add ppyoloe_r (#7105)
* add ppyoloe_r * modify code of ops.py * add ppyoloe_r docs and modify rotate docs * modify docs and refine connfigs * fix some problems * refine docs, add nms_rotated ext_op and fix some problems * add image and inference_benchmark.py * modify docs * fix some problems * modify code accroding to review Co-authored-by: wangxinxin08 <>
Showing
configs/datasets/dota_ms.yml
0 → 100644
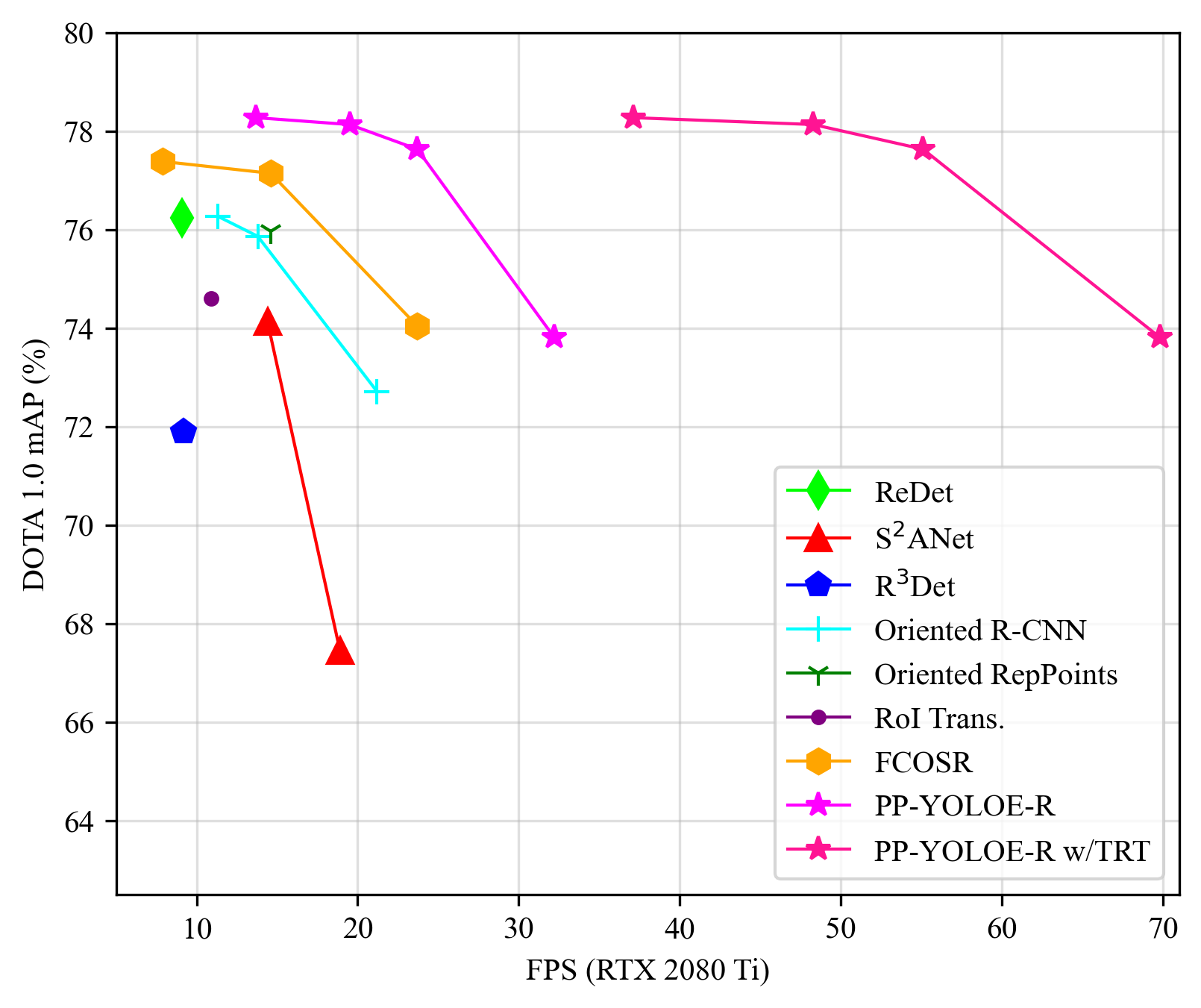
docs/images/ppyoloe_r_map_fps.png
0 → 100644
{kind=link}
144.6 KB