diff --git a/CMakeLists.txt b/CMakeLists.txt
index b1d0abdf2ceb4cf338dde782a97a6df906149655..c2fa5420e916fd5958f6198d6e97c9b1092b5aa1 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -213,9 +213,11 @@ include(configure) # add paddle env configuration
if(WITH_GPU)
include(cuda)
include(tensorrt)
+endif()
+if(WITH_MKL OR WITH_MKLML)
include(external/anakin)
elseif()
- set(WITH_ANAKIN OFF CACHE STRING "Anakin is used in GPU only now." FORCE)
+ set(WITH_ANAKIN OFF CACHE STRING "Anakin is used in MKL only now." FORCE)
endif()
include(generic) # simplify cmake module
diff --git a/Dockerfile b/Dockerfile
index 402adee2ea2822250ebc8f6229fd6a44545d58e5..634be18a51bf61e96a8bf6f263b6674a7932d6e4 100644
--- a/Dockerfile
+++ b/Dockerfile
@@ -53,7 +53,7 @@ RUN curl -s -q https://glide.sh/get | sh
# and its size is only one-third of the official one.
# 2. Manually add ~IPluginFactory() in IPluginFactory class of NvInfer.h, otherwise, it couldn't work in paddle.
# See https://github.com/PaddlePaddle/Paddle/issues/10129 for details.
-RUN wget -qO- http://paddlepaddledeps.bj.bcebos.com/TensorRT-4.0.0.3.Ubuntu-16.04.4.x86_64-gnu.cuda-8.0.cudnn7.0.tar.gz | \
+RUN wget -qO- http://paddlepaddledeps.cdn.bcebos.com/TensorRT-4.0.0.3.Ubuntu-16.04.4.x86_64-gnu.cuda-8.0.cudnn7.0.tar.gz | \
tar -xz -C /usr/local && \
cp -rf /usr/local/TensorRT/include /usr && \
cp -rf /usr/local/TensorRT/lib /usr
diff --git a/README.md b/README.md
index a67cb8ad439f462c361cb6bac2449c3a4b042126..60ffbe728178705b1734e682868614025214c2a4 100644
--- a/README.md
+++ b/README.md
@@ -76,33 +76,26 @@ pip install paddlepaddle-gpu==0.14.0.post85
## Installation
-It is recommended to check out the
-[Docker installation guide](http://www.paddlepaddle.org/docs/develop/documentation/fluid/en/build_and_install/docker_install_en.html)
-before looking into the
-[build from source guide](http://www.paddlepaddle.org/docs/develop/documentation/fluid/en/build_and_install/build_from_source_en.html).
+It is recommended to read [this doc](http://paddlepaddle.org/documentation/docs/zh/0.14.0/new_docs/beginners_guide/install/install_doc.html) on our website.
## Documentation
-We provide [English](http://www.paddlepaddle.org/docs/develop/documentation/en/getstarted/index_en.html) and
-[Chinese](http://www.paddlepaddle.org/docs/develop/documentation/zh/getstarted/index_cn.html) documentation.
+We provide [English](http://paddlepaddle.org/documentation/docs/en/0.14.0/getstarted/index_en.html) and
+[Chinese](http://paddlepaddle.org/documentation/docs/zh/0.14.0/new_docs/beginners_guide/index.html) documentation.
-- [Deep Learning 101](http://www.paddlepaddle.org/docs/develop/book/01.fit_a_line/index.html)
+- [Deep Learning 101](https://github.com/PaddlePaddle/book)
You might want to start from this online interactive book that can run in a Jupyter Notebook.
-- [Distributed Training](http://www.paddlepaddle.org/docs/develop/documentation/en/howto/cluster/index_en.html)
+- [Distributed Training](http://paddlepaddle.org/documentation/docs/zh/0.14.0/new_docs/user_guides/howto/training/cluster_howto.html)
You can run distributed training jobs on MPI clusters.
-- [Distributed Training on Kubernetes](http://www.paddlepaddle.org/docs/develop/documentation/en/howto/cluster/multi_cluster/k8s_en.html)
-
- You can also run distributed training jobs on Kubernetes clusters.
-
-- [Python API](http://www.paddlepaddle.org/docs/develop/api/en/overview.html)
+- [Python API](http://paddlepaddle.org/documentation/api/zh/0.14.0/fluid.html)
Our new API enables much shorter programs.
-- [How to Contribute](http://www.paddlepaddle.org/docs/develop/documentation/fluid/en/dev/contribute_to_paddle_en.html)
+- [How to Contribute](http://paddlepaddle.org/documentation/docs/zh/0.14.0/new_docs/advanced_usage/development/contribute_to_paddle.html)
We appreciate your contributions!
diff --git a/benchmark/fluid/Dockerfile b/benchmark/fluid/Dockerfile
index 707fadb1fae97cefe8a41715cd57d71754abda41..2e1e0d376899fd664866621263db62258e7c3869 100644
--- a/benchmark/fluid/Dockerfile
+++ b/benchmark/fluid/Dockerfile
@@ -11,6 +11,7 @@ RUN ln -s /usr/lib/x86_64-linux-gnu/libcudnn.so.7 /usr/lib/libcudnn.so && ln -s
# Add "ENV http_proxy=http://ip:port" if your download is slow, and don't forget to unset it at runtime.
# exmaple: unset http_proxy && unset https_proxy && python fluid_benchmark.py ...
+
RUN pip install -U pip
RUN pip install -U kubernetes paddlepaddle
@@ -27,5 +28,6 @@ ADD *.whl /
RUN pip install /*.whl && rm -f /*.whl
ENV LD_LIBRARY_PATH=/usr/local/lib
-ADD fluid_benchmark.py recordio_converter.py args.py recordio_converter.py run.sh run_fluid_benchmark.sh /workspace/
+ADD fluid_benchmark.py recordio_converter.py args.py recordio_converter.py run.sh run_fluid_benchmark.sh imagenet_reader.py /workspace/
ADD models/ /workspace/models/
+
diff --git a/benchmark/fluid/args.py b/benchmark/fluid/args.py
index a79f25ccc6ace1594f3f331633130eaace5e175b..ed696e82f8723eba573e8affd3f25e2aa6426e63 100644
--- a/benchmark/fluid/args.py
+++ b/benchmark/fluid/args.py
@@ -17,7 +17,8 @@ import argparse
__all__ = ['parse_args', ]
BENCHMARK_MODELS = [
- "machine_translation", "resnet", "vgg", "mnist", "stacked_dynamic_lstm"
+ "machine_translation", "resnet", "se_resnext", "vgg", "mnist",
+ "stacked_dynamic_lstm", "resnet_with_preprocess"
]
@@ -67,12 +68,12 @@ def parse_args():
'--cpus',
type=int,
default=1,
- help='If cpus > 1, will use ParallelDo to run, else use Executor.')
+ help='If cpus > 1, will set ParallelExecutor to use multiple threads.')
parser.add_argument(
'--data_set',
type=str,
default='flowers',
- choices=['cifar10', 'flowers'],
+ choices=['cifar10', 'flowers', 'imagenet'],
help='Optional dataset for benchmark.')
parser.add_argument(
'--infer_only', action='store_true', help='If set, run forward only.')
@@ -122,6 +123,11 @@ def parse_args():
type=str,
default="",
help='Directory that contains all the training recordio files.')
+ parser.add_argument(
+ '--test_data_path',
+ type=str,
+ default="",
+ help='Directory that contains all the test data (NOT recordio).')
parser.add_argument(
'--use_inference_transpiler',
action='store_true',
@@ -130,5 +136,9 @@ def parse_args():
'--no_random',
action='store_true',
help='If set, keep the random seed and do not shuffle the data.')
+ parser.add_argument(
+ '--use_lars',
+ action='store_true',
+ help='If set, use lars for optimizers, ONLY support resnet module.')
args = parser.parse_args()
return args
diff --git a/benchmark/fluid/fluid_benchmark.py b/benchmark/fluid/fluid_benchmark.py
index 6b22f8f520e3d9c6c89d41a7455a6f9ebbad6d80..11bd75e1d09a6b51c7c749c512f2b71f3604f3fb 100644
--- a/benchmark/fluid/fluid_benchmark.py
+++ b/benchmark/fluid/fluid_benchmark.py
@@ -16,6 +16,7 @@ import argparse
import cProfile
import time
import os
+import traceback
import numpy as np
@@ -27,7 +28,7 @@ import paddle.fluid.transpiler.distribute_transpiler as distribute_transpiler
from args import *
-def append_nccl2_prepare(trainer_id):
+def append_nccl2_prepare(trainer_id, startup_prog):
if trainer_id >= 0:
# append gen_nccl_id at the end of startup program
trainer_id = int(os.getenv("PADDLE_TRAINER_ID"))
@@ -40,11 +41,11 @@ def append_nccl2_prepare(trainer_id):
current_endpoint = os.getenv("PADDLE_CURRENT_IP") + ":" + port
worker_endpoints.remove(current_endpoint)
- nccl_id_var = fluid.default_startup_program().global_block().create_var(
+ nccl_id_var = startup_prog.global_block().create_var(
name="NCCLID",
persistable=True,
type=fluid.core.VarDesc.VarType.RAW)
- fluid.default_startup_program().global_block().append_op(
+ startup_prog.global_block().append_op(
type="gen_nccl_id",
inputs={},
outputs={"NCCLID": nccl_id_var},
@@ -59,7 +60,7 @@ def append_nccl2_prepare(trainer_id):
"nccl-based dist train.")
-def dist_transpile(trainer_id, args):
+def dist_transpile(trainer_id, args, train_prog, startup_prog):
if trainer_id < 0:
return None, None
@@ -80,132 +81,69 @@ def dist_transpile(trainer_id, args):
# the role, should be either PSERVER or TRAINER
training_role = os.getenv("PADDLE_TRAINING_ROLE")
- t = distribute_transpiler.DistributeTranspiler()
+ config = distribute_transpiler.DistributeTranspilerConfig()
+ config.slice_var_up = not args.no_split_var
+ t = distribute_transpiler.DistributeTranspiler(config=config)
t.transpile(
trainer_id,
+ # NOTE: *MUST* use train_prog, for we are using with guard to
+ # generate different program for train and test.
+ program=train_prog,
pservers=pserver_endpoints,
trainers=trainers,
sync_mode=not args.async_mode)
if training_role == "PSERVER":
pserver_program = t.get_pserver_program(current_endpoint)
- pserver_startup_program = t.get_startup_program(current_endpoint,
- pserver_program)
+ pserver_startup_program = t.get_startup_program(
+ current_endpoint, pserver_program, startup_program=startup_prog)
return pserver_program, pserver_startup_program
elif training_role == "TRAINER":
train_program = t.get_trainer_program()
- return train_program, fluid.default_startup_program()
+ return train_program, startup_prog
else:
raise ValueError(
'PADDLE_TRAINING_ROLE environment variable must be either TRAINER or PSERVER'
)
-def test(exe, inference_program, test_reader, feeder, batch_acc):
- accuracy_evaluator = fluid.metrics.Accuracy()
- for batch_id, data in enumerate(test_reader()):
- acc = exe.run(inference_program,
- feed=feeder.feed(data),
- fetch_list=[batch_acc])
- accuracy_evaluator.update(value=np.array(acc), weight=len(data))
+def test_parallel(exe, test_args, args, test_prog, feeder):
+ acc_evaluators = []
+ for i in xrange(len(test_args[2])):
+ acc_evaluators.append(fluid.metrics.Accuracy())
- return accuracy_evaluator.eval()
-
-
-# TODO(wuyi): replace train, train_parallel, test functions with new trainer
-# API once it is ready.
-def train(avg_loss, infer_prog, optimizer, train_reader, test_reader, batch_acc,
- args, train_prog, startup_prog):
- if os.getenv("PADDLE_TRAINING_ROLE") == "PSERVER":
- place = core.CPUPlace()
- exe = fluid.Executor(place)
- exe.run(startup_prog)
- exe.run(train_prog)
- return
-
- if args.use_fake_data:
- raise Exception(
- "fake data is not supported in single GPU test for now.")
-
- place = core.CPUPlace() if args.device == 'CPU' else core.CUDAPlace(0)
- exe = fluid.Executor(place)
- exe.run(startup_prog)
-
- # Use inference_transpiler to speedup
- if not args.use_reader_op:
- feed_var_list = [
- var for var in train_prog.global_block().vars.itervalues()
- if var.is_data
- ]
- feeder = fluid.DataFeeder(feed_var_list, place)
-
- iters, num_samples, start_time = 0, 0, time.time()
- for pass_id in range(args.pass_num):
- train_losses = []
- if not args.use_reader_op:
- reader_generator = train_reader()
- batch_id = 0
- data = None
+ to_fetch = [v.name for v in test_args[2]]
+ if args.use_reader_op:
+ test_args[4].start()
while True:
- if not args.use_reader_op:
- data = next(reader_generator, None)
- if data == None:
- break
- if iters == args.iterations:
+ try:
+ acc_rets = exe.run(fetch_list=to_fetch)
+ for i, e in enumerate(acc_evaluators):
+ e.update(
+ value=np.array(acc_rets[i]), weight=args.batch_size)
+ except fluid.core.EOFException as eof:
+ test_args[4].reset()
break
- if iters == args.skip_batch_num:
- start_time = time.time()
- num_samples = 0
+ else:
+ for batch_id, data in enumerate(test_args[3]()):
+ acc_rets = exe.run(feed=feeder.feed(data), fetch_list=to_fetch)
+ for i, e in enumerate(acc_evaluators):
+ e.update(value=np.array(acc_rets[i]), weight=len(data))
- if args.use_reader_op:
- try:
- loss = exe.run(train_prog, fetch_list=[avg_loss])
- except fluid.core.EnforceNotMet as ex:
- break
- else:
- loss = exe.run(train_prog,
- feed=feeder.feed(data),
- fetch_list=[avg_loss])
- iters += 1
- batch_id += 1
- # FIXME(wuyi): For use_reader_op, if the current
- # pass is not the last, the last batch of this pass
- # is also equal to args.batch_size.
- if args.use_reader_op:
- num_samples += args.batch_size * args.gpus
- else:
- num_samples += len(data)
- train_losses.append(loss)
- print("Pass: %d, Iter: %d, Loss: %f\n" %
- (pass_id, iters, np.mean(train_losses)))
- print_train_time(start_time, time.time(), num_samples)
- print("Pass: %d, Loss: %f" % (pass_id, np.mean(train_losses))),
- # evaluation
- if not args.no_test and batch_acc and not args.use_reader_op:
- if args.use_inference_transpiler:
- t = fluid.InferenceTranspiler()
- t.transpile(infer_prog, place)
-
- pass_test_acc = test(exe, infer_prog, test_reader, feeder,
- batch_acc)
- print(", Test Accuracy: %f" % pass_test_acc)
- print("\n")
- # TODO(wuyi): add warmup passes to get better perf data.
- exit(0)
+ return [e.eval() for e in acc_evaluators]
-# TODO(wuyi): replace train, train_parallel, test functions with new trainer
-# API once it is ready.
-def train_parallel(avg_loss, infer_prog, optimizer, train_reader, test_reader,
- batch_acc, args, train_prog, startup_prog, nccl_id_var,
- num_trainers, trainer_id):
+# NOTE: only need to benchmark using parallelexe
+def train_parallel(train_args, test_args, args, train_prog, test_prog,
+ startup_prog, nccl_id_var, num_trainers, trainer_id):
+ over_all_start = time.time()
place = core.CPUPlace() if args.device == 'CPU' else core.CUDAPlace(0)
+ feeder = None
if not args.use_reader_op:
feed_var_list = [
var for var in train_prog.global_block().vars.itervalues()
if var.is_data
]
feeder = fluid.DataFeeder(feed_var_list, place)
-
# generate fake:
if args.use_fake_data:
for var in feed_var_list:
@@ -229,62 +167,110 @@ def train_parallel(avg_loss, infer_prog, optimizer, train_reader, test_reader,
startup_exe = fluid.Executor(place)
startup_exe.run(startup_prog)
strategy = fluid.ExecutionStrategy()
- strategy.num_threads = 1
+ strategy.num_threads = args.cpus
strategy.allow_op_delay = False
+ avg_loss = train_args[0]
+
+ if args.update_method == "pserver":
+ # parameter server mode distributed training, merge
+ # gradients on local server, do not initialize
+ # ParallelExecutor with multi server all-reduce mode.
+ num_trainers = 1
+ trainer_id = 0
+
exe = fluid.ParallelExecutor(
True,
avg_loss.name,
+ main_program=train_prog,
exec_strategy=strategy,
num_trainers=num_trainers,
trainer_id=trainer_id)
+ if not args.no_test:
+ if args.update_method == "pserver":
+ test_scope = None
+ else:
+ # NOTE: use an empty scope to avoid test exe using NCCLID
+ test_scope = fluid.Scope()
+ test_exe = fluid.ParallelExecutor(
+ True, main_program=test_prog, share_vars_from=exe)
+
for pass_id in range(args.pass_num):
num_samples = 0
iters = 0
start_time = time.time()
if not args.use_reader_op:
- reader_generator = train_reader()
+ reader_generator = train_args[3]() #train_reader
batch_id = 0
data = None
+ if args.use_reader_op:
+ train_args[4].start()
while True:
if not args.use_reader_op:
data = next(reader_generator, None)
if data == None:
break
+ if args.profile and batch_id == 5:
+ profiler.start_profiler("All")
+ profiler.reset_profiler()
+ elif args.profile and batch_id == 10:
+ print("profiling total time: ", time.time() - start_time)
+ profiler.stop_profiler("total", "/tmp/profile_%d_pass%d" %
+ (trainer_id, pass_id))
if iters == args.iterations:
+ reader_generator.close()
break
- if args.profile and pass_id == 0 and batch_id == 5:
- profiler.start_profiler("All")
- elif args.profile and pass_id == 0 and batch_id == 10:
- profiler.stop_profiler("total", "/tmp/profile_%d" % trainer_id)
if iters == args.skip_batch_num:
start_time = time.time()
num_samples = 0
+ fetch_list = [avg_loss.name]
+ acc_name_list = [v.name for v in train_args[2]]
+ fetch_list.extend(acc_name_list)
+
if args.use_fake_data or args.use_reader_op:
try:
- loss, = exe.run([avg_loss.name])
+
+ fetch_ret = exe.run(fetch_list)
+ except fluid.core.EOFException as eof:
+ break
except fluid.core.EnforceNotMet as ex:
+ traceback.print_exc()
break
else:
- loss, = exe.run([avg_loss.name], feed=feeder.feed(data))
+ fetch_ret = exe.run(fetch_list, feed=feeder.feed(data))
if args.use_reader_op:
num_samples += args.batch_size * args.gpus
else:
num_samples += len(data)
+
iters += 1
if batch_id % 1 == 0:
- print("Pass %d, batch %d, loss %s" %
- (pass_id, batch_id, np.array(loss)))
+ fetched_data = [np.mean(np.array(d)) for d in fetch_ret]
+ print("Pass %d, batch %d, loss %s, accucacys: %s" %
+ (pass_id, batch_id, fetched_data[0], fetched_data[1:]))
batch_id += 1
print_train_time(start_time, time.time(), num_samples)
- if not args.no_test and batch_acc and not args.use_reader_op:
- # we have not implement record io for test
- # skip test when use args.use_reader_op
- test_acc = test(startup_exe, infer_prog, test_reader, feeder,
- batch_acc)
- print("Pass: %d, Test Accuracy: %f\n" % (pass_id, test_acc))
+ if args.use_reader_op:
+ train_args[4].reset() # reset reader handle
+ else:
+ del reader_generator
+
+ if not args.no_test and test_args[2]:
+ test_feeder = None
+ if not args.use_reader_op:
+ test_feed_var_list = [
+ var for var in test_prog.global_block().vars.itervalues()
+ if var.is_data
+ ]
+ test_feeder = fluid.DataFeeder(test_feed_var_list, place)
+ test_ret = test_parallel(test_exe, test_args, args, test_prog,
+ test_feeder)
+ print("Pass: %d, Test Accuracy: %s\n" %
+ (pass_id, [np.mean(np.array(v)) for v in test_ret]))
+
+ print("total train time: ", time.time() - over_all_start)
def print_arguments(args):
@@ -326,44 +312,46 @@ def main():
if args.use_cprof:
pr = cProfile.Profile()
pr.enable()
+
model_def = __import__("models.%s" % args.model, fromlist=["models"])
- train_args = list(model_def.get_model(args))
- train_args.append(args)
- # Run optimizer.minimize(avg_loss)
- train_args[2].minimize(train_args[0])
- if args.memory_optimize:
- fluid.memory_optimize(fluid.default_main_program())
+
+ train_prog = fluid.Program()
+ test_prog = fluid.Program()
+ startup_prog = fluid.Program()
+
+ train_args = list(model_def.get_model(args, True, train_prog, startup_prog))
+ test_args = list(model_def.get_model(args, False, test_prog, startup_prog))
+
+ all_args = [train_args, test_args, args]
if args.update_method == "pserver":
- train_prog, startup_prog = dist_transpile(trainer_id, args)
+ train_prog, startup_prog = dist_transpile(trainer_id, args, train_prog,
+ startup_prog)
if not train_prog:
raise Exception(
"Must configure correct environments to run dist train.")
- train_args.extend([train_prog, startup_prog])
+ all_args.extend([train_prog, test_prog, startup_prog])
if args.gpus > 1 and os.getenv("PADDLE_TRAINING_ROLE") == "TRAINER":
- train_args.extend([nccl_id_var, num_trainers, trainer_id])
- train_parallel(*train_args)
- train(*train_args)
+ all_args.extend([nccl_id_var, num_trainers, trainer_id])
+ train_parallel(*all_args)
+ elif os.getenv("PADDLE_TRAINING_ROLE") == "PSERVER":
+ # start pserver with Executor
+ server_exe = fluid.Executor(fluid.CPUPlace())
+ server_exe.run(startup_prog)
+ server_exe.run(train_prog)
exit(0)
# for other update methods, use default programs
- train_args.append(fluid.default_main_program())
- train_args.append(fluid.default_startup_program())
+ all_args.extend([train_prog, test_prog, startup_prog])
if args.update_method == "nccl2":
- nccl_id_var, num_trainers, trainer_id = append_nccl2_prepare(trainer_id)
- if args.gpus == 1:
- # NOTE: parallel executor use profiler interanlly
- if args.use_nvprof and args.device == 'GPU':
- with profiler.cuda_profiler("cuda_profiler.txt", 'csv') as nvprof:
- train(*train_args)
- else:
- train(*train_args)
- else:
- if args.device == "CPU":
- raise Exception("Only support GPU perf with parallel exe")
- train_args.extend([nccl_id_var, num_trainers, trainer_id])
- train_parallel(*train_args)
+ nccl_id_var, num_trainers, trainer_id = append_nccl2_prepare(
+ trainer_id, startup_prog)
+
+ if args.device == "CPU":
+ raise Exception("Only support GPU perf with parallel exe")
+ all_args.extend([nccl_id_var, num_trainers, trainer_id])
+ train_parallel(*all_args)
if __name__ == "__main__":
diff --git a/benchmark/fluid/imagenet_reader.py b/benchmark/fluid/imagenet_reader.py
new file mode 100644
index 0000000000000000000000000000000000000000..a39485a61f12417fbdb512fc81e90ec49c310bf5
--- /dev/null
+++ b/benchmark/fluid/imagenet_reader.py
@@ -0,0 +1,344 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import math
+import random
+import functools
+import numpy as np
+from threading import Thread
+import subprocess
+import time
+
+from Queue import Queue
+import paddle
+from PIL import Image, ImageEnhance
+
+random.seed(0)
+
+DATA_DIM = 224
+
+THREAD = int(os.getenv("PREPROCESS_THREADS", "10"))
+BUF_SIZE = 5120
+
+DATA_DIR = '/mnt/ImageNet'
+TRAIN_LIST = '/mnt/ImageNet/train.txt'
+TEST_LIST = '/mnt/ImageNet/val.txt'
+
+img_mean = np.array([0.485, 0.456, 0.406]).reshape((3, 1, 1))
+img_std = np.array([0.229, 0.224, 0.225]).reshape((3, 1, 1))
+
+
+def resize_short(img, target_size):
+ percent = float(target_size) / min(img.size[0], img.size[1])
+ resized_width = int(round(img.size[0] * percent))
+ resized_height = int(round(img.size[1] * percent))
+ img = img.resize((resized_width, resized_height), Image.LANCZOS)
+ return img
+
+
+def crop_image(img, target_size, center):
+ width, height = img.size
+ size = target_size
+ if center == True:
+ w_start = (width - size) / 2
+ h_start = (height - size) / 2
+ else:
+ w_start = random.randint(0, width - size)
+ h_start = random.randint(0, height - size)
+ w_end = w_start + size
+ h_end = h_start + size
+ img = img.crop((w_start, h_start, w_end, h_end))
+ return img
+
+
+def random_crop(img, size, scale=[0.08, 1.0], ratio=[3. / 4., 4. / 3.]):
+ aspect_ratio = math.sqrt(random.uniform(*ratio))
+ w = 1. * aspect_ratio
+ h = 1. / aspect_ratio
+
+ bound = min((float(img.size[0]) / img.size[1]) / (w**2),
+ (float(img.size[1]) / img.size[0]) / (h**2))
+ scale_max = min(scale[1], bound)
+ scale_min = min(scale[0], bound)
+
+ target_area = img.size[0] * img.size[1] * random.uniform(scale_min,
+ scale_max)
+ target_size = math.sqrt(target_area)
+ w = int(target_size * w)
+ h = int(target_size * h)
+
+ i = random.randint(0, img.size[0] - w)
+ j = random.randint(0, img.size[1] - h)
+
+ img = img.crop((i, j, i + w, j + h))
+ img = img.resize((size, size), Image.LANCZOS)
+ return img
+
+
+def rotate_image(img):
+ angle = random.randint(-10, 10)
+ img = img.rotate(angle)
+ return img
+
+
+def distort_color(img):
+ def random_brightness(img, lower=0.5, upper=1.5):
+ e = random.uniform(lower, upper)
+ return ImageEnhance.Brightness(img).enhance(e)
+
+ def random_contrast(img, lower=0.5, upper=1.5):
+ e = random.uniform(lower, upper)
+ return ImageEnhance.Contrast(img).enhance(e)
+
+ def random_color(img, lower=0.5, upper=1.5):
+ e = random.uniform(lower, upper)
+ return ImageEnhance.Color(img).enhance(e)
+
+ ops = [random_brightness, random_contrast, random_color]
+ random.shuffle(ops)
+
+ img = ops[0](img)
+ img = ops[1](img)
+ img = ops[2](img)
+
+ return img
+
+
+def process_image(sample, mode, color_jitter, rotate):
+ img_path = sample[0]
+
+ img = Image.open(img_path)
+ if mode == 'train':
+ if rotate: img = rotate_image(img)
+ img = random_crop(img, DATA_DIM)
+ else:
+ img = resize_short(img, target_size=256)
+ img = crop_image(img, target_size=DATA_DIM, center=True)
+ if mode == 'train':
+ if color_jitter:
+ img = distort_color(img)
+ if random.randint(0, 1) == 1:
+ img = img.transpose(Image.FLIP_LEFT_RIGHT)
+
+ if img.mode != 'RGB':
+ img = img.convert('RGB')
+
+ img = np.array(img).astype('float32').transpose((2, 0, 1)) / 255
+ img -= img_mean
+ img /= img_std
+
+ if mode == 'train' or mode == 'val':
+ return img, sample[1]
+ elif mode == 'test':
+ return [img]
+
+
+class XmapEndSignal():
+ pass
+
+
+def xmap_readers(mapper,
+ reader,
+ process_num,
+ buffer_size,
+ order=False,
+ print_queue_state=True):
+ end = XmapEndSignal()
+
+ # define a worker to read samples from reader to in_queue
+ def read_worker(reader, in_queue):
+ for i in reader():
+ in_queue.put(i)
+ in_queue.put(end)
+
+ # define a worker to read samples from reader to in_queue with order flag
+ def order_read_worker(reader, in_queue, file_queue):
+ in_order = 0
+ for i in reader():
+ in_queue.put((in_order, i))
+ in_order += 1
+ in_queue.put(end)
+
+ # define a worker to handle samples from in_queue by mapper
+ # and put mapped samples into out_queue
+ def handle_worker(in_queue, out_queue, mapper):
+ sample = in_queue.get()
+ while not isinstance(sample, XmapEndSignal):
+ r = mapper(sample)
+ out_queue.put(r)
+ sample = in_queue.get()
+ in_queue.put(end)
+ out_queue.put(end)
+
+ # define a worker to handle samples from in_queue by mapper
+ # and put mapped samples into out_queue by order
+ def order_handle_worker(in_queue, out_queue, mapper, out_order):
+ ins = in_queue.get()
+ while not isinstance(ins, XmapEndSignal):
+ order, sample = ins
+ r = mapper(sample)
+ while order != out_order[0]:
+ pass
+ out_queue.put(r)
+ out_order[0] += 1
+ ins = in_queue.get()
+ in_queue.put(end)
+ out_queue.put(end)
+
+ def xreader():
+ file_queue = Queue()
+ in_queue = Queue(buffer_size)
+ out_queue = Queue(buffer_size)
+ out_order = [0]
+ # start a read worker in a thread
+ target = order_read_worker if order else read_worker
+ t = Thread(target=target, args=(reader, in_queue))
+ t.daemon = True
+ t.start()
+ # start several handle_workers
+ target = order_handle_worker if order else handle_worker
+ args = (in_queue, out_queue, mapper, out_order) if order else (
+ in_queue, out_queue, mapper)
+ workers = []
+ for i in xrange(process_num):
+ worker = Thread(target=target, args=args)
+ worker.daemon = True
+ workers.append(worker)
+ for w in workers:
+ w.start()
+
+ sample = out_queue.get()
+ start_t = time.time()
+ while not isinstance(sample, XmapEndSignal):
+ yield sample
+ sample = out_queue.get()
+ if time.time() - start_t > 3:
+ if print_queue_state:
+ print("queue sizes: ", in_queue.qsize(), out_queue.qsize())
+ start_t = time.time()
+ finish = 1
+ while finish < process_num:
+ sample = out_queue.get()
+ if isinstance(sample, XmapEndSignal):
+ finish += 1
+ else:
+ yield sample
+
+ return xreader
+
+
+def _reader_creator(file_list,
+ mode,
+ shuffle=False,
+ color_jitter=False,
+ rotate=False,
+ xmap=True):
+ def reader():
+ with open(file_list) as flist:
+ full_lines = [line.strip() for line in flist]
+ if shuffle:
+ random.shuffle(full_lines)
+ if mode == 'train':
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID"))
+ trainer_count = int(os.getenv("PADDLE_TRAINERS"))
+ per_node_lines = len(full_lines) / trainer_count
+ lines = full_lines[trainer_id * per_node_lines:(trainer_id + 1)
+ * per_node_lines]
+ print(
+ "read images from %d, length: %d, lines length: %d, total: %d"
+ % (trainer_id * per_node_lines, per_node_lines, len(lines),
+ len(full_lines)))
+ else:
+ lines = full_lines
+
+ for line in lines:
+ if mode == 'train':
+ img_path, label = line.split()
+ img_path = img_path.replace("JPEG", "jpeg")
+ img_path = os.path.join(DATA_DIR, "train", img_path)
+ yield (img_path, int(label))
+ elif mode == 'val':
+ img_path, label = line.split()
+ img_path = img_path.replace("JPEG", "jpeg")
+ img_path = os.path.join(DATA_DIR, "val", img_path)
+ yield (img_path, int(label))
+ elif mode == 'test':
+ img_path = os.path.join(DATA_DIR, line)
+ yield [img_path]
+
+ mapper = functools.partial(
+ process_image, mode=mode, color_jitter=color_jitter, rotate=rotate)
+
+ return paddle.reader.xmap_readers(mapper, reader, THREAD, BUF_SIZE)
+
+
+def load_raw_image_uint8(sample):
+ img_arr = np.array(Image.open(sample[0])).astype('int64')
+ return img_arr, int(sample[1])
+
+
+def train_raw(file_list=TRAIN_LIST, shuffle=True):
+ def reader():
+ with open(file_list) as flist:
+ full_lines = [line.strip() for line in flist]
+ if shuffle:
+ random.shuffle(full_lines)
+
+ trainer_id = int(os.getenv("PADDLE_TRAINER_ID"))
+ trainer_count = int(os.getenv("PADDLE_TRAINERS"))
+ per_node_lines = len(full_lines) / trainer_count
+ lines = full_lines[trainer_id * per_node_lines:(trainer_id + 1) *
+ per_node_lines]
+ print("read images from %d, length: %d, lines length: %d, total: %d"
+ % (trainer_id * per_node_lines, per_node_lines, len(lines),
+ len(full_lines)))
+
+ for line in lines:
+ img_path, label = line.split()
+ img_path = img_path.replace("JPEG", "jpeg")
+ img_path = os.path.join(DATA_DIR, "train", img_path)
+ yield (img_path, int(label))
+
+ return paddle.reader.xmap_readers(load_raw_image_uint8, reader, THREAD,
+ BUF_SIZE)
+
+
+def train(file_list=TRAIN_LIST, xmap=True):
+ return _reader_creator(
+ file_list,
+ 'train',
+ shuffle=True,
+ color_jitter=False,
+ rotate=False,
+ xmap=xmap)
+
+
+def val(file_list=TEST_LIST, xmap=True):
+ return _reader_creator(file_list, 'val', shuffle=False, xmap=xmap)
+
+
+def test(file_list=TEST_LIST):
+ return _reader_creator(file_list, 'test', shuffle=False)
+
+
+if __name__ == "__main__":
+ c = 0
+ start_t = time.time()
+ for d in train()():
+ c += 1
+ if c >= 10000:
+ break
+ spent = time.time() - start_t
+ print("read 10000 speed: ", 10000 / spent, spent)
diff --git a/benchmark/fluid/kube_gen_job.py b/benchmark/fluid/kube_gen_job.py
index dfe8b5cdd58456902fa8ec355e9837dface3f7be..c1f22f1bfa02dd409edc8e1c39a72524240f4088 100644
--- a/benchmark/fluid/kube_gen_job.py
+++ b/benchmark/fluid/kube_gen_job.py
@@ -163,6 +163,19 @@ def gen_job():
volumes.append({"name": "dshm", "emptyDir": {"medium": "Memory"}})
volumeMounts.append({"mountPath": "/dev/shm", "name": "dshm"})
+ # add ceph volumes
+ volumes.append({
+ "name": "ceph-data",
+ "cephfs": {
+ "monitors": ["192.168.16.23:6789"],
+ "secretRef": {
+ "name": "ceph-secret"
+ },
+ "user": "admin",
+ }
+ })
+ volumeMounts.append({"mountPath": "/mnt/data", "name": "ceph-data"})
+
tn["spec"]["template"]["spec"]["volumes"] = volumes
tn_container["volumeMounts"] = volumeMounts
diff --git a/benchmark/fluid/models/__init__.py b/benchmark/fluid/models/__init__.py
index 1c3fcac8dd4a1ba0496ef013bd4eb468a0075125..1b8f63c7070c2cd45531966b0bcdff95a848574d 100644
--- a/benchmark/fluid/models/__init__.py
+++ b/benchmark/fluid/models/__init__.py
@@ -13,5 +13,6 @@
# limitations under the License.
__all__ = [
- "machine_translation", "resnet", "vgg", "mnist", "stacked_dynamic_lstm"
+ "machine_translation", "resnet", "vgg", "mnist", "stacked_dynamic_lstm",
+ "resnet_with_preprocess"
]
diff --git a/benchmark/fluid/models/machine_translation.py b/benchmark/fluid/models/machine_translation.py
index 17f6b03826ae818a3671ea7f9355a8e8c04b50be..18163c35d65a28c046cfeb33f5b96c34a1a6a35a 100644
--- a/benchmark/fluid/models/machine_translation.py
+++ b/benchmark/fluid/models/machine_translation.py
@@ -12,6 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
"""seq2seq model for fluid."""
+
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
@@ -181,7 +182,7 @@ def lodtensor_to_ndarray(lod_tensor):
return ndarray
-def get_model(args):
+def get_model(args, is_train, main_prog, startup_prog):
if args.use_reader_op:
raise Exception("machine_translation do not support reader op for now.")
embedding_dim = 512
@@ -190,30 +191,27 @@ def get_model(args):
dict_size = 30000
beam_size = 3
max_length = 250
- avg_cost, feeding_list = seq_to_seq_net(
- embedding_dim,
- encoder_size,
- decoder_size,
- dict_size,
- dict_size,
- False,
- beam_size=beam_size,
- max_length=max_length)
-
- # clone from default main program
- inference_program = fluid.default_main_program().clone()
-
- optimizer = fluid.optimizer.Adam(learning_rate=args.learning_rate)
-
- train_batch_generator = paddle.batch(
- paddle.reader.shuffle(
- paddle.dataset.wmt14.train(dict_size), buf_size=1000),
- batch_size=args.batch_size * args.gpus)
- test_batch_generator = paddle.batch(
+ with fluid.program_guard(main_prog, startup_prog):
+ with fluid.unique_name.guard():
+ avg_cost, feeding_list = seq_to_seq_net(
+ embedding_dim,
+ encoder_size,
+ decoder_size,
+ dict_size,
+ dict_size,
+ False,
+ beam_size=beam_size,
+ max_length=max_length)
+ if is_train:
+ optimizer = fluid.optimizer.Adam(learning_rate=args.learning_rate)
+ optimizer.minimize(avg_cost)
+
+ batch_generator = paddle.batch(
paddle.reader.shuffle(
- paddle.dataset.wmt14.test(dict_size), buf_size=1000),
- batch_size=args.batch_size)
+ paddle.dataset.wmt14.train(dict_size)
+ if is_train else paddle.dataset.wmt14.test(dict_size),
+ buf_size=1000),
+ batch_size=args.batch_size * args.gpus)
- return avg_cost, inference_program, optimizer, train_batch_generator, \
- test_batch_generator, None
+ return avg_cost, optimizer, [], batch_generator, None
diff --git a/benchmark/fluid/models/mnist.py b/benchmark/fluid/models/mnist.py
index 8e740dc6896b7eeeb82170aa13d32987c4df5c48..cef8657ee629dcbc19221fd3440844a56627e920 100644
--- a/benchmark/fluid/models/mnist.py
+++ b/benchmark/fluid/models/mnist.py
@@ -65,61 +65,50 @@ def cnn_model(data):
return predict
-def get_model(args):
- if args.use_reader_op:
- filelist = [
- os.path.join(args.data_path, f) for f in os.listdir(args.data_path)
- ]
- data_file = fluid.layers.open_files(
- filenames=filelist,
- shapes=[[-1, 1, 28, 28], (-1, 1)],
- lod_levels=[0, 0],
- dtypes=["float32", "int64"],
- thread_num=args.gpus,
- pass_num=args.pass_num)
- data_file = fluid.layers.double_buffer(
- fluid.layers.batch(
- data_file, batch_size=args.batch_size))
- images, label = fluid.layers.read_file(data_file)
- else:
- images = fluid.layers.data(name='pixel', shape=[1, 28, 28], dtype=DTYPE)
- label = fluid.layers.data(name='label', shape=[1], dtype='int64')
-
- if args.device == 'CPU' and args.cpus > 1:
- places = fluid.layers.get_places(args.cpus)
- pd = fluid.layers.ParallelDo(places)
- with pd.do():
- predict = cnn_model(pd.read_input(images))
- label = pd.read_input(label)
+def get_model(args, is_train, main_prog, startup_prog):
+ # NOTE: mnist is small, we don't implement data sharding yet.
+ filelist = [
+ os.path.join(args.data_path, f) for f in os.listdir(args.data_path)
+ ]
+ with fluid.program_guard(main_prog, startup_prog):
+ if args.use_reader_op:
+ data_file_handle = fluid.layers.open_files(
+ filenames=filelist,
+ shapes=[[-1, 1, 28, 28], (-1, 1)],
+ lod_levels=[0, 0],
+ dtypes=["float32", "int64"],
+ thread_num=1,
+ pass_num=1)
+ data_file = fluid.layers.double_buffer(
+ fluid.layers.batch(
+ data_file_handle, batch_size=args.batch_size))
+ with fluid.unique_name.guard():
+ if args.use_reader_op:
+ input, label = fluid.layers.read_file(data_file)
+ else:
+ images = fluid.layers.data(
+ name='pixel', shape=[1, 28, 28], dtype='float32')
+ label = fluid.layers.data(
+ name='label', shape=[1], dtype='int64')
+
+ predict = cnn_model(images)
cost = fluid.layers.cross_entropy(input=predict, label=label)
avg_cost = fluid.layers.mean(x=cost)
+ # Evaluator
batch_acc = fluid.layers.accuracy(input=predict, label=label)
-
- pd.write_output(avg_cost)
- pd.write_output(batch_acc)
-
- avg_cost, batch_acc = pd()
- avg_cost = fluid.layers.mean(avg_cost)
- batch_acc = fluid.layers.mean(batch_acc)
- else:
- # Train program
- predict = cnn_model(images)
- cost = fluid.layers.cross_entropy(input=predict, label=label)
- avg_cost = fluid.layers.mean(x=cost)
-
- # Evaluator
- batch_acc = fluid.layers.accuracy(input=predict, label=label)
-
- # inference program
- inference_program = fluid.default_main_program().clone()
-
- # Optimization
- opt = fluid.optimizer.AdamOptimizer(
- learning_rate=0.001, beta1=0.9, beta2=0.999)
+ # Optimization
+ if is_train:
+ opt = fluid.optimizer.AdamOptimizer(
+ learning_rate=0.001, beta1=0.9, beta2=0.999)
+ opt.minimize()
+ if args.memory_optimize:
+ fluid.memory_optimize(main_prog)
# Reader
- train_reader = paddle.batch(
- paddle.dataset.mnist.train(), batch_size=args.batch_size * args.gpus)
- test_reader = paddle.batch(
- paddle.dataset.mnist.test(), batch_size=args.batch_size)
- return avg_cost, inference_program, opt, train_reader, test_reader, batch_acc
+ if is_train:
+ reader = paddle.dataset.mnist.train()
+ else:
+ reader = paddle.dataset.mnist.test()
+ batched_reader = paddle.batch(
+ reader, batch_size=args.batch_size * args.gpus)
+ return avg_cost, opt, [batch_acc], batched_reader, data_file_handle
diff --git a/benchmark/fluid/models/resnet.py b/benchmark/fluid/models/resnet.py
index d44a9c07d31cfae9d54ad5949b85c77e60eae258..ae1baa48e17e40448e457052fd1464b9604a2128 100644
--- a/benchmark/fluid/models/resnet.py
+++ b/benchmark/fluid/models/resnet.py
@@ -27,10 +27,17 @@ import paddle
import paddle.fluid as fluid
import paddle.fluid.core as core
import paddle.fluid.profiler as profiler
-from recordio_converter import imagenet_train, imagenet_test
+# from recordio_converter import imagenet_train, imagenet_test
+from imagenet_reader import train, val
-def conv_bn_layer(input, ch_out, filter_size, stride, padding, act='relu'):
+def conv_bn_layer(input,
+ ch_out,
+ filter_size,
+ stride,
+ padding,
+ act='relu',
+ is_train=True):
conv1 = fluid.layers.conv2d(
input=input,
filter_size=filter_size,
@@ -39,29 +46,31 @@ def conv_bn_layer(input, ch_out, filter_size, stride, padding, act='relu'):
padding=padding,
act=None,
bias_attr=False)
- return fluid.layers.batch_norm(input=conv1, act=act)
+ return fluid.layers.batch_norm(input=conv1, act=act, is_test=not is_train)
-def shortcut(input, ch_out, stride):
+def shortcut(input, ch_out, stride, is_train=True):
ch_in = input.shape[1] # if args.data_format == 'NCHW' else input.shape[-1]
if ch_in != ch_out:
- return conv_bn_layer(input, ch_out, 1, stride, 0, None)
+ return conv_bn_layer(
+ input, ch_out, 1, stride, 0, None, is_train=is_train)
else:
return input
-def basicblock(input, ch_out, stride):
- short = shortcut(input, ch_out, stride)
- conv1 = conv_bn_layer(input, ch_out, 3, stride, 1)
- conv2 = conv_bn_layer(conv1, ch_out, 3, 1, 1, act=None)
+def basicblock(input, ch_out, stride, is_train=True):
+ short = shortcut(input, ch_out, stride, is_train=is_train)
+ conv1 = conv_bn_layer(input, ch_out, 3, stride, 1, is_train=is_train)
+ conv2 = conv_bn_layer(conv1, ch_out, 3, 1, 1, act=None, is_train=is_train)
return fluid.layers.elementwise_add(x=short, y=conv2, act='relu')
-def bottleneck(input, ch_out, stride):
- short = shortcut(input, ch_out * 4, stride)
- conv1 = conv_bn_layer(input, ch_out, 1, stride, 0)
- conv2 = conv_bn_layer(conv1, ch_out, 3, 1, 1)
- conv3 = conv_bn_layer(conv2, ch_out * 4, 1, 1, 0, act=None)
+def bottleneck(input, ch_out, stride, is_train=True):
+ short = shortcut(input, ch_out * 4, stride, is_train=is_train)
+ conv1 = conv_bn_layer(input, ch_out, 1, stride, 0, is_train=is_train)
+ conv2 = conv_bn_layer(conv1, ch_out, 3, 1, 1, is_train=is_train)
+ conv3 = conv_bn_layer(
+ conv2, ch_out * 4, 1, 1, 0, act=None, is_train=is_train)
return fluid.layers.elementwise_add(x=short, y=conv3, act='relu')
@@ -72,7 +81,11 @@ def layer_warp(block_func, input, ch_out, count, stride):
return res_out
-def resnet_imagenet(input, class_dim, depth=50, data_format='NCHW'):
+def resnet_imagenet(input,
+ class_dim,
+ depth=50,
+ data_format='NCHW',
+ is_train=True):
cfg = {
18: ([2, 2, 2, 1], basicblock),
@@ -115,8 +128,9 @@ def resnet_cifar10(input, class_dim, depth=32, data_format='NCHW'):
return out
-def get_model(args):
+def _model_reader_dshape_classdim(args, is_train):
model = resnet_cifar10
+ reader = None
if args.data_set == "cifar10":
class_dim = 10
if args.data_format == 'NCHW':
@@ -124,8 +138,10 @@ def get_model(args):
else:
dshape = [32, 32, 3]
model = resnet_cifar10
- train_reader = paddle.dataset.cifar.train10()
- test_reader = paddle.dataset.cifar.test10()
+ if is_train:
+ reader = paddle.dataset.cifar.train10()
+ else:
+ reader = paddle.dataset.cifar.test10()
elif args.data_set == "flowers":
class_dim = 102
if args.data_format == 'NCHW':
@@ -133,8 +149,10 @@ def get_model(args):
else:
dshape = [224, 224, 3]
model = resnet_imagenet
- train_reader = paddle.dataset.flowers.train()
- test_reader = paddle.dataset.flowers.test()
+ if is_train:
+ reader = paddle.dataset.flowers.train()
+ else:
+ reader = paddle.dataset.flowers.test()
elif args.data_set == "imagenet":
class_dim = 1000
if args.data_format == 'NCHW':
@@ -145,64 +163,89 @@ def get_model(args):
if not args.data_path:
raise Exception(
"Must specify --data_path when training with imagenet")
- train_reader = imagenet_train(args.data_path)
- test_reader = imagenet_test(args.data_path)
-
- if args.use_reader_op:
- filelist = [
- os.path.join(args.data_path, f) for f in os.listdir(args.data_path)
- ]
- data_file = fluid.layers.open_files(
- filenames=filelist,
- shapes=[[-1] + dshape, (-1, 1)],
- lod_levels=[0, 0],
- dtypes=["float32", "int64"],
- thread_num=args.gpus,
- pass_num=args.pass_num)
- data_file = fluid.layers.double_buffer(
- fluid.layers.batch(
- data_file, batch_size=args.batch_size))
- input, label = fluid.layers.read_file(data_file)
- else:
- input = fluid.layers.data(name='data', shape=dshape, dtype='float32')
- label = fluid.layers.data(name='label', shape=[1], dtype='int64')
-
- if args.device == 'CPU' and args.cpus > 1:
- places = fluid.layers.get_places(args.cpus)
- pd = fluid.layers.ParallelDo(places)
- with pd.do():
- predict = model(pd.read_input(input), class_dim)
- label = pd.read_input(label)
+ if not args.use_reader_op:
+ if is_train:
+ reader = train()
+ else:
+ reader = val()
+ else:
+ if is_train:
+ reader = train(xmap=False)
+ else:
+ reader = val(xmap=False)
+ return model, reader, dshape, class_dim
+
+
+def get_model(args, is_train, main_prog, startup_prog):
+ model, reader, dshape, class_dim = _model_reader_dshape_classdim(args,
+ is_train)
+
+ pyreader = None
+ trainer_count = int(os.getenv("PADDLE_TRAINERS"))
+ with fluid.program_guard(main_prog, startup_prog):
+ with fluid.unique_name.guard():
+ if args.use_reader_op:
+ pyreader = fluid.layers.py_reader(
+ capacity=args.batch_size * args.gpus,
+ shapes=([-1] + dshape, (-1, 1)),
+ dtypes=('float32', 'int64'),
+ name="train_reader" if is_train else "test_reader",
+ use_double_buffer=True)
+ input, label = fluid.layers.read_file(pyreader)
+ else:
+ input = fluid.layers.data(
+ name='data', shape=dshape, dtype='float32')
+ label = fluid.layers.data(
+ name='label', shape=[1], dtype='int64')
+
+ predict = model(input, class_dim, is_train=is_train)
cost = fluid.layers.cross_entropy(input=predict, label=label)
avg_cost = fluid.layers.mean(x=cost)
- batch_acc = fluid.layers.accuracy(input=predict, label=label)
-
- pd.write_output(avg_cost)
- pd.write_output(batch_acc)
- avg_cost, batch_acc = pd()
- avg_cost = fluid.layers.mean(avg_cost)
- batch_acc = fluid.layers.mean(batch_acc)
+ batch_acc1 = fluid.layers.accuracy(input=predict, label=label, k=1)
+ batch_acc5 = fluid.layers.accuracy(input=predict, label=label, k=5)
+
+ # configure optimize
+ optimizer = None
+ if is_train:
+ if args.use_lars:
+ lars_decay = 1.0
+ else:
+ lars_decay = 0.0
+
+ total_images = 1281167 / trainer_count
+
+ step = int(total_images / args.batch_size + 1)
+ epochs = [30, 60, 80, 90]
+ bd = [step * e for e in epochs]
+ base_lr = args.learning_rate
+ lr = []
+ lr = [base_lr * (0.1**i) for i in range(len(bd) + 1)]
+ optimizer = fluid.optimizer.Momentum(
+ learning_rate=base_lr,
+ #learning_rate=fluid.layers.piecewise_decay(
+ # boundaries=bd, values=lr),
+ momentum=0.9,
+ regularization=fluid.regularizer.L2Decay(1e-4))
+ optimizer.minimize(avg_cost)
+
+ if args.memory_optimize:
+ fluid.memory_optimize(main_prog)
+
+ # config readers
+ if not args.use_reader_op:
+ batched_reader = paddle.batch(
+ reader if args.no_random else paddle.reader.shuffle(
+ reader, buf_size=5120),
+ batch_size=args.batch_size * args.gpus,
+ drop_last=True)
else:
- predict = model(input, class_dim)
- cost = fluid.layers.cross_entropy(input=predict, label=label)
- avg_cost = fluid.layers.mean(x=cost)
- batch_acc = fluid.layers.accuracy(input=predict, label=label)
-
- inference_program = fluid.default_main_program().clone()
- with fluid.program_guard(inference_program):
- inference_program = fluid.io.get_inference_program(
- target_vars=[batch_acc])
-
- optimizer = fluid.optimizer.Momentum(learning_rate=0.01, momentum=0.9)
-
- batched_train_reader = paddle.batch(
- train_reader if args.no_random else paddle.reader.shuffle(
- train_reader, buf_size=5120),
- batch_size=args.batch_size * args.gpus,
- drop_last=True)
- batched_test_reader = paddle.batch(
- test_reader, batch_size=args.batch_size, drop_last=True)
-
- return avg_cost, inference_program, optimizer, batched_train_reader,\
- batched_test_reader, batch_acc
+ batched_reader = None
+ pyreader.decorate_paddle_reader(
+ paddle.batch(
+ reader if args.no_random else paddle.reader.shuffle(
+ reader, buf_size=5120),
+ batch_size=args.batch_size))
+
+ return avg_cost, optimizer, [batch_acc1,
+ batch_acc5], batched_reader, pyreader
diff --git a/benchmark/fluid/models/resnet_with_preprocess.py b/benchmark/fluid/models/resnet_with_preprocess.py
new file mode 100644
index 0000000000000000000000000000000000000000..e8d661d847516a15e4e28796960815935b82ae6f
--- /dev/null
+++ b/benchmark/fluid/models/resnet_with_preprocess.py
@@ -0,0 +1,268 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import absolute_import
+from __future__ import division
+from __future__ import print_function
+
+import functools
+import numpy as np
+import time
+import os
+
+import cProfile, pstats, StringIO
+
+import paddle
+import paddle.fluid as fluid
+import paddle.fluid.core as core
+import paddle.fluid.profiler as profiler
+# from recordio_converter import imagenet_train, imagenet_test
+from imagenet_reader import train_raw, val
+
+
+def conv_bn_layer(input,
+ ch_out,
+ filter_size,
+ stride,
+ padding,
+ act='relu',
+ is_train=True):
+ conv1 = fluid.layers.conv2d(
+ input=input,
+ filter_size=filter_size,
+ num_filters=ch_out,
+ stride=stride,
+ padding=padding,
+ act=None,
+ bias_attr=False)
+ return fluid.layers.batch_norm(input=conv1, act=act, is_test=not is_train)
+
+
+def shortcut(input, ch_out, stride, is_train=True):
+ ch_in = input.shape[1] # if args.data_format == 'NCHW' else input.shape[-1]
+ if ch_in != ch_out:
+ return conv_bn_layer(
+ input, ch_out, 1, stride, 0, None, is_train=is_train)
+ else:
+ return input
+
+
+def basicblock(input, ch_out, stride, is_train=True):
+ short = shortcut(input, ch_out, stride, is_train=is_train)
+ conv1 = conv_bn_layer(input, ch_out, 3, stride, 1, is_train=is_train)
+ conv2 = conv_bn_layer(conv1, ch_out, 3, 1, 1, act=None, is_train=is_train)
+ return fluid.layers.elementwise_add(x=short, y=conv2, act='relu')
+
+
+def bottleneck(input, ch_out, stride, is_train=True):
+ short = shortcut(input, ch_out * 4, stride, is_train=is_train)
+ conv1 = conv_bn_layer(input, ch_out, 1, stride, 0, is_train=is_train)
+ conv2 = conv_bn_layer(conv1, ch_out, 3, 1, 1, is_train=is_train)
+ conv3 = conv_bn_layer(
+ conv2, ch_out * 4, 1, 1, 0, act=None, is_train=is_train)
+ return fluid.layers.elementwise_add(x=short, y=conv3, act='relu')
+
+
+def layer_warp(block_func, input, ch_out, count, stride):
+ res_out = block_func(input, ch_out, stride)
+ for i in range(1, count):
+ res_out = block_func(res_out, ch_out, 1)
+ return res_out
+
+
+def resnet_imagenet(input,
+ class_dim,
+ depth=50,
+ data_format='NCHW',
+ is_train=True):
+
+ cfg = {
+ 18: ([2, 2, 2, 1], basicblock),
+ 34: ([3, 4, 6, 3], basicblock),
+ 50: ([3, 4, 6, 3], bottleneck),
+ 101: ([3, 4, 23, 3], bottleneck),
+ 152: ([3, 8, 36, 3], bottleneck)
+ }
+ stages, block_func = cfg[depth]
+ conv1 = conv_bn_layer(input, ch_out=64, filter_size=7, stride=2, padding=3)
+ pool1 = fluid.layers.pool2d(
+ input=conv1, pool_type='avg', pool_size=3, pool_stride=2)
+ res1 = layer_warp(block_func, pool1, 64, stages[0], 1)
+ res2 = layer_warp(block_func, res1, 128, stages[1], 2)
+ res3 = layer_warp(block_func, res2, 256, stages[2], 2)
+ res4 = layer_warp(block_func, res3, 512, stages[3], 2)
+ pool2 = fluid.layers.pool2d(
+ input=res4,
+ pool_size=7,
+ pool_type='avg',
+ pool_stride=1,
+ global_pooling=True)
+ out = fluid.layers.fc(input=pool2, size=class_dim, act='softmax')
+ return out
+
+
+def resnet_cifar10(input, class_dim, depth=32, data_format='NCHW'):
+ assert (depth - 2) % 6 == 0
+
+ n = (depth - 2) // 6
+
+ conv1 = conv_bn_layer(
+ input=input, ch_out=16, filter_size=3, stride=1, padding=1)
+ res1 = layer_warp(basicblock, conv1, 16, n, 1)
+ res2 = layer_warp(basicblock, res1, 32, n, 2)
+ res3 = layer_warp(basicblock, res2, 64, n, 2)
+ pool = fluid.layers.pool2d(
+ input=res3, pool_size=8, pool_type='avg', pool_stride=1)
+ out = fluid.layers.fc(input=pool, size=class_dim, act='softmax')
+ return out
+
+
+def _model_reader_dshape_classdim(args, is_train):
+ model = resnet_cifar10
+ reader = None
+ if args.data_set == "cifar10":
+ class_dim = 10
+ if args.data_format == 'NCHW':
+ dshape = [3, 32, 32]
+ else:
+ dshape = [32, 32, 3]
+ model = resnet_cifar10
+ if is_train:
+ reader = paddle.dataset.cifar.train10()
+ else:
+ reader = paddle.dataset.cifar.test10()
+ elif args.data_set == "flowers":
+ class_dim = 102
+ if args.data_format == 'NCHW':
+ dshape = [3, 224, 224]
+ else:
+ dshape = [224, 224, 3]
+ model = resnet_imagenet
+ if is_train:
+ reader = paddle.dataset.flowers.train()
+ else:
+ reader = paddle.dataset.flowers.test()
+ elif args.data_set == "imagenet":
+ class_dim = 1000
+ if args.data_format == 'NCHW':
+ dshape = [3, 224, 224]
+ else:
+ dshape = [224, 224, 3]
+ model = resnet_imagenet
+ if not args.data_path:
+ raise Exception(
+ "Must specify --data_path when training with imagenet")
+ if not args.use_reader_op:
+ if is_train:
+ reader = train_raw()
+ else:
+ reader = val()
+ else:
+ if is_train:
+ reader = train_raw()
+ else:
+ reader = val(xmap=False)
+ return model, reader, dshape, class_dim
+
+
+def get_model(args, is_train, main_prog, startup_prog):
+ model, reader, dshape, class_dim = _model_reader_dshape_classdim(args,
+ is_train)
+
+ pyreader = None
+ trainer_count = int(os.getenv("PADDLE_TRAINERS"))
+ with fluid.program_guard(main_prog, startup_prog):
+ with fluid.unique_name.guard():
+ if args.use_reader_op:
+ pyreader = fluid.layers.py_reader(
+ capacity=args.batch_size * args.gpus,
+ shapes=([-1] + dshape, (-1, 1)),
+ dtypes=('uint8', 'int64'),
+ name="train_reader" if is_train else "test_reader",
+ use_double_buffer=True)
+ input, label = fluid.layers.read_file(pyreader)
+ else:
+ input = fluid.layers.data(
+ name='data', shape=dshape, dtype='uint8')
+ label = fluid.layers.data(
+ name='label', shape=[1], dtype='int64')
+
+ # add imagenet preprocessors
+ random_crop = fluid.layers.random_crop(input, dshape)
+ casted = fluid.layers.cast(random_crop, 'float32')
+ # input is HWC
+ trans = fluid.layers.transpose(casted, [0, 3, 1, 2]) / 255.0
+ img_mean = fluid.layers.tensor.assign(
+ np.array([0.485, 0.456, 0.406]).astype('float32').reshape((3, 1,
+ 1)))
+ img_std = fluid.layers.tensor.assign(
+ np.array([0.229, 0.224, 0.225]).astype('float32').reshape((3, 1,
+ 1)))
+ h1 = fluid.layers.elementwise_sub(trans, img_mean, axis=1)
+ h2 = fluid.layers.elementwise_div(h1, img_std, axis=1)
+
+ # pre_out = (trans - img_mean) / img_std
+
+ predict = model(h2, class_dim, is_train=is_train)
+ cost = fluid.layers.cross_entropy(input=predict, label=label)
+ avg_cost = fluid.layers.mean(x=cost)
+
+ batch_acc1 = fluid.layers.accuracy(input=predict, label=label, k=1)
+ batch_acc5 = fluid.layers.accuracy(input=predict, label=label, k=5)
+
+ # configure optimize
+ optimizer = None
+ if is_train:
+ if args.use_lars:
+ lars_decay = 1.0
+ else:
+ lars_decay = 0.0
+
+ total_images = 1281167 / trainer_count
+
+ step = int(total_images / args.batch_size + 1)
+ epochs = [30, 60, 80, 90]
+ bd = [step * e for e in epochs]
+ base_lr = args.learning_rate
+ lr = []
+ lr = [base_lr * (0.1**i) for i in range(len(bd) + 1)]
+ optimizer = fluid.optimizer.Momentum(
+ learning_rate=base_lr,
+ #learning_rate=fluid.layers.piecewise_decay(
+ # boundaries=bd, values=lr),
+ momentum=0.9,
+ regularization=fluid.regularizer.L2Decay(1e-4))
+ optimizer.minimize(avg_cost)
+
+ if args.memory_optimize:
+ fluid.memory_optimize(main_prog)
+
+ # config readers
+ if not args.use_reader_op:
+ batched_reader = paddle.batch(
+ reader if args.no_random else paddle.reader.shuffle(
+ reader, buf_size=5120),
+ batch_size=args.batch_size * args.gpus,
+ drop_last=True)
+ else:
+ batched_reader = None
+ pyreader.decorate_paddle_reader(
+ paddle.batch(
+ # reader if args.no_random else paddle.reader.shuffle(
+ # reader, buf_size=5120),
+ reader,
+ batch_size=args.batch_size))
+
+ return avg_cost, optimizer, [batch_acc1,
+ batch_acc5], batched_reader, pyreader
diff --git a/benchmark/fluid/models/se_resnext.py b/benchmark/fluid/models/se_resnext.py
new file mode 100644
index 0000000000000000000000000000000000000000..9f887fb324dc86a30b708b9ef04068282a3e6c3e
--- /dev/null
+++ b/benchmark/fluid/models/se_resnext.py
@@ -0,0 +1,286 @@
+# Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import paddle
+import paddle.fluid as fluid
+import math
+import os
+from imagenet_reader import train, val
+
+__all__ = [
+ "SE_ResNeXt", "SE_ResNeXt50_32x4d", "SE_ResNeXt101_32x4d",
+ "SE_ResNeXt152_32x4d", "get_model"
+]
+
+train_parameters = {
+ "input_size": [3, 224, 224],
+ "input_mean": [0.485, 0.456, 0.406],
+ "input_std": [0.229, 0.224, 0.225],
+ "learning_strategy": {
+ "name": "piecewise_decay",
+ "batch_size": 256,
+ "epochs": [30, 60, 90],
+ "steps": [0.1, 0.01, 0.001, 0.0001]
+ }
+}
+
+
+class SE_ResNeXt():
+ def __init__(self, layers=50, is_train=True):
+ self.params = train_parameters
+ self.layers = layers
+ self.is_train = is_train
+
+ def net(self, input, class_dim=1000):
+ layers = self.layers
+ supported_layers = [50, 101, 152]
+ assert layers in supported_layers, \
+ "supported layers are {} but input layer is {}".format(supported_layers, layers)
+ if layers == 50:
+ cardinality = 32
+ reduction_ratio = 16
+ depth = [3, 4, 6, 3]
+ num_filters = [128, 256, 512, 1024]
+
+ conv = self.conv_bn_layer(
+ input=input,
+ num_filters=64,
+ filter_size=7,
+ stride=2,
+ act='relu')
+ conv = fluid.layers.pool2d(
+ input=conv,
+ pool_size=3,
+ pool_stride=2,
+ pool_padding=1,
+ pool_type='max')
+ elif layers == 101:
+ cardinality = 32
+ reduction_ratio = 16
+ depth = [3, 4, 23, 3]
+ num_filters = [128, 256, 512, 1024]
+
+ conv = self.conv_bn_layer(
+ input=input,
+ num_filters=64,
+ filter_size=7,
+ stride=2,
+ act='relu')
+ conv = fluid.layers.pool2d(
+ input=conv,
+ pool_size=3,
+ pool_stride=2,
+ pool_padding=1,
+ pool_type='max')
+ elif layers == 152:
+ cardinality = 64
+ reduction_ratio = 16
+ depth = [3, 8, 36, 3]
+ num_filters = [128, 256, 512, 1024]
+
+ conv = self.conv_bn_layer(
+ input=input,
+ num_filters=64,
+ filter_size=3,
+ stride=2,
+ act='relu')
+ conv = self.conv_bn_layer(
+ input=conv, num_filters=64, filter_size=3, stride=1, act='relu')
+ conv = self.conv_bn_layer(
+ input=conv,
+ num_filters=128,
+ filter_size=3,
+ stride=1,
+ act='relu')
+ conv = fluid.layers.pool2d(
+ input=conv, pool_size=3, pool_stride=2, pool_padding=1, \
+ pool_type='max')
+
+ for block in range(len(depth)):
+ for i in range(depth[block]):
+ conv = self.bottleneck_block(
+ input=conv,
+ num_filters=num_filters[block],
+ stride=2 if i == 0 and block != 0 else 1,
+ cardinality=cardinality,
+ reduction_ratio=reduction_ratio)
+
+ pool = fluid.layers.pool2d(
+ input=conv, pool_size=7, pool_type='avg', global_pooling=True)
+ drop = fluid.layers.dropout(x=pool, dropout_prob=0.5)
+ stdv = 1.0 / math.sqrt(drop.shape[1] * 1.0)
+ out = fluid.layers.fc(input=drop,
+ size=class_dim,
+ act='softmax',
+ param_attr=fluid.param_attr.ParamAttr(
+ initializer=fluid.initializer.Uniform(-stdv,
+ stdv)))
+ return out
+
+ def shortcut(self, input, ch_out, stride):
+ ch_in = input.shape[1]
+ if ch_in != ch_out or stride != 1:
+ filter_size = 1
+ return self.conv_bn_layer(input, ch_out, filter_size, stride)
+ else:
+ return input
+
+ def bottleneck_block(self, input, num_filters, stride, cardinality,
+ reduction_ratio):
+ conv0 = self.conv_bn_layer(
+ input=input, num_filters=num_filters, filter_size=1, act='relu')
+ conv1 = self.conv_bn_layer(
+ input=conv0,
+ num_filters=num_filters,
+ filter_size=3,
+ stride=stride,
+ groups=cardinality,
+ act='relu')
+ conv2 = self.conv_bn_layer(
+ input=conv1, num_filters=num_filters * 2, filter_size=1, act=None)
+ scale = self.squeeze_excitation(
+ input=conv2,
+ num_channels=num_filters * 2,
+ reduction_ratio=reduction_ratio)
+
+ short = self.shortcut(input, num_filters * 2, stride)
+
+ return fluid.layers.elementwise_add(x=short, y=scale, act='relu')
+
+ def conv_bn_layer(self,
+ input,
+ num_filters,
+ filter_size,
+ stride=1,
+ groups=1,
+ act=None):
+ conv = fluid.layers.conv2d(
+ input=input,
+ num_filters=num_filters,
+ filter_size=filter_size,
+ stride=stride,
+ padding=(filter_size - 1) / 2,
+ groups=groups,
+ act=None,
+ bias_attr=False)
+ return fluid.layers.batch_norm(
+ input=conv, act=act, is_test=not self.is_train)
+
+ def squeeze_excitation(self, input, num_channels, reduction_ratio):
+ pool = fluid.layers.pool2d(
+ input=input, pool_size=0, pool_type='avg', global_pooling=True)
+ stdv = 1.0 / math.sqrt(pool.shape[1] * 1.0)
+ squeeze = fluid.layers.fc(input=pool,
+ size=num_channels / reduction_ratio,
+ act='relu',
+ param_attr=fluid.param_attr.ParamAttr(
+ initializer=fluid.initializer.Uniform(
+ -stdv, stdv)))
+ stdv = 1.0 / math.sqrt(squeeze.shape[1] * 1.0)
+ excitation = fluid.layers.fc(input=squeeze,
+ size=num_channels,
+ act='sigmoid',
+ param_attr=fluid.param_attr.ParamAttr(
+ initializer=fluid.initializer.Uniform(
+ -stdv, stdv)))
+ scale = fluid.layers.elementwise_mul(x=input, y=excitation, axis=0)
+ return scale
+
+
+def SE_ResNeXt50_32x4d():
+ model = SE_ResNeXt(layers=50)
+ return model
+
+
+def SE_ResNeXt101_32x4d():
+ model = SE_ResNeXt(layers=101)
+ return model
+
+
+def SE_ResNeXt152_32x4d():
+ model = SE_ResNeXt(layers=152)
+ return model
+
+
+def get_model(args, is_train, main_prog, startup_prog):
+ model = SE_ResNeXt(layers=50)
+ batched_reader = None
+ pyreader = None
+ trainer_count = int(os.getenv("PADDLE_TRAINERS"))
+ dshape = train_parameters["input_size"]
+
+ with fluid.program_guard(main_prog, startup_prog):
+ with fluid.unique_name.guard():
+ if args.use_reader_op:
+ pyreader = fluid.layers.py_reader(
+ capacity=10,
+ shapes=([-1] + dshape, (-1, 1)),
+ dtypes=('float32', 'int64'),
+ name="train_reader" if is_train else "test_reader",
+ use_double_buffer=True)
+ input, label = fluid.layers.read_file(pyreader)
+ else:
+ input = fluid.layers.data(
+ name='data', shape=dshape, dtype='float32')
+ label = fluid.layers.data(
+ name='label', shape=[1], dtype='int64')
+
+ out = model.net(input=input)
+ cost = fluid.layers.cross_entropy(input=out, label=label)
+ avg_cost = fluid.layers.mean(x=cost)
+ acc_top1 = fluid.layers.accuracy(input=out, label=label, k=1)
+ acc_top5 = fluid.layers.accuracy(input=out, label=label, k=5)
+
+ optimizer = None
+ if is_train:
+ if args.use_lars:
+ lars_decay = 1.0
+ else:
+ lars_decay = 0.0
+
+ total_images = 1281167 / trainer_count
+
+ step = int(total_images / args.batch_size + 1)
+ epochs = [40, 80, 100]
+ bd = [step * e for e in epochs]
+ base_lr = args.learning_rate
+ lr = []
+ lr = [base_lr * (0.1**i) for i in range(len(bd) + 1)]
+ optimizer = fluid.optimizer.Momentum(
+ # learning_rate=base_lr,
+ learning_rate=fluid.layers.piecewise_decay(
+ boundaries=bd, values=lr),
+ momentum=0.9,
+ regularization=fluid.regularizer.L2Decay(1e-4),
+ LARS_weight_decay=lars_decay)
+ optimizer.minimize(avg_cost)
+
+ if args.memory_optimize:
+ fluid.memory_optimize(main_prog)
+
+ # config readers
+ if is_train:
+ reader = train()
+ else:
+ reader = val()
+
+ if not args.use_reader_op:
+ batched_reader = paddle.batch(
+ reader, batch_size=args.batch_size * args.gpus, drop_last=True)
+ else:
+ pyreader.decorate_paddle_reader(
+ paddle.batch(
+ reader, batch_size=args.batch_size))
+
+ return avg_cost, optimizer, [acc_top1, acc_top5], batched_reader, pyreader
diff --git a/benchmark/fluid/models/stacked_dynamic_lstm.py b/benchmark/fluid/models/stacked_dynamic_lstm.py
index 3231542a17ace99a17c9f9b9bdb3c2527637d9ef..f23bb59de9158b0481320cc409879b3b72cbd43e 100644
--- a/benchmark/fluid/models/stacked_dynamic_lstm.py
+++ b/benchmark/fluid/models/stacked_dynamic_lstm.py
@@ -26,7 +26,6 @@ import numpy
import paddle
import paddle.dataset.imdb as imdb
import paddle.fluid as fluid
-import paddle.batch as batch
import paddle.fluid.profiler as profiler
word_dict = imdb.word_dict()
@@ -43,19 +42,7 @@ def crop_sentence(reader, crop_size):
return __impl__
-def get_model(args):
- if args.use_reader_op:
- raise Exception(
- "stacked_dynamic_lstm do not support reader op for now.")
- lstm_size = 512
- emb_dim = 512
- crop_size = 1500
-
- data = fluid.layers.data(
- name="words", shape=[1], lod_level=1, dtype='int64')
- sentence = fluid.layers.embedding(
- input=data, size=[len(word_dict), emb_dim])
-
+def lstm_net(sentence, lstm_size):
sentence = fluid.layers.fc(input=sentence, size=lstm_size, act='tanh')
rnn = fluid.layers.DynamicRNN()
@@ -97,31 +84,47 @@ def get_model(args):
last = fluid.layers.sequence_pool(rnn(), 'last')
logit = fluid.layers.fc(input=last, size=2, act='softmax')
- loss = fluid.layers.cross_entropy(
- input=logit,
- label=fluid.layers.data(
- name='label', shape=[1], dtype='int64'))
- loss = fluid.layers.mean(x=loss)
+ return logit
- # add acc
- batch_size_tensor = fluid.layers.create_tensor(dtype='int64')
- batch_acc = fluid.layers.accuracy(input=logit, label=fluid.layers.data(name='label', \
- shape=[1], dtype='int64'), total=batch_size_tensor)
- inference_program = fluid.default_main_program().clone()
- with fluid.program_guard(inference_program):
- inference_program = fluid.io.get_inference_program(
- target_vars=[batch_acc, batch_size_tensor])
-
- adam = fluid.optimizer.Adam()
+def get_model(args, is_train, main_prog, startup_prog):
+ if args.use_reader_op:
+ raise Exception(
+ "stacked_dynamic_lstm do not support reader op for now.")
+ lstm_size = 512
+ emb_dim = 512
+ crop_size = 1500
- train_reader = batch(
+ with fluid.program_guard(main_prog, startup_prog):
+ with fluid.unique_name.guard():
+ data = fluid.layers.data(
+ name="words", shape=[1], lod_level=1, dtype='int64')
+ sentence = fluid.layers.embedding(
+ input=data, size=[len(word_dict), emb_dim])
+ logit = lstm_net(sentence, lstm_size)
+ loss = fluid.layers.cross_entropy(
+ input=logit,
+ label=fluid.layers.data(
+ name='label', shape=[1], dtype='int64'))
+ loss = fluid.layers.mean(x=loss)
+
+ # add acc
+ batch_size_tensor = fluid.layers.create_tensor(dtype='int64')
+ batch_acc = fluid.layers.accuracy(input=logit, label=fluid.layers.data(name='label', \
+ shape=[1], dtype='int64'), total=batch_size_tensor)
+
+ if is_train:
+ adam = fluid.optimizer.Adam()
+ adam.minimize(loss)
+
+ if is_train:
+ reader = crop_sentence(imdb.train(word_dict), crop_size)
+ else:
+ reader = crop_sentence(imdb.test(word_dict), crop_size)
+
+ batched_reader = paddle.batch(
paddle.reader.shuffle(
- crop_sentence(imdb.train(word_dict), crop_size), buf_size=25000),
+ reader, buf_size=25000),
batch_size=args.batch_size * args.gpus)
- test_reader = batch(
- paddle.reader.shuffle(
- crop_sentence(imdb.test(word_dict), crop_size), buf_size=25000),
- batch_size=args.batch_size)
- return loss, inference_program, adam, train_reader, test_reader, batch_acc
+ return loss, adam, [batch_acc], batched_reader, None
diff --git a/benchmark/fluid/models/vgg.py b/benchmark/fluid/models/vgg.py
index 932601302d2f5d56b53e3462af886429034d8989..cf9708d500684465dc8ec1666bf269e7e1300f59 100644
--- a/benchmark/fluid/models/vgg.py
+++ b/benchmark/fluid/models/vgg.py
@@ -25,7 +25,7 @@ import functools
import os
-def vgg16_bn_drop(input):
+def vgg16_bn_drop(input, is_train=True):
def conv_block(input, num_filter, groups, dropouts):
return fluid.nets.img_conv_group(
input=input,
@@ -46,13 +46,13 @@ def vgg16_bn_drop(input):
drop = fluid.layers.dropout(x=conv5, dropout_prob=0.5)
fc1 = fluid.layers.fc(input=drop, size=512, act=None)
- bn = fluid.layers.batch_norm(input=fc1, act='relu')
+ bn = fluid.layers.batch_norm(input=fc1, act='relu', is_test=not is_train)
drop2 = fluid.layers.dropout(x=bn, dropout_prob=0.5)
fc2 = fluid.layers.fc(input=drop2, size=512, act=None)
return fc2
-def get_model(args):
+def get_model(args, is_train, main_prog, startup_prog):
if args.data_set == "cifar10":
classdim = 10
if args.data_format == 'NCHW':
@@ -65,57 +65,56 @@ def get_model(args):
data_shape = [3, 224, 224]
else:
data_shape = [224, 224, 3]
+ filelist = [
+ os.path.join(args.data_path, f) for f in os.listdir(args.data_path)
+ ]
+ with fluid.program_guard(main_prog, startup_prog):
+ if args.use_reader_op:
+ data_file_handle = fluid.layers.open_files(
+ filenames=filelist,
+ shapes=[[-1] + data_shape, (-1, 1)],
+ lod_levels=[0, 0],
+ dtypes=["float32", "int64"],
+ thread_num=1,
+ pass_num=1)
+ data_file = fluid.layers.double_buffer(
+ fluid.layers.batch(
+ data_file_handle, batch_size=args.batch_size))
+ with fluid.unique_name.guard():
+ if args.use_reader_op:
+ images, label = fluid.layers.read_file(data_file)
+ else:
+ images = fluid.layers.data(
+ name='data', shape=data_shape, dtype='float32')
+ label = fluid.layers.data(
+ name='label', shape=[1], dtype='int64')
+ # Train program
+ net = vgg16_bn_drop(images, is_train=is_train)
+ predict = fluid.layers.fc(input=net, size=classdim, act='softmax')
+ cost = fluid.layers.cross_entropy(input=predict, label=label)
+ avg_cost = fluid.layers.mean(x=cost)
- if args.use_reader_op:
- filelist = [
- os.path.join(args.data_path, f) for f in os.listdir(args.data_path)
- ]
- data_file = fluid.layers.open_files(
- filenames=filelist,
- shapes=[[-1] + data_shape, (-1, 1)],
- lod_levels=[0, 0],
- dtypes=["float32", "int64"],
- thread_num=args.gpus,
- pass_num=args.pass_num)
- data_file = fluid.layers.double_buffer(
- fluid.layers.batch(
- data_file, batch_size=args.batch_size))
- images, label = fluid.layers.read_file(data_file)
- else:
- images = fluid.layers.data(
- name='data', shape=data_shape, dtype='float32')
- label = fluid.layers.data(name='label', shape=[1], dtype='int64')
-
- # Train program
- net = vgg16_bn_drop(images)
- predict = fluid.layers.fc(input=net, size=classdim, act='softmax')
- cost = fluid.layers.cross_entropy(input=predict, label=label)
- avg_cost = fluid.layers.mean(x=cost)
-
- # Evaluator
- batch_size_tensor = fluid.layers.create_tensor(dtype='int64')
- batch_acc = fluid.layers.accuracy(
- input=predict, label=label, total=batch_size_tensor)
-
- # inference program
- inference_program = fluid.default_main_program().clone()
- with fluid.program_guard(inference_program):
- inference_program = fluid.io.get_inference_program(
- target_vars=[batch_acc, batch_size_tensor])
-
- # Optimization
- optimizer = fluid.optimizer.Adam(learning_rate=args.learning_rate)
+ # Evaluator
+ batch_size_tensor = fluid.layers.create_tensor(dtype='int64')
+ batch_acc = fluid.layers.accuracy(
+ input=predict, label=label, total=batch_size_tensor)
+ # Optimization
+ if is_train:
+ optimizer = fluid.optimizer.Adam(
+ learning_rate=args.learning_rate)
+ optimizer.minimize(avg_cost)
# data reader
- train_reader = paddle.batch(
+ if is_train:
+ reader = paddle.dataset.cifar.train10() \
+ if args.data_set == 'cifar10' else paddle.dataset.flowers.train()
+ else:
+ reader = paddle.dataset.cifar.test10() \
+ if args.data_set == 'cifar10' else paddle.dataset.flowers.test()
+
+ batched_reader = paddle.batch(
paddle.reader.shuffle(
- paddle.dataset.cifar.train10()
- if args.data_set == 'cifar10' else paddle.dataset.flowers.train(),
- buf_size=5120),
+ reader, buf_size=5120),
batch_size=args.batch_size * args.gpus)
- test_reader = paddle.batch(
- paddle.dataset.cifar.test10()
- if args.data_set == 'cifar10' else paddle.dataset.flowers.test(),
- batch_size=args.batch_size)
- return avg_cost, inference_program, optimizer, train_reader, test_reader, batch_acc
+ return avg_cost, optimizer, [batch_acc], batched_reader, data_file_handle
diff --git a/cmake/cuda.cmake b/cmake/cuda.cmake
index b520c03a836a9e3f263ba050f151877ffe0d071d..03c73786a6c31868b1893bfcb319e43e37db1a3d 100644
--- a/cmake/cuda.cmake
+++ b/cmake/cuda.cmake
@@ -169,14 +169,19 @@ set(CUDA_PROPAGATE_HOST_FLAGS OFF)
# Release/Debug flags set by cmake. Such as -O3 -g -DNDEBUG etc.
# So, don't set these flags here.
+if (NOT WIN32) # windows msvc2015 support c++11 natively.
+# -std=c++11 -fPIC not recoginize by msvc, -Xcompiler will be added by cmake.
list(APPEND CUDA_NVCC_FLAGS "-std=c++11")
-list(APPEND CUDA_NVCC_FLAGS "--use_fast_math")
list(APPEND CUDA_NVCC_FLAGS "-Xcompiler -fPIC")
+endif(NOT WIN32)
+
+list(APPEND CUDA_NVCC_FLAGS "--use_fast_math")
# in cuda9, suppress cuda warning on eigen
list(APPEND CUDA_NVCC_FLAGS "-w")
# Set :expt-relaxed-constexpr to suppress Eigen warnings
list(APPEND CUDA_NVCC_FLAGS "--expt-relaxed-constexpr")
+if (NOT WIN32)
if(CMAKE_BUILD_TYPE STREQUAL "Debug")
list(APPEND CUDA_NVCC_FLAGS ${CMAKE_CXX_FLAGS_DEBUG})
elseif(CMAKE_BUILD_TYPE STREQUAL "Release")
@@ -187,6 +192,13 @@ elseif(CMAKE_BUILD_TYPE STREQUAL "MinSizeRel")
# nvcc 9 does not support -Os. Use Release flags instead
list(APPEND CUDA_NVCC_FLAGS ${CMAKE_CXX_FLAGS_RELEASE})
endif()
+else(NOT WIN32)
+if(CMAKE_BUILD_TYPE STREQUAL "Release")
+ list(APPEND CUDA_NVCC_FLAGS "-O3 -DNDEBUG")
+else()
+ message(FATAL "Windows only support Release build now. Please set visual studio build type to Release, x64 build.")
+endif()
+endif(NOT WIN32)
mark_as_advanced(CUDA_BUILD_CUBIN CUDA_BUILD_EMULATION CUDA_VERBOSE_BUILD)
mark_as_advanced(CUDA_SDK_ROOT_DIR CUDA_SEPARABLE_COMPILATION)
diff --git a/cmake/external/anakin.cmake b/cmake/external/anakin.cmake
index dc6730662f0b888f1981ac9c086320acc52d0a50..ed054ff41ae0ec5a4b31dd256e397129cba3e8f1 100644
--- a/cmake/external/anakin.cmake
+++ b/cmake/external/anakin.cmake
@@ -16,16 +16,6 @@ set(ANAKIN_LIBRARY ${ANAKIN_INSTALL_DIR})
set(ANAKIN_SHARED_LIB ${ANAKIN_LIBRARY}/libanakin.so)
set(ANAKIN_SABER_LIB ${ANAKIN_LIBRARY}/libanakin_saber_common.so)
-# TODO(luotao): ANAKIN_MODLE_URL etc will move to demo ci later.
-set(INFERENCE_URL "http://paddle-inference-dist.bj.bcebos.com")
-set(ANAKIN_MODLE_URL "${INFERENCE_URL}/mobilenet_v2.anakin.bin")
-set(ANAKIN_RNN_MODLE_URL "${INFERENCE_URL}/anakin_test%2Fditu_rnn.anakin2.model.bin")
-set(ANAKIN_RNN_DATA_URL "${INFERENCE_URL}/anakin_test%2Fditu_rnn_data.txt")
-execute_process(COMMAND bash -c "mkdir -p ${ANAKIN_SOURCE_DIR}")
-execute_process(COMMAND bash -c "cd ${ANAKIN_SOURCE_DIR}; wget -q --no-check-certificate ${ANAKIN_MODLE_URL} -N")
-execute_process(COMMAND bash -c "cd ${ANAKIN_SOURCE_DIR}; wget -q --no-check-certificate ${ANAKIN_RNN_MODLE_URL} -N")
-execute_process(COMMAND bash -c "cd ${ANAKIN_SOURCE_DIR}; wget -q --no-check-certificate ${ANAKIN_RNN_DATA_URL} -N")
-
include_directories(${ANAKIN_INCLUDE})
include_directories(${ANAKIN_INCLUDE}/saber/)
include_directories(${ANAKIN_INCLUDE}/saber/core/)
@@ -48,21 +38,24 @@ set(ANAKIN_COMPILE_EXTRA_FLAGS
-Wno-reorder
-Wno-error=cpp)
+if(WITH_GPU)
+ set(CMAKE_ARGS_PREFIX -DUSE_GPU_PLACE=YES -DCUDNN_ROOT=${CUDNN_ROOT} -DCUDNN_INCLUDE_DIR=${CUDNN_INCLUDE_DIR})
+else()
+ set(CMAKE_ARGS_PREFIX -DUSE_GPU_PLACE=NO)
+endif()
ExternalProject_Add(
extern_anakin
${EXTERNAL_PROJECT_LOG_ARGS}
DEPENDS ${MKLML_PROJECT}
GIT_REPOSITORY "https://github.com/PaddlePaddle/Anakin"
- GIT_TAG "9424277cf9ae180a14aff09560d3cd60a49c76d2"
+ GIT_TAG "3c8554f4978628183566ab7dd6c1e7e66493c7cd"
PREFIX ${ANAKIN_SOURCE_DIR}
UPDATE_COMMAND ""
- CMAKE_ARGS -DUSE_GPU_PLACE=YES
+ CMAKE_ARGS ${CMAKE_ARGS_PREFIX}
-DUSE_X86_PLACE=YES
-DBUILD_WITH_UNIT_TEST=NO
-DPROTOBUF_ROOT=${THIRD_PARTY_PATH}/install/protobuf
-DMKLML_ROOT=${THIRD_PARTY_PATH}/install/mklml
- -DCUDNN_ROOT=${CUDNN_ROOT}
- -DCUDNN_INCLUDE_DIR=${CUDNN_INCLUDE_DIR}
-DENABLE_OP_TIMER=${ANAKIN_ENABLE_OP_TIMER}
${EXTERNAL_OPTIONAL_ARGS}
CMAKE_CACHE_ARGS -DCMAKE_INSTALL_PREFIX:PATH=${ANAKIN_INSTALL_DIR}
diff --git a/cmake/external/grpc.cmake b/cmake/external/grpc.cmake
index 7fb67afbe15a5a019c978092d5ba3a4a0f66d996..fd9835d023c67b76579913f2ec56c2444fea8c15 100644
--- a/cmake/external/grpc.cmake
+++ b/cmake/external/grpc.cmake
@@ -44,7 +44,7 @@ ExternalProject_Add(
# 3. keep only zlib, cares, protobuf, boringssl under "third_party",
# checkout and clean other dirs under third_party
# 4. remove .git, and package the directory.
- URL "http://paddlepaddledeps.bj.bcebos.com/grpc-v1.10.x.tar.gz"
+ URL "http://paddlepaddledeps.cdn.bcebos.com/grpc-v1.10.x.tar.gz"
URL_MD5 "1f268a2aff6759839dccd256adcc91cf"
PREFIX ${GRPC_SOURCES_DIR}
UPDATE_COMMAND ""
diff --git a/cmake/inference_lib.cmake b/cmake/inference_lib.cmake
index bc36683a9facc253e7b9feb0c5a56e79491fb9b0..077072f6eadb0c48f4ae32f94828613d89ed01c9 100644
--- a/cmake/inference_lib.cmake
+++ b/cmake/inference_lib.cmake
@@ -128,16 +128,13 @@ set(src_dir "${PADDLE_SOURCE_DIR}/paddle/fluid")
set(dst_dir "${FLUID_INSTALL_DIR}/paddle/fluid")
set(module "framework")
if (NOT WIN32)
-copy(framework_lib DEPS framework_py_proto
- SRCS ${src_dir}/${module}/*.h ${src_dir}/${module}/details/*.h ${PADDLE_BINARY_DIR}/paddle/fluid/framework/framework.pb.h
- DSTS ${dst_dir}/${module} ${dst_dir}/${module}/details ${dst_dir}/${module}
-)
-else()
-copy(framework_lib
+set(framework_lib_deps framework_py_proto)
+endif(NOT WIN32)
+copy(framework_lib DEPS ${framework_lib_deps}
SRCS ${src_dir}/${module}/*.h ${src_dir}/${module}/details/*.h ${PADDLE_BINARY_DIR}/paddle/fluid/framework/framework.pb.h
- DSTS ${dst_dir}/${module} ${dst_dir}/${module}/details ${dst_dir}/${module}
+ ${src_dir}/${module}/ir/*.h
+ DSTS ${dst_dir}/${module} ${dst_dir}/${module}/details ${dst_dir}/${module} ${dst_dir}/${module}/ir
)
-endif(NOT WIN32)
set(module "memory")
copy(memory_lib
@@ -148,12 +145,12 @@ copy(memory_lib
set(inference_deps paddle_fluid_shared paddle_fluid)
set(module "inference/api")
-if (WITH_ANAKIN AND WITH_GPU)
+if (WITH_ANAKIN AND WITH_MKL)
copy(anakin_inference_lib DEPS paddle_inference_api inference_anakin_api
SRCS
${PADDLE_BINARY_DIR}/paddle/fluid/inference/api/libinference_anakin_api* # compiled anakin api
${ANAKIN_INSTALL_DIR} # anakin release
- DSTS ${dst_dir}/inference/anakin ${dst_dir}/inference/anakin)
+ DSTS ${dst_dir}/inference/anakin ${FLUID_INSTALL_DIR}/third_party/install/anakin)
list(APPEND inference_deps anakin_inference_lib)
endif()
@@ -161,7 +158,8 @@ set(module "inference")
copy(inference_lib DEPS ${inference_deps}
SRCS ${src_dir}/${module}/*.h ${PADDLE_BINARY_DIR}/paddle/fluid/inference/libpaddle_fluid.*
${src_dir}/${module}/api/paddle_inference_api.h ${src_dir}/${module}/api/demo_ci
- DSTS ${dst_dir}/${module} ${dst_dir}/${module} ${dst_dir}/${module} ${dst_dir}/${module}
+ ${PADDLE_BINARY_DIR}/paddle/fluid/inference/api/paddle_inference_pass.h
+ DSTS ${dst_dir}/${module} ${dst_dir}/${module} ${dst_dir}/${module} ${dst_dir}/${module} ${dst_dir}/${module}
)
set(module "platform")
diff --git a/doc/fluid/api/layers.rst b/doc/fluid/api/layers.rst
index ecbd8191ccf5aa6046e7875fe8afa2ed0105e4a0..6f0267cd7a1d0afcdcb1596a46ffe2d15eea100d 100644
--- a/doc/fluid/api/layers.rst
+++ b/doc/fluid/api/layers.rst
@@ -822,6 +822,14 @@ pad
.. autofunction:: paddle.fluid.layers.pad
:noindex:
+.. _api_fluid_layers_pad_constant_like:
+
+pad_constant_like
+---
+
+.. autofunction:: paddle.fluid.layers.pad_constant_like
+ :noindex:
+
.. _api_fluid_layers_label_smooth:
label_smooth
@@ -1145,6 +1153,14 @@ sigmoid
.. autofunction:: paddle.fluid.layers.sigmoid
:noindex:
+.. _api_fluid_layers_hsigmoid:
+
+hsigmoid
+-------
+
+.. autofunction:: paddle.fluid.layers.hsigmoid
+ :noindex:
+
.. _api_fluid_layers_logsigmoid:
logsigmoid
diff --git a/doc/fluid/new_docs/advanced_usage/deploy/index_anakin.rst b/doc/fluid/new_docs/advanced_usage/deploy/index_anakin.rst
index b782242a6632a5d42a512cf3b830d6e047c064ab..e4682ccb94e6fc60e184632dff9ee16a6bf16ec0 100644
--- a/doc/fluid/new_docs/advanced_usage/deploy/index_anakin.rst
+++ b/doc/fluid/new_docs/advanced_usage/deploy/index_anakin.rst
@@ -1,5 +1,5 @@
-服务器端部署 - Anakin
-#####################
+Anakin - 服务器端加速引擎
+#######################
使用文档
diff --git a/doc/fluid/new_docs/advanced_usage/deploy/index_native.rst b/doc/fluid/new_docs/advanced_usage/deploy/index_native.rst
deleted file mode 100644
index a5209e8560b31e9f0f776fba9a2b8c5bc150165c..0000000000000000000000000000000000000000
--- a/doc/fluid/new_docs/advanced_usage/deploy/index_native.rst
+++ /dev/null
@@ -1,8 +0,0 @@
-服务器端部署 - 原生引擎
-#######################
-
-.. toctree::
- :maxdepth: 2
-
- build_and_install_lib_cn.rst
- native_infer.rst
diff --git a/doc/fluid/new_docs/advanced_usage/index.rst b/doc/fluid/new_docs/advanced_usage/index.rst
index dea7c236619a0bdbf402f371571d947d1cdbba65..89166573eebca045e948046c69f3b7a3e0031d58 100644
--- a/doc/fluid/new_docs/advanced_usage/index.rst
+++ b/doc/fluid/new_docs/advanced_usage/index.rst
@@ -10,7 +10,6 @@
.. toctree::
:maxdepth: 2
- deploy/index_native.rst
deploy/index_anakin.rst
deploy/index_mobile.rst
development/contribute_to_paddle.md
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/image_classification/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..dc7c62b06287ad333dd41082e566b0553d3a5341
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/image_classification/.gitignore
@@ -0,0 +1,8 @@
+*.pyc
+train.log
+output
+data/cifar-10-batches-py/
+data/cifar-10-python.tar.gz
+data/*.txt
+data/*.list
+data/mean.meta
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md
index 8d645718e12e4d976a8e71de105e11f495191fbf..4f20843596aa676962a36241f59560ec2a41257b 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/image_classification/README.cn.md
@@ -21,7 +21,7 @@
图像分类包括通用图像分类、细粒度图像分类等。图1展示了通用图像分类效果,即模型可以正确识别图像上的主要物体。
-
+
图1. 通用图像分类展示
@@ -30,7 +30,7 @@
-
+
图2. 细粒度图像分类展示
@@ -38,7 +38,7 @@
一个好的模型既要对不同类别识别正确,同时也应该能够对不同视角、光照、背景、变形或部分遮挡的图像正确识别(这里我们统一称作图像扰动)。图3展示了一些图像的扰动,较好的模型会像聪明的人类一样能够正确识别。
-
+
图3. 扰动图片展示[22]
@@ -61,7 +61,7 @@
Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得了历史性的突破,效果大幅度超越传统方法,获得了ILSVRC2012冠军,该模型被称作AlexNet。这也是首次将深度学习用于大规模图像分类中。从AlexNet之后,涌现了一系列CNN模型,不断地在ImageNet上刷新成绩,如图4展示。随着模型变得越来越深以及精妙的结构设计,Top-5的错误率也越来越低,降到了3.5%附近。而在同样的ImageNet数据集上,人眼的辨识错误率大概在5.1%,也就是目前的深度学习模型的识别能力已经超过了人眼。
-
+
图4. ILSVRC图像分类Top-5错误率
@@ -70,7 +70,7 @@ Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得
传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数,一个典型的卷积神经网络如图5所示,我们先介绍用来构造CNN的常见组件。
-
+
图5. CNN网络示例[20]
@@ -89,7 +89,7 @@ Alex Krizhevsky在2012年ILSVRC提出的CNN模型 \[[9](#参考文献)\] 取得
牛津大学VGG(Visual Geometry Group)组在2014年ILSVRC提出的模型被称作VGG模型 \[[11](#参考文献)\] 。该模型相比以往模型进一步加宽和加深了网络结构,它的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,下图展示一个16层的网络结构。VGG模型结构相对简洁,提出之后也有很多文章基于此模型进行研究,如在ImageNet上首次公开超过人眼识别的模型\[[19](#参考文献)\]就是借鉴VGG模型的结构。
-
+
图6. 基于ImageNet的VGG16模型
@@ -106,7 +106,7 @@ NIN模型主要有两个特点:
Inception模块如下图7所示,图(a)是最简单的设计,输出是3个卷积层和一个池化层的特征拼接。这种设计的缺点是池化层不会改变特征通道数,拼接后会导致特征的通道数较大,经过几层这样的模块堆积后,通道数会越来越大,导致参数和计算量也随之增大。为了改善这个缺点,图(b)引入3个1x1卷积层进行降维,所谓的降维就是减少通道数,同时如NIN模型中提到的1x1卷积也可以修正线性特征。
-
+
图7. Inception模块
@@ -115,7 +115,7 @@ GoogleNet由多组Inception模块堆积而成。另外,在网络最后也没
GoogleNet整体网络结构如图8所示,总共22层网络:开始由3层普通的卷积组成;接下来由三组子网络组成,第一组子网络包含2个Inception模块,第二组包含5个Inception模块,第三组包含2个Inception模块;然后接均值池化层、全连接层。
-
+
图8. GoogleNet[12]
@@ -130,14 +130,14 @@ ResNet(Residual Network) \[[15](#参考文献)\] 是2015年ImageNet图像分类
残差模块如图9所示,左边是基本模块连接方式,由两个输出通道数相同的3x3卷积组成。右边是瓶颈模块(Bottleneck)连接方式,之所以称为瓶颈,是因为上面的1x1卷积用来降维(图示例即256->64),下面的1x1卷积用来升维(图示例即64->256),这样中间3x3卷积的输入和输出通道数都较小(图示例即64->64)。
-
+
图9. 残差模块
图10展示了50、101、152层网络连接示意图,使用的是瓶颈模块。这三个模型的区别在于每组中残差模块的重复次数不同(见图右上角)。ResNet训练收敛较快,成功的训练了上百乃至近千层的卷积神经网络。
-
+
图10. 基于ImageNet的ResNet模型
@@ -149,7 +149,7 @@ ResNet(Residual Network) \[[15](#参考文献)\] 是2015年ImageNet图像分类
由于ImageNet数据集较大,下载和训练较慢,为了方便大家学习,我们使用[CIFAR10]()数据集。CIFAR10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为测试集。图11从每个类别中随机抽取了10张图片,展示了所有的类别。
-
+
图11. CIFAR10数据集[21]
@@ -377,7 +377,7 @@ test_reader = paddle.batch(
`event_handler_plot`可以用来利用回调数据来打点画图:
-
+
图12. 训练结果
@@ -469,7 +469,7 @@ Test with Pass 0, Loss 1.1, Acc 0.6
图13是训练的分类错误率曲线图,运行到第200个pass后基本收敛,最终得到测试集上分类错误率为8.54%。
-
+
图13. CIFAR10数据集上VGG模型的分类错误率
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/cifar.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/cifar.png
deleted file mode 100644
index f3c5f2f7b0c84f83382b70124dcd439586ed4eb0..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/cifar.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog.png
deleted file mode 100644
index ca8f858a902ea723d886d2b88c2c0a1005301c50..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog_cat.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog_cat.png
deleted file mode 100644
index 38b21f21604b1bb84fc3f6aa96bd5fce45d15a55..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/dog_cat.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/fea_conv0.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/fea_conv0.png
deleted file mode 100644
index 647c822e52cd55d50e5f207978f5e6ada86cf34c..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/fea_conv0.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/flowers.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/flowers.png
deleted file mode 100644
index 04245cef60fe7126ae4c92ba8085273965078bee..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/flowers.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/googlenet.jpeg b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/googlenet.jpeg
deleted file mode 100644
index 249dbf96df61c3352ea5bd80470f6c4a1e03ff10..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/googlenet.jpeg and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/ilsvrc.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/ilsvrc.png
deleted file mode 100644
index 4660ac122e9d533023a21154d35eee29e3b08d27..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/ilsvrc.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception.png
deleted file mode 100644
index 9591a0c1e8c0165c40ca560be35a7b9a91cd5027..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception_en.png
deleted file mode 100644
index 39580c20b583f2a15d17fd124a572c84e6e2db1d..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/inception_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet.png
deleted file mode 100644
index 77f785e03bacd38c4c64a817874a58ff3298d2f3..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet_en.png
deleted file mode 100644
index 97a1e3eee45c0db95e6a943ca3b8c0cf6c34d4b6..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/lenet_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot.png
deleted file mode 100644
index 57e45cc0c27dd99b9918de2ff1228bc6b65f7424..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot_en.png
deleted file mode 100644
index 147e575bf49086811c43420d5a9c8f749e2da405..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/plot_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet.png
deleted file mode 100644
index 0aeb4f254639fdbf18e916dc219ca61602596d85..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet_block.jpg b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet_block.jpg
deleted file mode 100644
index c500eb01a90190ff66150871fe83ec275e2de8d7..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/resnet_block.jpg and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/train_and_test.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/train_and_test.png
deleted file mode 100644
index c6336a9a69b95dc978719ce68896e3e752e67fed..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/train_and_test.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations.png
deleted file mode 100644
index b4ebbbe6a50f5fd7cd0cccb52cdac5653e34654c..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations_en.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations_en.png
deleted file mode 100644
index 88c60fe87f802c5ce560bb15bbdbd229aeafc4e4..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/variations_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/vgg16.png b/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/vgg16.png
deleted file mode 100644
index 6270eefcfd7071bc1643ee06567e5b81aaf4c177..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/image_classification/image/vgg16.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/index.rst b/doc/fluid/new_docs/beginners_guide/basics/index.rst
index e1fd226116d88fbf137741242b304b367e598ba5..0fcb008e0a7773e81e5124da09fe07366130b924 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/index.rst
+++ b/doc/fluid/new_docs/beginners_guide/basics/index.rst
@@ -6,7 +6,7 @@
.. todo::
概述
-
+
.. toctree::
:maxdepth: 2
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..29b5622a53a1b0847e9f53febf1cc50dcf4f044a
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/.gitignore
@@ -0,0 +1,12 @@
+data/train.list
+data/test.*
+data/conll05st-release.tar.gz
+data/conll05st-release
+data/predicate_dict
+data/label_dict
+data/word_dict
+data/emb
+data/feature
+output
+predict.res
+train.log
diff --git a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md
index 47e948bd1ffc0ca692dc9899193e94831ce4234b..0891f5b6b16a1b715b44db6c47ba079adfcad4c5 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/label_semantic_roles/README.cn.md
@@ -21,7 +21,7 @@ $$\mbox{[小明]}_{\mbox{Agent}}\mbox{[昨天]}_{\mbox{Time}}\mbox{[晚上]}_\mb
5. 对第4步的结果,通过多分类得到论元的语义角色标签。可以看到,句法分析是基础,并且后续步骤常常会构造的一些人工特征,这些特征往往也来自句法分析。
-

+

图1. 依存句法分析句法树示例
-

+

图2. BIO标注方法示例
-
+
图3. 基于LSTM的栈式循环神经网络结构示意图
@@ -64,7 +64,7 @@ $$\mbox{[小明]}_{\mbox{Agent}}\mbox{[昨天]}_{\mbox{Time}}\mbox{[晚上]}_\mb
为了克服这一缺陷,我们可以设计一种双向循环网络单元,它的思想简单且直接:对上一节的栈式循环神经网络进行一个小小的修改,堆叠多个LSTM单元,让每一层LSTM单元分别以:正向、反向、正向 …… 的顺序学习上一层的输出序列。于是,从第2层开始,$t$时刻我们的LSTM单元便总是可以看到历史和未来的信息。图4是基于LSTM的双向循环神经网络结构示意图。
-
+
图4. 基于LSTM的双向循环神经网络结构示意图
@@ -79,7 +79,7 @@ CRF是一种概率化结构模型,可以看作是一个概率无向图模型
序列标注任务只需要考虑输入和输出都是一个线性序列,并且由于我们只是将输入序列作为条件,不做任何条件独立假设,因此输入序列的元素之间并不存在图结构。综上,在序列标注任务中使用的是如图5所示的定义在链式图上的CRF,称之为线性链条件随机场(Linear Chain Conditional Random Field)。
-
+
图5. 序列标注任务中使用的线性链条件随机场
@@ -123,7 +123,7 @@ $$\DeclareMathOperator*{\argmax}{arg\,max} L(\lambda, D) = - \text{log}\left(\pr
4. CRF以第3步中LSTM学习到的特征为输入,以标记序列为监督信号,完成序列标注;
-

+

图6. SRL任务上的深层双向LSTM模型
+
+

图1. 基于神经网络的机器翻译系统
-
+
-图3. 按时间步展开的双向循环神经网络
-
+
+
+
+图2. 按时间步展开的双向循环神经网络
+
-图4. 编码器-解码器框架
-
+
+

+图3. 编码器-解码器框架
+
-图5. 使用双向GRU的编码器
-
+
+
+图4. 使用双向GRU的编码器
+
`,表示解码开始;`$z_i$`是`$i$`时刻解码RNN的隐层状态,`$z_0$`是一个全零的向量。
+其中`$\phi _{\theta '}$`是一个非线性激活函数;`$c=q\mathbf{h}$`是源语言句子的上下文向量,在不使用注意力机制时,如果[编码器](#编码器)的输出是源语言句子编码后的最后一个元素,则可以定义`$c=h_T$`;`$u_i$`是目标语言序列的第`$i$`个单词,`$u_0$`是目标语言序列的开始标记``,表示解码开始;`$z_i$`是`$i$`时刻解码RNN的隐层状态,`$z_0$`是一个全零的向量。
2. 将`$z_{i+1}$`通过`softmax`归一化,得到目标语言序列的第`$i+1$`个单词的概率分布`$p_{i+1}$`。概率分布公式如下:
$$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
@@ -93,6 +94,7 @@ $$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
机器翻译任务的生成过程,通俗来讲就是根据预先训练的模型来翻译源语言句子。生成过程中的解码阶段和上述训练过程的有所差异,具体介绍请见[柱搜索算法](#柱搜索算法)。
+
### 柱搜索算法
柱搜索([beam search](http://en.wikipedia.org/wiki/Beam_search))是一种启发式图搜索算法,用于在图或树中搜索有限集合中的最优扩展节点,通常用在解空间非常大的系统(如机器翻译、语音识别)中,原因是内存无法装下图或树中所有展开的解。如在机器翻译任务中希望翻译“`你好`”,就算目标语言字典中只有3个词(``, ``, `hello`),也可能生成无限句话(`hello`循环出现的次数不定),为了找到其中较好的翻译结果,我们可采用柱搜索算法。
@@ -100,7 +102,6 @@ $$p\left ( u_{i+1}|u_{<i+1},\mathbf{x} \right )=softmax(W_sz_{i+1}+b_z)$$
柱搜索算法使用广度优先策略建立搜索树,在树的每一层,按照启发代价(heuristic cost)(本教程中,为生成词的log概率之和)对节点进行排序,然后仅留下预先确定的个数(文献中通常称为beam width、beam size、柱宽度等)的节点。只有这些节点会在下一层继续扩展,其他节点就被剪掉了,也就是说保留了质量较高的节点,剪枝了质量较差的节点。因此,搜索所占用的空间和时间大幅减少,但缺点是无法保证一定获得最优解。
使用柱搜索算法的解码阶段,目标是最大化生成序列的概率。思路是:
-
1. 每一个时刻,根据源语言句子的编码信息`$c$`、生成的第`$i$`个目标语言序列单词`$u_i$`和`$i$`时刻RNN的隐层状态`$z_i$`,计算出下一个隐层状态`$z_{i+1}$`。
2. 将`$z_{i+1}$`通过`softmax`归一化,得到目标语言序列的第`$i+1$`个单词的概率分布`$p_{i+1}$`。
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn.png
deleted file mode 100644
index 9d8efd50a49d0305586f550344472ab94c93bed3..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn_en.png
deleted file mode 100644
index 4b35c88fc8ea2c503473c0c15711744e784d6af6..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/bi_rnn_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention.png
deleted file mode 100644
index 1b355e7786d25487a3f564af758c2c52c43b4690..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention_en.png
deleted file mode 100644
index 3728f782ee09d9308d02b42305027b2735467ead..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/decoder_attention_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention.png
deleted file mode 100644
index 28d7a15a3bd65262bde22a3f41b5aa78b46b368a..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention_en.png
deleted file mode 100644
index ea8585565da1ecaf241654c278c6f9b15e283286..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_attention_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder.png
deleted file mode 100644
index 60aee0017de73f462e35708b1055aff8992c03e1..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder_en.png
deleted file mode 100644
index 6b73798fe632e0873b35c117b86f347c8cf3116a..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/encoder_decoder_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru.png
deleted file mode 100644
index 0cde685b84106650a4df18ce335a23e6338d3d11..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru_en.png
deleted file mode 100644
index a6af429f23f0f7e82650139bbd8dcbef27a34abe..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/gru_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt.png
deleted file mode 100644
index bf56d73ebf297fadf522389c7b6836dd379aa097..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt_en.png b/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt_en.png
deleted file mode 100644
index 557310e044b2b6687e5ea6895417ed946ac7bc11..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/machine_translation/image/nmt_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..f23901aeb3a9e7cd12611fc556742670d04a9bb5
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/.gitignore
@@ -0,0 +1,2 @@
+.idea
+.ipynb_checkpoints
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md
index 0f7c97021f8ad463fc51ed169604b789ea068c3d..4b79e62f74e587fcd939d9f9e911af80992ea6a3 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/README.cn.md
@@ -37,7 +37,7 @@ Prediction Score is 4.25
YouTube是世界上最大的视频上传、分享和发现网站,YouTube推荐系统为超过10亿用户从不断增长的视频库中推荐个性化的内容。整个系统由两个神经网络组成:候选生成网络和排序网络。候选生成网络从百万量级的视频库中生成上百个候选,排序网络对候选进行打分排序,输出排名最高的数十个结果。系统结构如图1所示:
-
+
图1. YouTube 推荐系统结构
@@ -48,7 +48,7 @@ YouTube是世界上最大的视频上传、分享和发现网站,YouTube推荐
首先,将观看历史及搜索词记录这类历史信息,映射为向量后取平均值得到定长表示;同时,输入人口学特征以优化新用户的推荐效果,并将二值特征和连续特征归一化处理到[0, 1]范围。接下来,将所有特征表示拼接为一个向量,并输入给非线形多层感知器(MLP,详见[识别数字](https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.cn.md)教程)处理。最后,训练时将MLP的输出给softmax做分类,预测时计算用户的综合特征(MLP的输出)与所有视频的相似度,取得分最高的$k$个作为候选生成网络的筛选结果。图2显示了候选生成网络结构。
-
+
图2. 候选生成网络结构
@@ -73,7 +73,7 @@ $$P(\omega=i|u)=\frac{e^{v_{i}u}}{\sum_{j \in V}e^{v_{j}u}}$$
卷积神经网络主要由卷积(convolution)和池化(pooling)操作构成,其应用及组合方式灵活多变,种类繁多。本小结我们以如图3所示的网络进行讲解:
-
+
图3. 卷积神经网络文本分类模型
@@ -107,7 +107,7 @@ $$\hat c=max(c)$$
-
+
图4. 融合推荐模型
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.en.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.en.png
deleted file mode 100644
index c213608e769f69fb2cfe8597f8e696ee53730e3d..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.png
deleted file mode 100644
index 8aedb2204371e7691140ceffa5992f6080bbf097..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/Deep_candidate_generation_model_architecture.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.en.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.en.png
deleted file mode 100644
index 4298567ac5600173343299999965b20612e7affe..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.png
deleted file mode 100644
index a98e7cc67606b31e4c945f7eb907563e46dcef56..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/YouTube_Overview.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/output_32_0.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/output_32_0.png
deleted file mode 100644
index 7fd97b9cc3a0b9105b41591af4e8f8e4646bd681..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/output_32_0.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network.png
deleted file mode 100644
index 90c9b09fb78db98391ee199934f2d16efd6d6652..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network_en.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network_en.png
deleted file mode 100644
index 6fc8e11967000ec48c1c0a6fa3c2eaecb80cbb84..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/rec_regression_network_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn.png
deleted file mode 100644
index 61e63d9147cbc2901706ef80776d706e5368c3c5..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn_en.png b/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn_en.png
deleted file mode 100644
index fbcae2be81141be955076e877b94b0ea5d7e4d4a..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/recommender_system/image/text_cnn_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..667762d327cb160376a4119fa9df9db41b6443b2
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/.gitignore
@@ -0,0 +1,10 @@
+data/aclImdb
+data/imdb
+data/pre-imdb
+data/mosesdecoder-master
+*.log
+model_output
+dataprovider_copy_1.py
+model.list
+*.pyc
+.DS_Store
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md
index 5844b6fe137c2401a04e47b5b489434ee9b363f1..8477cf32146c33947ced447c8bdd287a3e1e71f5 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/README.cn.md
@@ -37,7 +37,7 @@
循环神经网络是一种能对序列数据进行精确建模的有力工具。实际上,循环神经网络的理论计算能力是图灵完备的\[[4](#参考文献)\]。自然语言是一种典型的序列数据(词序列),近年来,循环神经网络及其变体(如long short term memory\[[5](#参考文献)\]等)在自然语言处理的多个领域,如语言模型、句法解析、语义角色标注(或一般的序列标注)、语义表示、图文生成、对话、机器翻译等任务上均表现优异甚至成为目前效果最好的方法。
-
+
图1. 循环神经网络按时间展开的示意图
@@ -66,7 +66,7 @@ $$ h_t = o_t\odot tanh(c_t) $$
其中,$i_t, f_t, c_t, o_t$分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的$W$及$b$为模型参数,$tanh$为双曲正切函数,$\odot$表示逐元素(elementwise)的乘法操作。输入门控制着新输入进入记忆单元$c$的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元$c$,如图2所示:
-
+
图2. 时刻$t$的LSTM [7]
@@ -83,7 +83,7 @@ $$ h_t=Recrurent(x_t,h_{t-1})$$
如图3所示(以三层为例),奇数层LSTM正向,偶数层LSTM反向,高一层的LSTM使用低一层LSTM及之前所有层的信息作为输入,对最高层LSTM序列使用时间维度上的最大池化即可得到文本的定长向量表示(这一表示充分融合了文本的上下文信息,并且对文本进行了深层次抽象),最后我们将文本表示连接至softmax构建分类模型。
-
+
图3. 栈式双向LSTM用于文本分类
@@ -149,6 +149,8 @@ def convolution_net(data, input_dim, class_dim, emb_dim, hid_dim):
网络的输入`input_dim`表示的是词典的大小,`class_dim`表示类别数。这里,我们使用[`sequence_conv_pool`](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/trainer_config_helpers/networks.py) API实现了卷积和池化操作。
+
+
### 栈式双向LSTM
栈式双向神经网络`stacked_lstm_net`的代码片段如下:
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm.png
deleted file mode 100644
index 98fbea413a98a619004ca669c67f5f867fe974c9..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm_en.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm_en.png
deleted file mode 100644
index d73a00bf2c1fca2f9b8c26bccf5ea844fa1db50b..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/lstm_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/rnn.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/rnn.png
deleted file mode 100644
index 26c904102a6e6c4e30f0048b81373ae8c148b355..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/rnn.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm.jpg b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm.jpg
deleted file mode 100644
index 6b2adf70f2b5112a2e82505da5cff9f5fd0c6298..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm.jpg and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm_en.png b/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm_en.png
deleted file mode 100644
index 8b5dbd726178b5555c513294e7b10a81acc96ff5..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/understand_sentiment/image/stacked_lstm_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/.gitignore b/doc/fluid/new_docs/beginners_guide/basics/word2vec/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..a620e0279c310d213d4e6d8e99e666962c11e352
--- /dev/null
+++ b/doc/fluid/new_docs/beginners_guide/basics/word2vec/.gitignore
@@ -0,0 +1,3 @@
+data/train.list
+data/test.list
+data/simple-examples*
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md b/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md
index d21c7ddcc501f863b5ce672123dbbc6c26528f15..904d99fe2ffc9ead69a86c9763568a5c098348d5 100644
--- a/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/basics/word2vec/README.cn.md
@@ -34,7 +34,7 @@ $$X = USV^T$$
本章中,当词向量训练好后,我们可以用数据可视化算法t-SNE\[[4](#参考文献)\]画出词语特征在二维上的投影(如下图所示)。从图中可以看出,语义相关的词语(如a, the, these; big, huge)在投影上距离很近,语意无关的词(如say, business; decision, japan)在投影上的距离很远。
- 
+ 
图1. 词向量的二维投影
@@ -50,7 +50,7 @@ similarity: -0.0997506977351
```
-以上结果可以通过运行`calculate_dis.py`, 加载字典里的单词和对应训练特征结果得到,我们将在[应用模型](#应用模型)中详细描述用法。
+以上结果可以通过运行`calculate_dis.py`, 加载字典里的单词和对应训练特征结果得到,我们将在[模型应用](#模型应用)中详细描述用法。
## 模型概览
@@ -90,7 +90,7 @@ $$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
其中$f(w_t, w_{t-1}, ..., w_{t-n+1})$表示根据历史n-1个词得到当前词$w_t$的条件概率,$R(\theta)$表示参数正则项。
- 
+ 
图2. N-gram神经网络模型
@@ -122,7 +122,7 @@ $$\frac{1}{T}\sum_t f(w_t, w_{t-1}, ..., w_{t-n+1};\theta) + R(\theta)$$
CBOW模型通过一个词的上下文(各N个词)预测当前词。当N=2时,模型如下图所示:
- 
+ 
图3. CBOW模型
@@ -137,7 +137,7 @@ $$context = \frac{x_{t-1} + x_{t-2} + x_{t+1} + x_{t+2}}{4}$$
CBOW的好处是对上下文词语的分布在词向量上进行了平滑,去掉了噪声,因此在小数据集上很有效。而Skip-gram的方法中,用一个词预测其上下文,得到了当前词上下文的很多样本,因此可用于更大的数据集。
- 
+ 
图4. Skip-gram模型
@@ -189,12 +189,13 @@ dream that one day
最后,每个输入会按其单词次在字典里的位置,转化成整数的索引序列,作为PaddlePaddle的输入。
+
## 编程实现
本配置的模型结构如下图所示:
- 
+ 
图5. 模型配置中的N-gram神经网络模型
@@ -349,6 +350,7 @@ Step 20: Average Cost 5.766995
...
```
+
## 模型应用
在模型训练后,我们可以用它做一些预测。
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/2d_similarity.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/2d_similarity.png
deleted file mode 100644
index 384f59919a2c8dedb198e97d51434616648932e1..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/2d_similarity.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow.png
deleted file mode 100644
index 76b7d4bc0f99372465bd9aa34721513d39ad0776..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow_en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow_en.png
deleted file mode 100644
index d985c393e618e9b79df05e4ff0ae57ccc93744d0..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/cbow_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.en.png
deleted file mode 100644
index 2e16ab2f443732b8ef5404a8e7cd2457bc5eee23..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.png
deleted file mode 100644
index 2449dce6a86b43b1b997ff418ed0dba56848463f..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/ngram.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm.png
deleted file mode 100644
index 1e0b40a8f7aefdf46d42761305511f281c08e595..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm_en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm_en.png
deleted file mode 100644
index 158bd64b8f8729dea67834a8d591d21bce8b8564..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/nnlm_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/sentence_emb.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/sentence_emb.png
deleted file mode 100644
index ce4a8bf4769183cbaff91793753d2350a3ce936c..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/sentence_emb.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram.png
deleted file mode 100644
index a3ab385845d3dc8b5c670bae91225bc8dd47a8bb..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram_en.png b/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram_en.png
deleted file mode 100644
index 3c36c6d1f66eb98ea78c0673965d02a4ee3aa288..0000000000000000000000000000000000000000
Binary files a/doc/fluid/new_docs/beginners_guide/basics/word2vec/image/skipgram_en.png and /dev/null differ
diff --git a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md
index 27d25b43961ce74d73e391b735369501fb80a231..9574dbea2f9a39bb196b61bb4fd12ba7c378f75a 100644
--- a/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md
+++ b/doc/fluid/new_docs/beginners_guide/quick_start/fit_a_line/README.cn.md
@@ -15,7 +15,7 @@ $$y_i = \omega_1x_{i1} + \omega_2x_{i2} + \ldots + \omega_dx_{id} + b, i=1,\ldo
## 效果展示
我们使用从[UCI Housing Data Set](https://archive.ics.uci.edu/ml/datasets/Housing)获得的波士顿房价数据集进行模型的训练和预测。下面的散点图展示了使用模型对部分房屋价格进行的预测。其中,每个点的横坐标表示同一类房屋真实价格的中位数,纵坐标表示线性回归模型根据特征预测的结果,当二者值完全相等的时候就会落在虚线上。所以模型预测得越准确,则点离虚线越近。
- 
+ 
图1. 预测值 V.S. 真实值
@@ -40,13 +40,9 @@ $$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
### 训练过程
定义好模型结构之后,我们要通过以下几个步骤进行模型训练
-
1. 初始化参数,其中包括权重$\omega_i$和偏置$b$,对其进行初始化(如0均值,1方差)。
-
2. 网络正向传播计算网络输出和损失函数。
-
3. 根据损失函数进行反向误差传播 ([backpropagation](https://en.wikipedia.org/wiki/Backpropagation)),将网络误差从输出层依次向前传递, 并更新网络中的参数。
-
4. 重复2~3步骤,直至网络训练误差达到规定的程度或训练轮次达到设定值。
## 数据集
@@ -84,7 +80,7 @@ $$MSE=\frac{1}{n}\sum_{i=1}^{n}{(\hat{Y_i}-Y_i)}^2$$
- 很多的机器学习技巧/模型(例如L1,L2正则项,向量空间模型-Vector Space Model)都基于这样的假设:所有的属性取值都差不多是以0为均值且取值范围相近的。
- 
+ 
图2. 各维属性的取值范围
@@ -199,10 +195,12 @@ step = 0
def event_handler_plot(event):
global step
if isinstance(event, fluid.EndStepEvent):
- if event.step % 10 == 0: # record the test cost every 10 seconds
+ if step % 10 == 0: # record a train cost every 10 batches
+ plot_cost.append(train_title, step, event.metrics[0])
+
+ if step % 100 == 0: # record a test cost every 100 batches
test_metrics = trainer.test(
reader=test_reader, feed_order=feed_order)
-
plot_cost.append(test_title, step, test_metrics[0])
plot_cost.plot()
@@ -210,12 +208,13 @@ def event_handler_plot(event):
# If the accuracy is good enough, we can stop the training.
print('loss is less than 10.0, stop')
trainer.stop()
-
- # We can save the trained parameters for the inferences later
- if params_dirname is not None:
- trainer.save_params(params_dirname)
-
step += 1
+
+ if isinstance(event, fluid.EndEpochEvent):
+ if event.epoch % 10 == 0:
+ # We can save the trained parameters for the inferences later
+ if params_dirname is not None:
+ trainer.save_params(params_dirname)
```
### 开始训练
@@ -231,11 +230,10 @@ trainer.train(
event_handler=event_handler_plot,
feed_order=feed_order)
```
-
-
- 
- 图3. 训练结果
-
+
+

+图3 训练结果
+
- 
- 图1. MNIST图片示例
+
+图1. MNIST图片示例
MNIST数据集是从 [NIST](https://www.nist.gov/srd/nist-special-database-19) 的Special Database 3(SD-3)和Special Database 1(SD-1)构建而来。由于SD-3是由美国人口调查局的员工进行标注,SD-1是由美国高中生进行标注,因此SD-3比SD-1更干净也更容易识别。Yann LeCun等人从SD-1和SD-3中各取一半作为MNIST的训练集(60000条数据)和测试集(10000条数据),其中训练集来自250位不同的标注员,此外还保证了训练集和测试集的标注员是不完全相同的。
@@ -40,12 +40,12 @@ $$ y_i = \text{softmax}(\sum_j W_{i,j}x_j + b_i) $$
在分类问题中,我们一般采用交叉熵代价损失函数(cross entropy loss),公式如下:
-$$ L_{cross-entropy} (label, y) = -\sum_i label_ilog(y_i) $$
+$$ L_{cross-entropy}(label, y) = -\sum_i label_ilog(y_i) $$
图2为softmax回归的网络图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
-
+
图2. softmax回归网络结构图
@@ -54,16 +54,14 @@ $$ L_{cross-entropy} (label, y) = -\sum_i label_ilog(y_i) $$
Softmax回归模型采用了最简单的两层神经网络,即只有输入层和输出层,因此其拟合能力有限。为了达到更好的识别效果,我们考虑在输入层和输出层中间加上若干个隐藏层\[[10](#参考文献)\]。
1. 经过第一个隐藏层,可以得到 $ H_1 = \phi(W_1X + b_1) $,其中$\phi$代表激活函数,常见的有sigmoid、tanh或ReLU等函数。
-
2. 经过第二个隐藏层,可以得到 $ H_2 = \phi(W_2H_1 + b_2) $。
-
3. 最后,再经过输出层,得到的$Y=\text{softmax}(W_3H_2 + b_3)$,即为最后的分类结果向量。
图3为多层感知器的网络结构图,图中权重用蓝线表示、偏置用红线表示、+1代表偏置参数的系数为1。
-
+
图3. 多层感知器网络结构图
@@ -72,7 +70,7 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
在多层感知器模型中,将图像展开成一维向量输入到网络中,忽略了图像的位置和结构信息,而卷积神经网络能够更好的利用图像的结构信息。[LeNet-5](http://yann.lecun.com/exdb/lenet/)是一个较简单的卷积神经网络。图4显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。下面我们主要介绍卷积层和池化层。
-
+
图4. LeNet-5卷积神经网络结构
@@ -81,7 +79,7 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
卷积层是卷积神经网络的核心基石。在图像识别里我们提到的卷积是二维卷积,即离散二维滤波器(也称作卷积核)与二维图像做卷积操作,简单的讲是二维滤波器滑动到二维图像上所有位置,并在每个位置上与该像素点及其领域像素点做内积。卷积操作被广泛应用与图像处理领域,不同卷积核可以提取不同的特征,例如边沿、线性、角等特征。在深层卷积神经网络中,通过卷积操作可以提取出图像低级到复杂的特征。
-
+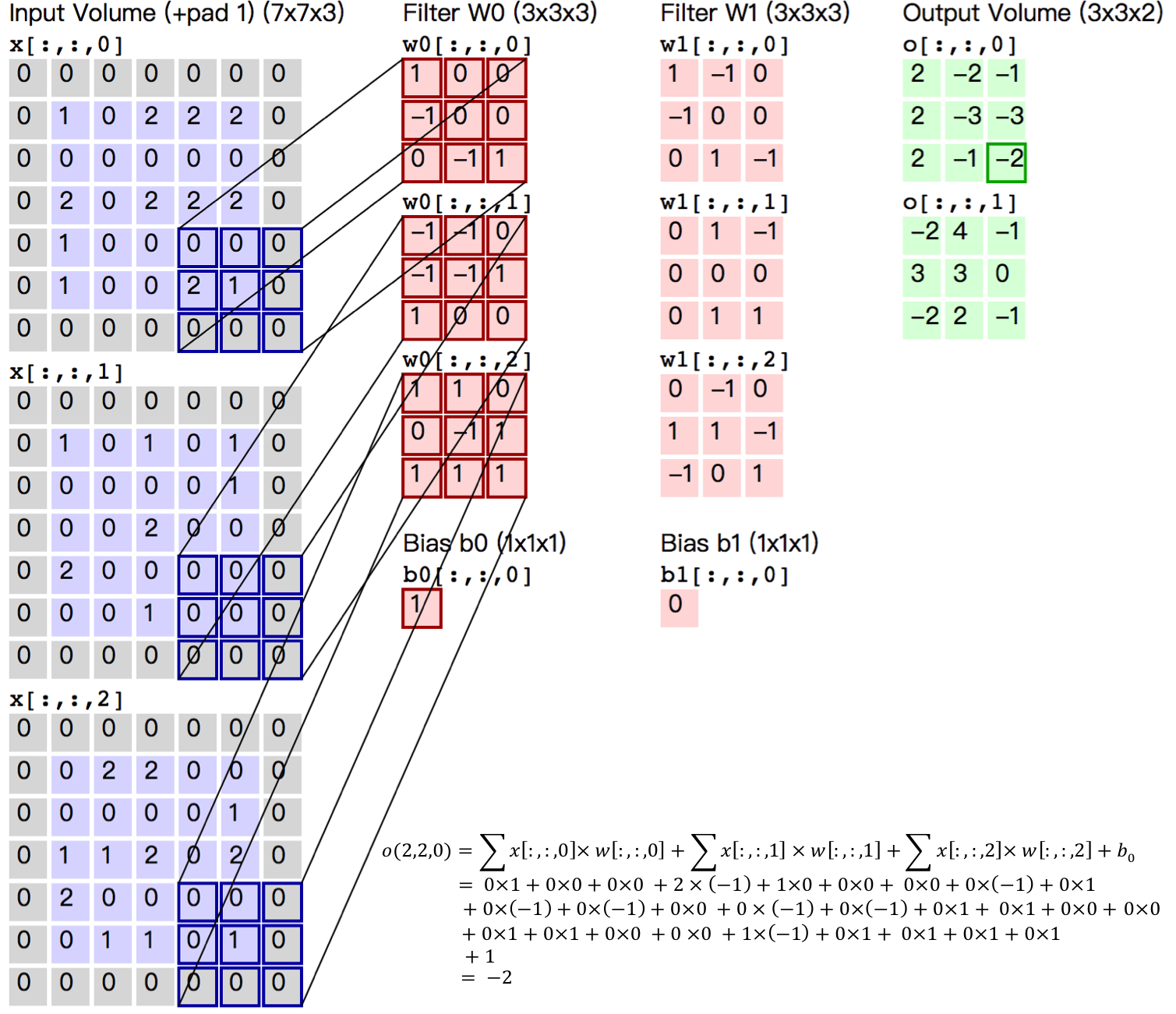
图5. 卷积层图片
@@ -98,16 +96,15 @@ Softmax回归模型采用了最简单的两层神经网络,即只有输入层
#### 池化层
-
+
图6. 池化层图片
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层,如图6所示。
-更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )和[图像分类](https://github.com/PaddlePaddle/book/blob/develop/image_classification/README.md)教程。
-
-### 常见激活函数介绍
+更详细的关于卷积神经网络的具体知识可以参考[斯坦福大学公开课]( http://cs231n.github.io/convolutional-networks/ )和[图像分类]( https://github.com/PaddlePaddle/book/tree/develop/03.image_classification )教程。
+### 常见激活函数介绍
- sigmoid激活函数: $ f(x) = sigmoid(x) = \frac{1}{1+e^{-x}} $
- tanh激活函数: $ f(x) = tanh(x) = \frac{e^x-e^{-x}}{e^x+e^{-x}} $
@@ -136,20 +133,18 @@ PaddlePaddle在API中提供了自动加载[MNIST](http://yann.lecun.com/exdb/mni
我们建议使用 Fluid API,因为它更容易学起来。
下面是快速的 Fluid API 概述。
-
1. `inference_program`:指定如何从数据输入中获得预测的函数。
这是指定网络流的地方。
-2. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数。
+1. `train_program`:指定如何从 `inference_program` 和`标签值`中获取 `loss` 的函数。
这是指定损失计算的地方。
-3. `optimizer_func`: “指定优化器配置的函数。优化器负责减少损失并驱动培训。Paddle 支持多种不同的优化器。
+1. `optimizer_func`: “指定优化器配置的函数。优化器负责减少损失并驱动培训。Paddle 支持多种不同的优化器。
-4. `Trainer`:PaddlePaddle Trainer 管理由 `train_program` 和 `optimizer` 指定的训练过程。
+1. `Trainer`:PaddlePaddle Trainer 管理由 `train_program` 和 `optimizer` 指定的训练过程。
通过 `event_handler` 回调函数,用户可以监控培训的进展。
-5. `Inferencer`:Fluid inferencer 加载 `inference_program` 和由 Trainer 训练的参数。
-
+1. `Inferencer`:Fluid inferencer 加载 `inference_program` 和由 Trainer 训练的参数。
然后,它可以推断数据和返回预测。
在这个演示中,我们将深入了解它们。
@@ -240,6 +235,7 @@ def train_program():
acc = fluid.layers.accuracy(input=predict, label=label)
return [avg_cost, acc]
+
```
#### Optimizer Function 配置
@@ -255,9 +251,9 @@ def optimizer_program():
下一步,我们开始训练过程。`paddle.dataset.movielens.train()`和`paddle.dataset.movielens.test()`分别做训练和测试数据集。这两个函数各自返回一个reader——PaddlePaddle中的reader是一个Python函数,每次调用的时候返回一个Python yield generator。
-下面`shuffle`是一个reader decorator,它接受一个reader A,返回另一个reader B 。reader B 每次读入`buffer_size`条训练数据到一个buffer里,然后随机打乱其顺序,并且逐条输出。
+下面`shuffle`是一个reader decorator,它接受一个reader A,返回另一个reader B。reader B 每次读入`buffer_size`条训练数据到一个buffer里,然后随机打乱其顺序,并且逐条输出。
-`batch`是一个特殊的decorator,它的输入是一个reader,输出是一个batched reader 。在PaddlePaddle里,一个reader每次yield一条训练数据,而一个batched reader每次yield一个minibatch。
+`batch`是一个特殊的decorator,它的输入是一个reader,输出是一个batched reader。在PaddlePaddle里,一个reader每次yield一条训练数据,而一个batched reader每次yield一个minibatch。
```python
train_reader = paddle.batch(
@@ -280,7 +276,6 @@ place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
trainer = fluid.Trainer(
train_func=train_program, place=place, optimizer_func=optimizer_program)
-
```
#### Event Handler 配置
@@ -315,11 +310,10 @@ def event_handler(event):
`event_handler_plot` 可以用来在训练过程中画图如下:
-
-
-
-图7. 训练结果
-
+
+

+图7 训练结果
+
@@ -69,9 +74,9 @@ digraph g {

-### 2) Pytorch uses Node Graph to encode the Tape
+### PyTorch: the Tape as a Graph
-The graph is composed of `Variable`s and `Function`s. During the forward execution, a `Variable` records its creator function, e.g. `h.creator = matmul`. And a Function records its inputs' previous/dependent functions `prev_func` through `creator`, e.g. `matmul.prev_func = matmul1`. At `loss.backward()`, a topological sort is performed on all `prev_func`s. Then the grad op is performed by the sorted order.
+The graph is composed of `Variable`s and `Function`s. During the forward execution, a `Variable` records its creator function, e.g. `h.creator = matmul`. And a Function records its inputs' previous/dependent functions `prev_func` through `creator`, e.g. `matmul.prev_func = matmul1`. At `loss.backward()`, a topological sort is performed on all `prev_func`s. Then the grad op is performed by the sorted order. Please be aware that a `Function` might have more than one `prev_func`s.
@@ -132,27 +137,22 @@ digraph g {

-Chainer and Autograd uses the similar techniques to record the forward pass. For details please refer to the appendix.
-
-## Design choices
+Chainer and Autograd use the similar techniques to record the forward pass. For details, please refer to the appendix.
-### 1) Dynet's List vs Pytorch's Node Graph
+## Comparison: List v.s. Graph
-What's good about List:
-1. It avoids a topological sort. One only needs to traverse the list of operators in reverse and calling the corresponding backward operator.
-1. It promises effient data parallelism implementations. One could count the time of usage of a certain variable during the construction list. Then in the play back, one knows the calculation of a variable has completed. This enables communication and computation overlapping.
+The list of DyNet could be considered the result of the topological sort of the graph of PyTorch. Or, the graph is the raw representation of the tape, which gives us the chance to *prune* part of the graph that is irrelevant with the backward pass before the topological sort [[2]](https://openreview.net/pdf?id=BJJsrmfCZ). Consider the following example, PyTorch only does backward on `SmallNet` while DyNet does both `SmallNet` and `BigNet`:
-What's good about Node Graph:
-1. More flexibility. PyTorch users can mix and match independent graphs however they like, in whatever threads they like (without explicit synchronization). An added benefit of structuring graphs this way is that when a portion of the graph becomes dead, it is automatically freed. [[2]](https://openreview.net/pdf?id=BJJsrmfCZ) Consider the following example, Pytorch only does backward on SmallNet while Dynet does both BigNet and SmallNet.
```python
result = BigNet(data)
loss = SmallNet(data)
loss.backward()
```
-### 2) Dynet's Lazy evaluation vs Pytorch's Immediate evaluation
+## Lazy v.s. Immediate Evaluation
+
+Another difference between DyNet and PyTorch is that DyNet lazily evaluates the forward pass, whereas PyTorch executes it immediately. Consider the following example:
-Dynet builds the list in a symbolic matter. Consider the following example
```python
for epoch in range(num_epochs):
for in_words, out_label in training_data:
@@ -164,16 +164,17 @@ for epoch in range(num_epochs):
loss_val = loss_sym.value()
loss_sym.backward()
```
+
The computation of `lookup`, `concat`, `matmul` and `softmax` didn't happen until the call of `loss_sym.value()`. This defered execution is useful because it allows some graph-like optimization possible, e.g. kernel fusion.
-Pytorch chooses immediate evaluation. It avoids ever materializing a "forward graph"/"tape" (no need to explicitly call `dy.renew_cg()` to reset the list), recording only what is necessary to differentiate the computation, i.e. `creator` and `prev_func`.
+PyTorch chooses immediate evaluation. It avoids ever materializing a "forward graph"/"tape" (no need to explicitly call `dy.renew_cg()` to reset the list), recording only what is necessary to differentiate the computation, i.e. `creator` and `prev_func`.
-## What can fluid learn from them?
+## Fluid: Learning the Lessons
Please refer to `paddle/contrib/dynamic/`.
-# Appendix
+## Appendix
### Overview
diff --git a/paddle/fluid/API.spec b/paddle/fluid/API.spec
index ed4e67879c795258683b094cfaeaff9063d66848..ae5f30e431aba4cae04b0fb35f00bce84f18de33 100644
--- a/paddle/fluid/API.spec
+++ b/paddle/fluid/API.spec
@@ -43,6 +43,7 @@ paddle.fluid.Executor.run ArgSpec(args=['self', 'program', 'feed', 'fetch_list',
paddle.fluid.global_scope ArgSpec(args=[], varargs=None, keywords=None, defaults=None)
paddle.fluid.scope_guard ArgSpec(args=[], varargs='args', keywords='kwds', defaults=None)
paddle.fluid.Trainer.__init__ ArgSpec(args=['self', 'train_func', 'optimizer_func', 'param_path', 'place', 'parallel', 'checkpoint_config'], varargs=None, keywords=None, defaults=(None, None, False, None))
+paddle.fluid.Trainer.save_inference_model ArgSpec(args=['self', 'param_path', 'feeded_var_names', 'target_var_indexes'], varargs=None, keywords=None, defaults=None)
paddle.fluid.Trainer.save_params ArgSpec(args=['self', 'param_path'], varargs=None, keywords=None, defaults=None)
paddle.fluid.Trainer.stop ArgSpec(args=['self'], varargs=None, keywords=None, defaults=None)
paddle.fluid.Trainer.test ArgSpec(args=['self', 'reader', 'feed_order'], varargs=None, keywords=None, defaults=None)
@@ -65,7 +66,7 @@ paddle.fluid.InferenceTranspiler.transpile ArgSpec(args=['self', 'program', 'pla
paddle.fluid.memory_optimize ArgSpec(args=['input_program', 'skip_opt_set', 'print_log', 'level'], varargs=None, keywords=None, defaults=(None, False, 0))
paddle.fluid.release_memory ArgSpec(args=['input_program', 'skip_opt_set'], varargs=None, keywords=None, defaults=(None,))
paddle.fluid.DistributeTranspilerConfig.__init__
-paddle.fluid.ParallelExecutor.__init__ ArgSpec(args=['self', 'use_cuda', 'loss_name', 'main_program', 'share_vars_from', 'exec_strategy', 'build_strategy', 'num_trainers', 'trainer_id'], varargs=None, keywords='kwargs', defaults=(None, None, None, None, None, 1, 0))
+paddle.fluid.ParallelExecutor.__init__ ArgSpec(args=['self', 'use_cuda', 'loss_name', 'main_program', 'share_vars_from', 'exec_strategy', 'build_strategy', 'num_trainers', 'trainer_id', 'scope'], varargs=None, keywords='kwargs', defaults=(None, None, None, None, None, 1, 0, None))
paddle.fluid.ParallelExecutor.run ArgSpec(args=['self', 'fetch_list', 'feed', 'feed_dict', 'return_numpy'], varargs=None, keywords=None, defaults=(None, None, True))
paddle.fluid.ExecutionStrategy.__init__ __init__(self: paddle.fluid.core.ExecutionStrategy) -> None
paddle.fluid.BuildStrategy.GradientScaleStrategy.__init__ __init__(self: paddle.fluid.core.GradientScaleStrategy, arg0: int) -> None
@@ -170,7 +171,9 @@ paddle.fluid.layers.prelu ArgSpec(args=['x', 'mode', 'param_attr', 'name'], vara
paddle.fluid.layers.flatten ArgSpec(args=['x', 'axis', 'name'], varargs=None, keywords=None, defaults=(1, None))
paddle.fluid.layers.sequence_mask ArgSpec(args=['x', 'maxlen', 'dtype', 'name'], varargs=None, keywords=None, defaults=(None, 'int64', None))
paddle.fluid.layers.stack ArgSpec(args=['x', 'axis'], varargs=None, keywords=None, defaults=(0,))
+paddle.fluid.layers.pad2d ArgSpec(args=['input', 'paddings', 'mode', 'pad_value', 'data_format', 'name'], varargs=None, keywords=None, defaults=([0, 0, 0, 0], 'constant', 0.0, 'NCHW', None))
paddle.fluid.layers.unstack ArgSpec(args=['x', 'axis', 'num'], varargs=None, keywords=None, defaults=(0, None))
+paddle.fluid.layers.sequence_enumerate ArgSpec(args=['input', 'win_size', 'pad_value', 'name'], varargs=None, keywords=None, defaults=(0, None))
paddle.fluid.layers.data ArgSpec(args=['name', 'shape', 'append_batch_size', 'dtype', 'lod_level', 'type', 'stop_gradient'], varargs=None, keywords=None, defaults=(True, 'float32', 0, VarType.LOD_TENSOR, True))
paddle.fluid.layers.open_recordio_file ArgSpec(args=['filename', 'shapes', 'lod_levels', 'dtypes', 'pass_num', 'for_parallel'], varargs=None, keywords=None, defaults=(1, True))
paddle.fluid.layers.open_files ArgSpec(args=['filenames', 'shapes', 'lod_levels', 'dtypes', 'thread_num', 'buffer_size', 'pass_num', 'is_test'], varargs=None, keywords=None, defaults=(None, None, 1, None))
@@ -310,7 +313,7 @@ paddle.fluid.layers.iou_similarity ArgSpec(args=[], varargs='args', keywords='kw
paddle.fluid.layers.box_coder ArgSpec(args=[], varargs='args', keywords='kwargs', defaults=None)
paddle.fluid.layers.polygon_box_transform ArgSpec(args=[], varargs='args', keywords='kwargs', defaults=None)
paddle.fluid.layers.accuracy ArgSpec(args=['input', 'label', 'k', 'correct', 'total'], varargs=None, keywords=None, defaults=(1, None, None))
-paddle.fluid.layers.auc ArgSpec(args=['input', 'label', 'curve', 'num_thresholds', 'topk'], varargs=None, keywords=None, defaults=('ROC', 200, 1))
+paddle.fluid.layers.auc ArgSpec(args=['input', 'label', 'curve', 'num_thresholds', 'topk'], varargs=None, keywords=None, defaults=('ROC', 4095, 1))
paddle.fluid.layers.exponential_decay ArgSpec(args=['learning_rate', 'decay_steps', 'decay_rate', 'staircase'], varargs=None, keywords=None, defaults=(False,))
paddle.fluid.layers.natural_exp_decay ArgSpec(args=['learning_rate', 'decay_steps', 'decay_rate', 'staircase'], varargs=None, keywords=None, defaults=(False,))
paddle.fluid.layers.inverse_time_decay ArgSpec(args=['learning_rate', 'decay_steps', 'decay_rate', 'staircase'], varargs=None, keywords=None, defaults=(False,))
@@ -374,7 +377,7 @@ paddle.fluid.optimizer.DecayedAdagradOptimizer.__init__ ArgSpec(args=['self', 'l
paddle.fluid.optimizer.DecayedAdagradOptimizer.minimize ArgSpec(args=['self', 'loss', 'startup_program', 'parameter_list', 'no_grad_set'], varargs=None, keywords=None, defaults=(None, None, None))
paddle.fluid.optimizer.FtrlOptimizer.__init__ ArgSpec(args=['self', 'learning_rate', 'l1', 'l2', 'lr_power'], varargs=None, keywords='kwargs', defaults=(0.0, 0.0, -0.5))
paddle.fluid.optimizer.FtrlOptimizer.minimize ArgSpec(args=['self', 'loss', 'startup_program', 'parameter_list', 'no_grad_set'], varargs=None, keywords=None, defaults=(None, None, None))
-paddle.fluid.optimizer.RMSPropOptimizer.__init__ ArgSpec(args=['self', 'learning_rate', 'rho', 'epsilon', 'momentum'], varargs=None, keywords='kwargs', defaults=(0.95, 1e-06, 0.0))
+paddle.fluid.optimizer.RMSPropOptimizer.__init__ ArgSpec(args=['self', 'learning_rate', 'rho', 'epsilon', 'momentum', 'centered'], varargs=None, keywords='kwargs', defaults=(0.95, 1e-06, 0.0, False))
paddle.fluid.optimizer.RMSPropOptimizer.minimize ArgSpec(args=['self', 'loss', 'startup_program', 'parameter_list', 'no_grad_set'], varargs=None, keywords=None, defaults=(None, None, None))
paddle.fluid.optimizer.AdadeltaOptimizer.__init__ ArgSpec(args=['self', 'learning_rate', 'epsilon', 'rho'], varargs=None, keywords='kwargs', defaults=(1e-06, 0.95))
paddle.fluid.optimizer.AdadeltaOptimizer.minimize ArgSpec(args=['self', 'loss', 'startup_program', 'parameter_list', 'no_grad_set'], varargs=None, keywords=None, defaults=(None, None, None))
diff --git a/paddle/fluid/framework/.gitignore b/paddle/fluid/framework/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..5132131e55e2feee8ae88b4c65ec102fbc9c5fe1
--- /dev/null
+++ b/paddle/fluid/framework/.gitignore
@@ -0,0 +1,2 @@
+.tensor_util.cu
+.data_type_transform.cu
\ No newline at end of file
diff --git a/paddle/fluid/framework/CMakeLists.txt b/paddle/fluid/framework/CMakeLists.txt
index 0668ff43c8192f53ff7e05abaeb575e2b78b1de4..cc7938b2ac07f11ceb7f33a2e37380d1e2ed2072 100644
--- a/paddle/fluid/framework/CMakeLists.txt
+++ b/paddle/fluid/framework/CMakeLists.txt
@@ -1,3 +1,22 @@
+# windows treat symbolic file as a real file, which is different with unix
+# We create a hidden file and compile it instead of origin source file.
+function(windows_symbolic TARGET)
+ set(oneValueArgs "")
+ set(multiValueArgs SRCS DEPS)
+ cmake_parse_arguments(windows_symbolic "${options}" "${oneValueArgs}" "${multiValueArgs}" ${ARGN})
+ foreach(src ${windows_symbolic_SRCS})
+ get_filename_component(src ${src} NAME_WE)
+ if (NOT EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/${src}.cc OR NOT EXISTS ${CMAKE_CURRENT_SOURCE_DIR}/${src}.cu)
+ message(FATAL " ${src}.cc and ${src}.cu must exsits, and ${src}.cu must be symbolic file.")
+ endif()
+ add_custom_command(OUTPUT .${src}.cu
+ COMMAND ${CMAKE_COMMAND} -E remove ${CMAKE_CURRENT_SOURCE_DIR}/.${src}.cu
+ COMMAND ${CMAKE_COMMAND} -E copy "${CMAKE_CURRENT_SOURCE_DIR}/${src}.cc" "${CMAKE_CURRENT_SOURCE_DIR}/.${src}.cu"
+ COMMENT "create hidden file of ${src}.cu")
+ add_custom_target(${TARGET} ALL DEPENDS .${src}.cu)
+ endforeach()
+endfunction()
+
add_subdirectory(ir)
if (NOT WIN32)
add_subdirectory(details)
@@ -11,7 +30,13 @@ nv_test(dim_test SRCS dim_test.cu DEPS ddim)
cc_library(data_type SRCS data_type.cc DEPS framework_proto ddim device_context)
cc_test(data_type_test SRCS data_type_test.cc DEPS data_type place tensor)
if(WITH_GPU)
- nv_library(tensor SRCS tensor.cc tensor_util.cu DEPS place memory data_type device_context)
+ if (WIN32)
+ windows_symbolic(tensor_util SRCS tensor_util.cu)
+ nv_library(tensor SRCS tensor.cc .tensor_util.cu DEPS place memory data_type device_context)
+ add_dependencies(tensor tensor_util)
+ else()
+ nv_library(tensor SRCS tensor.cc tensor_util.cu DEPS place memory data_type device_context)
+ endif(WIN32)
else()
cc_library(tensor SRCS tensor.cc tensor_util.cc DEPS place memory data_type device_context)
endif()
@@ -55,7 +80,13 @@ nv_test(data_device_transform_test SRCS data_device_transform_test.cu
DEPS operator op_registry device_context math_function)
if(WITH_GPU)
- nv_library(data_type_transform SRCS data_type_transform.cu DEPS tensor)
+ if (WIN32)
+ windows_symbolic(hidden_file SRCS data_type_transform.cu)
+ nv_library(data_type_transform SRCS .data_type_transform.cu DEPS tensor)
+ add_dependencies(data_type_transform hidden_file)
+ else()
+ nv_library(data_type_transform SRCS data_type_transform.cu DEPS tensor)
+ endif(WIN32)
nv_test(data_type_transform_test SRCS data_type_transform_test.cc data_type_transform_test.cu DEPS data_type_transform)
else()
cc_library(data_type_transform SRCS data_type_transform.cc DEPS tensor)
diff --git a/paddle/fluid/framework/data_layout_transform.cc b/paddle/fluid/framework/data_layout_transform.cc
index cd00b7de7338982308acfa1f1e8c38e010c6a43b..c9e3a8ac1d1e5228725bff49ecc6d91e640dfe57 100644
--- a/paddle/fluid/framework/data_layout_transform.cc
+++ b/paddle/fluid/framework/data_layout_transform.cc
@@ -46,7 +46,7 @@ struct CastDataLayout {
const std::vector axis_;
template
- void operator()() {
+ void apply() {
auto place = ctx_->GetPlace();
if (platform::is_cpu_place(place)) {
diff --git a/paddle/fluid/framework/data_type.h b/paddle/fluid/framework/data_type.h
index 84691a2059124960a3213802fec0863f8abe6df7..8ad2fb5f3ffd9641932bbbb024a31e81d31dc9bb 100644
--- a/paddle/fluid/framework/data_type.h
+++ b/paddle/fluid/framework/data_type.h
@@ -26,75 +26,40 @@ namespace framework {
extern proto::VarType::Type ToDataType(std::type_index type);
extern std::type_index ToTypeIndex(proto::VarType::Type type);
-#if !defined(_WIN32)
template
inline void VisitDataType(proto::VarType::Type type, Visitor visitor) {
switch (type) {
case proto::VarType::FP16:
- visitor.template operator()();
+ visitor.template apply();
break;
case proto::VarType::FP32:
- visitor.template operator()();
+ visitor.template apply();
break;
case proto::VarType::FP64:
- visitor.template operator()();
+ visitor.template apply();
break;
case proto::VarType::INT32:
- visitor.template operator()();
+ visitor.template apply();
break;
case proto::VarType::INT64:
- visitor.template operator()();
+ visitor.template apply();
break;
case proto::VarType::BOOL:
- visitor.template operator()();
+ visitor.template apply();
break;
case proto::VarType::UINT8:
- visitor.template operator()();
+ visitor.template apply();
break;
case proto::VarType::INT16:
- visitor.template operator()();
+ visitor.template apply();
break;
case proto::VarType::INT8:
- visitor.template operator()();
+ visitor.template apply();
break;
default:
PADDLE_THROW("Not supported %d", type);
}
}
-#else
-// the msvc compiler do not implement two-stage name lookup correctly.
-template
-inline void VisitDataType(proto::VarType::Type type, Visitor visitor) {
- switch (type) {
- case proto::VarType::FP16:
- visitor.operator()();
- break;
- case proto::VarType::FP32:
- visitor.operator()();
- break;
- case proto::VarType::FP64:
- visitor.operator()();
- break;
- case proto::VarType::INT32:
- visitor.operator()();
- break;
- case proto::VarType::INT64:
- visitor.operator()();
- break;
- case proto::VarType::BOOL:
- visitor.operator()();
- break;
- case proto::VarType::UINT8:
- visitor.operator()();
- break;
- case proto::VarType::INT16:
- visitor.operator()();
- break;
- default:
- PADDLE_THROW("Not supported %d", type);
- }
-}
-#endif // _WIN32
extern std::string DataTypeToString(const proto::VarType::Type type);
extern size_t SizeOfType(std::type_index type);
diff --git a/paddle/fluid/framework/data_type_transform.cc b/paddle/fluid/framework/data_type_transform.cc
index 5a57ec20585c26dbcd4251464718fc819148a7a5..d79f8cacb5f4727defc77380371e57bcea65f068 100644
--- a/paddle/fluid/framework/data_type_transform.cc
+++ b/paddle/fluid/framework/data_type_transform.cc
@@ -37,7 +37,7 @@ struct CastDataType {
const platform::DeviceContext* ctx_;
template
- void operator()() {
+ void apply() {
auto* in_begin = in_.data();
auto* in_end = in_begin + in_.numel();
auto* out_begin = out_->mutable_data(in_.place());
diff --git a/paddle/fluid/framework/details/multi_devices_graph_pass.cc b/paddle/fluid/framework/details/multi_devices_graph_pass.cc
index 0bfff745493d069e948e6d277ec2bbfb0673a70b..7a99169849debcbc57d6f197b36c5045b211f3ef 100644
--- a/paddle/fluid/framework/details/multi_devices_graph_pass.cc
+++ b/paddle/fluid/framework/details/multi_devices_graph_pass.cc
@@ -326,7 +326,7 @@ std::unique_ptr MultiDevSSAGraphBuilder::ApplyImpl(
ir::Graph &result = *graph;
for (auto &node : nodes) {
- if (node->NodeType() == ir::Node::Type::kVariable && node->Var()) {
+ if (node->IsVar() && node->Var()) {
all_vars_.emplace(node->Name(), node->Var());
}
}
@@ -583,18 +583,6 @@ void MultiDevSSAGraphBuilder::InsertDataBalanceOp(
}
}
-bool MultiDevSSAGraphBuilder::IsParameterGradientOnce(
- const std::string &og,
- std::unordered_set *og_has_been_broadcast) const {
- bool is_pg_once =
- grad_names_.count(og) != 0 && og_has_been_broadcast->count(og) == 0;
- if (is_pg_once) {
- // Insert NCCL AllReduce Op
- og_has_been_broadcast->insert(og);
- }
- return is_pg_once;
-}
-
int MultiDevSSAGraphBuilder::GetOpDeviceID(const ir::Graph &graph,
ir::Node *node) const {
if (strategy_.reduce_ != BuildStrategy::ReduceStrategy::kReduce) {
@@ -688,20 +676,6 @@ VarHandle *MultiDevSSAGraphBuilder::CreateReduceOp(ir::Graph *result,
return var;
}
-// Find the first occurence of `prev_op_name` and make current `op` depend
-// on it.
-void MultiDevSSAGraphBuilder::ConnectOp(ir::Graph *result, OpHandleBase *op,
- const std::string &prev_op_name) const {
- for (auto &prev_op : result->Get(kGraphOps)) {
- if (prev_op->Name() == prev_op_name) {
- auto *dep_var = new DummyVarHandle(result->CreateControlDepVar());
- prev_op->AddOutput(dep_var);
- result->Get(kGraphDepVars).emplace(dep_var);
- op->AddInput(dep_var);
- }
- }
-}
-
void MultiDevSSAGraphBuilder::CreateDistTrainOp(ir::Graph *result,
ir::Node *node) const {
int op_dev_id = -1;
diff --git a/paddle/fluid/framework/details/multi_devices_graph_pass.h b/paddle/fluid/framework/details/multi_devices_graph_pass.h
index 7a6f238f9cf7af18cb10ea271e453fec1902c833..ac6d9c5a64cfde60f75c76dae0a30cc7d735e996 100644
--- a/paddle/fluid/framework/details/multi_devices_graph_pass.h
+++ b/paddle/fluid/framework/details/multi_devices_graph_pass.h
@@ -69,9 +69,6 @@ class MultiDevSSAGraphBuilder : public ir::Pass {
std::vector FindDistTrainRecvVars(
const std::vector &nodes) const;
- void ConnectOp(ir::Graph *result, OpHandleBase *op,
- const std::string &prev_op_name) const;
-
void CreateComputationalOps(ir::Graph *result, ir::Node *node,
size_t num_places) const;
@@ -83,10 +80,6 @@ class MultiDevSSAGraphBuilder : public ir::Pass {
void CreateComputationalOp(ir::Graph *result, ir::Node *node,
int dev_id) const;
- bool IsParameterGradientOnce(
- const std::string &og,
- std::unordered_set *og_has_been_broadcast) const;
-
int GetOpDeviceID(const ir::Graph &graph, ir::Node *node) const;
void InsertAllReduceOp(ir::Graph *result, const std::string &og) const;
diff --git a/paddle/fluid/framework/details/reduce_and_gather.h b/paddle/fluid/framework/details/reduce_and_gather.h
index e28264eb32756f77ef5baed3dff77ba9f0943160..bd6153c0c736f6e32378eebcbf6c4d7e402c9b42 100644
--- a/paddle/fluid/framework/details/reduce_and_gather.h
+++ b/paddle/fluid/framework/details/reduce_and_gather.h
@@ -31,7 +31,7 @@ struct ReduceLoDTensor {
: src_tensors_(src), dst_tensor_(*dst) {}
template
- void operator()() const {
+ void apply() const {
PADDLE_ENFORCE(!src_tensors_.empty());
auto &t0 = *src_tensors_[0];
PADDLE_ENFORCE_NE(t0.numel(), 0);
diff --git a/paddle/fluid/framework/ir/CMakeLists.txt b/paddle/fluid/framework/ir/CMakeLists.txt
index bfc649017f19d67660bd11d590134cf56772bb27..78387c407398b58d3fab6eab12445c4198f809b5 100644
--- a/paddle/fluid/framework/ir/CMakeLists.txt
+++ b/paddle/fluid/framework/ir/CMakeLists.txt
@@ -1,20 +1,44 @@
+set(pass_file ${PADDLE_BINARY_DIR}/paddle/fluid/inference/api/paddle_inference_pass.h)
+file(WRITE ${pass_file} "// Generated by the paddle/fluid/framework/ir/CMakeLists.txt. DO NOT EDIT!\n\n")
+file(APPEND ${pass_file} "\#include \"paddle/fluid/framework/ir/pass.h\"\n")
+
+
+# Usage: pass_library(target inference) will append to paddle_inference_pass.h
+function(pass_library TARGET DEST)
+ set(options "")
+ set(oneValueArgs "")
+ set(multiValueArgs SRCS DEPS)
+ cmake_parse_arguments(op_library "${options}" "${oneValueArgs}" "${multiValueArgs}" ${ARGN})
+ cc_library(${TARGET} SRCS ${TARGET}.cc DEPS graph_pattern_detector pass ${op_library_DEPS})
+ # add more DEST here, such as train, dist and collect USE_PASS into a file automatically.
+ if (${DEST} STREQUAL "base" OR ${DEST} STREQUAL "inference")
+ message(STATUS "add pass ${TARGET} ${DEST}")
+ file(APPEND ${pass_file} "USE_PASS(${TARGET});\n")
+ set(PASS_LIBRARY ${TARGET} ${PASS_LIBRARY} PARENT_SCOPE)
+ endif()
+endfunction()
+
cc_library(node SRCS node.cc DEPS proto_desc)
cc_library(graph SRCS graph.cc DEPS node)
cc_library(graph_helper SRCS graph_helper.cc DEPS graph)
cc_library(pass SRCS pass.cc DEPS graph node graph_helper)
-cc_library(graph_viz_pass SRCS graph_viz_pass.cc DEPS graph pass graph_helper)
-cc_library(graph_to_program_pass SRCS graph_to_program_pass.cc DEPS graph pass graph_helper)
cc_library(graph_traits SRCS graph_traits.cc DEPS graph)
cc_library(graph_pattern_detector SRCS graph_pattern_detector.cc DEPS graph graph_helper graph_traits)
-cc_library(fc_fuse_pass SRCS fc_fuse_pass.cc DEPS graph graph_pattern_detector)
-cc_library(attention_lstm_fuse_pass SRCS attention_lstm_fuse_pass.cc DEPS graph graph_pattern_detector)
-cc_library(infer_clean_graph_pass SRCS infer_clean_graph_pass.cc DEPS graph pass)
-cc_library(fc_lstm_fuse_pass SRCS fc_lstm_fuse_pass.cc DEPS graph graph_pattern_detector)
-cc_library(seq_concat_fc_fuse_pass SRCS seq_concat_fc_fuse_pass.cc DEPS graph graph_pattern_detector)
+
+pass_library(graph_to_program_pass base)
+pass_library(graph_viz_pass base)
+pass_library(fc_fuse_pass inference)
+pass_library(attention_lstm_fuse_pass inference)
+pass_library(infer_clean_graph_pass inference)
+pass_library(fc_lstm_fuse_pass inference)
+pass_library(fc_gru_fuse_pass inference)
+pass_library(seq_concat_fc_fuse_pass inference)
+
+set(GLOB_PASS_LIB ${PASS_LIBRARY} CACHE INTERNAL "Global PASS library")
cc_test(pass_test SRCS pass_test.cc DEPS graph pass graph_helper)
cc_test(graph_test SRCS graph_test.cc DEPS graph graph_helper op_registry)
cc_test(graph_helper_test SRCS graph_helper_test.cc DEPS graph graph_helper op_registry)
cc_test(graph_to_program_pass_test SRCS graph_to_program_pass_test.cc DEPS graph_to_program_pass)
cc_test(test_graph_pattern_detector SRCS graph_pattern_detector_tester.cc DEPS graph_pattern_detector)
-cc_test(test_fc_fuse_pass SRCS fc_fuse_pass_tester.cc DEPS fc_fuse_pass graph_pattern_detector graph pass graph_traits framework_proto)
+cc_test(test_fc_fuse_pass SRCS fc_fuse_pass_tester.cc DEPS fc_fuse_pass framework_proto)
diff --git a/paddle/fluid/framework/ir/attention_lstm_fuse_pass.cc b/paddle/fluid/framework/ir/attention_lstm_fuse_pass.cc
index d2d051a69a33a38535e67227d4cc62f5b35e430c..bb52d7e498e55c02ddc2cd6d07ccccd51ce4edc5 100644
--- a/paddle/fluid/framework/ir/attention_lstm_fuse_pass.cc
+++ b/paddle/fluid/framework/ir/attention_lstm_fuse_pass.cc
@@ -13,10 +13,10 @@
// limitations under the License.
#include "paddle/fluid/framework/ir/attention_lstm_fuse_pass.h"
+#include
#include "paddle/fluid/framework/ir/graph_pattern_detector.h"
#include "paddle/fluid/framework/ir/graph_viz_pass.h"
#include "paddle/fluid/framework/lod_tensor.h"
-#include "paddle/fluid/inference/api/helper.h"
namespace paddle {
namespace framework {
@@ -96,17 +96,13 @@ void FindWhileOp(Graph* graph) {
auto* cell_init = graph->RetriveNode(6);
auto* hidden_init = graph->RetriveNode(8);
-#define LINK_TO(node0, node1) \
- node0->outputs.push_back(node1); \
- node1->inputs.push_back(node0);
-
auto* lstm_op = graph->CreateOpNode(&op_desc);
PrepareParameters(graph, param);
- LINK_TO(X, lstm_op);
- LINK_TO(cell_init, lstm_op);
- LINK_TO(hidden_init, lstm_op);
- LINK_TO(lstm_op, LSTMOUT);
+ IR_NODE_LINK_TO(X, lstm_op);
+ IR_NODE_LINK_TO(cell_init, lstm_op);
+ IR_NODE_LINK_TO(hidden_init, lstm_op);
+ IR_NODE_LINK_TO(lstm_op, LSTMOUT);
GraphSafeRemoveNodes(graph, marked_nodes);
}
@@ -216,11 +212,11 @@ void PrepareLSTMWeight(const LoDTensor& W_forget_w0,
float* out_data = out->mutable_data(platform::CPUPlace());
std::array tensors(
- {W_forget_w0.data(), W_input_w0.data(),
- W_output_w0.data(), W_cell_w0.data()});
+ {{W_forget_w0.data(), W_input_w0.data(),
+ W_output_w0.data(), W_cell_w0.data()}});
std::array tensors1(
- {W_forget_w1.data(), W_input_w1.data(),
- W_output_w1.data(), W_cell_w1.data()});
+ {{W_forget_w1.data(), W_input_w1.data(),
+ W_output_w1.data(), W_cell_w1.data()}});
for (int row = 0; row < D; row++) {
for (int col = 0; col < 4; col++) {
@@ -243,8 +239,8 @@ void PrepareLSTMBias(const LoDTensor& B_forget, const LoDTensor& B_input,
const LoDTensor& B_output, const LoDTensor& B_cell,
LoDTensor* out) {
std::array tensors(
- {B_forget.data(), B_input.data(), B_output.data(),
- B_cell.data()});
+ {{B_forget.data(), B_input.data(), B_output.data(),
+ B_cell.data()}});
PADDLE_ENFORCE_EQ(B_forget.dims().size(), 1);
int D = B_forget.dims()[0];
diff --git a/paddle/fluid/framework/ir/fc_fuse_pass.cc b/paddle/fluid/framework/ir/fc_fuse_pass.cc
index 513742bab69d465aac1bfb7bcef2fe89108c14a0..ca704c7f5631bbaa88f1bc2caaa22fd021de11c4 100644
--- a/paddle/fluid/framework/ir/fc_fuse_pass.cc
+++ b/paddle/fluid/framework/ir/fc_fuse_pass.cc
@@ -21,120 +21,51 @@ namespace paddle {
namespace framework {
namespace ir {
-bool VarOutLinksToOp(Node* node, const std::string& op_type) {
- for (auto* out : node->outputs) {
- if (out->IsOp() && out->Op()->Type() == op_type) {
- return true;
- }
- }
- return false;
-}
-
-void BuildFCPattern(PDPattern* pattern) {
- // Create Operators
- auto* mul_op = pattern->NewNode("mul")->assert_is_op("mul");
- auto* elementwise_add_op =
- pattern->NewNode("elementwise_add")->assert_is_op("elementwise_add");
- // Create variables
- // w
- auto* mul_weight_var = pattern->NewNode("mul_weight")
- ->AsInput()
- ->assert_is_op_nth_input("mul", "Y", 0);
- // x
- auto* mul_tmp_var = pattern->NewNode("mul_tmp_var")
- ->AsInput()
- ->assert_is_op_nth_input("mul", "X", 0);
- // intermediate variable, will be removed in the IR after fuse.
- auto* mul_out_var = pattern->NewNode("mul_out")
- ->AsIntermediate()
- ->assert_is_only_output_of_op("mul")
- ->assert_is_op_input("elementwise_add");
- // bias
- auto* elementwise_add_tmp_var = pattern->NewNode("elementwise_add_tmpvar")
- ->assert_is_op_input("elementwise_add")
- ->AsInput();
- // output
- auto* elementwise_add_out_var = pattern->NewNode("elementwise_add_out")
- ->AsOutput()
- ->assert_is_op_output("elementwise_add");
-
- mul_op->LinksFrom({mul_weight_var, mul_tmp_var}).LinksTo({mul_out_var});
- elementwise_add_op->LinksFrom({mul_out_var, elementwise_add_tmp_var})
- .LinksTo({elementwise_add_out_var});
-}
-
-// Replace the node `from` in the links to `to`
-bool LinksReplace(std::vector* links, Node* from, Node* to) {
- for (auto*& n : *links) {
- if (n == from) {
- n = to;
- return true;
- }
- }
- return false;
-}
-
std::unique_ptr FCFusePass::ApplyImpl(
std::unique_ptr graph) const {
PADDLE_ENFORCE(graph.get());
- FusePassBase::Init("fc", graph.get());
+ FusePassBase::Init("fc_fuse", graph.get());
std::unordered_set nodes2delete;
GraphPatternDetector gpd;
- BuildFCPattern(gpd.mutable_pattern());
-
-#define GET_NODE(id) \
- PADDLE_ENFORCE(subgraph.count(gpd.pattern().RetrieveNode(#id)), \
- "pattern has no Node called %s", #id); \
- auto* id = subgraph.at(gpd.pattern().RetrieveNode(#id)); \
- PADDLE_ENFORCE_NOT_NULL(id, "subgraph has no node %s", #id);
+ auto* x = gpd.mutable_pattern()
+ ->NewNode("fc_fuse/x")
+ ->AsInput()
+ ->assert_is_op_input("mul", "X");
+ patterns::FC fc_pattern(gpd.mutable_pattern(), "fc_fuse");
+ fc_pattern(x, true /*with bias*/);
int found_fc_count = 0;
auto handler = [&](const GraphPatternDetector::subgraph_t& subgraph,
Graph* g) {
VLOG(4) << "handle FC fuse";
- // Currently, there is no FC op available, so I will just simulate the
- // scenerio.
- // FC's fusion is simple, just op fuse, no need to process the
- // parameters.
- GET_NODE(mul_tmp_var); // x
- GET_NODE(mul_weight); // Y
- GET_NODE(elementwise_add_tmpvar); // bias
- GET_NODE(elementwise_add_out); // Out
- GET_NODE(mul); // MUL op
- GET_NODE(elementwise_add); // ELEMENT_ADD op
- GET_NODE(mul_out); // tmp
-#undef GET_NODE
+ GET_IR_NODE_FROM_SUBGRAPH(w, w, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(fc_bias, bias, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(fc_out, Out, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(mul, mul, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(elementwise_add, elementwise_add, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(mul_out, mul_out, fc_pattern);
// Create an FC Node.
OpDesc desc;
- std::string fc_x_in = mul_tmp_var->Name();
- std::string fc_Y_in = mul_weight->Name();
- std::string fc_bias_in = elementwise_add_tmpvar->Name();
- std::string fc_out = elementwise_add_out->Name();
+ std::string fc_x_in = subgraph.at(x)->Name();
+ std::string fc_Y_in = w->Name();
+ std::string fc_bias_in = fc_bias->Name();
+ std::string fc_out_out = fc_out->Name();
desc.SetInput("Input", std::vector({fc_x_in}));
desc.SetInput("W", std::vector({fc_Y_in}));
desc.SetInput("Bias", std::vector({fc_bias_in}));
- desc.SetOutput("Out", std::vector({fc_out}));
+ desc.SetOutput("Out", std::vector({fc_out_out}));
desc.SetType("fc");
auto fc_node = g->CreateOpNode(&desc); // OpDesc will be copied.
- fc_node->inputs =
- std::vector({mul_tmp_var, mul_weight, elementwise_add_tmpvar});
- fc_node->outputs.push_back(elementwise_add_out);
-
- // Update link relatons
- PADDLE_ENFORCE(LinksReplace(&mul_tmp_var->outputs, mul, fc_node));
- PADDLE_ENFORCE(LinksReplace(&mul_weight->outputs, mul, fc_node));
- PADDLE_ENFORCE(LinksReplace(&elementwise_add_tmpvar->outputs,
- elementwise_add, fc_node));
- PADDLE_ENFORCE(
- LinksReplace(&elementwise_add_out->inputs, elementwise_add, fc_node));
+ GraphSafeRemoveNodes(graph.get(), {mul, elementwise_add, mul_out});
- // Drop old nodes
- graph->RemoveNode(mul);
- graph->RemoveNode(elementwise_add);
- graph->RemoveNode(mul_out); // tmp variable
+ PADDLE_ENFORCE(subgraph.count(x));
+ IR_NODE_LINK_TO(subgraph.at(x), fc_node);
+ IR_NODE_LINK_TO(w, fc_node);
+ IR_NODE_LINK_TO(fc_bias, fc_node);
+ IR_NODE_LINK_TO(fc_node, fc_out);
found_fc_count++;
};
diff --git a/paddle/fluid/framework/ir/fc_gru_fuse_pass.cc b/paddle/fluid/framework/ir/fc_gru_fuse_pass.cc
new file mode 100644
index 0000000000000000000000000000000000000000..a902b0b50cf27ff84877053aca2ff921cd00b833
--- /dev/null
+++ b/paddle/fluid/framework/ir/fc_gru_fuse_pass.cc
@@ -0,0 +1,185 @@
+// Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include "paddle/fluid/framework/ir/fc_gru_fuse_pass.h"
+#include
+#include "paddle/fluid/framework/lod_tensor.h"
+
+namespace paddle {
+namespace framework {
+namespace ir {
+
+static int BuildFusion(Graph* graph, const std::string& name_scope,
+ Scope* scope, bool with_fc_bias) {
+ GraphPatternDetector gpd;
+ auto* pattern = gpd.mutable_pattern();
+
+ // Create pattern.
+ patterns::FC fc_pattern(pattern, name_scope);
+ patterns::GRU gru_pattern(pattern, name_scope);
+
+ PDNode* x =
+ pattern->NewNode(patterns::UniqueKey("x"))->assert_var_not_persistable();
+
+ auto* fc_out = fc_pattern(x, with_fc_bias);
+ fc_out->AsIntermediate(); // fc_out is a tmp var, will be removed after fuse.
+ gru_pattern(fc_out);
+
+ // Create New OpDesc
+ auto gru_creater = [&](Node* gru, Node* x, Node* weight_x, Node* weight_h,
+ Node* bias, Node* hidden, Node* fc_bias) {
+
+ OpDesc op_desc;
+ op_desc.SetType("fusion_gru");
+
+#define NEW_NAME(x) name_scope + "/at." #x ".new"
+#define SET_IN(Key, node__) op_desc.SetInput(#Key, {node__->Name()});
+ SET_IN(X, x);
+ SET_IN(WeightX, weight_x);
+ SET_IN(WeightH, weight_h);
+ if (with_fc_bias) {
+ op_desc.SetInput("Bias", {NEW_NAME(bias) + bias->Name()});
+ } else {
+ SET_IN(Bias, bias);
+ }
+#undef SET_IN
+ op_desc.SetInput("H0", {});
+ op_desc.SetOutput("Hidden", {hidden->Name()});
+ op_desc.SetAttr("is_reverse", gru->Op()->GetAttr("is_reverse"));
+ // TODO(TJ): This should be a option for infer
+ op_desc.SetAttr("use_seq", true);
+
+#define SET_IMTERMEDIATE_OUT(key) op_desc.SetOutput(#key, {NEW_NAME(key)})
+ SET_IMTERMEDIATE_OUT(ReorderedH0);
+ SET_IMTERMEDIATE_OUT(XX);
+ SET_IMTERMEDIATE_OUT(BatchedInput);
+ SET_IMTERMEDIATE_OUT(BatchedOut);
+#undef SET_IMTERMEDIATE_OUT
+
+ auto* op = graph->CreateOpNode(&op_desc);
+ PADDLE_ENFORCE(graph->Has(kParamScopeAttr));
+ auto* scope = graph->Get(kParamScopeAttr);
+ PADDLE_ENFORCE(scope);
+ if (with_fc_bias) {
+ // Fusion GRU bias = fcbias + grubias
+ auto* fusion_bias_var = scope->Var(NEW_NAME(bias) + bias->Name());
+ auto* out_bias_tensor =
+ fusion_bias_var->GetMutable();
+ PADDLE_ENFORCE(fusion_bias_var);
+ auto* gru_bias_var = scope->FindVar(bias->Name());
+ auto* fc_bias_var = scope->FindVar(fc_bias->Name());
+ PADDLE_ENFORCE(gru_bias_var);
+ PADDLE_ENFORCE(fc_bias_var);
+ const auto& gru_bias_tenosr = gru_bias_var->Get();
+ const auto& fc_bias_tensor = fc_bias_var->Get();
+ // new bias = fc bias + gru bias
+ out_bias_tensor->Resize(gru_bias_tenosr.dims());
+ auto* data = out_bias_tensor->mutable_data(platform::CPUPlace());
+ for (int i = 0; i < out_bias_tensor->numel(); i++) {
+ data[i] =
+ fc_bias_tensor.data()[i] + gru_bias_tenosr.data()[i];
+ }
+ }
+#undef GET_NODE
+
+#define NEW_IMTERMEDIATE_OUT(key) \
+ scope->Var(NEW_NAME(key))->GetMutable()
+ NEW_IMTERMEDIATE_OUT(ReorderedH0);
+ NEW_IMTERMEDIATE_OUT(XX);
+ NEW_IMTERMEDIATE_OUT(BatchedInput);
+ NEW_IMTERMEDIATE_OUT(BatchedOut);
+#undef NEW_NAME
+#undef NEW_IMTERMEDIATE_OUT
+
+ IR_NODE_LINK_TO(x, op);
+ IR_NODE_LINK_TO(weight_x, op);
+ IR_NODE_LINK_TO(weight_h, op);
+ IR_NODE_LINK_TO(bias, op); // actually should link to new bias if have
+ IR_NODE_LINK_TO(op, hidden);
+ // h0?
+ return op;
+ };
+
+ int fusion_count{0};
+ auto handler = [&](const GraphPatternDetector::subgraph_t& subgraph,
+ Graph* g) {
+ auto* x_n = subgraph.at(x);
+ GET_IR_NODE_FROM_SUBGRAPH(w, w, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(mul, mul, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(fc_out, Out, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(Weight, Weight, gru_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(gru, gru, gru_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(Bias, Bias, gru_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(Hidden, Hidden, gru_pattern);
+ // nodes need be removed
+ GET_IR_NODE_FROM_SUBGRAPH(BatchGate, BatchGate, gru_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(BatchResetHiddenPrev, BatchGate, gru_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(BatchHidden, BatchGate, gru_pattern);
+
+ if (with_fc_bias) {
+ GET_IR_NODE_FROM_SUBGRAPH(mul_out, mul_out, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(fc_bias, bias, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(elementwise_add, elementwise_add, fc_pattern);
+
+ gru_creater(gru, x_n, w, Weight, Bias, Hidden, fc_bias);
+ // Remove unneeded nodes.
+ std::unordered_set marked_nodes(
+ {mul, gru, elementwise_add, fc_bias, fc_out, mul_out, BatchGate,
+ BatchResetHiddenPrev, BatchHidden});
+ GraphSafeRemoveNodes(graph, marked_nodes);
+ } else {
+ gru_creater(gru, x_n, w, Weight, Bias, Hidden, nullptr);
+ // Remove unneeded nodes.
+ std::unordered_set marked_nodes(
+ {mul, gru, BatchGate, BatchResetHiddenPrev, BatchHidden});
+ GraphSafeRemoveNodes(graph, marked_nodes);
+ }
+#undef GET_NODE
+
+ ++fusion_count;
+ };
+
+ gpd(graph, handler);
+
+ return fusion_count;
+}
+
+std::unique_ptr MulGRUFusePass::ApplyImpl(
+ std::unique_ptr graph) const {
+ FusePassBase::Init(name_scope_, graph.get());
+
+ int fusion_count = BuildFusion(graph.get(), name_scope_, param_scope(),
+ false /*with_fc_bias*/);
+
+ AddStatis(fusion_count);
+ return graph;
+}
+
+std::unique_ptr FCGRUFusePass::ApplyImpl(
+ std::unique_ptr graph) const {
+ FusePassBase::Init(name_scope_, graph.get());
+
+ int fusion_count = BuildFusion(graph.get(), name_scope_, param_scope(),
+ true /*with_fc_bias*/);
+
+ AddStatis(fusion_count);
+ return graph;
+}
+
+} // namespace ir
+} // namespace framework
+} // namespace paddle
+
+REGISTER_PASS(mul_gru_fuse_pass, paddle::framework::ir::MulGRUFusePass);
+REGISTER_PASS(fc_gru_fuse_pass, paddle::framework::ir::FCGRUFusePass);
diff --git a/paddle/fluid/framework/ir/fc_gru_fuse_pass.h b/paddle/fluid/framework/ir/fc_gru_fuse_pass.h
new file mode 100644
index 0000000000000000000000000000000000000000..63e1c72bfb2e2641ae5d44858b342d5e427e9045
--- /dev/null
+++ b/paddle/fluid/framework/ir/fc_gru_fuse_pass.h
@@ -0,0 +1,50 @@
+// Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#pragma once
+
+#include
+#include "paddle/fluid/framework/ir/fuse_pass_base.h"
+#include "paddle/fluid/framework/ir/graph.h"
+#include "paddle/fluid/framework/ir/graph_pattern_detector.h"
+
+namespace paddle {
+namespace framework {
+namespace ir {
+
+// The MulGRUFusePass and MulGRUFusePass will fuse to the same FusionGRU op.
+
+class FCGRUFusePass : public FusePassBase {
+ public:
+ virtual ~FCGRUFusePass() {}
+
+ protected:
+ std::unique_ptr ApplyImpl(std::unique_ptr graph) const;
+
+ const std::string name_scope_{"fc_gru_fuse"};
+};
+
+// Just FC without bias
+class MulGRUFusePass : public FusePassBase {
+ public:
+ virtual ~MulGRUFusePass() {}
+
+ protected:
+ std::unique_ptr ApplyImpl(std::unique_ptr graph) const;
+ const std::string name_scope_{"fc_nobias_gru_fuse"};
+};
+
+} // namespace ir
+} // namespace framework
+} // namespace paddle
diff --git a/paddle/fluid/framework/ir/fc_lstm_fuse_pass.cc b/paddle/fluid/framework/ir/fc_lstm_fuse_pass.cc
index 5852705b6b8d1c650faeae3dc810aac65353b459..f7fda873574a0f8b10251d4fa6b604a9312ad7f9 100644
--- a/paddle/fluid/framework/ir/fc_lstm_fuse_pass.cc
+++ b/paddle/fluid/framework/ir/fc_lstm_fuse_pass.cc
@@ -13,109 +13,167 @@
// limitations under the License.
#include "paddle/fluid/framework/ir/fc_lstm_fuse_pass.h"
+#include
+#include "paddle/fluid/framework/lod_tensor.h"
namespace paddle {
namespace framework {
namespace ir {
-std::unique_ptr FCLstmFusePass::ApplyImpl(
- std::unique_ptr graph) const {
+int BuildFusion(Graph* graph, const std::string& name_scope, Scope* scope,
+ bool with_fc_bias) {
GraphPatternDetector gpd;
auto* pattern = gpd.mutable_pattern();
- std::unordered_set fused_ops({// first lstm
- 13, 15, 16,
- // second lstm
- 23, 25, 26});
-
- pattern->NewNode([&](Node* x) { return fused_ops.count(x->id()); },
- "any_node");
-
- std::unordered_set marked_nodes;
+ // Build pattern
+ PDNode* x = pattern->NewNode(patterns::PDNodeName(name_scope, "x"))
+ ->assert_is_op_input("mul")
+ ->assert_var_not_persistable();
+ patterns::FC fc_pattern(pattern, name_scope);
- auto handler = [&](const GraphPatternDetector::subgraph_t& subgraph,
- Graph* g) {
-
- auto* id = subgraph.at(gpd.pattern().RetrieveNode("any_node"));
- marked_nodes.insert(id);
- };
- gpd(graph.get(), handler);
+ // fc_out is a tmp var, will be removed after fuse, so marked as intermediate.
+ auto* fc_out = fc_pattern(x, with_fc_bias)->AsIntermediate();
+ patterns::LSTM lstm_pattern(pattern, name_scope);
+ lstm_pattern(fc_out);
// Create New OpDesc
- auto lstm_creator = [&](int lstm, int input, int weight_x, int weight_h,
- int bias, int hidden, int cell, int xx) {
-#define GET_NODE(x) auto* x##_n = graph->RetriveNode(x);
- GET_NODE(input);
- GET_NODE(weight_x);
- GET_NODE(weight_h);
- GET_NODE(bias);
- GET_NODE(hidden);
- GET_NODE(cell);
- GET_NODE(xx);
- GET_NODE(lstm);
-
+ auto lstm_creator = [&](Node* lstm, Node* input, Node* weight_x,
+ Node* weight_h, Node* bias, Node* hidden, Node* cell,
+ Node* xx, Node* fc_bias) {
OpDesc op_desc;
op_desc.SetType("fusion_lstm");
-#define SET_IN(Key, node__) op_desc.SetInput(#Key, {node__##_n->Name()});
+#define SET_IN(Key, node__) op_desc.SetInput(#Key, {node__->Name()});
SET_IN(X, input);
SET_IN(WeightX, weight_x);
SET_IN(WeightH, weight_h);
SET_IN(Bias, bias);
-#undef GET_NODE
#undef SET_IN
+ if (with_fc_bias) {
+ // Add FC-bias with LSTM-bias and create a new weight
+ PADDLE_ENFORCE(scope);
+ const std::string& new_bias_var = name_scope + "_bias.new";
+ auto* bias_var = scope->Var(new_bias_var);
+ PADDLE_ENFORCE(bias_var);
+ auto* bias_tensor = bias_var->GetMutable();
+ auto* lstm_bias_var = scope->FindVar(bias->Name());
+ PADDLE_ENFORCE(lstm_bias_var);
+ const auto& lstm_bias_tensor = lstm_bias_var->Get();
+ bias_tensor->Resize(lstm_bias_tensor.dims());
+
+ auto* fc_bias_var = scope->FindVar(fc_bias->Name());
+ const auto& fc_bias_tensor = fc_bias_var->Get();
+
+ auto* data = bias_tensor->mutable_data(platform::CPUPlace());
+
+ for (int i = 0; i < bias_tensor->numel(); i++) {
+ data[i] =
+ fc_bias_tensor.data()[i] + lstm_bias_tensor.data()[i];
+ }
+ op_desc.SetInput("Bias", {new_bias_var});
+ }
- VLOG(4) << "hidden_n: " << hidden_n->Name();
- VLOG(4) << "cell: " << cell_n->Name();
- VLOG(4) << "xx: " << xx_n->Name();
+ // Create temp variables.
+ const std::string BatchedInput = patterns::UniqueKey("BatchedInput");
+ const std::string BatchedCellPreAct =
+ patterns::UniqueKey("BatchedCellPreAct");
+ const std::string BatchedGate = patterns::UniqueKey("BatchedGate");
+
+ scope->Var(BatchedInput)->GetMutable();
+ scope->Var(BatchedCellPreAct)->GetMutable();
+ scope->Var(BatchedGate)->GetMutable();
op_desc.SetInput("H0", {});
op_desc.SetInput("C0", {});
- op_desc.SetOutput("Hidden", {hidden_n->Name()});
- op_desc.SetOutput("Cell", {cell_n->Name()});
- op_desc.SetOutput("XX", {xx_n->Name()});
- op_desc.SetOutput("BatchedGate", {"blstm_0.tmp_2"});
- op_desc.SetOutput("BatchCellPreAct", {"blstm_1.tmp_2"});
- op_desc.SetAttr("is_reverse", lstm_n->Op()->GetAttr("is_reverse"));
- op_desc.SetAttr("use_peepholes", false);
- auto* op = graph->CreateOpNode(&op_desc);
+ op_desc.SetOutput("Hidden", {hidden->Name()});
+ op_desc.SetOutput("Cell", {cell->Name()});
+ op_desc.SetOutput("XX", {xx->Name()});
+ op_desc.SetOutput("BatchedGate", {BatchedGate});
+ op_desc.SetOutput("BatchCellPreAct", {BatchedCellPreAct});
+ op_desc.SetOutput("BatchedInput", {BatchedInput});
+ op_desc.SetAttr("is_reverse", lstm->Op()->GetAttr("is_reverse"));
+ op_desc.SetAttr("use_peepholes", lstm->Op()->GetAttr("use_peepholes"));
+ // TODO(TJ): get from attr
+ op_desc.SetAttr("use_seq", true);
+
+ PADDLE_ENFORCE(graph->Has(kParamScopeAttr));
+ auto* scope = graph->Get(kParamScopeAttr);
+#define OP_SET_OUT(x) \
+ const std::string x = patterns::UniqueKey(#x); \
+ op_desc.SetOutput(#x, {x}); \
+ scope->Var(x)->GetMutable()
+ OP_SET_OUT(BatchedCell);
+ OP_SET_OUT(BatchedHidden);
+ OP_SET_OUT(ReorderedH0);
+ OP_SET_OUT(ReorderedC0);
+#undef OP_SET_OUT
-#define LINK_TO(a, b) \
- a->outputs.push_back(b); \
- b->inputs.push_back(a);
- LINK_TO(input_n, op);
- LINK_TO(weight_x_n, op);
- LINK_TO(weight_h_n, op);
- LINK_TO(bias_n, op);
- LINK_TO(op, hidden_n);
-#undef LINK_TO
+ auto* op = graph->CreateOpNode(&op_desc);
+ IR_NODE_LINK_TO(input, op);
+ IR_NODE_LINK_TO(weight_x, op);
+ IR_NODE_LINK_TO(weight_h, op);
+ IR_NODE_LINK_TO(bias, op);
+ IR_NODE_LINK_TO(op, hidden);
return op;
+ };
+ int fusion_count{0};
+
+ auto handler = [&](const GraphPatternDetector::subgraph_t& subgraph,
+ Graph* g) {
+
+ GET_IR_NODE_FROM_SUBGRAPH(lstm, lstm, lstm_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(Weight, Weight, lstm_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(Bias, Bias, lstm_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(Cell, Cell, lstm_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(Hidden, Hidden, lstm_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(w, w, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(mul, mul, fc_pattern);
+ if (with_fc_bias) {
+ GET_IR_NODE_FROM_SUBGRAPH(fc_out, Out, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(fc_bias, bias, fc_pattern);
+ GET_IR_NODE_FROM_SUBGRAPH(elementwise_add, elementwise_add, fc_pattern);
+ lstm_creator(lstm, subgraph.at(x), w, Weight, Bias, Hidden, Cell, fc_out,
+ fc_bias);
+ // Remove unneeded nodes.
+ std::unordered_set marked_nodes(
+ {mul, lstm, elementwise_add});
+ GraphSafeRemoveNodes(graph, marked_nodes);
+ } else {
+ GET_IR_NODE_FROM_SUBGRAPH(fc_out, mul_out, fc_pattern);
+ lstm_creator(lstm, subgraph.at(x), w, Weight, Bias, Hidden, Cell, fc_out,
+ nullptr);
+ // Remove unneeded nodes.
+ std::unordered_set marked_nodes({mul, lstm});
+ GraphSafeRemoveNodes(graph, marked_nodes);
+ }
+
+ ++fusion_count;
};
- lstm_creator(16, 12, 14, 18, 17, 22, 21, 19);
- lstm_creator(26, 12, 24, 28, 27, 32, 31, 29);
+ gpd(graph, handler);
- // remove all the nodes
+ return fusion_count;
+}
- for (auto* node : marked_nodes) {
- graph->RemoveNode(const_cast(node));
- }
+std::unique_ptr MulLstmFusePass::ApplyImpl(
+ std::unique_ptr graph) const {
+ FusePassBase::Init(name_scope_, graph.get());
- for (auto* node : graph->Nodes()) {
- for (auto it = node->inputs.begin(); it != node->inputs.end();) {
- if (marked_nodes.count(*it)) {
- it = const_cast(node)->inputs.erase(it);
- } else
- it++;
- }
- for (auto it = node->outputs.begin(); it != node->outputs.end();) {
- if (marked_nodes.count(*it)) {
- it = const_cast(node)->outputs.erase(it);
- } else
- it++;
- }
- }
+ int fusion_count = BuildFusion(graph.get(), name_scope_, param_scope(),
+ false /*with_fc_bias*/);
+
+ AddStatis(fusion_count);
+ return graph;
+}
+
+std::unique_ptr FCLstmFusePass::ApplyImpl(
+ std::unique_ptr graph) const {
+ FusePassBase::Init(name_scope_, graph.get());
+
+ int fusion_count = BuildFusion(graph.get(), name_scope_, param_scope(),
+ true /*with_fc_bias*/);
+ AddStatis(fusion_count);
return graph;
}
@@ -123,4 +181,5 @@ std::unique_ptr FCLstmFusePass::ApplyImpl(
} // namespace framework
} // namespace paddle
+REGISTER_PASS(mul_lstm_fuse_pass, paddle::framework::ir::MulLstmFusePass);
REGISTER_PASS(fc_lstm_fuse_pass, paddle::framework::ir::FCLstmFusePass);
diff --git a/paddle/fluid/framework/ir/fc_lstm_fuse_pass.h b/paddle/fluid/framework/ir/fc_lstm_fuse_pass.h
index 74b08ae558b12c9328db58687cd01edbc37291a8..3ee32c63a46fcc34bdccd1e14d4bbaf9668c49e9 100644
--- a/paddle/fluid/framework/ir/fc_lstm_fuse_pass.h
+++ b/paddle/fluid/framework/ir/fc_lstm_fuse_pass.h
@@ -12,20 +12,36 @@
// See the License for the specific language governing permissions and
// limitations under the License.
+#pragma once
+
+#include "paddle/fluid/framework/ir/fuse_pass_base.h"
#include "paddle/fluid/framework/ir/graph.h"
#include "paddle/fluid/framework/ir/graph_pattern_detector.h"
-#include "paddle/fluid/framework/ir/pass.h"
namespace paddle {
namespace framework {
namespace ir {
-class FCLstmFusePass : public Pass {
+// The MulLstmFusePass and MulLstmFusePass will fuse to the same FusionLstm op.
+
+// Just FC without bias
+class FCLstmFusePass : public FusePassBase {
public:
virtual ~FCLstmFusePass() {}
protected:
std::unique_ptr ApplyImpl(std::unique_ptr graph) const;
+
+ const std::string name_scope_{"fc_lstm_fuse"};
+};
+
+class MulLstmFusePass : public FusePassBase {
+ public:
+ virtual ~MulLstmFusePass() {}
+
+ protected:
+ std::unique_ptr ApplyImpl(std::unique_ptr graph) const;
+ const std::string name_scope_{"fc_nobias_lstm_fuse"};
};
} // namespace ir
diff --git a/paddle/fluid/framework/ir/graph.h b/paddle/fluid/framework/ir/graph.h
index 55e495a0ed75c3a09703438dcfe01ca8f9d36118..ae8496204d4aeb88c04154d571325d440274e821 100644
--- a/paddle/fluid/framework/ir/graph.h
+++ b/paddle/fluid/framework/ir/graph.h
@@ -167,7 +167,6 @@ class Graph {
std::map> attr_dels_;
std::map> nodes_;
std::unordered_set node_set_;
- int node_count_{0};
};
bool IsControlDepVar(const ir::Node &var);
diff --git a/paddle/fluid/framework/ir/graph_pattern_detector.cc b/paddle/fluid/framework/ir/graph_pattern_detector.cc
index 945ab110b148c320b6626cadaa47d483df68419e..fc7feca567e7a0f623ada77af189ef033b44fc53 100644
--- a/paddle/fluid/framework/ir/graph_pattern_detector.cc
+++ b/paddle/fluid/framework/ir/graph_pattern_detector.cc
@@ -19,7 +19,9 @@
#include "paddle/fluid/framework/ir/graph_helper.h"
#include "paddle/fluid/framework/ir/graph_pattern_detector.h"
#include "paddle/fluid/framework/ir/graph_traits.h"
+#include "paddle/fluid/framework/ir/graph_viz_pass.h"
#include "paddle/fluid/platform/enforce.h"
+#include "paddle/fluid/string/printf.h"
namespace paddle {
namespace framework {
@@ -71,7 +73,10 @@ void PDPattern::AddEdge(PDNode* a, PDNode* b) {
void GraphPatternDetector::operator()(Graph* graph,
GraphPatternDetector::handle_t handler) {
- if (!MarkPDNodesInGraph(*graph)) return;
+ if (!MarkPDNodesInGraph(*graph)) {
+ return;
+ }
+
auto subgraphs = DetectPatterns();
UniquePatterns(&subgraphs);
RemoveOverlappedMatch(&subgraphs);
@@ -81,13 +86,13 @@ void GraphPatternDetector::operator()(Graph* graph,
LOG(INFO) << "detect " << subgraphs.size() << " subgraph matches the pattern";
int id = 0;
for (auto& g : subgraphs) {
- LOG(INFO) << "optimizing #" << id++ << " subgraph";
+ VLOG(3) << "optimizing #" << id++ << " subgraph";
handler(g, graph);
}
}
bool GraphPatternDetector::MarkPDNodesInGraph(const ir::Graph& graph) {
- VLOG(4) << "mark pdnodes in graph";
+ VLOG(3) << "mark pdnodes in graph";
if (graph.Nodes().empty()) return false;
for (auto& node : GraphTraits::DFS(graph)) {
@@ -102,11 +107,16 @@ bool GraphPatternDetector::MarkPDNodesInGraph(const ir::Graph& graph) {
for (auto& pdnode : pattern_.nodes()) {
if (!pdnodes2nodes_.count(pdnode.get())) {
VLOG(4) << pdnode->name() << " can't find matched Node, early stop";
-
- return false;
+ // return false;
+ }
+ }
+ for (auto& item : pdnodes2nodes_) {
+ for (auto& n : item.second) {
+ GetMarkedNodes(const_cast(&graph)).insert(n);
}
}
VLOG(3) << pdnodes2nodes_.size() << " nodes marked";
+
return !pdnodes2nodes_.empty();
}
@@ -272,7 +282,7 @@ void GraphPatternDetector::RemoveOverlappedMatch(
for (const auto& subgraph : *subgraphs) {
bool valid = true;
for (auto& item : subgraph) {
- if (node_set.count(item.second)) {
+ if (item.first->IsIntermediate() && node_set.count(item.second)) {
valid = false;
break;
}
@@ -328,22 +338,22 @@ PDNode& PDNode::LinksFrom(const std::vector& others) {
}
PDNode* PDNode::assert_is_op() {
- asserts_.emplace_back([this](Node* x) { return x && x->IsOp(); });
+ asserts_.emplace_back([](Node* x) { return x && x->IsOp(); });
return this;
}
PDNode* PDNode::assert_is_op(const std::string& op_type) {
- asserts_.emplace_back([this, op_type](Node* x) {
+ asserts_.emplace_back([op_type](Node* x) {
return x && x->IsOp() && x->Op()->Type() == op_type;
});
return this;
}
PDNode* PDNode::assert_is_var() {
- asserts_.emplace_back([this](Node* x) { return x && x->IsVar(); });
+ asserts_.emplace_back([](Node* x) { return x && x->IsVar(); });
return this;
}
PDNode* PDNode::assert_var_not_persistable() {
assert_is_var();
- asserts_.emplace_back([this](Node* x) { return !x->Var()->Persistable(); });
+ asserts_.emplace_back([](Node* x) { return !x->Var()->Persistable(); });
return this;
}
PDNode* PDNode::assert_is_persistable_var() {
@@ -357,7 +367,9 @@ PDNode* PDNode::assert_is_op_nth_input(const std::string& op_type,
assert_is_op_input(op_type);
asserts_.emplace_back([=](Node* x) {
for (auto* op : x->outputs) {
- if (IsNthInput(x, op, argument, nth)) return true;
+ if (op->IsOp() && op->Op()->Type() == op_type &&
+ IsNthInput(x, op, argument, nth))
+ return true;
}
return false;
});
@@ -368,7 +380,9 @@ PDNode* PDNode::assert_is_op_nth_output(const std::string& op_type,
assert_is_var();
asserts_.emplace_back([=](Node* x) {
for (auto* op : x->inputs) {
- if (IsNthOutput(x, op, argument, nth)) return true;
+ if (op->IsOp() && op->Op()->Type() == op_type &&
+ IsNthOutput(x, op, argument, nth))
+ return true;
}
return false;
});
@@ -412,6 +426,12 @@ PDNode* PDNode::assert_is_op_output(const std::string& op_type) {
});
return this;
}
+PDNode* PDNode::assert_is_op_output(const std::string& op_type,
+ const std::string& argument) {
+ assert_is_var();
+ assert_is_op_nth_output(op_type, argument, 0);
+ return this;
+}
PDNode* PDNode::assert_is_op_input(const std::string& op_type) {
assert_is_var();
asserts_.emplace_back([=](Node* x) {
@@ -424,6 +444,12 @@ PDNode* PDNode::assert_is_op_input(const std::string& op_type) {
});
return this;
}
+PDNode* PDNode::assert_is_op_input(const std::string& op_type,
+ const std::string& argument) {
+ assert_is_var();
+ assert_is_op_nth_input(op_type, argument, 0);
+ return this;
+}
PDNode* PDNode::assert_op_has_n_inputs(const std::string& op_type, size_t n) {
assert_is_op(op_type);
asserts_.emplace_back([=](Node* x) { return x->inputs.size() == n; });
@@ -439,6 +465,151 @@ PDNode* PDNode::assert_more(PDNode::teller_t&& teller) {
return this;
}
+bool VarLinksToOp(Node* node, const std::string& op_type) {
+ for (auto* out : node->outputs) {
+ if (out->IsOp() && out->Op()->Type() == op_type) {
+ return true;
+ }
+ }
+ return false;
+}
+bool IsNthInput(Node* var, Node* op, const std::string& argument, size_t nth) {
+ PADDLE_ENFORCE(var->IsVar());
+ PADDLE_ENFORCE(op->IsOp());
+ if (op->Op()->Input(argument).size() <= nth) return false;
+ return var->Name() == op->Op()->Input(argument)[nth];
+}
+bool IsNthOutput(Node* var, Node* op, const std::string& argument, size_t nth) {
+ PADDLE_ENFORCE(var->IsVar());
+ PADDLE_ENFORCE(op->IsOp());
+ if (op->Op()->Output(argument).size() <= nth) return false;
+ return var->Name() == op->Op()->Output(argument)[nth];
+}
+void GraphSafeRemoveNodes(Graph* graph,
+ const std::unordered_set& nodes) {
+ for (auto* node : nodes) {
+ graph->RemoveNode(const_cast(node));
+ }
+
+ for (auto* node : graph->Nodes()) {
+ for (auto it = node->inputs.begin(); it != node->inputs.end();) {
+ if (nodes.count(*it)) {
+ it = const_cast(node)->inputs.erase(it);
+ } else {
+ it++;
+ }
+ }
+ for (auto it = node->outputs.begin(); it != node->outputs.end();) {
+ if (nodes.count(*it)) {
+ it = const_cast(node)->outputs.erase(it);
+ } else {
+ it++;
+ }
+ }
+ }
+}
+bool VarLinksFromOp(Node* node, const std::string& op_type) {
+ for (auto* out : node->inputs) {
+ if (out->IsOp() && out->Op()->Type() == op_type) {
+ return true;
+ }
+ }
+ return false;
+}
+
+PDNode* patterns::FC::operator()(paddle::framework::ir::PDNode* x,
+ bool with_bias) {
+ // Create shared nodes.
+ x->assert_is_op_input("mul", "X");
+ auto* mul = pattern->NewNode(mul_repr())->assert_is_op("mul");
+
+ auto* mul_w_var = pattern->NewNode(w_repr())
+ ->AsInput()
+ ->assert_is_persistable_var()
+ ->assert_is_op_input("mul", "Y");
+
+ auto* mul_out_var =
+ pattern->NewNode(mul_out_repr())->assert_is_op_output("mul");
+
+ if (!with_bias) { // not with bias
+ // Add links.
+ mul->LinksFrom({x, mul_w_var}).LinksTo({mul_out_var});
+ return mul_out_var;
+
+ } else { // with bias
+ mul_out_var->AsIntermediate()->assert_is_op_input("elementwise_add");
+ // Create operators.
+ auto* elementwise_add = pattern->NewNode(elementwise_add_repr())
+ ->assert_is_op("elementwise_add");
+ // Create variables.
+ auto* bias = pattern->NewNode(bias_repr())
+ ->assert_is_op_input("elementwise_add")
+ ->AsInput();
+
+ auto* fc_out = pattern->NewNode(Out_repr())
+ ->AsOutput()
+ ->assert_is_op_output("elementwise_add");
+
+ mul->LinksFrom({mul_w_var, x}).LinksTo({mul_out_var});
+ elementwise_add->LinksFrom({mul_out_var, bias}).LinksTo({fc_out});
+ return fc_out;
+ }
+}
+
+PDNode* patterns::LSTM::operator()(PDNode* x) {
+ x->assert_is_op_input("lstm", "Input");
+ auto* lstm_op = pattern->NewNode(lstm_repr())->assert_is_op("lstm");
+#define NEW_NODE(arg__, io__) \
+ auto* arg__ = \
+ pattern->NewNode(arg__##_repr())->assert_is_op_##io__("lstm", #arg__);
+
+ // Currently, the H0 and C0 are optional
+ // TODO(Superjomn) upgrade the fuse framework to support optional.
+ // NEW_NODE(H0, input);
+ // NEW_NODE(C0, input);
+ NEW_NODE(Weight, input);
+ NEW_NODE(Bias, input);
+
+ NEW_NODE(Hidden, output);
+ NEW_NODE(Cell, output);
+ NEW_NODE(BatchGate, output);
+ NEW_NODE(BatchCellPreAct, output);
+#undef NEW_NODE
+
+ lstm_op->LinksFrom({x, Weight, Bias});
+ lstm_op->LinksTo({Hidden, Cell, BatchGate, BatchCellPreAct});
+ return Hidden;
+}
+
+PDNode* patterns::GRU::operator()(PDNode* x) {
+ x->assert_is_op_input("gru", "Input");
+ auto* gru_op = pattern->NewNode(gru_repr())->assert_is_op("gru");
+#define NEW_NODE(arg__, io__) \
+ auto* arg__ = \
+ pattern->NewNode(arg__##_repr())->assert_is_op_##io__("gru", #arg__);
+
+ NEW_NODE(Weight, input);
+ // TODO(Superjomn): upgrade the fuse framework to support optional.
+ // H0 and bias are optional
+ NEW_NODE(Bias, input); // also optional
+ // NEW_NODE(H0, input);
+
+ NEW_NODE(Hidden, output);
+ // below are intermediate
+ NEW_NODE(BatchGate, output);
+ NEW_NODE(BatchResetHiddenPrev, output);
+ NEW_NODE(BatchHidden, output);
+#undef NEW_NODE
+
+ BatchGate->AsIntermediate();
+ BatchResetHiddenPrev->AsIntermediate();
+ BatchHidden->AsIntermediate();
+
+ gru_op->LinksFrom({x, Weight, Bias});
+ gru_op->LinksTo({Hidden, BatchGate, BatchResetHiddenPrev, BatchHidden});
+ return Hidden;
+}
+
} // namespace ir
} // namespace framework
} // namespace paddle
diff --git a/paddle/fluid/framework/ir/graph_pattern_detector.h b/paddle/fluid/framework/ir/graph_pattern_detector.h
index f8488c84962d1caa6e7817b3c0349d6da3a59182..57482a07b607ba1d9fa06a5f325f60ba58dce307 100644
--- a/paddle/fluid/framework/ir/graph_pattern_detector.h
+++ b/paddle/fluid/framework/ir/graph_pattern_detector.h
@@ -19,6 +19,9 @@
#endif
#include
+#include
+#include
+#include
#include "paddle/fluid/framework/ir/graph.h"
#include "paddle/fluid/framework/ir/node.h"
#include "paddle/fluid/inference/analysis/dot.h"
@@ -95,7 +98,11 @@ struct PDNode {
PDNode* assert_var_not_persistable();
PDNode* assert_is_persistable_var();
PDNode* assert_is_op_output(const std::string& op_type);
+ PDNode* assert_is_op_output(const std::string& op_type,
+ const std::string& argument);
PDNode* assert_is_op_input(const std::string& op_type);
+ PDNode* assert_is_op_input(const std::string& op_type,
+ const std::string& argument);
PDNode* assert_is_op_nth_input(const std::string& op_type,
const std::string& argument, int nth);
PDNode* assert_is_op_nth_output(const std::string& op_type,
@@ -167,6 +174,9 @@ class PDPattern {
PDNode* NewNode(PDNode::teller_t&& teller, const std::string& name = NewID());
PDNode* NewNode(const std::string& name = NewID());
+ PDNode* NewNode(const std::string& prefix, const std::string& name) {
+ return NewNode(prefix + "/" + name);
+ }
PDNode* RetrieveNode(const std::string& id) const;
const std::vector>& nodes() const { return nodes_; }
@@ -238,6 +248,8 @@ class GraphPatternDetector {
void UniquePatterns(std::vector* subgraphs);
// Remove overlapped match subgraphs, when overlapped, keep the previous one.
+ // The intermediate PDNodes will be removed, so can't shared by multiple
+ // patterns.
void RemoveOverlappedMatch(std::vector* subgraphs);
// Validate whether the intermediate nodes are linked by external nodes.
@@ -257,64 +269,168 @@ class GraphPatternDetector {
// some helper methods.
-// Op's input.
-static bool VarLinksToOp(Node* node, const std::string& op_type) {
- for (auto* out : node->outputs) {
- if (out->IsOp() && out->Op()->Type() == op_type) {
- return true;
- }
- }
- return false;
-}
+// Tell if a var links to an Op
+bool VarLinksToOp(Node* node, const std::string& op_type);
-// Op's output.
-static bool VarLinksFromOp(Node* node, const std::string& op_type) {
- for (auto* out : node->inputs) {
- if (out->IsOp() && out->Op()->Type() == op_type) {
- return true;
- }
- }
- return false;
-}
+// Tell if an op links to a var
+bool VarLinksFromOp(Node* node, const std::string& op_type);
// Check whether a var node is a op node's nth input.
-static bool IsNthInput(Node* var, Node* op, const std::string& argument,
- size_t nth) {
- PADDLE_ENFORCE(var->IsVar());
- PADDLE_ENFORCE(op->IsOp());
- if (op->inputs.size() <= nth) return false;
- return var->Name() == op->Op()->Input(argument)[nth];
-}
+bool IsNthInput(Node* var, Node* op, const std::string& argument, size_t nth);
-static bool IsNthOutput(Node* var, Node* op, const std::string& argument,
- size_t nth) {
- PADDLE_ENFORCE(var->IsVar());
- PADDLE_ENFORCE(op->IsOp());
- if (op->inputs.size() <= nth) return false;
- return var->Name() == op->Op()->Output(argument)[nth];
-}
+// Tell whether a var node is a op node's nth output.
+bool IsNthOutput(Node* var, Node* op, const std::string& argument, size_t nth);
-static void GraphSafeRemoveNodes(Graph* graph,
- const std::unordered_set& nodes) {
- for (auto* node : nodes) {
- graph->RemoveNode(const_cast(node));
- }
+// Graph safely remove some nodes, will automatically clean up the edges.
+void GraphSafeRemoveNodes(Graph* graph,
+ const std::unordered_set& nodes);
- for (auto* node : graph->Nodes()) {
- for (auto it = node->inputs.begin(); it != node->inputs.end();) {
- if (nodes.count(*it)) {
- it = const_cast(node)->inputs.erase(it);
- } else
- it++;
- }
- for (auto it = node->outputs.begin(); it != node->outputs.end();) {
- if (nodes.count(*it)) {
- it = const_cast(node)->outputs.erase(it);
- } else
- it++;
- }
+// Some pre-defined patterns those can be reused in multiple passes.
+// The related Fluid Layer or Op should be one pattern here for better reusage
+// accross different fusion.
+namespace patterns {
+
+struct KeyCounter {
+ static KeyCounter& Instance() {
+ static KeyCounter x;
+ return x;
}
+
+ int IncCounter(const std::string& key) { return dic_[key]++; }
+
+ private:
+ std::unordered_map dic_;
+};
+
+// Generate a unique PDNode's name with name_scope and id.
+// The format is {name_scope}/{repr}/{id}/{name}
+static std::string PDNodeName(const std::string& name_scope,
+ const std::string& repr, size_t id,
+ const std::string& name) {
+ return string::Sprintf("%s/%s/%d/%s", name_scope, repr, id, name);
+}
+// Generate a unique PDNode's name.
+// The format is {name_scope}/{repr}/{id}
+static std::string PDNodeName(const std::string& name_scope,
+ const std::string& repr) {
+ return string::Sprintf("%s/%s/%d", name_scope, repr,
+ KeyCounter::Instance().IncCounter(repr));
}
+// Generate a unique key. It can be used for a universally unique temporary
+// name.
+// The format is {repr}/{id}
+static std::string UniqueKey(const std::string& repr) {
+ return string::Sprintf("%s/%d", repr,
+ KeyCounter::Instance().IncCounter(repr));
+}
+
+// Declare a PDNode in a pattern, will create two methods:
+// std::string xxx_repr(); return this PDNode's string id.
+// PDNode* xxx_n(); return the corresponding PDNode.
+#define PATTERN_DECL_NODE(name__) \
+ std::string name__##_repr() const { \
+ return PDNodeName(name_scope_, repr_, id_, #name__); \
+ } \
+ PDNode* name__##_n() const { return pattern->RetrieveNode(name__##_repr()); }
+
+// Get an ir::Node* from the matched subgraph.
+// var: variable.
+// arg: the argument declared by PATTERN_DECL_NODE in a pattern definition.
+// pat: the pattern object.
+#define GET_IR_NODE_FROM_SUBGRAPH(var, arg, pat) \
+ PADDLE_ENFORCE(subgraph.count(pat.arg##_n()), \
+ "Node not found for PDNode %s", pat.arg##_repr()); \
+ Node* var = subgraph.at(pat.arg##_n()); \
+ PADDLE_ENFORCE(var, "node %s not exists in the sub-graph", #arg)
+
+// The base class of all the patterns.
+struct PatternBase {
+ PatternBase(PDPattern* pattern, const std::string& name_scope,
+ const std::string& repr)
+ : pattern(pattern),
+ name_scope_(name_scope),
+ repr_(repr),
+ id_(KeyCounter::Instance().IncCounter(repr)) {}
+
+ PDPattern* pattern;
+
+ protected:
+ std::string name_scope_;
+ std::string repr_;
+ size_t id_;
+};
+
+// FC with bias
+// op: mul + elementwise_add
+// named nodes:
+// mul, elementwise_add
+// w, mul_out, bias, fc_out
+struct FC : public PatternBase {
+ FC(PDPattern* pattern, const std::string& name_scope)
+ : PatternBase(pattern, name_scope, "fc") {}
+
+ PDNode* operator()(PDNode* x, bool with_bias);
+
+ // declare operator node's name
+ PATTERN_DECL_NODE(fc);
+ PATTERN_DECL_NODE(mul);
+ PATTERN_DECL_NODE(elementwise_add);
+ // declare variable node's name
+ PATTERN_DECL_NODE(w);
+ PATTERN_DECL_NODE(mul_out); // (x,w) -> mul_out
+ PATTERN_DECL_NODE(bias);
+ PATTERN_DECL_NODE(Out);
+};
+
+struct LSTM : public PatternBase {
+ LSTM(PDPattern* pattern, const std::string& name_scope)
+ : PatternBase(pattern, name_scope, "lstm") {}
+
+ PDNode* operator()(PDNode* x);
+
+ // Operators
+ PATTERN_DECL_NODE(lstm);
+
+ // Inputs
+ PATTERN_DECL_NODE(Input);
+ PATTERN_DECL_NODE(H0);
+ PATTERN_DECL_NODE(C0);
+ PATTERN_DECL_NODE(Weight);
+ PATTERN_DECL_NODE(Bias);
+
+ // Outputs
+ PATTERN_DECL_NODE(Hidden);
+ PATTERN_DECL_NODE(Cell);
+ PATTERN_DECL_NODE(BatchGate);
+ PATTERN_DECL_NODE(BatchCellPreAct);
+};
+
+struct GRU : public PatternBase {
+ GRU(PDPattern* pattern, const std::string& name_scope)
+ : PatternBase(pattern, name_scope, "lstm") {}
+
+ PDNode* operator()(PDNode* x);
+
+ // Operators
+ PATTERN_DECL_NODE(gru);
+
+ // Inputs
+ PATTERN_DECL_NODE(Bias);
+ PATTERN_DECL_NODE(Weight);
+
+ // Outputs
+ PATTERN_DECL_NODE(BatchGate);
+ PATTERN_DECL_NODE(BatchResetHiddenPrev);
+ PATTERN_DECL_NODE(BatchHidden);
+ PATTERN_DECL_NODE(Hidden);
+};
+
+} // namespace patterns
+
+// Link two ir::Nodes from each other.
+#define IR_NODE_LINK_TO(a, b) \
+ a->outputs.push_back(b); \
+ b->inputs.push_back(a);
} // namespace ir
} // namespace framework
diff --git a/paddle/fluid/framework/ir/graph_pattern_detector_tester.cc b/paddle/fluid/framework/ir/graph_pattern_detector_tester.cc
index 7e5c86b033a7c69a306491cf4bf8d099018c5f19..6c466fb21fb46e09961dc874e9e39655f83d17c6 100644
--- a/paddle/fluid/framework/ir/graph_pattern_detector_tester.cc
+++ b/paddle/fluid/framework/ir/graph_pattern_detector_tester.cc
@@ -140,8 +140,9 @@ TEST(GraphPatternDetecter, MultiSubgraph) {
return node->IsOp() && (node->Name() == "op2" || node->Name() == "op3");
},
"OP0");
- auto* any_var = x.mutable_pattern()->NewNode(
- [](Node* node) { return node->IsVar(); }, "VAR");
+ auto* any_var = x.mutable_pattern()
+ ->NewNode([](Node* node) { return node->IsVar(); }, "VAR")
+ ->AsIntermediate();
auto* any_op1 = x.mutable_pattern()->NewNode(
[](Node* node) { return node->IsOp(); }, "OP1");
diff --git a/paddle/fluid/framework/ir/graph_viz_pass.cc b/paddle/fluid/framework/ir/graph_viz_pass.cc
index 4c7ffe69e933de3d52c8f762a1eeb73de17e0561..31ed98db72c8fd4af8c970861d386687962001ce 100644
--- a/paddle/fluid/framework/ir/graph_viz_pass.cc
+++ b/paddle/fluid/framework/ir/graph_viz_pass.cc
@@ -50,20 +50,37 @@ std::unique_ptr GraphVizPass::ApplyImpl(
Dot dot;
- std::vector op_attrs({Dot::Attr("style", "filled"),
- Dot::Attr("shape", "box"),
- Dot::Attr("fillcolor", "red")});
- std::vector var_attrs({Dot::Attr("style", "filled,rounded"),
- // Dot::Attr("shape", "diamond"),
- Dot::Attr("fillcolor", "yellow")});
-
- std::vector marked_op_attrs({Dot::Attr("style", "filled"),
- Dot::Attr("shape", "box"),
- Dot::Attr("fillcolor", "lightgray")});
- std::vector marked_var_attrs(
- {Dot::Attr("style", "filled,rounded"),
- // Dot::Attr("shape", "diamond"),
- Dot::Attr("fillcolor", "lightgray")});
+ const std::vector op_attrs({
+ Dot::Attr("style", "rounded,filled,bold"), //
+ Dot::Attr("shape", "box"), //
+ Dot::Attr("color", "#303A3A"), //
+ Dot::Attr("fontcolor", "#ffffff"), //
+ Dot::Attr("width", "1.3"), //
+ Dot::Attr("height", "0.84"), //
+ Dot::Attr("fontname", "Arial"), //
+ });
+ const std::vector arg_attrs({
+ Dot::Attr("shape", "box"), //
+ Dot::Attr("style", "rounded,filled,bold"), //
+ Dot::Attr("fontname", "Arial"), //
+ Dot::Attr("fillcolor", "#999999"), //
+ Dot::Attr("color", "#dddddd"), //
+ });
+
+ const std::vector param_attrs({
+ Dot::Attr("shape", "box"), //
+ Dot::Attr("style", "rounded,filled,bold"), //
+ Dot::Attr("fontname", "Arial"), //
+ Dot::Attr("color", "#148b97"), //
+ Dot::Attr("fontcolor", "#ffffff"), //
+ });
+
+ const std::vector marked_op_attrs(
+ {Dot::Attr("style", "rounded,filled,bold"), Dot::Attr("shape", "box"),
+ Dot::Attr("fillcolor", "yellow")});
+ const std::vector marked_var_attrs(
+ {Dot::Attr("style", "filled,rounded"), Dot::Attr("shape", "box"),
+ Dot::Attr("fillcolor", "yellow")});
auto marked_nodes = ConsumeMarkedNodes(graph.get());
// Create nodes
@@ -74,9 +91,17 @@ std::unique_ptr GraphVizPass::ApplyImpl(
marked_nodes.count(n) ? marked_op_attrs : op_attrs;
dot.AddNode(node_id, attr, node_id);
} else if (n->IsVar()) {
- decltype(op_attrs) attr =
- marked_nodes.count(n) ? marked_var_attrs : var_attrs;
- dot.AddNode(node_id, attr, node_id);
+ decltype(op_attrs)* attr;
+ if (marked_nodes.count(n)) {
+ attr = &marked_var_attrs;
+ } else if (const_cast(n)->Var() &&
+ const_cast(n)->Var()->Persistable()) {
+ attr = ¶m_attrs;
+ } else {
+ attr = &arg_attrs;
+ }
+
+ dot.AddNode(node_id, *attr, node_id);
}
node2dot[n] = node_id;
}
diff --git a/paddle/fluid/framework/ir/graph_viz_pass.h b/paddle/fluid/framework/ir/graph_viz_pass.h
index 8d885cb9e4ee6e01de386b0f22423988dbe60ca6..e64916a5bb662e3b00cfe212f0bbbc537c7bc2cc 100644
--- a/paddle/fluid/framework/ir/graph_viz_pass.h
+++ b/paddle/fluid/framework/ir/graph_viz_pass.h
@@ -42,6 +42,13 @@ class GraphVizPass : public Pass {
marked_nodes_t ConsumeMarkedNodes(Graph* graph) const;
};
+static GraphVizPass::marked_nodes_t& GetMarkedNodes(Graph* graph) {
+ if (!graph->Has(kGraphvizMarkedNodeAttr)) {
+ graph->Set(kGraphvizMarkedNodeAttr, new GraphVizPass::marked_nodes_t);
+ }
+ return graph->Get(kGraphvizMarkedNodeAttr);
+}
+
} // namespace ir
} // namespace framework
} // namespace paddle
diff --git a/paddle/fluid/framework/ir/infer_clean_graph_pass.cc b/paddle/fluid/framework/ir/infer_clean_graph_pass.cc
index f885567da1965b997b2063e06c839af95b43e1e1..7713ed1eab88ee4fa16d52e7425075ae66f721a3 100644
--- a/paddle/fluid/framework/ir/infer_clean_graph_pass.cc
+++ b/paddle/fluid/framework/ir/infer_clean_graph_pass.cc
@@ -13,42 +13,41 @@
// limitations under the License.
#include
+#include "paddle/fluid/framework/ir/fuse_pass_base.h"
#include "paddle/fluid/framework/ir/graph.h"
-#include "paddle/fluid/framework/ir/pass.h"
+#include "paddle/fluid/framework/ir/graph_pattern_detector.h"
namespace paddle {
namespace framework {
namespace ir {
-class InferCleanGraphPass : public Pass {
+class InferCleanGraphPass : public FusePassBase {
public:
virtual ~InferCleanGraphPass() {}
protected:
std::unique_ptr ApplyImpl(std::unique_ptr graph) const {
+ FusePassBase::Init("original_graph", graph.get());
PADDLE_ENFORCE(graph.get());
auto is_valid_node = [](Node* x) {
return x && IsControlDepVar(*x) && x->IsVar() && !x->Var();
};
- std::unordered_set invalid_nodes;
+ std::unordered_set invalid_nodes;
+ int valid_op = 0;
for (auto* node : graph->Nodes()) {
if (is_valid_node(node)) {
invalid_nodes.insert(node);
+ } else if (node->IsOp()) {
+ // Collect all the operators to help tracking number of operators.
+ ++valid_op;
}
}
- // remove nodes from the graph.
- for (auto* node : invalid_nodes) {
- graph->RemoveNode(node);
- }
+ GraphSafeRemoveNodes(graph.get(), invalid_nodes);
- // clean edges.
- for (auto* node : graph->Nodes()) {
- CleanEdges(&node->inputs, invalid_nodes);
- CleanEdges(&node->outputs, invalid_nodes);
- }
+ AddStatis(valid_op);
return graph;
}
diff --git a/paddle/fluid/framework/ir/seq_concat_fc_fuse_pass.cc b/paddle/fluid/framework/ir/seq_concat_fc_fuse_pass.cc
index a776a898a5ee13b4dde12460dce71433268fb9d4..a7d5161c35db804703415066990f34da8109fbd9 100644
--- a/paddle/fluid/framework/ir/seq_concat_fc_fuse_pass.cc
+++ b/paddle/fluid/framework/ir/seq_concat_fc_fuse_pass.cc
@@ -192,6 +192,8 @@ std::unique_ptr SeqConcatFcFusePass::ApplyImpl(
auto* id = subgraph.at(pattern.RetrieveNode(#id)); \
PADDLE_ENFORCE_NOT_NULL(id, "subgraph has no node %s", #id);
+ int fuse_count{0};
+
detector(graph.get(), [&](const GraphPatternDetector::subgraph_t& subgraph,
Graph* graph) {
VLOG(4) << "get one concat pattern";
@@ -219,16 +221,13 @@ std::unique_ptr SeqConcatFcFusePass::ApplyImpl(
op_desc.SetAttr("fc_activation", act->Op()->Type());
auto* op_node = graph->CreateOpNode(&op_desc);
-// Add links
-#define NODE_LINKS(a, b) \
- a->outputs.push_back(b); \
- b->inputs.push_back(a);
- NODE_LINKS(fc_w, op_node);
- NODE_LINKS(fc_bias, op_node);
- NODE_LINKS(concat_in0, op_node);
- NODE_LINKS(sequence_expand0_in, op_node);
- NODE_LINKS(sequence_expand1_in, op_node);
- NODE_LINKS(op_node, fc_out);
+ // Add links
+ IR_NODE_LINK_TO(fc_w, op_node);
+ IR_NODE_LINK_TO(fc_bias, op_node);
+ IR_NODE_LINK_TO(concat_in0, op_node);
+ IR_NODE_LINK_TO(sequence_expand0_in, op_node);
+ IR_NODE_LINK_TO(sequence_expand1_in, op_node);
+ IR_NODE_LINK_TO(op_node, fc_out);
// Clean nodes.
std::unordered_set marked_nodes;
@@ -241,10 +240,13 @@ std::unique_ptr SeqConcatFcFusePass::ApplyImpl(
marked_nodes.erase(sequence_expand0_in);
marked_nodes.erase(sequence_expand1_in);
marked_nodes.erase(fc_out);
-
GraphSafeRemoveNodes(graph, marked_nodes);
+
+ ++fuse_count;
});
+ AddStatis(fuse_count);
+
return graph;
}
diff --git a/paddle/fluid/framework/selected_rows.cc b/paddle/fluid/framework/selected_rows.cc
index a4319ffabb04f39437b76d97845e021ef9de66d3..8c290bb095d554a973e66a3a19606a06759fd668 100644
--- a/paddle/fluid/framework/selected_rows.cc
+++ b/paddle/fluid/framework/selected_rows.cc
@@ -49,7 +49,7 @@ struct TensorCopyVisitor {
size_(size) {}
template
- void operator()() const {
+ void apply() const {
// TODO(Yancey1989): support other place
platform::CPUPlace cpu;
memory::Copy(cpu, dst_->mutable_data(cpu) + dst_offset_, cpu,
diff --git a/paddle/fluid/framework/tensor_util.cc b/paddle/fluid/framework/tensor_util.cc
index ab693004cfb038fd92afd9c60e0fcb4e16b9f8a9..05c4a17a01c6fabe48f3fe18544c13153feb0673 100644
--- a/paddle/fluid/framework/tensor_util.cc
+++ b/paddle/fluid/framework/tensor_util.cc
@@ -149,7 +149,7 @@ struct AnyDTypeVisitor {
: predicate_(predicate), tensor_(tensor), ctx_(ctx), out_(out) {}
template
- void operator()() const {
+ void apply() const {
auto t = EigenVector::Flatten(tensor_);
auto o = EigenScalar::From(*out_);
// return any of predicate_(t) is true.
@@ -302,7 +302,7 @@ struct DeserializedDataFunctor {
: buf_(buf), tensor_(tensor), place_(place) {}
template
- void operator()() {
+ void apply() {
*buf_ = tensor_->mutable_data(place_);
}
diff --git a/paddle/fluid/inference/CMakeLists.txt b/paddle/fluid/inference/CMakeLists.txt
index a4f6364ae5b7d832096c92e9c6d8b3e865713cff..2006e3b24f71d0ae32b4e2ae34f1a1e4d3a82f91 100644
--- a/paddle/fluid/inference/CMakeLists.txt
+++ b/paddle/fluid/inference/CMakeLists.txt
@@ -10,19 +10,19 @@ set(FLUID_CORE_MODULES proto_desc memory lod_tensor executor)
# TODO(panyx0718): Should this be called paddle_fluid_inference_api_internal?
cc_library(paddle_fluid_api
SRCS io.cc
- DEPS ${FLUID_CORE_MODULES} ${GLOB_OP_LIB} graph_to_program_pass)
+ DEPS ${FLUID_CORE_MODULES} ${GLOB_OP_LIB})
get_property(fluid_modules GLOBAL PROPERTY FLUID_MODULES)
# paddle_fluid_origin exclude inference api interface
cc_library(paddle_fluid_origin DEPS ${fluid_modules} paddle_fluid_api)
-if(NOT APPLE)
+#if(APPLE)
add_subdirectory(api)
-endif()
+#endif()
# Create static library
-cc_library(paddle_fluid DEPS ${fluid_modules} paddle_fluid_api paddle_inference_api)
+cc_library(paddle_fluid DEPS ${fluid_modules} paddle_fluid_api paddle_inference_api analysis_predictor)
if(NOT APPLE)
# TODO(liuyiqu: Temporarily disable the link flag because it is not support on Mac.
set(LINK_FLAGS "-Wl,--retain-symbols-file ${CMAKE_CURRENT_SOURCE_DIR}/paddle_fluid.sym")
@@ -32,6 +32,7 @@ endif()
# Create shared library
cc_library(paddle_fluid_shared SHARED
SRCS io.cc ${CMAKE_CURRENT_SOURCE_DIR}/api/api.cc ${CMAKE_CURRENT_SOURCE_DIR}/api/api_impl.cc
+ ${CMAKE_CURRENT_SOURCE_DIR}/api/analysis_predictor.cc
DEPS ${fluid_modules} paddle_fluid_api)
set_target_properties(paddle_fluid_shared PROPERTIES OUTPUT_NAME paddle_fluid)
diff --git a/paddle/fluid/inference/analysis/CMakeLists.txt b/paddle/fluid/inference/analysis/CMakeLists.txt
index 779ede5e460d0ceb6fd404c4a32374f9f9d92088..11a7509feb02a806e1e173bfb8bd7764f94d3457 100644
--- a/paddle/fluid/inference/analysis/CMakeLists.txt
+++ b/paddle/fluid/inference/analysis/CMakeLists.txt
@@ -6,6 +6,7 @@ cc_library(analysis SRCS pass_manager.cc node.cc data_flow_graph.cc graph_traits
analyzer.cc
helper.cc
# passes
+ analysis_pass.cc
fluid_to_data_flow_graph_pass.cc
data_flow_graph_to_fluid_pass.cc
dfg_graphviz_draw_pass.cc
@@ -25,61 +26,44 @@ function (inference_analysis_test TARGET)
if(WITH_TESTING)
set(options "")
set(oneValueArgs "")
- set(multiValueArgs SRCS EXTRA_DEPS)
+ set(multiValueArgs SRCS ARGS EXTRA_DEPS)
cmake_parse_arguments(analysis_test "${options}" "${oneValueArgs}" "${multiValueArgs}" ${ARGN})
-
set(mem_opt "")
if(WITH_GPU)
set(mem_opt "--fraction_of_gpu_memory_to_use=0.5")
endif()
cc_test(${TARGET}
SRCS "${analysis_test_SRCS}"
- DEPS analysis graph fc_fuse_pass graph_viz_pass infer_clean_graph_pass graph_pattern_detector pass ${analysis_test_EXTRA_DEPS}
- ARGS --inference_model_dir=${PYTHON_TESTS_DIR}/book/word2vec.inference.model ${mem_opt})
+ DEPS analysis pass ${GLOB_PASS_LIB} ${analysis_test_EXTRA_DEPS}
+ ARGS --inference_model_dir=${PYTHON_TESTS_DIR}/book/word2vec.inference.model ${mem_opt} ${analysis_test_ARGS})
set_tests_properties(${TARGET} PROPERTIES DEPENDS test_word2vec)
endif(WITH_TESTING)
endfunction(inference_analysis_test)
-set(DITU_RNN_MODEL_URL "http://paddle-inference-dist.bj.bcebos.com/ditu_rnn_fluid%2Fmodel.tar.gz")
-set(DITU_RNN_DATA_URL "http://paddle-inference-dist.bj.bcebos.com/ditu_rnn_fluid%2Fdata.txt.tar.gz")
-set(DITU_INSTALL_DIR "${THIRD_PARTY_PATH}/install/ditu_rnn" CACHE PATH "Ditu RNN model and data root." FORCE)
-set(DITU_RNN_MODEL ${DITU_INSTALL_DIR}/model)
-set(DITU_RNN_DATA ${DITU_INSTALL_DIR}/data.txt)
-
-function (inference_download_and_uncompress target url gz_filename)
+function (inference_download_and_uncompress install_dir url gz_filename)
message(STATUS "Download inference test stuff ${gz_filename} from ${url}")
- execute_process(COMMAND bash -c "mkdir -p ${DITU_INSTALL_DIR}")
- execute_process(COMMAND bash -c "cd ${DITU_INSTALL_DIR} && wget -q ${url}")
- execute_process(COMMAND bash -c "cd ${DITU_INSTALL_DIR} && tar xzf ${gz_filename}")
+ execute_process(COMMAND bash -c "mkdir -p ${install_dir}")
+ execute_process(COMMAND bash -c "cd ${install_dir} && wget -q ${url}")
+ execute_process(COMMAND bash -c "cd ${install_dir} && tar xzf ${gz_filename}")
message(STATUS "finish downloading ${gz_filename}")
endfunction(inference_download_and_uncompress)
-if (NOT EXISTS ${DITU_INSTALL_DIR})
- inference_download_and_uncompress(ditu_rnn_model ${DITU_RNN_MODEL_URL} "ditu_rnn_fluid%2Fmodel.tar.gz")
- inference_download_and_uncompress(ditu_rnn_data ${DITU_RNN_DATA_URL} "ditu_rnn_fluid%2Fdata.txt.tar.gz")
+set(RNN1_MODEL_URL "http://paddle-inference-dist.bj.bcebos.com/rnn1%2Fmodel.tar.gz")
+set(RNN1_DATA_URL "http://paddle-inference-dist.bj.bcebos.com/rnn1%2Fdata.txt.tar.gz")
+set(RNN1_INSTALL_DIR "${THIRD_PARTY_PATH}/inference_demo/rnn1" CACHE PATH "RNN1 model and data root." FORCE)
+if (NOT EXISTS ${RNN1_INSTALL_DIR} AND WITH_TESTING)
+ inference_download_and_uncompress(${RNN1_INSTALL_DIR} ${RNN1_MODEL_URL} "rnn1%2Fmodel.tar.gz")
+ inference_download_and_uncompress(${RNN1_INSTALL_DIR} ${RNN1_DATA_URL} "rnn1%2Fdata.txt.tar.gz")
endif()
inference_analysis_test(test_analyzer SRCS analyzer_tester.cc
- EXTRA_DEPS paddle_inference_api paddle_fluid_api ir_pass_manager analysis
- analysis_predictor
- # ir
- fc_fuse_pass
- fc_lstm_fuse_pass
- seq_concat_fc_fuse_pass
- graph_viz_pass
- infer_clean_graph_pass
- graph_pattern_detector
- infer_clean_graph_pass
- attention_lstm_fuse_pass
- paddle_inference_api
- pass
- ARGS --inference_model_dir=${PYTHON_TESTS_DIR}/book/word2vec.inference.model
- --infer_ditu_rnn_model=${DITU_INSTALL_DIR}/model
- --infer_ditu_rnn_data=${DITU_INSTALL_DIR}/data.txt)
+ EXTRA_DEPS paddle_inference_api paddle_fluid_api ir_pass_manager analysis_predictor
+ ARGS --infer_model=${RNN1_INSTALL_DIR}/model
+ --infer_data=${RNN1_INSTALL_DIR}/data.txt)
inference_analysis_test(test_data_flow_graph SRCS data_flow_graph_tester.cc)
-inference_analysis_test(test_data_flow_graph_to_fluid_pass SRCS data_flow_graph_to_fluid_pass_tester.cc EXTRA_DEPS paddle_inference_api)
-inference_analysis_test(test_fluid_to_ir_pass SRCS fluid_to_ir_pass_tester.cc EXTRA_DEPS paddle_fluid)
+inference_analysis_test(test_data_flow_graph_to_fluid_pass SRCS data_flow_graph_to_fluid_pass_tester.cc)
+inference_analysis_test(test_fluid_to_ir_pass SRCS fluid_to_ir_pass_tester.cc)
inference_analysis_test(test_fluid_to_data_flow_graph_pass SRCS fluid_to_data_flow_graph_pass_tester.cc)
inference_analysis_test(test_subgraph_splitter SRCS subgraph_splitter_tester.cc)
inference_analysis_test(test_dfg_graphviz_draw_pass SRCS dfg_graphviz_draw_pass_tester.cc)
@@ -87,3 +71,46 @@ inference_analysis_test(test_tensorrt_subgraph_pass SRCS tensorrt_subgraph_pass_
inference_analysis_test(test_pass_manager SRCS pass_manager_tester.cc)
inference_analysis_test(test_tensorrt_subgraph_node_mark_pass SRCS tensorrt_subgraph_node_mark_pass_tester.cc)
inference_analysis_test(test_model_store_pass SRCS model_store_pass_tester.cc)
+
+set(CHINESE_NER_MODEL_URL "http://paddle-inference-dist.bj.bcebos.com/chinese_ner_model.tar.gz")
+set(CHINESE_NER_DATA_URL "http://paddle-inference-dist.bj.bcebos.com/chinese_ner-data.txt.tar.gz")
+set(CHINESE_NER_INSTALL_DIR "${THIRD_PARTY_PATH}/inference_demo/chinese_ner" CACHE PATH "Chinese ner model and data root." FORCE)
+if (NOT EXISTS ${CHINESE_NER_INSTALL_DIR} AND WITH_TESTING AND WITH_INFERENCE)
+ inference_download_and_uncompress(${CHINESE_NER_INSTALL_DIR} ${CHINESE_NER_MODEL_URL} "chinese_ner_model.tar.gz")
+ inference_download_and_uncompress(${CHINESE_NER_INSTALL_DIR} ${CHINESE_NER_DATA_URL} "chinese_ner-data.txt.tar.gz")
+endif()
+
+inference_analysis_test(test_analyzer_ner SRCS analyzer_ner_tester.cc
+ EXTRA_DEPS paddle_inference_api paddle_fluid_api analysis_predictor
+ ARGS --infer_model=${CHINESE_NER_INSTALL_DIR}/model
+ --infer_data=${CHINESE_NER_INSTALL_DIR}/data.txt)
+
+set(LAC_MODEL_URL "http://paddle-inference-dist.bj.bcebos.com/lac_model.tar.gz")
+set(LAC_DATA_URL "http://paddle-inference-dist.bj.bcebos.com/lac_data.txt.tar.gz")
+set(LAC_INSTALL_DIR "${THIRD_PARTY_PATH}/inference_demo/lac" CACHE PATH "LAC model and data root." FORCE)
+if (NOT EXISTS ${LAC_INSTALL_DIR} AND WITH_TESTING AND WITH_INFERENCE)
+ inference_download_and_uncompress(${LAC_INSTALL_DIR} ${LAC_MODEL_URL} "lac_model.tar.gz")
+ inference_download_and_uncompress(${LAC_INSTALL_DIR} ${LAC_DATA_URL} "lac_data.txt.tar.gz")
+endif()
+
+inference_analysis_test(test_analyzer_lac SRCS analyzer_lac_tester.cc
+ EXTRA_DEPS paddle_inference_api paddle_fluid_api ir_pass_manager analysis_predictor
+ ARGS --infer_model=${LAC_INSTALL_DIR}/model
+ --infer_data=${LAC_INSTALL_DIR}/data.txt)
+
+
+set(TEXT_CLASSIFICATION_MODEL_URL "http://paddle-inference-dist.bj.bcebos.com/text-classification-Senta.tar.gz")
+set(TEXT_CLASSIFICATION_DATA_URL "http://paddle-inference-dist.bj.bcebos.com/text_classification_data.txt.tar.gz")
+set(TEXT_CLASSIFICATION_INSTALL_DIR "${THIRD_PARTY_PATH}/inference_demo/text_classification" CACHE PATH "Text Classification model and data root." FORCE)
+
+if (NOT EXISTS ${TEXT_CLASSIFICATION_INSTALL_DIR} AND WITH_TESTING AND WITH_INFERENCE)
+ inference_download_and_uncompress(${TEXT_CLASSIFICATION_INSTALL_DIR} ${TEXT_CLASSIFICATION_MODEL_URL} "text-classification-Senta.tar.gz")
+ inference_download_and_uncompress(${TEXT_CLASSIFICATION_INSTALL_DIR} ${TEXT_CLASSIFICATION_DATA_URL} "text_classification_data.txt.tar.gz")
+endif()
+
+inference_analysis_test(test_text_classification SRCS analyzer_text_classification_tester.cc
+ EXTRA_DEPS paddle_inference_api paddle_fluid_api analysis_predictor
+ ARGS --infer_model=${TEXT_CLASSIFICATION_INSTALL_DIR}/text-classification-Senta
+ --infer_data=${TEXT_CLASSIFICATION_INSTALL_DIR}/data.txt
+ --topn=1 # Just run top 1 batch.
+ )
diff --git a/paddle/fluid/inference/analysis/pass.cc b/paddle/fluid/inference/analysis/analysis_pass.cc
similarity index 91%
rename from paddle/fluid/inference/analysis/pass.cc
rename to paddle/fluid/inference/analysis/analysis_pass.cc
index 121b72c0a0aa9a0c568b04f7ee9a5bc5c1d6f5f8..9be9f755b9ed7273d842f8c0e2046f0ca0ce2247 100644
--- a/paddle/fluid/inference/analysis/pass.cc
+++ b/paddle/fluid/inference/analysis/analysis_pass.cc
@@ -12,4 +12,4 @@
// See the License for the specific language governing permissions and
// limitations under the License.
-#include "paddle/fluid/inference/analysis/pass.h"
+#include "paddle/fluid/inference/analysis/analysis_pass.h"
diff --git a/paddle/fluid/inference/analysis/pass.h b/paddle/fluid/inference/analysis/analysis_pass.h
similarity index 59%
rename from paddle/fluid/inference/analysis/pass.h
rename to paddle/fluid/inference/analysis/analysis_pass.h
index 7719c6f5ff3c940948c7bdbcb25513cdf430281b..b6edb5529ace2ad5bd1b35bfbee1f7a744457cc3 100644
--- a/paddle/fluid/inference/analysis/pass.h
+++ b/paddle/fluid/inference/analysis/analysis_pass.h
@@ -28,10 +28,10 @@ namespace paddle {
namespace inference {
namespace analysis {
-class Pass {
+class AnalysisPass {
public:
- Pass() = default;
- virtual ~Pass() = default;
+ AnalysisPass() = default;
+ virtual ~AnalysisPass() = default;
// Mutable Pass.
virtual bool Initialize(Argument *argument) { return false; }
// Readonly Pass.
@@ -42,23 +42,16 @@ class Pass {
virtual bool Finalize() { return false; }
// Get a Pass appropriate to print the Node this pass operates on.
- virtual Pass *CreatePrinterPass(std::ostream &os,
- const std::string &banner) const {
+ virtual AnalysisPass *CreatePrinterPass(std::ostream &os,
+ const std::string &banner) const {
return nullptr;
}
// Create a debugger Pass that draw the DFG by graphviz toolkit.
- virtual Pass *CreateGraphvizDebugerPass() const { return nullptr; }
+ virtual AnalysisPass *CreateGraphvizDebugerPass() const { return nullptr; }
- virtual void Run() { LOG(FATAL) << "not valid"; }
- // Run on a single Node.
- virtual void Run(Node *x) { LOG(FATAL) << "not valid"; }
- // Run on a single Function.
- virtual void Run(Function *x) { LOG(FATAL) << "not valid"; }
- // Run on a single FunctionBlock.
- virtual void Run(FunctionBlock *x) { LOG(FATAL) << "not valid"; }
// Run on a single DataFlowGraph.
- virtual void Run(DataFlowGraph *x) { LOG(FATAL) << "not valid"; }
+ virtual void Run(DataFlowGraph *x) = 0;
// Human-readable short representation.
virtual std::string repr() const = 0;
@@ -66,29 +59,8 @@ class Pass {
virtual std::string description() const { return "No DOC"; }
};
-// NodePass process on any Node types.
-class NodePass : public Pass {
- public:
- virtual void Run(Node *node) = 0;
-};
-
-// NodePass process on any Function node types.
-class FunctionPass : public Pass {
- public:
- virtual void Run(Function *node) = 0;
-};
-
-// NodePass process on any FunctionBlock node types.
-class FunctionBlockPass : public Pass {
- public:
- virtual void Run(FunctionBlock *node) = 0;
-};
-
// GraphPass processes on any GraphType.
-class DataFlowGraphPass : public Pass {
- public:
- virtual void Run(DataFlowGraph *graph) = 0;
-};
+class DataFlowGraphPass : public AnalysisPass {};
} // namespace analysis
} // namespace inference
diff --git a/paddle/fluid/inference/analysis/analyzer.cc b/paddle/fluid/inference/analysis/analyzer.cc
index e6e63544ffa2de09e39b02769aaaf0793d6b1111..6dc39cae0522efd48c2e2921611adebd6937ddf7 100644
--- a/paddle/fluid/inference/analysis/analyzer.cc
+++ b/paddle/fluid/inference/analysis/analyzer.cc
@@ -14,6 +14,8 @@
#include "paddle/fluid/inference/analysis/analyzer.h"
#include
+#include
+
#include "paddle/fluid/inference/analysis/data_flow_graph_to_fluid_pass.h"
#include "paddle/fluid/inference/analysis/dfg_graphviz_draw_pass.h"
#include "paddle/fluid/inference/analysis/fluid_to_data_flow_graph_pass.h"
@@ -41,27 +43,23 @@ class DfgPassManagerImpl final : public DfgPassManager {
public:
DfgPassManagerImpl() {
// TODO(Superjomn) set the key with pass reprs.
- LOG(INFO)
- << "-----------------------------------------------------------------";
- if (FLAGS_IA_enable_ir) {
- AddPass("fluid-to-ir-pass", new FluidToIrPass);
- } else {
+ if (!FLAGS_IA_enable_ir) {
AddPass("fluid-to-data-flow-graph", new FluidToDataFlowGraphPass);
+ } else {
+ AddPass("fluid-to-ir-pass", new FluidToIrPass);
}
TryAddTensorRtPass();
AddPass("data-flow-graph-to-fluid", new DataFlowGraphToFluidPass);
if (!FLAGS_IA_output_storage_path.empty()) {
AddPass("model-store-pass", new ModelStorePass);
}
- LOG(INFO)
- << "-----------------------------------------------------------------";
}
std::string repr() const override { return "dfg-pass-manager"; }
std::string description() const override { return "DFG pass manager."; }
private:
- void AddPass(const std::string& name, Pass* pass) {
+ void AddPass(const std::string& name, AnalysisPass* pass) {
VLOG(3) << "Adding pass " << name;
Register(name, pass);
AddGraphvizDebugerPass(pass);
@@ -90,7 +88,7 @@ class DfgPassManagerImpl final : public DfgPassManager {
}
// Add the graphviz debuger pass if the parent pass has one.
- void AddGraphvizDebugerPass(Pass* pass) {
+ void AddGraphvizDebugerPass(AnalysisPass* pass) {
auto* debuger_pass = pass->CreateGraphvizDebugerPass();
if (debuger_pass) {
Register(debuger_pass->repr(), debuger_pass);
@@ -101,18 +99,15 @@ class DfgPassManagerImpl final : public DfgPassManager {
Analyzer::Analyzer() { Register("manager1", new DfgPassManagerImpl); }
void Analyzer::Run(Argument* argument) {
- // Ugly support fluid-to-ir-pass
- argument->Set(kFluidToIrPassesAttr,
- new std::vector({
- // Manual update the passes here.
- "graph_viz_pass", //
- "infer_clean_graph_pass", "graph_viz_pass", //
- "attention_lstm_fuse_pass", "graph_viz_pass", //
- "fc_lstm_fuse_pass", "graph_viz_pass", //
- "seq_concat_fc_fuse_pass", "graph_viz_pass", //
- "fc_fuse_pass", "graph_viz_pass" //
-
- }));
+ std::vector passes;
+ for (auto& pass : all_ir_passes_) {
+ if (!disabled_ir_passes_.count(pass)) {
+ passes.push_back(pass);
+ passes.push_back("graph_viz_pass"); // add graphviz for debug.
+ }
+ }
+ passes.push_back("graph_viz_pass");
+ argument->Set(kFluidToIrPassesAttr, new std::vector(passes));
for (auto& x : data_) {
PADDLE_ENFORCE(x->Initialize(argument));
@@ -121,6 +116,11 @@ void Analyzer::Run(Argument* argument) {
}
}
+Analyzer& Analyzer::DisableIrPasses(const std::vector& passes) {
+ disabled_ir_passes_.insert(passes.begin(), passes.end());
+ return *this;
+}
+
} // namespace analysis
} // namespace inference
} // namespace paddle
diff --git a/paddle/fluid/inference/analysis/analyzer.h b/paddle/fluid/inference/analysis/analyzer.h
index 2e107c82dd50d5cf22797f4c82e69d302514f955..399afbe64a56393176795ecdd1ac70bfedd5c91a 100644
--- a/paddle/fluid/inference/analysis/analyzer.h
+++ b/paddle/fluid/inference/analysis/analyzer.h
@@ -36,16 +36,12 @@ limitations under the License. */
*/
#include
-#include "paddle/fluid/inference/analysis/pass.h"
+#include
+#include
+#include "paddle/fluid/inference/analysis/analysis_pass.h"
+#include "paddle/fluid/inference/analysis/flags.h"
#include "paddle/fluid/inference/analysis/pass_manager.h"
-// TODO(Superjomn) add a definition flag like PADDLE_WITH_TENSORRT and hide this
-// flag if not available.
-DECLARE_bool(IA_enable_tensorrt_subgraph_engine);
-DECLARE_string(IA_graphviz_log_root);
-DECLARE_string(IA_output_storage_path);
-DECLARE_bool(IA_enable_ir);
-
namespace paddle {
namespace inference {
namespace analysis {
@@ -57,7 +53,28 @@ class Analyzer : public OrderedRegistry {
void Run(Argument* argument);
+ Analyzer& DisableIrPasses(const std::vector& passes);
+
DISABLE_COPY_AND_ASSIGN(Analyzer);
+
+ private:
+ // All avaiable IR passes.
+ // The bigger fuse comes first, so that the small operators prefer to be
+ // merged in a larger fuse op. The small fusion will not break the pattern of
+ // larger fusion.
+ const std::vector all_ir_passes_{{
+ // Manual update the passes here.
+ "infer_clean_graph_pass", //
+ "attention_lstm_fuse_pass", //
+ "fc_lstm_fuse_pass", //
+ "mul_lstm_fuse_pass", //
+ "fc_gru_fuse_pass", //
+ "mul_gru_fuse_pass", //
+ "seq_concat_fc_fuse_pass", //
+ "fc_fuse_pass", //
+ }};
+
+ std::unordered_set disabled_ir_passes_;
};
} // namespace analysis
diff --git a/paddle/fluid/inference/analysis/analyzer_lac_tester.cc b/paddle/fluid/inference/analysis/analyzer_lac_tester.cc
new file mode 100644
index 0000000000000000000000000000000000000000..522d870db8583aac4006e8cdb7909625c3feb34b
--- /dev/null
+++ b/paddle/fluid/inference/analysis/analyzer_lac_tester.cc
@@ -0,0 +1,273 @@
+// Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include "paddle/fluid/inference/analysis/analyzer.h"
+#include
+#include "paddle/fluid/framework/ir/fuse_pass_base.h"
+#include "paddle/fluid/inference/analysis/ut_helper.h"
+#include "paddle/fluid/inference/api/analysis_predictor.h"
+#include "paddle/fluid/inference/api/helper.h"
+#include "paddle/fluid/inference/api/paddle_inference_pass.h"
+#include "paddle/fluid/platform/profiler.h"
+
+DEFINE_string(infer_model, "", "model path for LAC");
+DEFINE_string(infer_data, "", "data file for LAC");
+DEFINE_int32(batch_size, 1, "batch size.");
+DEFINE_int32(burning, 0, "Burning before repeat.");
+DEFINE_int32(repeat, 1, "Running the inference program repeat times.");
+DEFINE_bool(test_all_data, false, "Test the all dataset in data file.");
+
+namespace paddle {
+namespace inference {
+namespace analysis {
+
+struct DataRecord {
+ std::vector data;
+ std::vector lod;
+ // for dataset and nextbatch
+ size_t batch_iter{0};
+ std::vector> batched_lods;
+ std::vector> batched_datas;
+ std::vector> datasets;
+ DataRecord() = default;
+ explicit DataRecord(const std::string &path, int batch_size = 1) {
+ Load(path);
+ Prepare(batch_size);
+ batch_iter = 0;
+ }
+ void Load(const std::string &path) {
+ std::ifstream file(path);
+ std::string line;
+ int num_lines = 0;
+ datasets.resize(0);
+ while (std::getline(file, line)) {
+ num_lines++;
+ std::vector data;
+ split(line, ';', &data);
+ std::vector words_ids;
+ split_to_int64(data[1], ' ', &words_ids);
+ datasets.emplace_back(words_ids);
+ }
+ }
+ void Prepare(int bs) {
+ if (bs == 1) {
+ batched_datas = datasets;
+ for (auto one_sentence : datasets) {
+ batched_lods.push_back({0, one_sentence.size()});
+ }
+ } else {
+ std::vector one_batch;
+ std::vector lod{0};
+ int bs_id = 0;
+ for (auto one_sentence : datasets) {
+ bs_id++;
+ one_batch.insert(one_batch.end(), one_sentence.begin(),
+ one_sentence.end());
+ lod.push_back(lod.back() + one_sentence.size());
+ if (bs_id == bs) {
+ bs_id = 0;
+ batched_datas.push_back(one_batch);
+ batched_lods.push_back(lod);
+ one_batch.clear();
+ one_batch.resize(0);
+ lod.clear();
+ lod.resize(0);
+ lod.push_back(0);
+ }
+ }
+ if (one_batch.size() != 0) {
+ batched_datas.push_back(one_batch);
+ batched_lods.push_back(lod);
+ }
+ }
+ }
+ DataRecord NextBatch() {
+ DataRecord data;
+ data.data = batched_datas[batch_iter];
+ data.lod = batched_lods[batch_iter];
+ batch_iter++;
+ if (batch_iter >= batched_datas.size()) {
+ batch_iter = 0;
+ }
+ return data;
+ }
+};
+
+void GetOneBatch(std::vector *input_slots, DataRecord *data,
+ int batch_size) {
+ auto one_batch = data->NextBatch();
+ PaddleTensor input_tensor;
+ input_tensor.name = "word";
+ input_tensor.shape.assign({static_cast(one_batch.data.size()), 1});
+ input_tensor.lod.assign({one_batch.lod});
+ input_tensor.dtype = PaddleDType::INT64;
+ TensorAssignData(&input_tensor, {one_batch.data});
+ PADDLE_ENFORCE_EQ(batch_size, static_cast(one_batch.lod.size() - 1));
+ input_slots->assign({input_tensor});
+}
+
+void BenchAllData(const std::string &model_path, const std::string &data_file,
+ const int batch_size, const int repeat) {
+ NativeConfig config;
+ config.model_dir = model_path;
+ config.use_gpu = false;
+ config.device = 0;
+ config.specify_input_name = true;
+ std::vector input_slots, outputs_slots;
+ DataRecord data(data_file, batch_size);
+ auto predictor =
+ CreatePaddlePredictor(config);
+ GetOneBatch(&input_slots, &data, batch_size);
+ for (int i = 0; i < FLAGS_burning; i++) {
+ predictor->Run(input_slots, &outputs_slots);
+ }
+ Timer timer;
+ double sum = 0;
+ for (int i = 0; i < repeat; i++) {
+ for (size_t bid = 0; bid < data.batched_datas.size(); ++bid) {
+ GetOneBatch(&input_slots, &data, batch_size);
+ timer.tic();
+ predictor->Run(input_slots, &outputs_slots);
+ sum += timer.toc();
+ }
+ }
+ PrintTime(batch_size, repeat, 1, 0, sum / repeat);
+}
+
+const int64_t lac_ref_data[] = {24, 25, 25, 25, 38, 30, 31, 14, 15, 44, 24, 25,
+ 25, 25, 25, 25, 44, 24, 25, 25, 25, 36, 42, 43,
+ 44, 14, 15, 44, 14, 15, 44, 14, 15, 44, 38, 39,
+ 14, 15, 44, 22, 23, 23, 23, 23, 23, 23, 23};
+
+void TestLACPrediction(const std::string &model_path,
+ const std::string &data_file, const int batch_size,
+ const int repeat, bool test_all_data,
+ bool use_analysis = false) {
+ NativeConfig config;
+ config.model_dir = model_path;
+ config.use_gpu = false;
+ config.device = 0;
+ config.specify_input_name = true;
+ std::vector input_slots, outputs_slots;
+ DataRecord data(data_file, batch_size);
+ GetOneBatch(&input_slots, &data, batch_size);
+ std::unique_ptr predictor;
+ if (use_analysis) {
+ AnalysisConfig cfg;
+ cfg.model_dir = model_path;
+ cfg.use_gpu = false;
+ cfg.device = 0;
+ cfg.specify_input_name = true;
+ cfg.enable_ir_optim = true;
+ predictor =
+ CreatePaddlePredictor(cfg);
+ } else {
+ predictor =
+ CreatePaddlePredictor(config);
+ }
+ for (int i = 0; i < FLAGS_burning; i++) {
+ predictor->Run(input_slots, &outputs_slots);
+ }
+ Timer timer;
+ if (test_all_data) {
+ double sum = 0;
+ LOG(INFO) << "Total number of samples: " << data.datasets.size();
+ for (int i = 0; i < repeat; i++) {
+ for (size_t bid = 0; bid < data.batched_datas.size(); ++bid) {
+ GetOneBatch(&input_slots, &data, batch_size);
+ timer.tic();
+ predictor->Run(input_slots, &outputs_slots);
+ sum += timer.toc();
+ }
+ }
+ PrintTime(batch_size, repeat, 1, 0, sum / repeat);
+ LOG(INFO) << "Average latency of each sample: "
+ << sum / repeat / data.datasets.size() << " ms";
+ return;
+ }
+ timer.tic();
+ for (int i = 0; i < repeat; i++) {
+ predictor->Run(input_slots, &outputs_slots);
+ }
+ PrintTime(batch_size, repeat, 1, 0, timer.toc() / repeat);
+
+ // check result
+ EXPECT_EQ(outputs_slots.size(), 1UL);
+ auto &out = outputs_slots[0];
+ size_t size = std::accumulate(out.shape.begin(), out.shape.end(), 1,
+ [](int a, int b) { return a * b; });
+ size_t batch1_size = sizeof(lac_ref_data) / sizeof(int64_t);
+ PADDLE_ENFORCE_GT(size, 0);
+ EXPECT_GE(size, batch1_size);
+ int64_t *pdata = static_cast(out.data.data());
+ for (size_t i = 0; i < batch1_size; ++i) {
+ EXPECT_EQ(pdata[i], lac_ref_data[i]);
+ }
+
+ if (use_analysis) {
+ // run once for comparion as reference
+ auto ref_predictor =
+ CreatePaddlePredictor(config);
+ std::vector ref_outputs_slots;
+ ref_predictor->Run(input_slots, &ref_outputs_slots);
+ EXPECT_EQ(ref_outputs_slots.size(), outputs_slots.size());
+ auto &ref_out = ref_outputs_slots[0];
+ size_t ref_size =
+ std::accumulate(ref_out.shape.begin(), ref_out.shape.end(), 1,
+ [](int a, int b) { return a * b; });
+ EXPECT_EQ(size, ref_size);
+ int64_t *pdata_ref = static_cast(ref_out.data.data());
+ for (size_t i = 0; i < size; ++i) {
+ EXPECT_EQ(pdata_ref[i], pdata[i]);
+ }
+
+ AnalysisPredictor *analysis_predictor =
+ dynamic_cast(predictor.get());
+ auto &fuse_statis = analysis_predictor->analysis_argument()
+ .Get>(
+ framework::ir::kFuseStatisAttr);
+ for (auto &item : fuse_statis) {
+ LOG(INFO) << "fused " << item.first << " " << item.second;
+ }
+ int num_ops = 0;
+ for (auto &node :
+ analysis_predictor->analysis_argument().main_dfg->nodes.nodes()) {
+ if (node->IsFunction()) {
+ ++num_ops;
+ }
+ }
+ LOG(INFO) << "has num ops: " << num_ops;
+ ASSERT_TRUE(fuse_statis.count("fc_fuse"));
+ ASSERT_TRUE(fuse_statis.count("fc_gru_fuse"));
+ EXPECT_EQ(fuse_statis.at("fc_fuse"), 1);
+ EXPECT_EQ(fuse_statis.at("fc_gru_fuse"), 4);
+ EXPECT_EQ(num_ops, 11);
+ }
+}
+
+TEST(Analyzer_LAC, native) {
+ LOG(INFO) << "LAC with native";
+ TestLACPrediction(FLAGS_infer_model, FLAGS_infer_data, FLAGS_batch_size,
+ FLAGS_repeat, FLAGS_test_all_data);
+}
+
+TEST(Analyzer_LAC, analysis) {
+ LOG(INFO) << "LAC with analysis";
+ TestLACPrediction(FLAGS_infer_model, FLAGS_infer_data, FLAGS_batch_size,
+ FLAGS_repeat, FLAGS_test_all_data, true);
+}
+
+} // namespace analysis
+} // namespace inference
+} // namespace paddle
diff --git a/paddle/fluid/inference/analysis/analyzer_ner_tester.cc b/paddle/fluid/inference/analysis/analyzer_ner_tester.cc
new file mode 100644
index 0000000000000000000000000000000000000000..661b047ed7cb70545267e468d8c2c48596a2994c
--- /dev/null
+++ b/paddle/fluid/inference/analysis/analyzer_ner_tester.cc
@@ -0,0 +1,227 @@
+// Copyright (c) 2018 PaddlePaddle Authors. All Rights Reserved.
+//
+// Licensed under the Apache License, Version 2.0 (the "License");
+// you may not use this file except in compliance with the License.
+// You may obtain a copy of the License at
+//
+// http://www.apache.org/licenses/LICENSE-2.0
+//
+// Unless required by applicable law or agreed to in writing, software
+// distributed under the License is distributed on an "AS IS" BASIS,
+// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+// See the License for the specific language governing permissions and
+// limitations under the License.
+
+#include "paddle/fluid/inference/analysis/analyzer.h"
+#include
+#include "paddle/fluid/framework/ir/fuse_pass_base.h"
+#include "paddle/fluid/inference/analysis/ut_helper.h"
+#include "paddle/fluid/inference/api/analysis_predictor.h"
+#include "paddle/fluid/inference/api/helper.h"
+#include "paddle/fluid/inference/api/paddle_inference_pass.h"
+#include "paddle/fluid/platform/profiler.h"
+
+DEFINE_string(infer_model, "", "model path");
+DEFINE_string(infer_data, "", "data path");
+DEFINE_int32(batch_size, 10, "batch size.");
+DEFINE_int32(repeat, 1, "Running the inference program repeat times.");
+DEFINE_bool(test_all_data, false, "Test the all dataset in data file.");
+
+namespace paddle {
+namespace inference {
+
+struct DataRecord {
+ std::vector> word_data_all, mention_data_all;
+ std::vector> rnn_word_datas, rnn_mention_datas;
+ std::vector lod; // two inputs have the same lod info.
+ size_t batch_iter{0};
+ size_t batch_size{1};
+ size_t num_samples; // total number of samples
+ DataRecord() = default;
+ explicit DataRecord(const std::string &path, int batch_size = 1)
+ : batch_size(batch_size) {
+ Load(path);
+ }
+ DataRecord NextBatch() {
+ DataRecord data;
+ size_t batch_end = batch_iter + batch_size;
+ // NOTE skip the final batch, if no enough data is provided.
+ if (batch_end <= word_data_all.size()) {
+ data.word_data_all.assign(word_data_all.begin() + batch_iter,
+ word_data_all.begin() + batch_end);
+ data.mention_data_all.assign(mention_data_all.begin() + batch_iter,
+ mention_data_all.begin() + batch_end);
+ // Prepare LoDs
+ data.lod.push_back(0);
+ CHECK(!data.word_data_all.empty());
+ CHECK(!data.mention_data_all.empty());
+ CHECK_EQ(data.word_data_all.size(), data.mention_data_all.size());
+ for (size_t j = 0; j < data.word_data_all.size(); j++) {
+ data.rnn_word_datas.push_back(data.word_data_all[j]);
+ data.rnn_mention_datas.push_back(data.mention_data_all[j]);
+ // calculate lod
+ data.lod.push_back(data.lod.back() + data.word_data_all[j].size());
+ }
+ }
+ batch_iter += batch_size;
+ return data;
+ }
+ void Load(const std::string &path) {
+ std::ifstream file(path);
+ std::string line;
+ int num_lines = 0;
+ while (std::getline(file, line)) {
+ num_lines++;
+ std::vector data;
+ split(line, ';', &data);
+ // load word data
+ std::vector word_data;
+ split_to_int64(data[1], ' ', &word_data);
+ // load mention data
+ std::vector mention_data;
+ split_to_int64(data[3], ' ', &mention_data);
+ word_data_all.push_back(std::move(word_data));
+ mention_data_all.push_back(std::move(mention_data));
+ }
+ num_samples = num_lines;
+ }
+};
+
+void PrepareInputs(std::vector *input_slots, DataRecord *data,
+ int batch_size) {
+ PaddleTensor lod_word_tensor, lod_mention_tensor;
+ lod_word_tensor.name = "word";
+ lod_mention_tensor.name = "mention";
+ auto one_batch = data->NextBatch();
+ int size = one_batch.lod[one_batch.lod.size() - 1]; // token batch size
+ lod_word_tensor.shape.assign({size, 1});
+ lod_word_tensor.lod.assign({one_batch.lod});
+ lod_mention_tensor.shape.assign({size, 1});
+ lod_mention_tensor.lod.assign({one_batch.lod});
+ // assign data
+ TensorAssignData(&lod_word_tensor, one_batch.rnn_word_datas);
+ TensorAssignData(&lod_mention_tensor, one_batch.rnn_mention_datas);
+ // Set inputs.
+ input_slots->assign({lod_word_tensor, lod_mention_tensor});
+ for (auto &tensor : *input_slots) {
+ tensor.dtype = PaddleDType::INT64;
+ }
+}
+
+// the first inference result
+const int chinese_ner_result_data[] = {30, 45, 41, 48, 17, 26,
+ 48, 39, 38, 16, 25};
+
+void TestChineseNERPrediction(bool use_analysis) {
+ NativeConfig config;
+ config.prog_file = FLAGS_infer_model + "/__model__";
+ config.param_file = FLAGS_infer_model + "/param";
+ config.use_gpu = false;
+ config.device = 0;
+ config.specify_input_name = true;
+
+ std::vector input_slots, outputs;
+ std::unique_ptr predictor;
+ Timer timer;
+ if (use_analysis) {
+ AnalysisConfig cfg;
+ cfg.prog_file = FLAGS_infer_model + "/__model__";
+ cfg.param_file = FLAGS_infer_model + "/param";
+ cfg.use_gpu = false;
+ cfg.device = 0;
+ cfg.specify_input_name = true;
+ cfg.enable_ir_optim = true;
+ predictor =
+ CreatePaddlePredictor(cfg);
+ } else {
+ predictor =
+ CreatePaddlePredictor(config);
+ }
+
+ if (FLAGS_test_all_data) {
+ LOG(INFO) << "test all data";
+ double sum = 0;
+ size_t num_samples;
+ for (int i = 0; i < FLAGS_repeat; i++) {
+ DataRecord data(FLAGS_infer_data, FLAGS_batch_size);
+ num_samples = data.num_samples;
+ for (size_t bid = 0; bid < num_samples; ++bid) {
+ PrepareInputs(&input_slots, &data, FLAGS_batch_size);
+ timer.tic();
+ predictor->Run(input_slots, &outputs);
+ sum += timer.toc();
+ }
+ }
+ LOG(INFO) << "total number of samples: " << num_samples;
+ PrintTime(FLAGS_batch_size, FLAGS_repeat, 1, 0, sum / FLAGS_repeat);
+ LOG(INFO) << "average latency of each sample: "
+ << sum / FLAGS_repeat / num_samples;
+ return;
+ }
+ // Prepare inputs.
+ DataRecord data(FLAGS_infer_data, FLAGS_batch_size);
+ PrepareInputs(&input_slots, &data, FLAGS_batch_size);
+
+ timer.tic();
+ for (int i = 0; i < FLAGS_repeat; i++) {
+ predictor->Run(input_slots, &outputs);
+ }
+ PrintTime(FLAGS_batch_size, FLAGS_repeat, 1, 0, timer.toc() / FLAGS_repeat);
+
+ PADDLE_ENFORCE(outputs.size(), 1UL);
+ auto &out = outputs[0];
+ size_t size = std::accumulate(out.shape.begin(), out.shape.end(), 1,
+ [](int a, int b) { return a * b; });
+ PADDLE_ENFORCE_GT(size, 0);
+ int64_t *result = static_cast(out.data.data());
+ for (size_t i = 0; i < std::min(11UL, size); i++) {
+ PADDLE_ENFORCE(result[i], chinese_ner_result_data[i]);
+ }
+
+ if (use_analysis) {
+ // run once for comparion as reference
+ auto ref_predictor =
+ CreatePaddlePredictor(config);
+ std::vector ref_outputs_slots;
+ ref_predictor->Run(input_slots, &ref_outputs_slots);
+ EXPECT_EQ(ref_outputs_slots.size(), outputs.size());
+ auto &ref_out = ref_outputs_slots[0];
+ size_t ref_size =
+ std::accumulate(ref_out.shape.begin(), ref_out.shape.end(), 1,
+ [](int a, int b) { return a * b; });
+ EXPECT_EQ(size, ref_size);
+ int64_t *pdata_ref = static_cast