# Example to train gru4rec model with FedAvg Strategy
This doc introduce how to use PaddleFL to train model with Fl Strategy.
### Dependencies
- paddlepaddle>=1.6
### How to install PaddleFL
please use the python which has installed paddlepaddle.
```sh
python setup.py install
```
### Model
[Gru4rec](https://arxiv.org/abs/1511.06939) is the classical session-based recommendation model. The details implement by paddlepaddle is [here](https://github.com/PaddlePaddle/models/tree/develop/PaddleRec/gru4rec).
### Datasets
Public Dataset [Rsc15](https://2015.recsyschallenge.com)
```sh
#download data
cd example/gru4rec_demo
sh download.sh
```
### How to work in PaddleFL
PaddleFL has two period , CompileTime and RunTime. In CompileTime, define a federated learning task by fl_master. In RunTime, train a federated learning job by fl_server and fl_trainer .
```sh
sh run.sh
```
### How to work in CompileTime
In this example, we implement it in fl_master.py
```sh
# please run fl_master to generate fl_job
python fl_master.py
```
In fl_master.py, we first define FL-Strategy, User-Defined-Program and Distributed-Config. Then FL-Job-Generator generate FL-Job for federated server and worker.
```python
# define model
model = Model()
model.gru4rec_network()
# define JobGenerator and set model config
# feed_name and target_name are config for save model.
job_generator = JobGenerator()
optimizer = fluid.optimizer.SGD(learning_rate=2.0)
job_generator.set_optimizer(optimizer)
job_generator.set_losses([model.loss])
job_generator.set_startup_program(model.startup_program)
job_generator.set_infer_feed_and_target_names(
[x.name for x in model.inputs], [model.loss.name, model.recall.name])
# define FL-Strategy , we now support two flstrategy, fed_avg and dpsgd. Inner_step means fl_trainer locally train inner_step mini-batch.
build_strategy = FLStrategyFactory()
build_strategy.fed_avg = True
build_strategy.inner_step = 1
strategy = build_strategy.create_fl_strategy()
# define Distributed-Config and generate fl_job
endpoints = ["127.0.0.1:8181"]
output = "fl_job_config"
job_generator.generate_fl_job(
strategy, server_endpoints=endpoints, worker_num=2, output=output)
```
### How to work in RunTime
```sh
python -u fl_server.py >server0.log &
python -u fl_trainer.py 0 data/ >trainer0.log &
python -u fl_trainer.py 1 data/ >trainer1.log &
```
fl_trainer.py can define own reader according to data.
```python
r = Gru4rec_Reader()
train_reader = r.reader(train_file_dir, place, batch_size=10)
```
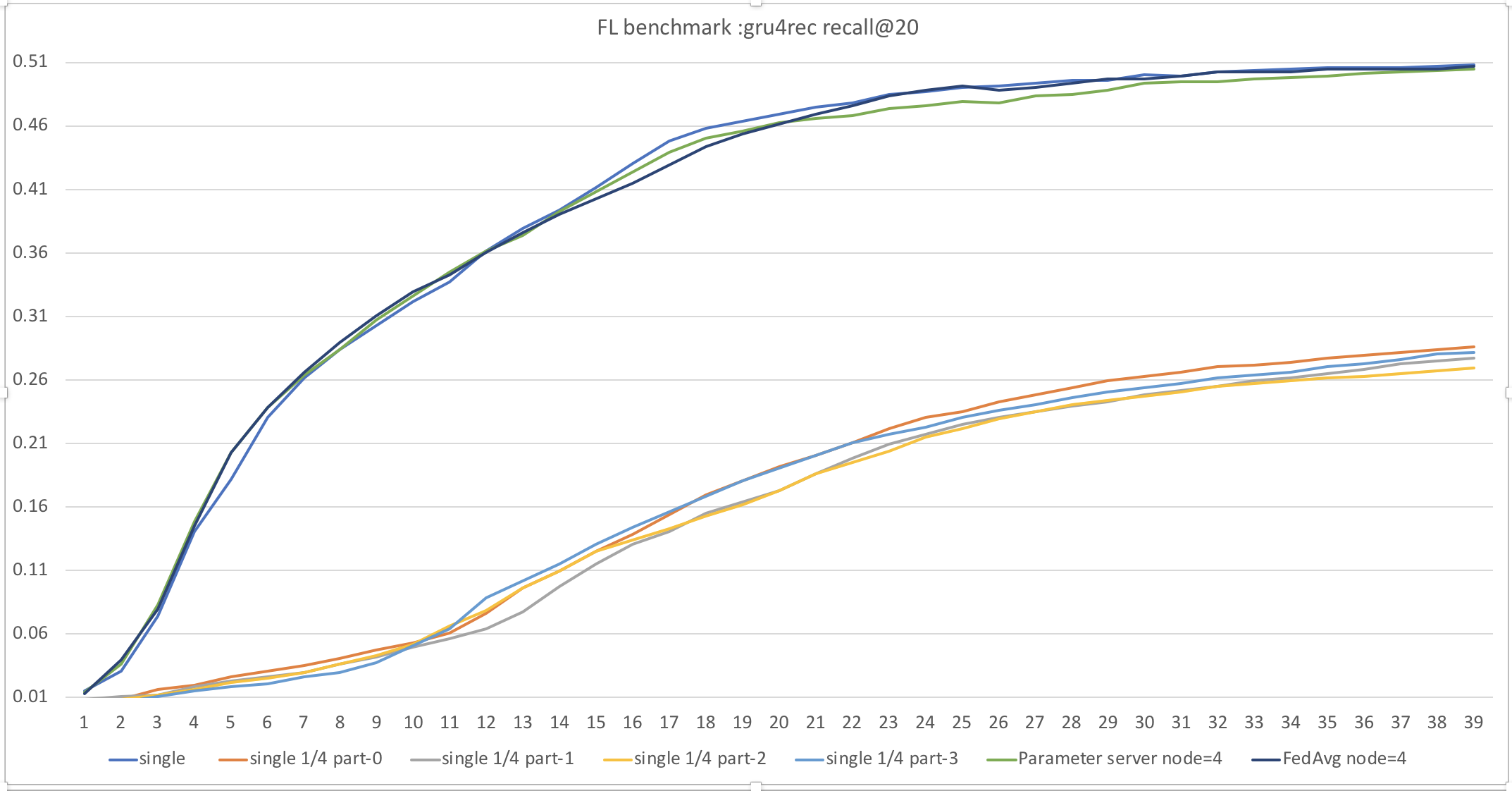
### Performance
We train gru4rec model with FedAvg Strategy for 40 epochs. We use first 1/20 rsc15 data as our dataset including 40w session and 3w7 item dictionary. We also constuct baselines including standard single mode and distributed parameter server mode.
```sh
# download code and readme
wget https://paddle-zwh.bj.bcebos.com/gru4rec_paddlefl_benchmark/gru4rec_benchmark.tar
```
| Dataset | single/distributed | distribute mode | recall@20|
| --- | --- | --- |---|
| all data | single | - | 0.508 |
| all data | distributed 4 node | Parameter Server | 0.504 |
| all data | distributed 4 node | FedAvg | 0.504 |
| 1/4 part-0 | single | - | 0.286 |
| 1/4 part-1 | single | - | 0.277 |
| 1/4 part-2 | single | - | 0.269 |
| 1/4 part-3 | single | - | 0.282 |
We can find Distributed mode PS and FedAvg is equal in recall@20 , and more data could offer better result.