

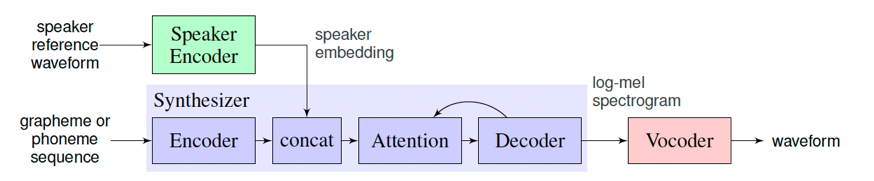
| Input Audio | +Recognition Result | +
|---|---|
|
+
+ + |
+ I knocked at the door on the ancient side of the building. | +
|
+
+ + |
+ 我认为跑步最重要的就是给我带来了身体健康。 | +
@@ -30,7 +30,7 @@ ## 简介与特性 - PaddleHub旨在为开发者提供丰富的、高质量的、直接可用的预训练模型 -- **【模型种类丰富】**: 涵盖CV、NLP、Audio、Video、工业应用主流五大品类的 300+ 预训练模型,全部开源下载,离线可运行 +- **【模型种类丰富】**: 涵盖CV、NLP、Audio、Video、工业应用主流五大品类的 **360+** 预训练模型,全部开源下载,离线可运行 - **【超低使用门槛】**:无需深度学习背景、无需数据与训练过程,可快速使用AI模型 - **【一键模型快速预测】**:通过一行命令行或者极简的Python API实现模型调用,可快速体验模型效果 - **【一键模型转服务化】**:一行命令,搭建深度学习模型API服务化部署能力 @@ -38,6 +38,7 @@ - **【跨平台兼容性】**:可运行于Linux、Windows、MacOS等多种操作系统 ## 近期更新 +- **2021.12.22**,发布v2.2.0版本。【1】新增100+高质量模型,涵盖对话、语音处理、语义分割、文字识别、文本处理、图像生成等多个领域,预训练模型总量达到[**【360+】**](https://www.paddlepaddle.org.cn/hublist);【2】新增模型[检索列表](./modules/README_ch.md),包含模型名称、网络、数据集和使用场景等信息,快速定位用户所需的模型;【3】模型文档排版优化,呈现数据集、指标、模型大小等更多实用信息。 - **2021.05.12**,新增轻量级中文对话模型[plato-mini](https://www.paddlepaddle.org.cn/hubdetail?name=plato-mini&en_category=TextGeneration),可以配合使用wechaty实现微信闲聊机器人,[参考demo](https://github.com/KPatr1ck/paddlehub-wechaty-demo) - **2021.04.27**,发布v2.1.0版本。【1】新增基于VOC数据集的高精度语义分割模型2个,语音分类模型3个。【2】新增图像语义分割、文本语义匹配、语音分类等相关任务的Fine-Tune能力以及相关任务数据集;完善部署能力:【3】新增ONNX和PaddleInference等模型格式的导出功能。【4】新增[BentoML](https://github.com/bentoml/BentoML) 云原生服务化部署能力,可以支持统一的多框架模型管理和模型部署的工作流,[详细教程](https://github.com/PaddlePaddle/PaddleHub/blob/release/v2.1/demo/serving/bentoml/cloud-native-model-serving-with-bentoml.ipynb). 更多内容可以参考BentoML 最新 v0.12.1 [Releasenote](https://github.com/bentoml/BentoML/releases/tag/v0.12.1).(感谢@[parano](https://github.com/parano) @[cqvu](https://github.com/cqvu) @[deehrlic](https://github.com/deehrlic))的贡献与支持。【5】预训练模型总量达到[**【300】**](https://www.paddlepaddle.org.cn/hublist)个。 - **2021.02.18**,发布v2.0.0版本,【1】模型开发调试更简单,finetune接口更加灵活易用。视觉类任务迁移学习能力全面升级,支持[图像分类](./demo/image_classification/README.md)、[图像着色](./demo/colorization/README.md)、[风格迁移](./demo/style_transfer/README.md)等多种任务;BERT、ERNIE、RoBERTa等Transformer类模型升级至动态图,支持[文本分类](./demo/text_classification/README.md)、[序列标注](./demo/sequence_labeling/README.md)的Fine-Tune能力;【2】优化服务化部署Serving能力,支持多卡预测、自动负载均衡,性能大幅度提升;【3】新增自动数据增强能力[Auto Augment](./demo/autoaug/README.md),能高效地搜索适合数据集的数据增强策略组合。【4】新增[词向量模型](./modules/text/embedding)61个,其中包含中文模型51个,英文模型10个;新增[图像分割](./modules/thirdparty/image/semantic_segmentation)模型4个、[深度模型](./modules/thirdparty/image/depth_estimation)2个、[图像生成](./modules/thirdparty/image/Image_gan/style_transfer)模型7个、[文本生成](./modules/thirdparty/text/text_generation)模型3个。【5】预训练模型总量达到[**【274】**](https://www.paddlepaddle.org.cn/hublist) 个。 @@ -47,9 +48,9 @@ -## **精品模型效果展示[【更多】](./docs/docs_ch/visualization.md)** +## **精品模型效果展示[【更多】](./docs/docs_ch/visualization.md)[【模型库】](./modules/README_ch.md)** -### **图像类(161个)** +### **[图像类(212个)](./modules/README_ch.md#图像)** - 包括图像分类、人脸检测、口罩检测、车辆检测、人脸/人体/手部关键点检测、人像分割、80+语言文本识别、图像超分/上色/动漫化等
@@ -58,7 +59,7 @@
- 感谢CopyRight@[PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR)、[PaddleDetection](https://github.com/PaddlePaddle/PaddleDetection)、[PaddleGAN](https://github.com/PaddlePaddle/PaddleGAN)、[AnimeGAN](https://github.com/TachibanaYoshino/AnimeGANv2)、[openpose](https://github.com/CMU-Perceptual-Computing-Lab/openpose)、[PaddleSeg](https://github.com/PaddlePaddle/PaddleSeg)、[Zhengxia Zou](https://github.com/jiupinjia/SkyAR)、[PaddleClas](https://github.com/PaddlePaddle/PaddleClas) 提供相关预训练模型,训练能力开放,欢迎体验。
-### **文本类(129个)**
+### **[文本类(130个)](./modules/README_ch.md#文本)**
- 包括中文分词、词性标注与命名实体识别、句法分析、AI写诗/对联/情话/藏头诗、中文的评论情感分析、中文色情文本审核等
@@ -67,9 +68,37 @@
- 感谢CopyRight@[ERNIE](https://github.com/PaddlePaddle/ERNIE)、[LAC](https://github.com/baidu/LAC)、[DDParser](https://github.com/baidu/DDParser)提供相关预训练模型,训练能力开放,欢迎体验。
-### **语音类(3个)**
+### **[语音类(15个)](./modules/README_ch.md#语音)**
+- ASR语音识别算法,多种算法可选
+- 语音识别效果如下:
+| Input Audio | +Recognition Result | +
|---|---|
|
+
+ + |
+ I knocked at the door on the ancient side of the building. | +
|
+
+ + |
+ 我认为跑步最重要的就是给我带来了身体健康。 | +
+
+
+
+
+
+
+
+
+
+
-
+
-
+
-
+
+
+
+ 
 +
+
+ 
 +
+

 - - user_guided_colorization 是基于''Real-Time User-Guided Image Colorization with Learned Deep Priors"的着色模型,该模型利用预先提供的着色块对图像进行着色。
+ - user_guided_colorization 是基于"Real-Time User-Guided Image Colorization with Learned Deep Priors"的着色模型,该模型利用预先提供的着色块对图像进行着色。
## 二、安装
diff --git a/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md b/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e17592c87ca4ee428e98afc8478411803471cd8
--- /dev/null
+++ b/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
@@ -0,0 +1,205 @@
+# user_guided_colorization
+
+|Module Name|user_guided_colorization|
+| :--- | :---: |
+|Category |Image editing|
+|Network| Local and Global Hints Network |
+|Dataset|ILSVRC 2012|
+|Fine-tuning supported or notFine-tuning|Yes|
+|Module Size|131MB|
+|Data indicators|-|
+|Latest update date |2021-02-26|
+
+
+
+## I. Basic Information
+
+
+- ### Application Effect Display
+
+ - Sample results:
+
- - user_guided_colorization 是基于''Real-Time User-Guided Image Colorization with Learned Deep Priors"的着色模型,该模型利用预先提供的着色块对图像进行着色。
+ - user_guided_colorization 是基于"Real-Time User-Guided Image Colorization with Learned Deep Priors"的着色模型,该模型利用预先提供的着色块对图像进行着色。
## 二、安装
diff --git a/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md b/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
new file mode 100644
index 0000000000000000000000000000000000000000..8e17592c87ca4ee428e98afc8478411803471cd8
--- /dev/null
+++ b/modules/image/Image_editing/colorization/user_guided_colorization/README_en.md
@@ -0,0 +1,205 @@
+# user_guided_colorization
+
+|Module Name|user_guided_colorization|
+| :--- | :---: |
+|Category |Image editing|
+|Network| Local and Global Hints Network |
+|Dataset|ILSVRC 2012|
+|Fine-tuning supported or notFine-tuning|Yes|
+|Module Size|131MB|
+|Data indicators|-|
+|Latest update date |2021-02-26|
+
+
+
+## I. Basic Information
+
+
+- ### Application Effect Display
+
+ - Sample results:
+
+
+
+ 
 +
+
+
+
+
+
+
+
+  +
+
+ 
+ The image attributes are: original image, Bald, Bangs, Black_Hair, Blond_Hair, Brown_Hair, Bushy_Eyebrows, Eyeglasses, Gender, Mouth_Slightly_Open, Mustache, No_Beard, Pale_Skin, Aged
+
+  +
+
+ Input image
+
+  +
+
+ Output image
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输入视频
+
+  +
+
+ 输出视频
+
+
+
+
+
+- ### 模型介绍
+
+ - 本模块采用一个像素风格迁移网络 Pix2PixHD,能够根据输入的语义分割标签生成照片风格的图片。为了解决模型归一化层导致标签语义信息丢失的问题,向 Pix2PixHD 的生成器网络中添加了 SPADE(Spatially-Adaptive
+ Normalization)空间自适应归一化模块,通过两个卷积层保留了归一化时训练的缩放与偏置参数的空间维度,以增强生成图片的质量。语义风格标签图像可以参考[coco_stuff数据集](https://github.com/nightrome/cocostuff)获取, 也可以通过[PaddleGAN repo中的该项目](https://github.com/PaddlePaddle/PaddleGAN/blob/87537ad9d4eeda17eaa5916c6a585534ab989ea8/docs/zh_CN/tutorials/photopen.md)来自定义生成图像进行体验。
+
+
+
+## 二、安装
+
+- ### 1、环境依赖
+ - ppgan
+
+- ### 2、安装
+
+ - ```shell
+ $ hub install photopen
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+## 三、模型API预测
+
+- ### 1、命令行预测
+
+ - ```shell
+ # Read from a file
+ $ hub run photopen --input_path "/PATH/TO/IMAGE"
+ ```
+ - 通过命令行方式实现图像生成模型的调用,更多请见 [PaddleHub命令行指令](../../../../docs/docs_ch/tutorial/cmd_usage.rst)
+
+- ### 2、预测代码示例
+
+ - ```python
+ import paddlehub as hub
+
+ module = hub.Module(name="photopen")
+ input_path = ["/PATH/TO/IMAGE"]
+ # Read from a file
+ module.photo_transfer(paths=input_path, output_dir='./transfer_result/', use_gpu=True)
+ ```
+
+- ### 3、API
+
+ - ```python
+ photo_transfer(images=None, paths=None, output_dir='./transfer_result/', use_gpu=False, visualization=True):
+ ```
+ - 图像转换生成API。
+
+ - **参数**
+
+ - images (list\[numpy.ndarray\]): 图片数据,ndarray.shape 为 \[H, W, C\];
+ - paths (list\[str\]): 图片的路径;
+ - output\_dir (str): 结果保存的路径;
+ - use\_gpu (bool): 是否使用 GPU;
+ - visualization(bool): 是否保存结果到本地文件夹
+
+
+## 四、服务部署
+
+- PaddleHub Serving可以部署一个在线图像转换生成服务。
+
+- ### 第一步:启动PaddleHub Serving
+
+ - 运行启动命令:
+ - ```shell
+ $ hub serving start -m photopen
+ ```
+
+ - 这样就完成了一个图像转换生成的在线服务API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA\_VISIBLE\_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+ import cv2
+ import base64
+
+
+ def cv2_to_base64(image):
+ data = cv2.imencode('.jpg', image)[1]
+ return base64.b64encode(data.tostring()).decode('utf8')
+
+ # 发送HTTP请求
+ data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
+ headers = {"Content-type": "application/json"}
+ url = "http://127.0.0.1:8866/predict/photopen"
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 打印预测结果
+ print(r.json()["results"])
+
+## 五、更新历史
+
+* 1.0.0
+
+ 初始发布
+
+ - ```shell
+ $ hub install photopen==1.0.0
+ ```
diff --git a/modules/image/Image_gan/gan/photopen/model.py b/modules/image/Image_gan/gan/photopen/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a0b0a4836b010ca4d72995c8857a8bb0ddd7aa2
--- /dev/null
+++ b/modules/image/Image_gan/gan/photopen/model.py
@@ -0,0 +1,62 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserve.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+
+import cv2
+import numpy as np
+import paddle
+from PIL import Image
+from PIL import ImageOps
+from ppgan.models.generators import SPADEGenerator
+from ppgan.utils.filesystem import load
+from ppgan.utils.photopen import data_onehot_pro
+
+
+class PhotoPenPredictor:
+ def __init__(self, weight_path, gen_cfg):
+
+ # 初始化模型
+ gen = SPADEGenerator(
+ gen_cfg.ngf,
+ gen_cfg.num_upsampling_layers,
+ gen_cfg.crop_size,
+ gen_cfg.aspect_ratio,
+ gen_cfg.norm_G,
+ gen_cfg.semantic_nc,
+ gen_cfg.use_vae,
+ gen_cfg.nef,
+ )
+ gen.eval()
+ para = load(weight_path)
+ if 'net_gen' in para:
+ gen.set_state_dict(para['net_gen'])
+ else:
+ gen.set_state_dict(para)
+
+ self.gen = gen
+ self.gen_cfg = gen_cfg
+
+ def run(self, image):
+ sem = Image.fromarray(image).convert('L')
+ sem = sem.resize((self.gen_cfg.crop_size, self.gen_cfg.crop_size), Image.NEAREST)
+ sem = np.array(sem).astype('float32')
+ sem = paddle.to_tensor(sem)
+ sem = sem.reshape([1, 1, self.gen_cfg.crop_size, self.gen_cfg.crop_size])
+
+ one_hot = data_onehot_pro(sem, self.gen_cfg)
+ predicted = self.gen(one_hot)
+ pic = predicted.numpy()[0].reshape((3, 256, 256)).transpose((1, 2, 0))
+ pic = ((pic + 1.) / 2. * 255).astype('uint8')
+
+ return pic
diff --git a/modules/image/Image_gan/gan/photopen/module.py b/modules/image/Image_gan/gan/photopen/module.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8a23e574c9823c52daf2e07a318e344b8220b70
--- /dev/null
+++ b/modules/image/Image_gan/gan/photopen/module.py
@@ -0,0 +1,133 @@
+# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import argparse
+import copy
+import os
+
+import cv2
+import numpy as np
+import paddle
+from ppgan.utils.config import get_config
+from skimage.io import imread
+from skimage.transform import rescale
+from skimage.transform import resize
+
+import paddlehub as hub
+from .model import PhotoPenPredictor
+from .util import base64_to_cv2
+from paddlehub.module.module import moduleinfo
+from paddlehub.module.module import runnable
+from paddlehub.module.module import serving
+
+
+@moduleinfo(
+ name="photopen", type="CV/style_transfer", author="paddlepaddle", author_email="", summary="", version="1.0.0")
+class Photopen:
+ def __init__(self):
+ self.pretrained_model = os.path.join(self.directory, "photopen.pdparams")
+ cfg = get_config(os.path.join(self.directory, "photopen.yaml"))
+ self.network = PhotoPenPredictor(weight_path=self.pretrained_model, gen_cfg=cfg.predict)
+
+ def photo_transfer(self,
+ images: list = None,
+ paths: list = None,
+ output_dir: str = './transfer_result/',
+ use_gpu: bool = False,
+ visualization: bool = True):
+ '''
+ images (list[numpy.ndarray]): data of images, shape of each is [H, W, C], color space must be BGR(read by cv2).
+ paths (list[str]): paths to images
+
+ output_dir (str): the dir to save the results
+ use_gpu (bool): if True, use gpu to perform the computation, otherwise cpu.
+ visualization (bool): if True, save results in output_dir.
+ '''
+ results = []
+ paddle.disable_static()
+ place = 'gpu:0' if use_gpu else 'cpu'
+ place = paddle.set_device(place)
+ if images == None and paths == None:
+ print('No image provided. Please input an image or a image path.')
+ return
+
+ if images != None:
+ for image in images:
+ image = image[:, :, ::-1]
+ out = self.network.run(image)
+ results.append(out)
+
+ if paths != None:
+ for path in paths:
+ image = cv2.imread(path)[:, :, ::-1]
+ out = self.network.run(image)
+ results.append(out)
+
+ if visualization == True:
+ if not os.path.exists(output_dir):
+ os.makedirs(output_dir, exist_ok=True)
+ for i, out in enumerate(results):
+ if out is not None:
+ cv2.imwrite(os.path.join(output_dir, 'output_{}.png'.format(i)), out[:, :, ::-1])
+
+ return results
+
+ @runnable
+ def run_cmd(self, argvs: list):
+ """
+ Run as a command.
+ """
+ self.parser = argparse.ArgumentParser(
+ description="Run the {} module.".format(self.name),
+ prog='hub run {}'.format(self.name),
+ usage='%(prog)s',
+ add_help=True)
+
+ self.arg_input_group = self.parser.add_argument_group(title="Input options", description="Input data. Required")
+ self.arg_config_group = self.parser.add_argument_group(
+ title="Config options", description="Run configuration for controlling module behavior, not required.")
+ self.add_module_config_arg()
+ self.add_module_input_arg()
+ self.args = self.parser.parse_args(argvs)
+ results = self.photo_transfer(
+ paths=[self.args.input_path],
+ output_dir=self.args.output_dir,
+ use_gpu=self.args.use_gpu,
+ visualization=self.args.visualization)
+ return results
+
+ @serving
+ def serving_method(self, images, **kwargs):
+ """
+ Run as a service.
+ """
+ images_decode = [base64_to_cv2(image) for image in images]
+ results = self.photo_transfer(images=images_decode, **kwargs)
+ tolist = [result.tolist() for result in results]
+ return tolist
+
+ def add_module_config_arg(self):
+ """
+ Add the command config options.
+ """
+ self.arg_config_group.add_argument('--use_gpu', action='store_true', help="use GPU or not")
+
+ self.arg_config_group.add_argument(
+ '--output_dir', type=str, default='transfer_result', help='output directory for saving result.')
+ self.arg_config_group.add_argument('--visualization', type=bool, default=False, help='save results or not.')
+
+ def add_module_input_arg(self):
+ """
+ Add the command input options.
+ """
+ self.arg_input_group.add_argument('--input_path', type=str, help="path to input image.")
diff --git a/modules/image/Image_gan/gan/photopen/photopen.yaml b/modules/image/Image_gan/gan/photopen/photopen.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..178f361736c06f1f816997dc4a52a9a6bd62bcc9
--- /dev/null
+++ b/modules/image/Image_gan/gan/photopen/photopen.yaml
@@ -0,0 +1,95 @@
+total_iters: 1
+output_dir: output_dir
+checkpoints_dir: checkpoints
+
+model:
+ name: PhotoPenModel
+ generator:
+ name: SPADEGenerator
+ ngf: 24
+ num_upsampling_layers: normal
+ crop_size: 256
+ aspect_ratio: 1.0
+ norm_G: spectralspadebatch3x3
+ semantic_nc: 14
+ use_vae: False
+ nef: 16
+ discriminator:
+ name: MultiscaleDiscriminator
+ ndf: 128
+ num_D: 4
+ crop_size: 256
+ label_nc: 12
+ output_nc: 3
+ contain_dontcare_label: True
+ no_instance: False
+ n_layers_D: 6
+ criterion:
+ name: PhotoPenPerceptualLoss
+ crop_size: 224
+ lambda_vgg: 1.6
+ label_nc: 12
+ contain_dontcare_label: True
+ batchSize: 1
+ crop_size: 256
+ lambda_feat: 10.0
+
+dataset:
+ train:
+ name: PhotoPenDataset
+ content_root: test/coco_stuff
+ load_size: 286
+ crop_size: 256
+ num_workers: 0
+ batch_size: 1
+ test:
+ name: PhotoPenDataset_test
+ content_root: test/coco_stuff
+ load_size: 286
+ crop_size: 256
+ num_workers: 0
+ batch_size: 1
+
+lr_scheduler: # abundoned
+ name: LinearDecay
+ learning_rate: 0.0001
+ start_epoch: 99999
+ decay_epochs: 99999
+ # will get from real dataset
+ iters_per_epoch: 1
+
+optimizer:
+ lr: 0.0001
+ optimG:
+ name: Adam
+ net_names:
+ - net_gen
+ beta1: 0.9
+ beta2: 0.999
+ optimD:
+ name: Adam
+ net_names:
+ - net_des
+ beta1: 0.9
+ beta2: 0.999
+
+log_config:
+ interval: 1
+ visiual_interval: 1
+
+snapshot_config:
+ interval: 1
+
+predict:
+ name: SPADEGenerator
+ ngf: 24
+ num_upsampling_layers: normal
+ crop_size: 256
+ aspect_ratio: 1.0
+ norm_G: spectralspadebatch3x3
+ semantic_nc: 14
+ use_vae: False
+ nef: 16
+ contain_dontcare_label: True
+ label_nc: 12
+ batchSize: 1
diff --git a/modules/image/Image_gan/gan/photopen/requirements.txt b/modules/image/Image_gan/gan/photopen/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..67e9bb6fa840355e9ed0d44b7134850f1fe22fe1
--- /dev/null
+++ b/modules/image/Image_gan/gan/photopen/requirements.txt
@@ -0,0 +1 @@
+ppgan
diff --git a/modules/image/Image_gan/gan/photopen/util.py b/modules/image/Image_gan/gan/photopen/util.py
new file mode 100644
index 0000000000000000000000000000000000000000..531a0ae0d487822a870ba7f09817e658967aff10
--- /dev/null
+++ b/modules/image/Image_gan/gan/photopen/util.py
@@ -0,0 +1,11 @@
+import base64
+
+import cv2
+import numpy as np
+
+
+def base64_to_cv2(b64str):
+ data = base64.b64decode(b64str.encode('utf8'))
+ data = np.fromstring(data, np.uint8)
+ data = cv2.imdecode(data, cv2.IMREAD_COLOR)
+ return data
diff --git a/modules/image/Image_gan/gan/pixel2style2pixel/README.md b/modules/image/Image_gan/gan/pixel2style2pixel/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..fa0c3925e23e62f30d6c4b3635c62a0ba1dfb6dd
--- /dev/null
+++ b/modules/image/Image_gan/gan/pixel2style2pixel/README.md
@@ -0,0 +1,133 @@
+# pixel2style2pixel
+
+|模型名称|pixel2style2pixel|
+| :--- | :---: |
+|类别|图像 - 图像生成|
+|网络|Pixel2Style2Pixel|
+|数据集|-|
+|是否支持Fine-tuning|否|
+|模型大小|1.7GB|
+|最新更新日期|2021-12-14|
+|数据指标|-|
+
+
+## 一、模型基本信息
+
+- ### 应用效果展示
+ - 样例结果示例:
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出图像
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出图像(修改age)
+
+
+  +
+
+ 输入图像1
+
+  +
+
+ 输入图像2
+
+  +
+
+ 输出图像
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出视频
+
+
+ 
+ The image attributes are: origial image, Black_Hair, Blond_Hair, Brown_Hair, Male, Aged
+
+ 
+ The image attributes are: original image, Bald, Bangs, Black_Hair, Blond_Hair, Brown_Hair, Bushy_Eyebrows, Eyeglasses, Gender, Mouth_Slightly_Open, Mustache, No_Beard, Pale_Skin, Aged
+
+  +
+
+ 
 +
+
+  +
+
+ 
+ Input image
+
+ 
+ Output image
+
+
+  +
+
+ Input image
+
+  +
+
+ Output image
+
+
+  +
+
+ 输入图像
+
+  +
+
+ 输出图像
+
+
+ 
 +
+
+
+
+ 输入内容图形
+
+  +
+
+ 输入妆容图形
+
+  +
+
+ 输出图像
+
+
+  +
+  +
+
+
+
+
+  +
+  +
+
+
+
+
+
+  +
+
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+
+
+ 
+
+ 

+ 
+
+
+
+
+ 
+
+ 
+
+ 
 +
+
+  +
+  +
+
+
+
+
+  +
+
+
+
+ 
 +
+
+
+
+ 
 +
+
+  +
+
+ 
 +
+
+
+
+  +
+
+
+
+
+
+
+
+
+
+
+
+  +
+
+  +
+
+  +
+
+
+
+
+
+
+
+
+
+
+
+
+
+ 
+
+ +
+