Add photo2cartoon model (#117)
* Add photo2cartoon model * Resolve conflicts * Remove comments * Add photo2cartoon tutorial * update p2c tutorials
Showing
configs/ugatit_photo2cartoon.yaml
0 → 100644
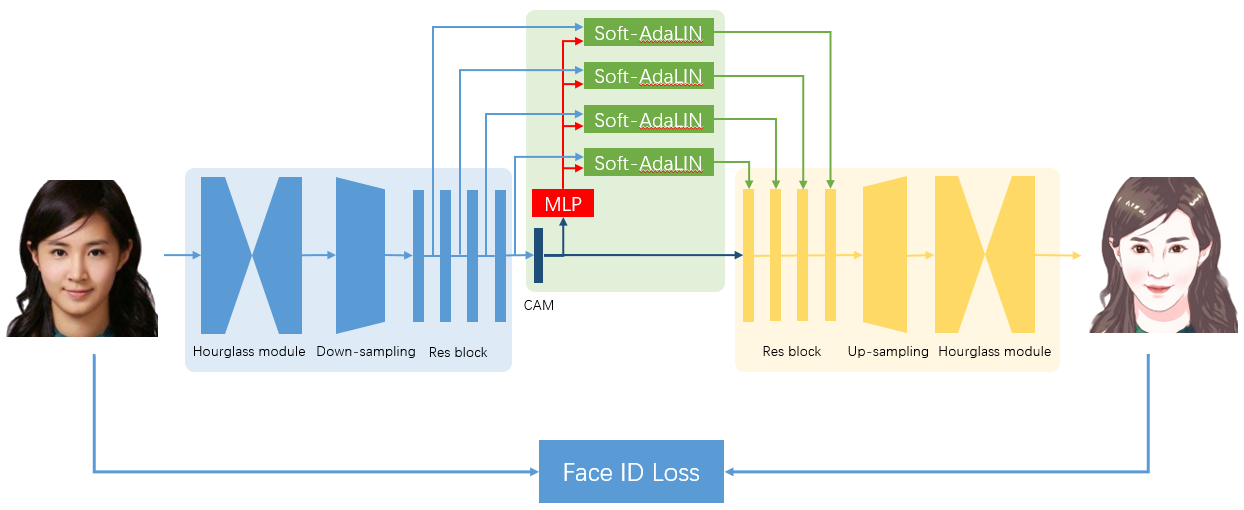
docs/imgs/photo2cartoon.png
0 → 100644
{kind=link}

882.9 KB
{kind=link}

100.9 KB
{kind=link}
144.0 KB
此差异已折叠。