From 14f9f3af06c4ab421c00d7cdede11dfb243dfef1 Mon Sep 17 00:00:00 2001
From: linjieccc <40840292+linjieccc@users.noreply.github.com>
Date: Thu, 16 Sep 2021 11:09:38 +0800
Subject: [PATCH] Update simnet_bow, word2vec_skipgram, lda_news and
lda_webpage docs (#1593)
---
.../embedding/word2vec_skipgram/README.md | 62 ++++--
.../text/language_model/lda_news/README.md | 172 ++++++++++-------
.../text/language_model/lda_webpage/README.md | 176 +++++++++++-------
.../text/language_model/simnet_bow/README.md | 174 ++++++++++-------
4 files changed, 361 insertions(+), 223 deletions(-)
diff --git a/modules/text/embedding/word2vec_skipgram/README.md b/modules/text/embedding/word2vec_skipgram/README.md
index d148d269..a21fa554 100644
--- a/modules/text/embedding/word2vec_skipgram/README.md
+++ b/modules/text/embedding/word2vec_skipgram/README.md
@@ -1,26 +1,40 @@
-## 概述
+# word2vec_skipgram
+|模型名称|word2vec_skipgram|
+| :--- | :---: |
+|类别|文本-词嵌入|
+|网络|skip-gram|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|是|
+|模型大小|861MB|
+|最新更新日期|2021-02-26|
+|数据指标|-|
-Word2vec是常用的词嵌入(word embedding)模型。该PaddleHub Module基于Skip-gram模型,在海量百度搜索数据集下预训练得到中文单词预训练词嵌入。其支持Fine-tune。Word2vec的预训练数据集的词汇表大小为1700249,word embedding维度为128。
+## 一、模型基本信息
-## API
+- ### 模型介绍
-### context(trainable=False, max_seq_len=128, num_slots=1)
+ - Word2vec是常用的词嵌入(word embedding)模型。该PaddleHub Module基于Skip-gram模型,在海量百度搜索数据集下预训练得到中文单词预训练词嵌入。其支持Fine-tune。Word2vec的预训练数据集的词汇表大小为1700249,word embedding维度为128。
-获取该Module的预训练program以及program相应的输入输出。
+## 二、安装
-**参数**
+- ### 1、环境依赖
-* trainable(bool): trainable=True表示program中的参数在Fine-tune时需要微调,否则保持不变。
-* max_seq_len(int): 模型使用的最大序列长度。
-* num_slots(int): 输入到模型所需要的文本个数,如完成单句文本分类任务,则num_slots=1;完成pointwise文本匹配任务,则num_slots=2;完成pairtwise文本匹配任务,则num_slots=3;
+ - paddlepaddle >= 1.8.2
-**返回**
+ - paddlehub >= 1.8.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-* inputs(dict): program的输入变量
-* outputs(dict): program的输出变量
-* main_program(Program): 带有预训练参数的program
+- ### 2、安装
-### 代码示例
+ - ```shell
+ $ hub install word2vec_skipgram
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
+
+
+## 三、模型API
+
+- ### 1、Finetune代码示例
```python
import paddlehub as hub
@@ -36,13 +50,25 @@ word_ids = inputs["text"]
embedding = outputs["emb"]
```
-## 依赖
+- ### 2、API
+
+ - ```python
+ context(trainable=False, max_seq_len=128, num_slots=1)
+ ```
+
+ - **参数**
+
+ - trainable(bool): trainable=True表示program中的参数在Fine-tune时需要微调,否则保持不变。
+ - max_seq_len(int): 模型使用的最大序列长度。
+ - num_slots(int): 输入到模型所需要的文本个数,如完成单句文本分类任务,则num_slots=1;完成pointwise文本匹配任务,则num_slots=2;完成pairtwise文本匹配任务,则num_slots=3;
-paddlepaddle >= 1.8.2
+ - **返回**
-paddlehub >= 1.8.0
+ - inputs(dict): program的输入变量
+ - outputs(dict): program的输出变量
+ - main_program(Program): 带有预训练参数的program
-## 更新历史
+## 四、更新历史
* 1.0.0
diff --git a/modules/text/language_model/lda_news/README.md b/modules/text/language_model/lda_news/README.md
index eb3b895c..3c0c3f6c 100644
--- a/modules/text/language_model/lda_news/README.md
+++ b/modules/text/language_model/lda_news/README.md
@@ -1,83 +1,47 @@
-## 模型概述
+# lda_news
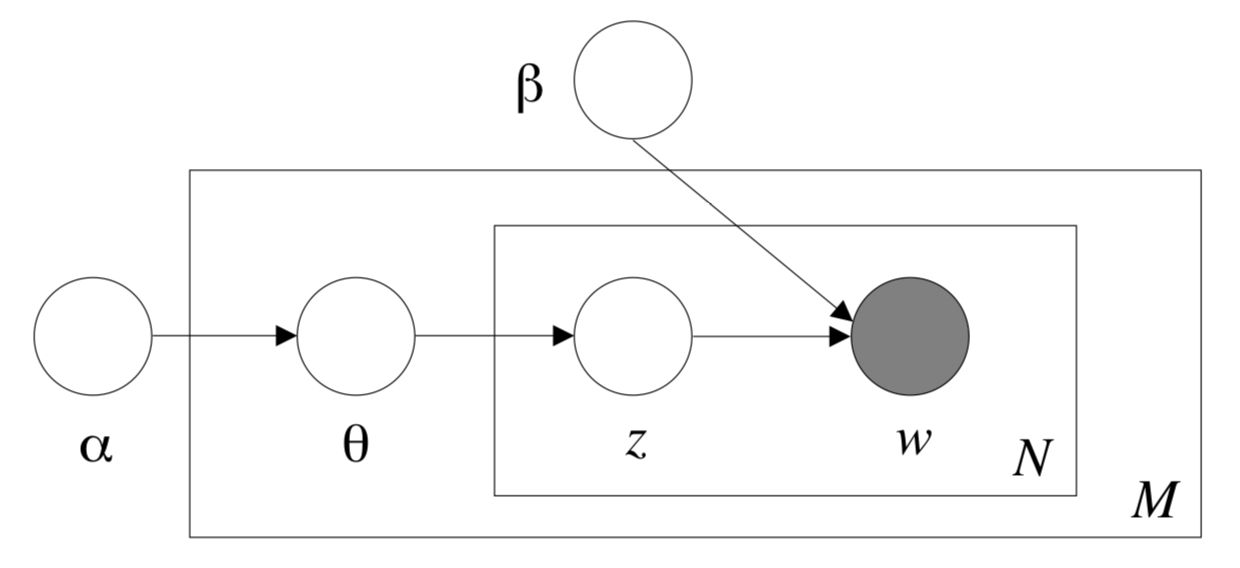
-主题模型(Topic Model)是以无监督学习的方式对文档的隐含语义结构进行聚类的统计模型,其中LDA(Latent Dirichlet Allocation)算法是主题模型的一种。LDA根据对词的共现信息的分析,拟合出词-文档-主题的分布,从而将词、文本映射到一个语义空间中。本Module基于的数据集为百度自建的新闻领域数据集。
+|模型名称|lda_news|
+| :--- | :---: |
+|类别|文本-主题模型|
+|网络|LDA|
+|数据集|百度自建新闻领域数据集|
+|是否支持Fine-tuning|否|
+|模型大小|19MB|
+|最新更新日期|2021-02-26|
+|数据指标|-|
-
-
-
+## 一、模型基本信息
-更多详情请参考[LDA论文](http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf)。
+- ### 模型介绍
-注:该Module由第三方开发者DesmonDay贡献。
+ - 主题模型(Topic Model)是以无监督学习的方式对文档的隐含语义结构进行聚类的统计模型,其中LDA(Latent Dirichlet Allocation)算法是主题模型的一种。LDA根据对词的共现信息的分析,拟合出词-文档-主题的分布,从而将词、文本映射到一个语义空间中。
-## LDA模型 API 说明
-### cal_doc_distance(doc_text1, doc_text2)
-用于计算两个输入文档之间的距离,包括Jensen-Shannon divergence(JS散度)、Hellinger Distance(海林格距离)。
+
+
+
-**参数**
+ 更多详情请参考[LDA论文](http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf)。
-- doc_text1(str): 输入的第一个文档。
-- doc_text2(str): 输入的第二个文档。
+## 二、安装
-**返回**
+- ### 1、环境依赖
-- jsd(float): 两个文档之间的JS散度([Jensen-Shannon divergence](https://blog.csdn.net/FrankieHello/article/details/80614422?utm_source=copy))。
-- hd(float): 两个文档之间的海林格距离([Hellinger Distance](http://blog.sina.com.cn/s/blog_85f1ffb70101e65d.html))。
+ - paddlepaddle >= 1.8.2
-### cal_doc_keywords_similarity(document, top_k=10)
+ - paddlehub >= 1.8.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-用于查找输入文档的前k个关键词及对应的与原文档的相似度。
+- ### 2、安装
-**参数**
+ - ```shell
+ $ hub install lda_news
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-- document(str): 输入文档。
-- top_k(int): 查找输入文档的前k个关键词。
+## 三、模型API预测
-**返回**
+- ### 1、预测代码示例
-- results(list): 包含每个关键词以及对应的与原文档的相似度。其中,list的基本元素为dict,dict的key为关键词,value为对应的与原文档的相似度。
-
-### cal_query_doc_similarity(query, document)
-
-用于计算短文档与长文档之间的相似度。
-
-**参数**
-
-- query(str): 输入的短文档。
-- document(str): 输入的长文档。
-
-**返回**
-
-- lda_sim(float): 返回短文档与长文档之间的相似度。
-
-### infer_doc_topic_distribution(document)
-
-用于推理出文档的主题分布。
-
-**参数**
-
-- document(str): 输入文档。
-
-**返回**
-
-- results(list): 包含主题分布下各个主题ID和对应的概率分布。其中,list的基本元素为dict,dict的key为主题ID,value为各个主题ID对应的概率。
-
-### show_topic_keywords(topic_id, k=10)
-
-用于展示出每个主题下对应的关键词,可配合推理主题分布的API使用。
-
-**参数**
-
-- topic_id(int): 主题ID。
-- k(int): 需要知道对应主题的前k个关键词。
-
-**返回**
-
-- results(dict): 返回对应文档的前k个关键词,以及各个关键词在文档中的出现概率。
-
-### 代码示例
-
-这里展示部分API的使用示例。
``` python
import paddlehub as hub
@@ -121,18 +85,84 @@ keywords = lda_news.show_topic_keywords(topic_id=216)
```
-## 查看代码
-https://github.com/baidu/Familia
+- ### 2、API
+
+ - ```python
+ cal_doc_distance(doc_text1, doc_text2)
+ ```
+
+ - 用于计算两个输入文档之间的距离,包括Jensen-Shannon divergence(JS散度)、Hellinger Distance(海林格距离)。
+
+ - **参数**
+
+ - doc_text1(str): 输入的第一个文档。
+ - doc_text2(str): 输入的第二个文档。
+
+ - **返回**
+
+ - jsd(float): 两个文档之间的JS散度([Jensen-Shannon divergence](https://blog.csdn.net/FrankieHello/article/details/80614422?utm_source=copy))。
+ - hd(float): 两个文档之间的海林格距离([Hellinger Distance](http://blog.sina.com.cn/s/blog_85f1ffb70101e65d.html))。
+
+ - ```python
+ cal_doc_keywords_similarity(document, top_k=10)
+ ```
+
+ - 用于查找输入文档的前k个关键词及对应的与原文档的相似度。
+
+ - **参数**
+
+ - document(str): 输入文档。
+ - top_k(int): 查找输入文档的前k个关键词。
+
+ - **返回**
+
+ - results(list): 包含每个关键词以及对应的与原文档的相似度。其中,list的基本元素为dict,dict的key为关键词,value为对应的与原文档的相似度。
+
+ - ```python
+ cal_query_doc_similarity(query, document)
+ ```
+
+ - 用于计算短文档与长文档之间的相似度。
+
+ - **参数**
+
+ - query(str): 输入的短文档。
+ - document(str): 输入的长文档。
+
+ - **返回**
+
+ - lda_sim(float): 返回短文档与长文档之间的相似度。
+
+ - ```python
+ infer_doc_topic_distribution(document)
+ ```
+
+ - 用于推理出文档的主题分布。
+
+ - **参数**
+
+ - document(str): 输入文档。
+
+ - **返回**
+
+ - results(list): 包含主题分布下各个主题ID和对应的概率分布。其中,list的基本元素为dict,dict的key为主题ID,value为各个主题ID对应的概率。
+
+ - ```python
+ show_topic_keywords(topic_id, k=10)
+ ```
+ - 用于展示出每个主题下对应的关键词,可配合推理主题分布的API使用。
-## 依赖
+ - **参数**
-paddlepaddle >= 1.8.2
+ - topic_id(int): 主题ID。
+ - k(int): 需要知道对应主题的前k个关键词。
-paddlehub >= 1.8.0
+ - **返回**
+ - results(dict): 返回对应文档的前k个关键词,以及各个关键词在文档中的出现概率。
-## 更新历史
+## 四、更新历史
* 1.0.0
diff --git a/modules/text/language_model/lda_webpage/README.md b/modules/text/language_model/lda_webpage/README.md
index bcf054eb..c70c8132 100644
--- a/modules/text/language_model/lda_webpage/README.md
+++ b/modules/text/language_model/lda_webpage/README.md
@@ -1,83 +1,49 @@
-## 模型概述
+# lda_webpage
-主题模型(Topic Model)是以无监督学习的方式对文档的隐含语义结构进行聚类的统计模型,其中LDA(Latent Dirichlet Allocation)算法是主题模型的一种。LDA根据对词的共现信息的分析,拟合出词-文档-主题的分布,从而将词、文本映射到一个语义空间中。本Module基于的数据集为百度自建的网页领域数据集。
+|模型名称|lda_webpage|
+| :--- | :---: |
+|类别|文本-主题模型|
+|网络|LDA|
+|数据集|百度自建网页领域数据集|
+|是否支持Fine-tuning|否|
+|模型大小|31MB|
+|最新更新日期|2021-02-26|
+|数据指标|-|
-
-
-
+## 一、模型基本信息
-更多详情请参考[LDA论文](http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf)。
+- ### 模型介绍
-注:该Module由第三方开发者DesmonDay贡献。
+ - 主题模型(Topic Model)是以无监督学习的方式对文档的隐含语义结构进行聚类的统计模型,其中LDA(Latent Dirichlet Allocation)算法是主题模型的一种。LDA根据对词的共现信息的分析,拟合出词-文档-主题的分布,从而将词、文本映射到一个语义空间中。
-## LDA模型 API 说明
-### cal_doc_distance(doc_text1, doc_text2)
-用于计算两个输入文档之间的距离,包括Jensen-Shannon divergence(JS散度)、Hellinger Distance(海林格距离)。
+
+
+
-**参数**
+ 更多详情请参考[LDA论文](http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf)。
-- doc_text1(str): 输入的第一个文档。
-- doc_text2(str): 输入的第二个文档。
+ 注:该Module由第三方开发者DesmonDay贡献。
-**返回**
+## 二、安装
-- jsd(float): 两个文档之间的JS散度([Jensen-Shannon divergence](https://blog.csdn.net/FrankieHello/article/details/80614422?utm_source=copy))。
-- hd(float): 两个文档之间的海林格距离([Hellinger Distance](http://blog.sina.com.cn/s/blog_85f1ffb70101e65d.html))。
+- ### 1、环境依赖
-### cal_doc_keywords_similarity(document, top_k=10)
+ - paddlepaddle >= 1.8.2
-用于查找输入文档的前k个关键词及对应的与原文档的相似度。
+ - paddlehub >= 1.8.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**参数**
+- ### 2、安装
-- document(str): 输入文档。
-- top_k(int): 查找输入文档的前k个关键词。
+ - ```shell
+ $ hub install lda_webpage
+ ```
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-**返回**
+## 三、模型API预测
-- results(list): 包含每个关键词以及对应的与原文档的相似度。其中,list的基本元素为dict,dict的key为关键词,value为对应的与原文档的相似度。
+- ### 1、预测代码示例
-### cal_query_doc_similarity(query, document)
-
-用于计算短文档与长文档之间的相似度。
-
-**参数**
-
-- query(str): 输入的短文档。
-- document(str): 输入的长文档。
-
-**返回**
-
-- lda_sim(float): 返回短文档与长文档之间的相似度。
-
-### infer_doc_topic_distribution(document)
-
-用于推理出文档的主题分布。
-
-**参数**
-
-- document(str): 输入文档。
-
-**返回**
-
-- results(list): 包含主题分布下各个主题ID和对应的概率分布。其中,list的基本元素为dict,dict的key为主题ID,value为各个主题ID对应的概率。
-
-### show_topic_keywords(topic_id, k=10)
-
-用于展示出每个主题下对应的关键词,可配合推理主题分布的API使用。
-
-**参数**
-
-- topic_id(int): 主题ID。
-- k(int): 需要知道对应主题的前k个关键词。
-
-**返回**
-
-- results(dict): 返回对应文档的前k个关键词,以及各个关键词在文档中的出现概率。
-
-### 代码示例
-
-这里展示部分API的使用示例。
``` python
import paddlehub as hub
@@ -118,17 +84,87 @@ keywords = lda_webpage.show_topic_keywords(3458)
```
-## 查看代码
-https://github.com/baidu/Familia
+ - #### 查看代码
+ https://github.com/baidu/Familia
+
+- ### 2、API
+
+ - ```python
+ cal_doc_distance(doc_text1, doc_text2)
+ ```
+
+ - 用于计算两个输入文档之间的距离,包括Jensen-Shannon divergence(JS散度)、Hellinger Distance(海林格距离)。
+
+ - **参数**
+
+ - doc_text1(str): 输入的第一个文档。
+ - doc_text2(str): 输入的第二个文档。
+
+ - **返回**
+
+ - jsd(float): 两个文档之间的JS散度([Jensen-Shannon divergence](https://blog.csdn.net/FrankieHello/article/details/80614422?utm_source=copy))。
+ - hd(float): 两个文档之间的海林格距离([Hellinger Distance](http://blog.sina.com.cn/s/blog_85f1ffb70101e65d.html))。
+
+ - ```python
+ cal_doc_keywords_similarity(document, top_k=10)
+ ```
+
+ - 用于查找输入文档的前k个关键词及对应的与原文档的相似度。
+
+ - **参数**
+
+ - document(str): 输入文档。
+ - top_k(int): 查找输入文档的前k个关键词。
+
+ - **返回**
+
+ - results(list): 包含每个关键词以及对应的与原文档的相似度。其中,list的基本元素为dict,dict的key为关键词,value为对应的与原文档的相似度。
+
+ - ```python
+ cal_query_doc_similarity(query, document)
+ ```
+
+ - 用于计算短文档与长文档之间的相似度。
+
+ - **参数**
+
+ - query(str): 输入的短文档。
+ - document(str): 输入的长文档。
+
+ - **返回**
+
+ - lda_sim(float): 返回短文档与长文档之间的相似度。
+
+ - ```python
+ infer_doc_topic_distribution(document)
+ ```
+
+ - 用于推理出文档的主题分布。
+
+ - **参数**
+
+ - document(str): 输入文档。
+
+ - **返回**
+
+ - results(list): 包含主题分布下各个主题ID和对应的概率分布。其中,list的基本元素为dict,dict的key为主题ID,value为各个主题ID对应的概率。
+
+ - ```python
+ show_topic_keywords(topic_id, k=10)
+ ```
+
+ - 用于展示出每个主题下对应的关键词,可配合推理主题分布的API使用。
+ - **参数**
-## 依赖
+ - topic_id(int): 主题ID。
+ - k(int): 需要知道对应主题的前k个关键词。
-paddlepaddle >= 1.8.2
+ - **返回**
-paddlehub >= 1.8.0
+ - results(dict): 返回对应文档的前k个关键词,以及各个关键词在文档中的出现概率。
-## 更新历史
+## 四、更新历史
* 1.0.0
diff --git a/modules/text/language_model/simnet_bow/README.md b/modules/text/language_model/simnet_bow/README.md
index 08811352..330dd023 100644
--- a/modules/text/language_model/simnet_bow/README.md
+++ b/modules/text/language_model/simnet_bow/README.md
@@ -1,100 +1,146 @@
-# SimnetBOW API说明
+# simnet_bow
+|模型名称|simnet_bow|
+| :--- | :---: |
+|类别|文本-语义匹配|
+|网络|BOW|
+|数据集|百度自建数据集|
+|是否支持Fine-tuning|否|
+|模型大小|245MB|
+|最新更新日期|2021-02-26|
+|数据指标|-|
-## similarity(texts=[], data={}, use_gpu=False, batch_size=1)
-simnet_bow预测接口,计算两个句子的cosin相似度
+## 一、模型基本信息
-**参数**
+- ### 模型介绍
-* texts(list): 待预测数据,第一个元素(list)为第一顺序句子,第二个元素(list)为第二顺序句子,两个元素长度相同。
-如texts=[["这道题太难了", "这道题太难了", "这道题太难了"], ["这道题是上一年的考题", "这道题不简单", "这道题很有意思"]]。
-如果使用texts参数,则不用传入data参数,二选一即可
-* data(dict): 预测数据,key必须为'text_1' 和'text_2',相应的value(list)是第一顺序句子和第二顺序句子。
-如data={"text_1": ["这道题太难了", "这道题太难了", "这道题太难了"], "text_2": ["这道题是上一年的考题", "这道题不简单", "这道题很有意思"]}。
-如果使用data参数,则不用传入texts参数,二选一即可。建议使用texts参数,data参数后续会废弃。
-* data(dict): 预测数据,key必须为'text_1' 和'text_2',相应的value(list)是第一顺序句子和第二顺序句子。如果使用data参数,则不用传入texts参数,二选一即可。建议使用texts参数,data参数后续会废弃。
-* use_gpu(bool): 是否使用GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置
-* batch_size(int): 批处理大小
+ - 短文本语义匹配(SimilarityNet, SimNet)是一个计算短文本相似度的模型,可以根据用户输入的两个文本,计算出相似度得分。SimNet在百度各产品上广泛应用,适用于信息检索、新闻推荐、智能客服等多个应用场景,帮助企业解决语义匹配问题。该PaddleHub Module基于BOW网络结构,支持预测。
-**返回**
+## 二、安装
-* results(list): 带预测数据的cosin相似度
+- ### 1、环境依赖
-### context(trainable=False, max_seq_len=128, num_slots=1)
+ - paddlepaddle >= 2.1.0
-获取该Module的预训练program以及program相应的输入输出。
+ - paddlehub >= 2.1.0 | [如何安装PaddleHub](../../../../docs/docs_ch/get_start/installation.rst)
-**参数**
+- ### 2、安装
-* trainable(bool): trainable=True表示program中的参数在Fine-tune时需要微调,否则保持不变。
-* max_seq_len(int): 模型使用的最大序列长度。
-* num_slots(int): 输入到模型所需要的文本个数,如完成单句文本分类任务,则num_slots=1;完成pointwise文本匹配任务,则num_slots=2;完成pairtwise文本匹配任务,则num_slots=3;
+ - ```shell
+ $ hub install simnet_bow
+ ```
-**返回**
+ - 如您安装时遇到问题,可参考:[零基础windows安装](../../../../docs/docs_ch/get_start/windows_quickstart.md)
+ | [零基础Linux安装](../../../../docs/docs_ch/get_start/linux_quickstart.md) | [零基础MacOS安装](../../../../docs/docs_ch/get_start/mac_quickstart.md)
-* inputs(dict): program的输入变量
-* outputs(dict): program的输出变量
-* main_program(Program): 带有预训练参数的program
+## 三、模型API预测
-## get_vocab_path()
+- ### 1、命令行预测
-获取预训练时使用的词汇表
+ - ```shell
+ $ hub run simnet_bow --text_1 "这道题很难" --text_2 "这道题不简单"
+ ```
+ - 通过命令行方式实现文字识别模型的调用,更多请见 [PaddleHub命令行指令](../../../../docs/docs_ch/tutorial/cmd_usage.rst)
-**返回**
+- ### 2、预测代码示例
-* vocab_path(str): 词汇表路径
+ - ```python
+ import paddlehub as hub
-# SimnetBow 服务部署
+ simnet_bow = hub.Module(name="simnet_bow")
-PaddleHub Serving可以部署一个在线语义匹配服务,可以将此接口用于在线web应用。
+ # Data to be predicted
+ test_text_1 = ["这道题太难了", "这道题太难了", "这道题太难了"]
+ test_text_2 = ["这道题是上一年的考题", "这道题不简单", "这道题很有意思"]
-## 第一步:启动PaddleHub Serving
+ inputs = {"text_1": test_text_1, "text_2": test_text_2}
+ results = simnet_bow.similarity(data=inputs, batch_size=2)
+ print(results)
-运行启动命令:
-```shell
-$ hub serving start -m simnet_bow
-```
+ # [{'text_1': '这道题太难了', 'text_2': '这道题是上一年的考题', 'similarity': 0.689}, {'text_1': '这道题太难了', 'text_2': '这道题不简单', 'similarity': 0.855}, {'text_1': '这道题太难了', 'text_2': '这道题很有意思', 'similarity': 0.8166}]
+ ```
+
+- ### 3、 API
-启动时会显示加载模型过程,启动成功后显示
-```shell
-Loading simnet_bow successful.
-```
+ - ```python
+ similarity(texts=[], use_gpu=False, batch_size=1)
+ ```
-这样就完成了服务化API的部署,默认端口号为8866。
+ - simnet_bow预测接口,计算两个句子的cosin相似度
-**NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+ - **参数**
-## 第二步:发送预测请求
+ - texts(list): 待预测数据,第一个元素(list)为第一顺序句子,第二个元素(list)为第二顺序句子,两个元素长度相同。
+ 如texts=[["这道题太难了", "这道题太难了", "这道题太难了"], ["这道题是上一年的考题", "这道题不简单", "这道题很有意思"]]。
+ - use_gpu(bool): 是否使用GPU预测,如果使用GPU预测,则在预测之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置
+ - batch_size(int): 批处理大小
-配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+ - **返回**
-```python
-import requests
-import json
+ - results(list): 带预测数据的cosin相似度
-# 待预测数据
-test_text_1 = ["这道题太难了", "这道题太难了", "这道题太难了"]
-test_text_2 = ["这道题是上一年的考题", "这道题不简单", "这道题很有意思"]
+ - ```python
+ get_vocab_path()
+ ```
+ - 获取预训练时使用的词汇表
-text = [test_text_1, test_text_2]
+ - **返回**
-# 设置运行配置
-# 对应本地预测simnet_bow.similarity(texts=text, batch_size=1, use_gpu=True)
-data = {"texts": text, "batch_size": 1, "use_gpu":True}
+ - vocab_path(str): 词汇表路径
-# 指定预测方法为simnet_bow并发送post请求,content-type类型应指定json方式
-# HOST_IP为服务器IP
-url = "http://HOST_IP:8866/predict/simnet_bow"
-headers = {"Content-Type": "application/json"}
-r = requests.post(url=url, headers=headers, data=json.dumps(data))
+## 四、服务部署
-# 打印预测结果
-print(json.dumps(r.json(), indent=4, ensure_ascii=False))
-```
+- PaddleHub Serving可以部署一个在线语义匹配服务,可以将此接口用于在线web应用。
-关于PaddleHub Serving更多信息参考[服务部署](https://github.com/PaddlePaddle/PaddleHub/blob/release/v1.6/docs/tutorial/serving.md)
+- ### 第一步:启动PaddleHub Serving
-## 更新历史
+ - 运行启动命令:
+
+ - ```shell
+ $ hub serving start -m simnet_bow
+ ```
+
+ - 启动时会显示加载模型过程,启动成功后显示
+
+ - ```shell
+ Loading simnet_bow successful.
+ ```
+
+ - 这样就完成了服务化API的部署,默认端口号为8866。
+
+ - **NOTE:** 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
+
+- ### 第二步:发送预测请求
+
+ - 配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
+
+ - ```python
+ import requests
+ import json
+
+ # 待预测数据
+ test_text_1 = ["这道题太难了", "这道题太难了", "这道题太难了"]
+ test_text_2 = ["这道题是上一年的考题", "这道题不简单", "这道题很有意思"]
+
+ text = [test_text_1, test_text_2]
+
+ # 设置运行配置
+ # 对应本地预测simnet_bow.similarity(texts=text, batch_size=1, use_gpu=True)
+ data = {"texts": text, "batch_size": 1, "use_gpu":True}
+
+ # 指定预测方法为simnet_bow并发送post请求,content-type类型应指定json方式
+ # HOST_IP为服务器IP
+ url = "http://HOST_IP:8866/predict/simnet_bow"
+ headers = {"Content-Type": "application/json"}
+ r = requests.post(url=url, headers=headers, data=json.dumps(data))
+
+ # 打印预测结果
+ print(json.dumps(r.json(), indent=4, ensure_ascii=False))
+ ```
+
+ - 关于PaddleHub Serving更多信息参考:[服务部署](../../../../docs/docs_ch/tutorial/serving.md)
+
+## 五、更新历史
* 1.0.0
--
GitLab