@@ -149,6 +149,8 @@ print(results)
!hub serving start -m lac
```
+ 更多迁移学习能力可以参考[教程文档](https://paddlehub.readthedocs.io/zh_CN/release-v2.1/transfer_learning_index.html)
+
@@ -208,3 +210,4 @@ print(results)
* 非常感谢[BurrowsWang](https://github.com/BurrowsWang)修复Markdown表格显示问题
* 非常感谢[huqi](https://github.com/hu-qi)修复了readme中的错别字
* 非常感谢[parano](https://github.com/parano)、[cqvu](https://github.com/cqvu)、[deehrlic](https://github.com/deehrlic)三位的贡献与支持
+* 非常感谢[paopjian](https://github.com/paopjian)修改了中文readme模型搜索指向的的网站地址错误[#1424](https://github.com/PaddlePaddle/PaddleHub/issues/1424)
diff --git a/demo/README.md b/demo/README.md
index e69de29bb2d1d6434b8b29ae775ad8c2e48c5391..1ae13ac94032a39d213e818b7b61b18a5584acc2 100644
--- a/demo/README.md
+++ b/demo/README.md
@@ -0,0 +1,2 @@
+### PaddleHub Office Website:https://www.paddlepaddle.org.cn/hub
+### PaddleHub Module Searching:https://www.paddlepaddle.org.cn/hublist
diff --git a/demo/text_classification/predict.py b/demo/text_classification/predict.py
index ad7721cafcc5292e02b3329eaa5510ec829b9db0..48a5688bfe48bc4d3728d06c9cdc78281013b9d0 100644
--- a/demo/text_classification/predict.py
+++ b/demo/text_classification/predict.py
@@ -28,6 +28,6 @@ if __name__ == '__main__':
task='seq-cls',
load_checkpoint='./test_ernie_text_cls/best_model/model.pdparams',
label_map=label_map)
- results = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=False)
+ results, probs = model.predict(data, max_seq_len=50, batch_size=1, use_gpu=False, return_prob=True)
for idx, text in enumerate(data):
print('Data: {} \t Lable: {}'.format(text[0], results[idx]))
diff --git a/docs/docs_ch/get_start/installation.rst b/docs/docs_ch/get_start/installation.rst
index 5d92979a46897ffc9cc0ae80e374e25832f07675..6391e2ea2280571740a09a9ae00cb04f08ef753b 100755
--- a/docs/docs_ch/get_start/installation.rst
+++ b/docs/docs_ch/get_start/installation.rst
@@ -21,7 +21,7 @@
安装命令
========================
-在安装PaddleHub之前,请先安装PaddlePaddle深度学习框架,更多安装说明请查阅`飞桨快速安装
`_.
+在安装PaddleHub之前,请先安装PaddlePaddle深度学习框架,更多安装说明请查阅`飞桨快速安装 `
.. code-block:: shell
@@ -30,6 +30,7 @@
除上述依赖外,PaddleHub的预训练模型和预置数据集需要连接服务端进行下载,请确保机器可以正常访问网络。若本地已存在相关的数据集和预训练模型,则可以离线运行PaddleHub。
.. note::
+
使用PaddleHub下载数据集、预训练模型等,要求机器可以访问外网。可以使用`server_check()`可以检查本地与远端PaddleHub-Server的连接状态,使用方法如下:
.. code-block:: Python
@@ -37,4 +38,4 @@
import paddlehub
paddlehub.server_check()
# 如果可以连接远端PaddleHub-Server,则显示Request Hub-Server successfully。
- # 如果无法连接远端PaddleHub-Server,则显示Request Hub-Server unsuccessfully。
\ No newline at end of file
+ # 如果无法连接远端PaddleHub-Server,则显示Request Hub-Server unsuccessfully。
diff --git a/docs/docs_ch/get_start/python_use_hub.rst b/docs/docs_ch/get_start/python_use_hub.rst
index b78d3f26c0c7a0db8261da5344ebd6dda737e7e4..839c7a9bf6e9bd5b164b38030c775af63c9299f9 100755
--- a/docs/docs_ch/get_start/python_use_hub.rst
+++ b/docs/docs_ch/get_start/python_use_hub.rst
@@ -32,7 +32,7 @@ PaddleHub采用模型即软件的设计理念,所有的预训练模型与Pytho
# module = hub.Module(name="humanseg_lite", version="1.1.1")
module = hub.Module(name="humanseg_lite")
- res = module.segmentation(
+ res = module.segment(
paths = ["./test_image.jpg"],
visualization=True,
output_dir='humanseg_output')
@@ -131,4 +131,4 @@ PaddleHub采用模型即软件的设计理念,所有的预训练模型与Pytho
----------------
- [{'text': '味道不错,确实不算太辣,适合不能吃辣的人。就在长江边上,抬头就能看到长江的风景。鸭肠、黄鳝都比较新鲜。', 'sentiment_label': 1, 'sentiment_key': 'positive', 'positive_probs': 0.9771, 'negative_probs': 0.0229}]
\ No newline at end of file
+ [{'text': '味道不错,确实不算太辣,适合不能吃辣的人。就在长江边上,抬头就能看到长江的风景。鸭肠、黄鳝都比较新鲜。', 'sentiment_label': 1, 'sentiment_key': 'positive', 'positive_probs': 0.9771, 'negative_probs': 0.0229}]
diff --git a/docs/imgs/joinus.JPEG b/docs/imgs/joinus.JPEG
deleted file mode 100644
index 3adc610f52aa7c24ee7a4d57746fb2efdcf612a9..0000000000000000000000000000000000000000
Binary files a/docs/imgs/joinus.JPEG and /dev/null differ
diff --git a/docs/imgs/joinus.PNG b/docs/imgs/joinus.PNG
index 1347a9acb42059e9bf0cf0b9ea9d4425ffcb2b46..a401d123cc3d7a43f7b7b7658b2aef6dcd34b3bc 100644
Binary files a/docs/imgs/joinus.PNG and b/docs/imgs/joinus.PNG differ
diff --git a/modules/audio/audio_classification/PANNs/cnn10/module.py b/modules/audio/audio_classification/PANNs/cnn10/module.py
index 4a45bbe84d78dd967241880d35ee9ca69e3f3e5b..4f474d1f67cbc17ea8b397173019b74bcfda934d 100644
--- a/modules/audio/audio_classification/PANNs/cnn10/module.py
+++ b/modules/audio/audio_classification/PANNs/cnn10/module.py
@@ -31,7 +31,7 @@ from paddlehub.utils.log import logger
name="panns_cnn10",
version="1.0.0",
summary="",
- author="Baidu",
+ author="paddlepaddle",
author_email="",
type="audio/sound_classification",
meta=AudioClassifierModule)
diff --git a/modules/audio/audio_classification/PANNs/cnn14/module.py b/modules/audio/audio_classification/PANNs/cnn14/module.py
index eb0efc318192c39b03b810824e0a7fd37071cf01..0bd1826e20b394dfbbf007f3ac5079f3f8727fbc 100644
--- a/modules/audio/audio_classification/PANNs/cnn14/module.py
+++ b/modules/audio/audio_classification/PANNs/cnn14/module.py
@@ -31,7 +31,7 @@ from paddlehub.utils.log import logger
name="panns_cnn14",
version="1.0.0",
summary="",
- author="Baidu",
+ author="paddlepaddle",
author_email="",
type="audio/sound_classification",
meta=AudioClassifierModule)
diff --git a/modules/audio/audio_classification/PANNs/cnn6/module.py b/modules/audio/audio_classification/PANNs/cnn6/module.py
index 360cccf2fc0c8092cb6f642f8f56e7cf47049b11..ec70e75d97045743468b3ecaea5de83e2767b49a 100644
--- a/modules/audio/audio_classification/PANNs/cnn6/module.py
+++ b/modules/audio/audio_classification/PANNs/cnn6/module.py
@@ -31,7 +31,7 @@ from paddlehub.utils.log import logger
name="panns_cnn6",
version="1.0.0",
summary="",
- author="Baidu",
+ author="paddlepaddle",
author_email="",
type="audio/sound_classification",
meta=AudioClassifierModule)
diff --git a/modules/audio/voice_cloning/lstm_tacotron2/README.md b/modules/audio/voice_cloning/lstm_tacotron2/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..58d6e846a25ddded31a10d6632aaaf6d7563f723
--- /dev/null
+++ b/modules/audio/voice_cloning/lstm_tacotron2/README.md
@@ -0,0 +1,102 @@
+```shell
+$ hub install lstm_tacotron2==1.0.0
+```
+
+## 概述
+
+声音克隆是指使用特定的音色,结合文字的读音合成音频,使得合成后的音频具有目标说话人的特征,从而达到克隆的目的。
+
+在训练语音克隆模型时,目标音色作为Speaker Encoder的输入,模型会提取这段语音的说话人特征(音色)作为Speaker Embedding。接着,在训练模型重新合成此类音色的语音时,除了输入的目标文本外,说话人的特征也将成为额外条件加入模型的训练。
+
+在预测时,选取一段新的目标音色作为Speaker Encoder的输入,并提取其说话人特征,最终实现输入为一段文本和一段目标音色,模型生成目标音色说出此段文本的语音片段。
+
+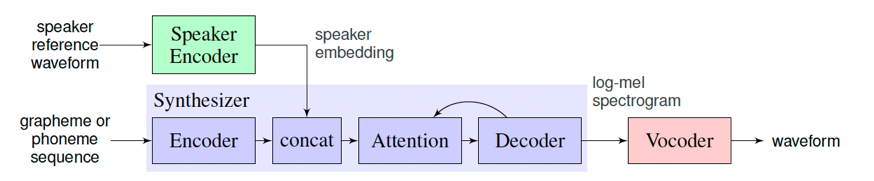
+
+`lstm_tacotron2`是一个支持中文的语音克隆模型,分别使用了LSTMSpeakerEncoder、Tacotron2和WaveFlow模型分别用于语音特征提取、目标音频特征合成和语音波形转换。
+
+关于模型的详请可参考[Parakeet](https://github.com/PaddlePaddle/Parakeet/tree/release/v0.3/parakeet/models)。
+
+
+## API
+
+```python
+def __init__(speaker_audio: str = None,
+ output_dir: str = './')
+```
+初始化module,可配置模型的目标音色的音频文件和输出的路径。
+
+**参数**
+- `speaker_audio`(str): 目标说话人语音音频文件(*.wav)的路径,默认为None(使用默认的女声作为目标音色)。
+- `output_dir`(str): 合成音频的输出文件,默认为当前目录。
+
+
+```python
+def get_speaker_embedding()
+```
+获取模型的目标说话人特征。
+
+**返回**
+* `results`(numpy.ndarray): 长度为256的numpy数组,代表目标说话人的特征。
+
+```python
+def set_speaker_embedding(speaker_audio: str)
+```
+设置模型的目标说话人特征。
+
+**参数**
+- `speaker_audio`(str): 必填,目标说话人语音音频文件(*.wav)的路径。
+
+```python
+def generate(data: List[str], batch_size: int = 1, use_gpu: bool = False):
+```
+根据输入文字,合成目标说话人的语音音频文件。
+
+**参数**
+- `data`(List[str]): 必填,目标音频的内容文本列表,目前只支持中文,不支持添加标点符号。
+- `batch_size`(int): 可选,模型合成语音时的batch_size,默认为1。
+- `use_gpu`(bool): 是否使用gpu执行计算,默认为False。
+
+
+**代码示例**
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='lstm_tacotron2', output_dir='./', speaker_audio='/data/man.wav') # 指定目标音色音频文件
+texts = [
+ '语音的表现形式在未来将变得越来越重要$',
+ '今天的天气怎么样$', ]
+wavs = model.generate(texts, use_gpu=True)
+
+for text, wav in zip(texts, wavs):
+ print('='*30)
+ print(f'Text: {text}')
+ print(f'Wav: {wav}')
+```
+
+输出
+```
+==============================
+Text: 语音的表现形式在未来将变得越来越重要$
+Wav: /data/1.wav
+==============================
+Text: 今天的天气怎么样$
+Wav: /data/2.wav
+```
+
+
+## 查看代码
+
+https://github.com/PaddlePaddle/Parakeet
+
+## 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.1.0
+
+## 更新历史
+
+* 1.0.0
+
+ 初始发布
diff --git a/modules/audio/voice_cloning/lstm_tacotron2/__init__.py b/modules/audio/voice_cloning/lstm_tacotron2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/modules/audio/voice_cloning/lstm_tacotron2/audio_processor.py b/modules/audio/voice_cloning/lstm_tacotron2/audio_processor.py
new file mode 100644
index 0000000000000000000000000000000000000000..a06d86ae3dfc15dca2e661b7ec180da2529c044b
--- /dev/null
+++ b/modules/audio/voice_cloning/lstm_tacotron2/audio_processor.py
@@ -0,0 +1,214 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from pathlib import Path
+from warnings import warn
+import struct
+
+from scipy.ndimage.morphology import binary_dilation
+import numpy as np
+import librosa
+
+try:
+ import webrtcvad
+except ModuleNotFoundError:
+ warn("Unable to import 'webrtcvad'." "This package enables noise removal and is recommended.")
+ webrtcvad = None
+
+INT16_MAX = (2**15) - 1
+
+
+def normalize_volume(wav, target_dBFS, increase_only=False, decrease_only=False):
+ # this function implements Loudness normalization, instead of peak
+ # normalization, See https://en.wikipedia.org/wiki/Audio_normalization
+ # dBFS: Decibels relative to full scale
+ # See https://en.wikipedia.org/wiki/DBFS for more details
+ # for 16Bit PCM audio, minimal level is -96dB
+ # compute the mean dBFS and adjust to target dBFS, with by increasing
+ # or decreasing
+ if increase_only and decrease_only:
+ raise ValueError("Both increase only and decrease only are set")
+ dBFS_change = target_dBFS - 10 * np.log10(np.mean(wav**2))
+ if ((dBFS_change < 0 and increase_only) or (dBFS_change > 0 and decrease_only)):
+ return wav
+ gain = 10**(dBFS_change / 20)
+ return wav * gain
+
+
+def trim_long_silences(wav, vad_window_length: int, vad_moving_average_width: int, vad_max_silence_length: int,
+ sampling_rate: int):
+ """
+ Ensures that segments without voice in the waveform remain no longer than a
+ threshold determined by the VAD parameters in params.py.
+
+ :param wav: the raw waveform as a numpy array of floats
+ :return: the same waveform with silences trimmed away (length <= original wav length)
+ """
+ # Compute the voice detection window size
+ samples_per_window = (vad_window_length * sampling_rate) // 1000
+
+ # Trim the end of the audio to have a multiple of the window size
+ wav = wav[:len(wav) - (len(wav) % samples_per_window)]
+
+ # Convert the float waveform to 16-bit mono PCM
+ pcm_wave = struct.pack("%dh" % len(wav), *(np.round(wav * INT16_MAX)).astype(np.int16))
+
+ # Perform voice activation detection
+ voice_flags = []
+ vad = webrtcvad.Vad(mode=3)
+ for window_start in range(0, len(wav), samples_per_window):
+ window_end = window_start + samples_per_window
+ voice_flags.append(vad.is_speech(pcm_wave[window_start * 2:window_end * 2], sample_rate=sampling_rate))
+ voice_flags = np.array(voice_flags)
+
+ # Smooth the voice detection with a moving average
+ def moving_average(array, width):
+ array_padded = np.concatenate((np.zeros((width - 1) // 2), array, np.zeros(width // 2)))
+ ret = np.cumsum(array_padded, dtype=float)
+ ret[width:] = ret[width:] - ret[:-width]
+ return ret[width - 1:] / width
+
+ audio_mask = moving_average(voice_flags, vad_moving_average_width)
+ audio_mask = np.round(audio_mask).astype(np.bool)
+
+ # Dilate the voiced regions
+ audio_mask = binary_dilation(audio_mask, np.ones(vad_max_silence_length + 1))
+ audio_mask = np.repeat(audio_mask, samples_per_window)
+
+ return wav[audio_mask]
+
+
+def compute_partial_slices(n_samples: int,
+ partial_utterance_n_frames: int,
+ hop_length: int,
+ min_pad_coverage: float = 0.75,
+ overlap: float = 0.5):
+ """
+ Computes where to split an utterance waveform and its corresponding mel spectrogram to obtain
+ partial utterances of each. Both the waveform and the mel
+ spectrogram slices are returned, so as to make each partial utterance waveform correspond to
+ its spectrogram. This function assumes that the mel spectrogram parameters used are those
+ defined in params_data.py.
+
+ The returned ranges may be indexing further than the length of the waveform. It is
+ recommended that you pad the waveform with zeros up to wave_slices[-1].stop.
+
+ :param n_samples: the number of samples in the waveform
+ :param partial_utterance_n_frames: the number of mel spectrogram frames in each partial
+ utterance
+ :param min_pad_coverage: when reaching the last partial utterance, it may or may not have
+ enough frames. If at least of are present,
+ then the last partial utterance will be considered, as if we padded the audio. Otherwise,
+ it will be discarded, as if we trimmed the audio. If there aren't enough frames for 1 partial
+ utterance, this parameter is ignored so that the function always returns at least 1 slice.
+ :param overlap: by how much the partial utterance should overlap. If set to 0, the partial
+ utterances are entirely disjoint.
+ :return: the waveform slices and mel spectrogram slices as lists of array slices. Index
+ respectively the waveform and the mel spectrogram with these slices to obtain the partial
+ utterances.
+ """
+ assert 0 <= overlap < 1
+ assert 0 < min_pad_coverage <= 1
+
+ # librosa's function to compute num_frames from num_samples
+ n_frames = int(np.ceil((n_samples + 1) / hop_length))
+ # frame shift between ajacent partials
+ frame_step = max(1, int(np.round(partial_utterance_n_frames * (1 - overlap))))
+
+ # Compute the slices
+ wav_slices, mel_slices = [], []
+ steps = max(1, n_frames - partial_utterance_n_frames + frame_step + 1)
+ for i in range(0, steps, frame_step):
+ mel_range = np.array([i, i + partial_utterance_n_frames])
+ wav_range = mel_range * hop_length
+ mel_slices.append(slice(*mel_range))
+ wav_slices.append(slice(*wav_range))
+
+ # Evaluate whether extra padding is warranted or not
+ last_wav_range = wav_slices[-1]
+ coverage = (n_samples - last_wav_range.start) / (last_wav_range.stop - last_wav_range.start)
+ if coverage < min_pad_coverage and len(mel_slices) > 1:
+ mel_slices = mel_slices[:-1]
+ wav_slices = wav_slices[:-1]
+
+ return wav_slices, mel_slices
+
+
+class SpeakerVerificationPreprocessor(object):
+ def __init__(self,
+ sampling_rate: int,
+ audio_norm_target_dBFS: float,
+ vad_window_length,
+ vad_moving_average_width,
+ vad_max_silence_length,
+ mel_window_length,
+ mel_window_step,
+ n_mels,
+ partial_n_frames: int,
+ min_pad_coverage: float = 0.75,
+ partial_overlap_ratio: float = 0.5):
+ self.sampling_rate = sampling_rate
+ self.audio_norm_target_dBFS = audio_norm_target_dBFS
+
+ self.vad_window_length = vad_window_length
+ self.vad_moving_average_width = vad_moving_average_width
+ self.vad_max_silence_length = vad_max_silence_length
+
+ self.n_fft = int(mel_window_length * sampling_rate / 1000)
+ self.hop_length = int(mel_window_step * sampling_rate / 1000)
+ self.n_mels = n_mels
+
+ self.partial_n_frames = partial_n_frames
+ self.min_pad_coverage = min_pad_coverage
+ self.partial_overlap_ratio = partial_overlap_ratio
+
+ def preprocess_wav(self, fpath_or_wav, source_sr=None):
+ # Load the wav from disk if needed
+ if isinstance(fpath_or_wav, (str, Path)):
+ wav, source_sr = librosa.load(str(fpath_or_wav), sr=None)
+ else:
+ wav = fpath_or_wav
+
+ # Resample if numpy.array is passed and sr does not match
+ if source_sr is not None and source_sr != self.sampling_rate:
+ wav = librosa.resample(wav, source_sr, self.sampling_rate)
+
+ # loudness normalization
+ wav = normalize_volume(wav, self.audio_norm_target_dBFS, increase_only=True)
+
+ # trim long silence
+ if webrtcvad:
+ wav = trim_long_silences(wav, self.vad_window_length, self.vad_moving_average_width,
+ self.vad_max_silence_length, self.sampling_rate)
+ return wav
+
+ def melspectrogram(self, wav):
+ mel = librosa.feature.melspectrogram(
+ wav, sr=self.sampling_rate, n_fft=self.n_fft, hop_length=self.hop_length, n_mels=self.n_mels)
+ mel = mel.astype(np.float32).T
+ return mel
+
+ def extract_mel_partials(self, wav):
+ wav_slices, mel_slices = compute_partial_slices(
+ len(wav), self.partial_n_frames, self.hop_length, self.min_pad_coverage, self.partial_overlap_ratio)
+
+ # pad audio if needed
+ max_wave_length = wav_slices[-1].stop
+ if max_wave_length >= len(wav):
+ wav = np.pad(wav, (0, max_wave_length - len(wav)), "constant")
+
+ # Split the utterance into partials
+ frames = self.melspectrogram(wav)
+ frames_batch = np.array([frames[s] for s in mel_slices])
+ return frames_batch # [B, T, C]
diff --git a/modules/audio/voice_cloning/lstm_tacotron2/chinese_g2p.py b/modules/audio/voice_cloning/lstm_tacotron2/chinese_g2p.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8000cb540577695037858af458e48af5cf715e6
--- /dev/null
+++ b/modules/audio/voice_cloning/lstm_tacotron2/chinese_g2p.py
@@ -0,0 +1,39 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import List, Tuple
+from pypinyin import lazy_pinyin, Style
+
+from .preprocess_transcription import split_syllable
+
+
+def convert_to_pinyin(text: str) -> List[str]:
+ """convert text into list of syllables, other characters that are not chinese, thus
+ cannot be converted to pinyin are splited.
+ """
+ syllables = lazy_pinyin(text, style=Style.TONE3, neutral_tone_with_five=True)
+ return syllables
+
+
+def convert_sentence(text: str) -> List[Tuple[str]]:
+ """convert a sentence into two list: phones and tones"""
+ syllables = convert_to_pinyin(text)
+ phones = []
+ tones = []
+ for syllable in syllables:
+ p, t = split_syllable(syllable)
+ phones.extend(p)
+ tones.extend(t)
+
+ return phones, tones
diff --git a/modules/audio/voice_cloning/lstm_tacotron2/module.py b/modules/audio/voice_cloning/lstm_tacotron2/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e60afa2bb9a74e4922e99eef219e1816f9968af
--- /dev/null
+++ b/modules/audio/voice_cloning/lstm_tacotron2/module.py
@@ -0,0 +1,188 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import importlib
+import os
+from typing import List
+
+import numpy as np
+import paddle
+import paddle.nn as nn
+from paddlehub.env import MODULE_HOME
+from paddlehub.module.module import moduleinfo
+from paddlehub.utils.log import logger
+from paddlenlp.data import Pad
+from parakeet.models import ConditionalWaveFlow, Tacotron2
+from parakeet.models.lstm_speaker_encoder import LSTMSpeakerEncoder
+import soundfile as sf
+
+from .audio_processor import SpeakerVerificationPreprocessor
+from .chinese_g2p import convert_sentence
+from .preprocess_transcription import voc_phones, voc_tones, phone_pad_token, tone_pad_token
+
+
+@moduleinfo(
+ name="lstm_tacotron2",
+ version="1.0.0",
+ summary="",
+ author="paddlepaddle",
+ author_email="",
+ type="audio/voice_cloning",
+)
+class VoiceCloner(nn.Layer):
+ def __init__(self, speaker_audio: str = None, output_dir: str = './'):
+ super(VoiceCloner, self).__init__()
+
+ self.sample_rate = 22050 # Hyper params for the following model ckpts.
+ speaker_encoder_ckpt = os.path.join(MODULE_HOME, 'lstm_tacotron2', 'assets',
+ 'ge2e_ckpt_0.3/step-3000000.pdparams')
+ synthesizer_ckpt = os.path.join(MODULE_HOME, 'lstm_tacotron2', 'assets',
+ 'tacotron2_aishell3_ckpt_0.3/step-450000.pdparams')
+ vocoder_ckpt = os.path.join(MODULE_HOME, 'lstm_tacotron2', 'assets',
+ 'waveflow_ljspeech_ckpt_0.3/step-2000000.pdparams')
+
+ # Speaker encoder
+ self.speaker_processor = SpeakerVerificationPreprocessor(
+ sampling_rate=16000,
+ audio_norm_target_dBFS=-30,
+ vad_window_length=30,
+ vad_moving_average_width=8,
+ vad_max_silence_length=6,
+ mel_window_length=25,
+ mel_window_step=10,
+ n_mels=40,
+ partial_n_frames=160,
+ min_pad_coverage=0.75,
+ partial_overlap_ratio=0.5)
+ self.speaker_encoder = LSTMSpeakerEncoder(n_mels=40, num_layers=3, hidden_size=256, output_size=256)
+ self.speaker_encoder.set_state_dict(paddle.load(speaker_encoder_ckpt))
+ self.speaker_encoder.eval()
+
+ # Voice synthesizer
+ self.synthesizer = Tacotron2(
+ vocab_size=68,
+ n_tones=10,
+ d_mels=80,
+ d_encoder=512,
+ encoder_conv_layers=3,
+ encoder_kernel_size=5,
+ d_prenet=256,
+ d_attention_rnn=1024,
+ d_decoder_rnn=1024,
+ attention_filters=32,
+ attention_kernel_size=31,
+ d_attention=128,
+ d_postnet=512,
+ postnet_kernel_size=5,
+ postnet_conv_layers=5,
+ reduction_factor=1,
+ p_encoder_dropout=0.5,
+ p_prenet_dropout=0.5,
+ p_attention_dropout=0.1,
+ p_decoder_dropout=0.1,
+ p_postnet_dropout=0.5,
+ d_global_condition=256,
+ use_stop_token=False)
+ self.synthesizer.set_state_dict(paddle.load(synthesizer_ckpt))
+ self.synthesizer.eval()
+
+ # Vocoder
+ self.vocoder = ConditionalWaveFlow(
+ upsample_factors=[16, 16], n_flows=8, n_layers=8, n_group=16, channels=128, n_mels=80, kernel_size=[3, 3])
+ self.vocoder.set_state_dict(paddle.load(vocoder_ckpt))
+ self.vocoder.eval()
+
+ # Speaking embedding
+ self._speaker_embedding = None
+ if speaker_audio is None or not os.path.isfile(speaker_audio):
+ speaker_audio = os.path.join(MODULE_HOME, 'lstm_tacotron2', 'assets', 'voice_cloning.wav')
+ logger.warning(f'Due to no speaker audio is specified, speaker encoder will use defult '
+ f'waveform({speaker_audio}) to extract speaker embedding. You can use '
+ '"set_speaker_embedding()" method to reset a speaker audio for voice cloning.')
+ self.set_speaker_embedding(speaker_audio)
+
+ self.output_dir = os.path.abspath(output_dir)
+ if not os.path.exists(self.output_dir):
+ os.makedirs(self.output_dir)
+
+ def get_speaker_embedding(self):
+ return self._speaker_embedding.numpy()
+
+ def set_speaker_embedding(self, speaker_audio: str):
+ assert os.path.exists(speaker_audio), f'Speaker audio file: {speaker_audio} does not exists.'
+ mel_sequences = self.speaker_processor.extract_mel_partials(
+ self.speaker_processor.preprocess_wav(speaker_audio))
+ self._speaker_embedding = self.speaker_encoder.embed_utterance(paddle.to_tensor(mel_sequences))
+ logger.info(f'Speaker embedding has been set from file: {speaker_audio}')
+
+ def forward(self, phones: paddle.Tensor, tones: paddle.Tensor, speaker_embeddings: paddle.Tensor):
+ outputs = self.synthesizer.infer(phones, tones=tones, global_condition=speaker_embeddings)
+ mel_input = paddle.transpose(outputs["mel_outputs_postnet"], [0, 2, 1])
+ waveforms = self.vocoder.infer(mel_input)
+ return waveforms
+
+ def _convert_text_to_input(self, text: str):
+ """
+ Convert input string to phones and tones.
+ """
+ phones, tones = convert_sentence(text)
+ phones = np.array([voc_phones.lookup(item) for item in phones], dtype=np.int64)
+ tones = np.array([voc_tones.lookup(item) for item in tones], dtype=np.int64)
+ return phones, tones
+
+ def _batchify(self, data: List[str], batch_size: int):
+ """
+ Generate input batches.
+ """
+ phone_pad_func = Pad(voc_phones.lookup(phone_pad_token))
+ tone_pad_func = Pad(voc_tones.lookup(tone_pad_token))
+
+ def _parse_batch(batch_data):
+ phones, tones = zip(*batch_data)
+ speaker_embeddings = paddle.expand(self._speaker_embedding, shape=(len(batch_data), -1))
+ return phone_pad_func(phones), tone_pad_func(tones), speaker_embeddings
+
+ examples = [] # [(phones, tones), ...]
+ for text in data:
+ examples.append(self._convert_text_to_input(text))
+
+ # Seperates data into some batches.
+ one_batch = []
+ for example in examples:
+ one_batch.append(example)
+ if len(one_batch) == batch_size:
+ yield _parse_batch(one_batch)
+ one_batch = []
+ if one_batch:
+ yield _parse_batch(one_batch)
+
+ def generate(self, data: List[str], batch_size: int = 1, use_gpu: bool = False):
+ assert self._speaker_embedding is not None, f'Set speaker embedding before voice cloning.'
+
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+ batches = self._batchify(data, batch_size)
+
+ results = []
+ for batch in batches:
+ phones, tones, speaker_embeddings = map(paddle.to_tensor, batch)
+ waveforms = self(phones, tones, speaker_embeddings).numpy()
+ results.extend(list(waveforms))
+
+ files = []
+ for idx, waveform in enumerate(results):
+ output_wav = os.path.join(self.output_dir, f'{idx+1}.wav')
+ sf.write(output_wav, waveform, samplerate=self.sample_rate)
+ files.append(output_wav)
+
+ return files
diff --git a/modules/audio/voice_cloning/lstm_tacotron2/preprocess_transcription.py b/modules/audio/voice_cloning/lstm_tacotron2/preprocess_transcription.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c88cb4c71af42d8479eb78e6b0b667f4d64fbac
--- /dev/null
+++ b/modules/audio/voice_cloning/lstm_tacotron2/preprocess_transcription.py
@@ -0,0 +1,181 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import argparse
+from pathlib import Path
+import pickle
+import re
+
+from parakeet.frontend import Vocab
+import tqdm
+
+zh_pattern = re.compile("[\u4e00-\u9fa5]")
+
+_tones = {'', '', '', '0', '1', '2', '3', '4', '5'}
+
+_pauses = {'%', '$'}
+
+_initials = {
+ 'b',
+ 'p',
+ 'm',
+ 'f',
+ 'd',
+ 't',
+ 'n',
+ 'l',
+ 'g',
+ 'k',
+ 'h',
+ 'j',
+ 'q',
+ 'x',
+ 'zh',
+ 'ch',
+ 'sh',
+ 'r',
+ 'z',
+ 'c',
+ 's',
+}
+
+_finals = {
+ 'ii',
+ 'iii',
+ 'a',
+ 'o',
+ 'e',
+ 'ea',
+ 'ai',
+ 'ei',
+ 'ao',
+ 'ou',
+ 'an',
+ 'en',
+ 'ang',
+ 'eng',
+ 'er',
+ 'i',
+ 'ia',
+ 'io',
+ 'ie',
+ 'iai',
+ 'iao',
+ 'iou',
+ 'ian',
+ 'ien',
+ 'iang',
+ 'ieng',
+ 'u',
+ 'ua',
+ 'uo',
+ 'uai',
+ 'uei',
+ 'uan',
+ 'uen',
+ 'uang',
+ 'ueng',
+ 'v',
+ 've',
+ 'van',
+ 'ven',
+ 'veng',
+}
+
+_ernized_symbol = {'&r'}
+
+_specials = {'', '', '', ''}
+
+_phones = _initials | _finals | _ernized_symbol | _specials | _pauses
+
+phone_pad_token = ''
+tone_pad_token = ''
+voc_phones = Vocab(sorted(list(_phones)))
+voc_tones = Vocab(sorted(list(_tones)))
+
+
+def is_zh(word):
+ global zh_pattern
+ match = zh_pattern.search(word)
+ return match is not None
+
+
+def ernized(syllable):
+ return syllable[:2] != "er" and syllable[-2] == 'r'
+
+
+def convert(syllable):
+ # expansion of o -> uo
+ syllable = re.sub(r"([bpmf])o$", r"\1uo", syllable)
+ # syllable = syllable.replace("bo", "buo").replace("po", "puo").replace("mo", "muo").replace("fo", "fuo")
+ # expansion for iong, ong
+ syllable = syllable.replace("iong", "veng").replace("ong", "ueng")
+
+ # expansion for ing, in
+ syllable = syllable.replace("ing", "ieng").replace("in", "ien")
+
+ # expansion for un, ui, iu
+ syllable = syllable.replace("un", "uen").replace("ui", "uei").replace("iu", "iou")
+
+ # rule for variants of i
+ syllable = syllable.replace("zi", "zii").replace("ci", "cii").replace("si", "sii")\
+ .replace("zhi", "zhiii").replace("chi", "chiii").replace("shi", "shiii")\
+ .replace("ri", "riii")
+
+ # rule for y preceding i, u
+ syllable = syllable.replace("yi", "i").replace("yu", "v").replace("y", "i")
+
+ # rule for w
+ syllable = syllable.replace("wu", "u").replace("w", "u")
+
+ # rule for v following j, q, x
+ syllable = syllable.replace("ju", "jv").replace("qu", "qv").replace("xu", "xv")
+
+ return syllable
+
+
+def split_syllable(syllable: str):
+ """Split a syllable in pinyin into a list of phones and a list of tones.
+ Initials have no tone, represented by '0', while finals have tones from
+ '1,2,3,4,5'.
+
+ e.g.
+
+ zhang -> ['zh', 'ang'], ['0', '1']
+ """
+ if syllable in _pauses:
+ # syllable, tone
+ return [syllable], ['0']
+
+ tone = syllable[-1]
+ syllable = convert(syllable[:-1])
+
+ phones = []
+ tones = []
+
+ global _initials
+ if syllable[:2] in _initials:
+ phones.append(syllable[:2])
+ tones.append('0')
+ phones.append(syllable[2:])
+ tones.append(tone)
+ elif syllable[0] in _initials:
+ phones.append(syllable[0])
+ tones.append('0')
+ phones.append(syllable[1:])
+ tones.append(tone)
+ else:
+ phones.append(syllable)
+ tones.append(tone)
+ return phones, tones
diff --git a/modules/audio/voice_cloning/lstm_tacotron2/requirements.txt b/modules/audio/voice_cloning/lstm_tacotron2/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..013164d7c3fa849c686cdde69a260f95d83a8e64
--- /dev/null
+++ b/modules/audio/voice_cloning/lstm_tacotron2/requirements.txt
@@ -0,0 +1 @@
+paddle-parakeet
diff --git a/modules/image/classification/ghostnet_x0_5_imagenet/README.md b/modules/image/classification/ghostnet_x0_5_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..40d83f30ccf0a11ddc149da0a92f32d0a78666ba
--- /dev/null
+++ b/modules/image/classification/ghostnet_x0_5_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install ghostnet_x0_5_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run ghostnet_x0_5_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='ghostnet_x0_5_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='ghostnet_x0_5_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='ghostnet_x0_5_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m ghostnet_x0_5_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/ghostnet_x0_5_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/ghostnet_x0_5_imagenet/label_list.txt b/modules/image/classification/ghostnet_x0_5_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/ghostnet_x0_5_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/ghostnet_x0_5_imagenet/module.py b/modules/image/classification/ghostnet_x0_5_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ab6d90613d8d1cd8a72fb2a6e81d77cbbcf6cda
--- /dev/null
+++ b/modules/image/classification/ghostnet_x0_5_imagenet/module.py
@@ -0,0 +1,324 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle import ParamAttr
+from paddle.nn.initializer import Uniform, KaimingNormal
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+ self._conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=(kernel_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(initializer=KaimingNormal(), name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + "_bn"
+
+ self._batch_norm = nn.BatchNorm(
+ num_channels=out_channels,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + "_scale", regularizer=paddle.regularizer.L2Decay(0.0)),
+ bias_attr=ParamAttr(name=bn_name + "_offset", regularizer=paddle.regularizer.L2Decay(0.0)),
+ moving_mean_name=bn_name + "_mean",
+ moving_variance_name=bn_name + "_variance")
+
+ def forward(self, inputs):
+ y = self._conv(inputs)
+ y = self._batch_norm(y)
+ return y
+
+
+class SEBlock(nn.Layer):
+ def __init__(self, num_channels, reduction_ratio=4, name=None):
+ super(SEBlock, self).__init__()
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+ self._num_channels = num_channels
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ med_ch = num_channels // reduction_ratio
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_1_weights"),
+ bias_attr=ParamAttr(name=name + "_1_offset"))
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_channels,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_2_weights"),
+ bias_attr=ParamAttr(name=name + "_2_offset"))
+
+ def forward(self, inputs):
+ pool = self.pool2d_gap(inputs)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = paddle.clip(x=excitation, min=0, max=1)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = paddle.multiply(inputs, excitation)
+ return out
+
+
+class GhostModule(nn.Layer):
+ def __init__(self, in_channels, output_channels, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True, name=None):
+ super(GhostModule, self).__init__()
+ init_channels = int(math.ceil(output_channels / ratio))
+ new_channels = int(init_channels * (ratio - 1))
+ self.primary_conv = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=init_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=1,
+ act="relu" if relu else None,
+ name=name + "_primary_conv")
+ self.cheap_operation = ConvBNLayer(
+ in_channels=init_channels,
+ out_channels=new_channels,
+ kernel_size=dw_size,
+ stride=1,
+ groups=init_channels,
+ act="relu" if relu else None,
+ name=name + "_cheap_operation")
+
+ def forward(self, inputs):
+ x = self.primary_conv(inputs)
+ y = self.cheap_operation(x)
+ out = paddle.concat([x, y], axis=1)
+ return out
+
+
+class GhostBottleneck(nn.Layer):
+ def __init__(self, in_channels, hidden_dim, output_channels, kernel_size, stride, use_se, name=None):
+ super(GhostBottleneck, self).__init__()
+ self._stride = stride
+ self._use_se = use_se
+ self._num_channels = in_channels
+ self._output_channels = output_channels
+ self.ghost_module_1 = GhostModule(
+ in_channels=in_channels,
+ output_channels=hidden_dim,
+ kernel_size=1,
+ stride=1,
+ relu=True,
+ name=name + "_ghost_module_1")
+ if stride == 2:
+ self.depthwise_conv = ConvBNLayer(
+ in_channels=hidden_dim,
+ out_channels=hidden_dim,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=hidden_dim,
+ act=None,
+ name=name + "_depthwise_depthwise" # looks strange due to an old typo, will be fixed later.
+ )
+ if use_se:
+ self.se_block = SEBlock(num_channels=hidden_dim, name=name + "_se")
+ self.ghost_module_2 = GhostModule(
+ in_channels=hidden_dim,
+ output_channels=output_channels,
+ kernel_size=1,
+ relu=False,
+ name=name + "_ghost_module_2")
+ if stride != 1 or in_channels != output_channels:
+ self.shortcut_depthwise = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=in_channels,
+ act=None,
+ name=name + "_shortcut_depthwise_depthwise" # looks strange due to an old typo, will be fixed later.
+ )
+ self.shortcut_conv = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=output_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ act=None,
+ name=name + "_shortcut_conv")
+
+ def forward(self, inputs):
+ x = self.ghost_module_1(inputs)
+ if self._stride == 2:
+ x = self.depthwise_conv(x)
+ if self._use_se:
+ x = self.se_block(x)
+ x = self.ghost_module_2(x)
+ if self._stride == 1 and self._num_channels == self._output_channels:
+ shortcut = inputs
+ else:
+ shortcut = self.shortcut_depthwise(inputs)
+ shortcut = self.shortcut_conv(shortcut)
+ return paddle.add(x=x, y=shortcut)
+
+
+@moduleinfo(
+ name="ghostnet_x0_5_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="ghostnet_x0_5_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class GhostNet(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(GhostNet, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.cfgs = [
+ # k, t, c, SE, s
+ [3, 16, 16, 0, 1],
+ [3, 48, 24, 0, 2],
+ [3, 72, 24, 0, 1],
+ [5, 72, 40, 1, 2],
+ [5, 120, 40, 1, 1],
+ [3, 240, 80, 0, 2],
+ [3, 200, 80, 0, 1],
+ [3, 184, 80, 0, 1],
+ [3, 184, 80, 0, 1],
+ [3, 480, 112, 1, 1],
+ [3, 672, 112, 1, 1],
+ [5, 672, 160, 1, 2],
+ [5, 960, 160, 0, 1],
+ [5, 960, 160, 1, 1],
+ [5, 960, 160, 0, 1],
+ [5, 960, 160, 1, 1]
+ ]
+ self.scale = 0.5
+ output_channels = int(self._make_divisible(16 * self.scale, 4))
+ self.conv1 = ConvBNLayer(
+ in_channels=3, out_channels=output_channels, kernel_size=3, stride=2, groups=1, act="relu", name="conv1")
+ # build inverted residual blocks
+ idx = 0
+ self.ghost_bottleneck_list = []
+ for k, exp_size, c, use_se, s in self.cfgs:
+ in_channels = output_channels
+ output_channels = int(self._make_divisible(c * self.scale, 4))
+ hidden_dim = int(self._make_divisible(exp_size * self.scale, 4))
+ ghost_bottleneck = self.add_sublayer(
+ name="_ghostbottleneck_" + str(idx),
+ sublayer=GhostBottleneck(
+ in_channels=in_channels,
+ hidden_dim=hidden_dim,
+ output_channels=output_channels,
+ kernel_size=k,
+ stride=s,
+ use_se=use_se,
+ name="_ghostbottleneck_" + str(idx)))
+ self.ghost_bottleneck_list.append(ghost_bottleneck)
+ idx += 1
+ # build last several layers
+ in_channels = output_channels
+ output_channels = int(self._make_divisible(exp_size * self.scale, 4))
+ self.conv_last = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=output_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ act="relu",
+ name="conv_last")
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+ in_channels = output_channels
+ self._fc0_output_channels = 1280
+ self.fc_0 = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=self._fc0_output_channels,
+ kernel_size=1,
+ stride=1,
+ act="relu",
+ name="fc_0")
+ self.dropout = nn.Dropout(p=0.2)
+ stdv = 1.0 / math.sqrt(self._fc0_output_channels * 1.0)
+ self.fc_1 = nn.Linear(
+ self._fc0_output_channels,
+ class_dim,
+ weight_attr=ParamAttr(name="fc_1_weights", initializer=Uniform(-stdv, stdv)),
+ bias_attr=ParamAttr(name="fc_1_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, inputs):
+ x = self.conv1(inputs)
+ for ghost_bottleneck in self.ghost_bottleneck_list:
+ x = ghost_bottleneck(x)
+ x = self.conv_last(x)
+ feature = self.pool2d_gap(x)
+ x = self.fc_0(feature)
+ x = self.dropout(x)
+ x = paddle.reshape(x, shape=[-1, self._fc0_output_channels])
+ x = self.fc_1(x)
+ return x, feature
+
+ def _make_divisible(self, v, divisor, min_value=None):
+ """
+ This function is taken from the original tf repo.
+ It ensures that all layers have a channel number that is divisible by 8
+ It can be seen here:
+ https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
+ """
+ if min_value is None:
+ min_value = divisor
+ new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than 10%.
+ if new_v < 0.9 * v:
+ new_v += divisor
+ return new_v
diff --git a/modules/image/classification/ghostnet_x1_0_imagenet/README.md b/modules/image/classification/ghostnet_x1_0_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..9e25c471b72cf96393766d3c46eeb161ea7489b2
--- /dev/null
+++ b/modules/image/classification/ghostnet_x1_0_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install ghostnet_x1_0_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run ghostnet_x1_0_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='ghostnet_x1_0_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='ghostnet_x1_0_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='ghostnet_x1_0_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m ghostnet_x1_0_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/ghostnet_x1_0_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/ghostnet_x1_0_imagenet/label_list.txt b/modules/image/classification/ghostnet_x1_0_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/ghostnet_x1_0_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/ghostnet_x1_0_imagenet/module.py b/modules/image/classification/ghostnet_x1_0_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..db3a496f9110a0752b85a8a69d8647d07edbf0df
--- /dev/null
+++ b/modules/image/classification/ghostnet_x1_0_imagenet/module.py
@@ -0,0 +1,324 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle import ParamAttr
+from paddle.nn.initializer import Uniform, KaimingNormal
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+ self._conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=(kernel_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(initializer=KaimingNormal(), name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + "_bn"
+
+ self._batch_norm = nn.BatchNorm(
+ num_channels=out_channels,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + "_scale", regularizer=paddle.regularizer.L2Decay(0.0)),
+ bias_attr=ParamAttr(name=bn_name + "_offset", regularizer=paddle.regularizer.L2Decay(0.0)),
+ moving_mean_name=bn_name + "_mean",
+ moving_variance_name=bn_name + "_variance")
+
+ def forward(self, inputs):
+ y = self._conv(inputs)
+ y = self._batch_norm(y)
+ return y
+
+
+class SEBlock(nn.Layer):
+ def __init__(self, num_channels, reduction_ratio=4, name=None):
+ super(SEBlock, self).__init__()
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+ self._num_channels = num_channels
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ med_ch = num_channels // reduction_ratio
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_1_weights"),
+ bias_attr=ParamAttr(name=name + "_1_offset"))
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_channels,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_2_weights"),
+ bias_attr=ParamAttr(name=name + "_2_offset"))
+
+ def forward(self, inputs):
+ pool = self.pool2d_gap(inputs)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = paddle.clip(x=excitation, min=0, max=1)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = paddle.multiply(inputs, excitation)
+ return out
+
+
+class GhostModule(nn.Layer):
+ def __init__(self, in_channels, output_channels, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True, name=None):
+ super(GhostModule, self).__init__()
+ init_channels = int(math.ceil(output_channels / ratio))
+ new_channels = int(init_channels * (ratio - 1))
+ self.primary_conv = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=init_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=1,
+ act="relu" if relu else None,
+ name=name + "_primary_conv")
+ self.cheap_operation = ConvBNLayer(
+ in_channels=init_channels,
+ out_channels=new_channels,
+ kernel_size=dw_size,
+ stride=1,
+ groups=init_channels,
+ act="relu" if relu else None,
+ name=name + "_cheap_operation")
+
+ def forward(self, inputs):
+ x = self.primary_conv(inputs)
+ y = self.cheap_operation(x)
+ out = paddle.concat([x, y], axis=1)
+ return out
+
+
+class GhostBottleneck(nn.Layer):
+ def __init__(self, in_channels, hidden_dim, output_channels, kernel_size, stride, use_se, name=None):
+ super(GhostBottleneck, self).__init__()
+ self._stride = stride
+ self._use_se = use_se
+ self._num_channels = in_channels
+ self._output_channels = output_channels
+ self.ghost_module_1 = GhostModule(
+ in_channels=in_channels,
+ output_channels=hidden_dim,
+ kernel_size=1,
+ stride=1,
+ relu=True,
+ name=name + "_ghost_module_1")
+ if stride == 2:
+ self.depthwise_conv = ConvBNLayer(
+ in_channels=hidden_dim,
+ out_channels=hidden_dim,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=hidden_dim,
+ act=None,
+ name=name + "_depthwise_depthwise" # looks strange due to an old typo, will be fixed later.
+ )
+ if use_se:
+ self.se_block = SEBlock(num_channels=hidden_dim, name=name + "_se")
+ self.ghost_module_2 = GhostModule(
+ in_channels=hidden_dim,
+ output_channels=output_channels,
+ kernel_size=1,
+ relu=False,
+ name=name + "_ghost_module_2")
+ if stride != 1 or in_channels != output_channels:
+ self.shortcut_depthwise = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=in_channels,
+ act=None,
+ name=name + "_shortcut_depthwise_depthwise" # looks strange due to an old typo, will be fixed later.
+ )
+ self.shortcut_conv = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=output_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ act=None,
+ name=name + "_shortcut_conv")
+
+ def forward(self, inputs):
+ x = self.ghost_module_1(inputs)
+ if self._stride == 2:
+ x = self.depthwise_conv(x)
+ if self._use_se:
+ x = self.se_block(x)
+ x = self.ghost_module_2(x)
+ if self._stride == 1 and self._num_channels == self._output_channels:
+ shortcut = inputs
+ else:
+ shortcut = self.shortcut_depthwise(inputs)
+ shortcut = self.shortcut_conv(shortcut)
+ return paddle.add(x=x, y=shortcut)
+
+
+@moduleinfo(
+ name="ghostnet_x1_0_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="ghostnet_x1_0_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class GhostNet(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(GhostNet, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.cfgs = [
+ # k, t, c, SE, s
+ [3, 16, 16, 0, 1],
+ [3, 48, 24, 0, 2],
+ [3, 72, 24, 0, 1],
+ [5, 72, 40, 1, 2],
+ [5, 120, 40, 1, 1],
+ [3, 240, 80, 0, 2],
+ [3, 200, 80, 0, 1],
+ [3, 184, 80, 0, 1],
+ [3, 184, 80, 0, 1],
+ [3, 480, 112, 1, 1],
+ [3, 672, 112, 1, 1],
+ [5, 672, 160, 1, 2],
+ [5, 960, 160, 0, 1],
+ [5, 960, 160, 1, 1],
+ [5, 960, 160, 0, 1],
+ [5, 960, 160, 1, 1]
+ ]
+ self.scale = 1.0
+ output_channels = int(self._make_divisible(16 * self.scale, 4))
+ self.conv1 = ConvBNLayer(
+ in_channels=3, out_channels=output_channels, kernel_size=3, stride=2, groups=1, act="relu", name="conv1")
+ # build inverted residual blocks
+ idx = 0
+ self.ghost_bottleneck_list = []
+ for k, exp_size, c, use_se, s in self.cfgs:
+ in_channels = output_channels
+ output_channels = int(self._make_divisible(c * self.scale, 4))
+ hidden_dim = int(self._make_divisible(exp_size * self.scale, 4))
+ ghost_bottleneck = self.add_sublayer(
+ name="_ghostbottleneck_" + str(idx),
+ sublayer=GhostBottleneck(
+ in_channels=in_channels,
+ hidden_dim=hidden_dim,
+ output_channels=output_channels,
+ kernel_size=k,
+ stride=s,
+ use_se=use_se,
+ name="_ghostbottleneck_" + str(idx)))
+ self.ghost_bottleneck_list.append(ghost_bottleneck)
+ idx += 1
+ # build last several layers
+ in_channels = output_channels
+ output_channels = int(self._make_divisible(exp_size * self.scale, 4))
+ self.conv_last = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=output_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ act="relu",
+ name="conv_last")
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+ in_channels = output_channels
+ self._fc0_output_channels = 1280
+ self.fc_0 = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=self._fc0_output_channels,
+ kernel_size=1,
+ stride=1,
+ act="relu",
+ name="fc_0")
+ self.dropout = nn.Dropout(p=0.2)
+ stdv = 1.0 / math.sqrt(self._fc0_output_channels * 1.0)
+ self.fc_1 = nn.Linear(
+ self._fc0_output_channels,
+ class_dim,
+ weight_attr=ParamAttr(name="fc_1_weights", initializer=Uniform(-stdv, stdv)),
+ bias_attr=ParamAttr(name="fc_1_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, inputs):
+ x = self.conv1(inputs)
+ for ghost_bottleneck in self.ghost_bottleneck_list:
+ x = ghost_bottleneck(x)
+ x = self.conv_last(x)
+ feature = self.pool2d_gap(x)
+ x = self.fc_0(feature)
+ x = self.dropout(x)
+ x = paddle.reshape(x, shape=[-1, self._fc0_output_channels])
+ x = self.fc_1(x)
+ return x, feature
+
+ def _make_divisible(self, v, divisor, min_value=None):
+ """
+ This function is taken from the original tf repo.
+ It ensures that all layers have a channel number that is divisible by 8
+ It can be seen here:
+ https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
+ """
+ if min_value is None:
+ min_value = divisor
+ new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than 10%.
+ if new_v < 0.9 * v:
+ new_v += divisor
+ return new_v
diff --git a/modules/image/classification/ghostnet_x1_3_imagenet/README.md b/modules/image/classification/ghostnet_x1_3_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..72189fcd68cd3b61d7937c3de43853d380fbf0c1
--- /dev/null
+++ b/modules/image/classification/ghostnet_x1_3_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install ghostnet_x1_3_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run ghostnet_x1_3_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='ghostnet_x1_3_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='ghostnet_x1_3_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='ghostnet_x1_3_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m ghostnet_x1_3_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/ghostnet_x1_3_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/ghostnet_x1_3_imagenet/label_list.txt b/modules/image/classification/ghostnet_x1_3_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/ghostnet_x1_3_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/ghostnet_x1_3_imagenet/module.py b/modules/image/classification/ghostnet_x1_3_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..7dfa5fd31c6b309eb8eb8e864fa7c38143a69232
--- /dev/null
+++ b/modules/image/classification/ghostnet_x1_3_imagenet/module.py
@@ -0,0 +1,324 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle import ParamAttr
+from paddle.nn.initializer import Uniform, KaimingNormal
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+ self._conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=(kernel_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(initializer=KaimingNormal(), name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + "_bn"
+
+ self._batch_norm = nn.BatchNorm(
+ num_channels=out_channels,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + "_scale", regularizer=paddle.regularizer.L2Decay(0.0)),
+ bias_attr=ParamAttr(name=bn_name + "_offset", regularizer=paddle.regularizer.L2Decay(0.0)),
+ moving_mean_name=bn_name + "_mean",
+ moving_variance_name=bn_name + "_variance")
+
+ def forward(self, inputs):
+ y = self._conv(inputs)
+ y = self._batch_norm(y)
+ return y
+
+
+class SEBlock(nn.Layer):
+ def __init__(self, num_channels, reduction_ratio=4, name=None):
+ super(SEBlock, self).__init__()
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+ self._num_channels = num_channels
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ med_ch = num_channels // reduction_ratio
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_1_weights"),
+ bias_attr=ParamAttr(name=name + "_1_offset"))
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_channels,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_2_weights"),
+ bias_attr=ParamAttr(name=name + "_2_offset"))
+
+ def forward(self, inputs):
+ pool = self.pool2d_gap(inputs)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = paddle.clip(x=excitation, min=0, max=1)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = paddle.multiply(inputs, excitation)
+ return out
+
+
+class GhostModule(nn.Layer):
+ def __init__(self, in_channels, output_channels, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True, name=None):
+ super(GhostModule, self).__init__()
+ init_channels = int(math.ceil(output_channels / ratio))
+ new_channels = int(init_channels * (ratio - 1))
+ self.primary_conv = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=init_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=1,
+ act="relu" if relu else None,
+ name=name + "_primary_conv")
+ self.cheap_operation = ConvBNLayer(
+ in_channels=init_channels,
+ out_channels=new_channels,
+ kernel_size=dw_size,
+ stride=1,
+ groups=init_channels,
+ act="relu" if relu else None,
+ name=name + "_cheap_operation")
+
+ def forward(self, inputs):
+ x = self.primary_conv(inputs)
+ y = self.cheap_operation(x)
+ out = paddle.concat([x, y], axis=1)
+ return out
+
+
+class GhostBottleneck(nn.Layer):
+ def __init__(self, in_channels, hidden_dim, output_channels, kernel_size, stride, use_se, name=None):
+ super(GhostBottleneck, self).__init__()
+ self._stride = stride
+ self._use_se = use_se
+ self._num_channels = in_channels
+ self._output_channels = output_channels
+ self.ghost_module_1 = GhostModule(
+ in_channels=in_channels,
+ output_channels=hidden_dim,
+ kernel_size=1,
+ stride=1,
+ relu=True,
+ name=name + "_ghost_module_1")
+ if stride == 2:
+ self.depthwise_conv = ConvBNLayer(
+ in_channels=hidden_dim,
+ out_channels=hidden_dim,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=hidden_dim,
+ act=None,
+ name=name + "_depthwise_depthwise" # looks strange due to an old typo, will be fixed later.
+ )
+ if use_se:
+ self.se_block = SEBlock(num_channels=hidden_dim, name=name + "_se")
+ self.ghost_module_2 = GhostModule(
+ in_channels=hidden_dim,
+ output_channels=output_channels,
+ kernel_size=1,
+ relu=False,
+ name=name + "_ghost_module_2")
+ if stride != 1 or in_channels != output_channels:
+ self.shortcut_depthwise = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=in_channels,
+ act=None,
+ name=name + "_shortcut_depthwise_depthwise" # looks strange due to an old typo, will be fixed later.
+ )
+ self.shortcut_conv = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=output_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ act=None,
+ name=name + "_shortcut_conv")
+
+ def forward(self, inputs):
+ x = self.ghost_module_1(inputs)
+ if self._stride == 2:
+ x = self.depthwise_conv(x)
+ if self._use_se:
+ x = self.se_block(x)
+ x = self.ghost_module_2(x)
+ if self._stride == 1 and self._num_channels == self._output_channels:
+ shortcut = inputs
+ else:
+ shortcut = self.shortcut_depthwise(inputs)
+ shortcut = self.shortcut_conv(shortcut)
+ return paddle.add(x=x, y=shortcut)
+
+
+@moduleinfo(
+ name="ghostnet_x1_3_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="ghostnet_x1_3_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class GhostNet(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(GhostNet, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.cfgs = [
+ # k, t, c, SE, s
+ [3, 16, 16, 0, 1],
+ [3, 48, 24, 0, 2],
+ [3, 72, 24, 0, 1],
+ [5, 72, 40, 1, 2],
+ [5, 120, 40, 1, 1],
+ [3, 240, 80, 0, 2],
+ [3, 200, 80, 0, 1],
+ [3, 184, 80, 0, 1],
+ [3, 184, 80, 0, 1],
+ [3, 480, 112, 1, 1],
+ [3, 672, 112, 1, 1],
+ [5, 672, 160, 1, 2],
+ [5, 960, 160, 0, 1],
+ [5, 960, 160, 1, 1],
+ [5, 960, 160, 0, 1],
+ [5, 960, 160, 1, 1]
+ ]
+ self.scale = 1.3
+ output_channels = int(self._make_divisible(16 * self.scale, 4))
+ self.conv1 = ConvBNLayer(
+ in_channels=3, out_channels=output_channels, kernel_size=3, stride=2, groups=1, act="relu", name="conv1")
+ # build inverted residual blocks
+ idx = 0
+ self.ghost_bottleneck_list = []
+ for k, exp_size, c, use_se, s in self.cfgs:
+ in_channels = output_channels
+ output_channels = int(self._make_divisible(c * self.scale, 4))
+ hidden_dim = int(self._make_divisible(exp_size * self.scale, 4))
+ ghost_bottleneck = self.add_sublayer(
+ name="_ghostbottleneck_" + str(idx),
+ sublayer=GhostBottleneck(
+ in_channels=in_channels,
+ hidden_dim=hidden_dim,
+ output_channels=output_channels,
+ kernel_size=k,
+ stride=s,
+ use_se=use_se,
+ name="_ghostbottleneck_" + str(idx)))
+ self.ghost_bottleneck_list.append(ghost_bottleneck)
+ idx += 1
+ # build last several layers
+ in_channels = output_channels
+ output_channels = int(self._make_divisible(exp_size * self.scale, 4))
+ self.conv_last = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=output_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ act="relu",
+ name="conv_last")
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+ in_channels = output_channels
+ self._fc0_output_channels = 1280
+ self.fc_0 = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=self._fc0_output_channels,
+ kernel_size=1,
+ stride=1,
+ act="relu",
+ name="fc_0")
+ self.dropout = nn.Dropout(p=0.2)
+ stdv = 1.0 / math.sqrt(self._fc0_output_channels * 1.0)
+ self.fc_1 = nn.Linear(
+ self._fc0_output_channels,
+ class_dim,
+ weight_attr=ParamAttr(name="fc_1_weights", initializer=Uniform(-stdv, stdv)),
+ bias_attr=ParamAttr(name="fc_1_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, inputs):
+ x = self.conv1(inputs)
+ for ghost_bottleneck in self.ghost_bottleneck_list:
+ x = ghost_bottleneck(x)
+ x = self.conv_last(x)
+ feature = self.pool2d_gap(x)
+ x = self.fc_0(feature)
+ x = self.dropout(x)
+ x = paddle.reshape(x, shape=[-1, self._fc0_output_channels])
+ x = self.fc_1(x)
+ return x, feature
+
+ def _make_divisible(self, v, divisor, min_value=None):
+ """
+ This function is taken from the original tf repo.
+ It ensures that all layers have a channel number that is divisible by 8
+ It can be seen here:
+ https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
+ """
+ if min_value is None:
+ min_value = divisor
+ new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than 10%.
+ if new_v < 0.9 * v:
+ new_v += divisor
+ return new_v
diff --git a/modules/image/classification/ghostnet_x1_3_imagenet_ssld/README.md b/modules/image/classification/ghostnet_x1_3_imagenet_ssld/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ef310be9ec7f4112fc7d02cc962bd5734da8a92f
--- /dev/null
+++ b/modules/image/classification/ghostnet_x1_3_imagenet_ssld/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install ghostnet_x1_3_imagenet_ssld==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run ghostnet_x1_3_imagenet_ssld --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='ghostnet_x1_3_imagenet_ssld',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='ghostnet_x1_3_imagenet_ssld',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='ghostnet_x1_3_imagenet_ssld', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m ghostnet_x1_3_imagenet_ssld
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/ghostnet_x1_3_imagenet_ssld"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/ghostnet_x1_3_imagenet_ssld/label_list.txt b/modules/image/classification/ghostnet_x1_3_imagenet_ssld/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/ghostnet_x1_3_imagenet_ssld/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/ghostnet_x1_3_imagenet_ssld/module.py b/modules/image/classification/ghostnet_x1_3_imagenet_ssld/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..e16539000af6ae0b4f181e779ee0d8e8784ec0ec
--- /dev/null
+++ b/modules/image/classification/ghostnet_x1_3_imagenet_ssld/module.py
@@ -0,0 +1,324 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle import ParamAttr
+from paddle.nn.initializer import Uniform, KaimingNormal
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+ self._conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=(kernel_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(initializer=KaimingNormal(), name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + "_bn"
+
+ self._batch_norm = nn.BatchNorm(
+ num_channels=out_channels,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + "_scale", regularizer=paddle.regularizer.L2Decay(0.0)),
+ bias_attr=ParamAttr(name=bn_name + "_offset", regularizer=paddle.regularizer.L2Decay(0.0)),
+ moving_mean_name=bn_name + "_mean",
+ moving_variance_name=bn_name + "_variance")
+
+ def forward(self, inputs):
+ y = self._conv(inputs)
+ y = self._batch_norm(y)
+ return y
+
+
+class SEBlock(nn.Layer):
+ def __init__(self, num_channels, reduction_ratio=4, name=None):
+ super(SEBlock, self).__init__()
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+ self._num_channels = num_channels
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ med_ch = num_channels // reduction_ratio
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_1_weights"),
+ bias_attr=ParamAttr(name=name + "_1_offset"))
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_channels,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_2_weights"),
+ bias_attr=ParamAttr(name=name + "_2_offset"))
+
+ def forward(self, inputs):
+ pool = self.pool2d_gap(inputs)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = paddle.clip(x=excitation, min=0, max=1)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = paddle.multiply(inputs, excitation)
+ return out
+
+
+class GhostModule(nn.Layer):
+ def __init__(self, in_channels, output_channels, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True, name=None):
+ super(GhostModule, self).__init__()
+ init_channels = int(math.ceil(output_channels / ratio))
+ new_channels = int(init_channels * (ratio - 1))
+ self.primary_conv = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=init_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=1,
+ act="relu" if relu else None,
+ name=name + "_primary_conv")
+ self.cheap_operation = ConvBNLayer(
+ in_channels=init_channels,
+ out_channels=new_channels,
+ kernel_size=dw_size,
+ stride=1,
+ groups=init_channels,
+ act="relu" if relu else None,
+ name=name + "_cheap_operation")
+
+ def forward(self, inputs):
+ x = self.primary_conv(inputs)
+ y = self.cheap_operation(x)
+ out = paddle.concat([x, y], axis=1)
+ return out
+
+
+class GhostBottleneck(nn.Layer):
+ def __init__(self, in_channels, hidden_dim, output_channels, kernel_size, stride, use_se, name=None):
+ super(GhostBottleneck, self).__init__()
+ self._stride = stride
+ self._use_se = use_se
+ self._num_channels = in_channels
+ self._output_channels = output_channels
+ self.ghost_module_1 = GhostModule(
+ in_channels=in_channels,
+ output_channels=hidden_dim,
+ kernel_size=1,
+ stride=1,
+ relu=True,
+ name=name + "_ghost_module_1")
+ if stride == 2:
+ self.depthwise_conv = ConvBNLayer(
+ in_channels=hidden_dim,
+ out_channels=hidden_dim,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=hidden_dim,
+ act=None,
+ name=name + "_depthwise_depthwise" # looks strange due to an old typo, will be fixed later.
+ )
+ if use_se:
+ self.se_block = SEBlock(num_channels=hidden_dim, name=name + "_se")
+ self.ghost_module_2 = GhostModule(
+ in_channels=hidden_dim,
+ output_channels=output_channels,
+ kernel_size=1,
+ relu=False,
+ name=name + "_ghost_module_2")
+ if stride != 1 or in_channels != output_channels:
+ self.shortcut_depthwise = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=in_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ groups=in_channels,
+ act=None,
+ name=name + "_shortcut_depthwise_depthwise" # looks strange due to an old typo, will be fixed later.
+ )
+ self.shortcut_conv = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=output_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ act=None,
+ name=name + "_shortcut_conv")
+
+ def forward(self, inputs):
+ x = self.ghost_module_1(inputs)
+ if self._stride == 2:
+ x = self.depthwise_conv(x)
+ if self._use_se:
+ x = self.se_block(x)
+ x = self.ghost_module_2(x)
+ if self._stride == 1 and self._num_channels == self._output_channels:
+ shortcut = inputs
+ else:
+ shortcut = self.shortcut_depthwise(inputs)
+ shortcut = self.shortcut_conv(shortcut)
+ return paddle.add(x=x, y=shortcut)
+
+
+@moduleinfo(
+ name="ghostnet_x1_3_imagenet_ssld",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="ghostnet_x1_3_imagenet_ssld is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class GhostNet(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(GhostNet, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.cfgs = [
+ # k, t, c, SE, s
+ [3, 16, 16, 0, 1],
+ [3, 48, 24, 0, 2],
+ [3, 72, 24, 0, 1],
+ [5, 72, 40, 1, 2],
+ [5, 120, 40, 1, 1],
+ [3, 240, 80, 0, 2],
+ [3, 200, 80, 0, 1],
+ [3, 184, 80, 0, 1],
+ [3, 184, 80, 0, 1],
+ [3, 480, 112, 1, 1],
+ [3, 672, 112, 1, 1],
+ [5, 672, 160, 1, 2],
+ [5, 960, 160, 0, 1],
+ [5, 960, 160, 1, 1],
+ [5, 960, 160, 0, 1],
+ [5, 960, 160, 1, 1]
+ ]
+ self.scale = 1.3
+ output_channels = int(self._make_divisible(16 * self.scale, 4))
+ self.conv1 = ConvBNLayer(
+ in_channels=3, out_channels=output_channels, kernel_size=3, stride=2, groups=1, act="relu", name="conv1")
+ # build inverted residual blocks
+ idx = 0
+ self.ghost_bottleneck_list = []
+ for k, exp_size, c, use_se, s in self.cfgs:
+ in_channels = output_channels
+ output_channels = int(self._make_divisible(c * self.scale, 4))
+ hidden_dim = int(self._make_divisible(exp_size * self.scale, 4))
+ ghost_bottleneck = self.add_sublayer(
+ name="_ghostbottleneck_" + str(idx),
+ sublayer=GhostBottleneck(
+ in_channels=in_channels,
+ hidden_dim=hidden_dim,
+ output_channels=output_channels,
+ kernel_size=k,
+ stride=s,
+ use_se=use_se,
+ name="_ghostbottleneck_" + str(idx)))
+ self.ghost_bottleneck_list.append(ghost_bottleneck)
+ idx += 1
+ # build last several layers
+ in_channels = output_channels
+ output_channels = int(self._make_divisible(exp_size * self.scale, 4))
+ self.conv_last = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=output_channels,
+ kernel_size=1,
+ stride=1,
+ groups=1,
+ act="relu",
+ name="conv_last")
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+ in_channels = output_channels
+ self._fc0_output_channels = 1280
+ self.fc_0 = ConvBNLayer(
+ in_channels=in_channels,
+ out_channels=self._fc0_output_channels,
+ kernel_size=1,
+ stride=1,
+ act="relu",
+ name="fc_0")
+ self.dropout = nn.Dropout(p=0.2)
+ stdv = 1.0 / math.sqrt(self._fc0_output_channels * 1.0)
+ self.fc_1 = nn.Linear(
+ self._fc0_output_channels,
+ class_dim,
+ weight_attr=ParamAttr(name="fc_1_weights", initializer=Uniform(-stdv, stdv)),
+ bias_attr=ParamAttr(name="fc_1_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, inputs):
+ x = self.conv1(inputs)
+ for ghost_bottleneck in self.ghost_bottleneck_list:
+ x = ghost_bottleneck(x)
+ x = self.conv_last(x)
+ feature = self.pool2d_gap(x)
+ x = self.fc_0(feature)
+ x = self.dropout(x)
+ x = paddle.reshape(x, shape=[-1, self._fc0_output_channels])
+ x = self.fc_1(x)
+ return x, feature
+
+ def _make_divisible(self, v, divisor, min_value=None):
+ """
+ This function is taken from the original tf repo.
+ It ensures that all layers have a channel number that is divisible by 8
+ It can be seen here:
+ https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
+ """
+ if min_value is None:
+ min_value = divisor
+ new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
+ # Make sure that round down does not go down by more than 10%.
+ if new_v < 0.9 * v:
+ new_v += divisor
+ return new_v
diff --git a/modules/image/classification/hrnet18_imagenet/README.md b/modules/image/classification/hrnet18_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d1530c8902706896bd01aa7c93a039109c7f3b2f
--- /dev/null
+++ b/modules/image/classification/hrnet18_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install hrnet18_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run hrnet18_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet18_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='hrnet18_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet18_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m hrnet18_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/hrnet18_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/hrnet18_imagenet/label_list.txt b/modules/image/classification/hrnet18_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/hrnet18_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/hrnet18_imagenet/module.py b/modules/image/classification/hrnet18_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..3358859bab3e7ef0094b2ea6d735e4dd216fb30f
--- /dev/null
+++ b/modules/image/classification/hrnet18_imagenet/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="hrnet18_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="hrnet18_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class HRNet18(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(HRNet18, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 18
+ self.has_se = False
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/classification/hrnet18_imagenet_ssld/README.md b/modules/image/classification/hrnet18_imagenet_ssld/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..5a33c39fd31ff02b838716d374d0dcc85a7b548c
--- /dev/null
+++ b/modules/image/classification/hrnet18_imagenet_ssld/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install hrnet18_imagenet_ssld==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run hrnet18_imagenet_ssld --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet18_imagenet_ssld',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='hrnet18_imagenet_ssld',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet18_imagenet_ssld', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m hrnet18_imagenet_ssld
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/hrnet18_imagenet_ssld"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/hrnet18_imagenet_ssld/label_list.txt b/modules/image/classification/hrnet18_imagenet_ssld/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/hrnet18_imagenet_ssld/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/hrnet18_imagenet_ssld/module.py b/modules/image/classification/hrnet18_imagenet_ssld/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..7f1192d4074ee998e26a58c99a00b6517390100c
--- /dev/null
+++ b/modules/image/classification/hrnet18_imagenet_ssld/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="hrnet18_imagenet_ssld",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="hrnet18_imagenet_ssld is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class HRNet18(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(HRNet18, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 18
+ self.has_se = False
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/classification/hrnet30_imagenet/README.md b/modules/image/classification/hrnet30_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4b447d1f3c4eacc623f5287af2ea8bdf71e111ed
--- /dev/null
+++ b/modules/image/classification/hrnet30_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install hrnet30_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run hrnet30_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet30_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='hrnet30_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet30_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m hrnet30_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/hrnet30_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/hrnet30_imagenet/label_list.txt b/modules/image/classification/hrnet30_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/hrnet30_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/hrnet30_imagenet/module.py b/modules/image/classification/hrnet30_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..491ccdd1c908a7738f7e85c425cee466e68d0a17
--- /dev/null
+++ b/modules/image/classification/hrnet30_imagenet/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="hrnet30_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="hrnet30_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class HRNet30(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(HRNet30, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 30
+ self.has_se = False
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/classification/hrnet32_imagenet/README.md b/modules/image/classification/hrnet32_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..af97dc62a0c95cea46adad5db8ae987eefc29ff4
--- /dev/null
+++ b/modules/image/classification/hrnet32_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install hrnet32_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run hrnet32_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet32_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='hrnet32_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet32_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m hrnet32_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/hrnet32_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/hrnet32_imagenet/label_list.txt b/modules/image/classification/hrnet32_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/hrnet32_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/hrnet32_imagenet/module.py b/modules/image/classification/hrnet32_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..b209fe93ef2b669e0e907f70268ac3e36d3c62e3
--- /dev/null
+++ b/modules/image/classification/hrnet32_imagenet/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="hrnet32_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="hrnet32_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class HRNet32(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(HRNet32, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 32
+ self.has_se = False
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/classification/hrnet40_imagenet/README.md b/modules/image/classification/hrnet40_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d09944004c371022fbc896710e16ee3d65a7db52
--- /dev/null
+++ b/modules/image/classification/hrnet40_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install hrnet40_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run hrnet40_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet40_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='hrnet40_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet40_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m hrnet40_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/hrnet40_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/hrnet40_imagenet/label_list.txt b/modules/image/classification/hrnet40_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/hrnet40_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/hrnet40_imagenet/module.py b/modules/image/classification/hrnet40_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..59a1364f81f586cfdbfaea7ad8d609d1bbeae053
--- /dev/null
+++ b/modules/image/classification/hrnet40_imagenet/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="hrnet40_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="hrnet40_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class HRNet40(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(HRNet40, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 40
+ self.has_se = False
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/classification/hrnet44_imagenet/README.md b/modules/image/classification/hrnet44_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..78031d1cacce6b85e3dee97957fba8326b00b608
--- /dev/null
+++ b/modules/image/classification/hrnet44_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install hrnet44_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run hrnet44_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet44_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='hrnet44_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet44_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m hrnet44_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/hrnet44_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/hrnet44_imagenet/label_list.txt b/modules/image/classification/hrnet44_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/hrnet44_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/hrnet44_imagenet/module.py b/modules/image/classification/hrnet44_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..823963018c2fed7ee96aee7bf77fce83fac04d8f
--- /dev/null
+++ b/modules/image/classification/hrnet44_imagenet/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="hrnet44_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="hrnet44_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class HRNet44(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(HRNet44, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 44
+ self.has_se = False
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/classification/hrnet48_imagenet/README.md b/modules/image/classification/hrnet48_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..1b82779201fb4ec941d9f31ed380e536a63c96a3
--- /dev/null
+++ b/modules/image/classification/hrnet48_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install hrnet48_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run hrnet48_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet48_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='hrnet48_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet48_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m hrnet48_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/hrnet48_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/hrnet48_imagenet/label_list.txt b/modules/image/classification/hrnet48_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/hrnet48_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/hrnet48_imagenet/module.py b/modules/image/classification/hrnet48_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..43e0bd1a9b1ee3471eb3a98e38009b3505b5d225
--- /dev/null
+++ b/modules/image/classification/hrnet48_imagenet/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="hrnet48_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="hrnet48_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class HRNet48(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(HRNet48, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 48
+ self.has_se = False
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/classification/hrnet48_imagenet_ssld/README.md b/modules/image/classification/hrnet48_imagenet_ssld/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4b9fa929af3a9df2e95e2b93189818e4f162fa9b
--- /dev/null
+++ b/modules/image/classification/hrnet48_imagenet_ssld/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install hrnet48_imagenet_ssld==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run hrnet48_imagenet_ssld --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet48_imagenet_ssld',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='hrnet48_imagenet_ssld',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet48_imagenet_ssld', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m hrnet48_imagenet_ssld
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/hrnet48_imagenet_ssld"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/hrnet48_imagenet_ssld/label_list.txt b/modules/image/classification/hrnet48_imagenet_ssld/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/hrnet48_imagenet_ssld/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/hrnet48_imagenet_ssld/module.py b/modules/image/classification/hrnet48_imagenet_ssld/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd3868f2d7b4f9880700070ddbcb38bd26a3a24c
--- /dev/null
+++ b/modules/image/classification/hrnet48_imagenet_ssld/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="hrnet48_imagenet_ssld",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="hrnet48_imagenet_ssld is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class HRNet48(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(HRNet48, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 48
+ self.has_se = False
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/classification/hrnet64_imagenet/README.md b/modules/image/classification/hrnet64_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ed6f1b153bf5e1113e3f2aa588ff15fcc5bf9c87
--- /dev/null
+++ b/modules/image/classification/hrnet64_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install hrnet64_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run hrnet64_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet64_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='hrnet64_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='hrnet64_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m hrnet64_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/hrnet64_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/hrnet64_imagenet/label_list.txt b/modules/image/classification/hrnet64_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/hrnet64_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/hrnet64_imagenet/module.py b/modules/image/classification/hrnet64_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b945a35144e311a5c8988a86922dc70a5e6e2ee
--- /dev/null
+++ b/modules/image/classification/hrnet64_imagenet/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="hrnet64_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="hrnet64_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class HRNet64(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(HRNet64, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 64
+ self.has_se = False
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/classification/repvgg_a0_imagenet/README.md b/modules/image/classification/repvgg_a0_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..826db2eae01b92b08972fa399114e396cec14c9c
--- /dev/null
+++ b/modules/image/classification/repvgg_a0_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_a0_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_a0_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_a0_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_a0_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_a0_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_a0_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_a0_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_a0_imagenet/label_list.txt b/modules/image/classification/repvgg_a0_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_a0_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_a0_imagenet/module.py b/modules/image/classification/repvgg_a0_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb76d3cd856c082bcaf5568d251364f4dcf53f6f
--- /dev/null
+++ b/modules/image/classification/repvgg_a0_imagenet/module.py
@@ -0,0 +1,252 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_a0_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_a0_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_A0(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_A0, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [2, 4, 14, 1]
+ width_multiplier = [0.75, 0.75, 0.75, 2.5]
+ self.override_groups_map = dict()
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/repvgg_a1_imagenet/README.md b/modules/image/classification/repvgg_a1_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0bda4997214a7709ae35af22e637e4234023f7a6
--- /dev/null
+++ b/modules/image/classification/repvgg_a1_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_a1_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_a1_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_a1_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_a1_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_a1_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_a1_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_a1_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_a1_imagenet/label_list.txt b/modules/image/classification/repvgg_a1_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_a1_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_a1_imagenet/module.py b/modules/image/classification/repvgg_a1_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..214c2da8be8a909496babeaed092a29086dfb59f
--- /dev/null
+++ b/modules/image/classification/repvgg_a1_imagenet/module.py
@@ -0,0 +1,252 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_a1_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_a1_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_A1(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_A1, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [2, 4, 14, 1]
+ width_multiplier = [1, 1, 1, 2.5]
+ self.override_groups_map = dict()
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/repvgg_a2_imagenet/README.md b/modules/image/classification/repvgg_a2_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..ee342fb033fdc00e6166d9074bc278293d22343e
--- /dev/null
+++ b/modules/image/classification/repvgg_a2_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_a2_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_a2_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_a2_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_a2_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_a2_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_a2_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_a2_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_a2_imagenet/label_list.txt b/modules/image/classification/repvgg_a2_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_a2_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_a2_imagenet/module.py b/modules/image/classification/repvgg_a2_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..9ea31515fdaa69edaaf6948264f992554ce42486
--- /dev/null
+++ b/modules/image/classification/repvgg_a2_imagenet/module.py
@@ -0,0 +1,252 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_a2_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_a2_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_A2(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_A2, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [2, 4, 14, 1]
+ width_multiplier = [1.5, 1.5, 1.5, 2.75]
+ self.override_groups_map = dict()
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/repvgg_b0_imagenet/README.md b/modules/image/classification/repvgg_b0_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..7a284dd6c937e7a78c2aebb574cf52961ccfdbc5
--- /dev/null
+++ b/modules/image/classification/repvgg_b0_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_b0_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_b0_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b0_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_b0_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b0_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_b0_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_b0_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_b0_imagenet/label_list.txt b/modules/image/classification/repvgg_b0_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_b0_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_b0_imagenet/module.py b/modules/image/classification/repvgg_b0_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..de8cc952b3b5b8e4a3c9efba44b04f3dbdd27e7e
--- /dev/null
+++ b/modules/image/classification/repvgg_b0_imagenet/module.py
@@ -0,0 +1,252 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_b0_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_b0_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_B0(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_B0, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [4, 6, 16, 1]
+ width_multiplier = [1, 1, 1, 2.5]
+ self.override_groups_map = dict()
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/repvgg_b1_imagenet/README.md b/modules/image/classification/repvgg_b1_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..1a1e4d05f33626856349bbeb48a20be4dea738d5
--- /dev/null
+++ b/modules/image/classification/repvgg_b1_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_b1_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_b1_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b1_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_b1_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b1_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_b1_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_b1_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_b1_imagenet/label_list.txt b/modules/image/classification/repvgg_b1_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_b1_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_b1_imagenet/module.py b/modules/image/classification/repvgg_b1_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b425b53da1ae912b7f8bdd96b7839069209c2e2
--- /dev/null
+++ b/modules/image/classification/repvgg_b1_imagenet/module.py
@@ -0,0 +1,252 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_b1_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_b1_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_B1(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_B1, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [4, 6, 16, 1]
+ width_multiplier = [2, 2, 2, 4]
+ self.override_groups_map = dict()
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/repvgg_b1g2_imagenet/README.md b/modules/image/classification/repvgg_b1g2_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..8fc6517eddc62157cd9ef506cc276c102fa1eb24
--- /dev/null
+++ b/modules/image/classification/repvgg_b1g2_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_b1g2_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_b1g2_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b1g2_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_b1g2_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b1g2_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_b1g2_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_b1g2_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_b1g2_imagenet/label_list.txt b/modules/image/classification/repvgg_b1g2_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_b1g2_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_b1g2_imagenet/module.py b/modules/image/classification/repvgg_b1g2_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e8befc668474b56540d448d5c4e6f6e7de4da9a
--- /dev/null
+++ b/modules/image/classification/repvgg_b1g2_imagenet/module.py
@@ -0,0 +1,253 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_b1g2_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_b1g2_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_B1G2(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_B1G2, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [4, 6, 16, 1]
+ width_multiplier = [2, 2, 2, 4]
+ optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
+ self.override_groups_map = {l: 2 for l in optional_groupwise_layers}
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/repvgg_b1g4_imagenet/README.md b/modules/image/classification/repvgg_b1g4_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..568c4e0c236e276ca137a397b21510904ad4c04d
--- /dev/null
+++ b/modules/image/classification/repvgg_b1g4_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_b1g4_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_b1g4_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b1g4_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_b1g4_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b1g4_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_b1g4_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_b1g4_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_b1g4_imagenet/label_list.txt b/modules/image/classification/repvgg_b1g4_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_b1g4_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_b1g4_imagenet/module.py b/modules/image/classification/repvgg_b1g4_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..4cb37fa17ba762192153b1a43c6da60ce81c0243
--- /dev/null
+++ b/modules/image/classification/repvgg_b1g4_imagenet/module.py
@@ -0,0 +1,253 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_b1g4_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_b1g4_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_B1G4(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_B1G4, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [4, 6, 16, 1]
+ width_multiplier = [2, 2, 2, 4]
+ optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
+ self.override_groups_map = {l: 4 for l in optional_groupwise_layers}
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/repvgg_b2_imagenet/README.md b/modules/image/classification/repvgg_b2_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..db2e51baf09648523a2b24b3c6d8722454af907e
--- /dev/null
+++ b/modules/image/classification/repvgg_b2_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_b2_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_b2_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b2_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_b2_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b2_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_b2_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_b2_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_b2_imagenet/label_list.txt b/modules/image/classification/repvgg_b2_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_b2_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_b2_imagenet/module.py b/modules/image/classification/repvgg_b2_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..448a31038c4d8e41aa3e2c8ea5bbc62fd19d348f
--- /dev/null
+++ b/modules/image/classification/repvgg_b2_imagenet/module.py
@@ -0,0 +1,252 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_b2_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_b2_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_B2(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_B2, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [4, 6, 16, 1]
+ width_multiplier = [2.5, 2.5, 2.5, 5]
+ self.override_groups_map = dict()
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/repvgg_b2g4_imagenet/README.md b/modules/image/classification/repvgg_b2g4_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..6e16aec1eed0cd2dab24a65052015727f08173da
--- /dev/null
+++ b/modules/image/classification/repvgg_b2g4_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_b2g4_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_b2g4_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b2g4_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_b2g4_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b2g4_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_b2g4_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_b2g4_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_b2g4_imagenet/label_list.txt b/modules/image/classification/repvgg_b2g4_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_b2g4_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_b2g4_imagenet/module.py b/modules/image/classification/repvgg_b2g4_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..8082c633b1b6412d6fd982a87bf6f55d7cfa6854
--- /dev/null
+++ b/modules/image/classification/repvgg_b2g4_imagenet/module.py
@@ -0,0 +1,253 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_b2g4_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_b2g4_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_B2G4(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_B2G4, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [4, 6, 16, 1]
+ width_multiplier = [2.5, 2.5, 2.5, 5]
+ optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
+ self.override_groups_map = {l: 4 for l in optional_groupwise_layers}
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/repvgg_b3g4_imagenet/README.md b/modules/image/classification/repvgg_b3g4_imagenet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..fd76f6b4110558ea9f6b222689fbf0abafc1fa07
--- /dev/null
+++ b/modules/image/classification/repvgg_b3g4_imagenet/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install repvgg_b3g4_imagenet==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run repvgg_b3g4_imagenet --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b3g4_imagenet',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='repvgg_b3g4_imagenet',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='repvgg_b3g4_imagenet', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m repvgg_b3g4_imagenet
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/repvgg_b3g4_imagenet"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/repvgg_b3g4_imagenet/label_list.txt b/modules/image/classification/repvgg_b3g4_imagenet/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/repvgg_b3g4_imagenet/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/repvgg_b3g4_imagenet/module.py b/modules/image/classification/repvgg_b3g4_imagenet/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..118bd0fd004b6ae17dfedc8ca547e191e0974539
--- /dev/null
+++ b/modules/image/classification/repvgg_b3g4_imagenet/module.py
@@ -0,0 +1,253 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBN(nn.Layer):
+ def __init__(self, in_channels, out_channels, kernel_size, stride, padding, groups=1):
+ super(ConvBN, self).__init__()
+ self.conv = nn.Conv2D(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups,
+ bias_attr=False)
+ self.bn = nn.BatchNorm2D(num_features=out_channels)
+
+ def forward(self, x):
+ y = self.conv(x)
+ y = self.bn(y)
+ return y
+
+
+class RepVGGBlock(nn.Layer):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ padding_mode='zeros'):
+ super(RepVGGBlock, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.padding_mode = padding_mode
+
+ assert kernel_size == 3
+ assert padding == 1
+
+ padding_11 = padding - kernel_size // 2
+
+ self.nonlinearity = nn.ReLU()
+
+ self.rbr_identity = nn.BatchNorm2D(
+ num_features=in_channels) if out_channels == in_channels and stride == 1 else None
+ self.rbr_dense = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ padding=padding,
+ groups=groups)
+ self.rbr_1x1 = ConvBN(
+ in_channels=in_channels,
+ out_channels=out_channels,
+ kernel_size=1,
+ stride=stride,
+ padding=padding_11,
+ groups=groups)
+
+ def forward(self, inputs):
+ if not self.training:
+ return self.nonlinearity(self.rbr_reparam(inputs))
+
+ if self.rbr_identity is None:
+ id_out = 0
+ else:
+ id_out = self.rbr_identity(inputs)
+ return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
+
+ def eval(self):
+ if not hasattr(self, 'rbr_reparam'):
+ self.rbr_reparam = nn.Conv2D(
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ kernel_size=self.kernel_size,
+ stride=self.stride,
+ padding=self.padding,
+ dilation=self.dilation,
+ groups=self.groups,
+ padding_mode=self.padding_mode)
+ self.training = False
+ kernel, bias = self.get_equivalent_kernel_bias()
+ self.rbr_reparam.weight.set_value(kernel)
+ self.rbr_reparam.bias.set_value(bias)
+ for layer in self.sublayers():
+ layer.eval()
+
+ def get_equivalent_kernel_bias(self):
+ kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
+ kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
+ kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
+ return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
+
+ def _pad_1x1_to_3x3_tensor(self, kernel1x1):
+ if kernel1x1 is None:
+ return 0
+ else:
+ return nn.functional.pad(kernel1x1, [1, 1, 1, 1])
+
+ def _fuse_bn_tensor(self, branch):
+ if branch is None:
+ return 0, 0
+ if isinstance(branch, ConvBN):
+ kernel = branch.conv.weight
+ running_mean = branch.bn._mean
+ running_var = branch.bn._variance
+ gamma = branch.bn.weight
+ beta = branch.bn.bias
+ eps = branch.bn._epsilon
+ else:
+ assert isinstance(branch, nn.BatchNorm2D)
+ if not hasattr(self, 'id_tensor'):
+ input_dim = self.in_channels // self.groups
+ kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
+ for i in range(self.in_channels):
+ kernel_value[i, i % input_dim, 1, 1] = 1
+ self.id_tensor = paddle.to_tensor(kernel_value)
+ kernel = self.id_tensor
+ running_mean = branch._mean
+ running_var = branch._variance
+ gamma = branch.weight
+ beta = branch.bias
+ eps = branch._epsilon
+ std = (running_var + eps).sqrt()
+ t = (gamma / std).reshape((-1, 1, 1, 1))
+ return kernel * t, beta - running_mean * gamma / std
+
+
+@moduleinfo(
+ name="repvgg_b3g4_imagenet",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="repvgg_b3g4_imagenet is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class RepVGG_B3G4(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(RepVGG_B3G4, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ num_blocks = [4, 6, 16, 1]
+ width_multiplier = [3, 3, 3, 5]
+ optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
+ self.override_groups_map = {l: 4 for l in optional_groupwise_layers}
+
+ assert 0 not in self.override_groups_map
+
+ self.in_planes = min(64, int(64 * width_multiplier[0]))
+
+ self.stage0 = RepVGGBlock(in_channels=3, out_channels=self.in_planes, kernel_size=3, stride=2, padding=1)
+ self.cur_layer_idx = 1
+ self.stage1 = self._make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride=2)
+ self.stage2 = self._make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride=2)
+ self.stage3 = self._make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride=2)
+ self.stage4 = self._make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride=2)
+ self.gap = nn.AdaptiveAvgPool2D(output_size=1)
+ self.linear = nn.Linear(int(512 * width_multiplier[3]), class_dim)
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def _make_stage(self, planes, num_blocks, stride):
+ strides = [stride] + [1] * (num_blocks - 1)
+ blocks = []
+ for stride in strides:
+ cur_groups = self.override_groups_map.get(self.cur_layer_idx, 1)
+ blocks.append(
+ RepVGGBlock(
+ in_channels=self.in_planes,
+ out_channels=planes,
+ kernel_size=3,
+ stride=stride,
+ padding=1,
+ groups=cur_groups))
+ self.in_planes = planes
+ self.cur_layer_idx += 1
+ return nn.Sequential(*blocks)
+
+ def eval(self):
+ self.training = False
+ for layer in self.sublayers():
+ layer.training = False
+ layer.eval()
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, x):
+ out = self.stage0(x)
+ out = self.stage1(out)
+ out = self.stage2(out)
+ out = self.stage3(out)
+ out = self.stage4(out)
+ feature = self.gap(out)
+ out = paddle.flatten(feature, start_axis=1)
+ out = self.linear(out)
+ return out, feature
diff --git a/modules/image/classification/se_hrnet64_imagenet_ssld/README.md b/modules/image/classification/se_hrnet64_imagenet_ssld/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..fd20f3862ecc053a12274fa2f5f4cbaa8ed41cf4
--- /dev/null
+++ b/modules/image/classification/se_hrnet64_imagenet_ssld/README.md
@@ -0,0 +1,192 @@
+```shell
+$ hub install se_hrnet64_imagenet_ssld==1.0.0
+```
+
+## 命令行预测
+
+```shell
+$ hub run se_hrnet64_imagenet_ssld --input_path "/PATH/TO/IMAGE" --top_k 5
+```
+
+## 脚本预测
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='se_hrnet64_imagenet_ssld',)
+ result = model.predict([PATH/TO/IMAGE])
+```
+
+## Fine-tune代码步骤
+
+使用PaddleHub Fine-tune API进行Fine-tune可以分为4个步骤。
+
+### Step1: 定义数据预处理方式
+```python
+import paddlehub.vision.transforms as T
+
+transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+```
+
+'transforms' 数据增强模块定义了丰富的数据预处理方式,用户可按照需求替换自己需要的数据预处理方式。
+
+### Step2: 下载数据集并使用
+```python
+from paddlehub.datasets import Flowers
+
+flowers = Flowers(transforms)
+flowers_validate = Flowers(transforms, mode='val')
+```
+* transforms(Callable): 数据预处理方式。
+* mode(str): 选择数据模式,可选项有 'train', 'test', 'val', 默认为'train'。
+
+'hub.datasets.Flowers()' 会自动从网络下载数据集并解压到用户目录下'$HOME/.paddlehub/dataset'目录。
+
+
+### Step3: 加载预训练模型
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='se_hrnet64_imagenet_ssld',
+ label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"],
+ load_checkpoint=None)
+```
+* name(str): 选择预训练模型的名字。
+* label_list(list): 设置标签对应分类类别, 默认为Imagenet2012类别。
+* load _checkpoint(str): 模型参数地址。
+
+PaddleHub提供许多图像分类预训练模型,如xception、mobilenet、efficientnet等,详细信息参见[图像分类模型](https://www.paddlepaddle.org.cn/hub?filter=en_category&value=ImageClassification)。
+
+如果想尝试efficientnet模型,只需要更换Module中的'name'参数即可.
+```python
+import paddlehub as hub
+
+# 更换name参数即可无缝切换efficientnet模型, 代码示例如下
+module = hub.Module(name="efficientnetb7_imagenet")
+```
+**NOTE:**目前部分模型还没有完全升级到2.0版本,敬请期待。
+
+### Step4: 选择优化策略和运行配置
+
+```python
+import paddle
+from paddlehub.finetune.trainer import Trainer
+
+optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+```
+
+#### 优化策略
+
+Paddle2.0rc提供了多种优化器选择,如'SGD', 'Adam', 'Adamax'等,详细参见[策略](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/optimizer/optimizer/Optimizer_cn.html)。
+
+其中'Adam':
+
+* learning_rate: 全局学习率。默认为1e-3;
+* parameters: 待优化模型参数。
+
+#### 运行配置
+'Trainer' 主要控制Fine-tune的训练,包含以下可控制的参数:
+
+* model: 被优化模型;
+* optimizer: 优化器选择;
+* use_vdl: 是否使用vdl可视化训练过程;
+* checkpoint_dir: 保存模型参数的地址;
+* compare_metrics: 保存最优模型的衡量指标;
+
+'trainer.train' 主要控制具体的训练过程,包含以下可控制的参数:
+
+* train_dataset: 训练时所用的数据集;
+* epochs: 训练轮数;
+* batch_size: 训练的批大小,如果使用GPU,请根据实际情况调整batch_size;
+* num_workers: works的数量,默认为0;
+* eval_dataset: 验证集;
+* log_interval: 打印日志的间隔, 单位为执行批训练的次数。
+* save_interval: 保存模型的间隔频次,单位为执行训练的轮数。
+
+## 模型预测
+
+当完成Fine-tune后,Fine-tune过程在验证集上表现最优的模型会被保存在'${CHECKPOINT_DIR}/best_model'目录下,其中'${CHECKPOINT_DIR}'目录为Fine-tune时所选择的保存checkpoint的目录。
+我们使用该模型来进行预测。predict.py脚本如下:
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+
+ model = hub.Module(name='se_hrnet64_imagenet_ssld', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['flower.jpg'])
+```
+
+参数配置正确后,请执行脚本'python predict.py', 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
+
+**NOTE:** 进行预测时,所选择的module,checkpoint_dir,dataset必须和Fine-tune所用的一样。
+
+## 服务部署
+
+PaddleHub Serving可以部署一个在线分类任务服务
+
+## Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m se_hrnet64_imagenet_ssld
+```
+
+这样就完成了一个分类任务服务化API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+## Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+import cv2
+import base64
+
+import numpy as np
+
+
+def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+# 发送HTTP请求
+org_im = cv2.imread('/PATH/TO/IMAGE')
+
+data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+headers = {"Content-type": "application/json"}
+url = "http://127.0.0.1:8866/predict/se_hrnet64_imagenet_ssld"
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+data =r.json()["results"]['data']
+```
+
+### 查看代码
+
+[PaddleClas](https://github.com/PaddlePaddle/PaddleClas)
+
+### 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.0.0
diff --git a/modules/image/classification/se_hrnet64_imagenet_ssld/label_list.txt b/modules/image/classification/se_hrnet64_imagenet_ssld/label_list.txt
new file mode 100644
index 0000000000000000000000000000000000000000..52baabc68e968dde482ca143728295355d83203a
--- /dev/null
+++ b/modules/image/classification/se_hrnet64_imagenet_ssld/label_list.txt
@@ -0,0 +1,1000 @@
+tench
+goldfish
+great white shark
+tiger shark
+hammerhead
+electric ray
+stingray
+cock
+hen
+ostrich
+brambling
+goldfinch
+house finch
+junco
+indigo bunting
+robin
+bulbul
+jay
+magpie
+chickadee
+water ouzel
+kite
+bald eagle
+vulture
+great grey owl
+European fire salamander
+common newt
+eft
+spotted salamander
+axolotl
+bullfrog
+tree frog
+tailed frog
+loggerhead
+leatherback turtle
+mud turtle
+terrapin
+box turtle
+banded gecko
+common iguana
+American chameleon
+whiptail
+agama
+frilled lizard
+alligator lizard
+Gila monster
+green lizard
+African chameleon
+Komodo dragon
+African crocodile
+American alligator
+triceratops
+thunder snake
+ringneck snake
+hognose snake
+green snake
+king snake
+garter snake
+water snake
+vine snake
+night snake
+boa constrictor
+rock python
+Indian cobra
+green mamba
+sea snake
+horned viper
+diamondback
+sidewinder
+trilobite
+harvestman
+scorpion
+black and gold garden spider
+barn spider
+garden spider
+black widow
+tarantula
+wolf spider
+tick
+centipede
+black grouse
+ptarmigan
+ruffed grouse
+prairie chicken
+peacock
+quail
+partridge
+African grey
+macaw
+sulphur-crested cockatoo
+lorikeet
+coucal
+bee eater
+hornbill
+hummingbird
+jacamar
+toucan
+drake
+red-breasted merganser
+goose
+black swan
+tusker
+echidna
+platypus
+wallaby
+koala
+wombat
+jellyfish
+sea anemone
+brain coral
+flatworm
+nematode
+conch
+snail
+slug
+sea slug
+chiton
+chambered nautilus
+Dungeness crab
+rock crab
+fiddler crab
+king crab
+American lobster
+spiny lobster
+crayfish
+hermit crab
+isopod
+white stork
+black stork
+spoonbill
+flamingo
+little blue heron
+American egret
+bittern
+crane
+limpkin
+European gallinule
+American coot
+bustard
+ruddy turnstone
+red-backed sandpiper
+redshank
+dowitcher
+oystercatcher
+pelican
+king penguin
+albatross
+grey whale
+killer whale
+dugong
+sea lion
+Chihuahua
+Japanese spaniel
+Maltese dog
+Pekinese
+Shih-Tzu
+Blenheim spaniel
+papillon
+toy terrier
+Rhodesian ridgeback
+Afghan hound
+basset
+beagle
+bloodhound
+bluetick
+black-and-tan coonhound
+Walker hound
+English foxhound
+redbone
+borzoi
+Irish wolfhound
+Italian greyhound
+whippet
+Ibizan hound
+Norwegian elkhound
+otterhound
+Saluki
+Scottish deerhound
+Weimaraner
+Staffordshire bullterrier
+American Staffordshire terrier
+Bedlington terrier
+Border terrier
+Kerry blue terrier
+Irish terrier
+Norfolk terrier
+Norwich terrier
+Yorkshire terrier
+wire-haired fox terrier
+Lakeland terrier
+Sealyham terrier
+Airedale
+cairn
+Australian terrier
+Dandie Dinmont
+Boston bull
+miniature schnauzer
+giant schnauzer
+standard schnauzer
+Scotch terrier
+Tibetan terrier
+silky terrier
+soft-coated wheaten terrier
+West Highland white terrier
+Lhasa
+flat-coated retriever
+curly-coated retriever
+golden retriever
+Labrador retriever
+Chesapeake Bay retriever
+German short-haired pointer
+vizsla
+English setter
+Irish setter
+Gordon setter
+Brittany spaniel
+clumber
+English springer
+Welsh springer spaniel
+cocker spaniel
+Sussex spaniel
+Irish water spaniel
+kuvasz
+schipperke
+groenendael
+malinois
+briard
+kelpie
+komondor
+Old English sheepdog
+Shetland sheepdog
+collie
+Border collie
+Bouvier des Flandres
+Rottweiler
+German shepherd
+Doberman
+miniature pinscher
+Greater Swiss Mountain dog
+Bernese mountain dog
+Appenzeller
+EntleBucher
+boxer
+bull mastiff
+Tibetan mastiff
+French bulldog
+Great Dane
+Saint Bernard
+Eskimo dog
+malamute
+Siberian husky
+dalmatian
+affenpinscher
+basenji
+pug
+Leonberg
+Newfoundland
+Great Pyrenees
+Samoyed
+Pomeranian
+chow
+keeshond
+Brabancon griffon
+Pembroke
+Cardigan
+toy poodle
+miniature poodle
+standard poodle
+Mexican hairless
+timber wolf
+white wolf
+red wolf
+coyote
+dingo
+dhole
+African hunting dog
+hyena
+red fox
+kit fox
+Arctic fox
+grey fox
+tabby
+tiger cat
+Persian cat
+Siamese cat
+Egyptian cat
+cougar
+lynx
+leopard
+snow leopard
+jaguar
+lion
+tiger
+cheetah
+brown bear
+American black bear
+ice bear
+sloth bear
+mongoose
+meerkat
+tiger beetle
+ladybug
+ground beetle
+long-horned beetle
+leaf beetle
+dung beetle
+rhinoceros beetle
+weevil
+fly
+bee
+ant
+grasshopper
+cricket
+walking stick
+cockroach
+mantis
+cicada
+leafhopper
+lacewing
+dragonfly
+damselfly
+admiral
+ringlet
+monarch
+cabbage butterfly
+sulphur butterfly
+lycaenid
+starfish
+sea urchin
+sea cucumber
+wood rabbit
+hare
+Angora
+hamster
+porcupine
+fox squirrel
+marmot
+beaver
+guinea pig
+sorrel
+zebra
+hog
+wild boar
+warthog
+hippopotamus
+ox
+water buffalo
+bison
+ram
+bighorn
+ibex
+hartebeest
+impala
+gazelle
+Arabian camel
+llama
+weasel
+mink
+polecat
+black-footed ferret
+otter
+skunk
+badger
+armadillo
+three-toed sloth
+orangutan
+gorilla
+chimpanzee
+gibbon
+siamang
+guenon
+patas
+baboon
+macaque
+langur
+colobus
+proboscis monkey
+marmoset
+capuchin
+howler monkey
+titi
+spider monkey
+squirrel monkey
+Madagascar cat
+indri
+Indian elephant
+African elephant
+lesser panda
+giant panda
+barracouta
+eel
+coho
+rock beauty
+anemone fish
+sturgeon
+gar
+lionfish
+puffer
+abacus
+abaya
+academic gown
+accordion
+acoustic guitar
+aircraft carrier
+airliner
+airship
+altar
+ambulance
+amphibian
+analog clock
+apiary
+apron
+ashcan
+assault rifle
+backpack
+bakery
+balance beam
+balloon
+ballpoint
+Band Aid
+banjo
+bannister
+barbell
+barber chair
+barbershop
+barn
+barometer
+barrel
+barrow
+baseball
+basketball
+bassinet
+bassoon
+bathing cap
+bath towel
+bathtub
+beach wagon
+beacon
+beaker
+bearskin
+beer bottle
+beer glass
+bell cote
+bib
+bicycle-built-for-two
+bikini
+binder
+binoculars
+birdhouse
+boathouse
+bobsled
+bolo tie
+bonnet
+bookcase
+bookshop
+bottlecap
+bow
+bow tie
+brass
+brassiere
+breakwater
+breastplate
+broom
+bucket
+buckle
+bulletproof vest
+bullet train
+butcher shop
+cab
+caldron
+candle
+cannon
+canoe
+can opener
+cardigan
+car mirror
+carousel
+carpenters kit
+carton
+car wheel
+cash machine
+cassette
+cassette player
+castle
+catamaran
+CD player
+cello
+cellular telephone
+chain
+chainlink fence
+chain mail
+chain saw
+chest
+chiffonier
+chime
+china cabinet
+Christmas stocking
+church
+cinema
+cleaver
+cliff dwelling
+cloak
+clog
+cocktail shaker
+coffee mug
+coffeepot
+coil
+combination lock
+computer keyboard
+confectionery
+container ship
+convertible
+corkscrew
+cornet
+cowboy boot
+cowboy hat
+cradle
+crane
+crash helmet
+crate
+crib
+Crock Pot
+croquet ball
+crutch
+cuirass
+dam
+desk
+desktop computer
+dial telephone
+diaper
+digital clock
+digital watch
+dining table
+dishrag
+dishwasher
+disk brake
+dock
+dogsled
+dome
+doormat
+drilling platform
+drum
+drumstick
+dumbbell
+Dutch oven
+electric fan
+electric guitar
+electric locomotive
+entertainment center
+envelope
+espresso maker
+face powder
+feather boa
+file
+fireboat
+fire engine
+fire screen
+flagpole
+flute
+folding chair
+football helmet
+forklift
+fountain
+fountain pen
+four-poster
+freight car
+French horn
+frying pan
+fur coat
+garbage truck
+gasmask
+gas pump
+goblet
+go-kart
+golf ball
+golfcart
+gondola
+gong
+gown
+grand piano
+greenhouse
+grille
+grocery store
+guillotine
+hair slide
+hair spray
+half track
+hammer
+hamper
+hand blower
+hand-held computer
+handkerchief
+hard disc
+harmonica
+harp
+harvester
+hatchet
+holster
+home theater
+honeycomb
+hook
+hoopskirt
+horizontal bar
+horse cart
+hourglass
+iPod
+iron
+jack-o-lantern
+jean
+jeep
+jersey
+jigsaw puzzle
+jinrikisha
+joystick
+kimono
+knee pad
+knot
+lab coat
+ladle
+lampshade
+laptop
+lawn mower
+lens cap
+letter opener
+library
+lifeboat
+lighter
+limousine
+liner
+lipstick
+Loafer
+lotion
+loudspeaker
+loupe
+lumbermill
+magnetic compass
+mailbag
+mailbox
+maillot
+maillot
+manhole cover
+maraca
+marimba
+mask
+matchstick
+maypole
+maze
+measuring cup
+medicine chest
+megalith
+microphone
+microwave
+military uniform
+milk can
+minibus
+miniskirt
+minivan
+missile
+mitten
+mixing bowl
+mobile home
+Model T
+modem
+monastery
+monitor
+moped
+mortar
+mortarboard
+mosque
+mosquito net
+motor scooter
+mountain bike
+mountain tent
+mouse
+mousetrap
+moving van
+muzzle
+nail
+neck brace
+necklace
+nipple
+notebook
+obelisk
+oboe
+ocarina
+odometer
+oil filter
+organ
+oscilloscope
+overskirt
+oxcart
+oxygen mask
+packet
+paddle
+paddlewheel
+padlock
+paintbrush
+pajama
+palace
+panpipe
+paper towel
+parachute
+parallel bars
+park bench
+parking meter
+passenger car
+patio
+pay-phone
+pedestal
+pencil box
+pencil sharpener
+perfume
+Petri dish
+photocopier
+pick
+pickelhaube
+picket fence
+pickup
+pier
+piggy bank
+pill bottle
+pillow
+ping-pong ball
+pinwheel
+pirate
+pitcher
+plane
+planetarium
+plastic bag
+plate rack
+plow
+plunger
+Polaroid camera
+pole
+police van
+poncho
+pool table
+pop bottle
+pot
+potters wheel
+power drill
+prayer rug
+printer
+prison
+projectile
+projector
+puck
+punching bag
+purse
+quill
+quilt
+racer
+racket
+radiator
+radio
+radio telescope
+rain barrel
+recreational vehicle
+reel
+reflex camera
+refrigerator
+remote control
+restaurant
+revolver
+rifle
+rocking chair
+rotisserie
+rubber eraser
+rugby ball
+rule
+running shoe
+safe
+safety pin
+saltshaker
+sandal
+sarong
+sax
+scabbard
+scale
+school bus
+schooner
+scoreboard
+screen
+screw
+screwdriver
+seat belt
+sewing machine
+shield
+shoe shop
+shoji
+shopping basket
+shopping cart
+shovel
+shower cap
+shower curtain
+ski
+ski mask
+sleeping bag
+slide rule
+sliding door
+slot
+snorkel
+snowmobile
+snowplow
+soap dispenser
+soccer ball
+sock
+solar dish
+sombrero
+soup bowl
+space bar
+space heater
+space shuttle
+spatula
+speedboat
+spider web
+spindle
+sports car
+spotlight
+stage
+steam locomotive
+steel arch bridge
+steel drum
+stethoscope
+stole
+stone wall
+stopwatch
+stove
+strainer
+streetcar
+stretcher
+studio couch
+stupa
+submarine
+suit
+sundial
+sunglass
+sunglasses
+sunscreen
+suspension bridge
+swab
+sweatshirt
+swimming trunks
+swing
+switch
+syringe
+table lamp
+tank
+tape player
+teapot
+teddy
+television
+tennis ball
+thatch
+theater curtain
+thimble
+thresher
+throne
+tile roof
+toaster
+tobacco shop
+toilet seat
+torch
+totem pole
+tow truck
+toyshop
+tractor
+trailer truck
+tray
+trench coat
+tricycle
+trimaran
+tripod
+triumphal arch
+trolleybus
+trombone
+tub
+turnstile
+typewriter keyboard
+umbrella
+unicycle
+upright
+vacuum
+vase
+vault
+velvet
+vending machine
+vestment
+viaduct
+violin
+volleyball
+waffle iron
+wall clock
+wallet
+wardrobe
+warplane
+washbasin
+washer
+water bottle
+water jug
+water tower
+whiskey jug
+whistle
+wig
+window screen
+window shade
+Windsor tie
+wine bottle
+wing
+wok
+wooden spoon
+wool
+worm fence
+wreck
+yawl
+yurt
+web site
+comic book
+crossword puzzle
+street sign
+traffic light
+book jacket
+menu
+plate
+guacamole
+consomme
+hot pot
+trifle
+ice cream
+ice lolly
+French loaf
+bagel
+pretzel
+cheeseburger
+hotdog
+mashed potato
+head cabbage
+broccoli
+cauliflower
+zucchini
+spaghetti squash
+acorn squash
+butternut squash
+cucumber
+artichoke
+bell pepper
+cardoon
+mushroom
+Granny Smith
+strawberry
+orange
+lemon
+fig
+pineapple
+banana
+jackfruit
+custard apple
+pomegranate
+hay
+carbonara
+chocolate sauce
+dough
+meat loaf
+pizza
+potpie
+burrito
+red wine
+espresso
+cup
+eggnog
+alp
+bubble
+cliff
+coral reef
+geyser
+lakeside
+promontory
+sandbar
+seashore
+valley
+volcano
+ballplayer
+groom
+scuba diver
+rapeseed
+daisy
+yellow ladys slipper
+corn
+acorn
+hip
+buckeye
+coral fungus
+agaric
+gyromitra
+stinkhorn
+earthstar
+hen-of-the-woods
+bolete
+ear
+toilet tissue
diff --git a/modules/image/classification/se_hrnet64_imagenet_ssld/module.py b/modules/image/classification/se_hrnet64_imagenet_ssld/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..73ec74d5e4b58884998d5467bb248f071b3028b2
--- /dev/null
+++ b/modules/image/classification/se_hrnet64_imagenet_ssld/module.py
@@ -0,0 +1,579 @@
+# copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+from typing import Union
+
+import paddle
+import paddle.nn as nn
+import paddle.nn.functional as F
+import paddlehub.vision.transforms as T
+import numpy as np
+from paddle.nn.initializer import Uniform
+from paddle import ParamAttr
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.cv_module import ImageClassifierModule
+
+
+class ConvBNLayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, filter_size, stride=1, groups=1, act="relu", name=None):
+ super(ConvBNLayer, self).__init__()
+
+ self._conv = nn.Conv2D(
+ in_channels=num_channels,
+ out_channels=num_filters,
+ kernel_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) // 2,
+ groups=groups,
+ weight_attr=ParamAttr(name=name + "_weights"),
+ bias_attr=False)
+ bn_name = name + '_bn'
+ self._batch_norm = nn.BatchNorm(
+ num_filters,
+ act=act,
+ param_attr=ParamAttr(name=bn_name + '_scale'),
+ bias_attr=ParamAttr(bn_name + '_offset'),
+ moving_mean_name=bn_name + '_mean',
+ moving_variance_name=bn_name + '_variance')
+
+ def forward(self, input):
+ y = self._conv(input)
+ y = self._batch_norm(y)
+ return y
+
+
+class Layer1(nn.Layer):
+ def __init__(self, num_channels, has_se=False, name=None):
+ super(Layer1, self).__init__()
+
+ self.bottleneck_block_list = []
+
+ for i in range(4):
+ bottleneck_block = self.add_sublayer(
+ "bb_{}_{}".format(name, i + 1),
+ BottleneckBlock(
+ num_channels=num_channels if i == 0 else 256,
+ num_filters=64,
+ has_se=has_se,
+ stride=1,
+ downsample=True if i == 0 else False,
+ name=name + '_' + str(i + 1)))
+ self.bottleneck_block_list.append(bottleneck_block)
+
+ def forward(self, input):
+ conv = input
+ for block_func in self.bottleneck_block_list:
+ conv = block_func(conv)
+ return conv
+
+
+class TransitionLayer(nn.Layer):
+ def __init__(self, in_channels, out_channels, name=None):
+ super(TransitionLayer, self).__init__()
+
+ num_in = len(in_channels)
+ num_out = len(out_channels)
+ out = []
+ self.conv_bn_func_list = []
+ for i in range(num_out):
+ residual = None
+ if i < num_in:
+ if in_channels[i] != out_channels[i]:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[i],
+ num_filters=out_channels[i],
+ filter_size=3,
+ name=name + '_layer_' + str(i + 1)))
+ else:
+ residual = self.add_sublayer(
+ "transition_{}_layer_{}".format(name, i + 1),
+ ConvBNLayer(
+ num_channels=in_channels[-1],
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ name=name + '_layer_' + str(i + 1)))
+ self.conv_bn_func_list.append(residual)
+
+ def forward(self, input):
+ outs = []
+ for idx, conv_bn_func in enumerate(self.conv_bn_func_list):
+ if conv_bn_func is None:
+ outs.append(input[idx])
+ else:
+ if idx < len(input):
+ outs.append(conv_bn_func(input[idx]))
+ else:
+ outs.append(conv_bn_func(input[-1]))
+ return outs
+
+
+class Branches(nn.Layer):
+ def __init__(self, block_num, in_channels, out_channels, has_se=False, name=None):
+ super(Branches, self).__init__()
+
+ self.basic_block_list = []
+
+ for i in range(len(out_channels)):
+ self.basic_block_list.append([])
+ for j in range(block_num):
+ in_ch = in_channels[i] if j == 0 else out_channels[i]
+ basic_block_func = self.add_sublayer(
+ "bb_{}_branch_layer_{}_{}".format(name, i + 1, j + 1),
+ BasicBlock(
+ num_channels=in_ch,
+ num_filters=out_channels[i],
+ has_se=has_se,
+ name=name + '_branch_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.basic_block_list[i].append(basic_block_func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ conv = input
+ basic_block_list = self.basic_block_list[idx]
+ for basic_block_func in basic_block_list:
+ conv = basic_block_func(conv)
+ outs.append(conv)
+ return outs
+
+
+class BottleneckBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se, stride=1, downsample=False, name=None):
+ super(BottleneckBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=1,
+ act="relu",
+ name=name + "_conv1",
+ )
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv2")
+ self.conv3 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters * 4, filter_size=1, act=None, name=name + "_conv3")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act=None,
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(
+ num_channels=num_filters * 4, num_filters=num_filters * 4, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+ conv3 = self.conv3(conv2)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv3 = self.se(conv3)
+
+ y = paddle.add(x=residual, y=conv3)
+ y = F.relu(y)
+ return y
+
+
+class BasicBlock(nn.Layer):
+ def __init__(self, num_channels, num_filters, stride=1, has_se=False, downsample=False, name=None):
+ super(BasicBlock, self).__init__()
+
+ self.has_se = has_se
+ self.downsample = downsample
+
+ self.conv1 = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ act="relu",
+ name=name + "_conv1")
+ self.conv2 = ConvBNLayer(
+ num_channels=num_filters, num_filters=num_filters, filter_size=3, stride=1, act=None, name=name + "_conv2")
+
+ if self.downsample:
+ self.conv_down = ConvBNLayer(
+ num_channels=num_channels,
+ num_filters=num_filters * 4,
+ filter_size=1,
+ act="relu",
+ name=name + "_downsample")
+
+ if self.has_se:
+ self.se = SELayer(num_channels=num_filters, num_filters=num_filters, reduction_ratio=16, name='fc' + name)
+
+ def forward(self, input):
+ residual = input
+ conv1 = self.conv1(input)
+ conv2 = self.conv2(conv1)
+
+ if self.downsample:
+ residual = self.conv_down(input)
+
+ if self.has_se:
+ conv2 = self.se(conv2)
+
+ y = paddle.add(x=residual, y=conv2)
+ y = F.relu(y)
+ return y
+
+
+class SELayer(nn.Layer):
+ def __init__(self, num_channels, num_filters, reduction_ratio, name=None):
+ super(SELayer, self).__init__()
+
+ self.pool2d_gap = nn.AdaptiveAvgPool2D(1)
+
+ self._num_channels = num_channels
+
+ med_ch = int(num_channels / reduction_ratio)
+ stdv = 1.0 / math.sqrt(num_channels * 1.0)
+ self.squeeze = nn.Linear(
+ num_channels,
+ med_ch,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_sqz_weights"),
+ bias_attr=ParamAttr(name=name + '_sqz_offset'))
+
+ stdv = 1.0 / math.sqrt(med_ch * 1.0)
+ self.excitation = nn.Linear(
+ med_ch,
+ num_filters,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name=name + "_exc_weights"),
+ bias_attr=ParamAttr(name=name + '_exc_offset'))
+
+ def forward(self, input):
+ pool = self.pool2d_gap(input)
+ pool = paddle.squeeze(pool, axis=[2, 3])
+ squeeze = self.squeeze(pool)
+ squeeze = F.relu(squeeze)
+ excitation = self.excitation(squeeze)
+ excitation = F.sigmoid(excitation)
+ excitation = paddle.unsqueeze(excitation, axis=[2, 3])
+ out = input * excitation
+ return out
+
+
+class Stage(nn.Layer):
+ def __init__(self, num_channels, num_modules, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(Stage, self).__init__()
+
+ self._num_modules = num_modules
+
+ self.stage_func_list = []
+ for i in range(num_modules):
+ if i == num_modules - 1 and not multi_scale_output:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels,
+ num_filters=num_filters,
+ has_se=has_se,
+ multi_scale_output=False,
+ name=name + '_' + str(i + 1)))
+ else:
+ stage_func = self.add_sublayer(
+ "stage_{}_{}".format(name, i + 1),
+ HighResolutionModule(
+ num_channels=num_channels, num_filters=num_filters, has_se=has_se,
+ name=name + '_' + str(i + 1)))
+
+ self.stage_func_list.append(stage_func)
+
+ def forward(self, input):
+ out = input
+ for idx in range(self._num_modules):
+ out = self.stage_func_list[idx](out)
+ return out
+
+
+class HighResolutionModule(nn.Layer):
+ def __init__(self, num_channels, num_filters, has_se=False, multi_scale_output=True, name=None):
+ super(HighResolutionModule, self).__init__()
+
+ self.branches_func = Branches(
+ block_num=4, in_channels=num_channels, out_channels=num_filters, has_se=has_se, name=name)
+
+ self.fuse_func = FuseLayers(
+ in_channels=num_filters, out_channels=num_filters, multi_scale_output=multi_scale_output, name=name)
+
+ def forward(self, input):
+ out = self.branches_func(input)
+ out = self.fuse_func(out)
+ return out
+
+
+class FuseLayers(nn.Layer):
+ def __init__(self, in_channels, out_channels, multi_scale_output=True, name=None):
+ super(FuseLayers, self).__init__()
+
+ self._actual_ch = len(in_channels) if multi_scale_output else 1
+ self._in_channels = in_channels
+
+ self.residual_func_list = []
+ for i in range(self._actual_ch):
+ for j in range(len(in_channels)):
+ residual_func = None
+ if j > i:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}".format(name, i + 1, j + 1),
+ ConvBNLayer(
+ num_channels=in_channels[j],
+ num_filters=out_channels[i],
+ filter_size=1,
+ stride=1,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1)))
+ self.residual_func_list.append(residual_func)
+ elif j < i:
+ pre_num_filters = in_channels[j]
+ for k in range(i - j):
+ if k == i - j - 1:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[i],
+ filter_size=3,
+ stride=2,
+ act=None,
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[i]
+ else:
+ residual_func = self.add_sublayer(
+ "residual_{}_layer_{}_{}_{}".format(name, i + 1, j + 1, k + 1),
+ ConvBNLayer(
+ num_channels=pre_num_filters,
+ num_filters=out_channels[j],
+ filter_size=3,
+ stride=2,
+ act="relu",
+ name=name + '_layer_' + str(i + 1) + '_' + str(j + 1) + '_' + str(k + 1)))
+ pre_num_filters = out_channels[j]
+ self.residual_func_list.append(residual_func)
+
+ def forward(self, input):
+ outs = []
+ residual_func_idx = 0
+ for i in range(self._actual_ch):
+ residual = input[i]
+ for j in range(len(self._in_channels)):
+ if j > i:
+ y = self.residual_func_list[residual_func_idx](input[j])
+ residual_func_idx += 1
+
+ y = F.upsample(y, scale_factor=2**(j - i), mode="nearest")
+ residual = paddle.add(x=residual, y=y)
+ elif j < i:
+ y = input[j]
+ for k in range(i - j):
+ y = self.residual_func_list[residual_func_idx](y)
+ residual_func_idx += 1
+
+ residual = paddle.add(x=residual, y=y)
+
+ residual = F.relu(residual)
+ outs.append(residual)
+
+ return outs
+
+
+class LastClsOut(nn.Layer):
+ def __init__(self, num_channel_list, has_se, num_filters_list=[32, 64, 128, 256], name=None):
+ super(LastClsOut, self).__init__()
+
+ self.func_list = []
+ for idx in range(len(num_channel_list)):
+ func = self.add_sublayer(
+ "conv_{}_conv_{}".format(name, idx + 1),
+ BottleneckBlock(
+ num_channels=num_channel_list[idx],
+ num_filters=num_filters_list[idx],
+ has_se=has_se,
+ downsample=True,
+ name=name + 'conv_' + str(idx + 1)))
+ self.func_list.append(func)
+
+ def forward(self, inputs):
+ outs = []
+ for idx, input in enumerate(inputs):
+ out = self.func_list[idx](input)
+ outs.append(out)
+ return outs
+
+
+@moduleinfo(
+ name="se_hrnet64_imagenet_ssld",
+ type="CV/classification",
+ author="paddlepaddle",
+ author_email="",
+ summary="se_hrnet64_imagenet_ssld is a classification model, "
+ "this module is trained with Imagenet dataset.",
+ version="1.0.0",
+ meta=ImageClassifierModule)
+class SE_HRNet64(nn.Layer):
+ def __init__(self, label_list: list = None, load_checkpoint: str = None):
+ super(SE_HRNet64, self).__init__()
+
+ if label_list is not None:
+ self.labels = label_list
+ class_dim = len(self.labels)
+ else:
+ label_list = []
+ label_file = os.path.join(self.directory, 'label_list.txt')
+ files = open(label_file)
+ for line in files.readlines():
+ line = line.strip('\n')
+ label_list.append(line)
+ self.labels = label_list
+ class_dim = len(self.labels)
+
+ self.width = 64
+ self.has_se = True
+ self.channels = {
+ 18: [[18, 36], [18, 36, 72], [18, 36, 72, 144]],
+ 30: [[30, 60], [30, 60, 120], [30, 60, 120, 240]],
+ 32: [[32, 64], [32, 64, 128], [32, 64, 128, 256]],
+ 40: [[40, 80], [40, 80, 160], [40, 80, 160, 320]],
+ 44: [[44, 88], [44, 88, 176], [44, 88, 176, 352]],
+ 48: [[48, 96], [48, 96, 192], [48, 96, 192, 384]],
+ 60: [[60, 120], [60, 120, 240], [60, 120, 240, 480]],
+ 64: [[64, 128], [64, 128, 256], [64, 128, 256, 512]]
+ }
+ self._class_dim = class_dim
+
+ channels_2, channels_3, channels_4 = self.channels[self.width]
+ num_modules_2, num_modules_3, num_modules_4 = 1, 4, 3
+
+ self.conv_layer1_1 = ConvBNLayer(
+ num_channels=3, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_1")
+
+ self.conv_layer1_2 = ConvBNLayer(
+ num_channels=64, num_filters=64, filter_size=3, stride=2, act='relu', name="layer1_2")
+
+ self.la1 = Layer1(num_channels=64, has_se=self.has_se, name="layer2")
+
+ self.tr1 = TransitionLayer(in_channels=[256], out_channels=channels_2, name="tr1")
+
+ self.st2 = Stage(
+ num_channels=channels_2, num_modules=num_modules_2, num_filters=channels_2, has_se=self.has_se, name="st2")
+
+ self.tr2 = TransitionLayer(in_channels=channels_2, out_channels=channels_3, name="tr2")
+ self.st3 = Stage(
+ num_channels=channels_3, num_modules=num_modules_3, num_filters=channels_3, has_se=self.has_se, name="st3")
+
+ self.tr3 = TransitionLayer(in_channels=channels_3, out_channels=channels_4, name="tr3")
+ self.st4 = Stage(
+ num_channels=channels_4, num_modules=num_modules_4, num_filters=channels_4, has_se=self.has_se, name="st4")
+
+ # classification
+ num_filters_list = [32, 64, 128, 256]
+ self.last_cls = LastClsOut(
+ num_channel_list=channels_4,
+ has_se=self.has_se,
+ num_filters_list=num_filters_list,
+ name="cls_head",
+ )
+
+ last_num_filters = [256, 512, 1024]
+ self.cls_head_conv_list = []
+ for idx in range(3):
+ self.cls_head_conv_list.append(
+ self.add_sublayer(
+ "cls_head_add{}".format(idx + 1),
+ ConvBNLayer(
+ num_channels=num_filters_list[idx] * 4,
+ num_filters=last_num_filters[idx],
+ filter_size=3,
+ stride=2,
+ name="cls_head_add" + str(idx + 1))))
+
+ self.conv_last = ConvBNLayer(
+ num_channels=1024, num_filters=2048, filter_size=1, stride=1, name="cls_head_last_conv")
+
+ self.pool2d_avg = nn.AdaptiveAvgPool2D(1)
+
+ stdv = 1.0 / math.sqrt(2048 * 1.0)
+
+ self.out = nn.Linear(
+ 2048,
+ class_dim,
+ weight_attr=ParamAttr(initializer=Uniform(-stdv, stdv), name="fc_weights"),
+ bias_attr=ParamAttr(name="fc_offset"))
+
+ if load_checkpoint is not None:
+ self.model_dict = paddle.load(load_checkpoint)
+ self.set_dict(self.model_dict)
+ print("load custom checkpoint success")
+ else:
+ checkpoint = os.path.join(self.directory, 'model.pdparams')
+ self.model_dict = paddle.load(checkpoint)
+ self.set_dict(self.model_dict)
+ print("load pretrained checkpoint success")
+
+ def transforms(self, images: Union[str, np.ndarray]):
+ transforms = T.Compose([
+ T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+ ],
+ to_rgb=True)
+ return transforms(images).astype('float32')
+
+ def forward(self, input):
+ conv1 = self.conv_layer1_1(input)
+ conv2 = self.conv_layer1_2(conv1)
+
+ la1 = self.la1(conv2)
+
+ tr1 = self.tr1([la1])
+ st2 = self.st2(tr1)
+
+ tr2 = self.tr2(st2)
+ st3 = self.st3(tr2)
+
+ tr3 = self.tr3(st3)
+ st4 = self.st4(tr3)
+
+ last_cls = self.last_cls(st4)
+
+ y = last_cls[0]
+ for idx in range(3):
+ y = paddle.add(last_cls[idx + 1], self.cls_head_conv_list[idx](y))
+
+ y = self.conv_last(y)
+ feature = self.pool2d_avg(y)
+ y = paddle.reshape(feature, shape=[-1, feature.shape[1]])
+ y = self.out(y)
+ return y, feature
diff --git a/modules/image/semantic_segmentation/deeplabv3p_resnet50_voc/layers.py b/modules/image/semantic_segmentation/deeplabv3p_resnet50_voc/layers.py
index f19373b3271fb7894a79e2e43a611b69b4189597..dc86c35e6830a47f535bd2b56fc159d8422419ab 100644
--- a/modules/image/semantic_segmentation/deeplabv3p_resnet50_voc/layers.py
+++ b/modules/image/semantic_segmentation/deeplabv3p_resnet50_voc/layers.py
@@ -15,7 +15,6 @@
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
-from paddle.nn.layer import activation
from paddle.nn import Conv2D, AvgPool2D
@@ -214,7 +213,7 @@ class Activation(nn.Layer):
super(Activation, self).__init__()
self._act = act
- upper_act_names = activation.__all__
+ upper_act_names = nn.layer.activation.__dict__.keys()
lower_act_names = [act.lower() for act in upper_act_names]
act_dict = dict(zip(lower_act_names, upper_act_names))
diff --git a/modules/image/semantic_segmentation/ocrnet_hrnetw18_voc/layers.py b/modules/image/semantic_segmentation/ocrnet_hrnetw18_voc/layers.py
index b9a70182b32ab2910cc23cd219b77914e0cba8bb..1c5a20b16a5743ddf8e8a0917d00d101dce43bbe 100644
--- a/modules/image/semantic_segmentation/ocrnet_hrnetw18_voc/layers.py
+++ b/modules/image/semantic_segmentation/ocrnet_hrnetw18_voc/layers.py
@@ -15,7 +15,6 @@
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
-from paddle.nn.layer import activation
from paddle.nn import Conv2D, AvgPool2D
@@ -214,7 +213,7 @@ class Activation(nn.Layer):
super(Activation, self).__init__()
self._act = act
- upper_act_names = activation.__all__
+ upper_act_names = nn.layer.activation.__dict__.keys()
lower_act_names = [act.lower() for act in upper_act_names]
act_dict = dict(zip(lower_act_names, upper_act_names))
diff --git a/modules/image/text_recognition/chinese_ocr_db_crnn_server/utils.py b/modules/image/text_recognition/chinese_ocr_db_crnn_server/utils.py
index 5a90b27defba39446eb82ce83485811494e9caba..c5bf34d04181cf228f4081024108550a1bc36187 100644
--- a/modules/image/text_recognition/chinese_ocr_db_crnn_server/utils.py
+++ b/modules/image/text_recognition/chinese_ocr_db_crnn_server/utils.py
@@ -172,6 +172,6 @@ def sorted_boxes(dt_boxes):
def base64_to_cv2(b64str):
data = base64.b64decode(b64str.encode('utf8'))
- data = np.fromstring(data, np.uint8)
+ data = np.frombuffer(data, np.uint8)
data = cv2.imdecode(data, cv2.IMREAD_COLOR)
return data
diff --git a/modules/text/language_model/simnet_bow/README.md b/modules/text/language_model/simnet_bow/README.md
index 8be40f23288a63b8bf7944b19de2dde6bfd3589e..08811352e2e016187476da10160c6e8dce1ad40d 100644
--- a/modules/text/language_model/simnet_bow/README.md
+++ b/modules/text/language_model/simnet_bow/README.md
@@ -69,7 +69,7 @@ Loading simnet_bow successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/lexical_analysis/jieba_paddle/README.md b/modules/text/lexical_analysis/jieba_paddle/README.md
index ed2ccca21331077b4b9da5ba3f2ab7505a7a8737..e6244a9e4ed19504817dfd6dc78c15706d2cc3c6 100644
--- a/modules/text/lexical_analysis/jieba_paddle/README.md
+++ b/modules/text/lexical_analysis/jieba_paddle/README.md
@@ -78,8 +78,9 @@ $ hub serving start -c serving_config.json
"modules_info": {
"jieba_paddle": {
"init_args": {
- "version": "2.2.0"
- }
+ "version": "1.0.0"
+ },
+ "predict_args": {}
}
},
"port": 8866,
@@ -96,7 +97,7 @@ $ hub serving start -c serving_config.json
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/lexical_analysis/lac/README.md b/modules/text/lexical_analysis/lac/README.md
index ac467e0d3d7db7ab2350a2274c3373179a40215a..6199a32b177065dc930c3b638bcff4bb371324bc 100644
--- a/modules/text/lexical_analysis/lac/README.md
+++ b/modules/text/lexical_analysis/lac/README.md
@@ -88,9 +88,10 @@ $ hub serving start -c serving_config.json
"modules_info": {
"lac": {
"init_args": {
- "version": "2.1.0"
+ "version": "2.1.0",
"user_dict": "./test_dict.txt"
- }
+ },
+ "predict_args": {}
}
},
"port": 8866,
@@ -109,7 +110,7 @@ $ hub serving start -c serving_config.json
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/machine_translation/transformer/en-de/README.md b/modules/text/machine_translation/transformer/en-de/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..586186ed26bcadcd52bc82575e2cdae395cf0690
--- /dev/null
+++ b/modules/text/machine_translation/transformer/en-de/README.md
@@ -0,0 +1,125 @@
+```shell
+$ hub install transformer_en-de==1.0.0
+```
+
+## 概述
+
+2017 年,Google机器翻译团队在其发表的论文[Attention Is All You Need](https://arxiv.org/abs/1706.03762)中,提出了用于完成机器翻译(Machine Translation)等序列到序列(Seq2Seq)学习任务的一种全新网络结构——Transformer。Tranformer网络完全使用注意力(Attention)机制来实现序列到序列的建模,并且取得了很好的效果。
+
+transformer_en-de包含6层的transformer结构,头数为8,隐藏层参数为512,参数量为64M。该模型在[WMT'14 EN-DE数据集](http://www.statmt.org/wmt14/translation-task.html)进行了预训练,加载后可直接用于预测,提供了英文翻译为德文的能力。
+
+关于机器翻译的Transformer模型训练方式和详情,可查看[Machine Translation using Transformer](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/machine_translation/transformer)。
+
+## API
+
+
+```python
+def __init__(max_length: int = 256,
+ max_out_len: int = 256,
+ beam_size: int = 5):
+```
+初始化module,可配置模型的输入输出文本的最大长度和解码时beam search的宽度。
+
+**参数**
+- `max_length`(int): 输入文本的最大长度,默认值为256。
+- `max_out_len`(int): 输出文本的最大解码长度,默认值为256。
+- `beam_size`(int): beam search方式解码的beam宽度,默认为5。
+
+
+```python
+def predict(data: List[str],
+ batch_size: int = 1,
+ n_best: int = 1,
+ use_gpu: bool = False):
+```
+预测API,输入源语言的文本句子,解码后输出翻译后的目标语言的文本候选句子。
+
+**参数**
+- `data`(List[str]): 源语言的文本列表,数据类型为List[str]
+- `batch_size`(int): 进行预测的batch_size,默认为1
+- `n_best`(int): 每个输入文本经过模型解码后,输出的得分最高的候选句子的数量,必须小于beam_size,默认为1
+- `use_gpu`(bool): 是否使用gpu执行预测,默认为False
+
+**返回**
+* `results`(List[str]): 翻译后的目标语言的候选句子,长度为`len(data)*n_best`
+
+
+**代码示例**
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='transformer_en-de', beam_size=5)
+src_texts = [
+ 'What are you doing now?',
+ 'The change was for the better; I eat well, I exercise, I take my drugs.',
+ 'Such experiments are not conducted for ethical reasons.',
+]
+
+n_best = 3 # 每个输入样本的输出候选句子数量
+trg_texts = model.predict(src_texts, n_best=n_best)
+for idx, st in enumerate(src_texts):
+ print('-'*30)
+ print(f'src: {st}')
+ for i in range(n_best):
+ print(f'trg[{i+1}]: {trg_texts[idx*n_best+i]}')
+```
+
+## 服务部署
+
+通过启动PaddleHub Serving,可以加载模型部署在线翻译服务。
+
+### Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m transformer_en-de
+```
+
+通过以上命令可完成一个英德机器翻译API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+### Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+
+texts = [
+ 'What are you doing now?',
+ 'The change was for the better; I eat well, I exercise, I take my drugs.',
+ 'Such experiments are not conducted for ethical reasons.',
+]
+data = {"data": texts}
+# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+url = "http://127.0.0.1:8866/predict/transformer_en-de"
+# 指定post请求的headers为application/json方式
+headers = {"Content-Type": "application/json"}
+
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+print(r.json())
+```
+
+## 查看代码
+
+https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/machine_translation/transformer
+
+## 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.1.0
+
+## 更新历史
+
+* 1.0.0
+
+ 初始发布
+
+* 1.0.1
+
+ 修复模型初始化的兼容性问题
diff --git a/modules/text/machine_translation/transformer/en-de/__init__.py b/modules/text/machine_translation/transformer/en-de/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/modules/text/machine_translation/transformer/en-de/module.py b/modules/text/machine_translation/transformer/en-de/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed60c5a82091b5e72f8e30d7a66741b7d3b71128
--- /dev/null
+++ b/modules/text/machine_translation/transformer/en-de/module.py
@@ -0,0 +1,182 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from packaging.version import Version
+from typing import List
+
+import paddle
+import paddle.nn as nn
+from paddlehub.env import MODULE_HOME
+from paddlehub.module.module import moduleinfo, serving
+import paddlenlp
+from paddlenlp.data import Pad, Vocab
+from paddlenlp.transformers import InferTransformerModel, position_encoding_init
+
+from transformer_en_de.utils import MTTokenizer, post_process_seq
+
+
+@moduleinfo(
+ name="transformer_en-de",
+ version="1.0.1",
+ summary="",
+ author="PaddlePaddle",
+ author_email="",
+ type="nlp/machine_translation",
+)
+class MTTransformer(nn.Layer):
+ """
+ Transformer model for machine translation.
+ """
+ # Language config
+ lang_config = {'source': 'en', 'target': 'de'}
+
+ # Model config
+ model_config = {
+ # Number of head used in multi-head attention.
+ "n_head": 8,
+ # The dimension for word embeddings, which is also the last dimension of
+ # the input and output of multi-head attention, position-wise feed-forward
+ # networks, encoder and decoder.
+ "d_model": 512,
+ # Size of the hidden layer in position-wise feed-forward networks.
+ "d_inner_hid": 2048,
+ # The flag indicating whether to share embedding and softmax weights.
+ # Vocabularies in source and target should be same for weight sharing.
+ "weight_sharing": True,
+ # Dropout rate
+ 'dropout': 0
+ }
+
+ # Number of sub-layers to be stacked in the encoder and decoder.
+ if Version(paddlenlp.__version__) <= Version('2.0.5'):
+ model_config.update({"n_layer": 6})
+ else:
+ model_config.update({"num_encoder_layers": 6, "num_decoder_layers": 6})
+
+ # Vocab config
+ vocab_config = {
+ # Used to pad vocab size to be multiple of pad_factor.
+ "pad_factor": 8,
+ # Index for token
+ "bos_id": 0,
+ "bos_token": "",
+ # Index for token
+ "eos_id": 1,
+ "eos_token": "",
+ # Index for token
+ "unk_id": 2,
+ "unk_token": "",
+ }
+
+ def __init__(self, max_length: int = 256, max_out_len: int = 256, beam_size: int = 5):
+ super(MTTransformer, self).__init__()
+ bpe_codes_file = os.path.join(MODULE_HOME, 'transformer_en_de', 'assets', 'bpe.33708')
+ vocab_file = os.path.join(MODULE_HOME, 'transformer_en_de', 'assets', 'vocab_all.bpe.33708')
+ checkpoint = os.path.join(MODULE_HOME, 'transformer_en_de', 'assets', 'transformer.pdparams')
+
+ self.max_length = max_length
+ self.beam_size = beam_size
+ self.tokenizer = MTTokenizer(
+ bpe_codes_file=bpe_codes_file, lang_src=self.lang_config['source'], lang_trg=self.lang_config['target'])
+ self.vocab = Vocab.load_vocabulary(
+ filepath=vocab_file,
+ unk_token=self.vocab_config['unk_token'],
+ bos_token=self.vocab_config['bos_token'],
+ eos_token=self.vocab_config['eos_token'])
+ self.vocab_size = (len(self.vocab) + self.vocab_config['pad_factor'] - 1) \
+ // self.vocab_config['pad_factor'] * self.vocab_config['pad_factor']
+ self.transformer = InferTransformerModel(
+ src_vocab_size=self.vocab_size,
+ trg_vocab_size=self.vocab_size,
+ bos_id=self.vocab_config['bos_id'],
+ eos_id=self.vocab_config['eos_id'],
+ max_length=self.max_length + 1,
+ max_out_len=max_out_len,
+ beam_size=self.beam_size,
+ **self.model_config)
+
+ state_dict = paddle.load(checkpoint)
+
+ # To avoid a longer length than training, reset the size of position
+ # encoding to max_length
+ state_dict["encoder.pos_encoder.weight"] = position_encoding_init(self.max_length + 1,
+ self.model_config['d_model'])
+ state_dict["decoder.pos_encoder.weight"] = position_encoding_init(self.max_length + 1,
+ self.model_config['d_model'])
+
+ self.transformer.set_state_dict(state_dict)
+
+ def forward(self, src_words: paddle.Tensor):
+ return self.transformer(src_words)
+
+ def _convert_text_to_input(self, text: str):
+ """
+ Convert input string to ids.
+ """
+ bpe_tokens = self.tokenizer.tokenize(text)
+ if len(bpe_tokens) > self.max_length:
+ bpe_tokens = bpe_tokens[:self.max_length]
+ return self.vocab.to_indices(bpe_tokens)
+
+ def _batchify(self, data: List[str], batch_size: int):
+ """
+ Generate input batches.
+ """
+ pad_func = Pad(self.vocab_config['eos_id'])
+
+ def _parse_batch(batch_ids):
+ return pad_func([ids + [self.vocab_config['eos_id']] for ids in batch_ids])
+
+ examples = []
+ for text in data:
+ examples.append(self._convert_text_to_input(text))
+
+ # Seperates data into some batches.
+ one_batch = []
+ for example in examples:
+ one_batch.append(example)
+ if len(one_batch) == batch_size:
+ yield _parse_batch(one_batch)
+ one_batch = []
+ if one_batch:
+ yield _parse_batch(one_batch)
+
+ @serving
+ def predict(self, data: List[str], batch_size: int = 1, n_best: int = 1, use_gpu: bool = False):
+
+ if n_best > self.beam_size:
+ raise ValueError(f'Predict arg "n_best" must be smaller or equal to self.beam_size, \
+ but got {n_best} > {self.beam_size}')
+
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+
+ batches = self._batchify(data, batch_size)
+
+ results = []
+ self.eval()
+ for batch in batches:
+ src_batch_ids = paddle.to_tensor(batch)
+ trg_batch_beams = self(src_batch_ids).numpy().transpose([0, 2, 1])
+
+ for trg_sample_beams in trg_batch_beams:
+ for beam_idx, beam in enumerate(trg_sample_beams):
+ if beam_idx >= n_best:
+ break
+ trg_sample_ids = post_process_seq(beam, self.vocab_config['bos_id'], self.vocab_config['eos_id'])
+ trg_sample_words = self.vocab.to_tokens(trg_sample_ids)
+ trg_sample_text = self.tokenizer.detokenize(trg_sample_words)
+ results.append(trg_sample_text)
+
+ return results
diff --git a/modules/text/machine_translation/transformer/en-de/requirements.txt b/modules/text/machine_translation/transformer/en-de/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..adf3e7fe61baa839a71c8b276b752c3ad2148ca4
--- /dev/null
+++ b/modules/text/machine_translation/transformer/en-de/requirements.txt
@@ -0,0 +1,2 @@
+sacremoses
+subword-nmt
diff --git a/modules/text/machine_translation/transformer/en-de/utils.py b/modules/text/machine_translation/transformer/en-de/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..ea3ceba9b327da9a5b7d879650e5e1e75b3094d2
--- /dev/null
+++ b/modules/text/machine_translation/transformer/en-de/utils.py
@@ -0,0 +1,66 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import re
+from typing import List
+
+import codecs
+from sacremoses import MosesTokenizer, MosesDetokenizer
+from subword_nmt.apply_bpe import BPE
+
+
+class MTTokenizer(object):
+ def __init__(self, bpe_codes_file: str, lang_src: str = 'en', lang_trg: str = 'de', separator='@@'):
+ self.moses_tokenizer = MosesTokenizer(lang=lang_src)
+ self.moses_detokenizer = MosesDetokenizer(lang=lang_trg)
+ self.bpe_tokenizer = BPE(
+ codes=codecs.open(bpe_codes_file, encoding='utf-8'),
+ merges=-1,
+ separator=separator,
+ vocab=None,
+ glossaries=None)
+
+ def tokenize(self, text: str):
+ """
+ Convert source string into bpe tokens.
+ """
+ moses_tokens = self.moses_tokenizer.tokenize(text)
+ tokenized_text = ' '.join(moses_tokens)
+ tokenized_bpe_text = self.bpe_tokenizer.process_line(tokenized_text) # Apply bpe to text
+ bpe_tokens = tokenized_bpe_text.split(' ')
+ return bpe_tokens
+
+ def detokenize(self, tokens: List[str]):
+ """
+ Convert target bpe tokens into string.
+ """
+ separator = self.bpe_tokenizer.separator
+ text_with_separators = ' '.join(tokens)
+ clean_text = re.sub(f'({separator} )|({separator} ?$)', '', text_with_separators)
+ clean_tokens = clean_text.split(' ')
+ detokenized_text = self.moses_detokenizer.tokenize(clean_tokens, return_str=True)
+ return detokenized_text
+
+
+def post_process_seq(seq, bos_idx, eos_idx, output_bos=False, output_eos=False):
+ """
+ Post-process the decoded sequence.
+ """
+ eos_pos = len(seq) - 1
+ for i, idx in enumerate(seq):
+ if idx == eos_idx:
+ eos_pos = i
+ break
+ seq = [int(idx) for idx in seq[:eos_pos + 1] if (output_bos or idx != bos_idx) and (output_eos or idx != eos_idx)]
+ return seq
diff --git a/modules/text/machine_translation/transformer/zh-en/README.md b/modules/text/machine_translation/transformer/zh-en/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..444b8cdb3e09bd203441e41c64ae59d3f2e06821
--- /dev/null
+++ b/modules/text/machine_translation/transformer/zh-en/README.md
@@ -0,0 +1,123 @@
+```shell
+$ hub install transformer_zh-en==1.0.0
+```
+
+## 概述
+
+2017 年,Google机器翻译团队在其发表的论文[Attention Is All You Need](https://arxiv.org/abs/1706.03762)中,提出了用于完成机器翻译(Machine Translation)等序列到序列(Seq2Seq)学习任务的一种全新网络结构——Transformer。Tranformer网络完全使用注意力(Attention)机制来实现序列到序列的建模,并且取得了很好的效果。
+
+transformer_zh-en包含6层的transformer结构,头数为8,隐藏层参数为512,参数量为64M。该模型在[CWMT2021的数据集](http://nlp.nju.edu.cn/cwmt-wmt)进行了预训练,加载后可直接用于预测, 提供了中文翻译为英文的能力。
+
+关于机器翻译的Transformer模型训练方式和详情,可查看[Machine Translation using Transformer](https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/machine_translation/transformer)。
+
+## API
+
+
+```python
+def __init__(max_length: int = 256,
+ max_out_len: int = 256,
+ beam_size: int = 5):
+```
+初始化module,可配置模型的输入输出文本的最大长度和解码时beam search的宽度。
+
+**参数**
+- `max_length`(int): 输入文本的最大长度,默认值为256。
+- `max_out_len`(int): 输出文本的最大解码长度,默认值为256。
+- `beam_size`(int): beam search方式解码的beam宽度,默认为5。
+
+
+```python
+def predict(data: List[str],
+ batch_size: int = 1,
+ n_best: int = 1,
+ use_gpu: bool = False):
+```
+预测API,输入源语言的文本句子,解码后输出翻译后的目标语言的文本候选句子。
+
+**参数**
+- `data`(List[str]): 源语言的文本列表,数据类型为List[str]
+- `batch_size`(int): 进行预测的batch_size,默认为1
+- `n_best`(int): 每个输入文本经过模型解码后,输出的得分最高的候选句子的数量,必须小于beam_size,默认为1
+- `use_gpu`(bool): 是否使用gpu执行预测,默认为False
+
+**返回**
+* `results`(List[str]): 翻译后的目标语言的候选句子,长度为`len(data)*n_best`
+
+
+**代码示例**
+
+```python
+import paddlehub as hub
+
+model = hub.Module(name='transformer_zh-en', beam_size=5)
+src_texts = [
+ '今天天气怎么样?',
+ '我们一起去吃饭吧。',
+]
+
+n_best = 3 # 每个输入样本的输出候选句子数量
+trg_texts = model.predict(src_texts, n_best=n_best)
+for idx, st in enumerate(src_texts):
+ print('-'*30)
+ print(f'src: {st}')
+ for i in range(n_best):
+ print(f'trg[{i+1}]: {trg_texts[idx*n_best+i]}')
+```
+
+## 服务部署
+
+通过启动PaddleHub Serving,可以加载模型部署在线翻译服务。
+
+### Step1: 启动PaddleHub Serving
+
+运行启动命令:
+
+```shell
+$ hub serving start -m transformer_zh-en
+```
+
+通过以上命令可完成一个中英机器翻译API的部署,默认端口号为8866。
+
+**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+### Step2: 发送预测请求
+
+配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+```python
+import requests
+import json
+
+texts = [
+ '今天天气怎么样啊?',
+ '我们一起去吃饭吧。',
+]
+data = {"data": texts}
+# 发送post请求,content-type类型应指定json方式,url中的ip地址需改为对应机器的ip
+url = "http://127.0.0.1:8866/predict/transformer_zh-en"
+# 指定post请求的headers为application/json方式
+headers = {"Content-Type": "application/json"}
+
+r = requests.post(url=url, headers=headers, data=json.dumps(data))
+print(r.json())
+```
+
+## 查看代码
+
+https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/machine_translation/transformer
+
+## 依赖
+
+paddlepaddle >= 2.0.0
+
+paddlehub >= 2.1.0
+
+## 更新历史
+
+* 1.0.0
+
+ 初始发布
+
+* 1.0.1
+
+ 修复模型初始化的兼容性问题
diff --git a/modules/text/machine_translation/transformer/zh-en/__init__.py b/modules/text/machine_translation/transformer/zh-en/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/modules/text/machine_translation/transformer/zh-en/module.py b/modules/text/machine_translation/transformer/zh-en/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..7d6d6a1a017b4cd589fa487cf26e932333f71467
--- /dev/null
+++ b/modules/text/machine_translation/transformer/zh-en/module.py
@@ -0,0 +1,190 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from packaging.version import Version
+from typing import List
+
+import paddle
+import paddle.nn as nn
+from paddlehub.env import MODULE_HOME
+from paddlehub.module.module import moduleinfo, serving
+import paddlenlp
+from paddlenlp.data import Pad, Vocab
+from paddlenlp.transformers import InferTransformerModel, position_encoding_init
+
+from transformer_zh_en.utils import MTTokenizer, post_process_seq
+
+
+@moduleinfo(
+ name="transformer_zh-en",
+ version="1.0.1",
+ summary="",
+ author="PaddlePaddle",
+ author_email="",
+ type="nlp/machine_translation",
+)
+class MTTransformer(nn.Layer):
+ """
+ Transformer model for machine translation.
+ """
+ # Language config
+ lang_config = {'source': 'zh', 'target': 'en'}
+
+ # Model config
+ model_config = {
+ # Number of head used in multi-head attention.
+ "n_head": 8,
+ # The dimension for word embeddings, which is also the last dimension of
+ # the input and output of multi-head attention, position-wise feed-forward
+ # networks, encoder and decoder.
+ "d_model": 512,
+ # Size of the hidden layer in position-wise feed-forward networks.
+ "d_inner_hid": 2048,
+ # The flag indicating whether to share embedding and softmax weights.
+ # Vocabularies in source and target should be same for weight sharing.
+ "weight_sharing": False,
+ # Dropout rate
+ 'dropout': 0
+ }
+
+ # Number of sub-layers to be stacked in the encoder and decoder.
+ if Version(paddlenlp.__version__) <= Version('2.0.5'):
+ model_config.update({"n_layer": 6})
+ else:
+ model_config.update({"num_encoder_layers": 6, "num_decoder_layers": 6})
+
+ # Vocab config
+ vocab_config = {
+ # Used to pad vocab size to be multiple of pad_factor.
+ "pad_factor": 8,
+ # Index for token
+ "bos_id": 0,
+ "bos_token": "",
+ # Index for token
+ "eos_id": 1,
+ "eos_token": "",
+ # Index for token
+ "unk_id": 2,
+ "unk_token": "",
+ }
+
+ def __init__(self, max_length: int = 256, max_out_len: int = 256, beam_size: int = 5):
+ super(MTTransformer, self).__init__()
+ bpe_codes_file = os.path.join(MODULE_HOME, 'transformer_zh_en', 'assets', '2M.zh2en.dict4bpe.zh')
+ src_vocab_file = os.path.join(MODULE_HOME, 'transformer_zh_en', 'assets', 'vocab.zh')
+ trg_vocab_file = os.path.join(MODULE_HOME, 'transformer_zh_en', 'assets', 'vocab.en')
+ checkpoint = os.path.join(MODULE_HOME, 'transformer_zh_en', 'assets', 'transformer.pdparams')
+
+ self.max_length = max_length
+ self.beam_size = beam_size
+ self.tokenizer = MTTokenizer(
+ bpe_codes_file=bpe_codes_file, lang_src=self.lang_config['source'], lang_trg=self.lang_config['target'])
+ self.src_vocab = Vocab.load_vocabulary(
+ filepath=src_vocab_file,
+ unk_token=self.vocab_config['unk_token'],
+ bos_token=self.vocab_config['bos_token'],
+ eos_token=self.vocab_config['eos_token'])
+ self.trg_vocab = Vocab.load_vocabulary(
+ filepath=trg_vocab_file,
+ unk_token=self.vocab_config['unk_token'],
+ bos_token=self.vocab_config['bos_token'],
+ eos_token=self.vocab_config['eos_token'])
+ self.src_vocab_size = (len(self.src_vocab) + self.vocab_config['pad_factor'] - 1) \
+ // self.vocab_config['pad_factor'] * self.vocab_config['pad_factor']
+ self.trg_vocab_size = (len(self.trg_vocab) + self.vocab_config['pad_factor'] - 1) \
+ // self.vocab_config['pad_factor'] * self.vocab_config['pad_factor']
+ self.transformer = InferTransformerModel(
+ src_vocab_size=self.src_vocab_size,
+ trg_vocab_size=self.trg_vocab_size,
+ bos_id=self.vocab_config['bos_id'],
+ eos_id=self.vocab_config['eos_id'],
+ max_length=self.max_length + 1,
+ max_out_len=max_out_len,
+ beam_size=self.beam_size,
+ **self.model_config)
+
+ state_dict = paddle.load(checkpoint)
+
+ # To avoid a longer length than training, reset the size of position
+ # encoding to max_length
+ state_dict["encoder.pos_encoder.weight"] = position_encoding_init(self.max_length + 1,
+ self.model_config['d_model'])
+ state_dict["decoder.pos_encoder.weight"] = position_encoding_init(self.max_length + 1,
+ self.model_config['d_model'])
+
+ self.transformer.set_state_dict(state_dict)
+
+ def forward(self, src_words: paddle.Tensor):
+ return self.transformer(src_words)
+
+ def _convert_text_to_input(self, text: str):
+ """
+ Convert input string to ids.
+ """
+ bpe_tokens = self.tokenizer.tokenize(text)
+ if len(bpe_tokens) > self.max_length:
+ bpe_tokens = bpe_tokens[:self.max_length]
+ return self.src_vocab.to_indices(bpe_tokens)
+
+ def _batchify(self, data: List[str], batch_size: int):
+ """
+ Generate input batches.
+ """
+ pad_func = Pad(self.vocab_config['eos_id'])
+
+ def _parse_batch(batch_ids):
+ return pad_func([ids + [self.vocab_config['eos_id']] for ids in batch_ids])
+
+ examples = []
+ for text in data:
+ examples.append(self._convert_text_to_input(text))
+
+ # Seperates data into some batches.
+ one_batch = []
+ for example in examples:
+ one_batch.append(example)
+ if len(one_batch) == batch_size:
+ yield _parse_batch(one_batch)
+ one_batch = []
+ if one_batch:
+ yield _parse_batch(one_batch)
+
+ @serving
+ def predict(self, data: List[str], batch_size: int = 1, n_best: int = 1, use_gpu: bool = False):
+
+ if n_best > self.beam_size:
+ raise ValueError(f'Predict arg "n_best" must be smaller or equal to self.beam_size, \
+ but got {n_best} > {self.beam_size}')
+
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+
+ batches = self._batchify(data, batch_size)
+
+ results = []
+ self.eval()
+ for batch in batches:
+ src_batch_ids = paddle.to_tensor(batch)
+ trg_batch_beams = self(src_batch_ids).numpy().transpose([0, 2, 1])
+
+ for trg_sample_beams in trg_batch_beams:
+ for beam_idx, beam in enumerate(trg_sample_beams):
+ if beam_idx >= n_best:
+ break
+ trg_sample_ids = post_process_seq(beam, self.vocab_config['bos_id'], self.vocab_config['eos_id'])
+ trg_sample_words = self.trg_vocab.to_tokens(trg_sample_ids)
+ trg_sample_text = self.tokenizer.detokenize(trg_sample_words)
+ results.append(trg_sample_text)
+
+ return results
diff --git a/modules/text/machine_translation/transformer/zh-en/requirements.txt b/modules/text/machine_translation/transformer/zh-en/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6029eb21ad870229e0cb41e4462cf741227e52e2
--- /dev/null
+++ b/modules/text/machine_translation/transformer/zh-en/requirements.txt
@@ -0,0 +1,3 @@
+jieba
+sacremoses
+subword-nmt
diff --git a/modules/text/machine_translation/transformer/zh-en/utils.py b/modules/text/machine_translation/transformer/zh-en/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..aea02ca859462b0a8820e4f116091c5ab47689d2
--- /dev/null
+++ b/modules/text/machine_translation/transformer/zh-en/utils.py
@@ -0,0 +1,71 @@
+# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import logging
+import re
+from typing import List
+
+import codecs
+import jieba
+
+jieba.setLogLevel(logging.INFO)
+
+from sacremoses import MosesTokenizer, MosesDetokenizer
+from subword_nmt.apply_bpe import BPE
+
+
+class MTTokenizer(object):
+ def __init__(self, bpe_codes_file: str, lang_src: str = 'zh', lang_trg: str = 'en', separator='@@'):
+ self.moses_detokenizer = MosesDetokenizer(lang=lang_trg)
+ self.bpe_tokenizer = BPE(
+ codes=codecs.open(bpe_codes_file, encoding='utf-8'),
+ merges=-1,
+ separator=separator,
+ vocab=None,
+ glossaries=None)
+
+ def tokenize(self, text: str):
+ """
+ Convert source string into bpe tokens.
+ """
+ text = text.replace(' ', '') # Remove blanks in Chinese text.
+ jieba_tokens = list(jieba.cut(text))
+ tokenized_text = ' '.join(jieba_tokens)
+ tokenized_bpe_text = self.bpe_tokenizer.process_line(tokenized_text) # Apply bpe to text
+ bpe_tokens = tokenized_bpe_text.split(' ')
+ return bpe_tokens
+
+ def detokenize(self, tokens: List[str]):
+ """
+ Convert target bpe tokens into string.
+ """
+ separator = self.bpe_tokenizer.separator
+ text_with_separators = ' '.join(tokens)
+ clean_text = re.sub(f'({separator} )|({separator} ?$)', '', text_with_separators)
+ clean_tokens = clean_text.split(' ')
+ detokenized_text = self.moses_detokenizer.tokenize(clean_tokens, return_str=True)
+ return detokenized_text
+
+
+def post_process_seq(seq, bos_idx, eos_idx, output_bos=False, output_eos=False):
+ """
+ Post-process the decoded sequence.
+ """
+ eos_pos = len(seq) - 1
+ for i, idx in enumerate(seq):
+ if idx == eos_idx:
+ eos_pos = i
+ break
+ seq = [int(idx) for idx in seq[:eos_pos + 1] if (output_bos or idx != bos_idx) and (output_eos or idx != eos_idx)]
+ return seq
diff --git a/modules/text/sentiment_analysis/emotion_detection_textcnn/README.md b/modules/text/sentiment_analysis/emotion_detection_textcnn/README.md
index 3445c6f590379132f273267d9eb33c8c3b0529d0..98a9fd0325f95de446649f791e816ecc434b130c 100644
--- a/modules/text/sentiment_analysis/emotion_detection_textcnn/README.md
+++ b/modules/text/sentiment_analysis/emotion_detection_textcnn/README.md
@@ -72,7 +72,7 @@ Loading emotion_detection_textcnn successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/sentiment_analysis/senta_bilstm/README.md b/modules/text/sentiment_analysis/senta_bilstm/README.md
index 01f8ff4bd19ffd6541afaf036904b50133de3c5a..f5dd65b56b6e94c9a3a7faf7eb0a72bf94ca67b7 100644
--- a/modules/text/sentiment_analysis/senta_bilstm/README.md
+++ b/modules/text/sentiment_analysis/senta_bilstm/README.md
@@ -72,7 +72,7 @@ Loading senta_bilstm successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/sentiment_analysis/senta_bow/README.md b/modules/text/sentiment_analysis/senta_bow/README.md
index c7abcd75555ab57b571ac485dba1a3218fdc899c..8b27e9afcbbfef3c7e93e7590c416c2513be9c9f 100644
--- a/modules/text/sentiment_analysis/senta_bow/README.md
+++ b/modules/text/sentiment_analysis/senta_bow/README.md
@@ -72,7 +72,7 @@ Loading senta_bow successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/sentiment_analysis/senta_cnn/README.md b/modules/text/sentiment_analysis/senta_cnn/README.md
index f17a6ce7777a9c4656594171d046b88a701f75de..892a67ff6c7e84fd9dcb7721c6897cccd07a8da1 100644
--- a/modules/text/sentiment_analysis/senta_cnn/README.md
+++ b/modules/text/sentiment_analysis/senta_cnn/README.md
@@ -72,7 +72,7 @@ Loading senta_cnn successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/sentiment_analysis/senta_gru/README.md b/modules/text/sentiment_analysis/senta_gru/README.md
index 75d8aae3d0373d566c1cbd90cbeba430ca34a2cc..3b4fbe76936153f597d354835abb1352d6321966 100644
--- a/modules/text/sentiment_analysis/senta_gru/README.md
+++ b/modules/text/sentiment_analysis/senta_gru/README.md
@@ -72,7 +72,7 @@ Loading senta_gru successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/sentiment_analysis/senta_lstm/README.md b/modules/text/sentiment_analysis/senta_lstm/README.md
index 84df3b0d1fd03d3bd95d27cf5625486aa757ee48..35e368e554ae3e3a4f7777163e5616040eba31bf 100644
--- a/modules/text/sentiment_analysis/senta_lstm/README.md
+++ b/modules/text/sentiment_analysis/senta_lstm/README.md
@@ -72,7 +72,7 @@ Loading senta_lstm successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/text_generation/ernie_gen/README.md b/modules/text/text_generation/ernie_gen/README.md
index fc3a08d3853147b33232ffc13ec6e487ec6a6cda..a7183c970e67ed6aec3f15390046471c8be5e3b5 100644
--- a/modules/text/text_generation/ernie_gen/README.md
+++ b/modules/text/text_generation/ernie_gen/README.md
@@ -170,9 +170,11 @@ https://github.com/PaddlePaddle/ERNIE/blob/repro/ernie-gen/
### 依赖
-paddlepaddle >= 1.8.2
+paddlepaddle >= 2.0.0
-paddlehub >= 1.7.0
+paddlehub >= 2.0.0
+
+paddlenlp >= 2.0.0
## 更新历史
@@ -188,3 +190,7 @@ paddlehub >= 1.7.0
* 1.0.2
修复windows运行中的bug
+
+* 1.1.0
+
+ 接入PaddleNLP
diff --git a/modules/text/text_generation/ernie_gen/decode.py b/modules/text/text_generation/ernie_gen/decode.py
index a9dd8609824a4b7bc5bb8c1dd738416573503813..3aadd245509bd5d1335b327c15a5c2de520f39ab 100644
--- a/modules/text/text_generation/ernie_gen/decode.py
+++ b/modules/text/text_generation/ernie_gen/decode.py
@@ -1,4 +1,4 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
@@ -12,75 +12,96 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-import re
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+import sys
+import re
+import argparse
+import logging
+import json
+import numpy as np
from collections import namedtuple
-import paddle.fluid as F
-import paddle.fluid.layers as L
-import paddle.fluid.dygraph as D
+import paddle
+import paddle.nn as nn
import numpy as np
-from paddlehub.common.logger import logger
+from paddlenlp.utils.log import logger
def gen_bias(encoder_inputs, decoder_inputs, step):
decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
- attn_bias = L.reshape(L.range(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
- decoder_bias = L.cast((L.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
- 'float32') # [1, 1, decoderlen, decoderlen]
- encoder_bias = L.unsqueeze(L.cast(L.ones_like(encoder_inputs), 'float32'), [1]) # [bsz, 1, encoderlen]
- encoder_bias = L.expand(encoder_bias, [1, decoder_seqlen, 1]) # [bsz,decoderlen, encoderlen]
- decoder_bias = L.expand(decoder_bias, [decoder_bsz, 1, 1]) # [bsz, decoderlen, decoderlen]
+ encoder_bsz, encoder_seqlen = encoder_inputs.shape[:2]
+ attn_bias = paddle.reshape(paddle.arange(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
+ decoder_bias = paddle.cast((paddle.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
+ 'float32') #[1, decoderlen, decoderlen]
+ encoder_bias = paddle.unsqueeze(paddle.cast(paddle.ones_like(encoder_inputs), 'float32'),
+ [1]) #[bsz, 1, encoderlen]
+ encoder_bias = paddle.expand(encoder_bias,
+ [encoder_bsz, decoder_seqlen, encoder_seqlen]) #[bsz,decoderlen, encoderlen]
+ decoder_bias = paddle.expand(decoder_bias,
+ [decoder_bsz, decoder_seqlen, decoder_seqlen]) #[bsz, decoderlen, decoderlen]
if step > 0:
- bias = L.concat([encoder_bias, L.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
+ bias = paddle.concat(
+ [encoder_bias, paddle.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
else:
- bias = L.concat([encoder_bias, decoder_bias], -1)
+ bias = paddle.concat([encoder_bias, decoder_bias], -1)
return bias
-@D.no_grad
+@paddle.no_grad()
def greedy_search_infilling(model,
- q_ids,
- q_sids,
+ token_ids,
+ token_type_ids,
sos_id,
eos_id,
attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
max_encode_len=640,
max_decode_len=100,
tgt_type_id=3):
- model.eval()
- _, logits, info = model(q_ids, q_sids)
- gen_ids = L.argmax(logits, -1)
- d_batch, d_seqlen = q_ids.shape
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
- logger.debug(seqlen.numpy())
- logger.debug(d_seqlen)
+ _, logits, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
has_stopped = np.zeros([d_batch], dtype=np.bool)
gen_seq_len = np.zeros([d_batch], dtype=np.int64)
output_ids = []
past_cache = info['caches']
- cls_ids = L.ones([d_batch], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch], dtype='int64') * attn_id
- ids = L.stack([cls_ids, attn_ids], -1)
+ cls_ids = paddle.ones([d_batch], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch], dtype='int64') * attn_id
+ ids = paddle.stack([cls_ids, attn_ids], -1)
for step in range(max_decode_len):
- logger.debug('decode step %d' % step)
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
pos_ids += seqlen
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
- gen_ids = L.argmax(logits, -1)
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ gen_ids = paddle.argmax(logits, -1)
past_cached_k, past_cached_v = past_cache
cached_k, cached_v = info['caches']
- cached_k = [L.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
- cached_v = [L.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
+ cached_k = [paddle.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
+ cached_v = [paddle.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
past_cache = (cached_k, cached_v)
gen_ids = gen_ids[:, 1]
- ids = L.stack([gen_ids, attn_ids], 1)
+ ids = paddle.stack([gen_ids, attn_ids], 1)
gen_ids = gen_ids.numpy()
has_stopped |= (gen_ids == eos_id).astype(np.bool)
@@ -102,13 +123,13 @@ def log_softmax(x):
def mask_prob(p, onehot_eos, finished):
- is_finished = L.cast(L.reshape(finished, [-1, 1]) != 0, 'float32')
- p = is_finished * (1. - L.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
+ is_finished = paddle.cast(paddle.reshape(finished, [-1, 1]) != 0, 'float32')
+ p = is_finished * (1. - paddle.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
return p
def hyp_score(log_probs, length, length_penalty):
- lp = L.pow((5. + L.cast(length, 'float32')) / 6., length_penalty)
+ lp = paddle.pow((5. + paddle.cast(length, 'float32')) / 6., length_penalty)
return log_probs / lp
@@ -117,36 +138,36 @@ def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_pe
_, vocab_size = logits.shape
bsz, beam_width = state.log_probs.shape
- onehot_eos = L.cast(F.one_hot(L.ones([1], 'int64') * eos_id, vocab_size), 'int64') # [1, V]
+ onehot_eos = paddle.cast(nn.functional.one_hot(paddle.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
- probs = L.log(L.softmax(logits)) # [B*W, V]
- probs = mask_prob(probs, onehot_eos, state.finished) # [B*W, V]
- allprobs = L.reshape(state.log_probs, [-1, 1]) + probs # [B*W, V]
+ probs = paddle.log(nn.functional.softmax(logits)) #[B*W, V]
+ probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
+ allprobs = paddle.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
- not_finished = 1 - L.reshape(state.finished, [-1, 1]) # [B*W,1]
+ not_finished = 1 - paddle.reshape(state.finished, [-1, 1]) #[B*W,1]
not_eos = 1 - onehot_eos
- length_to_add = not_finished * not_eos # [B*W,V]
- alllen = L.reshape(state.lengths, [-1, 1]) + length_to_add
+ length_to_add = not_finished * not_eos #[B*W,V]
+ alllen = paddle.reshape(state.lengths, [-1, 1]) + length_to_add
- allprobs = L.reshape(allprobs, [-1, beam_width * vocab_size])
- alllen = L.reshape(alllen, [-1, beam_width * vocab_size])
+ allprobs = paddle.reshape(allprobs, [-1, beam_width * vocab_size])
+ alllen = paddle.reshape(alllen, [-1, beam_width * vocab_size])
allscore = hyp_score(allprobs, alllen, length_penalty)
if is_first_step:
- allscore = L.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
- scores, idx = L.topk(allscore, k=beam_width) # [B, W]
- next_beam_id = idx // vocab_size # [B, W]
+ allscore = paddle.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
+ scores, idx = paddle.topk(allscore, k=beam_width) #[B, W]
+ next_beam_id = idx // vocab_size #[B, W]
next_word_id = idx % vocab_size
- gather_idx = L.concat([L.where(idx != -1)[:, :1], L.reshape(idx, [-1, 1])], 1)
- next_probs = L.reshape(L.gather_nd(allprobs, gather_idx), idx.shape)
- next_len = L.reshape(L.gather_nd(alllen, gather_idx), idx.shape)
+ gather_idx = paddle.concat([paddle.nonzero(idx != -1)[:, :1], paddle.reshape(idx, [-1, 1])], 1)
+ next_probs = paddle.reshape(paddle.gather_nd(allprobs, gather_idx), idx.shape)
+ next_len = paddle.reshape(paddle.gather_nd(alllen, gather_idx), idx.shape)
- gather_idx = L.concat([L.where(next_beam_id != -1)[:, :1], L.reshape(next_beam_id, [-1, 1])], 1)
- next_finished = L.reshape(L.gather_nd(state.finished, gather_idx),
- state.finished.shape) # [gather new beam state according to new beam id]
+ gather_idx = paddle.concat([paddle.nonzero(next_beam_id != -1)[:, :1], paddle.reshape(next_beam_id, [-1, 1])], 1)
+ next_finished = paddle.reshape(paddle.gather_nd(state.finished, gather_idx),
+ state.finished.shape) #[gather new beam state according to new beam id]
- next_finished += L.cast(next_word_id == eos_id, 'int64')
- next_finished = L.cast(next_finished > 0, 'int64')
+ next_finished += paddle.cast(next_word_id == eos_id, 'int64')
+ next_finished = paddle.cast(next_finished > 0, 'int64')
next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
@@ -154,42 +175,39 @@ def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_pe
return output, next_state
-@D.no_grad
+@paddle.no_grad()
def beam_search_infilling(model,
- q_ids,
- q_sids,
+ token_ids,
+ token_type_ids,
sos_id,
eos_id,
attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
max_encode_len=640,
max_decode_len=100,
beam_width=5,
tgt_type_id=3,
length_penalty=1.0):
- model.eval()
- _, __, info = model(q_ids, q_sids)
- d_batch, d_seqlen = q_ids.shape
-
- state = BeamSearchState(
- log_probs=L.zeros([d_batch, beam_width], 'float32'),
- lengths=L.zeros([d_batch, beam_width], 'int64'),
- finished=L.zeros([d_batch, beam_width], 'int64'))
+ _, __, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+
+ state = BeamSearchState(log_probs=paddle.zeros([d_batch, beam_width], 'float32'),
+ lengths=paddle.zeros([d_batch, beam_width], 'int64'),
+ finished=paddle.zeros([d_batch, beam_width], 'int64'))
outputs = []
def reorder_(t, parent_id):
"""reorder cache according to parent beam id"""
- gather_idx = L.where(parent_id != -1)[:, 0] * beam_width + L.reshape(parent_id, [-1])
- t = L.gather(t, gather_idx)
+ gather_idx = paddle.nonzero(parent_id != -1)[:, 0] * beam_width + paddle.reshape(parent_id, [-1])
+ t = paddle.gather(t, gather_idx)
return t
def tile_(t, times):
_shapes = list(t.shape[1:])
- ret = L.reshape(L.expand(L.unsqueeze(t, [1]), [
- 1,
- times,
- ] + [
- 1,
- ] * len(_shapes)), [
+ new_shape = [t.shape[0], times] + list(t.shape[1:])
+ ret = paddle.reshape(paddle.expand(paddle.unsqueeze(t, [1]), new_shape), [
-1,
] + _shapes)
return ret
@@ -199,49 +217,59 @@ def beam_search_infilling(model,
cached_v = [tile_(v, beam_width) for v in cached_v]
past_cache = (cached_k, cached_v)
- q_ids = tile_(q_ids, beam_width)
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
+ token_ids = tile_(token_ids, beam_width)
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
- cls_ids = L.ones([d_batch * beam_width], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
- ids = L.stack([cls_ids, attn_ids], -1)
+ cls_ids = paddle.ones([d_batch * beam_width], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
+ ids = paddle.stack([cls_ids, attn_ids], -1)
for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
pos_ids += seqlen
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
-
- output, state = beam_search_step(
- state,
- logits[:, 1],
- eos_id=eos_id,
- beam_width=beam_width,
- is_first_step=(step == 0),
- length_penalty=length_penalty)
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ output, state = beam_search_step(state,
+ logits[:, 1],
+ eos_id=eos_id,
+ beam_width=beam_width,
+ is_first_step=(step == 0),
+ length_penalty=length_penalty)
outputs.append(output)
past_cached_k, past_cached_v = past_cache
cached_k, cached_v = info['caches']
cached_k = [
- reorder_(L.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids) for pk, k in zip(past_cached_k, cached_k)
+ reorder_(paddle.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids)
+ for pk, k in zip(past_cached_k, cached_k)
] # concat cached
cached_v = [
- reorder_(L.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids) for pv, v in zip(past_cached_v, cached_v)
+ reorder_(paddle.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids)
+ for pv, v in zip(past_cached_v, cached_v)
]
past_cache = (cached_k, cached_v)
- pred_ids_flatten = L.reshape(output.predicted_ids, [d_batch * beam_width])
- ids = L.stack([pred_ids_flatten, attn_ids], 1)
+ pred_ids_flatten = paddle.reshape(output.predicted_ids, [d_batch * beam_width])
+ ids = paddle.stack([pred_ids_flatten, attn_ids], 1)
if state.finished.numpy().all():
break
- final_ids = L.stack([o.predicted_ids for o in outputs], 0)
- final_parent_ids = L.stack([o.beam_parent_ids for o in outputs], 0)
- final_ids = L.gather_tree(final_ids, final_parent_ids)[:, :, 0] # pick best beam
- final_ids = L.transpose(L.reshape(final_ids, [-1, d_batch * 1]), [1, 0])
- return final_ids
+ final_ids = paddle.stack([o.predicted_ids for o in outputs], 0)
+ final_parent_ids = paddle.stack([o.beam_parent_ids for o in outputs], 0)
+ final_ids = nn.functional.gather_tree(final_ids, final_parent_ids) #[:, :, 0] #pick best beam
+ final_ids = paddle.transpose(paddle.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
+
+ return final_ids.numpy()
en_patten = re.compile(r'^[a-zA-Z0-9]*$')
@@ -250,6 +278,8 @@ en_patten = re.compile(r'^[a-zA-Z0-9]*$')
def post_process(token):
if token.startswith('##'):
ret = token[2:]
+ elif token in ['[CLS]', '[SEP]', '[PAD]']:
+ ret = ''
else:
if en_patten.match(token):
ret = ' ' + token
diff --git a/modules/text/text_generation/ernie_gen/encode.py b/modules/text/text_generation/ernie_gen/encode.py
new file mode 100644
index 0000000000000000000000000000000000000000..370ba0004d8158b2357159c9b373caca0c815acd
--- /dev/null
+++ b/modules/text/text_generation/ernie_gen/encode.py
@@ -0,0 +1,131 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from copy import deepcopy
+
+import numpy as np
+
+
+def convert_example(tokenizer,
+ attn_id,
+ tgt_type_id=3,
+ max_encode_len=512,
+ max_decode_len=128,
+ is_test=False,
+ noise_prob=0.,
+ use_random_noice=False):
+ def warpper(example):
+ """convert an example into necessary features"""
+ tokens = example['tokens']
+ labels = example['labels']
+ encoded_src = tokenizer(tokens, max_seq_len=max_encode_len, pad_to_max_seq_len=False)
+ src_ids, src_sids = encoded_src["input_ids"], encoded_src["token_type_ids"]
+ src_pids = np.arange(len(src_ids))
+
+ if not is_test:
+ encoded_tgt = tokenizer(labels, max_seq_len=max_decode_len, pad_to_max_seq_len=False)
+ tgt_ids, tgt_sids = encoded_tgt["input_ids"], encoded_tgt["token_type_ids"]
+ tgt_ids = np.array(tgt_ids)
+ tgt_sids = np.array(tgt_sids) + tgt_type_id
+ tgt_pids = np.arange(len(tgt_ids)) + len(src_ids)
+
+ attn_ids = np.ones_like(tgt_ids) * attn_id
+ if noise_prob > 0.:
+ tgt_labels = deepcopy(tgt_ids)
+ if use_random_noice:
+ noice_ids = np.random.randint(1, len(tokenizer.vocab), size=tgt_ids.shape)
+ else:
+ noice_ids = np.ones_like(tgt_ids) * tokenizer.vocab['[NOISE]']
+ pos, = np.where(np.ones_like(tgt_ids))
+ np.random.shuffle(pos)
+ pos = pos[:int(noise_prob * len(pos))]
+ tgt_ids[pos, ] = noice_ids[pos, ]
+ else:
+ tgt_labels = tgt_ids
+
+ return [np.asarray(item, dtype=np.int64) for item \
+ in [src_ids, src_pids, src_sids, tgt_ids, tgt_pids, tgt_sids, attn_ids, tgt_labels]]
+
+ return warpper
+
+
+def gen_mask(batch_ids, mask_type='bidi', query_len=None, pad_value=0):
+ if query_len is None:
+ query_len = batch_ids.shape[1]
+ if mask_type != 'empty':
+ mask = (batch_ids != pad_value).astype(np.float32)
+ mask = np.tile(np.expand_dims(mask, 1), [1, query_len, 1])
+ if mask_type == 'causal':
+ assert query_len == batch_ids.shape[1]
+ mask = np.tril(mask)
+ elif mask_type == 'causal_without_diag':
+ assert query_len == batch_ids.shape[1]
+ mask = np.tril(mask, -1)
+ elif mask_type == 'diag':
+ assert query_len == batch_ids.shape[1]
+ # import pdb; pdb.set_trace()
+ mask = np.stack([np.diag(np.diag(m)) for m in mask], 0)
+
+ else:
+ mask_type == 'empty'
+ mask = np.zeros_like(batch_ids).astype(np.float32)
+ mask = np.tile(np.expand_dims(mask, 1), [1, query_len, 1])
+ return mask
+
+
+def after_padding(args):
+ '''
+ attention mask:
+ *** src, tgt, attn
+ src 00, 01, 11
+ tgt 10, 11, 12
+ attn 20, 21, 22
+
+ *** s1, s2 | t1 t2 t3| attn1 attn2 attn3
+ s1 1, 1 | 0, 0, 0,| 0, 0, 0,
+ s2 1, 1 | 0, 0, 0,| 0, 0, 0,
+ -
+ t1 1, 1, | 1, 0, 0,| 0, 0, 0,
+ t2 1, 1, | 1, 1, 0,| 0, 0, 0,
+ t3 1, 1, | 1, 1, 1,| 0, 0, 0,
+ -
+ attn1 1, 1, | 0, 0, 0,| 1, 0, 0,
+ attn2 1, 1, | 1, 0, 0,| 0, 1, 0,
+ attn3 1, 1, | 1, 1, 0,| 0, 0, 1,
+
+ for details, see Fig3. https://arxiv.org/abs/2001.11314
+ '''
+ src_ids, src_pids, src_sids, tgt_ids, tgt_pids, tgt_sids, attn_ids, tgt_labels = args
+ src_len = src_ids.shape[1]
+ tgt_len = tgt_ids.shape[1]
+ mask_00 = gen_mask(src_ids, 'bidi', query_len=src_len)
+ mask_01 = gen_mask(tgt_ids, 'empty', query_len=src_len)
+ mask_02 = gen_mask(attn_ids, 'empty', query_len=src_len)
+
+ mask_10 = gen_mask(src_ids, 'bidi', query_len=tgt_len)
+ mask_11 = gen_mask(tgt_ids, 'causal', query_len=tgt_len)
+ mask_12 = gen_mask(attn_ids, 'empty', query_len=tgt_len)
+
+ mask_20 = gen_mask(src_ids, 'bidi', query_len=tgt_len)
+ mask_21 = gen_mask(tgt_ids, 'causal_without_diag', query_len=tgt_len)
+ mask_22 = gen_mask(attn_ids, 'diag', query_len=tgt_len)
+
+ mask_src_2_src = mask_00
+ mask_tgt_2_srctgt = np.concatenate([mask_10, mask_11], 2)
+ mask_attn_2_srctgtattn = np.concatenate([mask_20, mask_21, mask_22], 2)
+
+ raw_tgt_labels = deepcopy(tgt_labels)
+ tgt_labels = tgt_labels[np.where(tgt_labels != 0)]
+ return (src_ids, src_sids, src_pids, tgt_ids, tgt_sids, tgt_pids, attn_ids, mask_src_2_src, mask_tgt_2_srctgt,
+ mask_attn_2_srctgtattn, tgt_labels, raw_tgt_labels)
diff --git a/modules/text/text_generation/ernie_gen/model.py b/modules/text/text_generation/ernie_gen/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..0583fafaac9972eb08db8e74c1b261485d3484ba
--- /dev/null
+++ b/modules/text/text_generation/ernie_gen/model.py
@@ -0,0 +1,50 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle
+import paddle.nn as nn
+import numpy as np
+
+
+class StackModel(nn.Layer):
+ def __init__(self, model):
+ super().__init__()
+ self.model = model
+
+ def forward(self, src_ids, src_sids, src_pids, tgt_ids, tgt_sids, tgt_pids, attn_ids, mask_src_2_src,
+ mask_tgt_2_srctgt, mask_attn_2_srctgtattn, tgt_labels, tgt_pos):
+ _, __, info = self.model(src_ids,
+ sent_ids=src_sids,
+ pos_ids=src_pids,
+ attn_bias=mask_src_2_src,
+ encode_only=True)
+ cached_k, cached_v = info['caches']
+ _, __, info = self.model(tgt_ids,
+ sent_ids=tgt_sids,
+ pos_ids=tgt_pids,
+ attn_bias=mask_tgt_2_srctgt,
+ past_cache=(cached_k, cached_v),
+ encode_only=True)
+ cached_k2, cached_v2 = info['caches']
+ past_cache_k = [paddle.concat([k, k2], 1) for k, k2 in zip(cached_k, cached_k2)]
+ past_cache_v = [paddle.concat([v, v2], 1) for v, v2 in zip(cached_v, cached_v2)]
+ loss, _, __ = self.model(attn_ids,
+ sent_ids=tgt_sids,
+ pos_ids=tgt_pids,
+ attn_bias=mask_attn_2_srctgtattn,
+ past_cache=(past_cache_k, past_cache_v),
+ tgt_labels=tgt_labels,
+ tgt_pos=tgt_pos)
+ loss = loss.mean()
+ return loss
diff --git a/modules/text/text_generation/ernie_gen/module.py b/modules/text/text_generation/ernie_gen/module.py
index 3a6ee5b7bafdf1c3a2eb6275a8ecef5fdba1e07b..e62c24e191278096301b100a59a594550435c5e9 100644
--- a/modules/text/text_generation/ernie_gen/module.py
+++ b/modules/text/text_generation/ernie_gen/module.py
@@ -18,68 +18,66 @@ import shutil
from copy import deepcopy
import numpy as np
-import paddle.fluid as F
-import paddle.fluid.layers as L
-import paddle.fluid.dygraph as D
-try:
- from ernie.modeling_ernie import ErnieModelForGeneration
- from ernie.tokenizing_ernie import ErnieTokenizer
- from ernie.optimization import AdamW, LinearDecay
-except:
- raise ImportError(
- "The module requires additional dependencies: ernie. You can install ernie via 'pip install paddle-ernie'")
+import paddle
+import paddle.nn as nn
+from paddle.io import DataLoader
import paddlehub as hub
from paddlehub.common.logger import logger
from paddlehub.module.module import moduleinfo
+from paddlenlp.datasets import MapDataset
+from paddlenlp.data import Stack, Tuple, Pad
+from paddlenlp.metrics import Rouge1, Rouge2
+from paddlenlp.transformers import ErnieTokenizer, ErnieForGeneration, LinearDecayWithWarmup
-from .decode import beam_search_infilling, post_process
-import ernie_gen.propeller.paddle as propeller
+from .encode import convert_example, after_padding
+from .decode import post_process, beam_search_infilling
+from .model import StackModel
@moduleinfo(
name="ernie_gen",
- version="1.0.2",
+ version="1.1.0",
summary="ERNIE-GEN is a multi-flow language generation framework for both pre-training and fine-tuning.",
author="baidu",
author_email="",
type="nlp/text_generation",
)
-class ErnieGen(hub.Module):
- def _initialize(self):
+class ErnieGen():
+ def __init__(self):
"""
initialize with the necessary elements
"""
- self.tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0", mask_token=None)
- self.rev_dict = {v: k for k, v in self.tokenizer.vocab.items()}
+ self.tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
+ self.rev_dict = self.tokenizer.vocab.idx_to_token
self.rev_lookup = np.vectorize(lambda i: self.rev_dict[i])
self._model = None
@property
def model(self):
if not self._model:
- self._model = ErnieModelForGeneration.from_pretrained("ernie-1.0")
+ self._model = ErnieForGeneration.from_pretrained("ernie-1.0")
return self._model
def finetune(
- self,
- train_path,
- dev_path=None,
- save_dir="ernie_gen_result",
- init_ckpt_path=None,
- use_gpu=True,
- max_steps=500,
- batch_size=8,
- max_encode_len=50,
- max_decode_len=50,
- learning_rate=5e-5,
- warmup_proportion=0.1,
- weight_decay=0.1,
- noise_prob=0,
- label_smooth=0,
- beam_width=5,
- length_penalty=1.0,
- log_interval=100,
- save_interval=200,
+ self,
+ train_path,
+ dev_path=None,
+ save_dir="ernie_gen_result",
+ init_ckpt_path=None,
+ use_gpu=True,
+ max_steps=500,
+ batch_size=8,
+ max_encode_len=50,
+ max_decode_len=50,
+ learning_rate=5e-5,
+ warmup_proportion=0.1,
+ weight_decay=0.1,
+ noise_prob=0,
+ label_smooth=0,
+ beam_width=5,
+ length_penalty=1.0,
+ log_interval=100,
+ save_interval=200,
):
"""
finetune with the specified dataset.
@@ -111,143 +109,129 @@ class ErnieGen(hub.Module):
last_ppl(float): last model ppl.
}
"""
- self.max_encode_len = max_encode_len
- self.max_decode_len = max_decode_len
- self.noise_prob = noise_prob
-
- place = F.CUDAPlace(0) if use_gpu else F.CPUPlace()
-
- with F.dygraph.guard(place):
- if init_ckpt_path is not None:
- logger.info('loading checkpoint from %s' % init_ckpt_path)
- sd, _ = D.load_dygraph(init_ckpt_path)
- self.model.set_dict(sd)
-
- feature_column = propeller.data.FeatureColumns([
- propeller.data.LabelColumn('id'),
- propeller.data.TextColumn(
- 'src',
- unk_id=self.tokenizer.unk_id,
- vocab_dict=self.tokenizer.vocab,
- tokenizer=self.tokenizer.tokenize),
- propeller.data.TextColumn(
- 'tgt',
- unk_id=self.tokenizer.unk_id,
- vocab_dict=self.tokenizer.vocab,
- tokenizer=self.tokenizer.tokenize),
- ])
-
- train_ds = feature_column.build_dataset('train', data_file=train_path, shuffle=False,
- repeat=True, use_gz=False)\
- .map(self._map_fn).shuffle(10000).padded_batch(batch_size).map(self._after_padding)
- train_ds.data_shapes = [[None, None]] * 7 + [[None, None, None]] * 3 + [[None]]
- train_ds.data_types = ['int64'] * 11
-
- if dev_path:
- dev_ds = feature_column.build_dataset('dev', data_file=dev_path, shuffle=False,
- repeat=False, use_gz=False) \
- .map(self._map_fn) \
- .padded_batch(1) \
- .map(self._after_padding)
- dev_ds.data_shapes = [[None, None]] * 7 + [[None, None, None]] * 3 + [[None]]
- dev_ds.data_types = ['int64'] * 11
-
- vocab_size, _ = self.model.word_emb.weight.shape
- g_clip = F.clip.GradientClipByGlobalNorm(1.0)
- opt = AdamW(
- learning_rate=LinearDecay(learning_rate, int(warmup_proportion * max_steps), max_steps),
- parameter_list=self.model.parameters(),
- weight_decay=weight_decay,
- grad_clip=g_clip)
-
- loss = None
-
- save_path = None
- ppl = None
-
- if save_dir and not os.path.exists(save_dir):
- os.makedirs(save_dir)
- for step, data in enumerate(train_ds.start(place)):
- (example_id, src_ids, src_sids, src_pids, tgt_ids, tgt_sids, tgt_pids, attn_ids, mask_src_2_src,
- mask_tgt_2_srctgt, mask_attn_2_srctgtattn, tgt_labels) = data
-
- _, __, info = self.model(
- src_ids, sent_ids=src_sids, pos_ids=src_pids, attn_bias=mask_src_2_src, encode_only=True)
- cached_k, cached_v = info['caches']
- _, __, info = self.model(
- tgt_ids,
- sent_ids=tgt_sids,
- pos_ids=tgt_pids,
- attn_bias=mask_tgt_2_srctgt,
- past_cache=(cached_k, cached_v),
- encode_only=True)
- cached_k2, cached_v2 = info['caches']
- past_cache_k = [L.concat([k, k2], 1) for k, k2 in zip(cached_k, cached_k2)]
- past_cache_v = [L.concat([v, v2], 1) for v, v2 in zip(cached_v, cached_v2)]
+ paddle.disable_static()
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+
+ if init_ckpt_path is not None:
+ logger.info('loading checkpoint from %s' % init_ckpt_path)
+ sd = paddle.load(init_ckpt_path)
+ self.model.set_state_dict(sd)
+
+ train_dataset = self._load_dataset(train_path)
+ attn_id = self.tokenizer.vocab['[MASK]']
+ trans_func = convert_example(tokenizer=self.tokenizer,
+ attn_id=attn_id,
+ tgt_type_id=1,
+ max_encode_len=max_encode_len,
+ max_decode_len=max_decode_len,
+ noise_prob=noise_prob)
+
+ train_dataset = train_dataset.map(trans_func)
+ train_batch_sampler = paddle.io.BatchSampler(train_dataset, batch_size=batch_size, shuffle=True)
+ batchify_fn = lambda samples, fn=Tuple(
+ Pad(axis=0, pad_val=self.tokenizer.pad_token_id), # src_ids
+ Pad(axis=0, pad_val=self.tokenizer.pad_token_id), # src_pids
+ Pad(axis=0, pad_val=self.tokenizer.pad_token_type_id), # src_tids
+ Pad(axis=0, pad_val=self.tokenizer.pad_token_id), # tgt_ids
+ Pad(axis=0, pad_val=self.tokenizer.pad_token_id), # tgt_pids
+ Pad(axis=0, pad_val=self.tokenizer.pad_token_type_id), # tgt_tids
+ Pad(axis=0, pad_val=self.tokenizer.pad_token_id), # attn_ids
+ Pad(axis=0, pad_val=self.tokenizer.pad_token_id), # tgt_labels
+ ): after_padding(fn(samples))
+ train_data_loader = DataLoader(dataset=train_dataset,
+ batch_sampler=train_batch_sampler,
+ collate_fn=batchify_fn,
+ num_workers=0,
+ return_list=True)
+
+ if dev_path:
+ dev_dataset = self._load_dataset(dev_path)
+ dev_dataset = dev_dataset.map(trans_func)
+ dev_data_loader = DataLoader(dataset=dev_dataset,
+ batch_size=batch_size,
+ collate_fn=batchify_fn,
+ num_workers=0,
+ return_list=True)
+
+ label_num = self.model.word_emb.weight.shape[0]
+ train_model = StackModel(self.model)
+ lr_scheduler = LinearDecayWithWarmup(learning_rate, max_steps, warmup_proportion)
+ # Generate parameter names needed to perform weight decay.
+ # All bias and LayerNorm parameters are excluded.
+ decay_params = [p.name for n, p in self.model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]
+ optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,
+ parameters=self.model.parameters(),
+ weight_decay=weight_decay,
+ grad_clip=nn.ClipGradByGlobalNorm(1.0),
+ apply_decay_param_fun=lambda x: x in decay_params)
+
+ rouge1 = Rouge1()
+ rouge2 = Rouge2()
+ global_step = 1
+ if save_dir and not os.path.exists(save_dir):
+ os.makedirs(save_dir)
+ while True:
+ for batch in train_data_loader:
+ (src_ids, src_tids, src_pids, tgt_ids, tgt_tids, tgt_pids, attn_ids, mask_src_2_src, mask_tgt_2_srctgt,
+ mask_attn_2_srctgtattn, tgt_labels, _) = batch
if label_smooth > 0.:
- tgt_labels = L.label_smooth(F.one_hot(tgt_labels, vocab_size), epsilon=label_smooth)
- loss, _, __ = self.model(
- attn_ids,
- sent_ids=tgt_sids,
- pos_ids=tgt_pids,
- attn_bias=mask_attn_2_srctgtattn,
- past_cache=(past_cache_k, past_cache_v),
- tgt_labels=tgt_labels,
- tgt_pos=L.where(attn_ids == self.tokenizer.vocab['[MASK]']))
+ tgt_labels = nn.functional.label_smooth(nn.functional.one_hot(tgt_labels, label_num),
+ epsilon=label_smooth)
+
+ tgt_pos = paddle.nonzero(attn_ids == attn_id)
+ loss = train_model(src_ids, src_tids, src_pids, tgt_ids, tgt_tids, tgt_pids, attn_ids, mask_src_2_src,
+ mask_tgt_2_srctgt, mask_attn_2_srctgtattn, tgt_labels, tgt_pos)
loss.backward()
- opt.minimize(loss)
- self.model.clear_gradients()
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.clear_grad()
- if step % log_interval == 0:
+ if global_step % log_interval == 0 and paddle.distributed.get_rank() == 0:
loss_np = loss.numpy()
ppl = np.exp(loss_np)
- logger.info('[step %d / %d]train loss %.5f, ppl %.5f, elr %.3e' % (step, max_steps, loss_np, ppl,
- opt.current_step_lr()))
- if save_dir and step % save_interval == 0 and step > 0:
+ logger.info('[step %d / %d]train loss %.5f, ppl %.5f, elr %.3e' %
+ (global_step, max_steps, loss_np, ppl, lr_scheduler.get_lr()))
+ if save_dir and global_step % save_interval == 0 and global_step > 0:
loss_np = loss.numpy()
ppl = np.exp(loss_np)
- save_name = "step_%s_ppl_%.5f" % (step, ppl)
+ save_name = "step_%s_ppl_%.5f.params" % (global_step, ppl)
save_path = os.path.join(save_dir, save_name)
logger.info("save the model in %s" % save_path)
- F.save_dygraph(self.model.state_dict(), save_path)
+ paddle.save(self.model.state_dict(), save_path)
if dev_path:
- logger.info('evaluating...')
- res = self._evaluate(dev_ds, place, beam_width, length_penalty)
- output_path = os.path.join(save_dir, "step_%s_ppl_%.5f.txt" % (step, ppl))
- logger.info('save the predict result in %s' % output_path)
- with open(output_path, 'w') as fout:
- fout.write(('\n'.join(res)))
-
- if step > max_steps:
+ self._evaluate(self.model, dev_data_loader, self.tokenizer, rouge1, rouge2, attn_id,
+ max_decode_len, max_encode_len, beam_width, length_penalty)
+
+ if global_step >= max_steps:
break
+ global_step += 1
- if loss:
- loss_np = loss.numpy()
- ppl = np.exp(loss_np)
- logger.info(
- '[final step %d]train loss %.5f, ppl %.5f, elr %.3e' % (step, loss_np, ppl, opt.current_step_lr()))
- if save_dir:
- save_name = "step_%s_ppl_%.5f" % (step, ppl)
- save_path = os.path.join(save_dir, save_name)
- logger.info("save the model in %s" % save_path)
- F.save_dygraph(self.model.state_dict(), save_path)
+ if global_step >= max_steps:
+ break
- if dev_path:
- logger.info('evaluating...')
- res = self._evaluate(dev_ds, place, beam_width, length_penalty)
- output_path = os.path.join(save_dir, "step_%s_ppl_%.5f.txt" % (step, ppl))
- logger.info('save the predict result in %s' % output_path)
- with open(output_path, 'w') as fout:
- fout.write(('\n'.join(res)))
+ if global_step % save_interval != 0:
+ loss_np = loss.numpy()
+ ppl = np.exp(loss_np)
+ logger.info('[final step %d]train loss %.5f, ppl %.5f, elr %.3e' %
+ (global_step, loss_np, ppl, lr_scheduler.get_lr()))
+ if save_dir:
+ save_name = "step_%s_ppl_%.5f.pdparams" % (global_step, ppl)
+ save_path = os.path.join(save_dir, save_name)
+ logger.info("save the model in %s" % save_path)
+ paddle.save(self.model.state_dict(), save_path)
+
+ if dev_path:
+ self._evaluate(self.model, dev_data_loader, self.tokenizer, rouge1, rouge2, attn_id, max_decode_len,
+ max_encode_len, beam_width, length_penalty)
- result = {
- "last_save_path": "%s.pdparams" % save_path,
- "last_ppl": ppl[0],
- }
+ result = {
+ "last_save_path": "%s" % save_path,
+ "last_ppl": ppl[0],
+ }
- return result
+ return result
def export(self,
params_path,
@@ -281,19 +265,20 @@ class ErnieGen(hub.Module):
logger.info("Begin export the model save in %s ..." % params_path)
assets_path = os.path.join(self.directory, "template", "assets")
- model_path = os.path.join(self.directory, "template", "model")
init_path = os.path.join(self.directory, "template", "__init__.py")
+ decode_path = os.path.join(self.directory, "template", "decode.py")
module_temp_path = os.path.join(self.directory, "template", "module.temp")
export_assets_path = os.path.join(export_module_path, "assets")
export_params_path = os.path.join(export_module_path, "assets", "ernie_gen.pdparams")
export_init_path = os.path.join(export_module_path, "__init__.py")
- export_model_path = os.path.join(export_module_path, "model")
+ export_decode_path = os.path.join(export_module_path, "decode.py")
+ if not os.path.exists(export_assets_path):
+ os.makedirs(export_assets_path)
shutil.copyfile(init_path, export_init_path)
- shutil.copytree(assets_path, export_assets_path)
shutil.copyfile(params_path, export_params_path)
- shutil.copytree(model_path, export_model_path)
+ shutil.copyfile(decode_path, export_decode_path)
module_path = os.path.join(export_module_path, "module.py")
with open(module_temp_path, encoding="utf8") as ftemp, open(module_path, "w") as fmodule:
@@ -304,134 +289,82 @@ class ErnieGen(hub.Module):
logger.info("The module has exported to %s" % os.path.abspath(export_module_path))
- def _evaluate(self, datasets, place, beam_width, length_penalty):
- self.model.eval()
- printables = []
- for step, data in enumerate(datasets.start(place)):
- (example_id, src_ids, src_sids, src_pids, _, _, _, _, _, _, _, _) = data # never use target when infer
- output_ids = beam_search_infilling(
- self.model,
- src_ids,
- src_sids,
- eos_id=self.tokenizer.sep_id,
- sos_id=self.tokenizer.cls_id,
- attn_id=self.tokenizer.vocab["[MASK]"],
- max_decode_len=self.max_decode_len,
- max_encode_len=self.max_encode_len,
- beam_width=beam_width,
- length_penalty=length_penalty,
- tgt_type_id=1,
- )
- output_str = self.rev_lookup(output_ids.numpy())
- for eid, ostr in zip(example_id.numpy().tolist(), output_str.tolist()):
- if '[SEP]' in ostr:
- ostr = ostr[:ostr.index('[SEP]')]
- ostr = ''.join(map(post_process, ostr))
- printables.append('%d\t%s' % (eid, ostr))
- self.model.train()
- return printables
-
- def _map_fn(self, example_id, src_ids, tgt_ids):
- src_ids = src_ids[:self.max_encode_len]
- tgt_ids = tgt_ids[:self.max_decode_len]
- src_ids, src_sids = self.tokenizer.build_for_ernie(src_ids)
- src_pids = np.arange(len(src_ids), dtype=np.int64)
-
- tgt_ids, tgt_sids = self.tokenizer.build_for_ernie(tgt_ids)
- tgt_pids = np.arange(len(tgt_ids), dtype=np.int64) + len(src_ids) # continues position
- tgt_sids = np.ones_like(tgt_sids)
-
- attn_ids = np.ones_like(tgt_ids) * self.tokenizer.vocab['[MASK]']
- if self.noise_prob > 0.:
- tgt_labels = deepcopy(tgt_ids)
- tgt_ids = self._make_some_noise(tgt_ids, self.noise_prob) #corrupted
- else:
- tgt_labels = tgt_ids
-
- return (example_id, src_ids, src_pids, src_sids, tgt_ids, tgt_pids, tgt_sids, attn_ids, tgt_labels)
-
- def _make_some_noise(self, ids, noise_prob):
- noise_ids = np.random.randint(1, len(self.tokenizer.vocab), size=ids.shape)
- pos, = np.where(np.ones_like(ids))
- np.random.shuffle(pos)
- pos = pos[:int(noise_prob * len(pos))]
- ids[pos, ] = noise_ids[pos, ]
- return ids
-
- def _after_padding(self, example_id, src_ids, src_pids, src_sids, tgt_ids, tgt_pids, tgt_sids, attn_ids,
- tgt_labels):
- '''
- attention mask:
- *** src, tgt, attn
- src 00, 01, 11
- tgt 10, 11, 12
- attn 20, 21, 22
- *** s1, s2 | t1 t2 t3| attn1 attn2 attn3
- s1 1, 1 | 0, 0, 0,| 0, 0, 0,
- s2 1, 1 | 0, 0, 0,| 0, 0, 0,
- -
- t1 1, 1, | 1, 0, 0,| 0, 0, 0,
- t2 1, 1, | 1, 1, 0,| 0, 0, 0,
- t3 1, 1, | 1, 1, 1,| 0, 0, 0,
- -
- attn1 1, 1, | 0, 0, 0,| 1, 0, 0,
- attn2 1, 1, | 1, 0, 0,| 0, 1, 0,
- attn3 1, 1, | 1, 1, 0,| 0, 0, 1,
- for details, see Fig3. https://arxiv.org/abs/2001.11314
- '''
-
- src_len = src_ids.shape[1]
- tgt_len = tgt_ids.shape[1]
- mask_00 = self._gen_mask(src_ids, 'bidi', query_len=src_len)
-
- mask_10 = self._gen_mask(src_ids, 'bidi', query_len=tgt_len)
- mask_11 = self._gen_mask(tgt_ids, 'causal', query_len=tgt_len)
-
- mask_20 = self._gen_mask(src_ids, 'bidi', query_len=tgt_len)
- mask_21 = self._gen_mask(tgt_ids, 'causal_without_diag', query_len=tgt_len)
- mask_22 = self._gen_mask(attn_ids, 'diag', query_len=tgt_len)
- '''
- mask = np.concatenate([
- np.concatenate([mask_00, mask_01, mask_02], 2),
- np.concatenate([mask_10, mask_11, mask_12], 2),
- np.concatenate([mask_20, mask_21, mask_22], 2),
- ], 1)
- ids = np.concatenate([src_ids, tgt_ids, attn_ids], 1)
- pids = np.concatenate([src_pids, tgt_pids, tgt_pids], 1)
- sids = np.concatenate([src_sids, tgt_sids, tgt_sids], 1)
- '''
-
- mask_src_2_src = mask_00
- mask_tgt_2_srctgt = np.concatenate([mask_10, mask_11], 2)
- mask_attn_2_srctgtattn = np.concatenate([mask_20, mask_21, mask_22], 2)
-
- tgt_labels = tgt_labels[np.where(tgt_labels != 0)]
- return (example_id, src_ids, src_sids, src_pids, tgt_ids, tgt_sids, tgt_pids, attn_ids, mask_src_2_src,
- mask_tgt_2_srctgt, mask_attn_2_srctgtattn, tgt_labels)
-
- def _gen_mask(self, batch_ids, mask_type='bidi', query_len=None, pad_value=0):
- if query_len is None:
- query_len = batch_ids.shape[1]
- if mask_type != 'empty':
- mask = (batch_ids != pad_value).astype(np.float32)
- mask = np.tile(np.expand_dims(mask, 1), [1, query_len, 1])
- if mask_type == 'causal':
- assert query_len == batch_ids.shape[1]
- mask = np.tril(mask)
- elif mask_type == 'causal_without_diag':
- assert query_len == batch_ids.shape[1]
- mask = np.tril(mask, -1)
- elif mask_type == 'diag':
- assert query_len == batch_ids.shape[1]
- mask = np.stack([np.diag(np.diag(m)) for m in mask], 0)
- else:
- mask = np.zeros_like(batch_ids).astype(np.float32)
- mask = np.tile(np.expand_dims(mask, 1), [1, query_len, 1])
- return mask
+ def _evaluate(self, model, data_loader, tokenizer, rouge1, rouge2, attn_id, max_decode_len, max_encode_len,
+ beam_width, length_penalty):
+ paddle.disable_static()
+ model.eval()
+
+ vocab = tokenizer.vocab
+ eos_id = vocab[tokenizer.sep_token]
+ sos_id = vocab[tokenizer.cls_token]
+ pad_id = vocab[tokenizer.pad_token]
+ unk_id = vocab[tokenizer.unk_token]
+ vocab_size = len(vocab)
+ evaluated_sentences_ids = []
+ reference_sentences_ids = []
+ logger.info("Evaluating...")
+ for data in data_loader:
+ (src_ids, src_tids, src_pids, _, _, _, _, _, _, _, _, raw_tgt_labels) = data # never use target when infer
+ # Use greedy_search_infilling or beam_search_infilling to get predictions
+ output_ids = beam_search_infilling(model,
+ src_ids,
+ src_tids,
+ eos_id=eos_id,
+ sos_id=sos_id,
+ attn_id=attn_id,
+ pad_id=pad_id,
+ unk_id=unk_id,
+ vocab_size=vocab_size,
+ max_decode_len=max_decode_len,
+ max_encode_len=max_encode_len,
+ beam_width=beam_width,
+ length_penalty=length_penalty,
+ tgt_type_id=1)
+
+ for ids in output_ids.tolist():
+ if eos_id in ids:
+ ids = ids[:ids.index(eos_id)]
+ evaluated_sentences_ids.append(ids[0])
+
+ for ids in raw_tgt_labels.numpy().tolist():
+ ids = ids[:ids.index(eos_id)]
+ reference_sentences_ids.append(ids)
+
+ score1 = rouge1.score(evaluated_sentences_ids, reference_sentences_ids)
+ score2 = rouge2.score(evaluated_sentences_ids, reference_sentences_ids)
+
+ logger.info("Rouge-1: %.5f ,Rouge-2: %.5f" % (score1 * 100, score2 * 100))
+
+ evaluated_sentences = []
+ reference_sentences = []
+ for ids in reference_sentences_ids[:3]:
+ reference_sentences.append(''.join(map(post_process, vocab.to_tokens(ids))))
+ for ids in evaluated_sentences_ids[:3]:
+ evaluated_sentences.append(''.join(map(post_process, vocab.to_tokens(ids))))
+ logger.debug(reference_sentences)
+ logger.debug(evaluated_sentences)
+
+ model.train()
+
+ def _load_dataset(self, datafiles):
+ def read(data_path):
+ with open(data_path, 'r', encoding='utf-8') as fp:
+ for line in fp.readlines():
+ order, words, labels = line.strip('\n').split('\t')
+ yield {'tokens': words, 'labels': labels}
+
+ if isinstance(datafiles, str):
+ return MapDataset(list(read(datafiles)))
+ elif isinstance(datafiles, list) or isinstance(datafiles, tuple):
+ return [MapDataset(list(read(datafile))) for datafile in datafiles]
if __name__ == "__main__":
module = ErnieGen()
- result = module.finetune(
- train_path='test_data/train.txt', dev_path='test_data/dev.txt', max_steps=300, batch_size=2)
+ result = module.finetune(train_path='test_data/train.txt',
+ dev_path='test_data/dev.txt',
+ max_steps=30,
+ batch_size=2,
+ log_interval=10,
+ save_interval=20)
module.export(params_path=result['last_save_path'], module_name="ernie_gen_test", author="test")
diff --git a/modules/text/text_generation/ernie_gen/propeller/__init__.py b/modules/text/text_generation/ernie_gen/propeller/__init__.py
deleted file mode 100644
index ffe4087655a02ab202a48144693853663878ff6a..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/__init__.py
+++ /dev/null
@@ -1,44 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Propeller"""
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import os
-import sys
-import logging
-import six
-from time import time
-
-__version__ = '0.2'
-
-log = logging.getLogger(__name__)
-stream_hdl = logging.StreamHandler(stream=sys.stderr)
-formatter = logging.Formatter(fmt='[%(levelname)s] %(asctime)s [%(filename)12s:%(lineno)5d]:\t%(message)s')
-
-try:
- from colorlog import ColoredFormatter
- fancy_formatter = ColoredFormatter(
- fmt='%(log_color)s[%(levelname)s] %(asctime)s [%(filename)12s:%(lineno)5d]:\t%(message)s')
- stream_hdl.setFormatter(fancy_formatter)
-except ImportError:
- stream_hdl.setFormatter(formatter)
-
-log.setLevel(logging.INFO)
-log.addHandler(stream_hdl)
-log.propagate = False
-
-from ernie_gen.propeller.types import *
-from ernie_gen.propeller.util import ArgumentParser, parse_hparam, parse_runconfig, parse_file
diff --git a/modules/text/text_generation/ernie_gen/propeller/data/__init__.py b/modules/text/text_generation/ernie_gen/propeller/data/__init__.py
deleted file mode 100644
index 31701fc080c5a896dffc3bf82c14a692d4d8e917..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/data/__init__.py
+++ /dev/null
@@ -1,16 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-doc
-"""
diff --git a/modules/text/text_generation/ernie_gen/propeller/data/functional.py b/modules/text/text_generation/ernie_gen/propeller/data/functional.py
deleted file mode 100644
index f4ab9644385c97dd2f986382b3ece8baa6c30c78..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/data/functional.py
+++ /dev/null
@@ -1,467 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Basic Dataset API"""
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import sys
-import logging
-import os
-import itertools
-import random
-import inspect
-import multiprocessing
-from contextlib import contextmanager
-import gzip
-import struct
-import functools
-
-import six
-from six.moves import zip, map, filter
-import numpy as np
-
-from ernie_gen.propeller.util import map_structure
-
-log = logging.getLogger(__name__)
-
-__all__ = ['Dataset']
-
-
-@contextmanager
-def _open_file(filename, format=None):
- if format is None:
- fd = open(filename, 'rb')
- elif format == 'GZIP':
- fd = gzip.open(filename, 'rb')
- else:
- raise ValueError('unkwon file format %s' % format)
- yield fd
- fd.close()
-
-
-def _open_record(filename):
- def _gen():
- with _open_file(filename, format='GZIP') as f:
- while True:
- data = f.read(struct.calcsize('i'))
- if not len(data):
- raise StopIteration
- l, = struct.unpack('i', data)
- data = f.read(l)
- yield data
-
- return _gen
-
-
-def _shuffle_func(dataset, buffer_size):
- def _gen():
- buf = []
- iterable = dataset()
- try:
- while len(buf) < buffer_size:
- buf.append(next(iterable))
- while 1:
- i = random.randint(0, buffer_size - 1)
- n = next(iterable)
- yield buf[i]
- buf[i] = n
- except StopIteration:
- if len(buf):
- random.shuffle(buf)
- for i in buf:
- yield i
-
- return _gen
-
-
-def _interleave_func(iterable, map_fn, cycle_length, block_length):
- def _gen():
- ls = itertools.tee(iterable(), cycle_length)
- buf = []
- for i, j in enumerate(ls):
- j = itertools.islice(j, i, None, cycle_length)
- j = map(map_fn, j)
- j = (jjj for jj in j for jjj in jj) #flatten
- buf.append(j)
-
- for tup in six.moves.zip_longest(*buf):
- for ii in (i for i in tup if i is not None):
- yield ii
-
- return _gen
-
-
-def _repeat_func(dataset, n):
- def _gen():
- iterable = dataset()
- if n >= 0:
- ret = itertools.chain(*itertools.tee(iterable, n))
- else:
- ret = itertools.cycle(iterable)
-
- for i in ret:
- yield i
-
- return _gen
-
-
-def _filter_func(dataset, fn):
- def _gen():
- for i in dataset():
- if isinstance(i, tuple) or isinstance(i, list):
- if fn(*i) is True:
- yield i
- else:
- if fn(i) is True:
- yield i
-
- return _gen
-
-
-def _map_func(dataset, fn):
- def _gen():
- for i in dataset():
- if isinstance(i, tuple) or isinstance(i, list):
- yield fn(*i)
- else:
- yield fn(i)
-
- return _gen
-
-
-def _shard_func(dataset, num_shards, index):
- def _gen():
- iterable = dataset()
- ret = itertools.islice(iterable, index, None, num_shards)
- for i in ret:
- yield i
-
- return _gen
-
-
-def _take_func(dataset, count):
- def _gen():
- iterable = dataset()
- ret = itertools.islice(iterable, count)
- for i in ret:
- yield i
-
- return _gen
-
-
-def _chain_func(dataset, dataset2):
- def _gen():
- iterable = dataset()
- iterable2 = dataset2()
- ret = itertools.chain(iterable, iterable2)
- for i in ret:
- yield i
-
- return _gen
-
-
-def _buffered_func(dataset, size):
- """
- Creates a buffered data reader.
-
- The buffered data reader will read and save data entries into a
- buffer. Reading from the buffered data reader will proceed as long
- as the buffer is not empty.
-
- :param reader: the data reader to read from.
- :type reader: callable
- :param size: max buffer size.
- :type size: int
-
- :returns: the buffered data reader.
- """
-
- class _EndSignal(object):
- pass
-
- end = _EndSignal()
-
- def _read_worker(r, q):
- for d in r:
- q.put(d)
- q.put(end)
-
- def _data_reader():
- r = dataset()
- q = multiprocessing.Queue(maxsize=size)
- t = multiprocessing.Process(
- target=_read_worker, args=(
- r,
- q,
- ))
- t.daemon = True
- t.start()
- e = q.get()
- while e != end:
- yield e
- e = q.get()
-
- return _data_reader
-
-
-def _batch_func(dataset, batch_size):
- def _gen():
- iterable = dataset()
- while True:
- buf = list(itertools.islice(iterable, batch_size))
- if not len(buf):
- raise StopIteration
- buf = list(zip(*buf)) # transpose
- buf = [np.stack(b) for b in buf]
- yield buf
-
- return _gen
-
-
-def _padded_batch_func(dataset, batch_size, pad_value=0, max_seqlen=None):
- if not isinstance(batch_size, int):
- raise ValueError('unknown batch_size: %s' % repr(batch_size))
-
- def _gen():
- iterable = dataset()
- pad_value_t = pad_value
- while True:
- buf = list(itertools.islice(iterable, batch_size))
- if not len(buf):
- raise StopIteration
- buf = list(zip(*buf)) # transpose
- if type(pad_value_t) not in [list, tuple]:
- pad_value_t = [pad_value_t] * len(buf)
- padded = []
- assert len(buf) == len(pad_value_t), 'pad_value [%d] != element size[%d]' % (len(pad_value_t), len(buf))
- for e, pv in zip(buf, pad_value_t):
- elem = e[0]
- if (not np.isscalar(elem)) and elem.shape != ():
- max_len = max(map(len, e)) if max_seqlen is None else max_seqlen
-
- def _fn(i):
- if max_len >= len(i):
- return np.pad(i, [0, max_len - len(i)], 'constant', constant_values=pv)
- else:
- return i[:max_len]
-
- e = map(_fn, e)
- padded.append(np.stack(list(e)))
- yield padded
-
- return _gen
-
-
-class Dataset(object):
- """Python Wrapper for PyReader"""
-
- @classmethod
- def from_generator_func(cls, _gen, data_shapes=None, data_types=None):
- """doc"""
- if not inspect.isgeneratorfunction(_gen):
- raise ValueError('expect generator function, got %s' % repr(_gen))
-
- def _wrapper(): #compat to py3.7
- try:
- for item in _gen():
- yield item
- except RuntimeError as e:
- if str(e) != 'generator raised StopIteration':
- raise e
-
- ret = cls()
- ret.generator = _wrapper
- ret.data_shapes = data_shapes
- ret.data_types = data_types
- return ret
-
- @classmethod
- def from_file(cls, filename, format=None):
- """doc"""
- if os.path.getsize(filename) == 0:
- raise RuntimeError('%s is empty' % filename)
-
- def _gen():
- with _open_file(filename, format) as f:
- for line in f:
- yield line
-
- ret = cls()
- ret.generator = _gen
- ret.data_shapes = []
- ret.data_types = str
- return ret
-
- @classmethod
- def from_record_file(cls, filename):
- """doc"""
- if os.path.getsize(filename) == 0:
- raise RuntimeError('%s is empty' % filename)
- _gen = _open_record(filename)
- ret = cls()
- ret.generator = _gen
- ret.data_shapes = []
- ret.data_types = str
- return ret
-
- @classmethod
- def from_list(cls, ls):
- """doc"""
- if not isinstance(ls, list):
- raise ValueError('expect list, got %s' % repr(ls))
-
- def _gen():
- for i in ls:
- yield i
-
- ret = cls()
- ret.generator = _gen
- ret.data_shapes = []
- ret.data_types = str
- return ret
-
- def __init__(self):
- self.name = None
- self._data_shapes = None
- self._data_types = None
- self.generator = None
- self.pyreader = None
-
- def __repr__(self):
- return 'Dataset: name: %s, data_shapes %s, data_types %s' % (self.name, self._data_shapes, self._data_types)
-
- def __eq__(self, other):
- return self.name == other.name and \
- self._data_shapes == other._data_shapes and \
- self._data_types == other._data_types
-
- def __iter__(self):
- return self.generator()
-
- #def __call__(self):
- # return self.generator()
-
- def _infer_shapes_and_types(self):
- if self.generator is not None and self.name is not None:
- log.info('Try to infer data shapes & types from generator')
- first_value = next(self.generator())
- shapes, types = [], []
- for v in first_value:
- if not isinstance(v, np.ndarray):
- raise ValueError('dataset generator should use numpy elements, got %s' % first_value)
- shapes.append(v.shape)
- types.append(v.dtype.name)
- self._data_shapes = shapes
- self._data_types = types
- log.info('Dataset `%s` has data_shapes: %s data_types: %s' % (self.name, repr(shapes), repr(types)))
- else:
- raise ValueError('Try to infer data shapes or types from incomplete Dataset')
-
- @property
- def data_shapes(self):
- """doc"""
- if self._data_shapes is None:
- self._infer_shapes_and_types()
- return self._data_shapes
- else:
- return self._data_shapes
-
- @data_shapes.setter
- def data_shapes(self, val):
- """doc"""
- self._data_shapes = val
-
- @property
- def data_types(self):
- """doc"""
- if self._data_types is None:
- self._infer_shapes_and_types()
- return self._data_types
- else:
- return self._data_types
-
- @data_types.setter
- def data_types(self, val):
- """doc"""
- self._data_types = val
-
- def apply(self, transform_func):
- """apply transform func to datasets"""
- #input_shapes = transform_func.input_shapes
- #input_types = transform_func.input_types
- #data_shapes = transform_func.data_shapes
- #data_types = transform_func.data_types
- #assert input_shapes == self._data_shapes
- #assert input_types = self._data_types
- ret_gen = transform_func(self.generator)
- ret = type(self).from_generator_func(ret_gen)
- if self.name is not None:
- ret.name = self.name
- #ret.data_shapes = data_shapes
- #ret.data_types = data_types
- return ret
-
- def shuffle(self, buffer_size):
- """doc"""
- func = functools.partial(_shuffle_func, buffer_size=buffer_size)
- return self.apply(func)
-
- def repeat(self, n=-1):
- """doc"""
- func = functools.partial(_repeat_func, n=n)
- return self.apply(func)
-
- def map(self, fn):
- """doc"""
- func = functools.partial(_map_func, fn=fn)
- return self.apply(func)
-
- def filter(self, fn):
- """doc"""
- func = functools.partial(_filter_func, fn=fn)
- return self.apply(func)
-
- def shard(self, num_shards, index):
- """doc"""
- func = functools.partial(_shard_func, num_shards=num_shards, index=index)
- return self.apply(func)
-
- def interleave(self, map_fn, cycle_length, block_length):
- """doc"""
- func = functools.partial(_interleave_func, map_fn=map_fn, cycle_length=cycle_length, block_length=block_length)
- return self.apply(func)
-
- def batch(self, batch_size):
- func = functools.partial(_batch_func, batch_size=batch_size)
- return self.apply(func)
-
- def padded_batch(self, batch_size, pad_value=0, max_seqlen=None):
- """doc"""
- func = functools.partial(_padded_batch_func, batch_size=batch_size, pad_value=pad_value, max_seqlen=max_seqlen)
- return self.apply(func)
-
- def take(self, count=1):
- """doc"""
- func = functools.partial(_take_func, count=count)
- return self.apply(func)
-
- def buffered(self, size=10):
- """doc"""
- func = functools.partial(_buffered_func, size=size)
- return self.apply(func)
-
- def chain(self, other):
- func = functools.partial(_chain_func, dataset2=other.generator)
- return self.apply(func)
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/__init__.py b/modules/text/text_generation/ernie_gen/propeller/paddle/__init__.py
deleted file mode 100644
index c35000cd7180892ee05613c010d05a465f455ecb..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/__init__.py
+++ /dev/null
@@ -1,51 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-doc
-"""
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import six
-import logging
-
-log = logging.getLogger(__name__)
-
-
-def enable_textone():
- try:
- import textone
- except ImportError:
- log.fatal('enable textone failed: textone not found!')
- raise
- global textone_enabled
- log.info('textone enabled')
- from ernie_gen.propeller.paddle.train.monitored_executor import MonitoredExecutor, TextoneTrainer
- if TextoneTrainer is None:
- raise RuntimeError('enable textone failed: textone not found!')
- MonitoredExecutor.saver_class = TextoneTrainer
-
-
-from ernie_gen.propeller.types import *
-from ernie_gen.propeller.util import ArgumentParser, parse_hparam, parse_runconfig, parse_file
-
-from ernie_gen.propeller.paddle import data
-from ernie_gen.propeller.paddle import train
-from ernie_gen.propeller.paddle.train import *
-
-import paddle
-paddle_version = [int(i) for i in paddle.__version__.split('.')]
-if paddle_version[1] < 7:
- raise RuntimeError('propeller 0.2 requires paddle 1.7+, got %s' % paddle.__version__)
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/collection.py b/modules/text/text_generation/ernie_gen/propeller/paddle/collection.py
deleted file mode 100644
index 8b85b37fa988db67630f4d9c05ea86ee34460786..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/collection.py
+++ /dev/null
@@ -1,61 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""global collections"""
-
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import sys
-
-_global_collection = None
-
-
-class Key(object):
- """predefine collection keys"""
- SUMMARY_SCALAR = 1
- SUMMARY_HISTOGRAM = 2
- SKIP_OPTIMIZE = 3
-
-
-class Collections(object):
- """global collections to record everything"""
-
- def __init__(self):
- self.col = {}
-
- def __enter__(self):
- global _global_collection
- _global_collection = self
- return self
-
- def __exit__(self, err_type, err_value, trace):
- global _global_collection
- _global_collection = None
-
- def add(self, key, val):
- """doc"""
- self.col.setdefault(key, []).append(val)
-
- def get(self, key):
- """doc"""
- return self.col.get(key, None)
-
-
-def default_collection():
- """return global collection"""
- global _global_collection
- if _global_collection is None:
- _global_collection = Collections()
- return _global_collection
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/data/__init__.py b/modules/text/text_generation/ernie_gen/propeller/paddle/data/__init__.py
deleted file mode 100644
index 615cdb76205f48099e76b2a63c30972652f0171b..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/data/__init__.py
+++ /dev/null
@@ -1,22 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-doc
-"""
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-from ernie_gen.propeller.paddle.data.functional import *
-from ernie_gen.propeller.paddle.data.feature_column import *
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/data/example.proto b/modules/text/text_generation/ernie_gen/propeller/paddle/data/example.proto
deleted file mode 100644
index 3c61391770f94f360da6265472797d5cb6ba0291..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/data/example.proto
+++ /dev/null
@@ -1,29 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-// Protocol messages for describing input data Examples for machine learning
-// model training or inference.
-syntax = "proto3";
-
-import "ernie_gen.propeller/paddle/data/feature.proto";
-package ernie_gen.propeller;
-
-message Example {
- Features features = 1;
-};
-
-message SequenceExample {
- Features context = 1;
- FeatureLists feature_lists = 2;
-};
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/data/example_pb2.py b/modules/text/text_generation/ernie_gen/propeller/paddle/data/example_pb2.py
deleted file mode 100644
index bd3cb4b12d005cbea6412043fe8ee1338fcb8a08..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/data/example_pb2.py
+++ /dev/null
@@ -1,148 +0,0 @@
-# -*- coding: utf-8 -*-
-# Generated by the protocol buffer compiler. DO NOT EDIT!
-# source: propeller/paddle/data/example.proto
-
-import sys
-_b = sys.version_info[0] < 3 and (lambda x: x) or (lambda x: x.encode('latin1'))
-from google.protobuf import descriptor as _descriptor
-from google.protobuf import message as _message
-from google.protobuf import reflection as _reflection
-from google.protobuf import symbol_database as _symbol_database
-# @@protoc_insertion_point(imports)
-
-_sym_db = _symbol_database.Default()
-
-from ernie_gen.propeller.paddle.data import feature_pb2 as propeller_dot_paddle_dot_data_dot_feature__pb2
-
-DESCRIPTOR = _descriptor.FileDescriptor(
- name='propeller/paddle/data/example.proto',
- package='propeller',
- syntax='proto3',
- serialized_options=None,
- serialized_pb=_b(
- '\n#propeller/paddle/data/example.proto\x12\tpropeller\x1a#propeller/paddle/data/feature.proto\"0\n\x07\x45xample\x12%\n\x08\x66\x65\x61tures\x18\x01 \x01(\x0b\x32\x13.propeller.Features\"g\n\x0fSequenceExample\x12$\n\x07\x63ontext\x18\x01 \x01(\x0b\x32\x13.propeller.Features\x12.\n\rfeature_lists\x18\x02 \x01(\x0b\x32\x17.propeller.FeatureListsb\x06proto3'
- ),
- dependencies=[
- propeller_dot_paddle_dot_data_dot_feature__pb2.DESCRIPTOR,
- ])
-
-_EXAMPLE = _descriptor.Descriptor(
- name='Example',
- full_name='propeller.Example',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='features',
- full_name='propeller.Example.features',
- index=0,
- number=1,
- type=11,
- cpp_type=10,
- label=1,
- has_default_value=False,
- default_value=None,
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=87,
- serialized_end=135,
-)
-
-_SEQUENCEEXAMPLE = _descriptor.Descriptor(
- name='SequenceExample',
- full_name='propeller.SequenceExample',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='context',
- full_name='propeller.SequenceExample.context',
- index=0,
- number=1,
- type=11,
- cpp_type=10,
- label=1,
- has_default_value=False,
- default_value=None,
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- _descriptor.FieldDescriptor(
- name='feature_lists',
- full_name='propeller.SequenceExample.feature_lists',
- index=1,
- number=2,
- type=11,
- cpp_type=10,
- label=1,
- has_default_value=False,
- default_value=None,
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=137,
- serialized_end=240,
-)
-
-_EXAMPLE.fields_by_name['features'].message_type = propeller_dot_paddle_dot_data_dot_feature__pb2._FEATURES
-_SEQUENCEEXAMPLE.fields_by_name['context'].message_type = propeller_dot_paddle_dot_data_dot_feature__pb2._FEATURES
-_SEQUENCEEXAMPLE.fields_by_name[
- 'feature_lists'].message_type = propeller_dot_paddle_dot_data_dot_feature__pb2._FEATURELISTS
-DESCRIPTOR.message_types_by_name['Example'] = _EXAMPLE
-DESCRIPTOR.message_types_by_name['SequenceExample'] = _SEQUENCEEXAMPLE
-_sym_db.RegisterFileDescriptor(DESCRIPTOR)
-
-Example = _reflection.GeneratedProtocolMessageType(
- 'Example',
- (_message.Message, ),
- dict(
- DESCRIPTOR=_EXAMPLE,
- __module__='propeller.paddle.data.example_pb2'
- # @@protoc_insertion_point(class_scope:propeller.Example)
- ))
-_sym_db.RegisterMessage(Example)
-
-SequenceExample = _reflection.GeneratedProtocolMessageType(
- 'SequenceExample',
- (_message.Message, ),
- dict(
- DESCRIPTOR=_SEQUENCEEXAMPLE,
- __module__='propeller.paddle.data.example_pb2'
- # @@protoc_insertion_point(class_scope:propeller.SequenceExample)
- ))
-_sym_db.RegisterMessage(SequenceExample)
-
-# @@protoc_insertion_point(module_scope)
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/data/feature.proto b/modules/text/text_generation/ernie_gen/propeller/paddle/data/feature.proto
deleted file mode 100644
index aa0f2dbc4de3295486109dee1dec0c25870d3e68..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/data/feature.proto
+++ /dev/null
@@ -1,46 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-syntax = "proto3";
-package ernie_gen.propeller;
-
-message BytesList {
- repeated bytes value = 1;
-}
-message FloatList {
- repeated float value = 1 [packed = true];
-}
-message Int64List {
- repeated int64 value = 1 [packed = true];
-}
-
-message Feature {
- oneof kind {
- BytesList bytes_list = 1;
- FloatList float_list = 2;
- Int64List int64_list = 3;
- }
-};
-
-message Features {
- map feature = 1;
-};
-
-message FeatureList {
- repeated Feature feature = 1;
-};
-
-message FeatureLists {
- map feature_list = 1;
-};
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/data/feature_column.py b/modules/text/text_generation/ernie_gen/propeller/paddle/data/feature_column.py
deleted file mode 100644
index b81937f5bc080370df22a62bd7417dc27892eabb..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/data/feature_column.py
+++ /dev/null
@@ -1,436 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""FeatureColumns and many Column"""
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import os
-import sys
-import struct
-from six.moves import zip, map
-import itertools
-import gzip
-from functools import partial
-import six
-import logging
-
-import numpy as np
-from glob import glob
-from ernie_gen.propeller.paddle.train import distribution
-
-from ernie_gen.propeller.data.functional import _interleave_func
-from ernie_gen.propeller.paddle.data.functional import Dataset
-from ernie_gen.propeller.paddle.data import example_pb2, feature_pb2
-import multiprocessing
-
-log = logging.getLogger(__name__)
-
-__all__ = ['FeatureColumns', 'TextColumn', 'TextIDColumn', 'LabelColumn', 'RawBytesColumn', 'basic_tokenizer', 'Column']
-
-
-def basic_tokenizer(sen):
- """doc"""
- seg = sen.split(b' ')
- seg = filter(lambda i: i != b' ', seg)
- return seg
-
-
-class Column(object):
- """doc"""
-
- def __init__(self, name):
- """doc"""
- pass
-
- def raw_to_proto(self, raw):
- """doc"""
- return feature_pb2.Feature()
-
- @property
- def output_shapes(self):
- """doc"""
- pass
-
- @property
- def output_types(self):
- """doc"""
- pass
-
- def proto_to_instance(self, proto):
- """doc"""
- raise NotImplementedError()
-
- def raw_to_instance(self, raw):
- """doc"""
- raise NotImplementedError()
-
-
-class LabelColumn(Column):
- """doc"""
-
- def __init__(self, name, vocab_dict=None, vocab_file=None):
- """doc"""
- self.name = name
- self.vocab = None
- if vocab_file:
- self.vocab = {j.strip(): i for i, j in enumerate(open(vocab_file, 'rb').readlines())}
- if vocab_dict:
- self.vocab = vocab_dict
-
- @property
- def output_shapes(self):
- """doc"""
- return [1]
-
- @property
- def output_types(self):
- """doc"""
- return 'int64'
-
- def raw_to_proto(self, raw):
- """doc"""
- if self.vocab is None:
- ids = [int(raw)]
- else:
- ids = [self.vocab[raw]]
- fe = feature_pb2.Feature(int64_list=feature_pb2.Int64List(value=ids))
- return fe
-
- def proto_to_instance(self, feature):
- """doc"""
- ret = np.array(feature.int64_list.value[0], dtype=np.int64)
- return ret
-
- def raw_to_instance(self, raw):
- """doc"""
- if self.vocab is None:
- ids = int(raw)
- else:
- ids = self.vocab[raw]
- return np.array(ids, dtype=np.int64)
-
-
-class TextColumn(Column):
- """doc"""
-
- def __init__(self, name, unk_id, vocab_file=None, vocab_dict=None, tokenizer=basic_tokenizer):
- self.name = name
- self.tokenizer = tokenizer
- self.unk_id = unk_id
- if not (vocab_file or vocab_dict):
- raise ValueError('at least specify vocab_file or vocab_dict')
- if vocab_file:
- self.vocab = {j.strip(): i for i, j in enumerate(open(vocab_file, 'rb').readlines())}
- if vocab_dict:
- self.vocab = vocab_dict
-
- @property
- def output_shapes(self):
- """doc"""
- return [-1]
-
- @property
- def output_types(self):
- """doc"""
- return 'int64'
-
- def raw_to_proto(self, raw):
- """doc"""
- ids = [s if isinstance(s, int) else self.vocab.get(s, self.unk_id) for s in self.tokenizer(raw)]
- fe = feature_pb2.Feature(int64_list=feature_pb2.Int64List(value=ids))
- return fe
-
- def proto_to_instance(self, feature):
- """doc"""
- ret = np.array(feature.int64_list.value, dtype=np.int64)
- return ret
-
- def raw_to_instance(self, raw):
- """doc"""
- ids = [s if isinstance(s, int) else self.vocab.get(s, self.unk_id) for s in self.tokenizer(raw)]
- return np.array(ids, dtype=np.int64)
-
-
-class RawBytesColumn(Column):
- def __init__(self, name):
- self.name = name
-
- @property
- def output_shapes(self):
- """doc"""
- return [-1]
-
- @property
- def output_types(self):
- """doc"""
- return 'bytes'
-
- # def raw_to_proto(self, raw):
- # """doc"""
- # fe = feature_pb2.Feature(bytes_list=BytesList(value=[raw]))
- # return fe
-
- def proto_to_instance(self, feature):
- """doc"""
- ret = feature.bytes_list.value[0] #np.array(feature.int64_list.value, dtype=np.int64)
- return ret
-
- def raw_to_instance(self, raw):
- """doc"""
- return raw
-
-
-class TextIDColumn(Column):
- """doc"""
-
- def __init__(self, name):
- """doc"""
- self.name = name
-
- @property
- def output_shapes(self):
- """doc"""
- return [-1]
-
- @property
- def output_types(self):
- """doc"""
- return 'int64'
-
- def raw_to_proto(self, raw):
- """doc"""
- ids = [int(s) for s in raw.split(b' ')]
- fe = feature_pb2.Feature(int64_list=feature_pb2.Int64List(value=ids))
- return fe
-
- def proto_to_instance(self, feature):
- """doc"""
- ret = np.array(feature.int64_list.value, dtype=np.int64)
- return ret
-
- def raw_to_instance(self, raw):
- """doc"""
- ret = np.array([int(i) for i in raw.split(b' ')], dtype=np.int64)
- return ret
-
-
-def _list_files(raw_dir):
- return [os.path.join(raw_dir, p) for p in os.listdir(raw_dir)]
-
-
-_columns = None
-
-
-def _init_worker(col):
- global _columns
- _columns = col
-
-
-def _worker_entrence(args):
- args = (_columns, ) + args
- return _make_gz(args)
-
-
-class FeatureColumns(object):
- """A Dataset Factory object"""
-
- def __init__(self, columns):
- """doc"""
- self._columns = columns
-
- def _make_gz_dataset(self, raw_dir, gz_dir):
- assert raw_dir or gz_dir, 'data_dir not specified when using gz mode'
- if raw_dir is not None:
- assert os.path.exists(raw_dir), 'raw_dir not exists: %s' % raw_dir
- raw_file = os.listdir(raw_dir)
- if gz_dir is None:
- gz_dir = '%s_gz' % raw_dir.rstrip('/')
-
- if not os.path.exists(gz_dir):
- os.mkdir(gz_dir)
-
- if raw_dir is not None:
- if len(raw_file) != 0:
- log.debug('try making gz')
- pool = multiprocessing.Pool(initializer=_init_worker, initargs=(self._columns, ))
- args = [(os.path.join(raw_dir, f), os.path.join(gz_dir, f), b'\t') for f in raw_file]
- pool.map(_worker_entrence, args)
- pool.close()
- pool.join()
- else:
- assert len(
- os.listdir(gz_dir)) != 0, 'cant find gz file or raw-txt file at [%s] and [%s]' % (raw_dir, gz_dir)
- return gz_dir
-
- def _read_gz_dataset(self, gz_files, shuffle=False, repeat=True, shard=False, **kwargs):
- if len(gz_files) == 0:
- raise ValueError('reading gz from empty file list: %s' % gz_files)
- log.info('reading gz from %s' % '\n'.join(gz_files))
- dataset = Dataset.from_list(gz_files)
- if repeat:
- dataset = dataset.repeat()
-
- # if shard and distribution.status.mode == distribution.DistributionMode.NCCL:
- # log.info('Apply dataset sharding in distribution env')
- # train_ds = train_ds.shard(distribution.status.num_replica,
- # distribution.status.replica_id)
-
- if shuffle:
- dataset = dataset.shuffle(buffer_size=len(gz_files))
- fn = partial(
- _interleave_func,
- map_fn=lambda filename: Dataset.from_record_file(filename),
- cycle_length=len(gz_files),
- block_length=1)
- dataset = dataset.apply(fn)
- if shuffle:
- dataset = dataset.shuffle(buffer_size=1000)
-
- def _parse_gz(record_str): # function that takes python_str as input
- ex = example_pb2.Example()
- ex.ParseFromString(record_str)
- ret = []
- fea_dict = ex.features.feature
- for c in self._columns:
- ins = c.proto_to_instance(fea_dict[c.name])
- ret.append(ins)
- return ret
-
- dataset = dataset.map(_parse_gz)
- return dataset
-
- def _read_txt_dataset(self, data_files, shuffle=False, repeat=True, **kwargs):
- log.info('reading raw files from %s' % '\n'.join(data_files))
- dataset = Dataset.from_list(data_files)
- if repeat:
- dataset = dataset.repeat()
- if shuffle:
- dataset = dataset.shuffle(buffer_size=len(data_files))
-
- fn = partial(
- _interleave_func,
- map_fn=lambda filename: Dataset.from_file(filename),
- cycle_length=len(data_files),
- block_length=1)
- dataset = dataset.apply(fn)
- if shuffle:
- dataset = dataset.shuffle(buffer_size=1000)
-
- def _parse_txt_file(record_str): # function that takes python_str as input
- features = record_str.strip(b'\n').split(b'\t')
- ret = [column.raw_to_instance(feature) for feature, column in zip(features, self._columns)]
- return ret
-
- dataset = dataset.map(_parse_txt_file)
- return dataset
-
- def _read_stdin_dataset(self, encoding='utf8', shuffle=False, **kwargs):
- log.info('reading raw files stdin')
-
- def _gen():
- if six.PY3:
- source = sys.stdin.buffer
- else:
- source = sys.stdin
- while True:
- line = source.readline()
- if len(line) == 0:
- break
- yield line,
-
- dataset = Dataset.from_generator_func(_gen)
- if shuffle:
- dataset = dataset.shuffle(buffer_size=1000)
-
- def _parse_stdin(record_str):
- """function that takes python_str as input"""
- features = record_str.strip(b'\n').split(b'\t')
- ret = [column.raw_to_instance(feature) for feature, column in zip(features, self._columns)]
- return ret
-
- dataset = dataset.map(_parse_stdin)
- return dataset
-
- def _prepare_dataset(self,
- dataset,
- map_func_before_batch=None,
- map_func_after_batch=None,
- shuffle_buffer_size=None,
- batch_size=1,
- pad_id=0,
- prefetch=None,
- **kwargs):
-
- if map_func_before_batch is not None:
- dataset = dataset.map(map_func_before_batch)
- if batch_size:
- dataset = dataset.padded_batch(batch_size, pad_id)
- if map_func_after_batch is not None:
- dataset = dataset.map(map_func_after_batch)
- return dataset
-
- def build_dataset(self, name, use_gz=True, data_dir=None, gz_dir=None, data_file=None, **kwargs):
- """
- build `Dataset` from `data_dir` or `data_file`
- if `use_gz`, will try to convert data_files to gz format and save to `gz_dir`, if `gz_dir` not given, will create one.
- """
- if use_gz:
- gz_dir = self._make_gz_dataset(data_dir, gz_dir)
- gz_files = _list_files(gz_dir) if gz_dir is not None else gz_dir
- ds = self._read_gz_dataset(gz_files, **kwargs)
- else:
- if data_dir is not None:
- data_files = _list_files(data_dir)
- elif data_file is not None:
- data_files = [data_file]
- else:
- raise ValueError('data_dir or data_files not specified')
- ds = self._read_txt_dataset(data_files, **kwargs)
- ds.name = name
- return ds
-
- def build_dataset_from_stdin(self, name, **kwargs):
- """doc"""
- ds = self._read_stdin_dataset(**kwargs)
- ds.name = name
- return ds
-
-
-def _make_gz(args):
- try:
- columns, from_file, to_file, sep = args
- if os.path.exists(to_file):
- return
- with open(from_file, 'rb') as fin, gzip.open(to_file, 'wb') as fout:
- log.debug('making gz %s => %s' % (from_file, to_file))
- for i, line in enumerate(fin):
- line = line.strip(b'\n').split(sep)
- #if i % 10000 == 0:
- # log.debug('making gz %s => %s [%d]' % (from_file, to_file, i))
- if len(line) != len(columns):
- log.error('columns not match at %s, got %d, expect %d' % (from_file, len(line), len(columns)))
- continue
- features = {}
- for l, c in zip(line, columns):
- features[c.name] = c.raw_to_proto(l)
- example = example_pb2.Example(features=feature_pb2.Features(feature=features))
- serialized = example.SerializeToString()
- l = len(serialized)
- data = struct.pack('i%ds' % l, l, serialized)
- fout.write(data)
- log.debug('done making gz %s => %s' % (from_file, to_file))
- except Exception as e:
- log.exception(e)
- raise e
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/data/feature_pb2.py b/modules/text/text_generation/ernie_gen/propeller/paddle/data/feature_pb2.py
deleted file mode 100644
index 21a96379e1fddf447b20c1c167294afc0f03c34a..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/data/feature_pb2.py
+++ /dev/null
@@ -1,549 +0,0 @@
-# -*- coding: utf-8 -*-
-# Generated by the protocol buffer compiler. DO NOT EDIT!
-# source: propeller/paddle/data/feature.proto
-
-import sys
-_b = sys.version_info[0] < 3 and (lambda x: x) or (lambda x: x.encode('latin1'))
-from google.protobuf import descriptor as _descriptor
-from google.protobuf import message as _message
-from google.protobuf import reflection as _reflection
-from google.protobuf import symbol_database as _symbol_database
-# @@protoc_insertion_point(imports)
-
-_sym_db = _symbol_database.Default()
-
-DESCRIPTOR = _descriptor.FileDescriptor(
- name='propeller/paddle/data/feature.proto',
- package='propeller',
- syntax='proto3',
- serialized_options=None,
- serialized_pb=_b(
- '\n#propeller/paddle/data/feature.proto\x12\tpropeller\"\x1a\n\tBytesList\x12\r\n\x05value\x18\x01 \x03(\x0c\"\x1e\n\tFloatList\x12\x11\n\x05value\x18\x01 \x03(\x02\x42\x02\x10\x01\"\x1e\n\tInt64List\x12\x11\n\x05value\x18\x01 \x03(\x03\x42\x02\x10\x01\"\x95\x01\n\x07\x46\x65\x61ture\x12*\n\nbytes_list\x18\x01 \x01(\x0b\x32\x14.propeller.BytesListH\x00\x12*\n\nfloat_list\x18\x02 \x01(\x0b\x32\x14.propeller.FloatListH\x00\x12*\n\nint64_list\x18\x03 \x01(\x0b\x32\x14.propeller.Int64ListH\x00\x42\x06\n\x04kind\"\x81\x01\n\x08\x46\x65\x61tures\x12\x31\n\x07\x66\x65\x61ture\x18\x01 \x03(\x0b\x32 .propeller.Features.FeatureEntry\x1a\x42\n\x0c\x46\x65\x61tureEntry\x12\x0b\n\x03key\x18\x01 \x01(\t\x12!\n\x05value\x18\x02 \x01(\x0b\x32\x12.propeller.Feature:\x02\x38\x01\"2\n\x0b\x46\x65\x61tureList\x12#\n\x07\x66\x65\x61ture\x18\x01 \x03(\x0b\x32\x12.propeller.Feature\"\x9a\x01\n\x0c\x46\x65\x61tureLists\x12>\n\x0c\x66\x65\x61ture_list\x18\x01 \x03(\x0b\x32(.propeller.FeatureLists.FeatureListEntry\x1aJ\n\x10\x46\x65\x61tureListEntry\x12\x0b\n\x03key\x18\x01 \x01(\t\x12%\n\x05value\x18\x02 \x01(\x0b\x32\x16.propeller.FeatureList:\x02\x38\x01\x62\x06proto3'
- ))
-
-_BYTESLIST = _descriptor.Descriptor(
- name='BytesList',
- full_name='propeller.BytesList',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='value',
- full_name='propeller.BytesList.value',
- index=0,
- number=1,
- type=12,
- cpp_type=9,
- label=3,
- has_default_value=False,
- default_value=[],
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=50,
- serialized_end=76,
-)
-
-_FLOATLIST = _descriptor.Descriptor(
- name='FloatList',
- full_name='propeller.FloatList',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='value',
- full_name='propeller.FloatList.value',
- index=0,
- number=1,
- type=2,
- cpp_type=6,
- label=3,
- has_default_value=False,
- default_value=[],
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=_b('\020\001'),
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=78,
- serialized_end=108,
-)
-
-_INT64LIST = _descriptor.Descriptor(
- name='Int64List',
- full_name='propeller.Int64List',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='value',
- full_name='propeller.Int64List.value',
- index=0,
- number=1,
- type=3,
- cpp_type=2,
- label=3,
- has_default_value=False,
- default_value=[],
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=_b('\020\001'),
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=110,
- serialized_end=140,
-)
-
-_FEATURE = _descriptor.Descriptor(
- name='Feature',
- full_name='propeller.Feature',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='bytes_list',
- full_name='propeller.Feature.bytes_list',
- index=0,
- number=1,
- type=11,
- cpp_type=10,
- label=1,
- has_default_value=False,
- default_value=None,
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- _descriptor.FieldDescriptor(
- name='float_list',
- full_name='propeller.Feature.float_list',
- index=1,
- number=2,
- type=11,
- cpp_type=10,
- label=1,
- has_default_value=False,
- default_value=None,
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- _descriptor.FieldDescriptor(
- name='int64_list',
- full_name='propeller.Feature.int64_list',
- index=2,
- number=3,
- type=11,
- cpp_type=10,
- label=1,
- has_default_value=False,
- default_value=None,
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[
- _descriptor.OneofDescriptor(
- name='kind', full_name='propeller.Feature.kind', index=0, containing_type=None, fields=[]),
- ],
- serialized_start=143,
- serialized_end=292,
-)
-
-_FEATURES_FEATUREENTRY = _descriptor.Descriptor(
- name='FeatureEntry',
- full_name='propeller.Features.FeatureEntry',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='key',
- full_name='propeller.Features.FeatureEntry.key',
- index=0,
- number=1,
- type=9,
- cpp_type=9,
- label=1,
- has_default_value=False,
- default_value=_b("").decode('utf-8'),
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- _descriptor.FieldDescriptor(
- name='value',
- full_name='propeller.Features.FeatureEntry.value',
- index=1,
- number=2,
- type=11,
- cpp_type=10,
- label=1,
- has_default_value=False,
- default_value=None,
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=_b('8\001'),
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=358,
- serialized_end=424,
-)
-
-_FEATURES = _descriptor.Descriptor(
- name='Features',
- full_name='propeller.Features',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='feature',
- full_name='propeller.Features.feature',
- index=0,
- number=1,
- type=11,
- cpp_type=10,
- label=3,
- has_default_value=False,
- default_value=[],
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[
- _FEATURES_FEATUREENTRY,
- ],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=295,
- serialized_end=424,
-)
-
-_FEATURELIST = _descriptor.Descriptor(
- name='FeatureList',
- full_name='propeller.FeatureList',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='feature',
- full_name='propeller.FeatureList.feature',
- index=0,
- number=1,
- type=11,
- cpp_type=10,
- label=3,
- has_default_value=False,
- default_value=[],
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=426,
- serialized_end=476,
-)
-
-_FEATURELISTS_FEATURELISTENTRY = _descriptor.Descriptor(
- name='FeatureListEntry',
- full_name='propeller.FeatureLists.FeatureListEntry',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='key',
- full_name='propeller.FeatureLists.FeatureListEntry.key',
- index=0,
- number=1,
- type=9,
- cpp_type=9,
- label=1,
- has_default_value=False,
- default_value=_b("").decode('utf-8'),
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- _descriptor.FieldDescriptor(
- name='value',
- full_name='propeller.FeatureLists.FeatureListEntry.value',
- index=1,
- number=2,
- type=11,
- cpp_type=10,
- label=1,
- has_default_value=False,
- default_value=None,
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=_b('8\001'),
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=559,
- serialized_end=633,
-)
-
-_FEATURELISTS = _descriptor.Descriptor(
- name='FeatureLists',
- full_name='propeller.FeatureLists',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='feature_list',
- full_name='propeller.FeatureLists.feature_list',
- index=0,
- number=1,
- type=11,
- cpp_type=10,
- label=3,
- has_default_value=False,
- default_value=[],
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[
- _FEATURELISTS_FEATURELISTENTRY,
- ],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=479,
- serialized_end=633,
-)
-
-_FEATURE.fields_by_name['bytes_list'].message_type = _BYTESLIST
-_FEATURE.fields_by_name['float_list'].message_type = _FLOATLIST
-_FEATURE.fields_by_name['int64_list'].message_type = _INT64LIST
-_FEATURE.oneofs_by_name['kind'].fields.append(_FEATURE.fields_by_name['bytes_list'])
-_FEATURE.fields_by_name['bytes_list'].containing_oneof = _FEATURE.oneofs_by_name['kind']
-_FEATURE.oneofs_by_name['kind'].fields.append(_FEATURE.fields_by_name['float_list'])
-_FEATURE.fields_by_name['float_list'].containing_oneof = _FEATURE.oneofs_by_name['kind']
-_FEATURE.oneofs_by_name['kind'].fields.append(_FEATURE.fields_by_name['int64_list'])
-_FEATURE.fields_by_name['int64_list'].containing_oneof = _FEATURE.oneofs_by_name['kind']
-_FEATURES_FEATUREENTRY.fields_by_name['value'].message_type = _FEATURE
-_FEATURES_FEATUREENTRY.containing_type = _FEATURES
-_FEATURES.fields_by_name['feature'].message_type = _FEATURES_FEATUREENTRY
-_FEATURELIST.fields_by_name['feature'].message_type = _FEATURE
-_FEATURELISTS_FEATURELISTENTRY.fields_by_name['value'].message_type = _FEATURELIST
-_FEATURELISTS_FEATURELISTENTRY.containing_type = _FEATURELISTS
-_FEATURELISTS.fields_by_name['feature_list'].message_type = _FEATURELISTS_FEATURELISTENTRY
-DESCRIPTOR.message_types_by_name['BytesList'] = _BYTESLIST
-DESCRIPTOR.message_types_by_name['FloatList'] = _FLOATLIST
-DESCRIPTOR.message_types_by_name['Int64List'] = _INT64LIST
-DESCRIPTOR.message_types_by_name['Feature'] = _FEATURE
-DESCRIPTOR.message_types_by_name['Features'] = _FEATURES
-DESCRIPTOR.message_types_by_name['FeatureList'] = _FEATURELIST
-DESCRIPTOR.message_types_by_name['FeatureLists'] = _FEATURELISTS
-_sym_db.RegisterFileDescriptor(DESCRIPTOR)
-
-BytesList = _reflection.GeneratedProtocolMessageType(
- 'BytesList',
- (_message.Message, ),
- dict(
- DESCRIPTOR=_BYTESLIST,
- __module__='propeller.paddle.data.feature_pb2'
- # @@protoc_insertion_point(class_scope:propeller.BytesList)
- ))
-_sym_db.RegisterMessage(BytesList)
-
-FloatList = _reflection.GeneratedProtocolMessageType(
- 'FloatList',
- (_message.Message, ),
- dict(
- DESCRIPTOR=_FLOATLIST,
- __module__='propeller.paddle.data.feature_pb2'
- # @@protoc_insertion_point(class_scope:propeller.FloatList)
- ))
-_sym_db.RegisterMessage(FloatList)
-
-Int64List = _reflection.GeneratedProtocolMessageType(
- 'Int64List',
- (_message.Message, ),
- dict(
- DESCRIPTOR=_INT64LIST,
- __module__='propeller.paddle.data.feature_pb2'
- # @@protoc_insertion_point(class_scope:propeller.Int64List)
- ))
-_sym_db.RegisterMessage(Int64List)
-
-Feature = _reflection.GeneratedProtocolMessageType(
- 'Feature',
- (_message.Message, ),
- dict(
- DESCRIPTOR=_FEATURE,
- __module__='propeller.paddle.data.feature_pb2'
- # @@protoc_insertion_point(class_scope:propeller.Feature)
- ))
-_sym_db.RegisterMessage(Feature)
-
-Features = _reflection.GeneratedProtocolMessageType(
- 'Features',
- (_message.Message, ),
- dict(
- FeatureEntry=_reflection.GeneratedProtocolMessageType(
- 'FeatureEntry',
- (_message.Message, ),
- dict(
- DESCRIPTOR=_FEATURES_FEATUREENTRY,
- __module__='propeller.paddle.data.feature_pb2'
- # @@protoc_insertion_point(class_scope:propeller.Features.FeatureEntry)
- )),
- DESCRIPTOR=_FEATURES,
- __module__='propeller.paddle.data.feature_pb2'
- # @@protoc_insertion_point(class_scope:propeller.Features)
- ))
-_sym_db.RegisterMessage(Features)
-_sym_db.RegisterMessage(Features.FeatureEntry)
-
-FeatureList = _reflection.GeneratedProtocolMessageType(
- 'FeatureList',
- (_message.Message, ),
- dict(
- DESCRIPTOR=_FEATURELIST,
- __module__='propeller.paddle.data.feature_pb2'
- # @@protoc_insertion_point(class_scope:propeller.FeatureList)
- ))
-_sym_db.RegisterMessage(FeatureList)
-
-FeatureLists = _reflection.GeneratedProtocolMessageType(
- 'FeatureLists',
- (_message.Message, ),
- dict(
- FeatureListEntry=_reflection.GeneratedProtocolMessageType(
- 'FeatureListEntry',
- (_message.Message, ),
- dict(
- DESCRIPTOR=_FEATURELISTS_FEATURELISTENTRY,
- __module__='propeller.paddle.data.feature_pb2'
- # @@protoc_insertion_point(class_scope:propeller.FeatureLists.FeatureListEntry)
- )),
- DESCRIPTOR=_FEATURELISTS,
- __module__='propeller.paddle.data.feature_pb2'
- # @@protoc_insertion_point(class_scope:propeller.FeatureLists)
- ))
-_sym_db.RegisterMessage(FeatureLists)
-_sym_db.RegisterMessage(FeatureLists.FeatureListEntry)
-
-_FLOATLIST.fields_by_name['value']._options = None
-_INT64LIST.fields_by_name['value']._options = None
-_FEATURES_FEATUREENTRY._options = None
-_FEATURELISTS_FEATURELISTENTRY._options = None
-# @@protoc_insertion_point(module_scope)
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/data/functional.py b/modules/text/text_generation/ernie_gen/propeller/paddle/data/functional.py
deleted file mode 100644
index 9b10424517bf41f1466c40362fab35c7622ad842..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/data/functional.py
+++ /dev/null
@@ -1,66 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Pyreader based Dataset"""
-
-import sys
-import numpy as np
-import logging
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from ernie_gen.propeller.data.functional import Dataset as DatasetBase
-
-log = logging.getLogger(__name__)
-
-
-class Dataset(DatasetBase):
- """Pyreader based Dataset"""
-
- def placeholders(self):
- """doc"""
- if self.name is None:
- raise ValueError('can not get feature from unnamed Dataset')
-
- ret = []
- for i, (shape, types) in enumerate(zip(self.data_shapes, self.data_types)):
- ret.append(L.data('%s_placeholder_%d' % (self.name, i), shape=shape, append_batch_size=False, dtype=types))
- return ret
-
- def features(self):
- """start point of net building. call this in a program scope"""
- if self.name is None:
- raise ValueError('can not get feature from unnamed Dataset')
-
- if len(self.data_shapes) != len(self.data_types):
- raise ValueError('Dataset shapes and types not match: shape:%s types%s' % (repr(self._data_shapes),
- repr(self._data_types)))
- return self.placeholders()
-
- def start(self, places=None):
- """start Pyreader"""
- if places is None:
- places = F.cuda_places() if F.core.is_compiled_with_cuda() else F.cpu_places()
- #assert self.pyreader is not None, 'use Dataset.features to build net first, then start dataset'
- def _gen():
- try:
- for idx, i in enumerate(self.generator()):
- yield i
- except Exception as e:
- log.exception(e)
- raise e
-
- r = F.io.PyReader(feed_list=self.placeholders(), capacity=50, iterable=True, return_list=F.in_dygraph_mode())
- r.decorate_batch_generator(_gen, places=places)
- return r()
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/summary.py b/modules/text/text_generation/ernie_gen/propeller/paddle/summary.py
deleted file mode 100644
index af1fc644bf0f4ab79c777bdbb3b4856d0c87a694..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/summary.py
+++ /dev/null
@@ -1,37 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""record summary tensor in a collection scope"""
-
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import sys
-
-import paddle.fluid as F
-from ernie_gen.propeller.paddle.collection import default_collection, Key
-
-
-def scalar(name, tensor):
- """scalar summary"""
- if not isinstance(tensor, F.framework.Variable):
- raise ValueError('expect paddle Variable, got %s' % repr(tensor))
- default_collection().add(Key.SUMMARY_SCALAR, (name, tensor))
-
-
-def histogram(name, tensor):
- """histogram summary"""
- if not isinstance(tensor, F.framework.Variable):
- raise ValueError('expect paddle Variable, got %s' % repr(tensor))
- default_collection().add(Key.SUMMARY_HISTOGRAM, (name, tensor))
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/train/__init__.py b/modules/text/text_generation/ernie_gen/propeller/paddle/train/__init__.py
deleted file mode 100644
index b7867c92669b0ee8d674306db7832394c7b40118..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/train/__init__.py
+++ /dev/null
@@ -1,33 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Propeller training"""
-
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import os
-import sys
-import logging
-from time import time
-
-log = logging.getLogger(__name__)
-
-from ernie_gen.propeller.paddle.train.monitored_executor import *
-from ernie_gen.propeller.paddle.train.trainer import *
-from ernie_gen.propeller.paddle.train.hooks import *
-from ernie_gen.propeller.train.model import Model
-from ernie_gen.propeller.paddle.train import exporter
-from ernie_gen.propeller.paddle.train import distribution
-from ernie_gen.propeller.paddle.train import metrics
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/train/distribution.py b/modules/text/text_generation/ernie_gen/propeller/paddle/train/distribution.py
deleted file mode 100644
index c1ccaf4abd4ed5328dd574c1f02331faeddc8fbf..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/train/distribution.py
+++ /dev/null
@@ -1,159 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import functools
-import six
-import os
-import logging
-from time import sleep
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-log = logging.getLogger(__name__)
-import ernie_gen.propeller.util
-
-__all__ = ['init_distribuition_env', 'status']
-
-status = None
-
-
-class DistributionMode(object):
- LOCAL = 0
- NCCL = 1
-
-
-class DistributionStatus(object):
- def __init__(self, config):
- if config is None:
- self._mode = DistributionMode.LOCAL
- self._env = None
- self._this = None
- else:
- try:
- self._mode = DistributionMode.NCCL
-
- cluster = config['cluster']
- task = config['task']['type']
- idx = int(config['task']['index'])
- self._this = cluster[task][idx]
-
- self._env = cluster['chief'] + cluster.get('worker', [])
- if len(set(self._env)) != len(self._env):
- raise ValueError('duplicate host in dis_config %s' % config)
-
- except KeyError as e:
- raise ValueError('PROPELLER_DISCONFIG wrong: %s not found in %s' % (e, repr(config)))
-
- @property
- def mode(self):
- return self._mode
-
- @property
- def num_replica(self):
- if self._mode == DistributionMode.LOCAL:
- return 1
- elif self._mode == DistributionMode.NCCL:
- return len(self._env)
- else:
- raise ValueError('Got unknow distribution mode %s' % repr(self._mode))
-
- @property
- def replica_id(self):
- if self._mode == DistributionMode.LOCAL:
- return 0
- elif self._mode == DistributionMode.NCCL:
- return self._env.index(self._this)
- else:
- raise ValueError('Got unknow distribution mode %s' % repr(self._mode))
-
- @property
- def is_master(self):
- if self._mode == DistributionMode.LOCAL:
- return True
- elif self._mode == DistributionMode.NCCL:
- return self.replica_id == 0
- else:
- raise ValueError('got unknow distribution mode %s' % repr(self._mode))
-
-
-def _get_paddlestype_disconfig():
- env = os.environ.copy()
- if not ('PADDLE_TRAINER_ID' in env and 'PADDLE_CURRENT_ENDPOINT' in env and 'PADDLE_TRAINERS_NUM' in env
- and 'PADDLE_TRAINER_ENDPOINTS' in env):
- return None
- else:
- ip_port_list = env['PADDLE_TRAINER_ENDPOINTS'].split(',')
- assert len(ip_port_list) == int(env['PADDLE_TRAINERS_NUM'])
- ip_port_self = env['PADDLE_CURRENT_ENDPOINT']
- world = {"chief": [ip_port_list[0]]}
- for ip_port in ip_port_list[1:]:
- world.setdefault('worker', []).append(ip_port)
- self_index = ip_port_list.index(ip_port_self)
- self_type = 'chief' if self_index == 0 else 'worker'
- if self_type == 'worker':
- self_index -= 1
- env_dict = {'cluster': world, 'task': {'type': self_type, 'index': self_index}}
- return env_dict
-
-
-dis_config = ernie_gen.propeller.util._get_dict_from_environ_or_json_or_file(None, 'PROPELLER_DISCONFIG')
-if dis_config is None:
- log.debug('no PROPELLER_DISCONFIG found, try paddlestype setting')
- dis_config = _get_paddlestype_disconfig()
- if dis_config is None:
- log.debug('no paddle stype setting found')
-status = DistributionStatus(dis_config)
-
-
-def run_on_master(func):
- """skip function in distribution env"""
-
- @functools.wraps(func)
- def f(*arg, **kwargs):
- """f"""
- if status is None:
- raise ValueError('distribution mode unkown at this point')
- if status.mode == DistributionMode.LOCAL:
- r = func(*arg, **kwargs)
- elif status.mode == DistributionMode.NCCL:
- if status.is_master:
- r = func(*arg, **kwargs)
- else:
- r = 0 # skip function
- #MPI.COMM_WORLD.Barrier()
- return r
-
- return f
-
-
-def init_distribuition_env(program):
- if status.mode == DistributionMode.LOCAL:
- log.info('Initializing local training')
- elif status.mode == DistributionMode.NCCL:
- config = F.DistributeTranspilerConfig()
- config.mode = "nccl2"
- config.nccl_comm_num = 1
- F.DistributeTranspiler(config=config).transpile(
- status.replica_id,
- trainers=','.join(status._env),
- current_endpoint=status._this,
- program=program.train_program,
- startup_program=program.startup_program)
- log.info('Initializing distribution training with config %s' % (repr(dis_config)))
- if status.is_master:
- sleep(30)
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/train/exporter.py b/modules/text/text_generation/ernie_gen/propeller/paddle/train/exporter.py
deleted file mode 100644
index cfdd60f4a7238de2e807cb2d4cf178bc451ba28a..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/train/exporter.py
+++ /dev/null
@@ -1,154 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-exporters
-"""
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import sys
-import os
-import itertools
-import six
-import inspect
-import abc
-import logging
-
-import numpy as np
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from ernie_gen.propeller.util import map_structure
-from ernie_gen.propeller.paddle.train import Saver
-from ernie_gen.propeller.types import InferenceSpec
-from ernie_gen.propeller.train.model import Model
-from ernie_gen.propeller.paddle.train.trainer import _build_net
-from ernie_gen.propeller.paddle.train.trainer import _build_model_fn
-from ernie_gen.propeller.types import RunMode
-from ernie_gen.propeller.types import ProgramPair
-
-log = logging.getLogger(__name__)
-
-
-@six.add_metaclass(abc.ABCMeta)
-class Exporter(object):
- """base exporter"""
-
- @abc.abstractmethod
- def export(self, exe, program, eval_result, state):
- """export"""
- raise NotImplementedError()
-
-
-class BestExporter(Exporter):
- """export saved model accordingto `cmp_fn`"""
-
- def __init__(self, export_dir, cmp_fn):
- """doc"""
- self._export_dir = export_dir
- self._best = None
- self.cmp_fn = cmp_fn
-
- def export(self, exe, program, eval_model_spec, eval_result, state):
- """doc"""
- log.debug('New evaluate result: %s \nold: %s' % (repr(eval_result), repr(self._best)))
- if self._best is None and state['best_model'] is not None:
- self._best = state['best_model']
- log.debug('restoring best state %s' % repr(self._best))
- if self._best is None or self.cmp_fn(old=self._best, new=eval_result):
- log.debug('[Best Exporter]: export to %s' % self._export_dir)
- eval_program = program.train_program
- # FIXME: all eval datasets has same name/types/shapes now!!! so every eval program are the smae
-
- saver = Saver(self._export_dir, exe, program=program, max_ckpt_to_keep=1)
- saver.save(state)
- eval_result = map_structure(float, eval_result)
- self._best = eval_result
- state['best_model'] = eval_result
- else:
- log.debug('[Best Exporter]: skip step %s' % state.gstep)
-
-
-class BestInferenceModelExporter(Exporter):
- """export inference model accordingto `cmp_fn`"""
-
- def __init__(self, export_dir, cmp_fn, model_class_or_model_fn=None, hparams=None, dataset=None):
- """doc"""
- self._export_dir = export_dir
- self._best = None
- self.cmp_fn = cmp_fn
- self.model_class_or_model_fn = model_class_or_model_fn
- self.hparams = hparams
- self.dataset = dataset
-
- def export(self, exe, program, eval_model_spec, eval_result, state):
- """doc"""
- if self.model_class_or_model_fn is not None and self.hparams is not None \
- and self.dataset is not None:
- log.info('Building program by user defined model function')
- if issubclass(self.model_class_or_model_fn, Model):
- _model_fn = _build_model_fn(self.model_class_or_model_fn)
- elif inspect.isfunction(self.model_class_or_model_fn):
- _model_fn = self.model_class_or_model_fn
- else:
- raise ValueError('unknown model %s' % self.model_class_or_model_fn)
-
- # build net
- infer_program = F.Program()
- startup_prog = F.Program()
- with F.program_guard(infer_program, startup_prog):
- #share var with Train net
- with F.unique_name.guard():
- log.info('Building Infer Graph')
- infer_fea = self.dataset.features()
- # run_config is None
- self.model_spec = _build_net(_model_fn, infer_fea, RunMode.PREDICT, self.hparams, None)
- log.info('Done')
- infer_program = infer_program.clone(for_test=True)
- self.program = ProgramPair(train_program=infer_program, startup_program=startup_prog)
-
- else:
- self.program = program
- self.model_spec = eval_model_spec
- if self._best is None and state['best_inf_model'] is not None:
- self._best = state['best_inf_model']
- log.debug('restoring best state %s' % repr(self._best))
- log.debug('New evaluate result: %s \nold: %s' % (repr(eval_result), repr(self._best)))
-
- if self._best is None or self.cmp_fn(old=self._best, new=eval_result):
- log.debug('[Best Exporter]: export to %s' % self._export_dir)
- if self.model_spec.inference_spec is None:
- raise ValueError('model_fn didnt return InferenceSpec')
-
- inf_spec_dict = self.model_spec.inference_spec
- if not isinstance(inf_spec_dict, dict):
- inf_spec_dict = {'inference': inf_spec_dict}
- for inf_spec_name, inf_spec in six.iteritems(inf_spec_dict):
- if not isinstance(inf_spec, InferenceSpec):
- raise ValueError('unknow inference spec type: %s' % inf_spec)
-
- save_dir = os.path.join(self._export_dir, inf_spec_name)
- log.debug('[Best Exporter]: save inference model: "%s" to %s' % (inf_spec_name, save_dir))
- feed_var = [i.name for i in inf_spec.inputs]
- fetch_var = inf_spec.outputs
-
- infer_program = self.program.train_program
- startup_prog = F.Program()
- F.io.save_inference_model(save_dir, feed_var, fetch_var, exe, main_program=infer_program)
- eval_result = map_structure(float, eval_result)
- state['best_inf_model'] = eval_result
- self._best = eval_result
- else:
- log.debug('[Best Exporter]: skip step %s' % state.gstep)
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/train/hooks.py b/modules/text/text_generation/ernie_gen/propeller/paddle/train/hooks.py
deleted file mode 100644
index 4b17ea217e7bba1e590839aada503f6e2cb9d5f3..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/train/hooks.py
+++ /dev/null
@@ -1,320 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""train hooks"""
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import sys
-import six
-import os
-import itertools
-
-import numpy as np
-import logging
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from ernie_gen.propeller import util
-from ernie_gen.propeller.paddle.train import distribution
-from ernie_gen.propeller.paddle.train.metrics import Metrics
-
-__all__ = [
- 'RunHook', 'TqdmProgressBarHook', 'TqdmNotebookProgressBarHook', 'CheckpointSaverHook', 'LoggingHook',
- 'StopAtStepHook', 'EvalHook'
-]
-
-log = logging.getLogger(__name__)
-
-
-class RunHook(object):
- """RunHook Base class"""
-
- def __init__(self):
- """doc"""
- pass
-
- def before_train(self, program):
- """doc"""
- pass
-
- def before_run(self, state):
- """doc"""
- return []
-
- def after_run(self, res_list, state):
- """doc"""
- pass
-
- def should_stop(self, state):
- """doc"""
- return False
-
- def after_train(self):
- """doc"""
- pass
-
-
-class TqdmProgressBarHook(RunHook):
- """show a progress bar when training"""
-
- def __init__(self, max_steps, desc=None):
- """doc"""
- self.tqdm = None
- import tqdm
- from ernie_gen.propeller import log as main_log
- hdl = main_log.handlers[0]
-
- class _TqdmLogginHandler(logging.Handler):
- def emit(self, record):
- """doc"""
- try:
- msg = self.format(record)
- tqdm.tqdm.write(msg, file=sys.stderr)
- self.flush()
- except (KeyboardInterrupt, SystemExit) as e:
- raise e
- except:
- self.handleError(record)
-
- tqdm_hdl = _TqdmLogginHandler()
- tqdm_hdl.setFormatter(hdl.formatter)
- main_log.removeHandler(hdl)
- main_log.addHandler(tqdm_hdl)
- self.tqdm = tqdm.tqdm(total=max_steps, desc=None)
-
- def before_run(self, state):
- self.tqdm.n = state.gstep
- return []
-
- def __del__(self):
- if self.tqdm:
- self.tqdm.close()
-
-
-class TqdmNotebookProgressBarHook(RunHook):
- """show a progress bar when training"""
-
- def __init__(self, max_steps, desc=None):
- """doc"""
- self.tqdm = None
- import tqdm
- from ernie_gen.propeller import log as main_log
- hdl = main_log.handlers[0]
-
- class _TqdmLogginHandler(logging.Handler):
- def emit(self, record):
- """doc"""
- try:
- msg = self.format(record)
- tqdm.tqdm.write(msg, file=sys.stderr)
- self.flush()
- except (KeyboardInterrupt, SystemExit) as e:
- raise e
- except:
- self.handleError(record)
-
- tqdm_hdl = _TqdmLogginHandler()
- tqdm_hdl.setFormatter(hdl.formatter)
- main_log.removeHandler(hdl)
- main_log.addHandler(tqdm_hdl)
- self.tqdm = tqdm.tqdm_notebook(total=max_steps, desc=None)
-
- def before_run(self, state):
- """doc"""
- self.tqdm.n = state.gstep
- self.tqdm.refresh()
- return []
-
- def __del__(self):
- """doc"""
- if self.tqdm:
- self.tqdm.close()
-
-
-class LoggingHook(RunHook):
- """log tensor in to screan and VisualDL"""
-
- def __init__(self, loss, per_step=10, skip_step=100, summary_writer=None, summary_record=None):
- """doc"""
- if per_step is None or skip_step is None:
- raise ValueError('wrong step argument, per step: %d skip_step %d' % (per_step, skip_step))
- self.loss = loss
- self.per_step = per_step
- self.skip_step = skip_step
- self.summary_record = summary_record
- self.writer = summary_writer
- self.last_state = None
-
- def before_train(self, program):
- """doc"""
- if self.summary_record:
- if self.summary_record.scalar:
- self.s_name, self.s_tolog = zip(*self.summary_record.scalar)
- else:
- self.s_name, self.s_tolog = [], []
-
- if self.summary_record.histogram:
- self.h_name, self.h_tolog = zip(*self.summary_record.histogram)
- else:
- self.h_name, self.h_tolog = [], []
-
- def before_run(self, state):
- """doc"""
- if state.gstep % self.per_step == 0 and state.step > self.skip_step:
- ret = [self.loss]
- if self.summary_record:
- ret += self.s_tolog
- ret += self.h_tolog
- return ret
- else:
- return []
-
- def after_run(self, res_list, state):
- """doc"""
- if state.gstep % self.per_step == 0 and state.step > self.skip_step:
- if not self.summary_record:
- return
-
- loss = float(res_list[0])
- s_np = res_list[1:1 + len(self.s_name)]
- h_np = res_list[1 + len(self.s_name):1 + len(self.s_name) + len(self.h_name)]
-
- if self.last_state is not None:
- speed = (state.gstep - self.last_state.gstep) / (state.time - self.last_state.time)
- else:
- speed = -1.
- self.last_state = state
-
- # log to VisualDL
- if self.writer is not None:
- self.writer.add_scalar('loss', loss, state.gstep)
- for name, t in zip(self.s_name, s_np):
- if np.isnan(t).any():
- log.warning('Nan summary: %s, skip' % name)
- else:
- self.writer.add_scalar(name, t, state.gstep)
-
- for name, t in zip(self.h_name, h_np):
- if np.isnan(t).any():
- log.warning('Nan summary: %s, skip' % name)
- else:
- self.writer.add_histogram(name, t, state.gstep)
-
- if speed > 0.:
- self.writer.add_scalar('global_step', speed, state.gstep)
-
- # log to stdout
- log.debug('\t'.join([
- 'step: %d' % state.gstep,
- 'steps/sec: %.5f' % speed,
- 'loss: %.5f' % loss,
- '' if self.summary_record is None else ' '.join(map(lambda t: '%s:%s' % t, zip(self.s_name, s_np))),
- ]))
-
-
-class StopAtStepHook(RunHook):
- """stop training at some step"""
-
- def __init__(self, stop_global_step, stop_step):
- """doc"""
- self._stop_gstep = stop_global_step
- self._stop_step = stop_step
-
- def should_stop(self, state):
- """doc"""
- if (self._stop_gstep and state.gstep >= self._stop_gstep) or \
- (self._stop_step and state.step >= self._stop_step):
- log.info('StopAtStepHook called stop')
- return True
- else:
- return False
-
-
-class EvalHook(RunHook):
- """hook this on a eval Executor"""
-
- def __init__(self, metrics, summary_writer=None):
- """doc"""
- self.writer = summary_writer
- self._result = None
-
- if not isinstance(metrics, dict):
- raise ValueError('metrics should be dict, got %s' % repr(metrics))
-
- for k, m in six.iteritems(metrics):
- if not isinstance(m, Metrics):
- raise ValueError('metrics %s should be instance of propeller.Metrics, got %s' % (k, repr(m)))
-
- if len(metrics):
- self.names = list(metrics.keys())
- self.metrics = list(metrics.values())
- else:
- self.names, self.metrics = [], []
-
- def before_train(self, program):
- """doc"""
- for m in self.metrics:
- m.reset()
-
- def before_run(self, state):
- """doc"""
- ls = [m.tensor for m in self.metrics]
- for i in ls:
- if not (isinstance(i, list) or isinstance(i, tuple)):
- raise ValueError('metrics should return tuple or list of tensors, got %s' % repr(i))
- for ii in i:
- if not isinstance(ii, F.framework.Variable):
- raise ValueError(
- 'metrics tensor be propeller.train.Metrics, got %s of type %s' % (repr(ii), type(ii)))
- ls_flt, self.schema = util.flatten(ls)
- #log.debug(ls_flt)
- return ls_flt
-
- def after_run(self, res_list, state):
- """doc"""
- res = util.unflatten(res_list, self.schema)
- for r, m in zip(res, self.metrics):
- m.update(r)
-
- @property
- def result(self):
- """doc"""
- return self._result
-
- def after_train(self):
- """doc"""
- printable = []
- self._result = {}
- for n, m in zip(self.names, self.metrics):
- val = m.eval()
- self._result[n] = val
-
- return self.result
-
-
-class CheckpointSaverHook(RunHook):
- """Save checkpoint every n step"""
-
- def __init__(self, saver, per_step=10, skip_step=100):
- """doc"""
- self.saver = saver
- self.per_step = per_step
- self.skip_step = skip_step
-
- def after_run(self, res_list, state):
- """doc"""
- if state.gstep % self.per_step == 0 and \
- state.step > self.skip_step:
- self.saver.save(state)
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/train/metrics.py b/modules/text/text_generation/ernie_gen/propeller/paddle/train/metrics.py
deleted file mode 100644
index 662c665759790ce5738239cdb6bc52cf4e696539..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/train/metrics.py
+++ /dev/null
@@ -1,666 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""predefined metrics"""
-
-import sys
-import os
-import six
-
-import numpy as np
-import itertools
-import logging
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-import sklearn.metrics
-
-log = logging.getLogger(__name__)
-
-__all__ = ['Metrics', 'F1', 'Recall', 'Precision', 'Mrr', 'Mean', 'Acc', 'ChunkF1', 'RecallAtPrecision']
-
-
-class Metrics(object):
- """Metrics base class"""
-
- def __init__(self):
- """doc"""
- self.saver = []
-
- @property
- def tensor(self):
- """doc"""
- pass
-
- def update(self, *args):
- """doc"""
- pass
-
- def eval(self):
- """doc"""
- pass
-
-
-class Mean(Metrics):
- """doc"""
-
- def __init__(self, t):
- """doc"""
- self.t = t
- self.reset()
-
- def reset(self):
- """doc"""
- self.saver = np.array([])
-
- @property
- def tensor(self):
- """doc"""
- return self.t,
-
- def update(self, args):
- """doc"""
- t, = args
- t = t.reshape([-1])
- self.saver = np.concatenate([self.saver, t])
-
- def eval(self):
- """doc"""
- return self.saver.mean()
-
-
-class Ppl(Mean):
- """doc"""
-
- def eval(self):
- """doc"""
- return np.exp(self.saver.mean())
-
-
-class Acc(Mean):
- """doc"""
-
- def __init__(self, label, pred):
- """doc"""
- if label.shape != pred.shape:
- raise ValueError(
- 'expect label shape == pred shape, got: label.shape=%s, pred.shape = %s' % (repr(label), repr(pred)))
- self.eq = L.equal(pred, label)
- self.reset()
-
- @property
- def tensor(self):
- """doc"""
- return self.eq,
-
-
-class MSE(Mean):
- """doc"""
-
- def __init__(self, label, pred):
- """doc"""
- if label.shape != pred.shape:
- raise ValueError(
- 'expect label shape == pred shape, got: label.shape=%s, pred.shape = %s' % (repr(label), repr(pred)))
-
- diff = pred - label
- self.mse = diff * diff
- self.reset()
-
- @property
- def tensor(self):
- """doc"""
- return self.mse,
-
-
-class Cosine(Mean):
- """doc"""
-
- def __init__(self, label, pred):
- """doc"""
- if label.shape != pred.shape:
- raise ValueError(
- 'expect label shape == pred shape, got: label.shape=%s, pred.shape = %s' % (repr(label), repr(pred)))
-
- self.cos = L.cos_sim(label, pred)
- self.reset()
-
- @property
- def tensor(self):
- """doc"""
- return self.cos,
-
-
-class MacroF1(Metrics):
- """doc"""
-
- def __init__(self, label, pred):
- """doc"""
- if label.shape != pred.shape:
- raise ValueError(
- 'expect label shape == pred shape, got: label.shape=%s, pred.shape = %s' % (repr(label), repr(pred)))
-
- self.label = label
- self.pred = pred
- self.reset()
-
- def reset(self):
- """doc"""
- self.label_saver = np.array([], dtype=np.bool)
- self.pred_saver = np.array([], dtype=np.bool)
-
- @property
- def tensor(self):
- """doc"""
- return self.label, self.pred
-
- def update(self, args):
- """doc"""
- label, pred = args
- label = label.reshape([-1]).astype(np.bool)
- pred = pred.reshape([-1]).astype(np.bool)
- if label.shape != pred.shape:
- raise ValueError('Metrics precesion: input not match: label:%s pred:%s' % (label, pred))
- self.label_saver = np.concatenate([self.label_saver, label])
- self.pred_saver = np.concatenate([self.pred_saver, pred])
-
- def eval(self):
- """doc"""
- return sklearn.metrics.f1_score(self.label_saver, self.pred_saver, average='macro')
-
-
-class Precision(Metrics):
- """doc"""
-
- def __init__(self, label, pred):
- """doc"""
- if label.shape != pred.shape:
- raise ValueError(
- 'expect label shape == pred shape, got: label.shape=%s, pred.shape = %s' % (repr(label), repr(pred)))
-
- self.label = label
- self.pred = pred
- self.reset()
-
- def reset(self):
- """doc"""
- self.label_saver = np.array([], dtype=np.bool)
- self.pred_saver = np.array([], dtype=np.bool)
-
- @property
- def tensor(self):
- """doc"""
- return self.label, self.pred
-
- def update(self, args):
- """doc"""
- label, pred = args
- label = label.reshape([-1]).astype(np.bool)
- pred = pred.reshape([-1]).astype(np.bool)
- if label.shape != pred.shape:
- raise ValueError('Metrics precesion: input not match: label:%s pred:%s' % (label, pred))
- self.label_saver = np.concatenate([self.label_saver, label])
- self.pred_saver = np.concatenate([self.pred_saver, pred])
-
- def eval(self):
- """doc"""
- tp = (self.label_saver & self.pred_saver).astype(np.int64).sum()
- p = self.pred_saver.astype(np.int64).sum()
- return tp / p
-
-
-class Recall(Precision):
- """doc"""
-
- def eval(self):
- """doc"""
- tp = (self.label_saver & self.pred_saver).astype(np.int64).sum()
- t = (self.label_saver).astype(np.int64).sum()
- return tp / t
-
-
-class F1(Precision):
- """doc"""
-
- def eval(self):
- """doc"""
- tp = (self.label_saver & self.pred_saver).astype(np.int64).sum()
- t = self.label_saver.astype(np.int64).sum()
- p = self.pred_saver.astype(np.int64).sum()
- precision = tp / (p + 1.e-6)
- recall = tp / (t + 1.e-6)
- return 2 * precision * recall / (precision + recall + 1.e-6)
-
-
-class Auc(Metrics):
- """doc"""
-
- def __init__(self, label, pred):
- """doc"""
- if label.shape != pred.shape:
- raise ValueError(
- 'expect label shape == pred shape, got: label.shape=%s, pred.shape = %s' % (repr(label), repr(pred)))
-
- self.pred = pred
- self.label = label
- self.reset()
-
- def reset(self):
- """doc"""
- self.pred_saver = np.array([], dtype=np.float32)
- self.label_saver = np.array([], dtype=np.bool)
-
- @property
- def tensor(self):
- """doc"""
- return [self.pred, self.label]
-
- def update(self, args):
- """doc"""
- pred, label = args
- pred = pred.reshape([-1]).astype(np.float32)
- label = label.reshape([-1]).astype(np.bool)
- self.pred_saver = np.concatenate([self.pred_saver, pred])
- self.label_saver = np.concatenate([self.label_saver, label])
-
- def eval(self):
- """doc"""
- fpr, tpr, thresholds = sklearn.metrics.roc_curve(self.label_saver.astype(np.int64), self.pred_saver)
- auc = sklearn.metrics.auc(fpr, tpr)
- return auc
-
-
-class RecallAtPrecision(Auc):
- """doc"""
-
- def __init__(self, label, pred, precision=0.9):
- """doc"""
- super(RecallAtPrecision, self).__init__(label, pred)
- self.precision = precision
-
- def eval(self):
- """doc"""
- self.pred_saver = self.pred_saver.reshape([self.label_saver.size, -1])[:, -1]
- precision, recall, thresholds = sklearn.metrics.precision_recall_curve(self.label_saver, self.pred_saver)
- for p, r in zip(precision, recall):
- if p > self.precision:
- return r
-
-
-class PrecisionAtThreshold(Auc):
- """doc"""
-
- def __init__(self, label, pred, threshold=0.5):
- """doc"""
- super().__init__(label, pred)
- self.threshold = threshold
-
- def eval(self):
- """doc"""
- infered = self.pred_saver > self.threshold
- correct_num = np.array(infered & self.label_saver).sum()
- infer_num = infered.sum()
- return correct_num / (infer_num + 1.e-6)
-
-
-class Mrr(Metrics):
- """doc"""
-
- def __init__(self, qid, label, pred):
- """doc"""
- if label.shape != pred.shape:
- raise ValueError(
- 'expect label shape == pred shape, got: label.shape=%s, pred.shape = %s' % (repr(label), repr(pred)))
-
- self.qid = qid
- self.label = label
- self.pred = pred
- self.reset()
-
- def reset(self):
- """doc"""
- self.qid_saver = np.array([], dtype=np.int64)
- self.label_saver = np.array([], dtype=np.int64)
- self.pred_saver = np.array([], dtype=np.float32)
-
- @property
- def tensor(self):
- """doc"""
- return [self.qid, self.label, self.pred]
-
- def update(self, args):
- """doc"""
- qid, label, pred = args
- if not (qid.shape[0] == label.shape[0] == pred.shape[0]):
- raise ValueError(
- 'Mrr dimention not match: qid[%s] label[%s], pred[%s]' % (qid.shape, label.shape, pred.shape))
- self.qid_saver = np.concatenate([self.qid_saver, qid.reshape([-1]).astype(np.int64)])
- self.label_saver = np.concatenate([self.label_saver, label.reshape([-1]).astype(np.int64)])
- self.pred_saver = np.concatenate([self.pred_saver, pred.reshape([-1]).astype(np.float32)])
-
- def eval(self):
- """doc"""
-
- def _key_func(tup):
- return tup[0]
-
- def _calc_func(tup):
- ranks = [
- 1. / (rank + 1.) for rank, (_, l, p) in enumerate(sorted(tup, key=lambda t: t[2], reverse=True))
- if l != 0
- ]
- if len(ranks):
- return ranks[0]
- else:
- return 0.
-
- mrr_for_qid = [
- _calc_func(tup) for _, tup in itertools.groupby(
- sorted(zip(self.qid_saver, self.label_saver, self.pred_saver), key=_key_func), key=_key_func)
- ]
- mrr = np.float32(sum(mrr_for_qid) / len(mrr_for_qid))
- return mrr
-
-
-class ChunkF1(Metrics):
- """doc"""
-
- def __init__(self, label, pred, seqlen, num_label):
- """doc"""
- self.label = label
- self.pred = pred
- self.seqlen = seqlen
- self.null_index = num_label - 1
- self.label_cnt = 0
- self.pred_cnt = 0
- self.correct_cnt = 0
-
- def _extract_bio_chunk(self, seq):
- chunks = []
- cur_chunk = None
-
- for index in range(len(seq)):
- tag = seq[index]
- tag_type = tag // 2
- tag_pos = tag % 2
-
- if tag == self.null_index:
- if cur_chunk is not None:
- chunks.append(cur_chunk)
- cur_chunk = None
- continue
-
- if tag_pos == 0:
- if cur_chunk is not None:
- chunks.append(cur_chunk)
- cur_chunk = {}
- cur_chunk = {"st": index, "en": index + 1, "type": tag_type}
- else:
- if cur_chunk is None:
- cur_chunk = {"st": index, "en": index + 1, "type": tag_type}
- continue
-
- if cur_chunk["type"] == tag_type:
- cur_chunk["en"] = index + 1
- else:
- chunks.append(cur_chunk)
- cur_chunk = {"st": index, "en": index + 1, "type": tag_type}
-
- if cur_chunk is not None:
- chunks.append(cur_chunk)
- return chunks
-
- def reset(self):
- """doc"""
- self.label_cnt = 0
- self.pred_cnt = 0
- self.correct_cnt = 0
-
- @property
- def tensor(self):
- """doc"""
- return [self.pred, self.label, self.seqlen]
-
- def update(self, args):
- """doc"""
- pred, label, seqlen = args
- pred = pred.reshape([-1]).astype(np.int32).tolist()
- label = label.reshape([-1]).astype(np.int32).tolist()
- seqlen = seqlen.reshape([-1]).astype(np.int32).tolist()
-
- max_len = 0
- for l in seqlen:
- max_len = max(max_len, l)
-
- for i in range(len(seqlen)):
- seq_st = i * max_len + 1
- seq_en = seq_st + (seqlen[i] - 2)
- pred_chunks = self._extract_bio_chunk(pred[seq_st:seq_en])
- label_chunks = self._extract_bio_chunk(label[seq_st:seq_en])
- self.pred_cnt += len(pred_chunks)
- self.label_cnt += len(label_chunks)
-
- pred_index = 0
- label_index = 0
- while label_index < len(label_chunks) and pred_index < len(pred_chunks):
- if pred_chunks[pred_index]['st'] < label_chunks[label_index]['st']:
- pred_index += 1
- elif pred_chunks[pred_index]['st'] > label_chunks[label_index]['st']:
- label_index += 1
- else:
- if pred_chunks[pred_index]['en'] == label_chunks[label_index]['en'] \
- and pred_chunks[pred_index]['type'] == label_chunks[label_index]['type']:
- self.correct_cnt += 1
- pred_index += 1
- label_index += 1
-
- def eval(self):
- """doc"""
- if self.pred_cnt == 0:
- precision = 0.0
- else:
- precision = 1.0 * self.correct_cnt / self.pred_cnt
-
- if self.label_cnt == 0:
- recall = 0.0
- else:
- recall = 1.0 * self.correct_cnt / self.label_cnt
-
- if self.correct_cnt == 0:
- f1 = 0.0
- else:
- f1 = 2 * precision * recall / (precision + recall)
-
- return np.float32(f1)
-
-
-class PNRatio(Metrics):
- """doc"""
-
- def __init__(self, qid, label, pred):
- """doc"""
- if label.shape != pred.shape:
- raise ValueError(
- 'expect label shape == pred shape, got: label.shape=%s, pred.shape = %s' % (repr(label), repr(pred)))
-
- self.qid = qid
- self.label = label
- self.pred = pred
- self.saver = {}
-
- def reset(self):
- """doc"""
- self.saver = {}
-
- @property
- def tensor(self):
- """doc"""
- return [self.qid, self.label, self.pred]
-
- def update(self, args):
- """doc"""
- qid, label, pred = args
- if not (qid.shape[0] == label.shape[0] == pred.shape[0]):
- raise ValueError('dimention not match: qid[%s] label[%s], pred[%s]' % (qid.shape, label.shape, pred.shape))
- qid = qid.reshape([-1]).tolist()
- label = label.reshape([-1]).tolist()
- pred = pred.reshape([-1]).tolist()
- assert len(qid) == len(label) == len(pred)
- for q, l, p in zip(qid, label, pred):
- if q not in self.saver:
- self.saver[q] = []
- self.saver[q].append((l, p))
-
- def eval(self):
- """doc"""
- p = 0
- n = 0
- for qid, outputs in self.saver.items():
- for i in range(0, len(outputs)):
- l1, p1 = outputs[i]
- for j in range(i + 1, len(outputs)):
- l2, p2 = outputs[j]
- if l1 > l2:
- if p1 > p2:
- p += 1
- elif p1 < p2:
- n += 1
- elif l1 < l2:
- if p1 < p2:
- p += 1
- elif p1 > p2:
- n += 1
- pn = p / n if n > 0 else 0.0
- return np.float32(pn)
-
-
-class BinaryPNRatio(PNRatio):
- """doc"""
-
- def __init__(self, qid, label, pred):
- """doc"""
- super(BinaryPNRatio, self).__init__(qid, label, pred)
-
- def eval(self):
- """doc"""
- p = 0
- n = 0
- for qid, outputs in self.saver.items():
- pos_set = []
- neg_set = []
- for label, score in outputs:
- if label == 1:
- pos_set.append(score)
- else:
- neg_set.append(score)
-
- for ps in pos_set:
- for ns in neg_set:
- if ps > ns:
- p += 1
- elif ps < ns:
- n += 1
- else:
- continue
- pn = p / n if n > 0 else 0.0
- return np.float32(pn)
-
-
-class PrecisionAtK(Metrics):
- """doc"""
-
- def __init__(self, qid, label, pred, k=1):
- """doc"""
- if label.shape != pred.shape:
- raise ValueError(
- 'expect label shape == pred shape, got: label.shape=%s, pred.shape = %s' % (repr(label), repr(pred)))
-
- self.qid = qid
- self.label = label
- self.pred = pred
- self.k = k
- self.saver = {}
-
- def reset(self):
- """doc"""
- self.saver = {}
-
- @property
- def tensor(self):
- """doc"""
- return [self.qid, self.label, self.pred]
-
- def update(self, args):
- """doc"""
- qid, label, pred = args
- if not (qid.shape[0] == label.shape[0] == pred.shape[0]):
- raise ValueError('dimention not match: qid[%s] label[%s], pred[%s]' % (qid.shape, label.shape, pred.shape))
- qid = qid.reshape([-1]).tolist()
- label = label.reshape([-1]).tolist()
- pred = pred.reshape([-1]).tolist()
-
- assert len(qid) == len(label) == len(pred)
- for q, l, p in zip(qid, label, pred):
- if q not in self.saver:
- self.saver[q] = []
- self.saver[q].append((l, p))
-
- def eval(self):
- """doc"""
- right = 0
- total = 0
- for v in self.saver.values():
- v = sorted(v, key=lambda x: x[1], reverse=True)
- k = min(self.k, len(v))
- for i in range(k):
- if v[i][0] == 1:
- right += 1
- break
- total += 1
-
- return np.float32(1.0 * right / total)
-
-
-#class SemanticRecallMetrics(Metrics):
-# def __init__(self, qid, vec, type_id):
-# self.qid = qid
-# self.vec = vec
-# self.type_id = type_id
-# self.reset()
-#
-# def reset(self):
-# self.saver = []
-#
-# @property
-# def tensor(self):
-# return [self.qid, self.vec, self.type_id]
-#
-# def update(self, args):
-# qid, vec, type_id = args
-# self.saver.append((qid, vec, type_id))
-#
-# def eval(self):
-# dic = {}
-# for qid, vec, type_id in self.saver():
-# dic.setdefault(i, {}).setdefault(k, []).append(vec)
-#
-# for qid in dic:
-# assert len(dic[qid]) == 3
-# qvec = np.arrray(dic[qid][0])
-# assert len(qvec) == 1
-# ptvec = np.array(dic[qid][1])
-# ntvec = np.array(dic[qid][2])
-#
-# np.matmul(qvec, np.transpose(ptvec))
-# np.matmul(qvec, np.transpose(ntvec))
-#
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/train/monitored_executor.py b/modules/text/text_generation/ernie_gen/propeller/paddle/train/monitored_executor.py
deleted file mode 100644
index ab0af2947513e2b34d777cafea3fc687cdce5be6..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/train/monitored_executor.py
+++ /dev/null
@@ -1,434 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-doc
-"""
-
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import os
-import sys
-import json
-from functools import reduce
-import six
-from time import time
-import shutil
-
-import logging
-import numpy as np
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from ernie_gen.propeller import util
-from ernie_gen.propeller.types import StopException, ProgramPair, WarmStartSetting, TextoneWarmStartSetting
-from ernie_gen.propeller.paddle.train import hooks
-from . import distribution
-
-log = logging.getLogger(__name__)
-
-__all__ = ['MonitoredExecutor', 'Saver']
-
-
-def _get_one_place():
- return F.cuda_places()[0] if F.core.is_compiled_with_cuda() else F.cpu_places()[0]
-
-
-class RunState(object):
- """serializable Run state object"""
-
- @classmethod
- def from_dict(cls, d):
- d['step'] = 0
- r = RunState()
- r.__dict__ = d
- return r
-
- @classmethod
- def from_str(cls, s):
- """doc"""
- j = json.loads(s)
- return cls.from_dict(j)
-
- def __init__(self):
- """doc"""
- self.__dict__ = {'gstep': 0, 'step': 0, 'time': time()}
-
- @property
- def gstep(self):
- """doc"""
- return self.__dict__.get('gstep', self.__dict__.get('global_step')) # backward compatibility
-
- @property
- def step(self):
- """doc"""
- return self.__dict__['step']
-
- def __setitem__(self, k, v):
- self.__dict__[k] = v
-
- def __getitem__(self, k):
- return self.__dict__.get(k, None)
-
- @property
- def time(self):
- """doc"""
- return self.__dict__['time']
-
- def state_dict(self):
- return self.__dict__
-
- def __repr__(self):
- """doc"""
- return repr(self.state_dict())
-
- def serialize(self):
- """doc"""
- return json.dumps(self.state_dict())
-
- def next(self):
- """doc"""
- newd = dict(self.__dict__, gstep=self.gstep + 1, step=self.step + 1, time=time())
- ret = RunState()
- ret.__dict__ = newd
- return ret
-
-
-class Saver(object):
- """checkpoint saver and manager"""
-
- def __init__(self, save_dir, exe, program, save_prefix='model', max_ckpt_to_keep=None):
- """doc"""
- assert isinstance(exe, F.Executor), 'expect normal executor to save, got executor of type %s' % repr(type(exe))
- self._exe = exe
- self._program = program
- self._save_dir = save_dir
- self._save_prefix = save_prefix
- self._max_ckpt_to_keep = 10 if max_ckpt_to_keep is None else max_ckpt_to_keep
-
- self.ckpt_info_path = os.path.join(save_dir, 'ckpt_info')
-
- if os.path.exists(self.ckpt_info_path):
- self.ckpt_list = [p.strip() for p in open(self.ckpt_info_path).readlines()]
- log.debug('ckpt_list in this Saver: %s' % (self.ckpt_list))
- else:
- self.ckpt_list = []
-
- @property
- def last_ckpt(self):
- """doc"""
- return self.ckpt_list[-1] if len(self.ckpt_list) else None
-
- def _save_program(self, dir):
- F.io.save_persistables(self._exe, dir, self._program.train_program)
-
- def _load_program(self, dir, predicate_fn=None):
- if predicate_fn is None:
-
- def _fn(v):
- vpath = os.path.join(dir, v.name)
- if F.io.is_persistable(v):
- if os.path.exists(vpath):
- return True
- else:
- log.warning('var %s not found in checkpoint, ignored' % v.name)
- return False
-
- predicate_fn = _fn
- try:
- F.io.load_vars(self._exe, dir, main_program=self._program.train_program, predicate=predicate_fn)
- except F.core.EnforceNotMet as e:
- log.exception(e)
- raise RuntimeError('can not load model from %s, is this a textone checkpoint?' % dir)
-
- def save(self, state):
- """doc"""
- save_name = '%s_%d' % (self._save_prefix, state.gstep)
- save_dir = os.path.join(self._save_dir, save_name)
- tmp_dir = os.path.join(self._save_dir, 'tmp')
- try:
- shutil.rmtree(save_dir)
- shutil.rmtree(tmp_dir)
- except OSError:
- pass
- log.debug('saving step %d to %s' % (state.gstep, save_dir))
- self._save_program(tmp_dir)
- shutil.move(tmp_dir, save_dir)
- meta = state.serialize()
- open(os.path.join(save_dir, 'meta'), 'w').write(meta)
-
- self.ckpt_list.append(save_name)
- if len(self.ckpt_list) > self._max_ckpt_to_keep:
- ckpt_to_keep = self.ckpt_list[-self._max_ckpt_to_keep:]
- ckpt_to_remove = set(self.ckpt_list) - set(ckpt_to_keep)
- self.ckpt_list = ckpt_to_keep
- for ckpt in ckpt_to_remove:
- ckpt_dir = os.path.join(self._save_dir, ckpt)
- if os.path.exists(ckpt_dir):
- shutil.rmtree(ckpt_dir)
- log.debug('No. of ckpt exceed %d, clean up: %s' % (self._max_ckpt_to_keep, ckpt_dir))
- open(self.ckpt_info_path, 'w').write('\n'.join(self.ckpt_list))
-
- def restore(self, ckpt=-1):
- """doc"""
- if isinstance(ckpt, int):
- try:
- path = os.path.join(self._save_dir, self.ckpt_list[ckpt])
- except IndexError:
- raise ValueError('invalid restore ckpt number %d' % ckpt)
- elif isinstance(ckpt, six.string_types):
- if not os.path.exists(ckpt):
- raise ValueError('ckpt: %s not found' % ckpt)
- path = ckpt
- else:
- raise ValueError('ckpt type not understood %s' % repr(ckpt))
-
- meta_file = os.path.join(path, 'meta')
- if not os.path.exists(meta_file):
- raise RuntimeError('meta not found in restore dir: %s' % path)
- state = RunState.from_str(open(meta_file).read())
- log.info('restore from ckpt %s, ckpt-status: %s' % (path, repr(state)))
-
- self._load_program(path)
- return state
-
-
-class SaverV2(Saver):
- def _save_program(self, dir):
- save_path = os.path.join(dir, 'ckpt')
- F.save(self._program.train_program, save_path)
-
- def _load_program(self, dir, predicate_fn=None):
- try:
- save_path = os.path.join(dir, 'ckpt')
- F.load(
- self._program.train_program,
- save_path,
- )
- except F.core.EnforceNotMet as e:
- log.exception(e)
- raise RuntimeError('can not load model from %s, is this a textone checkpoint?' % dir)
-
-
-TextoneTrainer = None
-
-
-class MonitoredExecutor(object):
- """An Executor wrapper handling the train loop"""
- saver_class = SaverV2 # will change if textone enabled
-
- def __init__(
- self,
- executor,
- program,
- loss=None, #must set in train
- state=None,
- run_config=None, #none if not load
- run_hooks=[],
- warm_start_setting=None):
- if not isinstance(executor, F.Executor):
- raise ValueError('PE is no longer supported')
- if isinstance(executor, F.ParallelExecutor):
- raise ValueError('ParallelExecutor is deprecatd, use Executor')
- if not isinstance(program, ProgramPair):
- raise ValueError('Expect ProgramPair, got %r' % type(program))
- self._exe = executor
- self._hooks = run_hooks
- self._state = RunState() # might be overwrite in freeze
- self._program = program
- self._loss = loss
- self._warm_start_setting = warm_start_setting
- self._saver = None # will set in prepare
- self.result = None # will set after train
- if run_config is not None:
- self._model_dir = run_config.model_dir
- self._save_dir = run_config.model_dir
- self._save_steps = run_config.save_steps
- self._skip_steps = run_config.skip_steps if run_config.skip_steps else 100
- self._save_prefix = 'model'
- self._max_ckpt = run_config.max_ckpt
-
- @property
- def state(self):
- """doc"""
- return self._state
-
- def init_or_restore_variables(self, ckpt=-1):
- """
- init vars or restore vars from model_dir
- call before train
- """
- # The order of this 2 steps really matters
- # 1. init train
-
- F.Executor(_get_one_place()).run(self._program.startup_program)
- # 2. restore param
-
- self._saver = self.saver_class(
- self._model_dir, F.Executor(_get_one_place()), program=self._program, max_ckpt_to_keep=self._max_ckpt)
-
- if self._warm_start_setting is not None:
- if not os.path.exists(self._warm_start_setting.from_dir):
- raise ValueError('warm start dir not exists: %s' % self._warm_start_setting.from_dir)
-
- if isinstance(self._warm_start_setting, WarmStartSetting):
- log.info("warm start from %s" % self._warm_start_setting.from_dir)
- log.info(self._saver)
- if (not type(self._saver) is Saver) and (not type(self._saver) is SaverV2):
- raise ValueError('try to warm start from standart dir, but textone enabled')
- if self._warm_start_setting.predicate_fn is not None:
-
- def _fn(v):
- ret = self._warm_start_setting.predicate_fn(v)
- if ret:
- log.info('warm start: %s' % v.name)
- return ret
-
- try:
- F.io.load_vars(
- self._exe,
- self._warm_start_setting.from_dir,
- main_program=self._program.train_program,
- predicate=_fn)
- except F.core.EnforceNotMet as e:
- log.exception(e)
- raise RuntimeError('can not load model from %s, is this a textone checkpoint?' % dir)
- else:
- raise NotImplementedError()
- elif isinstance(self._warm_start_setting, TextoneWarmStartSetting):
- if not type(self._saver) is TextoneTrainer:
- raise ValueError('try to warm start from textone pretrain dir, but textone not enabled')
- log.info("[texone] warm start from %s" % self._warm_start_setting.from_dir)
- self._saver._load_pretrained(self._warm_start_setting.from_dir)
- else:
- raise ValueError('expect _warm_start_setting to be TextoneWarmStartSetting of WarmStartSetting, got %s'
- % repr(self._warm_start_setting))
-
- if self._saver.last_ckpt is not None:
- self._state = self._saver.restore(ckpt)
-
- def _freeze(self):
- """
- call before enter train loop
- convert program to compiled program
- will do nothing if loss is None i.e. not in train mode
- """
- if self._loss is None:
- log.debug('will not freeze a program without loss')
- return
- if isinstance(self._program.train_program, F.compiler.CompiledProgram):
- log.debug('program has already been built')
- return
- exec_strategy = F.ExecutionStrategy()
- exec_strategy.num_threads = 4 #2 for fp32 4 for fp16
- exec_strategy.use_experimental_executor = True
- exec_strategy.num_iteration_per_drop_scope = 10 #important shit
-
- build_strategy = F.BuildStrategy()
- build_strategy.remove_unnecessary_lock = False
- #build_strategy.fuse_broadcast_ops = True
- build_strategy.num_trainers = distribution.status.num_replica
- build_strategy.trainer_id = distribution.status.replica_id
- build_strategy.memory_optimize = True
-
- log.info('replica id %d of %d' % (distribution.status.replica_id, distribution.status.num_replica))
-
- program = F.CompiledProgram(self._program.train_program).with_data_parallel(
- loss_name=self._loss.name, build_strategy=build_strategy, exec_strategy=exec_strategy)
- self._program = ProgramPair(train_program=program, startup_program=self._program.startup_program)
-
- def __enter__(self):
- """
- prepapre before enter train loop
- """
- if F.core.is_compiled_with_cuda():
- log.info('propeller runs in CUDA mode')
- else:
- log.info('propeller runs in CPU mode')
-
- #log.debug('freezing program')
- self._freeze()
- #log.debug('done freezing')
- log.info('********** Start Loop ************')
- # TODO init
-
- self.result = None
- for h in self._hooks:
- log.debug('train loop has hook %s' % h)
- h.before_train(self._program)
- return self
-
- def run(self, fetch_list=[], *args, **kwargs):
- """
- wrapper for Executor.run
- """
- #log.debug('Executor running step %d' % self._state.gstep)
- if self._hooks:
- fetch_list = [fetch_list]
- for h in self._hooks:
- #log.debug('calling hook.before_run %s' % h)
- fetch = h.before_run(self._state)
- fetch_list.append(fetch)
- fetch_list_len = map(len, fetch_list)
- fetch_list, schema = util.flatten(fetch_list)
- fetch_list = [f.name if not isinstance(f, six.string_types) else f for f in fetch_list]
- #if len(set(fetch_list)) != len(fetch_list):
- # log.error('strange shit happend when fetch list has idetity tensors %s' % fetch_list)
- #log.debug(fetch_list)
- res = self._exe.run(self._program.train_program, fetch_list=fetch_list, *args, **kwargs)
- res = [self._merge_result(r) for r in res]
- #log.debug(res)
-
- res = util.unflatten(res, schema)
- ret, res = res[0], res[1:]
- for r, h in zip(res, self._hooks):
- #log.debug('calling hook.after_run')
- h.after_run(r, self._state)
-
- if any(map(lambda i: i.should_stop(self._state), self._hooks)):
- raise StopException('hook call stop')
- else:
- ret = self._exe.run(self._program.train_program, fetch_list=fetch_list, *args, **kwargs)
- self._state = self._state.next()
- return ret
-
- def __exit__(self, err_type, err_value, trace):
- """
- clean up things and report hook result when exit train loop
- """
- if (err_type is None) or isinstance(err_value, (F.core.EOFException, StopException, KeyboardInterrupt)):
- try:
- log.info('********** Stop Loop ************')
- self.result = []
- for h in self._hooks:
- self.result.append(h.after_train())
- except Exception as e:
- log.exception('error occur after loop %s' % repr(e))
- else:
- log.info('********** Interupt Loop ************')
- log.exception('error occur during loop %s: %s' % (err_type, err_value))
-
- def _merge_result(self, ls):
- """
- merge results from multi gpu cards
- """
- dev_count = len(self._program.train_program._places) if isinstance(self._program.train_program,
- F.compiler.CompiledProgram) else 1
- if dev_count == 1:
- return ls
- else:
- shape = (-1, ls.shape[0] // dev_count) + ls.shape[1:]
- ret = np.reshape(ls, shape).mean(axis=0)
- return ret
diff --git a/modules/text/text_generation/ernie_gen/propeller/paddle/train/trainer.py b/modules/text/text_generation/ernie_gen/propeller/paddle/train/trainer.py
deleted file mode 100644
index 1851e0ce3be5c8b5f090acfcbbfaf0966b41908a..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/paddle/train/trainer.py
+++ /dev/null
@@ -1,466 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""common ML train and eval procedure"""
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import os
-import itertools
-import six
-import inspect
-from collections import namedtuple
-from contextlib import contextmanager
-from six.moves import zip, map
-import logging
-from time import time
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from ernie_gen.propeller.types import RunMode, StopException, SummaryRecord, StopException
-from ernie_gen.propeller.types import ModelSpec, InferenceSpec, ProgramPair, RunConfig
-from ernie_gen.propeller.paddle import summary, collection
-from ernie_gen.propeller.paddle.data.functional import Dataset
-from ernie_gen.propeller.paddle.train import distribution
-from ernie_gen.propeller.train.model import Model
-from ernie_gen.propeller.paddle.train.monitored_executor import Saver
-from ernie_gen.propeller.paddle.train import hooks, metrics
-
-from ernie_gen.propeller.paddle.train.monitored_executor import MonitoredExecutor
-
-log = logging.getLogger(__name__)
-
-__all__ = ['train_and_eval', 'Learner']
-
-
-def _get_summary_writer(path):
- summary_writer = None
- try:
- from visualdl import LogWriter
- if distribution.status.is_master:
- summary_writer = LogWriter(os.path.join(path))
- except ImportError:
- log.warning('VisualDL not installed, will not log to VisualDL')
- return summary_writer
-
-
-def _get_one_place():
- return F.cuda_places()[0] if F.core.is_compiled_with_cuda() else F.cpu_places()[0]
-
-
-def _log_eval_result(name, eval_result, swriter, state):
- log.debug(eval_result)
- printable = []
- for n, val in six.iteritems(eval_result):
- assert val.shape == (), 'metrics eval use float'
- printable.append('{}\t{}'.format(n, val))
- if swriter is not None:
- swriter.add_scalar(n, val, state.gstep)
- log.debug('write to VisualDL %s' % swriter.logdir)
-
- if len(printable):
- log.info('*** eval res: %10s ***' % name)
- for p in printable:
- log.info(p)
- log.info('******************************')
-
-
-def _build_net(model_fn, features, mode, params, run_config):
- model_spec = model_fn(features=features, mode=mode, params=params, run_config=run_config)
-
- if mode == RunMode.TRAIN:
- if not isinstance(model_spec.loss, F.framework.Variable):
- raise ValueError('model_spec.metrics should be Variable, got %s' % repr(model_spec.loss))
- if not (model_spec.loss.shape == () or model_spec.loss.shape == (1, )):
- raise ValueError('expect scarlar loss, got %s' % repr(model_spec.loss.shape))
- #model_spec.loss.persistable = True
- elif mode == RunMode.EVAL:
- if not isinstance(model_spec.metrics, dict):
- raise ValueError('model_spec.metrics should be dict, got %s' % repr(model_spec.metrics))
- elif mode == RunMode.PREDICT:
- if not isinstance(model_spec.predictions, (list, tuple)):
- raise ValueError('model_spec.predictions shuold be list, got %s' % repr(model_spec.predictions))
- else:
- raise ValueError('unkonw mode %s' % mode)
- return model_spec
-
-
-class Learner(object):
- """A Learner can train / eval / predict on a Dataset"""
-
- def __init__(self, model_class_or_model_fn, run_config, params=None, warm_start_setting=None):
- """
- model_class_or_model_fn(callable|propeller.train.Model): `model_class_or_model_fn` be specified in 2 ways:
- 1. subclass of propeller.train.Model which implements:
- 1. \_\_init\_\_ (hyper_param, mode, run_config)
- 2. forward (features) => (prediction)
- 3. backword (loss) => None
- 4. loss (predictoin) => (loss)
- 5. metrics (optional) (prediction) => (dict of propeller.Metrics)
-
- 2. a model_fn takes following args:
- 1. features
- 2. param
- 3. mode
- 4. run_config(optional)
- and returns a `propeller.ModelSpec`
-
- params: any python object, will pass to your `model_fn` or `propeller.train.Model`
- run_config (propeller.RunConfig): run_config.max_steps should not be None.
- warm_start_setting (propeller.WarmStartSetting): Optional. warm start variable will overwrite model variable.
- """
- if run_config.model_dir is None:
- raise ValueError('model_dir should specified in run_config')
-
- if inspect.isfunction(model_class_or_model_fn):
- _model_fn = model_class_or_model_fn
- elif issubclass(model_class_or_model_fn, Model):
- _model_fn = _build_model_fn(model_class_or_model_fn)
- else:
- raise ValueError('unknown model %s' % model_class_or_model_fn)
-
- self.model_fn = _model_fn
- self.params = params
- self.run_config = run_config
- self.warm_start_setting = warm_start_setting
-
- def _build_for_train(self, train_dataset):
- train_dataset.name = 'train'
- train_program = F.Program()
- startup_prog = F.Program()
- with F.program_guard(train_program, startup_prog):
- with collection.Collections() as collections:
- log.info('Building Train Graph...')
- fea = train_dataset.features()
- model_spec = _build_net(self.model_fn, fea, RunMode.TRAIN, self.params, self.run_config)
- log.info('Building Train Graph: Done')
-
- scalars = collections.get(collection.Key.SUMMARY_SCALAR)
- histograms = collections.get(collection.Key.SUMMARY_HISTOGRAM)
- skip_optimize_ops = collections.get(collection.Key.SKIP_OPTIMIZE)
- skip_opt = set()
- if skip_optimize_ops is not None:
- skip_opt |= set(skip_optimize_ops)
- if scalars is not None:
- skip_opt |= {t for _, t in scalars}
- if histograms is not None:
- skip_opt |= {t for _, t in histograms}
- skip_opt = list(skip_opt)
- log.info('Train with: \n> Run_config: %s\n> Params: %s\n> Train_model_spec: %s\n' % (repr(
- self.run_config), repr(self.params), repr(model_spec)))
-
- summary_record = SummaryRecord(
- scalar=collections.get(collection.Key.SUMMARY_SCALAR),
- histogram=collections.get(collection.Key.SUMMARY_HISTOGRAM),
- )
- return ProgramPair(train_program=train_program, startup_program=startup_prog), model_spec, summary_record
-
- def _build_for_eval(self, ds):
- ds.name = 'eval'
- program = F.Program()
- startup_prog = F.Program()
- with F.program_guard(program, startup_prog):
- #share var with Train net
- log.info('Building Eval Graph')
- fea = ds.features()
- model_spec = _build_net(self.model_fn, fea, RunMode.EVAL, self.params, self.run_config)
- log.info('Done')
- #program = program.clone(for_test=True)
- log.info('Eval with: \n> Run_config: %s\n> Params: %s\n> Train_model_spec: %s\n' % (repr(
- self.run_config), repr(self.params), repr(model_spec)))
- return ProgramPair(train_program=program, startup_program=startup_prog), model_spec
-
- def _build_for_predict(self, ds):
- ds.name = 'predict'
- program = F.Program()
- startup_prog = F.Program()
- with F.program_guard(program, startup_prog):
- #share var with Train net
- log.info('Building Predict Graph')
- fea = ds.features()
- model_spec = _build_net(self.model_fn, fea, RunMode.PREDICT, self.params, self.run_config)
- log.info('Done')
-
- #program = program.clone(for_test=True)
-
- log.info('Predict with: \n> Run_config: %s\n> Params: %s\n> Train_model_spec: %s\n' % (repr(
- self.run_config), repr(self.params), repr(model_spec)))
- return ProgramPair(train_program=program, startup_program=startup_prog), model_spec
-
- def train(self, train_ds, train_hooks=[]):
- """train on a `Dataset`"""
- if not isinstance(train_ds, Dataset):
- raise ValueError('expect dataset to be instance of Dataset, got %s' % repr(train_ds))
-
- train_program, model_spec, summary_record = self._build_for_train(train_ds)
- train_run_hooks = [
- hooks.StopAtStepHook(self.run_config.max_steps, self.run_config.run_steps),
- hooks.LoggingHook(
- model_spec.loss,
- summary_record=summary_record,
- summary_writer=_get_summary_writer(os.path.join(self.run_config.model_dir, 'train_history')),
- per_step=self.run_config.log_steps,
- skip_step=self.run_config.skip_steps),
- ]
- if model_spec.train_hooks is not None:
- train_run_hooks.extend(model_spec.train_hooks)
- train_run_hooks.extend(train_hooks)
-
- train_executor = F.Executor(_get_one_place())
-
- mon_exe = MonitoredExecutor(
- train_executor,
- train_program,
- loss=model_spec.loss,
- run_config=self.run_config,
- run_hooks=train_run_hooks,
- warm_start_setting=self.warm_start_setting)
-
- distribution.init_distribuition_env(train_program) #only initialize distribute training with
- mon_exe.init_or_restore_variables()
- if distribution.status.is_master:
- mon_exe._hooks.append(
- hooks.CheckpointSaverHook(mon_exe._saver, per_step=mon_exe._save_steps, skip_step=mon_exe._skip_steps))
-
- try:
- with mon_exe:
- for data in train_ds.start():
- mon_exe.run(feed=data)
- except (StopException, F.core.EOFException) as e:
- pass
-
- return mon_exe.result
-
- def evaluate(self, eval_dataset, eval_hooks=[]):
- """eval on a `Dataset`"""
- if not isinstance(eval_dataset, Dataset):
- raise ValueError('expect dataset to be instance of Dataset, got %s' % repr(eval_dataset))
- program, model_spec = self._build_for_eval(eval_dataset)
- single_card_place = _get_one_place()
- eval_executor = F.Executor(single_card_place)
-
- eval_run_hooks = [
- hooks.StopAtStepHook(self.run_config.eval_max_steps, self.run_config.eval_max_steps),
- hooks.EvalHook(model_spec.metrics, )
- ]
-
- if model_spec.eval_hooks is not None:
- eval_run_hooks.extend(model_spec.eval_hooks)
- eval_run_hooks.extend(eval_hooks)
-
- mon_exe = MonitoredExecutor(eval_executor, program, run_config=self.run_config, run_hooks=eval_run_hooks)
- mon_exe.init_or_restore_variables()
-
- try:
- with mon_exe:
- for data in eval_dataset.start(places=[single_card_place]):
- mon_exe.run(feed=data)
- except (StopException, F.core.EOFException) as e:
- pass
-
- _, eval_result = mon_exe.result
-
- summary_writer = _get_summary_writer(os.path.join(self.run_config.model_dir, 'eval_history'))
- _log_eval_result('eval', eval_result, summary_writer, mon_exe.state)
-
- return mon_exe.result
-
- def predict(self, predict_dataset, ckpt=-1, ckpt_path=None, steps=-1, split_batch=True):
- """
- Perform predictoin
- will call `model_fn` and initiate user-specifed model in `propeller.RunMode.PREDICT` mode
-
- Args:
- infer_dataset (propeller.data.Dataset): should not `shuffle` or `repeat`
- steps (int): steps to predict, if None is specifed,
- will stop when `StopException` is raised in `infer_dataset`
- ckpt_path (None|str): Path of a specific checkpoint to predict.
- If None, the latest checkpoint in model_dir is used.
- If there are no checkpoints in model_dir,
- prediction is run with newly initialized Variables instead of ones restored from checkpoint.
- ckpt (int): deprecated args
- split_batch (bool): if True, prediction of each example in a batch is returned.
-
- Yields:
- Evaluated values of predictions tensors.
-
- """
- if not isinstance(predict_dataset, Dataset):
- raise ValueError('expect dataset to be instance of Dataset, got %s' % repr(predict_dataset))
-
- program, model_spec = self._build_for_predict(predict_dataset)
- single_card_place = _get_one_place()
- executor = F.Executor(single_card_place)
- pred_run_config = RunConfig(run_steps=steps if steps == -1 else None, model_dir=self.run_config.model_dir)
- mon_exe = MonitoredExecutor(
- executor,
- program,
- run_config=pred_run_config,
- warm_start_setting=self.warm_start_setting,
- )
- mon_exe.init_or_restore_variables(ckpt if ckpt_path is None else ckpt_path)
- try:
- with mon_exe:
- log.info('Runining predict from dir: %s' % repr(mon_exe.state))
- single_card_place = _get_one_place()
- for data in predict_dataset.start(places=[single_card_place]):
- res = mon_exe.run(fetch_list=model_spec.predictions, feed=data)
- if split_batch:
- res = map(lambda i: i.tolist(), res)
- res = zip(*res) # transpose
- for r in res:
- yield r
- else:
- yield list(map(lambda i: i.tolist(), res))
- except (StopException, F.core.EOFException) as e:
- pass
-
-
-def train_and_eval(_placeholder=None,
- model_class_or_model_fn=None,
- params=None,
- run_config=None,
- train_dataset=None,
- eval_dataset=None,
- warm_start_setting=None,
- train_hooks=[],
- eval_hooks=[],
- exporters=[]):
- """
- Perform train and evaluate procesure.
- will call `model_fn` and initiate user-specifed model in `propeller.RunMode.PREDICT` mode
-
- Args:
- model_class_or_model_fn(callable|propeller.train.Model): `model_class_or_model_fn` be specified in 2 ways:
- 1. subclass of propeller.train.Model
- 2. a model_fn takes following args: 1. features; 2. param; 3. mode; 4. run_config(optional)
- and returns a `propeller.ModelSpec`
-
- params: any python object, will pass to your `model_fn` or `propeller.train.Model`
- run_config (propeller.RunConfig): run_config.max_steps should not be None.
- train_dataset (propeller.paddle.data.Dataset): training will stop if global_step > run_config.max_steps.
- eval_dataset (propeller.paddle.data.Dataset|dict): Optional, if Dict of propeller.data.Dataset were specified,
- will perform evluatation on every evaluation sets and report results.
- warm_start_setting (propeller.WarmStartSetting): Optional. warm start variable will overwrite model variable.
- train_hooks (list of propeller.paddle.train.RunHook): Optional.
- eval_hooks (list of propeller.paddle.train.RunHook): Optional.
- exporters (list of propeller.paddle.train.Exporter): Optional.
- """
- if _placeholder is not None:
- raise ValueError('specify keyword args to this function')
- if model_class_or_model_fn is None or params is None or run_config is None or train_dataset is None:
- raise ValueError('some argument is None: model_class_or_model_fn:%s params:%s run_config:%s train_dataset:%s' %
- (model_class_or_model_fn, params, run_config, train_dataset))
-
- #init distribution env if envvir PROPELLER_DISCONFIG is set
- if train_dataset is None:
- raise ValueError('train dataset not specified')
-
- if eval_dataset is None:
- raise ValueError('eval dataset not specifed')
-
- if not isinstance(eval_dataset, (dict, Dataset)):
- raise ValueError('Eval dataset should be propeller.Dataset of a list of that, got: %s' % eval_dataset)
- if isinstance(eval_dataset, Dataset):
- eval_dataset = {'eval': eval_dataset}
- ds_list = list(eval_dataset.values())
- for ds in ds_list:
- ds.name = 'eval'
- first = ds_list[0]
- for d in ds_list[1:]:
- if not first.__eq__(d):
- raise ValueError('eval dataset has different output_shapes or types: %s' % repr(ds_list))
-
- est = Learner(model_class_or_model_fn, run_config, params, warm_start_setting=warm_start_setting)
-
- class _EvalHookOnTrainLoop(hooks.RunHook):
- def __init__(self):
- self.program, self.model_spec = est._build_for_eval(list(
- eval_dataset.values())[0]) #eval_datasets must have same output shapes
- self.summary_writers = {
- ds_name: _get_summary_writer(os.path.join(os.path.join(run_config.model_dir, 'eval_history'), ds_name))
- for ds_name in eval_dataset
- }
-
- def after_run(self, _, state):
- """doc"""
- if state.step > run_config.skip_steps and state.gstep % run_config.eval_steps == 0:
- eval_results = {}
- for name, ds in six.iteritems(eval_dataset):
- ehooks = [
- hooks.StopAtStepHook(est.run_config.eval_max_steps, est.run_config.eval_max_steps),
- hooks.EvalHook(
- self.model_spec.metrics,
- summary_writer=self.summary_writers[name],
- )
- ]
- single_card_place = _get_one_place()
- eval_executor = F.Executor(single_card_place)
- mon_exe = MonitoredExecutor(
- eval_executor, self.program, run_config=est.run_config, run_hooks=ehooks + eval_hooks)
- try:
- with mon_exe:
- for data in ds.start(places=[single_card_place]):
- mon_exe.run(feed=data)
- except (StopException, F.core.EOFException) as e:
- pass
- hook_results = mon_exe.result
- eval_res = hook_results[1] # hook_results: [StopAtStepHook, EvalHook, ...]
- eval_results[name] = eval_res
- _log_eval_result(name, eval_res, self.summary_writers[name], state)
- for exporter in exporters:
- exporter.export(eval_executor, self.program, self.model_spec, eval_results, state)
- else:
- eval_results = {}
- return eval_results
-
- if distribution.status.is_master:
- train_hooks.append(_EvalHookOnTrainLoop())
- res = est.train(train_dataset, train_hooks=train_hooks)
- return res
-
-
-def _build_model_fn(model_class):
- def _model_fn(features, mode, params, run_config):
- if mode != RunMode.PREDICT:
- fea, label = features[:-1], features[-1]
- else:
- fea = features
-
- model = model_class(params, mode, run_config=run_config)
- pred = model.forward(fea)
- if isinstance(pred, F.framework.Variable):
- prediction = [pred]
- else:
- prediction = pred
- if mode == RunMode.TRAIN:
- loss = model.loss(pred, label)
- model.backward(loss)
- return ModelSpec(loss=loss, predictions=prediction, mode=mode)
- elif mode == RunMode.EVAL:
- loss = model.loss(pred, label)
- me = model.metrics(pred, label)
-
- inf_spec = InferenceSpec(inputs=fea, outputs=prediction)
- if 'loss' not in me:
- me['loss'] = metrics.Mean(loss)
- return ModelSpec(loss=loss, predictions=prediction, metrics=me, mode=mode, inference_spec=inf_spec)
- elif mode == RunMode.PREDICT:
- inf_spec = InferenceSpec(inputs=fea, outputs=prediction)
- return ModelSpec(predictions=prediction, mode=mode, inference_spec=inf_spec)
- else:
- raise RuntimeError('unknown run mode %s' % mode)
-
- return _model_fn
diff --git a/modules/text/text_generation/ernie_gen/propeller/service/__init__.py b/modules/text/text_generation/ernie_gen/propeller/service/__init__.py
deleted file mode 100644
index d90516534cca324e721758b6109ba3fe3a9a8c9c..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/service/__init__.py
+++ /dev/null
@@ -1,14 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""server"""
diff --git a/modules/text/text_generation/ernie_gen/propeller/service/client.py b/modules/text/text_generation/ernie_gen/propeller/service/client.py
deleted file mode 100644
index 827541fa2be4d0302458b89f69b9c6f14651979a..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/service/client.py
+++ /dev/null
@@ -1,101 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from __future__ import division
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import unicode_literals
-import asyncio
-import threading
-import math
-
-import zmq
-import zmq.asyncio
-import numpy as np
-
-from ernie_gen.propeller import log
-import ernie_gen.propeller.service.utils as serv_utils
-
-
-class InferenceBaseClient(object):
- def __init__(self, address):
- self.context = zmq.Context()
- self.address = address
- self.socket = self.context.socket(zmq.REQ)
- self.socket.connect(address)
- log.info("Connecting to server... %s" % address)
-
- def __call__(self, *args):
- for arg in args:
- if not isinstance(arg, np.ndarray):
- raise ValueError('expect ndarray slot data, got %s' % repr(arg))
- request = serv_utils.nparray_list_serialize(args)
-
- self.socket.send(request)
- reply = self.socket.recv()
- ret = serv_utils.nparray_list_deserialize(reply)
- return ret
-
-
-class InferenceClient(InferenceBaseClient):
- def __init__(self, address, batch_size=128, num_coroutine=10, timeout=10.):
- self.loop = asyncio.new_event_loop()
- asyncio.set_event_loop(self.loop)
- context = zmq.asyncio.Context()
- self.socket_pool = [context.socket(zmq.REQ) for _ in range(num_coroutine)]
- log.info("Connecting to server... %s" % address)
- for socket in self.socket_pool:
- socket.connect(address)
- self.num_coroutine = num_coroutine
- self.batch_size = batch_size
- self.timeout = int(timeout * 1000)
-
- #yapf: disable
- def __call__(self, *args):
- for arg in args:
- if not isinstance(arg, np.ndarray):
- raise ValueError('expect ndarray slot data, got %s' %
- repr(arg))
-
- num_tasks = math.ceil(1. * args[0].shape[0] / self.batch_size)
- rets = [None] * num_tasks
-
- async def get(coroutine_idx=0, num_coroutine=1):
- socket = self.socket_pool[coroutine_idx]
- while coroutine_idx < num_tasks:
- begin = coroutine_idx * self.batch_size
- end = (coroutine_idx + 1) * self.batch_size
-
- arr_list = [arg[begin:end] for arg in args]
- request = serv_utils.nparray_list_serialize(arr_list)
- try:
- await socket.send(request)
- await socket.poll(self.timeout, zmq.POLLIN)
- reply = await socket.recv(zmq.NOBLOCK)
- ret = serv_utils.nparray_list_deserialize(reply)
- except Exception as e:
- log.exception(e)
- ret = None
- rets[coroutine_idx] = ret
- coroutine_idx += num_coroutine
-
- futures = [
- get(i, self.num_coroutine) for i in range(self.num_coroutine)
- ]
- self.loop.run_until_complete(asyncio.wait(futures))
- for r in rets:
- if r is None:
- raise RuntimeError('Client call failed')
- return [np.concatenate(col, 0) for col in zip(*rets)]
- #yapf: enable
diff --git a/modules/text/text_generation/ernie_gen/propeller/service/interface.proto b/modules/text/text_generation/ernie_gen/propeller/service/interface.proto
deleted file mode 100644
index e94894c23c76898af34b6aed5bad88de415bc781..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/service/interface.proto
+++ /dev/null
@@ -1,46 +0,0 @@
-// Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-//
-// Licensed under the Apache License, Version 2.0 (the "License");
-// you may not use this file except in compliance with the License.
-// You may obtain a copy of the License at
-//
-// http://www.apache.org/licenses/LICENSE-2.0
-//
-// Unless required by applicable law or agreed to in writing, software
-// distributed under the License is distributed on an "AS IS" BASIS,
-// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-// See the License for the specific language governing permissions and
-// limitations under the License.
-
-syntax = "proto3";
-package interface;
-
-service Inference {
- rpc Infer(Slots) returns (Slots){}
-}
-
-message Slots {
- repeated Slot slots = 1;
-}
-
-message Slot {
- enum Type {
- // Pod Types
- BOOL = 0;
- INT16 = 1;
- INT32 = 2;
- INT64 = 3;
- FP16 = 4;
- FP32 = 5;
- FP64 = 6;
- // Tensor is used in C++.
- SIZE_T = 19;
- UINT8 = 20;
- INT8 = 21;
- }
-
- Type type = 1;
- repeated int64 dims = 2; // [UNK, 640, 480] is saved as [-1, 640, 480]
- bytes data = 3;
-}
-
diff --git a/modules/text/text_generation/ernie_gen/propeller/service/interface_pb2.py b/modules/text/text_generation/ernie_gen/propeller/service/interface_pb2.py
deleted file mode 100644
index 4509705bd0e4e98cb109614c45df3709d6643a8b..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/service/interface_pb2.py
+++ /dev/null
@@ -1,208 +0,0 @@
-# -*- coding: utf-8 -*-
-# Generated by the protocol buffer compiler. DO NOT EDIT!
-# source: interface.proto
-
-import sys
-_b = sys.version_info[0] < 3 and (lambda x: x) or (lambda x: x.encode('latin1'))
-from google.protobuf import descriptor as _descriptor
-from google.protobuf import message as _message
-from google.protobuf import reflection as _reflection
-from google.protobuf import symbol_database as _symbol_database
-# @@protoc_insertion_point(imports)
-
-_sym_db = _symbol_database.Default()
-
-DESCRIPTOR = _descriptor.FileDescriptor(
- name='interface.proto',
- package='interface',
- syntax='proto3',
- serialized_options=None,
- serialized_pb=_b(
- '\n\x0finterface.proto\x12\tinterface\"\'\n\x05Slots\x12\x1e\n\x05slots\x18\x01 \x03(\x0b\x32\x0f.interface.Slot\"\xb8\x01\n\x04Slot\x12\"\n\x04type\x18\x01 \x01(\x0e\x32\x14.interface.Slot.Type\x12\x0c\n\x04\x64ims\x18\x02 \x03(\x03\x12\x0c\n\x04\x64\x61ta\x18\x03 \x01(\x0c\"p\n\x04Type\x12\x08\n\x04\x42OOL\x10\x00\x12\t\n\x05INT16\x10\x01\x12\t\n\x05INT32\x10\x02\x12\t\n\x05INT64\x10\x03\x12\x08\n\x04\x46P16\x10\x04\x12\x08\n\x04\x46P32\x10\x05\x12\x08\n\x04\x46P64\x10\x06\x12\n\n\x06SIZE_T\x10\x13\x12\t\n\x05UINT8\x10\x14\x12\x08\n\x04INT8\x10\x15\x32:\n\tInference\x12-\n\x05Infer\x12\x10.interface.Slots\x1a\x10.interface.Slots\"\x00\x62\x06proto3'
- ))
-
-_SLOT_TYPE = _descriptor.EnumDescriptor(
- name='Type',
- full_name='interface.Slot.Type',
- filename=None,
- file=DESCRIPTOR,
- values=[
- _descriptor.EnumValueDescriptor(name='BOOL', index=0, number=0, serialized_options=None, type=None),
- _descriptor.EnumValueDescriptor(name='INT16', index=1, number=1, serialized_options=None, type=None),
- _descriptor.EnumValueDescriptor(name='INT32', index=2, number=2, serialized_options=None, type=None),
- _descriptor.EnumValueDescriptor(name='INT64', index=3, number=3, serialized_options=None, type=None),
- _descriptor.EnumValueDescriptor(name='FP16', index=4, number=4, serialized_options=None, type=None),
- _descriptor.EnumValueDescriptor(name='FP32', index=5, number=5, serialized_options=None, type=None),
- _descriptor.EnumValueDescriptor(name='FP64', index=6, number=6, serialized_options=None, type=None),
- _descriptor.EnumValueDescriptor(name='SIZE_T', index=7, number=19, serialized_options=None, type=None),
- _descriptor.EnumValueDescriptor(name='UINT8', index=8, number=20, serialized_options=None, type=None),
- _descriptor.EnumValueDescriptor(name='INT8', index=9, number=21, serialized_options=None, type=None),
- ],
- containing_type=None,
- serialized_options=None,
- serialized_start=144,
- serialized_end=256,
-)
-_sym_db.RegisterEnumDescriptor(_SLOT_TYPE)
-
-_SLOTS = _descriptor.Descriptor(
- name='Slots',
- full_name='interface.Slots',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='slots',
- full_name='interface.Slots.slots',
- index=0,
- number=1,
- type=11,
- cpp_type=10,
- label=3,
- has_default_value=False,
- default_value=[],
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=30,
- serialized_end=69,
-)
-
-_SLOT = _descriptor.Descriptor(
- name='Slot',
- full_name='interface.Slot',
- filename=None,
- file=DESCRIPTOR,
- containing_type=None,
- fields=[
- _descriptor.FieldDescriptor(
- name='type',
- full_name='interface.Slot.type',
- index=0,
- number=1,
- type=14,
- cpp_type=8,
- label=1,
- has_default_value=False,
- default_value=0,
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- _descriptor.FieldDescriptor(
- name='dims',
- full_name='interface.Slot.dims',
- index=1,
- number=2,
- type=3,
- cpp_type=2,
- label=3,
- has_default_value=False,
- default_value=[],
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- _descriptor.FieldDescriptor(
- name='data',
- full_name='interface.Slot.data',
- index=2,
- number=3,
- type=12,
- cpp_type=9,
- label=1,
- has_default_value=False,
- default_value=_b(""),
- message_type=None,
- enum_type=None,
- containing_type=None,
- is_extension=False,
- extension_scope=None,
- serialized_options=None,
- file=DESCRIPTOR),
- ],
- extensions=[],
- nested_types=[],
- enum_types=[
- _SLOT_TYPE,
- ],
- serialized_options=None,
- is_extendable=False,
- syntax='proto3',
- extension_ranges=[],
- oneofs=[],
- serialized_start=72,
- serialized_end=256,
-)
-
-_SLOTS.fields_by_name['slots'].message_type = _SLOT
-_SLOT.fields_by_name['type'].enum_type = _SLOT_TYPE
-_SLOT_TYPE.containing_type = _SLOT
-DESCRIPTOR.message_types_by_name['Slots'] = _SLOTS
-DESCRIPTOR.message_types_by_name['Slot'] = _SLOT
-_sym_db.RegisterFileDescriptor(DESCRIPTOR)
-
-Slots = _reflection.GeneratedProtocolMessageType(
- 'Slots',
- (_message.Message, ),
- {
- 'DESCRIPTOR': _SLOTS,
- '__module__': 'interface_pb2'
- # @@protoc_insertion_point(class_scope:interface.Slots)
- })
-_sym_db.RegisterMessage(Slots)
-
-Slot = _reflection.GeneratedProtocolMessageType(
- 'Slot',
- (_message.Message, ),
- {
- 'DESCRIPTOR': _SLOT,
- '__module__': 'interface_pb2'
- # @@protoc_insertion_point(class_scope:interface.Slot)
- })
-_sym_db.RegisterMessage(Slot)
-
-_INFERENCE = _descriptor.ServiceDescriptor(
- name='Inference',
- full_name='interface.Inference',
- file=DESCRIPTOR,
- index=0,
- serialized_options=None,
- serialized_start=258,
- serialized_end=316,
- methods=[
- _descriptor.MethodDescriptor(
- name='Infer',
- full_name='interface.Inference.Infer',
- index=0,
- containing_service=None,
- input_type=_SLOTS,
- output_type=_SLOTS,
- serialized_options=None,
- ),
- ])
-_sym_db.RegisterServiceDescriptor(_INFERENCE)
-
-DESCRIPTOR.services_by_name['Inference'] = _INFERENCE
-
-# @@protoc_insertion_point(module_scope)
diff --git a/modules/text/text_generation/ernie_gen/propeller/service/server.py b/modules/text/text_generation/ernie_gen/propeller/service/server.py
deleted file mode 100644
index 161cd02af5181ee0cb2e3d3a51cd974dd9f37a15..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/service/server.py
+++ /dev/null
@@ -1,182 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Never Never Never import paddle.fluid in main process, or any module would import fluid.
-"""
-
-from __future__ import division
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import os
-import logging
-import six
-from time import sleep, time
-import multiprocessing
-
-import zmq
-
-log = logging.getLogger(__name__)
-
-
-def _profile(msg):
- def _decfn(fn):
- def _retfn(*args, **kwargs):
- start = time()
- ret = fn(*args, **kwargs)
- end = time()
- log.debug('%s timecost: %.5f' % (msg, end - start))
- return ret
-
- return _retfn
-
- return _decfn
-
-
-class Predictor(object):
- """paddle predictor wrapper"""
-
- def __init__(self, model_dir, device_idx=0):
- import paddle.fluid as F
- log.debug('create predictor on card %d' % device_idx)
- config = F.core.AnalysisConfig(model_dir)
- config.enable_use_gpu(5000, device_idx)
- self._predictor = F.core.create_paddle_predictor(config)
-
- @_profile('paddle')
- def __call__(self, args):
- for i, a in enumerate(args):
- a.name = 'placeholder_%d' % i
- res = self._predictor.run(args)
- return res
-
-
-def run_worker(model_dir, device_idx, endpoint="ipc://worker.ipc"):
- """worker process entrence"""
- try:
- log.debug("run_worker %s" % device_idx)
- os.environ["CUDA_VISIBLE_DEVICES"] = os.getenv("CUDA_VISIBLE_DEVICES").split(",")[device_idx]
- log.debug('cuda_env %s' % os.environ["CUDA_VISIBLE_DEVICES"])
- import paddle.fluid as F
- from ernie_gen.propeller.service import interface_pb2
- import ernie_gen.propeller.service.utils as serv_utils
- context = zmq.Context()
- socket = context.socket(zmq.REP)
- socket.connect(endpoint)
- #socket.bind(endpoint)
- log.debug("Predictor building %s" % device_idx)
- predictor = Predictor(model_dir, 0)
- log.debug("Predictor %s" % device_idx)
- except Exception as e:
- log.exception(e)
-
- while True:
- # Wait for next request from client
- try:
- message = socket.recv()
- log.debug("get message %s" % device_idx)
- slots = interface_pb2.Slots()
- slots.ParseFromString(message)
- pts = [serv_utils.slot_to_paddlearray(s) for s in slots.slots]
- ret = predictor(pts)
- slots = interface_pb2.Slots(slots=[serv_utils.paddlearray_to_slot(r) for r in ret])
- socket.send(slots.SerializeToString())
- except Exception as e:
- log.exception(e)
- socket.send(e.message)
-
-
-class InferencePredictor(object):
- """control Predictor for multi gpu card"""
-
- def __init__(self, backend_addr, model_dir, n_devices=1):
- self.backend_addr = backend_addr
- self.model_dir = model_dir
- self.n_devices = n_devices
- self.children = []
-
- def start(self):
- """doc"""
- for device_idx in range(self.n_devices):
- p = multiprocessing.Process(target=run_worker, args=(self.model_dir, device_idx, self.backend_addr))
- p.start()
- self.children.append(p)
- return self
-
- def join(self):
- """doc"""
- for p in self.children:
- p.join()
-
- def term(self):
- """doc"""
- for p in self.children:
- log.debug("terminating children %s" % repr(p))
- p.terminate()
-
-
-class InferenceProxy(object):
- """zmq proxy"""
-
- def __init__(self):
- """doc"""
- self.backend = None
- self.frontend = None
-
- def listen(self, frontend_addr, backend_addr):
- """doc"""
- log.info("InferenceProxy starting...")
- try:
- context = zmq.Context(1)
- # Socket facing clients
- self.frontend = context.socket(zmq.ROUTER)
- self.frontend.bind(frontend_addr)
- # Socket facing services
- self.backend = context.socket(zmq.DEALER)
- self.backend.bind(backend_addr)
- log.info("Queue init done")
- zmq.device(zmq.QUEUE, self.frontend, self.backend)
- except Exception as e:
- log.exception(e)
- log.info("Bringing down zmq device")
- finally:
- log.debug('terminating proxy')
- if self.frontend is not None:
- self.frontend.close()
- if self.backend is not None:
- self.backend.close()
- context.term()
-
-
-class InferenceServer(object):
- """start InferencePredictor and InferenceProxy"""
-
- def __init__(self, model_dir, n_devices):
- """doc"""
- self.model_dir = model_dir
- self.n_devices = n_devices
-
- def listen(self, port):
- """doc"""
- frontend_addr = "tcp://*:%s" % port
- backend_addr = "ipc://backend.ipc"
- predictor = InferencePredictor(backend_addr, self.model_dir, self.n_devices).start()
- try:
- proxy = InferenceProxy()
- proxy.listen(frontend_addr, backend_addr)
- predictor.join()
- except KeyboardInterrupt:
- log.debug('terminating server')
- predictor.term()
diff --git a/modules/text/text_generation/ernie_gen/propeller/service/utils.py b/modules/text/text_generation/ernie_gen/propeller/service/utils.py
deleted file mode 100644
index 25d06249df6c99ddfa9a5355259ffa06c0fb7cc8..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/service/utils.py
+++ /dev/null
@@ -1,116 +0,0 @@
-#!/usr/bin/env python
-# -*- coding: utf-8 -*-
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""utils for server"""
-
-from __future__ import division
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import numpy as np
-import struct
-
-from ernie_gen.propeller.service import interface_pb2
-
-
-def slot_to_numpy(slot):
- """doc"""
- if slot.type == interface_pb2.Slot.FP32:
- dtype = np.float32
- type_str = 'f'
- elif slot.type == interface_pb2.Slot.INT32:
- type_str = 'i'
- dtype = np.int32
- elif slot.type == interface_pb2.Slot.INT64:
- dtype = np.int64
- type_str = 'q'
- else:
- raise RuntimeError('know type %s' % slot.type)
- num = len(slot.data) // struct.calcsize(type_str)
- arr = struct.unpack('%d%s' % (num, type_str), slot.data)
- shape = slot.dims
- ret = np.array(arr, dtype=dtype).reshape(shape)
- return ret
-
-
-def numpy_to_slot(arr):
- """doc"""
- if arr.dtype == np.float32:
- dtype = interface_pb2.Slot.FP32
- elif arr.dtype == np.int32:
- dtype = interface_pb2.Slot.INT32
- elif arr.dtype == np.int64:
- dtype = interface_pb2.Slot.INT64
- else:
- raise RuntimeError('know type %s' % arr.dtype)
- pb = interface_pb2.Slot(type=dtype, dims=list(arr.shape), data=arr.tobytes())
- return pb
-
-
-def slot_to_paddlearray(slot):
- """doc"""
- import paddle.fluid.core as core
- if slot.type == interface_pb2.Slot.FP32:
- dtype = np.float32
- type_str = 'f'
- elif slot.type == interface_pb2.Slot.INT32:
- dtype = np.int32
- type_str = 'i'
- elif slot.type == interface_pb2.Slot.INT64:
- dtype = np.int64
- type_str = 'q'
- else:
- raise RuntimeError('know type %s' % slot.type)
- num = len(slot.data) // struct.calcsize(type_str)
- arr = struct.unpack('%d%s' % (num, type_str), slot.data)
- ret = core.PaddleTensor(data=np.array(arr, dtype=dtype).reshape(slot.dims))
- return ret
-
-
-def paddlearray_to_slot(arr):
- """doc"""
- import paddle.fluid.core as core
- if arr.dtype == core.PaddleDType.FLOAT32:
- dtype = interface_pb2.Slot.FP32
- type_str = 'f'
- arr_data = arr.data.float_data()
- elif arr.dtype == core.PaddleDType.INT32:
- dtype = interface_pb2.Slot.INT32
- type_str = 'i'
- arr_data = arr.data.int32_data()
- elif arr.dtype == core.PaddleDType.INT64:
- dtype = interface_pb2.Slot.INT64
- type_str = 'q'
- arr_data = arr.data.int64_data()
- else:
- raise RuntimeError('know type %s' % arr.dtype)
- data = struct.pack('%d%s' % (len(arr_data), type_str), *arr_data)
- pb = interface_pb2.Slot(type=dtype, dims=list(arr.shape), data=data)
- return pb
-
-
-def nparray_list_serialize(arr_list):
- """doc"""
- slot_list = [numpy_to_slot(arr) for arr in arr_list]
- slots = interface_pb2.Slots(slots=slot_list)
- return slots.SerializeToString()
-
-
-def nparray_list_deserialize(string):
- """doc"""
- slots = interface_pb2.Slots()
- slots.ParseFromString(string)
- return [slot_to_numpy(slot) for slot in slots.slots]
diff --git a/modules/text/text_generation/ernie_gen/propeller/tools/__init__.py b/modules/text/text_generation/ernie_gen/propeller/tools/__init__.py
deleted file mode 100644
index d0c32e26092f6ea25771279418582a24ea449ab2..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/tools/__init__.py
+++ /dev/null
@@ -1,13 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
diff --git a/modules/text/text_generation/ernie_gen/propeller/tools/ckpt_inspector.py b/modules/text/text_generation/ernie_gen/propeller/tools/ckpt_inspector.py
deleted file mode 100644
index 9ba8a9e66cbd67209454dc604dc032d19c7422ad..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/tools/ckpt_inspector.py
+++ /dev/null
@@ -1,116 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from __future__ import absolute_import
-from __future__ import division
-from __future__ import print_function
-
-import sys
-import os
-import struct
-import logging
-import argparse
-import numpy as np
-import collections
-from distutils import dir_util
-import pickle
-
-import paddle.fluid as F
-from paddle.fluid.proto import framework_pb2
-
-log = logging.getLogger(__name__)
-formatter = logging.Formatter(fmt='[%(levelname)s] %(asctime)s [%(filename)12s:%(lineno)5d]:\t%(message)s')
-console = logging.StreamHandler()
-console.setFormatter(formatter)
-log.addHandler(console)
-log.setLevel(logging.DEBUG)
-
-
-def gen_arr(data, dtype):
- num = len(data) // struct.calcsize(dtype)
- arr = struct.unpack('%d%s' % (num, dtype), data)
- return arr
-
-
-def parse(filename):
- with open(filename, 'rb') as f:
- read = lambda fmt: struct.unpack(fmt, f.read(struct.calcsize(fmt)))
- _, = read('I') # version
- lodsize, = read('Q')
- if lodsize != 0:
- log.warning('shit, it is LOD tensor!!! skipped!!')
- return None
- _, = read('I') # version
- pbsize, = read('i')
- data = f.read(pbsize)
- proto = framework_pb2.VarType.TensorDesc()
- proto.ParseFromString(data)
- log.info('type: [%s] dim %s' % (proto.data_type, proto.dims))
- if proto.data_type == framework_pb2.VarType.FP32:
- arr = np.array(gen_arr(f.read(), 'f'), dtype=np.float32).reshape(proto.dims)
- elif proto.data_type == framework_pb2.VarType.INT64:
- arr = np.array(gen_arr(f.read(), 'q'), dtype=np.int64).reshape(proto.dims)
- elif proto.data_type == framework_pb2.VarType.INT32:
- arr = np.array(gen_arr(f.read(), 'i'), dtype=np.int32).reshape(proto.dims)
- elif proto.data_type == framework_pb2.VarType.INT8:
- arr = np.array(gen_arr(f.read(), 'B'), dtype=np.int8).reshape(proto.dims)
- elif proto.data_type == framework_pb2.VarType.FP16:
- arr = np.array(gen_arr(f.read(), 'H'), dtype=np.uint16).view(np.float16).reshape(proto.dims)
- else:
- raise RuntimeError('Unknown dtype %s' % proto.data_type)
-
- return arr
-
-
-def show(arr):
- print(repr(arr))
-
-
-def dump(arr, path):
- path = os.path.join(args.to, path)
- log.info('dump to %s' % path)
- try:
- os.makedirs(os.path.dirname(path))
- except FileExistsError:
- pass
- pickle.dump(arr, open(path, 'wb'), protocol=4)
-
-
-def list_dir(dir_or_file):
- if os.path.isfile(dir_or_file):
- return [dir_or_file]
- else:
- return [os.path.join(i, kk) for i, _, k in os.walk(dir_or_file) for kk in k]
-
-
-if __name__ == '__main__':
- parser = argparse.ArgumentParser()
- parser.add_argument('mode', choices=['show', 'dump'], type=str)
- parser.add_argument('file_or_dir', type=str)
- parser.add_argument('-t', "--to", type=str, default=None)
- parser.add_argument('-v', "--verbose", action='store_true')
- args = parser.parse_args()
-
- files = list_dir(args.file_or_dir)
- parsed_arr = map(parse, files)
- if args.mode == 'show':
- for arr in parsed_arr:
- if arr is not None:
- show(arr)
- elif args.mode == 'dump':
- if args.to is None:
- raise ValueError('--to dir_name not specified')
- for arr, path in zip(parsed_arr, files):
- if arr is not None:
- dump(arr, path.replace(args.file_or_dir, ''))
diff --git a/modules/text/text_generation/ernie_gen/propeller/tools/start_server.py b/modules/text/text_generation/ernie_gen/propeller/tools/start_server.py
deleted file mode 100644
index 58e45af62a3069f527a50e66250d2b185fafa232..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/tools/start_server.py
+++ /dev/null
@@ -1,39 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-from __future__ import division
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import sys
-import os
-import argparse
-import logging
-import logging.handlers
-from ernie_gen.propeller.service.server import InferenceServer
-from ernie_gen.propeller import log
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument('-m', '--model_dir', type=str, required=True)
- parser.add_argument('-p', '--port', type=int, required=True)
- parser.add_argument('-v', '--verbose', action='store_true')
- args = parser.parse_args()
-
- if args.verbose:
- log.setLevel(logging.DEBUG)
- n_devices = len(os.getenv("CUDA_VISIBLE_DEVICES").split(","))
- server = InferenceServer(args.model_dir, n_devices)
- log.info('propeller server listent on port %d' % args.port)
- server.listen(args.port)
diff --git a/modules/text/text_generation/ernie_gen/propeller/train/__init__.py b/modules/text/text_generation/ernie_gen/propeller/train/__init__.py
deleted file mode 100644
index 31701fc080c5a896dffc3bf82c14a692d4d8e917..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/train/__init__.py
+++ /dev/null
@@ -1,16 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-doc
-"""
diff --git a/modules/text/text_generation/ernie_gen/propeller/train/model.py b/modules/text/text_generation/ernie_gen/propeller/train/model.py
deleted file mode 100644
index a920cae63a77765f5638e18019b713194bb63a46..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/train/model.py
+++ /dev/null
@@ -1,88 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""
-Model template
-"""
-
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import sys
-import six
-import logging
-import os
-import itertools
-import json
-import abc
-import numpy as np
-
-
-@six.add_metaclass(abc.ABCMeta)
-class Model(object):
- """
- template
- """
-
- def __init__(self, config, mode):
- """
- Args:
- config (dict): hyper param
- mode (propeller.RunMode): will creat `TRAIN` and `EVAL` model in propeller.train_and_eval
- """
- self.mode = mode
-
- @abc.abstractmethod
- def forward(self, features):
- """
- Args:
- features (list of Tensor): inputs features that depends on your Dataset.output_shapes
- Returns:
- return (Tensor): prediction
- """
- pass
-
- @abc.abstractmethod
- def loss(self, predictions, label):
- """
- Args:
- predictions (Tensor): result of `self.forward`
- label (Tensor): depends on your Dataset.output_shapes
- Returns:
- return (paddle scalar): loss
- """
- pass
-
- @abc.abstractmethod
- def backward(self, loss):
- """
- Call in TRAIN mode
- Args:
- loss (Tensor): result of `self.loss`
- Returns:
- None
- """
- pass
-
- @abc.abstractmethod
- def metrics(self, predictions, label):
- """
- Call in EVAL mode
- Args:
- predictions (Tensor): result of `self.forward`
- label (Tensor): depends on your Dataset.output_shapes
- Returns:
- (dict): k-v map like: {"metrics_name": propeller.Metrics }
- """
- return {}
diff --git a/modules/text/text_generation/ernie_gen/propeller/types.py b/modules/text/text_generation/ernie_gen/propeller/types.py
deleted file mode 100644
index c30758adb29d3cb1a563c6b6d7dce803f36ca83e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/types.py
+++ /dev/null
@@ -1,118 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""Basic types"""
-
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import os
-import json
-from collections import namedtuple
-
-
-class RunMode(object):
- """model_fn will be called in 3 modes"""
- TRAIN = 1
- PREDICT = 2
- EVAL = 3
-
-
-class HParams(object):
- """Hyper paramerter"""
-
- def __init__(self, **kwargs):
- for k, v in kwargs.items():
- self.__dict__[k] = v
-
- def __contains__(self, key):
- return key in self.__dict__
-
- def __getitem__(self, key):
- if key not in self.__dict__:
- raise ValueError('key(%s) not in HParams.' % key)
- return self.__dict__[key]
-
- def __repr__(self):
- return repr(self.to_dict())
-
- def __setitem__(self, key, val):
- self.__dict__[key] = val
-
- @classmethod
- def from_json(cls, json_str):
- """doc"""
- d = json.loads(json_str)
- if type(d) != dict:
- raise ValueError('json object must be dict.')
- return HParams.from_dict(d)
-
- def get(self, key, default=None):
- """doc"""
- return self.__dict__.get(key, default)
-
- @classmethod
- def from_dict(cls, d):
- """doc"""
- if type(d) != dict:
- raise ValueError('input must be dict.')
- hp = HParams(**d)
- return hp
-
- def to_json(self):
- """doc"""
- return json.dumps(self.__dict__)
-
- def to_dict(self):
- """doc"""
- return self.__dict__
-
- def join(self, other):
- """doc"""
- if not isinstance(other, HParams):
- raise ValueError('input must be HParams instance. got %s' % type(other))
- self.__dict__.update(**other.__dict__)
- return self
-
-
-SummaryRecord = namedtuple('SummaryRecord', ['scalar', 'histogram'])
-
-WarmStartSetting = namedtuple('WarmStartSetting', ['predicate_fn', 'from_dir'])
-TextoneWarmStartSetting = namedtuple('TextoneWarmStartSetting', ['from_dir'])
-
-RunConfig = namedtuple('RunConfig', [
- 'model_dir', 'run_steps', 'max_steps', 'save_steps', 'eval_steps', 'eval_max_steps', 'skip_steps', 'log_steps',
- 'max_ckpt', 'shit'
-])
-RunConfig.__new__.__defaults__ = (None, ) * len(RunConfig._fields)
-
-ProgramPair = namedtuple('ProgramPair', ['train_program', 'startup_program'])
-
-InferenceSpec = namedtuple('InferenceSpec', ['inputs', 'outputs'])
-
-ModelSpec = namedtuple('ModelSpec', [
- 'loss',
- 'predictions',
- 'metrics',
- 'mode',
- 'inference_spec',
- 'train_hooks',
- 'eval_hooks',
-])
-ModelSpec.__new__.__defaults__ = (None, ) * len(ModelSpec._fields)
-
-
-class StopException(Exception):
- """doc"""
- pass
diff --git a/modules/text/text_generation/ernie_gen/propeller/util.py b/modules/text/text_generation/ernie_gen/propeller/util.py
deleted file mode 100644
index 53f7d789ddb4d5b89edb49d83d2910425835daee..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/propeller/util.py
+++ /dev/null
@@ -1,126 +0,0 @@
-# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-"""global utils"""
-from __future__ import print_function
-from __future__ import absolute_import
-from __future__ import unicode_literals
-
-import os
-import six
-import re
-import json
-import argparse
-import itertools
-import logging
-from functools import reduce
-
-from ernie_gen.propeller.types import RunConfig
-from ernie_gen.propeller.types import HParams
-
-log = logging.getLogger(__name__)
-
-
-def ArgumentParser(name):
- """predefined argparser"""
- parser = argparse.ArgumentParser('propeller model')
- parser.add_argument('--run_config', type=str, default='')
- parser.add_argument('--hparam', type=str, nargs='*', action='append', default=[['']])
- return parser
-
-
-def _get_dict_from_environ_or_json_or_file(args, env_name):
- if args == '':
- return None
- if args is None:
- s = os.environ.get(env_name)
- else:
- s = args
- if os.path.exists(s):
- s = open(s).read()
- if isinstance(s, six.string_types):
- try:
- r = json.loads(s)
- except ValueError:
- try:
- r = eval(s)
- except SyntaxError as e:
- raise ValueError('json parse error: %s \n>Got json: %s' % (repr(e), s))
- return r
- else:
- return s #None
-
-
-def parse_file(filename):
- """useless api"""
- d = _get_dict_from_environ_or_json_or_file(filename, None)
- if d is None:
- raise ValueError('file(%s) not found' % filename)
- return d
-
-
-def parse_runconfig(args=None):
- """get run_config from env or file"""
- d = _get_dict_from_environ_or_json_or_file(args.run_config, 'PROPELLER_RUNCONFIG')
- if d is None:
- raise ValueError('run_config not found')
- return RunConfig(**d)
-
-
-def parse_hparam(args=None):
- """get hparam from env or file"""
- if args is not None:
- hparam_strs = reduce(list.__add__, args.hparam)
- else:
- hparam_strs = [None]
-
- hparams = [_get_dict_from_environ_or_json_or_file(hp, 'PROPELLER_HPARAMS') for hp in hparam_strs]
- hparams = [HParams(**h) for h in hparams if h is not None]
- if len(hparams) == 0:
- return HParams()
- else:
- hparam = reduce(lambda x, y: x.join(y), hparams)
- return hparam
-
-
-def flatten(s):
- """doc"""
- assert is_struture(s)
- schema = [len(ss) for ss in s]
- flt = list(itertools.chain(*s))
- return flt, schema
-
-
-def unflatten(structure, schema):
- """doc"""
- start = 0
- res = []
- for _range in schema:
- res.append(structure[start:start + _range])
- start += _range
- return res
-
-
-def is_struture(s):
- """doc"""
- return isinstance(s, list) or isinstance(s, tuple)
-
-
-def map_structure(func, s):
- """same sa tf.map_structure"""
- if isinstance(s, list) or isinstance(s, tuple):
- return [map_structure(func, ss) for ss in s]
- elif isinstance(s, dict):
- return {k: map_structure(func, v) for k, v in six.iteritems(s)}
- else:
- return func(s)
diff --git a/modules/text/text_generation/ernie_gen/template/assets/ernie_config.json b/modules/text/text_generation/ernie_gen/template/assets/ernie_config.json
deleted file mode 100644
index 1f8c59306c1c56fa51859b27da767a14170115b8..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/template/assets/ernie_config.json
+++ /dev/null
@@ -1,12 +0,0 @@
-{
- "attention_probs_dropout_prob": 0.1,
- "hidden_act": "relu",
- "hidden_dropout_prob": 0.1,
- "hidden_size": 768,
- "initializer_range": 0.02,
- "max_position_embeddings": 513,
- "num_attention_heads": 12,
- "num_hidden_layers": 12,
- "type_vocab_size": 2,
- "vocab_size": 18000
-}
diff --git a/modules/text/text_generation/ernie_gen/template/assets/vocab.txt b/modules/text/text_generation/ernie_gen/template/assets/vocab.txt
deleted file mode 100644
index 5db20b3b96fb86ef2aec3b783e12e17041a02d45..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/template/assets/vocab.txt
+++ /dev/null
@@ -1,17964 +0,0 @@
-[PAD]
-[CLS]
-[SEP]
-[MASK]
-,
-的
-、
-一
-人
-有
-是
-在
-中
-为
-和
-了
-不
-年
-学
-大
-国
-生
-以
-“
-”
-作
-业
-个
-上
-用
-,
-地
-会
-成
-发
-工
-时
-于
-理
-出
-行
-要
-.
-等
-他
-到
-之
-这
-可
-后
-家
-对
-能
-公
-与
-》
-《
-主
-方
-分
-经
-来
-全
-其
-部
-多
-产
-自
-文
-高
-动
-进
-法
-化
-:
-我
-面
-)
-(
-实
-教
-建
-体
-而
-长
-子
-下
-现
-开
-本
-力
-定
-性
-过
-设
-合
-小
-同
-机
-市
-品
-水
-新
-内
-事
-也
-种
-及
-制
-入
-所
-心
-务
-就
-管
-们
-得
-展
-重
-民
-加
-区
-物
-者
-通
-天
-政
-三
-电
-关
-度
-第
-名
-术
-最
-系
-月
-外
-资
-日
-代
-员
-如
-间
-位
-并
-书
-科
-村
-应
-量
-道
-前
-当
-无
-里
-相
-平
-从
-计
-提
-保
-任
-程
-技
-都
-研
-十
-基
-特
-好
-被
-或
-目
-将
-使
-山
-二
-说
-数
-点
-明
-情
-元
-着
-收
-组
-然
-美
-各
-由
-场
-金
-形
-农
-期
-因
-表
-此
-色
-起
-还
-立
-世
-安
-活
-专
-质
-1
-规
-社
-万
-信
-西
-统
-结
-路
-利
-次
-南
-式
-意
-级
-常
-师
-校
-你
-育
-果
-究
-司
-服
-门
-海
-导
-流
-项
-她
-总
-处
-两
-传
-东
-正
-省
-院
-户
-手
-具
-2
-原
-强
-北
-向
-先
-但
-米
-城
-企
-件
-风
-军
-身
-更
-知
-已
-气
-战
-至
-单
-口
-集
-创
-解
-四
-标
-交
-比
-商
-论
-界
-题
-变
-花
-3
-改
-类
-运
-指
-型
-调
-女
-神
-接
-造
-受
-广
-只
-委
-去
-共
-治
-达
-持
-条
-网
-头
-构
-县
-些
-该
-又
-那
-想
-样
-办
-济
-5
-格
-责
-车
-很
-施
-求
-己
-光
-精
-林
-完
-爱
-线
-参
-少
-积
-清
-看
-优
-报
-王
-直
-没
-每
-据
-游
-效
-感
-五
-影
-别
-获
-领
-称
-选
-供
-乐
-老
-么
-台
-问
-划
-带
-器
-源
-织
-放
-深
-备
-视
-白
-功
-取
-装
-营
-见
-记
-环
-队
-节
-准
-石
-它
-回
-历
-负
-真
-增
-医
-联
-做
-职
-容
-士
-包
-义
-观
-团
-病
-4
-府
-息
-则
-考
-料
-华
-州
-语
-证
-整
-让
-江
-史
-空
-验
-需
-支
-命
-给
-离
-认
-艺
-较
-土
-古
-养
-才
-境
-推
-把
-均
-图
-际
-斯
-近
-片
-局
-修
-字
-德
-权
-步
-始
-复
-转
-协
-即
-打
-画
-投
-决
-何
-约
-反
-quot
-费
-议
-护
-极
-河
-房
-查
-布
-思
-干
-价
-儿
-非
-马
-党
-奖
-模
-故
-编
-音
-范
-识
-率
-存
-引
-客
-属
-评
-采
-尔
-配
-镇
-室
-再
-案
-监
-习
-注
-根
-克
-演
-食
-族
-示
-球
-状
-青
-号
-张
-百
-素
-首
-易
-热
-阳
-今
-园
-防
-版
-太
-乡
-英
-6
-材
-列
-便
-写
-住
-置
-层
-助
-确
-试
-难
-承
-象
-居
-10
-黄
-快
-断
-维
-却
-红
-速
-连
-众
-0
-细
-态
-话
-周
-言
-药
-培
-血
-亩
-龙
-越
-值
-几
-边
-读
-未
-曾
-测
-算
-京
-景
-余
-站
-低
-温
-消
-必
-切
-依
-随
-且
-志
-卫
-域
-照
-许
-限
-著
-销
-落
-足
-适
-争
-策
-8
-控
-武
-按
-7
-初
-角
-核
-死
-检
-富
-满
-显
-审
-除
-致
-亲
-占
-失
-星
-章
-善
-续
-千
-叶
-火
-副
-告
-段
-什
-声
-终
-况
-走
-木
-益
-戏
-独
-纪
-植
-财
-群
-六
-赛
-远
-拉
-亚
-密
-排
-超
-像
-课
-围
-往
-响
-击
-疗
-念
-八
-云
-险
-律
-请
-革
-诗
-批
-底
-压
-双
-男
-训
-例
-汉
-升
-拥
-势
-酒
-眼
-官
-牌
-油
-曲
-友
-望
-黑
-歌
-筑
-础
-香
-仅
-担
-括
-湖
-严
-秀
-剧
-九
-举
-执
-充
-兴
-督
-博
-草
-般
-李
-健
-喜
-授
-普
-预
-灵
-突
-良
-款
-罗
-9
-微
-七
-录
-朝
-飞
-宝
-令
-轻
-劳
-距
-异
-简
-兵
-树
-序
-候
-含
-福
-尽
-留
-20
-丰
-旅
-征
-临
-破
-移
-篇
-抗
-典
-端
-苏
-奇
-止
-康
-店
-毛
-觉
-春
-售
-络
-降
-板
-坚
-母
-讲
-早
-印
-略
-孩
-夫
-藏
-铁
-害
-互
-帝
-田
-融
-皮
-宗
-岁
-载
-析
-斗
-须
-伤
-12
-介
-另
-00
-半
-班
-馆
-味
-楼
-卡
-射
-述
-杀
-波
-绿
-免
-兰
-绝
-刻
-短
-察
-输
-择
-综
-杂
-份
-纳
-父
-词
-银
-送
-座
-左
-继
-固
-宣
-厂
-肉
-换
-补
-税
-派
-套
-欢
-播
-吸
-圆
-攻
-阿
-购
-听
-右
-减
-激
-巴
-背
-够
-遇
-智
-玉
-找
-宽
-陈
-练
-追
-毕
-彩
-软
-帮
-股
-荣
-托
-予
-佛
-堂
-障
-皇
-若
-守
-似
-届
-待
-货
-散
-额
-30
-尚
-穿
-丽
-骨
-享
-差
-针
-索
-稳
-宁
-贵
-酸
-液
-唐
-操
-探
-玩
-促
-笔
-库
-救
-虽
-久
-闻
-顶
-床
-港
-鱼
-亿
-登
-11
-永
-毒
-桥
-冷
-魔
-秘
-陆
-您
-童
-归
-侧
-沙
-染
-封
-紧
-松
-川
-刘
-15
-雄
-希
-毫
-卷
-某
-季
-菜
-庭
-附
-逐
-夜
-宫
-洲
-退
-顾
-尼
-胜
-剂
-纯
-舞
-遗
-苦
-梦
-挥
-航
-愿
-街
-招
-矿
-夏
-盖
-献
-怎
-茶
-申
-39
-吧
-脑
-亦
-吃
-频
-宋
-央
-威
-厚
-块
-冲
-叫
-熟
-礼
-厅
-否
-渐
-笑
-钱
-钟
-甚
-牛
-丝
-靠
-岛
-绍
-盘
-缘
-聚
-静
-雨
-氏
-圣
-顺
-唱
-刊
-阶
-困
-急
-饰
-弹
-庄
-既
-野
-阴
-混
-饮
-损
-齐
-末
-错
-轮
-宜
-鲜
-兼
-敌
-粉
-祖
-延
-100
-钢
-辑
-欧
-硬
-甲
-诉
-册
-痛
-订
-缺
-晚
-衣
-佳
-脉
-gt
-盛
-乎
-拟
-贸
-扩
-船
-仪
-谁
-警
-50
-停
-席
-竞
-释
-庆
-汽
-仍
-掌
-诸
-仙
-弟
-吉
-洋
-奥
-票
-危
-架
-买
-径
-塔
-休
-付
-恶
-雷
-怀
-秋
-借
-巨
-透
-誉
-厘
-句
-跟
-胞
-婚
-幼
-烈
-峰
-寻
-君
-汇
-趣
-纸
-假
-肥
-患
-杨
-雅
-罪
-谓
-亮
-脱
-寺
-烟
-判
-绩
-乱
-刚
-摄
-洞
-践
-码
-启
-励
-呈
-曰
-呢
-符
-哥
-媒
-疾
-坐
-雪
-孔
-倒
-旧
-菌
-岩
-鼓
-亡
-访
-症
-暗
-湾
-幸
-池
-讨
-努
-露
-吗
-繁
-途
-殖
-败
-蛋
-握
-刺
-耕
-洗
-沉
-概
-哈
-泛
-凡
-残
-隐
-虫
-朋
-虚
-餐
-殊
-慢
-询
-蒙
-孙
-谈
-鲁
-裂
-贴
-污
-漫
-谷
-违
-泉
-拿
-森
-横
-扬
-键
-膜
-迁
-尤
-涉
-净
-诚
-折
-冰
-械
-拍
-梁
-沿
-避
-吴
-惊
-犯
-灭
-湿
-迷
-姓
-阅
-灯
-妇
-触
-冠
-答
-俗
-档
-尊
-谢
-措
-筹
-竟
-韩
-签
-剑
-鉴
-灾
-贯
-迹
-洛
-沟
-束
-翻
-巧
-坏
-弱
-零
-壁
-枝
-映
-恩
-抓
-屋
-呼
-脚
-绘
-40
-淡
-辖
-2010
-伊
-粒
-欲
-震
-伯
-私
-蓝
-甘
-储
-胡
-卖
-梅
-16
-耳
-疑
-润
-伴
-泽
-牧
-烧
-尾
-累
-糖
-怪
-唯
-莫
-粮
-柱
-18
-竹
-灰
-岸
-缩
-井
-伦
-柔
-盟
-珠
-丹
-amp
-皆
-哪
-迎
-颜
-衡
-啊
-塑
-寒
-13
-紫
-镜
-25
-氧
-误
-伍
-彻
-刀
-览
-炎
-津
-耐
-秦
-尖
-潮
-描
-浓
-召
-禁
-阻
-胶
-译
-腹
-泰
-乃
-盐
-潜
-鸡
-诺
-遍
-2000
-纹
-冬
-牙
-麻
-辅
-猪
-弃
-楚
-羊
-晋
-14
-鸟
-赵
-洁
-谋
-隆
-滑
-60
-2008
-籍
-臣
-朱
-泥
-墨
-辆
-墙
-浪
-姐
-赏
-纵
-2006
-拔
-倍
-纷
-摩
-壮
-苗
-偏
-塞
-贡
-仁
-宇
-卵
-瓦
-枪
-覆
-殿
-刑
-贫
-妈
-幅
-幕
-忆
-丁
-估
-废
-萨
-舍
-详
-旗
-岗
-洪
-80
-贝
-2009
-迅
-凭
-勇
-雕
-奏
-旋
-杰
-煤
-阵
-乘
-溪
-奉
-畜
-挑
-昌
-硕
-庙
-惠
-薄
-逃
-爆
-哲
-浙
-珍
-炼
-栏
-暴
-币
-隔
-吨
-倾
-嘉
-址
-陶
-绕
-诊
-遭
-桃
-魂
-兽
-豆
-闲
-箱
-拓
-燃
-裁
-晶
-掉
-脂
-溶
-顿
-肤
-虑
-鬼
-2007
-灌
-徐
-龄
-陵
-恋
-侵
-坡
-寿
-勤
-磨
-妹
-瑞
-缓
-轴
-麦
-羽
-咨
-凝
-默
-驻
-敢
-债
-17
-浮
-幻
-株
-浅
-敬
-敏
-陷
-凤
-坛
-虎
-乌
-铜
-御
-乳
-讯
-循
-圈
-肌
-妙
-奋
-忘
-闭
-墓
-21
-汤
-忠
-2005
-跨
-怕
-振
-宾
-跑
-屏
-坦
-粗
-租
-悲
-伟
-拜
-24
-妻
-赞
-兄
-宿
-碑
-貌
-勒
-罚
-夺
-偶
-截
-纤
-2011
-齿
-郑
-聘
-偿
-扶
-豪
-慧
-跳
-the
-疏
-莱
-腐
-插
-恐
-郎
-辞
-挂
-娘
-肿
-徒
-伏
-磁
-杯
-丛
-旨
-琴
-19
-炮
-醒
-砖
-替
-辛
-暖
-锁
-杜
-肠
-孤
-饭
-脸
-邮
-贷
-lt
-俄
-毁
-荷
-谐
-荒
-肝
-链
-2004
-2012
-尺
-尘
-援
-a
-疫
-崇
-恢
-扎
-伸
-幽
-抵
-胸
-谱
-舒
-迫
-200
-畅
-泡
-岭
-喷
-70
-窗
-捷
-宏
-肯
-90
-狂
-铺
-骑
-抽
-券
-俱
-徽
-胆
-碎
-邀
-褐
-斤
-涂
-赋
-署
-颗
-2003
-渠
-仿
-迪
-炉
-辉
-涵
-耗
-22
-返
-邻
-斑
-董
-魏
-午
-娱
-浴
-尿
-曼
-锅
-柳
-舰
-搭
-旁
-宅
-趋
-of
-凉
-赢
-伙
-爷
-廷
-戴
-壤
-奶
-页
-玄
-驾
-阔
-轨
-朗
-捕
-肾
-稿
-惯
-侯
-乙
-渡
-稍
-恨
-脏
-2002
-姆
-腔
-抱
-杆
-垂
-赴
-赶
-莲
-辽
-荐
-旦
-妖
-2013
-稀
-驱
-沈
-役
-晓
-亭
-仲
-澳
-500
-炸
-绪
-28
-陕
-and
-23
-恒
-堡
-纠
-仇
-懂
-焦
-搜
-s
-忍
-贤
-添
-i
-艾
-赤
-犹
-尝
-锦
-稻
-撰
-填
-衰
-栽
-邪
-粘
-跃
-桌
-胃
-悬
-c
-翼
-彼
-睡
-曹
-刷
-摆
-悉
-锋
-26
-摇
-抢
-乏
-廉
-鼠
-盾
-瓷
-抑
-埃
-邦
-遂
-寸
-渔
-祥
-胎
-牵
-壳
-甜
-卓
-瓜
-袭
-遵
-巡
-逆
-玛
-韵
-2001
-桑
-酷
-赖
-桂
-郡
-肃
-仓
-寄
-塘
-瘤
-300
-碳
-搞
-燕
-蒸
-允
-忽
-斜
-穷
-郁
-囊
-奔
-昆
-盆
-愈
-递
-1000
-黎
-祭
-怒
-辈
-腺
-滚
-暂
-郭
-璃
-踪
-芳
-碍
-肺
-狱
-冒
-阁
-砂
-35
-苍
-揭
-踏
-颇
-柄
-闪
-孝
-葡
-腾
-茎
-鸣
-撤
-仰
-伐
-丘
-於
-泪
-荡
-扰
-纲
-拼
-欣
-纽
-癌
-堆
-27
-菲
-b
-披
-挖
-寓
-履
-捐
-悟
-乾
-嘴
-钻
-拳
-吹
-柏
-遥
-抚
-忧
-赠
-霸
-艰
-淋
-猫
-帅
-奈
-寨
-滴
-鼻
-掘
-狗
-驶
-朴
-拆
-惜
-玻
-扣
-萄
-蔬
-宠
-2014
-缴
-赫
-凯
-滨
-乔
-腰
-葬
-孟
-吾
-枚
-圳
-忙
-扫
-杭
-凌
-1998
-梯
-丈
-隶
-1999
-剪
-盗
-擅
-疆
-弯
-携
-拒
-秒
-颁
-醇
-割
-浆
-姑
-爸
-螺
-穗
-缝
-慈
-喝
-瓶
-漏
-悠
-猎
-番
-孕
-伪
-漂
-腿
-吐
-坝
-滤
-函
-匀
-偷
-浩
-矛
-僧
-辨
-俊
-棉
-铸
-29
-诞
-丧
-夹
-to
-姿
-睛
-淮
-阀
-姜
-45
-尸
-猛
-1997
-芽
-账
-旱
-醉
-弄
-坊
-烤
-萧
-矣
-雾
-倡
-榜
-弗
-氨
-朵
-锡
-袋
-拨
-湘
-岳
-烦
-肩
-熙
-炭
-婆
-棋
-禅
-穴
-宙
-汗
-艳
-儒
-叙
-晨
-颈
-峡
-拖
-烂
-茂
-戒
-飘
-氛
-蒂
-撞
-瓣
-箭
-叛
-1996
-31
-鞋
-劲
-祝
-娜
-饲
-侍
-诱
-叹
-卢
-弥
-32
-鼎
-厦
-屈
-慕
-魅
-m
-厨
-嫁
-绵
-逼
-扮
-叔
-酶
-燥
-狼
-滋
-汁
-辐
-怨
-翅
-佩
-坑
-旬
-沃
-剩
-蛇
-颖
-篮
-锐
-侠
-匹
-唤
-熊
-漠
-迟
-敦
-雌
-谨
-婴
-浸
-磷
-筒
-2015
-滩
-埋
-框
-弘
-吕
-碰
-纺
-硫
-堪
-契
-蜜
-蓄
-1995
-阐
-apos
-傲
-碱
-晰
-狭
-撑
-叉
-卧
-劫
-闹
-赐
-邓
-奴
-溉
-浦
-蹈
-辣
-遣
-耀
-耶
-翠
-t
-叠
-迈
-霍
-碧
-恰
-脊
-昭
-摸
-饱
-赔
-泄
-哭
-讼
-逝
-逻
-廊
-擦
-渗
-彰
-you
-卿
-旺
-宪
-36
-顷
-妆
-陪
-葛
-仔
-淀
-翰
-悦
-穆
-煮
-辩
-弦
-in
-串
-押
-蚀
-逢
-贺
-焊
-煌
-缔
-惑
-鹿
-袁
-糊
-逸
-舟
-勃
-侦
-涯
-蔡
-辟
-涌
-枯
-痕
-疼
-莉
-柴
-1993
-眉
-1992
-罢
-催
-衔
-秉
-妃
-鸿
-傅
-400
-辰
-聪
-咸
-1994
-扇
-盈
-勘
-佐
-泊
-抛
-搬
-牢
-宴
-牲
-贾
-摘
-姻
-慎
-帕
-忌
-卒
-夕
-卜
-惟
-挺
-崖
-炒
-爵
-冻
-椒
-鳞
-祸
-潭
-腊
-蒋
-缠
-寂
-眠
-冯
-芯
-槽
-吊
-33
-150
-聊
-梗
-嫩
-凶
-铭
-爽
-筋
-韦
-脾
-铝
-肢
-栋
-勾
-萌
-渊
-掩
-狮
-撒
-漆
-骗
-禽
-38
-蕴
-坪
-洒
-冶
-兹
-椭
-喻
-泵
-哀
-翔
-1990
-棒
-芝
-x
-扑
-3000
-毅
-衍
-惨
-疯
-欺
-贼
-肖
-轰
-巢
-臂
-轩
-扁
-淘
-犬
-宰
-祠
-挡
-厌
-帐
-蜂
-狐
-垃
-昂
-圾
-秩
-芬
-瞬
-枢
-舌
-唇
-棕
-1984
-霞
-霜
-艇
-侨
-鹤
-硅
-靖
-哦
-削
-泌
-奠
-d
-吏
-夷
-咖
-彭
-窑
-胁
-肪
-120
-贞
-劝
-钙
-柜
-鸭
-75
-庞
-兔
-荆
-丙
-纱
-34
-戈
-藤
-矩
-泳
-惧
-铃
-渴
-胀
-袖
-丸
-狠
-豫
-茫
-1985
-浇
-菩
-氯
-啡
-1988
-葱
-37
-梨
-霉
-脆
-氢
-巷
-丑
-娃
-锻
-愤
-贪
-蝶
-1991
-厉
-闽
-浑
-斩
-栖
-l
-茅
-昏
-龟
-碗
-棚
-滞
-慰
-600
-2016
-斋
-虹
-屯
-萝
-饼
-窄
-潘
-绣
-丢
-芦
-鳍
-42
-裕
-誓
-腻
-48
-95
-锈
-吞
-蜀
-啦
-扭
-5000
-巩
-髓
-1987
-劣
-拌
-谊
-涛
-勋
-郊
-莎
-痴
-窝
-驰
-1986
-跌
-笼
-挤
-溢
-1989
-隙
-55
-鹰
-诏
-帽
-65
-芒
-爬
-凸
-牺
-熔
-吻
-竭
-瘦
-冥
-800
-搏
-屡
-昔
-萼
-愁
-捉
-翁
-怖
-汪
-烯
-疲
-缸
-溃
-85
-泼
-剖
-涨
-橡
-谜
-悔
-嫌
-盒
-苯
-凹
-绳
-畏
-罐
-虾
-柯
-邑
-馨
-兆
-帖
-陌
-禄
-垫
-壶
-逊
-骤
-祀
-晴
-蓬
-e
-苞
-煎
-菊
-堤
-甫
-拱
-氮
-罕
-舶
-伞
-姚
-弓
-嵌
-1983
-1982
-馈
-琼
-噪
-雀
-呵
-汝
-焉
-陀
-胺
-惩
-沼
-枣
-桐
-酱
-遮
-孢
-钝
-呀
-锥
-妥
-酿
-巫
-闯
-沧
-崩
-蕊
-酬
-匠
-躲
-43
-喊
-98
-琳
-46
-绎
-喉
-凰
-抬
-93
-膨
-盲
-剥
-喂
-庸
-奸
-n
-钩
-冈
-募
-苑
-杏
-杉
-辱
-隋
-薪
-绒
-1980
-99
-欠
-尉
-r
-攀
-抹
-巾
-1958
-渣
-苹
-猴
-悄
-屠
-41
-颂
-湛
-魄
-颠
-1949
-呆
-粤
-岂
-娇
-暑
-44
-56
-52
-鹅
-筛
-膏
-樱
-p
-缆
-襄
-瑟
-恭
-泻
-匪
-兮
-恼
-吟
-仕
-蔽
-骄
-蚕
-斥
-椅
-姬
-谦
-for
-椎
-搅
-卸
-沫
-怜
-坎
-瑰
-1978
-钦
-h
-拾
-厕
-後
-逾
-薯
-衬
-钾
-崔
-稽
-蛮
-殷
-晒
-47
-菇
-臭
-弧
-擎
-粹
-纬
-1500
-焰
-玲
-竣
-咒
-歇
-糕
-诵
-茨
-妮
-酯
-麟
-卑
-浏
-咽
-罩
-舱
-酵
-晕
-顽
-赁
-咬
-枫
-冀
-贮
-艘
-亏
-薛
-瀑
-篆
-膀
-沸
-雍
-咳
-尹
-愉
-烹
-坠
-勿
-钠
-64
-坤
-甸
-墅
-闸
-藻
-韧
-鄂
-58
-51
-91
-j
-瑶
-舆
-夸
-54
-蕾
-栗
-咏
-丞
-抄
-鹏
-弊
-檐
-骂
-仆
-峻
-爪
-赚
-帆
-娶
-嘛
-钓
-澄
-猜
-1979
-裔
-抒
-铅
-卉
-彦
-f
-删
-衷
-禹
-寡
-蒲
-砌
-on
-棱
-72
-拘
-堵
-雁
-仄
-荫
-53
-k
-1981
-祈
-49
-奢
-赌
-寇
-3d
-隧
-摊
-雇
-卦
-婉
-敲
-挣
-皱
-虞
-亨
-懈
-挽
-珊
-饶
-滥
-锯
-闷
-it
-酮
-虐
-兑
-僵
-傻
-62
-沦
-巅
-鞭
-梳
-赣
-锌
-庐
-薇
-庵
-57
-96
-慨
-肚
-妄
-g
-仗
-绑
-2017
-枕
-牡
-000
-胖
-沪
-垒
-捞
-捧
-竖
-蜡
-桩
-厢
-孵
-黏
-拯
-63
-谭
-68
-诈
-灿
-釉
-1956
-裹
-钮
-俩
-o
-灶
-彝
-蟹
-涩
-醋
-110
-匙
-歧
-刹
-玫
-棘
-橙
-凑
-桶
-刃
-伽
-4000
-硝
-怡
-籽
-敞
-淳
-矮
-镶
-戚
-幢
-涡
-66
-尧
-膝
-is
-哉
-肆
-畔
-溯
-97
-媚
-烘
-01
-67
-窃
-焚
-澜
-愚
-棵
-乞
-86
-78
-佑
-76
-iphone
-暨
-敷
-饥
-俯
-蔓
-v
-05
-88
-暮
-砍
-邵
-仑
-毗
-剿
-馀
-180
-锤
-刮
-1950
-梭
-摧
-250
-掠
-躯
-诡
-匈
-侣
-胚
-疮
-59
-裙
-windows
-裸
-08
-塌
-吓
-俘
-糙
-藩
-楷
-羞
-with
-鲍
-帘
-裤
-宛
-憾
-桓
-痰
-寞
-骚
-惹
-笋
-萃
-92
-栓
-61
-挫
-矢
-垦
-09
-垄
-绸
-凄
-your
-镀
-熏
-钉
-1945
-led
-粪
-缅
-洽
-鞘
-蔗
-82
-迄
-沐
-凿
-勉
-昨
-喘
-700
-爹
-屑
-耻
-沥
-庶
-涅
-腕
-袍
-懒
-阜
-嗜
-朔
-1200
-蒜
-沛
-坟
-轿
-喀
-笛
-狄
-饿
-蓉
-泣
-窟
-130
-豹
-屿
-73
-崛
-迦
-诠
-贬
-腥
-83
-钥
-嗣
-瑜
-07
-倦
-萎
-拦
-冤
-讽
-潇
-谣
-趁
-1960
-妨
-84
-贩
-74
-萍
-窦
-纂
-缀
-矫
-淑
-墩
-梵
-沾
-淫
-乖
-汰
-莞
-81
-旷
-浊
-挚
-撼
-69
-87
-氟
-焕
-06
-庚
-掀
-诀
-kg
-盼
-71
-疹
-窖
-匆
-厥
-轧
-89
-淹
-94
-160
-亥
-鸦
-棍
-谅
-歼
-汕
-挪
-蚁
-敛
-魁
-畴
-炫
-丫
-奎
-菱
-沂
-撕
-阎
-詹
-03
-蛛
-77
-靡
-瞻
-咱
-愧
-烷
-畸
-灸
-眸
-that
-觅
-芜
-1955
-廓
-斌
-躁
-麓
-摔
-1970
-烛
-睹
-孜
-缚
-堕
-昼
-睿
-琪
-琉
-贱
-6000
-渝
-跋
-1959
-茄
-1957
-舜
-1976
-诛
-1952
-捣
-芙
-04
-1961
-倚
-1938
-酰
-澈
-慌
-帜
-颤
-陇
-1962
-02
-颌
-昧
-佣
-眷
-徙
-禾
-逮
-1948
-79
-莹
-碟
-梢
-朽
-粥
-喇
-1964
-榆
-驳
-楔
-1965
-啸
-肋
-dna
-踢
-1975
-1937
-u
-傍
-桔
-肴
-呕
-旭
-埠
-贿
-曝
-杖
-俭
-栩
-1953
-斧
-镁
-匾
-踩
-橘
-颅
-1963
-囚
-蛙
-1946
-膳
-坞
-琐
-荧
-瘟
-涤
-胰
-衫
-噬
-皖
-邱
-埔
-汀
-羡
-睐
-葵
-耿
-糟
-厄
-秧
-黔
-蹄
-140
-漳
-鞍
-谏
-腋
-簇
-梧
-戎
-1977
-榴
-诣
-宦
-苔
-揽
-簧
-狸
-阙
-扯
-耍
-棠
-脓
-烫
-翘
-芭
-躺
-羁
-藉
-拐
-1966
-陡
-1954
-漓
-棺
-钧
-琅
-扔
-寝
-绚
-熬
-驿
-邹
-杠
-1972
-w
-绥
-窥
-晃
-渭
-1947
-樊
-鑫
-祁
-陋
-哺
-堰
-祛
-y
-梓
-崎
-1968
-孽
-蝴
-蔚
-抖
-苟
-肇
-溜
-绅
-妾
-1940
-跪
-沁
-q
-1973
-莽
-虏
-be
-瞄
-砸
-稚
-僚
-崭
-迭
-皂
-彬
-雏
-ip
-羲
-缕
-绞
-俞
-簿
-耸
-廖
-嘲
-can
-1969
-翌
-榄
-裴
-槐
-1939
-洼
-睁
-1951
-灼
-啤
-臀
-啥
-濒
-醛
-峨
-葫
-悍
-笨
-嘱
-1935
-稠
-360
-韶
-1941
-陛
-峭
-1974
-酚
-翩
-舅
-8000
-寅
-1936
-蕉
-阮
-垣
-戮
-me
-趾
-犀
-巍
-re
-霄
-1942
-1930
-饪
-sci
-秆
-朕
-驼
-肛
-揉
-ipad
-楠
-岚
-疡
-帧
-柑
-iso9001
-赎
-逍
-滇
-璋
-礁
-黛
-钞
-邢
-涧
-劈
-瞳
-砚
-驴
-1944
-锣
-恳
-栅
-吵
-牟
-沌
-瞩
-咪
-毯
-炳
-淤
-盯
-芋
-粟
-350
-栈
-戊
-盏
-峪
-拂
-暇
-酥
-汛
-900
-pc
-嚣
-2500
-轼
-妒
-匿
-1934
-鸽
-蝉
-cd
-痒
-宵
-瘫
-1927
-1943
-璧
-汲
-1971
-冢
-碌
-琢
-磅
-卤
-105
-剔
-谎
-圩
-酌
-捏
-渺
-媳
-1933
-穹
-谥
-骏
-哨
-骆
-乒
-10000
-摹
-兜
-柿
-喧
-呜
-捡
-橄
-逗
-瑚
-呐
-檀
-辜
-妊
-祯
-1931
-苷
-don
-衙
-笃
-芸
-霖
-荔
-闺
-羌
-芹
-dvd
-哼
-糯
-吼
-蕃
-嵩
-矶
-绽
-坯
-娠
-1928
-祷
-锰
-qq
-by
-瘀
-108
-岐
-1932
-茵
-筝
-斐
-肽
-歉
-1929
-嗽
-恤
-汶
-聂
-樟
-擒
-鹃
-拙
-鲤
-絮
-鄙
-彪
-ipod
-z
-嗓
-墟
-骼
-渤
-僻
-豁
-谕
-荟
-姨
-婷
-挠
-哇
-炙
-220
-诅
-娥
-哑
-阱
-嫉
-圭
-乓
-橱
-歪
-禧
-甩
-坷
-晏
-驯
-讳
-泗
-煞
-my
-淄
-倪
-妓
-窍
-竿
-襟
-匡
-钛
-侈
-ll
-侄
-铲
-哮
-厩
-1967
-亢
-101
-辕
-瘾
-辊
-狩
-掷
-潍
-240
-伺
-嘿
-弈
-嘎
-陨
-娅
-1800
-昊
-犁
-屁
-蜘
-170
-寥
-滕
-毙
-as
-涝
-谛
-all
-郝
-痹
-溺
-汾
-脐
-馅
-蠢
-珀
-腌
-扼
-敕
-莓
-峦
-铬
-谍
-炬
-龚
-麒
-睦
-磺
-吁
-掺
-烁
-靶
-or
-圃
-饵
-褶
-娟
-滔
-挨
-android
-褒
-胱
-cpu
-晖
-脖
-垢
-抉
-冉
-茧
-from
-渲
-癫
-125
-de
-悼
-嫂
-瞒
-纶
-肘
-炖
-瀚
-皋
-姊
-颐
-1600
-俏
-颊
-gps
-讶
-札
-奕
-磊
-镖
-遐
-眺
-腑
-boss
-琦
-蚊
-窜
-渍
-嗯
-102
-1926
-touch
-夯
-1300
-笙
-蘑
-翡
-碘
-卯
-啼
-靓
-辍
-莺
-躬
-猿
-杞
-眩
-虔
-凋
-遁
-泾
-岔
-羟
-弛
-娄
-茸
-皓
-峙
-逅
-邂
-苇
-楹
-蹲
-拢
-甄
-鳃
-104
-邯
-捆
-勺
-450
-酉
-荚
-唑
-臻
-辗
-绰
-徊
-榨
-苛
-赦
-盔
-壬
-恍
-缉
-2020
-熨
-7000
-澡
-桨
-匣
-兢
-106
-驭
-x1
-镍
-孰
-绮
-馏
-蝇
-佼
-鲸
-128
-哎
-裳
-蜕
-嚼
-嘻
-web
-庇
-绢
-倩
-钵
-ii
-恪
-帷
-莆
-柠
-藕
-砾
-115
-绊
-喙
-坂
-徘
-荀
-瞧
-蛾
-1925
-晦
-ph
-mm
-铎
-107
-紊
-锚
-酪
-稷
-聋
-闵
-熹
-冕
-诫
-珑
-曦
-篷
-320
-迥
-蘖
-胤
-103
-檬
-瑾
-钳
-遏
-辄
-嬉
-隅
-ps
-秃
-112
-帛
-聆
-芥
-诬
-1100
-挟
-宕
-2018
-鹊
-琶
-膛
-mv
-兀
-gb
-懿
-碾
-叮
-863
-蠕
-譬
-缮
-烽
-妍
-榕
-260
-1920
-邃
-焙
-倘
-210
-戌
-茹
-豚
-晾
-浒
-玺
-醚
-祐
-炽
-this
-缪
-凛
-噩
-溅
-毋
-槛
-ei
-are
-嫡
-蝠
-娴
-稣
-禀
-壑
-殆
-敖
-cm
-ios
-倭
-挛
-侃
-蚌
-咀
-盎
-殉
-岑
-浚
-谬
-狡
-1924
-癸
-280
-逛
-耽
-俺
-璨
-巳
-茜
-郸
-蒴
-琵
-we
-230
-叩
-泸
-塾
-one
-稼
-reg
-侮
-锂
-曙
-3500
-up
-薰
-婿
-惶
-拭
-篱
-恬
-淌
-烙
-袜
-徵
-慷
-夭
-噶
-莘
-135
-鸳
-殡
-蚂
-1900
-憎
-喃
-佚
-龛
-潢
-烃
-at
-岱
-潺
-109
-衢
-璀
-5cm
-1400
-鹭
-揣
-痢
-know
-厮
-氓
-怠
-no
-nbsp
-痘
-硒
-镌
-乍
-咯
-惬
-not
-桦
-骇
-枉
-蜗
-睾
-淇
-耘
-娓
-弼
-鳌
-嗅
-gdp
-狙
-箫
-朦
-椰
-胥
-丐
-陂
-唾
-鳄
-柚
-谒
-journal
-戍
-1912
-刁
-鸾
-缭
-骸
-铣
-酋
-蝎
-掏
-耦
-怯
-娲
-拇
-汹
-胧
-疤
-118
-硼
-恕
-哗
-眶
-痫
-凳
-鲨
-擢
-歹
-樵
-瘠
-app
-茗
-翟
-黯
-蜒
-壹
-殇
-伶
-辙
-an
-瑕
-町
-孚
-痉
-铵
-搁
-漾
-戟
-镰
-鸯
-猩
-190
-蔷
-缤
-叭
-垩
-113
-曳
-usb
-奚
-毓
-ibm
-颓
-汐
-靴
-china
-傣
-尬
-濮
-赂
-媛
-懦
-扦
-111
-韬
-like
-戳
-java
-雯
-114
-蜿
-116
-1923
-笺
-裘
-尴
-侗
-mba
-3g
-钨
-1919
-苓
-1922
-寰
-蛊
-扳
-搓
-涟
-睫
-淬
-5mm
-123
-ve
-121
-赈
-恺
-瞎
-蝙
-1921
-枸
-萱
-颚
-憩
-秽
-秸
-拷
-阑
-貂
-粱
-煲
-隘
-暧
-惕
-沽
-time
-菠
-1911
-趟
-磋
-偕
-涕
-邸
-so
-踞
-惫
-122
-阪
-鞠
-饺
-汞
-颍
-氰
-屹
-蛟
-跻
-哟
-have
-126
-臼
-熄
-绛
-弩
-褪
-117
-渎
-亟
-匮
-撇
-internet
-霆
-攒
-舵
-扛
-彤
-nba
-蛤
-婢
-偃
-胫
-姥
-睑
-love
-iso
-pk
-诙
-what
-诲
-锭
-悚
-扒
-洱
-劾
-惰
-篡
-瓯
-徇
-铀
-骋
-flash
-1918
-out
-筷
-渚
-踵
-俨
-ceo
-榻
-糜
-捻
-釜
-哩
-萤
-270
-蛹
-隽
-垮
-鸠
-鸥
-漕
-瑙
-礴
-憧
-殴
-潼
-悯
-砺
-拽
-钗
-ct
-酣
-镂
-mp3
-膺
-楞
-竺
-迂
-嫣
-忱
-cad
-哄
-疣
-鹦
-1700
-枭
-憬
-疱
-will
-婪
-沮
-1914
-怅
-119
-筱
-扉
-瞰
-linux
-旌
-蔑
-铠
-瀛
-vip
-琥
-750
-127
-懵
-谴
-捍
-蟾
-漩
-1913
-拣
-汴
-university
-刨
-叱
-曜
-妞
-澎
-镑
-翎
-瞪
-sh
-倔
-芍
-璞
-瓮
-驹
-芷
-寐
-擂
-丕
-蟠
-诃
-悸
-亘
-溴
-宸
-廿
-恃
-棣
-1917
-荼
-筠
-羚
-慑
-唉
-纣
-麼
-蹦
-锄
-145
-international
-124
-淆
-甙
-132
-蚜
-椿
-禺
-绯
-冗
-168
-葩
-厝
-媲
-蒿
-痪
-650
-菁
-炊
-wifi
-俑
-new
-讥
-min
-桀
-祺
-129
-吡
-迩
-do
-john
-箔
-皿
-缎
-萦
-剃
-霓
-酝
-mg
-诰
-茉
-just
-get
-飙
-湍
-蜥
-箕
-蘸
-550
-4500
-柬
-韭
-溥
-but
-熠
-鹉
-咐
-剌
-138
-悖
-瞿
-槟
-娩
-闾
-pvc
-遴
-咫
-20000
-孺
-彷
-茬
-211
-蓟
-li
-if
-憨
-袅
-佬
-炯
-erp
-1910
-啶
-昙
-蚩
-136
-痔
-蕨
-瓢
-夔
-毡
-赃
-鳖
-沅
-wang
-go
-饷
-165
-臧
-掖
-褚
-羹
-ic
-勐
-tv
-谚
-畦
-眨
-贻
-攸
-涎
-弑
-咎
-铂
-瑛
-1905
-矗
-虱
-more
-133
-秤
-谟
-漱
-俸
-夙
-1915
-br
-game
-雉
-螨
-恣
-斛
-175
-谙
-隍
-131
-奄
-480
-yy
-1916
-壕
-髻
-155
-鄱
-嘶
-磕
-濡
-赘
-荞
-讹
-猕
-痞
-鬓
-铮
-腱
-幡
-榭
-爻
-5m
-涓
-晤
-咕
-惭
-钼
-匕
-ok
-撮
-庾
-笠
-窘
-癖
-365
-垛
-窒
-畲
-甬
-彗
-缨
-湮
-寮
-et
-衅
-谪
-156
-绫
-9000
-152
-兖
-疽
-磐
-380
-菏
-沱
-骁
-嫔
-盂
-娆
-钊
-蟒
-忏
-谤
-148
-137
-server
-2200
-晟
-ng
-15000
-google
-痈
-耆
-谧
-簪
-134
-ml
-疟
-扈
-脍
-琛
-咋
-胄
-142
-144
-葆
-轶
-桢
-973
-攘
-was
-邕
-拧
-茯
-205
-摒
-1908
-intel
-傀
-祚
-嘟
-帼
-1906
-wto
-筵
-when
-馒
-疚
-璇
-砧
-merge
-槃
-microsoft
-犷
-exe
-腓
-煜
-弋
-疸
-濑
-310
-201
-麝
-嗟
-忻
-愣
-facebook
-斓
-吝
-咧
-矾
-愫
-151
-158
-漪
-珂
-rna
-逞
-146
-206
-糠
-璐
-藓
-昕
-妩
-屌
-疵
-excel
-嘘
-he
-plc
-袂
-2400
-139
-稃
-剁
-侏
-掐
-猾
-匍
-2800
-坳
-黜
-邺
-闫
-猥
-湃
-斟
-癣
-1904
-185
-匐
-粳
-sql
-330
-141
-cp
-1909
-叟
-俾
-儡
-莒
-12000
-骥
-跤
-耙
-矜
-翱
-zhang
-ms
-赡
-1907
-浣
-栾
-拈
-science
-420
-螟
-aaa
-桧
-坍
-睢
-趴
-id
-伎
-2100
-婺
-霹
-痊
-膊
-眯
-豌
-202
-驮
-骈
-850
-iii
-嶂
-淞
-143
-腮
-髅
-炀
-啄
-亳
-麾
-147
-筐
-叨
-徨
-跷
-ac
-楂
-郴
-绶
-hp
-羔
-xp
-ieee
-咤
-now
-there
-靳
-they
-屎
-雳
-瘘
-蹬
-2300
-惮
-acid
-涪
-阖
-煽
-蹊
-225
-栉
-153
-俟
-涸
-辫
-锢
-佟
-176
-皎
-cctv
-啮
-钰
-螂
-dc
-啪
-绷
-204
-闰
-畿
-2d
-覃
-2600
-惘
-贰
-154
-碉
-卞
-酐
-枷
-葺
-芪
-207
-蕙
-192
-咚
-籁
-pro
-钴
-162
-冽
-玮
-骷
-啃
-焖
-猝
-榈
-滁
-拮
-跗
-讷
-蝗
-208
-蠡
-world
-烨
-been
-hd
-gmp
-256
-脯
-歙
-泠
-刍
-掳
-pe
-his
-僳
-340
-1902
-螯
-胳
-髦
-粽
-戾
-祜
-178
-186
-岷
-懋
-馥
-昵
-踊
-湄
-郢
-斡
-迢
-ce
-photoshop
-嗪
-about
-裨
-1903
-羧
-膈
-翊
-lcd
-鲫
-163
-螃
-沓
-疝
-笈
-ktv
-榔
-157
-诘
-autocad
-195
-颉
-蛀
-鸢
-焯
-囧
-make
-梆
-npc
-潞
-戛
-see
-system
-149
-佗
-艮
-chinese
-let
-霾
-鬟
-215
-net
-玖
-1898
-腭
-喔
-172
-罔
-佥
-粑
-visual
-舷
-泯
-m2
-198
-has
-203
-sd
-泓
-炜
-谗
-烬
-跆
-rpg
-傩
-飓
-浔
-钤
-惚
-胭
-踝
-镯
-ep
-221
-臆
-196
-蜚
-揪
-觞
-皈
-dj
-183
-api
-迸
-匝
-筏
-167
-醴
-黍
-洮
-滦
-侬
-甾
-290
-way
-3200
-188
-diy
-2cm
-com
-澧
-阈
-袱
-迤
-衮
-166
-濂
-娑
-砥
-砷
-铨
-缜
-箴
-30000
-逵
-猖
-159
-蛰
-箍
-侥
-2mm
-搂
-纨
-裱
-枋
-嫦
-敝
-挝
-贲
-潦
-235
-撩
-惺
-铰
-f1
-忒
-咆
-哆
-莅
-164
-炕
-抨
-涿
-龈
-猷
-got
-b1
-182
-2m
-212
-遒
-缥
-vs
-捂
-俐
-la
-瘙
-搐
-牍
-isbn
-馍
-our
-痿
-袤
-峥
-184
-栎
-罹
-燎
-喵
-209
-1901
-璜
-飒
-蔼
-珞
-澹
-奘
-岖
-芡
-簸
-杵
-甥
-骊
-216
-悴
-173
-惆
-5mg
-殃
-1895
-呃
-161
-5g
-祗
-3600
-髋
-169
-liu
-who
-幔
-down
-榛
-犊
-霁
-芮
-520
-牒
-佰
-her
-狈
-薨
-co
-吩
-鳝
-嵘
-濠
-呤
-纫
-3mm
-檄
-214
-浜
-370
-189
-缙
-缢
-煦
-蓦
-揖
-拴
-缈
-218
-褥
-铿
-312
-燮
-life
-锵
-174
-荥
-187
-忿
-4s
-僖
-婶
-171
-chen
-芾
-镐
-痣
-research
-眈
-460
-祇
-邈
-翳
-碣
-遨
-鳗
-诂
-never
-岫
-焘
-3cm
-co2
-茱
-tcp
-only
-255
-gsm
-say
-洵
-晁
-right
-噢
-she
-over
-偈
-旖
-david
-181
-232
-蚓
-柘
-珐
-遽
-岌
-桅
-213
-唔
-222
-鄞
-雹
-michael
-驸
-苻
-恻
-鬃
-玑
-磬
-崂
-304
-祉
-荤
-淼
-560
-264
-肱
-呗
-pp
-b2
-骡
-囱
-10cm
-佞
-back
-1890
-226
-耒
-伫
-嚷
-粼
-aa
-歆
-佃
-旎
-惋
-殁
-杳
-their
-阡
-red
-畈
-蔺
-os
-177
-map
-巽
-cbd
-昱
-啰
-吠
-179
-199
-嗔
-涮
-238
-奂
-1896
-撷
-301
-袒
-720
-爰
-捶
-赭
-蜓
-姗
-蔻
-垠
-193
-gis
-噻
-ab
-峒
-皙
-want
-245
-憔
-帚
-office
-xx
-杷
-蟆
-iso14001
-觐
-钒
-岙
-2700
-1899
-栀
-幄
-啧
-癜
-擀
-轲
-铆
-them
-讴
-樽
-霏
-mtv
-肮
-枳
-骞
-诧
-瘢
-虬
-拗
-play
-219
-蕲
-316
-茁
-唆
-technology
-word
-沭
-毂
-蛎
-芊
-銮
-瞥
-呱
-223
-羿
-吒
-傥
-髯
-濯
-蜻
-皴
-802
-430
-邳
-燧
-1860
-獭
-垭
-祟
-217
-虢
-how
-枇
-abs
-鹫
-194
-颞
-1894
-333
-皑
-脲
-197
-舔
-魇
-霭
-org
-坨
-郧
-baby
-椽
-舫
-228
-oh
-305
-荠
-琊
-溟
-1897
-煨
-265
-谯
-粲
-罂
-gonna
-屉
-佯
-郦
-亵
-诽
-芩
-嵇
-蚤
-哒
-315
-啬
-ain
-嚎
-玥
-twitter
-191
-隼
-唢
-铛
-cause
-壅
-藜
-won
-吱
-rom
-楣
-璟
-锆
-憋
-罡
-al
-咙
-1850
-腈
-oslash
-job
-233
-廪
-堑
-into
-诩
-b2c
-溧
-鹑
-讫
-哌
-铢
-蜴
-1ml
-稹
-噜
-镉
-224
-愕
-桁
-晔
-琰
-陲
-疙
-667
-崮
-need
-540
-8mm
-html
-颛
-through
-asp
-桡
-钜
-580
-take
-谑
-仞
-咦
-珪
-揍
-鱿
-阉
-3800
-瘩
-410
-槌
-滓
-茴
-tft
-泮
-涣
-atm
-pci
-柞
-渥
-飨
-孪
-沔
-谲
-桉
-vcd
-慵
-318
-oem
-other
-俚
-paul
-跖
-纭
-恙
-which
-fi
-佘
-236
-荃
-咄
-鞅
-叁
-james
-恽
-m3
-253
-炔
-萘
-钺
-6500
-1880
-ccd
-楫
-塬
-钡
-琮
-苄
-950
-325
-275
-1g
-day
-o2o
-960
-music
-骰
-偎
-粕
-amd
-咔
-鹄
-瓒
-阆
-捅
-嬴
-adobe
-箨
-name
-390
-680
-640
-氦
-倜
-b2b
-觊
-xml
-婕
-229
-jar
-锑
-撬
-chem
-掰
-嗷
-5500
-1cm
-饯
-蓓
-234
-good
-鼬
-spa
-佤
-5a
-ss
-蚯
-挞
-臾
-where
-atp
-227
-嶙
-幂
-饬
-闱
-live
-high
-煅
-嘧
-1mm
-蹭
-sun
-abc
-瞭
-顼
-箐
-here
-徉
-231
-骜
-302
-嗨
-邛
-庑
-柩
-饕
-俎
-4mm
-15g
-嘌
-50000
-颏
-cssci
-椁
-崧
-锉
-籼
-1870
-狞
-弁
-6mm
-羯
-踹
-糅
-248
-1840
-砼
-263
-嫖
-tmp
-252
-mac
-285
-豉
-啉
-榷
-嘈
-en
-俪
-痂
-308
-inf
-630
-儋
-4a
-芎
-ai
-man
-繇
-1889
-bt
-239
-meta
-蹇
-242
-530
-诋
-bbc
-煸
-峋
-淙
-324
-management
-1885
-泱
-徜
-crm
-4cm
-free
-汩
-纥
-246
-蝼
-囿
-uv
-暹
-谆
-蹂
-鞣
-3c
-mr
-螳
-cs
-馗
-幺
-鞑
-贽
-268
-istp
-243
-漯
-237
-牦
-淖
-engineering
-dr
-囤
-than
-gprs
-sp
-440
-晗
-1888
-258
-忡
-懊
-呋
-埂
-pcb
-307
-first
-321
-robert
-鲈
-sup2
-阕
-3m
-幌
-cg
-303
-鳅
-勰
-find
-8cm
-萸
-剽
-蚝
-wi
-绔
-pdf
-1250
-262
-php
-辇
-10mg
-use
-ie
-麋
-1884
-陟
-宥
-oracle
-锺
-喽
-620
-1892
-1893
-淅
-熵
-荨
-247
-忤
-american
-266
-seo
-轭
-嗦
-荪
-also
-骠
-鹘
-p2p
-4g
-聿
-绾
-诶
-985
-怆
-244
-喋
-恸
-湟
-睨
-翦
-fe
-蜈
-1875
-褂
-娼
-1886
-羸
-觎
-470
-瘁
-306
-蚣
-呻
-241
-1882
-昶
-谶
-猬
-荻
-school
-286
-酗
-unit
-肄
-躏
-膑
-288
-2g
-嗡
-273
-iv
-cam
-510
-庠
-崽
-254
-搪
-pcr
-胯
-309
-铉
-峤
-郯
-藐
-舂
-come
-蓼
-some
-薏
-窿
-羣
-氽
-徕
-冼
-rs
-阂
-欤
-殒
-窈
-脘
-780
-篝
-yang
-1861
-3300
-iso9000
-麸
-砭
-max
-砰
-骶
-豺
-lg
-窠
-獒
-think
-腴
-苕
-any
-its
-缇
-骅
-劭
-college
-卅
-ups
-揆
-垅
-na
-6cm
-琏
-镗
-苜
-胛
-1881
-black
-珏
-吮
-抠
-搔
-276
-rock
-251
-槎
-4200
-323
-掣
-pet
-1887
-ap
-琨
-餮
-375
-舛
-give
-si
-痤
-us
-311
-278
-埭
-english
-peter
-1891
-820
-胪
-喹
-妲
-婀
-帙
-10g
-oa
-7500
-箩
-灏
-霎
-logo
-袄
-dsp
-bl
-镭
-蓿
-power
-long
-墉
-too
-嵊
-1862
-girl
-堇
-king
-蟋
-610
-叽
-249
-钎
-30cm
-fm
-録
-group
-1883
-郓
-瘴
-vol
-丶
-呦
-邬
-頫
-272
-馁
-hiv
-鄢
-257
-1876
-ordm
-蛭
-322
-愍
-锲
-槿
-珈
-best
-4800
-mri
-1080
-fda
-10mm
-261
-nt
-660
-super
-1m
-center
-ui
-335
-蜃
-298
-拎
-鎏
-裟
-沏
-np
-螭
-7mm
-觑
-墒
-捺
-轸
-micro
-榫
-based
-319
-怔
-ram
-618
-昀
-even
-泷
-1864
-ca
-凫
-唠
-狰
-鲛
-氐
-呛
-绀
-碛
-茏
-盅
-蟀
-洙
-off
-訇
-蠹
-auml
-dos
-20cm
-267
-棂
-18000
-蚴
-篾
-two
-靛
-暄
-show
-1868
-泞
-cdma
-mark
-vc
-洄
-赓
-麽
-25000
-篓
-孑
-860
-烩
-980
-design
-颢
-钣
-var
-髂
-蹴
-wanna
-筮
-蝌
-醮
-home
-菖
-fun
-cmos
-獗
-friends
-business
-岘
-570
-鼐
-1865
-姣
-national
-1874
-蟑
-袈
-葶
-掬
-most
-vga
-emba
-躇
-30g
-鹌
-city
-踌
-282
-钹
-蚪
-颧
-001
-13000
-鹳
-274
-km
-345
-1050
-stop
-328
-then
-鲲
-驷
-潴
-295
-386
-焱
-稔
-悌
-mpeg
-st
-suv
-vista
-a1
-vi
-283
-help
-basic
-唏
-11000
-苒
-蹙
-house
-heart
-ouml
-281
-氩
-bug
-mobile
-宓
-service
-dll
-綦
-苎
-application
-疃
-methyl
-攫
-rfid
-100g
-287
-掾
-1871
-徭
-490
-舀
-逶
-嗤
-760
-0m
-ge
-1872
-people
-hr
-蜷
-茔
-512
-疳
-迳
-罄
-瓠
-100mg
-讪
-psp
-av
-傈
-ppp
-杲
-灞
-氲
-鬲
-獠
-柒
-骧
-1848
-away
-william
-326
-搀
-珩
-绦
-1879
-嚏
-710
-镛
-喱
-倏
-馋
-茭
-擘
-斫
-284
-1mg
-怂
-hdmi
-唧
-犍
-谩
-赊
-317
-271
-wu
-鬻
-禛
-15cm
-259
-840
-feel
-485
-圻
-10m
-蹶
-5kg
-1877
-1873
-缄
-瘿
-黠
-甑
-矸
-嘀
-il
-蹼
-jack
-lee
-269
-叼
-di
-313
-旻
-auc
-502
-1350
-鹜
-289
-fc
-稗
-336
-999
-association
-many
-293
-雒
-george
-td
-赉
-style
-馔
-颦
-ul
-ld50
-1867
-颔
-掇
-1863
-each
-赅
-桎
-inc
-痧
-dv
-谄
-孛
-笆
-鲶
-铳
-3100
-mc
-tell
-4m
-blue
-327
-299
-bios
-龋
-385
-盱
-笏
-2030
-窕
-苴
-314
-big
-1866
-296
-萋
-355
-辘
-琬
-cu
-梏
-much
-蚧
-3400
-1280
-镳
-24h
-own
-670
-studio
-瞅
-keep
-6g
-ppt
-conference
-around
-information
-睬
-1878
-class
-偌
-鲵
-惦
-1830
-蜍
-mp4
-why
-靼
-1851
-332
-阗
-菟
-黝
-1650
-control
-挈
-嵴
-剡
-358
-楸
-dha
-氤
-m1
-vr
-呎
-珲
-5ml
-馄
-滂
-338
-蹉
-蓑
-锷
-297
-279
-啜
-1644
-sm
-婵
-well
-鬣
-7cm
-钿
-bbs
-晌
-蛆
-隗
-酞
-枞
-352
-work
-always
-9g
-戬
-獾
-镕
-star
-easy
-饨
-娣
-缰
-邾
-334
-8m
-ni
-鹗
-277
-425
-end
-had
-嗒
-苋
-薮
-棹
-type
-richard
-880
-6m
-拄
-air
-埕
-勖
-鹞
-殚
-鲢
-pop
-a4
-1750
-ftp
-16000
-啖
-ad
-沣
-501
-靥
-葭
-诿
-htc
-鸪
-007
-饴
-t1
-疖
-抟
-睽
-770
-access
-tcl
-稞
-吋
-谀
-澍
-杈
-妤
-sata
-part
-峄
-systems
-漉
-40000
-ever
-気
-368
-咲
-qs
-ta
-璘
-ltd
-mol
-media
-萜
-僭
-朐
-742
-1855
-cc
-圜
-癞
-藿
-555
-珉
-isp
-set
-1450
-陉
-him
-僮
-292
-膻
-1853
-薹
-810
-汊
-still
-锗
-昉
-pvp
-猗
-http
-1859
-3700
-strong
-3a
-锶
-real
-跛
-art
-1869
-331
-1368
-嘹
-337
-瓤
-402
-衄
-1856
-1820
-1150
-matlab
-豕
-吆
-腆
-thomas
-a2
-294
-le
-366
-using
-356
-bb
-喆
-smith
-different
-莴
-401
-谌
-ci
-珙
-疥
-kw
-鲑
-405
-玷
-蛔
-砀
-361
-zh
-nasa
-materials
-329
-nature
-1h
-谔
-睥
-ch
-20mg
-2mg
-du
-mail
-data
-every
-蹑
-诒
-逋
-372
-while
-姝
-刈
-婧
-going
-喳
-镞
-铌
-291
-712
-辎
-鹧
-檩
-740
-扪
-10ml
-霰
-ar
-裆
-ol
-嬷
-0mm
-ufo
-charles
-20mm
-tvb
-apple
-刎
-iec
-project
-sbs
-嵋
-342
-690
-悱
-920
-嘤
-jean
-篁
-荸
-瞑
-殓
-搽
-50mg
-343
-橇
-include
-eva
-雎
-弭
-獐
-haccp
-恿
-video
-cf
-vpn
-society
-眦
-730
-铐
-song
-尕
-捎
-诟
-institute
-痨
-cn
-369
-笞
-756
-version
-des
-sns
-趺
-590
-award
-唬
-苣
-css
-lte
-xu
-fbi
-啾
-瘪
-垸
-357
-橹
-after
-濛
-曷
-level
-樾
-very
-汨
-仟
-姒
-1858
-again
-怦
-荏
-tom
-诤
-苡
-吭
-830
-dm
-before
-406
-崆
-氡
-young
-脩
-lan
-胝
-钏
-3ds
-cr
-arm
-pos
-night
-屐
-395
-忐
-彧
-拚
-鏖
-344
-100ml
-525
-孳
-1024
-yu
-忑
-384
-邝
-穰
-403
-摈
-庖
-351
-鸵
-398
-hello
-矽
-354
-鲟
-said
-381
-768
-発
-762
-sap
-1854
-msn
-菅
-book
-353
-true
-339
-javascript
-348
-2900
-圪
-蹋
-衾
-簋
-璎
-367
-噎
-911
-嬗
-346
-肼
-362
-359
-跎
-滟
-little
-4300
-701
-戦
-嵬
-look
-仝
-phys
-club
-惇
-纾
-times
-14000
-炁
-382
-xyz
-number
-ak
-mind
-huang
-闳
-骐
-秣
-眙
-谘
-碓
-iso9002
-疔
-412
-恂
-am
-top
-master
-鳕
-green
-鸱
-int
-爨
-镊
-404
-were
-4600
-em
-better
-钯
-圮
-楽
-堀
-1852
-408
-sat
-1857
-378
-422
-膘
-705
-噗
-347
-start
-486
-锹
-505
-杼
-酊
-same
-376
-white
-挎
-箸
-郗
-垌
-sa
-溏
-martin
-蔫
-偻
-364
-妫
-飚
-625
-601
-辔
-濬
-666
-ds
-瑄
-621
-觚
-5600
-nhk
-415
-express
-铍
-bit
-跚
-9mm
-翕
-煊
-these
-50mm
-gpu
-b6
-hip
-耄
-铋
-篦
-zhou
-阇
-骛
-nvidia
-莪
-吲
-youtube
-唁
-870
-箧
-503
-tm
-8500
-really
-珅
-潋
-迨
-哽
-without
-砦
-model
-缗
-hey
-謇
-呸
-mrna
-垓
-糍
-park
-wap
-璠
-妣
-狎
-攥
-396
-闇
-york
-蛉
-瑁
-joe
-腼
-蹒
-great
-review
-200mg
-chris
-www
-嶷
-online
-莠
-沤
-哚
-475
-遑
-v1
-such
-跺
-膦
-蹿
-unix
-hard
-40cm
-50cm
-nothing
-郫
-zhao
-玳
-ma
-boy
-埚
-url
-432
-network
-aaaa
-衿
-371
-try
-醪
-full
-挹
-raid
-bg
-绡
-汜
-digital
-mb
-c1
-坩
-ccc
-旃
-5200
-607
-itunes
-powerpoint
-鸨
-between
-407
-翈
-1842
-1844
-435
-838
-抡
-chemistry
-team
-party
-die
-晞
-place
-care
-盥
-藁
-蓖
-383
-cv
-臊
-made
-state
-465
-羰
-388
-1620
-sas
-楝
-噱
-ji
-饽
-苌
-soho
-褓
-佶
-mp
-581
-years
-1260
-1680
-hop
-稜
-瞠
-仡
-25mm
-605
-423
-341
-363
-374
-627
-text
-development
-518
-伉
-襁
-ug
-change
-713
-涞
-1849
-蜇
-抿
-瑗
-pda
-418
-un
-line
-958
-孱
-懑
-416
-von
-373
-淦
-赝
-core
-dns
-747
-427
-387
-would
-ipo
-醌
-551
-缫
-蠲
-alt
-嚓
-鲷
-湫
-捋
-1845
-咩
-裏
-avi
-犒
-2050
-墀
-yeah
-god
-445
-lesson
-硐
-蔸
-399
-758
-pu
-computer
-456
-钽
-1847
-麂
-brown
-store
-蒡
-鼹
-绻
-1821
-錾
-仃
-515
-篙
-蕤
-589
-applied
-737
-930
-c3
-1841
-铤
-billboard
-apec
-槁
-牖
-螈
-mary
-俦
-family
-笄
-color
-啻
-対
-jsp
-郤
-next
-iq
-645
-506
-hbv
-闼
-a3
-349
-value
-413
-igg
-411
-426
-醺
-赍
-檗
-usa
-裾
-head
-噫
-掸
-mike
-箓
-usb2
-things
-5800
-5v
-o2
-妪
-乂
-蝈
-砻
-胍
-220v
-392
-cba
-397
-535
-idc
-analysis
-25mg
-蜱
-ti
-2h
-聃
-雠
-碚
-椤
-缯
-昴
-890
-缱
-祎
-der
-缬
-ex
-508
-铙
-cnc
-pentium
-孀
-533
-advanced
-mpa
-yl
-笳
-蘇
-愆
-685
-榉
-old
-氙
-call
-alex
-燹
-撂
-菽
-583
-箬
-蛄
-瘸
-嬛
-495
-橐
-could
-60000
-something
-纡
-刽
-辂
-hong
-377
-law
-蒯
-邨
-1846
-1550
-r2
-1837
-赀
-player
-414
-跸
-phone
-邙
-hold
-rgb
-421
-henry
-2025
-黟
-409
-磴
-1815
-mode
-1843
-闿
-504
-letters
-1780
-428
-垟
-389
-t2
-london
-528
-jpeg
-嵯
-钚
-steve
-跄
-30min
-527
-潸
-h2
-35000
-崴
-eric
-379
-run
-three
-rf
-left
-455
-恁
-open
-楮
-556
-bc
-476
-腧
-458
-plus
-1812
-1839
-胨
-b12
-4d
-芫
-america
-est
-dream
-碴
-隰
-杓
-md
-ya
-global
-436
-15mm
-2ml
-貉
-欹
-sup3
-侑
-ea
-鳜
-910
-ben
-铄
-椴
-昇
-醍
-1020
-798
-midi
-肓
-features
-lc
-brian
-akb48
-缂
-1835
-test
-铡
-light
-978
-s1
-1799
-key
-sim
-1795
-simple
-energy
-蹠
-徂
-west
-725
-body
-豢
-424
-face
-蒽
-lin
-805
-1120
-479
-菡
-bill
-433
-衲
-阚
-believe
-brt
-pa
-last
-芗
-hu
-sam
-wei
-adsl
-602
-mk
-痍
-玠
-1832
-523
-晷
-604
-jj
-468
-淝
-1560
-鄯
-ck
-473
-糗
-耨
-榧
-394
-940
-eq
-498
-used
-sc
-胴
-c2
-蕈
-screen
-镬
-635
-鼾
-431
-education
-wwe
-摭
-鸮
-cl
-5400
-fpga
-恚
-419
-実
-asia
-534
-552
-砝
-100mm
-pid
-741
-珣
-under
-603
-寤
-埙
-mbc
-tc
-xxx
-didn
-478
-mn
-p1
-锏
-simon
-ansi
-438
-hi
-615
-喟
-蘅
-骺
-cell
-捭
-study
-586
-393
-莜
-should
-xi
-缶
-f2
-games
-0g
-1760
-mini
-johnson
-jones
-yes
-锟
-1825
-叵
-cm3
-炷
-1580
-stay
-675
-another
-6800
-鲧
-1736
-ps2
-胼
-517
-査
-岬
-2019
-1640
-rose
-鹂
-牯
-珥
-entertainment
-448
-und
-496
-莼
-software
-970
-邠
-5300
-h1n1
-488
-da
-眇
-卟
-変
-20m
-may
-417
-lady
-galaxy
-4100
-惴
-1789
-846
-801
-渑
-907
-put
-蚱
-gone
-606
-t3
-company
-632
-454
-516
-998
-548
-391
-4700
-瞌
-ide
-瘰
-7200
-佝
-together
-street
-旸
-626
-衽
-郅
-奁
-731
-30mg
-mvp
-1370
-60cm
-12cm
-魑
-1828
-628
-everything
-612
-san
-937
-缛
-2gb
-lu
-angel
-20ml
-576
-颙
-sony
-790
-press
-镫
-hall
-簌
-beautiful
-豇
-711
-453
-pm
-姹
-thing
-442
-邋
-alpha
-leave
-暝
-441
-30mm
-chapter
-507
-100000
-526
-directx
-511
-9cm
-words
-釐
-619
-洹
-444
-frank
-咿
-eyes
-483
-俳
-522
-蜊
-醐
-541
-water
-499
-聩
-non
-bob
-坻
-532
-757
-545
-毽
-oo
-喾
-alone
-scott
-744
-辋
-river
-zhu
-倌
-媪
-蛳
-滹
-哙
-nc
-20g
-阊
-gs
-queen
-趸
-1130
-1645
-祢
-4mg
-1814
-girls
-544
-e1
-籀
-1210
-1573
-徼
-ipv6
-訾
-髁
-1a
-jackson
-砜
-1836
-les
-4gb
-撸
-瓘
-1790
-缁
-镓
-sars
-eps
-519
-sod
-bp
-1810
-year
-縻
-sound
-617
-菀
-1125
-598
-酢
-桠
-466
-emc
-撵
-怏
-429
-1838
-ready
-渌
-546
-taylor
-452
-news
-1180
-568
-2a
-af
-538
-list
-hot
-1380
-etc
-1796
-摞
-mo
-槲
-levels
-ht
-浠
-诜
-魉
-韫
-daniel
-亓
-盤
-pv
-瑭
-魍
-1831
-emi
-襞
-social
-dreamweaver
-爿
-kbs
-565
-613
-990
-浃
-樯
-jb
-讵
-揩
-physics
-耋
-帏
-lng
-崃
-bs
-457
-enough
-shy
-521
-596
-ec
-451
-鸩
-遢
-turn
-臃
-available
-4400
-585
-粿
-1010
-禳
-hand
-439
-536
-桫
-link
-side
-earth
-mx
-髹
-7m
-482
-诳
-472
-1140
-707
-622
-wcdma
-513
-must
-492
-462
-踉
-40mg
-948
-cmax
-郃
-1320
-v2
-542
-email
-493
-嗖
-sup
-讧
-cnn
-446
-碁
-17000
-湎
-30m
-529
-653
-531
-575
-阏
-sr
-united
-pm2
-mt
-媾
-443
-様
-aac
-806
-哔
-舸
-vb
-611
-曩
-821
-gre
-gl
-cisco
-忝
-峁
-掂
-464
-葳
-487
-437
-including
-715
-鄄
-558
-both
-谵
-463
-jim
-608
-m4
-5100
-彊
-锴
-war
-郜
-money
-481
-葖
-1824
-tnt
-蓇
-瓴
-鳟
-橼
-5s
-louis
-434
-鲇
-邗
-el
-犄
-秭
-3900
-records
-view
-chemical
-1001
-1mol
-dance
-668
-dl
-槭
-缵
-que
-624
-rt
-1823
-1805
-005
-1826
-巯
-sgs
-user
-龊
-qc
-狍
-island
-language
-space
-擞
-saint
-2n
-pt
-share
-瞽
-hotel
-christian
-557
-栲
-撅
-2b
-1801
-447
-1822
-瑀
-smt
-hk
-1834
-戢
-825
-50ml
-朓
-逖
-general
-椹
-nm
-洺
-cae
-484
-艏
-wma
-zn
-苁
-single
-599
-c4
-滘
-777
-铧
-侪
-ocirc
-1kg
-684
-豳
-skf
-12mm
-489
-hla
-竦
-貔
-ld
-being
-562
-圄
-van
-gm
-688
-655
-special
-呷
-edition
-1s
-jiang
-131108
-514
-1792
-ncaa
-1833
-旄
-遛
-jr
-program
-656
-467
-ing
-901
-755
-509
-芈
-kong
-rp
-砣
-桷
-audio
-icp
-happy
-龌
-done
-疬
-japan
-ts
-mit
-p2
-524
-looking
-miss
-缟
-582
-洌
-35mm
-494
-grand
-跏
-those
-joseph
-ctrl
-547
-1040
-686
-蝮
-lp
-cod
-菰
-sio2
-txt
-1770
-1060
-帑
-767
-north
-fcc
-怙
-ester
-718
-story
-edi
-634
-1360
-豸
-1660
-lh
-雩
-1230
-magic
-誊
-549
-臬
-4k
-op
-1662
-651
-镣
-箇
-616
-title
-sciences
-25cm
-踱
-s2
-t4
-钍
-648
-100m
-543
-588
-苫
-554
-蝽
-r1
-3mg
-amino
-1776
-浯
-609
-772
-ca2
-vlan
-469
-500mg
-単
-road
-亶
-636
-metal
-device
-40mm
-囹
-穑
-1730
-佻
-1818
-绌
-12g
-537
-诔
-pve
-autodesk
-477
-v8
-ray
-gp
-span
-gc
-size
-716
-鹬
-ssl
-crt
-1670
-925
-髌
-pn
-1127
-702
-658
-services
-support
-1802
-蒌
-coming
-experience
-nbc
-鳏
-631
-638
-ace
-0cm
-ems
-9001
-殄
-yen
-soc
-ethyl
-怛
-tf
-筌
-刳
-studies
-theory
-1030
-578
-radio
-翮
-卍
-畹
-471
-704
-because
-1610
-箜
-save
-燔
-赳
-553
-1809
-篌
-窨
-翥
-785
-炅
-钕
-lett
-803
-1827
-academy
-ed
-629
-sf
-pr
-hill
-explorer
-future
-food
-莳
-662
-567
-dcs
-忖
-戡
-1086
-1190
-1829
-bad
-es
-15m
-order
-spring
-沢
-south
-497
-025
-move
-狒
-1630
-圉
-abb
-449
-learn
-l0
-d2
-5d
-wav
-琯
-邰
-cis
-quality
-odm
-926
-acta
-root
-smart
-1661
-苾
-cm2
-photos
-l2
-via
-sk
-犸
-623
-邡
-feeling
-572
-郏
-襦
-python
-bmw
-888
-guo
-epa
-williams
-沆
-813
-bot
-read
-function
-wilson
-1723
-enterprise
-玟
-50hz
-s26
-fire
-engineer
-tony
-1819
-濉
-rh
-洎
-莨
-氘
-pb
-咛
-1720
-佺
-1460
-815
-cbs
-腩
-beta
-鳔
-1735
-yan
-1gb
-x2
-剜
-秕
-牝
-芨
-din
-関
-del
-sms
-649
-pal
-1369
-far
-maya
-654
-拊
-812
-595
-竑
-50m
-圹
-close
-eos
-颡
-1420
-6300
-1816
-wrong
-break
-573
-765
-file
-friend
-002
-摺
-683
-nx
-沩
-蜉
-please
-1170
-ro
-6400
-筚
-nick
-acm
-愔
-ati
-point
-肟
-766
-俶
-fast
-ata
-d1
-678
-geforce
-1710
-yahoo
-堃
-绉
-mysql
-1793
-奭
-gap
-iso14000
-uk
-astm
-h2o
-n2
-film
-method
-1804
-罅
-so2
-嗳
-665
-adam
-uc
-蜢
-1806
-1775
-photo
-疠
-474
-image
-200mm
-sure
-561
-帔
-髡
-643
-黥
-1813
-proceedings
-褛
-柰
-beyond
-royal
-else
-eda
-808
-ddr
-gif
-鏊
-l1
-痼
-571
-waiting
-堞
-code
-652
-rss
-learning
-嗝
-461
-beijing
-娉
-566
-577
-708
-1520
-689
-kevin
-human
-661
-539
-875
-1811
-ssci
-6600
-戕
-587
-735
-3s
-铱
-耜
-觥
-867
-镒
-584
-呓
-1522
-904
-case
-1101
-491
-1080p
-history
-蒹
-栱
-im
-564
-f4
-卮
-琚
-salt
-jason
-rohs
-12v
-hydroxy
-逦
-modem
-font
-酩
-蓍
-cry
-65536
-health
-虺
-1798
-tonight
-small
-谠
-1570
-1220
-jane
-against
-597
-751
-459
-bd
-鼋
-焗
-udp
-process
-1070
-1807
-children
-8g
-eb
-62mm
-22000
-add
-1440
-褴
-rm
-25g
-ccedil
-706
-714
-5l
-砒
-赧
-蛏
-709
-蚬
-1530
-瘕
-5h
-559
-jay
-iga
-020
-fall
-scsi
-顗
-isdn
-death
-563
-today
-愠
-dvi
-勣
-wait
-1642
-飕
-徳
-滢
-琇
-鳙
-db
-瞟
-尻
-force
-400mg
-澶
-荽
-舐
-arts
-ha
-east
-lost
-effects
-1628
-album
-harry
-633
-dark
-public
-2250
-soul
-826
-659
-exo
-侂
-733
-se
-黼
-icu
-4h
-market
-潟
-7800
-绂
-瘗
-ngc
-1794
-crazy
-蓥
-竽
-濞
-igm
-scdma
-6200
-cb
-835
-699
-骖
-偁
-bmp
-809
-1270
-oled
-応
-1160
-1621
-锜
-g3
-ova
-cheng
-614
-匏
-thinkpad
-赑
-fps
-create
-kim
-讦
-1480
-诨
-1540
-rev
-1v1
-罘
-fans
-巖
-1740
-ag
-嫘
-1649
-ps3
-908
-颀
-g1
-703
-岿
-v3
-虻
-936
-fl
-c2c
-罴
-environmental
-paris
-594
-hear
-囗
-jump
-communications
-溆
-talk
-噤
-824
-骝
-003
-咂
-695
-728
-e2
-nec
-iptv
-1797
-kelly
-500ml
-锛
-721
-rc
-1808
-ldl
-1240
-槊
-radeon
-676
-啕
-tang
-plant
-50g
-驽
-professional
-凇
-698
-s36
-lord
-search
-alan
-籴
-pd
-1403
-硖
-1791
-816
-1636
-3h
-gsp
-811
-sky
-1632
-铯
-christmas
-怿
-笥
-matter
-574
-噙
-倨
-effect
-647
-779
-1803
-657
-sorry
-awards
-igbt
-pwm
-坭
-醅
-sos
-976
-592
-滏
-10min
-682
-cs3
-悻
-did
-mater
-579
-聒
-1724
-feng
-low
-mhz
-836
-722
-枥
-726
-昺
-bank
-memory
-rap
-975
-663
-ips
-酆
-2kg
-787
-簟
-睇
-轫
-溱
-骢
-榘
-642
-珺
-跹
-677
-series
-nlp
-raquo
-蚶
-stone
-1672
-1817
-1646
-827
-驺
-ko
-security
-perfect
-alexander
-746
-tt
-check
-804
-饧
-15mg
-sir
-moon
-doesn
-591
-inside
-tim
-672
-641
-噼
-儆
-1w
-氚
-646
-哧
-1783
-旒
-鸬
-1648
-夥
-ev
-1688
-score
-standard
-玦
-723
-貅
-揄
-戗
-fx
-938
-璩
-fu
-1654
-剐
-010
-cpi
-垴
-蘼
-hz
-1521
-1067
-727
-ah
-lv
-916
-裒
-639
-han
-躅
-1715
-唳
-form
-second
-嗑
-荦
-674
-霈
-jin
-缦
-啭
-pi
-1788
-rx
-隈
-gao
-sdk
-zheng
-悫
-745
-href
-593
-ngo
-multi
-d3
-彀
-637
-1276
-悭
-found
-jis
-5700
-焓
-1234
-80cm
-磔
-aim
-1778
-蓊
-act
-569
-xiao
-郾
-717
-786
-return
-5min
-1582
-etf
-1590
-action
-1625
-sarah
-yourself
-枧
-鹚
-10kg
-80000
-検
-775
-818
-stephen
-gui
-屃
-644
-9500
-v6
-馑
-wlan
-hs
-2048
-area
-1616
-andrew
-8226
-6mg
-1567
-1763
-1470
-嗲
-pps
-铟
-rca
-pierre
-687
-null
-manager
-738
-sdh
-828
-薤
-60g
-300mg
-jun
-1685
-favorite
-making
-playing
-summer
-754
-692
-涔
-樗
-664
-忾
-収
-绺
-945
-h2s
-bis
-self
-300mm
-烊
-opengl
-912
-acute
-螫
-黩
-996
-magazine
-edward
-su
-elisa
-hdl
-cyp3a4
-鞫
-foundation
-alice
-ddr3
-915
-923
-tbs
-andy
-field
-date
-transactions
-limited
-during
-1126
-鲠
-1057
-fan
-嘭
-缣
-845
-681
-rw
-mean
-1566
-become
-economic
-852
-johnny
-蒺
-unique
-黒
-tu
-boys
-1330
-885
-getting
-cj
-1072
-nh
-ne
-band
-cool
-724
-771
-骘
-氖
-content
-842
-镝
-俅
-谮
-te
-9600
-drive
-phenyl
-1275
-屦
-cao
-menu
-823
-摁
-氪
-蘧
-active
-sb
-appl
-988
-1622
-伝
-1725
-zero
-1008
-3kg
-腠
-叡
-hit
-鲂
-mi
-0kg
-748
-lite
-enjoy
-local
-789
-続
-1506
-seen
-s3
-1765
-european
-讣
-gold
-1279
-736
-965
-pl
-button
-耷
-1430
-986
-763
-toefl
-燊
-鸷
-jimmy
-dota
-955
-861
-猊
-732
-xbox
-days
-dan
-673
-833
-囡
-崤
-4c
-economics
-23000
-agent
-html5
-points
-ryan
-shi
-砬
-湜
-reading
-918
-mine
-adc
-917
-1592
-1781
-翚
-峯
-909
-once
-exchange
-choose
-current
-symbian
-ts16949
-dave
-machine
-鲎
-qos
-蕖
-1785
-9m
-cia
-until
-cs4
-759
-f3
-903
-24000
-968
-8mg
-lewis
-鹈
-凼
-snh48
-866
-泫
-荑
-黻
-牂
-1722
-鄣
-篑
-ho
-1110
-1784
-髭
-陬
-寔
-dt
-shanghai
-疴
-邽
-987
-45000
-1042
-喏
-彖
-sl
-saas
-814
-28000
-a5
-彘
-赟
-819
-foxpro
-shit
-822
-盹
-诮
-鸫
-per
-does
-150mm
-products
-camp
-select
-capital
-茕
-corporation
-26000
-铖
-954
-dd
-闩
-string
-page
-ba
-671
-読
-782
-鄜
-漈
-盍
-dlp
-729
-甭
-愎
-outlook
-wii
-ue
-1787
-festival
-communication
-channel
-gary
-1755
-1774
-8600
-copy
-150mg
-魃
-dragon
-1056
-c5
-炆
-track
-hdpe
-liang
-鍊
-1800mhz
-1619
-蛐
-995
-21000
-薜
-win
-1394
-1786
-rain
-楯
-table
-鲀
-逡
-itu
-applications
-mmorpg
-嘞
-s7
-696
-侔
-1069
-觇
-lbs
-0mg
-car
-wave
-糸
-踮
-狷
-1552
-1627
-latest
-step
-886
-761
-菘
-783
-寳
-esp
-扃
-865
-jazz
-k1
-fine
-child
-kind
-anna
-60mg
-997
-maria
-nk
-792
-raw
-late
-soa
-905
-cai
-ttl
-delphi
-prince
-1340
-禊
-synthesis
-喑
-rmb
-miller
-patrick
-933
-running
-50kg
-1398
-ast
-752
-location
-dead
-塍
-chateau
-allows
-forget
-tg
-921
-栝
-5w
-kiss
-1690
-691
-arthur
-瓿
-index
-csa
-rmvb
-msc
-廨
-cas
-known
-h1
-tj
-j2ee
-asian
-841
-1227
-g20
-cross
-cos
-ntilde
-719
-貘
-dnf
-california
-france
-modern
-pacific
-769
-1066
-turbo
-753
-795
-669
-1764
-868
-馕
-僰
-union
-1772
-2150
-1063
-哏
-double
-fight
-858
-math
-bo
-瑷
-men
-sea
-6700
-sem
-697
-疎
-882
-note
-qi
-uml
-902
-1637
-tp
-1290
-1085
-776
-蝣
-怵
-阃
-dps
-1687
-弢
-镲
-hcl
-al2o3
-js
-auto
-螅
-1683
-v5
-culture
-935
-吖
-edge
-碲
-voice
-1007
-bridge
-855
-008
-夼
-茌
-battle
-嗬
-靺
-dp
-ae
-1090
-895
-1012
-1162
-bi
-778
-髀
-1575
-pcm
-15min
-1598
-铊
-secret
-739
-200m
-6h
-matt
-谡
-card
-mic
-癔
-ecu
-16mm
-984
-镠
-5km
-dhcp
-1753
-巻
-秾
-living
-gn
-1643
-framework
-菪
-679
-赜
-1782
-four
-铈
-1777
-british
-shell
-santa
-yuan
-20ma
-fly
-927
-qu
-nds
-qaq
-bar
-髙
-arp
-1667
-1773
-693
-main
-鲳
-1510
-1002
-2022
-cdna
-box
-珰
-100km
-004
-畋
-bring
-泅
-959
-hpv
-makes
-cmv
-鲅
-tmd
-1762
-854
-泚
-ghost
-short
-mcu
-1768
-cat
-963
-1757
-1206
-1207
-puzzle
-793
-central
-859
-飏
-walter
-60hz
-anderson
-1727
-thought
-屍
-仨
-864
-molecular
-856
-dong
-financial
-1728
-surface
-g2
-mf
-葚
-叻
-solidworks
-res
-speed
-1195
-咻
-ascii
-1404
-784
-jeff
-衩
-1371
-land
-biology
-1655
-郄
-otc
-sio
-1310
-1605
-蹩
-mems
-1618
-m16
-complete
-industrial
-acs
-1603
-kids
-tour
-u2
-allen
-1756
-743
-嬖
-踽
-davis
-柽
-鞨
-65279
-7600
-30ml
-957
-0l
-734
-p450
-956
-ir
-麴
-500mm
-casio
-1038
-roger
-library
-015
-1652
-薙
-within
-hands
-874
-ntsc
-钇
-whole
-jq
-氵
-垆
-post
-sweet
-wall
-898
-cs5
-feo
-9800
-cms
-1390
-since
-medical
-犟
-1492
-罍
-stand
-justin
-lake
-i5
-1729
-bell
-ruby
-important
-bout
-images
-lab
-962
-1759
-rj
-cache
-nb
-production
-経
-807
-1771
-doing
-粜
-tnf
-ws
-guide
-bim
-events
-1626
-1016
-焜
-performance
-ra
-zl
-牀
-1568
-1647
-埝
-洧
-1615
-shift
-788
-shen
-1588
-60mm
-覧
-tuv
-1673
-electronic
-mos
-蓣
-8kg
-862
-echo
-1572
-section
-981
-甯
-sg
-1664
-understand
-hsk
-delta
-x86
-eap
-block
-1578
-er
-xl
-蒐
-馐
-nox
-畑
-ib
-trying
-ann
-1635
-apache
-naoh
-12345
-缑
-礽
-1624
-694
-瞋
-1601
-浍
-983
-773
-1000m
-someone
-15kg
-25m
-847
-袢
-桕
-1037
-jerry
-843
-picture
-919
-e3
-printf
-3gs
-marie
-853
-rj45
-侩
-913
-896
-lose
-unicode
-100cm
-1711
-charlie
-詈
-戸
-1689
-room
-烝
-beat
-堌
-伋
-hplc
-9300
-110kv
-nfc
-倬
-764
-iis
-圯
-solo
-碇
-ef
-round
-chang
-1366
-781
-1585
-982
-socket
-df
-892
-1536
-831
-ren
-6kg
-4900
-纰
-object
-forever
-832
-951
-qr
-1023
-8800
-4kg
-磾
-泔
-1131
-纮
-蓁
-971
-building
-1021
-铗
-939
-弇
-挲
-crystal
-艉
-smtp
-鱬
-cims
-fang
-1265
-trans
-pan
-1745
-1604
-泺
-橛
-817
-796
-袴
-cosplay
-1154
-1189
-749
-794
-1068
-881
-hc
-hope
-1410
-couldn
-1638
-992
-along
-age
-250mg
-clear
-aps
-1631
-1011
-provides
-1123
-1701
-36000
-csf
-韪
-n1
-works
-籓
-967
-ptc
-贶
-1111
-1651
-棰
-1726
-sar
-1666
-qvga
-hf
-coreldraw
-possible
-趵
-1629
-943
-marc
-luo
-樨
-848
-county
-944
-tb
-dts
-junior
-vba
-lot
-傕
-玕
-毎
-direct
-839
-繸
-2350
-774
-劵
-fsh
-wmv
-镧
-秫
-1094
-osi
-1602
-邶
-猞
-dior
-1766
-1623
-廛
-栌
-钲
-镦
-1607
-psa
-spss
-xy
-1769
-cells
-1465
-1577
-gon
-send
-vision
-thinking
-imf
-嘏
-carl
-蝰
-32000
-bay
-928
-is09001
-镏
-20kg
-淠
-imax
-novel
-qt
-1684
-荇
-逄
-au
-author
-mod
-80mm
-1748
-849
-1612
-yet
-嘅
-929
-6l
-karl
-6100
-students
-gmat
-myself
-kate
-jpg
-979
-1752
-829
-2450
-914
-876
-祕
-瑠
-48h
-mpv
-1734
-mis
-1565
-walk
-941
-1075
-1235
-natural
-k2
-977
-炝
-杪
-4050
-1669
-p3
-1004
-fn
-埴
-1555
-vmware
-chloride
-942
-steven
-1078
-獬
-966
-1135
-country
-947
-柢
-捱
-跣
-887
-涑
-75mm
-1278
-1583
-western
-watch
-撃
-伢
-堠
-1045
-12m
-museum
-1215
-document
-marketing
-952
-卽
-猁
-usb3
-906
-厣
-physical
-辏
-1668
-旆
-agp
-茆
-1488
-pg
-乜
-deep
-1082
-961
-踯
-1526
-#
-[
-yam
-lofter
-##s
-##0
-##a
-##2
-##1
-##3
-##e
-##8
-##5
-##6
-##4
-##9
-##7
-##t
-##o
-##d
-##i
-##n
-##m
-##c
-##l
-##y
-##r
-##g
-##p
-##f
-pixnet
-cookies
-tripadvisor
-##er
-##k
-##h
-##b
-##x
-##u
-##w
-##ing
-ctrip
-##on
-##v
-llc
-##an
-##z
-blogthis
-##le
-##in
-##mm
-##00
-ig
-##ng
-##us
-##te
-##ed
-ncc
-blog
-##10
-##al
-##ic
-##ia
-##q
-##ce
-##en
-##is
-##ra
-##es
-##j
-##cm
-tw
-##ne
-##re
-##tion
-pony
-##2017
-##ch
-##or
-##na
-cafe
-pinterest
-pixstyleme3c
-##ta
-##2016
-##ll
-##20
-##ie
-##ma
-##17
-##ion
-##th
-##st
-##se
-##et
-##ck
-##ly
-web885
-##ge
-xd
-##ry
-##11
-0fork
-##12
-##ter
-##ar
-##la
-##os
-##30
-##el
-##50
-##ml
-tue
-posted
-##at
-##man
-##15
-ago
-##it
-##me
-##de
-##nt
-##mb
-##16
-##ve
-##da
-##ps
-##to
-https
-momo
-##son
-##ke
-##80
-ebd
-apk
-##88
-##um
-wiki
-brake
-mon
-po
-june
-##ss
-fb
-##as
-leonardo
-safari
-##60
-wed
-win7
-kiehl
-##co
-##go
-vfm
-kanye
-##90
-##2015
-##id
-##ey
-##sa
-##ro
-##am
-##no
-thu
-fri
-##sh
-##ki
-comments
-##pe
-##ine
-uber
-##mi
-##ton
-wordpress
-##ment
-win10
-##ld
-##li
-gmail
-##rs
-##ri
-##rd
-##21
-##io
-##99
-paypal
-policy
-##40
-##ty
-##18
-##01
-##ba
-taiwan
-##ga
-privacy
-agoda
-##13
-##ny
-##24
-##22
-##by
-##ur
-##hz
-##ang
-cookie
-netscape
-##ka
-##ad
-nike
-survey
-##016
-wikia
-##32
-##017
-cbc
-##tor
-##kg
-##rt
-##14
-campaign
-##ct
-##ts
-##ns
-##ao
-##nd
-##70
-##ya
-##il
-##25
-0020
-897
-##23
-hotels
-##ian
-6606
-##ers
-##26
-##day
-##ay
-##line
-##be
-talk2yam
-yamservice
-coco
-##dy
-##ies
-##ha
-instagram
-##ot
-##va
-##mo
-##land
-ltxsw
-##ation
-##pa
-##ol
-tag
-##ue
-##31
-oppo
-##ca
-##om
-chrome
-##ure
-lol
-##19
-##bo
-##100
-##way
-##ko
-##do
-##un
-##ni
-herme
-##28
-##up
-##06
-##ds
-admin
-##48
-##015
-##35
-##ee
-tpp
-##ive
-##cc
-##ble
-##ity
-##ex
-##ler
-##ap
-##book
-##ice
-##km
-##mg
-##ms
-ebay
-##29
-ubuntu
-##cy
-##view
-##lo
-##oo
-##02
-step1
-july
-##net
-##ls
-##ii
-##05
-##33
-step2
-ios9
-##box
-##ley
-samsung
-pokemon
-##ent
-##les
-s8
-atom
-##said
-##55
-##2014
-##66
-adidas
-amazon
-##ber
-##ner
-visa
-##77
-##der
-connectivity
-##hi
-firefox
-skip
-##27
-##ir
-##61
-##ai
-##ver
-cafe2017
-##ron
-##ster
-##sk
-##ft
-longchamp
-ssd
-##ti
-reply
-##my
-apr
-##ker
-source
-##one
-##2013
-##ow
-goods
-##lin
-##ip
-##ics
-##45
-##03
-##ff
-##47
-ganji
-##nce
-##per
-faq
-comment
-##ock
-##bs
-##ah
-##lv
-##mp
-##000
-melody
-17life
-##au
-##71
-##04
-##95
-##age
-tips
-##68
-##ting
-##ung
-wonderland
-##ction
-mar
-article
-##db
-##07
-##ore
-##op
-##78
-##38
-##ong
-##73
-##08
-##ica
-##36
-##wa
-##64
-homemesh
-##85
-##tv
-##di
-macbook
-##ier
-##si
-##75
-##ok
-goris
-lock
-##ut
-carol
-##vi
-##ac
-anti
-jan
-tags
-##98
-##51
-august
-##86
-##fs
-##sion
-jordan
-##tt
-##lt
-##42
-##bc
-vivi
-##rry
-##ted
-##rn
-usd
-##t00
-##58
-##09
-##34
-goo
-##ui
-##ary
-item
-##pm
-##41
-##za
-##2012
-blogabstract
-##ger
-##62
-##44
-gr2
-asus
-cindy
-##hd
-esc
-##od
-booking
-##53
-fed
-##81
-##ina
-chan
-distribution
-steam
-pk10
-##ix
-##65
-##91
-dec
-##ana
-icecat
-00z
-##46
-##ji
-##ard
-oct
-##ain
-jp
-##ze
-##bi
-cio
-##56
-h5
-##39
-##port
-curve
-##nm
-##dia
-utc
-12345678910
-##52
-chanel
-##and
-##im
-##63
-vera
-vivo
-##ei
-2756
-##69
-msci
-##po
-##89
-##bit
-##out
-##zz
-##97
-##67
-opec
-##96
-##tes
-##ast
-##ling
-##ory
-##ical
-kitty
-##43
-step3
-##cn
-win8
-iphone7
-beauty
-##87
-dollars
-##ys
-##oc
-pay
-##2011
-##lly
-##ks
-download
-sep
-##board
-##37
-##lan
-winrar
-##que
-##ua
-##com
-ettoday
-##54
-##ren
-##via
-##72
-##79
-##tch
-##49
-##ial
-##nn
-step4
-2765
-gov
-##xx
-mandy
-##ser
-copyright
-fashion
-##ist
-##art
-##lm
-##ek
-##ning
-##if
-##ite
-iot
-##84
-##2010
-##ku
-october
-##ux
-trump
-##hs
-##ide
-##ins
-april
-##ight
-##83
-protected
-##fe
-##ho
-ofo
-gomaji
-march
-##lla
-##pp
-##ec
-6s
-720p
-##rm
-##ham
-##92
-fandom
-##ell
-info
-##82
-sina
-4066
-##able
-##ctor
-rights
-jul
-##76
-mall
-##59
-donald
-sodu
-##light
-reserved
-htm
-##han
-##57
-##ise
-##tions
-##shi
-doc
-055
-##ram
-shopping
-aug
-##pi
-##well
-wam
-##hu
-##gb
-##93
-mix
-##ef
-##uan
-bwl
-##plus
-##res
-##ess
-tea
-hktvmall
-##ate
-##ese
-feb
-inn
-nov
-##ci
-pass
-##bet
-##nk
-coffee
-airbnb
-##ute
-woshipm
-skype
-##fc
-##www
-##94
-##ght
-##gs
-##ile
-##wood
-##uo
-icon
-##em
-says
-##king
-##tive
-blogger
-##74
-##ox
-##zy
-##red
-##ium
-##lf
-nokia
-claire
-##ding
-november
-lohas
-##500
-##tic
-##cs
-##che
-##ire
-##gy
-##ult
-january
-ptt
-##fa
-##mer
-pchome
-udn
-##time
-##tte
-garden
-eleven
-309b
-bat
-##123
-##tra
-kindle
-##ern
-xperia
-ces
-travel
-##ous
-##int
-edu
-cho
-##car
-##our
-##ant
-rends
-##jo
-mastercard
-##2000
-kb
-##min
-##ino
-##ris
-##ud
-##set
-##her
-##ou
-taipei
-##fi
-##ill
-aphojoy
-december
-meiki
-##ick
-tweet
-##av
-iphone6
-##dd
-views
-##mark
-##ash
-##ome
-koreanmall
-##ak
-q2
-##200
-mlb
-##lle
-##watch
-##und
-##tal
-##less
-4399
-##rl
-update
-shop
-##mhz
-##house
-##key
-##001
-##hy
-##web
-##2009
-##gg
-##wan
-##val
-2021
-##ons
-doi
-trivago
-overdope
-##ance
-573032185
-wx17house
-##so
-audi
-##he
-##rp
-##ake
-beach
-cfa
-ps4
-##800
-##link
-##hp
-ferragamo
-##eng
-##style
-##gi
-i7
-##ray
-##max
-##pc
-september
-##ace
-vps
-february
-pantos
-wp
-lisa
-jquery
-offer
-##berg
-##news
-fks
-##all
-##rus
-##888
-##works
-blogtitle
-loftpermalink
-ling
-##ja
-outlet
-##ea
-##top
-##ness
-salvatore
-##lu
-swift
-##ul
-week
-##ean
-##300
-##gle
-##back
-powered
-##tan
-##nes
-canon
-##zi
-##las
-##oe
-##sd
-##bot
-##world
-##zo
-top100
-pmi
-##vr
-ball
-vogue
-ofweek
-##list
-##ort
-##lon
-##tc
-##of
-##bus
-##gen
-nas
-##lie
-##ria
-##coin
-##bt
-nata
-vive
-cup
-##ook
-##sy
-msg
-3ce
-##word
-ebooks
-r8
-nice
-months
-rewards
-##ther
-0800
-##xi
-##sc
-gg
-blogfp
-daily
-##bb
-##tar
-##ky
-anthony
-##yo
-##ara
-##aa
-##rc
-##tz
-##ston
-gear
-##eo
-##ade
-##win
-##ura
-##den
-##ita
-##sm
-png
-rakuten
-whatsapp
-##use
-pad
-gucci
-##ode
-##fo
-chicago
-##hone
-io
-sogo
-be2
-##ology
-cloud
-##con
-##ford
-##joy
-##kb
-##rade
-##ach
-docker
-##ful
-##ase
-ford
-##star
-edited
-##are
-##mc
-siri
-##ella
-bloomberg
-##read
-pizza
-##ison
-##vm
-node
-18k
-##play
-##cer
-##yu
-##ings
-asr
-##lia
-step5
-##cd
-pixstyleme
-##600
-##tus
-tokyo
-##rial
-##life
-##ae
-tcs
-##rk
-##wang
-##sp
-##ving
-premium
-netflix
-##lton
-##ple
-##cal
-021
-##sen
-##ville
-nexus
-##ius
-##mah
-tila
-##tin
-resort
-##ws
-p10
-report
-##360
-##ru
-bus
-vans
-##est
-links
-rebecca
-##dm
-azure
-##365
-##mon
-moto
-##eam
-blogspot
-##ments
-##ik
-##kw
-##bin
-##ata
-##vin
-##tu
-##ula
-station
-##ature
-files
-zara
-hdr
-top10
-s6
-marriott
-avira
-tab
-##ran
-##home
-oculus
-##ral
-rosie
-##force
-##ini
-ice
-##bert
-##nder
-##mber
-plurk
-##sis
-00kg
-##ence
-##nc
-##name
-log
-ikea
-malaysia
-##ncy
-##nie
-##ye
-##oid
-##chi
-xuehai
-##1000
-##orm
-##rf
-##ware
-##pro
-##era
-##ub
-##2008
-8891
-scp
-##zen
-qvod
-jcb
-##hr
-weibo
-##row
-##ish
-github
-mate
-##lot
-##ane
-##tina
-ed2k
-##vel
-##900
-final
-ns
-bytes
-##ene
-##cker
-##2007
-##px
-topapp
-helpapp
-14k
-g4g
-ldquo
-##fork
-##gan
-##zon
-##qq
-##google
-##ism
-##zer
-toyota
-category
-##labels
-restaurant
-##md
-posts
-##ico
-angelababy
-123456
-sports
-candy
-##new
-##here
-swissinfo
-dram
-##ual
-##vice
-##wer
-sport
-q1
-ios10
-##mll
-wan
-##uk
-x3
-0t
-##ming
-e5
-##3d
-h7n9
-worldcat
-##vo
-##led
-##580
-##ax
-##ert
-polo
-##lr
-##hing
-##chat
-##ule
-hotmail
-##pad
-bbq
-##ring
-wali
-2k
-costco
-switch
-##city
-philips
-##mann
-panasonic
-##cl
-##vd
-##ping
-##rge
-##lk
-css3
-##ney
-##ular
-##400
-##tter
-lz
-##tm
-##yan
-##let
-coach
-##pt
-a8
-follow
-##berry
-##ew
-##wn
-##og
-##code
-##rid
-villa
-git
-r11
-##cket
-error
-##anonymoussaid
-##ag
-##ame
-##gc
-qa
-##lis
-##gin
-vmalife
-##cher
-wedding
-##tis
-demo
-bye
-##rant
-orz
-acer
-##ats
-##ven
-macd
-yougou
-##dn
-##ano
-##urt
-##rent
-continue
-script
-##wen
-##ect
-paper
-##chel
-##cat
-x5
-fox
-##blog
-loading
-##yn
-##tp
-kuso
-799
-vdc
-forest
-prime
-ultra
-##rmb
-square
-##field
-##reen
-##ors
-##ju
-##air
-##map
-cdn
-##wo
-m8
-##get
-opera
-##base
-##ood
-vsa
-##aw
-##ail
-count
-##een
-##gp
-vsc
-tree
-##eg
-##ose
-##ories
-##shop
-alphago
-v4
-fluke62max
-zip
-##sta
-bas
-##yer
-hadoop
-##ube
-##wi
-0755
-hola
-##low
-centre
-##fer
-##750
-##media
-##san
-##bank
-q3
-##nge
-##mail
-##lp
-client
-event
-vincent
-##nse
-sui
-adchoice
-##stry
-##zone
-ga
-apps
-##ab
-##rner
-kymco
-##care
-##pu
-##yi
-minkoff
-annie
-collection
-kpi
-playstation
-bh
-##bar
-armani
-##xy
-iherb
-##ery
-##share
-##ob
-volvo
-##ball
-##hk
-##cp
-##rie
-##ona
-##sl
-gtx
-rdquo
-jayz
-##lex
-##rum
-namespace
-##ale
-##atic
-##erson
-##ql
-##ves
-##type
-enter
-##168
-##mix
-##bian
-a9
-ky
-##lc
-movie
-##hc
-tower
-##ration
-##mit
-##nch
-ua
-tel
-prefix
-##o2
-##point
-ott
-##http
-##ury
-baidu
-##ink
-member
-##logy
-bigbang
-nownews
-##js
-##shot
-##tb
-eba
-##tics
-##lus
-spark
-##ama
-##ions
-##lls
-##down
-##ress
-burberry
-day2
-##kv
-related
-edit
-##ark
-cx
-32gb
-g9
-##ans
-##tty
-s5
-##bee
-thread
-xr
-buy
-spotify
-##ari
-##verse
-7headlines
-nego
-sunny
-dom
-positioning
-fit
-##tton
-alexa
-##ties
-##llow
-amy
-##du
-##rth
-##lar
-2345
-##des
-sidebar
-site
-##cky
-##kit
-##ime
-##009
-season
-##fun
-gogoro
-a7
-lily
-twd600
-##vis
-##cture
-friday
-yi
-##tta
-##tel
-##lock
-economy
-tinker
-8gb
-##app
-oops
-##right
-edm
-##cent
-supreme
-##its
-##asia
-dropbox
-##tti
-books
-##tle
-##ller
-##ken
-##more
-##boy
-sex
-##dom
-##ider
-##unch
-##put
-##gh
-ka
-amoled
-div
-##tr
-##n1
-port
-howard
-##tags
-ken
-##nus
-adsense
-buff
-thunder
-##town
-##ique
-##body
-pin
-##erry
-tee
-##the
-##013
-udnbkk
-16gb
-##mic
-miui
-##tro
-##alk
-##nity
-s4
-##oa
-docomo
-##tf
-##ack
-fc2
-##ded
-##sco
-##014
-##rite
-linkedin
-##ada
-##now
-##ndy
-ucbug
-sputniknews
-legalminer
-##ika
-##xp
-##bu
-q10
-##rman
-cheese
-ming
-maker
-##gm
-nikon
-##fig
-ppi
-jchere
-ted
-fgo
-tech
-##tto
-##gl
-##len
-hair
-img
-##pper
-##a1
-acca
-##ition
-##ference
-suite
-##ig
-##mond
-##cation
-##pr
-101vip
-##999
-64gb
-airport
-##over
-##ith
-##su
-town
-piece
-##llo
-no1
-##qi
-focus
-reader
-##admin
-##ora
-false
-##log
-##ces
-##ume
-motel
-##oper
-flickr
-netcomponents
-##af
-pose
-##ound
-##cg
-##site
-##iko
-con
-##ath
-##hip
-##rey
-cream
-##cks
-012
-##dp
-facebooktwitterpinterestgoogle
-sso
-shtml
-swiss
-##mw
-lumia
-xdd
-tiffany
-insee
-russell
-dell
-##ations
-camera
-##vs
-##flow
-##late
-classic
-##nter
-##ever
-##lab
-##nger
-qe
-##cing
-editor
-##nap
-sunday
-##ens
-##700
-##bra
-acg
-sofascore
-mkv
-##ign
-jonathan
-build
-labels
-##oto
-tesla
-moba
-gohappy
-ajax
-##test
-##urs
-wps
-fedora
-##ich
-mozilla
-##480
-##dr
-urn
-##lina
-grace
-##die
-##try
-##ader
-elle
-##chen
-price
-##ten
-uhz
-##ough
-##hen
-states
-push
-session
-balance
-wow
-##cus
-##py
-##ward
-##ep
-34e
-wong
-prada
-##cle
-##ree
-q4
-##ctive
-##ool
-##ira
-##163
-rq
-buffet
-e6
-##ez
-##card
-##cha
-day3
-eye
-##end
-adi
-tvbs
-##ala
-nova
-##tail
-##ries
-##ved
-base
-##ways
-hero
-hgih
-profile
-fish
-mu
-ssh
-##wd
-click
-cake
-##ond
-pre
-##tom
-kic
-pixel
-##ov
-##fl
-product
-6a
-##pd
-dear
-##gate
-yumi
-##sky
-bin
-##ture
-##ape
-isis
-nand
-##101
-##load
-##ream
-a6
-##post
-##we
-zenfone
-##ike
-gd
-forum
-jessica
-##ould
-##ious
-lohasthree
-##gar
-##ggle
-##ric
-##own
-eclipse
-##side
-061
-##other
-##tech
-##ator
-engine
-##ged
-plaza
-##fit
-westbrook
-reuters
-##ily
-contextlink
-##hn
-##cil
-##cel
-cambridge
-##ize
-##aid
-##data
-frm
-##head
-butler
-##sun
-##mar
-puma
-pmid
-kitchen
-##lic
-day1
-##text
-##page
-##rris
-pm1
-##ket
-trackback
-##hai
-display
-##hl
-idea
-##sent
-airmail
-##ug
-##men
-028
-##lution
-schemas
-asics
-wikipedia
-##tional
-##vy
-##dget
-##ein
-contact
-pepper
-##uel
-##ument
-##hang
-q5
-##sue
-##ndi
-swatch
-##cept
-popular
-##ste
-##tag
-trc
-##west
-##live
-honda
-ping
-messenger
-##rap
-v9
-unity
-appqq
-leo
-##tone
-##ass
-uniqlo
-##010
-moneydj
-##tical
-12306
-##m2
-coc
-miacare
-##mn
-tmt
-##core
-vim
-kk
-##may
-target
-##2c
-##ope
-omega
-pinkoi
-##rain
-##ement
-p9
-rd
-##tier
-##vic
-zone
-isofix
-cpa
-kimi
-##lay
-lulu
-##uck
-050
-weeks
-##hop
-##ear
-eia
-##fly
-korea
-boost
-##ship
-eur
-valley
-##iel
-##ude
-rn
-##ena
-feed
-5757
-qqmei
-##thing
-aws
-pink
-##ters
-##kin
-board
-##vertisement
-wine
-##ien
-##dge
-##tant
-##twitter
-##3c
-cool1
-##012
-##150
-##fu
-##iner
-googlemsn
-pixnetfacebookyahoo
-x7
-##uce
-sao
-##ev
-##file
-9678
-xddd
-shirt
-##rio
-##hat
-givenchy
-bang
-##lio
-monday
-##abc
-ubuntuforumwikilinuxpastechat
-##vc
-##rity
-7866
-##ost
-imsean
-tiger
-##fet
-dji
-##come
-##beth
-##aft
-##don
-3p
-emma
-##khz
-x6
-##face
-pptv
-x4
-##mate
-sophie
-##jing
-fifa
-##mand
-sale
-inwedding
-##gn
-##mmy
-##pmlast
-nana
-##wu
-note7
-##340
-##bel
-window
-##dio
-##ht
-##ivity
-domain
-neo
-##isa
-##lter
-5k
-f5
-##cts
-ft
-zol
-##act
-mwc
-nbapop
-eds
-##room
-previous
-tomtom
-##ets
-5t
-chi
-##hg
-fairmont
-gay
-1b
-##raph
-##ils
-i3
-avenue
-##host
-##bon
-##tsu
-message
-navigation
-fintech
-h6
-##ject
-##vas
-##firm
-credit
-##wf
-xxxx
-##nor
-##space
-huawei
-plan
-json
-sbl
-##dc
-wish
-##120
-##sol
-windows7
-washington
-##nsis
-lo
-##sio
-##ym
-##bor
-planet
-##wt
-gpa
-##tw
-##oka
-connect
-##rss
-##work
-##atus
-chicken
-##times
-fa
-##ather
-##cord
-009
-##eep
-hitachi
-##pan
-disney
-##press
-wind
-frigidaire
-##tl
-hsu
-##ull
-expedia
-archives
-##wei
-cut
-ins
-6gb
-brand
-cf1
-##rip
-##nis
-128gb
-3t
-##oon
-quick
-15058
-wing
-##bug
-##cms
-##dar
-##oh
-zoom
-trip
-##nba
-rcep
-aspx
-080
-gnu
-##count
-##url
-##ging
-8591
-am09
-shadow
-##cia
-emily
-##tation
-host
-ff
-techorz
-##mini
-##mporary
-##ering
-##next
-cma
-##mbps
-##gas
-##ift
-##dot
-amana
-##ros
-##eet
-##ible
-##aka
-##lor
-maggie
-##011
-##iu
-##gt
-1tb
-articles
-##burg
-##iki
-database
-fantasy
-##rex
-##cam
-dlc
-dean
-##you
-path
-gaming
-victoria
-maps
-##lee
-##itor
-overchicstoretvhome
-##xt
-##nan
-x9
-install
-##ann
-##ph
-##rcle
-##nic
-##nar
-metro
-chocolate
-##rian
-##table
-skin
-##sn
-mountain
-##0mm
-inparadise
-7x24
-##jia
-eeworld
-creative
-g5
-parker
-ecfa
-village
-sylvia
-hbl
-##ques
-##onsored
-##x2
-##v4
-##tein
-ie6
-##stack
-ver
-##ads
-##baby
-bbe
-##110
-##lone
-##uid
-ads
-022
-gundam
-006
-scrum
-match
-##ave
-##470
-##oy
-##talk
-glass
-lamigo
-##eme
-##a5
-wade
-kde
-##lace
-ocean
-tvg
-##covery
-##r3
-##ners
-##rea
-##aine
-cover
-##ision
-##sia
-##bow
-msi
-##love
-soft
-z2
-##pl
-mobil
-##uy
-nginx
-##oi
-##rr
-6221
-##mple
-##sson
-##nts
-91tv
-comhd
-crv3000
-##uard
-gallery
-##bia
-rate
-spf
-redis
-traction
-icloud
-011
-jose
-##tory
-sohu
-899
-kicstart2
-##hia
-##sit
-##walk
-##xure
-500g
-##pact
-xa
-carlo
-##250
-##walker
-##can
-cto
-gigi
-pen
-##hoo
-ob
-##yy
-13913459
-##iti
-mango
-##bbs
-sense
-oxford
-walker
-jennifer
-##ola
-course
-##bre
-##pus
-##rder
-lucky
-075
-ivy
-##nia
-sotheby
-##ugh
-joy
-##orage
-##ush
-##bat
-##dt
-r9
-##2d
-##gio
-wear
-##lax
-##moon
-seven
-lonzo
-8k
-evolution
-##kk
-kd
-arduino
-##lux
-arpg
-##rdon
-cook
-##x5
-five
-##als
-##ida
-sign
-##nda
-##posted
-fresh
-##mine
-##skip
-##form
-##ssion
-##tee
-dyson
-stage
-##jie
-##night
-epson
-pack
-##ppy
-wd
-##eh
-##rence
-##lvin
-golden
-discovery
-##trix
-##n2
-loft
-##uch
-##dra
-##sse
-1mdb
-welcome
-##urn
-gaga
-##lmer
-teddy
-##160
-##f2016
-##sha
-rar
-holiday
-074
-##vg
-##nos
-##rail
-gartner
-gi
-6p
-##dium
-kit
-b3
-eco
-sean
-##stone
-nu
-##np
-f16
-write
-029
-m5
-##ias
-##dk
-fsm
-52kb
-##xxx
-##cake
-lim
-ru
-1v
-##ification
-published
-angela
-16g
-analytics
-##nel
-gmt
-##icon
-##bby
-ios11
-waze
-9985
-##ust
-##007
-delete
-52sykb
-wwdc
-027
-##fw
-1389
-##xon
-brandt
-##ses
-##dragon
-vetements
-anne
-monte
-official
-##ere
-##nne
-##oud
-etnews
-##a2
-##graphy
-##rtex
-##gma
-mount
-archive
-morning
-tan
-ddos
-e7
-day4
-factory
-bruce
-##ito
-guest
-##lling
-n3
-mega
-women
-dac
-church
-##jun
-singapore
-##facebook
-6991
-starbucks
-##tos
-##stin
-##shine
-zen
-##mu
-tina
-request
-##gence
-q7
-##zzi
-diary
-##tore
-##ead
-cst
-##osa
-canada
-va
-##jiang
-##lam
-##nix
-##sday
-g6
-##master
-bing
-##zl
-nb40
-thai
-ln284ct
-##itz
-##2f
-bonnie
-##food
-##lent
-originals
-##stro
-##lts
-##bscribe
-ntd
-yesstyle
-hmv
-##tment
-d5
-##pn
-topios9
-lifestyle
-virtual
-##ague
-xz
-##deo
-muji
-024
-unt
-##nnis
-faq1
-##ette
-curry
-##pop
-release
-##cast
-073
-##ews
-5c
-##stle
-ios7
-##ima
-dog
-lenovo
-##r4
-013
-vornado
-##desk
-##ald
-9595
-##van
-oil
-common
-##jy
-##lines
-g7
-twice
-ella
-nano
-belle
-##mes
-##self
-##note
-benz
-##ova
-##wing
-kai
-##hua
-##rect
-rainer
-##unge
-##0m
-guestname
-##uma
-##kins
-##zu
-tokichoi
-##price
-##med
-##mus
-rmk
-address
-vm
-openload
-##group
-##hin
-##iginal
-amg
-urban
-##oz
-jobs
-##public
-##sch
-##dden
-##bell
-hostel
-##drive
-##rmin
-boot
-##370
-##fx
-##nome
-##ctionary
-##oman
-##lish
-##cr
-##hm
-##how
-francis
-c919
-b5
-evernote
-##uc
-##3000
-coupe
-##urg
-##cca
-##uality
-019
-##ett
-##ani
-##tax
-##rma
-leonnhurt
-##jin
-ict
-bird
-notes
-##dical
-##lli
-result
-iu
-ee
-smap
-gopro
-##last
-yin
-pure
-32g
-##dan
-##rame
-mama
-##oot
-bean
-##hur
-2l
-bella
-sync
-xuite
-##ground
-discuz
-##getrelax
-##ince
-##bay
-##5s
-apt
-##pass
-jing
-##rix
-rich
-niusnews
-##ello
-bag
-##eting
-##mobile
-##ience
-details
-universal
-silver
-dit
-private
-ddd
-u11
-kanshu
-##ified
-fung
-##nny
-dx
-##520
-tai
-023
-##fr
-##lean
-##pin
-##rin
-ly
-rick
-##bility
-banner
-##baru
-##gion
-vdf
-qualcomm
-bear
-oldid
-ian
-jo
-##tors
-population
-##ernel
-##mv
-##bike
-ww
-##ager
-exhibition
-##del
-##pods
-fpx
-structure
-##free
-##tings
-kl
-##rley
-##copyright
-##mma
-orange
-yoga
-4l
-canmake
-honey
-##anda
-nikkie
-dhl
-publishing
-##mall
-##gnet
-e88
-##dog
-fishbase
-###
-##[
-。
-!
-?
-!
-?
-;
-:
-;
-##,
-##的
-##、
-##一
-##人
-##有
-##是
-##在
-##中
-##为
-##和
-##了
-##不
-##年
-##学
-##大
-##国
-##生
-##以
-##“
-##”
-##作
-##业
-##个
-##上
-##用
-##,
-##地
-##会
-##成
-##发
-##工
-##时
-##于
-##理
-##出
-##行
-##要
-##.
-##等
-##他
-##到
-##之
-##这
-##可
-##后
-##家
-##对
-##能
-##公
-##与
-##》
-##《
-##主
-##方
-##分
-##经
-##来
-##全
-##其
-##部
-##多
-##产
-##自
-##文
-##高
-##动
-##进
-##法
-##化
-##:
-##我
-##面
-##)
-##(
-##实
-##教
-##建
-##体
-##而
-##长
-##子
-##下
-##现
-##开
-##本
-##力
-##定
-##性
-##过
-##设
-##合
-##小
-##同
-##机
-##市
-##品
-##水
-##新
-##内
-##事
-##也
-##种
-##及
-##制
-##入
-##所
-##心
-##务
-##就
-##管
-##们
-##得
-##展
-##重
-##民
-##加
-##区
-##物
-##者
-##通
-##天
-##政
-##三
-##电
-##关
-##度
-##第
-##名
-##术
-##最
-##系
-##月
-##外
-##资
-##日
-##代
-##员
-##如
-##间
-##位
-##并
-##书
-##科
-##村
-##应
-##量
-##道
-##前
-##当
-##无
-##里
-##相
-##平
-##从
-##计
-##提
-##保
-##任
-##程
-##技
-##都
-##研
-##十
-##基
-##特
-##好
-##被
-##或
-##目
-##将
-##使
-##山
-##二
-##说
-##数
-##点
-##明
-##情
-##元
-##着
-##收
-##组
-##然
-##美
-##各
-##由
-##场
-##金
-##形
-##农
-##期
-##因
-##表
-##此
-##色
-##起
-##还
-##立
-##世
-##安
-##活
-##专
-##质
-##规
-##社
-##万
-##信
-##西
-##统
-##结
-##路
-##利
-##次
-##南
-##式
-##意
-##级
-##常
-##师
-##校
-##你
-##育
-##果
-##究
-##司
-##服
-##门
-##海
-##导
-##流
-##项
-##她
-##总
-##处
-##两
-##传
-##东
-##正
-##省
-##院
-##户
-##手
-##具
-##原
-##强
-##北
-##向
-##先
-##但
-##米
-##城
-##企
-##件
-##风
-##军
-##身
-##更
-##知
-##已
-##气
-##战
-##至
-##单
-##口
-##集
-##创
-##解
-##四
-##标
-##交
-##比
-##商
-##论
-##界
-##题
-##变
-##花
-##改
-##类
-##运
-##指
-##型
-##调
-##女
-##神
-##接
-##造
-##受
-##广
-##只
-##委
-##去
-##共
-##治
-##达
-##持
-##条
-##网
-##头
-##构
-##县
-##些
-##该
-##又
-##那
-##想
-##样
-##办
-##济
-##格
-##责
-##车
-##很
-##施
-##求
-##己
-##光
-##精
-##林
-##完
-##爱
-##线
-##参
-##少
-##积
-##清
-##看
-##优
-##报
-##王
-##直
-##没
-##每
-##据
-##游
-##效
-##感
-##五
-##影
-##别
-##获
-##领
-##称
-##选
-##供
-##乐
-##老
-##么
-##台
-##问
-##划
-##带
-##器
-##源
-##织
-##放
-##深
-##备
-##视
-##白
-##功
-##取
-##装
-##营
-##见
-##记
-##环
-##队
-##节
-##准
-##石
-##它
-##回
-##历
-##负
-##真
-##增
-##医
-##联
-##做
-##职
-##容
-##士
-##包
-##义
-##观
-##团
-##病
-##府
-##息
-##则
-##考
-##料
-##华
-##州
-##语
-##证
-##整
-##让
-##江
-##史
-##空
-##验
-##需
-##支
-##命
-##给
-##离
-##认
-##艺
-##较
-##土
-##古
-##养
-##才
-##境
-##推
-##把
-##均
-##图
-##际
-##斯
-##近
-##片
-##局
-##修
-##字
-##德
-##权
-##步
-##始
-##复
-##转
-##协
-##即
-##打
-##画
-##投
-##决
-##何
-##约
-##反
-##费
-##议
-##护
-##极
-##河
-##房
-##查
-##布
-##思
-##干
-##价
-##儿
-##非
-##马
-##党
-##奖
-##模
-##故
-##编
-##音
-##范
-##识
-##率
-##存
-##引
-##客
-##属
-##评
-##采
-##尔
-##配
-##镇
-##室
-##再
-##案
-##监
-##习
-##注
-##根
-##克
-##演
-##食
-##族
-##示
-##球
-##状
-##青
-##号
-##张
-##百
-##素
-##首
-##易
-##热
-##阳
-##今
-##园
-##防
-##版
-##太
-##乡
-##英
-##材
-##列
-##便
-##写
-##住
-##置
-##层
-##助
-##确
-##试
-##难
-##承
-##象
-##居
-##黄
-##快
-##断
-##维
-##却
-##红
-##速
-##连
-##众
-##细
-##态
-##话
-##周
-##言
-##药
-##培
-##血
-##亩
-##龙
-##越
-##值
-##几
-##边
-##读
-##未
-##曾
-##测
-##算
-##京
-##景
-##余
-##站
-##低
-##温
-##消
-##必
-##切
-##依
-##随
-##且
-##志
-##卫
-##域
-##照
-##许
-##限
-##著
-##销
-##落
-##足
-##适
-##争
-##策
-##控
-##武
-##按
-##初
-##角
-##核
-##死
-##检
-##富
-##满
-##显
-##审
-##除
-##致
-##亲
-##占
-##失
-##星
-##章
-##善
-##续
-##千
-##叶
-##火
-##副
-##告
-##段
-##什
-##声
-##终
-##况
-##走
-##木
-##益
-##戏
-##独
-##纪
-##植
-##财
-##群
-##六
-##赛
-##远
-##拉
-##亚
-##密
-##排
-##超
-##像
-##课
-##围
-##往
-##响
-##击
-##疗
-##念
-##八
-##云
-##险
-##律
-##请
-##革
-##诗
-##批
-##底
-##压
-##双
-##男
-##训
-##例
-##汉
-##升
-##拥
-##势
-##酒
-##眼
-##官
-##牌
-##油
-##曲
-##友
-##望
-##黑
-##歌
-##筑
-##础
-##香
-##仅
-##担
-##括
-##湖
-##严
-##秀
-##剧
-##九
-##举
-##执
-##充
-##兴
-##督
-##博
-##草
-##般
-##李
-##健
-##喜
-##授
-##普
-##预
-##灵
-##突
-##良
-##款
-##罗
-##微
-##七
-##录
-##朝
-##飞
-##宝
-##令
-##轻
-##劳
-##距
-##异
-##简
-##兵
-##树
-##序
-##候
-##含
-##福
-##尽
-##留
-##丰
-##旅
-##征
-##临
-##破
-##移
-##篇
-##抗
-##典
-##端
-##苏
-##奇
-##止
-##康
-##店
-##毛
-##觉
-##春
-##售
-##络
-##降
-##板
-##坚
-##母
-##讲
-##早
-##印
-##略
-##孩
-##夫
-##藏
-##铁
-##害
-##互
-##帝
-##田
-##融
-##皮
-##宗
-##岁
-##载
-##析
-##斗
-##须
-##伤
-##介
-##另
-##半
-##班
-##馆
-##味
-##楼
-##卡
-##射
-##述
-##杀
-##波
-##绿
-##免
-##兰
-##绝
-##刻
-##短
-##察
-##输
-##择
-##综
-##杂
-##份
-##纳
-##父
-##词
-##银
-##送
-##座
-##左
-##继
-##固
-##宣
-##厂
-##肉
-##换
-##补
-##税
-##派
-##套
-##欢
-##播
-##吸
-##圆
-##攻
-##阿
-##购
-##听
-##右
-##减
-##激
-##巴
-##背
-##够
-##遇
-##智
-##玉
-##找
-##宽
-##陈
-##练
-##追
-##毕
-##彩
-##软
-##帮
-##股
-##荣
-##托
-##予
-##佛
-##堂
-##障
-##皇
-##若
-##守
-##似
-##届
-##待
-##货
-##散
-##额
-##尚
-##穿
-##丽
-##骨
-##享
-##差
-##针
-##索
-##稳
-##宁
-##贵
-##酸
-##液
-##唐
-##操
-##探
-##玩
-##促
-##笔
-##库
-##救
-##虽
-##久
-##闻
-##顶
-##床
-##港
-##鱼
-##亿
-##登
-##永
-##毒
-##桥
-##冷
-##魔
-##秘
-##陆
-##您
-##童
-##归
-##侧
-##沙
-##染
-##封
-##紧
-##松
-##川
-##刘
-##雄
-##希
-##毫
-##卷
-##某
-##季
-##菜
-##庭
-##附
-##逐
-##夜
-##宫
-##洲
-##退
-##顾
-##尼
-##胜
-##剂
-##纯
-##舞
-##遗
-##苦
-##梦
-##挥
-##航
-##愿
-##街
-##招
-##矿
-##夏
-##盖
-##献
-##怎
-##茶
-##申
-##吧
-##脑
-##亦
-##吃
-##频
-##宋
-##央
-##威
-##厚
-##块
-##冲
-##叫
-##熟
-##礼
-##厅
-##否
-##渐
-##笑
-##钱
-##钟
-##甚
-##牛
-##丝
-##靠
-##岛
-##绍
-##盘
-##缘
-##聚
-##静
-##雨
-##氏
-##圣
-##顺
-##唱
-##刊
-##阶
-##困
-##急
-##饰
-##弹
-##庄
-##既
-##野
-##阴
-##混
-##饮
-##损
-##齐
-##末
-##错
-##轮
-##宜
-##鲜
-##兼
-##敌
-##粉
-##祖
-##延
-##钢
-##辑
-##欧
-##硬
-##甲
-##诉
-##册
-##痛
-##订
-##缺
-##晚
-##衣
-##佳
-##脉
-##盛
-##乎
-##拟
-##贸
-##扩
-##船
-##仪
-##谁
-##警
-##停
-##席
-##竞
-##释
-##庆
-##汽
-##仍
-##掌
-##诸
-##仙
-##弟
-##吉
-##洋
-##奥
-##票
-##危
-##架
-##买
-##径
-##塔
-##休
-##付
-##恶
-##雷
-##怀
-##秋
-##借
-##巨
-##透
-##誉
-##厘
-##句
-##跟
-##胞
-##婚
-##幼
-##烈
-##峰
-##寻
-##君
-##汇
-##趣
-##纸
-##假
-##肥
-##患
-##杨
-##雅
-##罪
-##谓
-##亮
-##脱
-##寺
-##烟
-##判
-##绩
-##乱
-##刚
-##摄
-##洞
-##践
-##码
-##启
-##励
-##呈
-##曰
-##呢
-##符
-##哥
-##媒
-##疾
-##坐
-##雪
-##孔
-##倒
-##旧
-##菌
-##岩
-##鼓
-##亡
-##访
-##症
-##暗
-##湾
-##幸
-##池
-##讨
-##努
-##露
-##吗
-##繁
-##途
-##殖
-##败
-##蛋
-##握
-##刺
-##耕
-##洗
-##沉
-##概
-##哈
-##泛
-##凡
-##残
-##隐
-##虫
-##朋
-##虚
-##餐
-##殊
-##慢
-##询
-##蒙
-##孙
-##谈
-##鲁
-##裂
-##贴
-##污
-##漫
-##谷
-##违
-##泉
-##拿
-##森
-##横
-##扬
-##键
-##膜
-##迁
-##尤
-##涉
-##净
-##诚
-##折
-##冰
-##械
-##拍
-##梁
-##沿
-##避
-##吴
-##惊
-##犯
-##灭
-##湿
-##迷
-##姓
-##阅
-##灯
-##妇
-##触
-##冠
-##答
-##俗
-##档
-##尊
-##谢
-##措
-##筹
-##竟
-##韩
-##签
-##剑
-##鉴
-##灾
-##贯
-##迹
-##洛
-##沟
-##束
-##翻
-##巧
-##坏
-##弱
-##零
-##壁
-##枝
-##映
-##恩
-##抓
-##屋
-##呼
-##脚
-##绘
-##淡
-##辖
-##伊
-##粒
-##欲
-##震
-##伯
-##私
-##蓝
-##甘
-##储
-##胡
-##卖
-##梅
-##耳
-##疑
-##润
-##伴
-##泽
-##牧
-##烧
-##尾
-##累
-##糖
-##怪
-##唯
-##莫
-##粮
-##柱
-##竹
-##灰
-##岸
-##缩
-##井
-##伦
-##柔
-##盟
-##珠
-##丹
-##皆
-##哪
-##迎
-##颜
-##衡
-##啊
-##塑
-##寒
-##紫
-##镜
-##氧
-##误
-##伍
-##彻
-##刀
-##览
-##炎
-##津
-##耐
-##秦
-##尖
-##潮
-##描
-##浓
-##召
-##禁
-##阻
-##胶
-##译
-##腹
-##泰
-##乃
-##盐
-##潜
-##鸡
-##诺
-##遍
-##纹
-##冬
-##牙
-##麻
-##辅
-##猪
-##弃
-##楚
-##羊
-##晋
-##鸟
-##赵
-##洁
-##谋
-##隆
-##滑
-##籍
-##臣
-##朱
-##泥
-##墨
-##辆
-##墙
-##浪
-##姐
-##赏
-##纵
-##拔
-##倍
-##纷
-##摩
-##壮
-##苗
-##偏
-##塞
-##贡
-##仁
-##宇
-##卵
-##瓦
-##枪
-##覆
-##殿
-##刑
-##贫
-##妈
-##幅
-##幕
-##忆
-##丁
-##估
-##废
-##萨
-##舍
-##详
-##旗
-##岗
-##洪
-##贝
-##迅
-##凭
-##勇
-##雕
-##奏
-##旋
-##杰
-##煤
-##阵
-##乘
-##溪
-##奉
-##畜
-##挑
-##昌
-##硕
-##庙
-##惠
-##薄
-##逃
-##爆
-##哲
-##浙
-##珍
-##炼
-##栏
-##暴
-##币
-##隔
-##吨
-##倾
-##嘉
-##址
-##陶
-##绕
-##诊
-##遭
-##桃
-##魂
-##兽
-##豆
-##闲
-##箱
-##拓
-##燃
-##裁
-##晶
-##掉
-##脂
-##溶
-##顿
-##肤
-##虑
-##鬼
-##灌
-##徐
-##龄
-##陵
-##恋
-##侵
-##坡
-##寿
-##勤
-##磨
-##妹
-##瑞
-##缓
-##轴
-##麦
-##羽
-##咨
-##凝
-##默
-##驻
-##敢
-##债
-##浮
-##幻
-##株
-##浅
-##敬
-##敏
-##陷
-##凤
-##坛
-##虎
-##乌
-##铜
-##御
-##乳
-##讯
-##循
-##圈
-##肌
-##妙
-##奋
-##忘
-##闭
-##墓
-##汤
-##忠
-##跨
-##怕
-##振
-##宾
-##跑
-##屏
-##坦
-##粗
-##租
-##悲
-##伟
-##拜
-##妻
-##赞
-##兄
-##宿
-##碑
-##貌
-##勒
-##罚
-##夺
-##偶
-##截
-##纤
-##齿
-##郑
-##聘
-##偿
-##扶
-##豪
-##慧
-##跳
-##疏
-##莱
-##腐
-##插
-##恐
-##郎
-##辞
-##挂
-##娘
-##肿
-##徒
-##伏
-##磁
-##杯
-##丛
-##旨
-##琴
-##炮
-##醒
-##砖
-##替
-##辛
-##暖
-##锁
-##杜
-##肠
-##孤
-##饭
-##脸
-##邮
-##贷
-##俄
-##毁
-##荷
-##谐
-##荒
-##肝
-##链
-##尺
-##尘
-##援
-##疫
-##崇
-##恢
-##扎
-##伸
-##幽
-##抵
-##胸
-##谱
-##舒
-##迫
-##畅
-##泡
-##岭
-##喷
-##窗
-##捷
-##宏
-##肯
-##狂
-##铺
-##骑
-##抽
-##券
-##俱
-##徽
-##胆
-##碎
-##邀
-##褐
-##斤
-##涂
-##赋
-##署
-##颗
-##渠
-##仿
-##迪
-##炉
-##辉
-##涵
-##耗
-##返
-##邻
-##斑
-##董
-##魏
-##午
-##娱
-##浴
-##尿
-##曼
-##锅
-##柳
-##舰
-##搭
-##旁
-##宅
-##趋
-##凉
-##赢
-##伙
-##爷
-##廷
-##戴
-##壤
-##奶
-##页
-##玄
-##驾
-##阔
-##轨
-##朗
-##捕
-##肾
-##稿
-##惯
-##侯
-##乙
-##渡
-##稍
-##恨
-##脏
-##姆
-##腔
-##抱
-##杆
-##垂
-##赴
-##赶
-##莲
-##辽
-##荐
-##旦
-##妖
-##稀
-##驱
-##沈
-##役
-##晓
-##亭
-##仲
-##澳
-##炸
-##绪
-##陕
-##恒
-##堡
-##纠
-##仇
-##懂
-##焦
-##搜
-##忍
-##贤
-##添
-##艾
-##赤
-##犹
-##尝
-##锦
-##稻
-##撰
-##填
-##衰
-##栽
-##邪
-##粘
-##跃
-##桌
-##胃
-##悬
-##翼
-##彼
-##睡
-##曹
-##刷
-##摆
-##悉
-##锋
-##摇
-##抢
-##乏
-##廉
-##鼠
-##盾
-##瓷
-##抑
-##埃
-##邦
-##遂
-##寸
-##渔
-##祥
-##胎
-##牵
-##壳
-##甜
-##卓
-##瓜
-##袭
-##遵
-##巡
-##逆
-##玛
-##韵
-##桑
-##酷
-##赖
-##桂
-##郡
-##肃
-##仓
-##寄
-##塘
-##瘤
-##碳
-##搞
-##燕
-##蒸
-##允
-##忽
-##斜
-##穷
-##郁
-##囊
-##奔
-##昆
-##盆
-##愈
-##递
-##黎
-##祭
-##怒
-##辈
-##腺
-##滚
-##暂
-##郭
-##璃
-##踪
-##芳
-##碍
-##肺
-##狱
-##冒
-##阁
-##砂
-##苍
-##揭
-##踏
-##颇
-##柄
-##闪
-##孝
-##葡
-##腾
-##茎
-##鸣
-##撤
-##仰
-##伐
-##丘
-##於
-##泪
-##荡
-##扰
-##纲
-##拼
-##欣
-##纽
-##癌
-##堆
-##菲
-##披
-##挖
-##寓
-##履
-##捐
-##悟
-##乾
-##嘴
-##钻
-##拳
-##吹
-##柏
-##遥
-##抚
-##忧
-##赠
-##霸
-##艰
-##淋
-##猫
-##帅
-##奈
-##寨
-##滴
-##鼻
-##掘
-##狗
-##驶
-##朴
-##拆
-##惜
-##玻
-##扣
-##萄
-##蔬
-##宠
-##缴
-##赫
-##凯
-##滨
-##乔
-##腰
-##葬
-##孟
-##吾
-##枚
-##圳
-##忙
-##扫
-##杭
-##凌
-##梯
-##丈
-##隶
-##剪
-##盗
-##擅
-##疆
-##弯
-##携
-##拒
-##秒
-##颁
-##醇
-##割
-##浆
-##姑
-##爸
-##螺
-##穗
-##缝
-##慈
-##喝
-##瓶
-##漏
-##悠
-##猎
-##番
-##孕
-##伪
-##漂
-##腿
-##吐
-##坝
-##滤
-##函
-##匀
-##偷
-##浩
-##矛
-##僧
-##辨
-##俊
-##棉
-##铸
-##诞
-##丧
-##夹
-##姿
-##睛
-##淮
-##阀
-##姜
-##尸
-##猛
-##芽
-##账
-##旱
-##醉
-##弄
-##坊
-##烤
-##萧
-##矣
-##雾
-##倡
-##榜
-##弗
-##氨
-##朵
-##锡
-##袋
-##拨
-##湘
-##岳
-##烦
-##肩
-##熙
-##炭
-##婆
-##棋
-##禅
-##穴
-##宙
-##汗
-##艳
-##儒
-##叙
-##晨
-##颈
-##峡
-##拖
-##烂
-##茂
-##戒
-##飘
-##氛
-##蒂
-##撞
-##瓣
-##箭
-##叛
-##鞋
-##劲
-##祝
-##娜
-##饲
-##侍
-##诱
-##叹
-##卢
-##弥
-##鼎
-##厦
-##屈
-##慕
-##魅
-##厨
-##嫁
-##绵
-##逼
-##扮
-##叔
-##酶
-##燥
-##狼
-##滋
-##汁
-##辐
-##怨
-##翅
-##佩
-##坑
-##旬
-##沃
-##剩
-##蛇
-##颖
-##篮
-##锐
-##侠
-##匹
-##唤
-##熊
-##漠
-##迟
-##敦
-##雌
-##谨
-##婴
-##浸
-##磷
-##筒
-##滩
-##埋
-##框
-##弘
-##吕
-##碰
-##纺
-##硫
-##堪
-##契
-##蜜
-##蓄
-##阐
-##傲
-##碱
-##晰
-##狭
-##撑
-##叉
-##卧
-##劫
-##闹
-##赐
-##邓
-##奴
-##溉
-##浦
-##蹈
-##辣
-##遣
-##耀
-##耶
-##翠
-##叠
-##迈
-##霍
-##碧
-##恰
-##脊
-##昭
-##摸
-##饱
-##赔
-##泄
-##哭
-##讼
-##逝
-##逻
-##廊
-##擦
-##渗
-##彰
-##卿
-##旺
-##宪
-##顷
-##妆
-##陪
-##葛
-##仔
-##淀
-##翰
-##悦
-##穆
-##煮
-##辩
-##弦
-##串
-##押
-##蚀
-##逢
-##贺
-##焊
-##煌
-##缔
-##惑
-##鹿
-##袁
-##糊
-##逸
-##舟
-##勃
-##侦
-##涯
-##蔡
-##辟
-##涌
-##枯
-##痕
-##疼
-##莉
-##柴
-##眉
-##罢
-##催
-##衔
-##秉
-##妃
-##鸿
-##傅
-##辰
-##聪
-##咸
-##扇
-##盈
-##勘
-##佐
-##泊
-##抛
-##搬
-##牢
-##宴
-##牲
-##贾
-##摘
-##姻
-##慎
-##帕
-##忌
-##卒
-##夕
-##卜
-##惟
-##挺
-##崖
-##炒
-##爵
-##冻
-##椒
-##鳞
-##祸
-##潭
-##腊
-##蒋
-##缠
-##寂
-##眠
-##冯
-##芯
-##槽
-##吊
-##聊
-##梗
-##嫩
-##凶
-##铭
-##爽
-##筋
-##韦
-##脾
-##铝
-##肢
-##栋
-##勾
-##萌
-##渊
-##掩
-##狮
-##撒
-##漆
-##骗
-##禽
-##蕴
-##坪
-##洒
-##冶
-##兹
-##椭
-##喻
-##泵
-##哀
-##翔
-##棒
-##芝
-##扑
-##毅
-##衍
-##惨
-##疯
-##欺
-##贼
-##肖
-##轰
-##巢
-##臂
-##轩
-##扁
-##淘
-##犬
-##宰
-##祠
-##挡
-##厌
-##帐
-##蜂
-##狐
-##垃
-##昂
-##圾
-##秩
-##芬
-##瞬
-##枢
-##舌
-##唇
-##棕
-##霞
-##霜
-##艇
-##侨
-##鹤
-##硅
-##靖
-##哦
-##削
-##泌
-##奠
-##吏
-##夷
-##咖
-##彭
-##窑
-##胁
-##肪
-##贞
-##劝
-##钙
-##柜
-##鸭
-##庞
-##兔
-##荆
-##丙
-##纱
-##戈
-##藤
-##矩
-##泳
-##惧
-##铃
-##渴
-##胀
-##袖
-##丸
-##狠
-##豫
-##茫
-##浇
-##菩
-##氯
-##啡
-##葱
-##梨
-##霉
-##脆
-##氢
-##巷
-##丑
-##娃
-##锻
-##愤
-##贪
-##蝶
-##厉
-##闽
-##浑
-##斩
-##栖
-##茅
-##昏
-##龟
-##碗
-##棚
-##滞
-##慰
-##斋
-##虹
-##屯
-##萝
-##饼
-##窄
-##潘
-##绣
-##丢
-##芦
-##鳍
-##裕
-##誓
-##腻
-##锈
-##吞
-##蜀
-##啦
-##扭
-##巩
-##髓
-##劣
-##拌
-##谊
-##涛
-##勋
-##郊
-##莎
-##痴
-##窝
-##驰
-##跌
-##笼
-##挤
-##溢
-##隙
-##鹰
-##诏
-##帽
-##芒
-##爬
-##凸
-##牺
-##熔
-##吻
-##竭
-##瘦
-##冥
-##搏
-##屡
-##昔
-##萼
-##愁
-##捉
-##翁
-##怖
-##汪
-##烯
-##疲
-##缸
-##溃
-##泼
-##剖
-##涨
-##橡
-##谜
-##悔
-##嫌
-##盒
-##苯
-##凹
-##绳
-##畏
-##罐
-##虾
-##柯
-##邑
-##馨
-##兆
-##帖
-##陌
-##禄
-##垫
-##壶
-##逊
-##骤
-##祀
-##晴
-##蓬
-##苞
-##煎
-##菊
-##堤
-##甫
-##拱
-##氮
-##罕
-##舶
-##伞
-##姚
-##弓
-##嵌
-##馈
-##琼
-##噪
-##雀
-##呵
-##汝
-##焉
-##陀
-##胺
-##惩
-##沼
-##枣
-##桐
-##酱
-##遮
-##孢
-##钝
-##呀
-##锥
-##妥
-##酿
-##巫
-##闯
-##沧
-##崩
-##蕊
-##酬
-##匠
-##躲
-##喊
-##琳
-##绎
-##喉
-##凰
-##抬
-##膨
-##盲
-##剥
-##喂
-##庸
-##奸
-##钩
-##冈
-##募
-##苑
-##杏
-##杉
-##辱
-##隋
-##薪
-##绒
-##欠
-##尉
-##攀
-##抹
-##巾
-##渣
-##苹
-##猴
-##悄
-##屠
-##颂
-##湛
-##魄
-##颠
-##呆
-##粤
-##岂
-##娇
-##暑
-##鹅
-##筛
-##膏
-##樱
-##缆
-##襄
-##瑟
-##恭
-##泻
-##匪
-##兮
-##恼
-##吟
-##仕
-##蔽
-##骄
-##蚕
-##斥
-##椅
-##姬
-##谦
-##椎
-##搅
-##卸
-##沫
-##怜
-##坎
-##瑰
-##钦
-##拾
-##厕
-##後
-##逾
-##薯
-##衬
-##钾
-##崔
-##稽
-##蛮
-##殷
-##晒
-##菇
-##臭
-##弧
-##擎
-##粹
-##纬
-##焰
-##玲
-##竣
-##咒
-##歇
-##糕
-##诵
-##茨
-##妮
-##酯
-##麟
-##卑
-##浏
-##咽
-##罩
-##舱
-##酵
-##晕
-##顽
-##赁
-##咬
-##枫
-##冀
-##贮
-##艘
-##亏
-##薛
-##瀑
-##篆
-##膀
-##沸
-##雍
-##咳
-##尹
-##愉
-##烹
-##坠
-##勿
-##钠
-##坤
-##甸
-##墅
-##闸
-##藻
-##韧
-##鄂
-##瑶
-##舆
-##夸
-##蕾
-##栗
-##咏
-##丞
-##抄
-##鹏
-##弊
-##檐
-##骂
-##仆
-##峻
-##爪
-##赚
-##帆
-##娶
-##嘛
-##钓
-##澄
-##猜
-##裔
-##抒
-##铅
-##卉
-##彦
-##删
-##衷
-##禹
-##寡
-##蒲
-##砌
-##棱
-##拘
-##堵
-##雁
-##仄
-##荫
-##祈
-##奢
-##赌
-##寇
-##隧
-##摊
-##雇
-##卦
-##婉
-##敲
-##挣
-##皱
-##虞
-##亨
-##懈
-##挽
-##珊
-##饶
-##滥
-##锯
-##闷
-##酮
-##虐
-##兑
-##僵
-##傻
-##沦
-##巅
-##鞭
-##梳
-##赣
-##锌
-##庐
-##薇
-##庵
-##慨
-##肚
-##妄
-##仗
-##绑
-##枕
-##牡
-##胖
-##沪
-##垒
-##捞
-##捧
-##竖
-##蜡
-##桩
-##厢
-##孵
-##黏
-##拯
-##谭
-##诈
-##灿
-##釉
-##裹
-##钮
-##俩
-##灶
-##彝
-##蟹
-##涩
-##醋
-##匙
-##歧
-##刹
-##玫
-##棘
-##橙
-##凑
-##桶
-##刃
-##伽
-##硝
-##怡
-##籽
-##敞
-##淳
-##矮
-##镶
-##戚
-##幢
-##涡
-##尧
-##膝
-##哉
-##肆
-##畔
-##溯
-##媚
-##烘
-##窃
-##焚
-##澜
-##愚
-##棵
-##乞
-##佑
-##暨
-##敷
-##饥
-##俯
-##蔓
-##暮
-##砍
-##邵
-##仑
-##毗
-##剿
-##馀
-##锤
-##刮
-##梭
-##摧
-##掠
-##躯
-##诡
-##匈
-##侣
-##胚
-##疮
-##裙
-##裸
-##塌
-##吓
-##俘
-##糙
-##藩
-##楷
-##羞
-##鲍
-##帘
-##裤
-##宛
-##憾
-##桓
-##痰
-##寞
-##骚
-##惹
-##笋
-##萃
-##栓
-##挫
-##矢
-##垦
-##垄
-##绸
-##凄
-##镀
-##熏
-##钉
-##粪
-##缅
-##洽
-##鞘
-##蔗
-##迄
-##沐
-##凿
-##勉
-##昨
-##喘
-##爹
-##屑
-##耻
-##沥
-##庶
-##涅
-##腕
-##袍
-##懒
-##阜
-##嗜
-##朔
-##蒜
-##沛
-##坟
-##轿
-##喀
-##笛
-##狄
-##饿
-##蓉
-##泣
-##窟
-##豹
-##屿
-##崛
-##迦
-##诠
-##贬
-##腥
-##钥
-##嗣
-##瑜
-##倦
-##萎
-##拦
-##冤
-##讽
-##潇
-##谣
-##趁
-##妨
-##贩
-##萍
-##窦
-##纂
-##缀
-##矫
-##淑
-##墩
-##梵
-##沾
-##淫
-##乖
-##汰
-##莞
-##旷
-##浊
-##挚
-##撼
-##氟
-##焕
-##庚
-##掀
-##诀
-##盼
-##疹
-##窖
-##匆
-##厥
-##轧
-##淹
-##亥
-##鸦
-##棍
-##谅
-##歼
-##汕
-##挪
-##蚁
-##敛
-##魁
-##畴
-##炫
-##丫
-##奎
-##菱
-##沂
-##撕
-##阎
-##詹
-##蛛
-##靡
-##瞻
-##咱
-##愧
-##烷
-##畸
-##灸
-##眸
-##觅
-##芜
-##廓
-##斌
-##躁
-##麓
-##摔
-##烛
-##睹
-##孜
-##缚
-##堕
-##昼
-##睿
-##琪
-##琉
-##贱
-##渝
-##跋
-##茄
-##舜
-##诛
-##捣
-##芙
-##倚
-##酰
-##澈
-##慌
-##帜
-##颤
-##陇
-##颌
-##昧
-##佣
-##眷
-##徙
-##禾
-##逮
-##莹
-##碟
-##梢
-##朽
-##粥
-##喇
-##榆
-##驳
-##楔
-##啸
-##肋
-##踢
-##傍
-##桔
-##肴
-##呕
-##旭
-##埠
-##贿
-##曝
-##杖
-##俭
-##栩
-##斧
-##镁
-##匾
-##踩
-##橘
-##颅
-##囚
-##蛙
-##膳
-##坞
-##琐
-##荧
-##瘟
-##涤
-##胰
-##衫
-##噬
-##皖
-##邱
-##埔
-##汀
-##羡
-##睐
-##葵
-##耿
-##糟
-##厄
-##秧
-##黔
-##蹄
-##漳
-##鞍
-##谏
-##腋
-##簇
-##梧
-##戎
-##榴
-##诣
-##宦
-##苔
-##揽
-##簧
-##狸
-##阙
-##扯
-##耍
-##棠
-##脓
-##烫
-##翘
-##芭
-##躺
-##羁
-##藉
-##拐
-##陡
-##漓
-##棺
-##钧
-##琅
-##扔
-##寝
-##绚
-##熬
-##驿
-##邹
-##杠
-##绥
-##窥
-##晃
-##渭
-##樊
-##鑫
-##祁
-##陋
-##哺
-##堰
-##祛
-##梓
-##崎
-##孽
-##蝴
-##蔚
-##抖
-##苟
-##肇
-##溜
-##绅
-##妾
-##跪
-##沁
-##莽
-##虏
-##瞄
-##砸
-##稚
-##僚
-##崭
-##迭
-##皂
-##彬
-##雏
-##羲
-##缕
-##绞
-##俞
-##簿
-##耸
-##廖
-##嘲
-##翌
-##榄
-##裴
-##槐
-##洼
-##睁
-##灼
-##啤
-##臀
-##啥
-##濒
-##醛
-##峨
-##葫
-##悍
-##笨
-##嘱
-##稠
-##韶
-##陛
-##峭
-##酚
-##翩
-##舅
-##寅
-##蕉
-##阮
-##垣
-##戮
-##趾
-##犀
-##巍
-##霄
-##饪
-##秆
-##朕
-##驼
-##肛
-##揉
-##楠
-##岚
-##疡
-##帧
-##柑
-##赎
-##逍
-##滇
-##璋
-##礁
-##黛
-##钞
-##邢
-##涧
-##劈
-##瞳
-##砚
-##驴
-##锣
-##恳
-##栅
-##吵
-##牟
-##沌
-##瞩
-##咪
-##毯
-##炳
-##淤
-##盯
-##芋
-##粟
-##栈
-##戊
-##盏
-##峪
-##拂
-##暇
-##酥
-##汛
-##嚣
-##轼
-##妒
-##匿
-##鸽
-##蝉
-##痒
-##宵
-##瘫
-##璧
-##汲
-##冢
-##碌
-##琢
-##磅
-##卤
-##剔
-##谎
-##圩
-##酌
-##捏
-##渺
-##媳
-##穹
-##谥
-##骏
-##哨
-##骆
-##乒
-##摹
-##兜
-##柿
-##喧
-##呜
-##捡
-##橄
-##逗
-##瑚
-##呐
-##檀
-##辜
-##妊
-##祯
-##苷
-##衙
-##笃
-##芸
-##霖
-##荔
-##闺
-##羌
-##芹
-##哼
-##糯
-##吼
-##蕃
-##嵩
-##矶
-##绽
-##坯
-##娠
-##祷
-##锰
-##瘀
-##岐
-##茵
-##筝
-##斐
-##肽
-##歉
-##嗽
-##恤
-##汶
-##聂
-##樟
-##擒
-##鹃
-##拙
-##鲤
-##絮
-##鄙
-##彪
-##嗓
-##墟
-##骼
-##渤
-##僻
-##豁
-##谕
-##荟
-##姨
-##婷
-##挠
-##哇
-##炙
-##诅
-##娥
-##哑
-##阱
-##嫉
-##圭
-##乓
-##橱
-##歪
-##禧
-##甩
-##坷
-##晏
-##驯
-##讳
-##泗
-##煞
-##淄
-##倪
-##妓
-##窍
-##竿
-##襟
-##匡
-##钛
-##侈
-##侄
-##铲
-##哮
-##厩
-##亢
-##辕
-##瘾
-##辊
-##狩
-##掷
-##潍
-##伺
-##嘿
-##弈
-##嘎
-##陨
-##娅
-##昊
-##犁
-##屁
-##蜘
-##寥
-##滕
-##毙
-##涝
-##谛
-##郝
-##痹
-##溺
-##汾
-##脐
-##馅
-##蠢
-##珀
-##腌
-##扼
-##敕
-##莓
-##峦
-##铬
-##谍
-##炬
-##龚
-##麒
-##睦
-##磺
-##吁
-##掺
-##烁
-##靶
-##圃
-##饵
-##褶
-##娟
-##滔
-##挨
-##褒
-##胱
-##晖
-##脖
-##垢
-##抉
-##冉
-##茧
-##渲
-##癫
-##悼
-##嫂
-##瞒
-##纶
-##肘
-##炖
-##瀚
-##皋
-##姊
-##颐
-##俏
-##颊
-##讶
-##札
-##奕
-##磊
-##镖
-##遐
-##眺
-##腑
-##琦
-##蚊
-##窜
-##渍
-##嗯
-##夯
-##笙
-##蘑
-##翡
-##碘
-##卯
-##啼
-##靓
-##辍
-##莺
-##躬
-##猿
-##杞
-##眩
-##虔
-##凋
-##遁
-##泾
-##岔
-##羟
-##弛
-##娄
-##茸
-##皓
-##峙
-##逅
-##邂
-##苇
-##楹
-##蹲
-##拢
-##甄
-##鳃
-##邯
-##捆
-##勺
-##酉
-##荚
-##唑
-##臻
-##辗
-##绰
-##徊
-##榨
-##苛
-##赦
-##盔
-##壬
-##恍
-##缉
-##熨
-##澡
-##桨
-##匣
-##兢
-##驭
-##镍
-##孰
-##绮
-##馏
-##蝇
-##佼
-##鲸
-##哎
-##裳
-##蜕
-##嚼
-##嘻
-##庇
-##绢
-##倩
-##钵
-##恪
-##帷
-##莆
-##柠
-##藕
-##砾
-##绊
-##喙
-##坂
-##徘
-##荀
-##瞧
-##蛾
-##晦
-##铎
-##紊
-##锚
-##酪
-##稷
-##聋
-##闵
-##熹
-##冕
-##诫
-##珑
-##曦
-##篷
-##迥
-##蘖
-##胤
-##檬
-##瑾
-##钳
-##遏
-##辄
-##嬉
-##隅
-##秃
-##帛
-##聆
-##芥
-##诬
-##挟
-##宕
-##鹊
-##琶
-##膛
-##兀
-##懿
-##碾
-##叮
-##蠕
-##譬
-##缮
-##烽
-##妍
-##榕
-##邃
-##焙
-##倘
-##戌
-##茹
-##豚
-##晾
-##浒
-##玺
-##醚
-##祐
-##炽
-##缪
-##凛
-##噩
-##溅
-##毋
-##槛
-##嫡
-##蝠
-##娴
-##稣
-##禀
-##壑
-##殆
-##敖
-##倭
-##挛
-##侃
-##蚌
-##咀
-##盎
-##殉
-##岑
-##浚
-##谬
-##狡
-##癸
-##逛
-##耽
-##俺
-##璨
-##巳
-##茜
-##郸
-##蒴
-##琵
-##叩
-##泸
-##塾
-##稼
-##侮
-##锂
-##曙
-##薰
-##婿
-##惶
-##拭
-##篱
-##恬
-##淌
-##烙
-##袜
-##徵
-##慷
-##夭
-##噶
-##莘
-##鸳
-##殡
-##蚂
-##憎
-##喃
-##佚
-##龛
-##潢
-##烃
-##岱
-##潺
-##衢
-##璀
-##鹭
-##揣
-##痢
-##厮
-##氓
-##怠
-##痘
-##硒
-##镌
-##乍
-##咯
-##惬
-##桦
-##骇
-##枉
-##蜗
-##睾
-##淇
-##耘
-##娓
-##弼
-##鳌
-##嗅
-##狙
-##箫
-##朦
-##椰
-##胥
-##丐
-##陂
-##唾
-##鳄
-##柚
-##谒
-##戍
-##刁
-##鸾
-##缭
-##骸
-##铣
-##酋
-##蝎
-##掏
-##耦
-##怯
-##娲
-##拇
-##汹
-##胧
-##疤
-##硼
-##恕
-##哗
-##眶
-##痫
-##凳
-##鲨
-##擢
-##歹
-##樵
-##瘠
-##茗
-##翟
-##黯
-##蜒
-##壹
-##殇
-##伶
-##辙
-##瑕
-##町
-##孚
-##痉
-##铵
-##搁
-##漾
-##戟
-##镰
-##鸯
-##猩
-##蔷
-##缤
-##叭
-##垩
-##曳
-##奚
-##毓
-##颓
-##汐
-##靴
-##傣
-##尬
-##濮
-##赂
-##媛
-##懦
-##扦
-##韬
-##戳
-##雯
-##蜿
-##笺
-##裘
-##尴
-##侗
-##钨
-##苓
-##寰
-##蛊
-##扳
-##搓
-##涟
-##睫
-##淬
-##赈
-##恺
-##瞎
-##蝙
-##枸
-##萱
-##颚
-##憩
-##秽
-##秸
-##拷
-##阑
-##貂
-##粱
-##煲
-##隘
-##暧
-##惕
-##沽
-##菠
-##趟
-##磋
-##偕
-##涕
-##邸
-##踞
-##惫
-##阪
-##鞠
-##饺
-##汞
-##颍
-##氰
-##屹
-##蛟
-##跻
-##哟
-##臼
-##熄
-##绛
-##弩
-##褪
-##渎
-##亟
-##匮
-##撇
-##霆
-##攒
-##舵
-##扛
-##彤
-##蛤
-##婢
-##偃
-##胫
-##姥
-##睑
-##诙
-##诲
-##锭
-##悚
-##扒
-##洱
-##劾
-##惰
-##篡
-##瓯
-##徇
-##铀
-##骋
-##筷
-##渚
-##踵
-##俨
-##榻
-##糜
-##捻
-##釜
-##哩
-##萤
-##蛹
-##隽
-##垮
-##鸠
-##鸥
-##漕
-##瑙
-##礴
-##憧
-##殴
-##潼
-##悯
-##砺
-##拽
-##钗
-##酣
-##镂
-##膺
-##楞
-##竺
-##迂
-##嫣
-##忱
-##哄
-##疣
-##鹦
-##枭
-##憬
-##疱
-##婪
-##沮
-##怅
-##筱
-##扉
-##瞰
-##旌
-##蔑
-##铠
-##瀛
-##琥
-##懵
-##谴
-##捍
-##蟾
-##漩
-##拣
-##汴
-##刨
-##叱
-##曜
-##妞
-##澎
-##镑
-##翎
-##瞪
-##倔
-##芍
-##璞
-##瓮
-##驹
-##芷
-##寐
-##擂
-##丕
-##蟠
-##诃
-##悸
-##亘
-##溴
-##宸
-##廿
-##恃
-##棣
-##荼
-##筠
-##羚
-##慑
-##唉
-##纣
-##麼
-##蹦
-##锄
-##淆
-##甙
-##蚜
-##椿
-##禺
-##绯
-##冗
-##葩
-##厝
-##媲
-##蒿
-##痪
-##菁
-##炊
-##俑
-##讥
-##桀
-##祺
-##吡
-##迩
-##箔
-##皿
-##缎
-##萦
-##剃
-##霓
-##酝
-##诰
-##茉
-##飙
-##湍
-##蜥
-##箕
-##蘸
-##柬
-##韭
-##溥
-##熠
-##鹉
-##咐
-##剌
-##悖
-##瞿
-##槟
-##娩
-##闾
-##遴
-##咫
-##孺
-##彷
-##茬
-##蓟
-##憨
-##袅
-##佬
-##炯
-##啶
-##昙
-##蚩
-##痔
-##蕨
-##瓢
-##夔
-##毡
-##赃
-##鳖
-##沅
-##饷
-##臧
-##掖
-##褚
-##羹
-##勐
-##谚
-##畦
-##眨
-##贻
-##攸
-##涎
-##弑
-##咎
-##铂
-##瑛
-##矗
-##虱
-##秤
-##谟
-##漱
-##俸
-##夙
-##雉
-##螨
-##恣
-##斛
-##谙
-##隍
-##奄
-##壕
-##髻
-##鄱
-##嘶
-##磕
-##濡
-##赘
-##荞
-##讹
-##猕
-##痞
-##鬓
-##铮
-##腱
-##幡
-##榭
-##爻
-##涓
-##晤
-##咕
-##惭
-##钼
-##匕
-##撮
-##庾
-##笠
-##窘
-##癖
-##垛
-##窒
-##畲
-##甬
-##彗
-##缨
-##湮
-##寮
-##衅
-##谪
-##绫
-##兖
-##疽
-##磐
-##菏
-##沱
-##骁
-##嫔
-##盂
-##娆
-##钊
-##蟒
-##忏
-##谤
-##晟
-##痈
-##耆
-##谧
-##簪
-##疟
-##扈
-##脍
-##琛
-##咋
-##胄
-##葆
-##轶
-##桢
-##攘
-##邕
-##拧
-##茯
-##摒
-##傀
-##祚
-##嘟
-##帼
-##筵
-##馒
-##疚
-##璇
-##砧
-##槃
-##犷
-##腓
-##煜
-##弋
-##疸
-##濑
-##麝
-##嗟
-##忻
-##愣
-##斓
-##吝
-##咧
-##矾
-##愫
-##漪
-##珂
-##逞
-##糠
-##璐
-##藓
-##昕
-##妩
-##屌
-##疵
-##嘘
-##袂
-##稃
-##剁
-##侏
-##掐
-##猾
-##匍
-##坳
-##黜
-##邺
-##闫
-##猥
-##湃
-##斟
-##癣
-##匐
-##粳
-##叟
-##俾
-##儡
-##莒
-##骥
-##跤
-##耙
-##矜
-##翱
-##赡
-##浣
-##栾
-##拈
-##螟
-##桧
-##坍
-##睢
-##趴
-##伎
-##婺
-##霹
-##痊
-##膊
-##眯
-##豌
-##驮
-##骈
-##嶂
-##淞
-##腮
-##髅
-##炀
-##啄
-##亳
-##麾
-##筐
-##叨
-##徨
-##跷
-##楂
-##郴
-##绶
-##羔
-##咤
-##靳
-##屎
-##雳
-##瘘
-##蹬
-##惮
-##涪
-##阖
-##煽
-##蹊
-##栉
-##俟
-##涸
-##辫
-##锢
-##佟
-##皎
-##啮
-##钰
-##螂
-##啪
-##绷
-##闰
-##畿
-##覃
-##惘
-##贰
-##碉
-##卞
-##酐
-##枷
-##葺
-##芪
-##蕙
-##咚
-##籁
-##钴
-##冽
-##玮
-##骷
-##啃
-##焖
-##猝
-##榈
-##滁
-##拮
-##跗
-##讷
-##蝗
-##蠡
-##烨
-##脯
-##歙
-##泠
-##刍
-##掳
-##僳
-##螯
-##胳
-##髦
-##粽
-##戾
-##祜
-##岷
-##懋
-##馥
-##昵
-##踊
-##湄
-##郢
-##斡
-##迢
-##嗪
-##裨
-##羧
-##膈
-##翊
-##鲫
-##螃
-##沓
-##疝
-##笈
-##榔
-##诘
-##颉
-##蛀
-##鸢
-##焯
-##囧
-##梆
-##潞
-##戛
-##佗
-##艮
-##霾
-##鬟
-##玖
-##腭
-##喔
-##罔
-##佥
-##粑
-##舷
-##泯
-##泓
-##炜
-##谗
-##烬
-##跆
-##傩
-##飓
-##浔
-##钤
-##惚
-##胭
-##踝
-##镯
-##臆
-##蜚
-##揪
-##觞
-##皈
-##迸
-##匝
-##筏
-##醴
-##黍
-##洮
-##滦
-##侬
-##甾
-##澧
-##阈
-##袱
-##迤
-##衮
-##濂
-##娑
-##砥
-##砷
-##铨
-##缜
-##箴
-##逵
-##猖
-##蛰
-##箍
-##侥
-##搂
-##纨
-##裱
-##枋
-##嫦
-##敝
-##挝
-##贲
-##潦
-##撩
-##惺
-##铰
-##忒
-##咆
-##哆
-##莅
-##炕
-##抨
-##涿
-##龈
-##猷
-##遒
-##缥
-##捂
-##俐
-##瘙
-##搐
-##牍
-##馍
-##痿
-##袤
-##峥
-##栎
-##罹
-##燎
-##喵
-##璜
-##飒
-##蔼
-##珞
-##澹
-##奘
-##岖
-##芡
-##簸
-##杵
-##甥
-##骊
-##悴
-##惆
-##殃
-##呃
-##祗
-##髋
-##幔
-##榛
-##犊
-##霁
-##芮
-##牒
-##佰
-##狈
-##薨
-##吩
-##鳝
-##嵘
-##濠
-##呤
-##纫
-##檄
-##浜
-##缙
-##缢
-##煦
-##蓦
-##揖
-##拴
-##缈
-##褥
-##铿
-##燮
-##锵
-##荥
-##忿
-##僖
-##婶
-##芾
-##镐
-##痣
-##眈
-##祇
-##邈
-##翳
-##碣
-##遨
-##鳗
-##诂
-##岫
-##焘
-##茱
-##洵
-##晁
-##噢
-##偈
-##旖
-##蚓
-##柘
-##珐
-##遽
-##岌
-##桅
-##唔
-##鄞
-##雹
-##驸
-##苻
-##恻
-##鬃
-##玑
-##磬
-##崂
-##祉
-##荤
-##淼
-##肱
-##呗
-##骡
-##囱
-##佞
-##耒
-##伫
-##嚷
-##粼
-##歆
-##佃
-##旎
-##惋
-##殁
-##杳
-##阡
-##畈
-##蔺
-##巽
-##昱
-##啰
-##吠
-##嗔
-##涮
-##奂
-##撷
-##袒
-##爰
-##捶
-##赭
-##蜓
-##姗
-##蔻
-##垠
-##噻
-##峒
-##皙
-##憔
-##帚
-##杷
-##蟆
-##觐
-##钒
-##岙
-##栀
-##幄
-##啧
-##癜
-##擀
-##轲
-##铆
-##讴
-##樽
-##霏
-##肮
-##枳
-##骞
-##诧
-##瘢
-##虬
-##拗
-##蕲
-##茁
-##唆
-##沭
-##毂
-##蛎
-##芊
-##銮
-##瞥
-##呱
-##羿
-##吒
-##傥
-##髯
-##濯
-##蜻
-##皴
-##邳
-##燧
-##獭
-##垭
-##祟
-##虢
-##枇
-##鹫
-##颞
-##皑
-##脲
-##舔
-##魇
-##霭
-##坨
-##郧
-##椽
-##舫
-##荠
-##琊
-##溟
-##煨
-##谯
-##粲
-##罂
-##屉
-##佯
-##郦
-##亵
-##诽
-##芩
-##嵇
-##蚤
-##哒
-##啬
-##嚎
-##玥
-##隼
-##唢
-##铛
-##壅
-##藜
-##吱
-##楣
-##璟
-##锆
-##憋
-##罡
-##咙
-##腈
-##廪
-##堑
-##诩
-##溧
-##鹑
-##讫
-##哌
-##铢
-##蜴
-##稹
-##噜
-##镉
-##愕
-##桁
-##晔
-##琰
-##陲
-##疙
-##崮
-##颛
-##桡
-##钜
-##谑
-##仞
-##咦
-##珪
-##揍
-##鱿
-##阉
-##瘩
-##槌
-##滓
-##茴
-##泮
-##涣
-##柞
-##渥
-##飨
-##孪
-##沔
-##谲
-##桉
-##慵
-##俚
-##跖
-##纭
-##恙
-##佘
-##荃
-##咄
-##鞅
-##叁
-##恽
-##炔
-##萘
-##钺
-##楫
-##塬
-##钡
-##琮
-##苄
-##骰
-##偎
-##粕
-##咔
-##鹄
-##瓒
-##阆
-##捅
-##嬴
-##箨
-##氦
-##倜
-##觊
-##婕
-##锑
-##撬
-##掰
-##嗷
-##饯
-##蓓
-##鼬
-##佤
-##蚯
-##挞
-##臾
-##嶙
-##幂
-##饬
-##闱
-##煅
-##嘧
-##蹭
-##瞭
-##顼
-##箐
-##徉
-##骜
-##嗨
-##邛
-##庑
-##柩
-##饕
-##俎
-##嘌
-##颏
-##椁
-##崧
-##锉
-##籼
-##狞
-##弁
-##羯
-##踹
-##糅
-##砼
-##嫖
-##豉
-##啉
-##榷
-##嘈
-##俪
-##痂
-##儋
-##芎
-##繇
-##蹇
-##诋
-##煸
-##峋
-##淙
-##泱
-##徜
-##汩
-##纥
-##蝼
-##囿
-##暹
-##谆
-##蹂
-##鞣
-##螳
-##馗
-##幺
-##鞑
-##贽
-##漯
-##牦
-##淖
-##囤
-##晗
-##忡
-##懊
-##呋
-##埂
-##鲈
-##阕
-##幌
-##鳅
-##勰
-##萸
-##剽
-##蚝
-##绔
-##辇
-##麋
-##陟
-##宥
-##锺
-##喽
-##淅
-##熵
-##荨
-##忤
-##轭
-##嗦
-##荪
-##骠
-##鹘
-##聿
-##绾
-##诶
-##怆
-##喋
-##恸
-##湟
-##睨
-##翦
-##蜈
-##褂
-##娼
-##羸
-##觎
-##瘁
-##蚣
-##呻
-##昶
-##谶
-##猬
-##荻
-##酗
-##肄
-##躏
-##膑
-##嗡
-##庠
-##崽
-##搪
-##胯
-##铉
-##峤
-##郯
-##藐
-##舂
-##蓼
-##薏
-##窿
-##羣
-##氽
-##徕
-##冼
-##阂
-##欤
-##殒
-##窈
-##脘
-##篝
-##麸
-##砭
-##砰
-##骶
-##豺
-##窠
-##獒
-##腴
-##苕
-##缇
-##骅
-##劭
-##卅
-##揆
-##垅
-##琏
-##镗
-##苜
-##胛
-##珏
-##吮
-##抠
-##搔
-##槎
-##掣
-##琨
-##餮
-##舛
-##痤
-##埭
-##胪
-##喹
-##妲
-##婀
-##帙
-##箩
-##灏
-##霎
-##袄
-##镭
-##蓿
-##墉
-##嵊
-##堇
-##蟋
-##叽
-##钎
-##録
-##郓
-##瘴
-##丶
-##呦
-##邬
-##頫
-##馁
-##鄢
-##蛭
-##愍
-##锲
-##槿
-##珈
-##蜃
-##拎
-##鎏
-##裟
-##沏
-##螭
-##觑
-##墒
-##捺
-##轸
-##榫
-##怔
-##昀
-##泷
-##凫
-##唠
-##狰
-##鲛
-##氐
-##呛
-##绀
-##碛
-##茏
-##盅
-##蟀
-##洙
-##訇
-##蠹
-##棂
-##蚴
-##篾
-##靛
-##暄
-##泞
-##洄
-##赓
-##麽
-##篓
-##孑
-##烩
-##颢
-##钣
-##髂
-##蹴
-##筮
-##蝌
-##醮
-##菖
-##獗
-##岘
-##鼐
-##姣
-##蟑
-##袈
-##葶
-##掬
-##躇
-##鹌
-##踌
-##钹
-##蚪
-##颧
-##鹳
-##鲲
-##驷
-##潴
-##焱
-##稔
-##悌
-##唏
-##苒
-##蹙
-##氩
-##宓
-##綦
-##苎
-##疃
-##攫
-##掾
-##徭
-##舀
-##逶
-##嗤
-##蜷
-##茔
-##疳
-##迳
-##罄
-##瓠
-##讪
-##傈
-##杲
-##灞
-##氲
-##鬲
-##獠
-##柒
-##骧
-##搀
-##珩
-##绦
-##嚏
-##镛
-##喱
-##倏
-##馋
-##茭
-##擘
-##斫
-##怂
-##唧
-##犍
-##谩
-##赊
-##鬻
-##禛
-##圻
-##蹶
-##缄
-##瘿
-##黠
-##甑
-##矸
-##嘀
-##蹼
-##叼
-##旻
-##鹜
-##稗
-##雒
-##赉
-##馔
-##颦
-##颔
-##掇
-##赅
-##桎
-##痧
-##谄
-##孛
-##笆
-##鲶
-##铳
-##龋
-##盱
-##笏
-##窕
-##苴
-##萋
-##辘
-##琬
-##梏
-##蚧
-##镳
-##瞅
-##睬
-##偌
-##鲵
-##惦
-##蜍
-##靼
-##阗
-##菟
-##黝
-##挈
-##嵴
-##剡
-##楸
-##氤
-##呎
-##珲
-##馄
-##滂
-##蹉
-##蓑
-##锷
-##啜
-##婵
-##鬣
-##钿
-##晌
-##蛆
-##隗
-##酞
-##枞
-##戬
-##獾
-##镕
-##饨
-##娣
-##缰
-##邾
-##鹗
-##嗒
-##苋
-##薮
-##棹
-##拄
-##埕
-##勖
-##鹞
-##殚
-##鲢
-##啖
-##沣
-##靥
-##葭
-##诿
-##鸪
-##饴
-##疖
-##抟
-##睽
-##稞
-##吋
-##谀
-##澍
-##杈
-##妤
-##峄
-##漉
-##気
-##咲
-##璘
-##萜
-##僭
-##朐
-##圜
-##癞
-##藿
-##珉
-##陉
-##僮
-##膻
-##薹
-##汊
-##锗
-##昉
-##猗
-##锶
-##跛
-##嘹
-##瓤
-##衄
-##豕
-##吆
-##腆
-##喆
-##莴
-##谌
-##珙
-##疥
-##鲑
-##玷
-##蛔
-##砀
-##谔
-##睥
-##蹑
-##诒
-##逋
-##姝
-##刈
-##婧
-##喳
-##镞
-##铌
-##辎
-##鹧
-##檩
-##扪
-##霰
-##裆
-##嬷
-##刎
-##嵋
-##悱
-##嘤
-##篁
-##荸
-##瞑
-##殓
-##搽
-##橇
-##雎
-##弭
-##獐
-##恿
-##眦
-##铐
-##尕
-##捎
-##诟
-##痨
-##笞
-##趺
-##唬
-##苣
-##啾
-##瘪
-##垸
-##橹
-##濛
-##曷
-##樾
-##汨
-##仟
-##姒
-##怦
-##荏
-##诤
-##苡
-##吭
-##崆
-##氡
-##脩
-##胝
-##钏
-##屐
-##忐
-##彧
-##拚
-##鏖
-##孳
-##忑
-##邝
-##穰
-##摈
-##庖
-##鸵
-##矽
-##鲟
-##発
-##菅
-##圪
-##蹋
-##衾
-##簋
-##璎
-##噎
-##嬗
-##肼
-##跎
-##滟
-##戦
-##嵬
-##仝
-##惇
-##纾
-##炁
-##闳
-##骐
-##秣
-##眙
-##谘
-##碓
-##疔
-##恂
-##鳕
-##鸱
-##爨
-##镊
-##钯
-##圮
-##楽
-##堀
-##膘
-##噗
-##锹
-##杼
-##酊
-##挎
-##箸
-##郗
-##垌
-##溏
-##蔫
-##偻
-##妫
-##飚
-##辔
-##濬
-##瑄
-##觚
-##铍
-##跚
-##翕
-##煊
-##耄
-##铋
-##篦
-##阇
-##骛
-##莪
-##吲
-##唁
-##箧
-##珅
-##潋
-##迨
-##哽
-##砦
-##缗
-##謇
-##呸
-##垓
-##糍
-##璠
-##妣
-##狎
-##攥
-##闇
-##蛉
-##瑁
-##腼
-##蹒
-##嶷
-##莠
-##沤
-##哚
-##遑
-##跺
-##膦
-##蹿
-##郫
-##玳
-##埚
-##衿
-##醪
-##挹
-##绡
-##汜
-##坩
-##旃
-##鸨
-##翈
-##抡
-##晞
-##盥
-##藁
-##蓖
-##臊
-##羰
-##楝
-##噱
-##饽
-##苌
-##褓
-##佶
-##稜
-##瞠
-##仡
-##伉
-##襁
-##涞
-##蜇
-##抿
-##瑗
-##孱
-##懑
-##淦
-##赝
-##醌
-##缫
-##蠲
-##嚓
-##鲷
-##湫
-##捋
-##咩
-##裏
-##犒
-##墀
-##硐
-##蔸
-##钽
-##麂
-##蒡
-##鼹
-##绻
-##錾
-##仃
-##篙
-##蕤
-##铤
-##槁
-##牖
-##螈
-##俦
-##笄
-##啻
-##対
-##郤
-##闼
-##醺
-##赍
-##檗
-##裾
-##噫
-##掸
-##箓
-##妪
-##乂
-##蝈
-##砻
-##胍
-##蜱
-##聃
-##雠
-##碚
-##椤
-##缯
-##昴
-##缱
-##祎
-##缬
-##铙
-##孀
-##笳
-##蘇
-##愆
-##榉
-##氙
-##燹
-##撂
-##菽
-##箬
-##蛄
-##瘸
-##嬛
-##橐
-##纡
-##刽
-##辂
-##蒯
-##邨
-##赀
-##跸
-##邙
-##黟
-##磴
-##闿
-##垟
-##嵯
-##钚
-##跄
-##潸
-##崴
-##恁
-##楮
-##腧
-##胨
-##芫
-##碴
-##隰
-##杓
-##貉
-##欹
-##侑
-##鳜
-##铄
-##椴
-##昇
-##醍
-##肓
-##缂
-##铡
-##蹠
-##徂
-##豢
-##蒽
-##菡
-##衲
-##阚
-##芗
-##痍
-##玠
-##晷
-##淝
-##鄯
-##糗
-##耨
-##榧
-##胴
-##蕈
-##镬
-##鼾
-##摭
-##鸮
-##恚
-##実
-##砝
-##珣
-##寤
-##埙
-##锏
-##喟
-##蘅
-##骺
-##捭
-##莜
-##缶
-##锟
-##叵
-##炷
-##鲧
-##胼
-##査
-##岬
-##鹂
-##牯
-##珥
-##莼
-##邠
-##眇
-##卟
-##変
-##惴
-##渑
-##蚱
-##瞌
-##瘰
-##佝
-##旸
-##衽
-##郅
-##奁
-##魑
-##缛
-##颙
-##镫
-##簌
-##豇
-##姹
-##邋
-##暝
-##釐
-##洹
-##咿
-##俳
-##蜊
-##醐
-##聩
-##坻
-##毽
-##喾
-##辋
-##倌
-##媪
-##蛳
-##滹
-##哙
-##阊
-##趸
-##祢
-##籀
-##徼
-##訾
-##髁
-##砜
-##撸
-##瓘
-##缁
-##镓
-##縻
-##菀
-##酢
-##桠
-##撵
-##怏
-##渌
-##摞
-##槲
-##浠
-##诜
-##魉
-##韫
-##亓
-##盤
-##瑭
-##魍
-##襞
-##爿
-##浃
-##樯
-##讵
-##揩
-##耋
-##帏
-##崃
-##鸩
-##遢
-##臃
-##粿
-##禳
-##桫
-##髹
-##诳
-##踉
-##郃
-##嗖
-##讧
-##碁
-##湎
-##阏
-##媾
-##様
-##哔
-##舸
-##曩
-##忝
-##峁
-##掂
-##葳
-##鄄
-##谵
-##彊
-##锴
-##郜
-##葖
-##蓇
-##瓴
-##鳟
-##橼
-##鲇
-##邗
-##犄
-##秭
-##槭
-##缵
-##巯
-##龊
-##狍
-##擞
-##瞽
-##栲
-##撅
-##瑀
-##戢
-##朓
-##逖
-##椹
-##洺
-##艏
-##苁
-##滘
-##铧
-##侪
-##豳
-##竦
-##貔
-##圄
-##呷
-##旄
-##遛
-##芈
-##砣
-##桷
-##龌
-##疬
-##缟
-##洌
-##跏
-##蝮
-##菰
-##帑
-##怙
-##豸
-##雩
-##誊
-##臬
-##镣
-##箇
-##踱
-##钍
-##苫
-##蝽
-##浯
-##単
-##亶
-##囹
-##穑
-##佻
-##绌
-##诔
-##鹬
-##髌
-##蒌
-##鳏
-##殄
-##怛
-##筌
-##刳
-##翮
-##卍
-##畹
-##箜
-##燔
-##赳
-##篌
-##窨
-##翥
-##炅
-##钕
-##莳
-##忖
-##戡
-##沢
-##狒
-##圉
-##琯
-##邰
-##苾
-##犸
-##邡
-##郏
-##襦
-##沆
-##玟
-##濉
-##洎
-##莨
-##氘
-##咛
-##佺
-##腩
-##鳔
-##剜
-##秕
-##牝
-##芨
-##関
-##拊
-##竑
-##圹
-##颡
-##摺
-##沩
-##蜉
-##筚
-##愔
-##肟
-##俶
-##堃
-##绉
-##奭
-##罅
-##嗳
-##蜢
-##疠
-##帔
-##髡
-##黥
-##褛
-##柰
-##鏊
-##痼
-##堞
-##嗝
-##娉
-##戕
-##铱
-##耜
-##觥
-##镒
-##呓
-##蒹
-##栱
-##卮
-##琚
-##逦
-##酩
-##蓍
-##虺
-##谠
-##鼋
-##焗
-##褴
-##砒
-##赧
-##蛏
-##蚬
-##瘕
-##顗
-##愠
-##勣
-##飕
-##徳
-##滢
-##琇
-##鳙
-##瞟
-##尻
-##澶
-##荽
-##舐
-##侂
-##黼
-##潟
-##绂
-##瘗
-##蓥
-##竽
-##濞
-##骖
-##偁
-##応
-##锜
-##匏
-##赑
-##讦
-##诨
-##罘
-##巖
-##嫘
-##颀
-##岿
-##虻
-##罴
-##囗
-##溆
-##噤
-##骝
-##咂
-##锛
-##槊
-##啕
-##驽
-##凇
-##籴
-##硖
-##铯
-##怿
-##笥
-##噙
-##倨
-##坭
-##醅
-##滏
-##悻
-##聒
-##枥
-##昺
-##酆
-##簟
-##睇
-##轫
-##溱
-##骢
-##榘
-##珺
-##跹
-##蚶
-##驺
-##饧
-##噼
-##儆
-##氚
-##哧
-##旒
-##鸬
-##夥
-##玦
-##貅
-##揄
-##戗
-##璩
-##剐
-##垴
-##蘼
-##裒
-##躅
-##唳
-##嗑
-##荦
-##霈
-##缦
-##啭
-##隈
-##悫
-##彀
-##悭
-##焓
-##磔
-##蓊
-##郾
-##枧
-##鹚
-##検
-##屃
-##馑
-##嗲
-##铟
-##薤
-##涔
-##樗
-##忾
-##収
-##绺
-##烊
-##螫
-##黩
-##鞫
-##鲠
-##嘭
-##缣
-##蒺
-##黒
-##骘
-##氖
-##镝
-##俅
-##谮
-##屦
-##摁
-##氪
-##蘧
-##伝
-##腠
-##叡
-##鲂
-##続
-##讣
-##耷
-##燊
-##鸷
-##猊
-##囡
-##崤
-##砬
-##湜
-##翚
-##峯
-##鲎
-##蕖
-##鹈
-##凼
-##泫
-##荑
-##黻
-##牂
-##鄣
-##篑
-##髭
-##陬
-##寔
-##疴
-##邽
-##喏
-##彖
-##彘
-##赟
-##盹
-##诮
-##鸫
-##茕
-##铖
-##闩
-##読
-##鄜
-##漈
-##盍
-##甭
-##愎
-##魃
-##炆
-##鍊
-##蛐
-##薜
-##楯
-##鲀
-##逡
-##嘞
-##侔
-##觇
-##糸
-##踮
-##狷
-##菘
-##寳
-##扃
-##禊
-##喑
-##塍
-##栝
-##瓿
-##廨
-##貘
-##馕
-##僰
-##哏
-##瑷
-##疎
-##蝣
-##怵
-##阃
-##弢
-##镲
-##螅
-##吖
-##碲
-##夼
-##茌
-##嗬
-##靺
-##髀
-##铊
-##谡
-##癔
-##镠
-##巻
-##秾
-##菪
-##赜
-##铈
-##髙
-##鲳
-##珰
-##畋
-##泅
-##鲅
-##泚
-##飏
-##屍
-##仨
-##葚
-##叻
-##咻
-##衩
-##郄
-##蹩
-##嬖
-##踽
-##柽
-##鞨
-##麴
-##薙
-##钇
-##氵
-##垆
-##犟
-##罍
-##経
-##粜
-##焜
-##牀
-##埝
-##洧
-##覧
-##蓣
-##甯
-##蒐
-##馐
-##畑
-##缑
-##礽
-##瞋
-##浍
-##袢
-##桕
-##侩
-##詈
-##戸
-##烝
-##堌
-##伋
-##倬
-##圯
-##碇
-##纰
-##磾
-##泔
-##纮
-##蓁
-##铗
-##弇
-##挲
-##艉
-##鱬
-##泺
-##橛
-##袴
-##韪
-##籓
-##贶
-##棰
-##趵
-##樨
-##傕
-##玕
-##毎
-##繸
-##劵
-##镧
-##秫
-##邶
-##猞
-##廛
-##栌
-##钲
-##镦
-##嘏
-##蝰
-##镏
-##淠
-##荇
-##逄
-##嘅
-##祕
-##瑠
-##炝
-##杪
-##埴
-##獬
-##柢
-##捱
-##跣
-##涑
-##撃
-##伢
-##堠
-##卽
-##猁
-##厣
-##辏
-##旆
-##茆
-##乜
-##踯
-##。
-##?
-##!
-##?
-##;
-[UNK]
diff --git a/modules/text/text_generation/ernie_gen/template/decode.py b/modules/text/text_generation/ernie_gen/template/decode.py
new file mode 100644
index 0000000000000000000000000000000000000000..3aadd245509bd5d1335b327c15a5c2de520f39ab
--- /dev/null
+++ b/modules/text/text_generation/ernie_gen/template/decode.py
@@ -0,0 +1,288 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+import re
+import argparse
+import logging
+import json
+import numpy as np
+from collections import namedtuple
+
+import paddle
+import paddle.nn as nn
+import numpy as np
+from paddlenlp.utils.log import logger
+
+
+def gen_bias(encoder_inputs, decoder_inputs, step):
+ decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
+ encoder_bsz, encoder_seqlen = encoder_inputs.shape[:2]
+ attn_bias = paddle.reshape(paddle.arange(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
+ decoder_bias = paddle.cast((paddle.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
+ 'float32') #[1, decoderlen, decoderlen]
+ encoder_bias = paddle.unsqueeze(paddle.cast(paddle.ones_like(encoder_inputs), 'float32'),
+ [1]) #[bsz, 1, encoderlen]
+ encoder_bias = paddle.expand(encoder_bias,
+ [encoder_bsz, decoder_seqlen, encoder_seqlen]) #[bsz,decoderlen, encoderlen]
+ decoder_bias = paddle.expand(decoder_bias,
+ [decoder_bsz, decoder_seqlen, decoder_seqlen]) #[bsz, decoderlen, decoderlen]
+ if step > 0:
+ bias = paddle.concat(
+ [encoder_bias, paddle.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
+ else:
+ bias = paddle.concat([encoder_bias, decoder_bias], -1)
+ return bias
+
+
+@paddle.no_grad()
+def greedy_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ tgt_type_id=3):
+ _, logits, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+ has_stopped = np.zeros([d_batch], dtype=np.bool)
+ gen_seq_len = np.zeros([d_batch], dtype=np.int64)
+ output_ids = []
+
+ past_cache = info['caches']
+
+ cls_ids = paddle.ones([d_batch], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch], dtype='int64') * attn_id
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ gen_ids = paddle.argmax(logits, -1)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [paddle.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
+ cached_v = [paddle.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
+ past_cache = (cached_k, cached_v)
+
+ gen_ids = gen_ids[:, 1]
+ ids = paddle.stack([gen_ids, attn_ids], 1)
+
+ gen_ids = gen_ids.numpy()
+ has_stopped |= (gen_ids == eos_id).astype(np.bool)
+ gen_seq_len += (1 - has_stopped.astype(np.int64))
+ output_ids.append(gen_ids.tolist())
+ if has_stopped.all():
+ break
+ output_ids = np.array(output_ids).transpose([1, 0])
+ return output_ids
+
+
+BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
+BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
+
+
+def log_softmax(x):
+ e_x = np.exp(x - np.max(x))
+ return np.log(e_x / e_x.sum())
+
+
+def mask_prob(p, onehot_eos, finished):
+ is_finished = paddle.cast(paddle.reshape(finished, [-1, 1]) != 0, 'float32')
+ p = is_finished * (1. - paddle.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
+ return p
+
+
+def hyp_score(log_probs, length, length_penalty):
+ lp = paddle.pow((5. + paddle.cast(length, 'float32')) / 6., length_penalty)
+ return log_probs / lp
+
+
+def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
+ """logits.shape == [B*W, V]"""
+ _, vocab_size = logits.shape
+
+ bsz, beam_width = state.log_probs.shape
+ onehot_eos = paddle.cast(nn.functional.one_hot(paddle.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
+
+ probs = paddle.log(nn.functional.softmax(logits)) #[B*W, V]
+ probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
+ allprobs = paddle.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
+
+ not_finished = 1 - paddle.reshape(state.finished, [-1, 1]) #[B*W,1]
+ not_eos = 1 - onehot_eos
+ length_to_add = not_finished * not_eos #[B*W,V]
+ alllen = paddle.reshape(state.lengths, [-1, 1]) + length_to_add
+
+ allprobs = paddle.reshape(allprobs, [-1, beam_width * vocab_size])
+ alllen = paddle.reshape(alllen, [-1, beam_width * vocab_size])
+ allscore = hyp_score(allprobs, alllen, length_penalty)
+ if is_first_step:
+ allscore = paddle.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
+ scores, idx = paddle.topk(allscore, k=beam_width) #[B, W]
+ next_beam_id = idx // vocab_size #[B, W]
+ next_word_id = idx % vocab_size
+
+ gather_idx = paddle.concat([paddle.nonzero(idx != -1)[:, :1], paddle.reshape(idx, [-1, 1])], 1)
+ next_probs = paddle.reshape(paddle.gather_nd(allprobs, gather_idx), idx.shape)
+ next_len = paddle.reshape(paddle.gather_nd(alllen, gather_idx), idx.shape)
+
+ gather_idx = paddle.concat([paddle.nonzero(next_beam_id != -1)[:, :1], paddle.reshape(next_beam_id, [-1, 1])], 1)
+ next_finished = paddle.reshape(paddle.gather_nd(state.finished, gather_idx),
+ state.finished.shape) #[gather new beam state according to new beam id]
+
+ next_finished += paddle.cast(next_word_id == eos_id, 'int64')
+ next_finished = paddle.cast(next_finished > 0, 'int64')
+
+ next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
+ output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
+
+ return output, next_state
+
+
+@paddle.no_grad()
+def beam_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ beam_width=5,
+ tgt_type_id=3,
+ length_penalty=1.0):
+ _, __, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+
+ state = BeamSearchState(log_probs=paddle.zeros([d_batch, beam_width], 'float32'),
+ lengths=paddle.zeros([d_batch, beam_width], 'int64'),
+ finished=paddle.zeros([d_batch, beam_width], 'int64'))
+ outputs = []
+
+ def reorder_(t, parent_id):
+ """reorder cache according to parent beam id"""
+ gather_idx = paddle.nonzero(parent_id != -1)[:, 0] * beam_width + paddle.reshape(parent_id, [-1])
+ t = paddle.gather(t, gather_idx)
+ return t
+
+ def tile_(t, times):
+ _shapes = list(t.shape[1:])
+ new_shape = [t.shape[0], times] + list(t.shape[1:])
+ ret = paddle.reshape(paddle.expand(paddle.unsqueeze(t, [1]), new_shape), [
+ -1,
+ ] + _shapes)
+ return ret
+
+ cached_k, cached_v = info['caches']
+ cached_k = [tile_(k, beam_width) for k in cached_k]
+ cached_v = [tile_(v, beam_width) for v in cached_v]
+ past_cache = (cached_k, cached_v)
+
+ token_ids = tile_(token_ids, beam_width)
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+
+ cls_ids = paddle.ones([d_batch * beam_width], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ output, state = beam_search_step(state,
+ logits[:, 1],
+ eos_id=eos_id,
+ beam_width=beam_width,
+ is_first_step=(step == 0),
+ length_penalty=length_penalty)
+ outputs.append(output)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [
+ reorder_(paddle.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids)
+ for pk, k in zip(past_cached_k, cached_k)
+ ] # concat cached
+ cached_v = [
+ reorder_(paddle.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids)
+ for pv, v in zip(past_cached_v, cached_v)
+ ]
+ past_cache = (cached_k, cached_v)
+
+ pred_ids_flatten = paddle.reshape(output.predicted_ids, [d_batch * beam_width])
+ ids = paddle.stack([pred_ids_flatten, attn_ids], 1)
+
+ if state.finished.numpy().all():
+ break
+
+ final_ids = paddle.stack([o.predicted_ids for o in outputs], 0)
+ final_parent_ids = paddle.stack([o.beam_parent_ids for o in outputs], 0)
+ final_ids = nn.functional.gather_tree(final_ids, final_parent_ids) #[:, :, 0] #pick best beam
+ final_ids = paddle.transpose(paddle.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
+
+ return final_ids.numpy()
+
+
+en_patten = re.compile(r'^[a-zA-Z0-9]*$')
+
+
+def post_process(token):
+ if token.startswith('##'):
+ ret = token[2:]
+ elif token in ['[CLS]', '[SEP]', '[PAD]']:
+ ret = ''
+ else:
+ if en_patten.match(token):
+ ret = ' ' + token
+ else:
+ ret = token
+ return ret
diff --git a/modules/text/text_generation/ernie_gen/template/model/decode.py b/modules/text/text_generation/ernie_gen/template/model/decode.py
deleted file mode 100644
index d07a58b559796b0331946561ed2dcbdc85ffadae..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/template/model/decode.py
+++ /dev/null
@@ -1,259 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import re
-import numpy as np
-from collections import namedtuple
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-import paddle.fluid.dygraph as D
-
-
-def gen_bias(encoder_inputs, decoder_inputs, step):
- decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
- attn_bias = L.reshape(L.range(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
- decoder_bias = L.cast((L.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
- 'float32') #[1, 1, decoderlen, decoderlen]
- encoder_bias = L.unsqueeze(L.cast(L.ones_like(encoder_inputs), 'float32'), [1]) #[bsz, 1, encoderlen]
- encoder_bias = L.expand(encoder_bias, [1, decoder_seqlen, 1]) #[bsz,decoderlen, encoderlen]
- decoder_bias = L.expand(decoder_bias, [decoder_bsz, 1, 1]) #[bsz, decoderlen, decoderlen]
- if step > 0:
- bias = L.concat([encoder_bias, L.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
- else:
- bias = L.concat([encoder_bias, decoder_bias], -1)
- return bias
-
-
-@D.no_grad
-def greedy_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- tgt_type_id=3):
- model.eval()
- _, logits, info = model(q_ids, q_sids)
- gen_ids = L.argmax(logits, -1)
- d_batch, d_seqlen = q_ids.shape
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
- has_stopped = np.zeros([d_batch], dtype=np.bool)
- gen_seq_len = np.zeros([d_batch], dtype=np.int64)
- output_ids = []
-
- past_cache = info['caches']
-
- cls_ids = L.ones([d_batch], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch], dtype='int64') * attn_id
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
- pos_ids += seqlen
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
- gen_ids = L.argmax(logits, -1)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [L.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
- cached_v = [L.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
- past_cache = (cached_k, cached_v)
-
- gen_ids = gen_ids[:, 1]
- ids = L.stack([gen_ids, attn_ids], 1)
-
- gen_ids = gen_ids.numpy()
- has_stopped |= (gen_ids == eos_id).astype(np.bool)
- gen_seq_len += (1 - has_stopped.astype(np.int64))
- output_ids.append(gen_ids.tolist())
- if has_stopped.all():
- break
- output_ids = np.array(output_ids).transpose([1, 0])
- return output_ids
-
-
-BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
-BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
-
-
-def log_softmax(x):
- e_x = np.exp(x - np.max(x))
- return np.log(e_x / e_x.sum())
-
-
-def mask_prob(p, onehot_eos, finished):
- is_finished = L.cast(L.reshape(finished, [-1, 1]) != 0, 'float32')
- p = is_finished * (1. - L.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
- return p
-
-
-def hyp_score(log_probs, length, length_penalty):
- lp = L.pow((5. + L.cast(length, 'float32')) / 6., length_penalty)
- return log_probs / lp
-
-
-def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
- """logits.shape == [B*W, V]"""
- beam_size, vocab_size = logits.shape # as batch size=1 in this hub module. the first dim means bsz * beam_size equals beam_size
- logits_np = logits.numpy()
- for i in range(beam_size):
- logits_np[i][17963] = 0 # make [UNK] prob = 0
- logits = D.to_variable(logits_np)
-
- bsz, beam_width = state.log_probs.shape
- onehot_eos = L.cast(F.one_hot(L.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
-
- probs = L.log(L.softmax(logits)) #[B*W, V]
- probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
- allprobs = L.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
-
- not_finished = 1 - L.reshape(state.finished, [-1, 1]) #[B*W,1]
- not_eos = 1 - onehot_eos
- length_to_add = not_finished * not_eos #[B*W,V]
- alllen = L.reshape(state.lengths, [-1, 1]) + length_to_add
-
- allprobs = L.reshape(allprobs, [-1, beam_width * vocab_size])
- alllen = L.reshape(alllen, [-1, beam_width * vocab_size])
- allscore = hyp_score(allprobs, alllen, length_penalty)
- if is_first_step:
- allscore = L.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
- scores, idx = L.topk(allscore, k=beam_width) #[B, W]
- next_beam_id = idx // vocab_size #[B, W]
- next_word_id = idx % vocab_size
-
- gather_idx = L.concat([L.where(idx != -1)[:, :1], L.reshape(idx, [-1, 1])], 1)
- next_probs = L.reshape(L.gather_nd(allprobs, gather_idx), idx.shape)
- next_len = L.reshape(L.gather_nd(alllen, gather_idx), idx.shape)
-
- gather_idx = L.concat([L.where(next_beam_id != -1)[:, :1], L.reshape(next_beam_id, [-1, 1])], 1)
- next_finished = L.reshape(L.gather_nd(state.finished, gather_idx),
- state.finished.shape) #[gather new beam state according to new beam id]
-
- next_finished += L.cast(next_word_id == eos_id, 'int64')
- next_finished = L.cast(next_finished > 0, 'int64')
-
- next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
- output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
-
- return output, next_state
-
-
-@D.no_grad
-def beam_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- beam_width=5,
- tgt_type_id=3,
- length_penalty=1.0):
- model.eval()
- _, __, info = model(q_ids, q_sids)
- d_batch, d_seqlen = q_ids.shape
-
- state = BeamSearchState(
- log_probs=L.zeros([d_batch, beam_width], 'float32'),
- lengths=L.zeros([d_batch, beam_width], 'int64'),
- finished=L.zeros([d_batch, beam_width], 'int64'))
- outputs = []
-
- def reorder_(t, parent_id):
- """reorder cache according to parent beam id"""
- gather_idx = L.where(parent_id != -1)[:, 0] * beam_width + L.reshape(parent_id, [-1])
- t = L.gather(t, gather_idx)
- return t
-
- def tile_(t, times):
- _shapes = list(t.shape[1:])
- ret = L.reshape(L.expand(L.unsqueeze(t, [1]), [
- 1,
- times,
- ] + [
- 1,
- ] * len(_shapes)), [
- -1,
- ] + _shapes)
- return ret
-
- cached_k, cached_v = info['caches']
- cached_k = [tile_(k, beam_width) for k in cached_k]
- cached_v = [tile_(v, beam_width) for v in cached_v]
- past_cache = (cached_k, cached_v)
-
- q_ids = tile_(q_ids, beam_width)
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
-
- cls_ids = L.ones([d_batch * beam_width], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
- pos_ids += seqlen
-
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
-
- output, state = beam_search_step(
- state,
- logits[:, 1],
- eos_id=eos_id,
- beam_width=beam_width,
- is_first_step=(step == 0),
- length_penalty=length_penalty)
- outputs.append(output)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [
- reorder_(L.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids) for pk, k in zip(past_cached_k, cached_k)
- ] # concat cached
- cached_v = [
- reorder_(L.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids) for pv, v in zip(past_cached_v, cached_v)
- ]
- past_cache = (cached_k, cached_v)
-
- pred_ids_flatten = L.reshape(output.predicted_ids, [d_batch * beam_width])
- ids = L.stack([pred_ids_flatten, attn_ids], 1)
-
- if state.finished.numpy().all():
- break
-
- final_ids = L.stack([o.predicted_ids for o in outputs], 0)
- final_parent_ids = L.stack([o.beam_parent_ids for o in outputs], 0)
- final_ids = L.gather_tree(final_ids, final_parent_ids) #[:, :,
- #0] #pick best beam
- final_ids = L.transpose(L.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
- return final_ids
-
-
-en_patten = re.compile(r'^[a-zA-Z0-9]*$')
-
-
-def post_process(token):
- if token.startswith('##'):
- ret = token[2:]
- else:
- if en_patten.match(token):
- ret = ' ' + token
- else:
- ret = token
- return ret
diff --git a/modules/text/text_generation/ernie_gen/template/model/file_utils.py b/modules/text/text_generation/ernie_gen/template/model/file_utils.py
deleted file mode 100644
index 608be4efc6644626f7f408df200fd299f2dd997e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/template/model/file_utils.py
+++ /dev/null
@@ -1,46 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-
-from tqdm import tqdm
-from paddlehub.common.logger import logger
-from paddlehub.common.dir import MODULE_HOME
-
-
-def _fetch_from_remote(url, force_download=False):
- import tempfile, requests, tarfile
- cached_dir = os.path.join(MODULE_HOME, "ernie_for_gen")
- if force_download or not os.path.exists(cached_dir):
- with tempfile.NamedTemporaryFile() as f:
- #url = 'https://ernie.bj.bcebos.com/ERNIE_stable.tgz'
- r = requests.get(url, stream=True)
- total_len = int(r.headers.get('content-length'))
- for chunk in tqdm(
- r.iter_content(chunk_size=1024), total=total_len // 1024, desc='downloading %s' % url, unit='KB'):
- if chunk:
- f.write(chunk)
- f.flush()
- logger.debug('extacting... to %s' % f.name)
- with tarfile.open(f.name) as tf:
- tf.extractall(path=cached_dir)
- logger.debug('%s cached in %s' % (url, cached_dir))
- return cached_dir
-
-
-def add_docstring(doc):
- def func(f):
- f.__doc__ += ('\n======other docs from supper class ======\n%s' % doc)
- return f
-
- return func
diff --git a/modules/text/text_generation/ernie_gen/template/model/modeling_ernie.py b/modules/text/text_generation/ernie_gen/template/model/modeling_ernie.py
deleted file mode 100644
index d5de28a5fee73371babd05b644e03a0f75ecdd5e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/template/model/modeling_ernie.py
+++ /dev/null
@@ -1,327 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from __future__ import division
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import logging
-
-import paddle.fluid.dygraph as D
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-log = logging.getLogger(__name__)
-
-
-def _build_linear(n_in, n_out, name, init, act=None):
- return D.Linear(
- n_in,
- n_out,
- param_attr=F.ParamAttr(name='%s.w_0' % name if name is not None else None, initializer=init),
- bias_attr='%s.b_0' % name if name is not None else None,
- act=act)
-
-
-def _build_ln(n_in, name):
- return D.LayerNorm(
- normalized_shape=n_in,
- param_attr=F.ParamAttr(
- name='%s_layer_norm_scale' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- bias_attr=F.ParamAttr(
- name='%s_layer_norm_bias' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- )
-
-
-def append_name(name, postfix):
- if name is None:
- return None
- elif name == '':
- return postfix
- else:
- return '%s_%s' % (name, postfix)
-
-
-class AttentionLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(AttentionLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- n_head = cfg['num_attention_heads']
- assert d_model % n_head == 0
- d_model_q = cfg.get('query_hidden_size_per_head', d_model // n_head) * n_head
- d_model_v = cfg.get('value_hidden_size_per_head', d_model // n_head) * n_head
- self.n_head = n_head
- self.d_key = d_model_q // n_head
- self.q = _build_linear(d_model, d_model_q, append_name(name, 'query_fc'), initializer)
- self.k = _build_linear(d_model, d_model_q, append_name(name, 'key_fc'), initializer)
- self.v = _build_linear(d_model, d_model_v, append_name(name, 'value_fc'), initializer)
- self.o = _build_linear(d_model_v, d_model, append_name(name, 'output_fc'), initializer)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=cfg['attention_probs_dropout_prob'],
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, queries, keys, values, attn_bias, past_cache):
- assert len(queries.shape) == len(keys.shape) == len(values.shape) == 3
-
- q = self.q(queries)
- k = self.k(keys)
- v = self.v(values)
-
- cache = (k, v)
- if past_cache is not None:
- cached_k, cached_v = past_cache
- k = L.concat([cached_k, k], 1)
- v = L.concat([cached_v, v], 1)
-
- q = L.transpose(L.reshape(q, [0, 0, self.n_head, q.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- k = L.transpose(L.reshape(k, [0, 0, self.n_head, k.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- v = L.transpose(L.reshape(v, [0, 0, self.n_head, v.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
-
- q = L.scale(q, scale=self.d_key**-0.5)
- score = L.matmul(q, k, transpose_y=True)
- if attn_bias is not None:
- score += attn_bias
- score = L.softmax(score, use_cudnn=True)
- score = self.dropout(score)
-
- out = L.matmul(score, v)
- out = L.transpose(out, [0, 2, 1, 3])
- out = L.reshape(out, [0, 0, out.shape[2] * out.shape[3]])
-
- out = self.o(out)
- return out, cache
-
-
-class PositionwiseFeedForwardLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(PositionwiseFeedForwardLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_ffn = cfg.get('intermediate_size', 4 * d_model)
- assert cfg['hidden_act'] in ['relu', 'gelu']
- self.i = _build_linear(d_model, d_ffn, append_name(name, 'fc_0'), initializer, act=cfg['hidden_act'])
- self.o = _build_linear(d_ffn, d_model, append_name(name, 'fc_1'), initializer)
- prob = cfg.get('intermediate_dropout_prob', 0.)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs):
- hidden = self.i(inputs)
- hidden = self.dropout(hidden)
- out = self.o(hidden)
- return out
-
-
-class ErnieBlock(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieBlock, self).__init__()
- d_model = cfg['hidden_size']
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.attn = AttentionLayer(cfg, name=append_name(name, 'multi_head_att'))
- self.ln1 = _build_ln(d_model, name=append_name(name, 'post_att'))
- self.ffn = PositionwiseFeedForwardLayer(cfg, name=append_name(name, 'ffn'))
- self.ln2 = _build_ln(d_model, name=append_name(name, 'post_ffn'))
- prob = cfg.get('intermediate_dropout_prob', cfg['hidden_dropout_prob'])
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- attn_out, cache = self.attn(inputs, inputs, inputs, attn_bias, past_cache=past_cache) #self attn
- attn_out = self.dropout(attn_out)
- hidden = attn_out + inputs
- hidden = self.ln1(hidden) # dropout/ add/ norm
-
- ffn_out = self.ffn(hidden)
- ffn_out = self.dropout(ffn_out)
- hidden = ffn_out + hidden
- hidden = self.ln2(hidden)
- return hidden, cache
-
-
-class ErnieEncoderStack(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieEncoderStack, self).__init__()
- n_layers = cfg['num_hidden_layers']
- self.block = D.LayerList([ErnieBlock(cfg, append_name(name, 'layer_%d' % i)) for i in range(n_layers)])
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- if past_cache is not None:
- assert isinstance(
- past_cache,
- tuple), 'unknown type of `past_cache`, expect tuple or list. got %s' % repr(type(past_cache))
- past_cache = list(zip(*past_cache))
- else:
- past_cache = [None] * len(self.block)
- cache_list_k, cache_list_v, hidden_list = [], [], [inputs]
-
- for b, p in zip(self.block, past_cache):
- inputs, cache = b(inputs, attn_bias=attn_bias, past_cache=p)
- cache_k, cache_v = cache
- cache_list_k.append(cache_k)
- cache_list_v.append(cache_v)
- hidden_list.append(inputs)
-
- return inputs, hidden_list, (cache_list_k, cache_list_v)
-
-
-class ErnieModel(D.Layer):
- def __init__(self, cfg, name=None):
- """
- Fundamental pretrained Ernie model
- """
- log.debug('init ErnieModel with config: %s' % repr(cfg))
- D.Layer.__init__(self)
- d_model = cfg['hidden_size']
- d_emb = cfg.get('emb_size', cfg['hidden_size'])
- d_vocab = cfg['vocab_size']
- d_pos = cfg['max_position_embeddings']
- d_sent = cfg.get("sent_type_vocab_size") or cfg['type_vocab_size']
- self.n_head = cfg['num_attention_heads']
- self.return_additional_info = cfg.get('return_additional_info', False)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.ln = _build_ln(d_model, name=append_name(name, 'pre_encoder'))
- self.word_emb = D.Embedding([d_vocab, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'word_embedding'), initializer=initializer))
- self.pos_emb = D.Embedding([d_pos, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'pos_embedding'), initializer=initializer))
- self.sent_emb = D.Embedding([d_sent, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'sent_embedding'), initializer=initializer))
- prob = cfg['hidden_dropout_prob']
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- self.encoder_stack = ErnieEncoderStack(cfg, append_name(name, 'encoder'))
- if cfg.get('has_pooler', True):
- self.pooler = _build_linear(
- cfg['hidden_size'], cfg['hidden_size'], append_name(name, 'pooled_fc'), initializer, act='tanh')
- else:
- self.pooler = None
- self.train()
-
- def eval(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).eval()
- self.training = False
- for l in self.sublayers():
- l.training = False
-
- def train(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).train()
- self.training = True
- for l in self.sublayers():
- l.training = True
-
- def forward(self,
- src_ids,
- sent_ids=None,
- pos_ids=None,
- input_mask=None,
- attn_bias=None,
- past_cache=None,
- use_causal_mask=False):
- """
- Args:
- src_ids (`Variable` of shape `[batch_size, seq_len]`):
- Indices of input sequence tokens in the vocabulary.
- sent_ids (optional, `Variable` of shape `[batch_size, seq_len]`):
- aka token_type_ids, Segment token indices to indicate first and second portions of the inputs.
- if None, assume all tokens come from `segment_a`
- pos_ids(optional, `Variable` of shape `[batch_size, seq_len]`):
- Indices of positions of each input sequence tokens in the position embeddings.
- input_mask(optional `Variable` of shape `[batch_size, seq_len]`):
- Mask to avoid performing attention on the padding token indices of the encoder input.
- attn_bias(optional, `Variable` of shape `[batch_size, seq_len, seq_len] or False`):
- 3D version of `input_mask`, if set, overrides `input_mask`; if set not False, will not apply attention mask
- past_cache(optional, tuple of two lists: cached key and cached value,
- each is a list of `Variable`s of shape `[batch_size, seq_len, hidden_size]`):
- cached key/value tensor that will be concated to generated key/value when performing self attention.
- if set, `attn_bias` should not be None.
-
- Returns:
- pooled (`Variable` of shape `[batch_size, hidden_size]`):
- output logits of pooler classifier
- encoded(`Variable` of shape `[batch_size, seq_len, hidden_size]`):
- output logits of transformer stack
- """
- assert len(src_ids.shape) == 2, 'expect src_ids.shape = [batch, sequecen], got %s' % (repr(src_ids.shape))
- assert attn_bias is not None if past_cache else True, 'if `past_cache` is specified; attn_bias should not be None'
- d_batch = L.shape(src_ids)[0]
- d_seqlen = L.shape(src_ids)[1]
- if pos_ids is None:
- pos_ids = L.reshape(L.range(0, d_seqlen, 1, dtype='int32'), [1, -1])
- pos_ids = L.cast(pos_ids, 'int64')
- if attn_bias is None:
- if input_mask is None:
- input_mask = L.cast(src_ids != 0, 'float32')
- assert len(input_mask.shape) == 2
- input_mask = L.unsqueeze(input_mask, axes=[-1])
- attn_bias = L.matmul(input_mask, input_mask, transpose_y=True)
- if use_causal_mask:
- sequence = L.reshape(L.range(0, d_seqlen, 1, dtype='float32') + 1., [1, 1, -1, 1])
- causal_mask = L.cast((L.matmul(sequence, 1. / sequence, transpose_y=True) >= 1.), 'float32')
- attn_bias *= causal_mask
- else:
- assert len(attn_bias.shape) == 3, 'expect attn_bias tobe rank 3, got %r' % attn_bias.shape
- attn_bias = (1. - attn_bias) * -10000.0
- attn_bias = L.unsqueeze(attn_bias, [1])
- attn_bias = L.expand(attn_bias, [1, self.n_head, 1, 1]) # avoid broadcast =_=
- attn_bias.stop_gradient = True
-
- if sent_ids is None:
- sent_ids = L.zeros_like(src_ids)
-
- src_embedded = self.word_emb(src_ids)
- pos_embedded = self.pos_emb(pos_ids)
- sent_embedded = self.sent_emb(sent_ids)
- embedded = src_embedded + pos_embedded + sent_embedded
-
- embedded = self.dropout(self.ln(embedded))
-
- encoded, hidden_list, cache_list = self.encoder_stack(embedded, attn_bias, past_cache=past_cache)
- if self.pooler is not None:
- pooled = self.pooler(encoded[:, 0, :])
- else:
- pooled = None
-
- additional_info = {
- 'hiddens': hidden_list,
- 'caches': cache_list,
- }
-
- if self.return_additional_info:
- return pooled, encoded, additional_info
- else:
- return pooled, encoded
diff --git a/modules/text/text_generation/ernie_gen/template/model/modeling_ernie_gen.py b/modules/text/text_generation/ernie_gen/template/model/modeling_ernie_gen.py
deleted file mode 100644
index bc3d783d622356fad1e48f2767640a59edc05d70..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/template/model/modeling_ernie_gen.py
+++ /dev/null
@@ -1,65 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from .modeling_ernie import ErnieModel
-from .modeling_ernie import _build_linear, _build_ln, append_name
-
-
-class ErnieModelForGeneration(ErnieModel):
- def __init__(self, cfg, name=None):
- cfg['return_additional_info'] = True
- cfg['has_pooler'] = False
- super(ErnieModelForGeneration, self).__init__(cfg, name=name)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_vocab = cfg['vocab_size']
-
- self.mlm = _build_linear(
- d_model, d_model, append_name(name, 'mask_lm_trans_fc'), initializer, act=cfg['hidden_act'])
- self.mlm_ln = _build_ln(d_model, name=append_name(name, 'mask_lm_trans'))
- self.mlm_bias = L.create_parameter(
- dtype='float32',
- shape=[d_vocab],
- attr=F.ParamAttr(
- name=append_name(name, 'mask_lm_out_fc.b_0'), initializer=F.initializer.Constant(value=0.0)),
- is_bias=True,
- )
-
- def forward(self, src_ids, *args, **kwargs):
- tgt_labels = kwargs.pop('tgt_labels', None)
- tgt_pos = kwargs.pop('tgt_pos', None)
- encode_only = kwargs.pop('encode_only', False)
- _, encoded, info = ErnieModel.forward(self, src_ids, *args, **kwargs)
- if encode_only:
- return None, None, info
- elif tgt_labels is None:
- encoded = self.mlm(encoded)
- encoded = self.mlm_ln(encoded)
- logits = L.matmul(encoded, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- output_ids = L.argmax(logits, -1)
- return output_ids, logits, info
- else:
- encoded_2d = L.gather_nd(encoded, tgt_pos)
- encoded_2d = self.mlm(encoded_2d)
- encoded_2d = self.mlm_ln(encoded_2d)
- logits_2d = L.matmul(encoded_2d, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- if len(tgt_labels.shape) == 1:
- tgt_labels = L.reshape(tgt_labels, [-1, 1])
-
- loss = L.reduce_mean(
- L.softmax_with_cross_entropy(logits_2d, tgt_labels, soft_label=(tgt_labels.shape[-1] != 1)))
- return loss, logits_2d, info
diff --git a/modules/text/text_generation/ernie_gen/template/model/tokenizing_ernie.py b/modules/text/text_generation/ernie_gen/template/model/tokenizing_ernie.py
deleted file mode 100644
index c9e5638f9a17207ce2d664c27376f08138876da3..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen/template/model/tokenizing_ernie.py
+++ /dev/null
@@ -1,163 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import six
-import re
-import logging
-from functools import partial
-
-import numpy as np
-
-import io
-
-open = partial(io.open, encoding='utf8')
-
-log = logging.getLogger(__name__)
-
-_max_input_chars_per_word = 100
-
-
-def _wordpiece(token, vocab, unk_token, prefix='##', sentencepiece_prefix=''):
- """ wordpiece: helloworld => [hello, ##world] """
- chars = list(token)
- if len(chars) > _max_input_chars_per_word:
- return [unk_token], [(0, len(chars))]
-
- is_bad = False
- start = 0
- sub_tokens = []
- sub_pos = []
- while start < len(chars):
- end = len(chars)
- cur_substr = None
- while start < end:
- substr = "".join(chars[start:end])
- if start == 0:
- substr = sentencepiece_prefix + substr
- if start > 0:
- substr = prefix + substr
- if substr in vocab:
- cur_substr = substr
- break
- end -= 1
- if cur_substr is None:
- is_bad = True
- break
- sub_tokens.append(cur_substr)
- sub_pos.append((start, end))
- start = end
- if is_bad:
- return [unk_token], [(0, len(chars))]
- else:
- return sub_tokens, sub_pos
-
-
-class ErnieTokenizer(object):
- def __init__(self,
- vocab,
- unk_token='[UNK]',
- sep_token='[SEP]',
- cls_token='[CLS]',
- pad_token='[PAD]',
- mask_token='[MASK]',
- wordpiece_prefix='##',
- sentencepiece_prefix='',
- lower=True,
- encoding='utf8',
- special_token_list=[]):
- if not isinstance(vocab, dict):
- raise ValueError('expect `vocab` to be instance of dict, got %s' % type(vocab))
- self.vocab = vocab
- self.lower = lower
- self.prefix = wordpiece_prefix
- self.sentencepiece_prefix = sentencepiece_prefix
- self.pad_id = self.vocab[pad_token]
- self.cls_id = cls_token and self.vocab[cls_token]
- self.sep_id = sep_token and self.vocab[sep_token]
- self.unk_id = unk_token and self.vocab[unk_token]
- self.mask_id = mask_token and self.vocab[mask_token]
- self.unk_token = unk_token
- special_tokens = {pad_token, cls_token, sep_token, unk_token, mask_token} | set(special_token_list)
- pat_str = ''
- for t in special_tokens:
- if t is None:
- continue
- pat_str += '(%s)|' % re.escape(t)
- pat_str += r'([a-zA-Z0-9]+|\S)'
- log.debug('regex: %s' % pat_str)
- self.pat = re.compile(pat_str)
- self.encoding = encoding
-
- def tokenize(self, text):
- if len(text) == 0:
- return []
- if six.PY3 and not isinstance(text, six.string_types):
- text = text.decode(self.encoding)
- if six.PY2 and isinstance(text, str):
- text = text.decode(self.encoding)
-
- res = []
- for match in self.pat.finditer(text):
- match_group = match.group(0)
- if match.groups()[-1]:
- if self.lower:
- match_group = match_group.lower()
- words, _ = _wordpiece(
- match_group,
- vocab=self.vocab,
- unk_token=self.unk_token,
- prefix=self.prefix,
- sentencepiece_prefix=self.sentencepiece_prefix)
- else:
- words = [match_group]
- res += words
- return res
-
- def convert_tokens_to_ids(self, tokens):
- return [self.vocab.get(t, self.unk_id) for t in tokens]
-
- def truncate(self, id1, id2, seqlen):
- len1 = len(id1)
- len2 = len(id2)
- half = seqlen // 2
- if len1 > len2:
- len1_truncated, len2_truncated = max(half, seqlen - len2), min(half, len2)
- else:
- len1_truncated, len2_truncated = min(half, seqlen - len1), max(half, seqlen - len1)
- return id1[:len1_truncated], id2[:len2_truncated]
-
- def build_for_ernie(self, text_id, pair_id=[]):
- """build sentence type id, add [CLS] [SEP]"""
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- ret_id = np.concatenate([[self.cls_id], text_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([[0], text_id_type, [0]], 0)
-
- if len(pair_id):
- pair_id_type = np.ones_like(pair_id, dtype=np.int64)
- ret_id = np.concatenate([ret_id, pair_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([ret_id_type, pair_id_type, [1]], 0)
- return ret_id, ret_id_type
-
- def encode(self, text, pair=None, truncate_to=None):
- text_id = np.array(self.convert_tokens_to_ids(self.tokenize(text)), dtype=np.int64)
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- if pair is not None:
- pair_id = np.array(self.convert_tokens_to_ids(self.tokenize(pair)), dtype=np.int64)
- else:
- pair_id = []
- if truncate_to is not None:
- text_id, pair_id = self.truncate(text_id, [] if pair_id is None else pair_id, truncate_to)
-
- ret_id, ret_id_type = self.build_for_ernie(text_id, pair_id)
- return ret_id, ret_id_type
diff --git a/modules/text/text_generation/ernie_gen/template/module.temp b/modules/text/text_generation/ernie_gen/template/module.temp
index 4a739a7c2075aa36f8ae3782ee7ee0432521a624..c217925217e1ceb9d571d0cfb95c844ced79b2f5 100644
--- a/modules/text/text_generation/ernie_gen/template/module.temp
+++ b/modules/text/text_generation/ernie_gen/template/module.temp
@@ -13,23 +13,19 @@
# limitations under the License.
import ast
import json
+import argparse
+import os
-import paddle.fluid as fluid
+import numpy as np
+import paddle
import paddlehub as hub
from paddlehub.module.module import runnable
from paddlehub.module.nlp_module import DataFormatError
from paddlehub.common.logger import logger
from paddlehub.module.module import moduleinfo, serving
+from paddlenlp.transformers import ErnieTokenizer, ErnieForGeneration
-import argparse
-import os
-import numpy as np
-
-import paddle.fluid.dygraph as D
-
-from .model.tokenizing_ernie import ErnieTokenizer
-from .model.decode import beam_search_infilling
-from .model.modeling_ernie_gen import ErnieModelForGeneration
+from .decode import beam_search_infilling
@moduleinfo(
@@ -42,32 +38,19 @@ from .model.modeling_ernie_gen import ErnieModelForGeneration
type="nlp/text_generation",
)
class ErnieGen(hub.NLPPredictionModule):
- def _initialize(self):
+ def __init__(self):
"""
initialize with the necessary elements
"""
assets_path = os.path.join(self.directory, "assets")
- gen_checkpoint_path = os.path.join(assets_path, "ernie_gen")
- ernie_cfg_path = os.path.join(assets_path, 'ernie_config.json')
- with open(ernie_cfg_path, encoding='utf8') as ernie_cfg_file:
- ernie_cfg = dict(json.loads(ernie_cfg_file.read()))
- ernie_vocab_path = os.path.join(assets_path, 'vocab.txt')
- with open(ernie_vocab_path, encoding='utf8') as ernie_vocab_file:
- ernie_vocab = {
- j.strip().split('\t')[0]: i
- for i, j in enumerate(ernie_vocab_file.readlines())
- }
-
- with fluid.dygraph.guard(fluid.CPUPlace()):
- with fluid.unique_name.guard():
- self.model = ErnieModelForGeneration(ernie_cfg)
- finetuned_states, _ = D.load_dygraph(gen_checkpoint_path)
- self.model.set_dict(finetuned_states)
-
- self.tokenizer = ErnieTokenizer(ernie_vocab)
- self.rev_dict = {v: k for k, v in self.tokenizer.vocab.items()}
- self.rev_dict[self.tokenizer.pad_id] = '' # replace [PAD]
- self.rev_dict[self.tokenizer.unk_id] = '' # replace [PAD]
+ gen_checkpoint_path = os.path.join(assets_path, "ernie_gen.pdparams")
+ self.model = ErnieForGeneration.from_pretrained("ernie-1.0")
+ model_state = paddle.load(gen_checkpoint_path)
+ self.model.set_dict(model_state)
+ self.tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
+ self.rev_dict = self.tokenizer.vocab.idx_to_token
+ self.rev_dict[self.tokenizer.vocab['[PAD]']] = '' # replace [PAD]
+ self.rev_dict[self.tokenizer.vocab['[UNK]']] = '' # replace [PAD]
self.rev_lookup = np.vectorize(lambda i: self.rev_dict[i])
@serving
@@ -83,6 +66,8 @@ class ErnieGen(hub.NLPPredictionModule):
Returns:
results(list): the predict result.
"""
+ paddle.disable_static()
+
if texts and isinstance(texts, list) and all(texts) and all(
[isinstance(text, str) for text in texts]):
predicted_data = texts
@@ -96,37 +81,37 @@ class ErnieGen(hub.NLPPredictionModule):
logger.warning(
"use_gpu has been set False as you didn't set the environment variable CUDA_VISIBLE_DEVICES while using use_gpu=True"
)
- if use_gpu:
- place = fluid.CUDAPlace(0)
- else:
- place = fluid.CPUPlace()
-
- with fluid.dygraph.guard(place):
- self.model.eval()
- results = []
- for text in predicted_data:
- sample_results = []
- ids, sids = self.tokenizer.encode(text)
- src_ids = D.to_variable(np.expand_dims(ids, 0))
- src_sids = D.to_variable(np.expand_dims(sids, 0))
- output_ids = beam_search_infilling(
- self.model,
- src_ids,
- src_sids,
- eos_id=self.tokenizer.sep_id,
- sos_id=self.tokenizer.cls_id,
- attn_id=self.tokenizer.vocab['[MASK]'],
- max_decode_len={max_decode_len},
- max_encode_len={max_encode_len},
- beam_width=beam_width,
- tgt_type_id=1)
- output_str = self.rev_lookup(output_ids[0].numpy())
-
- for ostr in output_str.tolist():
- if '[SEP]' in ostr:
- ostr = ostr[:ostr.index('[SEP]')]
- sample_results.append("".join(ostr))
- results.append(sample_results)
+
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+
+ self.model.eval()
+ results = []
+ for text in predicted_data:
+ sample_results = []
+ encode_text = self.tokenizer.encode(text)
+ src_ids = paddle.to_tensor(encode_text['input_ids']).unsqueeze(0)
+ src_sids = paddle.to_tensor(encode_text['token_type_ids']).unsqueeze(0)
+ output_ids = beam_search_infilling(
+ self.model,
+ src_ids,
+ src_sids,
+ eos_id=self.tokenizer.vocab['[SEP]'],
+ sos_id=self.tokenizer.vocab['[CLS]'],
+ attn_id=self.tokenizer.vocab['[MASK]'],
+ pad_id=self.tokenizer.vocab['[PAD]'],
+ unk_id=self.tokenizer.vocab['[UNK]'],
+ vocab_size=len(self.tokenizer.vocab),
+ max_decode_len={max_decode_len},
+ max_encode_len={max_encode_len},
+ beam_width=beam_width,
+ tgt_type_id=1)
+ output_str = self.rev_lookup(output_ids[0])
+
+ for ostr in output_str.tolist():
+ if '[SEP]' in ostr:
+ ostr = ostr[:ostr.index('[SEP]')]
+ sample_results.append("".join(ostr))
+ results.append(sample_results)
return results
def add_module_config_arg(self):
@@ -174,4 +159,4 @@ class ErnieGen(hub.NLPPredictionModule):
results = self.generate(
texts=input_data, use_gpu=args.use_gpu, beam_width=args.beam_width)
- return results
\ No newline at end of file
+ return results
diff --git a/modules/text/text_generation/ernie_gen_acrostic_poetry/README.md b/modules/text/text_generation/ernie_gen_acrostic_poetry/README.md
index c0db0a490df1099c44c6e77e09391ab9d199e6a5..5f31afd1a0831d624d259ac75114357dcfa5bd15 100644
--- a/modules/text/text_generation/ernie_gen_acrostic_poetry/README.md
+++ b/modules/text/text_generation/ernie_gen_acrostic_poetry/README.md
@@ -99,9 +99,11 @@ https://github.com/PaddlePaddle/ERNIE/blob/repro/ernie-gen/
### 依赖
-paddlepaddle >= 1.8.2
+paddlepaddle >= 2.0.0
-paddlehub >= 1.7.0
+paddlehub >= 2.0.0
+
+paddlenlp >= 2.0.0
## 更新历史
@@ -113,3 +115,7 @@ paddlehub >= 1.7.0
* 1.0.1
完善API的输入文本检查
+
+* 1.1.0
+
+ 接入PaddleNLP
diff --git a/modules/text/text_generation/ernie_gen_acrostic_poetry/decode.py b/modules/text/text_generation/ernie_gen_acrostic_poetry/decode.py
new file mode 100644
index 0000000000000000000000000000000000000000..3aadd245509bd5d1335b327c15a5c2de520f39ab
--- /dev/null
+++ b/modules/text/text_generation/ernie_gen_acrostic_poetry/decode.py
@@ -0,0 +1,288 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+import re
+import argparse
+import logging
+import json
+import numpy as np
+from collections import namedtuple
+
+import paddle
+import paddle.nn as nn
+import numpy as np
+from paddlenlp.utils.log import logger
+
+
+def gen_bias(encoder_inputs, decoder_inputs, step):
+ decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
+ encoder_bsz, encoder_seqlen = encoder_inputs.shape[:2]
+ attn_bias = paddle.reshape(paddle.arange(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
+ decoder_bias = paddle.cast((paddle.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
+ 'float32') #[1, decoderlen, decoderlen]
+ encoder_bias = paddle.unsqueeze(paddle.cast(paddle.ones_like(encoder_inputs), 'float32'),
+ [1]) #[bsz, 1, encoderlen]
+ encoder_bias = paddle.expand(encoder_bias,
+ [encoder_bsz, decoder_seqlen, encoder_seqlen]) #[bsz,decoderlen, encoderlen]
+ decoder_bias = paddle.expand(decoder_bias,
+ [decoder_bsz, decoder_seqlen, decoder_seqlen]) #[bsz, decoderlen, decoderlen]
+ if step > 0:
+ bias = paddle.concat(
+ [encoder_bias, paddle.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
+ else:
+ bias = paddle.concat([encoder_bias, decoder_bias], -1)
+ return bias
+
+
+@paddle.no_grad()
+def greedy_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ tgt_type_id=3):
+ _, logits, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+ has_stopped = np.zeros([d_batch], dtype=np.bool)
+ gen_seq_len = np.zeros([d_batch], dtype=np.int64)
+ output_ids = []
+
+ past_cache = info['caches']
+
+ cls_ids = paddle.ones([d_batch], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch], dtype='int64') * attn_id
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ gen_ids = paddle.argmax(logits, -1)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [paddle.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
+ cached_v = [paddle.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
+ past_cache = (cached_k, cached_v)
+
+ gen_ids = gen_ids[:, 1]
+ ids = paddle.stack([gen_ids, attn_ids], 1)
+
+ gen_ids = gen_ids.numpy()
+ has_stopped |= (gen_ids == eos_id).astype(np.bool)
+ gen_seq_len += (1 - has_stopped.astype(np.int64))
+ output_ids.append(gen_ids.tolist())
+ if has_stopped.all():
+ break
+ output_ids = np.array(output_ids).transpose([1, 0])
+ return output_ids
+
+
+BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
+BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
+
+
+def log_softmax(x):
+ e_x = np.exp(x - np.max(x))
+ return np.log(e_x / e_x.sum())
+
+
+def mask_prob(p, onehot_eos, finished):
+ is_finished = paddle.cast(paddle.reshape(finished, [-1, 1]) != 0, 'float32')
+ p = is_finished * (1. - paddle.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
+ return p
+
+
+def hyp_score(log_probs, length, length_penalty):
+ lp = paddle.pow((5. + paddle.cast(length, 'float32')) / 6., length_penalty)
+ return log_probs / lp
+
+
+def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
+ """logits.shape == [B*W, V]"""
+ _, vocab_size = logits.shape
+
+ bsz, beam_width = state.log_probs.shape
+ onehot_eos = paddle.cast(nn.functional.one_hot(paddle.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
+
+ probs = paddle.log(nn.functional.softmax(logits)) #[B*W, V]
+ probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
+ allprobs = paddle.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
+
+ not_finished = 1 - paddle.reshape(state.finished, [-1, 1]) #[B*W,1]
+ not_eos = 1 - onehot_eos
+ length_to_add = not_finished * not_eos #[B*W,V]
+ alllen = paddle.reshape(state.lengths, [-1, 1]) + length_to_add
+
+ allprobs = paddle.reshape(allprobs, [-1, beam_width * vocab_size])
+ alllen = paddle.reshape(alllen, [-1, beam_width * vocab_size])
+ allscore = hyp_score(allprobs, alllen, length_penalty)
+ if is_first_step:
+ allscore = paddle.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
+ scores, idx = paddle.topk(allscore, k=beam_width) #[B, W]
+ next_beam_id = idx // vocab_size #[B, W]
+ next_word_id = idx % vocab_size
+
+ gather_idx = paddle.concat([paddle.nonzero(idx != -1)[:, :1], paddle.reshape(idx, [-1, 1])], 1)
+ next_probs = paddle.reshape(paddle.gather_nd(allprobs, gather_idx), idx.shape)
+ next_len = paddle.reshape(paddle.gather_nd(alllen, gather_idx), idx.shape)
+
+ gather_idx = paddle.concat([paddle.nonzero(next_beam_id != -1)[:, :1], paddle.reshape(next_beam_id, [-1, 1])], 1)
+ next_finished = paddle.reshape(paddle.gather_nd(state.finished, gather_idx),
+ state.finished.shape) #[gather new beam state according to new beam id]
+
+ next_finished += paddle.cast(next_word_id == eos_id, 'int64')
+ next_finished = paddle.cast(next_finished > 0, 'int64')
+
+ next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
+ output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
+
+ return output, next_state
+
+
+@paddle.no_grad()
+def beam_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ beam_width=5,
+ tgt_type_id=3,
+ length_penalty=1.0):
+ _, __, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+
+ state = BeamSearchState(log_probs=paddle.zeros([d_batch, beam_width], 'float32'),
+ lengths=paddle.zeros([d_batch, beam_width], 'int64'),
+ finished=paddle.zeros([d_batch, beam_width], 'int64'))
+ outputs = []
+
+ def reorder_(t, parent_id):
+ """reorder cache according to parent beam id"""
+ gather_idx = paddle.nonzero(parent_id != -1)[:, 0] * beam_width + paddle.reshape(parent_id, [-1])
+ t = paddle.gather(t, gather_idx)
+ return t
+
+ def tile_(t, times):
+ _shapes = list(t.shape[1:])
+ new_shape = [t.shape[0], times] + list(t.shape[1:])
+ ret = paddle.reshape(paddle.expand(paddle.unsqueeze(t, [1]), new_shape), [
+ -1,
+ ] + _shapes)
+ return ret
+
+ cached_k, cached_v = info['caches']
+ cached_k = [tile_(k, beam_width) for k in cached_k]
+ cached_v = [tile_(v, beam_width) for v in cached_v]
+ past_cache = (cached_k, cached_v)
+
+ token_ids = tile_(token_ids, beam_width)
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+
+ cls_ids = paddle.ones([d_batch * beam_width], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ output, state = beam_search_step(state,
+ logits[:, 1],
+ eos_id=eos_id,
+ beam_width=beam_width,
+ is_first_step=(step == 0),
+ length_penalty=length_penalty)
+ outputs.append(output)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [
+ reorder_(paddle.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids)
+ for pk, k in zip(past_cached_k, cached_k)
+ ] # concat cached
+ cached_v = [
+ reorder_(paddle.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids)
+ for pv, v in zip(past_cached_v, cached_v)
+ ]
+ past_cache = (cached_k, cached_v)
+
+ pred_ids_flatten = paddle.reshape(output.predicted_ids, [d_batch * beam_width])
+ ids = paddle.stack([pred_ids_flatten, attn_ids], 1)
+
+ if state.finished.numpy().all():
+ break
+
+ final_ids = paddle.stack([o.predicted_ids for o in outputs], 0)
+ final_parent_ids = paddle.stack([o.beam_parent_ids for o in outputs], 0)
+ final_ids = nn.functional.gather_tree(final_ids, final_parent_ids) #[:, :, 0] #pick best beam
+ final_ids = paddle.transpose(paddle.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
+
+ return final_ids.numpy()
+
+
+en_patten = re.compile(r'^[a-zA-Z0-9]*$')
+
+
+def post_process(token):
+ if token.startswith('##'):
+ ret = token[2:]
+ elif token in ['[CLS]', '[SEP]', '[PAD]']:
+ ret = ''
+ else:
+ if en_patten.match(token):
+ ret = ' ' + token
+ else:
+ ret = token
+ return ret
diff --git a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/decode.py b/modules/text/text_generation/ernie_gen_acrostic_poetry/model/decode.py
deleted file mode 100644
index d07a58b559796b0331946561ed2dcbdc85ffadae..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/decode.py
+++ /dev/null
@@ -1,259 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import re
-import numpy as np
-from collections import namedtuple
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-import paddle.fluid.dygraph as D
-
-
-def gen_bias(encoder_inputs, decoder_inputs, step):
- decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
- attn_bias = L.reshape(L.range(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
- decoder_bias = L.cast((L.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
- 'float32') #[1, 1, decoderlen, decoderlen]
- encoder_bias = L.unsqueeze(L.cast(L.ones_like(encoder_inputs), 'float32'), [1]) #[bsz, 1, encoderlen]
- encoder_bias = L.expand(encoder_bias, [1, decoder_seqlen, 1]) #[bsz,decoderlen, encoderlen]
- decoder_bias = L.expand(decoder_bias, [decoder_bsz, 1, 1]) #[bsz, decoderlen, decoderlen]
- if step > 0:
- bias = L.concat([encoder_bias, L.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
- else:
- bias = L.concat([encoder_bias, decoder_bias], -1)
- return bias
-
-
-@D.no_grad
-def greedy_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- tgt_type_id=3):
- model.eval()
- _, logits, info = model(q_ids, q_sids)
- gen_ids = L.argmax(logits, -1)
- d_batch, d_seqlen = q_ids.shape
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
- has_stopped = np.zeros([d_batch], dtype=np.bool)
- gen_seq_len = np.zeros([d_batch], dtype=np.int64)
- output_ids = []
-
- past_cache = info['caches']
-
- cls_ids = L.ones([d_batch], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch], dtype='int64') * attn_id
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
- pos_ids += seqlen
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
- gen_ids = L.argmax(logits, -1)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [L.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
- cached_v = [L.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
- past_cache = (cached_k, cached_v)
-
- gen_ids = gen_ids[:, 1]
- ids = L.stack([gen_ids, attn_ids], 1)
-
- gen_ids = gen_ids.numpy()
- has_stopped |= (gen_ids == eos_id).astype(np.bool)
- gen_seq_len += (1 - has_stopped.astype(np.int64))
- output_ids.append(gen_ids.tolist())
- if has_stopped.all():
- break
- output_ids = np.array(output_ids).transpose([1, 0])
- return output_ids
-
-
-BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
-BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
-
-
-def log_softmax(x):
- e_x = np.exp(x - np.max(x))
- return np.log(e_x / e_x.sum())
-
-
-def mask_prob(p, onehot_eos, finished):
- is_finished = L.cast(L.reshape(finished, [-1, 1]) != 0, 'float32')
- p = is_finished * (1. - L.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
- return p
-
-
-def hyp_score(log_probs, length, length_penalty):
- lp = L.pow((5. + L.cast(length, 'float32')) / 6., length_penalty)
- return log_probs / lp
-
-
-def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
- """logits.shape == [B*W, V]"""
- beam_size, vocab_size = logits.shape # as batch size=1 in this hub module. the first dim means bsz * beam_size equals beam_size
- logits_np = logits.numpy()
- for i in range(beam_size):
- logits_np[i][17963] = 0 # make [UNK] prob = 0
- logits = D.to_variable(logits_np)
-
- bsz, beam_width = state.log_probs.shape
- onehot_eos = L.cast(F.one_hot(L.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
-
- probs = L.log(L.softmax(logits)) #[B*W, V]
- probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
- allprobs = L.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
-
- not_finished = 1 - L.reshape(state.finished, [-1, 1]) #[B*W,1]
- not_eos = 1 - onehot_eos
- length_to_add = not_finished * not_eos #[B*W,V]
- alllen = L.reshape(state.lengths, [-1, 1]) + length_to_add
-
- allprobs = L.reshape(allprobs, [-1, beam_width * vocab_size])
- alllen = L.reshape(alllen, [-1, beam_width * vocab_size])
- allscore = hyp_score(allprobs, alllen, length_penalty)
- if is_first_step:
- allscore = L.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
- scores, idx = L.topk(allscore, k=beam_width) #[B, W]
- next_beam_id = idx // vocab_size #[B, W]
- next_word_id = idx % vocab_size
-
- gather_idx = L.concat([L.where(idx != -1)[:, :1], L.reshape(idx, [-1, 1])], 1)
- next_probs = L.reshape(L.gather_nd(allprobs, gather_idx), idx.shape)
- next_len = L.reshape(L.gather_nd(alllen, gather_idx), idx.shape)
-
- gather_idx = L.concat([L.where(next_beam_id != -1)[:, :1], L.reshape(next_beam_id, [-1, 1])], 1)
- next_finished = L.reshape(L.gather_nd(state.finished, gather_idx),
- state.finished.shape) #[gather new beam state according to new beam id]
-
- next_finished += L.cast(next_word_id == eos_id, 'int64')
- next_finished = L.cast(next_finished > 0, 'int64')
-
- next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
- output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
-
- return output, next_state
-
-
-@D.no_grad
-def beam_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- beam_width=5,
- tgt_type_id=3,
- length_penalty=1.0):
- model.eval()
- _, __, info = model(q_ids, q_sids)
- d_batch, d_seqlen = q_ids.shape
-
- state = BeamSearchState(
- log_probs=L.zeros([d_batch, beam_width], 'float32'),
- lengths=L.zeros([d_batch, beam_width], 'int64'),
- finished=L.zeros([d_batch, beam_width], 'int64'))
- outputs = []
-
- def reorder_(t, parent_id):
- """reorder cache according to parent beam id"""
- gather_idx = L.where(parent_id != -1)[:, 0] * beam_width + L.reshape(parent_id, [-1])
- t = L.gather(t, gather_idx)
- return t
-
- def tile_(t, times):
- _shapes = list(t.shape[1:])
- ret = L.reshape(L.expand(L.unsqueeze(t, [1]), [
- 1,
- times,
- ] + [
- 1,
- ] * len(_shapes)), [
- -1,
- ] + _shapes)
- return ret
-
- cached_k, cached_v = info['caches']
- cached_k = [tile_(k, beam_width) for k in cached_k]
- cached_v = [tile_(v, beam_width) for v in cached_v]
- past_cache = (cached_k, cached_v)
-
- q_ids = tile_(q_ids, beam_width)
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
-
- cls_ids = L.ones([d_batch * beam_width], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
- pos_ids += seqlen
-
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
-
- output, state = beam_search_step(
- state,
- logits[:, 1],
- eos_id=eos_id,
- beam_width=beam_width,
- is_first_step=(step == 0),
- length_penalty=length_penalty)
- outputs.append(output)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [
- reorder_(L.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids) for pk, k in zip(past_cached_k, cached_k)
- ] # concat cached
- cached_v = [
- reorder_(L.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids) for pv, v in zip(past_cached_v, cached_v)
- ]
- past_cache = (cached_k, cached_v)
-
- pred_ids_flatten = L.reshape(output.predicted_ids, [d_batch * beam_width])
- ids = L.stack([pred_ids_flatten, attn_ids], 1)
-
- if state.finished.numpy().all():
- break
-
- final_ids = L.stack([o.predicted_ids for o in outputs], 0)
- final_parent_ids = L.stack([o.beam_parent_ids for o in outputs], 0)
- final_ids = L.gather_tree(final_ids, final_parent_ids) #[:, :,
- #0] #pick best beam
- final_ids = L.transpose(L.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
- return final_ids
-
-
-en_patten = re.compile(r'^[a-zA-Z0-9]*$')
-
-
-def post_process(token):
- if token.startswith('##'):
- ret = token[2:]
- else:
- if en_patten.match(token):
- ret = ' ' + token
- else:
- ret = token
- return ret
diff --git a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/file_utils.py b/modules/text/text_generation/ernie_gen_acrostic_poetry/model/file_utils.py
deleted file mode 100644
index 608be4efc6644626f7f408df200fd299f2dd997e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/file_utils.py
+++ /dev/null
@@ -1,46 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-
-from tqdm import tqdm
-from paddlehub.common.logger import logger
-from paddlehub.common.dir import MODULE_HOME
-
-
-def _fetch_from_remote(url, force_download=False):
- import tempfile, requests, tarfile
- cached_dir = os.path.join(MODULE_HOME, "ernie_for_gen")
- if force_download or not os.path.exists(cached_dir):
- with tempfile.NamedTemporaryFile() as f:
- #url = 'https://ernie.bj.bcebos.com/ERNIE_stable.tgz'
- r = requests.get(url, stream=True)
- total_len = int(r.headers.get('content-length'))
- for chunk in tqdm(
- r.iter_content(chunk_size=1024), total=total_len // 1024, desc='downloading %s' % url, unit='KB'):
- if chunk:
- f.write(chunk)
- f.flush()
- logger.debug('extacting... to %s' % f.name)
- with tarfile.open(f.name) as tf:
- tf.extractall(path=cached_dir)
- logger.debug('%s cached in %s' % (url, cached_dir))
- return cached_dir
-
-
-def add_docstring(doc):
- def func(f):
- f.__doc__ += ('\n======other docs from supper class ======\n%s' % doc)
- return f
-
- return func
diff --git a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/modeling_ernie.py b/modules/text/text_generation/ernie_gen_acrostic_poetry/model/modeling_ernie.py
deleted file mode 100644
index d5de28a5fee73371babd05b644e03a0f75ecdd5e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/modeling_ernie.py
+++ /dev/null
@@ -1,327 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from __future__ import division
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import logging
-
-import paddle.fluid.dygraph as D
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-log = logging.getLogger(__name__)
-
-
-def _build_linear(n_in, n_out, name, init, act=None):
- return D.Linear(
- n_in,
- n_out,
- param_attr=F.ParamAttr(name='%s.w_0' % name if name is not None else None, initializer=init),
- bias_attr='%s.b_0' % name if name is not None else None,
- act=act)
-
-
-def _build_ln(n_in, name):
- return D.LayerNorm(
- normalized_shape=n_in,
- param_attr=F.ParamAttr(
- name='%s_layer_norm_scale' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- bias_attr=F.ParamAttr(
- name='%s_layer_norm_bias' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- )
-
-
-def append_name(name, postfix):
- if name is None:
- return None
- elif name == '':
- return postfix
- else:
- return '%s_%s' % (name, postfix)
-
-
-class AttentionLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(AttentionLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- n_head = cfg['num_attention_heads']
- assert d_model % n_head == 0
- d_model_q = cfg.get('query_hidden_size_per_head', d_model // n_head) * n_head
- d_model_v = cfg.get('value_hidden_size_per_head', d_model // n_head) * n_head
- self.n_head = n_head
- self.d_key = d_model_q // n_head
- self.q = _build_linear(d_model, d_model_q, append_name(name, 'query_fc'), initializer)
- self.k = _build_linear(d_model, d_model_q, append_name(name, 'key_fc'), initializer)
- self.v = _build_linear(d_model, d_model_v, append_name(name, 'value_fc'), initializer)
- self.o = _build_linear(d_model_v, d_model, append_name(name, 'output_fc'), initializer)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=cfg['attention_probs_dropout_prob'],
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, queries, keys, values, attn_bias, past_cache):
- assert len(queries.shape) == len(keys.shape) == len(values.shape) == 3
-
- q = self.q(queries)
- k = self.k(keys)
- v = self.v(values)
-
- cache = (k, v)
- if past_cache is not None:
- cached_k, cached_v = past_cache
- k = L.concat([cached_k, k], 1)
- v = L.concat([cached_v, v], 1)
-
- q = L.transpose(L.reshape(q, [0, 0, self.n_head, q.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- k = L.transpose(L.reshape(k, [0, 0, self.n_head, k.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- v = L.transpose(L.reshape(v, [0, 0, self.n_head, v.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
-
- q = L.scale(q, scale=self.d_key**-0.5)
- score = L.matmul(q, k, transpose_y=True)
- if attn_bias is not None:
- score += attn_bias
- score = L.softmax(score, use_cudnn=True)
- score = self.dropout(score)
-
- out = L.matmul(score, v)
- out = L.transpose(out, [0, 2, 1, 3])
- out = L.reshape(out, [0, 0, out.shape[2] * out.shape[3]])
-
- out = self.o(out)
- return out, cache
-
-
-class PositionwiseFeedForwardLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(PositionwiseFeedForwardLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_ffn = cfg.get('intermediate_size', 4 * d_model)
- assert cfg['hidden_act'] in ['relu', 'gelu']
- self.i = _build_linear(d_model, d_ffn, append_name(name, 'fc_0'), initializer, act=cfg['hidden_act'])
- self.o = _build_linear(d_ffn, d_model, append_name(name, 'fc_1'), initializer)
- prob = cfg.get('intermediate_dropout_prob', 0.)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs):
- hidden = self.i(inputs)
- hidden = self.dropout(hidden)
- out = self.o(hidden)
- return out
-
-
-class ErnieBlock(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieBlock, self).__init__()
- d_model = cfg['hidden_size']
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.attn = AttentionLayer(cfg, name=append_name(name, 'multi_head_att'))
- self.ln1 = _build_ln(d_model, name=append_name(name, 'post_att'))
- self.ffn = PositionwiseFeedForwardLayer(cfg, name=append_name(name, 'ffn'))
- self.ln2 = _build_ln(d_model, name=append_name(name, 'post_ffn'))
- prob = cfg.get('intermediate_dropout_prob', cfg['hidden_dropout_prob'])
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- attn_out, cache = self.attn(inputs, inputs, inputs, attn_bias, past_cache=past_cache) #self attn
- attn_out = self.dropout(attn_out)
- hidden = attn_out + inputs
- hidden = self.ln1(hidden) # dropout/ add/ norm
-
- ffn_out = self.ffn(hidden)
- ffn_out = self.dropout(ffn_out)
- hidden = ffn_out + hidden
- hidden = self.ln2(hidden)
- return hidden, cache
-
-
-class ErnieEncoderStack(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieEncoderStack, self).__init__()
- n_layers = cfg['num_hidden_layers']
- self.block = D.LayerList([ErnieBlock(cfg, append_name(name, 'layer_%d' % i)) for i in range(n_layers)])
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- if past_cache is not None:
- assert isinstance(
- past_cache,
- tuple), 'unknown type of `past_cache`, expect tuple or list. got %s' % repr(type(past_cache))
- past_cache = list(zip(*past_cache))
- else:
- past_cache = [None] * len(self.block)
- cache_list_k, cache_list_v, hidden_list = [], [], [inputs]
-
- for b, p in zip(self.block, past_cache):
- inputs, cache = b(inputs, attn_bias=attn_bias, past_cache=p)
- cache_k, cache_v = cache
- cache_list_k.append(cache_k)
- cache_list_v.append(cache_v)
- hidden_list.append(inputs)
-
- return inputs, hidden_list, (cache_list_k, cache_list_v)
-
-
-class ErnieModel(D.Layer):
- def __init__(self, cfg, name=None):
- """
- Fundamental pretrained Ernie model
- """
- log.debug('init ErnieModel with config: %s' % repr(cfg))
- D.Layer.__init__(self)
- d_model = cfg['hidden_size']
- d_emb = cfg.get('emb_size', cfg['hidden_size'])
- d_vocab = cfg['vocab_size']
- d_pos = cfg['max_position_embeddings']
- d_sent = cfg.get("sent_type_vocab_size") or cfg['type_vocab_size']
- self.n_head = cfg['num_attention_heads']
- self.return_additional_info = cfg.get('return_additional_info', False)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.ln = _build_ln(d_model, name=append_name(name, 'pre_encoder'))
- self.word_emb = D.Embedding([d_vocab, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'word_embedding'), initializer=initializer))
- self.pos_emb = D.Embedding([d_pos, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'pos_embedding'), initializer=initializer))
- self.sent_emb = D.Embedding([d_sent, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'sent_embedding'), initializer=initializer))
- prob = cfg['hidden_dropout_prob']
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- self.encoder_stack = ErnieEncoderStack(cfg, append_name(name, 'encoder'))
- if cfg.get('has_pooler', True):
- self.pooler = _build_linear(
- cfg['hidden_size'], cfg['hidden_size'], append_name(name, 'pooled_fc'), initializer, act='tanh')
- else:
- self.pooler = None
- self.train()
-
- def eval(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).eval()
- self.training = False
- for l in self.sublayers():
- l.training = False
-
- def train(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).train()
- self.training = True
- for l in self.sublayers():
- l.training = True
-
- def forward(self,
- src_ids,
- sent_ids=None,
- pos_ids=None,
- input_mask=None,
- attn_bias=None,
- past_cache=None,
- use_causal_mask=False):
- """
- Args:
- src_ids (`Variable` of shape `[batch_size, seq_len]`):
- Indices of input sequence tokens in the vocabulary.
- sent_ids (optional, `Variable` of shape `[batch_size, seq_len]`):
- aka token_type_ids, Segment token indices to indicate first and second portions of the inputs.
- if None, assume all tokens come from `segment_a`
- pos_ids(optional, `Variable` of shape `[batch_size, seq_len]`):
- Indices of positions of each input sequence tokens in the position embeddings.
- input_mask(optional `Variable` of shape `[batch_size, seq_len]`):
- Mask to avoid performing attention on the padding token indices of the encoder input.
- attn_bias(optional, `Variable` of shape `[batch_size, seq_len, seq_len] or False`):
- 3D version of `input_mask`, if set, overrides `input_mask`; if set not False, will not apply attention mask
- past_cache(optional, tuple of two lists: cached key and cached value,
- each is a list of `Variable`s of shape `[batch_size, seq_len, hidden_size]`):
- cached key/value tensor that will be concated to generated key/value when performing self attention.
- if set, `attn_bias` should not be None.
-
- Returns:
- pooled (`Variable` of shape `[batch_size, hidden_size]`):
- output logits of pooler classifier
- encoded(`Variable` of shape `[batch_size, seq_len, hidden_size]`):
- output logits of transformer stack
- """
- assert len(src_ids.shape) == 2, 'expect src_ids.shape = [batch, sequecen], got %s' % (repr(src_ids.shape))
- assert attn_bias is not None if past_cache else True, 'if `past_cache` is specified; attn_bias should not be None'
- d_batch = L.shape(src_ids)[0]
- d_seqlen = L.shape(src_ids)[1]
- if pos_ids is None:
- pos_ids = L.reshape(L.range(0, d_seqlen, 1, dtype='int32'), [1, -1])
- pos_ids = L.cast(pos_ids, 'int64')
- if attn_bias is None:
- if input_mask is None:
- input_mask = L.cast(src_ids != 0, 'float32')
- assert len(input_mask.shape) == 2
- input_mask = L.unsqueeze(input_mask, axes=[-1])
- attn_bias = L.matmul(input_mask, input_mask, transpose_y=True)
- if use_causal_mask:
- sequence = L.reshape(L.range(0, d_seqlen, 1, dtype='float32') + 1., [1, 1, -1, 1])
- causal_mask = L.cast((L.matmul(sequence, 1. / sequence, transpose_y=True) >= 1.), 'float32')
- attn_bias *= causal_mask
- else:
- assert len(attn_bias.shape) == 3, 'expect attn_bias tobe rank 3, got %r' % attn_bias.shape
- attn_bias = (1. - attn_bias) * -10000.0
- attn_bias = L.unsqueeze(attn_bias, [1])
- attn_bias = L.expand(attn_bias, [1, self.n_head, 1, 1]) # avoid broadcast =_=
- attn_bias.stop_gradient = True
-
- if sent_ids is None:
- sent_ids = L.zeros_like(src_ids)
-
- src_embedded = self.word_emb(src_ids)
- pos_embedded = self.pos_emb(pos_ids)
- sent_embedded = self.sent_emb(sent_ids)
- embedded = src_embedded + pos_embedded + sent_embedded
-
- embedded = self.dropout(self.ln(embedded))
-
- encoded, hidden_list, cache_list = self.encoder_stack(embedded, attn_bias, past_cache=past_cache)
- if self.pooler is not None:
- pooled = self.pooler(encoded[:, 0, :])
- else:
- pooled = None
-
- additional_info = {
- 'hiddens': hidden_list,
- 'caches': cache_list,
- }
-
- if self.return_additional_info:
- return pooled, encoded, additional_info
- else:
- return pooled, encoded
diff --git a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/modeling_ernie_gen.py b/modules/text/text_generation/ernie_gen_acrostic_poetry/model/modeling_ernie_gen.py
deleted file mode 100644
index 2ad847a2ba0acd0d863ffea9a0cbe05e6e857908..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/modeling_ernie_gen.py
+++ /dev/null
@@ -1,65 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from ernie_gen_acrostic_poetry.model.modeling_ernie import ErnieModel
-from ernie_gen_acrostic_poetry.model.modeling_ernie import _build_linear, _build_ln, append_name
-
-
-class ErnieModelForGeneration(ErnieModel):
- def __init__(self, cfg, name=None):
- cfg['return_additional_info'] = True
- cfg['has_pooler'] = False
- super(ErnieModelForGeneration, self).__init__(cfg, name=name)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_vocab = cfg['vocab_size']
-
- self.mlm = _build_linear(
- d_model, d_model, append_name(name, 'mask_lm_trans_fc'), initializer, act=cfg['hidden_act'])
- self.mlm_ln = _build_ln(d_model, name=append_name(name, 'mask_lm_trans'))
- self.mlm_bias = L.create_parameter(
- dtype='float32',
- shape=[d_vocab],
- attr=F.ParamAttr(
- name=append_name(name, 'mask_lm_out_fc.b_0'), initializer=F.initializer.Constant(value=0.0)),
- is_bias=True,
- )
-
- def forward(self, src_ids, *args, **kwargs):
- tgt_labels = kwargs.pop('tgt_labels', None)
- tgt_pos = kwargs.pop('tgt_pos', None)
- encode_only = kwargs.pop('encode_only', False)
- _, encoded, info = ErnieModel.forward(self, src_ids, *args, **kwargs)
- if encode_only:
- return None, None, info
- elif tgt_labels is None:
- encoded = self.mlm(encoded)
- encoded = self.mlm_ln(encoded)
- logits = L.matmul(encoded, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- output_ids = L.argmax(logits, -1)
- return output_ids, logits, info
- else:
- encoded_2d = L.gather_nd(encoded, tgt_pos)
- encoded_2d = self.mlm(encoded_2d)
- encoded_2d = self.mlm_ln(encoded_2d)
- logits_2d = L.matmul(encoded_2d, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- if len(tgt_labels.shape) == 1:
- tgt_labels = L.reshape(tgt_labels, [-1, 1])
-
- loss = L.reduce_mean(
- L.softmax_with_cross_entropy(logits_2d, tgt_labels, soft_label=(tgt_labels.shape[-1] != 1)))
- return loss, logits_2d, info
diff --git a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/tokenizing_ernie.py b/modules/text/text_generation/ernie_gen_acrostic_poetry/model/tokenizing_ernie.py
deleted file mode 100644
index c9e5638f9a17207ce2d664c27376f08138876da3..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_acrostic_poetry/model/tokenizing_ernie.py
+++ /dev/null
@@ -1,163 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import six
-import re
-import logging
-from functools import partial
-
-import numpy as np
-
-import io
-
-open = partial(io.open, encoding='utf8')
-
-log = logging.getLogger(__name__)
-
-_max_input_chars_per_word = 100
-
-
-def _wordpiece(token, vocab, unk_token, prefix='##', sentencepiece_prefix=''):
- """ wordpiece: helloworld => [hello, ##world] """
- chars = list(token)
- if len(chars) > _max_input_chars_per_word:
- return [unk_token], [(0, len(chars))]
-
- is_bad = False
- start = 0
- sub_tokens = []
- sub_pos = []
- while start < len(chars):
- end = len(chars)
- cur_substr = None
- while start < end:
- substr = "".join(chars[start:end])
- if start == 0:
- substr = sentencepiece_prefix + substr
- if start > 0:
- substr = prefix + substr
- if substr in vocab:
- cur_substr = substr
- break
- end -= 1
- if cur_substr is None:
- is_bad = True
- break
- sub_tokens.append(cur_substr)
- sub_pos.append((start, end))
- start = end
- if is_bad:
- return [unk_token], [(0, len(chars))]
- else:
- return sub_tokens, sub_pos
-
-
-class ErnieTokenizer(object):
- def __init__(self,
- vocab,
- unk_token='[UNK]',
- sep_token='[SEP]',
- cls_token='[CLS]',
- pad_token='[PAD]',
- mask_token='[MASK]',
- wordpiece_prefix='##',
- sentencepiece_prefix='',
- lower=True,
- encoding='utf8',
- special_token_list=[]):
- if not isinstance(vocab, dict):
- raise ValueError('expect `vocab` to be instance of dict, got %s' % type(vocab))
- self.vocab = vocab
- self.lower = lower
- self.prefix = wordpiece_prefix
- self.sentencepiece_prefix = sentencepiece_prefix
- self.pad_id = self.vocab[pad_token]
- self.cls_id = cls_token and self.vocab[cls_token]
- self.sep_id = sep_token and self.vocab[sep_token]
- self.unk_id = unk_token and self.vocab[unk_token]
- self.mask_id = mask_token and self.vocab[mask_token]
- self.unk_token = unk_token
- special_tokens = {pad_token, cls_token, sep_token, unk_token, mask_token} | set(special_token_list)
- pat_str = ''
- for t in special_tokens:
- if t is None:
- continue
- pat_str += '(%s)|' % re.escape(t)
- pat_str += r'([a-zA-Z0-9]+|\S)'
- log.debug('regex: %s' % pat_str)
- self.pat = re.compile(pat_str)
- self.encoding = encoding
-
- def tokenize(self, text):
- if len(text) == 0:
- return []
- if six.PY3 and not isinstance(text, six.string_types):
- text = text.decode(self.encoding)
- if six.PY2 and isinstance(text, str):
- text = text.decode(self.encoding)
-
- res = []
- for match in self.pat.finditer(text):
- match_group = match.group(0)
- if match.groups()[-1]:
- if self.lower:
- match_group = match_group.lower()
- words, _ = _wordpiece(
- match_group,
- vocab=self.vocab,
- unk_token=self.unk_token,
- prefix=self.prefix,
- sentencepiece_prefix=self.sentencepiece_prefix)
- else:
- words = [match_group]
- res += words
- return res
-
- def convert_tokens_to_ids(self, tokens):
- return [self.vocab.get(t, self.unk_id) for t in tokens]
-
- def truncate(self, id1, id2, seqlen):
- len1 = len(id1)
- len2 = len(id2)
- half = seqlen // 2
- if len1 > len2:
- len1_truncated, len2_truncated = max(half, seqlen - len2), min(half, len2)
- else:
- len1_truncated, len2_truncated = min(half, seqlen - len1), max(half, seqlen - len1)
- return id1[:len1_truncated], id2[:len2_truncated]
-
- def build_for_ernie(self, text_id, pair_id=[]):
- """build sentence type id, add [CLS] [SEP]"""
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- ret_id = np.concatenate([[self.cls_id], text_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([[0], text_id_type, [0]], 0)
-
- if len(pair_id):
- pair_id_type = np.ones_like(pair_id, dtype=np.int64)
- ret_id = np.concatenate([ret_id, pair_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([ret_id_type, pair_id_type, [1]], 0)
- return ret_id, ret_id_type
-
- def encode(self, text, pair=None, truncate_to=None):
- text_id = np.array(self.convert_tokens_to_ids(self.tokenize(text)), dtype=np.int64)
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- if pair is not None:
- pair_id = np.array(self.convert_tokens_to_ids(self.tokenize(pair)), dtype=np.int64)
- else:
- pair_id = []
- if truncate_to is not None:
- text_id, pair_id = self.truncate(text_id, [] if pair_id is None else pair_id, truncate_to)
-
- ret_id, ret_id_type = self.build_for_ernie(text_id, pair_id)
- return ret_id, ret_id_type
diff --git a/modules/text/text_generation/ernie_gen_acrostic_poetry/module.py b/modules/text/text_generation/ernie_gen_acrostic_poetry/module.py
index 74c3c32f28451416e4a7a844dd48e7fc02a88dd9..f39c0605152e28eb11e329877395e22bfd62abff 100644
--- a/modules/text/text_generation/ernie_gen_acrostic_poetry/module.py
+++ b/modules/text/text_generation/ernie_gen_acrostic_poetry/module.py
@@ -14,28 +14,24 @@
# limitations under the License.
import ast
import json
+import argparse
+import os
-import paddle.fluid as fluid
+import numpy as np
+import paddle
import paddlehub as hub
from paddlehub.module.module import runnable
from paddlehub.module.nlp_module import DataFormatError
from paddlehub.common.logger import logger
from paddlehub.module.module import moduleinfo, serving
+from paddlenlp.transformers import ErnieTokenizer, ErnieForGeneration
-import argparse
-import os
-import numpy as np
-
-import paddle.fluid.dygraph as D
-
-from ernie_gen_acrostic_poetry.model.tokenizing_ernie import ErnieTokenizer
-from ernie_gen_acrostic_poetry.model.decode import beam_search_infilling
-from ernie_gen_acrostic_poetry.model.modeling_ernie_gen import ErnieModelForGeneration
+from ernie_gen_acrostic_poetry.decode import beam_search_infilling
@moduleinfo(
name="ernie_gen_acrostic_poetry",
- version="1.0.1",
+ version="1.1.0",
summary=
"ERNIE-GEN is a multi-flow language generation framework for both pre-training and fine-tuning. This module has fine-tuned for poetry generation task.",
author="adaxiadaxi",
@@ -43,7 +39,7 @@ from ernie_gen_acrostic_poetry.model.modeling_ernie_gen import ErnieModelForGene
type="nlp/text_generation",
)
class ErnieGen(hub.NLPPredictionModule):
- def _initialize(self, line=4, word=7):
+ def __init__(self, line=4, word=7):
"""
initialize with the necessary elements
"""
@@ -54,24 +50,14 @@ class ErnieGen(hub.NLPPredictionModule):
self.line = line
assets_path = os.path.join(self.directory, "assets")
- gen_checkpoint_path = os.path.join(assets_path, "ernie_gen_acrostic_poetry_L%sW%s" % (line, word))
- ernie_cfg_path = os.path.join(assets_path, 'ernie_config.json')
- with open(ernie_cfg_path, encoding='utf8') as ernie_cfg_file:
- ernie_cfg = dict(json.loads(ernie_cfg_file.read()))
- ernie_vocab_path = os.path.join(assets_path, 'vocab.txt')
- with open(ernie_vocab_path, encoding='utf8') as ernie_vocab_file:
- ernie_vocab = {j.strip().split('\t')[0]: i for i, j in enumerate(ernie_vocab_file.readlines())}
-
- with fluid.dygraph.guard(fluid.CPUPlace()):
- with fluid.unique_name.guard():
- self.model = ErnieModelForGeneration(ernie_cfg)
- finetuned_states, _ = D.load_dygraph(gen_checkpoint_path)
- self.model.set_dict(finetuned_states)
-
- self.tokenizer = ErnieTokenizer(ernie_vocab)
- self.rev_dict = {v: k for k, v in self.tokenizer.vocab.items()}
- self.rev_dict[self.tokenizer.pad_id] = '' # replace [PAD]
- self.rev_dict[self.tokenizer.unk_id] = '' # replace [PAD]
+ gen_checkpoint_path = os.path.join(assets_path, "ernie_gen_acrostic_poetry_L%sW%s.pdparams" % (line, word))
+ self.model = ErnieForGeneration.from_pretrained("ernie-1.0")
+ model_state = paddle.load(gen_checkpoint_path)
+ self.model.set_dict(model_state)
+ self.tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
+ self.rev_dict = self.tokenizer.vocab.idx_to_token
+ self.rev_dict[self.tokenizer.vocab['[PAD]']] = '' # replace [PAD]
+ self.rev_dict[self.tokenizer.vocab['[UNK]']] = '' # replace [PAD]
self.rev_lookup = np.vectorize(lambda i: self.rev_dict[i])
@serving
@@ -87,6 +73,8 @@ class ErnieGen(hub.NLPPredictionModule):
Returns:
results(list): the poetry continuations.
"""
+ paddle.disable_static()
+
if texts and isinstance(texts, list) and all(texts) and all([isinstance(text, str) for text in texts]):
predicted_data = texts
else:
@@ -108,37 +96,37 @@ class ErnieGen(hub.NLPPredictionModule):
logger.warning(
"use_gpu has been set False as you didn't set the environment variable CUDA_VISIBLE_DEVICES while using use_gpu=True"
)
- if use_gpu:
- place = fluid.CUDAPlace(0)
- else:
- place = fluid.CPUPlace()
-
- with fluid.dygraph.guard(place):
- self.model.eval()
- results = []
- for text in predicted_data:
- sample_results = []
- ids, sids = self.tokenizer.encode(text)
- src_ids = D.to_variable(np.expand_dims(ids, 0))
- src_sids = D.to_variable(np.expand_dims(sids, 0))
- output_ids = beam_search_infilling(
- self.model,
- src_ids,
- src_sids,
- eos_id=self.tokenizer.sep_id,
- sos_id=self.tokenizer.cls_id,
- attn_id=self.tokenizer.vocab['[MASK]'],
- max_decode_len=80,
- max_encode_len=20,
- beam_width=beam_width,
- tgt_type_id=1)
- output_str = self.rev_lookup(output_ids[0].numpy())
-
- for ostr in output_str.tolist():
- if '[SEP]' in ostr:
- ostr = ostr[:ostr.index('[SEP]')]
- sample_results.append("".join(ostr))
- results.append(sample_results)
+
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+
+ self.model.eval()
+ results = []
+ for text in predicted_data:
+ sample_results = []
+ encode_text = self.tokenizer.encode(text)
+ src_ids = paddle.to_tensor(encode_text['input_ids']).unsqueeze(0)
+ src_sids = paddle.to_tensor(encode_text['token_type_ids']).unsqueeze(0)
+ output_ids = beam_search_infilling(
+ self.model,
+ src_ids,
+ src_sids,
+ eos_id=self.tokenizer.vocab['[SEP]'],
+ sos_id=self.tokenizer.vocab['[CLS]'],
+ attn_id=self.tokenizer.vocab['[MASK]'],
+ pad_id=self.tokenizer.vocab['[PAD]'],
+ unk_id=self.tokenizer.vocab['[UNK]'],
+ vocab_size=len(self.tokenizer.vocab),
+ max_decode_len=80,
+ max_encode_len=20,
+ beam_width=beam_width,
+ tgt_type_id=1)
+ output_str = self.rev_lookup(output_ids[0])
+
+ for ostr in output_str.tolist():
+ if '[SEP]' in ostr:
+ ostr = ostr[:ostr.index('[SEP]')]
+ sample_results.append("".join(ostr))
+ results.append(sample_results)
return results
def add_module_config_arg(self):
diff --git a/modules/text/text_generation/ernie_gen_couplet/README.md b/modules/text/text_generation/ernie_gen_couplet/README.md
index 33c164a84fb44f02546db9542508df2276f4c572..71379fc0e5a5f7c28ed7f22314bef0e55bedb0a3 100644
--- a/modules/text/text_generation/ernie_gen_couplet/README.md
+++ b/modules/text/text_generation/ernie_gen_couplet/README.md
@@ -87,9 +87,11 @@ https://github.com/PaddlePaddle/ERNIE/blob/repro/ernie-gen/
### 依赖
-paddlepaddle >= 1.8.2
+paddlepaddle >= 2.0.0
-paddlehub >= 1.7.0
+paddlehub >= 2.0.0
+
+paddlenlp >= 2.0.0
## 更新历史
@@ -105,3 +107,7 @@ paddlehub >= 1.7.0
* 1.0.2
完善API的输入文本检查
+
+* 1.1.0
+
+ 接入PaddleNLP
diff --git a/modules/text/text_generation/ernie_gen_couplet/decode.py b/modules/text/text_generation/ernie_gen_couplet/decode.py
new file mode 100644
index 0000000000000000000000000000000000000000..3aadd245509bd5d1335b327c15a5c2de520f39ab
--- /dev/null
+++ b/modules/text/text_generation/ernie_gen_couplet/decode.py
@@ -0,0 +1,288 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+import re
+import argparse
+import logging
+import json
+import numpy as np
+from collections import namedtuple
+
+import paddle
+import paddle.nn as nn
+import numpy as np
+from paddlenlp.utils.log import logger
+
+
+def gen_bias(encoder_inputs, decoder_inputs, step):
+ decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
+ encoder_bsz, encoder_seqlen = encoder_inputs.shape[:2]
+ attn_bias = paddle.reshape(paddle.arange(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
+ decoder_bias = paddle.cast((paddle.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
+ 'float32') #[1, decoderlen, decoderlen]
+ encoder_bias = paddle.unsqueeze(paddle.cast(paddle.ones_like(encoder_inputs), 'float32'),
+ [1]) #[bsz, 1, encoderlen]
+ encoder_bias = paddle.expand(encoder_bias,
+ [encoder_bsz, decoder_seqlen, encoder_seqlen]) #[bsz,decoderlen, encoderlen]
+ decoder_bias = paddle.expand(decoder_bias,
+ [decoder_bsz, decoder_seqlen, decoder_seqlen]) #[bsz, decoderlen, decoderlen]
+ if step > 0:
+ bias = paddle.concat(
+ [encoder_bias, paddle.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
+ else:
+ bias = paddle.concat([encoder_bias, decoder_bias], -1)
+ return bias
+
+
+@paddle.no_grad()
+def greedy_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ tgt_type_id=3):
+ _, logits, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+ has_stopped = np.zeros([d_batch], dtype=np.bool)
+ gen_seq_len = np.zeros([d_batch], dtype=np.int64)
+ output_ids = []
+
+ past_cache = info['caches']
+
+ cls_ids = paddle.ones([d_batch], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch], dtype='int64') * attn_id
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ gen_ids = paddle.argmax(logits, -1)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [paddle.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
+ cached_v = [paddle.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
+ past_cache = (cached_k, cached_v)
+
+ gen_ids = gen_ids[:, 1]
+ ids = paddle.stack([gen_ids, attn_ids], 1)
+
+ gen_ids = gen_ids.numpy()
+ has_stopped |= (gen_ids == eos_id).astype(np.bool)
+ gen_seq_len += (1 - has_stopped.astype(np.int64))
+ output_ids.append(gen_ids.tolist())
+ if has_stopped.all():
+ break
+ output_ids = np.array(output_ids).transpose([1, 0])
+ return output_ids
+
+
+BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
+BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
+
+
+def log_softmax(x):
+ e_x = np.exp(x - np.max(x))
+ return np.log(e_x / e_x.sum())
+
+
+def mask_prob(p, onehot_eos, finished):
+ is_finished = paddle.cast(paddle.reshape(finished, [-1, 1]) != 0, 'float32')
+ p = is_finished * (1. - paddle.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
+ return p
+
+
+def hyp_score(log_probs, length, length_penalty):
+ lp = paddle.pow((5. + paddle.cast(length, 'float32')) / 6., length_penalty)
+ return log_probs / lp
+
+
+def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
+ """logits.shape == [B*W, V]"""
+ _, vocab_size = logits.shape
+
+ bsz, beam_width = state.log_probs.shape
+ onehot_eos = paddle.cast(nn.functional.one_hot(paddle.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
+
+ probs = paddle.log(nn.functional.softmax(logits)) #[B*W, V]
+ probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
+ allprobs = paddle.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
+
+ not_finished = 1 - paddle.reshape(state.finished, [-1, 1]) #[B*W,1]
+ not_eos = 1 - onehot_eos
+ length_to_add = not_finished * not_eos #[B*W,V]
+ alllen = paddle.reshape(state.lengths, [-1, 1]) + length_to_add
+
+ allprobs = paddle.reshape(allprobs, [-1, beam_width * vocab_size])
+ alllen = paddle.reshape(alllen, [-1, beam_width * vocab_size])
+ allscore = hyp_score(allprobs, alllen, length_penalty)
+ if is_first_step:
+ allscore = paddle.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
+ scores, idx = paddle.topk(allscore, k=beam_width) #[B, W]
+ next_beam_id = idx // vocab_size #[B, W]
+ next_word_id = idx % vocab_size
+
+ gather_idx = paddle.concat([paddle.nonzero(idx != -1)[:, :1], paddle.reshape(idx, [-1, 1])], 1)
+ next_probs = paddle.reshape(paddle.gather_nd(allprobs, gather_idx), idx.shape)
+ next_len = paddle.reshape(paddle.gather_nd(alllen, gather_idx), idx.shape)
+
+ gather_idx = paddle.concat([paddle.nonzero(next_beam_id != -1)[:, :1], paddle.reshape(next_beam_id, [-1, 1])], 1)
+ next_finished = paddle.reshape(paddle.gather_nd(state.finished, gather_idx),
+ state.finished.shape) #[gather new beam state according to new beam id]
+
+ next_finished += paddle.cast(next_word_id == eos_id, 'int64')
+ next_finished = paddle.cast(next_finished > 0, 'int64')
+
+ next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
+ output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
+
+ return output, next_state
+
+
+@paddle.no_grad()
+def beam_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ beam_width=5,
+ tgt_type_id=3,
+ length_penalty=1.0):
+ _, __, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+
+ state = BeamSearchState(log_probs=paddle.zeros([d_batch, beam_width], 'float32'),
+ lengths=paddle.zeros([d_batch, beam_width], 'int64'),
+ finished=paddle.zeros([d_batch, beam_width], 'int64'))
+ outputs = []
+
+ def reorder_(t, parent_id):
+ """reorder cache according to parent beam id"""
+ gather_idx = paddle.nonzero(parent_id != -1)[:, 0] * beam_width + paddle.reshape(parent_id, [-1])
+ t = paddle.gather(t, gather_idx)
+ return t
+
+ def tile_(t, times):
+ _shapes = list(t.shape[1:])
+ new_shape = [t.shape[0], times] + list(t.shape[1:])
+ ret = paddle.reshape(paddle.expand(paddle.unsqueeze(t, [1]), new_shape), [
+ -1,
+ ] + _shapes)
+ return ret
+
+ cached_k, cached_v = info['caches']
+ cached_k = [tile_(k, beam_width) for k in cached_k]
+ cached_v = [tile_(v, beam_width) for v in cached_v]
+ past_cache = (cached_k, cached_v)
+
+ token_ids = tile_(token_ids, beam_width)
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+
+ cls_ids = paddle.ones([d_batch * beam_width], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ output, state = beam_search_step(state,
+ logits[:, 1],
+ eos_id=eos_id,
+ beam_width=beam_width,
+ is_first_step=(step == 0),
+ length_penalty=length_penalty)
+ outputs.append(output)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [
+ reorder_(paddle.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids)
+ for pk, k in zip(past_cached_k, cached_k)
+ ] # concat cached
+ cached_v = [
+ reorder_(paddle.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids)
+ for pv, v in zip(past_cached_v, cached_v)
+ ]
+ past_cache = (cached_k, cached_v)
+
+ pred_ids_flatten = paddle.reshape(output.predicted_ids, [d_batch * beam_width])
+ ids = paddle.stack([pred_ids_flatten, attn_ids], 1)
+
+ if state.finished.numpy().all():
+ break
+
+ final_ids = paddle.stack([o.predicted_ids for o in outputs], 0)
+ final_parent_ids = paddle.stack([o.beam_parent_ids for o in outputs], 0)
+ final_ids = nn.functional.gather_tree(final_ids, final_parent_ids) #[:, :, 0] #pick best beam
+ final_ids = paddle.transpose(paddle.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
+
+ return final_ids.numpy()
+
+
+en_patten = re.compile(r'^[a-zA-Z0-9]*$')
+
+
+def post_process(token):
+ if token.startswith('##'):
+ ret = token[2:]
+ elif token in ['[CLS]', '[SEP]', '[PAD]']:
+ ret = ''
+ else:
+ if en_patten.match(token):
+ ret = ' ' + token
+ else:
+ ret = token
+ return ret
diff --git a/modules/text/text_generation/ernie_gen_couplet/model/decode.py b/modules/text/text_generation/ernie_gen_couplet/model/decode.py
deleted file mode 100644
index 1d706b52a42397455565cd20c8d3adfe819cec04..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_couplet/model/decode.py
+++ /dev/null
@@ -1,255 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import re
-import numpy as np
-from collections import namedtuple
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-import paddle.fluid.dygraph as D
-
-
-def gen_bias(encoder_inputs, decoder_inputs, step):
- decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
- attn_bias = L.reshape(L.range(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
- decoder_bias = L.cast((L.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
- 'float32') #[1, 1, decoderlen, decoderlen]
- encoder_bias = L.unsqueeze(L.cast(L.ones_like(encoder_inputs), 'float32'), [1]) #[bsz, 1, encoderlen]
- encoder_bias = L.expand(encoder_bias, [1, decoder_seqlen, 1]) #[bsz,decoderlen, encoderlen]
- decoder_bias = L.expand(decoder_bias, [decoder_bsz, 1, 1]) #[bsz, decoderlen, decoderlen]
- if step > 0:
- bias = L.concat([encoder_bias, L.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
- else:
- bias = L.concat([encoder_bias, decoder_bias], -1)
- return bias
-
-
-@D.no_grad
-def greedy_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- tgt_type_id=3):
- model.eval()
- _, logits, info = model(q_ids, q_sids)
- gen_ids = L.argmax(logits, -1)
- d_batch, d_seqlen = q_ids.shape
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
- has_stopped = np.zeros([d_batch], dtype=np.bool)
- gen_seq_len = np.zeros([d_batch], dtype=np.int64)
- output_ids = []
-
- past_cache = info['caches']
-
- cls_ids = L.ones([d_batch], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch], dtype='int64') * attn_id
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
- pos_ids += seqlen
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
- gen_ids = L.argmax(logits, -1)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [L.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
- cached_v = [L.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
- past_cache = (cached_k, cached_v)
-
- gen_ids = gen_ids[:, 1]
- ids = L.stack([gen_ids, attn_ids], 1)
-
- gen_ids = gen_ids.numpy()
- has_stopped |= (gen_ids == eos_id).astype(np.bool)
- gen_seq_len += (1 - has_stopped.astype(np.int64))
- output_ids.append(gen_ids.tolist())
- if has_stopped.all():
- break
- output_ids = np.array(output_ids).transpose([1, 0])
- return output_ids
-
-
-BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
-BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
-
-
-def log_softmax(x):
- e_x = np.exp(x - np.max(x))
- return np.log(e_x / e_x.sum())
-
-
-def mask_prob(p, onehot_eos, finished):
- is_finished = L.cast(L.reshape(finished, [-1, 1]) != 0, 'float32')
- p = is_finished * (1. - L.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
- return p
-
-
-def hyp_score(log_probs, length, length_penalty):
- lp = L.pow((5. + L.cast(length, 'float32')) / 6., length_penalty)
- return log_probs / lp
-
-
-def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
- """logits.shape == [B*W, V]"""
- _, vocab_size = logits.shape
-
- bsz, beam_width = state.log_probs.shape
- onehot_eos = L.cast(F.one_hot(L.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
-
- probs = L.log(L.softmax(logits)) #[B*W, V]
- probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
- allprobs = L.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
-
- not_finished = 1 - L.reshape(state.finished, [-1, 1]) #[B*W,1]
- not_eos = 1 - onehot_eos
- length_to_add = not_finished * not_eos #[B*W,V]
- alllen = L.reshape(state.lengths, [-1, 1]) + length_to_add
-
- allprobs = L.reshape(allprobs, [-1, beam_width * vocab_size])
- alllen = L.reshape(alllen, [-1, beam_width * vocab_size])
- allscore = hyp_score(allprobs, alllen, length_penalty)
- if is_first_step:
- allscore = L.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
- scores, idx = L.topk(allscore, k=beam_width) #[B, W]
- next_beam_id = idx // vocab_size #[B, W]
- next_word_id = idx % vocab_size
-
- gather_idx = L.concat([L.where(idx != -1)[:, :1], L.reshape(idx, [-1, 1])], 1)
- next_probs = L.reshape(L.gather_nd(allprobs, gather_idx), idx.shape)
- next_len = L.reshape(L.gather_nd(alllen, gather_idx), idx.shape)
-
- gather_idx = L.concat([L.where(next_beam_id != -1)[:, :1], L.reshape(next_beam_id, [-1, 1])], 1)
- next_finished = L.reshape(L.gather_nd(state.finished, gather_idx),
- state.finished.shape) #[gather new beam state according to new beam id]
-
- next_finished += L.cast(next_word_id == eos_id, 'int64')
- next_finished = L.cast(next_finished > 0, 'int64')
-
- next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
- output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
-
- return output, next_state
-
-
-@D.no_grad
-def beam_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- beam_width=5,
- tgt_type_id=3,
- length_penalty=1.0):
- model.eval()
- _, __, info = model(q_ids, q_sids)
- d_batch, d_seqlen = q_ids.shape
-
- state = BeamSearchState(
- log_probs=L.zeros([d_batch, beam_width], 'float32'),
- lengths=L.zeros([d_batch, beam_width], 'int64'),
- finished=L.zeros([d_batch, beam_width], 'int64'))
- outputs = []
-
- def reorder_(t, parent_id):
- """reorder cache according to parent beam id"""
- gather_idx = L.where(parent_id != -1)[:, 0] * beam_width + L.reshape(parent_id, [-1])
- t = L.gather(t, gather_idx)
- return t
-
- def tile_(t, times):
- _shapes = list(t.shape[1:])
- ret = L.reshape(L.expand(L.unsqueeze(t, [1]), [
- 1,
- times,
- ] + [
- 1,
- ] * len(_shapes)), [
- -1,
- ] + _shapes)
- return ret
-
- cached_k, cached_v = info['caches']
- cached_k = [tile_(k, beam_width) for k in cached_k]
- cached_v = [tile_(v, beam_width) for v in cached_v]
- past_cache = (cached_k, cached_v)
-
- q_ids = tile_(q_ids, beam_width)
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
-
- cls_ids = L.ones([d_batch * beam_width], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
- pos_ids += seqlen
-
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
-
- output, state = beam_search_step(
- state,
- logits[:, 1],
- eos_id=eos_id,
- beam_width=beam_width,
- is_first_step=(step == 0),
- length_penalty=length_penalty)
- outputs.append(output)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [
- reorder_(L.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids) for pk, k in zip(past_cached_k, cached_k)
- ] # concat cached
- cached_v = [
- reorder_(L.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids) for pv, v in zip(past_cached_v, cached_v)
- ]
- past_cache = (cached_k, cached_v)
-
- pred_ids_flatten = L.reshape(output.predicted_ids, [d_batch * beam_width])
- ids = L.stack([pred_ids_flatten, attn_ids], 1)
-
- if state.finished.numpy().all():
- break
-
- final_ids = L.stack([o.predicted_ids for o in outputs], 0)
- final_parent_ids = L.stack([o.beam_parent_ids for o in outputs], 0)
- final_ids = L.gather_tree(final_ids, final_parent_ids) #[:, :,
- #0] #pick best beam
- final_ids = L.transpose(L.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
- return final_ids
-
-
-en_patten = re.compile(r'^[a-zA-Z0-9]*$')
-
-
-def post_process(token):
- if token.startswith('##'):
- ret = token[2:]
- else:
- if en_patten.match(token):
- ret = ' ' + token
- else:
- ret = token
- return ret
diff --git a/modules/text/text_generation/ernie_gen_couplet/model/file_utils.py b/modules/text/text_generation/ernie_gen_couplet/model/file_utils.py
deleted file mode 100644
index 608be4efc6644626f7f408df200fd299f2dd997e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_couplet/model/file_utils.py
+++ /dev/null
@@ -1,46 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-
-from tqdm import tqdm
-from paddlehub.common.logger import logger
-from paddlehub.common.dir import MODULE_HOME
-
-
-def _fetch_from_remote(url, force_download=False):
- import tempfile, requests, tarfile
- cached_dir = os.path.join(MODULE_HOME, "ernie_for_gen")
- if force_download or not os.path.exists(cached_dir):
- with tempfile.NamedTemporaryFile() as f:
- #url = 'https://ernie.bj.bcebos.com/ERNIE_stable.tgz'
- r = requests.get(url, stream=True)
- total_len = int(r.headers.get('content-length'))
- for chunk in tqdm(
- r.iter_content(chunk_size=1024), total=total_len // 1024, desc='downloading %s' % url, unit='KB'):
- if chunk:
- f.write(chunk)
- f.flush()
- logger.debug('extacting... to %s' % f.name)
- with tarfile.open(f.name) as tf:
- tf.extractall(path=cached_dir)
- logger.debug('%s cached in %s' % (url, cached_dir))
- return cached_dir
-
-
-def add_docstring(doc):
- def func(f):
- f.__doc__ += ('\n======other docs from supper class ======\n%s' % doc)
- return f
-
- return func
diff --git a/modules/text/text_generation/ernie_gen_couplet/model/modeling_ernie.py b/modules/text/text_generation/ernie_gen_couplet/model/modeling_ernie.py
deleted file mode 100644
index d5de28a5fee73371babd05b644e03a0f75ecdd5e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_couplet/model/modeling_ernie.py
+++ /dev/null
@@ -1,327 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from __future__ import division
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import logging
-
-import paddle.fluid.dygraph as D
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-log = logging.getLogger(__name__)
-
-
-def _build_linear(n_in, n_out, name, init, act=None):
- return D.Linear(
- n_in,
- n_out,
- param_attr=F.ParamAttr(name='%s.w_0' % name if name is not None else None, initializer=init),
- bias_attr='%s.b_0' % name if name is not None else None,
- act=act)
-
-
-def _build_ln(n_in, name):
- return D.LayerNorm(
- normalized_shape=n_in,
- param_attr=F.ParamAttr(
- name='%s_layer_norm_scale' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- bias_attr=F.ParamAttr(
- name='%s_layer_norm_bias' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- )
-
-
-def append_name(name, postfix):
- if name is None:
- return None
- elif name == '':
- return postfix
- else:
- return '%s_%s' % (name, postfix)
-
-
-class AttentionLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(AttentionLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- n_head = cfg['num_attention_heads']
- assert d_model % n_head == 0
- d_model_q = cfg.get('query_hidden_size_per_head', d_model // n_head) * n_head
- d_model_v = cfg.get('value_hidden_size_per_head', d_model // n_head) * n_head
- self.n_head = n_head
- self.d_key = d_model_q // n_head
- self.q = _build_linear(d_model, d_model_q, append_name(name, 'query_fc'), initializer)
- self.k = _build_linear(d_model, d_model_q, append_name(name, 'key_fc'), initializer)
- self.v = _build_linear(d_model, d_model_v, append_name(name, 'value_fc'), initializer)
- self.o = _build_linear(d_model_v, d_model, append_name(name, 'output_fc'), initializer)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=cfg['attention_probs_dropout_prob'],
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, queries, keys, values, attn_bias, past_cache):
- assert len(queries.shape) == len(keys.shape) == len(values.shape) == 3
-
- q = self.q(queries)
- k = self.k(keys)
- v = self.v(values)
-
- cache = (k, v)
- if past_cache is not None:
- cached_k, cached_v = past_cache
- k = L.concat([cached_k, k], 1)
- v = L.concat([cached_v, v], 1)
-
- q = L.transpose(L.reshape(q, [0, 0, self.n_head, q.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- k = L.transpose(L.reshape(k, [0, 0, self.n_head, k.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- v = L.transpose(L.reshape(v, [0, 0, self.n_head, v.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
-
- q = L.scale(q, scale=self.d_key**-0.5)
- score = L.matmul(q, k, transpose_y=True)
- if attn_bias is not None:
- score += attn_bias
- score = L.softmax(score, use_cudnn=True)
- score = self.dropout(score)
-
- out = L.matmul(score, v)
- out = L.transpose(out, [0, 2, 1, 3])
- out = L.reshape(out, [0, 0, out.shape[2] * out.shape[3]])
-
- out = self.o(out)
- return out, cache
-
-
-class PositionwiseFeedForwardLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(PositionwiseFeedForwardLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_ffn = cfg.get('intermediate_size', 4 * d_model)
- assert cfg['hidden_act'] in ['relu', 'gelu']
- self.i = _build_linear(d_model, d_ffn, append_name(name, 'fc_0'), initializer, act=cfg['hidden_act'])
- self.o = _build_linear(d_ffn, d_model, append_name(name, 'fc_1'), initializer)
- prob = cfg.get('intermediate_dropout_prob', 0.)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs):
- hidden = self.i(inputs)
- hidden = self.dropout(hidden)
- out = self.o(hidden)
- return out
-
-
-class ErnieBlock(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieBlock, self).__init__()
- d_model = cfg['hidden_size']
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.attn = AttentionLayer(cfg, name=append_name(name, 'multi_head_att'))
- self.ln1 = _build_ln(d_model, name=append_name(name, 'post_att'))
- self.ffn = PositionwiseFeedForwardLayer(cfg, name=append_name(name, 'ffn'))
- self.ln2 = _build_ln(d_model, name=append_name(name, 'post_ffn'))
- prob = cfg.get('intermediate_dropout_prob', cfg['hidden_dropout_prob'])
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- attn_out, cache = self.attn(inputs, inputs, inputs, attn_bias, past_cache=past_cache) #self attn
- attn_out = self.dropout(attn_out)
- hidden = attn_out + inputs
- hidden = self.ln1(hidden) # dropout/ add/ norm
-
- ffn_out = self.ffn(hidden)
- ffn_out = self.dropout(ffn_out)
- hidden = ffn_out + hidden
- hidden = self.ln2(hidden)
- return hidden, cache
-
-
-class ErnieEncoderStack(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieEncoderStack, self).__init__()
- n_layers = cfg['num_hidden_layers']
- self.block = D.LayerList([ErnieBlock(cfg, append_name(name, 'layer_%d' % i)) for i in range(n_layers)])
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- if past_cache is not None:
- assert isinstance(
- past_cache,
- tuple), 'unknown type of `past_cache`, expect tuple or list. got %s' % repr(type(past_cache))
- past_cache = list(zip(*past_cache))
- else:
- past_cache = [None] * len(self.block)
- cache_list_k, cache_list_v, hidden_list = [], [], [inputs]
-
- for b, p in zip(self.block, past_cache):
- inputs, cache = b(inputs, attn_bias=attn_bias, past_cache=p)
- cache_k, cache_v = cache
- cache_list_k.append(cache_k)
- cache_list_v.append(cache_v)
- hidden_list.append(inputs)
-
- return inputs, hidden_list, (cache_list_k, cache_list_v)
-
-
-class ErnieModel(D.Layer):
- def __init__(self, cfg, name=None):
- """
- Fundamental pretrained Ernie model
- """
- log.debug('init ErnieModel with config: %s' % repr(cfg))
- D.Layer.__init__(self)
- d_model = cfg['hidden_size']
- d_emb = cfg.get('emb_size', cfg['hidden_size'])
- d_vocab = cfg['vocab_size']
- d_pos = cfg['max_position_embeddings']
- d_sent = cfg.get("sent_type_vocab_size") or cfg['type_vocab_size']
- self.n_head = cfg['num_attention_heads']
- self.return_additional_info = cfg.get('return_additional_info', False)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.ln = _build_ln(d_model, name=append_name(name, 'pre_encoder'))
- self.word_emb = D.Embedding([d_vocab, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'word_embedding'), initializer=initializer))
- self.pos_emb = D.Embedding([d_pos, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'pos_embedding'), initializer=initializer))
- self.sent_emb = D.Embedding([d_sent, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'sent_embedding'), initializer=initializer))
- prob = cfg['hidden_dropout_prob']
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- self.encoder_stack = ErnieEncoderStack(cfg, append_name(name, 'encoder'))
- if cfg.get('has_pooler', True):
- self.pooler = _build_linear(
- cfg['hidden_size'], cfg['hidden_size'], append_name(name, 'pooled_fc'), initializer, act='tanh')
- else:
- self.pooler = None
- self.train()
-
- def eval(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).eval()
- self.training = False
- for l in self.sublayers():
- l.training = False
-
- def train(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).train()
- self.training = True
- for l in self.sublayers():
- l.training = True
-
- def forward(self,
- src_ids,
- sent_ids=None,
- pos_ids=None,
- input_mask=None,
- attn_bias=None,
- past_cache=None,
- use_causal_mask=False):
- """
- Args:
- src_ids (`Variable` of shape `[batch_size, seq_len]`):
- Indices of input sequence tokens in the vocabulary.
- sent_ids (optional, `Variable` of shape `[batch_size, seq_len]`):
- aka token_type_ids, Segment token indices to indicate first and second portions of the inputs.
- if None, assume all tokens come from `segment_a`
- pos_ids(optional, `Variable` of shape `[batch_size, seq_len]`):
- Indices of positions of each input sequence tokens in the position embeddings.
- input_mask(optional `Variable` of shape `[batch_size, seq_len]`):
- Mask to avoid performing attention on the padding token indices of the encoder input.
- attn_bias(optional, `Variable` of shape `[batch_size, seq_len, seq_len] or False`):
- 3D version of `input_mask`, if set, overrides `input_mask`; if set not False, will not apply attention mask
- past_cache(optional, tuple of two lists: cached key and cached value,
- each is a list of `Variable`s of shape `[batch_size, seq_len, hidden_size]`):
- cached key/value tensor that will be concated to generated key/value when performing self attention.
- if set, `attn_bias` should not be None.
-
- Returns:
- pooled (`Variable` of shape `[batch_size, hidden_size]`):
- output logits of pooler classifier
- encoded(`Variable` of shape `[batch_size, seq_len, hidden_size]`):
- output logits of transformer stack
- """
- assert len(src_ids.shape) == 2, 'expect src_ids.shape = [batch, sequecen], got %s' % (repr(src_ids.shape))
- assert attn_bias is not None if past_cache else True, 'if `past_cache` is specified; attn_bias should not be None'
- d_batch = L.shape(src_ids)[0]
- d_seqlen = L.shape(src_ids)[1]
- if pos_ids is None:
- pos_ids = L.reshape(L.range(0, d_seqlen, 1, dtype='int32'), [1, -1])
- pos_ids = L.cast(pos_ids, 'int64')
- if attn_bias is None:
- if input_mask is None:
- input_mask = L.cast(src_ids != 0, 'float32')
- assert len(input_mask.shape) == 2
- input_mask = L.unsqueeze(input_mask, axes=[-1])
- attn_bias = L.matmul(input_mask, input_mask, transpose_y=True)
- if use_causal_mask:
- sequence = L.reshape(L.range(0, d_seqlen, 1, dtype='float32') + 1., [1, 1, -1, 1])
- causal_mask = L.cast((L.matmul(sequence, 1. / sequence, transpose_y=True) >= 1.), 'float32')
- attn_bias *= causal_mask
- else:
- assert len(attn_bias.shape) == 3, 'expect attn_bias tobe rank 3, got %r' % attn_bias.shape
- attn_bias = (1. - attn_bias) * -10000.0
- attn_bias = L.unsqueeze(attn_bias, [1])
- attn_bias = L.expand(attn_bias, [1, self.n_head, 1, 1]) # avoid broadcast =_=
- attn_bias.stop_gradient = True
-
- if sent_ids is None:
- sent_ids = L.zeros_like(src_ids)
-
- src_embedded = self.word_emb(src_ids)
- pos_embedded = self.pos_emb(pos_ids)
- sent_embedded = self.sent_emb(sent_ids)
- embedded = src_embedded + pos_embedded + sent_embedded
-
- embedded = self.dropout(self.ln(embedded))
-
- encoded, hidden_list, cache_list = self.encoder_stack(embedded, attn_bias, past_cache=past_cache)
- if self.pooler is not None:
- pooled = self.pooler(encoded[:, 0, :])
- else:
- pooled = None
-
- additional_info = {
- 'hiddens': hidden_list,
- 'caches': cache_list,
- }
-
- if self.return_additional_info:
- return pooled, encoded, additional_info
- else:
- return pooled, encoded
diff --git a/modules/text/text_generation/ernie_gen_couplet/model/modeling_ernie_gen.py b/modules/text/text_generation/ernie_gen_couplet/model/modeling_ernie_gen.py
deleted file mode 100644
index 7e512c61b4eca2d591c95cb4a6614f6f24a50309..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_couplet/model/modeling_ernie_gen.py
+++ /dev/null
@@ -1,65 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from ernie_gen_couplet.model.modeling_ernie import ErnieModel
-from ernie_gen_couplet.model.modeling_ernie import _build_linear, _build_ln, append_name
-
-
-class ErnieModelForGeneration(ErnieModel):
- def __init__(self, cfg, name=None):
- cfg['return_additional_info'] = True
- cfg['has_pooler'] = False
- super(ErnieModelForGeneration, self).__init__(cfg, name=name)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_vocab = cfg['vocab_size']
-
- self.mlm = _build_linear(
- d_model, d_model, append_name(name, 'mask_lm_trans_fc'), initializer, act=cfg['hidden_act'])
- self.mlm_ln = _build_ln(d_model, name=append_name(name, 'mask_lm_trans'))
- self.mlm_bias = L.create_parameter(
- dtype='float32',
- shape=[d_vocab],
- attr=F.ParamAttr(
- name=append_name(name, 'mask_lm_out_fc.b_0'), initializer=F.initializer.Constant(value=0.0)),
- is_bias=True,
- )
-
- def forward(self, src_ids, *args, **kwargs):
- tgt_labels = kwargs.pop('tgt_labels', None)
- tgt_pos = kwargs.pop('tgt_pos', None)
- encode_only = kwargs.pop('encode_only', False)
- _, encoded, info = ErnieModel.forward(self, src_ids, *args, **kwargs)
- if encode_only:
- return None, None, info
- elif tgt_labels is None:
- encoded = self.mlm(encoded)
- encoded = self.mlm_ln(encoded)
- logits = L.matmul(encoded, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- output_ids = L.argmax(logits, -1)
- return output_ids, logits, info
- else:
- encoded_2d = L.gather_nd(encoded, tgt_pos)
- encoded_2d = self.mlm(encoded_2d)
- encoded_2d = self.mlm_ln(encoded_2d)
- logits_2d = L.matmul(encoded_2d, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- if len(tgt_labels.shape) == 1:
- tgt_labels = L.reshape(tgt_labels, [-1, 1])
-
- loss = L.reduce_mean(
- L.softmax_with_cross_entropy(logits_2d, tgt_labels, soft_label=(tgt_labels.shape[-1] != 1)))
- return loss, logits_2d, info
diff --git a/modules/text/text_generation/ernie_gen_couplet/model/tokenizing_ernie.py b/modules/text/text_generation/ernie_gen_couplet/model/tokenizing_ernie.py
deleted file mode 100644
index c9e5638f9a17207ce2d664c27376f08138876da3..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_couplet/model/tokenizing_ernie.py
+++ /dev/null
@@ -1,163 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import six
-import re
-import logging
-from functools import partial
-
-import numpy as np
-
-import io
-
-open = partial(io.open, encoding='utf8')
-
-log = logging.getLogger(__name__)
-
-_max_input_chars_per_word = 100
-
-
-def _wordpiece(token, vocab, unk_token, prefix='##', sentencepiece_prefix=''):
- """ wordpiece: helloworld => [hello, ##world] """
- chars = list(token)
- if len(chars) > _max_input_chars_per_word:
- return [unk_token], [(0, len(chars))]
-
- is_bad = False
- start = 0
- sub_tokens = []
- sub_pos = []
- while start < len(chars):
- end = len(chars)
- cur_substr = None
- while start < end:
- substr = "".join(chars[start:end])
- if start == 0:
- substr = sentencepiece_prefix + substr
- if start > 0:
- substr = prefix + substr
- if substr in vocab:
- cur_substr = substr
- break
- end -= 1
- if cur_substr is None:
- is_bad = True
- break
- sub_tokens.append(cur_substr)
- sub_pos.append((start, end))
- start = end
- if is_bad:
- return [unk_token], [(0, len(chars))]
- else:
- return sub_tokens, sub_pos
-
-
-class ErnieTokenizer(object):
- def __init__(self,
- vocab,
- unk_token='[UNK]',
- sep_token='[SEP]',
- cls_token='[CLS]',
- pad_token='[PAD]',
- mask_token='[MASK]',
- wordpiece_prefix='##',
- sentencepiece_prefix='',
- lower=True,
- encoding='utf8',
- special_token_list=[]):
- if not isinstance(vocab, dict):
- raise ValueError('expect `vocab` to be instance of dict, got %s' % type(vocab))
- self.vocab = vocab
- self.lower = lower
- self.prefix = wordpiece_prefix
- self.sentencepiece_prefix = sentencepiece_prefix
- self.pad_id = self.vocab[pad_token]
- self.cls_id = cls_token and self.vocab[cls_token]
- self.sep_id = sep_token and self.vocab[sep_token]
- self.unk_id = unk_token and self.vocab[unk_token]
- self.mask_id = mask_token and self.vocab[mask_token]
- self.unk_token = unk_token
- special_tokens = {pad_token, cls_token, sep_token, unk_token, mask_token} | set(special_token_list)
- pat_str = ''
- for t in special_tokens:
- if t is None:
- continue
- pat_str += '(%s)|' % re.escape(t)
- pat_str += r'([a-zA-Z0-9]+|\S)'
- log.debug('regex: %s' % pat_str)
- self.pat = re.compile(pat_str)
- self.encoding = encoding
-
- def tokenize(self, text):
- if len(text) == 0:
- return []
- if six.PY3 and not isinstance(text, six.string_types):
- text = text.decode(self.encoding)
- if six.PY2 and isinstance(text, str):
- text = text.decode(self.encoding)
-
- res = []
- for match in self.pat.finditer(text):
- match_group = match.group(0)
- if match.groups()[-1]:
- if self.lower:
- match_group = match_group.lower()
- words, _ = _wordpiece(
- match_group,
- vocab=self.vocab,
- unk_token=self.unk_token,
- prefix=self.prefix,
- sentencepiece_prefix=self.sentencepiece_prefix)
- else:
- words = [match_group]
- res += words
- return res
-
- def convert_tokens_to_ids(self, tokens):
- return [self.vocab.get(t, self.unk_id) for t in tokens]
-
- def truncate(self, id1, id2, seqlen):
- len1 = len(id1)
- len2 = len(id2)
- half = seqlen // 2
- if len1 > len2:
- len1_truncated, len2_truncated = max(half, seqlen - len2), min(half, len2)
- else:
- len1_truncated, len2_truncated = min(half, seqlen - len1), max(half, seqlen - len1)
- return id1[:len1_truncated], id2[:len2_truncated]
-
- def build_for_ernie(self, text_id, pair_id=[]):
- """build sentence type id, add [CLS] [SEP]"""
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- ret_id = np.concatenate([[self.cls_id], text_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([[0], text_id_type, [0]], 0)
-
- if len(pair_id):
- pair_id_type = np.ones_like(pair_id, dtype=np.int64)
- ret_id = np.concatenate([ret_id, pair_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([ret_id_type, pair_id_type, [1]], 0)
- return ret_id, ret_id_type
-
- def encode(self, text, pair=None, truncate_to=None):
- text_id = np.array(self.convert_tokens_to_ids(self.tokenize(text)), dtype=np.int64)
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- if pair is not None:
- pair_id = np.array(self.convert_tokens_to_ids(self.tokenize(pair)), dtype=np.int64)
- else:
- pair_id = []
- if truncate_to is not None:
- text_id, pair_id = self.truncate(text_id, [] if pair_id is None else pair_id, truncate_to)
-
- ret_id, ret_id_type = self.build_for_ernie(text_id, pair_id)
- return ret_id, ret_id_type
diff --git a/modules/text/text_generation/ernie_gen_couplet/module.py b/modules/text/text_generation/ernie_gen_couplet/module.py
index 994e5ea0a61ef557e726f4615141d40d52d5a394..59bb39ad63996875360ed595a4d97de3583c9b70 100644
--- a/modules/text/text_generation/ernie_gen_couplet/module.py
+++ b/modules/text/text_generation/ernie_gen_couplet/module.py
@@ -14,28 +14,24 @@
# limitations under the License.
import ast
import json
+import argparse
+import os
-import paddle.fluid as fluid
+import numpy as np
+import paddle
import paddlehub as hub
from paddlehub.module.module import runnable
from paddlehub.module.nlp_module import DataFormatError
from paddlehub.common.logger import logger
from paddlehub.module.module import moduleinfo, serving
+from paddlenlp.transformers import ErnieTokenizer, ErnieForGeneration
-import argparse
-import os
-import numpy as np
-
-import paddle.fluid.dygraph as D
-
-from ernie_gen_couplet.model.tokenizing_ernie import ErnieTokenizer
-from ernie_gen_couplet.model.decode import beam_search_infilling
-from ernie_gen_couplet.model.modeling_ernie_gen import ErnieModelForGeneration
+from ernie_gen_couplet.decode import beam_search_infilling
@moduleinfo(
name="ernie_gen_couplet",
- version="1.0.2",
+ version="1.1.0",
summary=
"ERNIE-GEN is a multi-flow language generation framework for both pre-training and fine-tuning. This module has fine-tuned for couplet generation task.",
author="baidu-nlp",
@@ -43,29 +39,19 @@ from ernie_gen_couplet.model.modeling_ernie_gen import ErnieModelForGeneration
type="nlp/text_generation",
)
class ErnieGen(hub.NLPPredictionModule):
- def _initialize(self):
+ def __init__(self):
"""
initialize with the necessary elements
"""
assets_path = os.path.join(self.directory, "assets")
- gen_checkpoint_path = os.path.join(assets_path, "ernie_gen_couplet")
- ernie_cfg_path = os.path.join(assets_path, 'ernie_config.json')
- with open(ernie_cfg_path, encoding='utf8') as ernie_cfg_file:
- ernie_cfg = dict(json.loads(ernie_cfg_file.read()))
- ernie_vocab_path = os.path.join(assets_path, 'vocab.txt')
- with open(ernie_vocab_path, encoding='utf8') as ernie_vocab_file:
- ernie_vocab = {j.strip().split('\t')[0]: i for i, j in enumerate(ernie_vocab_file.readlines())}
-
- with fluid.dygraph.guard(fluid.CPUPlace()):
- with fluid.unique_name.guard():
- self.model = ErnieModelForGeneration(ernie_cfg)
- finetuned_states, _ = D.load_dygraph(gen_checkpoint_path)
- self.model.set_dict(finetuned_states)
-
- self.tokenizer = ErnieTokenizer(ernie_vocab)
- self.rev_dict = {v: k for k, v in self.tokenizer.vocab.items()}
- self.rev_dict[self.tokenizer.pad_id] = '' # replace [PAD]
- self.rev_dict[self.tokenizer.unk_id] = '' # replace [PAD]
+ gen_checkpoint_path = os.path.join(assets_path, "ernie_gen_couplet.pdparams")
+ self.model = ErnieForGeneration.from_pretrained("ernie-1.0")
+ model_state = paddle.load(gen_checkpoint_path)
+ self.model.set_dict(model_state)
+ self.tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
+ self.rev_dict = self.tokenizer.vocab.idx_to_token
+ self.rev_dict[self.tokenizer.vocab['[PAD]']] = '' # replace [PAD]
+ self.rev_dict[self.tokenizer.vocab['[UNK]']] = '' # replace [PAD]
self.rev_lookup = np.vectorize(lambda i: self.rev_dict[i])
@serving
@@ -81,6 +67,8 @@ class ErnieGen(hub.NLPPredictionModule):
Returns:
results(list): the right rolls.
"""
+ paddle.disable_static()
+
if texts and isinstance(texts, list) and all(texts) and all([isinstance(text, str) for text in texts]):
predicted_data = texts
else:
@@ -97,37 +85,37 @@ class ErnieGen(hub.NLPPredictionModule):
logger.warning(
"use_gpu has been set False as you didn't set the environment variable CUDA_VISIBLE_DEVICES while using use_gpu=True"
)
- if use_gpu:
- place = fluid.CUDAPlace(0)
- else:
- place = fluid.CPUPlace()
-
- with fluid.dygraph.guard(place):
- self.model.eval()
- results = []
- for text in predicted_data:
- sample_results = []
- ids, sids = self.tokenizer.encode(text)
- src_ids = D.to_variable(np.expand_dims(ids, 0))
- src_sids = D.to_variable(np.expand_dims(sids, 0))
- output_ids = beam_search_infilling(
- self.model,
- src_ids,
- src_sids,
- eos_id=self.tokenizer.sep_id,
- sos_id=self.tokenizer.cls_id,
- attn_id=self.tokenizer.vocab['[MASK]'],
- max_decode_len=20,
- max_encode_len=20,
- beam_width=beam_width,
- tgt_type_id=1)
- output_str = self.rev_lookup(output_ids[0].numpy())
-
- for ostr in output_str.tolist():
- if '[SEP]' in ostr:
- ostr = ostr[:ostr.index('[SEP]')]
- sample_results.append("".join(ostr))
- results.append(sample_results)
+
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+
+ self.model.eval()
+ results = []
+ for text in predicted_data:
+ sample_results = []
+ encode_text = self.tokenizer.encode(text)
+ src_ids = paddle.to_tensor(encode_text['input_ids']).unsqueeze(0)
+ src_sids = paddle.to_tensor(encode_text['token_type_ids']).unsqueeze(0)
+ output_ids = beam_search_infilling(
+ self.model,
+ src_ids,
+ src_sids,
+ eos_id=self.tokenizer.vocab['[SEP]'],
+ sos_id=self.tokenizer.vocab['[CLS]'],
+ attn_id=self.tokenizer.vocab['[MASK]'],
+ pad_id=self.tokenizer.vocab['[PAD]'],
+ unk_id=self.tokenizer.vocab['[UNK]'],
+ vocab_size=len(self.tokenizer.vocab),
+ max_decode_len=20,
+ max_encode_len=20,
+ beam_width=beam_width,
+ tgt_type_id=1)
+ output_str = self.rev_lookup(output_ids[0])
+
+ for ostr in output_str.tolist():
+ if '[SEP]' in ostr:
+ ostr = ostr[:ostr.index('[SEP]')]
+ sample_results.append("".join(ostr))
+ results.append(sample_results)
return results
def add_module_config_arg(self):
@@ -172,5 +160,5 @@ class ErnieGen(hub.NLPPredictionModule):
if __name__ == "__main__":
module = ErnieGen()
- for result in module.generate(['上海自来水来自海上', '风吹云乱天垂泪'], beam_width=5):
+ for result in module.generate(['人增福寿年增岁', '上海自来水来自海上', '风吹云乱天垂泪'], beam_width=5, use_gpu=True):
print(result)
diff --git a/modules/text/text_generation/ernie_gen_lover_words/README.md b/modules/text/text_generation/ernie_gen_lover_words/README.md
index afa89ca6949f8e34ce8be941ce47718cab7c70f3..9035e001d0d3455cdfef8d5babea25356896e4a5 100644
--- a/modules/text/text_generation/ernie_gen_lover_words/README.md
+++ b/modules/text/text_generation/ernie_gen_lover_words/README.md
@@ -87,9 +87,11 @@ https://github.com/PaddlePaddle/ERNIE/blob/repro/ernie-gen/
### 依赖
-paddlepaddle >= 1.8.2
+paddlepaddle >= 2.0.0
-paddlehub >= 1.7.0
+paddlehub >= 2.0.0
+
+paddlenlp >= 2.0.0
## 更新历史
@@ -101,3 +103,7 @@ paddlehub >= 1.7.0
* 1.0.1
完善API的输入文本检查
+
+* 1.1.0
+
+ 接入PaddleNLP
diff --git a/modules/text/text_generation/ernie_gen_lover_words/decode.py b/modules/text/text_generation/ernie_gen_lover_words/decode.py
new file mode 100644
index 0000000000000000000000000000000000000000..3aadd245509bd5d1335b327c15a5c2de520f39ab
--- /dev/null
+++ b/modules/text/text_generation/ernie_gen_lover_words/decode.py
@@ -0,0 +1,288 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+import re
+import argparse
+import logging
+import json
+import numpy as np
+from collections import namedtuple
+
+import paddle
+import paddle.nn as nn
+import numpy as np
+from paddlenlp.utils.log import logger
+
+
+def gen_bias(encoder_inputs, decoder_inputs, step):
+ decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
+ encoder_bsz, encoder_seqlen = encoder_inputs.shape[:2]
+ attn_bias = paddle.reshape(paddle.arange(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
+ decoder_bias = paddle.cast((paddle.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
+ 'float32') #[1, decoderlen, decoderlen]
+ encoder_bias = paddle.unsqueeze(paddle.cast(paddle.ones_like(encoder_inputs), 'float32'),
+ [1]) #[bsz, 1, encoderlen]
+ encoder_bias = paddle.expand(encoder_bias,
+ [encoder_bsz, decoder_seqlen, encoder_seqlen]) #[bsz,decoderlen, encoderlen]
+ decoder_bias = paddle.expand(decoder_bias,
+ [decoder_bsz, decoder_seqlen, decoder_seqlen]) #[bsz, decoderlen, decoderlen]
+ if step > 0:
+ bias = paddle.concat(
+ [encoder_bias, paddle.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
+ else:
+ bias = paddle.concat([encoder_bias, decoder_bias], -1)
+ return bias
+
+
+@paddle.no_grad()
+def greedy_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ tgt_type_id=3):
+ _, logits, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+ has_stopped = np.zeros([d_batch], dtype=np.bool)
+ gen_seq_len = np.zeros([d_batch], dtype=np.int64)
+ output_ids = []
+
+ past_cache = info['caches']
+
+ cls_ids = paddle.ones([d_batch], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch], dtype='int64') * attn_id
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ gen_ids = paddle.argmax(logits, -1)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [paddle.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
+ cached_v = [paddle.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
+ past_cache = (cached_k, cached_v)
+
+ gen_ids = gen_ids[:, 1]
+ ids = paddle.stack([gen_ids, attn_ids], 1)
+
+ gen_ids = gen_ids.numpy()
+ has_stopped |= (gen_ids == eos_id).astype(np.bool)
+ gen_seq_len += (1 - has_stopped.astype(np.int64))
+ output_ids.append(gen_ids.tolist())
+ if has_stopped.all():
+ break
+ output_ids = np.array(output_ids).transpose([1, 0])
+ return output_ids
+
+
+BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
+BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
+
+
+def log_softmax(x):
+ e_x = np.exp(x - np.max(x))
+ return np.log(e_x / e_x.sum())
+
+
+def mask_prob(p, onehot_eos, finished):
+ is_finished = paddle.cast(paddle.reshape(finished, [-1, 1]) != 0, 'float32')
+ p = is_finished * (1. - paddle.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
+ return p
+
+
+def hyp_score(log_probs, length, length_penalty):
+ lp = paddle.pow((5. + paddle.cast(length, 'float32')) / 6., length_penalty)
+ return log_probs / lp
+
+
+def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
+ """logits.shape == [B*W, V]"""
+ _, vocab_size = logits.shape
+
+ bsz, beam_width = state.log_probs.shape
+ onehot_eos = paddle.cast(nn.functional.one_hot(paddle.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
+
+ probs = paddle.log(nn.functional.softmax(logits)) #[B*W, V]
+ probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
+ allprobs = paddle.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
+
+ not_finished = 1 - paddle.reshape(state.finished, [-1, 1]) #[B*W,1]
+ not_eos = 1 - onehot_eos
+ length_to_add = not_finished * not_eos #[B*W,V]
+ alllen = paddle.reshape(state.lengths, [-1, 1]) + length_to_add
+
+ allprobs = paddle.reshape(allprobs, [-1, beam_width * vocab_size])
+ alllen = paddle.reshape(alllen, [-1, beam_width * vocab_size])
+ allscore = hyp_score(allprobs, alllen, length_penalty)
+ if is_first_step:
+ allscore = paddle.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
+ scores, idx = paddle.topk(allscore, k=beam_width) #[B, W]
+ next_beam_id = idx // vocab_size #[B, W]
+ next_word_id = idx % vocab_size
+
+ gather_idx = paddle.concat([paddle.nonzero(idx != -1)[:, :1], paddle.reshape(idx, [-1, 1])], 1)
+ next_probs = paddle.reshape(paddle.gather_nd(allprobs, gather_idx), idx.shape)
+ next_len = paddle.reshape(paddle.gather_nd(alllen, gather_idx), idx.shape)
+
+ gather_idx = paddle.concat([paddle.nonzero(next_beam_id != -1)[:, :1], paddle.reshape(next_beam_id, [-1, 1])], 1)
+ next_finished = paddle.reshape(paddle.gather_nd(state.finished, gather_idx),
+ state.finished.shape) #[gather new beam state according to new beam id]
+
+ next_finished += paddle.cast(next_word_id == eos_id, 'int64')
+ next_finished = paddle.cast(next_finished > 0, 'int64')
+
+ next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
+ output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
+
+ return output, next_state
+
+
+@paddle.no_grad()
+def beam_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ beam_width=5,
+ tgt_type_id=3,
+ length_penalty=1.0):
+ _, __, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+
+ state = BeamSearchState(log_probs=paddle.zeros([d_batch, beam_width], 'float32'),
+ lengths=paddle.zeros([d_batch, beam_width], 'int64'),
+ finished=paddle.zeros([d_batch, beam_width], 'int64'))
+ outputs = []
+
+ def reorder_(t, parent_id):
+ """reorder cache according to parent beam id"""
+ gather_idx = paddle.nonzero(parent_id != -1)[:, 0] * beam_width + paddle.reshape(parent_id, [-1])
+ t = paddle.gather(t, gather_idx)
+ return t
+
+ def tile_(t, times):
+ _shapes = list(t.shape[1:])
+ new_shape = [t.shape[0], times] + list(t.shape[1:])
+ ret = paddle.reshape(paddle.expand(paddle.unsqueeze(t, [1]), new_shape), [
+ -1,
+ ] + _shapes)
+ return ret
+
+ cached_k, cached_v = info['caches']
+ cached_k = [tile_(k, beam_width) for k in cached_k]
+ cached_v = [tile_(v, beam_width) for v in cached_v]
+ past_cache = (cached_k, cached_v)
+
+ token_ids = tile_(token_ids, beam_width)
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+
+ cls_ids = paddle.ones([d_batch * beam_width], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+ if logits.shape[-1] > vocab_size:
+ logits[:, :, vocab_size:] = 0
+ logits[:, :, pad_id] = 0
+ logits[:, :, unk_id] = 0
+ logits[:, :, attn_id] = 0
+
+ output, state = beam_search_step(state,
+ logits[:, 1],
+ eos_id=eos_id,
+ beam_width=beam_width,
+ is_first_step=(step == 0),
+ length_penalty=length_penalty)
+ outputs.append(output)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [
+ reorder_(paddle.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids)
+ for pk, k in zip(past_cached_k, cached_k)
+ ] # concat cached
+ cached_v = [
+ reorder_(paddle.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids)
+ for pv, v in zip(past_cached_v, cached_v)
+ ]
+ past_cache = (cached_k, cached_v)
+
+ pred_ids_flatten = paddle.reshape(output.predicted_ids, [d_batch * beam_width])
+ ids = paddle.stack([pred_ids_flatten, attn_ids], 1)
+
+ if state.finished.numpy().all():
+ break
+
+ final_ids = paddle.stack([o.predicted_ids for o in outputs], 0)
+ final_parent_ids = paddle.stack([o.beam_parent_ids for o in outputs], 0)
+ final_ids = nn.functional.gather_tree(final_ids, final_parent_ids) #[:, :, 0] #pick best beam
+ final_ids = paddle.transpose(paddle.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
+
+ return final_ids.numpy()
+
+
+en_patten = re.compile(r'^[a-zA-Z0-9]*$')
+
+
+def post_process(token):
+ if token.startswith('##'):
+ ret = token[2:]
+ elif token in ['[CLS]', '[SEP]', '[PAD]']:
+ ret = ''
+ else:
+ if en_patten.match(token):
+ ret = ' ' + token
+ else:
+ ret = token
+ return ret
diff --git a/modules/text/text_generation/ernie_gen_lover_words/model/decode.py b/modules/text/text_generation/ernie_gen_lover_words/model/decode.py
deleted file mode 100644
index 1d706b52a42397455565cd20c8d3adfe819cec04..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_lover_words/model/decode.py
+++ /dev/null
@@ -1,255 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import re
-import numpy as np
-from collections import namedtuple
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-import paddle.fluid.dygraph as D
-
-
-def gen_bias(encoder_inputs, decoder_inputs, step):
- decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
- attn_bias = L.reshape(L.range(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
- decoder_bias = L.cast((L.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
- 'float32') #[1, 1, decoderlen, decoderlen]
- encoder_bias = L.unsqueeze(L.cast(L.ones_like(encoder_inputs), 'float32'), [1]) #[bsz, 1, encoderlen]
- encoder_bias = L.expand(encoder_bias, [1, decoder_seqlen, 1]) #[bsz,decoderlen, encoderlen]
- decoder_bias = L.expand(decoder_bias, [decoder_bsz, 1, 1]) #[bsz, decoderlen, decoderlen]
- if step > 0:
- bias = L.concat([encoder_bias, L.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
- else:
- bias = L.concat([encoder_bias, decoder_bias], -1)
- return bias
-
-
-@D.no_grad
-def greedy_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- tgt_type_id=3):
- model.eval()
- _, logits, info = model(q_ids, q_sids)
- gen_ids = L.argmax(logits, -1)
- d_batch, d_seqlen = q_ids.shape
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
- has_stopped = np.zeros([d_batch], dtype=np.bool)
- gen_seq_len = np.zeros([d_batch], dtype=np.int64)
- output_ids = []
-
- past_cache = info['caches']
-
- cls_ids = L.ones([d_batch], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch], dtype='int64') * attn_id
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
- pos_ids += seqlen
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
- gen_ids = L.argmax(logits, -1)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [L.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
- cached_v = [L.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
- past_cache = (cached_k, cached_v)
-
- gen_ids = gen_ids[:, 1]
- ids = L.stack([gen_ids, attn_ids], 1)
-
- gen_ids = gen_ids.numpy()
- has_stopped |= (gen_ids == eos_id).astype(np.bool)
- gen_seq_len += (1 - has_stopped.astype(np.int64))
- output_ids.append(gen_ids.tolist())
- if has_stopped.all():
- break
- output_ids = np.array(output_ids).transpose([1, 0])
- return output_ids
-
-
-BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
-BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
-
-
-def log_softmax(x):
- e_x = np.exp(x - np.max(x))
- return np.log(e_x / e_x.sum())
-
-
-def mask_prob(p, onehot_eos, finished):
- is_finished = L.cast(L.reshape(finished, [-1, 1]) != 0, 'float32')
- p = is_finished * (1. - L.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
- return p
-
-
-def hyp_score(log_probs, length, length_penalty):
- lp = L.pow((5. + L.cast(length, 'float32')) / 6., length_penalty)
- return log_probs / lp
-
-
-def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
- """logits.shape == [B*W, V]"""
- _, vocab_size = logits.shape
-
- bsz, beam_width = state.log_probs.shape
- onehot_eos = L.cast(F.one_hot(L.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
-
- probs = L.log(L.softmax(logits)) #[B*W, V]
- probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
- allprobs = L.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
-
- not_finished = 1 - L.reshape(state.finished, [-1, 1]) #[B*W,1]
- not_eos = 1 - onehot_eos
- length_to_add = not_finished * not_eos #[B*W,V]
- alllen = L.reshape(state.lengths, [-1, 1]) + length_to_add
-
- allprobs = L.reshape(allprobs, [-1, beam_width * vocab_size])
- alllen = L.reshape(alllen, [-1, beam_width * vocab_size])
- allscore = hyp_score(allprobs, alllen, length_penalty)
- if is_first_step:
- allscore = L.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
- scores, idx = L.topk(allscore, k=beam_width) #[B, W]
- next_beam_id = idx // vocab_size #[B, W]
- next_word_id = idx % vocab_size
-
- gather_idx = L.concat([L.where(idx != -1)[:, :1], L.reshape(idx, [-1, 1])], 1)
- next_probs = L.reshape(L.gather_nd(allprobs, gather_idx), idx.shape)
- next_len = L.reshape(L.gather_nd(alllen, gather_idx), idx.shape)
-
- gather_idx = L.concat([L.where(next_beam_id != -1)[:, :1], L.reshape(next_beam_id, [-1, 1])], 1)
- next_finished = L.reshape(L.gather_nd(state.finished, gather_idx),
- state.finished.shape) #[gather new beam state according to new beam id]
-
- next_finished += L.cast(next_word_id == eos_id, 'int64')
- next_finished = L.cast(next_finished > 0, 'int64')
-
- next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
- output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
-
- return output, next_state
-
-
-@D.no_grad
-def beam_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- beam_width=5,
- tgt_type_id=3,
- length_penalty=1.0):
- model.eval()
- _, __, info = model(q_ids, q_sids)
- d_batch, d_seqlen = q_ids.shape
-
- state = BeamSearchState(
- log_probs=L.zeros([d_batch, beam_width], 'float32'),
- lengths=L.zeros([d_batch, beam_width], 'int64'),
- finished=L.zeros([d_batch, beam_width], 'int64'))
- outputs = []
-
- def reorder_(t, parent_id):
- """reorder cache according to parent beam id"""
- gather_idx = L.where(parent_id != -1)[:, 0] * beam_width + L.reshape(parent_id, [-1])
- t = L.gather(t, gather_idx)
- return t
-
- def tile_(t, times):
- _shapes = list(t.shape[1:])
- ret = L.reshape(L.expand(L.unsqueeze(t, [1]), [
- 1,
- times,
- ] + [
- 1,
- ] * len(_shapes)), [
- -1,
- ] + _shapes)
- return ret
-
- cached_k, cached_v = info['caches']
- cached_k = [tile_(k, beam_width) for k in cached_k]
- cached_v = [tile_(v, beam_width) for v in cached_v]
- past_cache = (cached_k, cached_v)
-
- q_ids = tile_(q_ids, beam_width)
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
-
- cls_ids = L.ones([d_batch * beam_width], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
- pos_ids += seqlen
-
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
-
- output, state = beam_search_step(
- state,
- logits[:, 1],
- eos_id=eos_id,
- beam_width=beam_width,
- is_first_step=(step == 0),
- length_penalty=length_penalty)
- outputs.append(output)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [
- reorder_(L.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids) for pk, k in zip(past_cached_k, cached_k)
- ] # concat cached
- cached_v = [
- reorder_(L.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids) for pv, v in zip(past_cached_v, cached_v)
- ]
- past_cache = (cached_k, cached_v)
-
- pred_ids_flatten = L.reshape(output.predicted_ids, [d_batch * beam_width])
- ids = L.stack([pred_ids_flatten, attn_ids], 1)
-
- if state.finished.numpy().all():
- break
-
- final_ids = L.stack([o.predicted_ids for o in outputs], 0)
- final_parent_ids = L.stack([o.beam_parent_ids for o in outputs], 0)
- final_ids = L.gather_tree(final_ids, final_parent_ids) #[:, :,
- #0] #pick best beam
- final_ids = L.transpose(L.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
- return final_ids
-
-
-en_patten = re.compile(r'^[a-zA-Z0-9]*$')
-
-
-def post_process(token):
- if token.startswith('##'):
- ret = token[2:]
- else:
- if en_patten.match(token):
- ret = ' ' + token
- else:
- ret = token
- return ret
diff --git a/modules/text/text_generation/ernie_gen_lover_words/model/file_utils.py b/modules/text/text_generation/ernie_gen_lover_words/model/file_utils.py
deleted file mode 100644
index 608be4efc6644626f7f408df200fd299f2dd997e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_lover_words/model/file_utils.py
+++ /dev/null
@@ -1,46 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-
-from tqdm import tqdm
-from paddlehub.common.logger import logger
-from paddlehub.common.dir import MODULE_HOME
-
-
-def _fetch_from_remote(url, force_download=False):
- import tempfile, requests, tarfile
- cached_dir = os.path.join(MODULE_HOME, "ernie_for_gen")
- if force_download or not os.path.exists(cached_dir):
- with tempfile.NamedTemporaryFile() as f:
- #url = 'https://ernie.bj.bcebos.com/ERNIE_stable.tgz'
- r = requests.get(url, stream=True)
- total_len = int(r.headers.get('content-length'))
- for chunk in tqdm(
- r.iter_content(chunk_size=1024), total=total_len // 1024, desc='downloading %s' % url, unit='KB'):
- if chunk:
- f.write(chunk)
- f.flush()
- logger.debug('extacting... to %s' % f.name)
- with tarfile.open(f.name) as tf:
- tf.extractall(path=cached_dir)
- logger.debug('%s cached in %s' % (url, cached_dir))
- return cached_dir
-
-
-def add_docstring(doc):
- def func(f):
- f.__doc__ += ('\n======other docs from supper class ======\n%s' % doc)
- return f
-
- return func
diff --git a/modules/text/text_generation/ernie_gen_lover_words/model/modeling_ernie.py b/modules/text/text_generation/ernie_gen_lover_words/model/modeling_ernie.py
deleted file mode 100644
index d5de28a5fee73371babd05b644e03a0f75ecdd5e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_lover_words/model/modeling_ernie.py
+++ /dev/null
@@ -1,327 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from __future__ import division
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import logging
-
-import paddle.fluid.dygraph as D
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-log = logging.getLogger(__name__)
-
-
-def _build_linear(n_in, n_out, name, init, act=None):
- return D.Linear(
- n_in,
- n_out,
- param_attr=F.ParamAttr(name='%s.w_0' % name if name is not None else None, initializer=init),
- bias_attr='%s.b_0' % name if name is not None else None,
- act=act)
-
-
-def _build_ln(n_in, name):
- return D.LayerNorm(
- normalized_shape=n_in,
- param_attr=F.ParamAttr(
- name='%s_layer_norm_scale' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- bias_attr=F.ParamAttr(
- name='%s_layer_norm_bias' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- )
-
-
-def append_name(name, postfix):
- if name is None:
- return None
- elif name == '':
- return postfix
- else:
- return '%s_%s' % (name, postfix)
-
-
-class AttentionLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(AttentionLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- n_head = cfg['num_attention_heads']
- assert d_model % n_head == 0
- d_model_q = cfg.get('query_hidden_size_per_head', d_model // n_head) * n_head
- d_model_v = cfg.get('value_hidden_size_per_head', d_model // n_head) * n_head
- self.n_head = n_head
- self.d_key = d_model_q // n_head
- self.q = _build_linear(d_model, d_model_q, append_name(name, 'query_fc'), initializer)
- self.k = _build_linear(d_model, d_model_q, append_name(name, 'key_fc'), initializer)
- self.v = _build_linear(d_model, d_model_v, append_name(name, 'value_fc'), initializer)
- self.o = _build_linear(d_model_v, d_model, append_name(name, 'output_fc'), initializer)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=cfg['attention_probs_dropout_prob'],
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, queries, keys, values, attn_bias, past_cache):
- assert len(queries.shape) == len(keys.shape) == len(values.shape) == 3
-
- q = self.q(queries)
- k = self.k(keys)
- v = self.v(values)
-
- cache = (k, v)
- if past_cache is not None:
- cached_k, cached_v = past_cache
- k = L.concat([cached_k, k], 1)
- v = L.concat([cached_v, v], 1)
-
- q = L.transpose(L.reshape(q, [0, 0, self.n_head, q.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- k = L.transpose(L.reshape(k, [0, 0, self.n_head, k.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- v = L.transpose(L.reshape(v, [0, 0, self.n_head, v.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
-
- q = L.scale(q, scale=self.d_key**-0.5)
- score = L.matmul(q, k, transpose_y=True)
- if attn_bias is not None:
- score += attn_bias
- score = L.softmax(score, use_cudnn=True)
- score = self.dropout(score)
-
- out = L.matmul(score, v)
- out = L.transpose(out, [0, 2, 1, 3])
- out = L.reshape(out, [0, 0, out.shape[2] * out.shape[3]])
-
- out = self.o(out)
- return out, cache
-
-
-class PositionwiseFeedForwardLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(PositionwiseFeedForwardLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_ffn = cfg.get('intermediate_size', 4 * d_model)
- assert cfg['hidden_act'] in ['relu', 'gelu']
- self.i = _build_linear(d_model, d_ffn, append_name(name, 'fc_0'), initializer, act=cfg['hidden_act'])
- self.o = _build_linear(d_ffn, d_model, append_name(name, 'fc_1'), initializer)
- prob = cfg.get('intermediate_dropout_prob', 0.)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs):
- hidden = self.i(inputs)
- hidden = self.dropout(hidden)
- out = self.o(hidden)
- return out
-
-
-class ErnieBlock(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieBlock, self).__init__()
- d_model = cfg['hidden_size']
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.attn = AttentionLayer(cfg, name=append_name(name, 'multi_head_att'))
- self.ln1 = _build_ln(d_model, name=append_name(name, 'post_att'))
- self.ffn = PositionwiseFeedForwardLayer(cfg, name=append_name(name, 'ffn'))
- self.ln2 = _build_ln(d_model, name=append_name(name, 'post_ffn'))
- prob = cfg.get('intermediate_dropout_prob', cfg['hidden_dropout_prob'])
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- attn_out, cache = self.attn(inputs, inputs, inputs, attn_bias, past_cache=past_cache) #self attn
- attn_out = self.dropout(attn_out)
- hidden = attn_out + inputs
- hidden = self.ln1(hidden) # dropout/ add/ norm
-
- ffn_out = self.ffn(hidden)
- ffn_out = self.dropout(ffn_out)
- hidden = ffn_out + hidden
- hidden = self.ln2(hidden)
- return hidden, cache
-
-
-class ErnieEncoderStack(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieEncoderStack, self).__init__()
- n_layers = cfg['num_hidden_layers']
- self.block = D.LayerList([ErnieBlock(cfg, append_name(name, 'layer_%d' % i)) for i in range(n_layers)])
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- if past_cache is not None:
- assert isinstance(
- past_cache,
- tuple), 'unknown type of `past_cache`, expect tuple or list. got %s' % repr(type(past_cache))
- past_cache = list(zip(*past_cache))
- else:
- past_cache = [None] * len(self.block)
- cache_list_k, cache_list_v, hidden_list = [], [], [inputs]
-
- for b, p in zip(self.block, past_cache):
- inputs, cache = b(inputs, attn_bias=attn_bias, past_cache=p)
- cache_k, cache_v = cache
- cache_list_k.append(cache_k)
- cache_list_v.append(cache_v)
- hidden_list.append(inputs)
-
- return inputs, hidden_list, (cache_list_k, cache_list_v)
-
-
-class ErnieModel(D.Layer):
- def __init__(self, cfg, name=None):
- """
- Fundamental pretrained Ernie model
- """
- log.debug('init ErnieModel with config: %s' % repr(cfg))
- D.Layer.__init__(self)
- d_model = cfg['hidden_size']
- d_emb = cfg.get('emb_size', cfg['hidden_size'])
- d_vocab = cfg['vocab_size']
- d_pos = cfg['max_position_embeddings']
- d_sent = cfg.get("sent_type_vocab_size") or cfg['type_vocab_size']
- self.n_head = cfg['num_attention_heads']
- self.return_additional_info = cfg.get('return_additional_info', False)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.ln = _build_ln(d_model, name=append_name(name, 'pre_encoder'))
- self.word_emb = D.Embedding([d_vocab, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'word_embedding'), initializer=initializer))
- self.pos_emb = D.Embedding([d_pos, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'pos_embedding'), initializer=initializer))
- self.sent_emb = D.Embedding([d_sent, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'sent_embedding'), initializer=initializer))
- prob = cfg['hidden_dropout_prob']
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- self.encoder_stack = ErnieEncoderStack(cfg, append_name(name, 'encoder'))
- if cfg.get('has_pooler', True):
- self.pooler = _build_linear(
- cfg['hidden_size'], cfg['hidden_size'], append_name(name, 'pooled_fc'), initializer, act='tanh')
- else:
- self.pooler = None
- self.train()
-
- def eval(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).eval()
- self.training = False
- for l in self.sublayers():
- l.training = False
-
- def train(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).train()
- self.training = True
- for l in self.sublayers():
- l.training = True
-
- def forward(self,
- src_ids,
- sent_ids=None,
- pos_ids=None,
- input_mask=None,
- attn_bias=None,
- past_cache=None,
- use_causal_mask=False):
- """
- Args:
- src_ids (`Variable` of shape `[batch_size, seq_len]`):
- Indices of input sequence tokens in the vocabulary.
- sent_ids (optional, `Variable` of shape `[batch_size, seq_len]`):
- aka token_type_ids, Segment token indices to indicate first and second portions of the inputs.
- if None, assume all tokens come from `segment_a`
- pos_ids(optional, `Variable` of shape `[batch_size, seq_len]`):
- Indices of positions of each input sequence tokens in the position embeddings.
- input_mask(optional `Variable` of shape `[batch_size, seq_len]`):
- Mask to avoid performing attention on the padding token indices of the encoder input.
- attn_bias(optional, `Variable` of shape `[batch_size, seq_len, seq_len] or False`):
- 3D version of `input_mask`, if set, overrides `input_mask`; if set not False, will not apply attention mask
- past_cache(optional, tuple of two lists: cached key and cached value,
- each is a list of `Variable`s of shape `[batch_size, seq_len, hidden_size]`):
- cached key/value tensor that will be concated to generated key/value when performing self attention.
- if set, `attn_bias` should not be None.
-
- Returns:
- pooled (`Variable` of shape `[batch_size, hidden_size]`):
- output logits of pooler classifier
- encoded(`Variable` of shape `[batch_size, seq_len, hidden_size]`):
- output logits of transformer stack
- """
- assert len(src_ids.shape) == 2, 'expect src_ids.shape = [batch, sequecen], got %s' % (repr(src_ids.shape))
- assert attn_bias is not None if past_cache else True, 'if `past_cache` is specified; attn_bias should not be None'
- d_batch = L.shape(src_ids)[0]
- d_seqlen = L.shape(src_ids)[1]
- if pos_ids is None:
- pos_ids = L.reshape(L.range(0, d_seqlen, 1, dtype='int32'), [1, -1])
- pos_ids = L.cast(pos_ids, 'int64')
- if attn_bias is None:
- if input_mask is None:
- input_mask = L.cast(src_ids != 0, 'float32')
- assert len(input_mask.shape) == 2
- input_mask = L.unsqueeze(input_mask, axes=[-1])
- attn_bias = L.matmul(input_mask, input_mask, transpose_y=True)
- if use_causal_mask:
- sequence = L.reshape(L.range(0, d_seqlen, 1, dtype='float32') + 1., [1, 1, -1, 1])
- causal_mask = L.cast((L.matmul(sequence, 1. / sequence, transpose_y=True) >= 1.), 'float32')
- attn_bias *= causal_mask
- else:
- assert len(attn_bias.shape) == 3, 'expect attn_bias tobe rank 3, got %r' % attn_bias.shape
- attn_bias = (1. - attn_bias) * -10000.0
- attn_bias = L.unsqueeze(attn_bias, [1])
- attn_bias = L.expand(attn_bias, [1, self.n_head, 1, 1]) # avoid broadcast =_=
- attn_bias.stop_gradient = True
-
- if sent_ids is None:
- sent_ids = L.zeros_like(src_ids)
-
- src_embedded = self.word_emb(src_ids)
- pos_embedded = self.pos_emb(pos_ids)
- sent_embedded = self.sent_emb(sent_ids)
- embedded = src_embedded + pos_embedded + sent_embedded
-
- embedded = self.dropout(self.ln(embedded))
-
- encoded, hidden_list, cache_list = self.encoder_stack(embedded, attn_bias, past_cache=past_cache)
- if self.pooler is not None:
- pooled = self.pooler(encoded[:, 0, :])
- else:
- pooled = None
-
- additional_info = {
- 'hiddens': hidden_list,
- 'caches': cache_list,
- }
-
- if self.return_additional_info:
- return pooled, encoded, additional_info
- else:
- return pooled, encoded
diff --git a/modules/text/text_generation/ernie_gen_lover_words/model/modeling_ernie_gen.py b/modules/text/text_generation/ernie_gen_lover_words/model/modeling_ernie_gen.py
deleted file mode 100644
index 135dc2bbeaaed290911537744f23e308340b51ce..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_lover_words/model/modeling_ernie_gen.py
+++ /dev/null
@@ -1,65 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from ernie_gen_lover_words.model.modeling_ernie import ErnieModel
-from ernie_gen_lover_words.model.modeling_ernie import _build_linear, _build_ln, append_name
-
-
-class ErnieModelForGeneration(ErnieModel):
- def __init__(self, cfg, name=None):
- cfg['return_additional_info'] = True
- cfg['has_pooler'] = False
- super(ErnieModelForGeneration, self).__init__(cfg, name=name)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_vocab = cfg['vocab_size']
-
- self.mlm = _build_linear(
- d_model, d_model, append_name(name, 'mask_lm_trans_fc'), initializer, act=cfg['hidden_act'])
- self.mlm_ln = _build_ln(d_model, name=append_name(name, 'mask_lm_trans'))
- self.mlm_bias = L.create_parameter(
- dtype='float32',
- shape=[d_vocab],
- attr=F.ParamAttr(
- name=append_name(name, 'mask_lm_out_fc.b_0'), initializer=F.initializer.Constant(value=0.0)),
- is_bias=True,
- )
-
- def forward(self, src_ids, *args, **kwargs):
- tgt_labels = kwargs.pop('tgt_labels', None)
- tgt_pos = kwargs.pop('tgt_pos', None)
- encode_only = kwargs.pop('encode_only', False)
- _, encoded, info = ErnieModel.forward(self, src_ids, *args, **kwargs)
- if encode_only:
- return None, None, info
- elif tgt_labels is None:
- encoded = self.mlm(encoded)
- encoded = self.mlm_ln(encoded)
- logits = L.matmul(encoded, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- output_ids = L.argmax(logits, -1)
- return output_ids, logits, info
- else:
- encoded_2d = L.gather_nd(encoded, tgt_pos)
- encoded_2d = self.mlm(encoded_2d)
- encoded_2d = self.mlm_ln(encoded_2d)
- logits_2d = L.matmul(encoded_2d, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- if len(tgt_labels.shape) == 1:
- tgt_labels = L.reshape(tgt_labels, [-1, 1])
-
- loss = L.reduce_mean(
- L.softmax_with_cross_entropy(logits_2d, tgt_labels, soft_label=(tgt_labels.shape[-1] != 1)))
- return loss, logits_2d, info
diff --git a/modules/text/text_generation/ernie_gen_lover_words/model/tokenizing_ernie.py b/modules/text/text_generation/ernie_gen_lover_words/model/tokenizing_ernie.py
deleted file mode 100644
index c9e5638f9a17207ce2d664c27376f08138876da3..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_lover_words/model/tokenizing_ernie.py
+++ /dev/null
@@ -1,163 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import six
-import re
-import logging
-from functools import partial
-
-import numpy as np
-
-import io
-
-open = partial(io.open, encoding='utf8')
-
-log = logging.getLogger(__name__)
-
-_max_input_chars_per_word = 100
-
-
-def _wordpiece(token, vocab, unk_token, prefix='##', sentencepiece_prefix=''):
- """ wordpiece: helloworld => [hello, ##world] """
- chars = list(token)
- if len(chars) > _max_input_chars_per_word:
- return [unk_token], [(0, len(chars))]
-
- is_bad = False
- start = 0
- sub_tokens = []
- sub_pos = []
- while start < len(chars):
- end = len(chars)
- cur_substr = None
- while start < end:
- substr = "".join(chars[start:end])
- if start == 0:
- substr = sentencepiece_prefix + substr
- if start > 0:
- substr = prefix + substr
- if substr in vocab:
- cur_substr = substr
- break
- end -= 1
- if cur_substr is None:
- is_bad = True
- break
- sub_tokens.append(cur_substr)
- sub_pos.append((start, end))
- start = end
- if is_bad:
- return [unk_token], [(0, len(chars))]
- else:
- return sub_tokens, sub_pos
-
-
-class ErnieTokenizer(object):
- def __init__(self,
- vocab,
- unk_token='[UNK]',
- sep_token='[SEP]',
- cls_token='[CLS]',
- pad_token='[PAD]',
- mask_token='[MASK]',
- wordpiece_prefix='##',
- sentencepiece_prefix='',
- lower=True,
- encoding='utf8',
- special_token_list=[]):
- if not isinstance(vocab, dict):
- raise ValueError('expect `vocab` to be instance of dict, got %s' % type(vocab))
- self.vocab = vocab
- self.lower = lower
- self.prefix = wordpiece_prefix
- self.sentencepiece_prefix = sentencepiece_prefix
- self.pad_id = self.vocab[pad_token]
- self.cls_id = cls_token and self.vocab[cls_token]
- self.sep_id = sep_token and self.vocab[sep_token]
- self.unk_id = unk_token and self.vocab[unk_token]
- self.mask_id = mask_token and self.vocab[mask_token]
- self.unk_token = unk_token
- special_tokens = {pad_token, cls_token, sep_token, unk_token, mask_token} | set(special_token_list)
- pat_str = ''
- for t in special_tokens:
- if t is None:
- continue
- pat_str += '(%s)|' % re.escape(t)
- pat_str += r'([a-zA-Z0-9]+|\S)'
- log.debug('regex: %s' % pat_str)
- self.pat = re.compile(pat_str)
- self.encoding = encoding
-
- def tokenize(self, text):
- if len(text) == 0:
- return []
- if six.PY3 and not isinstance(text, six.string_types):
- text = text.decode(self.encoding)
- if six.PY2 and isinstance(text, str):
- text = text.decode(self.encoding)
-
- res = []
- for match in self.pat.finditer(text):
- match_group = match.group(0)
- if match.groups()[-1]:
- if self.lower:
- match_group = match_group.lower()
- words, _ = _wordpiece(
- match_group,
- vocab=self.vocab,
- unk_token=self.unk_token,
- prefix=self.prefix,
- sentencepiece_prefix=self.sentencepiece_prefix)
- else:
- words = [match_group]
- res += words
- return res
-
- def convert_tokens_to_ids(self, tokens):
- return [self.vocab.get(t, self.unk_id) for t in tokens]
-
- def truncate(self, id1, id2, seqlen):
- len1 = len(id1)
- len2 = len(id2)
- half = seqlen // 2
- if len1 > len2:
- len1_truncated, len2_truncated = max(half, seqlen - len2), min(half, len2)
- else:
- len1_truncated, len2_truncated = min(half, seqlen - len1), max(half, seqlen - len1)
- return id1[:len1_truncated], id2[:len2_truncated]
-
- def build_for_ernie(self, text_id, pair_id=[]):
- """build sentence type id, add [CLS] [SEP]"""
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- ret_id = np.concatenate([[self.cls_id], text_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([[0], text_id_type, [0]], 0)
-
- if len(pair_id):
- pair_id_type = np.ones_like(pair_id, dtype=np.int64)
- ret_id = np.concatenate([ret_id, pair_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([ret_id_type, pair_id_type, [1]], 0)
- return ret_id, ret_id_type
-
- def encode(self, text, pair=None, truncate_to=None):
- text_id = np.array(self.convert_tokens_to_ids(self.tokenize(text)), dtype=np.int64)
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- if pair is not None:
- pair_id = np.array(self.convert_tokens_to_ids(self.tokenize(pair)), dtype=np.int64)
- else:
- pair_id = []
- if truncate_to is not None:
- text_id, pair_id = self.truncate(text_id, [] if pair_id is None else pair_id, truncate_to)
-
- ret_id, ret_id_type = self.build_for_ernie(text_id, pair_id)
- return ret_id, ret_id_type
diff --git a/modules/text/text_generation/ernie_gen_lover_words/module.py b/modules/text/text_generation/ernie_gen_lover_words/module.py
index ccb70425949bcbf25270b3e5b82ec0564d9959a1..55b12719b2496e48ce6cb1905188774b41ac066f 100644
--- a/modules/text/text_generation/ernie_gen_lover_words/module.py
+++ b/modules/text/text_generation/ernie_gen_lover_words/module.py
@@ -14,28 +14,24 @@
# limitations under the License.
import ast
import json
+import argparse
+import os
-import paddle.fluid as fluid
+import numpy as np
+import paddle
import paddlehub as hub
from paddlehub.module.module import runnable
from paddlehub.module.nlp_module import DataFormatError
from paddlehub.common.logger import logger
from paddlehub.module.module import moduleinfo, serving
+from paddlenlp.transformers import ErnieTokenizer, ErnieForGeneration
-import argparse
-import os
-import numpy as np
-
-import paddle.fluid.dygraph as D
-
-from ernie_gen_lover_words.model.tokenizing_ernie import ErnieTokenizer
-from ernie_gen_lover_words.model.decode import beam_search_infilling
-from ernie_gen_lover_words.model.modeling_ernie_gen import ErnieModelForGeneration
+from ernie_gen_lover_words.decode import beam_search_infilling
@moduleinfo(
name="ernie_gen_lover_words",
- version="1.0.1",
+ version="1.1.0",
summary=
"ERNIE-GEN is a multi-flow language generation framework for both pre-training and fine-tuning. This module has fine-tuned for lover's words generation task.",
author="adaxiadaxi",
@@ -43,29 +39,19 @@ from ernie_gen_lover_words.model.modeling_ernie_gen import ErnieModelForGenerati
type="nlp/text_generation",
)
class ErnieGen(hub.NLPPredictionModule):
- def _initialize(self):
+ def __init__(self):
"""
initialize with the necessary elements
"""
assets_path = os.path.join(self.directory, "assets")
- gen_checkpoint_path = os.path.join(assets_path, "ernie_gen_lover_words")
- ernie_cfg_path = os.path.join(assets_path, 'ernie_config.json')
- with open(ernie_cfg_path, encoding='utf8') as ernie_cfg_file:
- ernie_cfg = dict(json.loads(ernie_cfg_file.read()))
- ernie_vocab_path = os.path.join(assets_path, 'vocab.txt')
- with open(ernie_vocab_path, encoding='utf8') as ernie_vocab_file:
- ernie_vocab = {j.strip().split('\t')[0]: i for i, j in enumerate(ernie_vocab_file.readlines())}
-
- with fluid.dygraph.guard(fluid.CPUPlace()):
- with fluid.unique_name.guard():
- self.model = ErnieModelForGeneration(ernie_cfg)
- finetuned_states, _ = D.load_dygraph(gen_checkpoint_path)
- self.model.set_dict(finetuned_states)
-
- self.tokenizer = ErnieTokenizer(ernie_vocab)
- self.rev_dict = {v: k for k, v in self.tokenizer.vocab.items()}
- self.rev_dict[self.tokenizer.pad_id] = '' # replace [PAD]
- self.rev_dict[self.tokenizer.unk_id] = '' # replace [PAD]
+ gen_checkpoint_path = os.path.join(assets_path, "ernie_gen_lover_words.pdparams")
+ self.model = ErnieForGeneration.from_pretrained("ernie-1.0")
+ model_state = paddle.load(gen_checkpoint_path)
+ self.model.set_dict(model_state)
+ self.tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
+ self.rev_dict = self.tokenizer.vocab.idx_to_token
+ self.rev_dict[self.tokenizer.vocab['[PAD]']] = '' # replace [PAD]
+ self.rev_dict[self.tokenizer.vocab['[UNK]']] = '' # replace [PAD]
self.rev_lookup = np.vectorize(lambda i: self.rev_dict[i])
@serving
@@ -81,6 +67,8 @@ class ErnieGen(hub.NLPPredictionModule):
Returns:
results(list): the poetry continuations.
"""
+ paddle.disable_static()
+
if texts and isinstance(texts, list) and all(texts) and all([isinstance(text, str) for text in texts]):
predicted_data = texts
else:
@@ -91,37 +79,35 @@ class ErnieGen(hub.NLPPredictionModule):
logger.warning(
"use_gpu has been set False as you didn't set the environment variable CUDA_VISIBLE_DEVICES while using use_gpu=True"
)
- if use_gpu:
- place = fluid.CUDAPlace(0)
- else:
- place = fluid.CPUPlace()
-
- with fluid.dygraph.guard(place):
- self.model.eval()
- results = []
- for text in predicted_data:
- sample_results = []
- ids, sids = self.tokenizer.encode(text)
- src_ids = D.to_variable(np.expand_dims(ids, 0))
- src_sids = D.to_variable(np.expand_dims(sids, 0))
- output_ids = beam_search_infilling(
- self.model,
- src_ids,
- src_sids,
- eos_id=self.tokenizer.sep_id,
- sos_id=self.tokenizer.cls_id,
- attn_id=self.tokenizer.vocab['[MASK]'],
- max_decode_len=80,
- max_encode_len=20,
- beam_width=beam_width,
- tgt_type_id=1)
- output_str = self.rev_lookup(output_ids[0].numpy())
-
- for ostr in output_str.tolist():
- if '[SEP]' in ostr:
- ostr = ostr[:ostr.index('[SEP]')]
- sample_results.append("".join(ostr))
- results.append(sample_results)
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+ self.model.eval()
+ results = []
+ for text in predicted_data:
+ sample_results = []
+ encode_text = self.tokenizer.encode(text)
+ src_ids = paddle.to_tensor(encode_text['input_ids']).unsqueeze(0)
+ src_sids = paddle.to_tensor(encode_text['token_type_ids']).unsqueeze(0)
+ output_ids = beam_search_infilling(
+ self.model,
+ src_ids,
+ src_sids,
+ eos_id=self.tokenizer.vocab['[SEP]'],
+ sos_id=self.tokenizer.vocab['[CLS]'],
+ attn_id=self.tokenizer.vocab['[MASK]'],
+ pad_id=self.tokenizer.vocab['[PAD]'],
+ unk_id=self.tokenizer.vocab['[UNK]'],
+ vocab_size=len(self.tokenizer.vocab),
+ max_decode_len=80,
+ max_encode_len=20,
+ beam_width=beam_width,
+ tgt_type_id=1)
+ output_str = self.rev_lookup(output_ids[0])
+
+ for ostr in output_str.tolist():
+ if '[SEP]' in ostr:
+ ostr = ostr[:ostr.index('[SEP]')]
+ sample_results.append("".join(ostr))
+ results.append(sample_results)
return results
def add_module_config_arg(self):
@@ -166,5 +152,5 @@ class ErnieGen(hub.NLPPredictionModule):
if __name__ == "__main__":
module = ErnieGen()
- for result in module.generate(['昔年旅南服,始识王荆州。', '高名出汉阴,禅阁跨香岑。'], beam_width=5):
+ for result in module.generate(['情人节', '故乡', '小编带大家了解一下程序员情人节', '昔年旅南服,始识王荆州。', '高名出汉阴,禅阁跨香岑。'], beam_width=5):
print(result)
diff --git a/modules/text/text_generation/ernie_gen_poetry/README.md b/modules/text/text_generation/ernie_gen_poetry/README.md
index 3be94e7919ecdda0c49d188a7be6d89ea165fbf1..46cebd6526c5d8875846416c5fef51f3896d446f 100644
--- a/modules/text/text_generation/ernie_gen_poetry/README.md
+++ b/modules/text/text_generation/ernie_gen_poetry/README.md
@@ -87,9 +87,11 @@ https://github.com/PaddlePaddle/ERNIE/blob/repro/ernie-gen/
### 依赖
-paddlepaddle >= 1.8.2
+paddlepaddle >= 2.0.0
-paddlehub >= 1.7.0
+paddlehub >= 2.0.0
+
+paddlenlp >= 2.0.0
## 更新历史
@@ -105,3 +107,7 @@ paddlehub >= 1.7.0
* 1.0.2
完善API的输入文本检查
+
+* 1.1.0
+
+ 接入PaddleNLP
diff --git a/modules/text/text_generation/ernie_gen_poetry/decode.py b/modules/text/text_generation/ernie_gen_poetry/decode.py
new file mode 100644
index 0000000000000000000000000000000000000000..34d8259873160e9eb04b2c07ca15a24be727115a
--- /dev/null
+++ b/modules/text/text_generation/ernie_gen_poetry/decode.py
@@ -0,0 +1,277 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import division
+from __future__ import absolute_import
+from __future__ import print_function
+from __future__ import unicode_literals
+
+import sys
+import re
+import argparse
+import logging
+import json
+import numpy as np
+from collections import namedtuple
+
+import paddle
+import paddle.nn as nn
+import numpy as np
+from paddlenlp.utils.log import logger
+
+
+def gen_bias(encoder_inputs, decoder_inputs, step):
+ decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
+ encoder_bsz, encoder_seqlen = encoder_inputs.shape[:2]
+ attn_bias = paddle.reshape(paddle.arange(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
+ decoder_bias = paddle.cast((paddle.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
+ 'float32') #[1, decoderlen, decoderlen]
+ encoder_bias = paddle.unsqueeze(paddle.cast(paddle.ones_like(encoder_inputs), 'float32'),
+ [1]) #[bsz, 1, encoderlen]
+ encoder_bias = paddle.expand(encoder_bias,
+ [encoder_bsz, decoder_seqlen, encoder_seqlen]) #[bsz,decoderlen, encoderlen]
+ decoder_bias = paddle.expand(decoder_bias,
+ [decoder_bsz, decoder_seqlen, decoder_seqlen]) #[bsz, decoderlen, decoderlen]
+ if step > 0:
+ bias = paddle.concat(
+ [encoder_bias, paddle.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
+ else:
+ bias = paddle.concat([encoder_bias, decoder_bias], -1)
+ return bias
+
+
+@paddle.no_grad()
+def greedy_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ tgt_type_id=3):
+ _, logits, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+ has_stopped = np.zeros([d_batch], dtype=np.bool)
+ gen_seq_len = np.zeros([d_batch], dtype=np.int64)
+ output_ids = []
+
+ past_cache = info['caches']
+
+ cls_ids = paddle.ones([d_batch], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch], dtype='int64') * attn_id
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+
+ gen_ids = paddle.argmax(logits, -1)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [paddle.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
+ cached_v = [paddle.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
+ past_cache = (cached_k, cached_v)
+
+ gen_ids = gen_ids[:, 1]
+ ids = paddle.stack([gen_ids, attn_ids], 1)
+
+ gen_ids = gen_ids.numpy()
+ has_stopped |= (gen_ids == eos_id).astype(np.bool)
+ gen_seq_len += (1 - has_stopped.astype(np.int64))
+ output_ids.append(gen_ids.tolist())
+ if has_stopped.all():
+ break
+ output_ids = np.array(output_ids).transpose([1, 0])
+ return output_ids
+
+
+BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
+BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
+
+
+def log_softmax(x):
+ e_x = np.exp(x - np.max(x))
+ return np.log(e_x / e_x.sum())
+
+
+def mask_prob(p, onehot_eos, finished):
+ is_finished = paddle.cast(paddle.reshape(finished, [-1, 1]) != 0, 'float32')
+ p = is_finished * (1. - paddle.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
+ return p
+
+
+def hyp_score(log_probs, length, length_penalty):
+ lp = paddle.pow((5. + paddle.cast(length, 'float32')) / 6., length_penalty)
+ return log_probs / lp
+
+
+def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
+ """logits.shape == [B*W, V]"""
+ _, vocab_size = logits.shape
+
+ bsz, beam_width = state.log_probs.shape
+ onehot_eos = paddle.cast(nn.functional.one_hot(paddle.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
+
+ probs = paddle.log(nn.functional.softmax(logits)) #[B*W, V]
+ probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
+ allprobs = paddle.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
+
+ not_finished = 1 - paddle.reshape(state.finished, [-1, 1]) #[B*W,1]
+ not_eos = 1 - onehot_eos
+ length_to_add = not_finished * not_eos #[B*W,V]
+ alllen = paddle.reshape(state.lengths, [-1, 1]) + length_to_add
+
+ allprobs = paddle.reshape(allprobs, [-1, beam_width * vocab_size])
+ alllen = paddle.reshape(alllen, [-1, beam_width * vocab_size])
+ allscore = hyp_score(allprobs, alllen, length_penalty)
+ if is_first_step:
+ allscore = paddle.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
+ scores, idx = paddle.topk(allscore, k=beam_width) #[B, W]
+ next_beam_id = idx // vocab_size #[B, W]
+ next_word_id = idx % vocab_size
+
+ gather_idx = paddle.concat([paddle.nonzero(idx != -1)[:, :1], paddle.reshape(idx, [-1, 1])], 1)
+ next_probs = paddle.reshape(paddle.gather_nd(allprobs, gather_idx), idx.shape)
+ next_len = paddle.reshape(paddle.gather_nd(alllen, gather_idx), idx.shape)
+
+ gather_idx = paddle.concat([paddle.nonzero(next_beam_id != -1)[:, :1], paddle.reshape(next_beam_id, [-1, 1])], 1)
+ next_finished = paddle.reshape(paddle.gather_nd(state.finished, gather_idx),
+ state.finished.shape) #[gather new beam state according to new beam id]
+
+ next_finished += paddle.cast(next_word_id == eos_id, 'int64')
+ next_finished = paddle.cast(next_finished > 0, 'int64')
+
+ next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
+ output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
+
+ return output, next_state
+
+
+@paddle.no_grad()
+def beam_search_infilling(model,
+ token_ids,
+ token_type_ids,
+ sos_id,
+ eos_id,
+ attn_id,
+ pad_id,
+ unk_id,
+ vocab_size,
+ max_encode_len=640,
+ max_decode_len=100,
+ beam_width=5,
+ tgt_type_id=3,
+ length_penalty=1.0):
+ _, __, info = model(token_ids, token_type_ids)
+ d_batch, d_seqlen = token_ids.shape
+
+ state = BeamSearchState(log_probs=paddle.zeros([d_batch, beam_width], 'float32'),
+ lengths=paddle.zeros([d_batch, beam_width], 'int64'),
+ finished=paddle.zeros([d_batch, beam_width], 'int64'))
+ outputs = []
+
+ def reorder_(t, parent_id):
+ """reorder cache according to parent beam id"""
+ gather_idx = paddle.nonzero(parent_id != -1)[:, 0] * beam_width + paddle.reshape(parent_id, [-1])
+ t = paddle.gather(t, gather_idx)
+ return t
+
+ def tile_(t, times):
+ _shapes = list(t.shape[1:])
+ new_shape = [t.shape[0], times] + list(t.shape[1:])
+ ret = paddle.reshape(paddle.expand(paddle.unsqueeze(t, [1]), new_shape), [
+ -1,
+ ] + _shapes)
+ return ret
+
+ cached_k, cached_v = info['caches']
+ cached_k = [tile_(k, beam_width) for k in cached_k]
+ cached_v = [tile_(v, beam_width) for v in cached_v]
+ past_cache = (cached_k, cached_v)
+
+ token_ids = tile_(token_ids, beam_width)
+ seqlen = paddle.sum(paddle.cast(token_ids != 0, 'int64'), 1, keepdim=True)
+
+ cls_ids = paddle.ones([d_batch * beam_width], dtype='int64') * sos_id
+ attn_ids = paddle.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
+ ids = paddle.stack([cls_ids, attn_ids], -1)
+ for step in range(max_decode_len):
+ bias = gen_bias(token_ids, ids, step)
+ pos_ids = paddle.to_tensor(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
+ pos_ids += seqlen
+ _, logits, info = model(ids,
+ paddle.ones_like(ids) * tgt_type_id,
+ pos_ids=pos_ids,
+ attn_bias=bias,
+ past_cache=past_cache)
+
+ output, state = beam_search_step(state,
+ logits[:, 1],
+ eos_id=eos_id,
+ beam_width=beam_width,
+ is_first_step=(step == 0),
+ length_penalty=length_penalty)
+ outputs.append(output)
+
+ past_cached_k, past_cached_v = past_cache
+ cached_k, cached_v = info['caches']
+ cached_k = [
+ reorder_(paddle.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids)
+ for pk, k in zip(past_cached_k, cached_k)
+ ] # concat cached
+ cached_v = [
+ reorder_(paddle.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids)
+ for pv, v in zip(past_cached_v, cached_v)
+ ]
+ past_cache = (cached_k, cached_v)
+
+ pred_ids_flatten = paddle.reshape(output.predicted_ids, [d_batch * beam_width])
+ ids = paddle.stack([pred_ids_flatten, attn_ids], 1)
+
+ if state.finished.numpy().all():
+ break
+
+ final_ids = paddle.stack([o.predicted_ids for o in outputs], 0)
+ final_parent_ids = paddle.stack([o.beam_parent_ids for o in outputs], 0)
+ final_ids = nn.functional.gather_tree(final_ids, final_parent_ids) #[:, :, 0] #pick best beam
+ final_ids = paddle.transpose(paddle.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
+
+ return final_ids.numpy()
+
+
+en_patten = re.compile(r'^[a-zA-Z0-9]*$')
+
+
+def post_process(token):
+ if token.startswith('##'):
+ ret = token[2:]
+ elif token in ['[CLS]', '[SEP]', '[PAD]']:
+ ret = ''
+ else:
+ if en_patten.match(token):
+ ret = ' ' + token
+ else:
+ ret = token
+ return ret
diff --git a/modules/text/text_generation/ernie_gen_poetry/model/decode.py b/modules/text/text_generation/ernie_gen_poetry/model/decode.py
deleted file mode 100644
index 1d706b52a42397455565cd20c8d3adfe819cec04..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_poetry/model/decode.py
+++ /dev/null
@@ -1,255 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import re
-import numpy as np
-from collections import namedtuple
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-import paddle.fluid.dygraph as D
-
-
-def gen_bias(encoder_inputs, decoder_inputs, step):
- decoder_bsz, decoder_seqlen = decoder_inputs.shape[:2]
- attn_bias = L.reshape(L.range(0, decoder_seqlen, 1, dtype='float32') + 1, [1, -1, 1])
- decoder_bias = L.cast((L.matmul(attn_bias, 1. / attn_bias, transpose_y=True) >= 1.),
- 'float32') #[1, 1, decoderlen, decoderlen]
- encoder_bias = L.unsqueeze(L.cast(L.ones_like(encoder_inputs), 'float32'), [1]) #[bsz, 1, encoderlen]
- encoder_bias = L.expand(encoder_bias, [1, decoder_seqlen, 1]) #[bsz,decoderlen, encoderlen]
- decoder_bias = L.expand(decoder_bias, [decoder_bsz, 1, 1]) #[bsz, decoderlen, decoderlen]
- if step > 0:
- bias = L.concat([encoder_bias, L.ones([decoder_bsz, decoder_seqlen, step], 'float32'), decoder_bias], -1)
- else:
- bias = L.concat([encoder_bias, decoder_bias], -1)
- return bias
-
-
-@D.no_grad
-def greedy_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- tgt_type_id=3):
- model.eval()
- _, logits, info = model(q_ids, q_sids)
- gen_ids = L.argmax(logits, -1)
- d_batch, d_seqlen = q_ids.shape
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
- has_stopped = np.zeros([d_batch], dtype=np.bool)
- gen_seq_len = np.zeros([d_batch], dtype=np.int64)
- output_ids = []
-
- past_cache = info['caches']
-
- cls_ids = L.ones([d_batch], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch], dtype='int64') * attn_id
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch, 1]))
- pos_ids += seqlen
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
- gen_ids = L.argmax(logits, -1)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [L.concat([pk, k[:, :1, :]], 1) for pk, k in zip(past_cached_k, cached_k)] # concat cached
- cached_v = [L.concat([pv, v[:, :1, :]], 1) for pv, v in zip(past_cached_v, cached_v)]
- past_cache = (cached_k, cached_v)
-
- gen_ids = gen_ids[:, 1]
- ids = L.stack([gen_ids, attn_ids], 1)
-
- gen_ids = gen_ids.numpy()
- has_stopped |= (gen_ids == eos_id).astype(np.bool)
- gen_seq_len += (1 - has_stopped.astype(np.int64))
- output_ids.append(gen_ids.tolist())
- if has_stopped.all():
- break
- output_ids = np.array(output_ids).transpose([1, 0])
- return output_ids
-
-
-BeamSearchState = namedtuple('BeamSearchState', ['log_probs', 'lengths', 'finished'])
-BeamSearchOutput = namedtuple('BeamSearchOutput', ['scores', 'predicted_ids', 'beam_parent_ids'])
-
-
-def log_softmax(x):
- e_x = np.exp(x - np.max(x))
- return np.log(e_x / e_x.sum())
-
-
-def mask_prob(p, onehot_eos, finished):
- is_finished = L.cast(L.reshape(finished, [-1, 1]) != 0, 'float32')
- p = is_finished * (1. - L.cast(onehot_eos, 'float32')) * -9999. + (1. - is_finished) * p
- return p
-
-
-def hyp_score(log_probs, length, length_penalty):
- lp = L.pow((5. + L.cast(length, 'float32')) / 6., length_penalty)
- return log_probs / lp
-
-
-def beam_search_step(state, logits, eos_id, beam_width, is_first_step, length_penalty):
- """logits.shape == [B*W, V]"""
- _, vocab_size = logits.shape
-
- bsz, beam_width = state.log_probs.shape
- onehot_eos = L.cast(F.one_hot(L.ones([1], 'int64') * eos_id, vocab_size), 'int64') #[1, V]
-
- probs = L.log(L.softmax(logits)) #[B*W, V]
- probs = mask_prob(probs, onehot_eos, state.finished) #[B*W, V]
- allprobs = L.reshape(state.log_probs, [-1, 1]) + probs #[B*W, V]
-
- not_finished = 1 - L.reshape(state.finished, [-1, 1]) #[B*W,1]
- not_eos = 1 - onehot_eos
- length_to_add = not_finished * not_eos #[B*W,V]
- alllen = L.reshape(state.lengths, [-1, 1]) + length_to_add
-
- allprobs = L.reshape(allprobs, [-1, beam_width * vocab_size])
- alllen = L.reshape(alllen, [-1, beam_width * vocab_size])
- allscore = hyp_score(allprobs, alllen, length_penalty)
- if is_first_step:
- allscore = L.reshape(allscore, [bsz, beam_width, -1])[:, 0, :] # first step only consiter beam 0
- scores, idx = L.topk(allscore, k=beam_width) #[B, W]
- next_beam_id = idx // vocab_size #[B, W]
- next_word_id = idx % vocab_size
-
- gather_idx = L.concat([L.where(idx != -1)[:, :1], L.reshape(idx, [-1, 1])], 1)
- next_probs = L.reshape(L.gather_nd(allprobs, gather_idx), idx.shape)
- next_len = L.reshape(L.gather_nd(alllen, gather_idx), idx.shape)
-
- gather_idx = L.concat([L.where(next_beam_id != -1)[:, :1], L.reshape(next_beam_id, [-1, 1])], 1)
- next_finished = L.reshape(L.gather_nd(state.finished, gather_idx),
- state.finished.shape) #[gather new beam state according to new beam id]
-
- next_finished += L.cast(next_word_id == eos_id, 'int64')
- next_finished = L.cast(next_finished > 0, 'int64')
-
- next_state = BeamSearchState(log_probs=next_probs, lengths=next_len, finished=next_finished)
- output = BeamSearchOutput(scores=scores, predicted_ids=next_word_id, beam_parent_ids=next_beam_id)
-
- return output, next_state
-
-
-@D.no_grad
-def beam_search_infilling(model,
- q_ids,
- q_sids,
- sos_id,
- eos_id,
- attn_id,
- max_encode_len=640,
- max_decode_len=100,
- beam_width=5,
- tgt_type_id=3,
- length_penalty=1.0):
- model.eval()
- _, __, info = model(q_ids, q_sids)
- d_batch, d_seqlen = q_ids.shape
-
- state = BeamSearchState(
- log_probs=L.zeros([d_batch, beam_width], 'float32'),
- lengths=L.zeros([d_batch, beam_width], 'int64'),
- finished=L.zeros([d_batch, beam_width], 'int64'))
- outputs = []
-
- def reorder_(t, parent_id):
- """reorder cache according to parent beam id"""
- gather_idx = L.where(parent_id != -1)[:, 0] * beam_width + L.reshape(parent_id, [-1])
- t = L.gather(t, gather_idx)
- return t
-
- def tile_(t, times):
- _shapes = list(t.shape[1:])
- ret = L.reshape(L.expand(L.unsqueeze(t, [1]), [
- 1,
- times,
- ] + [
- 1,
- ] * len(_shapes)), [
- -1,
- ] + _shapes)
- return ret
-
- cached_k, cached_v = info['caches']
- cached_k = [tile_(k, beam_width) for k in cached_k]
- cached_v = [tile_(v, beam_width) for v in cached_v]
- past_cache = (cached_k, cached_v)
-
- q_ids = tile_(q_ids, beam_width)
- seqlen = L.reduce_sum(L.cast(q_ids != 0, 'int64'), 1, keep_dim=True)
-
- cls_ids = L.ones([d_batch * beam_width], dtype='int64') * sos_id
- attn_ids = L.ones([d_batch * beam_width], dtype='int64') * attn_id # SOS
- ids = L.stack([cls_ids, attn_ids], -1)
- for step in range(max_decode_len):
- bias = gen_bias(q_ids, ids, step)
- pos_ids = D.to_variable(np.tile(np.array([[step, step + 1]], dtype=np.int64), [d_batch * beam_width, 1]))
- pos_ids += seqlen
-
- _, logits, info = model(
- ids, L.ones_like(ids) * tgt_type_id, pos_ids=pos_ids, attn_bias=bias, past_cache=past_cache)
-
- output, state = beam_search_step(
- state,
- logits[:, 1],
- eos_id=eos_id,
- beam_width=beam_width,
- is_first_step=(step == 0),
- length_penalty=length_penalty)
- outputs.append(output)
-
- past_cached_k, past_cached_v = past_cache
- cached_k, cached_v = info['caches']
- cached_k = [
- reorder_(L.concat([pk, k[:, :1, :]], 1), output.beam_parent_ids) for pk, k in zip(past_cached_k, cached_k)
- ] # concat cached
- cached_v = [
- reorder_(L.concat([pv, v[:, :1, :]], 1), output.beam_parent_ids) for pv, v in zip(past_cached_v, cached_v)
- ]
- past_cache = (cached_k, cached_v)
-
- pred_ids_flatten = L.reshape(output.predicted_ids, [d_batch * beam_width])
- ids = L.stack([pred_ids_flatten, attn_ids], 1)
-
- if state.finished.numpy().all():
- break
-
- final_ids = L.stack([o.predicted_ids for o in outputs], 0)
- final_parent_ids = L.stack([o.beam_parent_ids for o in outputs], 0)
- final_ids = L.gather_tree(final_ids, final_parent_ids) #[:, :,
- #0] #pick best beam
- final_ids = L.transpose(L.reshape(final_ids, [-1, d_batch * 1, beam_width]), [1, 2, 0])
- return final_ids
-
-
-en_patten = re.compile(r'^[a-zA-Z0-9]*$')
-
-
-def post_process(token):
- if token.startswith('##'):
- ret = token[2:]
- else:
- if en_patten.match(token):
- ret = ' ' + token
- else:
- ret = token
- return ret
diff --git a/modules/text/text_generation/ernie_gen_poetry/model/file_utils.py b/modules/text/text_generation/ernie_gen_poetry/model/file_utils.py
deleted file mode 100644
index 608be4efc6644626f7f408df200fd299f2dd997e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_poetry/model/file_utils.py
+++ /dev/null
@@ -1,46 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-import os
-
-from tqdm import tqdm
-from paddlehub.common.logger import logger
-from paddlehub.common.dir import MODULE_HOME
-
-
-def _fetch_from_remote(url, force_download=False):
- import tempfile, requests, tarfile
- cached_dir = os.path.join(MODULE_HOME, "ernie_for_gen")
- if force_download or not os.path.exists(cached_dir):
- with tempfile.NamedTemporaryFile() as f:
- #url = 'https://ernie.bj.bcebos.com/ERNIE_stable.tgz'
- r = requests.get(url, stream=True)
- total_len = int(r.headers.get('content-length'))
- for chunk in tqdm(
- r.iter_content(chunk_size=1024), total=total_len // 1024, desc='downloading %s' % url, unit='KB'):
- if chunk:
- f.write(chunk)
- f.flush()
- logger.debug('extacting... to %s' % f.name)
- with tarfile.open(f.name) as tf:
- tf.extractall(path=cached_dir)
- logger.debug('%s cached in %s' % (url, cached_dir))
- return cached_dir
-
-
-def add_docstring(doc):
- def func(f):
- f.__doc__ += ('\n======other docs from supper class ======\n%s' % doc)
- return f
-
- return func
diff --git a/modules/text/text_generation/ernie_gen_poetry/model/modeling_ernie.py b/modules/text/text_generation/ernie_gen_poetry/model/modeling_ernie.py
deleted file mode 100644
index d5de28a5fee73371babd05b644e03a0f75ecdd5e..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_poetry/model/modeling_ernie.py
+++ /dev/null
@@ -1,327 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-from __future__ import division
-from __future__ import absolute_import
-from __future__ import print_function
-from __future__ import unicode_literals
-
-import logging
-
-import paddle.fluid.dygraph as D
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-log = logging.getLogger(__name__)
-
-
-def _build_linear(n_in, n_out, name, init, act=None):
- return D.Linear(
- n_in,
- n_out,
- param_attr=F.ParamAttr(name='%s.w_0' % name if name is not None else None, initializer=init),
- bias_attr='%s.b_0' % name if name is not None else None,
- act=act)
-
-
-def _build_ln(n_in, name):
- return D.LayerNorm(
- normalized_shape=n_in,
- param_attr=F.ParamAttr(
- name='%s_layer_norm_scale' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- bias_attr=F.ParamAttr(
- name='%s_layer_norm_bias' % name if name is not None else None, initializer=F.initializer.Constant(1.)),
- )
-
-
-def append_name(name, postfix):
- if name is None:
- return None
- elif name == '':
- return postfix
- else:
- return '%s_%s' % (name, postfix)
-
-
-class AttentionLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(AttentionLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- n_head = cfg['num_attention_heads']
- assert d_model % n_head == 0
- d_model_q = cfg.get('query_hidden_size_per_head', d_model // n_head) * n_head
- d_model_v = cfg.get('value_hidden_size_per_head', d_model // n_head) * n_head
- self.n_head = n_head
- self.d_key = d_model_q // n_head
- self.q = _build_linear(d_model, d_model_q, append_name(name, 'query_fc'), initializer)
- self.k = _build_linear(d_model, d_model_q, append_name(name, 'key_fc'), initializer)
- self.v = _build_linear(d_model, d_model_v, append_name(name, 'value_fc'), initializer)
- self.o = _build_linear(d_model_v, d_model, append_name(name, 'output_fc'), initializer)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=cfg['attention_probs_dropout_prob'],
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, queries, keys, values, attn_bias, past_cache):
- assert len(queries.shape) == len(keys.shape) == len(values.shape) == 3
-
- q = self.q(queries)
- k = self.k(keys)
- v = self.v(values)
-
- cache = (k, v)
- if past_cache is not None:
- cached_k, cached_v = past_cache
- k = L.concat([cached_k, k], 1)
- v = L.concat([cached_v, v], 1)
-
- q = L.transpose(L.reshape(q, [0, 0, self.n_head, q.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- k = L.transpose(L.reshape(k, [0, 0, self.n_head, k.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
- v = L.transpose(L.reshape(v, [0, 0, self.n_head, v.shape[-1] // self.n_head]),
- [0, 2, 1, 3]) #[batch, head, seq, dim]
-
- q = L.scale(q, scale=self.d_key**-0.5)
- score = L.matmul(q, k, transpose_y=True)
- if attn_bias is not None:
- score += attn_bias
- score = L.softmax(score, use_cudnn=True)
- score = self.dropout(score)
-
- out = L.matmul(score, v)
- out = L.transpose(out, [0, 2, 1, 3])
- out = L.reshape(out, [0, 0, out.shape[2] * out.shape[3]])
-
- out = self.o(out)
- return out, cache
-
-
-class PositionwiseFeedForwardLayer(D.Layer):
- def __init__(self, cfg, name=None):
- super(PositionwiseFeedForwardLayer, self).__init__()
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_ffn = cfg.get('intermediate_size', 4 * d_model)
- assert cfg['hidden_act'] in ['relu', 'gelu']
- self.i = _build_linear(d_model, d_ffn, append_name(name, 'fc_0'), initializer, act=cfg['hidden_act'])
- self.o = _build_linear(d_ffn, d_model, append_name(name, 'fc_1'), initializer)
- prob = cfg.get('intermediate_dropout_prob', 0.)
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs):
- hidden = self.i(inputs)
- hidden = self.dropout(hidden)
- out = self.o(hidden)
- return out
-
-
-class ErnieBlock(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieBlock, self).__init__()
- d_model = cfg['hidden_size']
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.attn = AttentionLayer(cfg, name=append_name(name, 'multi_head_att'))
- self.ln1 = _build_ln(d_model, name=append_name(name, 'post_att'))
- self.ffn = PositionwiseFeedForwardLayer(cfg, name=append_name(name, 'ffn'))
- self.ln2 = _build_ln(d_model, name=append_name(name, 'post_ffn'))
- prob = cfg.get('intermediate_dropout_prob', cfg['hidden_dropout_prob'])
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- attn_out, cache = self.attn(inputs, inputs, inputs, attn_bias, past_cache=past_cache) #self attn
- attn_out = self.dropout(attn_out)
- hidden = attn_out + inputs
- hidden = self.ln1(hidden) # dropout/ add/ norm
-
- ffn_out = self.ffn(hidden)
- ffn_out = self.dropout(ffn_out)
- hidden = ffn_out + hidden
- hidden = self.ln2(hidden)
- return hidden, cache
-
-
-class ErnieEncoderStack(D.Layer):
- def __init__(self, cfg, name=None):
- super(ErnieEncoderStack, self).__init__()
- n_layers = cfg['num_hidden_layers']
- self.block = D.LayerList([ErnieBlock(cfg, append_name(name, 'layer_%d' % i)) for i in range(n_layers)])
-
- def forward(self, inputs, attn_bias=None, past_cache=None):
- if past_cache is not None:
- assert isinstance(
- past_cache,
- tuple), 'unknown type of `past_cache`, expect tuple or list. got %s' % repr(type(past_cache))
- past_cache = list(zip(*past_cache))
- else:
- past_cache = [None] * len(self.block)
- cache_list_k, cache_list_v, hidden_list = [], [], [inputs]
-
- for b, p in zip(self.block, past_cache):
- inputs, cache = b(inputs, attn_bias=attn_bias, past_cache=p)
- cache_k, cache_v = cache
- cache_list_k.append(cache_k)
- cache_list_v.append(cache_v)
- hidden_list.append(inputs)
-
- return inputs, hidden_list, (cache_list_k, cache_list_v)
-
-
-class ErnieModel(D.Layer):
- def __init__(self, cfg, name=None):
- """
- Fundamental pretrained Ernie model
- """
- log.debug('init ErnieModel with config: %s' % repr(cfg))
- D.Layer.__init__(self)
- d_model = cfg['hidden_size']
- d_emb = cfg.get('emb_size', cfg['hidden_size'])
- d_vocab = cfg['vocab_size']
- d_pos = cfg['max_position_embeddings']
- d_sent = cfg.get("sent_type_vocab_size") or cfg['type_vocab_size']
- self.n_head = cfg['num_attention_heads']
- self.return_additional_info = cfg.get('return_additional_info', False)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
-
- self.ln = _build_ln(d_model, name=append_name(name, 'pre_encoder'))
- self.word_emb = D.Embedding([d_vocab, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'word_embedding'), initializer=initializer))
- self.pos_emb = D.Embedding([d_pos, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'pos_embedding'), initializer=initializer))
- self.sent_emb = D.Embedding([d_sent, d_emb],
- param_attr=F.ParamAttr(
- name=append_name(name, 'sent_embedding'), initializer=initializer))
- prob = cfg['hidden_dropout_prob']
- self.dropout = lambda i: L.dropout(
- i,
- dropout_prob=prob,
- dropout_implementation="upscale_in_train",
- ) if self.training else i
-
- self.encoder_stack = ErnieEncoderStack(cfg, append_name(name, 'encoder'))
- if cfg.get('has_pooler', True):
- self.pooler = _build_linear(
- cfg['hidden_size'], cfg['hidden_size'], append_name(name, 'pooled_fc'), initializer, act='tanh')
- else:
- self.pooler = None
- self.train()
-
- def eval(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).eval()
- self.training = False
- for l in self.sublayers():
- l.training = False
-
- def train(self):
- if F.in_dygraph_mode():
- super(ErnieModel, self).train()
- self.training = True
- for l in self.sublayers():
- l.training = True
-
- def forward(self,
- src_ids,
- sent_ids=None,
- pos_ids=None,
- input_mask=None,
- attn_bias=None,
- past_cache=None,
- use_causal_mask=False):
- """
- Args:
- src_ids (`Variable` of shape `[batch_size, seq_len]`):
- Indices of input sequence tokens in the vocabulary.
- sent_ids (optional, `Variable` of shape `[batch_size, seq_len]`):
- aka token_type_ids, Segment token indices to indicate first and second portions of the inputs.
- if None, assume all tokens come from `segment_a`
- pos_ids(optional, `Variable` of shape `[batch_size, seq_len]`):
- Indices of positions of each input sequence tokens in the position embeddings.
- input_mask(optional `Variable` of shape `[batch_size, seq_len]`):
- Mask to avoid performing attention on the padding token indices of the encoder input.
- attn_bias(optional, `Variable` of shape `[batch_size, seq_len, seq_len] or False`):
- 3D version of `input_mask`, if set, overrides `input_mask`; if set not False, will not apply attention mask
- past_cache(optional, tuple of two lists: cached key and cached value,
- each is a list of `Variable`s of shape `[batch_size, seq_len, hidden_size]`):
- cached key/value tensor that will be concated to generated key/value when performing self attention.
- if set, `attn_bias` should not be None.
-
- Returns:
- pooled (`Variable` of shape `[batch_size, hidden_size]`):
- output logits of pooler classifier
- encoded(`Variable` of shape `[batch_size, seq_len, hidden_size]`):
- output logits of transformer stack
- """
- assert len(src_ids.shape) == 2, 'expect src_ids.shape = [batch, sequecen], got %s' % (repr(src_ids.shape))
- assert attn_bias is not None if past_cache else True, 'if `past_cache` is specified; attn_bias should not be None'
- d_batch = L.shape(src_ids)[0]
- d_seqlen = L.shape(src_ids)[1]
- if pos_ids is None:
- pos_ids = L.reshape(L.range(0, d_seqlen, 1, dtype='int32'), [1, -1])
- pos_ids = L.cast(pos_ids, 'int64')
- if attn_bias is None:
- if input_mask is None:
- input_mask = L.cast(src_ids != 0, 'float32')
- assert len(input_mask.shape) == 2
- input_mask = L.unsqueeze(input_mask, axes=[-1])
- attn_bias = L.matmul(input_mask, input_mask, transpose_y=True)
- if use_causal_mask:
- sequence = L.reshape(L.range(0, d_seqlen, 1, dtype='float32') + 1., [1, 1, -1, 1])
- causal_mask = L.cast((L.matmul(sequence, 1. / sequence, transpose_y=True) >= 1.), 'float32')
- attn_bias *= causal_mask
- else:
- assert len(attn_bias.shape) == 3, 'expect attn_bias tobe rank 3, got %r' % attn_bias.shape
- attn_bias = (1. - attn_bias) * -10000.0
- attn_bias = L.unsqueeze(attn_bias, [1])
- attn_bias = L.expand(attn_bias, [1, self.n_head, 1, 1]) # avoid broadcast =_=
- attn_bias.stop_gradient = True
-
- if sent_ids is None:
- sent_ids = L.zeros_like(src_ids)
-
- src_embedded = self.word_emb(src_ids)
- pos_embedded = self.pos_emb(pos_ids)
- sent_embedded = self.sent_emb(sent_ids)
- embedded = src_embedded + pos_embedded + sent_embedded
-
- embedded = self.dropout(self.ln(embedded))
-
- encoded, hidden_list, cache_list = self.encoder_stack(embedded, attn_bias, past_cache=past_cache)
- if self.pooler is not None:
- pooled = self.pooler(encoded[:, 0, :])
- else:
- pooled = None
-
- additional_info = {
- 'hiddens': hidden_list,
- 'caches': cache_list,
- }
-
- if self.return_additional_info:
- return pooled, encoded, additional_info
- else:
- return pooled, encoded
diff --git a/modules/text/text_generation/ernie_gen_poetry/model/modeling_ernie_gen.py b/modules/text/text_generation/ernie_gen_poetry/model/modeling_ernie_gen.py
deleted file mode 100644
index 4753b6e85220c55a324c47c3e4a47e63d29fa6ca..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_poetry/model/modeling_ernie_gen.py
+++ /dev/null
@@ -1,65 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import paddle.fluid as F
-import paddle.fluid.layers as L
-
-from ernie_gen_poetry.model.modeling_ernie import ErnieModel
-from ernie_gen_poetry.model.modeling_ernie import _build_linear, _build_ln, append_name
-
-
-class ErnieModelForGeneration(ErnieModel):
- def __init__(self, cfg, name=None):
- cfg['return_additional_info'] = True
- cfg['has_pooler'] = False
- super(ErnieModelForGeneration, self).__init__(cfg, name=name)
- initializer = F.initializer.TruncatedNormal(scale=cfg['initializer_range'])
- d_model = cfg['hidden_size']
- d_vocab = cfg['vocab_size']
-
- self.mlm = _build_linear(
- d_model, d_model, append_name(name, 'mask_lm_trans_fc'), initializer, act=cfg['hidden_act'])
- self.mlm_ln = _build_ln(d_model, name=append_name(name, 'mask_lm_trans'))
- self.mlm_bias = L.create_parameter(
- dtype='float32',
- shape=[d_vocab],
- attr=F.ParamAttr(
- name=append_name(name, 'mask_lm_out_fc.b_0'), initializer=F.initializer.Constant(value=0.0)),
- is_bias=True,
- )
-
- def forward(self, src_ids, *args, **kwargs):
- tgt_labels = kwargs.pop('tgt_labels', None)
- tgt_pos = kwargs.pop('tgt_pos', None)
- encode_only = kwargs.pop('encode_only', False)
- _, encoded, info = ErnieModel.forward(self, src_ids, *args, **kwargs)
- if encode_only:
- return None, None, info
- elif tgt_labels is None:
- encoded = self.mlm(encoded)
- encoded = self.mlm_ln(encoded)
- logits = L.matmul(encoded, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- output_ids = L.argmax(logits, -1)
- return output_ids, logits, info
- else:
- encoded_2d = L.gather_nd(encoded, tgt_pos)
- encoded_2d = self.mlm(encoded_2d)
- encoded_2d = self.mlm_ln(encoded_2d)
- logits_2d = L.matmul(encoded_2d, self.word_emb.weight, transpose_y=True) + self.mlm_bias
- if len(tgt_labels.shape) == 1:
- tgt_labels = L.reshape(tgt_labels, [-1, 1])
-
- loss = L.reduce_mean(
- L.softmax_with_cross_entropy(logits_2d, tgt_labels, soft_label=(tgt_labels.shape[-1] != 1)))
- return loss, logits_2d, info
diff --git a/modules/text/text_generation/ernie_gen_poetry/model/tokenizing_ernie.py b/modules/text/text_generation/ernie_gen_poetry/model/tokenizing_ernie.py
deleted file mode 100644
index c9e5638f9a17207ce2d664c27376f08138876da3..0000000000000000000000000000000000000000
--- a/modules/text/text_generation/ernie_gen_poetry/model/tokenizing_ernie.py
+++ /dev/null
@@ -1,163 +0,0 @@
-# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
-#
-# Licensed under the Apache License, Version 2.0 (the "License");
-# you may not use this file except in compliance with the License.
-# You may obtain a copy of the License at
-#
-# http://www.apache.org/licenses/LICENSE-2.0
-#
-# Unless required by applicable law or agreed to in writing, software
-# distributed under the License is distributed on an "AS IS" BASIS,
-# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
-# See the License for the specific language governing permissions and
-# limitations under the License.
-
-import six
-import re
-import logging
-from functools import partial
-
-import numpy as np
-
-import io
-
-open = partial(io.open, encoding='utf8')
-
-log = logging.getLogger(__name__)
-
-_max_input_chars_per_word = 100
-
-
-def _wordpiece(token, vocab, unk_token, prefix='##', sentencepiece_prefix=''):
- """ wordpiece: helloworld => [hello, ##world] """
- chars = list(token)
- if len(chars) > _max_input_chars_per_word:
- return [unk_token], [(0, len(chars))]
-
- is_bad = False
- start = 0
- sub_tokens = []
- sub_pos = []
- while start < len(chars):
- end = len(chars)
- cur_substr = None
- while start < end:
- substr = "".join(chars[start:end])
- if start == 0:
- substr = sentencepiece_prefix + substr
- if start > 0:
- substr = prefix + substr
- if substr in vocab:
- cur_substr = substr
- break
- end -= 1
- if cur_substr is None:
- is_bad = True
- break
- sub_tokens.append(cur_substr)
- sub_pos.append((start, end))
- start = end
- if is_bad:
- return [unk_token], [(0, len(chars))]
- else:
- return sub_tokens, sub_pos
-
-
-class ErnieTokenizer(object):
- def __init__(self,
- vocab,
- unk_token='[UNK]',
- sep_token='[SEP]',
- cls_token='[CLS]',
- pad_token='[PAD]',
- mask_token='[MASK]',
- wordpiece_prefix='##',
- sentencepiece_prefix='',
- lower=True,
- encoding='utf8',
- special_token_list=[]):
- if not isinstance(vocab, dict):
- raise ValueError('expect `vocab` to be instance of dict, got %s' % type(vocab))
- self.vocab = vocab
- self.lower = lower
- self.prefix = wordpiece_prefix
- self.sentencepiece_prefix = sentencepiece_prefix
- self.pad_id = self.vocab[pad_token]
- self.cls_id = cls_token and self.vocab[cls_token]
- self.sep_id = sep_token and self.vocab[sep_token]
- self.unk_id = unk_token and self.vocab[unk_token]
- self.mask_id = mask_token and self.vocab[mask_token]
- self.unk_token = unk_token
- special_tokens = {pad_token, cls_token, sep_token, unk_token, mask_token} | set(special_token_list)
- pat_str = ''
- for t in special_tokens:
- if t is None:
- continue
- pat_str += '(%s)|' % re.escape(t)
- pat_str += r'([a-zA-Z0-9]+|\S)'
- log.debug('regex: %s' % pat_str)
- self.pat = re.compile(pat_str)
- self.encoding = encoding
-
- def tokenize(self, text):
- if len(text) == 0:
- return []
- if six.PY3 and not isinstance(text, six.string_types):
- text = text.decode(self.encoding)
- if six.PY2 and isinstance(text, str):
- text = text.decode(self.encoding)
-
- res = []
- for match in self.pat.finditer(text):
- match_group = match.group(0)
- if match.groups()[-1]:
- if self.lower:
- match_group = match_group.lower()
- words, _ = _wordpiece(
- match_group,
- vocab=self.vocab,
- unk_token=self.unk_token,
- prefix=self.prefix,
- sentencepiece_prefix=self.sentencepiece_prefix)
- else:
- words = [match_group]
- res += words
- return res
-
- def convert_tokens_to_ids(self, tokens):
- return [self.vocab.get(t, self.unk_id) for t in tokens]
-
- def truncate(self, id1, id2, seqlen):
- len1 = len(id1)
- len2 = len(id2)
- half = seqlen // 2
- if len1 > len2:
- len1_truncated, len2_truncated = max(half, seqlen - len2), min(half, len2)
- else:
- len1_truncated, len2_truncated = min(half, seqlen - len1), max(half, seqlen - len1)
- return id1[:len1_truncated], id2[:len2_truncated]
-
- def build_for_ernie(self, text_id, pair_id=[]):
- """build sentence type id, add [CLS] [SEP]"""
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- ret_id = np.concatenate([[self.cls_id], text_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([[0], text_id_type, [0]], 0)
-
- if len(pair_id):
- pair_id_type = np.ones_like(pair_id, dtype=np.int64)
- ret_id = np.concatenate([ret_id, pair_id, [self.sep_id]], 0)
- ret_id_type = np.concatenate([ret_id_type, pair_id_type, [1]], 0)
- return ret_id, ret_id_type
-
- def encode(self, text, pair=None, truncate_to=None):
- text_id = np.array(self.convert_tokens_to_ids(self.tokenize(text)), dtype=np.int64)
- text_id_type = np.zeros_like(text_id, dtype=np.int64)
- if pair is not None:
- pair_id = np.array(self.convert_tokens_to_ids(self.tokenize(pair)), dtype=np.int64)
- else:
- pair_id = []
- if truncate_to is not None:
- text_id, pair_id = self.truncate(text_id, [] if pair_id is None else pair_id, truncate_to)
-
- ret_id, ret_id_type = self.build_for_ernie(text_id, pair_id)
- return ret_id, ret_id_type
diff --git a/modules/text/text_generation/ernie_gen_poetry/module.py b/modules/text/text_generation/ernie_gen_poetry/module.py
index 3c5c4724f750c8e273ef1f0a562a517dbbe9fe4c..a5b8f02c863fc7455110762a0f7c6cf13573cd41 100644
--- a/modules/text/text_generation/ernie_gen_poetry/module.py
+++ b/modules/text/text_generation/ernie_gen_poetry/module.py
@@ -14,28 +14,24 @@
# limitations under the License.
import ast
import json
+import argparse
+import os
-import paddle.fluid as fluid
+import numpy as np
+import paddle
import paddlehub as hub
from paddlehub.module.module import runnable
from paddlehub.module.nlp_module import DataFormatError
from paddlehub.common.logger import logger
from paddlehub.module.module import moduleinfo, serving
+from paddlenlp.transformers import ErnieTokenizer, ErnieForGeneration
-import argparse
-import os
-import numpy as np
-
-import paddle.fluid.dygraph as D
-
-from ernie_gen_poetry.model.tokenizing_ernie import ErnieTokenizer
-from ernie_gen_poetry.model.decode import beam_search_infilling
-from ernie_gen_poetry.model.modeling_ernie_gen import ErnieModelForGeneration
+from ernie_gen_poetry.decode import beam_search_infilling
@moduleinfo(
name="ernie_gen_poetry",
- version="1.0.2",
+ version="1.1.0",
summary=
"ERNIE-GEN is a multi-flow language generation framework for both pre-training and fine-tuning. This module has fine-tuned for poetry generation task.",
author="baidu-nlp",
@@ -43,29 +39,19 @@ from ernie_gen_poetry.model.modeling_ernie_gen import ErnieModelForGeneration
type="nlp/text_generation",
)
class ErnieGen(hub.NLPPredictionModule):
- def _initialize(self):
+ def __init__(self):
"""
initialize with the necessary elements
"""
assets_path = os.path.join(self.directory, "assets")
- gen_checkpoint_path = os.path.join(assets_path, "ernie_gen_poetry")
- ernie_cfg_path = os.path.join(assets_path, 'ernie_config.json')
- with open(ernie_cfg_path, encoding='utf8') as ernie_cfg_file:
- ernie_cfg = dict(json.loads(ernie_cfg_file.read()))
- ernie_vocab_path = os.path.join(assets_path, 'vocab.txt')
- with open(ernie_vocab_path, encoding='utf8') as ernie_vocab_file:
- ernie_vocab = {j.strip().split('\t')[0]: i for i, j in enumerate(ernie_vocab_file.readlines())}
-
- with fluid.dygraph.guard(fluid.CPUPlace()):
- with fluid.unique_name.guard():
- self.model = ErnieModelForGeneration(ernie_cfg)
- finetuned_states, _ = D.load_dygraph(gen_checkpoint_path)
- self.model.set_dict(finetuned_states)
-
- self.tokenizer = ErnieTokenizer(ernie_vocab)
- self.rev_dict = {v: k for k, v in self.tokenizer.vocab.items()}
- self.rev_dict[self.tokenizer.pad_id] = '' # replace [PAD]
- self.rev_dict[self.tokenizer.unk_id] = '' # replace [PAD]
+ gen_checkpoint_path = os.path.join(assets_path, "ernie_gen_poetry.pdparams")
+ self.model = ErnieForGeneration.from_pretrained("ernie-1.0")
+ model_state = paddle.load(gen_checkpoint_path)
+ self.model.set_dict(model_state)
+ self.tokenizer = ErnieTokenizer.from_pretrained("ernie-1.0")
+ self.rev_dict = self.tokenizer.vocab.idx_to_token
+ self.rev_dict[self.tokenizer.vocab['[PAD]']] = '' # replace [PAD]
+ self.rev_dict[self.tokenizer.vocab['[UNK]']] = '' # replace [PAD]
self.rev_lookup = np.vectorize(lambda i: self.rev_dict[i])
@serving
@@ -81,6 +67,8 @@ class ErnieGen(hub.NLPPredictionModule):
Returns:
results(list): the poetry continuations.
"""
+ paddle.disable_static()
+
if texts and isinstance(texts, list) and all(texts) and all([isinstance(text, str) for text in texts]):
predicted_data = texts
else:
@@ -108,37 +96,35 @@ class ErnieGen(hub.NLPPredictionModule):
logger.warning(
"use_gpu has been set False as you didn't set the environment variable CUDA_VISIBLE_DEVICES while using use_gpu=True"
)
- if use_gpu:
- place = fluid.CUDAPlace(0)
- else:
- place = fluid.CPUPlace()
-
- with fluid.dygraph.guard(place):
- self.model.eval()
- results = []
- for text in predicted_data:
- sample_results = []
- ids, sids = self.tokenizer.encode(text)
- src_ids = D.to_variable(np.expand_dims(ids, 0))
- src_sids = D.to_variable(np.expand_dims(sids, 0))
- output_ids = beam_search_infilling(
- self.model,
- src_ids,
- src_sids,
- eos_id=self.tokenizer.sep_id,
- sos_id=self.tokenizer.cls_id,
- attn_id=self.tokenizer.vocab['[MASK]'],
- max_decode_len=80,
- max_encode_len=20,
- beam_width=beam_width,
- tgt_type_id=1)
- output_str = self.rev_lookup(output_ids[0].numpy())
-
- for ostr in output_str.tolist():
- if '[SEP]' in ostr:
- ostr = ostr[:ostr.index('[SEP]')]
- sample_results.append("".join(ostr))
- results.append(sample_results)
+ paddle.set_device('gpu') if use_gpu else paddle.set_device('cpu')
+ self.model.eval()
+ results = []
+ for text in predicted_data:
+ sample_results = []
+ encode_text = self.tokenizer.encode(text)
+ src_ids = paddle.to_tensor(encode_text['input_ids']).unsqueeze(0)
+ src_sids = paddle.to_tensor(encode_text['token_type_ids']).unsqueeze(0)
+ output_ids = beam_search_infilling(
+ self.model,
+ src_ids,
+ src_sids,
+ eos_id=self.tokenizer.vocab['[SEP]'],
+ sos_id=self.tokenizer.vocab['[CLS]'],
+ attn_id=self.tokenizer.vocab['[MASK]'],
+ pad_id=self.tokenizer.vocab['[PAD]'],
+ unk_id=self.tokenizer.vocab['[UNK]'],
+ vocab_size=len(self.tokenizer.vocab),
+ max_decode_len=80,
+ max_encode_len=20,
+ beam_width=beam_width,
+ tgt_type_id=1)
+ output_str = self.rev_lookup(output_ids[0])
+
+ for ostr in output_str.tolist():
+ if '[SEP]' in ostr:
+ ostr = ostr[:ostr.index('[SEP]')]
+ sample_results.append("".join(ostr))
+ results.append(sample_results)
return results
def add_module_config_arg(self):
@@ -183,5 +169,5 @@ class ErnieGen(hub.NLPPredictionModule):
if __name__ == "__main__":
module = ErnieGen()
- for result in module.generate(['昔年旅南服,始识王荆州。', '高名出汉阴,禅阁跨香岑。'], beam_width=5):
+ for result in module.generate(['昔年旅南服,始识王荆州。', '高名出汉阴,禅阁跨香岑。'], beam_width=5, use_gpu=True):
print(result)
diff --git a/modules/text/text_generation/plato-mini/module.py b/modules/text/text_generation/plato-mini/module.py
index c25f09901849ad508b66c8f8d0b9a3ae1c7342d1..b6ba1be9e4c3033b4ff2e8f1aaac3b7f68f400dd 100644
--- a/modules/text/text_generation/plato-mini/module.py
+++ b/modules/text/text_generation/plato-mini/module.py
@@ -30,7 +30,7 @@ from plato_mini.utils import select_response
name="plato-mini",
version="1.0.0",
summary="",
- author="PaddlePaddle",
+ author="paddlepaddle",
author_email="",
type="nlp/text_generation",
)
@@ -54,7 +54,7 @@ class UnifiedTransformer(nn.Layer):
Generate input batches.
"""
padding = False if batch_size == 1 else True
- pad_func = Pad(pad_val=self.tokenizer.pad_token_id, pad_right=False)
+ pad_func = Pad(pad_val=self.tokenizer.pad_token_id, pad_right=False, dtype=np.int64)
def pad_mask(batch_attention_mask):
batch_size = len(batch_attention_mask)
@@ -75,9 +75,9 @@ class UnifiedTransformer(nn.Layer):
position_ids = pad_func([example['position_ids'] for example in batch_examples])
attention_mask = pad_mask([example['attention_mask'] for example in batch_examples])
else:
- input_ids = np.asarray([example['input_ids'] for example in batch_examples])
- token_type_ids = np.asarray([example['token_type_ids'] for example in batch_examples])
- position_ids = np.asarray([example['position_ids'] for example in batch_examples])
+ input_ids = np.asarray([example['input_ids'] for example in batch_examples], dtype=np.int64)
+ token_type_ids = np.asarray([example['token_type_ids'] for example in batch_examples], dtype=np.int64)
+ position_ids = np.asarray([example['position_ids'] for example in batch_examples], dtype=np.int64)
attention_mask = np.asarray([example['attention_mask'] for example in batch_examples])
attention_mask = np.expand_dims(attention_mask, 0)
diff --git a/modules/text/text_generation/unified_transformer-12L-cn-luge/module.py b/modules/text/text_generation/unified_transformer-12L-cn-luge/module.py
index e6bb87f525eb72d8fe5cabcc915535f22fecbdff..52ef5532db84d696960d4ac28ef1cba4bbfbc75c 100644
--- a/modules/text/text_generation/unified_transformer-12L-cn-luge/module.py
+++ b/modules/text/text_generation/unified_transformer-12L-cn-luge/module.py
@@ -30,7 +30,7 @@ from unified_transformer_12L_cn_luge.utils import select_response
name="unified_transformer_12L_cn_luge",
version="1.0.0",
summary="",
- author="PaddlePaddle",
+ author="paddlepaddle",
author_email="",
type="nlp/text_generation",
)
diff --git a/modules/text/text_generation/unified_transformer-12L-cn/module.py b/modules/text/text_generation/unified_transformer-12L-cn/module.py
index 6292921b432036a8e1d2747d1a0edcb2e2b58a7b..ee09a55d0c2853a7abfcf6a19bc727c1de5c1ad2 100644
--- a/modules/text/text_generation/unified_transformer-12L-cn/module.py
+++ b/modules/text/text_generation/unified_transformer-12L-cn/module.py
@@ -30,7 +30,7 @@ from unified_transformer_12L_cn.utils import select_response
name="unified_transformer_12L_cn",
version="1.0.0",
summary="",
- author="PaddlePaddle",
+ author="paddlepaddle",
author_email="",
type="nlp/text_generation",
)
diff --git a/modules/text/text_review/porn_detection_cnn/README.md b/modules/text/text_review/porn_detection_cnn/README.md
index 190b1bb8b0a03c66d4a20822db12758151ab043e..e72a71a633cf9aea44fbc7f1c2ef84a2fe31711e 100644
--- a/modules/text/text_review/porn_detection_cnn/README.md
+++ b/modules/text/text_review/porn_detection_cnn/README.md
@@ -70,7 +70,7 @@ Loading porn_detection_cnn successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/text_review/porn_detection_gru/README.md b/modules/text/text_review/porn_detection_gru/README.md
index 5a41684e11a189090a0cbc9188369ef336df067d..add8f9f971a6ea692d2091a571678b7dd1e0b042 100644
--- a/modules/text/text_review/porn_detection_gru/README.md
+++ b/modules/text/text_review/porn_detection_gru/README.md
@@ -70,7 +70,7 @@ Loading porn_detection_gru successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/modules/text/text_review/porn_detection_lstm/README.md b/modules/text/text_review/porn_detection_lstm/README.md
index f6b01a505c44db10f702d7d141bd10d732ebceae..6d7040c209ea7b8a2595e858b018de04d60a0e01 100644
--- a/modules/text/text_review/porn_detection_lstm/README.md
+++ b/modules/text/text_review/porn_detection_lstm/README.md
@@ -70,7 +70,7 @@ Loading porn_detection_lstm successful.
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
```python
-import request
+import requests
import json
# 待预测数据
diff --git a/paddlehub/module/cv_module.py b/paddlehub/module/cv_module.py
index 4c5aa03ef58f79a596749282f2ee06615e7cbf40..62e2a30350f23d4d5bb8099f1edaa18481c09231 100644
--- a/paddlehub/module/cv_module.py
+++ b/paddlehub/module/cv_module.py
@@ -70,6 +70,7 @@ class ImageClassifierModule(RunModule, ImageServing):
'''
images = batch[0]
labels = paddle.unsqueeze(batch[1], axis=-1)
+ labels = labels.astype('int64')
preds, feature = self(images)
@@ -104,7 +105,7 @@ class ImageClassifierModule(RunModule, ImageServing):
batch_data.append(image)
except:
pass
- batch_image = np.array(batch_data)
+ batch_image = np.array(batch_data, dtype='float32')
preds, feature = self(paddle.to_tensor(batch_image))
preds = F.softmax(preds, axis=1).numpy()
pred_idxs = np.argsort(preds)[:, ::-1][:, :top_k]
diff --git a/paddlehub/module/nlp_module.py b/paddlehub/module/nlp_module.py
index d0b06231180466fe7cab1865f8bd53940aafc758..9e39d3467e1440bbbf12f94088c4ba23b4902106 100644
--- a/paddlehub/module/nlp_module.py
+++ b/paddlehub/module/nlp_module.py
@@ -18,7 +18,7 @@ import io
import json
import os
import six
-from typing import List, Tuple
+from typing import List, Tuple, Union
import paddle
import paddle.nn as nn
@@ -91,7 +91,6 @@ class InitTrackerMeta(type(nn.Layer)):
help_func (callable, optional): If provided, it would be hooked after
`init_func` and called as `_wrap_init(self, init_func, *init_args, **init_args)`.
Default None.
-
Returns:
function: the wrapped function
"""
@@ -142,7 +141,6 @@ class PretrainedModel(nn.Layer):
- `pretrained_init_configuration` (dict): The dict has pretrained model names
as keys, and the values are also dict preserving corresponding configuration
for model initialization.
-
- `base_model_prefix` (str): represents the the attribute associated to the
base model in derived classes of the same architecture adding layers on
top of the base model.
@@ -365,14 +363,12 @@ class TextServing(object):
1. seq-cls: sequence classification;
2. token-cls: sequence labeling;
3. None: embedding.
-
Args:
data (obj:`List(List(str))`): The processed data whose each element is the list of a single text or a pair of texts.
max_seq_len (:obj:`int`, `optional`, defaults to 128):
If set to a number, will limit the total sequence returned so that it has a maximum length.
batch_size(obj:`int`, defaults to 1): The number of batch.
use_gpu(obj:`bool`, defaults to `False`): Whether to use gpu to run or not.
-
Returns:
results(obj:`list`): All the predictions labels.
"""
@@ -465,11 +461,12 @@ class TransformerModule(RunModule, TextServing):
title_segment_ids = [entry[3] for entry in batch]
return query_input_ids, query_segment_ids, title_input_ids, title_segment_ids
- tokenizer = self.get_tokenizer()
+ if not hasattr(self, 'tokenizer'):
+ self.tokenizer = self.get_tokenizer()
examples = []
for texts in data:
- encoded_inputs = self._convert_text_to_input(tokenizer, texts, max_seq_len, split_char)
+ encoded_inputs = self._convert_text_to_input(self.tokenizer, texts, max_seq_len, split_char)
example = []
for inp in encoded_inputs:
input_ids = inp['input_ids']
@@ -538,7 +535,6 @@ class TransformerModule(RunModule, TextServing):
Args:
data (obj:`List(List(str))`): The processed data whose each element is the list of a single text or a pair of texts.
use_gpu(obj:`bool`, defaults to `False`): Whether to use gpu to run or not.
-
Returns:
results(obj:`list`): All the tokens and sentences embeddings.
"""
@@ -552,10 +548,10 @@ class TransformerModule(RunModule, TextServing):
max_seq_len: int = 128,
split_char: str = '\002',
batch_size: int = 1,
- use_gpu: bool = False):
+ use_gpu: bool = False,
+ return_prob: bool = False):
"""
Predicts the data labels.
-
Args:
data (obj:`List(List(str))`): The processed data whose each element is the list of a single text or a pair of texts.
max_seq_len (:obj:`int`, `optional`, defaults to :int:`None`):
@@ -563,7 +559,7 @@ class TransformerModule(RunModule, TextServing):
split_char(obj:`str`, defaults to '\002'): The char used to split input tokens in token-cls task.
batch_size(obj:`int`, defaults to 1): The number of batch.
use_gpu(obj:`bool`, defaults to `False`): Whether to use gpu to run or not.
-
+ return_prob(obj:`bool`, defaults to `False`): Whether to return label probabilities.
Returns:
results(obj:`list`): All the predictions labels.
"""
@@ -579,6 +575,8 @@ class TransformerModule(RunModule, TextServing):
batches = self._batchify(data, max_seq_len, batch_size, split_char)
results = []
+ batch_probs = []
+
self.eval()
for batch in batches:
if self.task == 'text-matching':
@@ -589,32 +587,38 @@ class TransformerModule(RunModule, TextServing):
title_segment_ids = paddle.to_tensor(title_segment_ids)
probs = self(query_input_ids=query_input_ids, query_token_type_ids=query_segment_ids, \
title_input_ids=title_input_ids, title_token_type_ids=title_segment_ids)
+
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [self.label_map[i] for i in idx]
- results.extend(labels)
else:
input_ids, segment_ids = batch
input_ids = paddle.to_tensor(input_ids)
segment_ids = paddle.to_tensor(segment_ids)
-
if self.task == 'seq-cls':
probs = self(input_ids, segment_ids)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [self.label_map[i] for i in idx]
- results.extend(labels)
elif self.task == 'token-cls':
probs = self(input_ids, segment_ids)
batch_ids = paddle.argmax(probs, axis=2).numpy() # (batch_size, max_seq_len)
batch_ids = batch_ids.tolist()
- token_labels = [[self.label_map[i] for i in token_ids] for token_ids in batch_ids]
- results.extend(token_labels)
+ # token labels
+ labels = [[self.label_map[i] for i in token_ids] for token_ids in batch_ids]
elif self.task == None:
sequence_output, pooled_output = self(input_ids, segment_ids)
results.append(
[pooled_output.squeeze(0).numpy().tolist(),
sequence_output.squeeze(0).numpy().tolist()])
+ if self.task:
+ # save probs only when return prob
+ if return_prob:
+ batch_probs.extend(probs.numpy().tolist())
+ results.extend(labels)
+
+ if self.task and return_prob:
+ return results, batch_probs
return results

 -- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR) for the pre-trained models, you can try to train your models with them.
+- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
### **Natural Language Processing (129 models)**
@@ -118,14 +118,21 @@ If you have any questions during the use of the model, you can join the official
-- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR) for the pre-trained models, you can try to train your models with them.
+- Many thanks to CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) for the pre-trained models, you can try to train your models with them.
### **Natural Language Processing (129 models)**
@@ -118,14 +118,21 @@ If you have any questions during the use of the model, you can join the official