diff --git a/modules/image/text_recognition/ch_pp-ocrv3/README.md b/modules/image/text_recognition/ch_pp-ocrv3/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0bf8f21566d1b436cc90485d38b4b4715018beca
--- /dev/null
+++ b/modules/image/text_recognition/ch_pp-ocrv3/README.md
@@ -0,0 +1,180 @@
+# ch_pp-ocrv3
+
+|模型名称|ch_pp-ocrv3|
+| :--- | :---: |
+|类别|图像-文字识别|
+|网络|Differentiable Binarization+SVTR_LCNet|
+|数据集|icdar2015数据集|
+|是否支持Fine-tuning|否|
+|模型大小|13M|
+|最新更新日期|2022-05-11|
+|数据指标|-|
+
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+ - [OCR文字识别场景在线体验](https://www.paddlepaddle.org.cn/hub/scene/ocr)
+ - 样例结果示例:
+
+
+
+
+- ### 模型介绍
+
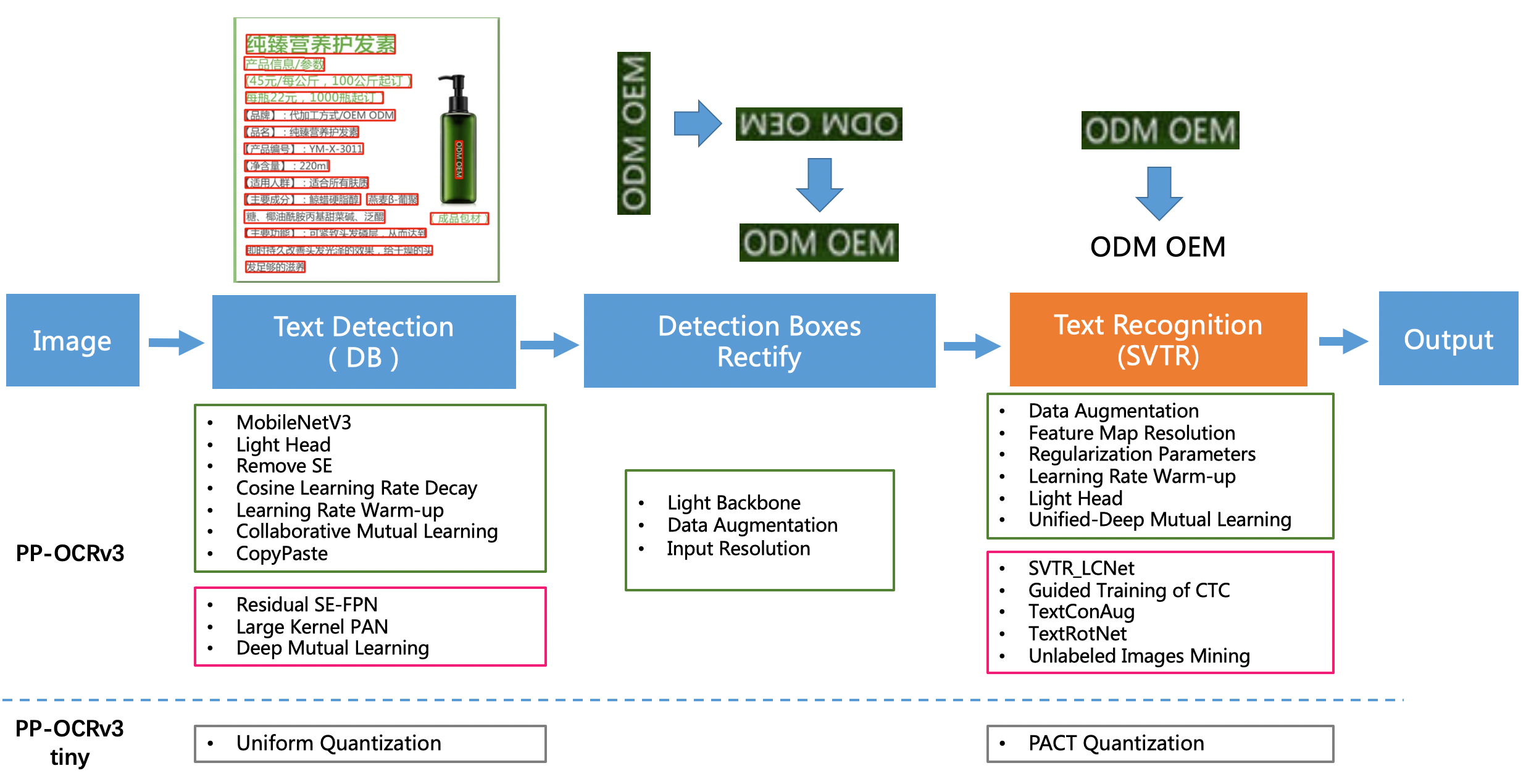
+ - PP-OCR是PaddleOCR自研的实用的超轻量OCR系统。在实现前沿算法的基础上,考虑精度与速度的平衡,进行模型瘦身和深度优化,使其尽可能满足产业落地需求。该系统包含文本检测和文本识别两个阶段,其中文本检测算法选用DB,文本识别算法选用CRNN,并在检测和识别模块之间添加文本方向分类器,以应对不同方向的文本识别。当前模块为PP-OCRv3,在PP-OCRv2的基础上,针对检测模型和识别模型,进行了共计9个方面的升级,进一步提升了模型效果。
+
+
+
+
+ - 更多详情参考:[PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md)。
+
+
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 1.7.2
+
+ - paddlehub >= 1.6.0 | [如何安装paddlehub](../../../../docs/docs_ch/get_start/installation.rst)
+
+ - shapely
+
+ - pyclipper
+
+ - ```shell
+ $ pip install shapely pyclipper
+ ```
+ - **该Module依赖于第三方库shapely和pyclipper,使用该Module之前,请先安装shapely和pyclipper。**
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install ch_pp-ocrv3
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run ch_pp-ocrv3 --input_path "/PATH/TO/IMAGE"
+ ```
+ - 通过命令行方式实现文字识别模型的调用,更多请见 [PaddleHub命令行指令](../../../../docs/docs_ch/tutorial/cmd_usage.rst)
+
+- ### 2、代码示例
+
+ - ```python
+ import paddlehub as hub
+ import cv2
+
+ ocr = hub.Module(name="ch_pp-ocrv3", enable_mkldnn=True) # mkldnn加速仅在CPU下有效
+ result = ocr.recognize_text(images=[cv2.imread('/PATH/TO/IMAGE')])
+
+ # or
+ # result = ocr.recognize_text(paths=['/PATH/TO/IMAGE'])
+ ```
+
+- ### 3、API
+
+ - ```python
+ __init__(text_detector_module=None, enable_mkldnn=False)
+ ```
+
+ - 构造用于文本检测的模块
+
+ - **参数**
+
+ - text_detector_module(str): 文字检测PaddleHub Module名字,如设置为None,则默认使用[ch_pp-ocrv3_det Module](../ch_pp-ocrv3_det/)。其作用为检测图片当中的文本。
+ - enable_mkldnn(bool): 是否开启mkldnn加速CPU计算。该参数仅在CPU运行下设置有效。默认为False。
+
+
+ - ```python
+ def recognize_text(images=[],
+ paths=[],
+ use_gpu=False,
+ output_dir='ocr_result',
+ visualization=False,
+ box_thresh=0.5,
+ text_thresh=0.5,
+ angle_classification_thresh=0.9,
+ det_db_unclip_ratio=1.5)
+ ```
+
+ - 预测API,检测输入图片中的所有中文文本的位置。
+
+ - **参数**
+
+ - paths (list\[str\]): 图片的路径;
+ - images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ - use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量**
+ - box\_thresh (float): 检测文本框置信度的阈值;
+ - text\_thresh (float): 识别中文文本置信度的阈值;
+ - angle_classification_thresh(float): 文本角度分类置信度的阈值
+ - visualization (bool): 是否将识别结果保存为图片文件;
+ - output\_dir (str): 图片的保存路径,默认设为 ocr\_result;
+ - det\_db\_unclip\_ratio: 设置检测框的大小;
+ - **返回**
+
+ - res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
+ - data (list\[dict\]): 识别文本结果,列表中每一个元素为 dict,各字段为:
+ - text(str): 识别得到的文本
+ - confidence(float): 识别文本结果置信度
+ - text_box_position(list): 文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标
+ 如果无识别结果则data为\[\]
+ - save_path (str, optional): 识别结果的保存路径,如不保存图片则save_path为''
+
+
+## 四、服务部署
+
+- PaddleHub Serving 可以部署一个目标检测的在线服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+ - ```shell
+ $ hub serving start -m ch_pp-ocrv3
+ ```
+
+ - 这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ # 发送HTTP请求
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/ch_pp-ocrv3"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 打印预测结果
+ print(r.json()["results"])
+ ```
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ - ```shell
+ $ hub install ch_pp-ocrv3==1.0.0
+ ```
diff --git a/modules/image/text_recognition/ch_pp-ocrv3_det/README.md b/modules/image/text_recognition/ch_pp-ocrv3_det/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a974bdd989d4ac9db6919ee8f3403e3c6846ae80
--- /dev/null
+++ b/modules/image/text_recognition/ch_pp-ocrv3_det/README.md
@@ -0,0 +1,172 @@
+# ch_pp-ocrv3_det
+
+|模型名称|ch_pp-ocrv3_det|
+| :--- | :---: |
+|类别|图像-文字检测|
+|网络|Differentiable Binarization|
+|数据集|icdar2015数据集|
+|是否支持Fine-tuning|否|
+|模型大小|3.7MB|
+|最新更新日期|2022-05-11|
+|数据指标|-|
+
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+ - 样例结果示例:
+
+ +
+
+
+
+
+- ### 模型介绍
+
+ - DB(Differentiable Binarization)是一种基于分割的文本检测算法。此类算法可以更好地处理弯曲等不规则形状文本,因此检测效果往往会更好。但其后处理步骤中将分割结果转化为检测框的流程复杂,耗时严重。DB将二值化阈值加入训练中学习,可以获得更准确的检测边界,从而简化后处理流程。该Module是PP-OCRv3的检测模型,对PP-OCRv2中的CML(Collaborative Mutual Learning) 协同互学习文本检测蒸馏策略进行了升级。
+
+
+
+
+
+ - 更多详情参考:[PP-OCRv3](https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/doc/doc_ch/PP-OCRv3_introduction.md)
+
+
+## 二、安装
+
+- ### 1、环境依赖
+
+ - paddlepaddle >= 1.7.2
+
+ - paddlehub >= 1.6.0 | [如何安装paddlehub](../../../../docs/docs_ch/get_start/installation.rst)
+
+ - shapely
+
+ - pyclipper
+
+ - ```shell
+ $ pip install shapely pyclipper
+ ```
+ - **该Module依赖于第三方库shapely和pyclipper,使用该Module之前,请先安装shapely和pyclipper。**
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install ch_pp-ocrv3_det
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ $ hub run ch_pp-ocrv3_det --input_path "/PATH/TO/IMAGE"
+ ```
+ - 通过命令行方式实现文字识别模型的调用,更多请见 [PaddleHub命令行指令](../../../../docs/docs_ch/tutorial/cmd_usage.rst)
+
+- ### 2、代码示例
+
+ - ```python
+ import paddlehub as hub
+ import cv2
+
+ text_detector = hub.Module(name="ch_pp-ocrv3_det", enable_mkldnn=True) # mkldnn加速仅在CPU下有效
+ result = text_detector.detect_text(images=[cv2.imread('/PATH/TO/IMAGE')])
+
+ # or
+ # result =text_detector.detect_text(paths=['/PATH/TO/IMAGE'])
+ ```
+
+- ### 3、API
+
+ - ```python
+ __init__(enable_mkldnn=False)
+ ```
+
+ - 构造检测模块的对象
+
+ - **参数**
+ - enable_mkldnn(bool): 是否开启mkldnn加速CPU计算。该参数仅在CPU运行下设置有效。默认为False。
+
+
+ - ```python
+ def detect_text(paths=[],
+ images=[],
+ use_gpu=False,
+ output_dir='detection_result',
+ box_thresh=0.5,
+ visualization=False,
+ det_db_unclip_ratio=1.5)
+ ```
+
+ - 预测API,检测输入图片中的所有中文文本的位置。
+
+ - **参数**
+
+ - paths (list\[str\]): 图片的路径;
+ - images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\],BGR格式;
+ - use\_gpu (bool): 是否使用 GPU;**若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量**
+ - box\_thresh (float): 检测文本框置信度的阈值;
+ - visualization (bool): 是否将识别结果保存为图片文件;
+ - output\_dir (str): 图片的保存路径,默认设为 detection\_result;
+ - det\_db\_unclip\_ratio: 设置检测框的大小;
+ - **返回**
+
+ - res (list\[dict\]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
+ - data (list): 检测文本框结果,文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标
+ - save_path (str): 识别结果的保存路径, 如不保存图片则save_path为''
+
+
+
+## 四、服务部署
+
+- PaddleHub Serving 可以部署一个目标检测的在线服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+ - ```shell
+ $ hub serving start -m ch_pp-ocrv3_det
+ ```
+
+ - 这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ # 发送HTTP请求
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/ch_pp-ocrv3_det"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 打印预测结果
+ print(r.json()["results"])
+ ```
+
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ - ```shell
+ $ hub install ch_pp-ocrv3_det==1.0.0
+ ```