[cherry-pick] add release 2.5 doc (#6762)
* update release note, test=document_fix * update README, test=document_fix * update link, test=document_fix * add en doc, test=document_fix * add ocsort, test=document_fix
Showing
{kind=link}
{kind=link}
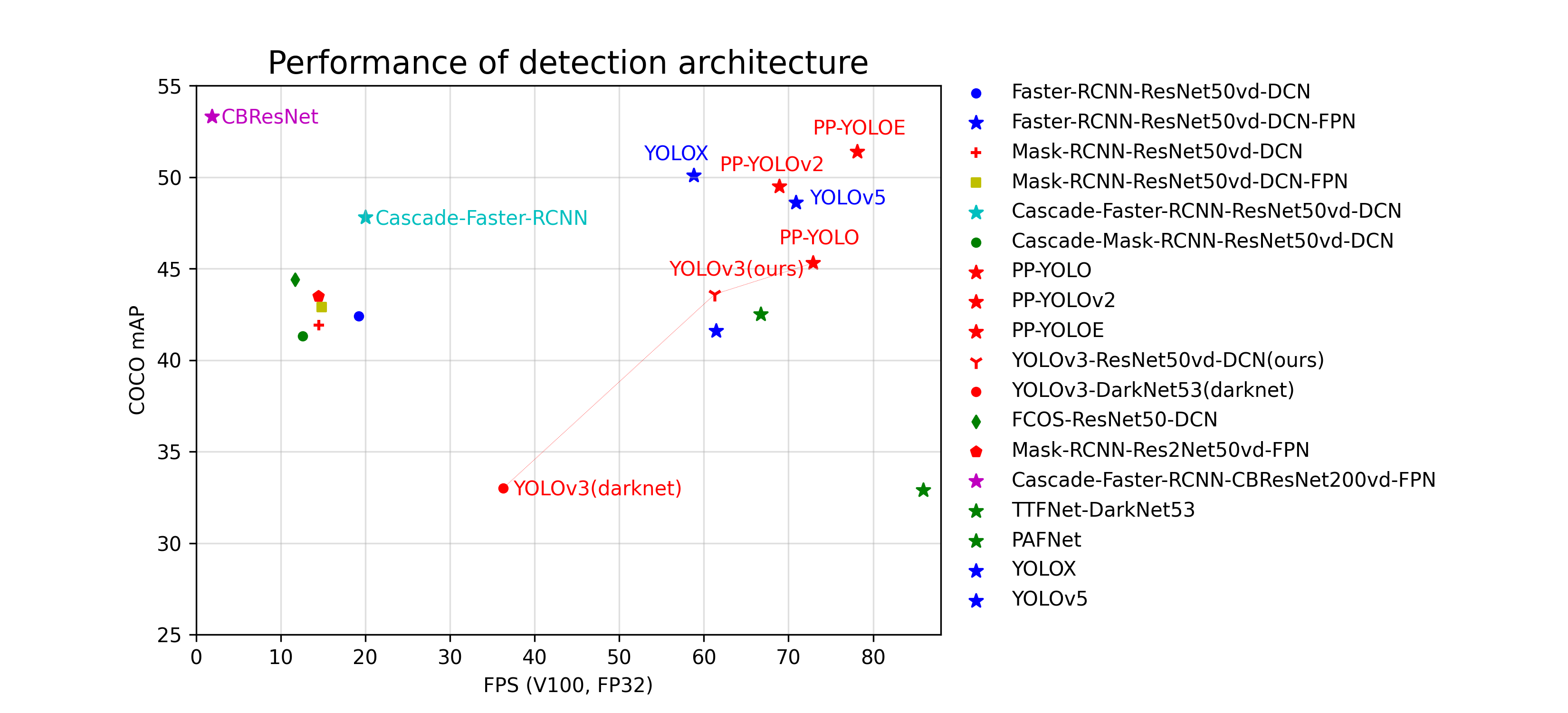
| W: | H:

| W: | H: