diff --git a/modules/audio/asr/u2_conformer_wenetspeech/README.md b/modules/audio/asr/u2_conformer_wenetspeech/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..3cc2442c3b577f4059202ea9f53a5f2eaa9cf192
--- /dev/null
+++ b/modules/audio/asr/u2_conformer_wenetspeech/README.md
@@ -0,0 +1,157 @@
+# u2_conformer_wenetspeech
+
+|模型名称|u2_conformer_wenetspeech|
+| :--- | :---: |
+|类别|语音-语音识别|
+|网络|Conformer|
+|数据集|WenetSpeech|
+|是否支持Fine-tuning|否|
+|模型大小|494MB|
+|最新更新日期|2021-12-10|
+|数据指标|中文CER 0.087 |
+
+## 一、模型基本信息
+
+### 模型介绍
+
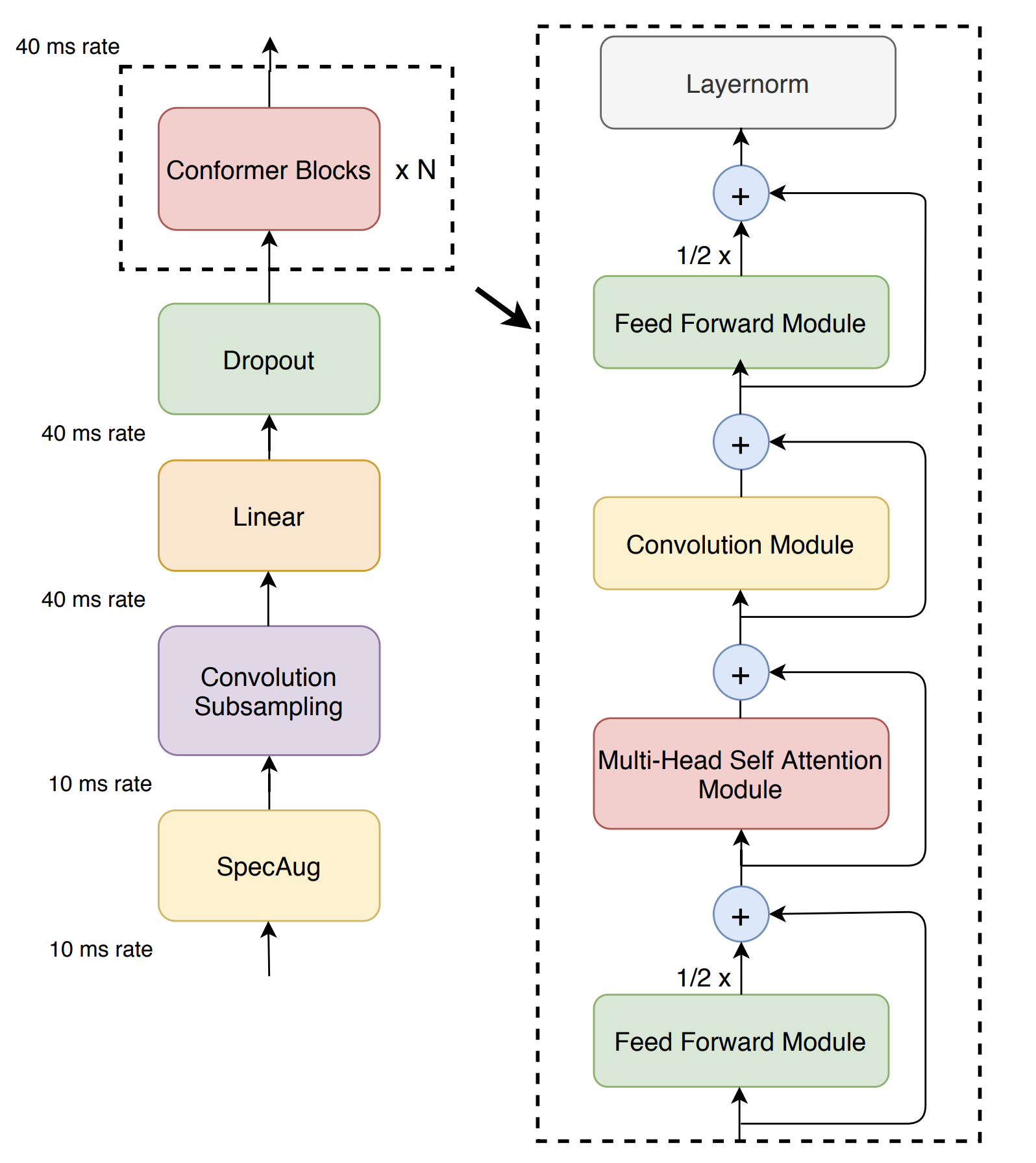
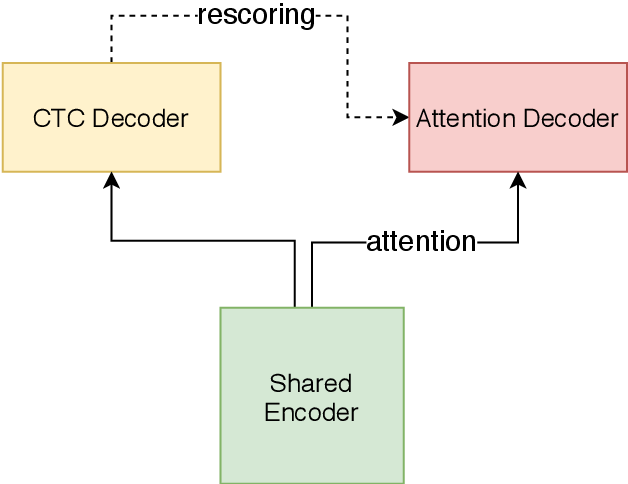
+U2 Conformer模型是一种适用于英文和中文的end-to-end语音识别模型。u2_conformer_wenetspeech采用了conformer的encoder和transformer的decoder的模型结构,并且使用了ctc-prefix beam search的方式进行一遍打分,再利用attention decoder进行二次打分的方式进行解码来得到最终结果。
+
+u2_conformer_wenetspeech在中文普通话开源语音数据集[WenetSpeech](https://wenet-e2e.github.io/WenetSpeech/)进行了预训练,该模型在其DEV测试集上的CER指标是0.087。
+
+
+
+
+
+
+
+
+
+更多详情请参考:
+- [Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition](https://arxiv.org/abs/2012.05481)
+- [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100)
+- [WenetSpeech: A 10000+ Hours Multi-domain Mandarin Corpus for Speech Recognition](https://arxiv.org/abs/2110.03370)
+
+## 二、安装
+
+- ### 1、系统依赖
+
+ - libsndfile
+ - Linux
+ ```shell
+ $ sudo apt-get install libsndfile
+ or
+ $ sudo yum install libsndfile
+ ```
+ - MacOs
+ ```
+ $ brew install libsndfile
+ ```
+
+- ### 2、环境依赖
+
+ - paddlepaddle >= 2.2.0
+
+ - paddlehub >= 2.1.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 3、安装
+
+ - ```shell
+ $ hub install u2_conformer_wenetspeech
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、预测代码示例
+
+ ```python
+ import paddlehub as hub
+
+ # 采样率为16k,格式为wav的中文语音音频
+ wav_file = '/PATH/TO/AUDIO'
+
+ model = hub.Module(
+ name='u2_conformer_wenetspeech',
+ version='1.0.0')
+ text = model.speech_recognize(wav_file)
+
+ print(text)
+ ```
+
+- ### 2、API
+ - ```python
+ def check_audio(audio_file)
+ ```
+ - 检查输入音频格式和采样率是否满足为16000,如果不满足,则重新采样至16000并将新的音频文件保存至相同目录。
+
+ - **参数**
+
+ - `audio_file`:本地音频文件(*.wav)的路径,如`/path/to/input.wav`
+
+ - ```python
+ def speech_recognize(
+ audio_file,
+ device='cpu',
+ )
+ ```
+ - 将输入的音频识别成文字
+
+ - **参数**
+
+ - `audio_file`:本地音频文件(*.wav)的路径,如`/path/to/input.wav`
+ - `device`:预测时使用的设备,默认为�`cpu`,如需使用gpu预测,请设置为`gpu`。
+
+ - **返回**
+
+ - `text`:str类型,返回输入音频的识别文字结果。
+
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线的语音识别服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - ```shell
+ $ hub serving start -m u2_conformer_wenetspeech
+ ```
+
+ - 这样就完成了一个语音识别服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ # 需要识别的音频的存放路径,确保部署服务的机器可访问
+ file = '/path/to/input.wav'
+
+ # 以key的方式指定text传入预测方法的时的参数,此例中为"audio_file"
+ data = {"audio_file": file}
+
+ # 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+ url = "http://127.0.0.1:8866/predict/u2_conformer_wenetspeech"
+
+ # 指定post请求的headers为application/json方式
+ headers = {"Content-Type": "application/json"}
+
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ print(r.json())
+ ```
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install u2_conformer_wenetspeech
+ ```
diff --git a/modules/audio/asr/u2_conformer_wenetspeech/__init__.py b/modules/audio/asr/u2_conformer_wenetspeech/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/modules/audio/asr/u2_conformer_wenetspeech/module.py b/modules/audio/asr/u2_conformer_wenetspeech/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..51ff08c77a2baf29e31ca70dac9d9109279b00c1
--- /dev/null
+++ b/modules/audio/asr/u2_conformer_wenetspeech/module.py
@@ -0,0 +1,56 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+
+import paddle
+from paddleaudio import load, save_wav
+from paddlespeech.cli import ASRExecutor
+from paddlehub.module.module import moduleinfo, serving
+from paddlehub.utils.log import logger
+
+
+@moduleinfo(
+ name="u2_conformer_wenetspeech", version="1.0.0", summary="", author="Wenet", author_email="", type="audio/asr")
+class U2Conformer(paddle.nn.Layer):
+ def __init__(self):
+ super(U2Conformer, self).__init__()
+ self.asr_executor = ASRExecutor()
+ self.asr_kw_args = {
+ 'model': 'conformer_wenetspeech',
+ 'lang': 'zh',
+ 'sample_rate': 16000,
+ 'config': None, # Set `config` and `ckpt_path` to None to use pretrained model.
+ 'ckpt_path': None,
+ }
+
+ @staticmethod
+ def check_audio(audio_file):
+ assert audio_file.endswith('.wav'), 'Input file must be a wave file `*.wav`.'
+ sig, sample_rate = load(audio_file)
+ if sample_rate != 16000:
+ sig, _ = load(audio_file, 16000)
+ audio_file_16k = audio_file[:audio_file.rindex('.')] + '_16k.wav'
+ logger.info('Resampling to 16000 sample rate to new audio file: {}'.format(audio_file_16k))
+ save_wav(sig, 16000, audio_file_16k)
+ return audio_file_16k
+ else:
+ return audio_file
+
+ @serving
+ def speech_recognize(self, audio_file, device='cpu'):
+ assert os.path.isfile(audio_file), 'File not exists: {}'.format(audio_file)
+ audio_file = self.check_audio(audio_file)
+ text = self.asr_executor(audio_file=audio_file, device=device, **self.asr_kw_args)
+ return text
diff --git a/modules/audio/asr/u2_conformer_wenetspeech/requirements.txt b/modules/audio/asr/u2_conformer_wenetspeech/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..697ab54b76553598c45dfe7764a014826b393114
--- /dev/null
+++ b/modules/audio/asr/u2_conformer_wenetspeech/requirements.txt
@@ -0,0 +1 @@
+paddlespeech==0.1.0a9
diff --git a/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/README.md b/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a4f9ac8a29269f31ea653db70d5ff92f36718672
--- /dev/null
+++ b/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/README.md
@@ -0,0 +1,111 @@
+# ge2e_fastspeech2_pwgan
+
+|模型名称|ge2e_fastspeech2_pwgan|
+| :--- | :---: |
+|类别|语音-声音克隆|
+|网络|FastSpeech2|
+|数据集|AISHELL-3|
+|是否支持Fine-tuning|否|
+|模型大小|462MB|
+|最新更新日期|2021-12-17|
+|数据指标|-|
+
+## 一、模型基本信息
+
+### 模型介绍
+
+声音克隆是指使用特定的音色,结合文字的读音合成音频,使得合成后的音频具有目标说话人的特征,从而达到克隆的目的。
+
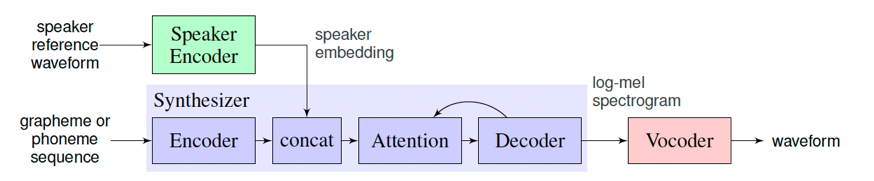
+在训练语音克隆模型时,目标音色作为Speaker Encoder的输入,模型会提取这段语音的说话人特征(音色)作为Speaker Embedding。接着,在训练模型重新合成此类音色的语音时,除了输入的目标文本外,说话人的特征也将成为额外条件加入模型的训练。
+
+在预测时,选取一段新的目标音色作为Speaker Encoder的输入,并提取其说话人特征,最终实现输入为一段文本和一段目标音色,模型生成目标音色说出此段文本的语音片段。
+
+
+
+`ge2e_fastspeech2_pwgan`是一个支持中文的语音克隆模型,分别使用了LSTMSpeakerEncoder、FastSpeech2和PWGan模型分别用于语音特征提取、目标音频特征合成和语音波形转换。
+
+关于模型的详请可参考[PaddleSpeech](https://github.com/PaddlePaddle/PaddleSpeech)。
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.2.0
+
+ - paddlehub >= 2.1.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install ge2e_fastspeech2_pwgan
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API预测
+
+- ### 1、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ model = hub.Module(name='ge2e_fastspeech2_pwgan', output_dir='./', speaker_audio='/data/man.wav') # 指定目标音色音频文件
+ texts = [
+ '语音的表现形式在未来将变得越来越重要$',
+ '今天的天气怎么样$', ]
+ wavs = model.generate(texts, use_gpu=True)
+
+ for text, wav in zip(texts, wavs):
+ print('='*30)
+ print(f'Text: {text}')
+ print(f'Wav: {wav}')
+ ```
+
+- ### 2、API
+ - ```python
+ def __init__(speaker_audio: str = None,
+ output_dir: str = './')
+ ```
+ - 初始化module,可配置模型的目标音色的音频文件和输出的路径。
+
+ - **参数**
+ - `speaker_audio`(str): 目标说话人语音音频文件(*.wav)的路径,默认为None(使用默认的女声作为目标音色)。
+ - `output_dir`(str): 合成音频的输出文件,默认为当前目录。
+
+
+ - ```python
+ def get_speaker_embedding()
+ ```
+ - 获取模型的目标说话人特征。
+
+ - **返回**
+ - `results`(numpy.ndarray): 长度为256的numpy数组,代表目标说话人的特征。
+
+ - ```python
+ def set_speaker_embedding(speaker_audio: str)
+ ```
+ - 设置模型的目标说话人特征。
+
+ - **参数**
+ - `speaker_audio`(str): 必填,目标说话人语音音频文件(*.wav)的路径。
+
+ - ```python
+ def generate(data: Union[str, List[str]], use_gpu: bool = False):
+ ```
+ - 根据输入文字,合成目标说话人的语音音频文件。
+
+ - **参数**
+ - `data`(Union[str, List[str]]): 必填,目标音频的内容文本列表,目前只支持中文,不支持添加标点符号。
+ - `use_gpu`(bool): 是否使用gpu执行计算,默认为False。
+
+
+## 四、更新历史
+
+* 1.0.0
+
+ 初始发布。
+
+ ```shell
+ $ hub install ge2e_fastspeech2_pwgan
+ ```
diff --git a/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/__init__.py b/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/module.py b/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..9bea0832b9d67319a9ecf318ca1f3df9128df305
--- /dev/null
+++ b/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/module.py
@@ -0,0 +1,160 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import List, Union
+
+import numpy as np
+import paddle
+import soundfile as sf
+import yaml
+from yacs.config import CfgNode
+
+from paddlehub.env import MODULE_HOME
+from paddlehub.module.module import moduleinfo, serving
+from paddlehub.utils.log import logger
+from paddlespeech.t2s.frontend.zh_frontend import Frontend
+from paddlespeech.t2s.models.fastspeech2 import FastSpeech2
+from paddlespeech.t2s.models.fastspeech2 import FastSpeech2Inference
+from paddlespeech.t2s.models.parallel_wavegan import PWGGenerator
+from paddlespeech.t2s.models.parallel_wavegan import PWGInference
+from paddlespeech.t2s.modules.normalizer import ZScore
+from paddlespeech.vector.exps.ge2e.audio_processor import SpeakerVerificationPreprocessor
+from paddlespeech.vector.models.lstm_speaker_encoder import LSTMSpeakerEncoder
+
+
+@moduleinfo(
+ name="ge2e_fastspeech2_pwgan",
+ version="1.0.0",
+ summary="",
+ author="paddlepaddle",
+ author_email="",
+ type="audio/voice_cloning",
+)
+class VoiceCloner(paddle.nn.Layer):
+ def __init__(self, speaker_audio: str = None, output_dir: str = './'):
+ super(VoiceCloner, self).__init__()
+
+ speaker_encoder_ckpt = os.path.join(MODULE_HOME, 'ge2e_fastspeech2_pwgan', 'assets',
+ 'ge2e_ckpt_0.3/step-3000000.pdparams')
+ synthesizer_res_dir = os.path.join(MODULE_HOME, 'ge2e_fastspeech2_pwgan', 'assets',
+ 'fastspeech2_nosil_aishell3_vc1_ckpt_0.5')
+ vocoder_res_dir = os.path.join(MODULE_HOME, 'ge2e_fastspeech2_pwgan', 'assets', 'pwg_aishell3_ckpt_0.5')
+
+ # Speaker encoder
+ self.speaker_processor = SpeakerVerificationPreprocessor(
+ sampling_rate=16000,
+ audio_norm_target_dBFS=-30,
+ vad_window_length=30,
+ vad_moving_average_width=8,
+ vad_max_silence_length=6,
+ mel_window_length=25,
+ mel_window_step=10,
+ n_mels=40,
+ partial_n_frames=160,
+ min_pad_coverage=0.75,
+ partial_overlap_ratio=0.5)
+ self.speaker_encoder = LSTMSpeakerEncoder(n_mels=40, num_layers=3, hidden_size=256, output_size=256)
+ self.speaker_encoder.set_state_dict(paddle.load(speaker_encoder_ckpt))
+ self.speaker_encoder.eval()
+
+ # Voice synthesizer
+ with open(os.path.join(synthesizer_res_dir, 'default.yaml'), 'r') as f:
+ fastspeech2_config = CfgNode(yaml.safe_load(f))
+ with open(os.path.join(synthesizer_res_dir, 'phone_id_map.txt'), 'r') as f:
+ phn_id = [line.strip().split() for line in f.readlines()]
+
+ model = FastSpeech2(idim=len(phn_id), odim=fastspeech2_config.n_mels, **fastspeech2_config["model"])
+ model.set_state_dict(paddle.load(os.path.join(synthesizer_res_dir, 'snapshot_iter_96400.pdz'))["main_params"])
+ model.eval()
+
+ stat = np.load(os.path.join(synthesizer_res_dir, 'speech_stats.npy'))
+ mu, std = stat
+ mu = paddle.to_tensor(mu)
+ std = paddle.to_tensor(std)
+ fastspeech2_normalizer = ZScore(mu, std)
+ self.sample_rate = fastspeech2_config.fs
+
+ self.fastspeech2_inference = FastSpeech2Inference(fastspeech2_normalizer, model)
+ self.fastspeech2_inference.eval()
+
+ # Vocoder
+ with open(os.path.join(vocoder_res_dir, 'default.yaml')) as f:
+ pwg_config = CfgNode(yaml.safe_load(f))
+
+ vocoder = PWGGenerator(**pwg_config["generator_params"])
+ vocoder.set_state_dict(
+ paddle.load(os.path.join(vocoder_res_dir, 'snapshot_iter_1000000.pdz'))["generator_params"])
+ vocoder.remove_weight_norm()
+ vocoder.eval()
+
+ stat = np.load(os.path.join(vocoder_res_dir, 'feats_stats.npy'))
+ mu, std = stat
+ mu = paddle.to_tensor(mu)
+ std = paddle.to_tensor(std)
+ pwg_normalizer = ZScore(mu, std)
+
+ self.pwg_inference = PWGInference(pwg_normalizer, vocoder)
+ self.pwg_inference.eval()
+
+ # Text frontend
+ self.frontend = Frontend(phone_vocab_path=os.path.join(synthesizer_res_dir, 'phone_id_map.txt'))
+
+ # Speaking embedding
+ self._speaker_embedding = None
+ if speaker_audio is None or not os.path.isfile(speaker_audio):
+ speaker_audio = os.path.join(MODULE_HOME, 'ge2e_fastspeech2_pwgan', 'assets', 'voice_cloning.wav')
+ logger.warning(f'Due to no speaker audio is specified, speaker encoder will use defult '
+ f'waveform({speaker_audio}) to extract speaker embedding. You can use '
+ '"set_speaker_embedding()" method to reset a speaker audio for voice cloning.')
+ self.set_speaker_embedding(speaker_audio)
+
+ self.output_dir = os.path.abspath(output_dir)
+ if not os.path.exists(self.output_dir):
+ os.makedirs(self.output_dir)
+
+ def get_speaker_embedding(self):
+ return self._speaker_embedding.numpy()
+
+ @paddle.no_grad()
+ def set_speaker_embedding(self, speaker_audio: str):
+ assert os.path.exists(speaker_audio), f'Speaker audio file: {speaker_audio} does not exists.'
+ mel_sequences = self.speaker_processor.extract_mel_partials(
+ self.speaker_processor.preprocess_wav(speaker_audio))
+ self._speaker_embedding = self.speaker_encoder.embed_utterance(paddle.to_tensor(mel_sequences))
+
+ logger.info(f'Speaker embedding has been set from file: {speaker_audio}')
+
+ @paddle.no_grad()
+ def generate(self, data: Union[str, List[str]], use_gpu: bool = False):
+ assert self._speaker_embedding is not None, f'Set speaker embedding before voice cloning.'
+
+ if isinstance(data, str):
+ data = [data]
+ elif isinstance(data, list):
+ assert len(data) > 0 and isinstance(data[0],
+ str) and len(data[0]) > 0, f'Input data should be str of List[str].'
+ else:
+ raise Exception(f'Input data should be str of List[str].')
+
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+ files = []
+ for idx, text in enumerate(data):
+ phone_ids = self.frontend.get_input_ids(text, merge_sentences=True)["phone_ids"][0]
+ wav = self.pwg_inference(self.fastspeech2_inference(phone_ids, spk_emb=self._speaker_embedding))
+ output_wav = os.path.join(self.output_dir, f'{idx+1}.wav')
+ sf.write(output_wav, wav.numpy(), samplerate=self.sample_rate)
+ files.append(output_wav)
+
+ return files
diff --git a/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/requirements.txt b/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..120598fd26d619a674601ca3de0a9f7c1609ca99
--- /dev/null
+++ b/modules/audio/voice_cloning/ge2e_fastspeech2_pwgan/requirements.txt
@@ -0,0 +1 @@
+paddlespeech==0.1.0a13