diff --git a/hub_module/modules/text/text_generation/ernie_gen_couplet/README.md b/hub_module/modules/text/text_generation/ernie_gen_couplet/README.md
index b6a8d230efa022c7207b9d95c371310968b23122..fc120e8632e0a2a33d6dd2797260a8848dce68ed 100644
--- a/hub_module/modules/text/text_generation/ernie_gen_couplet/README.md
+++ b/hub_module/modules/text/text_generation/ernie_gen_couplet/README.md
@@ -1,8 +1,8 @@
## 概述
-ERNIE-GEN 是面向生成任务的预训练-微调框架,首次在预训练阶段加入span-by-span 生成任务,让模型每次能够生成一个语义完整的片段。在预训练和微调中通过填充式生成机制和噪声感知机制来缓解曝光偏差问题。此外, ERNIE-GEN 采样多片段-多粒度目标文本采样策略, 增强源文本和目标文本的关联性,加强了编码器和解码器的交互。
+ERNIE-GEN 是面向生成任务的预训练-微调框架,首次在预训练阶段加入span-by-span 生成任务,让模型每次能够生成一个语义完整的片段。在预训练和微调中通过填充式生成机制和噪声感知机制来缓解曝光偏差问题。此外, ERNIE-GEN 采样多片段-多粒度目标文本采样策略, 增强源文本和目标文本的关联性,加强了编码器和解码器的交互。ernie_gen_couplet采用开源对联数据集进行微调,可用于生成下联。
-
+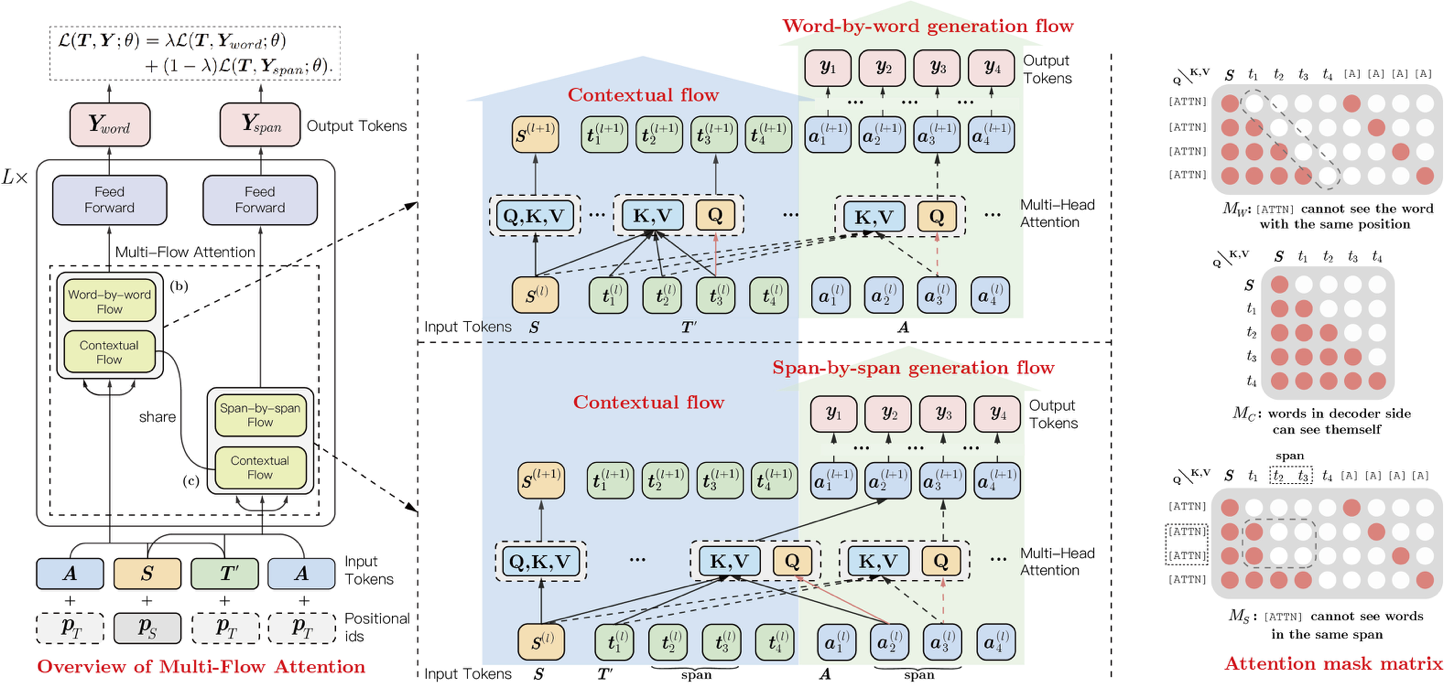
更多详情参考论文[ERNIE-GEN:An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation](https://arxiv.org/abs/2001.11314)
@@ -25,11 +25,11 @@ def generate(texts, use_gpu=False, beam_width=5):
* texts (list\[str\]): 上联文本;
* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA\_VISIBLE\_DEVICES环境变量**;
-* beam_width: beam search宽度,决定每个上联输出的下联数量。
+* beam\_width: beam search宽度,决定每个上联输出的下联数量。
**返回**
-* results (list[list][str]): 下联文本,每个上联会生成beam_width个下联。
+* results (list\[list\]\[str\]): 下联文本,每个上联会生成beam_width个下联。
**代码示例**
@@ -39,7 +39,7 @@ import paddlehub as hub
module = hub.Module(name="ernie_gen_couplet")
test_texts = ["人增福寿年增岁", "风吹云乱天垂泪"]
-results = module.genrate(texts=test_texts, use_gpu=True, beam_width=5)
+results = module.generate(texts=test_texts, use_gpu=True, beam_width=5)
for result in results:
print(result)
```
diff --git a/hub_module/modules/text/text_generation/ernie_gen_couplet/module.py b/hub_module/modules/text/text_generation/ernie_gen_couplet/module.py
index f9f9141444804c889993eb9040136b03e87a2c71..1d698412de80b257999c6a98cafb2e3560adf158 100644
--- a/hub_module/modules/text/text_generation/ernie_gen_couplet/module.py
+++ b/hub_module/modules/text/text_generation/ernie_gen_couplet/module.py
@@ -175,13 +175,6 @@ class ErnieGen(hub.NLPPredictionModule):
return results
- @serving
- def serving_method(self, texts, use_gpu=False):
- """
- Run as a service.
- """
- return self.generate(texts, use_gpu)
-
if __name__ == "__main__":
module = ErnieGen()
diff --git a/hub_module/modules/text/text_generation/ernie_gen_poetry/README.md b/hub_module/modules/text/text_generation/ernie_gen_poetry/README.md
index 60cb8f180ae56c6d556f4302019932192ac91514..3c5a85d85f4a8df2c23388f2f7288c085ba0a465 100644
--- a/hub_module/modules/text/text_generation/ernie_gen_poetry/README.md
+++ b/hub_module/modules/text/text_generation/ernie_gen_poetry/README.md
@@ -1,8 +1,8 @@
## 概述
-ERNIE-GEN 是面向生成任务的预训练-微调框架,首次在预训练阶段加入span-by-span 生成任务,让模型每次能够生成一个语义完整的片段。在预训练和微调中通过填充式生成机制和噪声感知机制来缓解曝光偏差问题。此外, ERNIE-GEN 采样多片段-多粒度目标文本采样策略, 增强源文本和目标文本的关联性,加强了编码器和解码器的交互。
+ERNIE-GEN 是面向生成任务的预训练-微调框架,首次在预训练阶段加入span-by-span 生成任务,让模型每次能够生成一个语义完整的片段。在预训练和微调中通过填充式生成机制和噪声感知机制来缓解曝光偏差问题。此外, ERNIE-GEN 采样多片段-多粒度目标文本采样策略, 增强源文本和目标文本的关联性,加强了编码器和解码器的交互。ernie_gen_poetry采用开源诗歌数据集进行微调,可用于生成诗歌。
-
+
更多详情参考论文[ERNIE-GEN:An Enhanced Multi-Flow Pre-training and Fine-tuning Framework for Natural Language Generation](https://arxiv.org/abs/2001.11314)
@@ -25,11 +25,11 @@ def generate(texts, use_gpu=False, beam_width=5):
* texts (list\[str\]): 诗歌的开头;
* use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA\_VISIBLE\_DEVICES环境变量**;
-* beam_width: beam search宽度,决定每个诗歌开头输出的下文数目。
+* beam\_width: beam search宽度,决定每个诗歌开头输出的下文数目。
**返回**
-* results (list[list][str]): 诗歌下文,每个诗歌开头会生成beam_width个下文。
+* results (list\[list\]\[str\]): 诗歌下文,每个诗歌开头会生成beam_width个下文。
**代码示例**
@@ -39,7 +39,7 @@ import paddlehub as hub
module = hub.Module(name="ernie_gen_poetry")
test_texts = ['昔年旅南服,始识王荆州。', '高名出汉阴,禅阁跨香岑。']
-results = module.genrate(texts=test_texts, use_gpu=True, beam_width=5)
+results = module.generate(texts=test_texts, use_gpu=True, beam_width=5)
for result in results:
print(result)
```
diff --git a/hub_module/modules/text/text_generation/ernie_gen_poetry/module.py b/hub_module/modules/text/text_generation/ernie_gen_poetry/module.py
index 5b73adb73589aad796d672018e7ba636d44edf50..33fc9e25f9f516d833ff480f3ef689ec94da3d90 100644
--- a/hub_module/modules/text/text_generation/ernie_gen_poetry/module.py
+++ b/hub_module/modules/text/text_generation/ernie_gen_poetry/module.py
@@ -175,13 +175,6 @@ class ErnieGen(hub.NLPPredictionModule):
return results
- @serving
- def serving_method(self, texts, use_gpu=False):
- """
- Run as a service.
- """
- return self.generate(texts, use_gpu)
-
if __name__ == "__main__":
module = ErnieGen()
diff --git a/hub_module/modules/text/text_generation/ernie_tiny_couplet/README.md b/hub_module/modules/text/text_generation/ernie_tiny_couplet/README.md
index 77a34dec9d39d41a960576c2b2cc7e1d614542cb..051cc8376d9cfca94a1be67e483260c664deb2ca 100644
--- a/hub_module/modules/text/text_generation/ernie_tiny_couplet/README.md
+++ b/hub_module/modules/text/text_generation/ernie_tiny_couplet/README.md
@@ -1,10 +1,13 @@
+ernie_tiny_couplet是一个对联生成模型,它由ernie_tiny预训练模型经PaddleHub TextGenerationTask微调而来,仅支持预测,如需进一步微调请参考PaddleHub text_generation demo。
+
```shell
$ hub install ernie_tiny_couplet==1.0.0
```
-本预测module系由TextGenerationTask微调而来,转换方式可以参考[Fine-tune保存的模型如何转化为一个PaddleHub Module](https://github.com/PaddlePaddle/PaddleHub/blob/develop/docs/tutorial/finetuned_model_to_module.md)。
+
+本预测module系ernie_tiny预训练模型经由TextGenerationTask微调而来,有关ernie\_tiny的介绍请参考[ernie_tiny module](https://www.paddlepaddle.org.cn/hubdetail?name=ernie_tiny&en_category=SemanticModel),微调方式请参考[text_generation demo](https://github.com/PaddlePaddle/PaddleHub/tree/release/v1.8/demo/text_generation),预训练模型转换成预测module的转换方式请参考[Fine-tune保存的模型如何转化为一个PaddleHub Module](https://github.com/PaddlePaddle/PaddleHub/blob/develop/docs/tutorial/finetuned_model_to_module.md)
## 命令行预测
@@ -22,11 +25,11 @@ def generate(texts)
**参数**
-> texts(list[str]): 上联文本。
+> texts(list\[str\]): 上联文本。
**返回**
-> result(list[str]): 下联文本。每个上联会对应输出10个下联。
+> result(list\[str\]): 下联文本。每个上联会对应输出10个下联。
**代码示例**
@@ -34,7 +37,7 @@ def generate(texts)
import paddlehub as hub
# Load ernie pretrained model
-module = hub.Module(name="ernie_tiny_couplet")
+module = hub.Module(name="ernie_tiny_couplet", use_gpu=True)
results = module.generate(["风吹云乱天垂泪", "若有经心风过耳"])
for result in results:
print(result)
diff --git a/hub_module/modules/text/text_generation/ernie_tiny_couplet/module.py b/hub_module/modules/text/text_generation/ernie_tiny_couplet/module.py
index 49d4723850ffbfc2e87936b1a9947320ffc27dcc..53d5b6c8aa9d21ac1a344b9b17843381ca571d18 100644
--- a/hub_module/modules/text/text_generation/ernie_tiny_couplet/module.py
+++ b/hub_module/modules/text/text_generation/ernie_tiny_couplet/module.py
@@ -77,7 +77,7 @@ class ErnieTinyCouplet(hub.NLPPredictionModule):
tokenizer.encode(text=text, max_seq_len=128)
for text in formatted_text_a
]
- results = self.gen_task.generate(
+ results = self.gen_task.predict(
data=encoded_data,
label_list=self.label_list,
accelerate_mode=False)