简体中文 | [English](README.md)
# PP-YOLOE
## 内容
- [简介](#简介)
- [模型库](#模型库)
- [使用说明](#使用说明)
- [附录](#附录)
## 简介
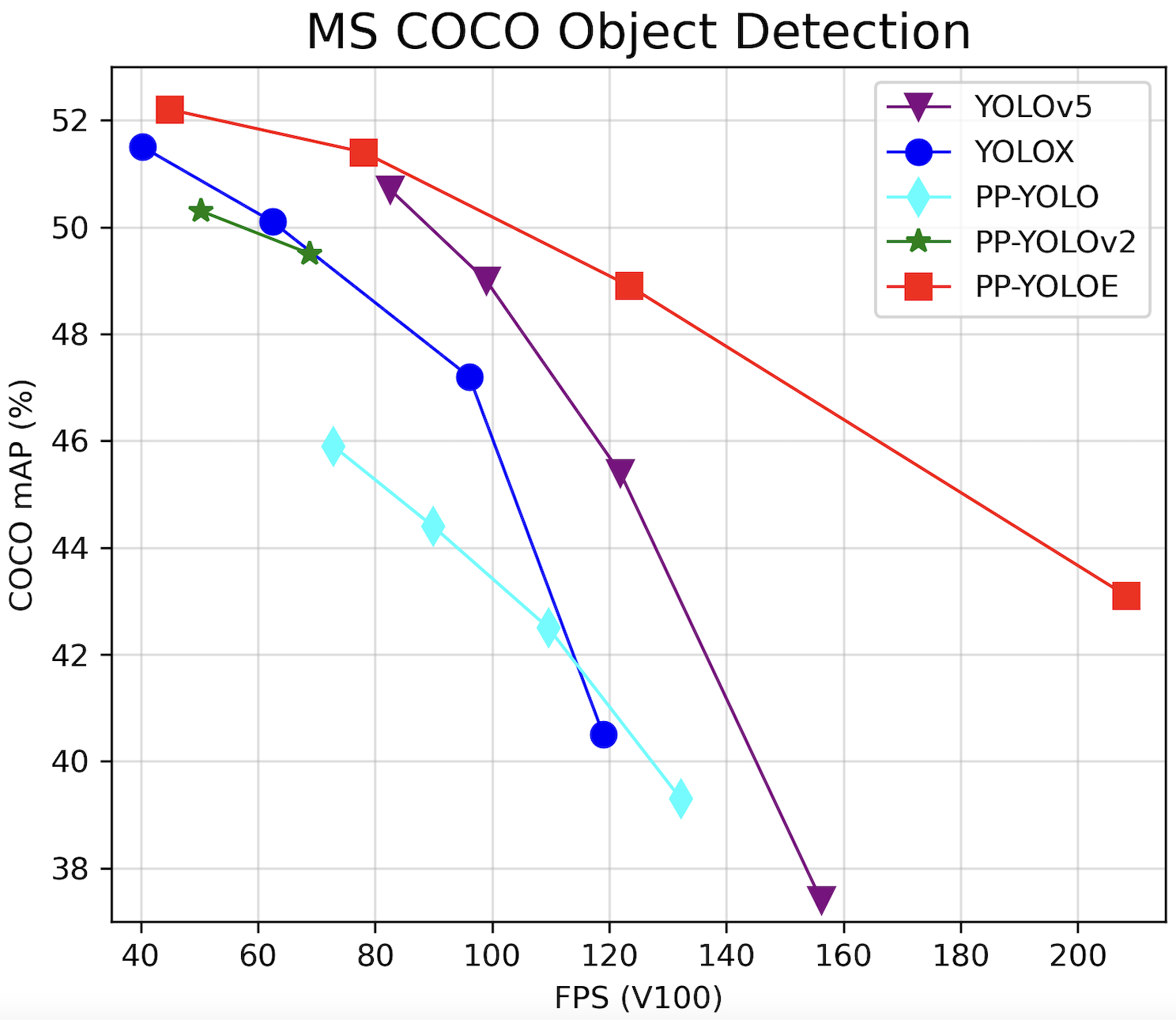
PP-YOLOE是基于PP-YOLOv2的卓越的单阶段Anchor-free模型,超越了多种流行的yolo模型。PP-YOLOE有一系列的模型,即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免使用诸如deformable convolution或者matrix nms之类的特殊算子,以使其能轻松地部署在多种多样的硬件上。更多细节可以参考我们的[report](https://arxiv.org/abs/2203.16250)。
PP-YOLOE-l在COCO test-dev2017达到了51.4的mAP, 同时其速度在Tesla V100上达到了78.1 FPS。PP-YOLOE-s/m/x同样具有卓越的精度速度性价比, 其精度速度可以在[模型库](#模型库)中找到。
PP-YOLOE由以下方法组成
- 可扩展的backbone和neck
- [Task Alignment Learning](https://arxiv.org/abs/2108.07755)
- Efficient Task-aligned head with [DFL](https://arxiv.org/abs/2006.04388)和[VFL](https://arxiv.org/abs/2008.13367)
- [SiLU激活函数](https://arxiv.org/abs/1710.05941)
## 模型库
| 模型 | GPU个数 | 每GPU图片个数 | 骨干网络 | 输入尺寸 | Box APval | Box APtest | Params(M) | FLOPs(G) | V100 FP32(FPS) | V100 TensorRT FP16(FPS) | 模型下载 | 配置文件 |
|:------------------------:|:-------:|:--------:|:----------:| :-------:| :------------------: | :-------------------: |:---------:|:--------:|:---------------:| :---------------------: | :------: | :------: |
| PP-YOLOE-s | 8 | 32 | cspresnet-s | 640 | 42.7 | 43.1 | 7.93 | 17.36 | 208.3 | 333.3 | [model](https://paddledet.bj.bcebos.com/models/ppyoloe_crn_s_300e_coco.pdparams) | [config](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/ppyoloe/ppyoloe_crn_s_300e_coco.yml) |
| PP-YOLOE-m | 8 | 28 | cspresnet-m | 640 | 48.6 | 48.9 | 23.43 | 49.91 | 123.4 | 208.3 | [model](https://paddledet.bj.bcebos.com/models/ppyoloe_crn_m_300e_coco.pdparams) | [config](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml) |
| PP-YOLOE-l | 8 | 20 | cspresnet-l | 640 | 50.9 | 51.4 | 52.20 | 110.07 | 78.1 | 149.2 | [model](https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams) | [config](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml) |
| PP-YOLOE-x | 8 | 16 | cspresnet-x | 640 | 51.9 | 52.2 | 98.42 | 206.59 | 45.0 | 95.2 | [model](https://paddledet.bj.bcebos.com/models/ppyoloe_crn_x_300e_coco.pdparams) | [config](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/ppyoloe/ppyoloe_crn_x_300e_coco.yml) |
**注意:**
- PP-YOLOE模型使用COCO数据集中train2017作为训练集,使用val2017和test-dev2017作为测试集,Box APtest为`mAP(IoU=0.5:0.95)`评估结果。
- PP-YOLOE模型训练过程中使用8 GPUs进行混合精度训练,如果训练GPU数和batch size不使用上述配置,须参考[FAQ](https://github.com/PaddlePaddle/PaddleDetection/blob/develop/docs/tutorials/FAQ)调整学习率和迭代次数。
- PP-YOLOE模型推理速度测试采用单卡V100,batch size=1进行测试,使用**CUDA 10.2**, **CUDNN 7.6.5**,TensorRT推理速度测试使用**TensorRT 6.0.1.8**。
- 参考[速度测试](##速度测试)以复现PP-YOLOE推理速度测试结果。
- 如果你设置了`--run_benchnark=True`, 你首先需要安装以下依赖`pip install pynvml psutil GPUtil`。
## 使用教程
### 训练
执行以下指令使用混合精度训练PP-YOLOE
```bash
python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml --amp
```
** 注意: ** 使用默认配置训练需要设置`--amp`以避免显存溢出.
### 评估
执行以下命令在单个GPU上评估COCO val2017数据集
```bash
CUDA_VISIBLE_DEVICES=0 python tools/eval.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
```
在coco test-dev2017上评估,请先从[COCO数据集下载](https://cocodataset.org/#download)下载COCO test-dev2017数据集,然后解压到COCO数据集文件夹并像`configs/ppyolo/ppyolo_test.yml`一样配置`EvalDataset`。
### 推理
使用以下命令在单张GPU上预测图片,使用`--infer_img`推理单张图片以及使用`--infer_dir`推理文件中的所有图片。
```bash
# 推理单张图片
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams --infer_img=demo/000000014439_640x640.jpg
# 推理文件中的所有图片
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams --infer_dir=demo
```
### 模型导出
PP-YOLOE在GPU上部署或者速度测试需要通过`tools/export_model.py`导出模型。
当你**使用Paddle Inference但不使用TensorRT**时,运行以下的命令导出模型
```bash
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
```
当你**使用Paddle Inference且使用TensorRT**时,需要指定`-o trt=True`来导出模型。
```bash
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams trt=True
```
如果你想将PP-YOLOE模型导出为**ONNX格式**,参考
[PaddleDetection模型导出为ONNX格式教程](../../deploy/EXPORT_ONNX_MODEL.md),运行以下命令:
```bash
# 导出推理模型
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml --output_dir=output_inference -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
# 安装paddle2onnx
pip install paddle2onnx
# 转换成onnx格式
paddle2onnx --model_dir output_inference/ppyoloe_crn_l_300e_coco --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file ppyoloe_crn_l_300e_coco.onnx
```
**注意:**ONNX模型目前只支持batch_size=1
### 速度测试
为了公平起见,在[模型库](#模型库)中的速度测试结果均为不包含数据预处理和模型输出后处理(NMS)的数据(与[YOLOv4(AlexyAB)](https://github.com/AlexeyAB/darknet)测试方法一致),需要在导出模型时指定`-o exclude_nms=True`.
**使用Paddle Inference但不使用TensorRT**进行测速,执行以下命令:
```bash
# 导出模型
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams exclude_nms=True
# 速度测试,使用run_benchmark=True
CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_300e_coco --image_file=demo/000000014439_640x640.jpg --run_mode=paddle --device=gpu --run_benchmark=True
```
**使用Paddle Inference且使用TensorRT**进行测速,执行以下命令:
```bash
# 导出模型,使用trt=True
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams exclude_nms=True trt=True
# 速度测试,使用run_benchmark=True, run_mode=trt_fp32/trt_fp16
CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_300e_coco --image_file=demo/000000014439_640x640.jpg --run_mode=trt_fp16 --device=gpu --run_benchmark=True
```
### 部署
PP-YOLOE可以使用以下方式进行部署:
- Paddle Inference [Python](../../deploy/python) & [C++](../../deploy/cpp)
- [Paddle-TensorRT](../../deploy/TENSOR_RT.md)
- [PaddleServing](https://github.com/PaddlePaddle/Serving)
接下来,我们将介绍PP-YOLOE如何使用Paddle Inference在TensorRT FP16模式下部署
首先,参考[Paddle Inference文档](https://www.paddlepaddle.org.cn/inference/master/user_guides/download_lib.html#python),下载并安装与你的CUDA, CUDNN和TensorRT相应的wheel包。
然后,运行以下命令导出模型
```bash
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams trt=True
```
最后,使用TensorRT FP16进行推理
```bash
# 推理单张图片
CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py --model_dir=output_inference/ppyolo_r50vd_dcn_1x_coco --image_file=demo/000000014439_640x640.jpg --device=gpu --run_mode=trt_fp16
# 推理文件夹下的所有图片
CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py --model_dir=output_inference/ppyolo_r50vd_dcn_1x_coco --image_dir=demo/ --device=gpu --run_mode=trt_fp16
```
**注意:**
- TensorRT会根据网络的定义,执行针对当前硬件平台的优化,生成推理引擎并序列化为文件。该推理引擎只适用于当前软硬件平台。如果你的软硬件平台没有发生变化,你可以设置[enable_tensorrt_engine](https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.4/deploy/python/infer.py#L660)的参数`use_static=True`,这样生成的序列化文件将会保存在`output_inference`文件夹下,下次执行TensorRT时将加载保存的序列化文件。
- PaddleDetection release/2.4及其之后的版本将支持NMS调用TensorRT,需要依赖PaddlePaddle release/2.3及其之后的版本
### 泛化性验证
模型 | AP | AP50
---|---|---
[YOLOX](https://github.com/Megvii-BaseDetection/YOLOX) | 22.6 | 37.5
[YOLOv5](https://github.com/ultralytics/yolov5) | 26.0 | 42.7
**PP-YOLOE** | **30.5** | **46.4**
**注意**
- 试验使用[VisDrone](https://github.com/VisDrone/VisDrone-Dataset)数据集, 并且检测其中的9类,包括 `person, bicycles, car, van, truck, tricyle, awning-tricyle, bus, motor`.
- 以上模型训练均采用官方提供的默认参数,并且加载COCO预训练参数
- *由于人力/时间有限,后续将会持续补充更多验证结果,也欢迎各位开源用户贡献,共同优化PP-YOLOE*
## 附录
PP-YOLOE消融实验
| 序号 | 模型 | Box APval | 参数量(M) | FLOPs(G) | V100 FP32 FPS |
| :--: | :---------------------------: | :-------------------: | :-------: | :------: | :-----------: |
| A | PP-YOLOv2 | 49.1 | 54.58 | 115.77 | 68.9 |
| B | A + Anchor-free | 48.8 | 54.27 | 114.78 | 69.8 |
| C | B + CSPRepResNet | 49.5 | 47.42 | 101.87 | 85.5 |
| D | C + TAL | 50.4 | 48.32 | 104.75 | 84.0 |
| E | D + ET-Head | 50.9 | 52.20 | 110.07 | 78.1 |