+grace 11045
+##die 11046
+##try 11047
+##ader 11048
+elle 11049
+##chen 11050
+price 11051
+##ten 11052
+uhz 11053
+##ough 11054
+##hen 11055
+states 11056
+push 11057
+session 11058
+balance 11059
+wow 11060
+##cus 11061
+##py 11062
+##ward 11063
+##ep 11064
+34e 11065
+wong 11066
+prada 11067
+##cle 11068
+##ree 11069
+q4 11070
+##ctive 11071
+##ool 11072
+##ira 11073
+##163 11074
+rq 11075
+buffet 11076
+e6 11077
+##ez 11078
+##card 11079
+##cha 11080
+day3 11081
+eye 11082
+##end 11083
+adi 11084
+tvbs 11085
+##ala 11086
+nova 11087
+##tail 11088
+##ries 11089
+##ved 11090
+base 11091
+##ways 11092
+hero 11093
+hgih 11094
+profile 11095
+fish 11096
+mu 11097
+ssh 11098
+##wd 11099
+click 11100
+cake 11101
+##ond 11102
+pre 11103
+##tom 11104
+kic 11105
+pixel 11106
+##ov 11107
+##fl 11108
+product 11109
+6a 11110
+##pd 11111
+dear 11112
+##gate 11113
+yumi 11114
+##sky 11115
+bin 11116
+##ture 11117
+##ape 11118
+isis 11119
+nand 11120
+##101 11121
+##load 11122
+##ream 11123
+a6 11124
+##post 11125
+##we 11126
+zenfone 11127
+##ike 11128
+gd 11129
+forum 11130
+jessica 11131
+##ould 11132
+##ious 11133
+lohasthree 11134
+##gar 11135
+##ggle 11136
+##ric 11137
+##own 11138
+eclipse 11139
+##side 11140
+061 11141
+##other 11142
+##tech 11143
+##ator 11144
+engine 11145
+##ged 11146
+plaza 11147
+##fit 11148
+westbrook 11149
+reuters 11150
+##ily 11151
+contextlink 11152
+##hn 11153
+##cil 11154
+##cel 11155
+cambridge 11156
+##ize 11157
+##aid 11158
+##data 11159
+frm 11160
+##head 11161
+butler 11162
+##sun 11163
+##mar 11164
+puma 11165
+pmid 11166
+kitchen 11167
+##lic 11168
+day1 11169
+##text 11170
+##page 11171
+##rris 11172
+pm1 11173
+##ket 11174
+trackback 11175
+##hai 11176
+display 11177
+##hl 11178
+idea 11179
+##sent 11180
+airmail 11181
+##ug 11182
+##men 11183
+028 11184
+##lution 11185
+schemas 11186
+asics 11187
+wikipedia 11188
+##tional 11189
+##vy 11190
+##dget 11191
+##ein 11192
+contact 11193
+pepper 11194
+##uel 11195
+##ument 11196
+##hang 11197
+q5 11198
+##sue 11199
+##ndi 11200
+swatch 11201
+##cept 11202
+popular 11203
+##ste 11204
+##tag 11205
+trc 11206
+##west 11207
+##live 11208
+honda 11209
+ping 11210
+messenger 11211
+##rap 11212
+v9 11213
+unity 11214
+appqq 11215
+leo 11216
+##tone 11217
+##ass 11218
+uniqlo 11219
+##010 11220
+moneydj 11221
+##tical 11222
+12306 11223
+##m2 11224
+coc 11225
+miacare 11226
+##mn 11227
+tmt 11228
+##core 11229
+vim 11230
+kk 11231
+##may 11232
+target 11233
+##2c 11234
+##ope 11235
+omega 11236
+pinkoi 11237
+##rain 11238
+##ement 11239
+p9 11240
+rd 11241
+##tier 11242
+##vic 11243
+zone 11244
+isofix 11245
+cpa 11246
+kimi 11247
+##lay 11248
+lulu 11249
+##uck 11250
+050 11251
+weeks 11252
+##hop 11253
+##ear 11254
+eia 11255
+##fly 11256
+korea 11257
+boost 11258
+##ship 11259
+eur 11260
+valley 11261
+##iel 11262
+##ude 11263
+rn 11264
+##ena 11265
+feed 11266
+5757 11267
+qqmei 11268
+##thing 11269
+aws 11270
+pink 11271
+##ters 11272
+##kin 11273
+board 11274
+##vertisement 11275
+wine 11276
+##ien 11277
+##dge 11278
+##tant 11279
+##twitter 11280
+##3c 11281
+cool1 11282
+##012 11283
+##150 11284
+##fu 11285
+##iner 11286
+googlemsn 11287
+pixnetfacebookyahoo 11288
+x7 11289
+##uce 11290
+sao 11291
+##ev 11292
+##file 11293
+9678 11294
+xddd 11295
+shirt 11296
+##rio 11297
+##hat 11298
+givenchy 11299
+bang 11300
+##lio 11301
+monday 11302
+##abc 11303
+ubuntuforumwikilinuxpastechat 11304
+##vc 11305
+##rity 11306
+7866 11307
+##ost 11308
+imsean 11309
+tiger 11310
+##fet 11311
+dji 11312
+##come 11313
+##beth 11314
+##aft 11315
+##don 11316
+3p 11317
+emma 11318
+##khz 11319
+x6 11320
+##face 11321
+pptv 11322
+x4 11323
+##mate 11324
+sophie 11325
+##jing 11326
+fifa 11327
+##mand 11328
+sale 11329
+inwedding 11330
+##gn 11331
+##mmy 11332
+##pmlast 11333
+nana 11334
+##wu 11335
+note7 11336
+##340 11337
+##bel 11338
+window 11339
+##dio 11340
+##ht 11341
+##ivity 11342
+domain 11343
+neo 11344
+##isa 11345
+##lter 11346
+5k 11347
+f5 11348
+##cts 11349
+ft 11350
+zol 11351
+##act 11352
+mwc 11353
+nbapop 11354
+eds 11355
+##room 11356
+previous 11357
+tomtom 11358
+##ets 11359
+5t 11360
+chi 11361
+##hg 11362
+fairmont 11363
+gay 11364
+1b 11365
+##raph 11366
+##ils 11367
+i3 11368
+avenue 11369
+##host 11370
+##bon 11371
+##tsu 11372
+message 11373
+navigation 11374
+fintech 11375
+h6 11376
+##ject 11377
+##vas 11378
+##firm 11379
+credit 11380
+##wf 11381
+xxxx 11382
+##nor 11383
+##space 11384
+huawei 11385
+plan 11386
+json 11387
+sbl 11388
+##dc 11389
+wish 11390
+##120 11391
+##sol 11392
+windows7 11393
+washington 11394
+##nsis 11395
+lo 11396
+##sio 11397
+##ym 11398
+##bor 11399
+planet 11400
+##wt 11401
+gpa 11402
+##tw 11403
+##oka 11404
+connect 11405
+##rss 11406
+##work 11407
+##atus 11408
+chicken 11409
+##times 11410
+fa 11411
+##ather 11412
+##cord 11413
+009 11414
+##eep 11415
+hitachi 11416
+##pan 11417
+disney 11418
+##press 11419
+wind 11420
+frigidaire 11421
+##tl 11422
+hsu 11423
+##ull 11424
+expedia 11425
+archives 11426
+##wei 11427
+cut 11428
+ins 11429
+6gb 11430
+brand 11431
+cf1 11432
+##rip 11433
+##nis 11434
+128gb 11435
+3t 11436
+##oon 11437
+quick 11438
+15058 11439
+wing 11440
+##bug 11441
+##cms 11442
+##dar 11443
+##oh 11444
+zoom 11445
+trip 11446
+##nba 11447
+rcep 11448
+aspx 11449
+080 11450
+gnu 11451
+##count 11452
+##url 11453
+##ging 11454
+8591 11455
+am09 11456
+shadow 11457
+##cia 11458
+emily 11459
+##tation 11460
+host 11461
+ff 11462
+techorz 11463
+##mini 11464
+##mporary 11465
+##ering 11466
+##next 11467
+cma 11468
+##mbps 11469
+##gas 11470
+##ift 11471
+##dot 11472
+amana 11473
+##ros 11474
+##eet 11475
+##ible 11476
+##aka 11477
+##lor 11478
+maggie 11479
+##011 11480
+##iu 11481
+##gt 11482
+1tb 11483
+articles 11484
+##burg 11485
+##iki 11486
+database 11487
+fantasy 11488
+##rex 11489
+##cam 11490
+dlc 11491
+dean 11492
+##you 11493
+path 11494
+gaming 11495
+victoria 11496
+maps 11497
+##lee 11498
+##itor 11499
+overchicstoretvhome 11500
+##xt 11501
+##nan 11502
+x9 11503
+install 11504
+##ann 11505
+##ph 11506
+##rcle 11507
+##nic 11508
+##nar 11509
+metro 11510
+chocolate 11511
+##rian 11512
+##table 11513
+skin 11514
+##sn 11515
+mountain 11516
+##0mm 11517
+inparadise 11518
+7x24 11519
+##jia 11520
+eeworld 11521
+creative 11522
+g5 11523
+parker 11524
+ecfa 11525
+village 11526
+sylvia 11527
+hbl 11528
+##ques 11529
+##onsored 11530
+##x2 11531
+##v4 11532
+##tein 11533
+ie6 11534
+##stack 11535
+ver 11536
+##ads 11537
+##baby 11538
+bbe 11539
+##110 11540
+##lone 11541
+##uid 11542
+ads 11543
+022 11544
+gundam 11545
+006 11546
+scrum 11547
+match 11548
+##ave 11549
+##470 11550
+##oy 11551
+##talk 11552
+glass 11553
+lamigo 11554
+##eme 11555
+##a5 11556
+wade 11557
+kde 11558
+##lace 11559
+ocean 11560
+tvg 11561
+##covery 11562
+##r3 11563
+##ners 11564
+##rea 11565
+##aine 11566
+cover 11567
+##ision 11568
+##sia 11569
+##bow 11570
+msi 11571
+##love 11572
+soft 11573
+z2 11574
+##pl 11575
+mobil 11576
+##uy 11577
+nginx 11578
+##oi 11579
+##rr 11580
+6221 11581
+##mple 11582
+##sson 11583
+##nts 11584
+91tv 11585
+comhd 11586
+crv3000 11587
+##uard 11588
+gallery 11589
+##bia 11590
+rate 11591
+spf 11592
+redis 11593
+traction 11594
+icloud 11595
+011 11596
+jose 11597
+##tory 11598
+sohu 11599
+899 11600
+kicstart2 11601
+##hia 11602
+##sit 11603
+##walk 11604
+##xure 11605
+500g 11606
+##pact 11607
+xa 11608
+carlo 11609
+##250 11610
+##walker 11611
+##can 11612
+cto 11613
+gigi 11614
+pen 11615
+##hoo 11616
+ob 11617
+##yy 11618
+13913459 11619
+##iti 11620
+mango 11621
+##bbs 11622
+sense 11623
+oxford 11624
+walker 11625
+jennifer 11626
+##ola 11627
+course 11628
+##bre 11629
+##pus 11630
+##rder 11631
+lucky 11632
+075 11633
+ivy 11634
+##nia 11635
+sotheby 11636
+##ugh 11637
+joy 11638
+##orage 11639
+##ush 11640
+##bat 11641
+##dt 11642
+r9 11643
+##2d 11644
+##gio 11645
+wear 11646
+##lax 11647
+##moon 11648
+seven 11649
+lonzo 11650
+8k 11651
+evolution 11652
+##kk 11653
+kd 11654
+arduino 11655
+##lux 11656
+arpg 11657
+##rdon 11658
+cook 11659
+##x5 11660
+five 11661
+##als 11662
+##ida 11663
+sign 11664
+##nda 11665
+##posted 11666
+fresh 11667
+##mine 11668
+##skip 11669
+##form 11670
+##ssion 11671
+##tee 11672
+dyson 11673
+stage 11674
+##jie 11675
+##night 11676
+epson 11677
+pack 11678
+##ppy 11679
+wd 11680
+##eh 11681
+##rence 11682
+##lvin 11683
+golden 11684
+discovery 11685
+##trix 11686
+##n2 11687
+loft 11688
+##uch 11689
+##dra 11690
+##sse 11691
+1mdb 11692
+welcome 11693
+##urn 11694
+gaga 11695
+##lmer 11696
+teddy 11697
+##160 11698
+##f2016 11699
+##sha 11700
+rar 11701
+holiday 11702
+074 11703
+##vg 11704
+##nos 11705
+##rail 11706
+gartner 11707
+gi 11708
+6p 11709
+##dium 11710
+kit 11711
+b3 11712
+eco 11713
+sean 11714
+##stone 11715
+nu 11716
+##np 11717
+f16 11718
+write 11719
+029 11720
+m5 11721
+##ias 11722
+##dk 11723
+fsm 11724
+52kb 11725
+##xxx 11726
+##cake 11727
+lim 11728
+ru 11729
+1v 11730
+##ification 11731
+published 11732
+angela 11733
+16g 11734
+analytics 11735
+##nel 11736
+gmt 11737
+##icon 11738
+##bby 11739
+ios11 11740
+waze 11741
+9985 11742
+##ust 11743
+##007 11744
+delete 11745
+52sykb 11746
+wwdc 11747
+027 11748
+##fw 11749
+1389 11750
+##xon 11751
+brandt 11752
+##ses 11753
+##dragon 11754
+vetements 11755
+anne 11756
+monte 11757
+official 11758
+##ere 11759
+##nne 11760
+##oud 11761
+etnews 11762
+##a2 11763
+##graphy 11764
+##rtex 11765
+##gma 11766
+mount 11767
+archive 11768
+morning 11769
+tan 11770
+ddos 11771
+e7 11772
+day4 11773
+factory 11774
+bruce 11775
+##ito 11776
+guest 11777
+##lling 11778
+n3 11779
+mega 11780
+women 11781
+dac 11782
+church 11783
+##jun 11784
+singapore 11785
+##facebook 11786
+6991 11787
+starbucks 11788
+##tos 11789
+##stin 11790
+##shine 11791
+zen 11792
+##mu 11793
+tina 11794
+request 11795
+##gence 11796
+q7 11797
+##zzi 11798
+diary 11799
+##tore 11800
+##ead 11801
+cst 11802
+##osa 11803
+canada 11804
+va 11805
+##jiang 11806
+##lam 11807
+##nix 11808
+##sday 11809
+g6 11810
+##master 11811
+bing 11812
+##zl 11813
+nb40 11814
+thai 11815
+ln284ct 11816
+##itz 11817
+##2f 11818
+bonnie 11819
+##food 11820
+##lent 11821
+originals 11822
+##stro 11823
+##lts 11824
+##bscribe 11825
+ntd 11826
+yesstyle 11827
+hmv 11828
+##tment 11829
+d5 11830
+##pn 11831
+topios9 11832
+lifestyle 11833
+virtual 11834
+##ague 11835
+xz 11836
+##deo 11837
+muji 11838
+024 11839
+unt 11840
+##nnis 11841
+faq1 11842
+##ette 11843
+curry 11844
+##pop 11845
+release 11846
+##cast 11847
+073 11848
+##ews 11849
+5c 11850
+##stle 11851
+ios7 11852
+##ima 11853
+dog 11854
+lenovo 11855
+##r4 11856
+013 11857
+vornado 11858
+##desk 11859
+##ald 11860
+9595 11861
+##van 11862
+oil 11863
+common 11864
+##jy 11865
+##lines 11866
+g7 11867
+twice 11868
+ella 11869
+nano 11870
+belle 11871
+##mes 11872
+##self 11873
+##note 11874
+benz 11875
+##ova 11876
+##wing 11877
+kai 11878
+##hua 11879
+##rect 11880
+rainer 11881
+##unge 11882
+##0m 11883
+guestname 11884
+##uma 11885
+##kins 11886
+##zu 11887
+tokichoi 11888
+##price 11889
+##med 11890
+##mus 11891
+rmk 11892
+address 11893
+vm 11894
+openload 11895
+##group 11896
+##hin 11897
+##iginal 11898
+amg 11899
+urban 11900
+##oz 11901
+jobs 11902
+##public 11903
+##sch 11904
+##dden 11905
+##bell 11906
+hostel 11907
+##drive 11908
+##rmin 11909
+boot 11910
+##370 11911
+##fx 11912
+##nome 11913
+##ctionary 11914
+##oman 11915
+##lish 11916
+##cr 11917
+##hm 11918
+##how 11919
+francis 11920
+c919 11921
+b5 11922
+evernote 11923
+##uc 11924
+##3000 11925
+coupe 11926
+##urg 11927
+##cca 11928
+##uality 11929
+019 11930
+##ett 11931
+##ani 11932
+##tax 11933
+##rma 11934
+leonnhurt 11935
+##jin 11936
+ict 11937
+bird 11938
+notes 11939
+##dical 11940
+##lli 11941
+result 11942
+iu 11943
+ee 11944
+smap 11945
+gopro 11946
+##last 11947
+yin 11948
+pure 11949
+32g 11950
+##dan 11951
+##rame 11952
+mama 11953
+##oot 11954
+bean 11955
+##hur 11956
+2l 11957
+bella 11958
+sync 11959
+xuite 11960
+##ground 11961
+discuz 11962
+##getrelax 11963
+##ince 11964
+##bay 11965
+##5s 11966
+apt 11967
+##pass 11968
+jing 11969
+##rix 11970
+rich 11971
+niusnews 11972
+##ello 11973
+bag 11974
+##eting 11975
+##mobile 11976
+##ience 11977
+details 11978
+universal 11979
+silver 11980
+dit 11981
+private 11982
+ddd 11983
+u11 11984
+kanshu 11985
+##ified 11986
+fung 11987
+##nny 11988
+dx 11989
+##520 11990
+tai 11991
+023 11992
+##fr 11993
+##lean 11994
+##pin 11995
+##rin 11996
+ly 11997
+rick 11998
+##bility 11999
+banner 12000
+##baru 12001
+##gion 12002
+vdf 12003
+qualcomm 12004
+bear 12005
+oldid 12006
+ian 12007
+jo 12008
+##tors 12009
+population 12010
+##ernel 12011
+##mv 12012
+##bike 12013
+ww 12014
+##ager 12015
+exhibition 12016
+##del 12017
+##pods 12018
+fpx 12019
+structure 12020
+##free 12021
+##tings 12022
+kl 12023
+##rley 12024
+##copyright 12025
+##mma 12026
+orange 12027
+yoga 12028
+4l 12029
+canmake 12030
+honey 12031
+##anda 12032
+nikkie 12033
+dhl 12034
+publishing 12035
+##mall 12036
+##gnet 12037
+e88 12038
+##dog 12039
+fishbase 12040
+### 12041
+##[ 12042
+。 12043
+! 12044
+? 12045
+! 12046
+? 12047
+; 12048
+: 12049
+; 12050
+- 12051
+( 12052
+) 12053
+/ 12054
++ 12055
+" 12056
+_ 12057
+… 12058
+~ 12059
+= 12060
+' 12061
+% 12062
+& 12063
+· 12064
+* 12065
+@ 12066
+\ 12067
+] 12068
+— 12069
+~ 12070
+^ 12071
+> 12072
+丨 12073
+| 12074
+< 12075
+】 12076
+の 12077
+【 12078
+〔 12079
+〕 12080
+ー 12081
+★ 12082
+’ 12083
+$ 12084
+{ 12085
+} 12086
+‘ 12087
+[UNK] 12088
diff --git a/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/model/__init__.py b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/model/ernie.py b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/model/ernie.py
new file mode 100644
index 0000000000000000000000000000000000000000..5846878cd1fdface78bc1704a48e86e9f6d00250
--- /dev/null
+++ b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/model/ernie.py
@@ -0,0 +1,377 @@
+# -*- coding:utf-8 -**
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""ERNIE"""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import json
+import logging
+
+import paddle.fluid as fluid
+import six
+
+from .transformer_encoder import encoder, pre_process_layer
+from .transformer_encoder import gelu
+
+
+class ErnieModel(object):
+ """
+ ErnieModel
+ """
+
+ def __init__(self,
+ src_ids,
+ position_ids,
+ sentence_ids,
+ input_mask,
+ config,
+ weight_sharing=True,
+ use_fp16=False):
+ """
+ :param src_ids:
+ :param position_ids:
+ :param sentence_ids:
+ :param input_mask:
+ :param config:
+ :param weight_sharing:
+ :param use_fp16:
+ """
+ self._hidden_size = config.get('hidden_size', 768)
+ self._emb_size = config.get('emb_size', self._hidden_size)
+ self._n_layer = config.get('num_hidden_layers', 12)
+ self._n_head = config.get('num_attention_heads', 12)
+ self._voc_size = config.get('vocab_size', 30522)
+ self._max_position_seq_len = config.get('max_position_embeddings', 512)
+ self._param_share = config.get('param_share', "normal")
+ self._pre_encoder_cmd = config.get('pre_encoder_cmd', "nd")
+ self._preprocess_cmd = config.get('preprocess_cmd', "")
+ self._postprocess_cmd = config.get('postprocess_cmd', "dan")
+ self._epsilon = config.get('epsilon', 1e-05)
+ self._emb_mapping_in = config.get('emb_mapping_in', False)
+ self._n_layer_per_block = config.get('n_layer_per_block', 1)
+
+ if config.has('sent_type_vocab_size'):
+ self._sent_types = config['sent_type_vocab_size']
+ else:
+ self._sent_types = config.get('type_vocab_size', 2)
+
+ self._use_sentence_id = config.get('use_sentence_id', True)
+ self._use_task_id = config.get('use_task_id', False)
+ if self._use_task_id:
+ self._task_types = config.get('task_type_vocab_size', 3)
+ self._hidden_act = config.get('hidden_act', 'gelu')
+ self._prepostprocess_dropout = config.get('hidden_dropout_prob', 0.1)
+ self._attention_dropout = config.get('attention_probs_dropout_prob',
+ 0.1)
+ self._weight_sharing = weight_sharing
+
+ self._word_emb_name = "word_embedding"
+ self._pos_emb_name = "pos_embedding"
+ self._sent_emb_name = "sent_embedding"
+ self._task_emb_name = "task_embedding"
+ self._dtype = "float16" if use_fp16 else "float32"
+ self._emb_dtype = "float32"
+ # Initialize all weigths by truncated normal initializer, and all biases
+ # will be initialized by constant zero by default.
+ self._param_initializer = fluid.initializer.TruncatedNormal(
+ scale=config.get('initializer_range', 0.02))
+
+ self._build_model(src_ids, position_ids, sentence_ids, input_mask)
+
+ def _build_model(self, src_ids, position_ids, sentence_ids, input_mask):
+ """
+ :param src_ids:
+ :param position_ids:
+ :param sentence_ids:
+ :param input_mask:
+ :return:
+ """
+ # padding id in vocabulary must be set to 0
+ emb_out = fluid.layers.embedding(
+ input=src_ids,
+ dtype=self._emb_dtype,
+ size=[self._voc_size, self._emb_size],
+ param_attr=fluid.ParamAttr(
+ name=self._word_emb_name, initializer=self._param_initializer),
+ is_sparse=False)
+
+ position_emb_out = fluid.layers.embedding(
+ input=position_ids,
+ dtype=self._emb_dtype,
+ size=[self._max_position_seq_len, self._emb_size],
+ param_attr=fluid.ParamAttr(
+ name=self._pos_emb_name, initializer=self._param_initializer))
+
+ emb_out = emb_out + position_emb_out
+
+ if self._use_sentence_id:
+ sent_emb_out = fluid.layers.embedding(
+ sentence_ids,
+ dtype=self._emb_dtype,
+ size=[self._sent_types, self._emb_size],
+ param_attr=fluid.ParamAttr(
+ name=self._sent_emb_name,
+ initializer=self._param_initializer))
+
+ emb_out = emb_out + sent_emb_out
+
+ emb_out = pre_process_layer(
+ emb_out,
+ self._pre_encoder_cmd,
+ self._prepostprocess_dropout,
+ name='pre_encoder',
+ epsilon=self._epsilon)
+
+ if self._emb_mapping_in:
+ emb_out = fluid.layers.fc(
+ input=emb_out,
+ num_flatten_dims=2,
+ size=self._hidden_size,
+ param_attr=fluid.ParamAttr(
+ name='emb_hidden_mapping',
+ initializer=self._param_initializer),
+ bias_attr='emb_hidden_mapping_bias')
+
+ if self._dtype == "float16":
+ emb_out = fluid.layers.cast(x=emb_out, dtype=self._dtype)
+ input_mask = fluid.layers.cast(x=input_mask, dtype=self._dtype)
+ self_attn_mask = fluid.layers.matmul(
+ x=input_mask, y=input_mask, transpose_y=True)
+
+ self_attn_mask = fluid.layers.scale(
+ x=self_attn_mask, scale=10000.0, bias=-1.0, bias_after_scale=False)
+ n_head_self_attn_mask = fluid.layers.stack(
+ x=[self_attn_mask] * self._n_head, axis=1)
+ n_head_self_attn_mask.stop_gradient = True
+
+ self._enc_out, self._checkpoints = encoder(
+ enc_input=emb_out,
+ attn_bias=n_head_self_attn_mask,
+ n_layer=self._n_layer,
+ n_head=self._n_head,
+ d_key=self._hidden_size // self._n_head,
+ d_value=self._hidden_size // self._n_head,
+ d_model=self._hidden_size,
+ d_inner_hid=self._hidden_size * 4,
+ prepostprocess_dropout=self._prepostprocess_dropout,
+ attention_dropout=self._attention_dropout,
+ relu_dropout=0,
+ hidden_act=self._hidden_act,
+ preprocess_cmd=self._preprocess_cmd,
+ postprocess_cmd=self._postprocess_cmd,
+ param_initializer=self._param_initializer,
+ name='encoder',
+ param_share=self._param_share,
+ epsilon=self._epsilon,
+ n_layer_per_block=self._n_layer_per_block)
+ if self._dtype == "float16":
+ self._enc_out = fluid.layers.cast(
+ x=self._enc_out, dtype=self._emb_dtype)
+
+ def get_sequence_output(self):
+ """
+ :return:
+ """
+ return self._enc_out
+
+ def get_pooled_output(self):
+ """Get the first feature of each sequence for classification"""
+ next_sent_feat = fluid.layers.slice(
+ input=self._enc_out, axes=[1], starts=[0], ends=[1])
+ """
+ if self._dtype == "float16":
+ next_sent_feat = fluid.layers.cast(
+ x=next_sent_feat, dtype=self._emb_dtype)
+
+ next_sent_feat = fluid.layers.fc(
+ input=next_sent_feat,
+ size=self._emb_size,
+ param_attr=fluid.ParamAttr(
+ name="mask_lm_trans_fc.w_0", initializer=self._param_initializer),
+ bias_attr="mask_lm_trans_fc.b_0")
+ """
+ """
+ next_sent_feat = fluid.layers.fc(
+ input=next_sent_feat,
+ size=self._emb_size,
+ param_attr=fluid.ParamAttr(
+ name="mask_lm_trans_fc.w_0", initializer=self._param_initializer),
+ bias_attr="mask_lm_trans_fc.b_0")
+
+ """
+ next_sent_feat = fluid.layers.fc(
+ input=next_sent_feat,
+ size=self._hidden_size,
+ act="tanh",
+ param_attr=fluid.ParamAttr(
+ name="pooled_fc.w_0", initializer=self._param_initializer),
+ bias_attr="pooled_fc.b_0")
+ return next_sent_feat
+
+ def get_lm_output(self, mask_label, mask_pos):
+ """Get the loss & accuracy for pretraining"""
+ mask_pos = fluid.layers.cast(x=mask_pos, dtype='int32')
+ # extract the first token feature in each sentence
+ self.next_sent_feat = self.get_pooled_output()
+ reshaped_emb_out = fluid.layers.reshape(
+ x=self._enc_out, shape=[-1, self._hidden_size])
+ # extract masked tokens' feature
+ mask_feat = fluid.layers.gather(input=reshaped_emb_out, index=mask_pos)
+
+ if self._dtype == "float16":
+ mask_feat = fluid.layers.cast(x=mask_feat, dtype=self._emb_dtype)
+
+ # transform: fc
+ if self._hidden_act == 'gelu' or self._hidden_act == 'gelu.precise':
+ _hidden_act = 'gelu'
+ elif self._hidden_act == 'gelu.approximate':
+ _hidden_act = None
+ else:
+ _hidden_act = self._hidden_act
+ mask_trans_feat = fluid.layers.fc(
+ input=mask_feat,
+ size=self._emb_size,
+ act=_hidden_act,
+ param_attr=fluid.ParamAttr(
+ name='mask_lm_trans_fc.w_0',
+ initializer=self._param_initializer),
+ bias_attr=fluid.ParamAttr(name='mask_lm_trans_fc.b_0'))
+ if self._hidden_act == 'gelu.approximate':
+ mask_trans_feat = gelu(mask_trans_feat)
+ else:
+ pass
+ # transform: layer norm
+ mask_trans_feat = fluid.layers.layer_norm(
+ mask_trans_feat,
+ begin_norm_axis=len(mask_trans_feat.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name='mask_lm_trans_layer_norm_scale',
+ initializer=fluid.initializer.Constant(1.)),
+ bias_attr=fluid.ParamAttr(
+ name='mask_lm_trans_layer_norm_bias',
+ initializer=fluid.initializer.Constant(1.)))
+ # transform: layer norm
+ # mask_trans_feat = pre_process_layer(
+ # mask_trans_feat, 'n', name='mask_lm_trans')
+
+ mask_lm_out_bias_attr = fluid.ParamAttr(
+ name="mask_lm_out_fc.b_0",
+ initializer=fluid.initializer.Constant(value=0.0))
+ if self._weight_sharing:
+ fc_out = fluid.layers.matmul(
+ x=mask_trans_feat,
+ y=fluid.default_main_program().global_block().var(
+ self._word_emb_name),
+ transpose_y=True)
+ fc_out += fluid.layers.create_parameter(
+ shape=[self._voc_size],
+ dtype=self._emb_dtype,
+ attr=mask_lm_out_bias_attr,
+ is_bias=True)
+
+ else:
+ fc_out = fluid.layers.fc(
+ input=mask_trans_feat,
+ size=self._voc_size,
+ param_attr=fluid.ParamAttr(
+ name="mask_lm_out_fc.w_0",
+ initializer=self._param_initializer),
+ bias_attr=mask_lm_out_bias_attr)
+
+ mask_lm_loss = fluid.layers.softmax_with_cross_entropy(
+ logits=fc_out, label=mask_label)
+ mean_mask_lm_loss = fluid.layers.mean(mask_lm_loss)
+
+ return mean_mask_lm_loss
+
+ def get_task_output(self, task, task_labels):
+ """
+ :param task:
+ :param task_labels:
+ :return:
+ """
+ task_fc_out = fluid.layers.fc(
+ input=self.next_sent_feat,
+ size=task["num_labels"],
+ param_attr=fluid.ParamAttr(
+ name=task["task_name"] + "_fc.w_0",
+ initializer=self._param_initializer),
+ bias_attr=task["task_name"] + "_fc.b_0")
+ task_loss, task_softmax = fluid.layers.softmax_with_cross_entropy(
+ logits=task_fc_out, label=task_labels, return_softmax=True)
+ task_acc = fluid.layers.accuracy(input=task_softmax, label=task_labels)
+ mean_task_loss = fluid.layers.mean(task_loss)
+ return mean_task_loss, task_acc
+
+
+class ErnieConfig(object):
+ """parse ernie config"""
+
+ def __init__(self, config_path):
+ """
+ :param config_path:
+ """
+ self._config_dict = self._parse(config_path)
+
+ def _parse(self, config_path):
+ """
+ :param config_path:
+ :return:
+ """
+ try:
+ with open(config_path, 'r') as json_file:
+ config_dict = json.load(json_file)
+ except Exception:
+ raise IOError(
+ "Error in parsing Ernie model config file '%s'" % config_path)
+ else:
+ return config_dict
+
+ def __getitem__(self, key):
+ """
+ :param key:
+ :return:
+ """
+ return self._config_dict.get(key, None)
+
+ def has(self, key):
+ """
+ :param key:
+ :return:
+ """
+ if key in self._config_dict:
+ return True
+ return False
+
+ def get(self, key, default_value):
+ """
+ :param key,default_value:
+ :retrun:
+ """
+ if key in self._config_dict:
+ return self._config_dict[key]
+ else:
+ return default_value
+
+ def print_config(self):
+ """
+ :return:
+ """
+ for arg, value in sorted(six.iteritems(self._config_dict)):
+ logging.info('%s: %s' % (arg, value))
+ logging.info('------------------------------------------------')
diff --git a/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/model/transformer_encoder.py b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/model/transformer_encoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..80f7a7759ac16943dde323385b6351c7c5643bb4
--- /dev/null
+++ b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/model/transformer_encoder.py
@@ -0,0 +1,501 @@
+# -*- coding:utf-8 -**
+# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Transformer encoder."""
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+from functools import partial
+
+import paddle.fluid as fluid
+import paddle.fluid.layers as layers
+import numpy as np
+
+
+def gelu(x):
+ """Gaussian Error Linear Unit.
+
+ This is a smoother version of the RELU.
+ Original paper: https://arxiv.org/abs/1606.08415
+ Args:
+ x: float Tensor to perform activation.
+
+ Returns:
+ `x` with the GELU activation applied.
+ """
+ cdf = 0.5 * (1.0 + fluid.layers.tanh(
+ (np.sqrt(2.0 / np.pi) * (x + 0.044715 * fluid.layers.pow(x, 3.0)))))
+ return x * cdf
+
+
+def multi_head_attention(queries,
+ keys,
+ values,
+ attn_bias,
+ d_key,
+ d_value,
+ d_model,
+ n_head=1,
+ dropout_rate=0.,
+ cache=None,
+ param_initializer=None,
+ name='multi_head_att'):
+ """
+ Multi-Head Attention. Note that attn_bias is added to the logit before
+ computing softmax activiation to mask certain selected positions so that
+ they will not considered in attention weights.
+ """
+ keys = queries if keys is None else keys
+ values = keys if values is None else values
+ if not (len(queries.shape) == len(keys.shape) == len(values.shape) == 3):
+ raise ValueError(
+ "Inputs: quries, keys and values should all be 3-D tensors. but {} v.s. {} v.s. {}"\
+ .format(queries.shape, keys.shape, values.shape))
+
+ def __compute_qkv(queries, keys, values, n_head, d_key, d_value):
+ """
+ Add linear projection to queries, keys, and values.
+ """
+ q = layers.fc(
+ input=queries,
+ size=d_key * n_head,
+ num_flatten_dims=2,
+ param_attr=fluid.ParamAttr(
+ name=name + '_query_fc.w_0', initializer=param_initializer),
+ bias_attr=name + '_query_fc.b_0')
+ k = layers.fc(
+ input=keys,
+ size=d_key * n_head,
+ num_flatten_dims=2,
+ param_attr=fluid.ParamAttr(
+ name=name + '_key_fc.w_0', initializer=param_initializer),
+ bias_attr=name + '_key_fc.b_0')
+ v = layers.fc(
+ input=values,
+ size=d_value * n_head,
+ num_flatten_dims=2,
+ param_attr=fluid.ParamAttr(
+ name=name + '_value_fc.w_0', initializer=param_initializer),
+ bias_attr=name + '_value_fc.b_0')
+ return q, k, v
+
+ def __split_heads(x, n_head):
+ """
+ Reshape the last dimension of inpunt tensor x so that it becomes two
+ dimensions and then transpose. Specifically, input a tensor with shape
+ [bs, max_sequence_length, n_head * hidden_dim] then output a tensor
+ with shape [bs, n_head, max_sequence_length, hidden_dim].
+ """
+ hidden_size = x.shape[-1]
+ # The value 0 in shape attr means copying the corresponding dimension
+ # size of the input as the output dimension size.
+ reshaped = layers.reshape(
+ x=x, shape=[0, 0, n_head, hidden_size // n_head], inplace=True)
+
+ # permuate the dimensions into:
+ # [batch_size, n_head, max_sequence_len, hidden_size_per_head]
+ return layers.transpose(x=reshaped, perm=[0, 2, 1, 3])
+
+ def __combine_heads(x):
+ """
+ Transpose and then reshape the last two dimensions of inpunt tensor x
+ so that it becomes one dimension, which is reverse to __split_heads.
+ """
+ if len(x.shape) == 3: return x
+ if len(x.shape) != 4:
+ raise ValueError("Input(x) should be a 4-D Tensor.")
+
+ trans_x = layers.transpose(x, perm=[0, 2, 1, 3])
+ # The value 0 in shape attr means copying the corresponding dimension
+ # size of the input as the output dimension size.
+ return layers.reshape(
+ x=trans_x,
+ shape=[0, 0, trans_x.shape[2] * trans_x.shape[3]],
+ inplace=True)
+
+ def scaled_dot_product_attention(q, k, v, attn_bias, d_key, dropout_rate):
+ """
+ Scaled Dot-Product Attention
+ """
+ scaled_q = layers.scale(x=q, scale=d_key**-0.5)
+ product = layers.matmul(x=scaled_q, y=k, transpose_y=True)
+ if attn_bias:
+ product += attn_bias
+ weights = layers.softmax(product)
+ if dropout_rate:
+ weights = layers.dropout(
+ weights,
+ dropout_prob=dropout_rate,
+ dropout_implementation="upscale_in_train",
+ is_test=False)
+ out = layers.matmul(weights, v)
+ return out
+
+ q, k, v = __compute_qkv(queries, keys, values, n_head, d_key, d_value)
+
+ if cache is not None: # use cache and concat time steps
+ # Since the inplace reshape in __split_heads changes the shape of k and
+ # v, which is the cache input for next time step, reshape the cache
+ # input from the previous time step first.
+ k = cache["k"] = layers.concat(
+ [layers.reshape(cache["k"], shape=[0, 0, d_model]), k], axis=1)
+ v = cache["v"] = layers.concat(
+ [layers.reshape(cache["v"], shape=[0, 0, d_model]), v], axis=1)
+
+ q = __split_heads(q, n_head)
+ k = __split_heads(k, n_head)
+ v = __split_heads(v, n_head)
+
+ ctx_multiheads = scaled_dot_product_attention(q, k, v, attn_bias, d_key,
+ dropout_rate)
+
+ out = __combine_heads(ctx_multiheads)
+
+ # Project back to the model size.
+ proj_out = layers.fc(
+ input=out,
+ size=d_model,
+ num_flatten_dims=2,
+ param_attr=fluid.ParamAttr(
+ name=name + '_output_fc.w_0', initializer=param_initializer),
+ bias_attr=name + '_output_fc.b_0')
+ return proj_out
+
+
+def positionwise_feed_forward(x,
+ d_inner_hid,
+ d_hid,
+ dropout_rate,
+ hidden_act,
+ param_initializer=None,
+ name='ffn'):
+ """
+ Position-wise Feed-Forward Networks.
+ This module consists of two linear transformations with a ReLU activation
+ in between, which is applied to each position separately and identically.
+ """
+ if hidden_act == 'gelu' or hidden_act == 'gelu.precise':
+ _hidden_act = 'gelu'
+ elif hidden_act == 'gelu.approximate':
+ _hidden_act = None
+ else:
+ _hidden_act = hidden_act
+ hidden = layers.fc(
+ input=x,
+ size=d_inner_hid,
+ num_flatten_dims=2,
+ act=_hidden_act,
+ param_attr=fluid.ParamAttr(
+ name=name + '_fc_0.w_0', initializer=param_initializer),
+ bias_attr=name + '_fc_0.b_0')
+ if hidden_act == 'gelu.approximate':
+ hidden = gelu(hidden)
+
+ if dropout_rate:
+ hidden = layers.dropout(
+ hidden,
+ dropout_prob=dropout_rate,
+ dropout_implementation="upscale_in_train",
+ is_test=False)
+ out = layers.fc(
+ input=hidden,
+ size=d_hid,
+ num_flatten_dims=2,
+ param_attr=fluid.ParamAttr(
+ name=name + '_fc_1.w_0', initializer=param_initializer),
+ bias_attr=name + '_fc_1.b_0')
+ return out
+
+
+def pre_post_process_layer(prev_out,
+ out,
+ process_cmd,
+ dropout_rate=0.,
+ epsilon=1e-12,
+ name=''):
+ """
+ Add residual connection, layer normalization and droput to the out tensor
+ optionally according to the value of process_cmd.
+ This will be used before or after multi-head attention and position-wise
+ feed-forward networks.
+ """
+ for cmd in process_cmd:
+ if cmd == "a": # add residual connection
+ out = out + prev_out if prev_out else out
+ elif cmd == "n": # add layer normalization
+ out_dtype = out.dtype
+ if out_dtype == fluid.core.VarDesc.VarType.FP16:
+ out = layers.cast(x=out, dtype="float32")
+ out = layers.layer_norm(
+ out,
+ begin_norm_axis=len(out.shape) - 1,
+ param_attr=fluid.ParamAttr(
+ name=name + '_layer_norm_scale',
+ initializer=fluid.initializer.Constant(1.)),
+ bias_attr=fluid.ParamAttr(
+ name=name + '_layer_norm_bias',
+ initializer=fluid.initializer.Constant(0.)),
+ epsilon=epsilon)
+ if out_dtype == fluid.core.VarDesc.VarType.FP16:
+ out = layers.cast(x=out, dtype="float16")
+ elif cmd == "d": # add dropout
+ if dropout_rate:
+ out = layers.dropout(
+ out,
+ dropout_prob=dropout_rate,
+ dropout_implementation="upscale_in_train",
+ is_test=False)
+ return out
+
+
+pre_process_layer = partial(pre_post_process_layer, None)
+post_process_layer = pre_post_process_layer
+
+
+def encoder_layer(
+ enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd="n",
+ postprocess_cmd="da",
+ param_initializer=None,
+ name='',
+ epsilon=1e-12,
+):
+ """The encoder layers that can be stacked to form a deep encoder.
+ This module consits of a multi-head (self) attention followed by
+ position-wise feed-forward networks and both the two components companied
+ with the post_process_layer to add residual connection, layer normalization
+ and droput.
+ """
+
+ attn_output = multi_head_attention(
+ enc_input,
+ None,
+ None,
+ attn_bias,
+ d_key,
+ d_value,
+ d_model,
+ n_head,
+ attention_dropout,
+ param_initializer=param_initializer,
+ name=name + '_multi_head_att')
+
+ attn_output = post_process_layer(
+ enc_input,
+ attn_output,
+ postprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_post_att',
+ epsilon=epsilon)
+
+ ffd_output = positionwise_feed_forward(
+ attn_output,
+ d_inner_hid,
+ d_model,
+ relu_dropout,
+ hidden_act,
+ param_initializer=param_initializer,
+ name=name + '_ffn')
+
+ return post_process_layer(
+ attn_output,
+ ffd_output,
+ postprocess_cmd,
+ prepostprocess_dropout,
+ name=name + '_post_ffn',
+ epsilon=epsilon), ffd_output
+
+
+def encoder_inner_share(enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ epsilon,
+ param_initializer=None,
+ name='',
+ n_layer_per_block=1):
+ """
+ The encoder_inner_share is composed of n_layer_per_block layers returned by calling
+ encoder_layer.
+ """
+ _checkpoints = []
+ for i in range(n_layer_per_block):
+ enc_output, cp = encoder_layer(
+ enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ param_initializer=param_initializer,
+ name=name + '_layer_' + str(i),
+ epsilon=epsilon,
+ )
+ _checkpoints.append(cp)
+ enc_input = enc_output
+
+ return enc_output, _checkpoints
+
+
+def encoder_outer_share(enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ epsilon,
+ param_initializer=None,
+ name='',
+ n_layer_per_block=1):
+ """
+ The encoder_outer_share is composed of n_layer_per_block layers returned by calling
+ encoder_layer.
+ """
+ _checkpoints = []
+ for i in range(n_layer_per_block):
+ enc_output, cp = encoder_layer(
+ enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ param_initializer=param_initializer,
+ name=name,
+ epsilon=epsilon)
+ _checkpoints.append(cp)
+ enc_input = enc_output
+
+ return enc_output, _checkpoints
+
+
+def encoder(enc_input,
+ attn_bias,
+ n_layer,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ epsilon,
+ n_layer_per_block,
+ param_initializer=None,
+ name='',
+ param_share=None):
+ """
+ The encoder is composed of a stack of identical layers returned by calling
+ encoder_layer .
+ """
+ checkpoints = []
+ # for outer_share it will share same param in one block,
+ # and for inner_share it will share param across blocks, rather than in one same block
+ #
+ # outer-share inner-share
+ # [1] [1] ----\ 1st block
+ # [1] [2] ----/
+ # [2] [1] ----\ 2nd block
+ # [2] [2] ----/
+
+ if param_share == "normal" or param_share == 'outer_share':
+ #n_layer_per_block=1, n_layer=24 for bert-large
+ #n_layer_per_block=1, n_layer=12 for bert-base
+ #n_layer_per_block=12, n_layer=12 for albert-xxlarge
+ #n_layer_per_block=6, n_layer=12 for albert-xxlarge-outershare
+ enc_fn = encoder_outer_share
+ name_fn = lambda i: name + '_layer_' + str(i)
+ elif param_share == "inner_share":
+ #n_layer_per_block = 2
+ enc_fn = encoder_inner_share
+ name_fn = lambda i: name
+ else:
+ raise ValueError('unsupported param share mode')
+
+ for i in range(n_layer // n_layer_per_block):
+ enc_output, cp = enc_fn(
+ enc_input,
+ attn_bias,
+ n_head,
+ d_key,
+ d_value,
+ d_model,
+ d_inner_hid,
+ prepostprocess_dropout,
+ attention_dropout,
+ relu_dropout,
+ hidden_act,
+ preprocess_cmd,
+ postprocess_cmd,
+ param_initializer=param_initializer,
+ name=name_fn(i),
+ n_layer_per_block=n_layer_per_block,
+ epsilon=epsilon,
+ )
+ checkpoints.extend(cp)
+ enc_input = enc_output
+ enc_output = pre_process_layer(
+ enc_output,
+ preprocess_cmd,
+ prepostprocess_dropout,
+ name="post_encoder",
+ epsilon=epsilon)
+
+ return enc_output, checkpoints
diff --git a/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/module.py b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..87187836e8a3c5c32a1c0620ea26cf8230729e0a
--- /dev/null
+++ b/hub_module/modules/text/sentiment_analysis/ernie_skep_sentiment_analysis/module.py
@@ -0,0 +1,258 @@
+# coding:utf-8
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License"
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import argparse
+import ast
+import os
+
+from paddle.fluid.core import PaddleTensor, AnalysisConfig, create_paddle_predictor
+from paddlehub import TransformerModule
+from paddlehub.module.module import moduleinfo, runnable, serving
+from paddlehub.reader.tokenization import convert_to_unicode, FullTokenizer
+from paddlehub.reader.batching import pad_batch_data
+import numpy as np
+
+from ernie_skep_sentiment_analysis.model.ernie import ErnieModel, ErnieConfig
+
+
+@moduleinfo(
+ name="ernie_skep_sentiment_analysis",
+ version="1.0.0",
+ summary=
+ "SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis. Ernie_skep_sentiment_analysis module is initialize with enie_1.0_chn_large when pretraining. This module is finetuned on ChnSentiCorp dataset to do sentiment claasification. It can do sentiment analysis prediction directly, label as positive or negative.",
+ author="baidu-nlp",
+ author_email="",
+ type="nlp/sentiment_analysis",
+)
+class ErnieSkepSentimentAnalysis(TransformerModule):
+ """
+ Ernie_skep_sentiment_analysis module is initialize with enie_1.0_chn_large when pretraining.
+ This module is finetuned on ChnSentiCorp dataset to do sentiment claasification.
+ It can do sentiment analysis prediction directly, label as positive or negative.
+ """
+
+ def _initialize(self):
+ ernie_config_path = os.path.join(self.directory, "assets",
+ "ernie_1.0_large_ch.config.json")
+ self.ernie_config = ErnieConfig(ernie_config_path)
+ self.MAX_SEQ_LEN = 512
+ self.vocab_path = os.path.join(self.directory, "assets",
+ "ernie_1.0_large_ch.vocab.txt")
+ self.params_path = os.path.join(self.directory, "assets", "params")
+
+ self.infer_model_path = os.path.join(self.directory, "assets",
+ "inference_step_601")
+ self.tokenizer = FullTokenizer(vocab_file=self.vocab_path)
+
+ self.vocab = self.tokenizer.vocab
+ self.pad_id = self.vocab["[PAD]"]
+ self.label_map = {0: 'negative', 1: 'positive'}
+
+ self._set_config()
+
+ def _set_config(self):
+ """
+ predictor config setting
+ """
+ model_file_path = os.path.join(self.infer_model_path, 'model')
+ params_file_path = os.path.join(self.infer_model_path, 'params')
+
+ config = AnalysisConfig(model_file_path, params_file_path)
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ use_gpu = True
+ except:
+ use_gpu = False
+
+ if use_gpu:
+ config.enable_use_gpu(8000, 0)
+ else:
+ config.disable_gpu()
+
+ config.disable_glog_info()
+
+ self.predictor = create_paddle_predictor(config)
+
+ def net(self, input_ids, position_ids, segment_ids, input_mask):
+ """
+ create neural network.
+ Args:
+ input_ids (tensor): the word ids.
+ position_ids (tensor): the position ids.
+ segment_ids (tensor): the segment ids.
+ input_mask (tensor): the padding mask.
+
+ Returns:
+ pooled_output (tensor): sentence-level output for classification task.
+ sequence_output (tensor): token-level output for sequence task.
+ """
+ ernie = ErnieModel(
+ src_ids=input_ids,
+ position_ids=position_ids,
+ sentence_ids=segment_ids,
+ input_mask=input_mask,
+ config=self.ernie_config,
+ use_fp16=False)
+
+ pooled_output = ernie.get_pooled_output()
+ sequence_output = ernie.get_sequence_output()
+ return pooled_output, sequence_output
+
+ def array2tensor(self, arr_data):
+ """
+ convert numpy array to PaddleTensor
+ """
+ tensor_data = PaddleTensor(arr_data)
+ return tensor_data
+
+ @serving
+ def predict_sentiment(self, texts=[], use_gpu=False):
+ """
+ Get the sentiment label for the predicted texts. It will be classified as positive and negative.
+ Args:
+ texts (list(str)): the data to be predicted.
+ use_gpu (bool): Whether to use gpu or not.
+ Returns:
+ res (list): The result of sentiment label and probabilties.
+ """
+
+ if use_gpu:
+ try:
+ _places = os.environ["CUDA_VISIBLE_DEVICES"]
+ int(_places[0])
+ except:
+ raise RuntimeError(
+ "Environment Variable CUDA_VISIBLE_DEVICES is not set correctly. If you wanna use gpu, please set CUDA_VISIBLE_DEVICES as cuda_device_id."
+ )
+
+ results = []
+ for text in texts:
+ feature = self._convert_text_to_feature(text)
+ inputs = [self.array2tensor(ndarray) for ndarray in feature]
+ output = self.predictor.run(inputs)
+ probilities = np.array(output[0].data.float_data())
+ label = self.label_map[np.argmax(probilities)]
+ result = {
+ 'text': text,
+ 'sentiment_label': label,
+ 'positive_probs': probilities[1],
+ 'negative_probs': probilities[0]
+ }
+ results.append(result)
+
+ return results
+
+ def _convert_text_to_feature(self, text):
+ """
+ Convert the raw text to feature which is needed to run program (feed_vars).
+ """
+ text_a = convert_to_unicode(text)
+ tokens_a = self.tokenizer.tokenize(text_a)
+ max_seq_len = 512
+
+ # Account for [CLS] and [SEP] with "- 2"
+ if len(tokens_a) > max_seq_len - 2:
+ tokens_a = tokens_a[0:(max_seq_len - 2)]
+
+ tokens = []
+ text_type_ids = []
+ tokens.append("[CLS]")
+ text_type_ids.append(0)
+ for token in tokens_a:
+ tokens.append(token)
+ text_type_ids.append(0)
+ tokens.append("[SEP]")
+ text_type_ids.append(0)
+
+ token_ids = self.tokenizer.convert_tokens_to_ids(tokens)
+ position_ids = list(range(len(token_ids)))
+ task_ids = [0] * len(token_ids)
+
+ padded_token_ids, input_mask = pad_batch_data([token_ids],
+ max_seq_len=max_seq_len,
+ pad_idx=self.pad_id,
+ return_input_mask=True)
+ padded_text_type_ids = pad_batch_data([text_type_ids],
+ max_seq_len=max_seq_len,
+ pad_idx=self.pad_id)
+ padded_position_ids = pad_batch_data([position_ids],
+ max_seq_len=max_seq_len,
+ pad_idx=self.pad_id)
+ padded_task_ids = pad_batch_data([task_ids],
+ max_seq_len=max_seq_len,
+ pad_idx=self.pad_id)
+
+ feature = [
+ padded_token_ids, padded_position_ids, padded_text_type_ids,
+ input_mask, padded_task_ids
+ ]
+ return feature
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command
+ """
+ self.parser = argparse.ArgumentParser(
+ description="Run the %s module." % self.name,
+ prog='hub run %s' % self.name,
+ usage='%(prog)s',
+ add_help=True)
+
+ self.arg_input_group = self.parser.add_argument_group(
+ title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options",
+ description=
+ "Run configuration for controlling module behavior, not required.")
+
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+
+ args = self.parser.parse_args(argvs)
+ results = self.predict_sentiment(
+ texts=[args.input_text], use_gpu=args.use_gpu)
+ return results
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options
+ """
+ self.arg_config_group.add_argument(
+ '--use_gpu',
+ type=ast.literal_eval,
+ default=False,
+ help="whether use GPU or not")
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options
+ """
+ self.arg_input_group.add_argument(
+ '--input_text', type=str, default=None, help="data to be predicted")
+
+
+if __name__ == '__main__':
+ test_module = ErnieSkepSentimentAnalysis()
+ test_texts = ['你不是不聪明,而是不认真', '虽然小明很努力,但是他还是没有考100分']
+ results = test_module.predict_sentiment(test_texts, use_gpu=False)
+ print(results)
+ test_module.context(max_seq_len=128)
+ print(test_module.get_embedding(texts=[['你不是不聪明,而是不认真']]))
+ print(test_module.get_params_layer())
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/README.md b/hub_module/modules/video/classification/videotag_tsn_lstm/README.md
index 2748164a7ccc911da85852ffa46e985701e4c6c7..86cf2f3f460039c523d142735707049bfe7b6b5e 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/README.md
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/README.md
@@ -1,9 +1,8 @@
```shell
$ hub install videotag_tsn_lstm==1.0.0
```
-
-
-
+
+
具体网络结构可参考论文[TSN](https://arxiv.org/abs/1608.00859)和[AttentionLSTM](https://arxiv.org/abs/1503.08909)。
## 命令行预测示例
@@ -16,10 +15,10 @@ hub run videotag_tsn_lstm --input_path 1.mp4 --use_gpu False
## API
```python
-def classification(paths,
- use_gpu=False,
- threshold=0.5,
- top_k=10)
+def classify(paths,
+ use_gpu=False,
+ threshold=0.5,
+ top_k=10)
```
用于视频分类预测
@@ -46,14 +45,13 @@ import paddlehub as hub
videotag = hub.Module(name="videotag_tsn_lstm")
# execute predict and print the result
-results = videotag.classification(paths=["1.mp4","2.mp4"], use_gpu=True)
-for result in results:
- print(result)
+results = videotag.classify(paths=["1.mp4","2.mp4"], use_gpu=True)
+print(results)
```
## 依赖
-paddlepaddle >= 1.6.2
+paddlepaddle >= 1.7.2
paddlehub >= 1.6.0
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/module.py b/hub_module/modules/video/classification/videotag_tsn_lstm/module.py
index dc70f8f200d38e0d2052cb4519d5d884dcacbc72..f0988172e81d1594e10c5373637daa5493f3906b 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/module.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/module.py
@@ -88,12 +88,9 @@ class VideoTag(hub.Module):
extractor_model.load_test_weights(exe, args.extractor_weights,
extractor_main_prog)
- # get reader and metrics
- extractor_reader = get_reader("TSN", 'infer',
- extractor_infer_config)
extractor_feeder = fluid.DataFeeder(
place=place, feed_list=extractor_feeds)
- return extractor_reader, extractor_main_prog, extractor_fetch_list, extractor_feeder, extractor_scope
+ return extractor_main_prog, extractor_fetch_list, extractor_feeder, extractor_scope
def _predictor(self, args, exe, place):
predictor_scope = fluid.Scope()
@@ -129,11 +126,10 @@ class VideoTag(hub.Module):
@runnable
def run_cmd(self, argsv):
args = self.parser.parse_args(argsv)
- results = self.classification(
- paths=[args.input_path], use_gpu=args.use_gpu)
+ results = self.classify(paths=[args.input_path], use_gpu=args.use_gpu)
return results
- def classification(self, paths, use_gpu=False, threshold=0.5, top_k=10):
+ def classify(self, paths, use_gpu=False, threshold=0.5, top_k=10):
"""
API of Classification.
@@ -169,15 +165,20 @@ class VideoTag(hub.Module):
self.place = fluid.CUDAPlace(
0) if args.use_gpu else fluid.CPUPlace()
self.exe = fluid.Executor(self.place)
- self.extractor_reader, self.extractor_main_prog, self.extractor_fetch_list, self.extractor_feeder, self.extractor_scope = self._extractor(
+ self.extractor_main_prog, self.extractor_fetch_list, self.extractor_feeder, self.extractor_scope = self._extractor(
args, self.exe, self.place)
self.predictor_main_prog, self.predictor_fetch_list, self.predictor_feeder, self.predictor_scope = self._predictor(
args, self.exe, self.place)
self._has_load = True
+ extractor_config = parse_config(args.extractor_config)
+ extractor_infer_config = merge_configs(extractor_config, 'infer',
+ vars(args))
+ extractor_reader = get_reader("TSN", 'infer', extractor_infer_config)
feature_list = []
file_list = []
- for idx, data in enumerate(self.extractor_reader()):
+
+ for idx, data in enumerate(extractor_reader()):
file_id = [item[-1] for item in data]
feed_data = [item[:-1] for item in data]
feature_out = self.exe.run(
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/metrics/metrics_util.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/metrics/metrics_util.py
index d85d4fa921aac71c28ad1dd6cf1f30186ddca107..c6205007aef0c19915ba6d33e64196a547110d21 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/metrics/metrics_util.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/metrics/metrics_util.py
@@ -17,12 +17,11 @@ from __future__ import unicode_literals
from __future__ import print_function
from __future__ import division
-import os
import io
import logging
import numpy as np
-import json
+
from videotag_tsn_lstm.resource.metrics.youtube8m import eval_util as youtube8m_metrics
logger = logging.getLogger(__name__)
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/attention_lstm/attention_lstm.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/attention_lstm/attention_lstm.py
index fc57e46a6858b9dd287f69813b2ddcffc263c603..4bd0630732c78e664ea5bcfc1fe00d550b6106b2 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/attention_lstm/attention_lstm.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/attention_lstm/attention_lstm.py
@@ -12,7 +12,7 @@
#See the License for the specific language governing permissions and
#limitations under the License.
-import numpy as np
+import logging
import paddle.fluid as fluid
from paddle.fluid import ParamAttr
@@ -20,10 +20,8 @@ from paddle.fluid import ParamAttr
from ..model import ModelBase
from .lstm_attention import LSTMAttentionModel
-import logging
-logger = logging.getLogger(__name__)
-
__all__ = ["AttentionLSTM"]
+logger = logging.getLogger(__name__)
class AttentionLSTM(ModelBase):
@@ -51,7 +49,6 @@ class AttentionLSTM(ModelBase):
self.feature_input.append(
fluid.data(
shape=[None, dim], lod_level=1, dtype='float32', name=name))
-# self.label_input = None
if use_dataloader:
assert self.mode != 'infer', \
'dataloader is not recommendated when infer, please set use_dataloader to be false.'
@@ -138,15 +135,6 @@ class AttentionLSTM(ModelBase):
)
def load_pretrain_params(self, exe, pretrain, prog, place):
- #def is_parameter(var):
- # return isinstance(var, fluid.framework.Parameter)
-
- #params_list = list(filter(is_parameter, prog.list_vars()))
- #for param in params_list:
- # print(param.name)
-
- #assert False, "stop here"
-
logger.info(
"Load pretrain weights from {}, exclude fc layer.".format(pretrain))
@@ -159,18 +147,3 @@ class AttentionLSTM(ModelBase):
'Delete {} from pretrained parameters. Do not load it'.
format(name))
fluid.set_program_state(prog, state_dict)
-
-
-# def load_test_weights(self, exe, weights, prog):
-# def is_parameter(var):
-# return isinstance(var, fluid.framework.Parameter)
-# params_list = list(filter(is_parameter, prog.list_vars()))
-
-# state_dict = np.load(weights)
-# for p in params_list:
-# if p.name in state_dict.keys():
-# logger.info('########### load param {} from file'.format(p.name))
-# else:
-# logger.info('----------- param {} not in file'.format(p.name))
-# fluid.set_program_state(prog, state_dict)
-# fluid.save(prog, './weights/attention_lstm')
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/attention_lstm/lstm_attention.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/attention_lstm/lstm_attention.py
index 57bf636997c433bb2ae71eec4d8b98bfb1595ff3..d92da5c33c8fe33a05681842e5798834420af2b9 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/attention_lstm/lstm_attention.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/attention_lstm/lstm_attention.py
@@ -11,10 +11,8 @@
#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
#See the License for the specific language governing permissions and
#limitations under the License.
-
import paddle.fluid as fluid
from paddle.fluid import ParamAttr
-import numpy as np
class LSTMAttentionModel(object):
@@ -39,15 +37,6 @@ class LSTMAttentionModel(object):
initializer=fluid.initializer.NormalInitializer(scale=0.0)),
name='rgb_fc')
- #lstm_forward_fc = fluid.layers.fc(
- # input=input_fc,
- # size=self.lstm_size * 4,
- # act=None,
- # bias_attr=ParamAttr(
- # regularizer=fluid.regularizer.L2Decay(0.0),
- # initializer=fluid.initializer.NormalInitializer(scale=0.0)),
- # name='rgb_fc_forward')
-
lstm_forward_fc = fluid.layers.fc(
input=input_fc,
size=self.lstm_size * 4,
@@ -61,15 +50,6 @@ class LSTMAttentionModel(object):
is_reverse=False,
name='rgb_lstm_forward')
- #lsmt_backward_fc = fluid.layers.fc(
- # input=input_fc,
- # size=self.lstm_size * 4,
- # act=None,
- # bias_attr=ParamAttr(
- # regularizer=fluid.regularizer.L2Decay(0.0),
- # initializer=fluid.initializer.NormalInitializer(scale=0.0)),
- # name='rgb_fc_backward')
-
lsmt_backward_fc = fluid.layers.fc(
input=input_fc,
size=self.lstm_size * 4,
@@ -91,15 +71,6 @@ class LSTMAttentionModel(object):
dropout_prob=self.drop_rate,
is_test=(not is_training))
- #lstm_weight = fluid.layers.fc(
- # input=lstm_dropout,
- # size=1,
- # act='sequence_softmax',
- # bias_attr=ParamAttr(
- # regularizer=fluid.regularizer.L2Decay(0.0),
- # initializer=fluid.initializer.NormalInitializer(scale=0.0)),
- # name='rgb_weight')
-
lstm_weight = fluid.layers.fc(
input=lstm_dropout,
size=1,
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/model.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/model.py
index 88a337bdd1ccb29a573b54e1edd6805a2a97b4f4..f5733835913346f4c876c8d67139264be289e36c 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/model.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/model.py
@@ -13,7 +13,6 @@
#limitations under the License.
import os
-import wget
import logging
try:
from configparser import ConfigParser
@@ -21,7 +20,6 @@ except:
from ConfigParser import ConfigParser
import paddle.fluid as fluid
-from .utils import download, AttrDict
WEIGHT_DIR = os.path.join(os.path.expanduser('~'), '.paddle', 'weights')
@@ -103,21 +101,6 @@ class ModelBase(object):
"get model weight default path and download url"
raise NotImplementError(self, self.weights_info)
- def get_weights(self):
- "get model weight file path, download weight from Paddle if not exist"
- path, url = self.weights_info()
- path = os.path.join(WEIGHT_DIR, path)
- if not os.path.isdir(WEIGHT_DIR):
- logger.info('{} not exists, will be created automatically.'.format(
- WEIGHT_DIR))
- os.makedirs(WEIGHT_DIR)
- if os.path.exists(path):
- return path
-
- logger.info("Download weights of {} from {}".format(self.name, url))
- wget.download(url, path)
- return path
-
def dataloader(self):
return self.dataloader
@@ -129,25 +112,6 @@ class ModelBase(object):
"get pretrain base model directory"
return (None, None)
- def get_pretrain_weights(self):
- "get model weight file path, download weight from Paddle if not exist"
- path, url = self.pretrain_info()
- if not path:
- return None
-
- path = os.path.join(WEIGHT_DIR, path)
- if not os.path.isdir(WEIGHT_DIR):
- logger.info('{} not exists, will be created automatically.'.format(
- WEIGHT_DIR))
- os.makedirs(WEIGHT_DIR)
- if os.path.exists(path):
- return path
-
- logger.info("Download pretrain weights of {} from {}".format(
- self.name, url))
- download(url, path)
- return path
-
def load_pretrain_params(self, exe, pretrain, prog, place):
logger.info("Load pretrain weights from {}".format(pretrain))
state_dict = fluid.load_program_state(pretrain)
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/utils.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/utils.py
deleted file mode 100644
index 3eead927ea23d1268386f0f545eea6358bafc64b..0000000000000000000000000000000000000000
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/models/utils.py
+++ /dev/null
@@ -1,47 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserve.
-#
-#Licensed under the Apache License, Version 2.0 (the "License");
-#you may not use this file except in compliance with the License.
-#You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-#Unless required by applicable law or agreed to in writing, software
-#distributed under the License is distributed on an "AS IS" BASIS,
-#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-#See the License for the specific language governing permissions and
-#limitations under the License.
-
-import os
-import wget
-import tarfile
-
-__all__ = ['decompress', 'download', 'AttrDict']
-
-
-def decompress(path):
- t = tarfile.open(path)
- t.extractall(path=os.path.split(path)[0])
- t.close()
- os.remove(path)
-
-
-def download(url, path):
- weight_dir = os.path.split(path)[0]
- if not os.path.exists(weight_dir):
- os.makedirs(weight_dir)
-
- path = path + ".tar.gz"
- wget.download(url, path)
- decompress(path)
-
-
-class AttrDict(dict):
- def __getattr__(self, key):
- return self[key]
-
- def __setattr__(self, key, value):
- if key in self.__dict__:
- self.__dict__[key] = value
- else:
- self[key] = value
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/kinetics_reader.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/kinetics_reader.py
index ccf59ea26a6bf30be063941dd27f360c9f487e77..06847d0e04f9981bc5bdaa25f17fb8b76a69d814 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/kinetics_reader.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/kinetics_reader.py
@@ -11,23 +11,22 @@
#WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
#See the License for the specific language governing permissions and
#limitations under the License.
-
-import os
import sys
-import cv2
-import math
+
import random
import functools
+import logging
try:
import cPickle as pickle
from cStringIO import StringIO
except ImportError:
import pickle
from io import BytesIO
-import numpy as np
+
import paddle
-from PIL import Image, ImageEnhance
-import logging
+import cv2
+import numpy as np
+from PIL import Image
from .reader_utils import DataReader
@@ -87,38 +86,15 @@ class KineticsReader(DataReader):
def _batch_reader():
batch_out = []
for imgs, label in _reader():
- #for imgs in _reader():
if imgs is None:
continue
batch_out.append((imgs, label))
- #batch_out.append((imgs,))
if len(batch_out) == self.batch_size:
yield batch_out
batch_out = []
return _batch_reader
- def _inference_reader_creator(self, video_path, mode, seg_num, seglen,
- short_size, target_size, img_mean, img_std):
- def reader():
- try:
- imgs = mp4_loader(video_path, seg_num, seglen, mode)
- if len(imgs) < 1:
- logger.error('{} frame length {} less than 1.'.format(
- video_path, len(imgs)))
- yield None, None
- except:
- logger.error('Error when loading {}'.format(video_path))
- yield None, None
-
- imgs_ret = imgs_transform(imgs, mode, seg_num, seglen, short_size,
- target_size, img_mean, img_std)
- label_ret = video_path
-
- yield imgs_ret, label_ret
-
- return reader
-
def _reader_creator(self,
pickle_list,
mode,
@@ -149,37 +125,7 @@ class KineticsReader(DataReader):
return imgs_transform(imgs, mode, seg_num, seglen, \
short_size, target_size, img_mean, img_std, name = self.name), mp4_path
- def decode_pickle(sample, mode, seg_num, seglen, short_size,
- target_size, img_mean, img_std):
- pickle_path = sample[0]
- try:
- if python_ver < (3, 0):
- data_loaded = pickle.load(open(pickle_path, 'rb'))
- else:
- data_loaded = pickle.load(
- open(pickle_path, 'rb'), encoding='bytes')
-
- vid, label, frames = data_loaded
- if len(frames) < 1:
- logger.error('{} frame length {} less than 1.'.format(
- pickle_path, len(frames)))
- return None, None
- except:
- logger.info('Error when loading {}'.format(pickle_path))
- return None, None
-
- if mode == 'train' or mode == 'valid' or mode == 'test':
- ret_label = label
- elif mode == 'infer':
- ret_label = vid
-
- imgs = video_loader(frames, seg_num, seglen, mode)
- return imgs_transform(imgs, mode, seg_num, seglen, \
- short_size, target_size, img_mean, img_std, name = self.name), ret_label
-
def reader():
- # with open(pickle_list) as flist:
- # lines = [line.strip() for line in flist]
lines = [line.strip() for line in pickle_list]
if shuffle:
random.shuffle(lines)
@@ -187,15 +133,8 @@ class KineticsReader(DataReader):
pickle_path = line.strip()
yield [pickle_path]
- if format == 'pkl':
- decode_func = decode_pickle
- elif format == 'mp4':
- decode_func = decode_mp4
- else:
- raise "Not implemented format {}".format(format)
-
mapper = functools.partial(
- decode_func,
+ decode_mp4,
mode=mode,
seg_num=seg_num,
seglen=seglen,
@@ -218,142 +157,26 @@ def imgs_transform(imgs,
name=''):
imgs = group_scale(imgs, short_size)
- if mode == 'train':
- if name == "TSM":
- imgs = group_multi_scale_crop(imgs, short_size)
- imgs = group_random_crop(imgs, target_size)
- imgs = group_random_flip(imgs)
- else:
- imgs = group_center_crop(imgs, target_size)
-
- np_imgs = (np.array(imgs[0]).astype('float32').transpose(
- (2, 0, 1))).reshape(1, 3, target_size, target_size) / 255
- for i in range(len(imgs) - 1):
- img = (np.array(imgs[i + 1]).astype('float32').transpose(
- (2, 0, 1))).reshape(1, 3, target_size, target_size) / 255
- np_imgs = np.concatenate((np_imgs, img))
- imgs = np_imgs
- imgs -= img_mean
- imgs /= img_std
- imgs = np.reshape(imgs, (seg_num, seglen * 3, target_size, target_size))
+ np_imgs = np.array([np.array(img).astype('float32') for img in imgs]) #dhwc
+ np_imgs = group_center_crop(np_imgs, target_size)
+ np_imgs = np_imgs.transpose(0, 3, 1, 2) / 255 #dchw
+ np_imgs -= img_mean
+ np_imgs /= img_std
- return imgs
+ return np_imgs
-def group_multi_scale_crop(img_group, target_size, scales=None, \
- max_distort=1, fix_crop=True, more_fix_crop=True):
- scales = scales if scales is not None else [1, .875, .75, .66]
- input_size = [target_size, target_size]
-
- im_size = img_group[0].size
-
- # get random crop offset
- def _sample_crop_size(im_size):
- image_w, image_h = im_size[0], im_size[1]
-
- base_size = min(image_w, image_h)
- crop_sizes = [int(base_size * x) for x in scales]
- crop_h = [
- input_size[1] if abs(x - input_size[1]) < 3 else x
- for x in crop_sizes
- ]
- crop_w = [
- input_size[0] if abs(x - input_size[0]) < 3 else x
- for x in crop_sizes
- ]
-
- pairs = []
- for i, h in enumerate(crop_h):
- for j, w in enumerate(crop_w):
- if abs(i - j) <= max_distort:
- pairs.append((w, h))
-
- crop_pair = random.choice(pairs)
- if not fix_crop:
- w_offset = random.randint(0, image_w - crop_pair[0])
- h_offset = random.randint(0, image_h - crop_pair[1])
- else:
- w_step = (image_w - crop_pair[0]) / 4
- h_step = (image_h - crop_pair[1]) / 4
-
- ret = list()
- ret.append((0, 0)) # upper left
- if w_step != 0:
- ret.append((4 * w_step, 0)) # upper right
- if h_step != 0:
- ret.append((0, 4 * h_step)) # lower left
- if h_step != 0 and w_step != 0:
- ret.append((4 * w_step, 4 * h_step)) # lower right
- if h_step != 0 or w_step != 0:
- ret.append((2 * w_step, 2 * h_step)) # center
-
- if more_fix_crop:
- ret.append((0, 2 * h_step)) # center left
- ret.append((4 * w_step, 2 * h_step)) # center right
- ret.append((2 * w_step, 4 * h_step)) # lower center
- ret.append((2 * w_step, 0 * h_step)) # upper center
-
- ret.append((1 * w_step, 1 * h_step)) # upper left quarter
- ret.append((3 * w_step, 1 * h_step)) # upper right quarter
- ret.append((1 * w_step, 3 * h_step)) # lower left quarter
- ret.append((3 * w_step, 3 * h_step)) # lower righ quarter
-
- w_offset, h_offset = random.choice(ret)
-
- return crop_pair[0], crop_pair[1], w_offset, h_offset
-
- crop_w, crop_h, offset_w, offset_h = _sample_crop_size(im_size)
- crop_img_group = [
- img.crop((offset_w, offset_h, offset_w + crop_w, offset_h + crop_h))
- for img in img_group
- ]
- ret_img_group = [
- img.resize((input_size[0], input_size[1]), Image.BILINEAR)
- for img in crop_img_group
- ]
-
- return ret_img_group
-
-
-def group_random_crop(img_group, target_size):
- w, h = img_group[0].size
- th, tw = target_size, target_size
+def group_center_crop(np_imgs, target_size):
+ d, h, w, c = np_imgs.shape
+ th, tw = target_size, target_size
assert (w >= target_size) and (h >= target_size), \
- "image width({}) and height({}) should be larger than crop size".format(w, h, target_size)
-
- out_images = []
- x1 = random.randint(0, w - tw)
- y1 = random.randint(0, h - th)
-
- for img in img_group:
- if w == tw and h == th:
- out_images.append(img)
- else:
- out_images.append(img.crop((x1, y1, x1 + tw, y1 + th)))
+ "image width({}) and height({}) should be larger than crop size".format(w, h, target_size)
- return out_images
-
-
-def group_random_flip(img_group):
- v = random.random()
- if v < 0.5:
- ret = [img.transpose(Image.FLIP_LEFT_RIGHT) for img in img_group]
- return ret
- else:
- return img_group
-
-
-def group_center_crop(img_group, target_size):
- img_crop = []
- for img in img_group:
- w, h = img.size
- th, tw = target_size, target_size
- assert (w >= target_size) and (h >= target_size), \
- "image width({}) and height({}) should be larger than crop size".format(w, h, target_size)
- x1 = int(round((w - tw) / 2.))
- y1 = int(round((h - th) / 2.))
- img_crop.append(img.crop((x1, y1, x1 + tw, y1 + th)))
+ h_off = int(round((h - th) / 2.))
+ w_off = int(round((w - tw) / 2.))
+ img_crop = np_imgs[:, h_off:h_off + target_size, w_off:w_off +
+ target_size, :]
return img_crop
@@ -378,47 +201,6 @@ def group_scale(imgs, target_size):
return resized_imgs
-def imageloader(buf):
- if isinstance(buf, str):
- img = Image.open(StringIO(buf))
- else:
- img = Image.open(BytesIO(buf))
-
- return img.convert('RGB')
-
-
-def video_loader(frames, nsample, seglen, mode):
- videolen = len(frames)
- average_dur = int(videolen / nsample)
-
- imgs = []
- for i in range(nsample):
- idx = 0
- if mode == 'train':
- if average_dur >= seglen:
- idx = random.randint(0, average_dur - seglen)
- idx += i * average_dur
- elif average_dur >= 1:
- idx += i * average_dur
- else:
- idx = i
- else:
- if average_dur >= seglen:
- idx = (average_dur - seglen) // 2
- idx += i * average_dur
- elif average_dur >= 1:
- idx += i * average_dur
- else:
- idx = i
-
- for jj in range(idx, idx + seglen):
- imgbuf = frames[int(jj % videolen)]
- img = imageloader(imgbuf)
- imgs.append(img)
-
- return imgs
-
-
def mp4_loader(filepath, nsample, seglen, mode):
cap = cv2.VideoCapture(filepath)
videolen = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
@@ -434,26 +216,16 @@ def mp4_loader(filepath, nsample, seglen, mode):
imgs = []
for i in range(nsample):
idx = 0
- if mode == 'train':
- if average_dur >= seglen:
- idx = random.randint(0, average_dur - seglen)
- idx += i * average_dur
- elif average_dur >= 1:
- idx += i * average_dur
- else:
- idx = i
+ if average_dur >= seglen:
+ idx = (average_dur - 1) // 2
+ idx += i * average_dur
+ elif average_dur >= 1:
+ idx += i * average_dur
else:
- if average_dur >= seglen:
- idx = (average_dur - 1) // 2
- idx += i * average_dur
- elif average_dur >= 1:
- idx += i * average_dur
- else:
- idx = i
+ idx = i
for jj in range(idx, idx + seglen):
imgbuf = sampledFrames[int(jj % len(sampledFrames))]
img = Image.fromarray(imgbuf, mode='RGB')
imgs.append(img)
-
return imgs
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/reader_utils.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/reader_utils.py
index b3741188e11350231600b50fb7fabad72340768c..54b2d7ad82e6cfe2142c0bc66942f775d7720c01 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/reader_utils.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/reader/reader_utils.py
@@ -12,11 +12,6 @@
#See the License for the specific language governing permissions and
#limitations under the License.
-import pickle
-import cv2
-import numpy as np
-import random
-
class ReaderNotFoundError(Exception):
"Error: reader not found"
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/config_utils.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/config_utils.py
index 7be5ed7d07ae7a858918ef84fe9ca36f30c827bf..05947265b5d8cea165fe9a97d024cbf4b1309181 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/config_utils.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/config_utils.py
@@ -12,9 +12,10 @@
#See the License for the specific language governing permissions and
#limitations under the License.
-import yaml
-from .utility import AttrDict
import logging
+
+from .utility import AttrDict
+
logger = logging.getLogger(__name__)
CONFIG_SECS = [
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/train_utils.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/train_utils.py
index d84d80af4e7204bfbf8aa550f4840664955c491a..2909479b9132e2ffbd3d870f005a12a9c7f68151 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/train_utils.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/train_utils.py
@@ -14,13 +14,12 @@
import os
import sys
+import logging
+
import time
import numpy as np
-import paddle
import paddle.fluid as fluid
from paddle.fluid import profiler
-import logging
-import shutil
logger = logging.getLogger(__name__)
diff --git a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/utility.py b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/utility.py
index ced1e7d757ff5697c0fe61f130849524491da3b0..7ea906ef56eafc51526844f3ca2d4c7f1c97f223 100644
--- a/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/utility.py
+++ b/hub_module/modules/video/classification/videotag_tsn_lstm/resource/utils/utility.py
@@ -16,7 +16,7 @@ import os
import sys
import signal
import logging
-import paddle
+
import paddle.fluid as fluid
__all__ = ['AttrDict']
diff --git a/hub_module/scripts/configs/chinese_ocr_db_crnn_mobile.yml b/hub_module/scripts/configs/chinese_ocr_db_crnn_mobile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..08616bbdfb4430786e00b979cacbe8e59ee1eebb
--- /dev/null
+++ b/hub_module/scripts/configs/chinese_ocr_db_crnn_mobile.yml
@@ -0,0 +1,10 @@
+name: chinese_ocr_db_crnn_mobile
+dir: "modules/image/text_recognition/chinese_ocr_db_crnn_mobile"
+exclude:
+ - README.md
+
+resources:
+ -
+ url: https://bj.bcebos.com/paddlehub/model/image/ocr/chinese_ocr_db_rcnn_infer_model.tar.gz
+ dest: .
+ uncompress: True
diff --git a/hub_module/scripts/configs/chinese_ocr_db_crnn_server.yml b/hub_module/scripts/configs/chinese_ocr_db_crnn_server.yml
new file mode 100644
index 0000000000000000000000000000000000000000..fc827322e4e1c5f4880adf277493bca228d5c21c
--- /dev/null
+++ b/hub_module/scripts/configs/chinese_ocr_db_crnn_server.yml
@@ -0,0 +1,10 @@
+name: chinese_ocr_db_crnn_mobile
+dir: "modules/image/text_recognition/chinese_ocr_db_crnn_server"
+exclude:
+ - README.md
+
+resources:
+ -
+ url: https://bj.bcebos.com/paddlehub/model/image/ocr/chinese_ocr_db_crnn_server_assets.tar.gz
+ dest: .
+ uncompress: True
diff --git a/hub_module/scripts/configs/chinese_text_detection_db_mobile.yml b/hub_module/scripts/configs/chinese_text_detection_db_mobile.yml
new file mode 100644
index 0000000000000000000000000000000000000000..106f0a2eac97f59d36261a2fb7a93550a568b2f0
--- /dev/null
+++ b/hub_module/scripts/configs/chinese_text_detection_db_mobile.yml
@@ -0,0 +1,10 @@
+name: chinese_text_detection_db_mobile
+dir: "modules/image/text_recognition/chinese_text_detection_db_mobile"
+exclude:
+ - README.md
+
+resources:
+ -
+ url: https://bj.bcebos.com/paddlehub/model/image/ocr/chinese_text_detection_db_infer_model.tar.gz
+ dest: .
+ uncompress: True
diff --git a/hub_module/scripts/configs/chinese_text_detection_db_server.yml b/hub_module/scripts/configs/chinese_text_detection_db_server.yml
new file mode 100644
index 0000000000000000000000000000000000000000..0fc9a4f45cba33f5aad14f000c09fc75d1728af0
--- /dev/null
+++ b/hub_module/scripts/configs/chinese_text_detection_db_server.yml
@@ -0,0 +1,10 @@
+name: chinese_text_detection_db_mobile
+dir: "modules/image/text_recognition/chinese_text_detection_db_server"
+exclude:
+ - README.md
+
+resources:
+ -
+ url: https://bj.bcebos.com/paddlehub/model/image/ocr/ch_det_r50_vd_db.tar.gz
+ dest: .
+ uncompress: True
diff --git a/hub_module/scripts/configs/ernie_skep_sentiment_analysis.yml b/hub_module/scripts/configs/ernie_skep_sentiment_analysis.yml
new file mode 100644
index 0000000000000000000000000000000000000000..a50edc199995183fe02cc84783e7c38b0306b3dc
--- /dev/null
+++ b/hub_module/scripts/configs/ernie_skep_sentiment_analysis.yml
@@ -0,0 +1,9 @@
+name: ernie_skep_sentiment_analysis
+dir: "modules/text/sentiment_analysis/ernie_skep_sentiment_analysis"
+exclude:
+ - README.md
+resources:
+ -
+ url: https://paddlehub.bj.bcebos.com/model/nlp/ernie_skep_sentiment_analysis/assets.tar.gz
+ dest: assets
+ uncompress: True
diff --git a/hub_module/tests/image_dataset/text_recognition/11.jpg b/hub_module/tests/image_dataset/text_recognition/11.jpg
new file mode 100755
index 0000000000000000000000000000000000000000..ed91b8c5ca2a348fe7b138e83114ff81ecb107de
Binary files /dev/null and b/hub_module/tests/image_dataset/text_recognition/11.jpg differ
diff --git a/hub_module/tests/image_dataset/text_recognition/test_image.jpg b/hub_module/tests/image_dataset/text_recognition/test_image.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..be103f39ec5c2a4e4681ffb82bf8231feef1c048
Binary files /dev/null and b/hub_module/tests/image_dataset/text_recognition/test_image.jpg differ
diff --git a/hub_module/tests/unittests/test_chinese_ocr_db_crnn_mobile.py b/hub_module/tests/unittests/test_chinese_ocr_db_crnn_mobile.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb39ad8d0a33b341f40c9521b0a05650af42fa6c
--- /dev/null
+++ b/hub_module/tests/unittests/test_chinese_ocr_db_crnn_mobile.py
@@ -0,0 +1,56 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+from unittest import TestCase, main
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+import cv2
+import paddlehub as hub
+
+
+class ChineseOCRDBCRNNTestCase(TestCase):
+ def setUp(self):
+ self.module = hub.Module(name='chinese_ocr_db_crnn_mobile')
+ self.test_images = [
+ "../image_dataset/text_recognition/11.jpg",
+ "../image_dataset/text_recognition/test_image.jpg"
+ ]
+
+ def test_detect_text(self):
+ results_1 = self.module.recognize_text(
+ paths=self.test_images, use_gpu=True)
+ results_2 = self.module.recognize_text(
+ paths=self.test_images, use_gpu=False)
+
+ test_images = [cv2.imread(img) for img in self.test_images]
+ results_3 = self.module.recognize_text(
+ images=test_images, use_gpu=False)
+ for i, res in enumerate(results_1):
+ self.assertEqual(res['save_path'], '')
+
+ for j, item in enumerate(res['data']):
+ self.assertEqual(item['confidence'],
+ results_2[i]['data'][j]['confidence'])
+ self.assertEqual(item['confidence'],
+ results_3[i]['data'][j]['confidence'])
+ self.assertEqual(item['text'], results_2[i]['data'][j]['text'])
+ self.assertEqual(item['text'], results_3[i]['data'][j]['text'])
+ self.assertEqual(item['text_box_position'],
+ results_2[i]['data'][j]['text_box_position'])
+ self.assertEqual(item['text_box_position'],
+ results_3[i]['data'][j]['text_box_position'])
+
+
+if __name__ == '__main__':
+ main()
diff --git a/hub_module/tests/unittests/test_chinese_ocr_db_crnn_server.py b/hub_module/tests/unittests/test_chinese_ocr_db_crnn_server.py
new file mode 100644
index 0000000000000000000000000000000000000000..a3e74d0730b93848d7b65dddee22e2693833c5c2
--- /dev/null
+++ b/hub_module/tests/unittests/test_chinese_ocr_db_crnn_server.py
@@ -0,0 +1,56 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+from unittest import TestCase, main
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+import cv2
+import paddlehub as hub
+
+
+class ChineseOCRDBCRNNTestCase(TestCase):
+ def setUp(self):
+ self.module = hub.Module(name='chinese_ocr_db_crnn_server')
+ self.test_images = [
+ "../image_dataset/text_recognition/11.jpg",
+ "../image_dataset/text_recognition/test_image.jpg"
+ ]
+
+ def test_detect_text(self):
+ results_1 = self.module.recognize_text(
+ paths=self.test_images, use_gpu=True)
+ results_2 = self.module.recognize_text(
+ paths=self.test_images, use_gpu=False)
+
+ test_images = [cv2.imread(img) for img in self.test_images]
+ results_3 = self.module.recognize_text(
+ images=test_images, use_gpu=False)
+ for i, res in enumerate(results_1):
+ self.assertEqual(res['save_path'], '')
+
+ for j, item in enumerate(res['data']):
+ self.assertEqual(item['confidence'],
+ results_2[i]['data'][j]['confidence'])
+ self.assertEqual(item['confidence'],
+ results_3[i]['data'][j]['confidence'])
+ self.assertEqual(item['text'], results_2[i]['data'][j]['text'])
+ self.assertEqual(item['text'], results_3[i]['data'][j]['text'])
+ self.assertEqual(item['text_box_position'],
+ results_2[i]['data'][j]['text_box_position'])
+ self.assertEqual(item['text_box_position'],
+ results_3[i]['data'][j]['text_box_position'])
+
+
+if __name__ == '__main__':
+ main()
diff --git a/hub_module/tests/unittests/test_chinese_text_detection_db_mobile.py b/hub_module/tests/unittests/test_chinese_text_detection_db_mobile.py
new file mode 100644
index 0000000000000000000000000000000000000000..01819f98141f5f399f912e051f7b17ed8e53e40f
--- /dev/null
+++ b/hub_module/tests/unittests/test_chinese_text_detection_db_mobile.py
@@ -0,0 +1,45 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+from unittest import TestCase, main
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+import cv2
+import paddlehub as hub
+
+
+class ChineseTextDetectionDBTestCase(TestCase):
+ def setUp(self):
+ self.module = hub.Module(name='chinese_text_detection_db_mobile')
+ self.test_images = [
+ "../image_dataset/text_recognition/11.jpg",
+ "../image_dataset/text_recognition/test_image.jpg"
+ ]
+
+ def test_detect_text(self):
+ results_1 = self.module.detect_text(
+ paths=self.test_images, use_gpu=True)
+ results_2 = self.module.detect_text(
+ paths=self.test_images, use_gpu=False)
+
+ test_images = [cv2.imread(img) for img in self.test_images]
+ results_3 = self.module.detect_text(images=test_images, use_gpu=False)
+ for index, res in enumerate(results_1):
+ self.assertEqual(res['save_path'], '')
+ self.assertEqual(res['data'], results_2[index]['data'])
+ self.assertEqual(res['data'], results_3[index]['data'])
+
+
+if __name__ == '__main__':
+ main()
diff --git a/hub_module/tests/unittests/test_chinese_text_detection_db_server.py b/hub_module/tests/unittests/test_chinese_text_detection_db_server.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f0fd98910284275ade8dab1c5f502fbd5702183
--- /dev/null
+++ b/hub_module/tests/unittests/test_chinese_text_detection_db_server.py
@@ -0,0 +1,45 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+from unittest import TestCase, main
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+import cv2
+import paddlehub as hub
+
+
+class ChineseTextDetectionDBTestCase(TestCase):
+ def setUp(self):
+ self.module = hub.Module(name='chinese_text_detection_db_server')
+ self.test_images = [
+ "../image_dataset/text_recognition/11.jpg",
+ "../image_dataset/text_recognition/test_image.jpg"
+ ]
+
+ def test_detect_text(self):
+ results_1 = self.module.detect_text(
+ paths=self.test_images, use_gpu=True)
+ results_2 = self.module.detect_text(
+ paths=self.test_images, use_gpu=False)
+
+ test_images = [cv2.imread(img) for img in self.test_images]
+ results_3 = self.module.detect_text(images=test_images, use_gpu=False)
+ for index, res in enumerate(results_1):
+ self.assertEqual(res['save_path'], '')
+ self.assertEqual(res['data'], results_2[index]['data'])
+ self.assertEqual(res['data'], results_3[index]['data'])
+
+
+if __name__ == '__main__':
+ main()
diff --git a/hub_module/tests/unittests/test_ernie_skep_sentiment_analysis.py b/hub_module/tests/unittests/test_ernie_skep_sentiment_analysis.py
new file mode 100644
index 0000000000000000000000000000000000000000..bcceb2382f1d3daea413928321c915dc8130715f
--- /dev/null
+++ b/hub_module/tests/unittests/test_ernie_skep_sentiment_analysis.py
@@ -0,0 +1,129 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+from unittest import TestCase, main
+os.environ['CUDA_VISIBLE_DEVICES'] = '1'
+
+import numpy as np
+import paddlehub as hub
+
+
+class ErnieSkepSentimentAnalysisTestCase(TestCase):
+ def setUp(self):
+ self.module = hub.Module(name='ernie_skep_sentiment_analysis')
+ self.test_text = [[
+ '飞桨(PaddlePaddle)是国内开源产业级深度学习平台', 'PaddleHub是飞桨生态的预训练模型应用工具'
+ ], ["飞浆PaddleHub"]]
+ self.test_data = ['你不是不聪明,而是不认真', '虽然小明很努力,但是他还是没有考100分']
+ self.results = [{
+ 'text': '你不是不聪明,而是不认真',
+ 'sentiment_label': 'negative',
+ 'positive_probs': 0.10738213360309601,
+ 'negative_probs': 0.8926178216934204
+ },
+ {
+ 'text': '虽然小明很努力,但是他还是没有考100分',
+ 'sentiment_label': 'negative',
+ 'positive_probs': 0.053915347903966904,
+ 'negative_probs': 0.9460846185684204
+ }]
+
+ def test_predict_sentiment(self):
+ results_1 = self.module.predict_sentiment(self.test_data, use_gpu=False)
+ results_2 = self.module.predict_sentiment(self.test_data, use_gpu=True)
+
+ for index, res in enumerate(results_1):
+ self.assertEqual(res['text'], self.results[index]['text'])
+ self.assertEqual(res['sentiment_label'],
+ self.results[index]['sentiment_label'])
+ self.assertTrue(
+ abs(res['positive_probs'] -
+ self.results[index]['positive_probs']) < 1e-6)
+ self.assertTrue(
+ abs(res['negative_probs'] -
+ self.results[index]['negative_probs']) < 1e-6)
+
+ self.assertEqual(res['text'], results_2[index]['text'])
+ self.assertEqual(res['sentiment_label'],
+ results_2[index]['sentiment_label'])
+ self.assertTrue(
+ abs(res['positive_probs'] -
+ results_2[index]['positive_probs']) < 1e-6)
+ self.assertTrue(
+ abs(res['negative_probs'] -
+ results_2[index]['negative_probs']) < 1e-6)
+
+ def test_get_embedding(self):
+ # test batch_size
+ max_seq_len = 128
+ results = self.module.get_embedding(
+ texts=self.test_text,
+ use_gpu=False,
+ batch_size=1,
+ max_seq_len=max_seq_len)
+ results_2 = self.module.get_embedding(
+ texts=self.test_text,
+ use_gpu=False,
+ batch_size=10,
+ max_seq_len=max_seq_len)
+ # 2 sample results
+ self.assertEqual(len(results), 2)
+ self.assertEqual(len(results_2), 2)
+ # sequence embedding and token embedding results per sample
+ self.assertEqual(len(results[0]), 2)
+ self.assertEqual(len(results_2[0]), 2)
+ # sequence embedding shape
+ self.assertEqual(results[0][0].shape, (1024, ))
+ self.assertEqual(results_2[0][0].shape, (1024, ))
+ # token embedding shape
+ self.assertEqual(results[0][1].shape, (max_seq_len, 1024))
+ self.assertEqual(results_2[0][1].shape, (max_seq_len, 1024))
+
+ # test gpu
+ results_3 = self.module.get_embedding(
+ texts=self.test_text,
+ use_gpu=True,
+ batch_size=1,
+ max_seq_len=max_seq_len)
+ diff = np.abs(results[0][0] - results_3[0][0])
+ self.assertTrue((diff < 1e-6).all)
+ diff = np.abs(results[0][1] - results_3[0][1])
+ self.assertTrue((diff < 1e-6).all)
+ diff = np.abs(results[1][0] - results_3[1][0])
+ self.assertTrue((diff < 1e-6).all)
+ diff = np.abs(results[1][1] - results_3[1][1])
+ self.assertTrue((diff < 1e-6).all)
+
+ def test_get_params_layer(self):
+ self.module.context()
+ layers = self.module.get_params_layer()
+ layers = list(set(layers.values()))
+ true_layers = [i for i in range(24)]
+ self.assertEqual(layers, true_layers)
+
+ def test_get_spm_path(self):
+ self.assertEqual(self.module.get_spm_path(), None)
+
+ def test_get_word_dict_path(self):
+ self.assertEqual(self.module.get_word_dict_path(), None)
+
+ def test_get_vocab_path(self):
+ vocab_path = self.module.get_vocab_path()
+ true_vocab_path = os.path.join(self.module.directory, "assets",
+ "ernie_1.0_large_ch.vocab.txt")
+ self.assertEqual(vocab_path, true_vocab_path)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/hub_module/tests/unittests/test_videotag_tsn_lstm.py b/hub_module/tests/unittests/test_videotag_tsn_lstm.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c28a8ea8de3775d49b5690dc567bb253c610d91
--- /dev/null
+++ b/hub_module/tests/unittests/test_videotag_tsn_lstm.py
@@ -0,0 +1,51 @@
+# coding=utf-8
+import unittest
+import paddlehub as hub
+
+
+class TestVideoTag(unittest.TestCase):
+ def setUp(self):
+ "Call setUp() to prepare environment\n"
+ self.module = hub.Module(name='videotag_tsn_lstm')
+ self.test_video = [
+ "../video_dataset/classification/1.mp4",
+ "../video_dataset/classification/2.mp4"
+ ]
+
+ def test_classification(self):
+ default_expect1 = {
+ '训练': 0.9771281480789185,
+ '蹲': 0.9389840960502625,
+ '杠铃': 0.8554490804672241,
+ '健身房': 0.8479971885681152
+ }
+ default_expect2 = {'舞蹈': 0.8504238724708557}
+ for use_gpu in [True, False]:
+ for threshold in [0.5, 0.9]:
+ for top_k in [10, 1]:
+ expect1 = {}
+ expect2 = {}
+ for key, value in default_expect1.items():
+ if value >= threshold:
+ expect1[key] = value
+ if len(expect1.keys()) >= top_k:
+ break
+ for key, value in default_expect2.items():
+ if value >= threshold:
+ expect2[key] = value
+ if len(expect2.keys()) >= top_k:
+ break
+ results = self.module.classify(
+ paths=self.test_video,
+ use_gpu=use_gpu,
+ threshold=threshold,
+ top_k=top_k)
+ for result in results:
+ if '1.mp4' in result['path']:
+ self.assertEqual(result['prediction'], expect1)
+ else:
+ self.assertEqual(result['prediction'], expect2)
+
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/hub_module/tests/video_dataset/classification/1.mp4 b/hub_module/tests/video_dataset/classification/1.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..391b057e3bd99c0bb0c1bf8ed95194dd984fd23a
Binary files /dev/null and b/hub_module/tests/video_dataset/classification/1.mp4 differ
diff --git a/hub_module/tests/video_dataset/classification/2.mp4 b/hub_module/tests/video_dataset/classification/2.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..e276117a207a860769b8c5a4b5f207e743a45ccc
Binary files /dev/null and b/hub_module/tests/video_dataset/classification/2.mp4 differ
diff --git a/paddlehub/__init__.py b/paddlehub/__init__.py
index 2b4721b8132ae3131cee9a8560e0eff5fbdcb164..cd7e88471732675d13df23f0cd4f193dc90eb4de 100644
--- a/paddlehub/__init__.py
+++ b/paddlehub/__init__.py
@@ -22,6 +22,8 @@ if six.PY2:
reload(sys) # noqa
sys.setdefaultencoding("UTF-8")
+from .version import hub_version as __version__
+
from . import module
from . import common
from . import io
diff --git a/paddlehub/finetune/strategy.py b/paddlehub/finetune/strategy.py
index 9073f9414e4b44078c59dfa5cb251cc031456a9f..080017d23ed7adf18b9fee278cee9eefb7ba331c 100644
--- a/paddlehub/finetune/strategy.py
+++ b/paddlehub/finetune/strategy.py
@@ -133,39 +133,39 @@ def set_gradual_unfreeze(depth_params_dict, unfreeze_depths):
class DefaultStrategy(object):
- def __init__(self, learning_rate=1e-4, optimizer_name="adam"):
+ def __init__(self, learning_rate=1e-4, optimizer_name="adam", **kwargs):
self.learning_rate = learning_rate
self._optimizer_name = optimizer_name
if self._optimizer_name.lower() == "sgd":
self.optimizer = fluid.optimizer.SGD(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
elif self._optimizer_name.lower() == "adagrad":
self.optimizer = fluid.optimizer.Adagrad(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
elif self._optimizer_name.lower() == "adamax":
self.optimizer = fluid.optimizer.Adamax(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
elif self._optimizer_name.lower() == "decayedadagrad":
self.optimizer = fluid.optimizer.DecayedAdagrad(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
elif self._optimizer_name.lower() == "ftrl":
self.optimizer = fluid.optimizer.Ftrl(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
elif self._optimizer_name.lower() == "larsmomentum":
self.optimizer = fluid.optimizer.LarsMomentum(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
elif self._optimizer_name.lower() == "momentum":
self.optimizer = fluid.optimizer.Momentum(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
elif self._optimizer_name.lower() == "decayedadagrad":
self.optimizer = fluid.optimizer.DecayedAdagrad(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
elif self._optimizer_name.lower() == "rmsprop":
self.optimizer = fluid.optimizer.RMSPropOptimizer(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
else:
self.optimizer = fluid.optimizer.Adam(
- learning_rate=self.learning_rate)
+ learning_rate=self.learning_rate, **kwargs)
def execute(self, loss, data_reader, config, dev_count):
if self.optimizer is not None:
@@ -186,10 +186,13 @@ class CombinedStrategy(DefaultStrategy):
learning_rate=1e-4,
scheduler=None,
regularization=None,
- clip=None):
+ clip=None,
+ **kwargs):
super(CombinedStrategy, self).__init__(
- optimizer_name=optimizer_name, learning_rate=learning_rate)
-
+ optimizer_name=optimizer_name,
+ learning_rate=learning_rate,
+ **kwargs)
+ self.kwargs = kwargs
# init set
self.scheduler = {
"warmup": 0.0,
@@ -379,7 +382,9 @@ class CombinedStrategy(DefaultStrategy):
# set optimizer
super(CombinedStrategy, self).__init__(
- optimizer_name=self._optimizer_name, learning_rate=scheduled_lr)
+ optimizer_name=self._optimizer_name,
+ learning_rate=scheduled_lr,
+ **self.kwargs)
# discriminative learning rate
# based on layer
@@ -511,10 +516,6 @@ class CombinedStrategy(DefaultStrategy):
unfreeze_depths=self.
sorted_depth[:self.max_depth * self.epoch //
self.scheduler["gradual_unfreeze"]["blocks"]])
- else:
- logger.warning(
- "The max op-depth in the network is %s. That results in that can't use the gradual unfreeze finetune strategy."
- % (self.max_depth))
elif self.scheduler["gradual_unfreeze"]["params_layer"]:
max_layer = max(
self.scheduler["gradual_unfreeze"]["params_layer"].values())
@@ -568,7 +569,8 @@ class AdamWeightDecayStrategy(CombinedStrategy):
lr_scheduler="linear_decay",
warmup_proportion=0.1,
weight_decay=0.01,
- optimizer_name="adam"):
+ optimizer_name="adam",
+ **kwargs):
scheduler = {"warmup": warmup_proportion}
if lr_scheduler == "noam_decay":
scheduler["noam_decay"] = True
@@ -587,14 +589,16 @@ class AdamWeightDecayStrategy(CombinedStrategy):
learning_rate=learning_rate,
scheduler=scheduler,
regularization=regularization,
- clip=clip)
+ clip=clip,
+ **kwargs)
class L2SPFinetuneStrategy(CombinedStrategy):
def __init__(self,
learning_rate=1e-4,
optimizer_name="adam",
- regularization_coeff=1e-3):
+ regularization_coeff=1e-3,
+ **kwargs):
scheduler = {}
regularization = {"L2SP": regularization_coeff}
clip = {}
@@ -603,14 +607,16 @@ class L2SPFinetuneStrategy(CombinedStrategy):
learning_rate=learning_rate,
scheduler=scheduler,
regularization=regularization,
- clip=clip)
+ clip=clip,
+ **kwargs)
class DefaultFinetuneStrategy(CombinedStrategy):
def __init__(self,
learning_rate=1e-4,
optimizer_name="adam",
- regularization_coeff=1e-3):
+ regularization_coeff=1e-3,
+ **kwargs):
scheduler = {}
regularization = {"L2": regularization_coeff}
clip = {}
@@ -620,7 +626,8 @@ class DefaultFinetuneStrategy(CombinedStrategy):
learning_rate=learning_rate,
scheduler=scheduler,
regularization=regularization,
- clip=clip)
+ clip=clip,
+ **kwargs)
class ULMFiTStrategy(CombinedStrategy):
@@ -631,8 +638,10 @@ class ULMFiTStrategy(CombinedStrategy):
ratio=32,
dis_blocks=3,
factor=2.6,
+ dis_params_layer=None,
frz_blocks=3,
- params_layer=None):
+ frz_params_layer=None,
+ **kwargs):
scheduler = {
"slanted_triangle": {
@@ -641,12 +650,12 @@ class ULMFiTStrategy(CombinedStrategy):
},
"gradual_unfreeze": {
"blocks": frz_blocks,
- "params_layer": params_layer
+ "params_layer": frz_params_layer
},
"discriminative": {
"blocks": dis_blocks,
"factor": factor,
- "params_layer": params_layer
+ "params_layer": dis_params_layer
}
}
regularization = {}
@@ -656,4 +665,5 @@ class ULMFiTStrategy(CombinedStrategy):
learning_rate=learning_rate,
scheduler=scheduler,
regularization=regularization,
- clip=clip)
+ clip=clip,
+ **kwargs)
diff --git a/paddlehub/finetune/task/base_task.py b/paddlehub/finetune/task/base_task.py
index cd2ffd9e9edd880e328bef63840239b43ed31ed0..910364981236cbfb558450317f089dec08e2bba0 100644
--- a/paddlehub/finetune/task/base_task.py
+++ b/paddlehub/finetune/task/base_task.py
@@ -36,7 +36,7 @@ from visualdl import LogWriter
import paddlehub as hub
from paddlehub.common.paddle_helper import dtype_map, clone_program
-from paddlehub.common.utils import mkdir, version_compare
+from paddlehub.common.utils import mkdir
from paddlehub.common.dir import tmp_dir
from paddlehub.common.logger import logger
from paddlehub.finetune.checkpoint import load_checkpoint, save_checkpoint
@@ -832,7 +832,10 @@ class BaseTask(object):
self.config.checkpoint_dir,
self.exe,
main_program=self.main_program)
-
+ # Revise max_train_steps when incremental training
+ if is_load_successful:
+ self.max_train_steps = self.env.current_step + self.max_train_steps / self.config.num_epoch * (
+ self.config.num_epoch - self.env.current_epoch + 1)
return is_load_successful
def load_parameters(self, dirname):
@@ -951,12 +954,6 @@ class BaseTask(object):
Returns:
RunState: the running result of predict phase
"""
-
- if isinstance(self._base_data_reader, hub.reader.LACClassifyReader):
- raise Exception(
- "LACClassifyReader does not support predictor, please close accelerate_mode"
- )
-
global_run_states = []
period_run_states = []
@@ -998,6 +995,12 @@ class BaseTask(object):
Returns:
RunState: the running result of predict phase
"""
+ if accelerate_mode and isinstance(self._base_data_reader,
+ hub.reader.LACClassifyReader):
+ logger.warning(
+ "LACClassifyReader does not support predictor, the accelerate_mode is closed now."
+ )
+ accelerate_mode = False
self.accelerate_mode = accelerate_mode
with self.phase_guard(phase="predict"):
diff --git a/paddlehub/finetune/task/reading_comprehension_task.py b/paddlehub/finetune/task/reading_comprehension_task.py
index f0d6ab61e158e33b1319f614030cd099af3d6187..cb01f0eb7075915d78f8835b08c70ff82cef5959 100644
--- a/paddlehub/finetune/task/reading_comprehension_task.py
+++ b/paddlehub/finetune/task/reading_comprehension_task.py
@@ -205,7 +205,7 @@ def get_predictions(all_examples, all_features, all_results, n_best_size,
for (feature_index, feature) in enumerate(features):
if feature.unique_id not in unique_id_to_result:
logger.info(
- "As using pyreader, the last one batch is so small that the feature %s in the last batch is discarded "
+ "As using multidevice, the last one batch is so small that the feature %s in the last batch is discarded "
% feature.unique_id)
continue
result = unique_id_to_result[feature.unique_id]
diff --git a/paddlehub/module/nlp_module.py b/paddlehub/module/nlp_module.py
index 0ebcf23636de3e548560710806d90df580118abb..211f7313ea1a8819463a821c6153ea485b4b4a37 100644
--- a/paddlehub/module/nlp_module.py
+++ b/paddlehub/module/nlp_module.py
@@ -229,6 +229,9 @@ class _TransformerEmbeddingTask(hub.BaseTask):
self.seq_feature = seq_feature
def _build_net(self):
+ # ClassifyReader will return the seqence length of an input text
+ self.seq_len = fluid.layers.data(
+ name="seq_len", shape=[1], dtype='int64', lod_level=0)
return [self.pooled_feature, self.seq_feature]
def _postprocessing(self, run_states):
@@ -242,6 +245,18 @@ class _TransformerEmbeddingTask(hub.BaseTask):
[batch_pooled_features[i], batch_seq_features[i]])
return results
+ @property
+ def feed_list(self):
+ feed_list = [varname
+ for varname in self._base_feed_list] + [self.seq_len.name]
+ return feed_list
+
+ @property
+ def fetch_list(self):
+ fetch_list = [output.name
+ for output in self.outputs] + [self.seq_len.name]
+ return fetch_list
+
class TransformerModule(NLPBaseModule):
"""
@@ -265,7 +280,7 @@ class TransformerModule(NLPBaseModule):
**kwargs)
self.max_seq_len = max_seq_len
- if version_compare(paddle.__version__, '1.8.0'):
+ if version_compare(paddle.__version__, '1.8'):
with tmp_dir() as _dir:
input_dict, output_dict, program = self.context(
max_seq_len=max_seq_len)
@@ -304,8 +319,6 @@ class TransformerModule(NLPBaseModule):
pretraining_params_path,
main_program=main_program,
predicate=existed_params)
- logger.info("Load pretraining parameters from {}.".format(
- pretraining_params_path))
def param_prefix(self):
return "@HUB_%s@" % self.name
@@ -397,7 +410,8 @@ class TransformerModule(NLPBaseModule):
return inputs, outputs, module_program
- def get_embedding(self, texts, use_gpu=False, batch_size=1):
+ def get_embedding(self, texts, max_seq_len=512, use_gpu=False,
+ batch_size=1):
"""
get pooled_output and sequence_output for input texts.
Warnings: this method depends on Paddle Inference Library, it may not work properly in PaddlePaddle <= 1.6.2.
@@ -405,6 +419,7 @@ class TransformerModule(NLPBaseModule):
Args:
texts (list): each element is a text sample, each sample include text_a and text_b where text_b can be omitted.
for example: [[sample0_text_a, sample0_text_b], [sample1_text_a, sample1_text_b], ...]
+ max_seq_len (int): the max sequence length.
use_gpu (bool): use gpu or not, default False.
batch_size (int): the data batch size, default 1.
@@ -417,12 +432,12 @@ class TransformerModule(NLPBaseModule):
) or self.emb_job["batch_size"] != batch_size or self.emb_job[
"use_gpu"] != use_gpu:
inputs, outputs, program = self.context(
- trainable=True, max_seq_len=self.MAX_SEQ_LEN)
+ trainable=True, max_seq_len=max_seq_len)
reader = hub.reader.ClassifyReader(
dataset=None,
vocab_path=self.get_vocab_path(),
- max_seq_len=self.MAX_SEQ_LEN,
+ max_seq_len=max_seq_len,
sp_model_path=self.get_spm_path() if hasattr(
self, "get_spm_path") else None,
word_dict_path=self.get_word_dict_path() if hasattr(
@@ -477,7 +492,7 @@ class TransformerModule(NLPBaseModule):
return self.params_layer
def forward(self, input_ids, position_ids, segment_ids, input_mask):
- if version_compare(paddle.__version__, '1.8.0'):
+ if version_compare(paddle.__version__, '1.8'):
pooled_output, sequence_output = self.model_runner(
input_ids, position_ids, segment_ids, input_mask)
return {
@@ -486,5 +501,5 @@ class TransformerModule(NLPBaseModule):
}
else:
raise RuntimeError(
- '{} only support dynamic graph mode in paddle >= 1.8.0'.format(
+ '{} only support dynamic graph mode in paddle >= 1.8'.format(
self.name))
diff --git a/paddlehub/network/classification.py b/paddlehub/network/classification.py
index 8543d0f091bb21279d8e7fbd396f81f44f5244f7..c441246531a237c007f9aa7d4920df7dce2f36db 100644
--- a/paddlehub/network/classification.py
+++ b/paddlehub/network/classification.py
@@ -22,7 +22,7 @@ import paddle.fluid as fluid
def bilstm(token_embeddings, hid_dim=128, hid_dim2=96):
"""
- bilstm net
+ BiLSTM network.
"""
fc0 = fluid.layers.fc(input=token_embeddings, size=hid_dim * 4)
rfc0 = fluid.layers.fc(input=token_embeddings, size=hid_dim * 4)
@@ -44,7 +44,7 @@ def bilstm(token_embeddings, hid_dim=128, hid_dim2=96):
def bow(token_embeddings, hid_dim=128, hid_dim2=96):
"""
- bow net
+ BOW network.
"""
# bow layer
bow = fluid.layers.sequence_pool(input=token_embeddings, pool_type='sum')
@@ -57,7 +57,7 @@ def bow(token_embeddings, hid_dim=128, hid_dim2=96):
def cnn(token_embeddings, hid_dim=128, win_size=3):
"""
- cnn net
+ CNN network.
"""
# cnn layer
conv = fluid.nets.sequence_conv_pool(
@@ -77,7 +77,8 @@ def dpcnn(token_embeddings,
emb_dim=1024,
blocks=6):
"""
- deepcnn net
+ Deep Pyramid Convolutional Neural Networks is implemented as ACL2017 'Deep Pyramid Convolutional Neural Networks for Text Categorization'
+ For more information, please refer to https://www.aclweb.org/anthology/P17-1052.pdf.
"""
def _block(x):
@@ -110,7 +111,7 @@ def dpcnn(token_embeddings,
def gru(token_embeddings, hid_dim=128, hid_dim2=96):
"""
- gru net
+ GRU network.
"""
fc0 = fluid.layers.fc(input=token_embeddings, size=hid_dim * 3)
gru_h = fluid.layers.dynamic_gru(input=fc0, size=hid_dim, is_reverse=False)
@@ -122,7 +123,7 @@ def gru(token_embeddings, hid_dim=128, hid_dim2=96):
def lstm(token_embeddings, hid_dim=128, hid_dim2=96):
"""
- lstm net
+ LSTM network.
"""
# lstm layer
fc0 = fluid.layers.fc(input=token_embeddings, size=hid_dim * 4)
diff --git a/paddlehub/reader/nlp_reader.py b/paddlehub/reader/nlp_reader.py
index dc7549983b01b16496178801ebb49fb7ce84033b..7cf4cf67ce70de850ca0c04dc4cc37d58ee8c6f2 100644
--- a/paddlehub/reader/nlp_reader.py
+++ b/paddlehub/reader/nlp_reader.py
@@ -1113,7 +1113,7 @@ class LACClassifyReader(BaseReader):
return processed
- if not self.has_processed[phase]:
+ if not self.has_processed[phase] or phase == "predict":
logger.info(
"processing %s data now... this may take a few minutes" % phase)
for i in range(len(data)):
diff --git a/paddlehub/version.py b/paddlehub/version.py
index 32de895003f31db1c1dbe1a7142484c1099f6fe0..20ffa0f4fcebb044d85e0bb58b0f5c5956fa5be9 100644
--- a/paddlehub/version.py
+++ b/paddlehub/version.py
@@ -13,5 +13,5 @@
# See the License for the specific language governing permissions and
# limitations under the License.
""" PaddleHub version string """
-hub_version = "1.6.2"
+hub_version = "1.7.1"
module_proto_version = "1.0.0"
diff --git a/requirements.txt b/requirements.txt
index 2885c961a1c389848f89d5a09980e48f22117323..5824da115cd595900900a4baba6d4bddb35f7744 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,27 +1,16 @@
pre-commit
protobuf >= 3.6.0
yapf == 0.26.0
-pyyaml
-Pillow
six >= 1.10.0
-chardet == 3.0.4
-requests
flask >= 1.1.0
flake8
-visualdl == 2.0.0a0
-cma == 2.7.0
+visualdl >= 2.0.0b
+cma >= 2.7.0
sentencepiece
-nltk
colorlog
-opencv-python
-
-# numpy no longer support python2 in version 1.17 and above
-numpy ; python_version >= "3"
-numpy < 1.17.0 ; python_version < "3"
# pandas no longer support python2 in version 0.25 and above
pandas ; python_version >= "3"
-pandas < 0.25.0 ; python_version < "3"
# gunicorn not support windows
gunicorn >= 19.10.0; sys_platform != "win32"