English | [简体中文](README_cn.md)
# PP-YOLOE
## Table of Contents
- [Introduction](#Introduction)
- [Model Zoo](#Model-Zoo)
- [Getting Start](#Getting-Start)
- [Appendix](#Appendix)
## Introduction
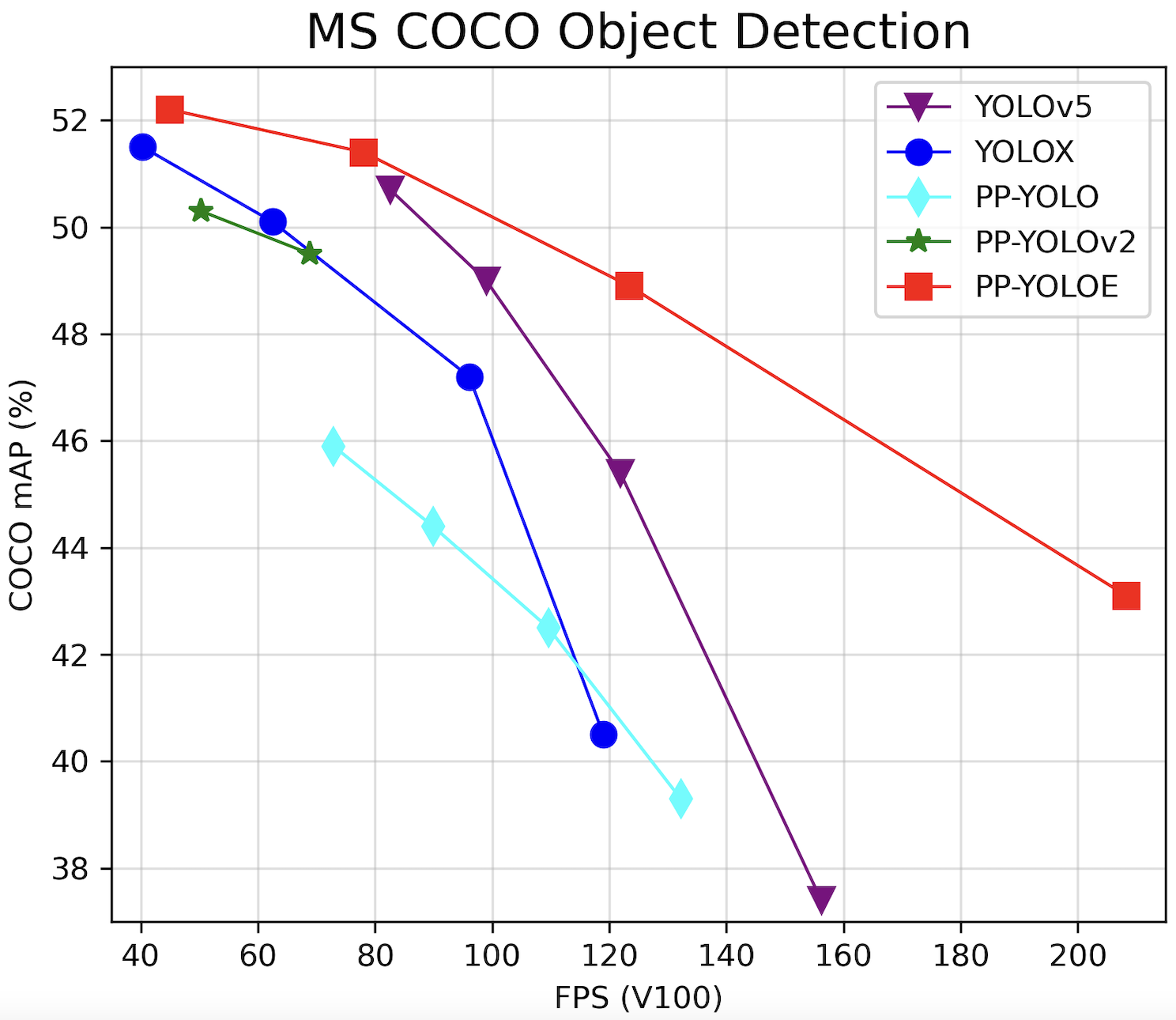
PP-YOLOE is an excellent single-stage anchor-free model based on PP-YOLOv2, surpassing a variety of popular yolo models. PP-YOLOE has a series of models, named s/m/l/x, which are configured through width multiplier and depth multiplier. PP-YOLOE avoids using special operators, such as deformable convolution or matrix nms, to be deployed friendly on various hardware. For more details, please refer to our [report](https://arxiv.org/abs/2203.16250).
PP-YOLOE-l achieves 51.4 mAP on COCO test-dev2017 dataset with 78.1 FPS on Tesla V100. While using TensorRT FP16, PP-YOLOE-l can be further accelerated to 149.2 FPS. PP-YOLOE-s/m/x also have excellent accuracy and speed performance, which can be found in [Model Zoo](#Model-Zoo)
PP-YOLOE is composed of following methods:
- Scalable backbone and neck
- [Task Alignment Learning](https://arxiv.org/abs/2108.07755)
- Efficient Task-aligned head with [DFL](https://arxiv.org/abs/2006.04388) and [VFL](https://arxiv.org/abs/2008.13367)
- [SiLU activation function](https://arxiv.org/abs/1710.05941)
## Model Zoo
| Model | GPU number | images/GPU | backbone | input shape | Box APval | Box APtest | Params(M) | FLOPs(G) | V100 FP32(FPS) | V100 TensorRT FP16(FPS) | download | config |
|:------------------------:|:-------:|:----------:|:----------:| :-------:| :------------------: | :-------------------: |:---------:|:--------:| :------------: | :---------------------: | :------: | :------: |
| PP-YOLOE-s | 8 | 32 | cspresnet-s | 640 | 42.7 | 43.1 | 7.93 | 17.36 | 208.3 | 333.3 | [model](https://paddledet.bj.bcebos.com/models/ppyoloe_crn_s_300e_coco.pdparams) | [config](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/ppyoloe/ppyoloe_crn_s_300e_coco.yml) |
| PP-YOLOE-m | 8 | 28 | cspresnet-m | 640 | 48.6 | 48.9 | 23.43 | 49.91 | 123.4 | 208.3 | [model](https://paddledet.bj.bcebos.com/models/ppyoloe_crn_m_300e_coco.pdparams) | [config](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/ppyoloe/ppyoloe_crn_m_300e_coco.yml) |
| PP-YOLOE-l | 8 | 20 | cspresnet-l | 640 | 50.9 | 51.4 | 52.20 | 110.07 | 78.1 | 149.2 | [model](https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams) | [config](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml) |
| PP-YOLOE-x | 8 | 16 | cspresnet-x | 640 | 51.9 | 52.2 | 98.42 | 206.59 | 45.0 | 95.2 | [model](https://paddledet.bj.bcebos.com/models/ppyoloe_crn_x_300e_coco.pdparams) | [config](https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/ppyoloe/ppyoloe_crn_x_300e_coco.yml) |
**Notes:**
- PP-YOLOE is trained on COCO train2017 dataset and evaluated on val2017 & test-dev2017 dataset,Box APtest is evaluation results of `mAP(IoU=0.5:0.95)`.
- PP-YOLOE used 8 GPUs for mixed precision training, if **GPU number** or **mini-batch size** is changed, **learning rate** should be adjusted according to the formula **lrnew = lrdefault * (batch_sizenew * GPU_numbernew) / (batch_sizedefault * GPU_numberdefault)**.
- PP-YOLOE inference speed is tesed on single Tesla V100 with batch size as 1, **CUDA 10.2**, **CUDNN 7.6.5**, **TensorRT 6.0.1.8** in TensorRT mode.
- Refer to [Speed testing](#Speed-testing) to reproduce the speed testing results of PP-YOLOE.
- If you set `--run_benchmark=True`,you should install these dependencies at first, `pip install pynvml psutil GPUtil`.
## Getting Start
### Training
Training PP-YOLOE with mixed precision on 8 GPUs with following command
```bash
python -m paddle.distributed.launch --gpus 0,1,2,3,4,5,6,7 tools/train.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml --amp
```
**Notes:** use `--amp` to train with default config to avoid out of memeory.
### Evaluation
Evaluating PP-YOLOE on COCO val2017 dataset in single GPU with following commands:
```bash
CUDA_VISIBLE_DEVICES=0 python tools/eval.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
```
For evaluation on COCO test-dev2017 dataset, please download COCO test-dev2017 dataset from [COCO dataset download](https://cocodataset.org/#download) and decompress to COCO dataset directory and configure `EvalDataset` like `configs/ppyolo/ppyolo_test.yml`.
### Inference
Inference images in single GPU with following commands, use `--infer_img` to inference a single image and `--infer_dir` to inference all images in the directory.
```bash
# inference single image
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams --infer_img=demo/000000014439_640x640.jpg
# inference all images in the directory
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams --infer_dir=demo
```
### Exporting models
For deployment on GPU or speed testing, model should be first exported to inference model using `tools/export_model.py`.
**Exporting PP-YOLOE for Paddle Inference without TensorRT**, use following command
```bash
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
```
**Exporting PP-YOLOE for Paddle Inference with TensorRT** for better performance, use following command with extra `-o trt=True` setting.
```bash
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams trt=True
```
If you want to export PP-YOLOE model to **ONNX format**, use following command refer to [PaddleDetection Model Export as ONNX Format Tutorial](../../deploy/EXPORT_ONNX_MODEL_en.md).
```bash
# export inference model
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml --output_dir=output_inference -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams
# install paddle2onnx
pip install paddle2onnx
# convert to onnx
paddle2onnx --model_dir output_inference/ppyoloe_crn_l_300e_coco --model_filename model.pdmodel --params_filename model.pdiparams --opset_version 11 --save_file ppyoloe_crn_l_300e_coco.onnx
```
**Notes:** ONNX model only supports batch_size=1 now
### Speed testing
For fair comparison, the speed in [Model Zoo](#Model-Zoo) do not contains the time cost of data reading and post-processing(NMS), which is same as [YOLOv4(AlexyAB)](https://github.com/AlexeyAB/darknet) in testing method. Thus, you should export model with extra `-o exclude_nms=True` setting.
**Using Paddle Inference without TensorRT** to test speed, run following command
```bash
# export inference model
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams exclude_nms=True
# speed testing with run_benchmark=True
CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_300e_coco --image_file=demo/000000014439_640x640.jpg --run_mode=paddle --device=gpu --run_benchmark=True
```
**Using Paddle Inference with TensorRT** to test speed, run following command
```bash
# export inference model with trt=True
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams exclude_nms=True trt=True
# speed testing with run_benchmark=True,run_mode=trt_fp32/trt_fp16
CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_300e_coco --image_file=demo/000000014439_640x640.jpg --run_mode=trt_fp16 --device=gpu --run_benchmark=True
```
### Deployment
PP-YOLOE can be deployed by following approches:
- Paddle Inference [Python](../../deploy/python) & [C++](../../deploy/cpp)
- [Paddle-TensorRT](../../deploy/TENSOR_RT.md)
- [PaddleServing](https://github.com/PaddlePaddle/Serving)
- [PaddleSlim](../slim)
Next, we will introduce how to use Paddle Inference to deploy PP-YOLOE models in TensorRT FP16 mode.
First, refer to [Paddle Inference Docs](https://www.paddlepaddle.org.cn/inference/master/user_guides/download_lib.html#python), download and install packages corresponding to CUDA, CUDNN and TensorRT version.
Then, Exporting PP-YOLOE for Paddle Inference **with TensorRT**, use following command.
```bash
python tools/export_model.py -c configs/ppyoloe/ppyoloe_crn_l_300e_coco.yml -o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_l_300e_coco.pdparams trt=True
```
Finally, inference in TensorRT FP16 mode.
```bash
# inference single image
CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_300e_coco --image_file=demo/000000014439_640x640.jpg --device=gpu --run_mode=trt_fp16
# inference all images in the directory
CUDA_VISIBLE_DEVICES=0 python deploy/python/infer.py --model_dir=output_inference/ppyoloe_crn_l_300e_coco --image_dir=demo/ --device=gpu --run_mode=trt_fp16
```
**Notes:**
- TensorRT will perform optimization for the current hardware platform according to the definition of the network, generate an inference engine and serialize it into a file. This inference engine is only applicable to the current hardware hardware platform. If your hardware and software platform has not changed, you can set `use_static=True` in [enable_tensorrt_engine](https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.4/deploy/python/infer.py#L660). In this way, the serialized file generated will be saved in the `output_inference` folder, and the saved serialized file will be loaded the next time when TensorRT is executed.
- PaddleDetection release/2.4 and later versions will support NMS calling TensorRT, which requires PaddlePaddle release/2.3 and later versions.
### Other Datasets
Model | AP | AP50
---|---|---
[YOLOX](https://github.com/Megvii-BaseDetection/YOLOX) | 22.6 | 37.5
[YOLOv5](https://github.com/ultralytics/yolov5) | 26.0 | 42.7
**PP-YOLOE** | **30.5** | **46.4**
**Notes**
- Here, we use [VisDrone](https://github.com/VisDrone/VisDrone-Dataset) dataset, and to detect 9 objects including `person, bicycles, car, van, truck, tricyle, awning-tricyle, bus, motor`.
- Above models trained using official default config, and load pretrained parameters on COCO dataset.
- *Due to the limited time, more verification results will be supplemented in the future. You are also welcome to contribute to PP-YOLOE*
### Feature Models
The PaddleDetection team provides configs and weights of various feature detection models based on PP-YOLOE, which users can download for use:
|Scenarios | Related Datasets | Links|
| :--------: | :---------: | :------: |
|Pedestrian Detection | CrowdHuman | [pphuman](../pphuman) |
|Vehicle Detection | BDD100K,UA-DETRAC | [ppvehicle](../ppvehicle) |
|Small Object Detection | VisDrone | [visdrone](../visdrone) |
## Appendix
Ablation experiments of PP-YOLOE.
| NO. | Model | Box APval | Params(M) | FLOPs(G) | V100 FP32 FPS |
| :--: | :---------------------------: | :------------------: | :-------: | :------: | :-----------: |
| A | PP-YOLOv2 | 49.1 | 54.58 | 115.77 | 68.9 |
| B | A + Anchor-free | 48.8 | 54.27 | 114.78 | 69.8 |
| C | B + CSPRepResNet | 49.5 | 47.42 | 101.87 | 85.5 |
| D | C + TAL | 50.4 | 48.32 | 104.75 | 84.0 |
| E | D + ET-Head | 50.9 | 52.20 | 110.07 | 78.1 |