Merge pull request #9080 from reyoung/cpp_parallel_executor
Cpp parallel executor
Showing
cmake/external/threadpool.cmake
0 → 100644
{kind=link}
175.1 KB
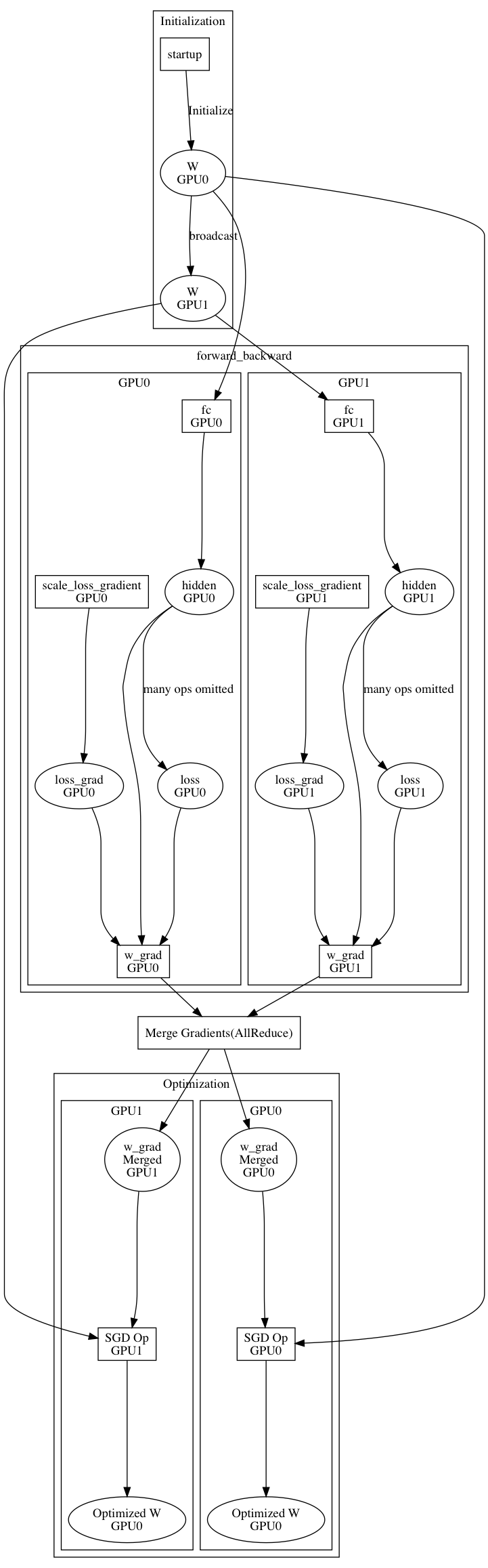
doc/design/parallel_executor.md
0 → 100644
Cpp parallel executor
175.1 KB