[English](action_en.md) | 简体中文
# PP-Human行为识别模块
行为识别在智慧社区,安防监控等方向具有广泛应用,根据行为的不同,PP-Human中集成了基于视频分类、基于检测、基于图像分类以及基于骨骼点的行为识别模块,方便用户根据需求进行选择。
## 模型库
在这里,我们提供了检测/跟踪、关键点识别、识别打架、打电话行为、抽烟行为、以及摔倒动作的预训练模型,用户可以直接下载使用。
| 任务 | 算法 | 精度 | 预测速度(ms) | 模型权重 | 预测部署模型 |
|:---------------------|:---------:|:------:|:------:| :------: |:---------------------------------------------------------------------------------: |
| 行人检测/跟踪 | PP-YOLOE | mAP: 56.3
MOTA: 72.0 | 检测: 28ms
跟踪:33.1ms |[下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.pdparams) |[下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip) |
| 打电话行为识别 | PP-HGNet | 准确率: 86.85 | 单人 2.94ms | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPHGNet_tiny_calling_halfbody.pdparams) | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPHGNet_tiny_calling_halfbody.zip) |
| 抽烟行为识别 | PP-YOLOE | mAP: 39.7 | 单人 2.0ms | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/ppyoloe_crn_s_80e_smoking_visdrone.pdparams) | [下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/ppyoloe_crn_s_80e_smoking_visdrone.zip) |
| 关键点识别 | HRNet | AP: 87.1 | 单人 2.9ms |[下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/dark_hrnet_w32_256x192.pdparams) |[下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/dark_hrnet_w32_256x192.zip)|
| 摔倒行为识别 | ST-GCN | 准确率: 96.43 | 单人 2.7ms | - |[下载链接](https://bj.bcebos.com/v1/paddledet/models/pipeline/STGCN.zip) |
| 打架识别 | PP-TSM | 准确率:89.06% | 2s视频 128ms | [下载链接](https://videotag.bj.bcebos.com/PaddleVideo-release2.3/ppTSM_fight.pdparams) | [下载链接](https://videotag.bj.bcebos.com/PaddleVideo-release2.3/ppTSM_fight.zip) |
注:
1. 检测/跟踪模型精度为[MOT17](https://motchallenge.net/),[CrowdHuman](http://www.crowdhuman.org/),[HIEVE](http://humaninevents.org/)和部分业务数据融合训练测试得到。
2. 关键点模型使用[COCO](https://cocodataset.org/),[UAV-Human](https://github.com/SUTDCV/UAV-Human)和部分业务数据融合训练, 精度在业务数据测试集上得到。
3. 摔倒行为识别模型使用[NTU-RGB+D](https://rose1.ntu.edu.sg/dataset/actionRecognition/),[UR Fall Detection Dataset](http://fenix.univ.rzeszow.pl/~mkepski/ds/uf.html)和部分业务数据融合训练,精度在业务数据测试集上得到。
4. 打电话行为识别模型使用[UAV-Human](https://github.com/SUTDCV/UAV-Human)的打电话行为部分进行训练和测试。
5. 抽烟行为识别模型使用业务数据进行训练和测试。
6. 打架识别模型基于6个公开数据集训练得到:Surveillance Camera Fight Dataset、A Dataset for Automatic Violence Detection in Videos、Hockey Fight Detection Dataset、Video Fight Detection Dataset、Real Life Violence Situations Dataset、UBI Abnormal Event Detection Dataset。
7. 预测速度为NVIDIA T4 机器上使用TensorRT FP16时的速度, 速度包含数据预处理、模型预测、后处理全流程。
## 基于骨骼点的行为识别——摔倒识别
 数据来源及版权归属:天覆科技,感谢提供并开源实际场景数据,仅限学术研究使用
数据来源及版权归属:天覆科技,感谢提供并开源实际场景数据,仅限学术研究使用
### 配置说明
[配置文件](../../config/infer_cfg_pphuman.yml)中与行为识别相关的参数如下:
```
SKELETON_ACTION: # 基于骨骼点的行为识别模型配置
model_dir: output_inference/STGCN # 模型所在路径
batch_size: 1 # 预测批大小。 当前仅支持为1进行推理
max_frames: 50 # 动作片段对应的帧数。在行人ID对应时序骨骼点结果时达到该帧数后,会通过行为识别模型判断该段序列的动作类型。与训练设置一致时效果最佳。
display_frames: 80 # 显示帧数。当预测结果为摔倒时,在对应人物ID中显示状态的持续时间。
coord_size: [384, 512] # 坐标统一缩放到的尺度大小。与训练设置一致时效果最佳。
basemode: "skeletonbased" # 模型基于的路线分支,是否需要skeleton作为输入
enable: False # 是否开启该功能
```
### 使用方法
1. 从`模型库`中下载`行人检测/跟踪`、`关键点识别`、`摔倒行为识别`三个预测部署模型并解压到```./output_inference```路径下;默认自动下载模型,如果手动下载,需要修改模型文件夹为模型存放路径。
2. 目前行为识别模块仅支持视频输入,根据期望开启的行为识别方案类型,设置infer_cfg_pphuman.yml中`SKELETON_ACTION`的enable: True, 然后启动命令如下:
```python
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu \
```
3. 若修改模型路径,有以下两种方式:
- ```./deploy/pipeline/config/infer_cfg_pphuman.yml```下可以配置不同模型路径,关键点模型和摔倒行为识别模型分别对应`KPT`和`SKELETON_ACTION`字段,修改对应字段下的路径为实际期望的路径即可。
- 命令行中增加`--model_dir`修改模型路径:
```python
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu \
--model_dir kpt=./dark_hrnet_w32_256x192 action=./STGCN
```
4. 启动命令中的完整参数说明,请参考[参数说明](./QUICK_STARTED.md)。
### 方案说明
1. 使用目标检测与多目标跟踪获取视频输入中的行人检测框及跟踪ID序号,模型方案为PP-YOLOE,详细文档参考[PP-YOLOE](../../../../configs/ppyoloe/README_cn.md)。
2. 通过行人检测框的坐标在输入视频的对应帧中截取每个行人。
3. 使用[关键点识别模型](../../../configs/keypoint/hrnet/dark_hrnet_w32_256x192.yml)得到对应的17个骨骼特征点。骨骼特征点的顺序及类型与COCO一致,详见[如何准备关键点数据集](../../../docs/tutorials/PrepareKeypointDataSet_cn.md)中的`COCO数据集`部分。
4. 每个跟踪ID对应的目标行人各自累计骨骼特征点结果,组成该人物的时序关键点序列。当累计到预定帧数或跟踪丢失后,使用行为识别模型判断时序关键点序列的动作类型。当前版本模型支持摔倒行为的识别,预测得到的`class id`对应关系为:
```
0: 摔倒,
1: 其他
```
- 摔倒行为识别模型使用了[ST-GCN](https://arxiv.org/abs/1801.07455),并基于[PaddleVideo](https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/model_zoo/recognition/stgcn.md)套件完成模型训练。
## 基于图像分类的行为识别——打电话识别
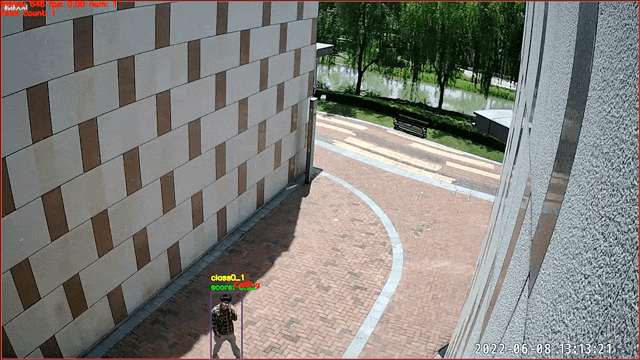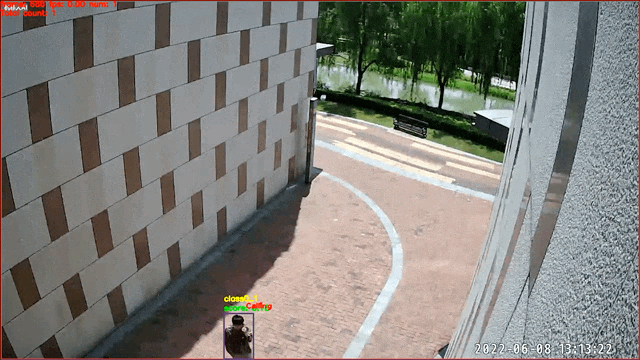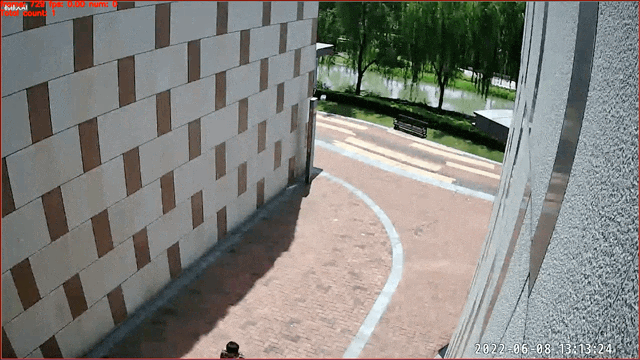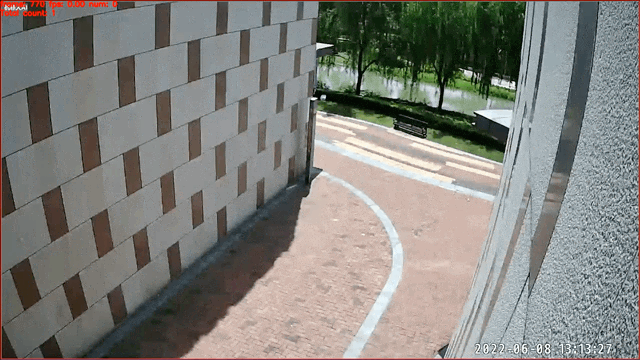 数据来源及版权归属:天覆科技,感谢提供并开源实际场景数据,仅限学术研究使用
数据来源及版权归属:天覆科技,感谢提供并开源实际场景数据,仅限学术研究使用
### 配置说明
[配置文件](../../config/infer_cfg_pphuman.yml)中相关的参数如下:
```
ID_BASED_CLSACTION: # 基于分类的行为识别模型配置
model_dir: output_inference/PPHGNet_tiny_calling_halfbody # 模型所在路径
batch_size: 8 # 预测批大小
basemode: "idbased" # 模型基于的路线分支,是否基于跟踪获得的ID信息
threshold: 0.45 #识别为对应行为的阈值
display_frames: 80 # 显示帧数。当识别到对应动作时,在对应人物ID中显示状态的持续时间。
enable: False # 是否开启该功能
```
### 使用方法
1. 从`模型库`中下载`行人检测/跟踪`、`打电话行为识别`两个预测部署模型并解压到`./output_inference`路径下;默认自动下载模型,如果手动下载,需要修改模型文件夹为模型存放路径。
2. 修改配置文件`deploy/pipeline/config/infer_cfg_pphuman.yml`中`ID_BASED_CLSACTION`下的`enable`为`True`;
3. 仅支持输入视频,启动命令如下:
```
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu
```
4. 启动命令中的完整参数说明,请参考[参数说明](./QUICK_STARTED.md)。
### 方案说明
1. 使用目标检测与多目标跟踪获取视频输入中的行人检测框及跟踪ID序号,模型方案为PP-YOLOE,详细文档参考[PP-YOLOE](../../../../configs/ppyoloe/README_cn.md)。
2. 通过行人检测框的坐标在输入视频的对应帧中截取每个行人。
3. 通过在帧级别的行人图像通过图像分类的方式实现。当图片所属类别为对应行为时,即认为在一定时间段内该人物处于该行为状态中。该任务使用[PP-HGNet](https://github.com/PaddlePaddle/PaddleClas/blob/develop/docs/zh_CN/models/PP-HGNet.md)实现,当前版本模型支持打电话行为的识别,预测得到的`class id`对应关系为:
```
0: 打电话,
1: 其他
```
- 基于分类的行为识别基于[PaddleClas](https://github.com/PaddlePaddle/PaddleClas/blob/develop/docs/zh_CN/models/PP-HGNet.md#3.3)完成模型训练。
## 基于检测的行为识别——吸烟识别
 数据来源及版权归属:天覆科技,感谢提供并开源实际场景数据,仅限学术研究使用
数据来源及版权归属:天覆科技,感谢提供并开源实际场景数据,仅限学术研究使用
### 配置说明
[配置文件](../../config/infer_cfg_pphuman.yml)中相关的参数如下:
```
ID_BASED_DETACTION: # 基于检测的行为识别模型配置
model_dir: output_inference/ppyoloe_crn_s_80e_smoking_visdrone # 模型所在路径
batch_size: 8 # 预测批大小
basemode: "idbased" # 模型基于的路线分支,是否基于跟踪获得的ID信息
threshold: 0.4 # 识别为对应行为的阈值
display_frames: 80 # 显示帧数。当识别到对应动作时,在对应人物ID中显示状态的持续时间。
enable: False # 是否开启该功能
```
### 使用方法
1. 从`模型库`中下载`行人检测/跟踪`、`抽烟行为识别`两个预测部署模型并解压到`./output_inference`路径下;默认自动下载模型,如果手动下载,需要修改模型文件夹为模型存放路径。
2. 修改配置文件`deploy/pipeline/config/infer_cfg_pphuman.yml`中`ID_BASED_DETACTION`下的`enable`为`True`;
3. 仅支持输入视频,启动命令如下:
```
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu
```
4. 启动命令中的完整参数说明,请参考[参数说明](./QUICK_STARTED.md)。
### 方案说明
1. 使用目标检测与多目标跟踪获取视频输入中的行人检测框及跟踪ID序号,模型方案为PP-YOLOE,详细文档参考[PP-YOLOE](../../../../configs/ppyoloe/README_cn.md)。
2. 通过行人检测框的坐标在输入视频的对应帧中截取每个行人。
3. 通过在帧级别的行人图像中检测该行为的典型特定目标实现。当检测到特定目标(在这里即烟头)以后,即认为在一定时间段内该人物处于该行为状态中。该任务使用[PP-YOLOE](../../../../configs/ppyoloe/README_cn.md)实现,当前版本模型支持吸烟行为的识别,预测得到的`class id`对应关系为:
```
0: 吸烟,
1: 其他
```
## 基于检测的行为识别——闯入识别
具体使用请参照[PP-Human检测跟踪模块](mot.md)的`5. 区域闯入判断和计数`。
### 方案说明
1. 使用目标检测与多目标跟踪获取视频输入中的行人检测框及跟踪ID序号,模型方案为PP-YOLOE,详细文档参考[PP-YOLOE](../../../../configs/ppyoloe/README_cn.md)。
2. 通过行人检测框的下边界中点在相邻帧位于用户所选区域的内外位置,来识别是否闯入所选区域。
## 基于视频分类的行为识别——打架识别
随着监控摄像头部署覆盖范围越来越广,人工查看是否存在打架等异常行为耗时费力、效率低,AI+安防助理智慧安防。PP-Human中集成了打架识别模块,识别视频中是否存在打架行为。我们提供了预训练模型,用户可直接下载使用。
| 任务 | 算法 | 精度 | 预测速度(ms) | 模型权重 | 预测部署模型 |
| ---- | ---- | ---------- | ---- | ---- | ---------- |
| 打架识别 | PP-TSM | 准确率:89.06% | T4, 2s视频128ms | [下载链接](https://videotag.bj.bcebos.com/PaddleVideo-release2.3/ppTSM_fight.pdparams) | [下载链接](https://videotag.bj.bcebos.com/PaddleVideo-release2.3/ppTSM_fight.zip) |
打架识别模型基于6个公开数据集训练得到:Surveillance Camera Fight Dataset、A Dataset for Automatic Violence Detection in Videos、Hockey Fight Detection Dataset、Video Fight Detection Dataset、Real Life Violence Situations Dataset、UBI Abnormal Event Detection Dataset。
本项目关注的场景为监控摄像头下的打架行为识别。打架行为涉及多人,基于骨骼点技术的方案更适用于单人的行为识别。此外,打架行为对时序信息依赖较强,基于检测和分类的方案也不太适用。由于监控场景背景复杂,人的密集程度、光线、拍摄角度等都会对识别造成影响,本方案采用基于视频分类的方式判断视频中是否存在打架行为。针对摄像头距离人较远的情况,通过增大输入图像分辨率优化。由于训练数据有限,采用数据增强的方式提升模型的泛化性能。
### 配置说明
[配置文件](../../config/infer_cfg_pphuman.yml)中与行为识别相关的参数如下:
```
VIDEO_ACTION: # 基于视频分类的行为识别模型配置
model_dir: output_inference/ppTSM # 模型所在路径
batch_size: 1 # 预测批大小。当前仅支持为1进行推理
frame_len: 8 # 累计抽样帧数量,达到该数量后执行一次识别
sample_freq: 7 # 抽样频率,即间隔多少帧抽样一帧
short_size: 340 # 视频帧尺度变换最小边的长度
target_size: 320 # 目标视频帧的大小
basemode: "videobased" # 模型基于的路线分支,是否直接使用视频进行输入
enable: False # 是否开启该功能
```
### 使用方法
1. 从上表链接中下载`打架识别`任务的预测部署模型并解压到`./output_inference`路径下;默认自动下载模型,如果手动下载,需要修改模型文件夹为模型存放路径。
2. 修改配置文件`deploy/pphuman/config/infer_cfg_pphuman.yml`中`VIDEO_ACTION`下的`enable`为`True`;
3. 仅支持输入视频,启动命令如下:
```
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu
```
4. 启动命令中的完整参数说明,请参考[参数说明](./QUICK_STARTED.md)。
测试效果如下:
数据来源及版权归属:Surveillance Camera Fight Dataset。
### 方案说明
目前打架识别模型使用的是[PP-TSM](https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/model_zoo/recognition/pp-tsm.md),并在PP-TSM视频分类模型训练流程的基础上修改适配,完成模型训练。对于输入的视频或者视频流,进行等间隔抽帧,当视频帧累计到指定数目时,输入到视频分类模型中判断是否存在打架行为。
## 自定义模型训练
我们已经提供了检测/跟踪、关键点识别以及识别摔倒、吸烟、打电话以及打架的预训练模型,可直接下载使用。如果希望使用自定义场景数据训练,或是对模型进行优化,根据具体模型,分别参考下面的链接:
| 任务 | 算法 | 模型开发文档 |
| ---- | ---- | -------- |
| 行人检测/跟踪 | PP-YOLOE | [使用教程](../../../../configs/ppyoloe/README_cn.md#使用教程) |
| 关键点识别 | HRNet | [使用教程](../../../../configs/keypoint#3训练与测试) |
| 行为识别(摔倒)| ST-GCN | [使用教程](../../../../docs/advanced_tutorials/customization/action_recognotion/skeletonbased_rec.md) |
| 行为识别(吸烟)| PP-YOLOE | [使用教程](../../../../docs/advanced_tutorials/customization/action_recognotion/idbased_det.md) |
| 行为识别(打电话)| PP-HGNet | [使用教程](../../../../docs/advanced_tutorials/customization/action_recognotion/idbased_clas.md) |
| 行为识别 (打架)| PP-TSM | [使用教程](../../../../docs/advanced_tutorials/customization/action_recognotion/videobased_rec.md)
## 参考文献
```
@inproceedings{stgcn2018aaai,
title = {Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition},
author = {Sijie Yan and Yuanjun Xiong and Dahua Lin},
booktitle = {AAAI},
year = {2018},
}
```
