Merge branch 'develop' of github.com:PaddlePaddle/Paddle into overlap_send_op
Showing
contrib/inference/README.md
0 → 100644
{kind=link}
doc/fluid/images/op.dot
0 → 100644
doc/v2/images/FullyConnected.jpg
0 → 100644
{kind=link}
49.7 KB
{kind=link}
116.2 KB
doc/v2/images/bi_lstm.jpg
0 → 100644
{kind=link}
34.8 KB
doc/v2/images/checkpointing.png
0 → 100644
{kind=link}
179.1 KB
doc/v2/images/create_efs.png
0 → 100644
{kind=link}
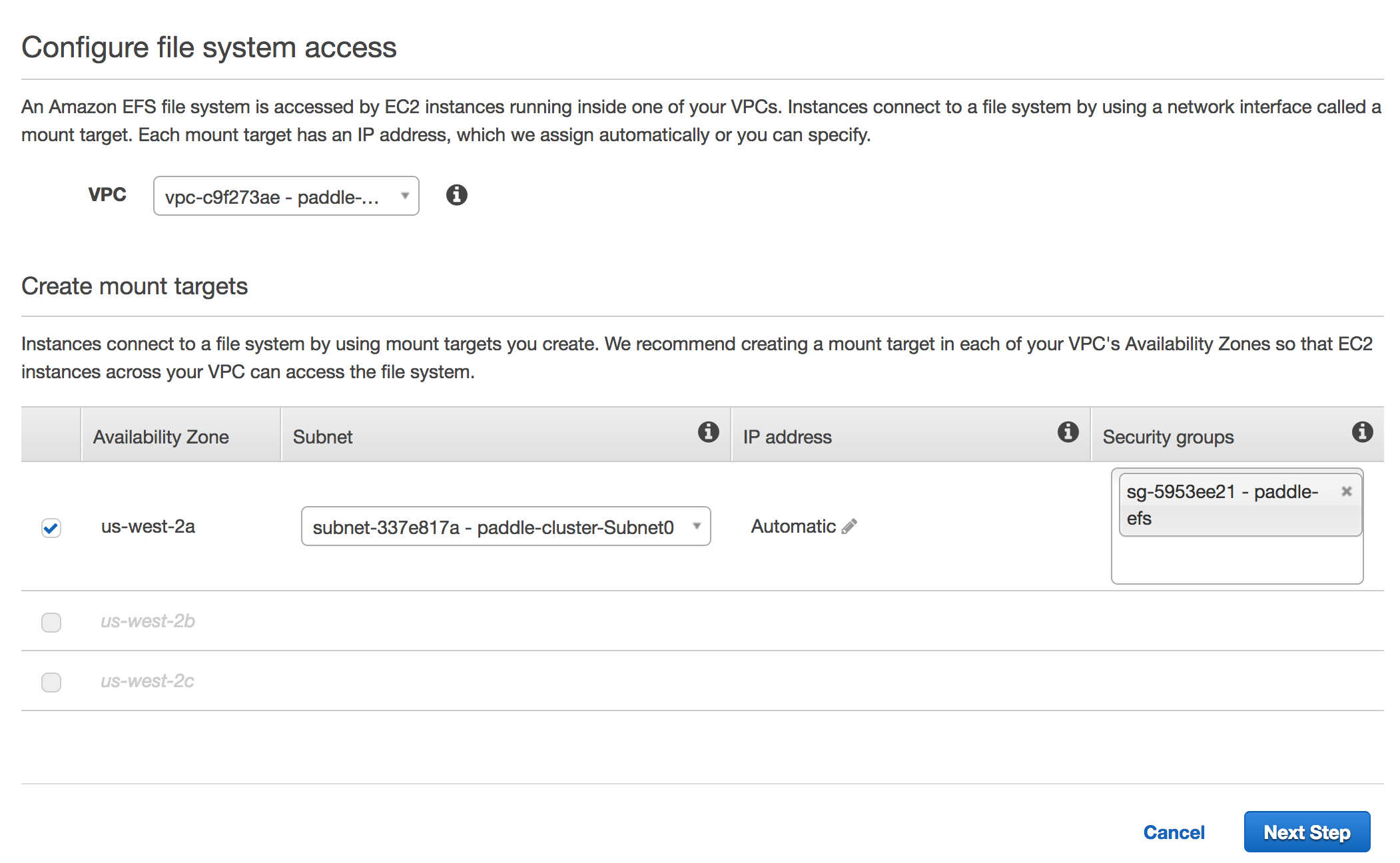
236.1 KB
doc/v2/images/csr.png
0 → 100644
{kind=link}
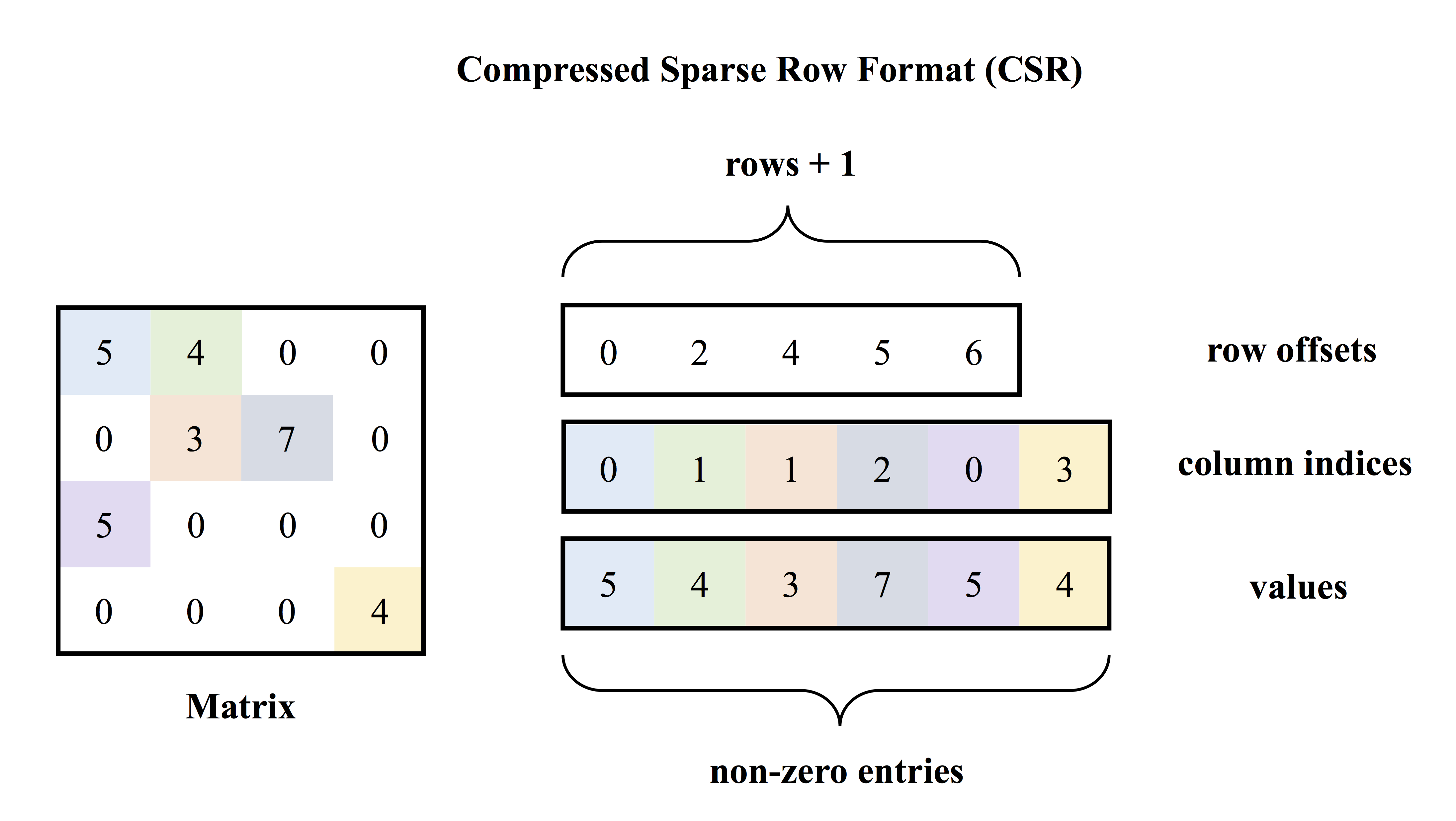
361.4 KB
doc/v2/images/data_dispatch.png
0 → 100644
{kind=link}
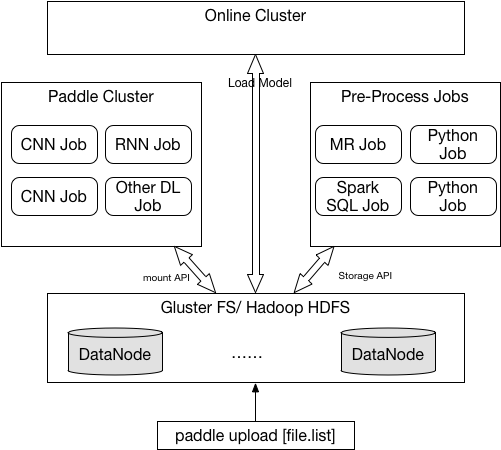
33.1 KB
doc/v2/images/dataset.graffle
0 → 100644
文件已添加
doc/v2/images/dataset.png
0 → 100644
{kind=link}
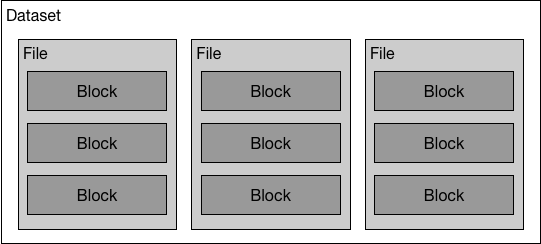
10.6 KB
doc/v2/images/doc_en.png
0 → 100644
{kind=link}

159.0 KB
doc/v2/images/efs_mount.png
0 → 100644
{kind=link}
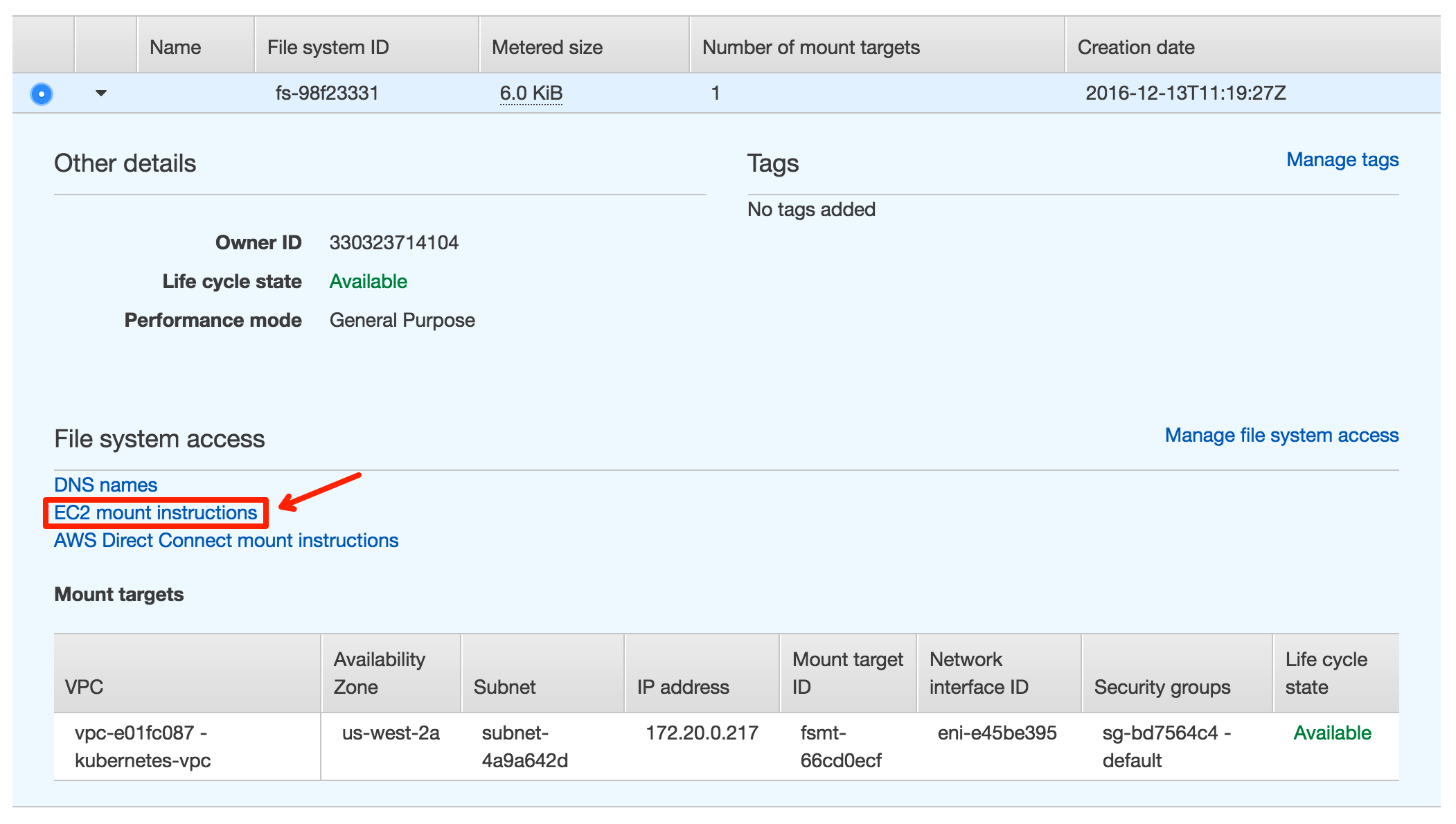
225.2 KB
{kind=link}
66.5 KB
doc/v2/images/engine.png
0 → 100644
{kind=link}
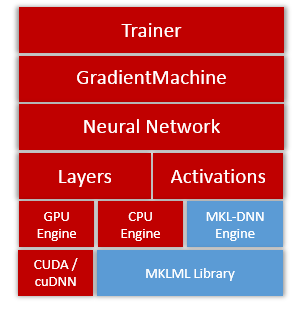
13.3 KB
文件已添加
doc/v2/images/file_storage.png
0 → 100644
{kind=link}
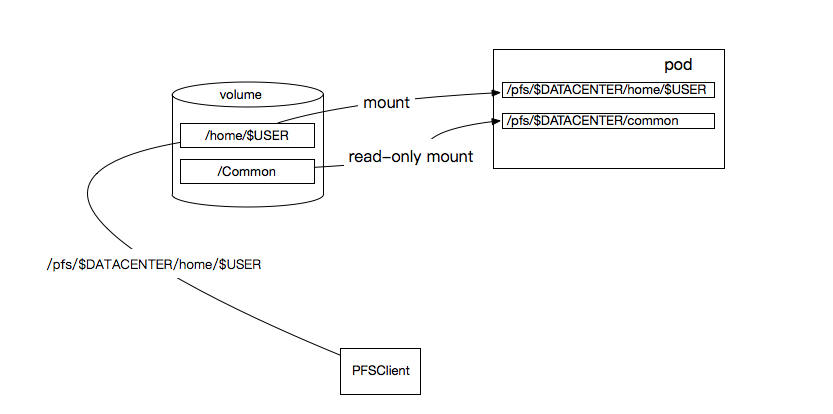
42.4 KB
doc/v2/images/glossary_rnn.dot
0 → 100644
doc/v2/images/gradients.png
0 → 100644
{kind=link}
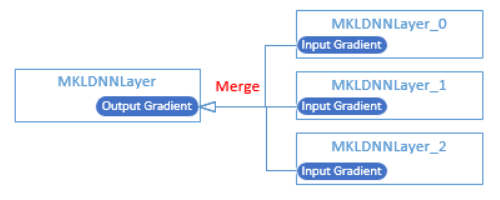
22.4 KB
doc/v2/images/init_lock.graffle
0 → 100644
文件已添加
doc/v2/images/init_lock.png
0 → 100644
{kind=link}
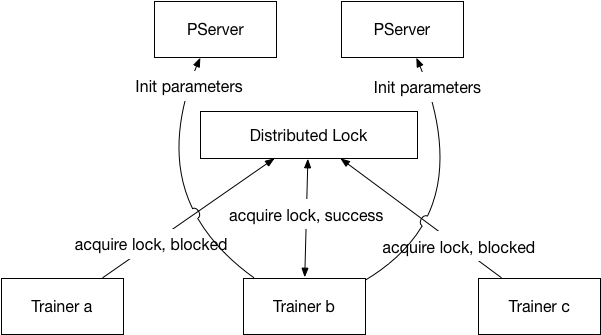
26.1 KB
doc/v2/images/k8s-paddle-arch.png
0 → 100644
{kind=link}
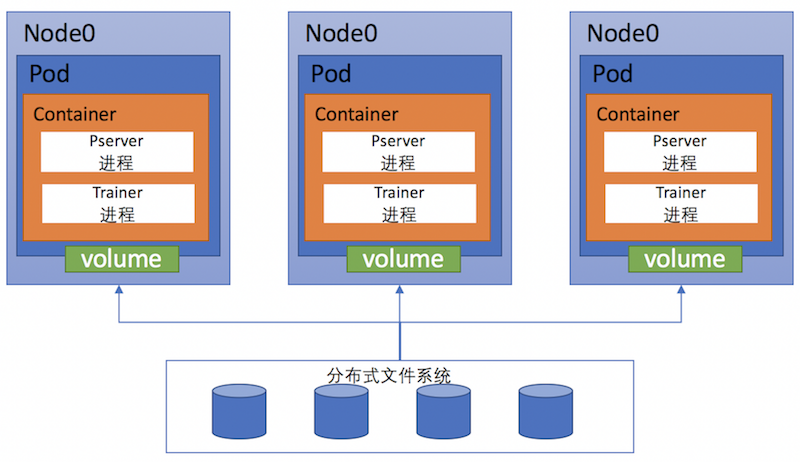
420.9 KB
doc/v2/images/layers.png
0 → 100644
{kind=link}
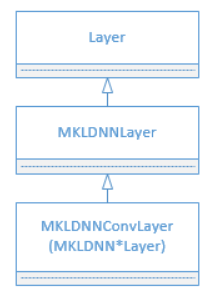
11.4 KB
doc/v2/images/managed_policy.png
0 → 100644
{kind=link}
241.5 KB
doc/v2/images/matrix.png
0 → 100644
{kind=link}
18.0 KB
doc/v2/images/nvvp1.png
0 → 100644
{kind=link}
416.1 KB
doc/v2/images/nvvp2.png
0 → 100644
{kind=link}
483.5 KB
doc/v2/images/nvvp3.png
0 → 100644
{kind=link}
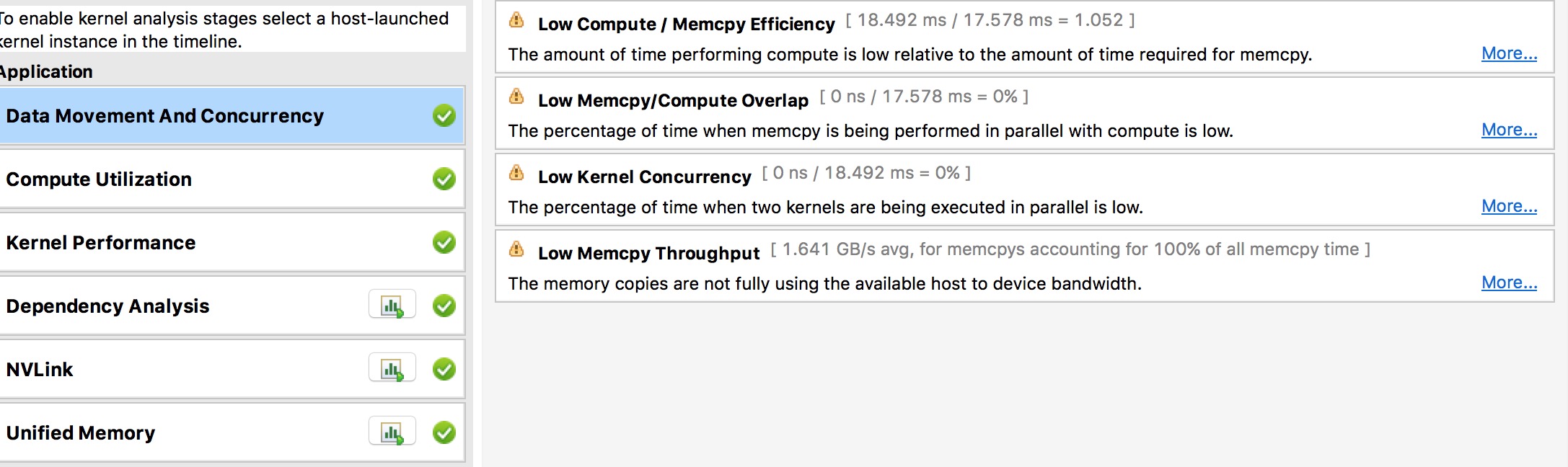
247.8 KB
doc/v2/images/nvvp4.png
0 → 100644
{kind=link}

276.6 KB
doc/v2/images/overview.png
0 → 100644
{kind=link}
10.5 KB
{kind=link}
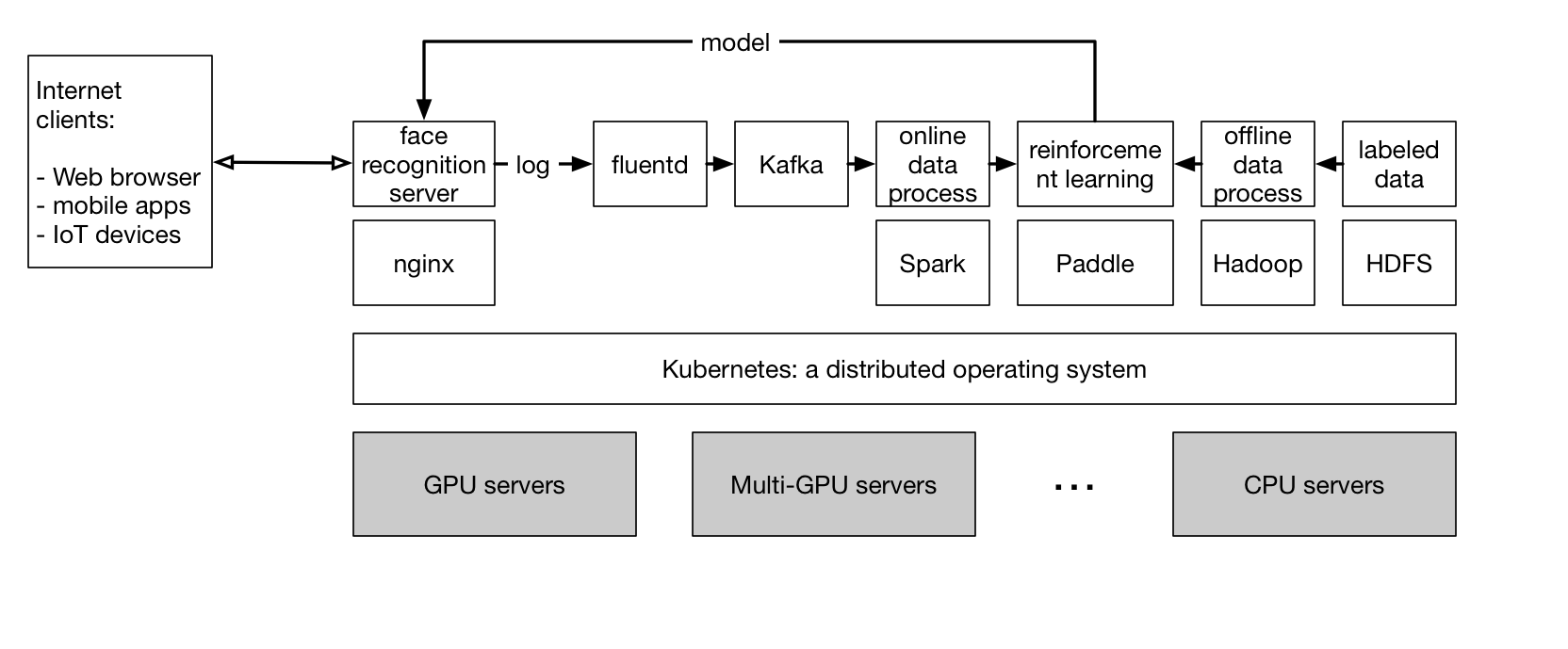
76.7 KB
doc/v2/images/paddle-etcd.graffle
0 → 100644
文件已添加
doc/v2/images/paddle-etcd.png
0 → 100644
{kind=link}
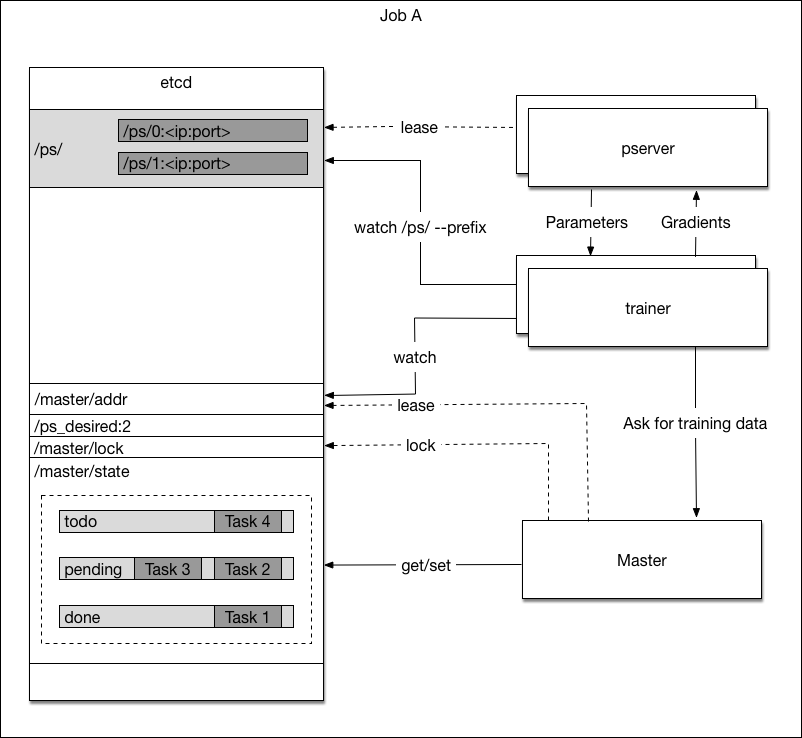
49.2 KB
文件已添加
{kind=link}
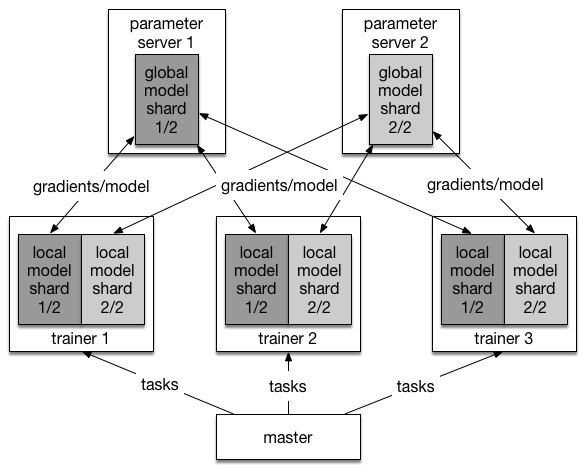
37.5 KB
doc/v2/images/paddle-ps-0.png
0 → 100644
{kind=link}
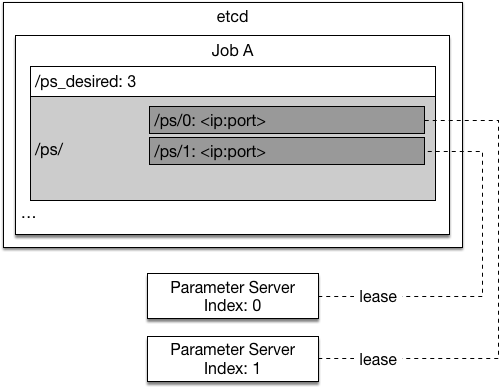
20.9 KB
doc/v2/images/paddle-ps-1.png
0 → 100644
{kind=link}
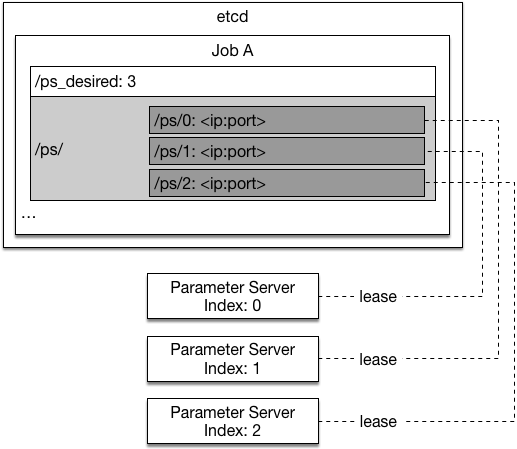
27.7 KB
doc/v2/images/paddle-ps.graffle
0 → 100644
文件已添加
文件已添加
{kind=link}
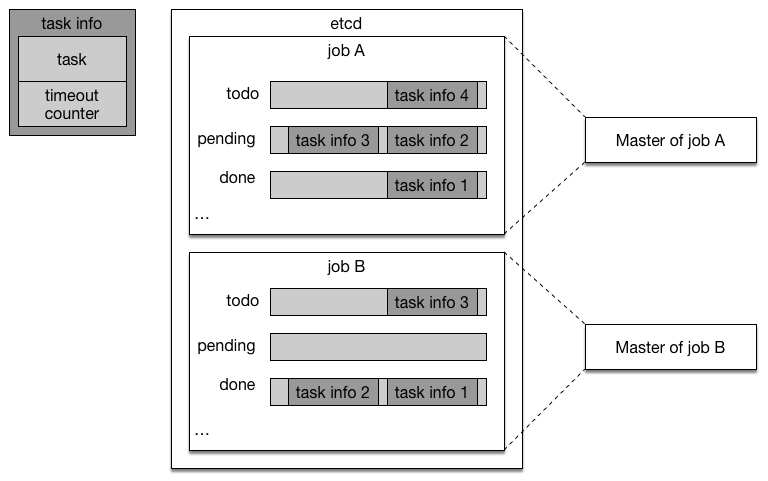
33.9 KB
文件已添加
{kind=link}
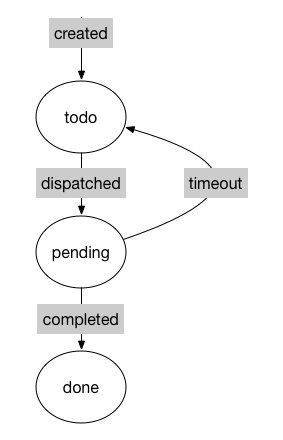
17.8 KB
doc/v2/images/ps_cn.png
0 → 100644
{kind=link}
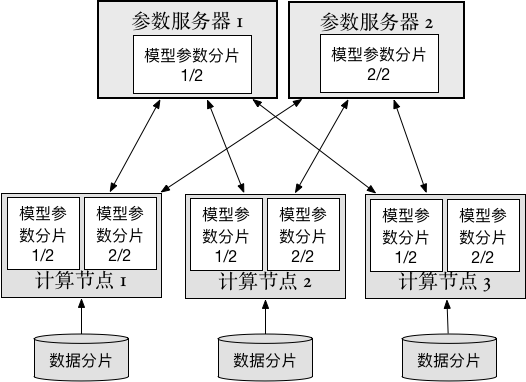
33.1 KB
doc/v2/images/ps_en.png
0 → 100644
{kind=link}
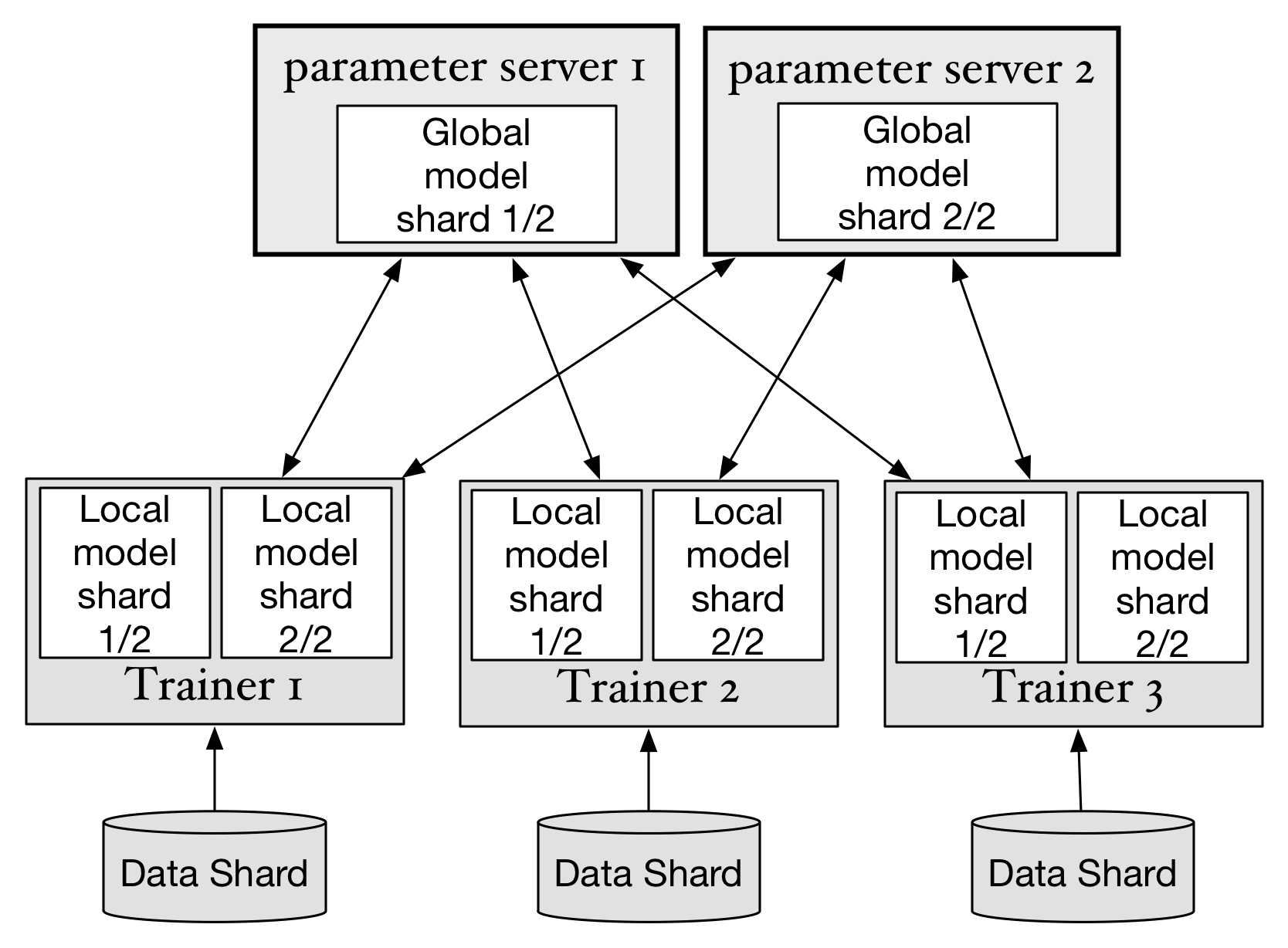
141.7 KB
{kind=link}
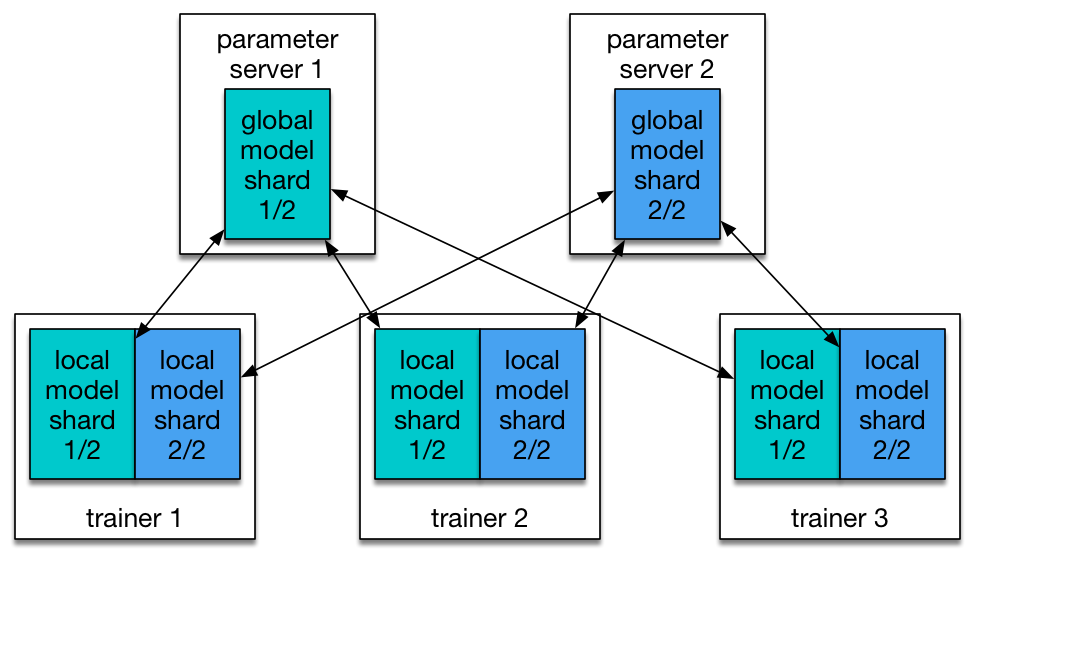
70.0 KB
文件已添加
doc/v2/images/pserver_init.png
0 → 100644
{kind=link}
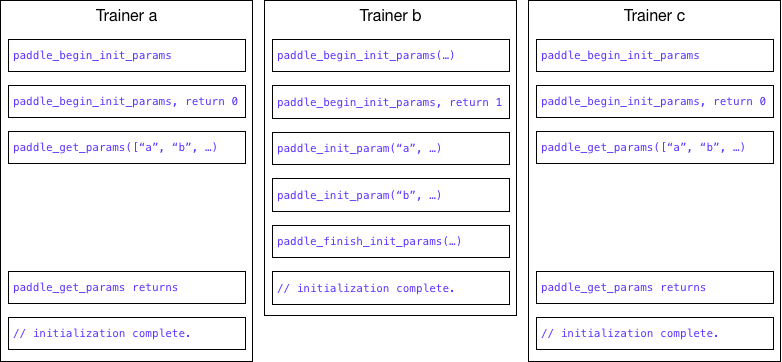
27.9 KB
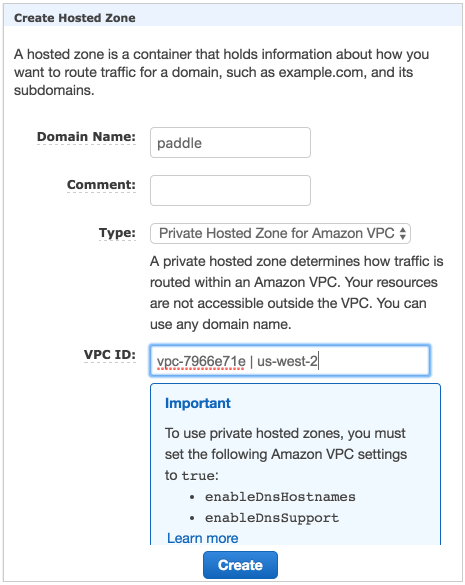
{kind=link}
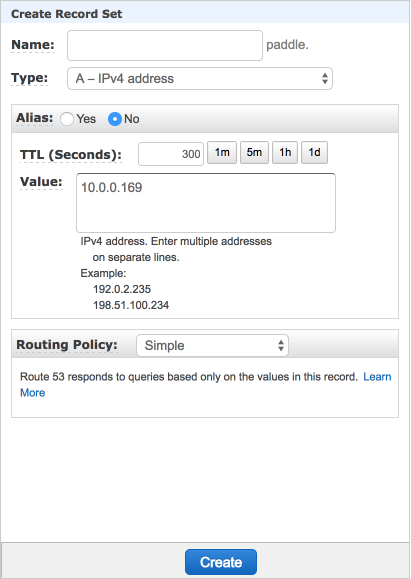
34.9 KB
{kind=link}
50.8 KB
doc/v2/images/sequence_data.png
0 → 100644
{kind=link}
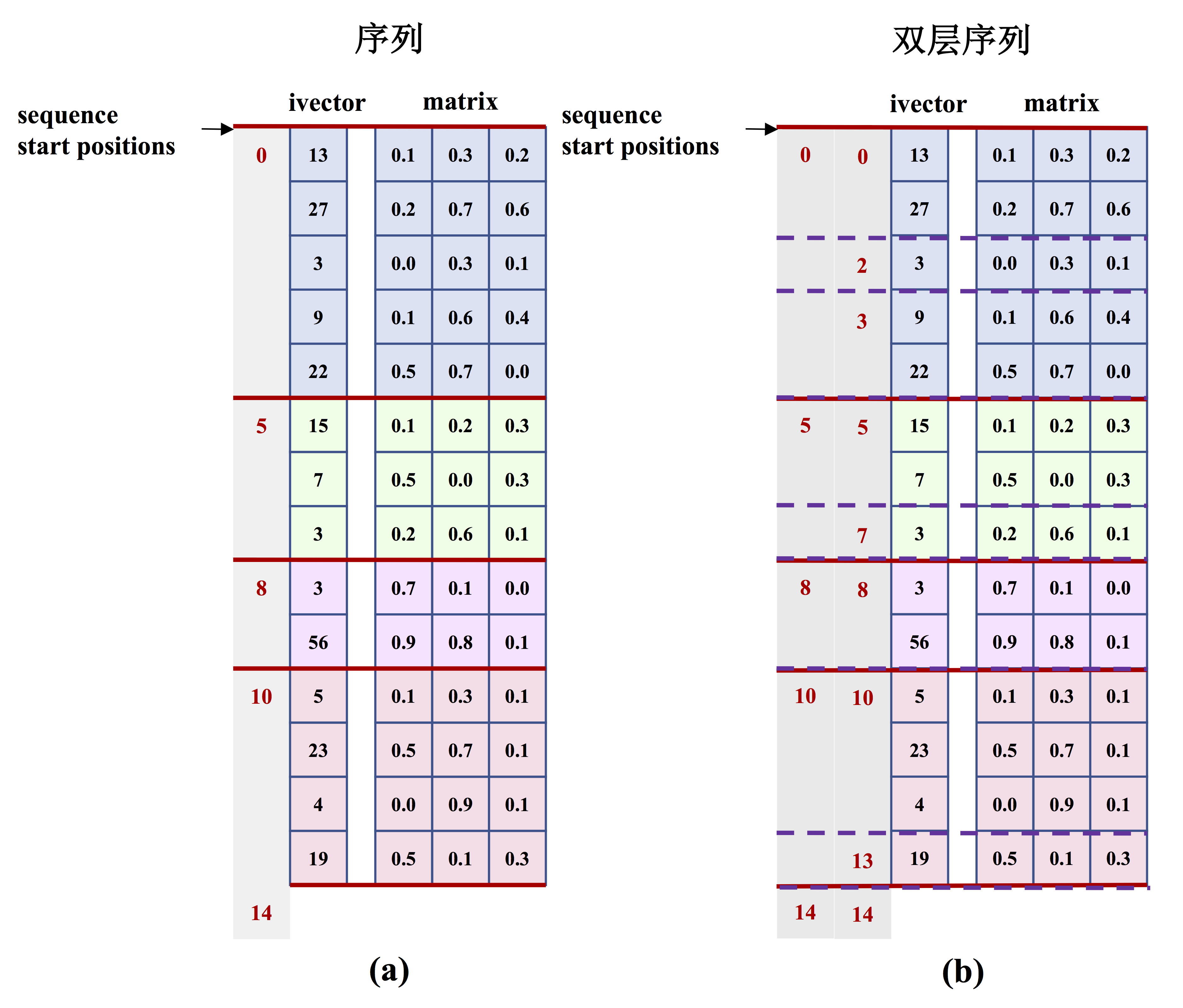
470.2 KB
doc/v2/images/submit-job.graffle
0 → 100644
文件已添加
doc/v2/images/submit-job.png
0 → 100644
{kind=link}
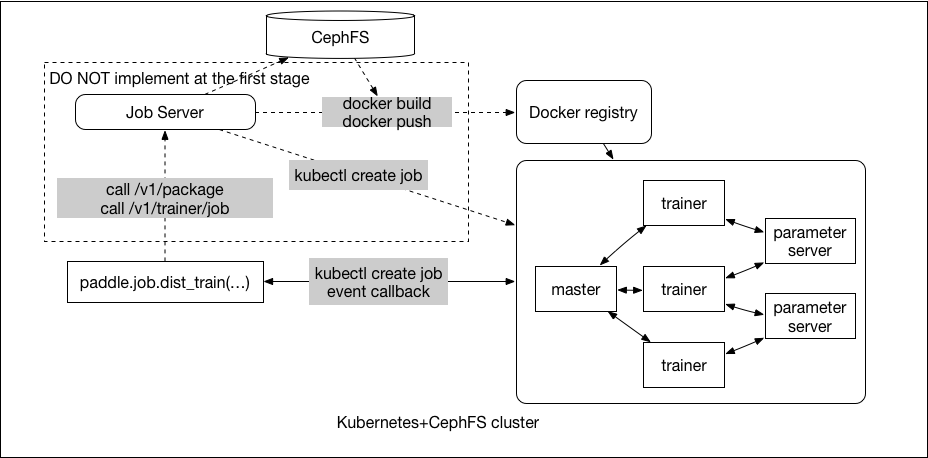
51.5 KB
doc/v2/images/trainer.graffle
0 → 100644
文件已添加
doc/v2/images/trainer.png
0 → 100644
{kind=link}
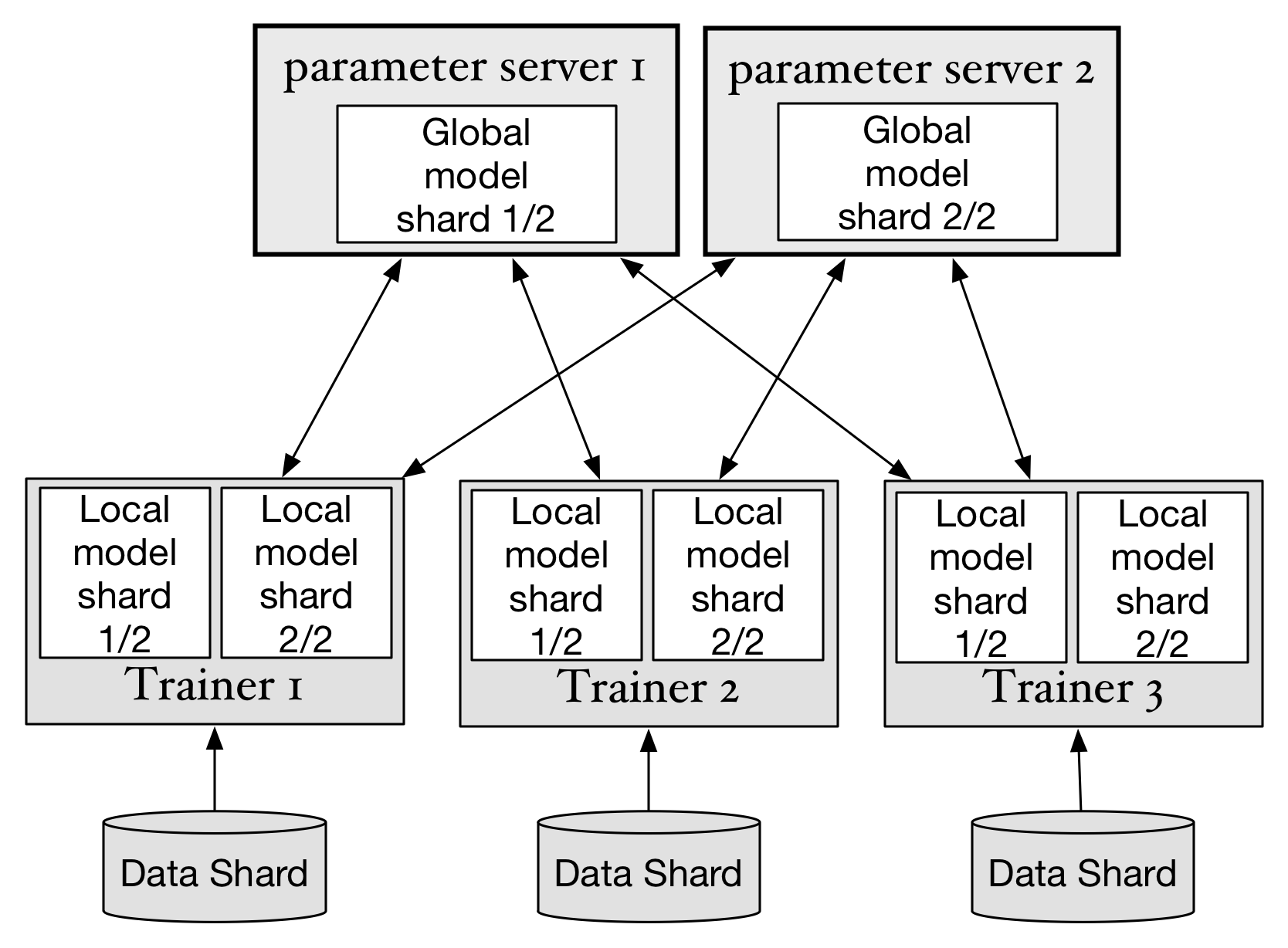
141.7 KB
doc/v2/images/trainer_cn.png
0 → 100644
{kind=link}
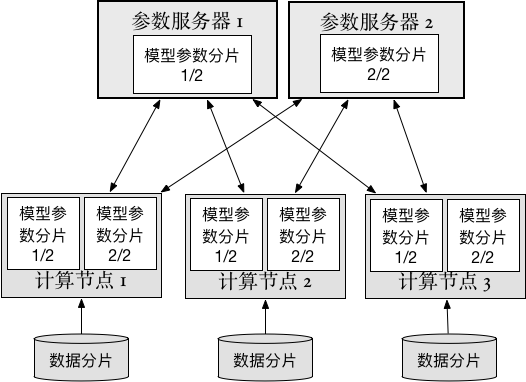
33.1 KB
{kind=link}

87.1 KB
{kind=link}
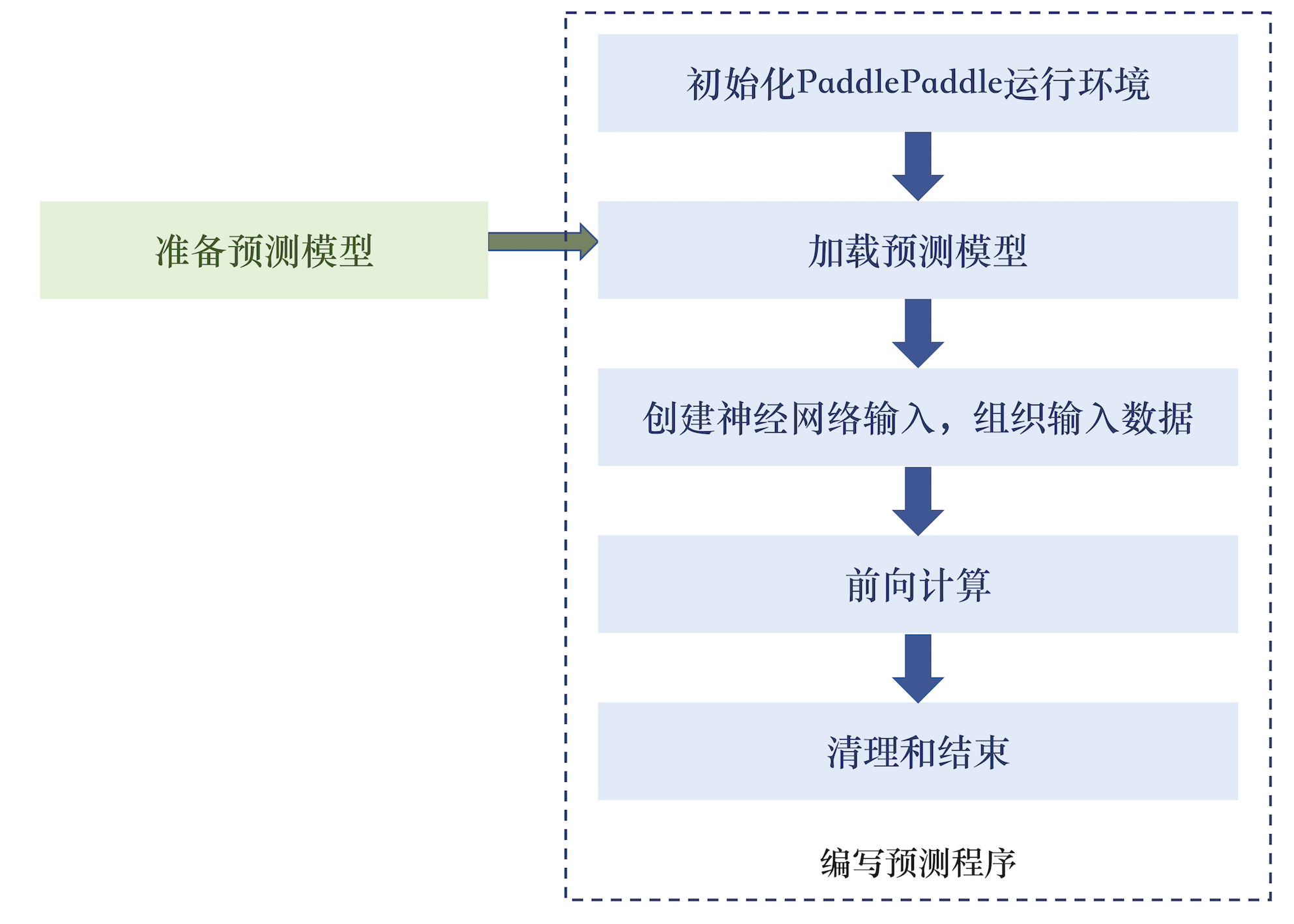
447.8 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
patches/mkldnn.hpp
0 → 100644
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
文件已移动
此差异已折叠。