“456788ba5a59077449c6ce765c37d0f8dc639c2e”上不存在“doc/getstarted/build_and_install/pip_install_en.html”
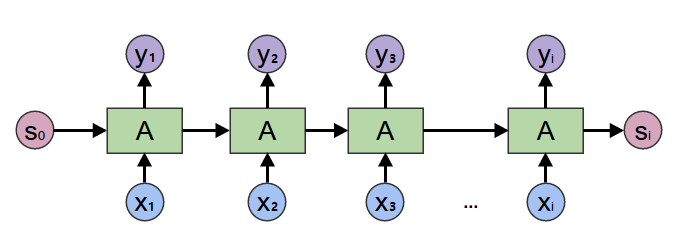
Image mistaken of RNN sample in demo\sequence_labeling\README.md
Showing
docs/imgs/RNN_Sample.png
0 → 100644
{kind=link}
13.9 KB
13.9 KB