From 57d977303b4f6002eb8cc40ccb774146921c984a Mon Sep 17 00:00:00 2001
From: jm12138 <2286040843@qq.com>
Date: Mon, 24 Oct 2022 15:15:39 +0800
Subject: [PATCH] Add swinir_m_real_sr_x2 Module (#2074)
* add swinir_m_real_sr_x2
* update README
* fix typo
* fix typo
---
.../swinir_m_real_sr_x2/README.md | 163 ++++
.../swinir_m_real_sr_x2/module.py | 129 +++
.../swinir_m_real_sr_x2/swinir.py | 903 ++++++++++++++++++
.../swinir_m_real_sr_x2/test.py | 58 ++
4 files changed, 1253 insertions(+)
create mode 100644 modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/README.md
create mode 100644 modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/module.py
create mode 100644 modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/swinir.py
create mode 100644 modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/test.py
diff --git a/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/README.md b/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/README.md
new file mode 100644
index 00000000..b79ccd86
--- /dev/null
+++ b/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/README.md
@@ -0,0 +1,163 @@
+# swinir_m_real_sr_x2
+
+|模型名称|swinir_m_real_sr_x2|
+| :--- | :---: |
+|类别|图像-图像编辑|
+|网络|SwinIR|
+|数据集|DIV2K / Flickr2K|
+|是否支持Fine-tuning|否|
+|模型大小|66.8MB|
+|指标|-|
+|最新更新日期|2022-10-10|
+
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+
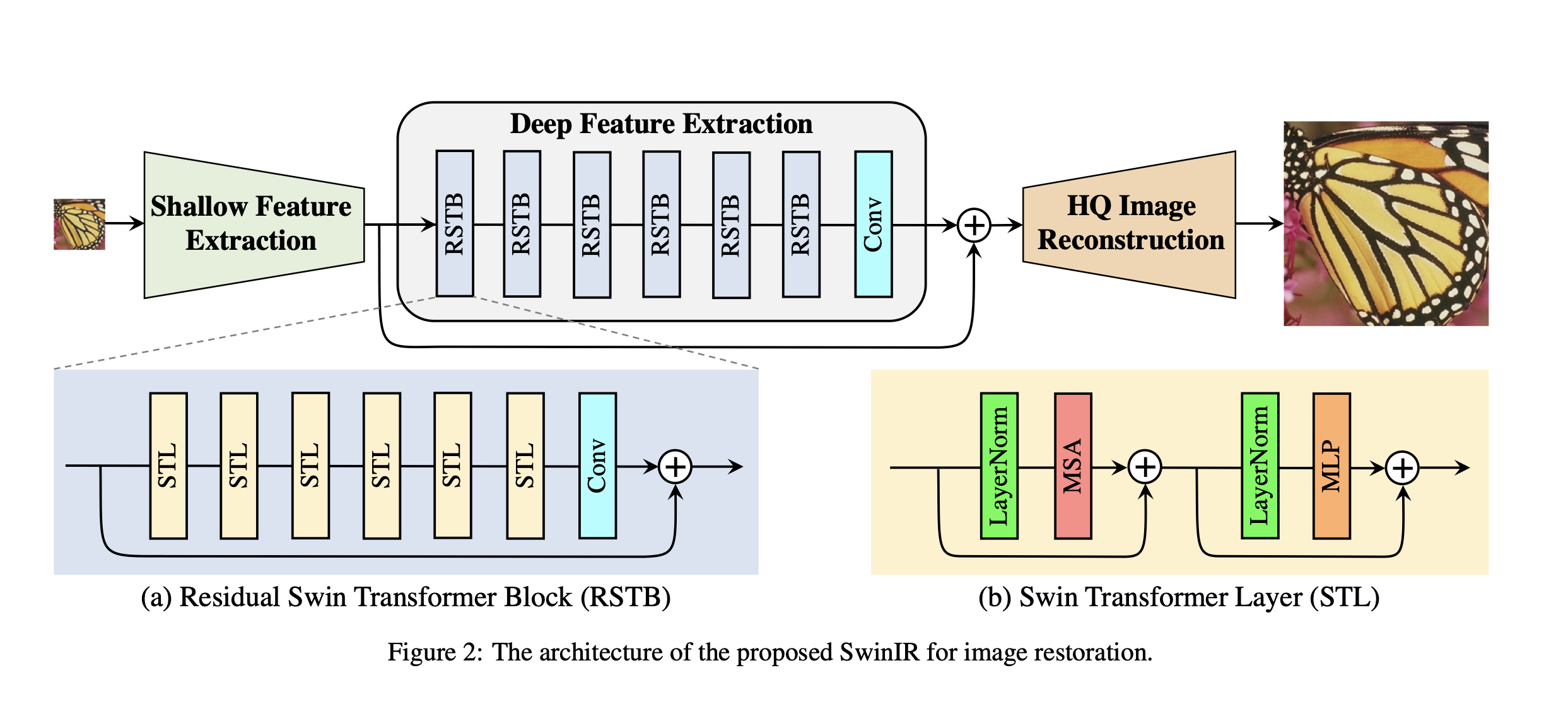
+ - 网络结构:
+
+ 
+
+
+ - 样例结果示例:
+
+  +
+  +
+
+
+- ### 模型介绍
+
+ - SwinIR 是一个基于 Swin Transformer 的图像恢复模型。swinir_m_real_sr_x2 是基于 SwinIR-M 的 2 倍现实图像超分辨率模型。
+
+
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2.安装
+
+ - ```shell
+ $ hub install swinir_m_real_sr_x2
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## 三、模型API预测
+ - ### 1、命令行预测
+
+ ```shell
+ $ hub run swinir_m_real_sr_x2 \
+ --input_path "/PATH/TO/IMAGE" \
+ --output_dir "swinir_m_real_sr_x2_output"
+ ```
+
+ - ### 2、预测代码示例
+
+ ```python
+ import paddlehub as hub
+ import cv2
+
+ module = hub.Module(name="swinir_m_real_sr_x2")
+ result = module.real_sr(
+ image=cv2.imread('/PATH/TO/IMAGE'),
+ visualization=True,
+ output_dir='swinir_m_real_sr_x2_output'
+ )
+ ```
+
+ - ### 3、API
+
+ ```python
+ def real_sr(
+ image: Union[str, numpy.ndarray],
+ visualization: bool = True,
+ output_dir: str = "swinir_m_real_sr_x2_output"
+ ) -> numpy.ndarray
+ ```
+
+ - 超分辨率 API
+
+ - **参数**
+
+ * image (Union\[str, numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ * visualization (bool): 是否将识别结果保存为图片文件;
+ * output\_dir (str): 保存处理结果的文件目录。
+
+ - **返回**
+
+ * res (numpy.ndarray): 图像超分辨率结果 (BGR);
+
+## 四、服务部署
+
+- PaddleHub Serving 可以部署一个图像超分辨率的在线服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+
+ ```shell
+ $ hub serving start -m swinir_m_real_sr_x2
+ ```
+
+ - 这样就完成了一个图像超分辨率服务化API的部署,默认端口号为8866。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ ```python
+ import requests
+ import json
+ import base64
+
+ import cv2
+ import numpy as np
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tobytes()).decode('utf8')
+
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.frombuffer(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # 发送HTTP请求
+ org_im = cv2.imread('/PATH/TO/IMAGE')
+ data = {
+ 'image': cv2_to_base64(org_im)
+ }
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/swinir_m_real_sr_x2"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 结果转换
+ results = r.json()['results']
+ results = base64_to_cv2(results)
+
+ # 保存结果
+ cv2.imwrite('output.jpg', results)
+ ```
+
+## 五、参考资料
+
+* 论文:[SwinIR: Image Restoration Using Swin Transformer](https://arxiv.org/abs/2108.10257)
+
+* 官方实现:[JingyunLiang/SwinIR](https://github.com/JingyunLiang/SwinIR)
+
+## 六、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ ```shell
+ $ hub install swinir_m_real_sr_x2==1.0.0
+ ```
diff --git a/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/module.py b/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/module.py
new file mode 100644
index 00000000..7e2fd80f
--- /dev/null
+++ b/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/module.py
@@ -0,0 +1,129 @@
+import argparse
+import base64
+import os
+import time
+from typing import Union
+
+import cv2
+import numpy as np
+import paddle
+import paddle.nn as nn
+
+from .swinir import SwinIR
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tobytes()).decode('utf8')
+
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.frombuffer(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+
+@moduleinfo(
+ name='swinir_m_real_sr_x2',
+ version='1.0.0',
+ type="CV/image_editing",
+ author="",
+ author_email="",
+ summary="Image Restoration (Real image Super Resolution) Using Swin Transformer.",
+)
+class SwinIRMRealSR(nn.Layer):
+
+ def __init__(self):
+ super(SwinIRMRealSR, self).__init__()
+ self.default_pretrained_model_path = os.path.join(self.directory,
+ '003_realSR_BSRGAN_DFO_s64w8_SwinIR-M_x2_GAN.pdparams')
+ self.swinir = SwinIR(upscale=2,
+ in_chans=3,
+ img_size=64,
+ window_size=8,
+ img_range=1.,
+ depths=[6, 6, 6, 6, 6, 6],
+ embed_dim=180,
+ num_heads=[6, 6, 6, 6, 6, 6],
+ mlp_ratio=2,
+ upsampler='nearest+conv',
+ resi_connection='1conv')
+ state_dict = paddle.load(self.default_pretrained_model_path)
+ self.swinir.set_state_dict(state_dict)
+ self.swinir.eval()
+
+ def preprocess(self, img: np.ndarray) -> np.ndarray:
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
+ img = img.transpose((2, 0, 1))
+ img = img / 255.0
+ return img.astype(np.float32)
+
+ def postprocess(self, img: np.ndarray) -> np.ndarray:
+ img = img.clip(0, 1)
+ img = img * 255.0
+ img = img.transpose((1, 2, 0))
+ img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
+ return img.astype(np.uint8)
+
+ def real_sr(self,
+ image: Union[str, np.ndarray],
+ visualization: bool = True,
+ output_dir: str = "swinir_m_real_sr_x2_output") -> np.ndarray:
+ if isinstance(image, str):
+ _, file_name = os.path.split(image)
+ save_name, _ = os.path.splitext(file_name)
+ save_name = save_name + '_' + str(int(time.time())) + '.jpg'
+ image = cv2.imdecode(np.fromfile(image, dtype=np.uint8), cv2.IMREAD_COLOR)
+ elif isinstance(image, np.ndarray):
+ save_name = str(int(time.time())) + '.jpg'
+ image = image
+ else:
+ raise Exception("image should be a str / np.ndarray")
+
+ with paddle.no_grad():
+ img_input = self.preprocess(image)
+ img_input = paddle.to_tensor(img_input[None, ...], dtype=paddle.float32)
+
+ img_output = self.swinir(img_input)
+ img_output = img_output.numpy()[0]
+ img_output = self.postprocess(img_output)
+
+ if visualization:
+ if not os.path.isdir(output_dir):
+ os.makedirs(output_dir)
+ save_path = os.path.join(output_dir, save_name)
+ cv2.imwrite(save_path, img_output)
+
+ return img_output
+
+ @runnable
+ def run_cmd(self, argvs):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+ self.parser.add_argument('--input_path', type=str, help="Path to image.")
+ self.parser.add_argument('--output_dir',
+ type=str,
+ default='swinir_m_real_sr_x2_output',
+ help="The directory to save output images.")
+ args = self.parser.parse_args(argvs)
+ self.real_sr(image=args.input_path, visualization=True, output_dir=args.output_dir)
+ return 'Results are saved in %s' % args.output_dir
+
+ @serving
+ def serving_method(self, image, **kwargs):
+ """
+ Run as a service.
+ """
+ image = base64_to_cv2(image)
+ img_output = self.real_sr(image=image, **kwargs)
+
+ return cv2_to_base64(img_output)
diff --git a/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/swinir.py b/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/swinir.py
new file mode 100644
index 00000000..f4c490a4
--- /dev/null
+++ b/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/swinir.py
@@ -0,0 +1,903 @@
+import math
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+
+
+def to_2tuple(x):
+ if isinstance(x, int):
+ return (x, x)
+ else:
+ return tuple(x)
+
+
+class Mlp(nn.Layer):
+
+ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+def window_partition(x, window_size):
+ """
+ Args:
+ x: (B, H, W, C)
+ window_size (int): window size
+ Returns:
+ windows: (num_windows*B, window_size, window_size, C)
+ """
+ B, H, W, C = x.shape
+ x = x.reshape((B, H // window_size, window_size, W // window_size, window_size, C))
+ windows = x.transpose((0, 1, 3, 2, 4, 5)).reshape((-1, window_size, window_size, C))
+ return windows
+
+
+def window_reverse(windows, window_size, H, W):
+ """
+ Args:
+ windows: (num_windows*B, window_size, window_size, C)
+ window_size (int): Window size
+ H (int): Height of image
+ W (int): Width of image
+ Returns:
+ x: (B, H, W, C)
+ """
+ B = int(windows.shape[0] / (H * W / window_size / window_size))
+ x = windows.reshape((B, H // window_size, W // window_size, window_size, window_size, -1))
+ x = x.transpose((0, 1, 3, 2, 4, 5)).reshape((B, H, W, -1))
+ return x
+
+
+class WindowAttention(nn.Layer):
+ r""" Window based multi-head self attention (W-MSA) module with relative position bias.
+ It supports both of shifted and non-shifted window.
+ Args:
+ dim (int): Number of input channels.
+ window_size (tuple[int]): The height and width of the window.
+ num_heads (int): Number of attention heads.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
+ attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
+ proj_drop (float, optional): Dropout ratio of output. Default: 0.0
+ """
+
+ def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
+
+ super().__init__()
+ self.dim = dim
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = self.create_parameter(shape=((2 * window_size[0] - 1) *
+ (2 * window_size[1] - 1), num_heads),
+ default_initializer=nn.initializer.Constant(0.0))
+
+ # get pair-wise relative position index for each token inside the window
+ coords_h = paddle.arange(self.window_size[0])
+ coords_w = paddle.arange(self.window_size[1])
+ coords = paddle.stack(paddle.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
+ coords_flatten = paddle.flatten(coords, 1) # 2, Wh*Ww
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
+ relative_coords = relative_coords.transpose((1, 2, 0)) # Wh*Ww, Wh*Ww, 2
+ relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
+ relative_coords[:, :, 1] += self.window_size[1] - 1
+ relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
+ relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
+ self.register_buffer("relative_position_index", relative_position_index)
+
+ self.qkv = nn.Linear(dim, dim * 3, bias_attr=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+
+ self.proj_drop = nn.Dropout(proj_drop)
+
+ self.softmax = nn.Softmax(axis=-1)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+ x: input features with shape of (num_windows*B, N, C)
+ mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
+ """
+ B_, N, C = x.shape
+ qkv = self.qkv(x).reshape((B_, N, 3, self.num_heads, C // self.num_heads)).transpose((2, 0, 3, 1, 4))
+ q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
+
+ q = q * self.scale
+ attn = (q @ k.transpose((0, 1, 3, 2)))
+
+ relative_position_bias = self.relative_position_bias_table[self.relative_position_index.reshape(
+ (-1, ))].reshape((self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1],
+ -1)) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.transpose((2, 0, 1)) # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nW = mask.shape[0]
+ attn = attn.reshape((B_ // nW, nW, self.num_heads, N, N)) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.reshape((-1, self.num_heads, N, N))
+ attn = self.softmax(attn)
+ else:
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose((0, 2, 1, 3)).reshape((B_, N, C))
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
+
+ def flops(self, N):
+ # calculate flops for 1 window with token length of N
+ flops = 0
+ # qkv = self.qkv(x)
+ flops += N * self.dim * 3 * self.dim
+ # attn = (q @ k.transpose(-2, -1))
+ flops += self.num_heads * N * (self.dim // self.num_heads) * N
+ # x = (attn @ v)
+ flops += self.num_heads * N * N * (self.dim // self.num_heads)
+ # x = self.proj(x)
+ flops += N * self.dim * self.dim
+ return flops
+
+
+class SwinTransformerBlock(nn.Layer):
+ r""" Swin Transformer Block.
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resulotion.
+ num_heads (int): Number of attention heads.
+ window_size (int): Window size.
+ shift_size (int): Shift size for SW-MSA.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float, optional): Stochastic depth rate. Default: 0.0
+ act_layer (nn.Layer, optional): Activation layer. Default: nn.GELU
+ norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ num_heads,
+ window_size=7,
+ shift_size=0,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.mlp_ratio = mlp_ratio
+ if min(self.input_resolution) <= self.window_size:
+ # if window size is larger than input resolution, we don't partition windows
+ self.shift_size = 0
+ self.window_size = min(self.input_resolution)
+ assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
+
+ self.norm1 = norm_layer(dim)
+ self.attn = WindowAttention(dim,
+ window_size=to_2tuple(self.window_size),
+ num_heads=num_heads,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop)
+
+ self.drop_path = nn.Identity()
+ self.norm2 = norm_layer(dim)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
+
+ if self.shift_size > 0:
+ attn_mask = self.calculate_mask(self.input_resolution)
+ else:
+ attn_mask = None
+
+ self.register_buffer("attn_mask", attn_mask)
+
+ def calculate_mask(self, x_size):
+ # calculate attention mask for SW-MSA
+ H, W = x_size
+ img_mask = paddle.zeros((1, H, W, 1)) # 1 H W 1
+
+ h_slices = (slice(0, -self.window_size), slice(-self.window_size,
+ -self.shift_size if self.shift_size else None),
+ slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size), slice(-self.window_size,
+ -self.shift_size if self.shift_size else None),
+ slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
+ mask_windows = mask_windows.reshape((-1, self.window_size * self.window_size))
+
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ _h = paddle.full_like(attn_mask, -100.0, dtype='float32')
+ _z = paddle.full_like(attn_mask, 0.0, dtype='float32')
+ attn_mask = paddle.where(attn_mask != 0, _h, _z)
+
+ return attn_mask
+
+ def forward(self, x, x_size):
+ H, W = x_size
+ B, L, C = x.shape
+ # assert L == H * W, "input feature has wrong size"
+
+ shortcut = x
+ x = self.norm1(x)
+ x = x.reshape((B, H, W, C))
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_x = paddle.roll(x, shifts=(-self.shift_size, -self.shift_size), axis=(1, 2))
+ else:
+ shifted_x = x
+
+ # partition windows
+ x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
+ x_windows = x_windows.reshape((-1, self.window_size * self.window_size, C)) # nW*B, window_size*window_size, C
+
+ # W-MSA/SW-MSA (to be compatible for testing on images whose shapes are the multiple of window size
+ if self.input_resolution == x_size:
+ attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
+ else:
+ attn_windows = self.attn(x_windows, mask=self.calculate_mask(x_size))
+
+ # merge windows
+ attn_windows = attn_windows.reshape((-1, self.window_size, self.window_size, C))
+ shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
+
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = paddle.roll(shifted_x, shifts=(self.shift_size, self.shift_size), axis=(1, 2))
+ else:
+ x = shifted_x
+ x = x.reshape((B, H * W, C))
+
+ # FFN
+ x = shortcut + self.drop_path(x)
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
+ f"window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}"
+
+ def flops(self):
+ flops = 0
+ H, W = self.input_resolution
+ # norm1
+ flops += self.dim * H * W
+ # W-MSA/SW-MSA
+ nW = H * W / self.window_size / self.window_size
+ flops += nW * self.attn.flops(self.window_size * self.window_size)
+ # mlp
+ flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
+ # norm2
+ flops += self.dim * H * W
+ return flops
+
+
+class PatchMerging(nn.Layer):
+ r""" Patch Merging Layer.
+ Args:
+ input_resolution (tuple[int]): Resolution of input feature.
+ dim (int): Number of input channels.
+ norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(4 * dim)
+
+ def forward(self, x):
+ """
+ x: B, H*W, C
+ """
+ H, W = self.input_resolution
+ B, L, C = x.shape
+ assert L == H * W, "input feature has wrong size"
+ assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
+
+ x = x.reshape((B, H, W, C))
+
+ x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
+ x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
+ x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
+ x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
+ x = paddle.concat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
+ x = x.reshape((B, -1, 4 * C)) # B H/2*W/2 4*C
+
+ x = self.norm(x)
+ x = self.reduction(x)
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f"input_resolution={self.input_resolution}, dim={self.dim}"
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = H * W * self.dim
+ flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
+ return flops
+
+
+class BasicLayer(nn.Layer):
+ """ A basic Swin Transformer layer for one stage.
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
+ downsample (nn.Layer | None, optional): Downsample layer at the end of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ downsample=None,
+ use_checkpoint=False):
+
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.LayerList([
+ SwinTransformerBlock(dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=0 if (i % 2 == 0) else window_size // 2,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop,
+ attn_drop=attn_drop,
+ drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer) for i in range(depth)
+ ])
+
+ # patch merging layer
+ if downsample is not None:
+ self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
+ else:
+ self.downsample = None
+
+ def forward(self, x, x_size):
+ for blk in self.blocks:
+ x = blk(x, x_size)
+ if self.downsample is not None:
+ x = self.downsample(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
+
+ def flops(self):
+ flops = 0
+ for blk in self.blocks:
+ flops += blk.flops()
+ if self.downsample is not None:
+ flops += self.downsample.flops()
+ return flops
+
+
+class RSTB(nn.Layer):
+ """Residual Swin Transformer Block (RSTB).
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Layer, optional): Normalization layer. Default: nn.LayerNorm
+ downsample (nn.Layer | None, optional): Downsample layer at the end of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
+ img_size: Input image size.
+ patch_size: Patch size.
+ resi_connection: The convolutional block before residual connection.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ downsample=None,
+ use_checkpoint=False,
+ img_size=224,
+ patch_size=4,
+ resi_connection='1conv'):
+ super(RSTB, self).__init__()
+
+ self.dim = dim
+ self.input_resolution = input_resolution
+
+ self.residual_group = BasicLayer(dim=dim,
+ input_resolution=input_resolution,
+ depth=depth,
+ num_heads=num_heads,
+ window_size=window_size,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop,
+ attn_drop=attn_drop,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ downsample=downsample,
+ use_checkpoint=use_checkpoint)
+
+ if resi_connection == '1conv':
+ self.conv = nn.Conv2D(dim, dim, 3, 1, 1)
+ elif resi_connection == '3conv':
+ # to save parameters and memory
+ self.conv = nn.Sequential(nn.Conv2D(dim, dim // 4, 3, 1, 1), nn.LeakyReLU(negative_slope=0.2),
+ nn.Conv2D(dim // 4, dim // 4, 1, 1, 0), nn.LeakyReLU(negative_slope=0.2),
+ nn.Conv2D(dim // 4, dim, 3, 1, 1))
+
+ self.patch_embed = PatchEmbed(img_size=img_size,
+ patch_size=patch_size,
+ in_chans=0,
+ embed_dim=dim,
+ norm_layer=None)
+
+ self.patch_unembed = PatchUnEmbed(img_size=img_size,
+ patch_size=patch_size,
+ in_chans=0,
+ embed_dim=dim,
+ norm_layer=None)
+
+ def forward(self, x, x_size):
+ return self.patch_embed(self.conv(self.patch_unembed(self.residual_group(x, x_size), x_size))) + x
+
+ def flops(self):
+ flops = 0
+ flops += self.residual_group.flops()
+ H, W = self.input_resolution
+ flops += H * W * self.dim * self.dim * 9
+ flops += self.patch_embed.flops()
+ flops += self.patch_unembed.flops()
+
+ return flops
+
+
+class PatchEmbed(nn.Layer):
+ r""" Image to Patch Embedding
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels. Default: 96.
+ norm_layer (nn.Layer, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ if norm_layer is not None:
+ self.norm = norm_layer(embed_dim)
+ else:
+ self.norm = None
+
+ def forward(self, x):
+ x = x.flatten(2).transpose((0, 2, 1)) # B Ph*Pw C
+ if self.norm is not None:
+ x = self.norm(x)
+ return x
+
+ def flops(self):
+ flops = 0
+ H, W = self.img_size
+ if self.norm is not None:
+ flops += H * W * self.embed_dim
+ return flops
+
+
+class PatchUnEmbed(nn.Layer):
+ r""" Image to Patch Unembedding
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels. Default: 96.
+ norm_layer (nn.Layer, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ def forward(self, x, x_size):
+ B, HW, C = x.shape
+ x = x.transpose((0, 2, 1)).reshape((B, self.embed_dim, x_size[0], x_size[1])) # B Ph*Pw C
+ return x
+
+ def flops(self):
+ flops = 0
+ return flops
+
+
+class Upsample(nn.Sequential):
+ """Upsample module.
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_feat):
+ m = []
+ if (scale & (scale - 1)) == 0: # scale = 2^n
+ for _ in range(int(math.log(scale, 2))):
+ m.append(nn.Conv2D(num_feat, 4 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(2))
+ elif scale == 3:
+ m.append(nn.Conv2D(num_feat, 9 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(3))
+ else:
+ raise ValueError(f'scale {scale} is not supported. '
+ 'Supported scales: 2^n and 3.')
+ super(Upsample, self).__init__(*m)
+
+
+class UpsampleOneStep(nn.Sequential):
+ """UpsampleOneStep module (the difference with Upsample is that it always only has 1conv + 1pixelshuffle)
+ Used in lightweight SR to save parameters.
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_feat, num_out_ch, input_resolution=None):
+ self.num_feat = num_feat
+ self.input_resolution = input_resolution
+ m = []
+ m.append(nn.Conv2D(num_feat, (scale**2) * num_out_ch, 3, 1, 1))
+ m.append(nn.PixelShuffle(scale))
+ super(UpsampleOneStep, self).__init__(*m)
+
+ def flops(self):
+ H, W = self.input_resolution
+ flops = H * W * self.num_feat * 3 * 9
+ return flops
+
+
+class SwinIR(nn.Layer):
+ r""" SwinIR
+ A PyTorch impl of : `SwinIR: Image Restoration Using Swin Transformer`, based on Swin Transformer.
+ Args:
+ img_size (int | tuple(int)): Input image size. Default 64
+ patch_size (int | tuple(int)): Patch size. Default: 1
+ in_chans (int): Number of input image channels. Default: 3
+ embed_dim (int): Patch embedding dimension. Default: 96
+ depths (tuple(int)): Depth of each Swin Transformer layer.
+ num_heads (tuple(int)): Number of attention heads in different layers.
+ window_size (int): Window size. Default: 7
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
+ qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
+ drop_rate (float): Dropout rate. Default: 0
+ attn_drop_rate (float): Attention dropout rate. Default: 0
+ drop_path_rate (float): Stochastic depth rate. Default: 0.1
+ norm_layer (nn.Layer): Normalization layer. Default: nn.LayerNorm.
+ ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
+ patch_norm (bool): If True, add normalization after patch embedding. Default: True
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
+ upscale: Upscale factor. 2/3/4/8 for image SR, 1 for denoising and compress artifact reduction
+ img_range: Image range. 1. or 255.
+ upsampler: The reconstruction reconstruction module. 'pixelshuffle'/'pixelshuffledirect'/'nearest+conv'/None
+ resi_connection: The convolutional block before residual connection. '1conv'/'3conv'
+ """
+
+ def __init__(self,
+ img_size=64,
+ patch_size=1,
+ in_chans=3,
+ embed_dim=96,
+ depths=[6, 6, 6, 6],
+ num_heads=[6, 6, 6, 6],
+ window_size=7,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ norm_layer=nn.LayerNorm,
+ ape=False,
+ patch_norm=True,
+ use_checkpoint=False,
+ upscale=2,
+ img_range=1.,
+ upsampler='',
+ resi_connection='1conv',
+ **kwargs):
+ super(SwinIR, self).__init__()
+ num_in_ch = in_chans
+ num_out_ch = in_chans
+ num_feat = 64
+ self.img_range = img_range
+ if in_chans == 3:
+ rgb_mean = (0.4488, 0.4371, 0.4040)
+ self.mean = paddle.to_tensor(rgb_mean).reshape((1, 3, 1, 1))
+ else:
+ self.mean = paddle.zeros((1, 1, 1, 1))
+ self.upscale = upscale
+ self.upsampler = upsampler
+ self.window_size = window_size
+
+ #####################################################################################################
+ ################################### 1, shallow feature extraction ###################################
+ self.conv_first = nn.Conv2D(num_in_ch, embed_dim, 3, 1, 1)
+
+ #####################################################################################################
+ ################################### 2, deep feature extraction ######################################
+ self.num_layers = len(depths)
+ self.embed_dim = embed_dim
+ self.ape = ape
+ self.patch_norm = patch_norm
+ self.num_features = embed_dim
+ self.mlp_ratio = mlp_ratio
+
+ # split image into non-overlapping patches
+ self.patch_embed = PatchEmbed(img_size=img_size,
+ patch_size=patch_size,
+ in_chans=embed_dim,
+ embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+ num_patches = self.patch_embed.num_patches
+ patches_resolution = self.patch_embed.patches_resolution
+ self.patches_resolution = patches_resolution
+
+ # merge non-overlapping patches into image
+ self.patch_unembed = PatchUnEmbed(img_size=img_size,
+ patch_size=patch_size,
+ in_chans=embed_dim,
+ embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+
+ # absolute position embedding
+ if self.ape:
+ # self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
+ self.absolute_pos_embed = self.create_parameter(shape=(1, num_patches, embed_dim),
+ default_initializer=nn.initializer.Constant(0.0))
+
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ # stochastic depth
+ dpr = [x.item() for x in paddle.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
+
+ # build Residual Swin Transformer blocks (RSTB)
+ self.layers = nn.LayerList()
+ for i_layer in range(self.num_layers):
+ layer = RSTB(
+ dim=embed_dim,
+ input_resolution=(patches_resolution[0], patches_resolution[1]),
+ depth=depths[i_layer],
+ num_heads=num_heads[i_layer],
+ window_size=window_size,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], # no impact on SR results
+ norm_layer=norm_layer,
+ downsample=None,
+ use_checkpoint=use_checkpoint,
+ img_size=img_size,
+ patch_size=patch_size,
+ resi_connection=resi_connection)
+ self.layers.append(layer)
+ self.norm = norm_layer(self.num_features)
+
+ # build the last conv layer in deep feature extraction
+ if resi_connection == '1conv':
+ self.conv_after_body = nn.Conv2D(embed_dim, embed_dim, 3, 1, 1)
+ elif resi_connection == '3conv':
+ # to save parameters and memory
+ self.conv_after_body = nn.Sequential(nn.Conv2D(embed_dim, embed_dim // 4, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.2),
+ nn.Conv2D(embed_dim // 4, embed_dim // 4, 1, 1, 0),
+ nn.LeakyReLU(negative_slope=0.2),
+ nn.Conv2D(embed_dim // 4, embed_dim, 3, 1, 1))
+
+ #####################################################################################################
+ ################################ 3, high quality image reconstruction ################################
+ if self.upsampler == 'pixelshuffle':
+ # for classical SR
+ self.conv_before_upsample = nn.Sequential(nn.Conv2D(embed_dim, num_feat, 3, 1, 1), nn.LeakyReLU())
+ self.upsample = Upsample(upscale, num_feat)
+ self.conv_last = nn.Conv2D(num_feat, num_out_ch, 3, 1, 1)
+ elif self.upsampler == 'pixelshuffledirect':
+ # for lightweight SR (to save parameters)
+ self.upsample = UpsampleOneStep(upscale, embed_dim, num_out_ch,
+ (patches_resolution[0], patches_resolution[1]))
+ elif self.upsampler == 'nearest+conv':
+ # for real-world SR (less artifacts)
+ self.conv_before_upsample = nn.Sequential(nn.Conv2D(embed_dim, num_feat, 3, 1, 1), nn.LeakyReLU())
+ self.conv_up1 = nn.Conv2D(num_feat, num_feat, 3, 1, 1)
+ if self.upscale == 4:
+ self.conv_up2 = nn.Conv2D(num_feat, num_feat, 3, 1, 1)
+ self.conv_hr = nn.Conv2D(num_feat, num_feat, 3, 1, 1)
+ self.conv_last = nn.Conv2D(num_feat, num_out_ch, 3, 1, 1)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2)
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ self.conv_last = nn.Conv2D(embed_dim, num_out_ch, 3, 1, 1)
+
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ nn.initializer.Constant(0.0)(m.bias)
+ elif isinstance(m, nn.LayerNorm):
+ nn.initializer.Constant(0.0)(m.bias)
+ nn.initializer.Constant(1.0)(m.weight)
+
+ def check_image_size(self, x):
+ _, _, h, w = x.shape
+ mod_pad_h = (self.window_size - h % self.window_size) % self.window_size
+ mod_pad_w = (self.window_size - w % self.window_size) % self.window_size
+ x = F.pad(x, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
+ return x
+
+ def forward_features(self, x):
+ x_size = (x.shape[2], x.shape[3])
+ x = self.patch_embed(x)
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+
+ for layer in self.layers:
+ x = layer(x, x_size)
+
+ x = self.norm(x) # B L C
+ x = self.patch_unembed(x, x_size)
+
+ return x
+
+ def forward(self, x):
+ H, W = x.shape[2:]
+ x = self.check_image_size(x)
+
+ self.mean = self.mean.cast(x.dtype)
+ x = (x - self.mean) * self.img_range
+
+ if self.upsampler == 'pixelshuffle':
+ # for classical SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.conv_before_upsample(x)
+ x = self.conv_last(self.upsample(x))
+ elif self.upsampler == 'pixelshuffledirect':
+ # for lightweight SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.upsample(x)
+ elif self.upsampler == 'nearest+conv':
+ # for real-world SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.conv_before_upsample(x)
+ x = self.lrelu(self.conv_up1(nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
+ if self.upscale == 4:
+ x = self.lrelu(self.conv_up2(nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
+ x = self.conv_last(self.lrelu(self.conv_hr(x)))
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ x_first = self.conv_first(x)
+ res = self.conv_after_body(self.forward_features(x_first)) + x_first
+ x = x + self.conv_last(res)
+
+ x = x / self.img_range + self.mean
+
+ return x[:, :, :H * self.upscale, :W * self.upscale]
+
+ def flops(self):
+ flops = 0
+ H, W = self.patches_resolution
+ flops += H * W * 3 * self.embed_dim * 9
+ flops += self.patch_embed.flops()
+ for i, layer in enumerate(self.layers):
+ flops += layer.flops()
+ flops += H * W * 3 * self.embed_dim * self.embed_dim
+ flops += self.upsample.flops()
+ return flops
diff --git a/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/test.py b/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/test.py
new file mode 100644
index 00000000..f56226e5
--- /dev/null
+++ b/modules/image/Image_editing/super_resolution/swinir_m_real_sr_x2/test.py
@@ -0,0 +1,58 @@
+import os
+import shutil
+import unittest
+
+import cv2
+import numpy as np
+import requests
+
+import paddlehub as hub
+
+os.environ['CUDA_VISIBLE_DEVICES'] = '0'
+
+
+class TestHubModule(unittest.TestCase):
+
+ @classmethod
+ def setUpClass(cls) -> None:
+ img_url = 'https://unsplash.com/photos/mJaD10XeD7w/download?ixid=MnwxMjA3fDB8MXxzZWFyY2h8M3x8Y2F0fGVufDB8fHx8MTY2MzczNDc3Mw&force=true&w=640'
+ if not os.path.exists('tests'):
+ os.makedirs('tests')
+ response = requests.get(img_url)
+ assert response.status_code == 200, 'Network Error.'
+ with open('tests/test.jpg', 'wb') as f:
+ f.write(response.content)
+ img = cv2.imread('tests/test.jpg')
+ img = cv2.resize(img, (0, 0), fx=0.5, fy=0.5)
+ cv2.imwrite('tests/test.jpg', img)
+ cls.module = hub.Module(name="swinir_m_real_sr_x2")
+
+ @classmethod
+ def tearDownClass(cls) -> None:
+ shutil.rmtree('tests')
+ shutil.rmtree('swinir_m_real_sr_x2_output')
+
+ def test_real_sr1(self):
+ results = self.module.real_sr(image='tests/test.jpg', visualization=False)
+
+ self.assertIsInstance(results, np.ndarray)
+
+ def test_real_sr2(self):
+ results = self.module.real_sr(image=cv2.imread('tests/test.jpg'), visualization=True)
+
+ self.assertIsInstance(results, np.ndarray)
+
+ def test_real_sr3(self):
+ results = self.module.real_sr(image=cv2.imread('tests/test.jpg'), visualization=True)
+
+ self.assertIsInstance(results, np.ndarray)
+
+ def test_real_sr4(self):
+ self.assertRaises(Exception, self.module.real_sr, image=['tests/test.jpg'])
+
+ def test_real_sr5(self):
+ self.assertRaises(FileNotFoundError, self.module.real_sr, image='no.jpg')
+
+
+if __name__ == "__main__":
+ unittest.main()
--
GitLab