English | [简体中文](pphuman_action.md)
# Action Recognition Module of PP-Human
Action Recognition is widely used in the intelligent community/smart city, and security monitoring. PP-Human provides the module of video-classification-based, detection-based, image-classification-based and skeleton-based action recognition.
## Model Zoo
There are multiple available pretrained models including pedestrian detection/tracking, keypoint detection, fighting, calling, smoking and fall detection models. Users can download and use them directly.
| Task | Algorithm | Precision | Inference Speed(ms) | Model Weights |Model Inference and Deployment |
|:----------------------------- |:---------:|:-------------------------:|:-----------------------------------:| :-----------------: |:-----------------------------------------------------------------------------------------:|
| Pedestrian Detection/Tracking | PP-YOLOE | mAP: 56.3
MOTA: 72.0 | Detection: 28ms
Tracking:33.1ms |[Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.pdparams) |[Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/mot_ppyoloe_l_36e_pipeline.zip) |
| Calling Recognition | PP-HGNet | Precision Rate: 86.85 | Single Person 2.94ms | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPHGNet_tiny_calling_halfbody.pdparams) | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/PPHGNet_tiny_calling_halfbody.zip) |
| Smoking Recognition | PP-YOLOE | mAP: 39.7 | Single Person 2.0ms | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/ppyoloe_crn_s_80e_smoking_visdrone.pdparams) | [Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/ppyoloe_crn_s_80e_smoking_visdrone.zip) |
| Keypoint Detection | HRNet | AP: 87.1 | Single Person 2.9ms |[Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/dark_hrnet_w32_256x192.pdparams) |[Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/dark_hrnet_w32_256x192.zip) |
| Falling Recognition | ST-GCN | Precision Rate: 96.43 | Single Person 2.7ms | - |[Link](https://bj.bcebos.com/v1/paddledet/models/pipeline/STGCN.zip) |
| Fighting Recognition | PP-TSM | Precision Rate: 89.06% | 128ms for a 2sec video | [Link](https://videotag.bj.bcebos.com/PaddleVideo-release2.3/ppTSM_fight.pdparams) | [Link](https://videotag.bj.bcebos.com/PaddleVideo-release2.3/ppTSM_fight.zip) |
Note:
1. The precision of the pedestrian detection/ tracking model is obtained by trainning and testing on [MOT17](https://motchallenge.net/), [CrowdHuman](http://www.crowdhuman.org/), [HIEVE](http://humaninevents.org/) and some business data.
2. The keypoint detection model is trained on [COCO](https://cocodataset.org/), [UAV-Human](https://github.com/SUTDCV/UAV-Human), and some business data, and the precision is obtained on test sets of business data.
3. The falling action recognition model is trained on [NTU-RGB+D](https://rose1.ntu.edu.sg/dataset/actionRecognition/), [UR Fall Detection Dataset](http://fenix.univ.rzeszow.pl/~mkepski/ds/uf.html), and some business data, and the precision is obtained on the testing set of business data.
4. The calling action recognition model is trained and tested on [UAV-Human](https://github.com/SUTDCV/UAV-Human), by using video frames of calling in this dataset.
5. The smoking action recognition model is trained and tested on business data.
6. The fighting action recognition model is trained and tested on 6 public datasets, including Surveillance Camera Fight Dataset, A Dataset for Automatic Violence Detection in Videos, Hockey Fight Detection Dataset, Video Fight Detection Dataset, Real Life Violence Situations Dataset, UBI Abnormal Event Detection Dataset.
7. The inference speed is the speed of using TensorRT FP16 on NVIDIA T4, including the total time of data pre-training, model inference, and post-processing.
## Skeleton-based action recognition -- falling detection
 Data source and copyright owner:Skyinfor
Technology. Thanks for the provision of actual scenario data, which are only
used for academic research here.
Data source and copyright owner:Skyinfor
Technology. Thanks for the provision of actual scenario data, which are only
used for academic research here.
### Description of Configuration
Parameters related to action recognition in the [config file](../../config/infer_cfg_pphuman.yml) are as follow:
```
SKELETON_ACTION: # Config for skeleton-based action recognition model
model_dir: output_inference/STGCN # Path of the model
batch_size: 1 # The size of the inference batch. Current now only support 1.
max_frames: 50 # The number of frames of action segments. When frames of time-ordered skeleton keypoints of each pedestrian ID achieve the max value,the action type will be judged by the action recognition model. If the setting is the same as the training, there will be an ideal inference result.
display_frames: 80 # The number of display frames. When the inferred action type is falling down, the time length of the act will be displayed in the ID.
coord_size: [384, 512] # The unified size of the coordinate, which is the best when it is the same as the training setting.
basemode: "skeletonbased" # The models which is based on,whether we need the skeleton model.
enable: False # Whether to enable this function
```
## How to Use
1. Download models `Pedestrian Detection/Tracking`, `Keypoint Detection` and `Falling Recognition` from the links in the Model Zoo and unzip them to ```./output_inference```. The models are automatically downloaded by default. If you download them manually, you need to modify the `model_dir` as the model storage path.
2. Now the only available input is the video input in the action recognition module. set the "enable: True" of `SKELETON_ACTION` in infer_cfg_pphuman.yml. And then run the command:
```python
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu
```
3. There are two ways to modify the model path:
- In ```./deploy/pipeline/config/infer_cfg_pphuman.yml```, you can configurate different model paths,which is proper only if you match keypoint models and action recognition models with the fields of `KPT` and `SKELETON_ACTION` respectively, and modify the corresponding path of each field into the expected path.
- Add `--model_dir` in the command line to revise the model path:
```python
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu \
--model_dir kpt=./dark_hrnet_w32_256x192 action=./STGCN
```
4. For detailed parameter description, please refer to [Parameter Description](./PPHuman_QUICK_STARTED.md)
### Introduction to the Solution
1. Get the pedestrian detection box and the tracking ID number of the video input through object detection and multi-object tracking. The adopted model is PP-YOLOE, and for details, please refer to [PP-YOLOE](../../../../configs/ppyoloe).
2. Capture every pedestrian in frames of the input video accordingly by using the coordinate of the detection box.
3. In this strategy, we use the [keypoint detection model](../../../../configs/keypoint/hrnet/dark_hrnet_w32_256x192.yml) to obtain 17 skeleton keypoints. Their sequences and types are identical to those of COCO. For details, please refer to the `COCO dataset` part of [how to prepare keypoint datasets](../../../../docs/tutorials/data/PrepareKeypointDataSet_en.md).
4. Each target pedestrian with a tracking ID has their own accumulation of skeleton keypoints, which is used to form a keypoint sequence in time order. When the number of accumulated frames reach a preset threshold or the tracking is lost, the action recognition model will be applied to judging the action type of the time-ordered keypoint sequence. The current model only supports the recognition of the act of falling down, and the relationship between the action type and `class id` is:
```
0: Fall down
1: Others
```
- The falling action recognition model uses [ST-GCN](https://arxiv.org/abs/1801.07455), and employ the [PaddleVideo](https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/model_zoo/recognition/stgcn.md) toolkit to complete model training.
## Image-Classification-Based Action Recognition -- Calling Recognition
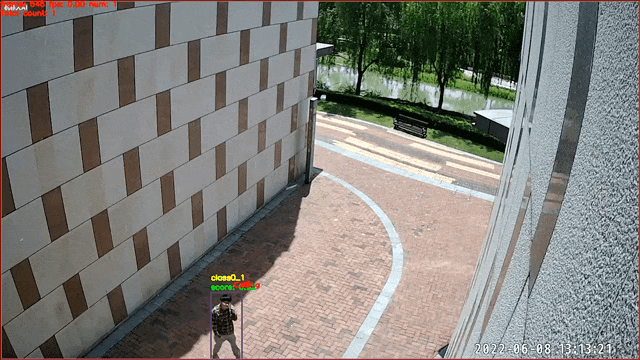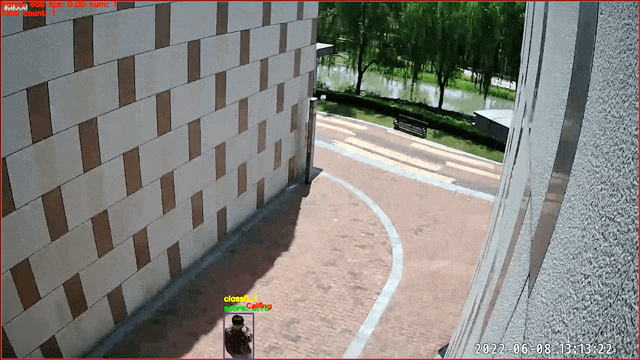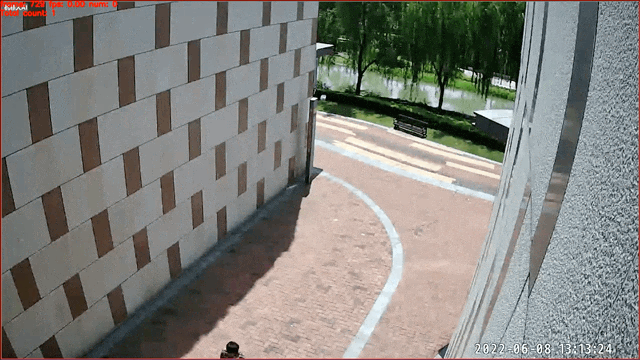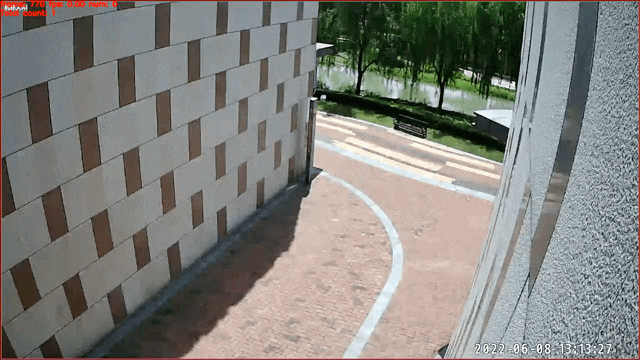 Data source and copyright owner:Skyinfor
Technology. Thanks for the provision of actual scenario data, which are only
used for academic research here.
Data source and copyright owner:Skyinfor
Technology. Thanks for the provision of actual scenario data, which are only
used for academic research here.
### Description of Configuration
Parameters related to action recognition in the [config file](../../config/infer_cfg_pphuman.yml) are as follow:
```
ID_BASED_CLSACTION: # config for classfication-based action recognition model
model_dir: output_inference/PPHGNet_tiny_calling_halfbody # Path of the model
batch_size: 8 # The size of the inference batch
basemode: "idbased" # the models which is based on, whether the id of each object obtained by tracking is needed.
threshold: 0.45 # Threshold for corresponding behavior
display_frames: 80 # The number of display frames. When the corresponding action is detected, the time length of the act will be displayed in the ID.
enable: False # Whether to enable this function
```
### How to Use
1. Download models `Pedestrian Detection/Tracking` and `Calling Recognition` from the links in `Model Zoo` and unzip them to ```./output_inference```. The models are automatically downloaded by default. If you download them manually, you need to modify the `model_dir` as the model storage path.
2. Now the only available input is the video input in the action recognition module. Set the "enable: True" of `ID_BASED_CLSACTION` in infer_cfg_pphuman.yml.
3. Run this command:
```python
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu
```
4. For detailed parameter description, please refer to [Parameter Description](./PPHuman_QUICK_STARTED.md)
### Introduction to the Solution
1. Get the pedestrian detection box and the tracking ID number of the video input through object detection and multi-object tracking. The adopted model is PP-YOLOE, and for details, please refer to [PP-YOLOE](../../../configs/ppyoloe).
2. Capture every pedestrian in frames of the input video accordingly by using the coordinate of the detection box.
3. With image classification through pedestrian images at the frame level, when the category to which the image belongs is the corresponding behavior, it is considered that the character is in the behavior state for a certain period of time. This task is implemented with [PP-HGNet](https://github.com/PaddlePaddle/PaddleClas/blob/develop/docs/zh_CN/models/PP-HGNet.md). In current version, the behavior of calling is supported and the relationship between the action type and `class id` is:
```
0: Calling
1: Others
```
## Detection-based Action Recognition -- Smoking Detection
 Data source and copyright owner:Skyinfor
Technology. Thanks for the provision of actual scenario data, which are only
used for academic research here.
Data source and copyright owner:Skyinfor
Technology. Thanks for the provision of actual scenario data, which are only
used for academic research here.
### Description of Configuration
Parameters related to action recognition in the [config file](../../config/infer_cfg_pphuman.yml) are as follow:
```
ID_BASED_DETACTION: # Config for detection-based action recognition model
model_dir: output_inference/ppyoloe_crn_s_80e_smoking_visdrone # Path of the model
batch_size: 8 # The size of the inference batch
basemode: "idbased" # The models which is based on, whether the id of each object obtained by tracking is needed.
threshold: 0.4 # Threshold for corresponding behavior.
display_frames: 80 # The number of display frames. When the corresponding action is detected, the time length of the act will be displayed in the ID.
enable: False # Whether to enable this function
```
### How to Use
1. Download models `Pedestrian Detection/Tracking` and `Smoking Recognition` from the links in `Model Zoo` and unzip them to ```./output_inference```. The models are automatically downloaded by default. If you download them manually, you need to modify the `model_dir` as the model storage path.
2. Now the only available input is the video input in the action recognition module. set the "enable: True" of `ID_BASED_DETACTION` in infer_cfg_pphuman.yml.
3. Run this command:
```python
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu
```
4. For detailed parameter description, please refer to [Parameter Description](./PPHuman_QUICK_STARTED.md)
### Introduction to the Solution
1. Get the pedestrian detection box and the tracking ID number of the video input through object detection and multi-object tracking. The adopted model is PP-YOLOE, and for details, please refer to [PP-YOLOE](../../../../configs/ppyoloe).
2. Capture every pedestrian in frames of the input video accordingly by using the coordinate of the detection box.
3. We detecting the typical specific target of this behavior in frame-level pedestrian images. When a specific target (in this case, cigarette is the target) is detected, it is considered that the character is in the behavior state for a certain period of time. This task is implemented by [PP-YOLOE](../../../../configs/ppyoloe/). In current version, the behavior of smoking is supported and the relationship between the action type and `class id` is:
```
0: Smoking
1: Others
```
## Video-Classification-Based Action Recognition -- Fighting Detection
With wider and wider deployment of surveillance cameras, it is time-consuming and labor-intensive and inefficient to manually check whether there are abnormal behaviors such as fighting. AI + security assistant smart security. A fight recognition module is integrated into PP-Human to identify whether there is fighting in the video. We provide pre-trained models that users can download and use directly.
| Task | Model | Acc. | Speed(ms) | Weight | Deploy Model |
| ---- | ---- | ---------- | ---- | ---- | ---------- |
| Fighting Detection | PP-TSM | 89.06% | 128ms for a 2-sec video| [Link](https://videotag.bj.bcebos.com/PaddleVideo-release2.3/ppTSM_fight.pdparams) | [Link](https://videotag.bj.bcebos.com/PaddleVideo-release2.3/ppTSM_fight.zip) |
The model is trained with 6 public dataset, including Surveillance Camera Fight Dataset、A Dataset for Automatic Violence Detection in Videos、Hockey Fight Detection Dataset、Video Fight Detection Dataset、Real Life Violence Situations Dataset、UBI Abnormal Event Detection Dataset.
This project focuses on is the identification of fighting behavior under surveillance cameras. Fighting behavior involves multiple people, and the skeleton-based technology is more suitable for single-person behavior recognition. In addition, fighting behavior is strongly dependent on timing information, and the detection and classification-based scheme is not suitable. Due to the complex background of the monitoring scene, the density of people, light, filming angle may affect the accuracy. This solution uses video-classification-based method to determine whether there is fighting in the video.
For the case where the camera is far away from the person, it is optimized by increasing the resolution of the input image. Due to the limited training data, data augmentation is used to improve the generalization performance of the model.
### Description of Configuration
Parameters related to action recognition in the [config file](../../config/infer_cfg_pphuman.yml) are as follow:
```
VIDEO_ACTION: # Config for detection-based action recognition model
model_dir: output_inference/ppTSM # Path of the model
batch_size: 1 # The size of the inference batch. Current now only support 1.
frame_len: 8 # Accumulate the number of sampling frames. Inference will be executed when sampled frames reached this value.
sample_freq: 7 # Sampling frequency. It means how many frames to sample one frame.
short_size: 340 # The shortest length for video frame scaling transforms.
target_size: 320 # Target size for input video
basemode: "videobased" # The models which is based on, whether to use video as model input.
enable: False # Whether to enable this function
```
### How to Use
1. Download model `Fighting Detection` from the links of the above table and unzip it to ```./output_inference```. The models are automatically downloaded by default. If you download them manually, you need to modify the `model_dir` as the model storage path.
2. Modify the file names in the `ppTSM` folder to `model.pdiparams, model.pdiparams.info and model.pdmodel`;
3. Now the only available input is the video input in the action recognition module. set the "enable: True" of `VIDEO_ACTION` in infer_cfg_pphuman.yml.
4. Run this command:
```python
python deploy/pipeline/pipeline.py --config deploy/pipeline/config/infer_cfg_pphuman.yml \
--video_file=test_video.mp4 \
--device=gpu
```
5. For detailed parameter description, please refer to [Parameter Description](./PPHuman_QUICK_STARTED.md).
The result is shown as follow:
Data source and copyright owner: Surveillance Camera Fight Dataset.
### Introduction to the Solution
The current fight recognition model is using [PP-TSM](https://github.com/PaddlePaddle/PaddleVideo/blob/develop/docs/zh-CN/model_zoo/recognition/pp-tsm.md), and adaptated to complete the model training. For the input video or video stream, we extraction frame at a certain interval. When the video frame accumulates to the specified number, it is input into the video classification model to determine whether there is fighting.
## Custom Training
The pretrained models are provided and can be used directly, including pedestrian detection/ tracking, keypoint detection, smoking, calling and fighting recognition. If users need to train custom action or optimize the model performance, please refer the link below.
| Task | Model | Development Document |
| ---- | ---- | -------- |
| pedestrian detection/tracking | PP-YOLOE | [doc](../../../../configs/ppyoloe/README.md#getting-start) |
| keypoint detection | HRNet | [doc](../../../../configs/keypoint/README_en.md#3training-and-testing) |
| action recognition (fall down) | ST-GCN | [doc](../../../../docs/advanced_tutorials/customization/action_recognotion/skeletonbased_rec.md) |
| action recognition (smoking) | PP-YOLOE | [doc](../../../../docs/advanced_tutorials/customization/action_recognotion/idbased_det.md) |
| action recognition (calling) | PP-HGNet | [doc](../../../../docs/advanced_tutorials/customization/action_recognotion/idbased_clas.md) |
| action recognition (fighting) | PP-TSM | [doc](../../../../docs/advanced_tutorials/customization/action_recognotion/videobased_rec.md) |
## Reference
```
@inproceedings{stgcn2018aaai,
title = {Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition},
author = {Sijie Yan and Yuanjun Xiong and Dahua Lin},
booktitle = {AAAI},
year = {2018},
}
```
