# RNNOp design
This document is about an RNN operator which requires that instances in a mini-batch have the same length. We will have a more flexible RNN operator.
## RNN Algorithm Implementation
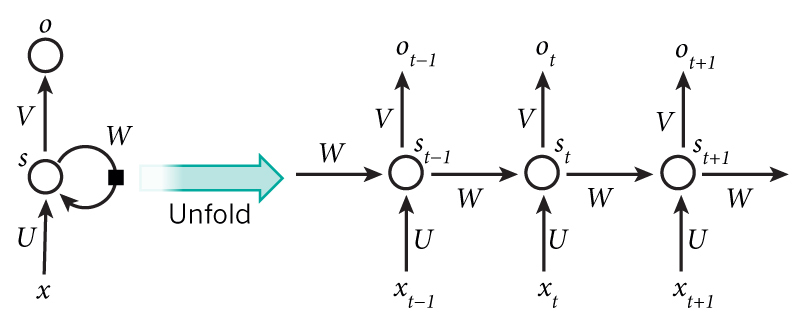
The above diagram shows an RNN unrolled into a full network.
There are several important concepts:
- *step-net*: the sub-graph to run at each step,
- *memory*, $h_t$, the state of the current step,
- *ex-memory*, $h_{t-1}$, the state of the previous step,
- *initial memory value*, the ex-memory of the first step.
### Step-scope
There could be local variables defined in step-nets. PaddlePaddle runtime realizes these variables in *step-scopes* -- scopes created for each step.
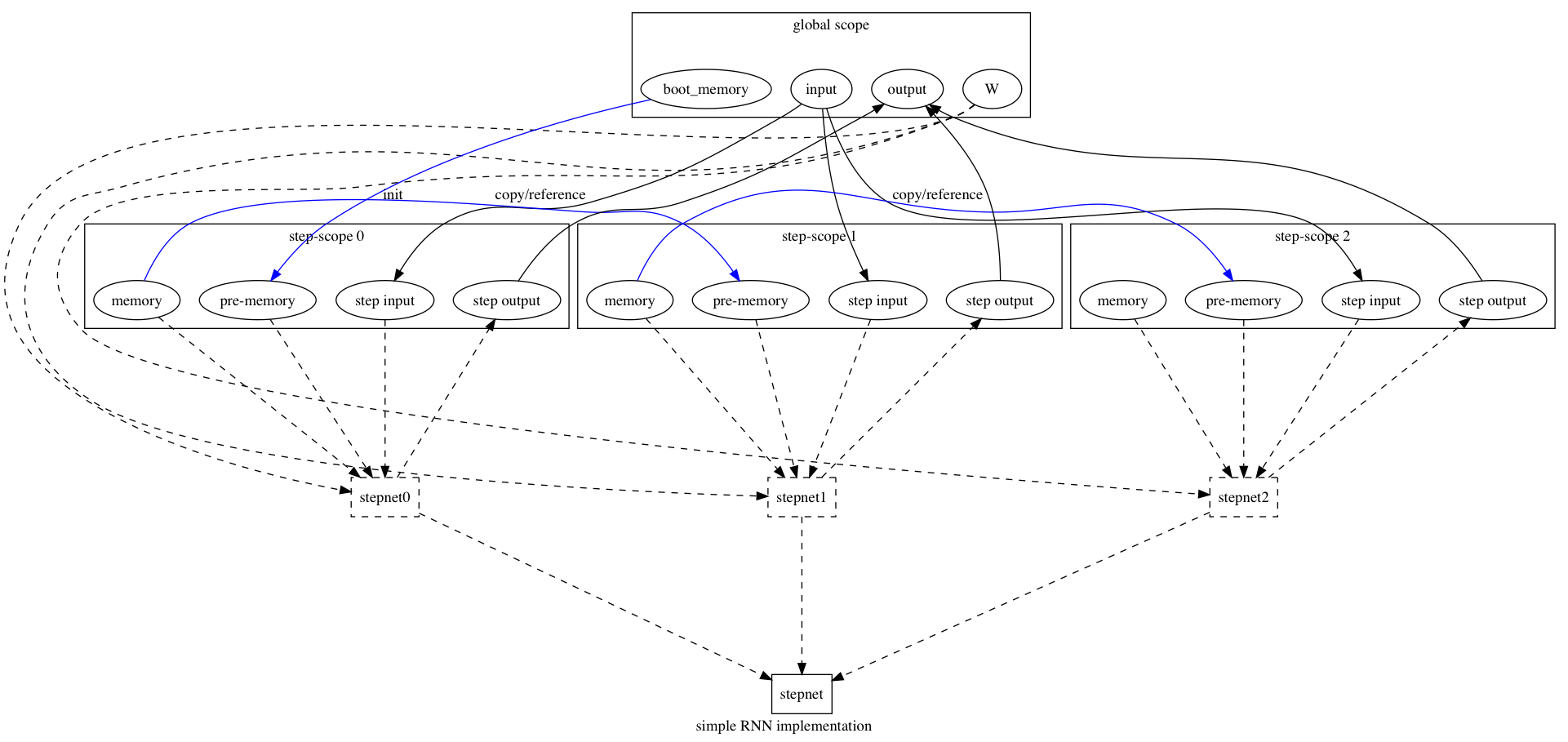
Figure 2 the RNN's data flow
Please be aware that all steps run the same step-net. Each step
1. creates the step-scope,
2. realizes local variables, including step-outputs, in the step-scope, and
3. runs the step-net, which could use these variables.
The RNN operator will compose its output from step outputs in step scopes.
### Memory and Ex-memory
Let's give more details about memory and ex-memory via a simply example:
$$
h_t = U h_{t-1} + W x_t
$$,
where $h_t$ and $h_{t-1}$ are the memory and ex-memory of step $t$'s respectively.
In the implementation, we can make an ex-memory variable either "refers to" the memory variable of the previous step,
or copy the value of the previous memory value to the current ex-memory variable.
### Usage in Python
For more information on Block, please refer to the [design doc](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/block.md).
We can define an RNN's step-net using Block:
```python
import paddle as pd
X = some_op() # x is some operator's output, and is a LoDTensor
a = some_op()
# declare parameters
W = pd.Variable(shape=[20, 30])
U = pd.Variable(shape=[20, 30])
rnn = pd.create_rnn_op(output_num=1)
with rnn.stepnet():
x = rnn.add_input(X)
# declare a memory (rnn's step)
h = rnn.add_memory(init=a)
# h.pre_state() means previous memory of rnn
new_state = pd.add_two( pd.matmul(W, x) + pd.matmul(U, h.pre_state()))
# update current memory
h.update(new_state)
# indicate that h variables in all step scopes should be merged
rnn.add_outputs(h)
out = rnn()
```
Python API functions in above example:
- `rnn.add_input` indicates the parameter is a variable that will be segmented into step-inputs.
- `rnn.add_memory` creates a variable used as the memory.
- `rnn.add_outputs` mark the variables that will be concatenated across steps into the RNN output.
### Nested RNN and LoDTensor
An RNN whose step-net includes other RNN operators is known as an *nested RNN*.
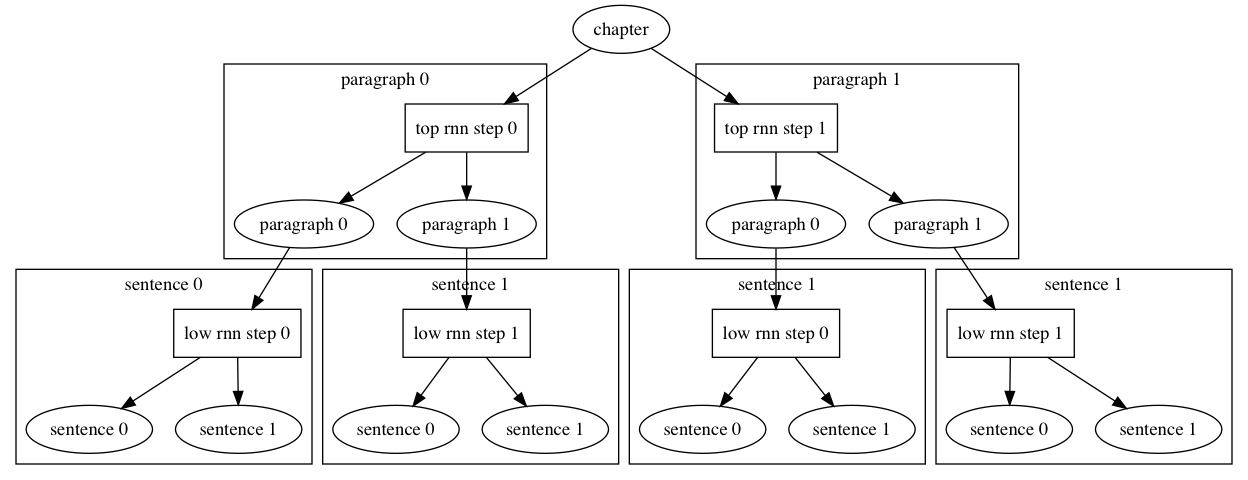
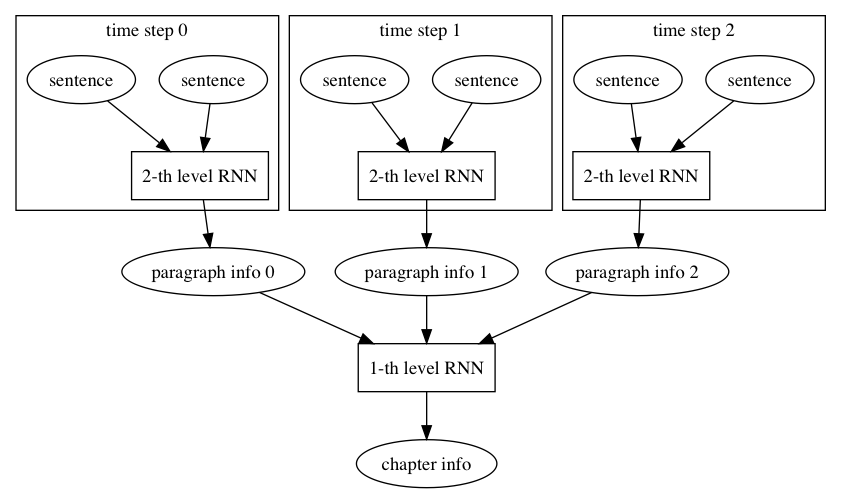
For example, we could have a 2-level RNN, where the top level corresponds to paragraphs, and the lower level corresponds to sentences.
The following figure illustrates the feeding of text into the lower level, one sentence each step, and the feeding of step outputs to the top level. The final top level output is about the whole text.
```python
import paddle as pd
W = pd.Variable(shape=[20, 30])
U = pd.Variable(shape=[20, 30])
W0 = pd.Variable(shape=[20, 30])
U0 = pd.Variable(shape=[20, 30])
# a is output of some op
a = some_op()
# chapter_data is a set of 128-dim word vectors
# the first level of LoD is sentence
# the second level of LoD is chapter
chapter_data = pd.Variable(shape=[None, 128], type=pd.lod_tensor, level=2)
def lower_level_rnn(paragraph):
'''
x: the input
'''
rnn = pd.create_rnn_op(output_num=1)
with rnn.stepnet():
sentence = rnn.add_input(paragraph, level=0)
h = rnn.add_memory(shape=[20, 30])
h.update(
pd.matmul(W, sentence) + pd.matmul(U, h.pre_state()))
# get the last state as sentence's info
rnn.add_outputs(h)
return rnn
top_level_rnn = pd.create_rnn_op(output_num=1)
with top_level_rnn.stepnet():
paragraph_data = rnn.add_input(chapter_data, level=1)
low_rnn = lower_level_rnn(paragraph_data)
paragraph_out = low_rnn()
h = rnn.add_memory(init=a)
h.update(
pd.matmul(W0, paragraph_data) + pd.matmul(U0, h.pre_state()))
top_level_rnn.add_outputs(h)
# just output the last step
chapter_out = top_level_rnn(output_all_steps=False)
```
in above example, the construction of the `top_level_rnn` calls `lower_level_rnn`. The input is a LoD Tensor. The top level RNN segments input text data into paragraphs, and the lower level RNN segments each paragraph into sentences.
By default, the `RNNOp` will concatenate the outputs from all the time steps,
if the `output_all_steps` set to False, it will only output the final time step.