Now, PaddlePaddle Fluid with Distribution has relatively large network bottleneck, We want to use RDMA and GPUDriect to improve and solve it, so we enabled the features to PaddlePaddle with the help of MPI.
We will introduce Open MPI API to PaddlePaddle, which can bring two benefits to PaddlePaddle:
We will introduce Open MPI API to PaddlePaddle, which can bring two benefits to PaddlePaddle:
1. Enable RDMA with PaddlePaddle, which bring highperformance low latency networks.
1. Enable RDMA with PaddlePaddle, which bring high-performance low latency networks.
2. Enable GPUDriect with PaddlePaddle, which bring highest throughput and lowest latency GPU read and write.
2. Enable GPUDriect with PaddlePaddle, which bring the highest throughput and lowest latency GPU read and write.
## Global Config
## Execute args
Launch the script using the 'mpirun' launcher, For example: ```mpirun -np 3 -hosts node1,node2,node3 python train.py```. By doing this, We can number the actors (trainer/pserver/master) whith o .. (n-1). The actor's number is the Rank of the calling process in group of comm (integer), The MPI processes identify each other using an Rank ID. We have to create a mapping between PaddlePaddle's actors and there Rank ID, so that we can communicate with the correct destinations when using MPI operations.
Launch the script using the ```mpirun``` launcher, For example: ```mpirun -np 3 -hosts node1,node2,node3 python train.py```. By doing this, We can number the actors (trainer/pserver/master) with o .. (n-1). The node's number is the Rank of the calling process in a group of comm (integer), The MPI processes identify each other using a Rank ID. We have to create a mapping between PaddlePaddle's actors and their Rank ID so that we can communicate with the correct destinations when using MPI operations.
**We have to store the Rank ID and the mapping in global variables.**
**We have to store the Rank ID and the mapping in global variables.**
#Utils
## New OP/MODULE
We will build mpi_send_recv_utils Class to unify package interface about MPI Send and Receive.
We won't replace all the gRPC requests to MPI requests, the standard gRPC library is used for all administrative operations and the MPI API will be used to transfer tensor or selectRows to Pservers. The base of this idea, we create two new operators to handle requests and receives, the two operators are send_mpi_op and listenandserve_mpi_op. They are a little similar with [send_op](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/operators/send_op.cc) and [listen_and_serv_op](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/operators/listen_and_serv_op.cc), also, We will build a new module to package MPI send and receive process.
```c++
#mpi send and receive utils
### mpi_module
classMpi_ISend{
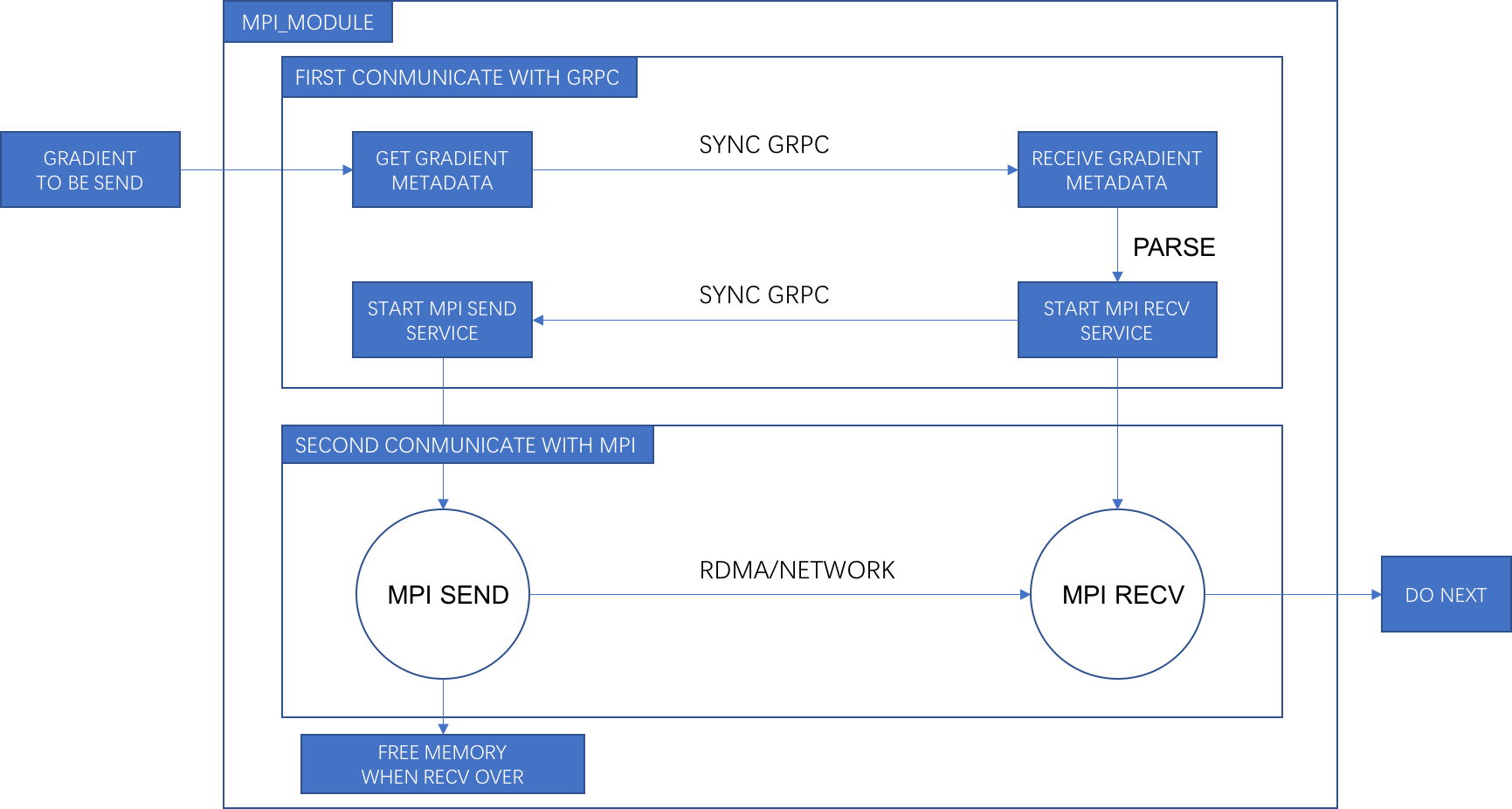
We will build a new module to package MPI send and receive process. MPI send and recvice are defferent to gRPC, the MPI [recvice](https://www.open-mpi.org/doc/v1.8/man3/MPI_Irecv.3.php) must know receive buffer size and receive buffer element. For this reason, We have to make conmunications twice, the first one is to send metadata about gradient through gRPC, the second one is the real conmunications through MPI which send gradient data to mpi_listenandserve_op.
Very similar with ```send_op```, we will replace gRPC code which used to send gradient with ```mpi_module```, at the same time , we will wrap it with ```framework::Async```.
classMPIUtils{
### mpi_listenandserve_op
public:
Very similar with ```listen_and_serv_op```, we will replace gRPC code which used to receive gradient with ```mpi_module```, at the same time , we will wrap it with ```framework::Async```.
constintGetRankID(conststd::string&task_id);
voidInitMPI();
### modify distribute_transpiler.py
private:
Need to add args to distinguish use MPI or not. if confirm to use MPI, we will modify ```send_op``` to ```mpi_send_op``` in distribute_transpiler, and modify ```listenandserve_op``` to ```mpi_listenandserve_op``` also.
std::map<std::string,int>name_to_id_;
}
```
```c++
classMPIServer{
public:
SetCond();
ShutDown();
WaitClientGet();
reset();
Push();
SetScope();
SetDevCtx();
get();
}
```
## New OP
We won't replace all the gRPC requests to MPI requests, the standard gRPC library is used for all administrative operations and the MPI API will used to transfer tensor or selectRows to Pservers. Base of this idea, we create two new operators to handle requests and receives, the two operators are send_mpi_op and listenandserve_mpi_op. They are a little similar with [send_op](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/operators/send_op.cc) and [listen_and_serv_op](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/operators/listen_and_serv_op.cc).
### send_mpi_op
vary similar with send_op, we will replace grpc with mpi send service.
### listenandserve_mpi_op
vary similar with listen_and_serv_op, we will replace grpc with mpi receive service.
## Build args
## Build args
Beause MPI or CUDA need hardware supported, so we will add some build args to control compiling.
Because MPI or CUDA need hardware supported, so we will add some build args to control compiling.
**The specific arguments is under design**
**The specific arguments are under design**
## Execute args
\ No newline at end of file
Launch the script using the 'mpirun' launcher, For example: ```mpirun -np 3 -hosts node1,node2,node3 python train.py```.
{kind=link}