+
+
 @@ -41,4 +41,3 @@ deoldify.run("/home/aistudio/先烈.jpg") #原图片所在路径
**1. [Old Beijing City Video Restoration](https://aistudio.baidu.com/aistudio/projectdetail/1161285)**
**2. [PaddleGAN ❤️ 520 Edition](https://aistudio.baidu.com/aistudio/projectdetail/1956943?channelType=0&channel=0)**
-
diff --git a/docs/zh_CN/industrial_solution/photo_color_cn.md b/docs/zh_CN/industrial_solution/photo_color_cn.md
index db8872c..5427b80 100644
--- a/docs/zh_CN/industrial_solution/photo_color_cn.md
+++ b/docs/zh_CN/industrial_solution/photo_color_cn.md
@@ -1,9 +1,9 @@
# 图片上色
-针对图片的上色,PaddleGAN提供了[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeoldifypredictor)模型。
+针对图片的上色,PaddleGAN提供了[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeoldifypredictor)模型。
## DeOldifyPredictor
-[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeoldifypredictor)采用自注意力机制的生成对抗网络,生成器是一个U-NET结构的网络。在图像/视频的上色方面有着较好的效果。
+[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeoldifypredictor)采用自注意力机制的生成对抗网络,生成器是一个U-NET结构的网络。在图像/视频的上色方面有着较好的效果。
diff --git a/docs/zh_CN/industrial_solution/photo_sr_cn.md b/docs/zh_CN/industrial_solution/photo_sr_cn.md
index 18895bb..f87010a 100644
--- a/docs/zh_CN/industrial_solution/photo_sr_cn.md
+++ b/docs/zh_CN/industrial_solution/photo_sr_cn.md
@@ -5,7 +5,7 @@
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/single_image_super_resolution.md)
-[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsrealsrpredictor)模型通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。并且提出了一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,该模型能够有效降低了噪声并提高了视觉质量。
+[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsrealsrpredictor)模型通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。并且提出了一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,该模型能够有效降低了噪声并提高了视觉质量。
@@ -41,4 +41,3 @@ deoldify.run("/home/aistudio/先烈.jpg") #原图片所在路径
**1. [Old Beijing City Video Restoration](https://aistudio.baidu.com/aistudio/projectdetail/1161285)**
**2. [PaddleGAN ❤️ 520 Edition](https://aistudio.baidu.com/aistudio/projectdetail/1956943?channelType=0&channel=0)**
-
diff --git a/docs/zh_CN/industrial_solution/photo_color_cn.md b/docs/zh_CN/industrial_solution/photo_color_cn.md
index db8872c..5427b80 100644
--- a/docs/zh_CN/industrial_solution/photo_color_cn.md
+++ b/docs/zh_CN/industrial_solution/photo_color_cn.md
@@ -1,9 +1,9 @@
# 图片上色
-针对图片的上色,PaddleGAN提供了[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeoldifypredictor)模型。
+针对图片的上色,PaddleGAN提供了[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeoldifypredictor)模型。
## DeOldifyPredictor
-[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeoldifypredictor)采用自注意力机制的生成对抗网络,生成器是一个U-NET结构的网络。在图像/视频的上色方面有着较好的效果。
+[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeoldifypredictor)采用自注意力机制的生成对抗网络,生成器是一个U-NET结构的网络。在图像/视频的上色方面有着较好的效果。
diff --git a/docs/zh_CN/industrial_solution/photo_sr_cn.md b/docs/zh_CN/industrial_solution/photo_sr_cn.md
index 18895bb..f87010a 100644
--- a/docs/zh_CN/industrial_solution/photo_sr_cn.md
+++ b/docs/zh_CN/industrial_solution/photo_sr_cn.md
@@ -5,7 +5,7 @@
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/single_image_super_resolution.md)
-[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsrealsrpredictor)模型通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。并且提出了一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,该模型能够有效降低了噪声并提高了视觉质量。
+[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsrealsrpredictor)模型通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。并且提出了一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,该模型能够有效降低了噪声并提高了视觉质量。
 @@ -35,7 +35,7 @@ deep_remaster.run("docs/imgs/先烈.jpg") #原图片所在路径
--process_order DeepRemaster \ #对原视频处理的顺序
--output output_dir #成品视频所在的路径
```
-## ESRGAN
+## ESRGAN
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/single_image_super_resolution.md)
@@ -46,7 +46,7 @@ deep_remaster.run("docs/imgs/先烈.jpg") #原图片所在路径
| esrgan_psnr_x4 | DIV2K | [esrgan_psnr_x4](https://paddlegan.bj.bcebos.com/models/esrgan_psnr_x4.pdparams)
| esrgan_x4 | DIV2K | [esrgan_x4](https://paddlegan.bj.bcebos.com/models/esrgan_x4.pdparams)
-## LESRCNN
+## LESRCNN
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/single_image_super_resolution.md)
diff --git a/docs/zh_CN/industrial_solution/video_color_cn.md b/docs/zh_CN/industrial_solution/video_color_cn.md
index ea90043..09e1c6b 100644
--- a/docs/zh_CN/industrial_solution/video_color_cn.md
+++ b/docs/zh_CN/industrial_solution/video_color_cn.md
@@ -1,9 +1,9 @@
# 视频上色
-针对视频上色,PaddleGAN提供两种上色模型:[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeoldifypredictor)与[DeepRemaster](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeepremasterpredictor)。
+针对视频上色,PaddleGAN提供两种上色模型:[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeoldifypredictor)与[DeepRemaster](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeepremasterpredictor)。
## DeOldifyPredictor
-[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeoldifypredictor)采用自注意力机制的生成对抗网络,生成器是一个U-NET结构的网络。在图像/视频的上色方面有着较好的效果。
+[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeoldifypredictor)采用自注意力机制的生成对抗网络,生成器是一个U-NET结构的网络。在图像/视频的上色方面有着较好的效果。
@@ -38,7 +38,7 @@ deoldify.run("/home/aistudio/Peking_input360p_clip6_5s.mp4") #原视频所在路
## DeepRemasterPredictor
-[DeepRemaster](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeepremasterpredictor) 模型目前只能用于对视频上色,基于时空卷积神经网络和自注意力机制。并且能够根据输入的任意数量的参考帧对视频中的每一帧图片进行上色。
+[DeepRemaster](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeepremasterpredictor) 模型目前只能用于对视频上色,基于时空卷积神经网络和自注意力机制。并且能够根据输入的任意数量的参考帧对视频中的每一帧图片进行上色。

@@ -35,7 +35,7 @@ deep_remaster.run("docs/imgs/先烈.jpg") #原图片所在路径
--process_order DeepRemaster \ #对原视频处理的顺序
--output output_dir #成品视频所在的路径
```
-## ESRGAN
+## ESRGAN
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/single_image_super_resolution.md)
@@ -46,7 +46,7 @@ deep_remaster.run("docs/imgs/先烈.jpg") #原图片所在路径
| esrgan_psnr_x4 | DIV2K | [esrgan_psnr_x4](https://paddlegan.bj.bcebos.com/models/esrgan_psnr_x4.pdparams)
| esrgan_x4 | DIV2K | [esrgan_x4](https://paddlegan.bj.bcebos.com/models/esrgan_x4.pdparams)
-## LESRCNN
+## LESRCNN
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/single_image_super_resolution.md)
diff --git a/docs/zh_CN/industrial_solution/video_color_cn.md b/docs/zh_CN/industrial_solution/video_color_cn.md
index ea90043..09e1c6b 100644
--- a/docs/zh_CN/industrial_solution/video_color_cn.md
+++ b/docs/zh_CN/industrial_solution/video_color_cn.md
@@ -1,9 +1,9 @@
# 视频上色
-针对视频上色,PaddleGAN提供两种上色模型:[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeoldifypredictor)与[DeepRemaster](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeepremasterpredictor)。
+针对视频上色,PaddleGAN提供两种上色模型:[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeoldifypredictor)与[DeepRemaster](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeepremasterpredictor)。
## DeOldifyPredictor
-[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeoldifypredictor)采用自注意力机制的生成对抗网络,生成器是一个U-NET结构的网络。在图像/视频的上色方面有着较好的效果。
+[DeOldify](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeoldifypredictor)采用自注意力机制的生成对抗网络,生成器是一个U-NET结构的网络。在图像/视频的上色方面有着较好的效果。
@@ -38,7 +38,7 @@ deoldify.run("/home/aistudio/Peking_input360p_clip6_5s.mp4") #原视频所在路
## DeepRemasterPredictor
-[DeepRemaster](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsdeepremasterpredictor) 模型目前只能用于对视频上色,基于时空卷积神经网络和自注意力机制。并且能够根据输入的任意数量的参考帧对视频中的每一帧图片进行上色。
+[DeepRemaster](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsdeepremasterpredictor) 模型目前只能用于对视频上色,基于时空卷积神经网络和自注意力机制。并且能够根据输入的任意数量的参考帧对视频中的每一帧图片进行上色。

 @@ -26,7 +26,7 @@ ppgan.apps.DAINPredictor(
- `remove_duplicates (bool,可选的)`: 是否删除重复帧,默认值:`False`.
### 使用方式
-**1. API预测**
+**1. API预测**
除了定义输入视频路径外,此接口还需定义time_step,同时,目前API预测方式只支持在静态图下运行,需加上启动静态图命令,后续会支持动态图,敬请期待~
diff --git a/docs/zh_CN/industrial_solution/video_sr_cn.md b/docs/zh_CN/industrial_solution/video_sr_cn.md
index 0ea7641..0526fe0 100644
--- a/docs/zh_CN/industrial_solution/video_sr_cn.md
+++ b/docs/zh_CN/industrial_solution/video_sr_cn.md
@@ -6,7 +6,7 @@
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/single_image_super_resolution.md)
-[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsrealsrpredictor)模型通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。并且提出了一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,该模型能够有效降低了噪声并提高了视觉质量。
+[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsrealsrpredictor)模型通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。并且提出了一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,该模型能够有效降低了噪声并提高了视觉质量。
@@ -44,9 +44,9 @@ deep_remaster.run("/home/aistudio/Peking_input360p_clip6_5s.mp4") #原视频所
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/video_super_resolution.md)
-[EDVR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsedvrpredictor)模型提出了一个新颖的视频具有增强可变形卷积的还原框架:第一,为了处理大动作而设计的一个金字塔,级联和可变形(PCD)对齐模块,使用可变形卷积以从粗到精的方式在特征级别完成对齐;第二,提出时空注意力机制(TSA)融合模块,在时间和空间上都融合了注意机制,用以增强复原的功能。
+[EDVR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsedvrpredictor)模型提出了一个新颖的视频具有增强可变形卷积的还原框架:第一,为了处理大动作而设计的一个金字塔,级联和可变形(PCD)对齐模块,使用可变形卷积以从粗到精的方式在特征级别完成对齐;第二,提出时空注意力机制(TSA)融合模块,在时间和空间上都融合了注意机制,用以增强复原的功能。
-[EDVR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsedvrpredictor)模型是一个基于连续帧的超分模型,能够有效利用帧间的信息,速度比[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsrealsrpredictor)模型快。
+[EDVR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsedvrpredictor)模型是一个基于连续帧的超分模型,能够有效利用帧间的信息,速度比[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsrealsrpredictor)模型快。
@@ -26,7 +26,7 @@ ppgan.apps.DAINPredictor(
- `remove_duplicates (bool,可选的)`: 是否删除重复帧,默认值:`False`.
### 使用方式
-**1. API预测**
+**1. API预测**
除了定义输入视频路径外,此接口还需定义time_step,同时,目前API预测方式只支持在静态图下运行,需加上启动静态图命令,后续会支持动态图,敬请期待~
diff --git a/docs/zh_CN/industrial_solution/video_sr_cn.md b/docs/zh_CN/industrial_solution/video_sr_cn.md
index 0ea7641..0526fe0 100644
--- a/docs/zh_CN/industrial_solution/video_sr_cn.md
+++ b/docs/zh_CN/industrial_solution/video_sr_cn.md
@@ -6,7 +6,7 @@
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/single_image_super_resolution.md)
-[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsrealsrpredictor)模型通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。并且提出了一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,该模型能够有效降低了噪声并提高了视觉质量。
+[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsrealsrpredictor)模型通过估计各种模糊内核以及实际噪声分布,为现实世界的图像设计一种新颖的真实图片降采样框架。基于该降采样框架,可以获取与真实世界图像共享同一域的低分辨率图像。并且提出了一个旨在提高感知度的真实世界超分辨率模型。对合成噪声数据和真实世界图像进行的大量实验表明,该模型能够有效降低了噪声并提高了视觉质量。
@@ -44,9 +44,9 @@ deep_remaster.run("/home/aistudio/Peking_input360p_clip6_5s.mp4") #原视频所
[完整模型教程](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/tutorials/video_super_resolution.md)
-[EDVR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsedvrpredictor)模型提出了一个新颖的视频具有增强可变形卷积的还原框架:第一,为了处理大动作而设计的一个金字塔,级联和可变形(PCD)对齐模块,使用可变形卷积以从粗到精的方式在特征级别完成对齐;第二,提出时空注意力机制(TSA)融合模块,在时间和空间上都融合了注意机制,用以增强复原的功能。
+[EDVR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsedvrpredictor)模型提出了一个新颖的视频具有增强可变形卷积的还原框架:第一,为了处理大动作而设计的一个金字塔,级联和可变形(PCD)对齐模块,使用可变形卷积以从粗到精的方式在特征级别完成对齐;第二,提出时空注意力机制(TSA)融合模块,在时间和空间上都融合了注意机制,用以增强复原的功能。
-[EDVR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsedvrpredictor)模型是一个基于连续帧的超分模型,能够有效利用帧间的信息,速度比[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md#ppganappsrealsrpredictor)模型快。
+[EDVR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsedvrpredictor)模型是一个基于连续帧的超分模型,能够有效利用帧间的信息,速度比[RealSR](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md#ppganappsrealsrpredictor)模型快。
 @@ -63,7 +63,7 @@ ppgan.apps.EDVRPredictor(output='output', weight_path=None)
### 使用方式
-**1. API预测**
+**1. API预测**
目前API预测方式只支持在静态图下运行,需加上启动静态图命令,后续会支持动态图,敬请期待~
diff --git a/paddlegan-wechaty-demo/README.md b/paddlegan-wechaty-demo/README.md
index 4d3e15f..821052f 100644
--- a/paddlegan-wechaty-demo/README.md
+++ b/paddlegan-wechaty-demo/README.md
@@ -40,7 +40,7 @@
3. 安装项目所需的PaddleGAN的module
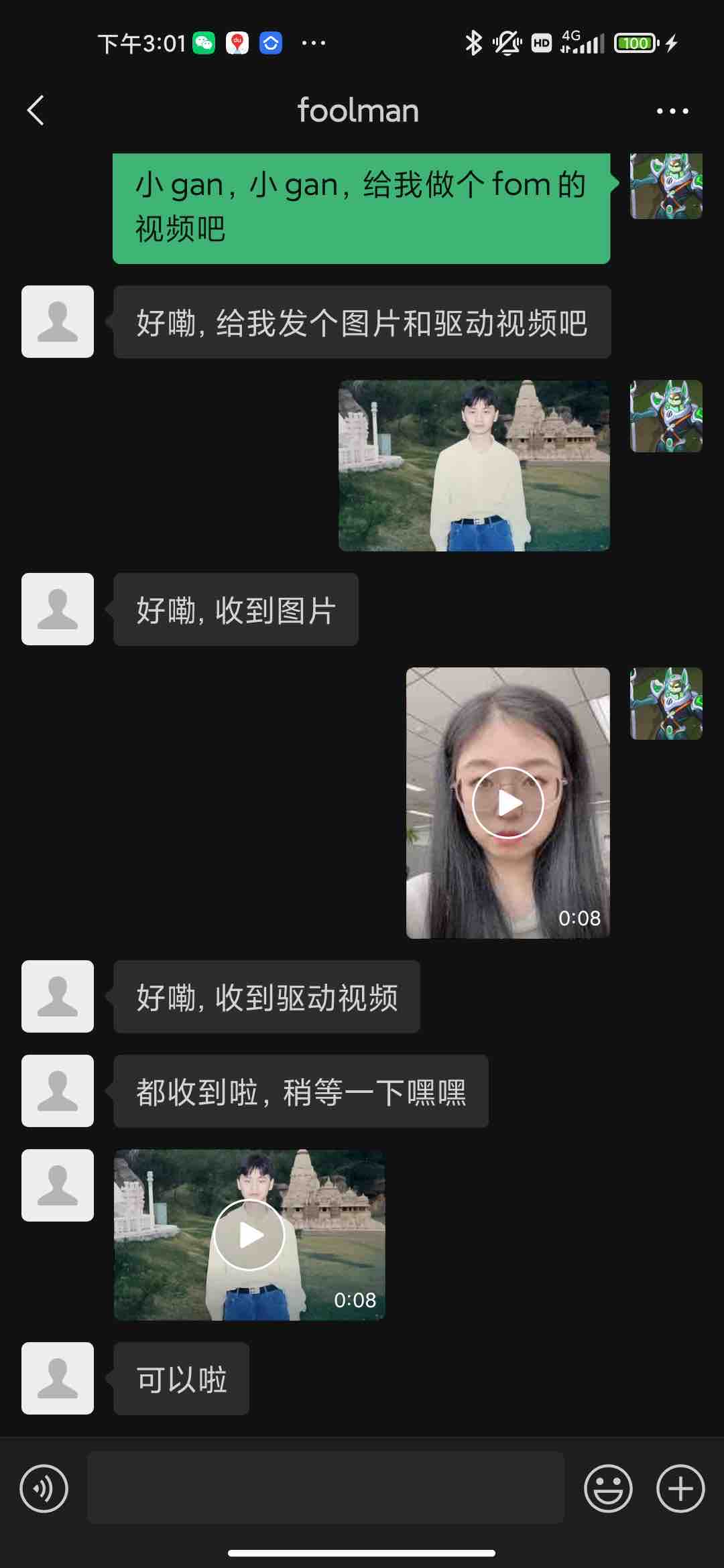
- 此demo以`first order motion`为示例,其他module根据项目所需安装,更多的模型请查阅[PaddleGAN模型API接口说明](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md)。
+ 此demo以`first order motion`为示例,其他module根据项目所需安装,更多的模型请查阅[PaddleGAN模型API接口说明](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md)。
4. Set token for your bot
@@ -82,9 +82,9 @@ async def on_message(msg: Message):
Message Handler for the Bot
"""
### PaddleGAN fom
-
+
global fom, source, driving
-
+
if isinstance(msg.text(), str) and len(msg.text()) > 0 \
and msg._payload.type == MessageType.MESSAGE_TYPE_TEXT \
and "fom" in msg.text():
@@ -95,21 +95,21 @@ async def on_message(msg: Message):
if fom and msg._payload.type == MessageType.MESSAGE_TYPE_IMAGE:
fileBox = await msg.to_file_box()
await fileBox.to_file("test_fom/source.jpg", True)
-
+
bot_response = u"好嘞, 收到图片"
await msg.say(bot_response)
source = True
-
+
if fom and msg._payload.type == MessageType.MESSAGE_TYPE_VIDEO:
fileBox = await msg.to_file_box()
await fileBox.to_file("test_fom/driving.mp4", True)
-
+
bot_response = u"好嘞, 收到驱动视频"
await msg.say(bot_response)
driving = True
-
+
if source and driving:
bot_response = u"都收到啦,稍等一下嘿嘿"
await msg.say(bot_response)
@@ -120,7 +120,7 @@ async def on_message(msg: Message):
file_box = FileBox.from_file("test_fom/result.mp4")
await msg.say(file_box)
- ###
+ ###
```
@@ -128,4 +128,3 @@ async def on_message(msg: Message):
@@ -63,7 +63,7 @@ ppgan.apps.EDVRPredictor(output='output', weight_path=None)
### 使用方式
-**1. API预测**
+**1. API预测**
目前API预测方式只支持在静态图下运行,需加上启动静态图命令,后续会支持动态图,敬请期待~
diff --git a/paddlegan-wechaty-demo/README.md b/paddlegan-wechaty-demo/README.md
index 4d3e15f..821052f 100644
--- a/paddlegan-wechaty-demo/README.md
+++ b/paddlegan-wechaty-demo/README.md
@@ -40,7 +40,7 @@
3. 安装项目所需的PaddleGAN的module
- 此demo以`first order motion`为示例,其他module根据项目所需安装,更多的模型请查阅[PaddleGAN模型API接口说明](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/zh_CN/apis/apps.md)。
+ 此demo以`first order motion`为示例,其他module根据项目所需安装,更多的模型请查阅[PaddleGAN模型API接口说明](https://github.com/PaddlePaddle/PaddleGAN/blob/develop/docs/en_US/apis/apps.md)。
4. Set token for your bot
@@ -82,9 +82,9 @@ async def on_message(msg: Message):
Message Handler for the Bot
"""
### PaddleGAN fom
-
+
global fom, source, driving
-
+
if isinstance(msg.text(), str) and len(msg.text()) > 0 \
and msg._payload.type == MessageType.MESSAGE_TYPE_TEXT \
and "fom" in msg.text():
@@ -95,21 +95,21 @@ async def on_message(msg: Message):
if fom and msg._payload.type == MessageType.MESSAGE_TYPE_IMAGE:
fileBox = await msg.to_file_box()
await fileBox.to_file("test_fom/source.jpg", True)
-
+
bot_response = u"好嘞, 收到图片"
await msg.say(bot_response)
source = True
-
+
if fom and msg._payload.type == MessageType.MESSAGE_TYPE_VIDEO:
fileBox = await msg.to_file_box()
await fileBox.to_file("test_fom/driving.mp4", True)
-
+
bot_response = u"好嘞, 收到驱动视频"
await msg.say(bot_response)
driving = True
-
+
if source and driving:
bot_response = u"都收到啦,稍等一下嘿嘿"
await msg.say(bot_response)
@@ -120,7 +120,7 @@ async def on_message(msg: Message):
file_box = FileBox.from_file("test_fom/result.mp4")
await msg.say(file_box)
- ###
+ ###
```
@@ -128,4 +128,3 @@ async def on_message(msg: Message):