diff --git a/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md b/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
index 4856100379f4855be930c5ff90442111df714c82..b968f4008541ae9a3c45222fd9d630906d423821 100644
--- a/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
+++ b/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
@@ -77,7 +77,7 @@
T.RGB2LAB()], to_rgb=True)
```
- - `transforms` The data enhancement module defines lots of data preprocessing methods. Users can replace the data preprocessing methods according to their needs.
+ - `transforms` The data enhancement module defines lots of data preprocessing methods. Users can replace the data preprocessing methods according to their needs.
- Step2: Download the dataset
- ```python
diff --git a/modules/image/Image_gan/style_transfer/msgnet/README.md b/modules/image/Image_gan/style_transfer/msgnet/README.md
index b2ead3a2a4c3e185ef2edf31c8b0e8ceac817451..8314a252f61cb92a8d121d129c6ee47ea9f8ad65 100644
--- a/modules/image/Image_gan/style_transfer/msgnet/README.md
+++ b/modules/image/Image_gan/style_transfer/msgnet/README.md
@@ -50,13 +50,14 @@ $ hub run msgnet --input_path "/PATH/TO/ORIGIN/IMAGE" --style_path "/PATH/TO/STY
- ### 2.预测代码示例
+
```python
import paddle
import paddlehub as hub
if __name__ == '__main__':
model = hub.Module(name='msgnet')
- result = model.predict(origin=["venice-boat.jpg"], style="candy.jpg", visualization=True, save_path ='style_tranfer')
+ result = model.predict(origin=["/PATH/TO/ORIGIN/IMAGE"], style="/PATH/TO/STYLE/IMAGE", visualization=True, save_path ="/PATH/TO/SAVE/IMAGE")
```
@@ -86,7 +87,7 @@ if __name__ == '__main__':
- `transforms`: 数据预处理方式。
- `mode`: 选择数据模式,可选项有 `train`, `test`, 默认为`train`。
- - 数据集的准备代码可以参考 [minicoco.py](../../paddlehub/datasets/flowers.py)。`hub.datasets.MiniCOCO()`会自动从网络下载数据集并解压到用户目录下`$HOME/.paddlehub/dataset`目录。
+ - 数据集的准备代码可以参考 [minicoco.py](../../paddlehub/datasets/minicoco.py)。`hub.datasets.MiniCOCO()`会自动从网络下载数据集并解压到用户目录下`$HOME/.paddlehub/dataset`目录。
- Step3: 加载预训练模型
@@ -117,7 +118,7 @@ if __name__ == '__main__':
if __name__ == '__main__':
model = hub.Module(name='msgnet', load_checkpoint="/PATH/TO/CHECKPOINT")
- result = model.predict(origin=["venice-boat.jpg"], style="candy.jpg", visualization=True, save_path ='style_tranfer')
+ result = model.predict(origin=["/PATH/TO/ORIGIN/IMAGE"], style="/PATH/TO/STYLE/IMAGE", visualization=True, save_path ="/PATH/TO/SAVE/IMAGE")
```
- 参数配置正确后,请执行脚本`python predict.py`, 加载模型具体可参见[加载](https://www.paddlepaddle.org.cn/documentation/docs/zh/2.0-rc/api/paddle/framework/io/load_cn.html#load)。
diff --git a/modules/image/Image_gan/style_transfer/msgnet/README_en.md b/modules/image/Image_gan/style_transfer/msgnet/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..1aeac4aa3587a026188b25aac7bb896c58d0265b
--- /dev/null
+++ b/modules/image/Image_gan/style_transfer/msgnet/README_en.md
@@ -0,0 +1,185 @@
+# msgnet
+
+|Module Name|msgnet|
+| :--- | :---: |
+|Category|image editing|
+|Network|msgnet|
+|Dataset|COCO2014|
+|Fine-tuning supported or not|Yes|
+|Module Size|68MB|
+|Data indicators|-|
+|Latest update date|2021-07-29|
+
+
+## I. Basic Information
+
+- ### Application Effect Display
+ - Sample results:
+
+ 
 +
+
+
+- ### Module Introduction
+
+ - Msgnet is a style transfer model. We will show how to use PaddleHub to finetune the pre-trained model and complete the prediction.
+ - For more information, please refer to [msgnet](https://github.com/zhanghang1989/PyTorch-Multi-Style-Transfer)
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+
+ - ```shell
+ $ hub install msgnet
+ ```
+
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## III. Module API Prediction
+
+- ### 1、Command line Prediction
+
+```
+$ hub run msgnet --input_path "/PATH/TO/ORIGIN/IMAGE" --style_path "/PATH/TO/STYLE/IMAGE"
+```
+
+- ### 2、Prediction Code Example
+
+```python
+import paddle
+import paddlehub as hub
+
+if __name__ == '__main__':
+ model = hub.Module(name='msgnet')
+ result = model.predict(origin=["/PATH/TO/ORIGIN/IMAGE"], style="/PATH/TO/STYLE/IMAGE", visualization=True, save_path ="/PATH/TO/SAVE/IMAGE")
+```
+
+
+
+- ### 3.Fine-tune and Encapsulation
+
+ - After completing the installation of PaddlePaddle and PaddleHub, you can start using the msgnet model to fine-tune datasets such as [MiniCOCO](../../docs/reference/datasets.md#class-hubdatasetsMiniCOCO) by executing `python train.py`.
+
+ - Steps:
+
+ - Step1: Define the data preprocessing method
+
+ - ```python
+ import paddlehub.vision.transforms as T
+
+ transform = T.Compose([T.Resize((256, 256), interpolation='LINEAR')])
+ ```
+
+ - `transforms` The data enhancement module defines lots of data preprocessing methods. Users can replace the data preprocessing methods according to their needs.
+
+ - Step2: Download the dataset
+ - ```python
+ from paddlehub.datasets.minicoco import MiniCOCO
+
+ styledata = MiniCOCO(transform=transform, mode='train')
+
+ ```
+ * `transforms`: data preprocessing methods.
+ * `mode`: Select the data mode, the options are `train`, `test`, `val`. Default is `train`.
+
+ - Dataset preparation can be referred to [minicoco.py](../../paddlehub/datasets/minicoco.py). `hub.datasets.MiniCOCO()` will be automatically downloaded from the network and decompressed to the `$HOME/.paddlehub/dataset` directory under the user directory.
+
+ - Step3: Load the pre-trained model
+
+ - ```python
+ model = hub.Module(name='msgnet', load_checkpoint=None)
+ ```
+ * `name`: model name.
+ * `load_checkpoint`: Whether to load the self-trained model, if it is None, load the provided parameters.
+
+ - Step4: Optimization strategy
+
+ - ```python
+ optimizer = paddle.optimizer.Adam(learning_rate=0.0001, parameters=model.parameters())
+ trainer = Trainer(model, optimizer, checkpoint_dir='test_style_ckpt')
+ trainer.train(styledata, epochs=101, batch_size=4, eval_dataset=styledata, log_interval=10, save_interval=10)
+ ```
+
+
+ - Model prediction
+
+ - When Fine-tune is completed, the model with the best performance on the verification set will be saved in the `${CHECKPOINT_DIR}/best_model` directory. We use this model to make predictions. The `predict.py` script is as follows:
+ ```python
+ import paddle
+ import paddlehub as hub
+
+ if __name__ == '__main__':
+ model = hub.Module(name='msgnet', load_checkpoint="/PATH/TO/CHECKPOINT")
+ result = model.predict(origin=["/PATH/TO/ORIGIN/IMAGE"], style="/PATH/TO/STYLE/IMAGE", visualization=True, save_path ="/PATH/TO/SAVE/IMAGE")
+ ```
+
+ - **Args**
+ * `origin`: Image path or ndarray data with format [H, W, C], BGR;
+ * `style`: Style image path;
+ * `visualization`: Whether to save the recognition results as picture files;
+ * `save_path`: Save path of the result, default is 'style_tranfer'.
+
+
+## IV. Server Deployment
+
+- PaddleHub Serving can deploy an online service of style transfer.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+
+ - ```shell
+ $ hub serving start -m msgnet
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result:
+
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+ import numpy as np
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # Send an HTTP request
+ org_im = cv2.imread('/PATH/TO/ORIGIN/IMAGE')
+ style_im = cv2.imread('/PATH/TO/STYLE/IMAGE')
+ data = {'images':[[cv2_to_base64(org_im)], cv2_to_base64(style_im)]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/msgnet"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ data = base64_to_cv2(r.json()["results"]['data'][0])
+ cv2.imwrite('style.png', data)
+ ```
+
+## V. Release Note
+
+- 1.0.0
+
+ First release
diff --git a/modules/image/classification/resnet50_vd_animals/README_en.md b/modules/image/classification/resnet50_vd_animals/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..000b62e1337f011f0be1c215f95d459d60e91d50
--- /dev/null
+++ b/modules/image/classification/resnet50_vd_animals/README_en.md
@@ -0,0 +1,173 @@
+# resnet50_vd_animals
+
+|Module Name|resnet50_vd_animals|
+| :--- | :---: |
+|Category |image classification|
+|Network|ResNet50_vd|
+|Dataset|Baidu self-built dataset|
+|Fine-tuning supported or not|No|
+|Module Size|154MB|
+|Latest update date|2021-02-26|
+|Data indicators|-|
+
+
+## I. Basic Information
+
+- ### Application Effect Display
+
+ - ResNet-vd is a variant of ResNet, which can be used for image classification and feature extraction. This module is trained by Baidu self-built animal data set and supports the classification and recognition of 7,978 animal species.
+ - For more information, please refer to [ResNet-vd](https://arxiv.org/pdf/1812.01187.pdf)
+
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+
+- ### 2、Installation
+
+ - ```shell
+ $ hub install resnet50_vd_animals
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## III. Module API Prediction
+
+- ### 1、Command line Prediction
+
+ - ```shell
+ $ hub run resnet50_vd_animals --input_path "/PATH/TO/IMAGE"
+ ```
+ - If you want to call the Hub module through the command line, please refer to: [PaddleHub Command Line Instruction](../../../../docs/docs_ch/tutorial/cmd_usage.rst)
+
+- ### 2、Prediction Code Example
+
+ - ```python
+ import paddlehub as hub
+ import cv2
+
+ classifier = hub.Module(name="resnet50_vd_animals")
+
+ result = classifier.classification(images=[cv2.imread('/PATH/TO/IMAGE')])
+ # or
+ # result = classifier.classification(paths=['/PATH/TO/IMAGE'])
+ ```
+
+- ### 3、API
+
+ - ```python
+ def get_expected_image_width()
+ ```
+
+ - Returns the preprocessed image width, which is 224.
+
+ - ```python
+ def get_expected_image_height()
+ ```
+
+ - Returns the preprocessed image height, which is 224.
+
+ - ```python
+ def get_pretrained_images_mean()
+ ```
+
+ - Returns the mean value of the preprocessed image, which is \[0.485, 0.456, 0.406\].
+
+ - ```python
+ def get_pretrained_images_std()
+ ```
+
+ - Return the standard deviation of the preprocessed image, which is \[0.229, 0.224, 0.225\].
+
+
+ - ```python
+ def classification(images=None,
+ paths=None,
+ batch_size=1,
+ use_gpu=False,
+ top_k=1):
+ ```
+
+ - **Parameter**
+
+ * images (list\[numpy.ndarray\]): image data, ndarray.shape is in the format [H, W, C], BGR;
+ * paths (list\[str\]): image path;
+ * batch\_size (int): batch size;
+ * use\_gpu (bool): use GPU or not; **set the CUDA_VISIBLE_DEVICES environment variable first if you are using GPU**
+ * top\_k (int): return the top k prediction results.
+
+ - **Return**
+
+ - res (list\[dict\]): the list of classification results,key is the prediction label, value is the corresponding confidence.
+
+ - ```python
+ def save_inference_model(dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True)
+ ```
+
+ - Save the model to the specified path.
+
+ - **Parameters**
+ * dirname: Save path.
+ * model\_filename: model file name,defalt is \_\_model\_\_
+ * params\_filename: parameter file name,defalt is \_\_params\_\_(Only takes effect when `combined` is True)
+ * combined: Whether to save the parameters to a unified file.
+
+
+
+## IV. Server Deployment
+
+- PaddleHub Serving can deploy an online service of animal classification.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+
+ - ```shell
+ $ hub serving start -m resnet50_vd_animals
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result
+
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+
+ # Send an HTTP request
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/resnet50_vd_animals"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # print prediction results
+ print(r.json()["results"])
+ ```
+
+
+## V. Release Note
+
+- 1.0.0
+
+ First release
+
diff --git a/modules/image/classification/resnet50_vd_imagenet_ssld/README.md b/modules/image/classification/resnet50_vd_imagenet_ssld/README.md
index 229e5d0c8400152d73f354f13dab546a3f8b749c..7563ae023257a077ef302d8992ee51307246e3c4 100644
--- a/modules/image/classification/resnet50_vd_imagenet_ssld/README.md
+++ b/modules/image/classification/resnet50_vd_imagenet_ssld/README.md
@@ -50,7 +50,7 @@
if __name__ == '__main__':
model = hub.Module(name='resnet50_vd_imagenet_ssld')
- result = model.predict(['flower.jpg'])
+ result = model.predict(['/PATH/TO/IMAGE'])
```
- ### 3.如何开始Fine-tune
@@ -134,7 +134,7 @@
if __name__ == '__main__':
model = hub.Module(name='resnet50_vd_imagenet_ssld', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
- result = model.predict(['flower.jpg'])
+ result = model.predict(['/PATH/TO/IMAGE'])
```
diff --git a/modules/image/classification/resnet50_vd_imagenet_ssld/README_en.md b/modules/image/classification/resnet50_vd_imagenet_ssld/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..47300415678c3cf354655945fcbe9a2a33280486
--- /dev/null
+++ b/modules/image/classification/resnet50_vd_imagenet_ssld/README_en.md
@@ -0,0 +1,198 @@
+# resnet50_vd_imagenet_ssld
+
+|Module Name|resnet50_vd_imagenet_ssld|
+| :--- | :---: |
+|Category |image classification|
+|Network|ResNet_vd|
+|Dataset|ImageNet-2012|
+|Fine-tuning supported or notFine-tuning|Yes|
+|Module Size|148MB|
+|Data indicators|-|
+|Latest update date|2021-02-26|
+
+
+## I. Basic Information
+
+- ### Module Introduction
+
+ - ResNet-vd is a variant of ResNet, which can be used for image classification and feature extraction.
+
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+
+ - ```shell
+ $ hub install resnet50_vd_imagenet_ssld
+ ```
+
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## III. Module API Prediction
+
+- ### 1、Command line Prediction
+
+ ```shell
+ $ hub run resnet50_vd_imagenet_ssld --input_path "/PATH/TO/IMAGE" --top_k 5
+ ```
+- ### 2、Prediction Code Example
+
+ ```python
+ import paddle
+ import paddlehub as hub
+
+ if __name__ == '__main__':
+
+ model = hub.Module(name='resnet50_vd_imagenet_ssld')
+ result = model.predict(['/PATH/TO/IMAGE'])
+ ```
+- ### 3.Fine-tune and Encapsulation
+
+ - After completing the installation of PaddlePaddle and PaddleHub, you can start using the user_guided_colorization model to fine-tune datasets such as [Flowers](../../docs/reference/datasets.md#class-hubdatasetsflowers) by excuting `python train.py`.
+
+ - Steps:
+
+ - Step1: Define the data preprocessing method
+ - ```python
+ import paddlehub.vision.transforms as T
+
+ transforms = T.Compose([T.Resize((256, 256)),
+ T.CenterCrop(224),
+ T.Normalize(mean=[0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])],
+ to_rgb=True)
+ ```
+
+ - `transforms` The data enhancement module defines lots of data preprocessing methods. Users can replace the data preprocessing methods according to their needs.
+
+
+ - Step2: Download the dataset
+
+ - ```python
+ from paddlehub.datasets import Flowers
+
+ flowers = Flowers(transforms)
+
+ flowers_validate = Flowers(transforms, mode='val')
+ ```
+
+ * `transforms`: data preprocessing methods.
+ * `mode`: Select the data mode, the options are `train`, `test`, `val`. Default is `train`.
+ * `hub.datasets.Flowers()` will be automatically downloaded from the network and decompressed to the `$HOME/.paddlehub/dataset` directory under the user directory.
+
+ - Step3: Load the pre-trained model
+
+ - ```python
+ model = hub.Module(name="resnet50_vd_imagenet_ssld", label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"])
+ ```
+ * `name`: model name.
+ * `label_list`: set the output classification category. Default is Imagenet2012 category.
+
+ - Step4: Optimization strategy
+
+ ```python
+ optimizer = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
+ trainer = Trainer(model, optimizer, checkpoint_dir='img_classification_ckpt')
+
+ trainer.train(flowers, epochs=100, batch_size=32, eval_dataset=flowers_validate, save_interval=1)
+ ```
+
+
+ - Run configuration
+
+ - `Trainer` mainly control the training of Fine-tune, including the following controllable parameters:
+
+ * `model`: Optimized model;
+ * `optimizer`: Optimizer selection;
+ * `use_vdl`: Whether to use vdl to visualize the training process;
+ * `checkpoint_dir`: The storage address of the model parameters;
+ * `compare_metrics`: The measurement index of the optimal model;
+
+ - `trainer.train` mainly control the specific training process, including the following controllable parameters:
+
+ * `train_dataset`: Training dataset;
+ * `epochs`: Epochs of training process;
+ * `batch_size`: Batch size;
+ * `num_workers`: Number of workers.
+ * `eval_dataset`: Validation dataset;
+ * `log_interval`:The interval for printing logs;
+ * `save_interval`: The interval for saving model parameters.
+
+
+ - Model prediction
+
+ - When Fine-tune is completed, the model with the best performance on the verification set will be saved in the `${CHECKPOINT_DIR}/best_model` directory. We use this model to make predictions. The `predict.py` script is as follows:
+
+ - ```python
+ import paddle
+ import paddlehub as hub
+
+ if __name__ == '__main__':
+
+ model = hub.Module(name='resnet50_vd_imagenet_ssld', label_list=["roses", "tulips", "daisy", "sunflowers", "dandelion"], load_checkpoint='/PATH/TO/CHECKPOINT')
+ result = model.predict(['/PATH/TO/IMAGE'])
+ ```
+
+## IV. Server Deployment
+
+- PaddleHub Serving can deploy an online service of classification.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+
+ - ```shell
+ $ hub serving start -m resnet50_vd_imagenet_ssld
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result
+
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+ import numpy as np
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # Send an HTTP request
+ org_im = cv2.imread('/PATH/TO/IMAGE')
+
+ data = {'images':[cv2_to_base64(org_im)], 'top_k':2}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/resnet50_vd_imagenet_ssld"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+ data =r.json()["results"]['data']
+ ```
+## V. Release Note
+
+* 1.0.0
+
+ First release
+
+* 1.1.0
+
+ Upgrade to dynamic version.
diff --git a/modules/image/classification/resnet_v2_50_imagenet/README_en.md b/modules/image/classification/resnet_v2_50_imagenet/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..f45dc9a8e7f14f73123a8e8d4e59e943de76a219
--- /dev/null
+++ b/modules/image/classification/resnet_v2_50_imagenet/README_en.md
@@ -0,0 +1,86 @@
+# resnet_v2_50_imagenet
+
+|Module Name|resnet_v2_50_imagenet|
+| :--- | :---: |
+|Category |image classification|
+|Network|ResNet V2|
+|Dataset|ImageNet-2012|
+|Fine-tuning supported or not|No|
+|Module Size|99MB|
+|Latest update date|2021-02-26|
+|Data indicators|-|
+
+
+## I. Basic Information
+
+- ### Application Effect Display
+
+ - This module utilizes ResNet50 structure and it is trained on ImageNet-2012.
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 1.4.0
+
+ - paddlehub >= 1.0.0 | [How to install PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
+
+
+- ### 2、Installation
+
+ - ```shell
+ $ hub install resnet_v2_50_imagenet
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## III. Module API Prediction
+
+- ### 1、Command line Prediction
+
+ - ```shell
+ $ hub run resnet_v2_50_imagenet --input_path "/PATH/TO/IMAGE"
+ ```
+ - If you want to call the Hub module through the command line, please refer to: [PaddleHub Command Line Instruction](../../../../docs/docs_ch/tutorial/cmd_usage.rst)
+
+- ### 2、Prediction Code Example
+
+ - ```python
+ import paddlehub as hub
+ import cv2
+
+ classifier = hub.Module(name="resnet_v2_50_imagenet")
+ test_img_path = "/PATH/TO/IMAGE"
+ input_dict = {"image": [test_img_path]}
+ result = classifier.classification(data=input_dict)
+ ```
+
+- ### 3、API
+
+ - ```python
+ def classification(data)
+ ```
+ - Prediction API for classification.
+
+ - **Parameter**
+ - data (dict): key is 'image',value is the list of image path.
+
+ - **Return**
+ - result (list[dict]): the list of classification results,key is the prediction label, value is the corresponding confidence.
+
+
+
+
+## IV. Release Note
+
+- 1.0.0
+
+ First release
+
+- 1.0.1
+ Fix encoding problem in python2
+
+ - ```shell
+ $ hub install resnet_v2_50_imagenet==1.0.1
+ ```
diff --git a/modules/image/semantic_segmentation/ExtremeC3_Portrait_Segmentation/README_en.md b/modules/image/semantic_segmentation/ExtremeC3_Portrait_Segmentation/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..15ac80e05b615611a75591b5e1e6d42a66521564
--- /dev/null
+++ b/modules/image/semantic_segmentation/ExtremeC3_Portrait_Segmentation/README_en.md
@@ -0,0 +1,89 @@
+# ExtremeC3_Portrait_Segmentation
+
+|Module Name|ExtremeC3_Portrait_Segmentation|
+| :--- | :---: |
+|Category|image segmentation|
+|Network |ExtremeC3|
+|Dataset|EG1800, Baidu fashion dataset|
+|Fine-tuning supported or not|No|
+|Module Size|0.038MB|
+|Data indicators|-|
+|Latest update date|2021-02-26|
+
+## I. Basic Information
+
+- ### Application Effect Display
+
+ - Sample results:
+
+ 
+
+
+
+- ### Module Introduction
+ * ExtremeC3_Portrait_Segmentation is a light weigth module based on ExtremeC3 to achieve portrait segmentation.
+
+ * For more information, please refer to: [ExtremeC3_Portrait_Segmentation](https://github.com/clovaai/ext_portrait_segmentation).
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+
+ - ```shell
+ $ hub install ExtremeC3_Portrait_Segmentation
+ ```
+
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## III. Module API Prediction
+
+- ### 1、Prediction Code Example
+
+ ```python
+ import cv2
+ import paddlehub as hub
+
+ model = hub.Module(name='ExtremeC3_Portrait_Segmentation')
+
+ result = model.Segmentation(
+ images=[cv2.imread('/PATH/TO/IMAGE')],
+ paths=None,
+ batch_size=1,
+ output_dir='output',
+ visualization=False)
+ ```
+
+- ### 2、API
+
+ ```python
+ def Segmentation(
+ images=None,
+ paths=None,
+ batch_size=1,
+ output_dir='output',
+ visualization=False):
+ ```
+ - Prediction API, used for portrait segmentation.
+
+ - **Parameter**
+ * images (list[np.ndarray]) : image data, ndarray.shape is in the format [H, W, C], BGR;
+ * paths (list[str]) :image path
+ * batch_size (int) : batch size
+ * output_dir (str) : save path of images, 'output' by default.
+ * visualization (bool) : whether to save the segmentation results as picture files.
+ - **Return**
+ * results (list[dict{"mask":np.ndarray,"result":np.ndarray}]): list of recognition results.
+
+## IV. Release Note
+
+- 1.0.0
+
+ First release
diff --git a/modules/image/semantic_segmentation/Pneumonia_CT_LKM_PP/README_en.md b/modules/image/semantic_segmentation/Pneumonia_CT_LKM_PP/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..74aa6de8449d65fdde3f2a4d36ef41ba7f1b5e16
--- /dev/null
+++ b/modules/image/semantic_segmentation/Pneumonia_CT_LKM_PP/README_en.md
@@ -0,0 +1,91 @@
+# Pneumonia_CT_LKM_PP
+
+|Module Name|Pneumonia_CT_LKM_PP|
+| :--- | :---: |
+|Category|image segmentation|
+|Network |-|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size|35M|
+|Data indicators|-|
+|Latest update date|2021-02-26|
+
+
+## I. Basic Information
+
+
+- ### Module Introduction
+
+ - Pneumonia CT analysis model (Pneumonia-CT-LKM-PP) can efficiently complete the detection of lesions and outline the patient's CT images. Through post-processing codes, the number, volume, and lesions of lung lesions can be analyzed. This model has been fully trained by high-resolution and low-resolution CT image data, which can adapt to the examination data collected by different levels of CT imaging equipment.
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+
+ - ```shell
+ $ hub install Pneumonia_CT_LKM_PP==1.0.0
+ ```
+
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## III. Module API Prediction
+
+- ### 1、Prediction Code Example
+
+ ```python
+ import paddlehub as hub
+
+ pneumonia = hub.Module(name="Pneumonia_CT_LKM_PP")
+
+ input_only_lesion_np_path = "/PATH/TO/ONLY_LESION_NP"
+ input_both_lesion_np_path = "/PATH/TO/LESION_NP"
+ input_both_lung_np_path = "/PATH/TO/LUNG_NP"
+
+ # set input dict
+ input_dict = {"image_np_path": [
+ [input_only_lesion_np_path],
+ [input_both_lesion_np_path, input_both_lung_np_path],
+ ]}
+
+ # execute predict and print the result
+ results = pneumonia.segmentation(data=input_dict)
+ for result in results:
+ print(result)
+
+ ```
+
+
+- ### 2、API
+
+ ```python
+ def segmentation(data)
+ ```
+
+ - Prediction API, used for CT analysis of pneumonia.
+
+ - **Parameter**
+
+ * data (dict): key is "image_np_path", value is the list of results which contains lesion and lung segmentation masks.
+
+
+ - **Return**
+
+ * result (list\[dict\]): the list of recognition results, where each element is dict and each field is:
+ * input_lesion_np_path: input path of lesion;
+ * output_lesion_np: segmentation result path of lesion;
+ * input_lung_np_path: input path of lung;
+ * output_lung_np:segmentation result path of lung.
+
+
+## IV. Release Note
+
+* 1.0.0
+
+ First release
diff --git a/modules/image/semantic_segmentation/Pneumonia_CT_LKM_PP_lung/README_en.md b/modules/image/semantic_segmentation/Pneumonia_CT_LKM_PP_lung/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..32bb76489e9d269f3dae8d3e28f883285ade1086
--- /dev/null
+++ b/modules/image/semantic_segmentation/Pneumonia_CT_LKM_PP_lung/README_en.md
@@ -0,0 +1,91 @@
+# Pneumonia_CT_LKM_PP_lung
+
+|Module Name|Pneumonia_CT_LKM_PP_lung|
+| :--- | :---: |
+|Category|image segmentation|
+|Network |-|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size|35M|
+|Data indicators|-|
+|Latest update date|2021-02-26|
+
+
+## I. Basic Information
+
+
+- ### Module Introduction
+
+ - Pneumonia CT analysis model (Pneumonia-CT-LKM-PP) can efficiently complete the detection of lesions and outline the patient's CT images. Through post-processing codes, the number, volume, and lesions of lung lesions can be analyzed. This model has been fully trained by high-resolution and low-resolution CT image data, which can adapt to the examination data collected by different levels of CT imaging equipment. (This module is a submodule of Pneumonia_CT_LKM_PP.)
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+
+ - ```shell
+ $ hub install Pneumonia_CT_LKM_PP_lung==1.0.0
+ ```
+
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## III. Module API Prediction
+
+- ### 1、Prediction Code Example
+
+ ```python
+ import paddlehub as hub
+
+ pneumonia = hub.Module(name="Pneumonia_CT_LKM_PP_lung")
+
+ input_only_lesion_np_path = "/PATH/TO/ONLY_LESION_NP"
+ input_both_lesion_np_path = "/PATH/TO/LESION_NP"
+ input_both_lung_np_path = "/PATH/TO/LUNG_NP"
+
+ # set input dict
+ input_dict = {"image_np_path": [
+ [input_only_lesion_np_path],
+ [input_both_lesion_np_path, input_both_lung_np_path],
+ ]}
+
+ # execute predict and print the result
+ results = pneumonia.segmentation(data=input_dict)
+ for result in results:
+ print(result)
+
+ ```
+
+
+- ### 2、API
+
+ ```python
+ def segmentation(data)
+ ```
+
+ - Prediction API, used for CT analysis of pneumonia.
+
+ - **Parameter**
+
+ * data (dict): key is "image_np_path", value is the list of results which contains lesion and lung segmentation masks.
+
+
+ - **Return**
+
+ * result (list\[dict\]): the list of recognition results, where each element is dict and each field is:
+ * input_lesion_np_path: input path of lesion;
+ * output_lesion_np: segmentation result path of lesion;
+ * input_lung_np_path: input path of lung;
+ * output_lung_np:segmentation result path of lung.
+
+
+## IV. Release Note
+
+* 1.0.0
+
+ First release
diff --git a/modules/image/semantic_segmentation/U2Net/README_en.md b/modules/image/semantic_segmentation/U2Net/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..68eb2daa28b6da853e0eaa5bb1a38a0b4940f1e4
--- /dev/null
+++ b/modules/image/semantic_segmentation/U2Net/README_en.md
@@ -0,0 +1,96 @@
+# U2Net
+
+|Module Name |U2Net|
+| :--- | :---: |
+|Category |image segmentation|
+|Network |U^2Net|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size |254MB|
+|Data indicators|-|
+|Latest update date|2021-02-26|
+
+
+## I. Basic Information
+
+- ### Application Effect Display
+
+ - Sample results:
+
+
+ 
 +
+
+
+
+- ### Module Introduction
+
+ - Network architecture:
+
+ 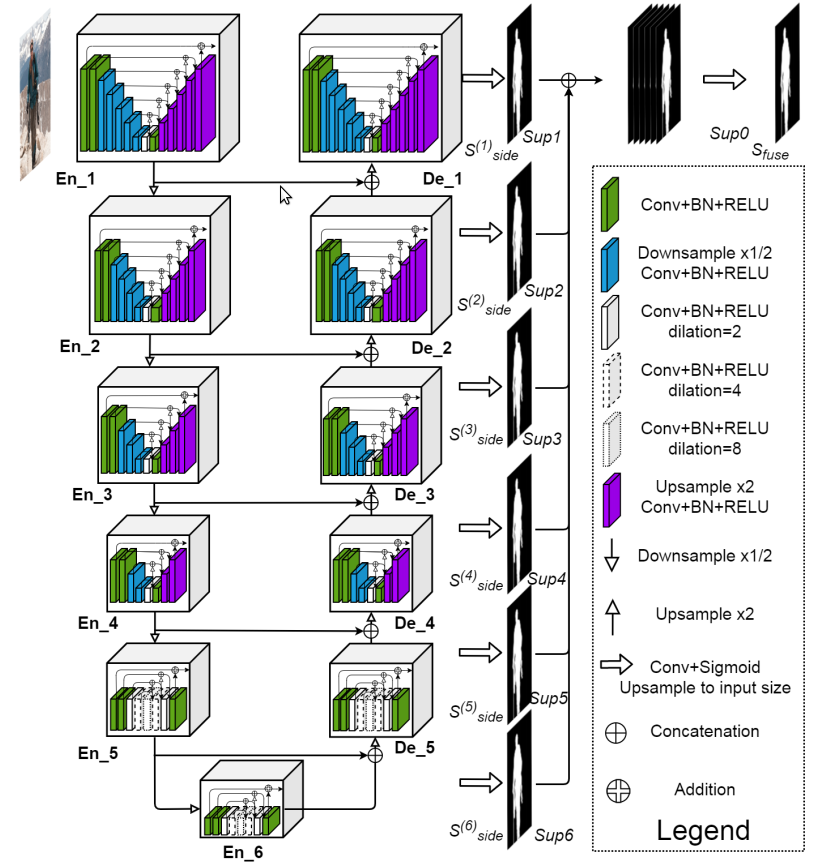
+
+
+ - For more information, please refer to: [U2Net](https://github.com/xuebinqin/U-2-Net)
+
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+ - ```shell
+ $ hub install U2Net
+ ```
+
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## III. Module API Prediction
+
+- ### 1、Prediction Code Example
+
+ ```python
+ import cv2
+ import paddlehub as hub
+
+ model = hub.Module(name='U2Net')
+
+ result = model.Segmentation(
+ images=[cv2.imread('/PATH/TO/IMAGE')],
+ paths=None,
+ batch_size=1,
+ input_size=320,
+ output_dir='output',
+ visualization=True)
+ ```
+ - ### 2、API
+
+ ```python
+ def Segmentation(
+ images=None,
+ paths=None,
+ batch_size=1,
+ input_size=320,
+ output_dir='output',
+ visualization=False):
+ ```
+ - Prediction API, obtaining segmentation result.
+
+ - **Parameter**
+ * images (list[np.ndarray]) : image data, ndarray.shape is in the format [H, W, C], BGR;
+ * paths (list[str]) : image path;
+ * batch_size (int) : batch size;
+ * input_size (int) : input image size, default is 320;
+ * output_dir (str) : save path of images, 'output' by default;
+ * visualization (bool) : whether to save the results as picture files.
+
+ - **Return**
+ * results (list[np.ndarray]): The list of segmentation results.
+
+## IV. Release Note
+
+- 1.0.0
+
+ First release
diff --git a/modules/image/semantic_segmentation/U2Netp/README_en.md b/modules/image/semantic_segmentation/U2Netp/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..f47ba5a0ddaa0a5d3e094d4499c11cee334656e5
--- /dev/null
+++ b/modules/image/semantic_segmentation/U2Netp/README_en.md
@@ -0,0 +1,96 @@
+# U2Netp
+
+|Module Name |U2Netp|
+| :--- | :---: |
+|Category |image segmentation|
+|Network |U^2Net|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size |6.7MB|
+|Data indicators|-|
+|Latest update date|2021-02-26|
+
+
+## I. Basic Information
+
+- ### Application Effect Display
+
+ - Sample results:
+
+
+
+
+
+
+- ### Module Introduction
+
+ - Network architecture:
+
+
+
+
+ - For more information, please refer to: [U2Net](https://github.com/xuebinqin/U-2-Net)
+
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+ - ```shell
+ $ hub install U2Netp
+ ```
+
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## III. Module API Prediction
+
+- ### 1、Prediction Code Example
+
+ ```python
+ import cv2
+ import paddlehub as hub
+
+ model = hub.Module(name='U2Netp')
+
+ result = model.Segmentation(
+ images=[cv2.imread('/PATH/TO/IMAGE')],
+ paths=None,
+ batch_size=1,
+ input_size=320,
+ output_dir='output',
+ visualization=True)
+ ```
+ - ### 2、API
+
+ ```python
+ def Segmentation(
+ images=None,
+ paths=None,
+ batch_size=1,
+ input_size=320,
+ output_dir='output',
+ visualization=False):
+ ```
+ - Prediction API, obtaining segmentation result.
+
+ - **Parameter**
+ * images (list[np.ndarray]) : image data, ndarray.shape is in the format [H, W, C], BGR;
+ * paths (list[str]) : image path;
+ * batch_size (int) : batch size;
+ * input_size (int) : input image size, default is 320;
+ * output_dir (str) : save path of images, 'output' by default;
+ * visualization (bool) : whether to save the results as picture files.
+
+ - **Return**
+ * results (list[np.ndarray]): the list of segmentation results.
+
+## IV. Release Note
+
+- 1.0.0
+
+ First release
diff --git a/modules/image/semantic_segmentation/ace2p/README.md b/modules/image/semantic_segmentation/ace2p/README.md
index 710c2424a45298d86b1486afbf751eb874ae4764..702003938f3cbfd9b2bcc53d96d2368661419adf 100644
--- a/modules/image/semantic_segmentation/ace2p/README.md
+++ b/modules/image/semantic_segmentation/ace2p/README.md
@@ -57,7 +57,7 @@
- ### 1、命令行预测
```shell
- $ hub install ace2p==1.1.0
+ $ hub run ace2p --input_path "/PATH/TO/IMAGE"
```
- ### 2、代码示例
diff --git a/modules/image/semantic_segmentation/ace2p/README_en.md b/modules/image/semantic_segmentation/ace2p/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..2b9313ff36b69e61877825da0c1d3f0f447b40ec
--- /dev/null
+++ b/modules/image/semantic_segmentation/ace2p/README_en.md
@@ -0,0 +1,181 @@
+# ace2p
+
+|Module Name|ace2p|
+| :--- | :---: |
+|Category|image segmentation|
+|Network|ACE2P|
+|Dataset|LIP|
+|Fine-tuning supported or not|No|
+|Module Size|259MB|
+|Data indicators|-|
+|Latest update date |2021-02-26|
+
+
+## I. Basic Information
+
+- ### Application Effect Display
+
+ - Network architecture:
+
+ 
+
+
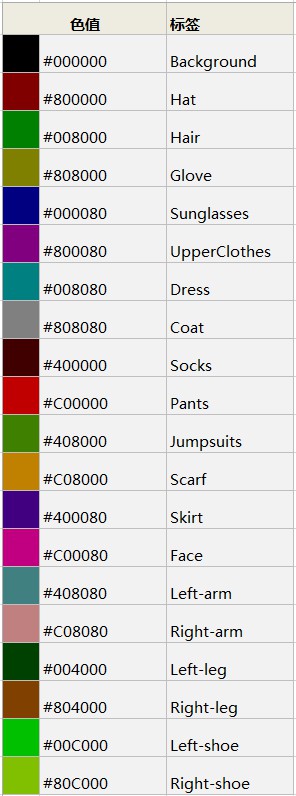
+ - Color palette
+
+
+ 
+
+
+ - Sample results:
+
+ 
 +
+
+
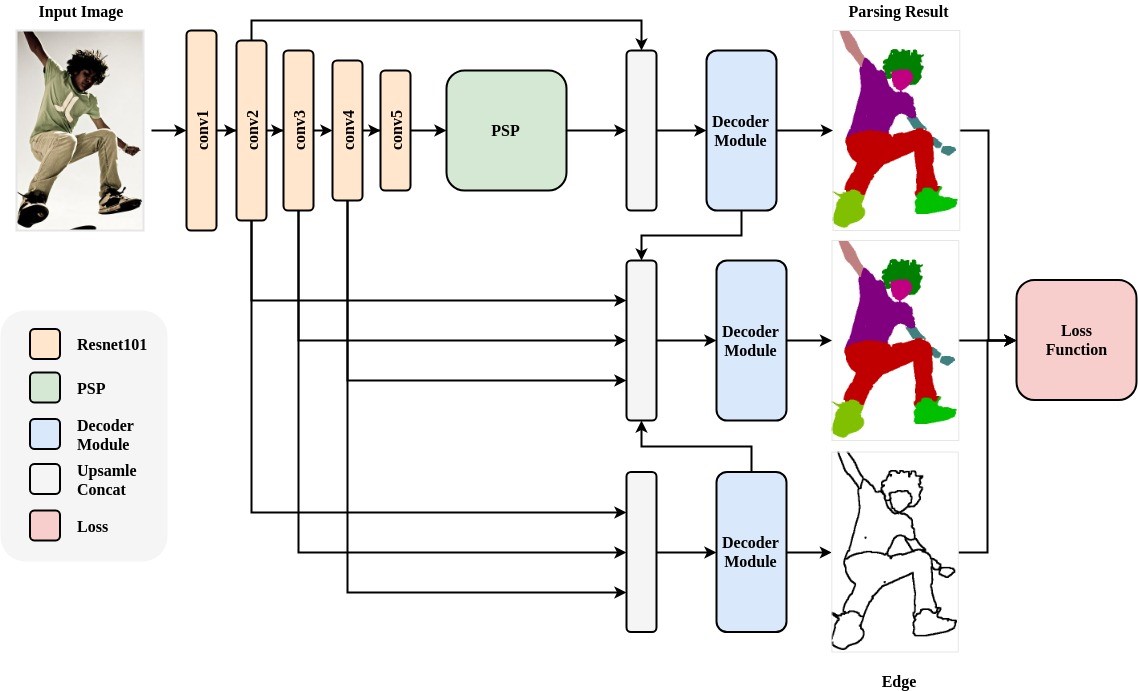
+- ### Module Introduction
+
+ - Human Parsing is a fine-grained semantic segmentation task that aims to identify the components (for example, body parts and clothing) of a human image at the pixel level. The PaddleHub Module uses ResNet101 as the backbone network, and accepts input image sizes of 473x473x3.
+
+
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+
+ - ```shell
+ $ hub install ace2p
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## III. Module API Prediction
+
+- ### 1、Command line Prediction
+
+ ```shell
+ $ hub run ace2p --input_path "/PATH/TO/IMAGE"
+ ```
+
+- ### 2、Prediction Code Example
+
+ ```python
+ import paddlehub as hub
+ import cv2
+
+ human_parser = hub.Module(name="ace2p")
+ result = human_parser.segmentation(images=[cv2.imread('/PATH/TO/IMAGE')])
+ ```
+
+ - ### 3、API
+
+ ```python
+ def segmentation(images=None,
+ paths=None,
+ batch_size=1,
+ use_gpu=False,
+ output_dir='ace2p_output',
+ visualization=False):
+ ```
+
+ - Prediction API, used for human parsing.
+
+ - **Parameter**
+
+ * images (list\[numpy.ndarray\]): image data, ndarray.shape is in the format [H, W, C], BGR;
+ * paths (list\[str\]): image path;
+ * batch\_size (int): batch size;
+ * use\_gpu (bool): use GPU or not; **set the CUDA_VISIBLE_DEVICES environment variable first if you are using GPU**
+ * output\_dir (str): save path of output, default is 'ace2p_output';
+ * visualization (bool): Whether to save the recognition results as picture files.
+
+ - **Return**
+
+ * res (list\[dict\]): The list of recognition results, where each element is dict and each field is:
+ * save\_path (str, optional): Save path of the result;
+ * data (numpy.ndarray): The result of portrait segmentation.
+
+
+ ```python
+ def save_inference_model(dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True)
+ ```
+
+ - Save the model to the specified path.
+
+ - **Parameters**
+ * dirname: Save path.
+ * model\_filename: model file name,defalt is \_\_model\_\_
+ * params\_filename: parameter file name,defalt is \_\_params\_\_(Only takes effect when `combined` is True)
+ * combined: Whether to save the parameters to a unified file.
+
+
+## IV. Server Deployment
+
+- PaddleHub Serving can deploy an online service of human parsing
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+
+ ```shell
+ $ hub serving start -m ace2p
+ ```
+
+ - The servitization API is now deployed and the default port number is 8866.
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result
+
+
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+ import numpy as np
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+
+ # Send an HTTP request
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/ace2p"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # print prediction results
+ print(base64_to_cv2(r.json()["results"][0]['data']))
+ ```
+
+
+## 五、更新历史
+
+- 1.0.0
+
+ First release
+
+* 1.1.0
+
+ Adapt to paddlehub2.0
diff --git a/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/README_en.md b/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..0852edb439bf426892bc45065555e8cba5a6371d
--- /dev/null
+++ b/modules/image/semantic_segmentation/deeplabv3p_xception65_humanseg/README_en.md
@@ -0,0 +1,175 @@
+# deeplabv3p_xception65_humanseg
+
+|Module Name |deeplabv3p_xception65_humanseg|
+| :--- | :---: |
+|Category|image segmentation|
+|Network|deeplabv3p|
+|Dataset|Baidu self-built dataset|
+|Fine-tuning supported or not|No|
+|Module Size|162MB|
+|Data indicators |-|
+|Latest update date|2021-02-26|
+
+## I. Basic Information
+
+- ### Application Effect Display
+
+ - Sample results:
+
+  +
+
+
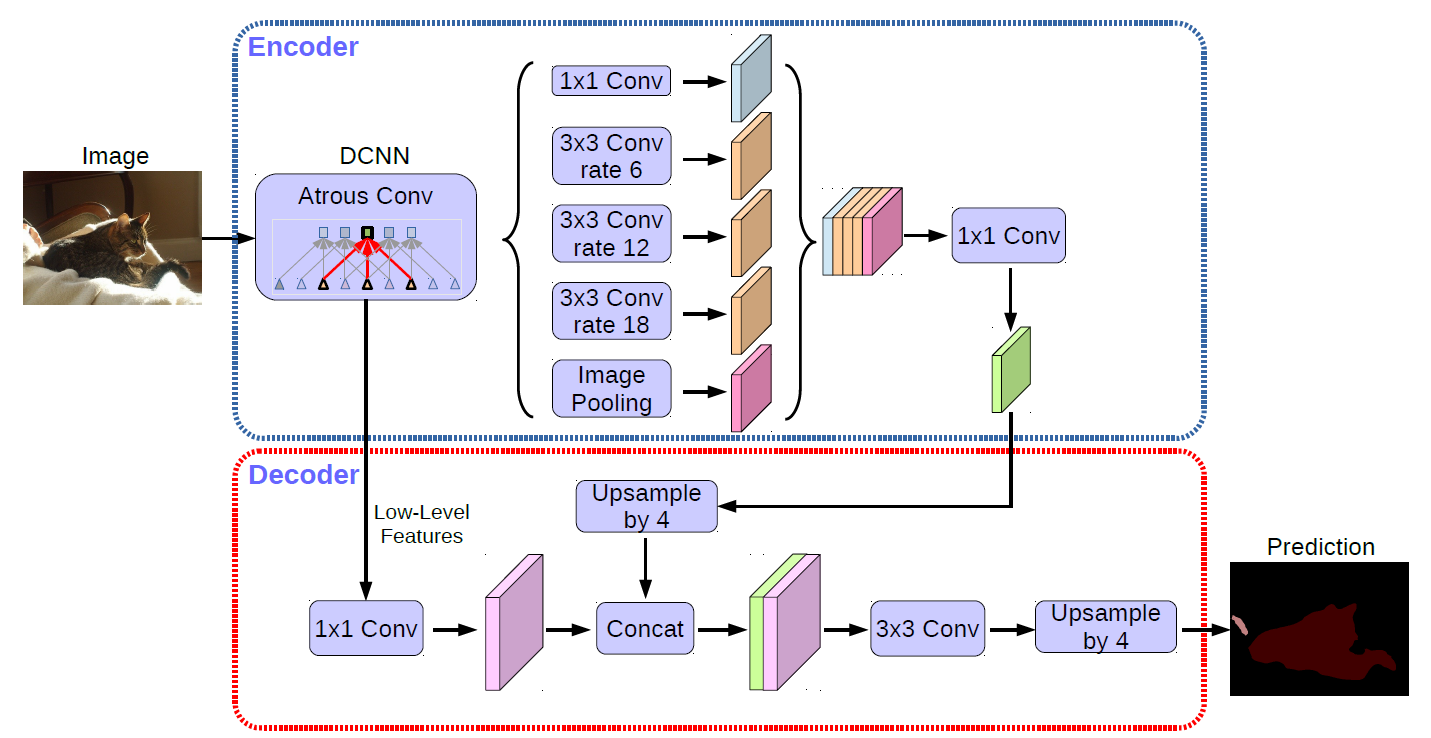
+- ### Module Introduction
+
+ - DeepLabv3+ model is trained by Baidu self-built dataset, which can be used for portrait segmentation.
+
+
+
+
+- For more information, please refer to: [deeplabv3p](https://github.com/PaddlePaddle/PaddleSeg)
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+
+ - ```shell
+ $ hub install deeplabv3p_xception65_humanseg
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## III. Module API Prediction
+
+- ### 1、Command line Prediction
+
+ ```shell
+ hub run deeplabv3p_xception65_humanseg --input_path "/PATH/TO/IMAGE"
+ ```
+
+
+
+- ### 2、Prediction Code Example
+
+ ```python
+ import paddlehub as hub
+ import cv2
+
+ human_seg = hub.Module(name="deeplabv3p_xception65_humanseg")
+ result = human_seg.segmentation(images=[cv2.imread('/PATH/TO/IMAGE')])
+
+ ```
+
+- ### 3.API
+
+ ```python
+ def segmentation(images=None,
+ paths=None,
+ batch_size=1,
+ use_gpu=False,
+ visualization=False,
+ output_dir='humanseg_output')
+ ```
+
+ - Prediction API, generating segmentation result.
+
+ - **Parameter**
+ * images (list\[numpy.ndarray\]): image data, ndarray.shape is in the format [H, W, C], BGR;
+ * paths (list\[str\]): image path;
+ * batch\_size (int): batch size;
+ * use\_gpu (bool): use GPU or not; **set the CUDA_VISIBLE_DEVICES environment variable first if you are using GPU**
+ * visualization (bool): Whether to save the recognition results as picture files;
+ * output\_dir (str): save path of images.
+
+ - **Return**
+
+ * res (list\[dict\]): The list of recognition results, where each element is dict and each field is:
+ * save\_path (str, optional): Save path of the result;
+ * data (numpy.ndarray): The result of portrait segmentation.
+
+ ```python
+ def save_inference_model(dirname,
+ model_filename=None,
+ params_filename=None,
+ combined=True)
+ ```
+
+ - Save the model to the specified path.
+
+ - **Parameters**
+ * dirname: Save path.
+ * model\_filename: model file name,defalt is \_\_model\_\_
+ * params\_filename: parameter file name,defalt is \_\_params\_\_(Only takes effect when `combined` is True)
+ * combined: Whether to save the parameters to a unified file.
+
+
+## IV. Server Deployment
+
+- PaddleHub Serving can deploy an online service of for human segmentation.
+
+- ### Step 1: Start PaddleHub Serving
+
+ - Run the startup command:
+
+ - ```shell
+ $ hub serving start -m deeplabv3p_xception65_humanseg
+ ```
+
+ - **NOTE:** If GPU is used for prediction, set CUDA_VISIBLE_DEVICES environment variable before the service, otherwise it need not be set.
+
+
+- ### Step 2: Send a predictive request
+
+ - With a configured server, use the following lines of code to send the prediction request and obtain the result
+
+ ```python
+ import requests
+ import json
+ import cv2
+ import base64
+ import numpy as np
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+
+ def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
+
+ # Send an HTTP request
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/deeplabv3p_xception65_humanseg"
+ r = requests.post(url=url, headers=headers,
+ mask =cv2.cvtColor(base64_to_cv2(r.json()["results"][0]['data']), cv2.COLOR_BGR2GRAY)
+ rgba = np.concatenate((org_im, np.expand_dims(mask, axis=2)), axis=2)
+ cv2.imwrite("segment_human_server.png", rgba)
+ ```
+## V. Release Note
+
+- 1.0.0
+
+ First release
+
+* 1.1.0
+
+ Improve prediction performance
+
+* 1.1.1
+
+ Fix the bug of image value out of range
+
+* 1.1.2
+
+ Fix memory leakage problem of on cudnn 8.0.4
diff --git a/modules/image/semantic_segmentation/humanseg_lite/README_en.md b/modules/image/semantic_segmentation/humanseg_lite/README_en.md
index 32ec5b2973c3c198e8e4b10b5c402c7c82d732c0..1cfb7fb1ef158309613d2342da0061f739adfabb 100644
--- a/modules/image/semantic_segmentation/humanseg_lite/README_en.md
+++ b/modules/image/semantic_segmentation/humanseg_lite/README_en.md
@@ -250,4 +250,4 @@
Added video stream portrait segmentation interface
* 1.1.1
- Fix the video memory leakage problem of on cudnn 8.0.4
+ Fix memory leakage problem of on cudnn 8.0.4
diff --git a/modules/image/semantic_segmentation/humanseg_server/README_en.md b/modules/image/semantic_segmentation/humanseg_server/README_en.md
index f25ffb94222b1ed4692a723b4273361a6b2ca224..6ed70ac64cc802e4ef0d35f8e517b04431ad0471 100644
--- a/modules/image/semantic_segmentation/humanseg_server/README_en.md
+++ b/modules/image/semantic_segmentation/humanseg_server/README_en.md
@@ -248,6 +248,7 @@
Added video portrait split interface
Added video stream portrait segmentation interface
+
* 1.1.1
- Fix the video memory leakage problem of on cudnn 8.0.4
+ Fix memory leakage problem of on cudnn 8.0.4
diff --git a/modules/video/Video_editing/SkyAR/README.md b/modules/video/Video_editing/SkyAR/README.md
index 7e6cb468f2220dcdc12d58cdf8be2986372d5f66..6a0ec9569a5c8a4bf7a4b6953dda181760df2ad7 100644
--- a/modules/video/Video_editing/SkyAR/README.md
+++ b/modules/video/Video_editing/SkyAR/README.md
@@ -2,9 +2,9 @@
|模型名称|SkyAR|
| :--- | :---: |
-|类别|图像-图像分割|
+|类别|视频-视频编辑|
|网络|UNet|
-|数据集|UNet|
+|数据集|-|
|是否支持Fine-tuning|否|
|模型大小|206MB|
|指标|-|
diff --git a/modules/video/Video_editing/SkyAR/README_en.md b/modules/video/Video_editing/SkyAR/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..14989bbe756f70a3c9b0a97e4711d8047b41c003
--- /dev/null
+++ b/modules/video/Video_editing/SkyAR/README_en.md
@@ -0,0 +1,127 @@
+# SkyAR
+
+|Module Name|SkyAR|
+| :--- | :---: |
+|Category|video editing|
+|Network|UNet|
+|Dataset|-|
+|Fine-tuning supported or not|No|
+|Module Size|206MB|
+|Data indicators|-|
+|Latest update date|2021-02-26|
+
+## I. Basic Information
+
+- ### Application Effect Display
+
+ - Sample results:
+ * Input video:
+
+ 
+
+ * Jupiter:
+
+ 
+ * Rainy day:
+
+ 
+ * Galaxy:
+
+ 
+ * Ninth area spacecraft:
+
+ 
+
+ * Input video:
+
+ 
+ * Floating castle:
+
+ 
+ * Thunder and lightning:
+
+ 
+
+ * Super moon:
+
+ 
+
+- ### Module Introduction
+
+ - SkyAR is based on [Castle in the Sky: Dynamic Sky Replacement and Harmonization in Videos](https://arxiv.org/abs/2010.11800). It mainly consists of three parts: sky matting network, motion estimation and image fusion.
+
+ - For more information, please refer to:[SkyAR](https://github.com/jiupinjia/SkyAR)
+
+
+## II. Installation
+
+- ### 1、Environmental Dependence
+
+ - paddlepaddle >= 2.0.0
+
+ - paddlehub >= 2.0.0
+
+- ### 2、Installation
+
+ ```shell
+ $hub install SkyAR
+ ```
+ - In case of any problems during installation, please refer to:[Windows_Quickstart](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [Linux_Quickstart](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [Mac_Quickstart](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## III. Module API Prediction
+
+- ### 1、Prediction Code Example
+
+ ```python
+ import paddlehub as hub
+
+ model = hub.Module(name='SkyAR')
+
+ model.MagicSky(
+ video_path=[path to input video path],
+ save_path=[path to save video path]
+ )
+ ```
+- ### 2、API
+
+ ```python
+ def MagicSky(
+ video_path, save_path, config='jupiter',
+ is_rainy=False, preview_frames_num=0, is_video_sky=False, is_show=False,
+ skybox_img=None, skybox_video=None, rain_cap_path=None,
+ halo_effect=True, auto_light_matching=False,
+ relighting_factor=0.8, recoloring_factor=0.5, skybox_center_crop=0.5
+ )
+ ```
+
+ - **Parameter**
+
+ * video_path(str):input video path.
+ * save_path(str):save videp path.
+ * config(str): SkyBox configuration, all preset configurations are as follows, if you use a custom SkyBox, please set it to None:
+ ```
+ [
+ 'cloudy', 'district9ship', 'floatingcastle', 'galaxy', 'jupiter',
+ 'rainy', 'sunny', 'sunset', 'supermoon', 'thunderstorm'
+ ]
+ ```
+ * skybox_img(str):custom SkyBox image path
+ * skybox_video(str):custom SkyBox video path
+ * is_video_sky(bool):customize whether SkyBox is a video
+ * rain_cap_path(str):custom video path with rain
+ * is_rainy(bool): whether the sky is raining
+ * halo_effect(bool):whether to open halo effect
+ * auto_light_matching(bool):whether to enable automatic brightness matching
+ * relighting_factor(float): relighting factor
+ * recoloring_factor(float): recoloring factor
+ * skybox_center_crop(float):skyBox center crop factor
+ * preview_frames_num(int):set the number of preview frames
+ * is_show(bool):whether to preview graphically
+
+
+## IV. Release Note
+
+- 1.0.0
+
+ First release