diff --git a/README.md b/README.md
index 997827360603b932c53e3614d47e43cf473cbbe9..da6aa7385fe2b637ec03e38f9c33c5805391e7ad 100644
--- a/README.md
+++ b/README.md
@@ -17,6 +17,8 @@ PaddleHub是基于PaddlePaddle生态下的预训练模型管理和迁移学习
* [回归任务](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.2/demo/sentence_similarity)
* [句子语义相似度计算](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.2/demo/sentence_similarity)
* [阅读理解任务](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.2/demo/reading-comprehension)
+* PaddleHub支持超参优化(Auto Fine-tune),给定Finetune任务运行脚本以及超参搜索范围,Auto Fine-tune即可给出对于当前任务的较佳超参数组合。
+ * [PaddleHub超参优化功能autofinetune使用教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.2/tutorial/autofinetune.md)
* PaddleHub引入『**模型即软件**』的设计理念,支持通过Python API或者命令行工具,一键完成预训练模型地预测,更方便的应用PaddlePaddle模型库。
* [PaddleHub命令行工具介绍](https://github.com/PaddlePaddle/PaddleHub/wiki/PaddleHub%E5%91%BD%E4%BB%A4%E8%A1%8C%E5%B7%A5%E5%85%B7)
@@ -105,8 +107,6 @@ PaddleHub如何自定义迁移任务,详情参考[wiki教程](https://github.c
如何使用PaddleHub超参优化功能,详情参考[autofinetune使用教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.2/tutorial/autofinetune.md)
-如何使用PaddleHub“端到端地”完成文本相似度计算,详情参考[word2vce使用教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.2/tutorial/sentence_sim.ipynb)
-
如何使用ULMFiT策略微调PaddleHub预训练模型,详情参考[PaddleHub 迁移学习与ULMFiT微调策略](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.2/tutorial/strategy_exp.md)
## FAQ
diff --git a/docs/imgs/pbt_optimization.gif b/docs/imgs/pbt_optimization.gif
new file mode 100644
index 0000000000000000000000000000000000000000..a9bdc8694fe5ee2e7ee088fce1d05eb310aa54ab
Binary files /dev/null and b/docs/imgs/pbt_optimization.gif differ
diff --git a/docs/imgs/thermodynamics.gif b/docs/imgs/thermodynamics.gif
new file mode 100644
index 0000000000000000000000000000000000000000..c367c80b9e805447ceaac18b00cb061b81399b2e
Binary files /dev/null and b/docs/imgs/thermodynamics.gif differ
diff --git a/paddlehub/common/lock.py b/paddlehub/common/lock.py
index ea44f0a36a1e49752fb5e123d34ecaaa71771bf5..814b834f20d2f8008069aafdc52564e4a3453537 100644
--- a/paddlehub/common/lock.py
+++ b/paddlehub/common/lock.py
@@ -1,5 +1,6 @@
-import fcntl
import os
+if os.name == "posix":
+ import fcntl
class WinLock(object):
@@ -15,23 +16,22 @@ class Lock(object):
_owner = None
def __init__(self):
- self.LOCK_EX = fcntl.LOCK_EX
- self.LOCK_UN = fcntl.LOCK_UN
- self.LOCK_TE = ""
if os.name == "posix":
self.lock = fcntl
else:
self.lock = WinLock()
_lock = self.lock
+ self.LOCK_EX = self.lock.LOCK_EX
+ self.LOCK_UN = self.lock.LOCK_UN
def get_lock(self):
return self.lock
def flock(self, fp, cmd):
- if cmd == fcntl.LOCK_UN:
+ if cmd == self.lock.LOCK_UN:
Lock._owner = None
self.lock.flock(fp, cmd)
- elif cmd == fcntl.LOCK_EX:
+ elif cmd == self.lock.LOCK_EX:
if Lock._owner is None:
Lock._owner = os.getpid()
self.lock.flock(fp, cmd)
diff --git a/tutorial/autofinetune.md b/tutorial/autofinetune.md
index a22f3f279a984135be680029b87809514fda4b52..4fbe8f1fd514e1369f227737d36d40a727b78b10 100644
--- a/tutorial/autofinetune.md
+++ b/tutorial/autofinetune.md
@@ -8,11 +8,17 @@ PaddleHub Auto Fine-tune提供两种超参优化策略:
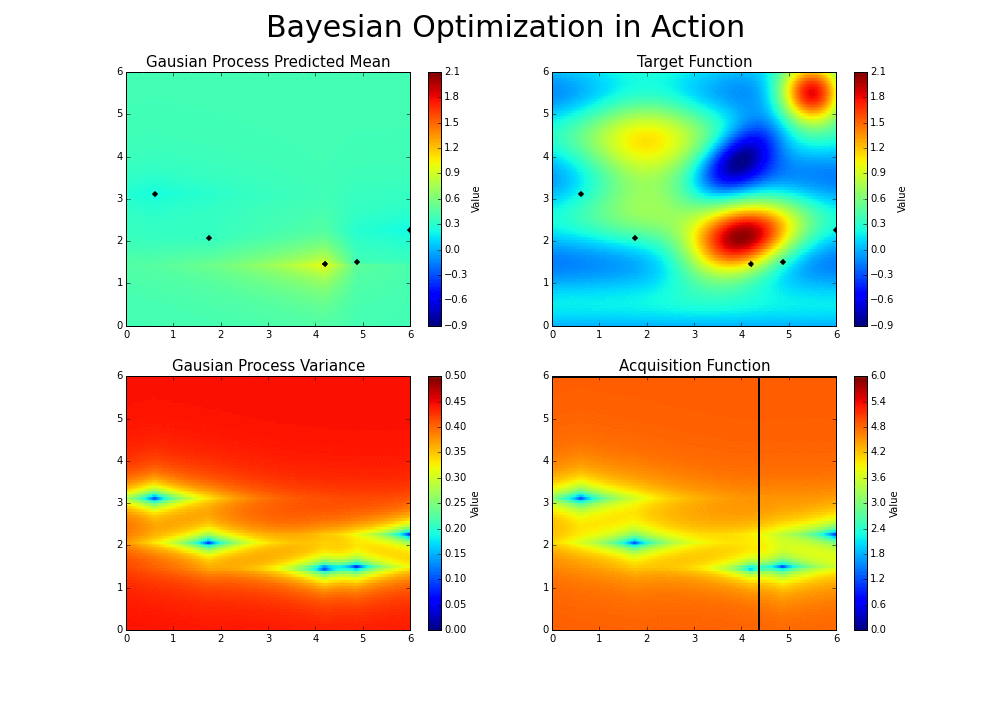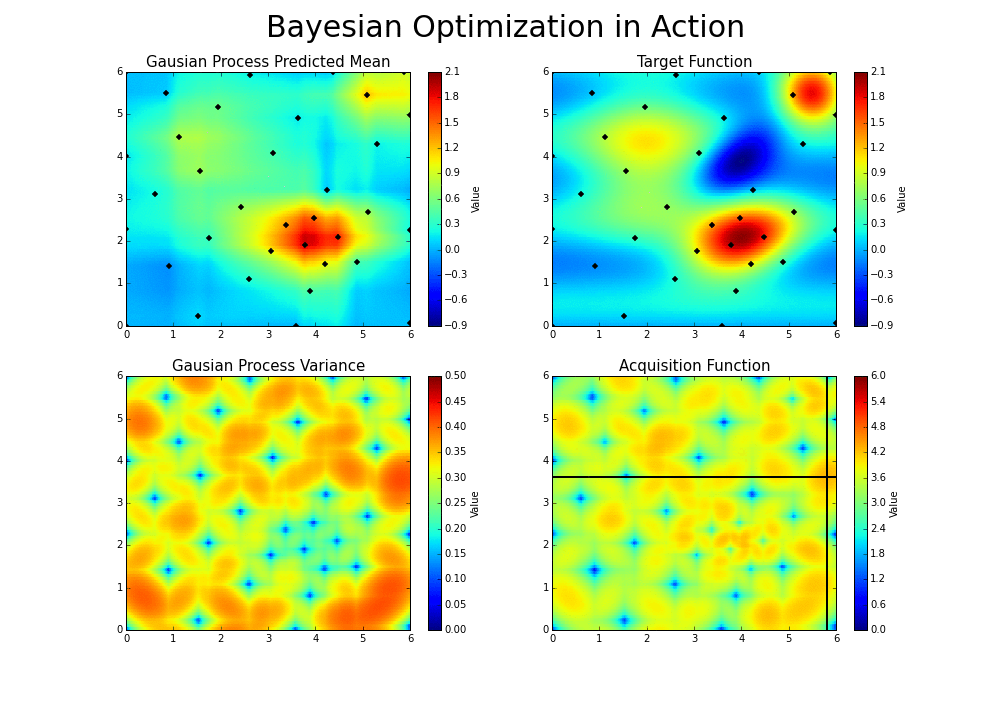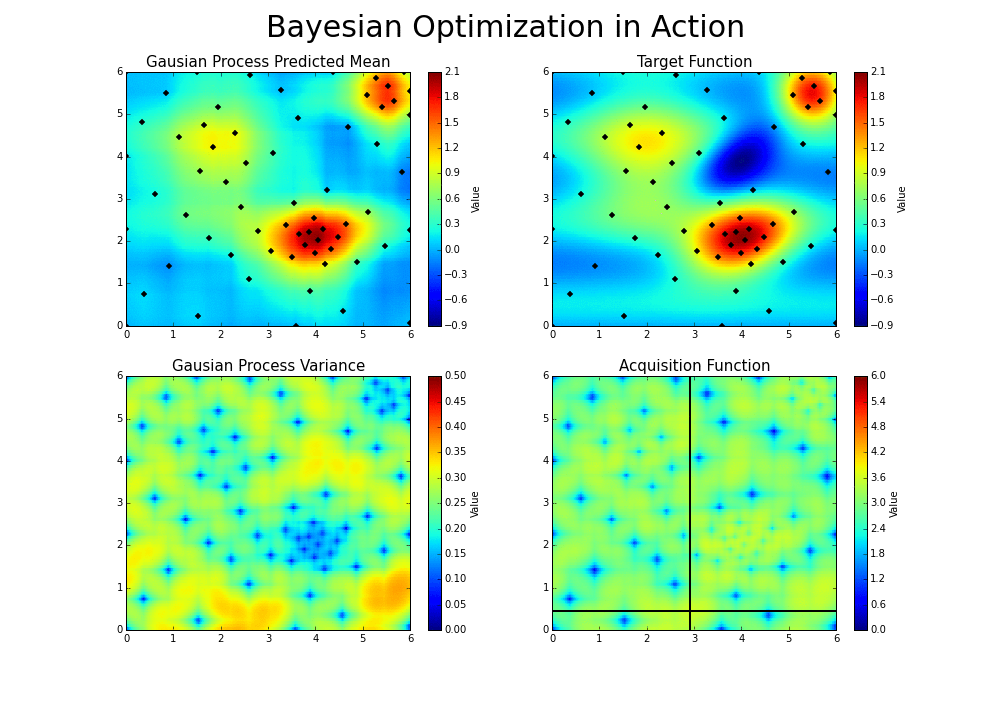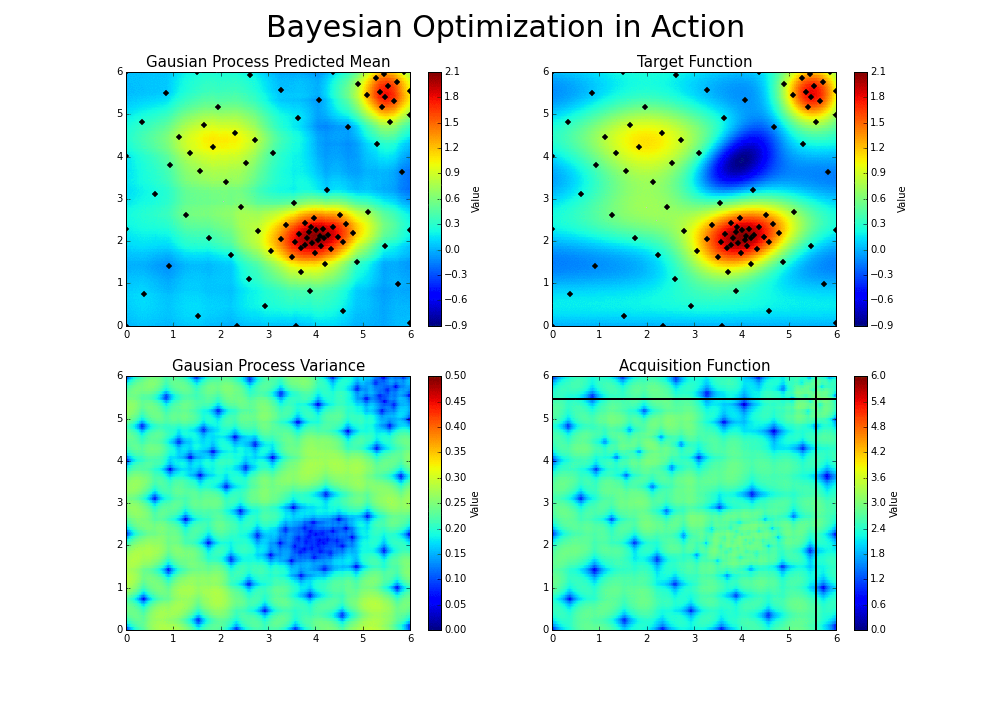
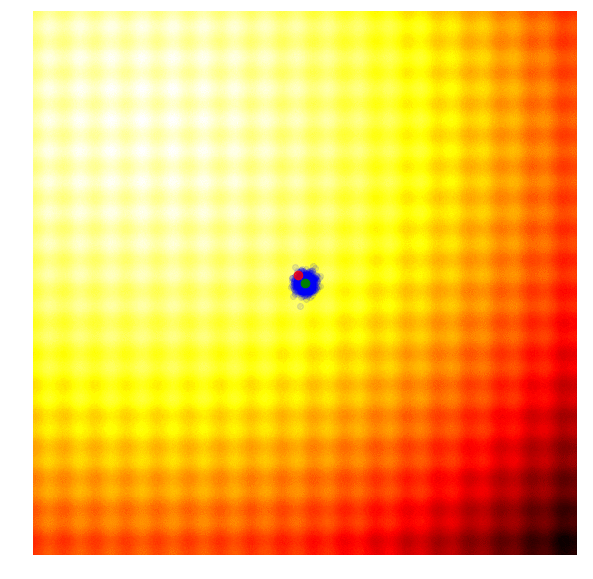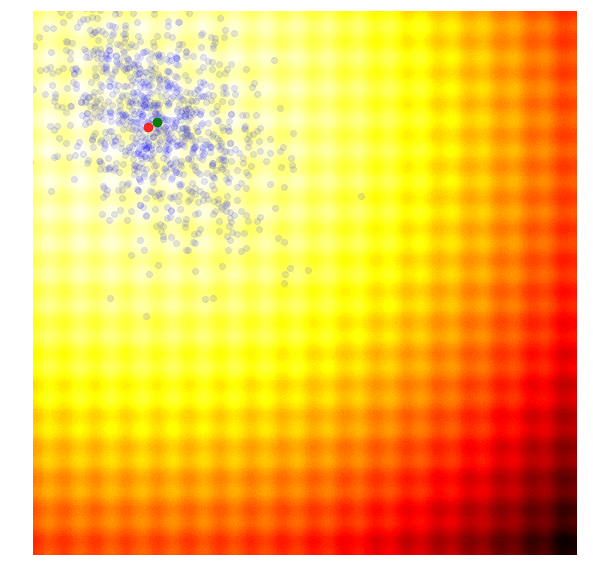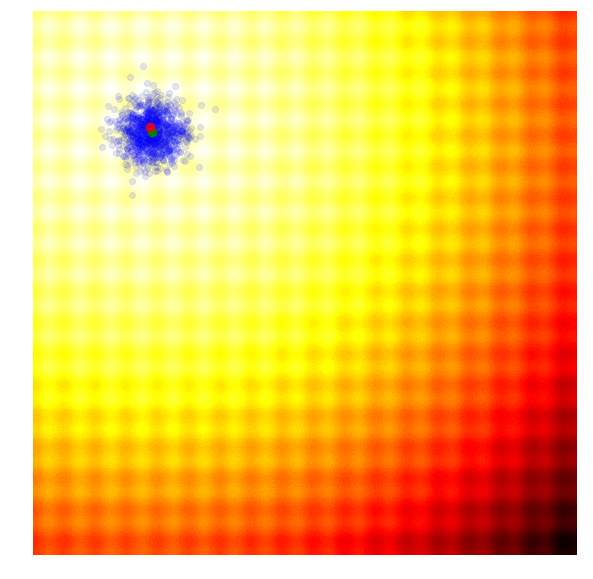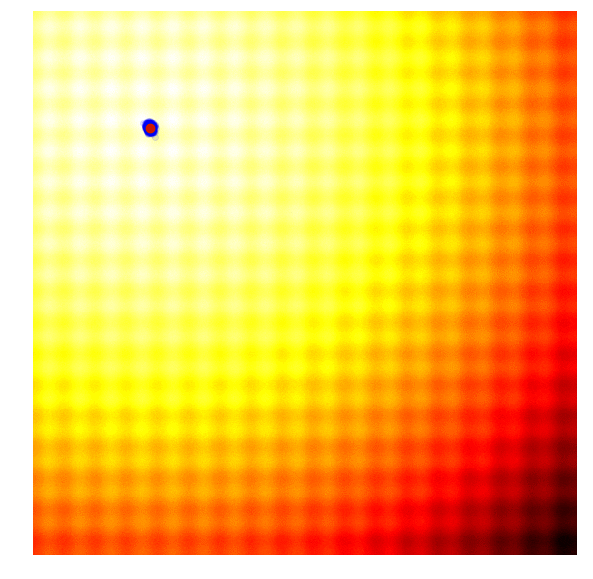
* HAZero: 核心思想是通过对正态分布中协方差矩阵的调整来处理变量之间的依赖关系和scaling。算法基本可以分成以下三步: 采样产生新解;计算目标函数值;更新正态分布参数。调整参数的基本思路为,调整参数使得产生更优解的概率逐渐增大。优化过程如下图:
-
+
+
+
*图片来源于https://www.kaggle.com/clair14/tutorial-bayesian-optimization*
* PSHE2: 采用粒子群算法,最优超参数组合就是所求问题的解。现在想求得最优解就是要找到更新超参数组合,即如何更新超参数,才能让算法更快更好的收敛到最优解。PSHE2算法根据超参数本身历史的最优,在一定随机扰动的情况下决定下一步的更新方向。
+
+
+
+
PaddleHub Auto Fine-tune提供两种超参评估策略:
* FullTrail: 给定一组超参,利用这组超参从头开始Finetune一个新模型,之后在数据集dev部分评估这个模型
@@ -58,14 +64,14 @@ finetunee.py用于接受PaddleHub搜索到的超参进行一次优化过程,
```python
print("AutoFinetuneEval"+"\t" + str(eval_acc))
```
-
+
* 输出的评价效果取值范围应该为`(-∞, 1]`,取值越高,表示效果越好。
### 示例
-[PaddleHub Auto Fine-tune超参优化--NLP情感分类任务]()
+[PaddleHub Auto Fine-tune超参优化--NLP情感分类任务](./autofinetune-nlp.md)
-[PaddleHub Auto Fine-tune超参优化--CV图像分类任务]()
+[PaddleHub Auto Fine-tune超参优化--CV图像分类任务](./autofinetune-cv.md)
## 三、启动方式
@@ -94,21 +100,53 @@ $ hub autofinetune finetunee.py --param_file=hparam.yaml --cuda=['1','2'] --pops
> `--tuning_strategy`: 设置自动优化超参策略,可选hazero和pshe2,默认为hazero
-**NOTE:** Auto Fine-tune功能会根据popsize和cuda自动实现排队使用GPU,如popsize=5,cuda=['0','1','2','3'],则每搜索一轮,Auto Fine-tune自动起四个进程训练,所以第5组超参组合需要排队一次。为了提高GPU利用率以及超参优化效率,此时建议可以设置为3张可用的卡,cuda=['0','1','2']。
+`NOTE`
+* 进行超参搜索时,一共会进行n轮(--round指定),每轮产生m组超参(--popsize指定)进行搜索。每一轮的超参会根据上一轮的优化结果决定,当指定GPU数量不足以同时跑一轮时,Auto Fine-tune功能自动实现排队,为了提高GPU利用率,建议卡数为刚好可以被popsize整除。如popsize=6,cuda=['0','1','2','3'],则每搜索一轮,Auto Fine-tune自动起四个进程训练,所以第5/6组超参组合需要排队一次,在搜索第5/6两组超参时,会存在两张卡出现空闲等待的情况,如果设置为3张可用的卡,则可以避免这种情况的出现。
+
+## 四、目录结构
+
+进行自动超参搜索时,PaddleHub会生成以下目录
+```
+./output_dir/
+ ├── log_file.txt
+ ├── visualization
+ ├── round0
+ ├── round1
+ ├── ...
+ └── roundn
+ ├── log-0.info
+ ├── log-1.info
+ ├── ...
+ ├── log-m.info
+ ├── model-0
+ ├── model-1
+ ├── ...
+ └── model-m
+```
+其中output_dir为启动autofinetune命令时指定的根目录,目录下:
+
+* log_file.txt记录了每一轮搜索所有的超参以及整个过程中所搜索到的最优超参
+
+* visualization记录了可视化过程的日志文件
+
+* round0 ~ roundn记录了每一轮的数据,在每个round目录下,还存在以下文件:
+
+ * log-0.info ~ log-m.info记录了每个搜索方向的日志
+ * model-0 ~ model-m记录了对应搜索的参数
-## 四、可视化
+## 五、可视化
Auto Finetune API在优化超参过程中会自动对关键训练指标进行打点,启动程序后执行下面命令
```shell
-$ tensorboard --logdir $OUTPUT/tb_paddle --host ${HOST_IP} --port ${PORT_NUM}
+$ tensorboard --logdir ${OUTPUT}/visualization --host ${HOST_IP} --port ${PORT_NUM}
```
-其中${HOST_IP}为本机IP地址,${PORT_NUM}为可用端口号,如本机IP地址为192.168.0.1,端口号8040,
-用浏览器打开192.168.0.1:8040,即可看到搜素过程中各超参以及指标的变化情况
+其中${OUTPUT}为AutoDL根目录,${HOST_IP}为本机IP地址,${PORT_NUM}为可用端口号,如本机IP地址为192.168.0.1,端口号8040,
+用浏览器打开192.168.0.1:8040,即可看到搜索过程中各超参以及指标的变化情况
-## 五、其他
+## 六、其他
1. 如在使用Auto Fine-tune功能时,输出信息中包含如下字样:
@@ -116,7 +154,8 @@ $ tensorboard --logdir $OUTPUT/tb_paddle --host ${HOST_IP} --port ${PORT_NUM}
首先根据终端上的输出信息,确定这个输出信息是在第几个round(如round 3),之后查看${OUTPUT}/round3/下的日志文件信息log.info, 查看具体出错原因。
-2. PaddleHub AutoFinetune 命令行支持从启动命令hub autofinetune传入finetunee.py中不需要搜索的选项参数,如上述示例中的max_seq_len选项,可以参照以下方式传入。
+2. PaddleHub AutoFinetune 命令行支持从启动命令hub autofinetune传入finetunee.py中不需要搜索的选项参数,如
+[PaddleHub Auto Fine-tune超参优化--NLP情感分类任务](./autofinetune-nlp.md)示例中的max_seq_len选项,可以参照以下方式传入。
```shell
$ OUTPUT=result/